| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФЭЈЙ§ЖдhbaseМмЙЙЕФУшЪівдМАгХЛЏЃЌВћЪіСЫHBaseЕФЕФдРэЁЃ |
|
HBaseЪЧApache HadoopжаЕФвЛИізгЯюФПЃЌHbaseвРЭагкHadoopЕФHDFSзїЮЊзюЛљБОДцДЂЛљДЁЕЅдЊЃЌЭЈЙ§ЪЙгУhadoopЕФDFSЙЄОпОЭПЩвдПДЕНетаЉетаЉЪ§ОнДцДЂЮФМўМаЕФНсЙЙ,ЛЙПЩвдЭЈЙ§Map/ReduceЕФПђМм(ЫуЗЈ)ЖдHBaseНјааВйзї
вЛЁЂ hbaseМмЙЙ
1.ИХЪіЁЃ
HBaseЪЧApache HadoopЕФЪ§ОнПтЃЌФмЙЛЖдДѓаЭЪ§ОнЬсЙЉЫцЛњЁЂЪЕЪБЕФЖСаДЗУЮЪЁЃHBaseЕФФПБъЪЧДцДЂВЂДІРэДѓаЭЕФЪ§ОнЁЃHBaseЪЧвЛИіПЊдДЕФЃЌЗжВМЪНЕФЃЌЖрАцБОЕФЃЌУцЯђСаЕФДцДЂФЃаЭЁЃЫќДцДЂЕФЪЧЫЩЩЂаЭЪ§ОнЁЃ
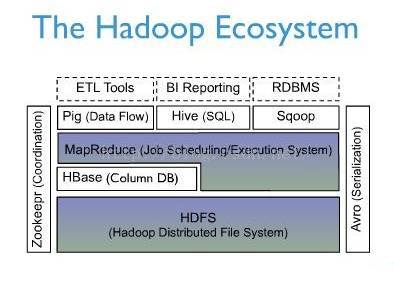
ЩЯЭМЪЧhadoopЕФЩњЬЌЯЕЭГУшЪіЃЌhadoopЫљгагІгУЖМЪЧЙЙНЈгкhdfsЃЈЫќЬсЙЉИпПЩППЕФЕзВуДцДЂжЇГжЃЌМИКѕвбОГЩЮЊЗжВМЪНЮФМўДцДЂЯЕЭГЪТЪЕЩЯЕФЙЄвЕБъзМЃЉжЎЩЯЕФЗжВМЪНСаДцДЂЯЕЭГЃЌжївЊгУгкКЃСПНсЙЙЛЏЪ§ОнДцДЂЁЃ
HBaseЪЧвЛжжNoSQLЪ§ОнПт. NoSQLЪЧвЛИіЭЈгУДЪБэЪОЪ§ОнПтВЛЪЧRDBMS ЃЌКѓепжЇГж SQL
зїЮЊжївЊЗУЮЪЪжЖЮЁЃгааэЖржж NoSQL Ъ§ОнПт: BerkeleyDB ЪЧБОЕи NoSQL Ъ§ОнПтР§зг,
Жј HBase ЪЧДѓаЭЗжВМЪНЪ§ОнПтЁЃ ММЪѕЩЯРДЫЕ, HBase ИќЯёЪЧ"Ъ§ОнДцДЂ(Data
Store)" Жргк "Ъ§ОнПт(Data Base)"ЁЃвђЮЊШБЩйКмЖрRDBMSЬиад,
ШчСаРраЭЃЌЕкЖўЫїв§ЃЌДЅЗЂЦїЃЌИпМЖВщбЏгябдЕШ
ШЛЖј, HBase гааэЖрЬиеїЭЌЪБжЇГжЯпадЛЏКЭФЃПщЛЏРЉГфЁЃ HBase МЏШКЭЈЙ§діМгRegionServersНјааРЉГфЁЃ
ЫќПЩвдЗХдкЦеЭЈЕФЗўЮёЦїжаЁЃР§ШчЃЌШчЙћМЏШКДг10ИіРЉГфЕН20ИіRegionServerЃЌДцДЂПеМфКЭДІРэШнСПЖМЭЌЪБЗБЖЁЃ
RDBMS вВФмКмКУРЉГфЃЌ ЕЋНіЖдвЛИіЕу - ЬиБ№ЪЧЖдвЛИіЕЅЖРЪ§ОнПтЗўЮёЦїЕФДѓаЁ - ЭЌЪБЃЌЮЊСЫИќКУЕФадФмЃЌашвЊЬиЪтЕФгВМўКЭДцДЂЩшБИЁЃHbaseЬиадЃК
ЧПвЛжТадЖСаД: HBase ВЛЪЧ "зюжевЛжТад(eventually consistent)"
Ъ§ОнДцДЂ. етШУЫќКмЪЪКЯИпЫйМЦЪ§ОлКЯРрШЮЮёЁЃ
здЖЏЗжЦЌ(Automatic sharding):HBase БэЭЈЙ§regionЗжВМдкМЏШКжаЁЃЪ§ОндіГЄЪБЃЌregionЛсздЖЏЗжИюВЂжиаТЗжВМЁЃ
RegionServer здЖЏЙЪеЯзЊвЦ
Hadoop/HDFS МЏГЩ: HBase жЇГжБОЛњЭтHDFS зїЮЊЫќЕФЗжВМЪНЮФМўЯЕЭГЁЃ
MapReduce: HBase ЭЈЙ§MapReduceжЇГжДѓВЂЗЂДІРэЃЌ HBase ПЩвдЭЌЪБзідДКЭФПБъ.
Java ПЭЛЇЖЫ API: HBase жЇГжвзгкЪЙгУЕФ Java API НјааБрГЬЗУЮЪ.
Thrift/REST API:HBase вВжЇГжThriftКЭ REST зїЮЊЗЧJava ЧАЖЫ.
Block Cache КЭ Bloom Filters: ЖдгкДѓШнСПВщбЏгХЛЏЃЌ HBaseжЇГж Block
Cache КЭ Bloom FiltersЁЃ
дЫЮЌЙмРэ: HBaseЬсЙЉФкжУЭјвГгУгкдЫЮЌЪгНЧКЭJMX ЖШСП.
ЧАЮФЬсЕНHbaseЪЧвЛИіСаЪНДцДЂЕФЪ§ОнПтЃЌФЧУДЪВУДЪЧСаЪНДцДЂЃЌЫќгыДЋЭГЕФRDBMSВЩгУЕФааЪНДцДЂгжгаЪВУДЧјБ№ЃПСаДцДЂВЛЭЌгкДЋЭГЕФЙиЯЕаЭЪ§ОнПтЃЌЦфЪ§ОндкБэжаЪЧАДааДцДЂЕФЃЌСаЗНЪНЫљДјРДЕФживЊКУДІжЎвЛОЭЪЧЃЌгЩгкВщбЏжаЕФбЁдёЙцдђЪЧЭЈЙ§СаРДЖЈвхЕФЃЌвђДЫећИіЪ§ОнПтЪЧздЖЏЫїв§ЛЏЕФЁЃАДСаДцДЂУПИізжЖЮЕФЪ§ОнОлМЏДцДЂЃЌдкВщбЏжЛашвЊЩйЪ§МИИізжЖЮЕФЪБКђЃЌФмДѓДѓМѕЩйЖСШЁЕФЪ§ОнСПЃЌвЛИізжЖЮЕФЪ§ОнОлМЏДцДЂЃЌФЧОЭИќШнвзЮЊетжжОлМЏДцДЂЩшМЦИќКУЕФбЙЫѕ/НтбЙЫуЗЈЁЃетеХЭМНВЪіСЫДЋЭГЕФааДцДЂКЭСаДцДЂЕФЧјБ№ЃК
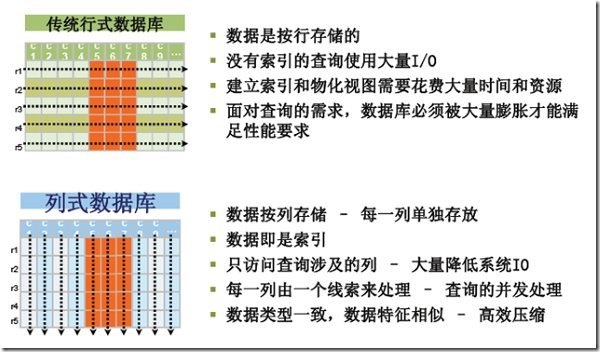
2.hbaseМмЙЙ
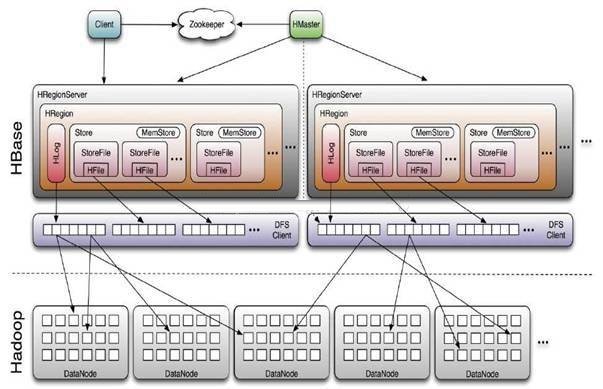
зЂЃКзМШЗЕФЫЕЮЛгкЩЯЭМЯТАыВПЗжЕФзщНЈгІИУЪЧhdfsЖјЗЧhadoopЃЌhbaseВЂВЛвРРЕгкhadoopЃЌЕЋЪЧЫќЙЙНЈгкhdfsжЎЩЯЁЃ
ZookeeperЃК
Zookeeper QuorumДцДЂ-ROOT-БэЕижЗЁЂHMasterЕижЗ
HRegionServerАбздМКвдEphedralЗНЪНзЂВсЕНZookeeperжаЃЌHMasterЫцЪБИажЊИїИіHRegionServerЕФНЁПЕзДПі
ZookeeperБмУтHMasterЕЅЕуЮЪЬт
HMasterЃК
HMasterУЛгаЕЅЕуЮЪЬтЃЌHBaseжаПЩвдЦєЖЏЖрИіHMasterЃЌЭЈЙ§ZookeeperЕФMasterElectionЛњжЦБЃжЄзмгавЛИіMasterдкдЫаа
жївЊИКд№TableКЭRegionЕФЙмРэЙЄзїЃК
1 ЙмРэгУЛЇЖдБэЕФдіЩОИФВщВйзї
2 ЙмРэHRegionServerЕФИКдиОљКтЃЌЕїећRegionЗжВМ
3 Region SplitКѓЃЌИКд№аТRegionЕФЗжВМ
4 дкHRegionServerЭЃЛњКѓЃЌИКд№ЪЇаЇHRegionServerЩЯRegionЧЈвЦ
HRegionServerЃК
HBaseжазюКЫаФЕФФЃПщЃЌжївЊИКд№ЯьгІгУЛЇI/OЧыЧѓЃЌЯђHDFSЮФМўЯЕЭГжаЖСаДЪ§Он
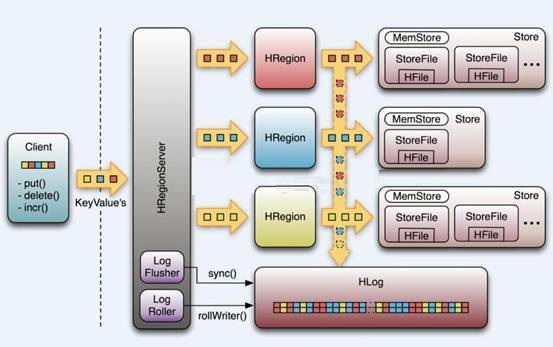
HRegionServerЙмРэвЛаЉСаHRegionЖдЯѓЃЛ
УПИіHRegionЖдгІTableжавЛИіRegionЃЌHRegionгЩЖрИіHStoreзщГЩЃЛ
УПИіHStoreЖдгІTableжавЛИіColumn FamilyЕФДцДЂЃЛ
Column FamilyОЭЪЧвЛИіМЏжаЕФДцДЂЕЅдЊЃЌЙЪНЋОпгаЯрЭЌIOЬиадЕФColumnЗХдквЛИіColumn
FamilyЛсИќИпаЇ
HStoreЃК
HBaseДцДЂЕФКЫаФЁЃгЩMemStoreКЭStoreFileзщГЩЁЃ
MemStoreЪЧSorted Memory BufferЁЃгУЛЇаДШыЪ§ОнЕФСїГЬЃК
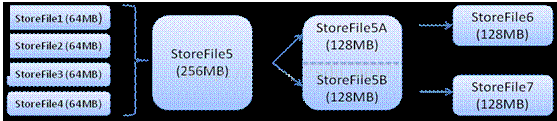
ClientаДШы -> ДцШыMemStoreЃЌвЛжБЕНMemStoreТњ -> FlushГЩвЛИіStoreFileЃЌжБжСдіГЄЕНвЛЖЈуажЕ -> ГіЗЂCompactКЯВЂВйзї -> ЖрИіStoreFileКЯВЂГЩвЛИіStoreFileЃЌЭЌЪБНјааАцБОКЯВЂКЭЪ§ОнЩОГ§
-> ЕБStoreFiles CompactКѓЃЌж№ВНаЮГЩдНРДдНДѓЕФStoreFile ->ЕЅИіStoreFileДѓаЁГЌЙ§вЛЖЈуажЕКѓЃЌДЅЗЂSplitВйзїЃЌАбЕБЧАRegion
SplitГЩ2ИіRegionЃЌRegionЛсЯТЯпЃЌаТSplitГіЕФ2ИіКЂзгRegionЛсБЛHMasterЗжХфЕНЯргІЕФHRegionServer
ЩЯЃЌЪЙЕУдЯШ1ИіRegionЕФбЙСІЕУвдЗжСїЕН2ИіRegionЩЯ
гЩДЫЙ§ГЬПЩжЊЃЌHBaseжЛЪЧдіМгЪ§ОнЃЌЫљгаЕФИќаТКЭЩОГ§ВйзїЃЌЖМЪЧдкCompactНзЖЮзіЕФЃЌЫљвдЃЌгУЛЇаДВйзїжЛашвЊНјШыЕНФкДцМДПЩСЂМДЗЕЛиЃЌДгЖјБЃжЄI/OИпадФмЁЃ
HLog
в§ШыHLogдвђЃК
дкЗжВМЪНЯЕЭГЛЗОГжаЃЌЮоЗЈБмУтЯЕЭГГіДэЛђепхДЛњЃЌвЛЕЉHRegionServerвтЭтЭЫГіЃЌMemStoreжаЕФФкДцЪ§ОнОЭЛсЖЊЪЇЃЌв§ШыHLogОЭЪЧЗРжЙетжжЧщПі
ЙЄзїЛњжЦЃК
УП ИіHRegionServerжаЖМЛсгавЛИіHLogЖдЯѓЃЌHLogЪЧвЛИіЪЕЯжWrite Ahead
LogЕФРрЃЌУПДЮгУЛЇВйзїаДШыMemstoreЕФЭЌЪБЃЌвВЛсаДвЛЗнЪ§ОнЕНHLogЮФМўЃЌHLogЮФМўЖЈЦкЛсЙіЖЏГіаТЃЌВЂЩОГ§ОЩЕФЮФМў(вбГжОУЛЏЕН
StoreFileжаЕФЪ§Он)ЁЃЕБHRegionServerвтЭтжежЙКѓЃЌHMasterЛсЭЈЙ§ZookeeperИажЊЃЌHMasterЪзЯШДІРэвХСєЕФ
HLogЮФМўЃЌНЋВЛЭЌregionЕФlogЪ§ОнВ№ЗжЃЌЗжБ№ЗХЕНЯргІregionФПТМЯТЃЌШЛКѓдйНЋЪЇаЇЕФregionжиаТЗжХфЃЌСьШЁЕНетаЉregionЕФ
HRegionServerдкLoad RegionЕФЙ§ГЬжаЃЌЛсЗЂЯжгаРњЪЗHLogашвЊДІРэЃЌвђДЫЛсReplay
HLogжаЕФЪ§ОнЕНMemStoreжаЃЌШЛКѓflushЕНStoreFilesЃЌЭъГЩЪ§ОнЛжИДЁЃ
HBaseДцДЂИёЪН
HBaseжаЕФЫљгаЪ§ОнЮФМўЖМДцДЂдкHadoop HDFSЮФМўЯЕЭГЩЯЃЌИёЪНжївЊгаСНжжЃК
1 HFile HBaseжаKeyValueЪ§ОнЕФДцДЂИёЪНЃЌHFileЪЧHadoopЕФЖўНјжЦИёЪНЮФМўЃЌЪЕМЪЩЯStoreFileОЭЪЧЖдHFileзіСЫЧсСПМЖАќзАЃЌМДStoreFileЕзВуОЭЪЧHFile
2 HLog FileЃЌHBaseжаWALЃЈWrite Ahead LogЃЉ ЕФДцДЂИёЪНЃЌЮяРэЩЯЪЧHadoopЕФSequence
File
HFile
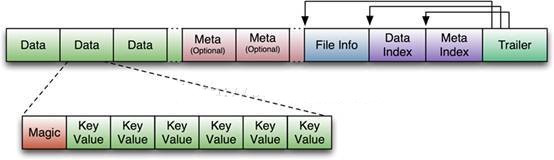
HFileЮФМўВЛЖЈГЄЃЌГЄЖШЙЬЖЈЕФПщжЛгаСНИіЃКTrailerКЭFileInfo
TrailerжажИеыжИЯђЦфЫћЪ§ОнПщЕФЦ№ЪМЕу
File InfoжаМЧТМСЫЮФМўЕФвЛаЉMetaаХЯЂЃЌР§ШчЃКAVG_KEY_LEN,AVG_VALUE_LEN,
LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEYЕШ
Data IndexКЭMeta IndexПщМЧТМСЫУПИіDataПщКЭMetaПщЕФЦ№ЪМЕу
Data BlockЪЧHBase I/OЕФЛљБОЕЅдЊЃЌЮЊСЫЬсИпаЇТЪЃЌHRegionServerжагаЛљгкLRUЕФBlock
CacheЛњжЦ
УПИіDataПщЕФДѓаЁПЩвддкДДНЈвЛИіTableЕФЪБКђЭЈЙ§ВЮЪ§жИЖЈЃЌДѓКХЕФBlockгаРћгкЫГађScanЃЌаЁКХBlockРћгкЫцЛњВщбЏ
УПИіDataПщГ§СЫПЊЭЗЕФMagicвдЭтОЭЪЧвЛИіИіKeyValueЖдЦДНгЖјГЩ, MagicФкШнОЭЪЧвЛаЉЫцЛњЪ§зжЃЌФПЕФЪЧЗРжЙЪ§ОнЫ№ЛЕ
HFileРяУцЕФУПИіKeyValueЖдОЭЪЧвЛИіМђЕЅЕФbyteЪ§зщЁЃетИіbyteЪ§зщРяУцАќКЌСЫКмЖрЯюЃЌВЂЧвгаЙЬЖЈЕФНсЙЙЁЃ

KeyLengthКЭValueLengthЃКСНИіЙЬЖЈЕФГЄЖШЃЌЗжБ№ДњБэKeyКЭValueЕФГЄЖШ
KeyВПЗжЃКRow LengthЪЧЙЬЖЈГЄЖШЕФЪ§жЕЃЌБэЪОRowKeyЕФГЄЖШЃЌRow ОЭЪЧRowKey
Column Family LengthЪЧЙЬЖЈГЄЖШЕФЪ§жЕЃЌБэЪОFamilyЕФГЄЖШ
НгзХОЭЪЧColumn FamilyЃЌдйНгзХЪЧQualifierЃЌШЛКѓЪЧСНИіЙЬЖЈГЄЖШЕФЪ§жЕЃЌБэЪОTime
StampКЭKey TypeЃЈPut/DeleteЃЉ
ValueВПЗжУЛгаетУДИДдгЕФНсЙЙЃЌОЭЪЧДПДтЕФЖўНјжЦЪ§Он
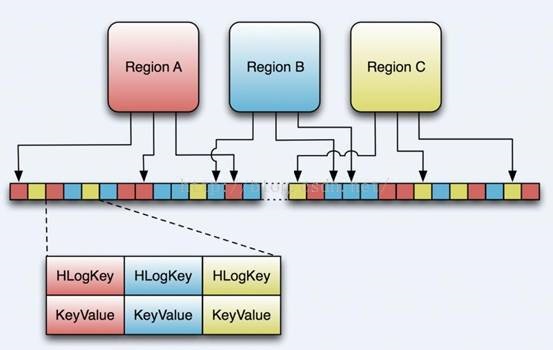
HLogЮФМўОЭЪЧвЛИіЦеЭЈЕФHadoop Sequence FileЃЌSequence File ЕФKeyЪЧHLogKeyЖдЯѓЃЌHLogKeyжаМЧТМСЫаДШыЪ§ОнЕФЙщЪєаХЯЂЃЌГ§СЫtableКЭregionУћзжЭтЃЌЭЌЪБЛЙАќРЈ
sequence numberКЭtimestampЃЌtimestampЪЧЁАаДШыЪБМфЁБЃЌsequence
numberЕФЦ№ЪМжЕЮЊ0ЃЌЛђепЪЧзюНќвЛДЮДцШыЮФМўЯЕЭГжаsequence numberЁЃ
HLog Sequece FileЕФValueЪЧHBaseЕФKeyValueЖдЯѓЃЌМДЖдгІHFileжаЕФKeyValue
3.ЪВУДЪБКђгІИУЪЙгУhbase
дкбЇЯАвЛУХаТММЪѕЕФЪБКђЪзЯШашвЊУїАзЃЌЮвУЧЕНЕзгІИУдкЪВУДЪБКђЪЙгУЫќЃЌШЛКѓВХЪЧдѕУДШЅЪЙгУЫќЃЌHbaseВЂВЛЪЪКЯЫљгаЮЪЬтЁЃ
ЪзЯШЃЌШЗаХгазуЙЛЖрЪ§ОнЃЌШчЙћгаЩЯвкЛђЩЯЧЇвкааЪ§ОнЃЌHBaseЪЧКмКУЕФБИбЁЁЃШчЙћжЛгаЩЯЧЇЛђЩЯАйЭђааЃЌдђгУДЋЭГЕФRDBMSПЩФмЪЧИќКУЕФбЁдёЁЃвђЮЊЫљгаЪ§ОнПЩвддквЛСНИіНкЕуБЃДцЃЌМЏШКЦфЫћНкЕуПЩФмЯажУЁЃ
ЦфДЮЃЌШЗаХПЩвдВЛвРРЕЫљгаRDBMSЕФЖюЭтЬиад (e.g., СаЪ§ОнРраЭ, ЕкЖўЫїв§,ЪТЮя,ИпМЖВщбЏгябдЕШ.)
вЛИіНЈСЂдкRDBMSЩЯгІгУЃЌШчВЛФмНіЭЈЙ§ИФБфвЛИіJDBCЧ§ЖЏвЦжВЕНHBaseЁЃЯрЖдгквЦжВЃЌ ашПМТЧДгRDBMS
ЕН HBaseЪЧвЛДЮЭъШЋЕФжиаТЩшМЦЁЃ
ЕкШ§ЃЌ ШЗаХФугазуЙЛгВМўЁЃЩѕжС HDFS дкаЁгк5ИіЪ§ОнНкЕуЪБЃЌИЩВЛКУЪВУДЪТЧщ (ИљОнШчHDFS
ПщИДжЦОпгаШБЪЁжЕ 3), ЛЙвЊМгЩЯвЛИіNameNode.
HBase ФмдкЕЅЖРЕФБЪМЧБОЩЯдЫааСМКУЁЃЕЋетгІНіЕБГЩПЊЗЂХфжУЁЃ
4.ФПТМБэЃЈ.meta.КЭ-root-ЃЉ
-ROOT- БЃДц .META. БэДцдкФФРяЕФзйМЃ. -ROOT- БэНсЙЙШчЯТ:
Key:
.META. region key (.META.,,1)
Values:
info:regioninfo (ађСаЛЏ.META.ЕФ HRegionInfo ЪЕР§ )
info:server ( БЃДц .META.ЕФRegionServerЕФserver:port)
info:serverstartcode ( БЃДц .META.ЕФRegionServerНјГЬЕФЦєЖЏЪБМф)
.META. БЃДцЯЕЭГжаЫљгаregionСаБэЁЃ .META.БэНсЙЙШчЯТ:
Key:
Region key ИёЪН ([table],[region start key],[region
id])
Values:
info:regioninfo (ађСаЛЏ.META.ЕФ HRegionInfo ЪЕР§ )
info:server ( БЃДц .META.ЕФRegionServerЕФserver:port)
info:serverstartcode ( БЃДц .META.ЕФRegionServerНјГЬЕФЦєЖЏЪБМф)
вдЩЯЪЧЙйЭјЮФЕЕЖдгк.meta.КЭ-root-ЕФУшЪіЃЌМђЖјбджЎЃЌ-root-жаДцДЂСЫ.meta.ЕФЮЛжУЃЌЖјдк.meta.жаБЃДцСЫОпЬхЪ§ОнЃЈregionЃЉЕФДцДЂЮЛжУЁЃШчЭМЃК
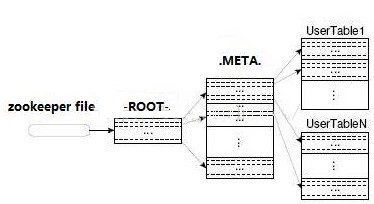
ZookeeperжаМЧТМСЫ-ROOT-БэЕФlocation
ПЭЛЇЖЫЗУЮЪЪ§ОнЕФСїГЬЃК
Client -> Zookeeper -> -ROOT- -> .META.->
гУЛЇЪ§ОнБэ
ЖрДЮЭјТчВйзїЃЌВЛЙ§clientЖЫгаcacheЛКДц
a. ЦєЖЏЪБађ
1.ЦєЖЏЪБжїЗўЮёЦїЕїгУAssignmentManager.
2.AssignmentManager дкMETAжаВщеввбОДцдкЕФЧјгђЗжХфЁЃ
3.ШчЙћЧјгђЗжХфЛЙгааЇ(Шч RegionServer ЛЙдкЯп)ЃЌФЧУДЗжХфМЬајБЃГжЁЃ
4.ШчЙћЧјгђЗжХфЪЇаЇЃЌLoadBalancerFactory БЛЕїгУРДЗжХфЧјгђЁЃ DefaultLoadBalancer
НЋЫцЛњЗжХфЧјгђЕНRegionServer.
5.META ЫцRegionServer ЗжХфИќаТ(ШчЙћашвЊ) ЃЌ RegionServer ЦєЖЏЧјгђПЊЦєДњТы(RegionServer
ЦєЖЏЪБНјГЬ)
b.ЙЪеЯзЊвЦ
ЕБregionServerЙЪеЯЭЫГіЪБЃК
1.ЧјгђСЂМДВЛПЩЛёШЁЃЌвђЮЊЧјгђЗўЮёЦїЭЫГіЁЃ
2.жїЗўЮёЦїЛсМьВтЕНЧјгђЗўЮёЦїЭЫГіЁЃ
3.ЧјгђЗжХфЛсЪЇаЇВЂБЛжиаТЗжХфЃЌШчЭЌЦєЖЏЪБађЁЃ
5.дЄаДШежОЃЈwalЃЉ
УПИіRegionServerЛсНЋИќаТ(Puts, Deletes)ЯШМЧТМЕНдЄаДШежОжа(WAL)ЃЌШЛКѓНЋЦфИќаТдкStoreЕФMemStoreРяУцЁЃетбљОЭБЃжЄСЫHBaseЕФаДЕФПЩППадЁЃШчЙћУЛгаWAL,ЕБRegionServerхДЕєЕФЪБКђЃЌMemStoreЛЙУЛгаflushЃЌStoreFileЛЙУЛгаБЃДцЃЌЪ§ОнОЭЛсЖЊЪЇЁЃHLog
ЪЧHBaseЕФвЛИіWALЪЕЯжЃЌвЛИіRegionServerгавЛИіHLogЪЕР§ЁЃ
WAL БЃДцдкHDFS ЕФ /hbase/.logs/ РяУцЃЌУПИіregionвЛИіЮФМўЁЃ
ЖўЁЂ Ъ§ОнФЃаЭ
1.ИХФюЪгЭМ
вдbigTableТлЮФжаЕФР§згРДЫЕУїЃЌгавЛИіУћЮЊwebtableЕФБэЃЌАќКЌСНИіСазхЃКcontentsКЭanchor.дкетИіР§згРяУцЃЌanchorгаСНИіСа
(anchor:cssnsi.com,anchor:my.look.ca)ЃЌcontentsНігавЛСа(contents:html)
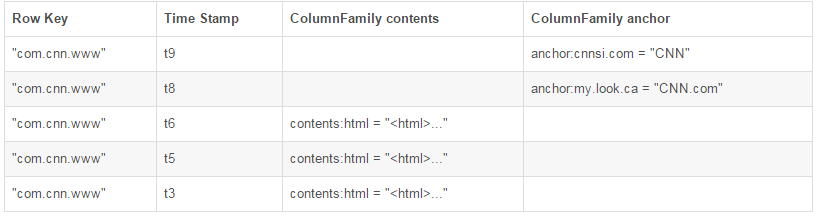

RowKeyЃКааМќЃЌЪЧБэжаУПЬѕМЧТМЕФЁАжїМќЁБЃЌЗНБуПьЫйВщевЃЌRowkeyЕФЩшМЦЗЧГЃживЊЁЃ
Column FamilyЃКСазхЃЌгЕгавЛИіУћГЦ(string)ЃЌАќКЌвЛИіЛђепЖрИіЯрЙиСа
ColumnЃКЪєгкФГвЛИіcolumnfamilyЃЌУПЬѕМЧТМПЩЖЏЬЌЬэМг
Version NumberЃКРраЭЮЊLongЃЌФЌШЯжЕЪЧЯЕЭГЪБМфДСЃЌПЩгЩгУЛЇздЖЈвх
Value(Cell)ЃКвЛИіcellгЩfamilyName:columnNameЮЈвЛЖЈвх
2.ЮяРэЪгЭМ
ОЁЙмдкИХФюЪгЭМРяЃЌБэПЩвдБЛПДГЩЪЧвЛИіЯЁЪшЕФааЕФМЏКЯЁЃЕЋдкЮяРэЩЯЃЌЫќЕФЪЧЧјЗжСазх ДцДЂЕФЁЃаТЕФcolumnsПЩвдВЛОЙ§ЩљУїжБНгМгШывЛИіСазх.

жЕЕУзЂвтЕФЪЧдкЩЯУцЕФИХФюЪгЭМжаПеАзcellдкЮяРэЩЯЪЧВЛДцДЂЕФЃЌвђЮЊИљБОУЛгаБивЊДцДЂЁЃвђДЫШєвЛИіЧыЧѓЮЊвЊЛёШЁt8ЪБМфЕФcontents:htmlЃЌЫћЕФНсЙћОЭЪЧПеЁЃЯрЫЦЕФЃЌШєЧыЧѓЮЊЛёШЁt9ЪБМфЕФanchor:my.look.caЃЌНсЙћвВЪЧПеЁЃЕЋЪЧЃЌШчЙћВЛжИУїЪБМфЃЌНЋЛсЗЕЛизюаТЪБМфЕФааЃЌУПИізюаТЕФЖМЛсЗЕЛиЁЃР§ШчЃЌШчЙћЧыЧѓЮЊЛёШЁааМќЮЊ"com.cnn.www"ЃЌУЛгажИУїЪБМфДСЕФЛАЃЌЛюЖЏЕФНсЙћЪЧt6ЯТЕФcontents:htmlЃЌt9ЯТЕФanchor:cnnsi.comКЭt8ЯТanchor:my.look.caЁЃ
ЖдгкhbaseЮввЛжБгавЛИівЩЮЪЃЌдкhbaseЬсЙЉСЫаоИФКЭЩОГ§ЕФНгПкЃЌЕЋЪЧhdfsБОЩэКмФбЪЕЯжаоИФКЭЩОГ§ЃЈПЩвдНЋЮФМўПщДгhdfsжаЯТдиЃЌНјаааоИФдйЩЯДЋЃЉЃЌФЧУДhbaseЪЧШчКЮЪЕЯжПьЫйЕФЩОГ§гыаоИФФиЃПЪЕМЪЩЯдкHBaseжаЃЌаоИФКЭЩОГ§Ъ§ОнЖМЪЧдіМг1ИіаТАцБОЕФЪ§ОнЃЈЪБМфДСЮЊзюаТЃЉЃЌОЩАцБОЕФЪ§ОнВЂУЛгаЗЂЩњБфЛЏЃЌЖјЪЕМЪЩЯЕФаоИФКЭЩОГ§ЪЧдкHfileЕФКЯВЂНзЖЮЪЕЯжЕФЁЃ
Ш§ЁЂ HbaseгХЛЏ
1. дЄЯШЗжЧј
ФЌШЯЧщПіЯТЃЌдкДДНЈ HBase БэЕФЪБКђЛсздЖЏДДНЈвЛИі Region ЗжЧјЃЌЕБЕМШыЪ§ОнЕФЪБКђЃЌЫљгаЕФ
HBase ПЭЛЇЖЫЖМЯђетвЛИі Region аДЪ§ОнЃЌжБЕНетИі Region зуЙЛДѓСЫВХНјааЧаЗжЁЃвЛжжПЩвдМгПьХњСПаДШыЫйЖШЕФЗНЗЈЪЧЭЈЙ§дЄЯШДДНЈвЛаЉПеЕФ
RegionsЃЌетбљЕБЪ§ОнаДШы HBase ЪБЃЌЛсАДее Region ЗжЧјЧщПіЃЌдкМЏШКФкзіЪ§ОнЕФИКдиОљКтЁЃ
2. RowkeyгХЛЏ
HBase жа Rowkey ЪЧАДеезжЕфађДцДЂЃЌвђДЫЃЌЩшМЦ Rowkey ЪБЃЌвЊГфЗжРћгУХХађЬиЕуЃЌНЋОГЃвЛЦ№ЖСШЁЕФЪ§ОнДцДЂЕНвЛПщЃЌНЋзюНќПЩФмЛсБЛЗУЮЪЕФЪ§ОнЗХдквЛПщЁЃ
ДЫЭтЃЌRowkey ШєЪЧЕндіЕФЩњГЩЃЌНЈвщВЛвЊЪЙгУе§ађжБНгаДШы RowkeyЃЌЖјЪЧВЩгУ reverse
ЕФЗНЪНЗДзЊRowkeyЃЌЪЙЕУ Rowkey ДѓжТОљКтЗжВМЃЌетбљЩшМЦгаИіКУДІЪЧФмНЋ RegionServer
ЕФИКдиОљКтЃЌЗёдђШнвзВњЩњЫљгааТЪ§ОнЖМдквЛИі RegionServer ЩЯЖбЛ§ЕФЯжЯѓЃЌетвЛЕуЛЙПЩвдНсКЯ
table ЕФдЄЧаЗжвЛЦ№ЩшМЦЁЃ
3. МѕЩйСазхЪ§СП
ВЛвЊдквЛеХБэРяЖЈвхЬЋЖрЕФ ColumnFamilyЁЃФПЧА Hbase ВЂВЛФмКмКУЕФДІРэГЌЙ§ 2~3
Иі ColumnFamily ЕФБэЁЃвђЮЊФГИі ColumnFamily дк flush ЕФЪБКђЃЌЫќСкНќЕФ
ColumnFamily вВЛсвђЙиСЊаЇгІБЛДЅЗЂ flushЃЌзюжеЕМжТЯЕЭГВњЩњИќЖрЕФ I/OЁЃ
4. ЛКДцВпТд
ДДНЈБэЕФЪБКђЃЌПЩвдЭЈЙ§ HColumnDescriptor.setInMemory(true) НЋБэЗХЕН
RegionServer ЕФЛКДцжаЃЌБЃжЄдкЖСШЁЕФЪБКђБЛ cache УќжаЁЃ
5. ЩшжУДцДЂЩњУќЦк
ДДНЈБэЕФЪБКђЃЌПЩвдЭЈЙ§ HColumnDescriptor.setTimeToLive(int timeToLive)
ЩшжУБэжаЪ§ОнЕФДцДЂЩњУќЦкЃЌЙ§ЦкЪ§ОнНЋздЖЏБЛЩОГ§ЁЃ
6. гВХЬХфжУ
УПЬЈ RegionServer ЙмРэ 10~1000 Иі RegionsЃЌУПИі Region дк
1~2GЃЌдђУПЬЈ Server зюЩйвЊ 10GЃЌзюДѓвЊ1000*2G=2TBЃЌПМТЧ 3 БИЗнЃЌдђвЊ
6TBЁЃЗНАИвЛЪЧгУ 3 Пщ 2TB гВХЬЃЌЖўЪЧгУ 12 Пщ 500G гВХЬЃЌДјПэзуЙЛЪБЃЌКѓепФмЬсЙЉИќДѓЕФЭЬЭТТЪЃЌИќЯИСЃЖШЕФШпгрБИЗнЃЌИќПьЫйЕФЕЅХЬЙЪеЯЛжИДЁЃ
7. ЗжХфКЯЪЪЕФФкДцИјRegionServerЗўЮё
дкВЛгАЯьЦфЫћЗўЮёЕФЧщПіЯТЃЌдНДѓдНКУЁЃР§Шчдк HBase ЕФ conf ФПТМЯТЕФ hbase-env.sh
ЕФзюКѓЬэМг export HBASE_REGIONSERVER_OPTS="-Xmx16000m$HBASE_REGIONSERVER_OPTSЁБ
Цфжа 16000m ЮЊЗжХфИј RegionServer ЕФФкДцДѓаЁЁЃ
8. аДЪ§ОнЕФБИЗнЪ§
БИЗнЪ§гыЖСадФмГЩе§БШЃЌгыаДадФмГЩЗДБШЃЌЧвБИЗнЪ§гАЯьИпПЩгУадЁЃгаСНжжХфжУЗНЪНЃЌвЛжжЪЧНЋ hdfs-site.xmlПНБДЕН
hbase ЕФ conf ФПТМЯТЃЌШЛКѓдкЦфжаЬэМгЛђаоИФХфжУЯю dfs.replication ЕФжЕЮЊвЊЩшжУЕФБИЗнЪ§ЃЌетжжаоИФЖдЫљгаЕФ
HBase гУЛЇБэЖМЩњаЇЃЌСэЭтвЛжжЗНЪНЃЌЪЧИФаД HBase ДњТыЃЌШУ HBase жЇГжеыЖдСазхЩшжУБИЗнЪ§ЃЌдкДДНЈБэЪБЃЌЩшжУСазхБИЗнЪ§ЃЌФЌШЯЮЊ
3ЃЌДЫжжБИЗнЪ§жЛЖдЩшжУЕФСазхЩњаЇЁЃ
9. WALЃЈдЄаДШежОЃЉ
ПЩЩшжУПЊЙиЃЌБэЪО HBase дкаДЪ§ОнЧАгУВЛгУЯШаДШежОЃЌФЌШЯЪЧДђПЊЃЌЙиЕєЛсЬсИпадФмЃЌЕЋЪЧШчЙћЯЕЭГГіЯжЙЪеЯ(ИКд№ВхШыЕФ
RegionServer ЙвЕє)ЃЌЪ§ОнПЩФмЛсЖЊЪЇЁЃХфжУ WAL дкЕїгУ JavaAPI аДШыЪБЃЌЩшжУ
Put ЪЕР§ЕФWALЃЌЕїгУ Put.setWriteToWAL(boolean)ЁЃ
10. ХњСПаД
HBase ЕФ Put жЇГжЕЅЬѕВхШыЃЌвВжЇГжХњСПВхШыЃЌвЛАуРДЫЕХњСПаДИќПьЃЌНкЪЁРДЛиЕФЭјТчПЊЯњЁЃдкПЭЛЇЖЫЕїгУJavaAPI
ЪБЃЌЯШНЋХњСПЕФ Put ЗХШывЛИі Put СаБэЃЌШЛКѓЕїгУ HTable ЕФ Put(Put СаБэ)
КЏЪ§РДХњСПаДЁЃ
11. ПЭЛЇЖЫвЛДЮДгЗўЮёЦїРШЁЕФЪ§СП
ЭЈЙ§ХфжУвЛДЮРШЅЕФНЯДѓЕФЪ§ОнСППЩвдМѕЩйПЭЛЇЖЫЛёШЁЪ§ОнЕФЪБМфЃЌЕЋЪЧЫќЛсеМгУПЭЛЇЖЫФкДцЁЃгаШ§ИіЕиЗНПЩНјааХфжУЃК
1ЃЉдк HBase ЕФ conf ХфжУЮФМўжаНјааХфжУ hbase.client.scanner.cachingЃЛ
2ЃЉЭЈЙ§ЕїгУ HTable.setScannerCaching(intscannerCaching)
НјааХфжУЃЛ
3ЃЉЭЈЙ§ЕїгУ Scan.setCaching(intcaching) НјааХфжУЁЃШ§епЕФгХЯШМЖдНРДдНИпЁЃ
12. RegionServerЕФЧыЧѓДІРэI/OЯпГЬЪ§
НЯЩйЕФ IO ЯпГЬЪЪгУгкДІРэЕЅДЮЧыЧѓФкДцЯћКФНЯИпЕФ Big Put ГЁОА (ДѓШнСПЕЅДЮ Put ЛђЩшжУСЫНЯДѓ
cache ЕФScanЃЌОљЪєгк Big Put) Лђ ReigonServer ЕФФкДцБШНЯНєеХЕФГЁОАЁЃ
НЯЖрЕФ IO ЯпГЬЃЌЪЪгУгкЕЅДЮЧыЧѓФкДцЯћКФЕЭЃЌTPS вЊЧѓ (УПУыЪТЮёДІРэСП (TransactionPerSecond))
ЗЧГЃИпЕФГЁОАЁЃЩшжУИУжЕЕФЪБКђЃЌвдМрПиФкДцЮЊжївЊВЮПМЁЃ
дк hbase-site.xml ХфжУЮФМўжаХфжУЯюЮЊ hbase.regionserver.handler.countЁЃ
13. RegionЕФДѓаЁЩшжУ
ХфжУЯюЮЊ hbase.hregion.max.filesizeЃЌЫљЪєХфжУЮФМўЮЊ hbase-site.xml.ЃЌФЌШЯДѓаЁ
256MЁЃ
дкЕБЧА ReigonServer ЩЯЕЅИі Reigon ЕФзюДѓДцДЂПеМфЃЌЕЅИі Region ГЌЙ§ИУжЕЪБЃЌетИі
Region ЛсБЛздЖЏ splitГЩИќаЁЕФ RegionЁЃаЁ Region Жд split КЭ compaction
гбКУЃЌвђЮЊВ№Зж Region Лђ compact аЁ Region РяЕФStoreFile ЫйЖШКмПьЃЌФкДцеМгУЕЭЁЃШБЕуЪЧ
split КЭ compaction ЛсКмЦЕЗБЃЌЬиБ№ЪЧЪ§СПНЯЖрЕФаЁ Region ВЛЭЃЕиsplit,
compactionЃЌЛсЕМжТМЏШКЯьгІЪБМфВЈЖЏКмДѓЃЌRegion Ъ§СПЬЋЖрВЛНіИјЙмРэЩЯДјРДТщЗГЃЌЩѕжСЛсв§ЗЂвЛаЉHbase
ЕФ bugЁЃвЛАу 512M вдЯТЕФЖМЫуаЁ RegionЁЃДѓ Region дђВЛЬЋЪЪКЯОГЃ split
КЭ compactionЃЌвђЮЊзівЛДЮ compact КЭ split ЛсВњЩњНЯГЄЪБМфЕФЭЃЖйЃЌЖдгІгУЕФЖСаДадФмГхЛїЗЧГЃДѓЁЃ
ДЫЭтЃЌДѓ Region втЮЖзХНЯДѓЕФ StoreFileЃЌcompaction ЪБЖдФкДцвВЪЧвЛИіЬєеНЁЃШчЙћФуЕФгІгУГЁОАжаЃЌФГИіЪБМфЕуЕФЗУЮЪСПНЯЕЭЃЌФЧУДдкДЫЪБзі
compact КЭ splitЃЌМШФмЫГРћЭъГЩ split КЭ compactionЃЌгжФмБЃжЄОјДѓЖрЪ§ЪБМфЦНЮШЕФЖСаДадФмЁЃcompaction
ЪЧЮоЗЈБмУтЕФЃЌsplit ПЩвдДгздЖЏЕїећЮЊЪжЖЏЁЃжЛвЊЭЈЙ§НЋетИіВЮЪ§жЕЕїДѓЕНФГИіКмФбДяЕНЕФжЕЃЌБШШч 100GЃЌОЭПЩвдМфНгНћгУздЖЏ
split(RegionServer ВЛЛсЖдЮДЕНДя 100G ЕФ Region зіsplit)ЁЃдйХфКЯ
RegionSplitter етИіЙЄОпЃЌдкашвЊ split ЪБЃЌЪжЖЏ splitЁЃЪжЖЏ split
дкСщЛюадКЭЮШЖЈадЩЯБШЦ№здЖЏsplit вЊИпКмЖрЃЌЖјЧвЙмРэГЩБОдіМгВЛЖрЃЌБШНЯЭЦМі online ЪЕЪБЯЕЭГЪЙгУЁЃФкДцЗНУцЃЌаЁ
Region дкЩшжУmemstore ЕФДѓаЁжЕЩЯБШНЯСщЛюЃЌДѓ Region дђЙ§ДѓЙ§аЁЖМВЛааЃЌЙ§ДѓЛсЕМжТ
flush ЪБ app ЕФ IO wait діИпЃЌЙ§аЁдђвђ StoreFile Й§ЖргАЯьЖСадФмЁЃ
14. ВйзїЯЕЭГВЮЪ§
LinuxЯЕЭГзюДѓПЩДђПЊЮФМўЪ§вЛАуФЌШЯЕФВЮЪ§жЕЪЧ1024,ШчЙћФуВЛНјаааоИФВЂЗЂСПЩЯРДЕФЪБКђЛсГіЯжЁАToo
Many Open FilesЁБЕФДэЮѓЃЌЕМжТећИіHBaseВЛПЩдЫааЃЌФуПЩвдгУulimit -n УќСюНјаааоИФЃЌЛђепаоИФ/etc/security/limits.confКЭ/proc/sys/fs/file-max
ЕФВЮЪ§ЃЌОпЬхШчКЮаоИФПЩвдШЅGoogle ЙиМќзж ЁАlinux limits.conf ЁБ
15. JvmХфжУ
аоИФ hbase-env.sh ЮФМўжаЕФХфжУВЮЪ§ЃЌИљОнФуЕФЛњЦїгВМўКЭЕБЧАВйзїЯЕЭГЕФJVM(32/64ЮЛ)ХфжУЪЪЕБЕФВЮЪ§
1.HBASE_HEAPSIZE 4000 HBaseЪЙгУЕФ JVM
ЖбЕФДѓаЁ
2.HBASE_OPTS "Љ\server Љ\XX:+UseConcMarkSweepGC"JVM
GC бЁЯю
3.HBASE_MANAGES_ZKfalse ЪЧЗёЪЙгУZookeeperНјааЗжВМЪНЙмРэ
16. ГжОУЛЏ
жиЦєВйзїЯЕЭГКѓHBaseжаЪ§ОнШЋЮоЃЌФуПЩвдВЛзіШЮКЮаоИФЕФЧщПіЯТЃЌДДНЈвЛеХБэЃЌаДвЛЬѕЪ§ОнНјааЃЌШЛКѓНЋЛњЦїжиЦєЃЌжиЦєКѓФудйНјШыHBaseЕФshellжаЪЙгУ
list УќСюВщПДЕБЧАЫљДцдкЕФБэЃЌвЛИіЖМУЛгаСЫЁЃЪЧВЛЪЧКмБОпЃПУЛгаЙиЯЕФуПЩвддкhbase/conf/hbase-default.xmlжаЩшжУhbase.rootdirЕФжЕЃЌРДЩшжУЮФМўЕФБЃДцЮЛжУжИЖЈвЛИіЮФМўМаЃЌР§ШчЃК<value>file:///you/hbase-data/path</value>ЃЌФуНЈСЂЕФHBaseжаЕФБэКЭЪ§ОнОЭжБНгаДЕНСЫФуЕФДХХЬЩЯЃЌЭЌбљФувВПЩвджИЖЈФуЕФЗжВМЪНЮФМўЯЕЭГHDFSЕФТЗОЖР§Шч:hdfs://NAMENODE_SERVER:PORT/HBASE_ROOTDIRЃЌетбљОЭаДЕНСЫФуЕФЗжВМЪНЮФМўЯЕЭГЩЯСЫЁЃ
17. ЛКГхЧјДѓаЁ
hbase.client.write.buffer
етИіВЮЪ§ПЩвдЩшжУаДШыЪ§ОнЛКГхЧјЕФДѓаЁЃЌЕБПЭЛЇЖЫКЭЗўЮёЦїЖЫДЋЪфЪ§ОнЃЌЗўЮёЦїЮЊСЫЬсИпЯЕЭГдЫааадФмПЊБйвЛИіаДЕФЛКГхЧјРДДІРэЫќЃЌетИіВЮЪ§ЩшжУШчЙћЩшжУЕФДѓСЫЃЌНЋЛсЖдЯЕЭГЕФФкДцгавЛЖЈЕФвЊЧѓЃЌжБНггАЯьЯЕЭГЕФадФмЁЃ
18. ЩЈУшФПТМБэ
hbase.master.meta.thread.rescanfrequency
ЖЈвхЖрГЄЪБМфHMasterЖдЯЕЭГБэ root КЭ meta ЩЈУшвЛДЮЃЌетИіВЮЪ§ПЩвдЩшжУЕФГЄвЛаЉЃЌНЕЕЭЯЕЭГЕФФмКФЁЃ
19. split/compactionЪБМфМфИє
hbase.regionserver.thread.splitcompactcheckfrequency
етИіВЮЪ§ЪЧБэЪОЖрОУШЅRegionServerЗўЮёЦїдЫаавЛДЮsplit/compactionЕФЪБМфМфИєЃЌЕБШЛsplitжЎЧАЛсЯШНјаавЛИіcompactВйзї.етИіcompactВйзїПЩФмЪЧminorcompactвВПЩФмЪЧmajor
compact.compactКѓ,ЛсДгЫљгаЕФStoreЯТЕФЫљгаStoreFileЮФМўзюДѓЕФФЧИіШЁmidkey.етИіmidkeyПЩФмВЂВЛДІгкШЋВПЪ§ОнЕФmidжа.вЛИіrow-keyЕФЯТУцЕФЪ§ОнПЩФмЛсПчВЛЭЌЕФHRegionЁЃ
20. ЛКДцдкJVMЖбжаЗжХфЕФАйЗжБШ
hfile.block.cache.size
жИЖЈHFile/StoreFile ЛКДцдкJVMЖбжаЗжХфЕФАйЗжБШЃЌФЌШЯжЕЪЧ0.2ЃЌвтЫМОЭЪЧ20%ЃЌЖјШчЙћФуЩшжУГЩ0ЃЌОЭБэЪОЖдИУбЁЯюЦСБЮЁЃ
21. ZooKeeperПЭЛЇЖЫЭЌЪБЗУЮЪЕФВЂЗЂСЌНгЪ§
hbase.zookeeper.property.maxClientCnxns
етЯюХфжУЕФбЁЯюОЭЪЧДгzookeeperжаРДЕФЃЌБэЪОZooKeeperПЭЛЇЖЫЭЌЪБЗУЮЪЕФВЂЗЂСЌНгЪ§ЃЌZooKeeperЖдгкHBaseРДЫЕОЭЪЧвЛИіШыПкетИіВЮЪ§ЕФжЕПЩвдЪЪЕБЗХДѓаЉЁЃ
22. memstoresеМгУЖбЕФДѓаЁВЮЪ§ХфжУ
hbase.regionserver.global.memstore.upperLimit
дкRegionServerжаЫљгаmemstoresеМгУЖбЕФДѓаЁВЮЪ§ХфжУЃЌФЌШЯжЕЪЧ0.4ЃЌБэЪО40%ЃЌШчЙћЩшжУЮЊ0ЃЌОЭЪЧЖдбЁЯюНјааЦСБЮЁЃ
23. MemstoreжаЛКДцаДШыДѓаЁ
hbase.hregion.memstore.flush.size
MemstoreжаЛКДцЕФФкШнГЌЙ§ХфжУЕФЗЖЮЇКѓНЋЛсаДЕНДХХЬЩЯЃЌР§ШчЃКЩОГ§ВйзїЪЧЯШаДШыMemStoreРязіИіБъМЧЃЌжИЪОФЧИіvalue,
column Лђ familyЕШЯТЪЧвЊЩОГ§ЕФЃЌHBaseЛсЖЈЦкЖдДцДЂЮФМўзівЛИіmajor compactionЃЌдкФЧЪБHBaseЛсАбMemStoreЫЂШывЛИіаТЕФHFileДцДЂЮФМўжаЁЃШчЙћдквЛЖЈЪБМфЗЖЮЇФкУЛгазіmajor
compactionЃЌЖјMemstoreжаГЌГіЕФЗЖЮЇОЭаДШыДХХЬЩЯСЫЁЃ |









