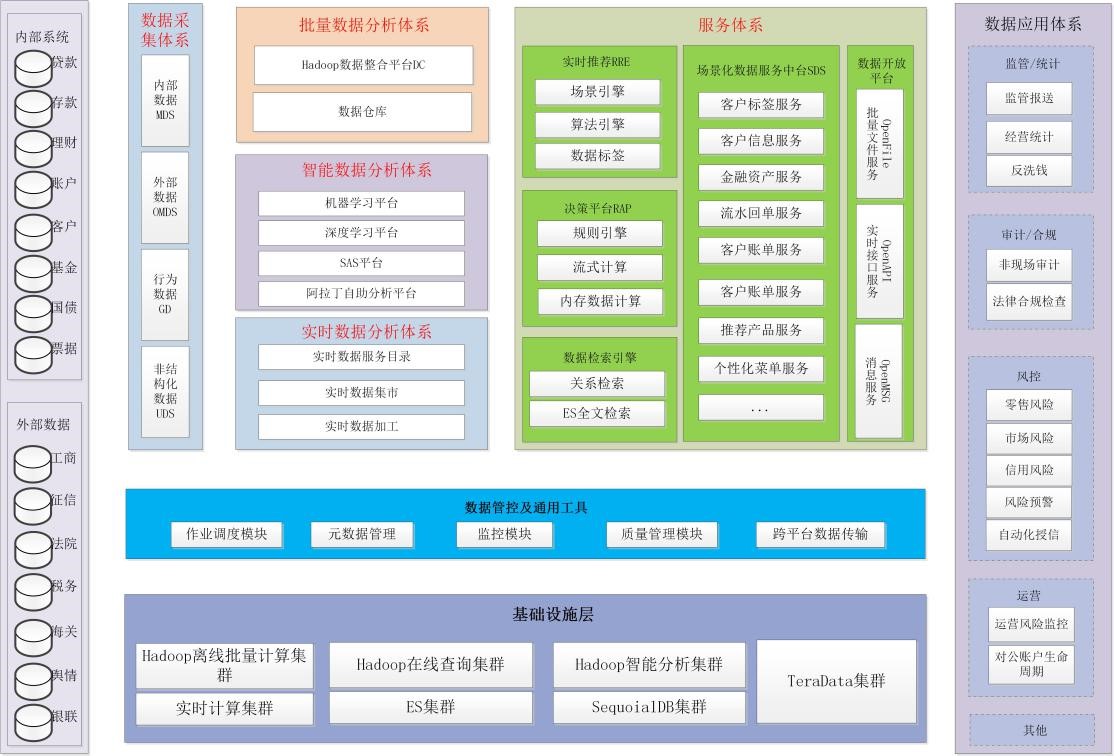
| БрМЭЦМі: |
| БОЮФРДздгкinfoqЃЌБОЮФЭЈЙ§ВћЪіДѓЪ§ОнЬхЯЕЙцЛЎвдМАЪ§ОнВЩМЏКЭХфжУЃЌНщЩмСЫУёЩњвјааДѓЪ§ОнЬхЯЕМмЙЙЩшМЦгыбнНјЁЃ |
|
НќФъРДЃЌЫцзХДѓЪ§ОнгыШЫЙЄжЧФмЯрЙиММЪѕЕФбИЫйЗЂеЙЃЌаТММЪѕж№ВНдкШЋЩчЛсИїааИївЕЕУЕНгІгУЁЃвјаавЕзїЮЊвЛИіИпЖШаХЯЂЛЏЕФаавЕЃЌЪзЕБЦфГхУцСйзХЛЅСЊЭјаТММЪѕгІгУЕФЬєеНЁЃУёЩњвјаадк2013ФъПЊЪМВМОжЗжВМЪНЁЂДѓЪ§ОнМАШЫЙЄжЧФмММЪѕЕШСьгђЃЌдкШЋааЗяЛЫМЦЛЎЕФЧЃЭЗЯТЃЌж№ВНЕФНЋаТММЪѕгыЮвааЗЂеЙеНТдвЕЮёЪЕЪЉВпТдНјааСЫЩюЖШШкКЯЃЌЮЊН№ШкПЦММвјааЕФЗЂеЙЕьЖЈСЫдњЪЕЕФЛљДЁЁЃ
вЛЁЂДѓЪ§ОнМђНщ
ДѓЪ§ОнЦ№дДгкЛЅСЊЭјЃЌдк2003ФъзѓгвгЩGoogleЗЂВМGFSКЭMapReduceТлЮФЮЊНкЕуРПЊСЫаТММЪѕгІгУЕФађФЛЃЌНщЩмСЫвЛжжРћгУЦеЭЈPCЗўЮёЦїЙЙНЈДѓЙцФЃЗжВМЪНЯЕЭГЃЌРДНтОіКЃСПЪ§ОнЕФДцДЂКЭМЦЫуЮЪЬтЁЃдкДЫТлЮФЛљДЁЩЯЗЂеЙГіРДЕФHadoopПЊдДЬхЯЕж№ВНГЩЮЊКЃСПЪ§ОнДІРэЕФвЛжжЭЈгУММЪѕПђМмЁЃ2008ФъзѓгвHadoopММЪѕБЛЙуЗКЕФЪЙгУдкИїИіЛЅСЊЭјЦѓвЕжаЃЌМЋДѓЕФЭЦНјHadoopММЪѕЬхЯЕЕФГЩЪьЃЌЫцзХдчЦкSingle
Point of FailureЮЪЬтБЛНтОіЃЌдкMAP-REDUCEСННзЖЮЕФМЦЫуФЃЪНЩЯЃЌЕЎЩњСЫИќЗсИЛЕФSparkЁЂFlinkЕШМЦЫуПђМмЁЃ2013ФъзѓгвХњСПЪ§ОнЕФМЦЫуФЃЪНж№ВНГЩЪьЃЌдкашЧѓЕФЭЦЖЏЯТЛЅСЊЭјПЊЪМНјвЛВНЕФЙЅМсЪЕЪБЪ§ОнМЦЫуСьгђЁЃЭЌФъВПЗжвјааПЊЪМГЂЪдв§ШыHadoopДѓЪ§ОнММЪѕЁЃУёЩњвјаазїЮЊвјаавЕЕквЛХњЃЌдк2013ФъДгЛЅСЊЭјв§ШыСЫДѓЪ§ОнзЈвЕВХШЫЃЌЦєЖЏСЫHadoopДѓЪ§ОнЬхЯЕЛЏЕФНЈЩшЁЃ
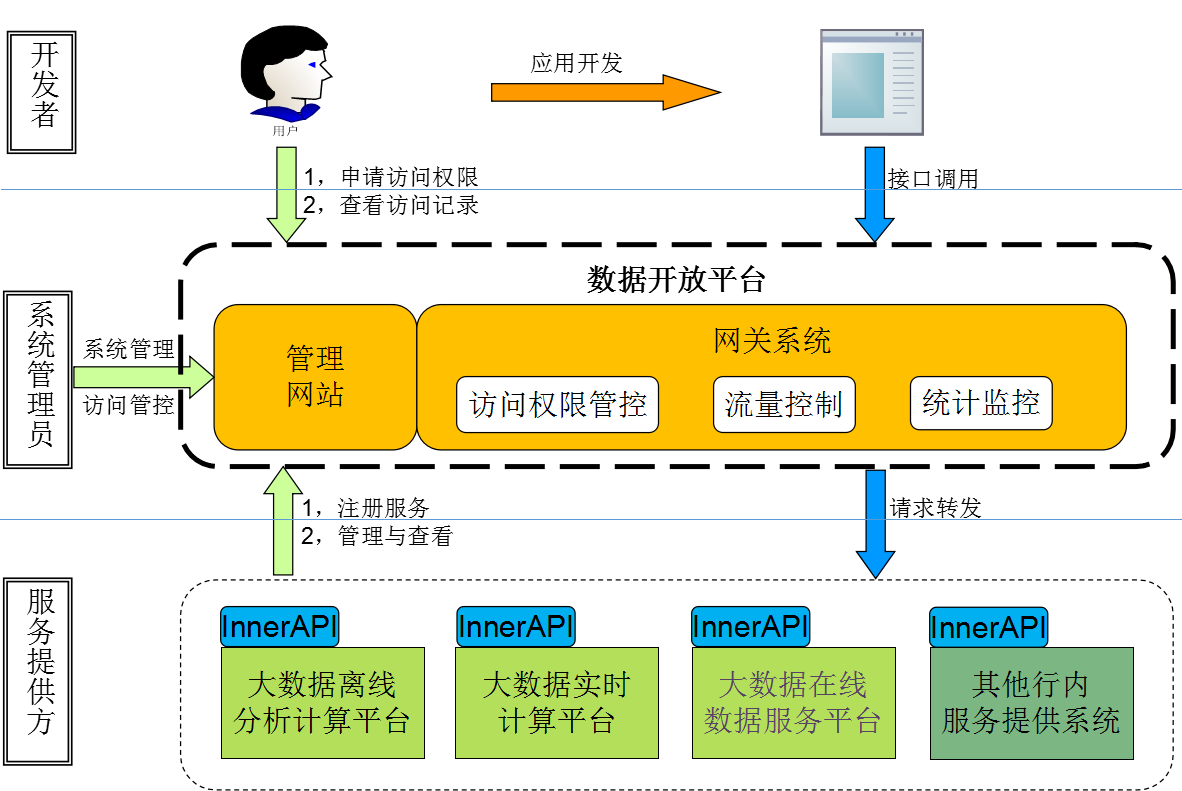
аТММЪѕЕФгІгУЪзвЊЪЧНтОіЮЪЬтЃЌЬсИпЪ§ОнЪЙгУЕФаЇТЪЃЌНЕЕЭЪ§ОнЪЙгУГЩБОЃЌзюжеЭЦЖЏвЕЮёЪ§зжЛЏЁЂжЧФмЛЏзЊаЭЁЃдкДѓЪ§ОнЬхЯЕЛЏЙцЛЎЯТЃЌвдЗўЮёгУЛЇЮЊФПБъЃЌвдНтОіЮЪЬтЮЊзЅЪжж№ВНЭЦЖЏДѓЪ§ОнММЪѕТфЕиЁЃУёЩњвјааДѓЪ§ОнећЬхЙцЛЎШчЯТЭМЃК
ЭМ1ЁЂДѓЪ§ОнЦНЬЈЬхЯЕЙцЛЎ
дкећИіЙцЛЎЕФжИЕМЯТЃЌАДееВЛЭЌНзЖЮЕФжїСІашЧѓЃЌУёЩњвјааДѓЪ§ОнНЈЩшПЩвдМђЕЅЗжЮЊШ§ИіНзЖЮЃК
ЕквЛИіНзЖЮЪЧУцЯђПЭЛЇЕФдкЯпДцДЂВщбЏНзЖЮЃК
вјаагаКмЖрУцЯђПЭЛЇЕФЪ§ОнЃЌЪ§ОнЛ§РлЗЧГЃПьвВЗЧГЃЖрЃЌвдСїЫЎЪ§ОнЮЊР§ЃЌЮЊСЫБЃжЄЯЕЭГЗўЮёжЪСПЃЌЭЈГЃЪЧЫѕЖЬПЩВщбЏЕФжмЦкЃЌвРЭаДѓЪ§ОнЕФКЃСПЪ§ОнДцДЂФмСІЃЌЛљгкЗжВМЪНЬхЯЕЙЙНЈСЫРњЪЗЪ§ОнЙмРэЦНЬЈРДТњзувЕЮёГЁОАжаКЃСПЪ§ОнЕФДцДЂКЭВщбЏЗўЮёашЧѓЁЃ
ЕкЖўИіНзЖЮЪЧРыЯпЕФХњСПЪ§ОнМЦЫуМАжЧФмЪ§ОнЗжЮіНзЖЮЃК
дк2015ФъШЋУцЦєЖЏЗяЛЫМЦЛЎНЈЩшКѓЃЌИїСьгђЯЕЭГадЕФЪсРэСЫвЕЮёеНТдКЭЪЕЪЉВпТдЃЌХфКЯЗяЛЫМЦЛЎжаЪ§зжЛЏеНТдЕФТфЕиЃЌвЕЮёСїГЬКЭФЃЪНжагПЯжГіДѓСПЕФХњСПЪ§ОнМгЙЄМЦЫуКЭНсЙћЪ§ОнЗўЮёЕФгІгУГЁОАЁЃдкетИіНзЖЮИљОнЪ§ОнСїзЊжмЦкКЭЗўЮёГЁОАЃЌНсКЯећЬхЕФЪ§ОнЙмПиашЧѓЃЌНЈСЂСЫЦѓвЕМЖЪ§ОнПЊЗЂФЃаЭЃЌж№ВНЭЦЖЏКЭЭъЩЦСЫШЋааЭГвЛЕФЪ§ОнЗўЮёжаЬЈЃЌЯШКѓЮЊЪ§ЪЎИівЕЮёГЁОАЬсЙЉЪ§ОнжЇГжЁЃЭЌЪБЫцзХЪ§ОнжаЬЈЕФГЩЪьЃЌдЪМЪ§ОнЕФЛ§РлЃЌЛљгкЪ§ОнЕФЛњЦїбЇЯАШЫЙЄжЧФмЗжЮіЕШГЁОАж№ВНгПЯжЃЌЮЊСЫНЕЕЭаТММЪѕЕФЪЙгУУХМїЃЌПьЫйЕќДњГЁОАЯТЕФЛњЦїбЇЯАЫуЗЈФЃаЭЃЌдкетИіНзЖЮЭЌВННЈЩшСЫПЩЪгЛЏЕФЛњЦїбЇЯАЦНЬЈЃЌЖдНгЪ§ОнжаЬЈЃЌЮЊИіадЛЏЭЦМіЁЂЗчЯедЄОЏМАдЫгЊЖрИіСьгђФкЕФЯИЗжГЁОАЬсЙЉЗўЮёФмСІЪфГіЁЃ
ЕкШ§ИіНзЖЮЪЧШЋУцЭЦЖЏдкЯпЪЕЪБЪ§ОнМЦЫуМАЗжЮіНзЖЮЃК
ЫцзХХњСПЪ§ОнЬхЯЕЕФГЩЪьЃЌвЕЮёГЁОАЖдЪЕЪБЪ§ОнЕФашЧѓбИЫйгПЯжЃЌЮвааПЦММЦєЖЏСЫШЋУцЕФЪЕЪБЪ§ОнЬхЯЕНЈЩшЃЌЖдЪЕЪБЗчПиКЭЪЕЪБЪТМўЧ§ЖЏЕФгЊЯњКЭдЫгЊаЮГЩСЫШЋУцЕФжЇГХЁЃ
ЭЈЙ§Ш§ИіНзЖЮЃЌдкжЇГХвЕЮёгІгУГЁОАЗЂеЙЕФЭЌЪБЃЌФПЧАЦНЬЈВуУцвбГѕВНЭъГЩШчЯТМИДѓЦНЬЈНЈЩшЃК
1.Ъ§ОнВЩМЏЗжЮіЦНЬЈ
2.HadoopЪ§ОнМгЙЄећКЯЦНЬЈ
3.ПЩЪгЛЏЛњЦїбЇЯАЦНЬЈ
4.ЪЕЪБЭЦМів§Чц
5.Ъ§ОнПЊЗХЦНЬЈ
ЭМ2ЁЂДѓЪ§ОнжївЊЦНЬЈЪгЭМ
дкЪ§ОнВЩМЏВуЭЈЙ§ааЮЊЪ§ОнЦНЬЈКЭЭтВПЪ§ОнЦНЬЈЃЌЗсИЛСЫећИіЪ§ОнЬхЯЕЁЃЭЈЙ§Ъ§ОнећКЯЦНЬЈЃЈDCЃЉЃЌДђЭЈвдгУЛЇЮЊжааФЕФШЋЮЌЖШЕФЪ§ОнЪгЭМЃЌЮЊКѓајЕФЛњЦїбЇЯАКЭШЫЙЄжЧФмгІгУЬсЙЉСЫПЩааЕФЪ§ОнЛљДЁЃЌЭЈЙ§ПЩЪгЛЏЕФЛњЦїбЇЯАЦНЬЈЭъГЩЪ§ОнгыЫуЗЈЕФНсКЯЃЌгЩЪ§ОнЗўЮёВуЭГвЛЙмПиЪфГіЁЃ
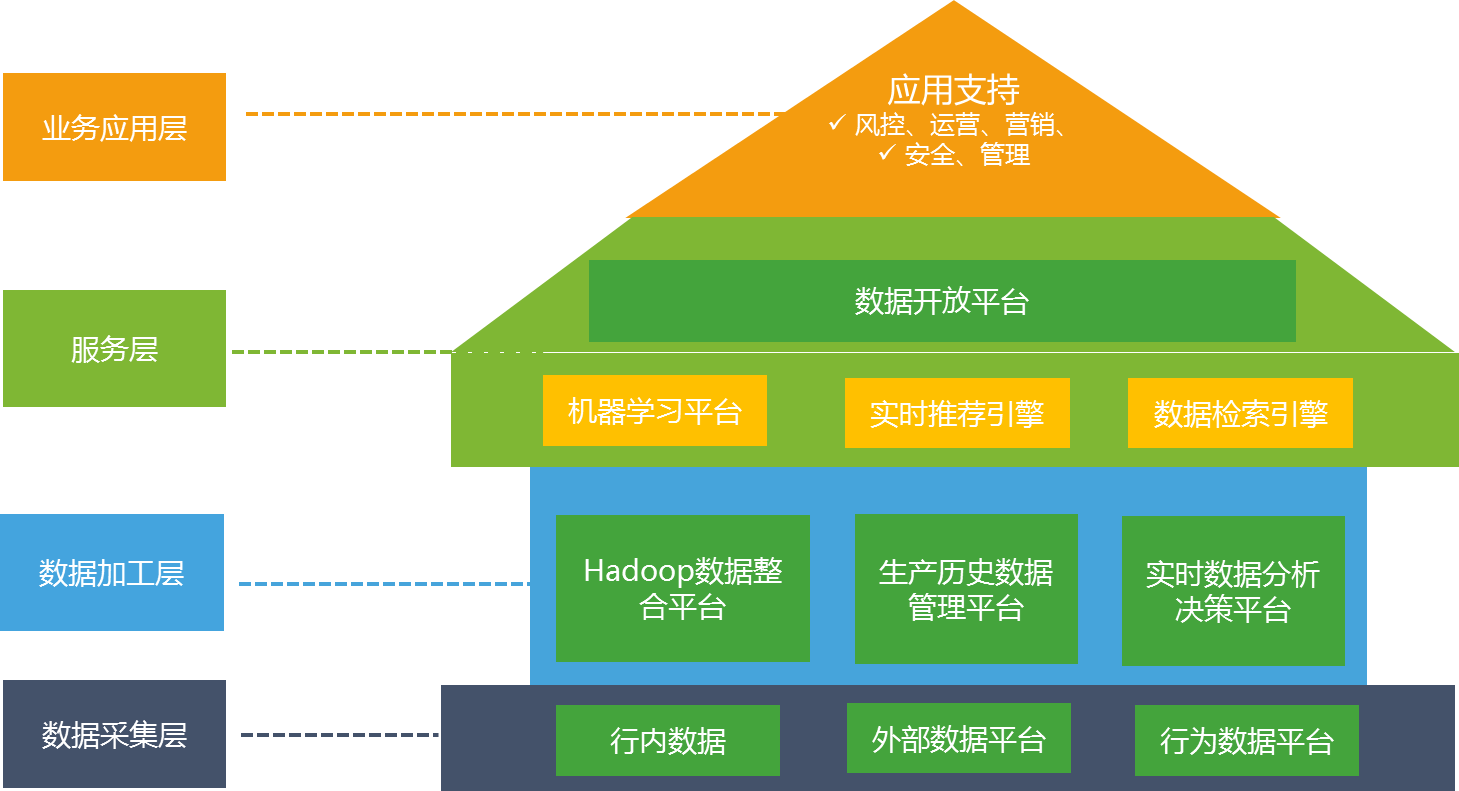
ФПЧАЫцзХДѓЪ§ОнЖрИіЦНЬЈЕФНЈЩшЃЌЮЊЮвааЖрИіеНТдМЖЯюФПЬсЙЉСЫШЋУцЕФЕзВуЪ§ОнКЭФЃаЭФмСІЪфГіЃЌАќРЈжЇГжСЫЗяЛЫМЦЛЎЯюФПжИФЯеыдЄОЏЯюФПЁЂЪ§ОнЛЏЦНЬЈаЭЪкаХОіВпБфИяЯюФПЁЂдЫгЊЗчЯеМрПиЬхЯЕЯюФПЁЂаТвЛДњСуЪлаХДћЬхЯЕЁЂДхеђвјааЕШЖрИіЯюФПЕФНЈЩшЁЃ
ЖўЁЂЪ§ОнВЩМЏЦНЬЈ
БГОАМАФПБъ
вјаадкЙ§ШЅЕФаХЯЂЛЏНЈЩшжаЃЌИќЖрЕФзЂжиЪЧНЛвзЪ§ОнЕФЛ§РлЃЌЖдгУЛЇЕФЪЙгУЦЋКУЁЂфЏРРЕуЛїааЮЊЁЂЭЃСєЪБМфЕШааЮЊВуУцЕФЪ§ОнНЯЩйЩцМАЁЃЫцзХДѓЪ§ОнЕФЗЂеЙЃЌЭЈЙ§ЖдгУЛЇЪ§ОнЕФЪеМЏЃЌећКЯЃЌЗжЮіЃЌЭкОђЃЌФмЙЛКмКУЕФЖдгУЛЇЪЧЫЃЌгУЛЇДгФФРДЃЌвЊЕНФФРяШЅЕШЮЪЬтНјааЖЈвхКЭНтЮіЁЃдкНЛвзЪ§ОнЕФЛљДЁЩЯЃЌЖдгУЛЇааЮЊЪ§ОнКЭЭтВПЪ§ОнНјааВЙГфНЈЩшЃЌгаСЫетаЉЪ§ОнЃЌЪзЯШПЩвддкЮвааЕФAPPЁЂЭјеОвдМАATMЕШгыгУЛЇУмЧаЯрЙиЕФГЁОАРяЃЌЬсЙЉИќЬљаФЃЌИќгХжЪЕФЗўЮёЃЛЦфДЮЖдЙЋЫОФкВПИїИіН№ШквЕЮёВњЦЗгУЛЇЬхбщгХЛЏЕШЗНЯђЩЯЬсЙЉгУЛЇЪ§ОнЗДРЁжЇГХЁЃ
ааЮЊЪ§ОнВЩМЏМАЗжЮі
ЭМ3ЁЂааЮЊЪ§ОнЦНЬЈ
ДгааЮЊЪ§ОнЕФВЩМЏЁЂЪ§ОнЗжЮіећКЯМАЪ§ОнгІгУШ§ИіЗНУцЭГГяНјааЙцЛЎКЭЩшМЦЃЌЭъГЩСЫааЮЊЪ§ОнЦНЬЈЃЈGDЃЉЕФНЈЩшЁЃЪ§ОнВЩМЏВПЗжзїЮЊећИіЯюФПЕФЪ§ОнРДдДВуЃЌЭъГЩЖдгУЛЇВњЩњЕФдЪМааЮЊЪ§ОнЕФЪеМЏКЭДцДЂЁЃЪ§ОнЗжЮіВПЗжзїЮЊGDЕФжаМфВуЃЌЖдЪеМЏРДЕФгУЛЇааЮЊЪ§ОнНјааЭГМЦЗжЮіЃЌДѓжТПЩвдЕУЕНШ§РрЪ§ОнЃЌвЛРрЪЧЗДгІгІгУећЬхдЫгЊЧщПіЕФжИБъЪ§ОнЃЌЕкЖўРрЪЧЗДгІгУЛЇааЮЊЙьМЃЁЂЕиРэЮЛжУЙьМЃЕШЕФгУЛЇЩњУќжмЦкЪ§ОнЃЌЛЙгавЛРрЪЧБъЪЖУПвЛИіЮЂЙлгУЛЇЕФБъЧЉЪ§ОнЁЃЪ§ОнгІгУВПЗжзїЮЊGDЖдЭтеЙЪОКЭЗўЮёВуЃЌвЛЗНУцЮЊЪЕЪБЭЦМіЁЂОЋзМгЊЯњЕШгІгУЬсЙЉЪ§ОнжЇГжЃЌвЛЗНУцЭЈЙ§КѓЬЈЙмРэЯЕЭГЃЌЙЉгІгУдЫгЊЗННјааВщПДЁЃ
дкЪ§ОнВЩМЏВуЭЈЙ§ЙЙНЈВЩМЏПЭЛЇЖЫSDKЃЌЧЖШыЮвааЭГвЛЕФвЦЖЏПЊЗЂПђМмFireflyвдМАЧАЖЫПЊЗЂПђМмApolloжаЃЌНсКЯЮоТыВЩМЏЕФММЪѕФмСІдЫгУЃЌЪЙЕУЮвааЫљгаЛљгкЭЌвЛПђМмПЊЗЂЕФвЦЖЏЖЫAPPКЭWebЭјеОЬьШЛОпБИгУЛЇааЮЊЪ§ОнВЩМЏКЭЗжЮіЕФФмСІЁЃ
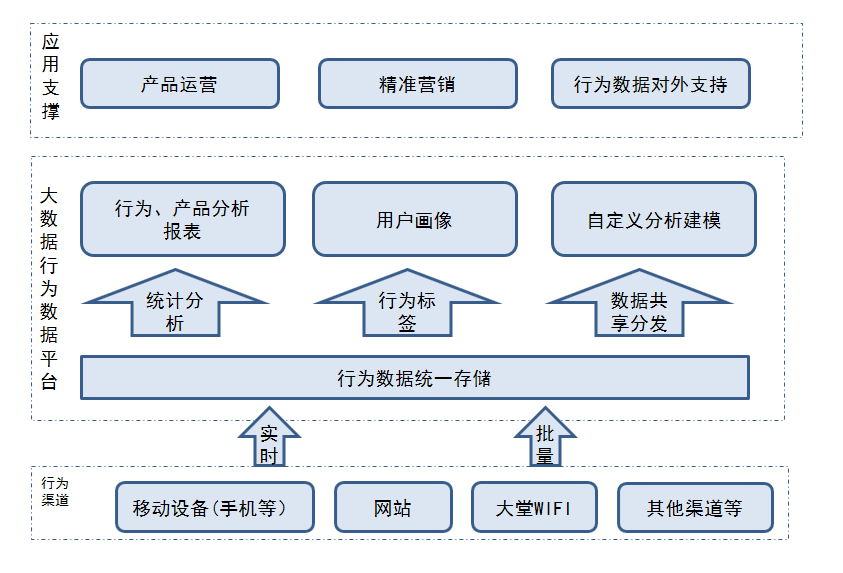
ааЮЊЪ§ОнЦНЬЈзд2015ФъЩЯЯпЕНЯждкЮЊжЙЃЌвбОНгШыСЫЪжЛњвјааЁЂжБЯњвјааЁЂРжЪевјМАПЭЛЇЛЏдЫгЊЕШУёЩњвјааДѓВПЗжAPPгІгУЃЌЖдетаЉгІгУжаЕФгУЛЇЕФааЮЊЪ§ОнНјааВЩМЏЃЌ2017ФъгждіМгСЫЖдЭјвГЖЫааЮЊЪ§ОнВЩМЏЕФЙІФмЁЃФПЧАУПЬьВЩМЏЕФЪ§ОнГЌЙ§ЧЇЭђЬѕЃЌРлЛ§ЕФааЮЊЪ§ОнвбОДяЕНЪ§ЪЎвкЬѕЃЌЭЈЙ§ДѓЪ§ОнЗжЮіММЪѕЃЌЖдВЩМЏЕНЕФЪ§ОнНјааСЫБЈБэЭГМЦКЭЗжЮіЃЌвбЕУЕНЮхРрЕФЭГМЦБЈБэЪ§ОнЃЌАќРЈгІгУжагУЛЇЕФаТдіЪ§ФПЁЂЛюдОЪ§ФПЁЂРлМЦЪ§ФПМАгУЛЇЕФЩшБИЗжВМЁЂЕигђЗжВМЁЂВйзїЯЕЭГЁЂСєДцЧщПіЁЂгУЛЇфЏРРЪБГЄЭГМЦЁЂЕуЛїЪТМўЭГМЦМАгІгУЕФДэЮѓЭГМЦЕШЃЌФПЧАНјвЛВНЕФдкЭЦЖЏааЮЊЪ§ОнЖдгЊЯњКЭЗчПиЕФЪЕЪБЪ§ОнВЙГфЁЃ
ЭтВПЪ§ОнВЩМЏМАЗжЮі
ЭМ4ЁЂЭтВПЪ§ОнЦНЬЈ
дкЦєЖЏЭтВПЪ§ОнЦНЬЈНЈЩшжЎЧАЃЌЮвааЭтВПЪ§ОнгЩИївЕЮёЬѕЯпЖРСЂЙцЛЎЪЕЪЉЃЌИїИіММЪѕЭХЖгНЈЩшСЫздМКвЕЮёСьгђФкЕФЭтВПЪ§ОнСДТЗМАЗўЮёЃЌаЮГЩСЫЁАбЬДбЁБЪНЕФЪ§ОнМгЙЄЗўЮёФЃЪНЁЃЫцзХHadoopДѓЪ§ОнЦНЬЈЕФЭЦНјЃЌ2016ФъдкЭГвЛЭтВПЪ§ОнЙмРэМАЪЙгУЕФЫМЯыЯТЃЌЦєЖЏСЫЭтВПЪ§ОнЦНЬЈЕФНЈЩшЃЌКЫаФЖЈЮЛдкгкЃКИКд№ЫљгаЭтВПЪ§ОнЕФЭГвЛДцДЂЁЂЭГвЛМгЙЄвдМАЭГвЛЕФВщбЏЗўЮёЃЌвЊЧѓжЇГжКЃСПЕФНсЙЙЛЏЁЂЗЧНсЙЙЛЏЭтВПЪ§ОнЕФв§ШыЗжЮіФмСІЁЃ
ЭтВПЪ§ОнЦНЬЈOMDSгк2016Фъ9дТЭъГЩЩЯЯпЃЌФПЧАвбОећКЯНгШыАќРЈеїаХЁЂЙЄЩЬЁЂЗЈдКЁЂЙЋАВЁЂЧЇРяблЁЂАйЖШЁЂвјСЊЁЂЪРСЊЦРЙРЁЂаавЕЗжЮіЁЂЭђЕТВЦБЈЕШдМЖўЪЎжжЭтВПЪ§ОнЕФЭГвЛЙмПиКЭЗўЮёЁЃ
Ш§ЁЂХфжУЛЏЕФЪ§ОнМгЙЄећКЯЦНЬЈ
БГОАМАФПБъ
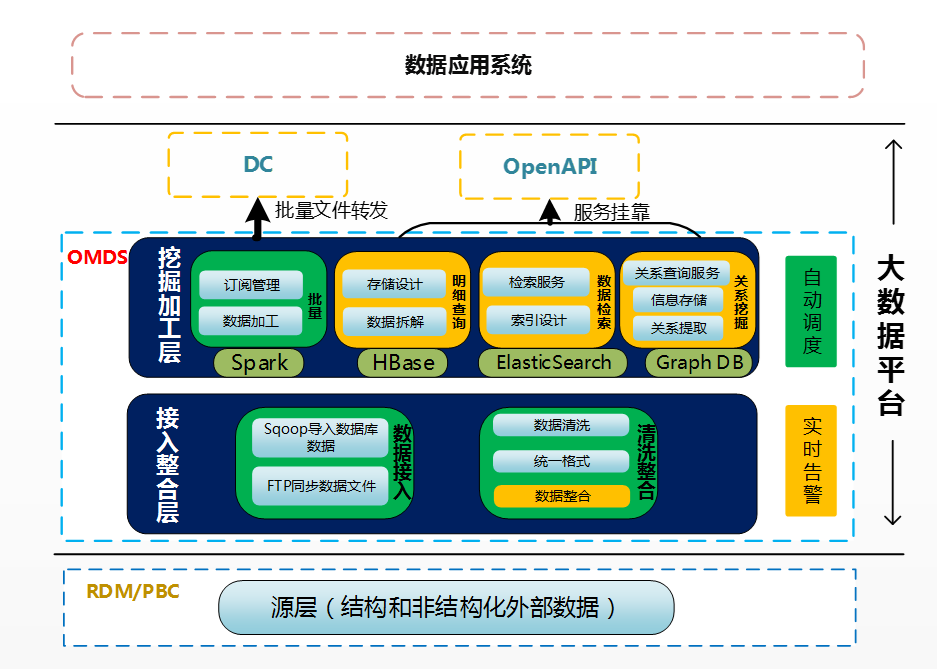
HadoopЪ§ОнећКЯЦНЃЈDCЃЉдкааФкДѓЪ§ОнЬхЯЕжаГаЕЃзХГаЩЯЦєЯТЕФНЧЩЋЃЌЛуМЏИїЧўЕРЕФЪ§ОнЕНДѓЪ§ОнЦНЬЈЃЌОЙ§ЭГвЛЧхЯДЁЂМгЙЄЁЂжЮРэЃЌНјЖјЯђЩЯгЮгІгУЬсЙЉЗўЮёЃЌДгКѓЬЈзпЕНжаЬЈЃЌжБНгЁЂПьЫйЕиЯђгІгУЯЕЭГЬсЙЉЪ§ОнЗўЮёКЭДѓЪ§ОнФмСІЃЌЗЂЛгЪ§ОнФкдкЕФЭўСІЁЃЪ§ОнЕФЛёШЁВЂВЛЪЧФПЕФЃЌШчКЮРћгУДѓЪ§ОнЦНЬЈММЪѕЃЌЪЕЯжЪ§ОнЕФЙмРэКЭаХЯЂЕФМгЙЄЬсСЖЃЌВЂЖдЩЯгЮЯЕЭГЬсЙЉИїРрЪ§ОнжЇжЇГжЁЃеыЖдетаЉЮЪЬтКЭЬєеНЃЌDCДгЪ§ОнКЭММЪѕСНИіЗНУцзХЪжЖдЦНЬЈНјааЙЙНЈЁЃ
Ъ§ОнВуДЮ

ЭМ5ЁЂDCЪ§ОнВуДЮ
ЮЊЗНБуЪ§ОнЕФЙмРэЁЂМгЙЄКЭЪЙгУЃЌDCНЋЪ§ОнНјааСЫЗжВуЃКНќдДВуКЭЙВадМгЙЄВуЃЌЦфжаНќдДВуЮЊРДздгкMDSЁЂOMDSЁЂGDКЭEDWЕФдЪМЪ§ОнЃЌАќКЌааФкЪ§ОнЁЂЭтВПЪ§ОнЁЂааЮЊЪ§ОнЁЂЗжааЪ§ОнКЭЪ§ВжЪ§ОнЁЃ
НќдДВуЪ§ОнОЙ§ЙиСЊЁЂЛузмКЭЗжЮіжЎКѓЃЌеыЖдЩЯгЮгІгУЕФашЧѓЃЌНјааЪ§ОнЙВадМгЙЄЃЌАќРЈСїЫЎМгЙЄЁЂгІгУЭГМЦЁЂжИБъМгЙЄЁЂБъЧЉМЦЫуЁЂЗчЯеСьгђКЭдЫгЊСьгђЁЃ
ЭЈЙ§OpenFileЃЈХњСПЮФМўЗўЮёЃЉЪЕЯжЪ§ОнЕФЖЉдФЙмРэЃЌЬсЙЉСЫНќдДВуЁЂЙВадМгЙЄВуЕШЪ§ОнЕФВщПДЁЂЖЉдФЙІФмЁЃ
ММЪѕМмЙЙ
ЛљгкЩЯЪіЪ§ОнМмЙЙМАгІгУашЧѓЃЌDCДгЪ§ОнДІРэЁЂШЮЮёЕїЖШЁЂЪ§ОнЙмРэКЭПЊЗЂИЈжњЫФПщНјааЦНЬЈЕФНЈЩшЃЌММЪѕМмЙЙШчЯТЭМЃК
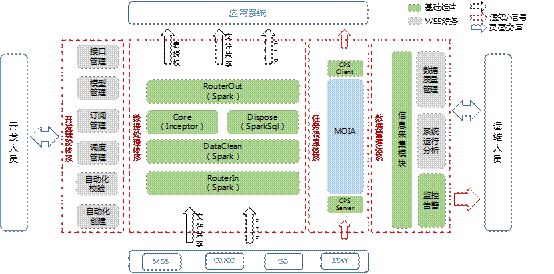
ЭМ6ЁЂDCММЪѕМмЙЙЭМ
1ЁЂ Ъ§ОнДІРэЬхЯЕ
Ъ§ОнЕФДцДЂЁЂМЦЫуКЭЗжЮіЮЊЛљгкHadoopЩњЬЌЬхЯЕЃЌАќРЈHadoopЁЂSparkЁЂInceptorЁЂHBaseЕШЗжВМЪНМЦЫуМАДцДЂПђМмЃЌРДЭъГЩЪ§ОнЕФДцДЂЁЂМЦЫуЁЂЗжЮіећИіЩњУќжмЦкЁЃ
Ъ§ОнДІРэздЯТЕНЩЯАќКЌЪ§ОнЛёШЁRouterInЁЂЪ§ОнЧхЯД(DataClean)ЁЂЙВадМгЙЄ(SparkSql/Inceptor
Sql)КЭХњСПЪ§ОнЗУЮЪЗўЮёOpenFileЁЃ
ЭЈЙ§RouterЪЕЯжВЛЭЌЪ§ОнЦНЬЈМфЕФЪ§ОнНЛЛЅЃЌЦСБЮЦНЬЈМфЕФВювьЃЌХфжУЛЏПЊЗЂЃЌЬсЩ§СЫПЊЗЂаЇТЪЃЌНЕЕЭСЫШЫЮЊЪЇЮѓЕМжТЕФЮЪЬтЃЌЪЕЯжСЫЪ§ОнЕФПьЫйНгШыКЭЗжЗЂЁЃ
ЛљгкInceptorКЭSparkSqlЩшМЦПЊЗЂСЫЪ§ОнЙВадМгЙЄФЃПщDcCoreКЭDisposeЃЌЪЕЯжСЫЪ§ОнЕФПьЫйМгЙЄЃЌВЂжЇГжФЃАхЪНЕФХфжУПЊЗЂЃЌгааЇЬсЩ§СЫЙВадМгЙЄЕФПЊЗЂаЇТЪЁЃ
2ЁЂ ШЮЮёЕїЖШЬхЯЕ
ЮЊЪЕЯжЕїЖШХњДЮЧсСПЛЏЃЌОЋЯИЛЏЪ§ОнвРРЕЃЌБмУтХњДЮЕШД§ЃЌЭЈЙ§ШЮЮёзщжЏФЃПщЛЏЃЌРДЪЕЯжзївЕЕїЖШЕФЕМГігыЩЯЯпЁЃ
ЯЕЭГМфЕФЕїЖШЭЈЙ§CPSЃЌЪЕЯжХњСПзївЕжДааЃЌЯЕЭГФкВПЕїЖШЭЈЙ§moiaСЊЖЏЃЌПЩжЇГжИќаЁСЃЖШЕФзївЕЕїЖШЃЌЪЕЯжСЫзївЕЕїЪдЕФаЇТЪКЭСщЛюЁЃ
3ЁЂ ПЊЗЂИЈжњЬхЯЕ
ПЊЗЂШЫдБашвЊЖдЪ§ОнДІРэМАШЮЮёЕїЖШЕЅЖРПЊЗЂвЛЯЕСаЕФДњТыКЭХфжУЮФМўЃЌШЫЮЊВйзїВЛНіаЇТЪЕЭЃЌЖјЧввзГіДэЁЃЭЈЙ§ИЈжњПЊЗЂЙЄОпЃЌПЩИљОнУПИіФЃПщЕФЙцЗЖЃЌздЖЏЩњГЩДњТыМАХфжУЮФМўЃЌВЂЬсЙЉПЩЪгЛЏНчУцЃЌЬсЩ§ПЊЗЂаЇТЪЃЌНЕЕЭГЩБОКЭЗчЯеЁЃ
жЇГжЕФЙІФмЗжЮЊздЖЏЛЏДДНЈЁЂздЖЏЛЏаЃбщЁЂЕїЖШЙмРэЁЂФЃаЭЙмРэКЭдЊЪ§ОнЙмРэЁЃ
4ЁЂ Ъ§ОнЙмРэЬхЯЕ
Ъ§ОнЙмРэЬхЯЕНЈЩшФПЕФЪЧЮЊСЫНЕЕЭдЫЮЌГЩБОЃЌЖддДЪ§ОнЁЂМгЙЄЪ§ОнЁЂЪ§ОнжЪСПЁЂзївЕдЫааНјааЭГМЦЗжЮіЃЌЗжЮіНсЙћЭЈЙ§WebвГУцеЙЪОвдЗНБуЖдЯЕЭГМАЪ§ОнЕФВщПДЙмРэЃЌВЂЖдгкживЊаХЯЂНјааМрПиИцОЏЃЌЦфКЫаФФЃПщАќРЈаХЯЂВЩМЏФЃПщЁЂЪ§ОнжЪСПЙмРэЁЂЯЕЭГдЫааЗжЮіКЭМрПиИцОЏЁЃ
DCЕФЙЙНЈдкУёЩњвјаажаЦ№ЕНГаЩЯЦєЯТЕФзїгУЃЌЛуМЏСЫИїЧўЕРЕФЪ§ОнЃЌОЙ§ЭГвЛЧхЯДЁЂЙиСЊећКЯЃЌВЂЖдЪ§ОнНјааЩюВуЕФЗжЮіЭкОђЃЌНјЖјЯђЩЯгЮгІгУЬсЙЉЗўЮёЃЌДгКѓЬЈзпЕНжаЬЈЃЌжБНгЁЂПьЫйЕиЯђгІгУЯЕЭГЬсЙЉЪ§ОнЗўЮёКЭДѓЪ§ОнФмСІЃЌЗЂЛгЪ§ОнФкдкЕФЭўСІЁЃФПЧАDCЯЕЭГЙмРэСЫНќдДЪ§Он5000грЯюЁЂЙВадМгЙЄЪ§Он800грЯюЃЌЮЊАќРЈЗчЯеСьгђЁЂдЫгЊСьгђЁЂвЦЖЏЛЅСЊСьгђЕШ8ИіСьгђЃЌ20грИіЯЕЭГЃЌ50грИіГЁОАЬсЙЉЪ§ОнЛђМЦЫужЇГжЁЃ
ЫФЁЂдкЯпЛњЦїбЇЯАЦНЬЈ
БГОАМАФПБъ
ФПЧАЕФЛњЦїбЇЯАММЪѕЃЌгШЦфЪЧжЧФмЫуЗЈЃЌОпгаКмИпЕФММЪѕУХМїЃЌашвЊЖЅМЖзЈвЕЭХЖгЕФГжајЭЖШыЃЌУПИіЯюФПЕЅЖРШЅЙизЂММЪѕЕФБфЛЏВЂТфЕиДњМлЬЋИпЁЃФЃаЭбаЗЂЪЕМљиНашвЛИіЭГвЛЕФЛњЦїбЇЯАЦНЬЈЃЌгУвдЙцЗЖФЃаЭПЊЗЂСїГЬЃЌЗтзАКЭМђЛЏИїРрЫуЗЈЕФЪЙгУЃЌжЇГжЖржжЖрбљЕФЪ§ОндЄМгЙЄЃЌЬсЙЉКЭЙмРэФЃаЭдЄВтЗўЮёЁЃзюжеТњзуЪ§ОнЗжЮіЪІЁЂвЕЮёзЈМвЁЂШэМўПЊЗЂЕШВЛЭЌНЧЩЋЕФВЛЭЌВуДЮЕФФЃаЭбаЗЂЪЕМљЫпЧѓЁЃ
ЛњЦїбЇЯАЦНЬЈНЈЩшжМдкЃК
1.ЛљгкHadoopММЪѕеЛЕФЦНЬЈаЭЛЗОГЃЌЬсЙЉвЕФкзюаТЕФФЃаЭЫуЗЈЃЛ
2.ЛљгкHadoopММЪѕеЛЕФЗжВМЪНЛЗОГЃЌжЇГжГЌДѓЙцФЃЕФФЃаЭГЁОАЃЛ
3.ЮЊвЛАуФЃаЭбаОПШЫдБЬсЙЉБуНнЕФЛљгкЫузгКЭЙЄзїСїЕФЭМаЮЛЗОГЃЛ
4.ЮЊИпНзФЃаЭбаОПШЫдБЬсЙЉШЋУцЕФЛљгкБрГЬЕФФЃаЭПЊЗЂЙмРэЛЗОГЁЃ
ЛњЦїбЇЯАЦНЬЈвЊФмЙЛЪЪХфИїжжвбгаЕФЪ§ОндДЃЌШчДЋЭГЙиЯЕаЭЪ§ОнПтЃЌTeraDataЪ§ОнВжПтЕШЃЌЬсЙЉЪ§ОнЕФИїжжПЩЪгЛЏЬНЫїМАНЈФЃЭкОђЃЛВЂФмЖдЪ§ОнКЭФЃаЭЛљгкНЧЩЋНјааЭъЩЦЕФШЈЯоЙмРэЃЛЖдгкбаОПШЫдБОЋаФЬєбЁЕїЪдЖјРДЕФФЃаЭЃЌЦНЬЈФмЙЛНЋЦфвЛМќВПЪ№ЮЊдкЯпЗўЮёЃЌНЋОбщЪ§ОнМАЪБзЊЛЏЮЊЖдЮДРДЕФОЋзМдЄВтФмСІЁЃ
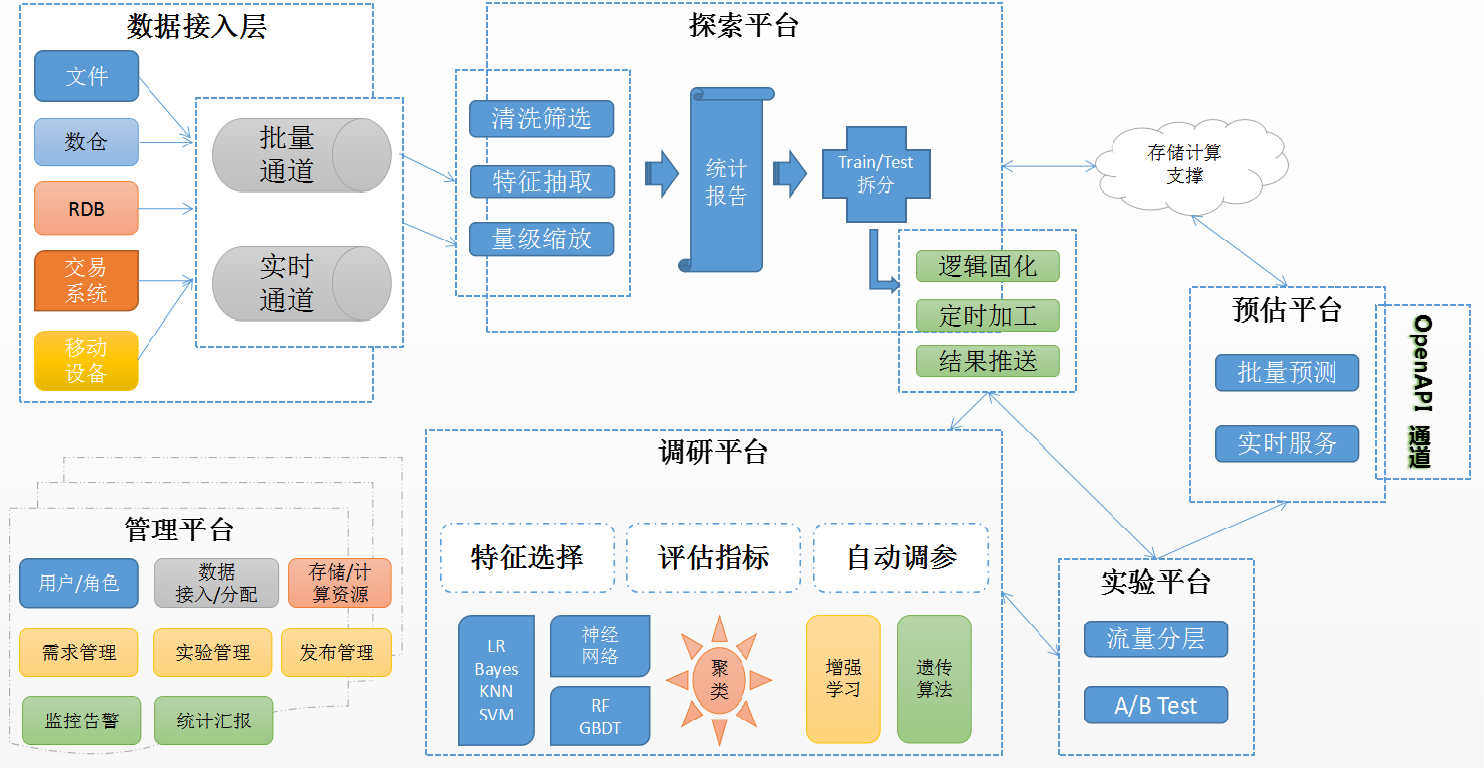
ЭМ7ЁЂЛњЦїбЇЯАЦНЬЈЙІФмМмЙЙЭМ
НЈЩшЯжзД
ЯюФПвЛЦкжаНЈЩшСЫЛњЦїбЇЯАЦНЬЈЯЕЭГКЫаФФЃПщЃЌИВИЧСЫФЃаЭбаЗЂЕФжївЊСїГЬЃЌжївЊЗжЮЊЕїбаЦНЬЈКЭдЄЙРЗўЮёСНДѓзгФЃПщЁЃКЃСПбљБОбЇЯАЁЂИпЮЌЬиеїЗжЮіДІРэКЭздЖЏЬиеїзщКЯФмСІЪЧЦфзюДѓССЕуЃЌЪОвтЭМШчЯТЃК

ЭМ8ЁЂЛњЦїбЇЯАЦНЬЈЯЕЭГЛљБОЪОвтЭМ
ећИіЦНЬЈжївЊЭЈЙ§ЭјеОНЛЛЅЪНЙІФмЮЊгУЛЇЬсЙЉЗўЮёЁЃФЃаЭЩњУќжмЦкФкЕФМИИіДѓЕФНзЖЮЖМвбОЗтзАГЩЫузгЕФЙІФмФЃПщЃЌФЃаЭЕФбаЗЂЙ§ГЬОЭЪЧдквЛПщЁАЛВМЁБЩЯЃЌЭЈЙ§ЭЯзЇЫузгЃЌДЎСЊФЃаЭбаЗЂЕФИїИіНзЖЮЃЌЛцжЦДДвтРЖЭМЁЃШчЯТЭМЫљЪОЃК
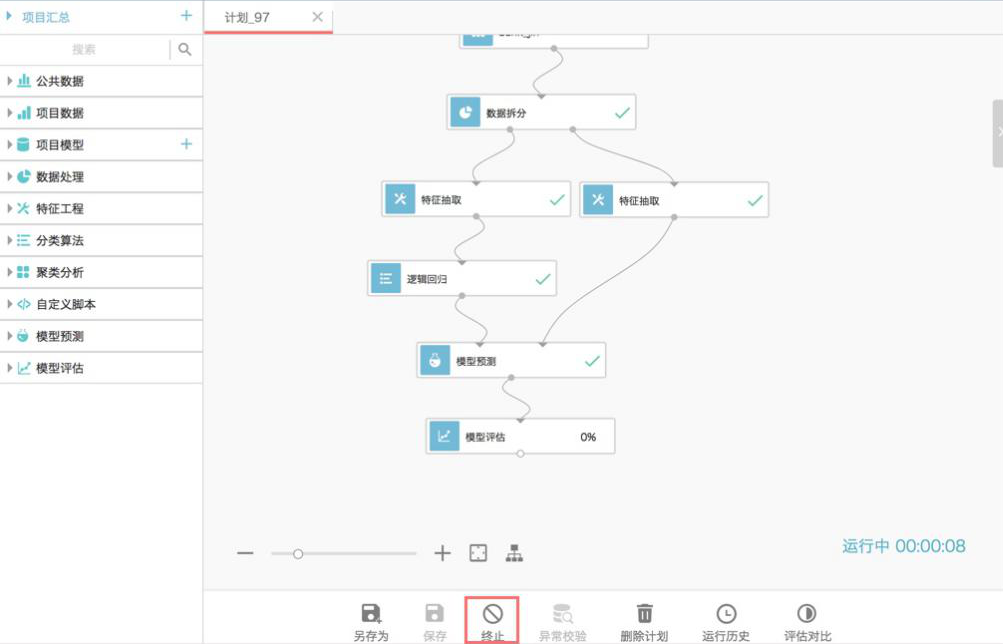
ЭМ9ЁЂЭЯзЇЫузгНјааФЃаЭбаЗЂ
ЖдгкбЕСЗКУЕФФЃаЭЃЌЦНЬЈжЇГжвЛМќЗЂВМЮЊдкЯпдЄВтЗўЮёЁЃДгбаЗЂЕНЗўЮёЃЌВЛдйашвЊХгдгЕФДњТыгыСїГЬЁЃжЛвЊЖдбЇЯАФЃаЭгаИХФюЃЌЖдгкСьгђЮЪЬтгаКУЕФДДвтЁЃОЭФмдкЭЯзЇжЎМфЃЌЕубЁжЎКѓЛёЕУвЛИіИпадФмЕФЃЌИпПЩгУЕФдЄВтЗўЮёЁЃОЭФмЪЕЯжвЕЮёОіВпЕФИќМгОЋШЗЛЏЁЂжЧФмЛЏЁЃ
ЕфаЭАИР§
ЦНЬЈФПЧАЖдНгСЫвдЯТМИЗНУцЕФгІгУЃК
дЫгЊЗчЯеМрПижЎПЩвЩОГЭтШЁЯж
дЫгЊЗчЯеМрПижЎПЩвЩОГЭтШЁЯжГЁОАЃЌЭЈЙ§ЛњЦїбЇЯАЗНЗЈЗжЮівбеЦЮеЕФПЩвЩШЁЯжааЮЊЬиеїЃЌздЖЏЗЂЯжЦфжаФЃЪНЃЌДгЖјИќШЋУцЁЂИќМАЪБЕиЗЂОђПЩвЩШЁЯжеЫКХЁЃОЙ§ЭЗФдЗчБЉЃЌЮвУЧГщШЁСЫЯњПЈ/жиПЊ/ЛЛПЈДЮЪ§ЁЂПЊЛЇЛњЙЙЁЂНЛвзЕигђ/ЪБЖЮ/ЦЕТЪ/Н№ЖюЁЂзЪН№СїШыСїГіЧўЕР/ЪБМфВюЁЂПЭЛЇЛљБОаХЯЂЕШЬиеїЃЌОЋШЗТЪДг~65%ЬсЩ§ЕНСЫ~90%ЃЌЛКНтСЫШЫЙЄИДКЫНзЖЮЕФПЊЯњЁЃ
СуЪлЗчЯеЩъЧыЗДЦлеЉЦРЗжЪЕбщ
СуЪлЗчЯеЙмРэжЎЩъЧы/ЗДЦлеЉЦРЗжЪЕбщЬНЫї--НсКЯаХгУЗчЯеКЭЗДЦлеЉСНЗНУцЃЌНЈСЂЭГвЛЕФаЁЮЂЗДЦлеЉЦРЗжФЃаЭЁЃЦкЭћЭЈЙ§ЛњЦїбЇЯАЦНЬЈЯЕЭГЕФаТЛњЦїбЇЯАЫуЗЈКЭИпЮЌЬиеїДІРэФмСІЪЙЮваааЁЮЂЩъЧыЗДЦлеЉЦРЗжФЃаЭЕФаЇЙћгаБШНЯУїЯдЕФЬсЩ§КЭгХЛЏЃЌЬсИпЖдаХгУЗчЯеКЭЦлеЉЗчЯеЕФЪЖБ№ФмСІЁЃЭЈЙ§ЖдЪ§TBЕФеїаХЁЂЙЄЩЬЁЂЩшБИКЭПЭЛЇЛљБОаХЯЂМгвдОлКЯЗжЮіЃЌГщШЁСЫНќЧЇИіЬиеїзжЖЮЃЌЬиеїздЖЏзщКЯНзЖЮгжЗЂЯжСЫЪ§ЪЎИіИпаЇЬиеїЃЌдйНсКЯЦНЬЈФкжУЫуЗЈФЃаЭЕФ
AUC ДяЕНСЫ0.9ЃЌKSжЕЬсЩ§20%ЁЃ
ЮхЁЂжЧФмЛЏЪЕЪБЭЦМів§ЧцЦНЬЈ
БГОАМАФПБъ
ЪЕЪБЭЦМів§ЧцЪЧЮвааДѓЪ§ОнЬхЯЕжаУцЯђгІгУГЁОАНЈСЂЕФгІгУВуУцЕФЭЈгУжЧФмв§ЧцЃЌИУв§ЧцНЋДѓЪ§ОнЛљДЁЦНЬЈЕФЖржжЕзВуЪ§ОнВњГіЯЕЭГЃЌАќРЈБъЧЉЯЕЭГЁЂЛњЦїбЇЯАЦНЬЈЁЂДѓЪ§ОнЦНЬЈМАЪЕЪБЪ§ОнЦНЬЈЃЌЭЈЙ§гІгУГЁОАСДНгЦ№РДЃЌЙЙНЈСЫОпБИЪЕЪБЭЦМіФмСІЕФЪ§ОнЗўЮёВуЁЃЪЕЪБЭЦМів§ЧцЕФКЫаФЪЧЪЕЪБЪ§ОнДІРэЬхЯЕвдМАЛњЦїбЇЯАЭЦМіФЃаЭЁЃЪЕЪБЭЦМів§ЧцЕФНЈЩшЃЌЮЊОЋЯИЛЏЕФПЭШКОгЊЁЂИіадЛЏПЭЛЇЗўЮёЬсЙЉСЫЧЇШЫЧЇУцЕФжЇГжЃЌГЩЮЊДѓЪ§ОнФмСІТфЕиЁЂзЊЛЏЮЊаЇвцЕФживЊЛЗНкЁЃЪЕЪБЭЦМіНЈЩшЕФФПБъАќРЈЃК
1.ЙЙНЈдкЯпЭЦМіЯЕЭГЃЌНЈЩшЬсЙЉИїГЁОАЕФЪЕЪБЭЦМіЗўЮёЕФЛљДЁФмСІЃЛ
2.ДђЭЈгУЛЇЪЕЪБЕуЛїааЮЊСДТЗЃЌНЋЪЕЪБЪ§ОнНсКЯЕНдкЯпЭЦМіЗўЮёжаЃЛ
3.ДђЭЈЛњЦїбЇЯАЦНЬЈФЃаЭЭЦМіНсЙћЃЌНЋФЃаЭНсЙћЪ§ОнШкКЯЕНдкЯпЭЦМіЗўЮёжаЃЛ
ГщЯѓгУЛЇЁЂВњЦЗЪ§ОнФЃЪНЃЌНЈЩшЭЦМіВуУцЙцдђв§ЧцЃЌжЇГжвЕЮёВпТдСщЛюХфжУЃЌВЂжЇГжШкКЯдкЯпЪЕЪБааЮЊЭЦМіНсЙћвдМАЛњЦїбЇЯАХњСПФЃаЭНсЙћЕШЪ§ОнЁЃ
ЯЕЭГМмЙЙ
ДгММЪѕЩЯЪЕЪБЭЦМів§ЧцЗжЮЊЪ§ОнМгЙЄЬхЯЕКЭЪ§ОнЗўЮёЬхЯЕСНВПЗжЃЌЭЈЙ§RedisВуРДНЋСНВПЗжСДНгЦ№РДЁЃ
Ъ§ОнМгЙЄЩЯЩцМАЕНКѓЖЫЖрЦНЬЈЩЯЕФЪ§ОнМгЙЄЃЌдкЭЈгУРрЪ§ОнМгЙЄЩЯЃЌАќРЈСЫЭЈЙ§Ъ§ВжЦНЬЈНЈСЂЕФМЏЪаВуЪ§ОнМгЙЄвдМАDCЦНЬЈЭъГЩЕФааЮЊКЭЭтВПЪ§ОнБъЧЉМгЙЄЁЃетВПЗжМгЙЄЕФЪ§ОнзїЮЊПЭЛЇЕФЪєадЪ§ОнЃЌЙрШыЕНRedisжаЙЉв§ЧцВуПьЫйВщбЏКЭЙ§ТЫЪЙгУЁЃЭЌбљдкКѓЖЫЪ§ОнМгЙЄЩЯЃЌЛЙЩцМАЕНЫуЗЈВуУцЕФЪ§ОнМгЙЄЃЌЭЈЙ§ЛњЦїбЇЯАЦНЬЈЭъГЩПЭЛЇЙКТђдЄВтЃЌНЋЛљгкХњСПГжгааХЯЂЕФМЦЫуНсЙћЃЌЭЈЙ§T-1УПШеХњСПЕФФЃЪНЭЦШыReidsзїЮЊЭЦМіНсЙћМЏЕФЪ§ОнРДдДжЎвЛЁЃЖдгкгУЛЇЪЕЪБЕуЛїЕФЪ§ОнЃЌЭЈЙ§GDЕФааЮЊЪ§ОнВЩМЏЃЌЭЦЫЭЕНЪЕЪБЪ§ОнДІРэЦНЬЈЩЯЃЌЭЈЙ§СїЪНзївЕМЦЫудкЯпЪЕЪБЕФЯрЙиадОиеѓЃЌНЋгУЛЇЕФЪЕЪБааЮЊЭЈЙ§аЭЌЙ§ТЫЫуЗЈЬхЯжЕНЭЦМіНсЙћжаШЅЁЃЖдгкЗўЮёВуЃЌзХжиНЈЩшСЫКЫаФЕФв§ЧцЃЈАќРЈЫуЗЈв§ЧцКЭЙцдђв§ЧцЃЉЃЌгУЛЇЗУЮЪНЋДЅЗЂв§ЧцЗУЮЪRedisЖдгІФЃПщЕФЪ§ОнЃЌЭЈЙ§вЕЮёВпТдвдМАдкЯпЕФЫуЗЈЖдИїЭЦМіНсЙћБИбЁМЏНјааЩИбЁКЭХХађЃЌзюжеИјГізюЪЪКЯЕФНсЙћЁЃ
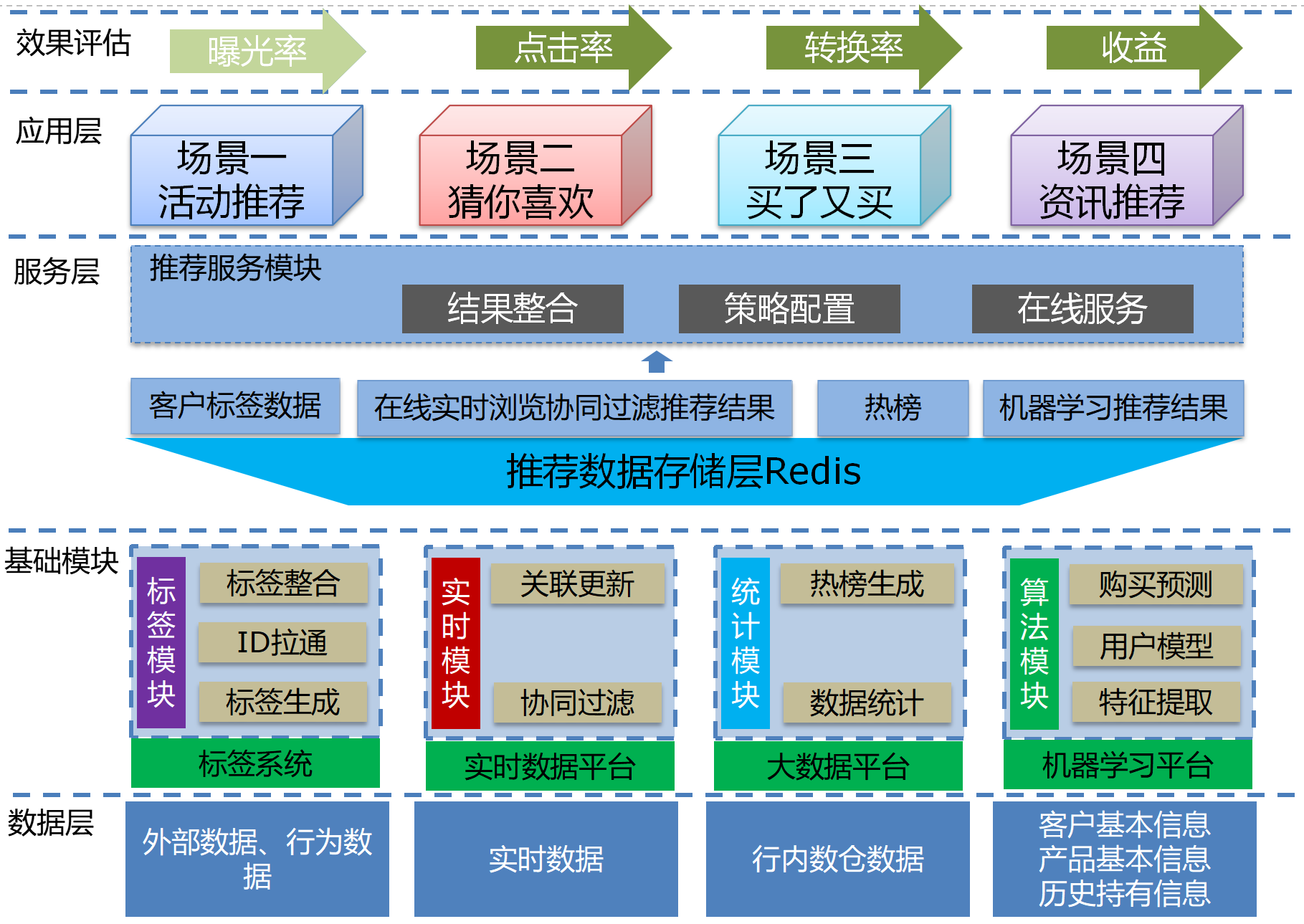
ЭМ10ЁЂЪЕЪБЭЦМів§Чц
ЕфаЭАИР§
ЪжЛњвјааРэВЦВњЦЗЭЦМі
ЕБЧАЪжЛњвјааЩЯЭЦМіЕФРэВЦЪЧЛљгкПЭЛЇзЪВњЁЂГжВжвдМАдкЪлРэВЦВњЦЗаХЯЂЃЌАДееЯргІЭЦМіЙцдђМЦЫуЕУЕНЃЌЪЙгУЕФЪ§ОнЮЌЖШЩйЃЌСщЛюадНЯВюЁЃвђДЫЮЊСЫНјвЛВНЮЊСЫЬсЩ§ПЭЛЇЬхбщЃЌдкЪжЛњвјааЩЯЪЕЯжИіадЛЏЕФРэВЦЭЦМіЗўЮёЁЃ
ВЦИЛШІзЪбЖЭЦМі
вдЭђЕТЕФаТЮХзЪбЖЪ§ОнЮЊЛљДЁЃЌвРОнПЭЛЇдкЮвааЕФВњЦЗЙКТђЃЌНЛвзааЮЊвдМАЩЯЯпжЎКѓЕФфЏРРааЮЊЕШаХЯЂЃЌЭЦМіЗћКЯПЭЛЇЭЖзЪЁЂдФЖСЦЋКУЕФаТЮХзЪбЖЃЌВЂЧвдкЭЦМіЙ§ГЬжаЖдаТЮХЕФМлжЕзїГіМђвЊХаЖЯЃЌвдЖдПЭЛЇаЮГЩМђвЊЕФЭЖзЪжЇГжЁЃ
СљЁЂЪ§ОнПЊЗХЦНЬЈ
БГОАМАФПБъ
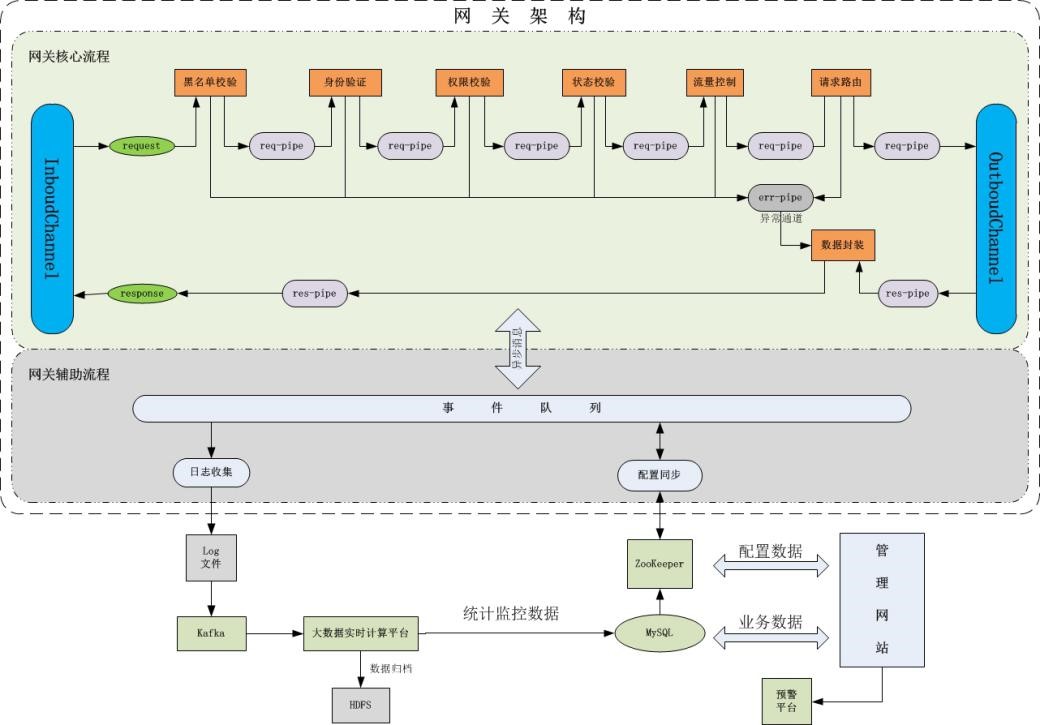
ШчКЮЪЕЯжДѓЪ§ОнМлжЕзЊЛЏЪЧЦфжаЗЧГЃживЊЕФПЮЬтЃЌДгЕБЧАЪ§ОнгІгУЕФЧїЪЦРДПДЃЌвЛЪЧдНРДдНПДжиЪ§ОнЕФЪБаЇадЃЌДгЪ§ОнЗжЮіЕНЪ§ОнЬсЙЉЃЌЖМвЊЧѓДгРыЯпзпЯђдкЯпЃЛЖўЪЧзЂжиГЁОАЛЏЃЌвЊЧѓЪ§ОнФмЙЛСщЛюКЭПьЫйЕиЪЪХфИїРргІгУГЁОАЁЃЮЊЪЪгІетбљЕФЧїЪЦЃЌДѓЪ§ОнЕФЗўЮёВуОЭБиаыЩшМЦЯргІЕФЛњжЦЁЃГЁОАЛЏЪ§ОнПЊЗХЦНЬЈДгДѓЪ§ОнЗўЮёЕФЖЅВуЩшМЦГіЗЂЃЌЮЊЭГвЛЗўЮёГіПкЃЌдіЧПЪ§ОнЪфГіЙцЗЖЃЌЖдЭтЪЙгУЩЯЬсЙЉЭГвЛЕФAPIЗўЮёЭјЙиЃЌЬсЙЉЗўЮёСїСПЕФЛуОлЕуЃЌЮЊЪ§ОнЗўЮёФЃаЭЗўЮёЕФЙВЯэКЭЕќДњЬсЙЉПЩФмЁЃ
дкЪ§ОнПЊЗХЦНЬЈжаЃЌAPIЪЧЪ§ОнЛљДЁЁЃдкИїРрЪ§ОнЙцЗЖЕФжИв§ЯТЃЌЖдЪ§ОнНјааЗжУХБ№РрЃЌЮЌЖШЧаЗжКѓЃЌвддкЯпAPIЕФЗНЪНЬсЙЉАќРЈЪ§ОнНгШыЁЂЪ§ОнЙЉИјЕШИїРрЗўЮёЃЌЙЉИїгІгУГЁОАЪЕЪБЁЂзщКЯЪНЕїгУЁЃЭЈЙ§ЭГвЛЕФПЊЗХЭјЙиЪЕЯжЗўЮёНгШыЁЂЗЂВМЁЂМјШЈЁЂЗУЮЪЁЂЭГМЦКЭМрПиЃЌЪЕЯжЪ§ОнАВШЋгыЙмПиЁЃ
ЙІФмМмЙЙ
Ъ§ОнПЊЗХЦНЬЈећЬхЩЯАќКЌЙмРэЭјеОКЭЭјЙиЯЕЭГСНВПЗжЁЃЙмРэЭјеОИКд№APIЕФНгШыЁЂЗЂВМЁЂЮЌЛЄЁЂМрПиЃЌЗУЮЪЭГМЦЪ§ОнЕФеЙЪОКЭAPIЕФЗУЮЪЩъЧыЩѓХњЁЃЭјЙиЯЕЭГЪЧЗУЮЪAPIЧыЧѓЕФЭГвЛГіШыПкЃЌИКд№ЧыЧѓЕФМјШЈЁЂЗУЮЪПижЦЁЂСїСППижЦЁЂЭГМЦМрПиЕШЙІФмЁЃ
ЭМ11ЁЂЙІФмМмЙЙЭМ
ММЪѕМмЙЙ
ЙмРэЭјеОНЋAPIЪ§ОнЁЂМјШЈЪ§ОнКЭЗУЮЪПижЦХфжУаХЯЂЕШГжОУЛЏЕНMySQLЪ§ОнПтЃЌЭЌЪБНЋетаЉЪ§ОнКЭХфжУаХЯЂЭЈЙ§ZookeeperЗўЮёЭЌВНЕНЭјЙиЯЕЭГЁЃЮЊСЫЪЕЯжЖдЧыЧѓЕФСщЛюЙмПиЃЌЭјЙиЯЕЭГеыЖдКкУћЕЅЁЂЩэЗнбщжЄЁЂШЈЯоаЃбщЁЂСїСППижЦЕШЙІФмВЩгУВхМўЛЏПЊЗЂЃЌЧвУПИіВхМўОљФмЖЏЬЌПЊЙиЁЃУПИіЧыЧѓЕФДІРэШежОаХЯЂЭЈЙ§вьВНЗНЪНЗЂЫЭЕНЪТМўЖгСаЃЌВЂгЩЕЅЖРЕФШежОЪеМЏНјГЬНјааЪеМЏЃЌДѓЪ§ОнЪЕЪБМЦЫуЦНЬЈЖдЪеМЏЕФШежОНјааЗжЮіДІРэНЋЗУЮЪЭГМЦЪ§ОнДцДЂЕНЪ§ОнПтЙЉгУЛЇВщПДЁЃ
ЭМ12ЁЂММЪѕМмЙЙЭМ
НЈЩшЯжзД
Ъ§ОнПЊЗХЦНЬЈЩЯЕФAPIЗўЮёЗжЮЊПЭЛЇааЮЊРрЁЂПЭЛЇзЪВњРрЁЂааЭтЪ§ОнРрЁЂЛљДЁЗўЮёРрЕШЃЌЦфжаЛљДЁЗўЮёРржавбОНгШыСЫЪЕЪБЪ§ОнНгЪеAPIЃЌИУAPIгУгкНгЪеИїИіЯЕЭГЪЕЪБЪ§ОнЙЉКѓајЪЕЪБМЦЫуШЮЮёЯћЗбЁЃвбОПЊЗЂЭъГЩПЭЛЇааЮЊРрAPIЙВ16ИіЁЂПЭЛЇзЪВњРрAPIЙВ6ИіЁЂааЭтЪ§ОнРрAPIЙВ13ИіЃЌOpenAPIЦНЬЈЪєгкГѕВНЭъГЩНЈЩшЃЌКѓајЛсгаИќЗсИЛЕФЪ§ОнЗўЮёAPIЭЈЙ§Ъ§ОнПЊЗХЦНЬЈЖдЭтЗўЮёЁЃ
змНс
УёЩњвјааДѓЪ§ОнНЈЩшжЎТЗЪЧвЛИіХфКЯвЕЮёГЁОАашЧѓЗДИДЕќДњЧАНјЕФвЛИіЯпТЗЃЌЗЂеЙЕННёЬьЃЌДгЖрИіВЛЭЌЕФЦНЬЈЁЂФЃПщж№ВНЕФаЮГЩСЫМИДѓЬхЯЕЃКЪ§ОнВЩМЏЬхЯЕЁЂЪ§ОнЗўЮёЬхЯЕЁЂХњСПЪ§ОнЗжЮіЬхЯЕЁЂЪЕЪБЪ§ОнЗжЮіЬхЯЕвдМАжЧФмЪ§ОнЗжЮіЬхЯЕЁЃЖдгкЪ§ОнЗўЮёЬхЯЕЃЌжїЬхЪЧећЬхЙцЛЎжаЬсЕНЕФЪ§ОнжаЬЈбнЛЏЖјРДЃЌЪЧЪ§ОнвЕЮёЛЏЪфГіЕФживЊГадиЬхЁЃЪ§ОнЗўЮёЬхЯЕаЮГЩЭГвЛЕФЪ§ОнЗўЮёФПТМЃЌгЩПЊЗХЦНЬЈВуУцЕФЭјЙиЭГвЛНјааАбПиЃЌЭЈЙ§ГЁОАЛЏЪ§ОнЗўЮёжаЬЈЖдЪ§ОнКЭФЃаЭгІгУНјааЗўЮёЛЏЃЌЮЊЖдЪ§зжЛЏЁЂГЁОАЛЏЕФвЕЮёзЊаЭЬсЙЉСЫМсЪЕЕФЕзВужЇГХФмСІЁЃ |









