| 编辑推荐: |
本文来自dongkelun,讲各种情况下的sc.defaultParallelism,defaultMinPartitions,各种情况下创建以及转化。
|
|
前言
熟悉Spark的分区对于Spark性能调优很重要,本文总结Spark通过各种函数创建RDD、DataFrame时默认的分区数,其中主要和sc.defaultParallelism、sc.defaultMinPartitions以及HDFS文件的Block数量有关,还有很坑的某些情况的默认分区数为1。
如果分区数少,那么并行执行的task就少,特别情况下,分区数为1,即使你分配的Executor很多,而实际执行的Executor只有1个,如果数据很大的话,那么任务执行的就很慢,好像是卡死了~,所以熟悉各种情况下默认的分区数对于Spark调优就很有必要了,特别是执行完算子返回的结果分区数为1的情况,更需要特别注意。(我就被坑过,我已经分配了足够多的Executor、默认的并行度、以及执行之前的数据集分区数,但分区数依然为1)
1、关于 sc.defaultMinPartitions
sc.defaultMinPartitions=min(sc.defaultParallelism,2)
也就是sc.defaultMinPartitions只有两个值1和2,当sc.defaultParallelism>1时值为2,当sc.defaultParallelism=1时,值为1
上面的公式是在源码里定义的(均在类SparkContext里):
def defaultMinPartitions:
Int = math.min (default Parallelism , 2)
def defaultParallelism: Int = {
assertNotStopped ()
taskScheduler.defaultParallelism
} |
2、关于sc.defaultParallelism
2.1 首先可通过spark.default.parallelism设置sc.defaultParallelism的值
2.1.1 在文件中配置
在文件spark-defaults.conf添加一行(这里用的我的windows环境)
spark.default.parallelism=20
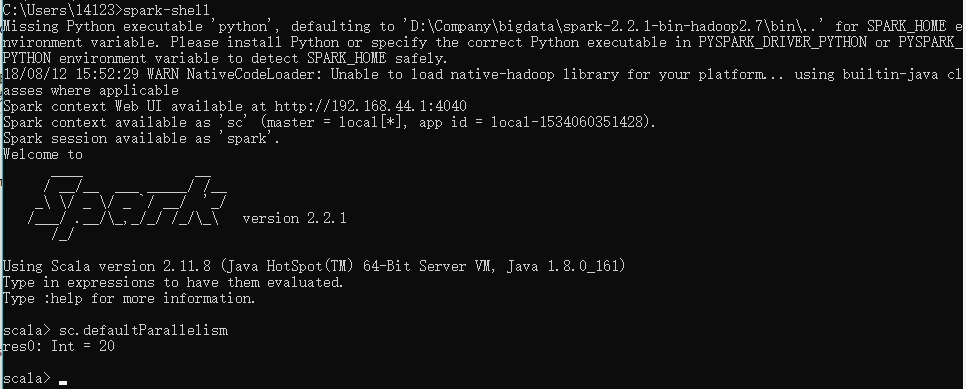
验证:
在spark-shell里输入sc.defaultParallelism,输出结果为20
2.1.2 在代码里配置
val spark =
SparkSession.builder()
.appName ("TestPartitionNums")
.master ("local")
.config ("spark.default.parallelism",
20)
.getOrCreate()
val sc = spark.sparkContext
println (sc.defaultParallelism)
spark.stop |

2.1.3 spark-submit配置
通过–conf spark.default.parallelism=20即可
| spark-submit
--conf spark. default. parallelism = 160 ... |
2.2 没有配置spark.default.parallelism时的默认值
2.2.1 spark-shell
spark-shell里的值等于cpu的核数,比如我的windows的cpu的核数为4
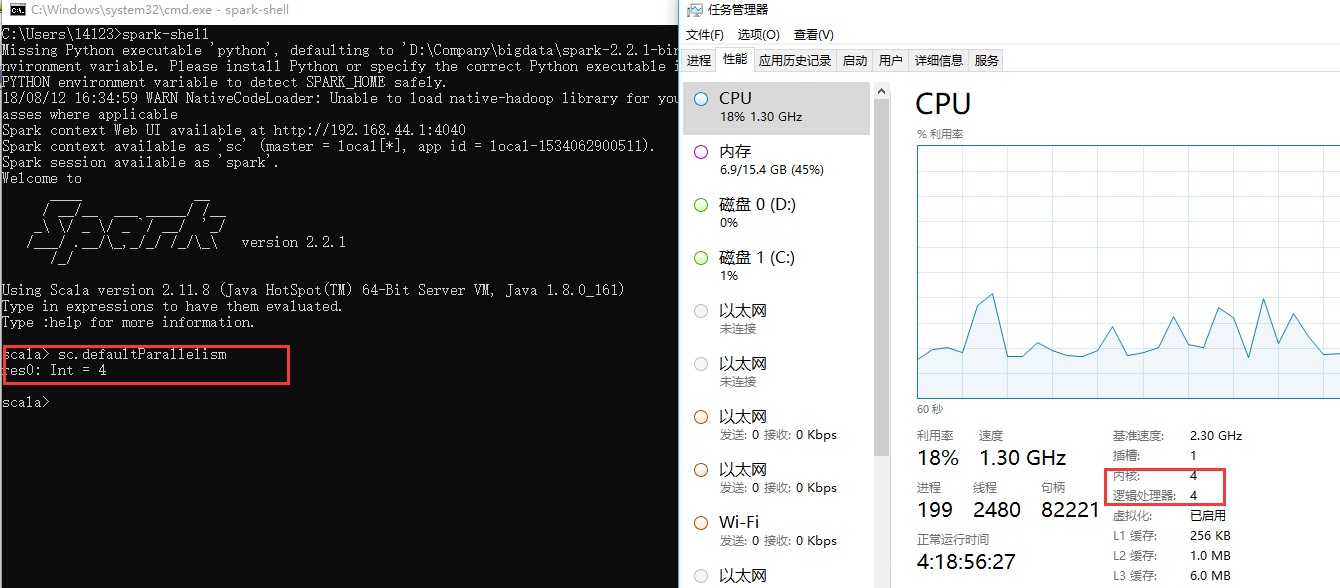
再比如测试机的核数为8

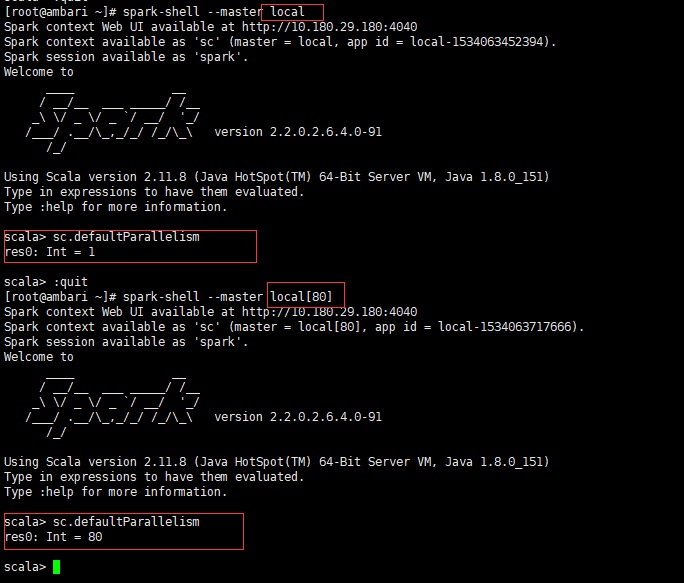
2.2.2 指定master为local
注:在spark-shell里通过–master local和在代码里通过.master(“local”)的结果是一样的,这里以spark-shell为例
当master为local时,值为1,当master为local[n]时,值为n
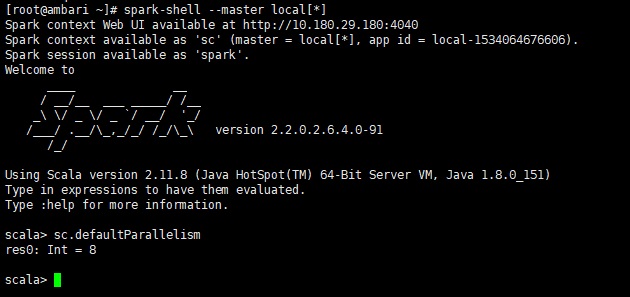
2.2.3 master为local[*]和不指定master(2.2.1)一样,都为cpu核数
2.2.4 master为yarn
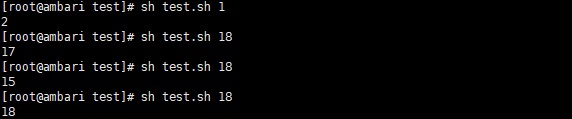
master为yarn模式时为分配的所有的Executor的cpu核数的总和或者2,两者取最大值,将2.1.2的代码的master注释掉并打包,然后用下面的脚本执行测试
test.sh
| spark-submit
-- num-executors $1 --executor-cores 1 -- executor-memory
640M --master yarn --class com.dkl.leanring.spark.TestPartitionNums
spark -scala_2.11-1.0.jar |
之所用这种方式不用spark-shell是因为这种方式截图的话,占得空间比较小
因为yarn模式时使用的cpu核数为虚拟的cpu核数,和实际cpu的核数有偏差,具体应该和yarn的配置有关,而且根据结果,每次申请的实际的cpu核数不完全一样,这里没有去深究原因
2.2.5 Standalone、其他集群模式
因本人工作用yarn模式,Standalone和其他模式没法在这里截图验证了,根据网上的资料,应该和yarn模式默认值是一样的。
3、HDFS文件的默认分区
这里及后面讨论的是rdd和dataframe的分区,也就是读取hdfs文件并不会改变前面讲的sc.defaultParallelism和sc.defaultMinPartitions的值。
3.1 sc.textFile()
rdd的分区数 = max(hdfs文件的block数目, sc.defaultMinPartitions)
3.1.1 测试大文件(block的数量大于2)
这里我上传了一个1.52G的txt到hdfs上用来测试,其中每个block的大小为默认的128M,那么该文件有13个分区
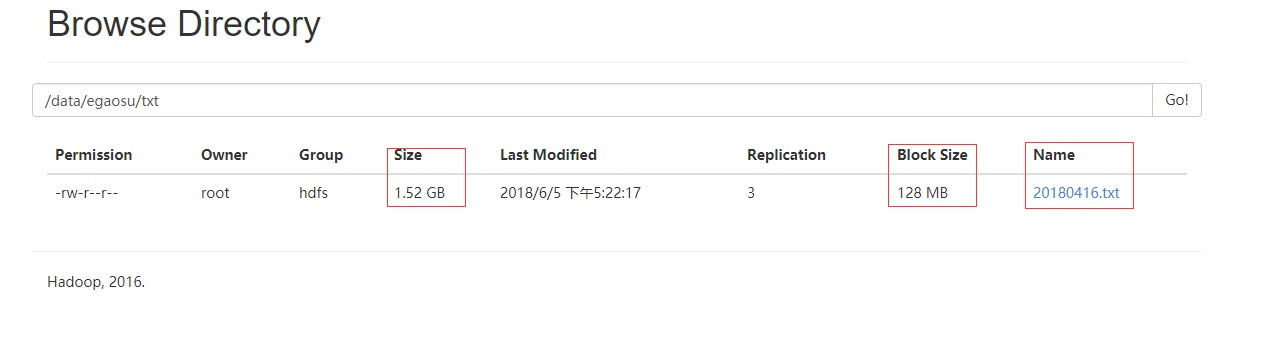
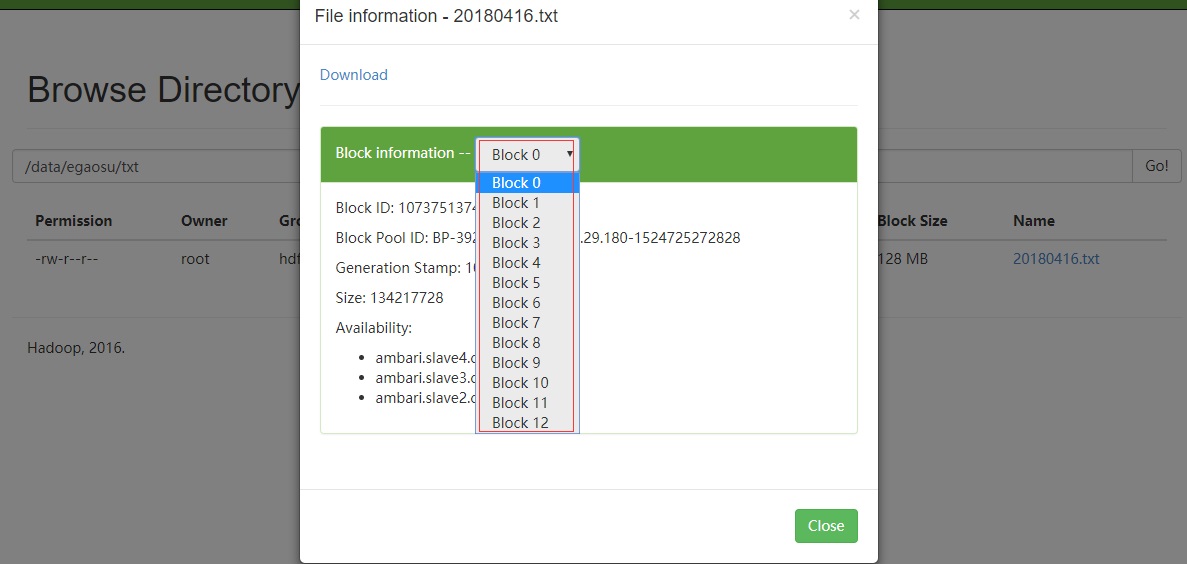
用下面代码可以测试读取hdfs文件的分区数
val rdd = sc.textFile
("hdfs: //ambari .master. com /data /egaosu
/txt /20180416 .txt")
rdd.rdd .getNumPartitions |
这种方式无论是sc.defaultParallelism大于block数还是sc.defaultParallelism小于block数,rdd的默认分区数都为block数
注:之所以说是默认分区,因为textFile可以指定分区数,sc.textFile(path,
minPartitions),通过第二个参数可以指定分区数
sc.defaultMinPartitions大于block数
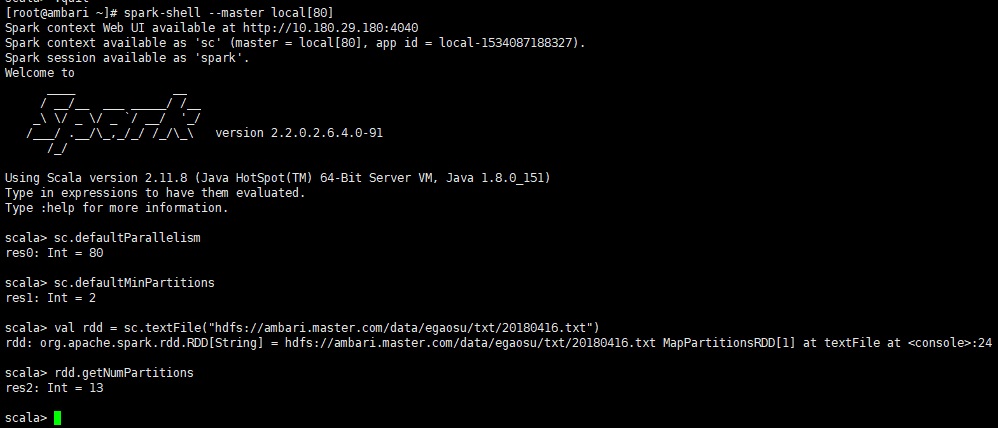
sc.defaultMinPartitions小于block数

当用参数指定分区数时,有两种情况,当参数大于block数时,则rdd的分区数为指定的参数值,否则分区数为block数

3.1.2 测试小文件(block数量等于1)
这种情况的默认分区数为sc.defaultMinPartitions,下面是对应的hdfs文件:
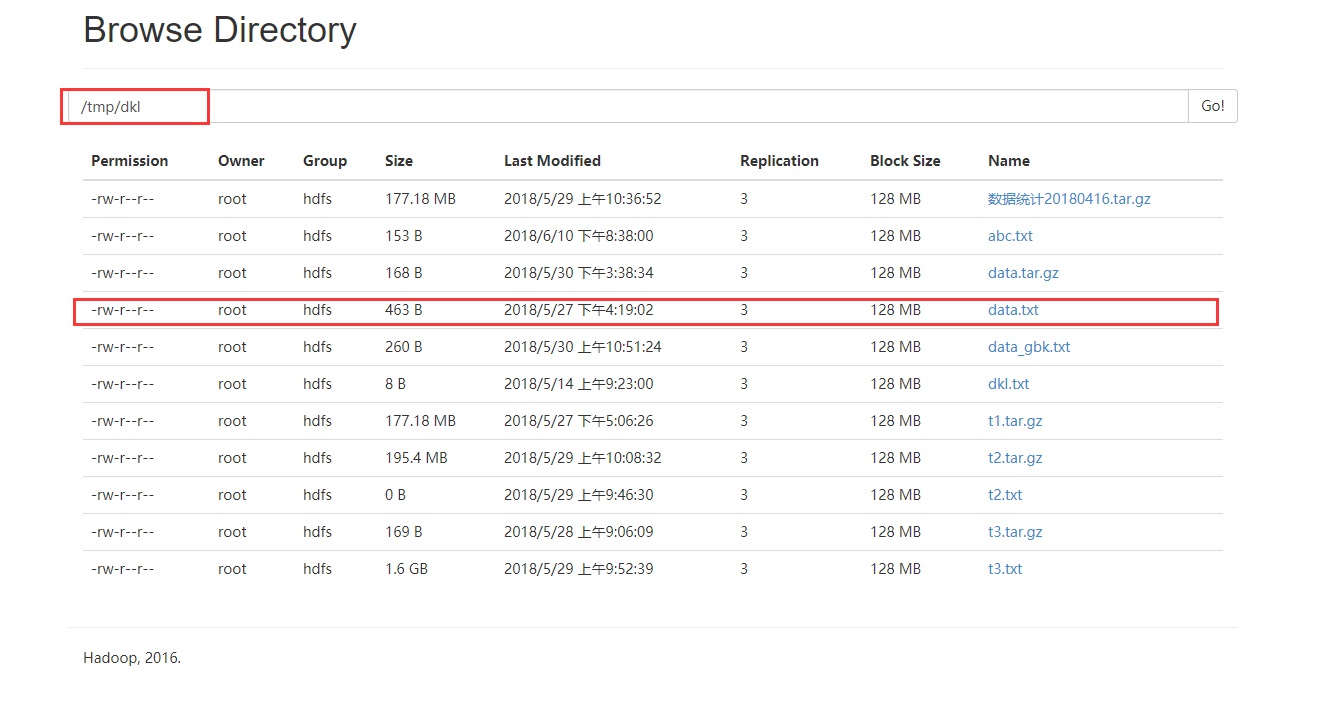
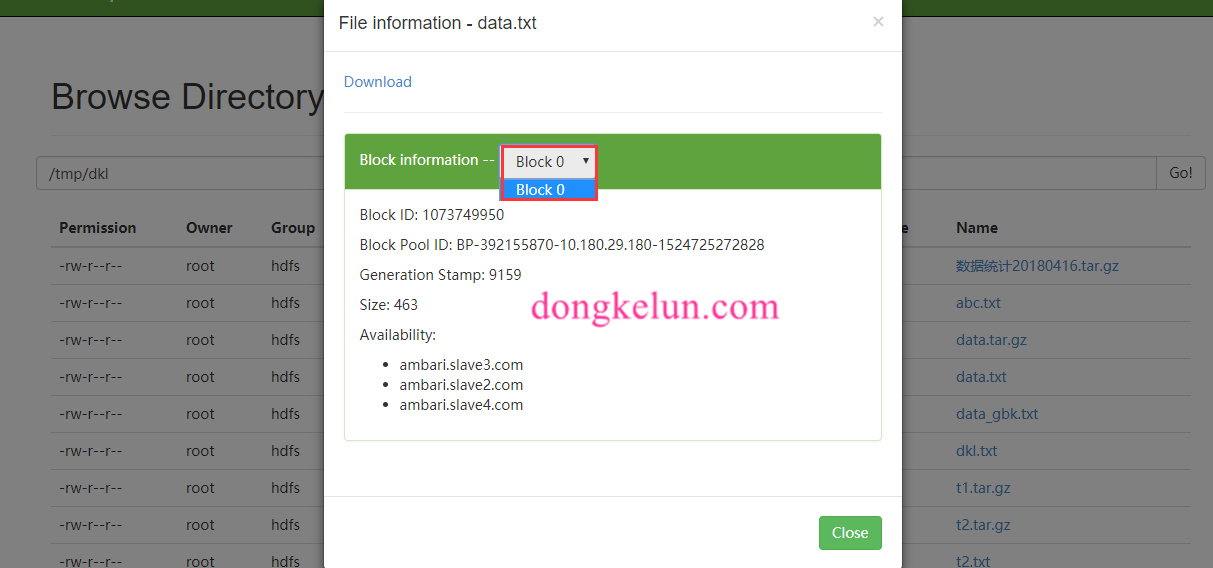
将上面的hdfs路径改为:hdfs://ambari.master.com/tmp/dkl/data.txt,结果:


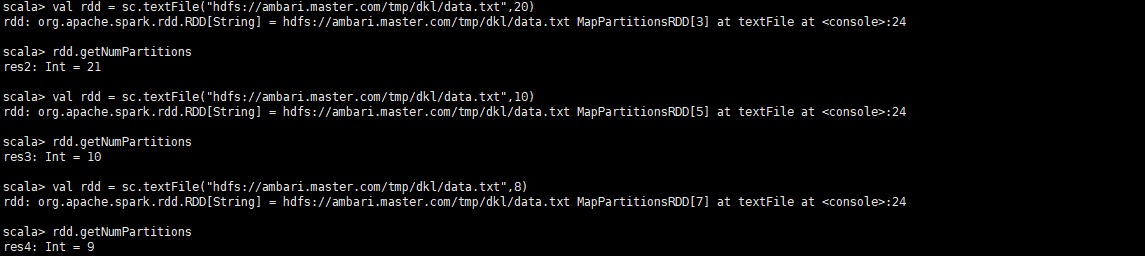
当用参数指定分区数时,rdd的分区数大于等于参数值,本次测试为等于参数值或参数值+1
3.2 spark.read.csv()
大文件(block较多):df的分区数 = max(hdfs文件的block数目, sc.defaultParallelism)
小文件(本次测试的block为1):df的分区数=1,也就是和sc.defaultParallelism无关(一般小文件也没必要用很多分区,一个分区很快就可以处理完成)
3.2.1 大文件
文件大小8.98G,block数为72
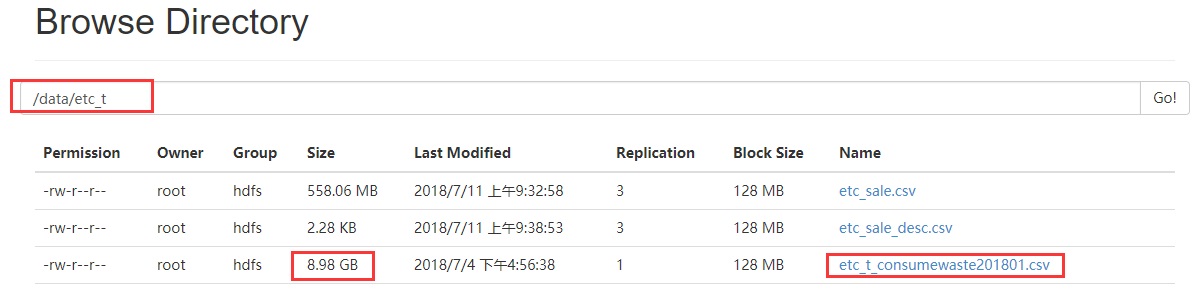
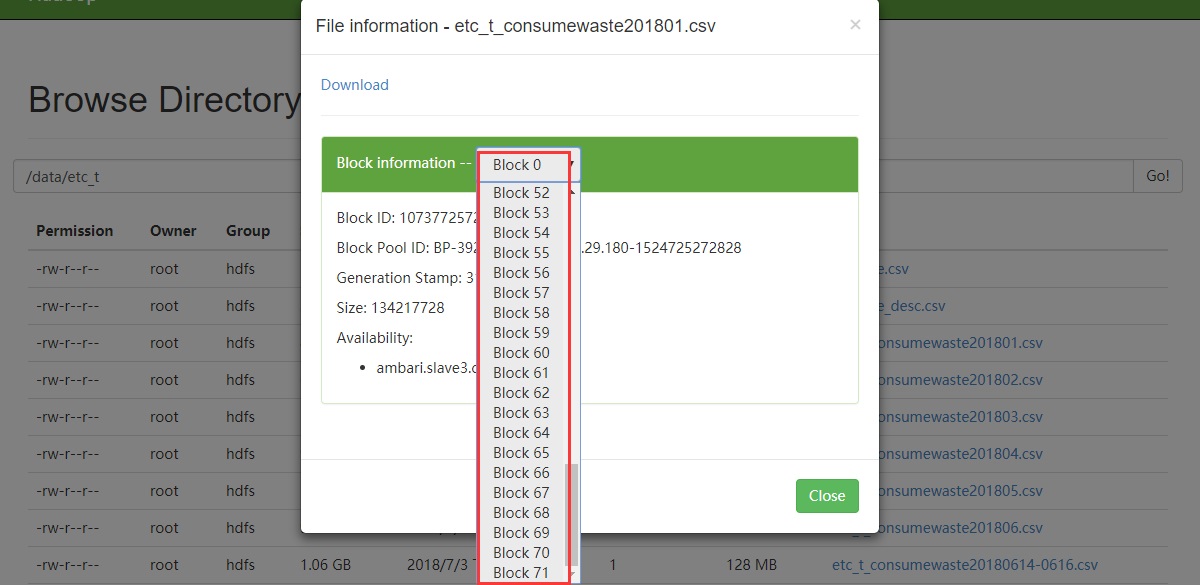
读取代码:
| val df = spark.read.option("header",
"true"). csv ( "hdfs: //ambari
.master .com //data /etc_t / etc _t_ consumewaste201801.csv")
|
分区数
1、当sc.defaultParallelism小于block,分区数默认为block数:72

2、当sc.defaultParallelism大于于block,分区数默认为sc.defaultParallelism

3.2.2 小文件(1个block)
分区数为1
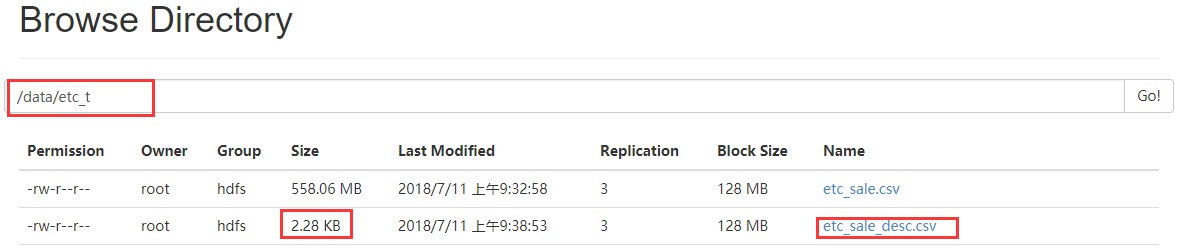
读取代码:
| val df = spark.read.option("header",
"true") .csv ("hdfs: //ambari .master
.com //data /etc_t / etc _ sale_ desc.csv ") |

3.3 测试读取hive表创建的DataFrame的分区数
下面是该表的hdfs路径,从下面的图可以看出该表对应的hdfs文件的block的数目为10(2*5)
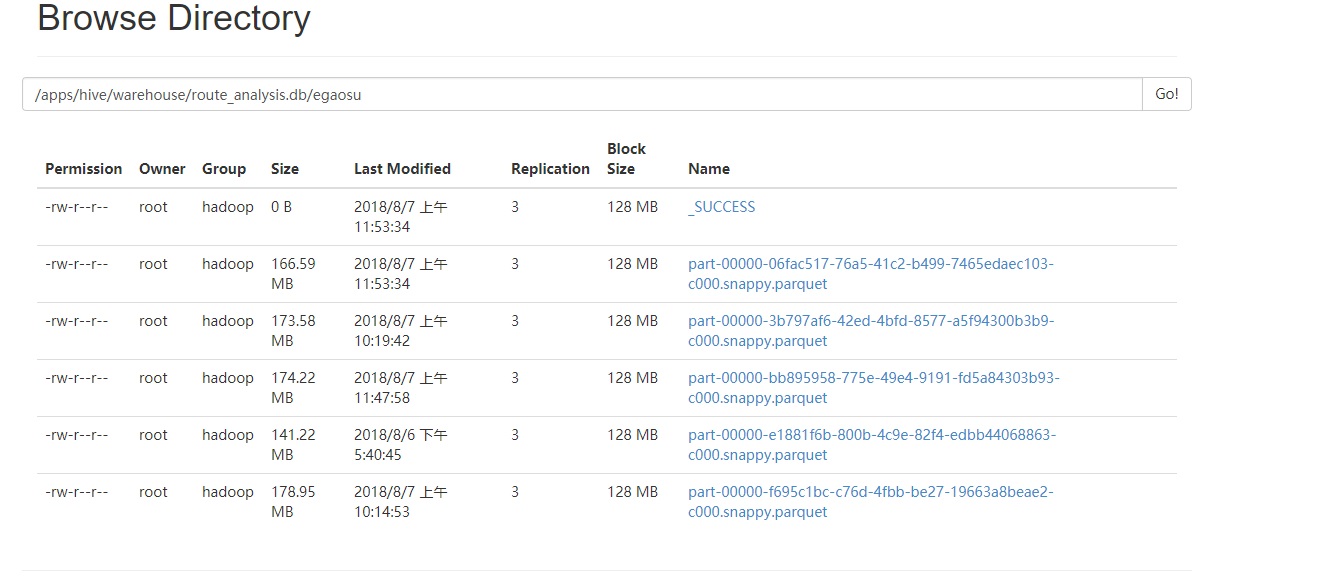
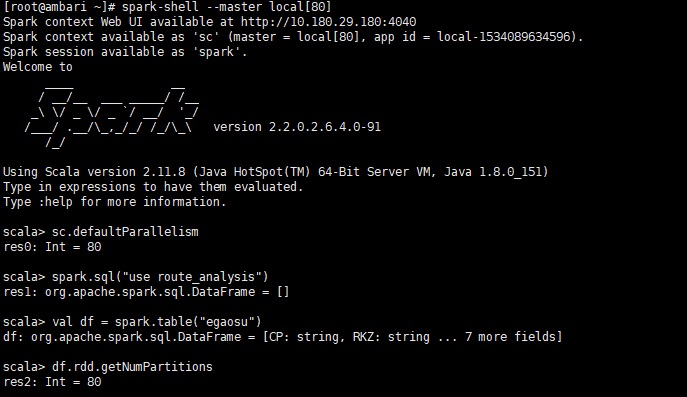
用下面的代码测试:
//切换数据库
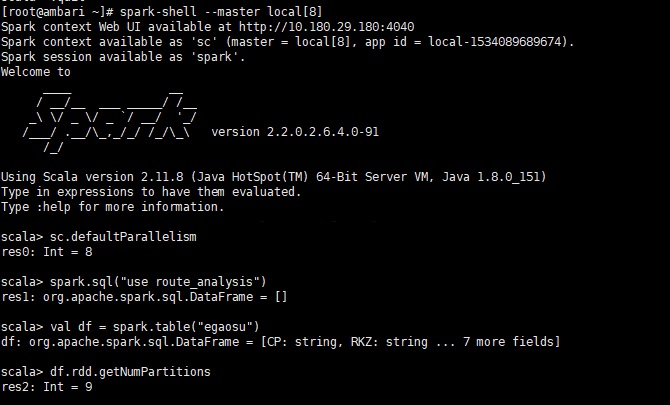
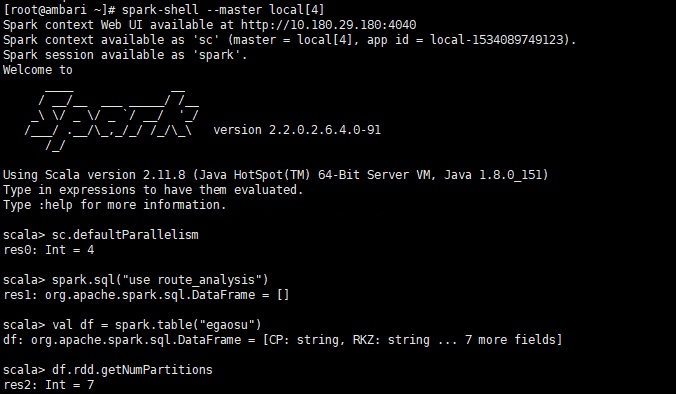
spark.sql ("use route_analysis")
//读取该数据库下的egaosu表为df
val df = spark.table("egaosu")
//打印df对应的rdd的分区数
df.rdd.getNumPartitions |
测试发现,当sc.defaultParallelism大于block时,df的分区是等于sc.defaultParallelism,当小于block时,df的分区数介于sc.defaultParallelism和block之间,至于详细的分配策略,我还没有查到~
用spark.sql(“select * from egaosu”)这种方式得到df和上面的分区数是一样的
上面讲的是我经常使用的几种读取hdfs文件的方法,至于利用其他方法读取hdfs文件的默认的分区,大家可以自己测试(比如json文件,因我没有比较大的hdfs文件就不做测试了)
4、非HDFS文件的默认分区(本地文件)
实际工作中用到本地文件的情况很少,一般都是hdfs、关系型数据库和代码里的集合
4.1 sc.textFile()
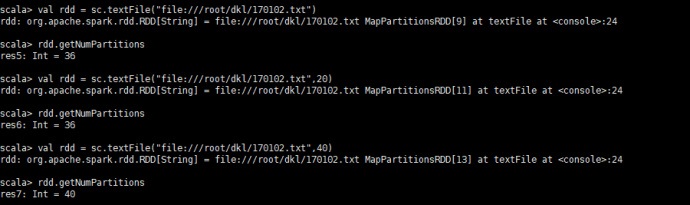
4.1.1 大文件
文件大小为1142M,经测试本地文件也会像hdfs一样进行类似于block的划分,固定按32M来分片(这里的32M参考Spark
RDD的默认分区数:(spark 2.1.0))

所以应该默认有36个分区(1142/32=35.6875)
当用参数值指定时,参数小于block时,分区数为block的数目,大于block时,分区数为参数值,即分区数
= max(本地文件的block数目, 参数值)
读取代码:
| val rdd = sc.textFile
("file: ///root /dkl / 170102 .txt") |
4.1.2 小文件
默认的分区数为sc.defaultMinPartitions
新建一个测试文件text.txt,内容自己造几行
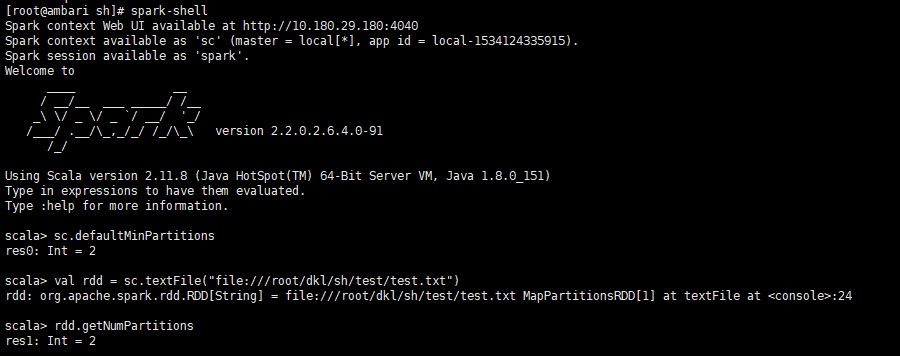
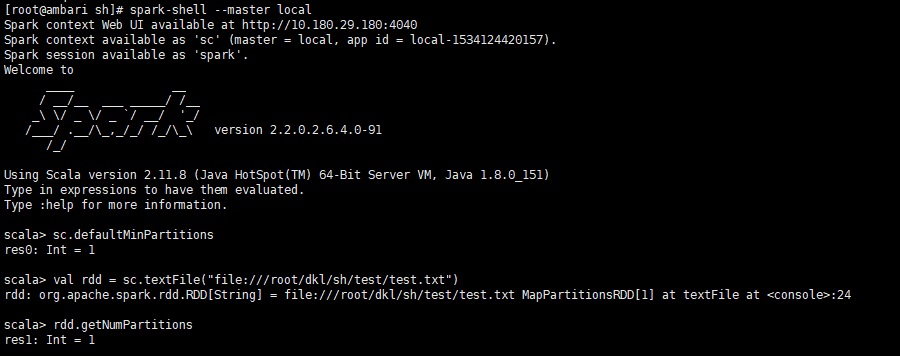
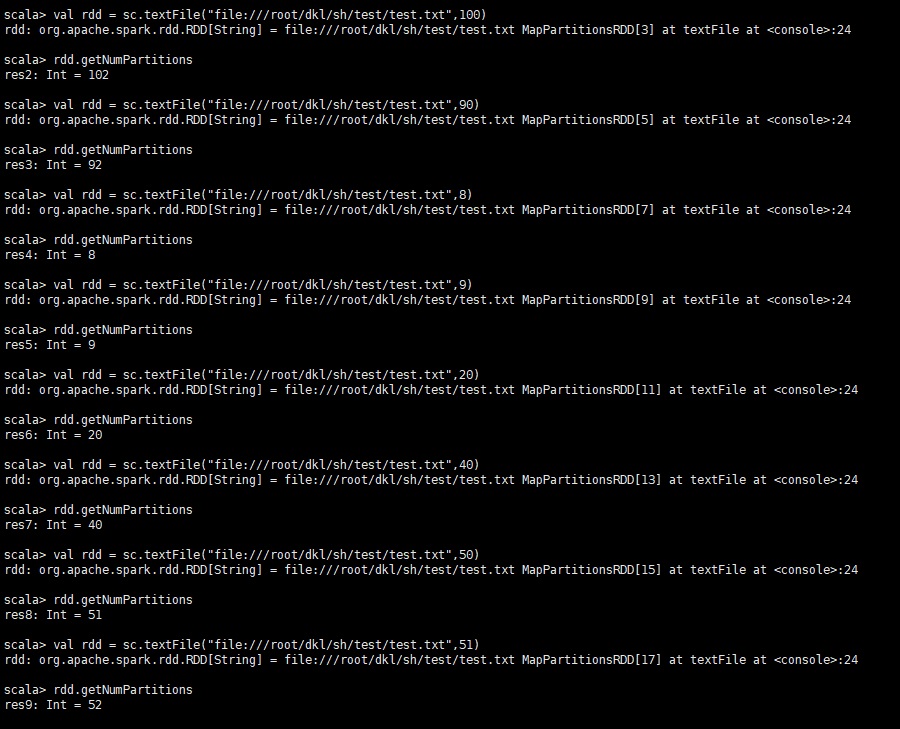
当用参数指定分区数时,本以为分区数为指定的参数值,结果经测试,当参数值在一定的范围内分区数确实为指定的参数值,当参数值大于某个数值时,分区数实际比参数值大一点,不知道是不是Spark的bug还是有自己的策略。
读取代码:
| val rdd = sc.textFile
("file: ///root /dkl /sh / test /test.txt")
|
4.2 spark.read.csv()
规律和HDFS文件是一样的(见3.2),且按128M来分block,这里和上面讲的txt不一样,txt是按32M
4.2.1 大文件
1081M,那么block为9(1081/128),分区数 = max(本地文件的block数目,
sc.defaultParallelism)

读取代码:
| val df = spark.read.option("header",
"true") .csv ("file: /// root /dir/etc_t
/etc_t_ consumewaste 20180614 - 0616.csv")
|

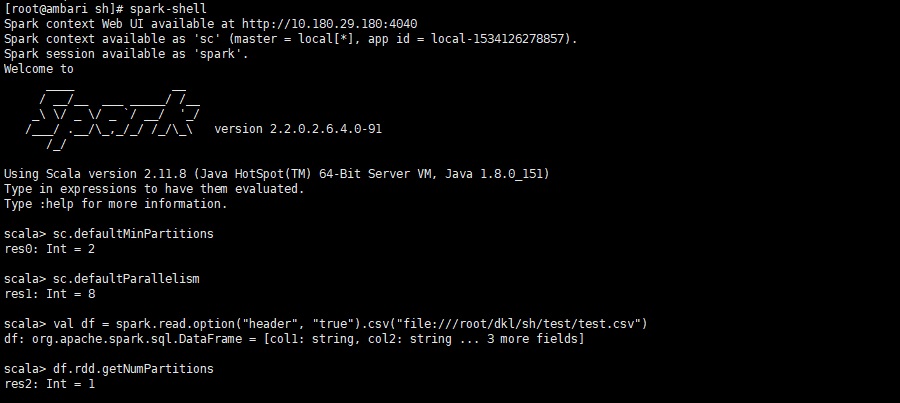
4.2.2 小文件
大小6K,block为1,分区数为1

读取代码:
| val df = spark.read.option("header",
"true") .csv ("file: ///root /dkl
/sh /test /test.csv") |
5、关系型数据库
从关系型数据库表读取的df的分区数为1,以mysql为例,我这里拿一张1000万条数据的表进行测试

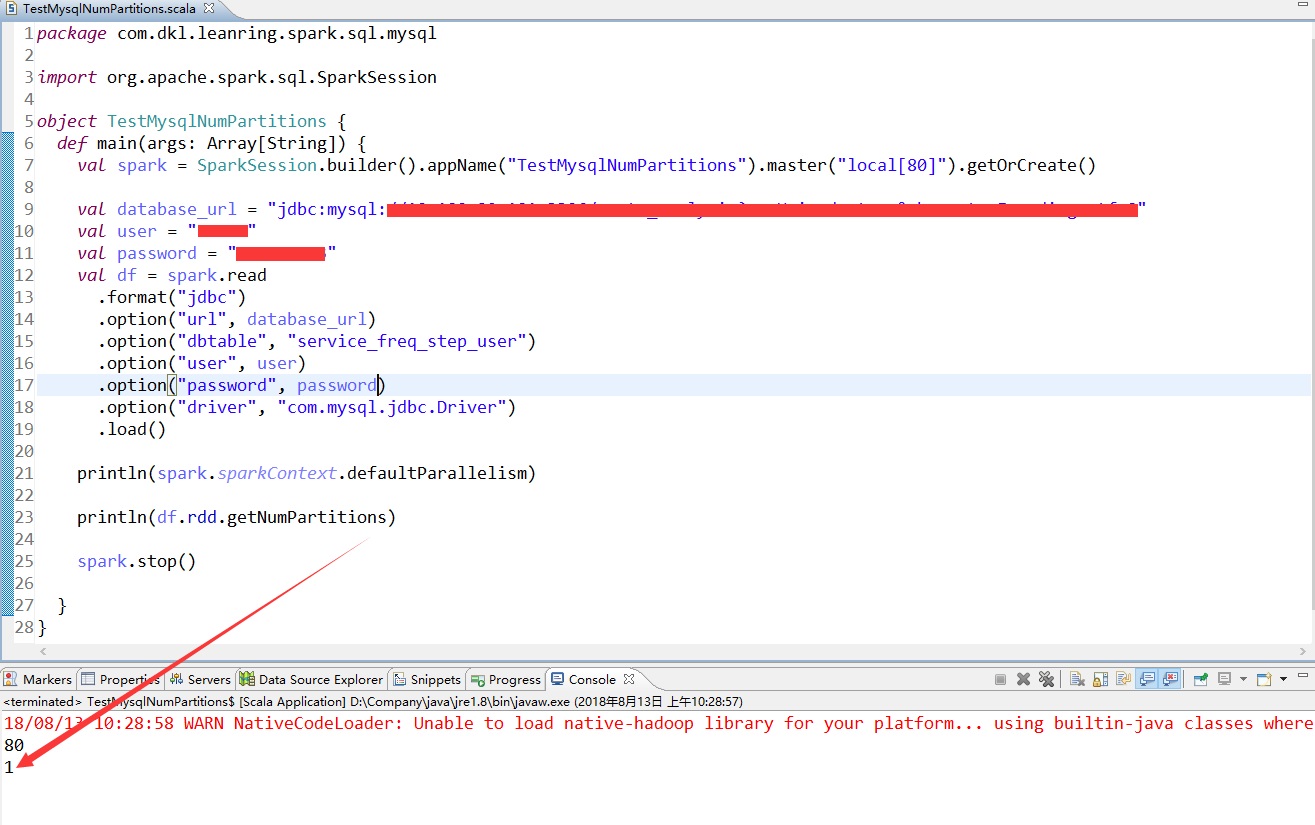
Spark连接mysql的代码都可以参考Spark Sql 连接mysql
设置df的默认分区数也可以参考Spark Sql 连接mysql
6、从代码里的内部数据集创建
6.1 sc.parallelize()创建RDD
默认分区数等于sc.defaultParallelism,指定参数时分区数值等于参数值。
6.2 spark.createDataFrame(data)创建DataFrame
当data的长度小于sc.defaultParallelism,分区数等于data长度,否则分区数等于sc.
default Parallelism
如图:
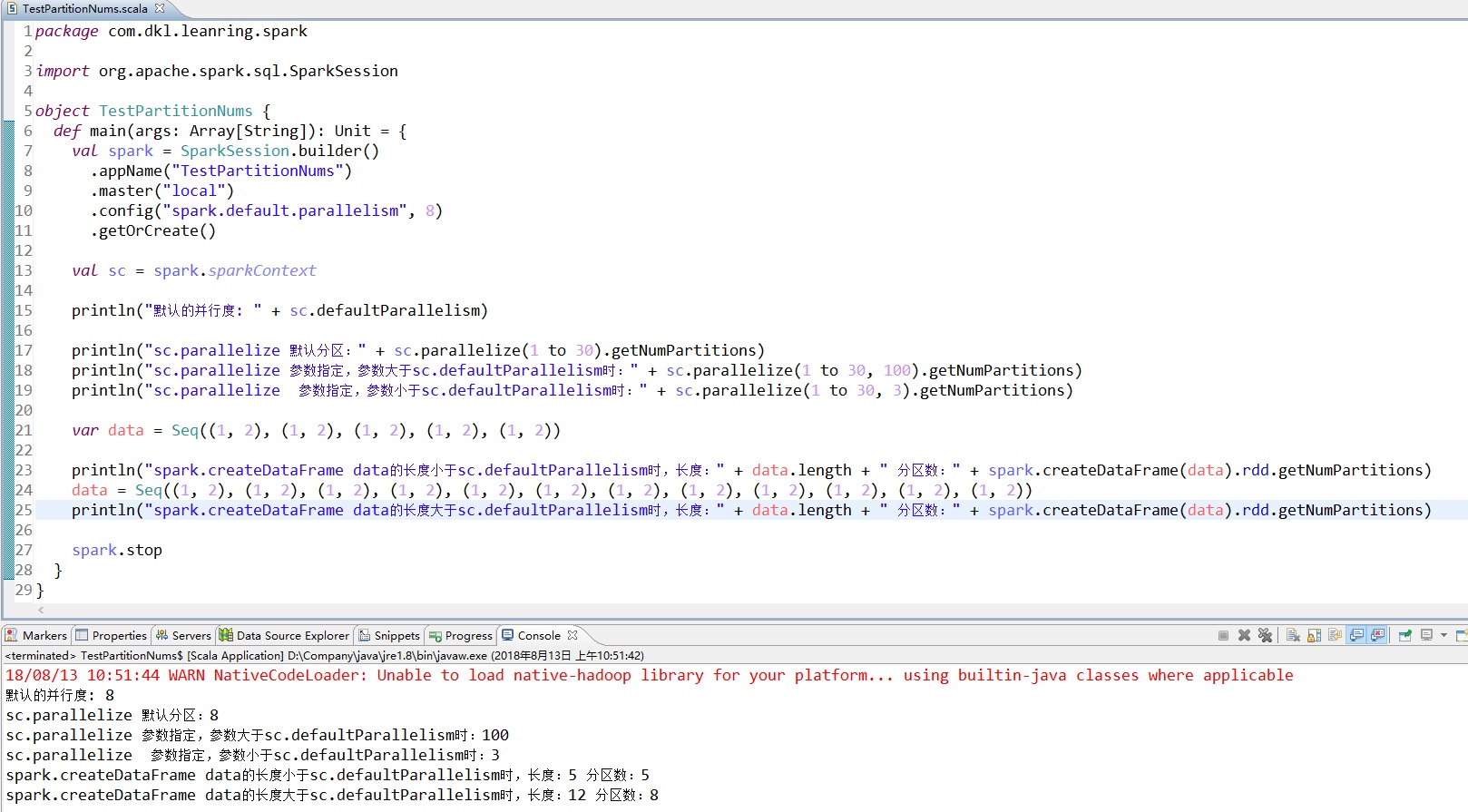
6.3 代码
下面是上面图中的代码:
package com.dkl.leanring.spark
import org .apache.spark.sql.SparkSession
object TestPartitionNums {
def main (args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName ("TestPartitionNums")
.master ("local")
.config ("spark.default.parallelism",
8)
.getOrCreate()
val sc = spark.sparkContext
println("默认的并行度: " + sc.defaultParallelism
)
println ("sc.parallelize 默认分区:" + sc.
parallelize (1 to 30).getNumPartitions)
println ("sc.parallelize 参数指定,参数大于sc. defaultParallelism
时:" + sc.parallelize(1 to 30, 100).getNumPartitions)
println("sc.parallelize 参数指定,参数小于sc. defaultParallelism时:"
+ sc.parallelize(1 to 30, 3) .getNumPartitions)
var data = Seq((1, 2), (1, 2), (1, 2), (1,
2), (1, 2))
println ("spark.createDataFrame data的长度小于sc.
defaultParallelism时 ,长度:" + data.length +
" 分区数:" + spark. createDataFrame (data)
.rdd. getNumPartitions )
data = Seq((1, 2), (1, 2), (1, 2), (1, 2), (1,
2 ), (1, 2), (1, 2), (1, 2), (1, 2), (1, 2), (1,
2), (1, 2))
println ("spark.createDataFrame data的长度大于sc.
defaultParallelism 时,长度:" + data.length +
" 分区数:" + spark.createDataFrame (data).
rdd. getNumPartitions )
spark .stop
}
} |
7、其他改变分区数的算子
7.1 分区数为1
上面已经讲过几个分区数为1(当默认的并行度大于1时)的情况:
1、spark.read.csv()读取本地文件
2、读取关系型数据库表
上面是从外部数据源加载进来就为1的情况,还有就是对df或rdd进行转换操作之后的分区数为1的情况:
1、df.limit(n)
7.2 分区数不为1的情况
df.distinct()分区数为200
如图:

8、合理的设置分区数
根据自己集群的情况和数据大小等合理设置分区的数目,对于Spark性能调优很有必要,根据前面讲的可知,可通过配置spark.default.parallelism、传参设置分区数,遇到那些分区数为1的特殊算子可以利用repartition()进行重新分区即可。
9、总结
本文首先讲了各种情况下的sc.defaultParallelism,defaultMinPartitions,然后讲了各种情况下创建以及转化RDD、DataFrame的分区数,因为Spark的外部数据源很多,创建以及转化RDD、DataFrame的方法和算子也很多,所以主要是讲了我个人常用的各种情况,并不能包含所有情况,至于其他情况,大家可以自己测试总结。还有一点就是本文并没有从源码的层次去分析,只是总结一些规律,对于前面提到的一些还不太清楚的规律,以后如果有时间的话可以从源码的层次去分析为什么~ |









