| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФжївЊНщЩмСЫИљОнОпЬхвЕЮёФПЕФКЭгІгУГЁОАЕФВЛЭЌЃЌЮвУЧШчКЮдкВЛЭЌЕФЯЕЭГжЎМфНјааЪ§ОнЕФЭЌВНЁЃ |
|
ЪВУДЪЧЪ§ОнЭЌВНЗўЮёЃПЙЫУћЫМвхЃЌОЭЪЧдкВЛЭЌЕФЯЕЭГжЎМфЭЌВНЪ§ОнЁЃИљОнОпЬхвЕЮёФПЕФКЭгІгУГЁОАЕФВЛЭЌЃЌИїжжЪ§ОнЭЌВНЗўЮёПђМмЕФЙІФмВржиЕуЭљЭљВЛОЁЯрЭЌЃЌвђЖјДѓМввВЛсгУИїжжДѓЭЌаЁвьЕФУћГЦРДГЦКєетРрЗўЮёЃЌБШШчЪ§ОнДЋЪфЗўЮёЃЌЪ§ОнВЩМЏЗўЮёЃЌЪ§ОнНЛЛЛЗўЮёЕШЕШ
жСгкДѓЪ§ОнПЊЗЂЦНЬЈЕФЪ§ОнЭЌВНЗўЮёЃЌМгЩЯСЫЯоЖЈДЪЃЌФЧЕБШЛЪЧНјвЛВНАбвЕЮёЕФЗЖЮЇЯоЖЈдкСЫКЭЪ§ОнЦНЬЈвЕЮёЯрЙиЕФвЛаЉзщМўКЭгІгУГЁОАжЎЯТСЫЁЃ
ДѓЪ§ОнЦНЬЈЪ§ОнЭЌВНЗўЮёвЕЮёГЁОА
ЬжТлГЁОАжЎЧАЃЌЯШРДПДвЛЯТЪ§ОнЭЌВНЕФФПЕФЃЌЮЊЪВУДЮвУЧашвЊдкВЛЭЌЕФЯЕЭГжЎМфНјааЪ§ОнЕФЭЌВНЃП
ДгДѓЪ§ОнПЊЗЂЦНЬЈЕФНЧЖШРДЫЕЃЌКмЯдШЛЃЌЪЧвђЮЊЮвУЧЭЈГЃВЛФмжБНгЖдЯпЩЯвЕЮёЯЕЭГЫљДцДЂЛђЩњГЩЕФЪ§ОнНјааИїжждЫЫуЛђМьЫїДІРэЃЌзщМўММЪѕМмЙЙЪЧвЛЗНУцдвђЃЌвЕЮёАВШЋадИєРыЪЧСэвЛЗНУцдвђЁЃ
ЫљвдЃЌЮвУЧОЭашвЊАбетаЉЪ§ОнВЩМЏЕНПЊЗЂЦНЬЈЕФИїжжДцДЂМЦЫузщМўжаРДНјааМгЙЄДІРэЃЌетИіЙ§ГЬвВОЭЪЧЫљЮНЕФETLЙ§ГЬЁЃ
ШЛКѓЃЌдкПЊЗЂЦНЬЈжаДІРэЭъБЯЕФЪ§ОнЃЌгаЪБКђвВВЂВЛФмЛђзХВЛЪЪКЯдкДѓЪ§ОнПЊЗЂЦНЬЈЕФЯрЙиЗўЮёжажБНгЪЙгУЃЌашвЊЗДРЁЛиЯпЩЯЕФвЕЮёЯЕЭГжаЃЌетИіЙ§ГЬЮвУЧГЦЮЊЪ§ОнЕФЛиаДЛђЕМГіЁЃ
зюКѓЃЌМДЪЙдкДѓЪ§ОнПЊЗЂЦНЬЈздЩэЕФИїжжДцДЂЃЏМЦЫуЃЏВщбЏЗўЮёзщМўжЎМфЃЌвђЮЊМмЙЙЗНАИЃЌЖСаДЗНЪНЃЌвЕЮёашЧѓЕФВЛЭЌЃЌвВПЩФмДцдкЪ§ОнЕФДЋЪфЭЌВНашЧѓЁЃ
ДгЩЯЪіШ§РргІгУГЁОАРДПДЃЌЮвУЧПЩвдПДЕНЃЌЭЈГЃРДЫЕЮвУЧЫљЫЕЕФДѓЪ§ОнПЊЗЂЦНЬЈЛЗОГЯТЕФЪ§ОнЭЌВНЗўЮёЃЌжївЊДІРэЕФЪЧВЛЭЌЯЕЭГзщМўжЎМфЕФЪ§ОнЕМШыЕМГіЙЄзїЁЃ
БШШчНЋDBЕФЪ§ОнВЩМЏЕНHiveжаРДЃЌНЋHiveжаЕФЪ§ОнЕМГіИјHBaseжЎРрЁЃвВОЭЪЧЪфШыКЭЪфГіЕФЪ§ОндДЪЧвьЙЙЕФЃЌЪ§ОнЭЌВНЕФФПЕФЪЧШУЪ§ОнПЩвдЪЪКЯвЕЮёашЧѓЕФаЮЪНЃЌдкВЛЭЌЕФЯЕЭГжагУИїздЩУГЄЕФЗНЪНдЫзЊЦ№РДЁЃ
Г§ДЫжЎЭтЃЌЛЙгаСэЭтвЛжжГігкЪ§ОнБИЗнЃЌЛђепИКдиОљКтЕФФПЕФЖјДцдкЕФЪ§ОнЭЌВНГЁОАЁЃБШШчDBЕФжїДгЭЌВНЃЌHBaseМЏШКЕФReplicatorБИЗнЕШЕШЃЌЫћУЧЕФЪфШыЪфГіЪ§ОндДЭљЭљЪЧЭЌЙЙЕФЁЃетРрГЁОАЯТЃЌОпЬхЕФЭЌВНЗНАИКЭСїГЬЭЈГЃКЭЯЕЭГздЩэЕФНЁПЕЃЌЙІФмТпМЃЌЗўЮёЫпЧѓЕШгазХНЯЧПЕФЙиСЊадЃЌЫљвдЭљЭљЖдгІЕФЯЕЭГЛсздДјЭЌВНЗНАИЪЕЯжЃЌЪєгкЯЕЭГздЩэЙІФмЪЕЯжЕФвЛВПЗжЃЌБШШчMySQLЕФbinlogжїДгЭЌВНИДжЦЛњжЦЁЃетРрЬиЖЈЯЕЭГздДјЕФЪ§ОнЭЌВНМмЙЙЗНАИЪЕЯжЃЌВЛдкБОЮФЬжТлЕФЗЖЮЇжЎРрЁЃ
Ъ§ОндД
вЕЮёЗЖЮЇУїШЗСЫЃЌФЧУДШУЮвУЧРДПДПДдкетжжвЕЮёГЁОАЯТЃЌашвЊДІРэЕФЪ§ОндДПЩФмЖМгаФФаЉЃЌМђЕЅЗжвдвЛЯТРрЃЌГЃМћЕФЪ§ОндДДѓжТПЩвдЗжЮЊЃЛ
1.ЙиЯЕаЭЪ§ОнПтРр : БШШч MySql, Oracle, SqlServer,
PostgreSQL ЕШЕШ
2.ЮФМўРрЃКБШШчШежОlogЃЌcsvЃЌexcelЕШИїжжДЋЭГЕЅЛњЮФМў
3.ЯћЯЂЖгСаРрЃКБШШчkafkaКЭИїжжMQ
4.ИїжжДѓЪ§ОнЯрЙизщМўЃКБШШчHDFSЃЏHiveЃЏHBaseЃЏES ЃЏCansandra
5.ЦфЫќЭјТчНгПкЛђЗўЮёРрЃКБШШчFTPЃЏHTTPЃЏSocket ЕШ
ЯжгаЕФНтОіЗНАИНщЩм
ШчЩЯЫљЪіЃЌЪ§ОнЭЌВНЗўЮёПЩФмЩцМАЕНЕФЭтВПЯЕЭГЖржжЖрбљЃЌЪЕМЪЩЯЃЌЕЋЗВФмДцДЂЛђВњЩњЪ§ОнЕФЯЕЭГЃЌЖМПЩФмГЩЮЊашвЊНгШыЪ§ОнЭЌВНЗўЮёЕФЪ§ОндДЁЃвђДЫЃЌвВВЛФбЯыЯѓЃЌЪаУцЩЯвЛЖЈДцдкжкЖрЕФНтОіЗНАИЁЃ
ЮЊЪВУДФиЃПКмЯдШЛЃЌетаЉИїЪНИїбљЕФЪ§ОнЭЌВНЗўЮёЗНАИЃЌдкВЛЭЌЕФвЕЮёГЁОАжаЃЌЮоТлећЬхЙІФмЖЈЮЛЛЙЪЧвЕЮёИВИЧЗЖЮЇЖМПЩФмЧЇВюЭђБ№ЁЃМДЪЙФГаЉЗНАИЕФвЕЮёЖЈЮЛРрЫЦЃЌдкОпЬхЕФЙІФмЪЕЯжЗНУцЃЌДѓМвЙизЂЕФжиЕувВПЩФмгаЫљЧјБ№ЁЃДЫЭтВПЗжЯЕЭГдкЩшМЦЕФЪБКђЃЌЮЊСЫБЃжЄвзгУадЛђепЬсЙЉвЛеОЪНЕФНтОіЗНАИЃЌЦфМмЙЙКЭОпЬхЕФЙІФмТпМгыЩЯЯТгЮЯЕЭГПЩФмЛЙгавЛЖЈЕФвЕЮёЙиСЊадЃЌдйМгЩЯГЬађдБгжЯВЛЖгУИїжжПЊЗЂгябдРДелЬквЛБщ,
PythonЃЏJavaЃЏRubyЃЏGo ЁЃЫљвдЃЌетРрЗўЮёЯЕЭГЕФНтОіЗНАИЯыВЛЖрвВКмФбАЁЁЃ
ФЧУДГЃМћЕФНтОіЗНАИЖМгаФФаЉФиЃП
вдЙиЯЕаЭЪ§ОнПтЮЊжївЊДІРэЖдЯѓЕФЯЕЭГЃК
Tungsten-replicator
ЪЧContinuentЙЋЫОПЊЗЂЕФЪ§ОнПтдЫЮЌЙмРэЕФСНИіЯрЙиСЊЕФЙЄОпВњЦЗЬзМўжаЕФвЛИіЃЌИКд№Oracle
КЭ MySQLСНИіЪ§ОнПтжЎМфвьЙЙЕФЪ§ОнИДжЦЭЌВНЙЄзїЃЌвдМАЖдЭтЕМГіЕНБШШчRedshiftЃЌVerticaЕШЪ§ОнПтЃЌвВАќРЈЕМГіЕНHadoopЛЗОГЁЃ
ContinuentЕФСэвЛИіВњЦЗЪЧtungsten-clusteringЃЌЮЊMySQLЕШЪ§ОнПтЬсЙЉЭиЦЫТпМЙмРэЃЌджБИЃЌЪ§ОнЛжИДЃЌИпПЩгУЕШЙІФмЃЌКмЯдШЛетаЉЙІФмКмДѓГЬЖШЩЯЪЧКЭReplicatorЯрНсКЯЕФЁЃ
ЮвУЧУЛгаеце§ЪЙгУЙ§TungstenЕФВњЦЗЃЌжЛЪЧдкМмЙЙКЭДњТыЗНУцгаЙ§вЛаЉЕїбаСЫНтЃЌзмЬхИаОѕЃЌзїЮЊЩЬвЕНтОіЗНАИЃЌМмЙЙЭъЩЦЃЌЕЋЪЧЯрЖдИДдгЃЌвЛаЉвЕЮёСїГЬЗНАИЪЧЖЈжЦЛЏЕФЃЌЖдЙиЯЕаЭЪ§ОнПтздЩэЕФЪ§ОнЭЌВНКЭЙмРэвдМАЮШЖЈадгІИУЪЧЫќЕФЧПЯюЃЌВЛЙ§зїЮЊвЛИіПЊЗХЕФЯЕЭГРДгУЕФЛАЃЌНгШыГЩБОПЩФмгаЕуИпЁЃ
Canal КЭ Otter
CanalЪЧАЂРяЕФMySqlдіСПЪ§ОнЭЌВНЙЄОпЃЌOtterдђЪЧЙЙНЈдкCanalжЎЩЯЕФЪ§ОнПтдЖГЬЭЌВНЙмРэЙЄОпЁЃСНепНсКЯЦ№РДЃЌВњЦЗЕФФПБъЗЖГыДѓжТКЭTungsten-replicatorВюВЛЖрЁЃ
КЭTungstenРрЫЦЃЌCanalвВЪЧЛљгкMySqlЕФBinlogЛњжЦРДЛёШЁдіСПЪ§ОнЕФЃЌЭЈЙ§ЮБзАMySqlЕФSlaveЃЌРДЛёШЁBinlogВЂНтЮідіСПЪ§ОнЁЃ
етСНжжЗНАИЭЈГЃЪЧДѓМвгУРДНгШыMysql binlogЕФзюГЃМћЕФбЁдёЃЌБЯОЙMySql BinlogЕФИёЪННтЮіФЃПщвВЪЧвЛИіЯрЖдзЈвЕЛЏЕФИёЪНФцЯђЙЄГЬЙЄзїЃЌМДЪЙВЛжБНгЪЙгУетСНИіЗНАИЃЌДѓМввВЛсНшгУетСНИіЗНАИжаЕФbinlog
ParserФЃПщРДзіЖўДЮПЊЗЂЁЃ
CanalЕФжївЊгХЕуЪЧНсЙЙСїГЬБШНЯМђЕЅЃЌВПЪ№Ц№РДВЂВЛЬЋФбЃЌЖюЭтзівЛаЉХфжУЙмРэЗНУцЕФИФдьОЭПЩвдИќМгздЖЏЛЏЕФЪЙгУЦ№РДЁЃВЛЙ§ЃЌжївЊЮЪЬтЪЧServerКЭClientжЎМфЪЧвЛЖдвЛЕФЯћЗбЁЃВЛЬЋЪЪгУгкашвЊЖрЯћЗбКЭЪ§ОнЗжЗЂЕФГЁОАЁЃ
ЮвЫОжЎЧАМШгаЖдCanalМђЕЅЕФЗтзАгІгУЃЌвВгадкНшгУCanalЕФBinlog ParserЕФЛљДЁЩЯЃЌПЊЗЂЕФDBдіСПЪ§ОнЗжЗЂЯЕЭГ
АЂРяЕФDRCЃЏОЋЮРЕШ
DRCАДАЂРяЙйЗНЕФЫЕЗЈЖЈЮЛгкжЇГжвьЙЙЪ§ОнПтЪЕЪБЭЌВНЃЌЪ§ОнМЧТМБфИќЖЉдФЗўЮёЁЃЮЊПчгђЪЕЪБЭЌВНЁЂЪЕЪБдіСПЗжЗЂЁЂвьЕиЫЋЛюЁЂЗжВМЪНЪ§ОнПтЕШГЁОАЬсЙЉВњЦЗМЖЕФНтОіЗНАИЁЃ
ЦфЪЕОЋЮРвВЪЧРрЫЦЕФВњЦЗЃЌВЛЙ§ЪЧгЩВЛЭЌЕФЭХЖгПЊЗЂЕФЃЌГ§СЫетСНепЃЌАЂРяФкВППЩФмвВЛЙгаЙ§ЦфЫќДѓДѓаЁаЁРрЫЦЕФВњЦЗЃЌзюКѓДѓИХЖМећКЯКЯВЂСЫЃЌDRCЪЄГі
ЃЛЃЉ
ДгЖЈЮЛЫЕУїОЭПЩвдПДЕНЃЌКмУїЯдЃЌГ§СЫЕуЖдЕуЭЌВНЃЌDRCЛЙашвЊжЇГжвЛЖдЖрЕФЯћЗбКЭСщЛюЕФЯћЗбСДТЗДЎСЊЃЌЖдадФмЃЌЫГађвЛжТадЕШЗНУцЕФвЊЧѓвВПЩФмЛсвђДЫЖјБфЕУИќМгИДдгЃЈЮДБиИќФбЪЕЯжЛђвЊЧѓИќПСПЬЃЌЕЋЪЧПЩФмгаИќЖрВЛЭЌНЧЖШЕФЙІФмашЧѓЃЉЃЌБШШчЃЌПЩФмашвЊжЇГжгаЯоЪБМфЖЮФкЕФЛиЫнЃЌКЭОЋШЗЖЈЮЛЯћЗбЕФФмСІЕШЁЃ
DRCЯрЙиЯЕЭГЃЌАЂРяВЂУЛгаПЊдДЃЌВЛЙ§ЮвЫОжЎЧАКЭАЂРяЕФЭЌбЇгаЙ§вЛаЉМђЕЅНЛСїЃЌЮвУЧвВДгжаСЫНтКЭбЇЯАСЫвЛаЉВњЦЗЩшМЦКЭМмЙЙЗНУцЕФЫМЯыЁЃ
ЮвЫОЕФDBдіСПЪ§ОнЗжЗЂЯЕЭГPigeonЕФЕквЛАцЃЌОЭЪЧдкCanalЕФBinlogНтЮіДњТыФЃПщЛљДЁЩЯЃЌВЮееDRCЕФВПЗжЫМЯыНјааПЊЗЂЕФЁЃДѓжТЕФЗНАИЪЧНЋЧАЖЫЕФParserЖдНгЕНЯћЯЂЖгСаЩЯЃЌШУЯћЯЂЖгСаРДГаЕЃЯћЯЂГжОУЛЏКЭЗжЗЂЕФЙЄзїЃЌДЫЭтдкServerВуУцдйИЈжњвдЗўЮёНкЕуКЭЯћЗбСДТЗЕФЖЏЬЌЙмРэЃЌИКдиОљКтЃЌМгЩЯЪ§ОнЕФЙ§ТЫЃЌзЊЛЛКЭЗжЗЂФЃПщМАВпТдЕФЙмРэЃЌЯћЗбЖЫSDKЕФЗтзАЕШЙЄзїЁЃ
вдШежОЛђЯћЯЂЖгСаЮЊжївЊвЕЮёЖдЯѓЕФЯЕЭГ
етРрЯЕЭГвЛПЊЪМПЩФмЪЧвдШежОВщбЏЮЊжївЊвЕЮёГЁОАЃЌЦфжаЕФЪ§ОнЭЌВНЗўЮёЯрЙизщМўЃЌгааЉЪЧЖРСЂЕФзщМўЃЌгааЉдђЪЧвЛећЬзВЩМЏЃЌМЦЫуЃЌеЙЪОЕШЭъећЕФвЕЮёЗНАИжаЕФвЛВПЗжЁЃВЛЙ§ЫцзХМмЙЙЕФВЛЖЯЗЂеЙКЭГЩЪьЃЌгааЉЯЕЭГНЅНЅЕФвВВЛНіНіЪЧжЛЖЈЮЛгкДІРэШежОРрвЕЮёГЁОАСЫЃЌПЊЪМЯђЭЈгУЪ§ОнВЩМЏДЋЪфЗўЮёЕФНЧЩЋППНќЁЃ
Flume
FlumeЯждкДѓМвгУЕФЖрЕФЃЌЪЧFlume-NGетИіredesignЙ§ЕФАцБОЃЌЫќЕФЖЈЮЛЪЧРыЯпЕФШежОВЩМЏЃЌОлКЯКЭДЋЪфЁЃFlumeЕФЬиЕуЪЧдкОлКЯДЋЪфетПщЛЈСЫБШНЯЖрЕФСІЦјЃЌЬиБ№ЪЧдчЦкЕФАцБОЃЌашвЊХфжУИїжжНкЕуНЧЩЋЃЌЖјдкNGАцБОЕФЩшМЦжаЃЌЦфЭиЦЫТпМвбОМђЛЏГЩжЛгаAgentвЛИіЕЅвЛНЧЩЋСЫ
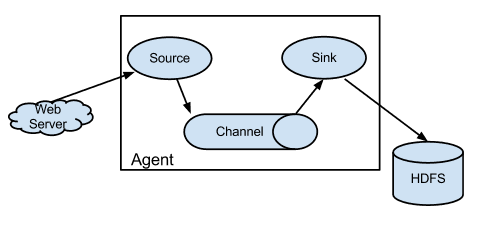
ЭЈЙ§AgentЕФДЎСЊПЩвдЙЙНЈГіИДдгЕФЪ§ОнДЋЪфСДТЗЃЌДЫЭтЛЙгаЪТЮёЕФЛњжЦЩшМЦРДШЗБЃСДТЗДЋЪфЕФПЩППадЁЃ
ВЛЙ§ЃЌИіШЫОѕЕУЃЌгЩгкKafkaЕШЭЈгУЯћЯЂЖгСаЕФЙуЗКЪЙгУЃЌFlumeдкОлКЯЃЌДЋЪфетЗНУцЕФзїгУЃЌдквЛаЉГЁОАЯТЦфЪЕЪЧПЩвдЭЈЙ§ЦфЫќЗНЪНРДЪЕЯжКЭШѕЛЏЕФЃЈБШШчУЛгаЭјТчДјПэЛђдЖГЬЖўДЮДЋЪфЮЪЬтЕФГЁОАжаЃЉЁЃ
ЮвЫОЕФШежОСДТЗжаЃЌвВУЛгаЪЙгУFlumeЃЌЖјЪЧВЩгУСЫзджїбаЗЂЕФAgentВЩМЏЦїжБНгЖдНгKafkaЃЈЕБШЛЃЌвЛаЉГЁОАЯТЃЌвВЮДБиОјЖдКЯРэЃЉ
LogStash
LogStashЪЧжјУћЕФELKЬзМўжаЕФвЛИізщМўЃЌИКд№ШежОВЩМЏКЭзЊЛЛЃЌСэЭтESИКд№ДцДЂКЭМьЫїЃЌKibanaИКд№ВщбЏНсЙћЕФеЙЪО
LogStashДгЩшМЦЩЯРДПДЃЌдкЪ§ОнДЋЪфКЭСДТЗДЎСЊЗНУцЕФПМСПОЭМђЕЅСЫКмЖрЃЌЫќЕФжиЕуЗХдкСЫЪ§ОнЕФзЊЛЛДІРэЩЯЁЃЫљвдЫќдкЙ§ТЫЦїЃЌБрНтТыЦїЕШЛЗНкЯТСЫКмЖрЕФЙІЗђЃЌБШШчжЇГжgrokНХБОзіЙ§ТЫЦїТпМПЊЗЂЃЌдкФкВПСДТЗЩЯЛЙгаИїжжЕФbufferЩшМЦЃЌгУРДжЇГжЪ§ОнЕФКЯВЂЃЌзЊЛЛЃЌЬѕМўДЅЗЂЪфГіЕШЙІФм
гІИУЫЕДгЪ§ОнзЊЛЛДІРэЕФНЧЖШРДПДЃЌИіШЫОѕЕУLogStashЕФЩшМЦвбОзуЙЛСщЛюКЭЭъБИСЫЁЃВЛЙ§ЃЌЫќЕФжїЬхЪЕЯжгябдЪЧRuby...
Camus
CamusбЯИёЕФЫЕЫуВЛЩЯЪЧвЛИіПђМмЃЌЫќЪЧLinkedinПЊЗЂЕФЛљгкKafkaЯћЗбШежОЃЌХњСПаДШыHdfsЕФвЛИіЙЄОпЃЌВЛЙ§гУЕФШЫвВВЛЩйЃЌЫљвдЬсвЛЯТЃЌЮвЫОжЎЧАвВгаДѓСПЕФШежОЪЧЭЈЙ§CamusРДВЩМЏЕФЁЃЃЈЛАЫЕLinkedinЪЧАбздМвЕФkafkaгУЕНМЋжТСЫЃЌИїжжСДТЗЕЋЗВФмвРЭаkafkaЪЕЯжЕФЃЌДѓИХЖМВЛЛсПМТЧЦфЫќЕФЪЕЯжЗНЪНЃЉ
CamusЕФМмЙЙЗНАИЃЌЛљБОЩЯОЭЪЧаДСЫвЛИіMRШЮЮёЃЌЪЕЯжХњСПДгKafkaЖСШЁШежОВЂаДШыHdfsЃЌДЫЭтздЩэЮЌЛЄСЫkafkaжаИїИіtopicЕФЯћЗбНјЖШЁЃгУЫќРДзіkafka
topicЕФМђЕЅгГЩфВЩМЏЃЌЩдЮЂзівЛЕуЙмРэЗНУцЕФЪЪХфПЊЗЂЃЌЛљБОЛЙЪЧПЩааЕФЁЃВЛЙ§ЃЌЫќЕФШБЕужївЊЪЧЖдTopicНјааЖЈжЦЛЏЕФДІРэБШНЯРЇФбЃЌашШЛвВЬсЙЉСЫвЛаЉHookНгПкЃЌЕЋЪЧБЯОЙМмЙЙЙ§гкМђЕЅЃЌЖдЪ§ОнНјаавЛаЉPer
topicЕФЙ§ТЫзЊЛЛЙЄзїЃЌОЭгаЕуСІВЛДгаФСЫЁЃ
СэЭтвЛаЉЯыВЛГідѕУДЧПааЗжРрЕФЪ§ОнЭЌВННтОіЗНАИ
Sqoop :
SqoopДѓМвгІИУВЛФАЩњСЫЃЌМДЪЙУЛгУЙ§змгІИУвВЬ§Й§ЃЌвВгаВЛЩйЙЋЫОЪЙгУSqoopРДЙЙНЈздМКЕФДѓЪ§ОнЦНЬЈЪ§ОнВЩМЏЭЌВНЗНАИЁЃSqoopДгвЛПЊЪМЃЌОЭМИКѕЪЧЭъШЋЖЈЮЛгкДѓЪ§ОнЦНЬЈЕФЪ§ОнВЩМЏвЕЮёЕФЃЌећЬхПђМмвдHadoopЮЊКЫаФЃЌАќРЈШЮЮёЕФЗжВМжДааетаЉЃЌЖрАыЖМЪЧвРЭаMRШЮЮёРДЪЕЯжЕФЁЃЪ§ОнЭЌВНЕФЙЄзїЃЌвВЪЧвдШЮЮёЕФЗНЪНЬсНЛИјServerРДжДааЃЌвдЗўЮёЕФаЮЪНЖдЭтЬсЙЉвЕЮёжЇГжЁЃ
SqoopЕФДІРэСїГЬЃЌЖЈжЦЛЏГЬЖШБШНЯИпЃЌжївЊЭЈЙ§ВЮЪ§ХфжУЕФЗНЪНРДЕїећзщМўааЮЊЃЌдкгУЛЇздЖЈвхТпМКЭвЕЮёСДТЗСїГЬЗНУцФмСІБШНЯШѕЃЌСэЭтЃЌвРЭагкMRЕФШЮЮёДІРэЗНЪНЃЌдкЙІФмЭиеЙЗНУцвВгавЛаЉдМЪјКЭОжЯоадЁЃДЫЭтИїжжЪ§ОндДЕФЪфШыЪфГіЪЕЯжВПЗжЃЌЮШЖЈадКЭЙЄГЬЪЕЯжЯИНкЗНУцЃЌвВжЛЪЧПЩгУЃЌЕЋЫуВЛЩЯЭъЩЦКЭГЩЪьЁЃ
ЮвЫОвВУЛгаЪЙгУSqoopРДЙЙНЈДѓЪ§ОнЦНЬЈЕФЪ§ОнВЩМЏЃЌЕМШыЕМГіЗўЮёЁЃЩЯЪідвђЫфШЛЪЧвЛЗНУцдвђЃЌЕЋОјЖдВЛЪЧжївЊЕФдвђЁЃзюжївЊдвђЛЙЪЧвђЮЊЪ§ОнЕФВЩМЏКЭЕМШыЕМГіЗўЮёЬхЯЕЃЌОпЬхЕФЪфШыЪфГіФЃПщЕФЙЙНЈжЛЪЧвЛВПЗжФкШнЁЃИќживЊЕФЪЧвЊЙЙНЈШЮЮёЕФХфжУЃЌЙмРэЃЌМрПиЃЌЕїЖШЕШЗўЮёЃЌвдМАЖдећИіЪ§ОнЭЌВНвЕЮёСїГЬКЭЩњУќжмЦкЕФЗтзАЃЌКЭЖдгУЛЇНЛЛЅЬхбщМАВњЦЗаЮЬЌЕФЭъЩЦЁЃРэЯыжаЃЌашвЊКЭПЊЗЂЦНЬЈећЬхПЊЗЂЛЗОГЩюЖШМЏГЩЁЃ
DataX
DataXЪЧАЂРяПЊдДЕФвЛПюВхМўЪНЕФЃЌвдЭЈгУЕФвьЙЙЪ§ОнНЛЛЛЮЊФПБъЕФВњЦЗЁЃЦфКЫаФЫМЯыЃЌМђЕЅЕФЫЕЃЌОЭЪЧжЎЧААЂРяЕФЭЌбЇаДИїжжЪ§ОндДжЎМфЕФЭЌВНЙЄОпЃЌЖМЪЧЕуЖдЕуЕФЪЕЯжЃЌаДЖрСЫвдКѓЃЌЗЂЯжетжжСНСНжЎМфЭјзДСДТЗЕФПЊЗЂДњМлБШНЯИпЁЃЖјDataXФиЃЌЪЧЭЈЙ§БъзМЛЏЕФЪфШыЪфГіФЃПщЃЌНЋЕуЖдЕуЕФЪЕЯжБфГЩСЫаЧаЮЕФЭиЦЫНсЙЙЃЌдіМгвЛИіЪ§ОндДжЛвЊЕЅЖРаДетИіЪ§ОндДЕФЪфШыЪфГіЪЕЯжФЃПщОЭКУСЫЁЃ
ЦфЪЕЃЌетИіЫМТЗвВУЛЪВУДДѓВЛСЫЕФЃЌКЭЧАУцЕФFlumeЃЏLogStashЕШЕФЫМЯыВЂУЛгаБОжЪЕФВюБ№ЃЌШЫМввЛПЊЪМОЭУЛгазпЭјзДНсЙЙЕФТЗ
ЃКЃЉ
ВЛЙ§ЃЌDataXЕФЬиЕуЪЧФкВПЕФНсЙЙИќМгМђЕЅвЛаЉЃЌУЛгаchannelАЁжЎРрЕФИХФюЃЌВЛОпБИГжОУЛЏФмСІЃЌвВУЛДђЫуЙЙНЈИДдгЕФЪ§ОнСїЖЏСДТЗЁЃФуПЩвдШЯЮЊЫќБОжЪЩЯОЭЪЧНЋСНИіЪ§ОндДжЎМфЕуЖдЕуЕФДЋЪфЙЄзїФЃПщЛЏБъзМЛЏСЫЃЌзюжеЙЙНЈГіРДЕФЃЌЛЙЪЧвЛИіМђЕЅЕФНјГЬФкжБСЌЕФЪ§ОнЖСаДСДТЗЁЃ
ДЫЭтДгвЛПЊЪМЃЌDataXЕФФПБъОЭЪЧдкМђЛЏаТСДТЗПЊЗЂДњМлЕФЛљДЁЩЯЃЌзЗЧѓЪ§ОнЕФДЋЪфаЇТЪЁЃБШШчЃЌЪЙгУСЫRingbufferРрЕФММЪѕРДзіinputКЭoutputФЃПщжЎМфЕФЪ§ОнзЊЗЂЙЄзїЁЃ
вђЮЊDataXМђЕЅКЭБъзМЛЏЕФЬиЕуЃЌЫљвдвВгаВЛЩйЙЋЫОЛљгкDataXРДЙЙНЈздМКЕФвьЙЙЪ§ОнНЛЛЛЗўЮёЯЕЭГЁЃ
ЕБШЛЃЌDataXвВдкГжајИФНјжаЃЌФПЧАЕФ3.0АцБОдкзївЕЕФЗжЦЌДІРэЃЌвЕЮёШнДэЃЌЪ§ОнзЊЛЛЃЌСїСППижЦЕШЗНУцвВзіСЫВЛЩйЕФЙІФмЭиеЙЁЃ
Heka
HekaЪЧMozillaПЊдДЕФвЛЬзСїЪНЪ§ОнВЩМЏКЭЗжЮіЙЄОпЃЌзюжївЊЕФМмЙЙЪЕЯжЃЌЦфЪЕвВОЭЪЧЪ§ОнВЩМЏЭЌВНетВПЗжПђМмЁЃећЬхЕФНсЙЙЩшМЦКЭLogStashЕШЯЕЭГПДЦ№РДДѓЭЌаЁвьЁЃетИіЯЕЭГЃЌЮвВЂУЛгазіЙ§ЪЕМЪЕФЪЕМљгІгУЃЌжЛЪЧМђЕЅСЫНтСЫвЛЯТВњЦЗЩшМЦЃЌЬсЫќФиЃЌЪЧвђЮЊМмЙЙПДЦ№РДвВЯрЖдБШНЯЭъЩЦЃЌСэЭтЃЌЫќЪЧгУGoаДЕФЃЌЦЋЕзВуКѓЖЫЗўЮёПЊЗЂЕФЭЌбЇПЩФмЛсЯВЛЖЁЃ
Ъ§ОнНЛЛЛЗўЮёВњЦЗЩшМЦКЭашЧѓЗжЮі
ДгЧАУцЕФвЕЮёГЁОАЬжТлКЭЪаУцЩЯГЃМћЕФЯЕЭГЕФНщЩмжаЃЌФугІИУВЛФбПДГіЃЌЪ§ОнЭЌВНЪЧвЛИівЕЮёИВИЧЗЖЮЇКмЙуЕФЪѕгяЃЌОпЬхЕФВњЦЗаЮЬЌЩшМЦКЭЙІФмашЧѓЃЌЦфЪЕдкКмДѓГЬЖШЩЯШЁОігкФуЫљЖЈЮЛЕФвЕЮёЕФжАФмЗЖЮЇЁЃ
ЮвЫОЕФДѓЪ§ОнПЊЗЂЦНЬЈжаЃЌЪ§ОнНЛЛЛЗўЮёЯЕЭГЕФЖЈЮЛЃЌКЭDataXБШНЯРрЫЦЃЌЯЕЭГЕФЙІФмКЭВњЦЗаЮЬЌЖЈЮЛЃЌЪЧвьЙЙЪ§ОндДжЎМфЕФЕуЖдЕуЪ§ОнЖСаДСДТЗЕФЙЙНЈЁЃжСгкБШШчвЕЮёЖЫЕФЪ§ОнВЩМЏЃЌЪ§ОнЗжМЖДЋЪфСДТЗЕФЙЙНЈЃЌдіСПЪ§ОнЕФЗжЗЂЃЌЪ§ОнПтЭЌВНЭиЦЫТпМЙмРэЕШЛЗНкЃЌВЂВЛдкЮвУЧЕФЪ§ОнНЛЛЛЗўЮёЯЕЭГЕФЙІФмЖЈвхЗЖЮЇжЎФкЃЌетаЉЛЗНкВЂВЛЪЧВЛживЊЃЌжЛЪЧдкЮвЫОЕФЪЕМљжаЃЌЪЧгЩЦфЫќЕФЯЕЭГРДЖРСЂЬсЙЉЗўЮёЕФЁЃ
ЖјЕуЖдЕуЕФЪ§ОнЖСаДСДТЗЗўЮёВњЦЗЕФзщГЩЃЌгжПЩвдЗжЮЊСНВПЗжЃЌвЛЪЧЕзВуОпЬхГадиСЫЕЅИіЪ§ОнНЛЛЛШЮЮёЕФВхМўЪНЕФЪ§ОнНЛЛЛзщМўЃЌЖўЪЧЩЯВуЕФЪ§ОнНЛЛЛШЮЮёЙмПиЦНЬЈЃЌЦфжАФмЗЖЮЇВЛНіАќРЈЯЕЭГКЭШЮЮёздЩэЕФХфжУдЫааЙмРэЃЌгаЪБКђЛЙашвЊПМТЧеыЖдЩЯЯТгЮЯЕЭГКЭОпЬхвЕЮёЕФвЛаЉЬиадНјааСїГЬЩЯЕФЪЪХфКЭЖЈжЦЁЃ
ЯТУцЕФЬжТлЛљгкЩЯЪіВњЦЗЖЈЮЛеЙПЊЃК
Ъ§ОнНЛЛЛЕзВузщМў
ЕзВузщМўЩшМЦашвЊЙизЂЕФЕиЗНЃЌдкЧАУцЕФИїжжПЊдДЯЕЭГЕФНщЩмжаЃЌЦфЪЕДѓЖрЖМвбОЩцМАЕНСЫЁЃ
ЪзЯШЃЌДгПђМмНсЙЙЕФНЧЖШРДЫЕ
ећИіЪ§ОнЕФЖСаДзЊЛЛСїГЬЃЌРэЯыжаЕБШЛЪЧУПИіЛЗНкЖМФмвдPluginЕФЗНЪННјааСщЛюЭиеЙЁЃСДТЗЛЗНкВ№ЕУдНЯИЃЌЖЈжЦФмСІЕБШЛОЭдНКУЃЌЕЋЪЧвЊЭЌЪББЃГжЯЕЭГећЬхЕФвзгУадвВОЭЯрЖдИќМгРЇФбвЛЕуЁЃ
ФЧУДЃЌЪ§ОнНЛЛЛЖСаДСДТЗЕФЗжНтЃЌДѓжТПЩвдЗжЮЊМИИіФЃПщФиЃЌЭљДѓСЫВ№ЗжЃЌВюВЛЖрОЭЪЧЃКЪфШыЃЌЙ§ТЫзЊЛЛЃЌЪфГіетШ§ИіФЃПщЁЃ
дйЯИЛЏвЛаЉЃЌЮЊСЫЬсИпФЃПщЕФИДгУФмСІЃЌФЧУДЛЙПЩвдДгЪфШыФЃПщжаВ№НтГіDecoderФЃПщЃЌДгЪфГіФЃПщжаВ№НтГіEncoderФЃПщ
зюКѓЃЌЮЊСЫДяЕНЪ§ОнСДТЗИДгУЕФФПЕФЃЌЛЙПЩвддкЪфГіФЃПщжЎЧАдіМгвЛИіТЗгЩФЃПщЃЌНЋвЛЗнЪ§ОнВ№ЗжЛђИДжЦЪфГіЕНЖрИіФПБъдДжаЁЃВЛЙ§ЃЌШчЙћдкПђМмжав§ШыСЫетбљЕФЩшМЦЃЌЪЕМЪЩЯЪЧНЋвЕЮёСїГЬЗНУцЕФИДдгЖШЯТГСЕНЕзВузщМўжаРДЃЌЪЧЗёжЕЕУЃЌШчКЮШЁЩсЃЌОЭвЊПДећЬхЯЕЭГЕФЩшМЦЫМТЗСЫЁЃ
ЦфДЮЃЌДгадФмЕФНЧЖШПМТЧ
ЮЊСЫЬсЩ§адФмЃЌГ§СЫвЊЧѓжДааНкЕуОпБИЫЎЦНЭиеЙФмСІЃЌЛЙашвЊПМТЧжЇГжЕЅИізївЕЕФЗжВМЪНжДааФмСІЁЃ
ЧАепШчКЮЪЕЯжШЁОігкЪ§ОнЭЌВНЗўЮёЯЕЭГЕФМмЙЙЩшМЦЃЌШчЙћЪЧВЩгУserverФЃЪНЕФЗўЮёЃЌПЭЛЇЖЫЬсНЛШЮЮёЧыЧѓЕНЗўЮёЖЫжДааЕФЃЌФЧУДашвЊServerЖЫФмЙЛЫЎЦНЭиеЙШЮЮёЕФworkerжДааНкЕуЃЌетИіЭЈГЃВЛЛсЬЋФбЃЌОЭЪЧашвЊздМКЙмРэЙЄзїНкЕуЃЌЛђепвРЭаЦфЫќМЏШКЗўЮёЃЌБШШчЬсНЛMRШЮЮёЕНHadoopМЏШКЩЯжДааЁЃЖјШчЙћВЩгУЕФЪЧБОЕиНјГЬФЃЪНЃЌПЭЛЇЖЫдкФФРяЗЂЦ№ЕїгУОЭдкФФРяжДааЃЌФЧУДзЪдДЕїЖШКЭИКдиОљКтЕФЙЄзїЃЌЭЈГЃОЭЛсЩЯвЦЕНЙЄзїСїЕїЖШЯЕЭГЩЯРДЙмРэЃЌЪ§ОнЭЌВНЗўЮёздЩэВЛИКд№ЙЄзїНкЕуЕФЙмПиЁЃ
КѓепЃЌЕЅИізївЕЕФЗжВМЪНжДааФмСІЃЌЪЕЯжЦ№РДОЭИДдгвЛаЉСЫЁЃвђЮЊетЩцМАЕНЕЅИізївЕФкВПЪ§ОнЕФЗжЦЌДІРэЁЃЕБЪ§ОндДЪЧHadoopРрЕФЯЕЭГЪБЃЌгЩгкетРрЯЕЭГДгМмЙЙЩшМЦЕФНЧЖШЃЌЬьЩњОЭжЇГжЪ§ОнЗжЦЌЕФФмСІЃЌЫљвдЪЕЯжЦ№РДЭЈГЃЖМВЛЛсЬЋРЇФбЃЌЕЋЪЧЖдгкDBЃЌЯћЯЂЖгСаРрЕФЪ§ОндДЃЌШчКЮЪЕЯжЗжЦЌЃЌЭљЭљОЭвЊИДдгвЛаЉСЫЁЃ
вдDBЩЈБэШЮЮёЮЊР§ЃЌФувЊЗжЦЌжДааЃЌФЧОЭашвЊЪ§ОнБэОпБИЗжЖЮМьЫїЕФФмСІЃЌзюКУЪЧПЩвдЛљгкжїМќЫїв§НјааЗжЖЮМьЫїЃЌЗёдђжЛЪЧЕЅДПЕФЬѕМўЙ§ТЫЃЌЛсДѓДѓМгДѓЖдDBЕФбЙСІЁЃЕЋЪЧЃЌЯжЪЕгІгУжаЃЌКмПЩФмВЂВЛЪЧЫљгаЕФБэЖМОпБИШЗЖЈЗЖЮЇЕФжїМќЃЌгааЉжїМќвВПЩФмЪЧЗЧСЌајРыЩЂЕФЃЌетаЉЖМЛсЕМжТКмФбОљКтЕФЖдЪ§ОнНјааЗжЦЌЃЌНјЖјгАЯьЗжЦЌжДааЕФаЇТЪЁЃ
СэЭтЃЌЛљгкDataXетжжЪфШыЪфГіЖЫЖРСЂВхМўЫМЯыЙЙНЈЕФЪ§ОнНЛЛЛСДТЗЃЌШчКЮКЭHadoopЬхЯЕЕФЪ§ОндДЕФЪ§ОнЗжЦЌДІРэСїГЬИќКУЕФНсКЯЃЌГфЗжРћгУКУдЩњЕФЗжВМЪНДІРэФмСІЃЌвВЪЧашвЊзаЯИЙЙЫМЕФЁЃ
зюКѓЃЌДгвЕЮёЮШЖЈадЕФНЧЖШПМТЧ
вЊБЃжЄвЕЮёЕФЮШЖЈадЃЌДгЕзВузщМўЕФНЧЖШРДЫЕЃЌећЬхЯЕЭГЕФСїПиКЭЪЇАмжиЪдетСНИіЛЗНкЭљЭљвВЪЧашвЊжиЕуПМТЧЕФЁЃвђЮЊЪ§ОнНЛЛЛЗўЮёЫљЖдНгЕФЭтВПДцДЂЯЕЭГЃЌЭЈГЃЛЙГадиСЫЦфЫќЕФвЕЮёЁЃЫљвдЦфИКдиФмСІЭљЭљЖМгавЛЖЈЕФдМЪјвЊЧѓЃЌЦфвЕЮёЛЗОГвВВЛЪЧЭъШЋПЩПиЕФЁЃвђДЫЪ§ОнНЛЛЛЗўЮёзщМўЃЌашвЊФмЙЛдМЪјздМКЕФааЮЊЃЌЭЌЪБгІЖдПЩФмЗЂЩњЕФДэЮѓЁЃЦфФПЕФЃЌЖМЪЧЮЊСЫЬсЩ§ећЬхСДТЗЕФЮШЖЈадЃЌНЕЕЭЮЌЛЄДњМлЁЃ
Ъ§ОнНЛЛЛЗўЮёЙмПиЦНЬЈ
зїЮЊЗўЮёЃЌВЛЬсЙЉПЩЪгЛЏЕФЙмПиЦНЬЈЃЌжЛЬсЙЉУќСюааНЛЛЅЗНЪНЃЌФЧОЭЪЧЫЃСїУЅЁЃ
ЙмПиЦНЬЈЙмЪВУДЃПЪзЯШЃЌЕБШЛЪЧЙмРэЪ§ОнНЛЛЛзївЕЕФШЮЮёХфжУаХЯЂСЫ
БъзМЕФзіЗЈЃЌЛљБОЖМЪЧШУгУЛЇЭЈЙ§UIНчУцЃЌвдВЮЪ§ЕФаЮЪНХфжУШЮЮёаХЯЂЃЌБШШчЪфШыЪфГіЪ§ОндДЃЌБэИёЃЌзжЖЮаХЯЂЃЌЗжЧјаХЯЂЃЌЙ§ТЫЬѕМўЃЌвьГЃЪ§ОнДІРэЗНЪНЃЌЕїЖШЪБМфЃЌВЂЗЂЖШПижЦЃЌСїСППижЦЃЌдіСПЛђШЋСПХфжУЃЌЩњУќжмЦкЕШЕШЁЃзмжЎЃЌОЭЪЧОЁСПШУгУЛЇФмЙЛЭЈЙ§ХфжУаХЯЂРДБэДяздМКЕФвЕЮёЫпЧѓЁЃ
ЕБШЛЃЌШЮЮёПЩЙЉХфжУЕФВЮЪ§дНЖрЃЌЪЙгУЦ№РДПЩФмОЭдНЗБЫіЃЌДЫЭтЃЌвЛаЉИДдгЕФЙ§ТЫЃЌОлКЯЛђзЊЛЛТпМЃЌКмПЩФмвВУЛАьЗЈМђЕЅЕФгУХфжУЕФЗНЪННјааБэДяЃЌетЪБКђОЭашвЊПМТЧЬсЙЉздЖЈвхзщМўЕФЙмРэЗНЪНСЫЁЃ
Г§ШЅЪ§ОнНЛЛЛШЮЮёздЩэХфжУаХЯЂЕФЙмРэЃЌЪ§ОнНЛЛЛЗўЮёЙмПиЦНЬЈашвЊЬсЙЉЕФЦфЫќЗўЮёЃЌЦфЪЕКЭДѓЪ§ОнПЊЗЂЦНЬЈЩЯЦфЫќРраЭЕФзївЕШЮЮёЕФЙмРэЪЎЗжРрЫЦЃЌБШШч:
1.ЬсЙЉЪ§ОнНЛЛЛШЮЮёЕФжДааСїЫЎаХЯЂЃЌБугкгУЛЇВщбЏШЮЮёжДааЧщПіКЭНјаавЕЮёНЁПЕЗжЮі
2.ЬсЙЉШЈЯоЙмПиКЭвЕЮёЗжзщЙмРэЃЌИќКУЕФжЇГжЖрзтЛЇЛЗОГгІгУГЁОА
3.ЬсЙЉЯЕЭГСїСПИКдиМрПиЃЌШЮЮёДэЮѓИњзйБЈОЏЕШЃЌИќКУЕФжЇГжШеГЃЕФЯЕЭГМАвЕЮёдЫааЮЌЛЄЙЄзїЁЃ
етаЉЗўЮёПЩвдгЩЪ§ОнНЛЛЛЗўЮёЦНЬЈЖРСЂЬсЙЉЃЌЕЋзюРэЯыЕФЃЌЛЙЪЧКЭПЊЗЂЦНЬЈЕФЦфЫќзївЕШЮЮёШкКЯЕНЭЌвЛИіЦНЬЈЩЯНјааЙмРэЃЌМДЪЙЕзВужЇГХЖдгІЗўЮёЕФКѓЬЈПЩФмЪЧЖРСЂЕФЃЌдкгУЛЇНЛЛЅКѓЬЈЩЯЃЌвВвЊОЁПЩФмМЏГЩЕНвЛЦ№ЁЃвЛЗНУцМѕЩйжиИДПЊЗЂЕФДњМлЃЌСэвЛЗНУцЃЌНЕЕЭгУЛЇЕФбЇЯАЪЙгУГЩБОЁЃ
ЩЯЯТгЮЯЕЭГКЭвЕЮёСїГЬЪЪХф
ФуЮоЗЈзѓгвБ№ШЫЃЌЕЋЪЧФуПЩвдИФБфздМКЁЃКмЖрЪБКђЃЌЪ§ОнЭЌВНЗўЮёЃЌашвЊХфКЯЩЯЯТгЮЯЕЭГЃЌНјааБивЊЕФСїГЬЖЈжЦЃЌРДТњзувЕЮёЕФашЧѓЁЃ
Ъ§ОнНсЙЙБфИќ
Ъ§ОнЭЌВНвЕЮёЃЌзюОГЃгіЕНЕФЮЪЬтЃЌОЭЪЧвЕЮёDBЕФЪ§ОнНсЙЙЗЂЩњБфИќЃЌЕМжТШЮЮёдЫааЪЇАмЁЃ
Ъ§ОнНсЙЙЕФБфИќЃЌЭЈГЃКмФбздЖЏНтОіЁЃБШШчгУЛЇздЖЈвхСЫЪ§ОнЩЈУшЕФгяЗЈЃЌЕБЪ§ОнНсЙЙБфИќвдКѓЃЌвбОЗЧЗЈСЫЃЛБШШчдДБэЕФзжЖЮаХЯЂЗЂЩњСЫдіЩОИФЃЌФПБъБэШчКЮгГЩфЪЪХфЃПРњЪЗЪ§ОнФмЗёзЊЛЛДІРэЃЌЪЧЗёашвЊзЊЛЛДІРэЃПСэЭтЃЌВЛЭЌЕФЪ§ОндДЃЌдіЩОИФЕФДІРэЗНЪНвВПЩФмВЛЭЌЃЌвЕЮёЗНЯЃЭћВЩШЁЕФгІЖдЗНЪНПЩФмвВКЭОпЬхвЕЮёТпМЯрЙиЁЃЫљвдЃЌКмЖрЧщПіЯТЃЌЪ§ОнНсЙЙЕФБфИќЃЌЖМЪЧашвЊШЫЙЄИЩдЄЕФЁЃ
ФЧУДЯЕЭГФмзіаЉЪВУДФиЃПздШЛЪЧЭЈЙ§ЙЄОпОЁПЩФмЕФНЕЕЭетИіБфИќЙ§ГЬЕФДњМлЃЌБШШч
1.МрПидДБэдЊЪ§ОнЕФБфИќЃЌЬсдчЗЂЯжЮЪЬтЃЌЬсдчНтОіЃЌБмУтдкАывЙеце§жДааШЮЮёЪБВХГіДэБЈОЏ
2.ЙцЗЖвЕЮёСїГЬЃЌБШШчдМЖЈзжЖЮЕФБфИќЗНЪНЃЌБфИќЕФЭЈжЊЛњжЦЕШЃЌЭЈЙ§зюМбЪЕМљНЕЕЭЮЪЬтЗчЯеИХТЪ
3.ЖдвЛаЉвбжЊГЁОАЬсЙЉБъзМЛЏЕФздЖЏДІРэЗНЪНЃЌМѕЩйШЫЙЄИЩдЄЕФашвЊЃЌМгПьЪ§ОнзЊЛЛЃЌжиНЈДІРэСїГЬЕШЕШ
Ъ§ОнЪБМфЮЪЬт
дкРыЯпвЕЮёжаЃЌДѓСПЕФЪ§ОнЕМШыШЮЮёЖМЪЧдкСшГПИННќЕМШыЧАвЛЬьЕФЪ§ОнНјааХњДІРэЗжЮіЁЃетжжГЁОАЯТОГЃПЩФмЛсгіЕНвдЯТЮЪЬтЃК
Ъ§ОнПЩФмгЩгкИїжждвђЭэЕНЃЌдкЪ§ОнЕМШыШЮЮёПЊЪМжДааЕФЪБКђЃЌЧАвЛЬьЕФЪ§ОнЛЙУЛгаЭъШЋЕНЮЛЁЃ
Ъ§ОнЭэЕНЕФПЩФмдвђКмЖрЃЌБШШчDBжїДгбгГйЬЋДѓЃЌПЭЛЇЖЫЩЯБЈВЛМАЪБЃЌвЕЮёЖЫВЩМЏСДТЗвђЮЊСїСПЛђИКдиЛђЙЪеЯЕШдвђЮДФмМАЪБВЩМЏЪ§ОнЕШЕШЁЃ
етЪБКђЃЌЭЈГЃЕФзіЗЈЃЌвЛЪЧНЋШеГЃЪ§ОнВЩМЏЪБМфЪЪЕБЭљКѓЭЦГйвЛаЁЖЮЪБМфЃЈБШШч15ЗжжгЕНАыИіаЁЪБЃЉНЕЕЭЮЪЬтГіЯжЕФИХТЪЁЃЖўЪЧЭљЭљашвЊЖдИїжжСДТЗвбжЊПЩФмбгГйЕФЛЗНкНјааМрПиЃЌБШШчВЩМЏDBжїДгбгГйЪБМфЃЌЖгСаЯћЗбНјЖШЕШЕШЃЌМАЪББЈОЏЛђзшЖЯЯТгЮШЮЮёЕФжДааЁЃШ§ЪЧЖдЭэЕНЕФЪ§ОнЃЌашвЊИљОнвЕЮёашЧѓжЦЖЈЪЪЕБДІРэВпТдЃЌЪЧЖЊЦњЛЙЪЧВЙГфЛиаДЕНЧАвЛЬьЕФЪ§ОнжаЃЌЛЙЪЧжБНгЛЎШыЕкЖўЬьЕФЪ§ОнРяЕШЕШЁЃ
Ъ§ОнБОЩэУЛгаЪжЖЮЧјЗжвЕЮёИќаТЪБМфЃЌОпЬхжДааНсЙћвРРЕгкШЮЮёжДааЪБМф
БШШчDBЩЈБэЕФШЮЮёЃЌШчЙћБэИёжаУЛгагУгкЧјЗжвЕЮёЪБМфЕФзжЖЮЃЌЕЋЪЧЭГМЦвЕЮёжаШДашвЊАДШеЦкЛЎЗжЭГМЦЃЌОЭжЛФмППСшГПОЋШЗЕФЪБМфЕуВЩМЏРДЪЕЯжСЫЃЌетОЭКмоЯоЮСЫЃЌвђЮЊФуКмПЩФмЮоЗЈБЃжЄШЮЮёПЊЪМжДааЕФЪБМфЁЃФуПЩФмЛсЫЕетжжЧщПіЪЧDBБэНсЙЙЩшМЦЕУгаЮЪЬтЃЌЕФШЗШчДЫЃЌетЪБКђОЭашвЊЭЦЖЏвЕЮёЗННјааИФдьСЫЁЃ
ЛЙгавЛжжЧщПіИќГЃМћвЛаЉЃЌОЭЪЧDBБэИёжаЕФШЗДцдквЕЮёИќаТзжЖЮЃЌЕЋЪЧЃЌЭЌвЛжїМќЕФЪ§ОнПЩФмгаЖрИізДЬЌБфЧЈЃЌЛсБЛИќаТЖрДЮЁЃЖјЪБМфДСжЛгавЛИіЁЃОйИіР§згЃЌБШШчФугавЛИіЖЉЕЅаХЯЂБэИёЃЌРяУцМЧТМСЫЯТЕЅЃЌИЖПюЃЌЗЂЛѕЃЌЪеЛѕЃЌШЗШЯЕШЕШВЛЭЌЕФзДЬЌЃЌЕЋЪЧЃЌжЛгавЛИіupdateзжЖЮЁЃФЧУДИљОнФГвЛИіЪБМфЕуЩЈУшЕФЪ§ОнЃЌФуПЩФмЮоЗЈХаЖЯГіетаЉзДЬЌЗЂЩњБфЛЏЕФзМШЗЪБМфЃЌФЧУДОЭгаПЩФмЗЂЩњЭГМЦЙщЪєДэЮѓЛђепвХТЉЕФЧщПіЁЃ
етСНжжЧщПіЃЌЭЈГЃЖМЪЧвђЮЊвЕЮёЗНЕФвЕЮёСїГЬБОЩэВЂВЛвРРЕгкетаЉЪБМфаХЯЂЕФМЧТМЃЌЕЋЪЧзіЪ§ОнЭГМЦЕФЪБКђашвЊетаЉаХЯЂЃЌЖјвЕЮёПЊЗЂЗНКЭЪ§ОнЭГМЦЗНИКд№ЕФЭЌбЇЪЧСНВІШЫЃЌПЊЗЂЗНУЛгаГфЗжПМТЧЭГМЦЕФашЧѓЁЃ
гаЪБКђетжжЧщПіЮЪЬтвВВЛДѓЃЌБШШчАывЙвЕЮёБфИќВЛЦЕЗБЃЌЪ§ОнВЩМЏЙ§ГЬГйвЛаЉдчвЛаЉЃЌЪ§ОнЦЋВюЖМВЛДѓЃЌЛђепетРрЪ§ОнЭГМЦЕНЧАвЛЬьЛЙЪЧКѓвЛЬьЖМУЛгаЬЋДѓЕФЙиЯЕЁЃЕЋЪЧЃЌЕБГіЯжДѓЗЖЮЇЪБМфЦЋвЦЃЌЛђепФуашвЊжиХмРњЪЗЪ§ОнЕФЪБКђЃЌБШШчНёЬьжиХмЩЯжмЕФЪ§ОнЃЌФЧУДДгЕБЧАDBПьееЮоЗЈИДдвЕЮёзжЖЮБфИќЕФОпЬхЪБМфЕуЃЌОЭЛсГЩЮЊвЛИіЮоЗЈКіЪгЕФЮЪЬтСЫЁЃ
змЬхРДЫЕЃЌетРрЮЪЬтЕФНтОіЃЌЪзЯШЪ§ОнЭЌВНЗўЮёздЩэЕУЬсЙЉИљОнвЕЮёЪБМфЙ§ТЫЪ§ОнЕФЪжЖЮЃЌЦфДЮвЊЭЦЖЏвЕЮёЗНИФдьЪ§ОнНсЙЙЃЌБмУтГіЯжЮоЗЈЛЙдЕФГЁОАЃЌзюКѓЃЌгааЉвЕЮёЛЙПЩвдЭЈЙ§ВЩМЏbinlogЕШЪЕЪБдіСПЕФаЮЪНЃЌЭЈЙ§ЗжЮіУПДЮЪ§ОнЕФОпЬхБфЛЏЪБађРДНтОіЃЈЕБШЛЃЌгЩгкlogБЃДцЪБМфгаЯоЃЌЖдгкГЄЪБМфПчЖШжиХмЕФГЁОАЃЌЪЧЮоЗЈЭЈЙ§етжжЗНЪНРДНтОіЕФЃЉ
ЗжПтЗжБэДІРэ
ЗжПтЗжБэЃЌДѓИХЪЧвЕЮёЩЯСЫЙцФЃвдКѓЃЌДѓМвЖМЯВЛЖзіЕФЪТЁЃЕЋЪЧDBжаЗжБэПЩвдЃЌЕМШыЕНБШШчHiveжавдКѓЃЌФуЕУЯыАьЗЈКЯВЂАЁЃЌБугкКѓајИїжждЫЫуТпМЕФПЊЗЂКЭЭГМЦВщбЏНХБОЕФзЋаДЃЌФЧУДЮЪЬтРДСЫЃК
БШШчФуЪЧЭЈЙ§ЩЈБэЕФЗНЪНЛёШЁЪ§ОнЃЌШчЙћУЛгаРрЫЦАЂРяЕФTDDLетбљЕФЗжПтЗжБэжаМфМўРДЦСБЮDBЗжПтЗжБэЯИНкЃЌФуЛсашвЊздМКДІРэЯрЙиТпМЃЌЙмРэКЭСЌНгЫљгаЪ§ОнЪЕР§ЁЃШчЙћзпbinlogЛёШЁЪ§ОнЃЌдкЗжПтЕФГЁОАЯТвВашвЊздМКЯыАьЗЈКЯВЂЪ§ОнВЩМЏСїГЬКЭНсЙћЁЃ
ИќТщЗГЕФЪЧЃЌШчЙћФуЕФвЕЮёЗНЗжБэЩшМЦЕФЪБКђЃЌВЛЙЛЙцЗЖЃЌВЛЭЌЕФЗжБэжЎМфУЛгаЮЈвЛЕФжїМќПЩвдМгвдЧјЗжЃЈПЩвдЧјЗжЕФзжЖЮЃЌвВПЩФмВЛЪЧжїМќЃЉЃЌФЧУДдкКЯВЂЪ§ОнЕФЪБКђЃЌФуПЩФмОЭашвЊдЪаэгУЛЇздЖЈвхКЯВЂгУзжЖЮЃЌЛђепздЖЏФѓдьГівЛИіжїМќГіРДЃЌБмУтЪ§ОнЕФГхЭЛ
етИіЮЪЬтЭЌбљЃЌзюРэЯыЕФНтОіЗНАИвВЪЧЭЈЙ§ЭЦЖЏDBЗжПтЗжБэжаМфМўЕФНЈЩшКЭвЕЮёЙцЗЖЕФНЈСЂРДНтОіЃЌЕЋетЖдКмЖрЙЋЫОРДЫЕЭљЭљВЛЪЧвЛМўМђЕЅЕФЪТЃЌЫљвдЃЌдкДЫжЎЧАЃЌОЭашвЊздМКЯыАьЗЈЖЈжЦНтОіСЫЁЃ
Ъ§ОнКЯВЂШЅжиЕШ
ЭЈЙ§binlogдіСПЗНЪНРДЛёШЁDBБфИќЪ§ОнЃЌгХЪЦЪЧЪБаЇадКУЃЌгаЪБвВЪЧФГаЉГЁОАЯТЮЈвЛЕФНтОіЗНАИЁЃЕЋЪЧвђЮЊзпBinlogРДИјРыЯпХњДІРэШЮЮёЭЌВНЪ§ОнЃЌЪЕМЪЩЯЃЌЪ§ОнЪЧОЙ§СЫБэ-Сї-БэетжжФЃЪНЕФЧаЛЛЃЌЖјетжжЧаЛЛвВЛсДјРДИНМгЕФЮЪЬт
ДгБэЕФБфЛЏНтЮіГЩЪ§ОнСїЃЌетИіЙ§ГЬЮЪЬтВЛДѓЃЌЕЋДгЪ§ОнСїжиаТЙЙНЈЛиБэИёЃЌОЭЛсгаМИИіЮЪЬташвЊЙизЂСЫЃК
ШЁОігкЪ§ОнСїДЋЪфЕФЗНЪНЃЌЪ§ОнСїПЩФмЗЂЩњТвађЃЌжиИДЕФЮЪЬтЃЌЖджиЙЙБэИёДјРДРЇФбЁЃ
БШШчгУЯћЯЂЖгСаДЋЪфЪ§ОнЃЌИїИіЗжЧјЕФЪ§ОнПЩФмЮоЗЈБЃГжШЋОжгаађадЃЌЯћЯЂЖгСаБОЩэПЩФмвВЮоЗЈБЃжЄExactly
onceЕФЭЖЕнЁЃШчЙћвЕЮёСїГЬВЛФмдЪаэетРрЮЪЬтЕФЗЂЩњЃЌФЧОЭашвЊеыЖдадЕФМгвдЗРЗЖСЫЃЌБШШчНсКЯвЕЮёжЊЪЖЃЌЪЙгУКЯЪЪЕФЗжЧјзжЖЮЃЌЪЙЕУОжВПгаађЕФЪ§ОнЖдвЕЮёНсЙћВЛЛсдьГЩгАЯьЁЃ
ФПБъЖЫЪ§ОндДЃЌБШШчЯёHDFSЛђHiveЮФМўЃЌПЩФмжЛдЪаэЬэМгМЧТМЃЌЛђШЋОжжиаДЃЌЖјЮоЗЈЕЅЬѕЩОГ§ЛђепИќаТМЧТМЁЃ
етжжЧщПіЯТШчЙћдДЖЫЪ§ОндДРрЫЦDBжаЃЌвЛЬѕМЧТМЗЂЩњЖрДЮБфИќЃЌОЭЛсЩњГЩЖрЬѕБфИќМЧТМЃЌЖјЯТгЮШЮЮёБШШчвЛЬьЕФХњДІРэШЮЮёЃЌжЛашвЊзюКѓСшГПЪБМфЕуЩЯЕФзДЬЌаХЯЂЃЌетЪБКђОЭашвЊЖдБфИќМЧТМНјааКЯВЂСЫЁЃ
КЯВЂЪ§ОнЕФПЩФмЗНЗЈКмЖрЃЌШЁОігкОпЬхЕФвЕЮёГЁОАКЭДњМлЃЌЮДБигаЭГвЛЕФзюМбЗНАИЁЃЪзЯШФуашвЊНтОіЪ§ОнТвађЮЪЬтЃЌШЛКѓЃК
ФуПЩвддкЪ§ОнСїЪНВЩМЏЗНАИЕФКѓЖЫЃЌНЋЪ§ОнЯШаДШывЛИіжЇГжЕЅЬѕМЧТМЩОИФВйзїЕФжаМфЪ§ОндДЃЌШЛКѓЕНЕудйДгетИіжаМфЪ§ОндДЕМГізюжеЪ§ОнЕНФПБъЪ§ОндДЁЃ
ШчЙћЪ§ОнСПВЛДѓЃЌФувВПЩвддкВЩМЏГЬађжаЛузмЫљгаЪ§ОнЃЌШЅжиЭъдйаДГіЕНФПБъЪ§ОндДЁЃ
ФувВПЩвдВЛШЅжижБНгНЋЫљгаБфИќСїЫЎаДШыФПБъЪ§ОндДЃЌЪТКѓдйдЫаавЛИіЧхРэГЬађНјааШЅжиЃЌЧАЬсЪЧГ§ШЅВЩМЏЪБМфЃЌдЪМЪ§ОнжаЛЙОпБИПЩвдгУзїШЅжиХаЖЯЕФвРОнЁЃ
ЮвЫОЯрЙиЗўЮёЕФЯжзДКЭЮДРДИФНјМЦЛЎ
ФПЧАЮвЫОЕФЪ§ОнНЛЛЛЗўЮёЃЌШежОЯрЙиСДТЗЃЌВЩгУCamusКЭздЖЈвхЕФHive Kafka HandlerСНжжЗНЪНВЩМЏЃЌКѓепдкВЩМЏЕФЛљДЁЩЯЬэМгСЫPer
topicЕФЙ§ТЫзЊЛЛТпМЃЌПЩвдЭЈЙ§здЖЈвхHiveqlвЛВНЭъГЩЪ§ОнЕФВЩМЏКЭзЊЛЛЙЄзїЁЃ
ЦфЫќДѓЪ§ОнзщМўжЎМфвдМАгыDBМфЕФЪ§ОнНЛЛЛЗўЮёЃЌгЩздбаЕФгыDataXРрЫЦМмЙЙЕФЯЕЭГГаЕЃЃЌВхМўЪНПЊЗЂЃЌФмЙЛДІРэдіСПЃЏШЋСПЃЌВЂЗЂСїПиЃЌЗжПтЗжБэЕШЧАУцЫљУшЪіЕФГЃМћашЧѓЁЃСэЭтЃЌЙмПиЦНЬЈЛљБОЪЕЯжСЫгУЛЇПЩЪгЛЏЕФХфжУЃЌЙмРэЃЌжДааСїЫЎВщбЏЃЌБфИќМЧТМВщбЏЃЌЯЕЭГИКдиКЭвЕЮёНјЖШМрПиБЈОЏЕШЙІФмЁЃДЫЭтЃЌдкЪ§ОнНЛЛЛШЮЮёЕФЪ§ОнжЪСПМрПиЗНУцЃЌвВзіСЫВПЗжВЩМЏКЭЭГМЦЗжЮіЙЄзїЁЃ
ећЬхРДЫЕЃЌжївЊЕФЗўЮёПђМмСїГЬУЛгаКмДѓЕФЮЪЬтЃЌЕЋЪЧдкгыПЊЗЂЦНЬЈЕФећЬхМЏГЩКЭгУЛЇзджњЗўЮёЕФвзгУадЗНУцгыРэЯыЕФзДЬЌЛЙгаКмДѓЕФВюОрЃЌЦфДЮдкадФмЃЌЮШЖЈадЃЌЭиеЙадЕШЗНУцвВгаКмЖрЙЄзїЕШД§ПЊеЙЃЌдкЪ§ОнжЪСПМрПиЗНУцзіЕФЙЄзївВЯрЖдДжВкЃЌЫљвдЮДРДЕФИФНјЗНЯђЃЌАќРЈЃК
1.ЕзВуЪ§ОнНЛЛЛзщМўЕФНјвЛВНФЃПщЛЏЃЌБъзМЛЏЃЌжиЕуМгЧПгУЛЇздЖЈвхЪ§ОнЙ§ТЫКЭзЊЛЛФЃПщЕФНЈЩш
2.ЕЅИізївЕЗжВМЪНЗжЦЌДІРэЗНАИЕФИФНјЃЌЬсЩ§ДѓБэЭЌВНзївЕЕФДІРэаЇТЪ
3.Ъ§ОнКЯВЂЃЏШЅжиЗНАИЕФИФНјЃЌЬсЩ§адФмЙцБмШнСПЦПОБЃЈФПЧАЕФБфИќКЯВЂЙЄзїЛЙЪЧЭЈЙ§ЖўДЮаДШызЈЪєDBРДЪЕЯжЃЉ
4.ШЮЮёСїСПЃЌИКдиЃЌНјЖШЃЌвьГЃЕШMetricsаХЯЂЕФШЋУцВЩМЏКЭЛузмЗжЮіЃЌБугкМАЪБЗЂЯжЮЪЬтЃЌГжајИФНјвЕЮё
5.ШЋСДТЗЕФЗжМЖШнДэКЭздЖЏжиЪдЛжИДЛњжЦЕФЭъЩЦИФНјЃЈФПЧАЕФШнДэжиЪдЛњжЦЪЧзївЕМЖБ№ЕФЃЌСЃЖШЬЋДжЃЉ
6.ИќМгздЖЏЃЌИќМгЦНЛЌЕФСїПиКЭИКдиИєРыЛњжЦ
7.Ъ§ОнНЛЛЛЗўЮёЙмПиКѓЬЈгыДѓЪ§ОнЦНЬЈећЬхПЊЗЂЛЗОГЕФНјвЛВНШкКЯЃЌЬсЩ§гУЛЇзджїЗўЮёФмСІЃЌНЕЕЭвЕЮёПЊЗЂЮЌЛЄГЩБО
8.ЭъЩЦвьГЃЃЌДэЮѓЗДРЁЛњжЦ: БШШчЖдГЃМћЮЪЬтЃЌЛузмЃЌНтЮіКѓдйУїШЗЕФЗДРЁИјгУЛЇЃЌПЩФмЕФЛАЃЌЬсЙЉНтОівтМћКЭЗНАИЃЌЖјВЛЪЧжБНгХзГівьГЃДњТыЃЌНЕЕЭгУЛЇжЇГжЕФДњМлЁЃ
9.ЧАЪівЕЮёЪ§ОнЪБМфЮЪЬтЕФШЋУцЭЦЖЏИФНјЃЌНЕЕЭЪ§ОнЭЌВНШЮЮёНсЙћЕФВЛШЗЖЈад
аЁНс
змЬхРДЫЕЃЌДѓЪ§ОнПЊЗЂЦНЬЈЕФЪ§ОнЭЌВНЗўЮёЕФЙЙНЈЃЌПЩвдВЮПМЕФЗНАИКмЖрЃЌОпЬхЕФЖСаДзщМўЕФПЊЗЂвВВЂВЛРЇФбЃЌФмЙЛевЕНКмЖрЯжГЩЕФНтОіЗНАИЁЃЖдгкЖрЪ§ЙЋЫОЕФДѓЖрЪ§вЕЮёРДЫЕЃЌЕзВуВЛТлВЩШЁЪВУДЗНАИЃЌЭЈГЃЖМЪЧПЩааЕФЁЃЫљвдЪ§ОнЭЌВНЗўЮёНЈЩшЕФГЩЪьЖШЫЎЦНЃЌЭљЭљЬхЯждкЙмПиЦНЬЈЕФЗўЮёФмСІЫЎЦНКЭвЕЮёНгШыМАдЫЮЌДњМлЕФИпЕЭЁЃ |









