| 编辑推荐: |
本文来自于hbasefly.com,介绍了Region-In-Trasition机制,Region
状态变迁的完整流程,案例分析等。
|
|
相信长时间运维HBase集群的童鞋肯定都会对RIT(Region-In-Transition,很多参考资料误解为Region-In-Transaction,需要注意)有一种咬牙切齿的痛恨感,一旦Region处于长时间的RIT就会有些不知所措,至少以前的我就是这样过来的。正所谓“恐惧来源于未知”,不知所措意味着我们对RIT知之甚少,然而“凡事都有因果,万事皆有源头”,处于RIT状态的Region只是肉眼看到的一个结果,为什么会处于RIT状态才是问题探索的根本,也是解决问题的关键。本文就基于hbase
0.98.9 版本对RIT的工作机制以及实现原理进行普及性的介绍,同时在此基础上通过真实案例讲解如何正确合理地处理处于RIT状态的
Region。一方面希望大家能够更好的了解RIT机制,另一方面希望通过本文的学习之后可以不再’惧怕’RIT,正确认识处于RIT状态的Region。
Region-In-Trasition机制
从字面意思来看,Region-In-Transition说的是Region变迁机制,实际上是指在一次特定操作行为中Region状态的变迁,那这里就涉及这么几个问题:Region存在多少种状态?HBase有哪些操作会触发Region状态变迁?一次正常操作过程中Region状态变迁的完整流程是怎么样的?如果Region状态在变迁的过程中出现异常又会怎么样?
Region存在多少种状态?有哪些操作会触发状态变迁?
HBase在RegionState类中定义了Region的主要状态,主要有如下:
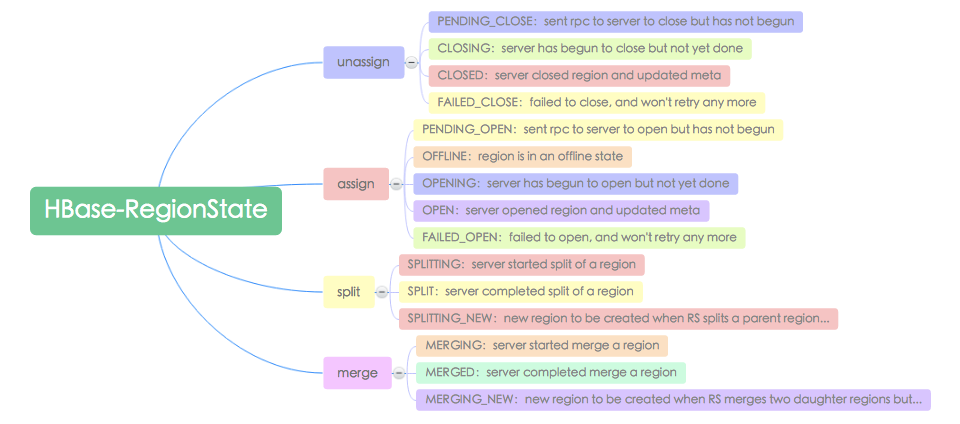
上图中实际上定义了四种会触发Region状态变迁的操作以及操作对应的Region状态。其中特定操作行为通常包括assign、unassign、split以及merge等,而很多其他操作都可以拆成unassign和assign
,比如move操作实际上是先unassign再assign;
Region状态迁移是如何发生的?
这个过程有点类似于状态机,也是通过事件驱动的。和Region状态一样,HBase
还定义了很多事件(具体见EventType类)。此处以unassign过程为例说明事件是如何驱动状态变迁的,见下图:
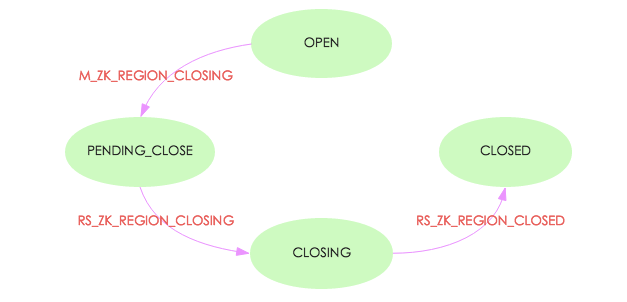
上图所示是Region在close时的状态变迁图,其中红字部分就是发生的各种事件。可见,如果发生M_ZK_
REGION_ CLOSING事件,Region就会从OPEN状态迁移到PENDING_CLOSE状态,而发生RS_ZK
_REGION_ CLOSING事件,Region会从PENDING_CLOSE状态迁移到CLOSING状态,以此类推,发生RS_
ZK_ REGION_CLOSED事件,Region就会从CLOSING状态迁移到CLOSED状态。当然,除了这些事件之外,HBase还定义了很多其他事件,在此就不一一列举。截至到此,我们知道Region是一个有限状态机,那这个状态机是如何正常工作的,HMaster、RegionServer、Zookeeper又在状态机工作过程中扮演了什么角色,那就接着往下看~
一次正常操作过程中Region状态变迁的完整流程是怎么样的?
接下来本节以unassign操作为例对这个流程进行解析:
整个unassign操作是一个比较复杂的过程,涉及HMaster、RegionServer和Zookeeper三个组件:
1. HMaster负责维护Region在整个操作过程中的状态变化,起到一个枢纽的作用。它有两个重要的HashMap数据结构,分别为regionStates和regionsInTransition,前者用来存储整个集群中所有Region及其当时状态,而后者主要存储在变迁过程中的Region及其状态,后者是前者的一个子集,不包含OPEN状态的Regions;
2. RegionServer负责接收HMaster的指令执行具体unassign操作,实际上就是关闭region操作;
3. Zookeeper负责存储操作过程中的事件,它有一个路径为/hbase/region-in-transition的节点。一旦一个Region发生unssign操作,就会在这个节点下生成一个子节点,子节点的内容是一个“事件”经过序列化的字符串,并且Master会监听在这个子节点上,一旦发生任何事件,Master就会监听到并更新Region的状态。
下图是整个流程示意图:
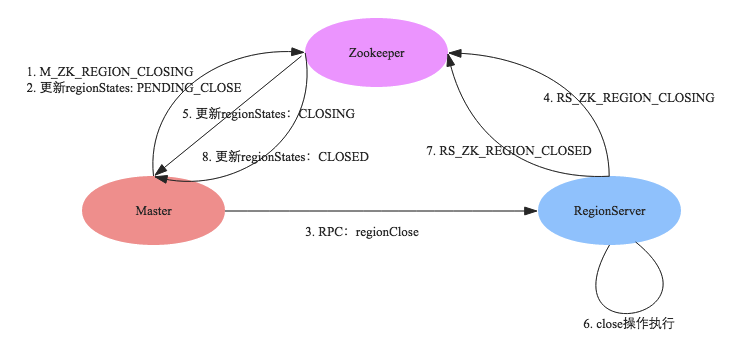
1. HMaster先执行事件M_ZK_REGION_CLOSING并更新RegionStates,将该Region的状态改为PENDING_
CLOSE ,并在regionsInTransition 中插入一条记录;
2. 发送一条RPC命令给拥有该Region的RegionServer,责令其关闭该Region;
3. RegionServer接收到HMaster发送过来的命令之后,首先生成一个RS_ZK_REGION_CLOSING事件,更新到Zookeeper,Master监听到ZK节点变动之后更新regionStates,将该Region的状态改为CLOSING
;
4. RegionServer执行真正的Region关闭操作:如果该Region正在执行flush或者compaction,等待操作完成;否则将该Region下的所有Memstore强制flush;
5. 完成之后生成事件RS_ZK_REGION_CLOSED,更新到Zookeeper,Master监听到ZK节点变动之后更新regionStates,将该Region的状态改为CLOSED;
到这里,基本上将unssign操作过程中涉及到的Region状态变迁解释清楚了,当然,其他诸如assign操作基本类似,在此不再赘述。这里其实还有一个问题,即关于HMaster上所有Region状态是否需要持久化的问题,刚开始接触这个问题的时候想想并不需要,这些处于RIT的状态信息完全可以通过Zookeeper上/region-in-transition的子节点信息构建出来。然而,在阅读HBase
Book的相关章节时,看到如下信息:
于是就充满了疑惑,一方面Master更新hbase:meta是一个远程操作,代价相对很大;另一方面Region
状态内存更新和远程更新保证一致性比较困难;再者,Zookeeper上已经有相应RIT信息,再持久化一份并没有太大意义。为了对其进行确认,就查阅跟踪了一下源码,发现是否持久化取决于一个参数:hbase.assignment.usezk,默认情况下该参数为true,表示使用zk情况下并不会对Region
状态进行持久化(详见RegionStateStore类),可见HBase Book的那段说明存在问题,在此特别说明~
如果Region状态在变迁的过程中出现异常会怎么样?
再回顾unassign的整个过程就会发现一次完整操作涉及太多流程,任何异常都可能会导致Region
处于较长时间的RIT状态,好在HBase针对常见的异常做了最基本的容错处理:
1. Master宕机重启:Master在宕机之后会丢失所有内存中的信息,也包括RIT信息以及Region状态信息,因此在重启之后会第一时间重建这些信息。重启之后会遍历Zookeeper上/hbase
/regions-in- transition 节点下的所有子节点,解析所有子节点对应的最后一个‘事件’,解析完成之后一方面借此重建全局的Region状态,另一方面根据状态机转移图对处于RIT状态的Region
进行处理。比如如果发现当前Region的状态是PENDING_CLOSE,Master就会再次据此向RegionServer
发送’关闭 Region’的RPC命令。
2. 其他异常宕机:HBase会在后台开启一个线程定期检查内存中处于RIT中的Region,一旦这些Region
处于RIT状态的时长超过一定的阈值(由参数hbase.master .assignment .timeoutmonitor
.timeout 定义,默认600000ms )就会重新执行unassign或者assign操作。比如如果当前Region的状态是PENDING_
CLOSE,而且处于该状态的时间超过了600000ms,Master就会重新执行unassign操作,向RegionServer
再次发送’关闭Region’的RPC命令。
可见,HBase提供了基本的重试机制,保证在一些短暂异常的情况下能够通过不断重试拉起那些处于RIT状态的Region,进而保证操作的完整性和状态的一致性。然而不幸的是,因为各种各样的原因,很多Region还是会掉入长时间的RIT状态,甚至是永久的RIT状态,必须人为干预才能解决,下面一节内容让我们看看都有哪些常见的场景会导致Region会处于永久RIT状态,以及遇到这类问题应该如何解决。
永久RIT状态案例分析
通过RIT机制的了解,其实可以发现处于RIT状态Region并不是什么怪物,大部分处于RIT状态的Region
都是短暂的,即使在大多数短暂异常的情况下HBase也提供了重试机制保证Region能够很快恢复正常。然而在一些特别极端的场景下还是会发生一些异常导致部分Region掉入永久的RIT状态,进而会引起表读写阻塞甚至整个集群的读写阻塞。下面我们举两个相关的案例进行说明:
案例一:Compaction永久阻塞
现象:线上一个集群因为未知原因忽然就卡住了,读写完全进不来了;另外还有很多处于PENDING_
CLOSE 状态的Region。
分析:集群卡住常见原因无非两个,一是Memstore总消耗内存大小超过了上限进而触发Region
Server 级别flush ,此时系统会阻塞集群执行长时间flush操作;二是storefile数量过多超过设定的上限阈值(参见:hbase.hstore.blockingStoreFiles),此时系统会阻塞所有flush请求而执行compaction。
诊断:
(1)首先查看了各个RegionServer上的Memstore使用大小,并没有达到设定的upperLimit。
(2)再查看了一下所有RegionServer的storefile数量,瞬间石化了,store数为250的RegionServer上storefile数量竟然达到了1.5w+,很多单个store的storefile都超过了设定阈值100
(3)初步怀疑是因为storefile数量过多引起的,看到这么多storefile的第一反应是手动执行major
_ compaction,然而所有的compact命令好像都没有起任何作用
(4)无意中发现所有RegionServer的Compaction任务都是同一张表music_actions的,而且Compaction
时间都基本持续了一两天。到此基本可以确认是因为表music_actions的Compaction任务长时间阻塞,占用了所有的Compaction线程资源,导致集群中所有其他表都无法执行Compaction
任务,最后导致StoreFile 大量堆积
(5)那为什么会存在PENDING_CLOSE状态的Region呢?经查看,这些处于PENDING_CLOSE状态的Region
全部来自于表music_actions,进一步诊断确认是由于在执行graceful_stop过程中unassign
时遇到Compaction 长时间阻塞导致RegionServer无法执行Region关闭(参考上文unassign过程),因而掉入了永久RIT
解决方案:
(1)这个问题中RIT和集群卡住原因都在于music_actions这张表的Compaction阻塞,因此需要定位Compaction
阻塞的具体原因。经过一段时间的定位初步怀疑是因为这张表的编码导致,anyway ,具体原因不重要,因为一旦Compaction阻塞,好像是没办法通过正常命令解除这种阻塞的。临时有用的办法是增大集群的Compaction
线程,以期望有更多空闲线程可以处理集群中其他Compaction 任务,消化大量堆积的StoreFiles
(2)而永久性消灭这种Compaction 阻塞只能先将这张表数据迁移出来,然后将这张表暴力删除。暴力删除就是先将HDFS对应文件删除,再将hbase:meta中该表对应的相关数据清除,最后重启整个集群即可。这张表删除之后使用hbck检查一致性之后,集群Compaction阻塞现象就消失了,集群就完全恢复正常。
案例二:HDFS文件异常
现象:线上集群很多RegionServer短时间内频频宕机,有几个Region处于FAILED_
OPEN 状态
分析诊断:
(1)查看系统监控以及RegionServer日志,确认RegionServer频繁宕机是因为大量CLOSE
_WAIT状态的短连接导致。监控显示短时间内(4h)CLOSE_WAIT的数量从0增长到6w+。
(2)再查看RegionServer日志查看到如下日志:
2016-07-27
09: 42:14,932 [RS_ OPEN_REGION- inspur 250 .photo.163
.org,60020,1469581282053- 0] ERROR org .apache
.hadoop.hbase. regionserver.handler . OpenRegionHandler
- Failed open of region = news _ user_ actions,|
u :cfcd208495d565ef6 6e7dff9f98764da
|1462799167 | 30671473410714402 ,1469522128310
.3b3ae24c65fc5094bc2acfebaa7a56de ., starting
to roll back the global memstore size.
java. io.IOException : java.io .IOException :
java .io .FileNotFoundException : File does not
exist : /hbase /news_ user_actions /b7b3faab86527b88
a92f2a248a54d3dc /meta / 0f47cda55fa 44cf9aa 2599079894aed6
2016-07-27 09:42 :14,934 [RS_ OPEN_REGION- inspur
250 .photo.163 .org,60020 ,1469581282053 -0 ]
INFO org .apache.hadoop .hbase .regionserver .handler
.Open Region Handler - Opening of region { NAME
= > 'news_ user_ actions,|u :cfcd208495 d565ef66e7
dff9f9
8764da |1462799167 |30671473410714402 , 1469522128310
.3b3ae24c65fc5094b c2acfebaa7a56de .', STARTKEY
= > '|u: cfcd208495d565ef66 e7dff9f98764da
|1462799167 | 30671473410714402 ', ENDKEY = >
'|u :d0', ENCODED => 3b3ae24c65fc5094 bc2acfebaa7a56de
,} faile
d , marking as FAILED_OPEN in ZK |
日志显示,Region ‘3b3ae24c65fc5094bc2acfebaa7a56de’打开失败,因此状态被设置为FAILED_
OPEN ,原因初步认为是FileNotFoundException 导致,找不到的文件是Region
‘b7b3faab8652 7b88a92f2a248a54d3dc ’ 下的一个文件,这两者之间有什么联系呢?
(3)使用hbck检查了一把,得到如下错误信息:
| ERROR: Found
lingering reference file hdfs: //mycluster /hbase
/news_user_actions /3b3ae24c 65fc5094bc2acfebaa7a56de
/meta /0f47cda55fa44cf9aa 2599079894aed6 .b7b3faab
86527b88a92f2a248a54d3dc |
看到这里就一下恍然大悟,从引用文件可以看出来,Region ‘3b3ae24c65fc5094bc2acfebaa
7a56 de ’是‘ b7b3faab86527b88a92f2a248a54d3dc’的子Region,熟悉
Split 过程的童鞋就会知道,父Region分裂成两个子Region其实并没有涉及到数据文件的分裂,而是会在子Region的HDFS目录下生成一个指向父Region目录的引用文件,直到子Region执行Compactio
n操作才会将父Regio n的文件合并过来。
到这里,就可以理解为什么子Region会长时间处于FAILED_OPEN状态:因为子Region引用了父Region
的文件,然而父Region的文件因为未知原因丢失了,所以子Region在打开的时候因为找不到引用文件因而会失败。而这种异常并不能通过简单的重试可以解决,所以会长时间掉入RI
T状态。
(4)现在基本可以通过RegionServer日志和hbck日志确定Region处于FAILED_OPEN的原因是因为子Region
所引用的父Region的文件丢失导致。那为什么会出现CLOSE_WAIT数量暴涨的问题呢?经确认是因为Region
在打开的时候会读取Region对应HDFS相关文件,但因为引用文件丢失所以读取失败,读取失败之后系统会不断重试,每次重试都会同datanode建立短连接,这些短连接因为hbase
的bug 一直得不到合理处理就会引起CLOSEE_WAIT数量暴涨。
解决方案:删掉HDFS上所有检查出来的引用文件即可
(5)有朋友咨询为什么会出现父文件丢失,在此补充一下。目前有可能有几个官方bug触发这个问题,详见https://issues.apache.org/jira/browse/HBASE-13331以及https://issues
.apache.org /jira /browse /HBASE-16527。
简单来说下在split完成之后父region会在什么情况下被删除,实际上Master会启动一个线程定时检查完成split之后的父目录是否可以被有效删除,系统meta表中会记录该父region切分后的子region
,只需要检查此两个子region是否还存在引用文件,如果都不存在引用文件就可以认为该父region
对应的文件可以被删除。
HBASE-13331 bug是说检查引用文件时候(检查是否存在、检查是否可以正常打开)如果抛出IO
Exception 异常,函数就会返回没有引用文件,导致父region被删掉。正常情况下应该保险起见返回存在引用文件,保留父
region,并打印日志手工介入查看。
案例分析
经过上面两个案例的讲解其实看出得出这么几点:
1. 永久性掉入RIT状态其实出现的概率并不高,都是在一些极端情况下才会出现。绝大部分RIT状态都是暂时的。
2. 一旦掉入永久性RIT状态,说明一定有根本性的问题原因,只有定位出这些问题才能彻底解决问题
3. 如果Region长时间处于PENDING_CLOSE或者CLOSING状态,一般是因为RegionServer在关闭Region
的时候遇到了长时间Compaction任务或Flush任务,所以如果Region在做类似于Major_
Compact的操作时尽量不要执行unassign操作,比如move操作、disable操作等;而如果Region长时间处于FAILED
_ OPEN 状态,一般是因为HDFS文件出现异常所致,可以通过RegionServer 日志以及hbck定位出来
写在文章最后
RIT在很多运维HBase的人看来是一个很神秘的东西,这是因为RIT很少出现,而一旦出现就很致命,运维起来往往不知所措。本文就希望能够打破这种神秘感,还原它的真实本性。文章第一部分通过层层递进的方式介绍了Region-In-Transition机制,第二部分通过生产环境的真实案例分析永久性RIT出现的场景以及应对的方案。希望大家能够更多的了解RIT,通过不断的运维实践最后再也不用惧怕它~~ |









