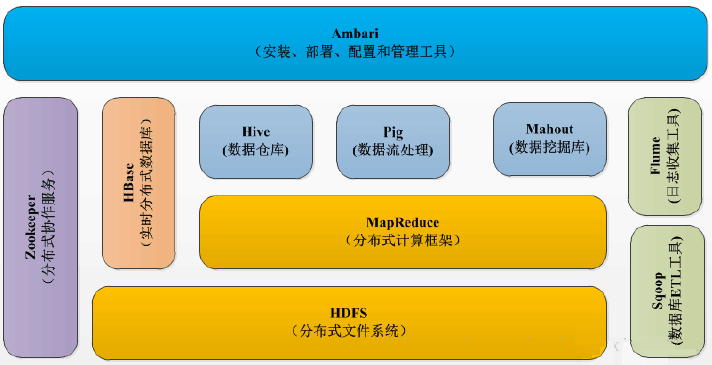
| БрМЭЦМі: |
| БОЮФРДздгкtencent.comЃЌНщЩмСЫHadoopЕФЛљДЁаХЯЂЃЌSpark
ЛљгкФкДцЕФМЦЫуПђМмЕШжЊЪЖЁЃ |
|
Hadoop
1. HadoopЪЧЪВУД
HadoopШэМўПтЪЧвЛИіРћгУМђЕЅЕФБрГЬФЃаЭдкДѓСПМЦЫуЛњМЏШКЩЯЖдДѓаЭЪ§ОнМЏНјааЗжВМЪНДІРэЕФПђМмЁЃ
ЬиЕуЃКВПЪ№ГЩБОЕЭЁЂРЉеЙЗНБуЁЂБрГЬФЃаЭМђЕЅЁЃ
Hadoop ЪЕЯжСЫдкаавЕБъзМЕФЗўЮёЦїЩЯНјааПЩППЁЂПЩЫѕЗХЕФЗжВМЪНМЦЫуЃЌШУФуФмЙЛвдНЯЕЭЕФдЄЫуИњзйЪ§
PB вдЩЯЕФЪ§ОнЃЌЖјВЛБиашвЊГЌМЖМЦЫуЛњКЭЦфЫћАКЙѓЕФзЈУХгВМўЁЃ
Hadoop ЛЙФмЙЛДгЕЅЬЈЗўЮёЦїРЉеЙЕНЪ§ЧЇЬЈМЦЫуЛњЃЌМьВтКЭДІРэгІгУГЬађВуЩЯЕФЙЪеЯЃЌДгЖјЬсИпПЩППадЁЃ
2. HadoopЕФзщГЩВПЗж ЃЈHadoop 2.0ЃЉ
1ЁЂHadoop Common: The common utilities that support
the other Hadoop modules.
2ЁЂHadoop Distributed File System (HDFS:tm:): A distributed
file system that provides high-throughput access to
application data.
3ЁЂHadoop YARN: A framework for job scheduling and
cluster resource management.
4ЁЂHadoop MapReduce: A YARN-based system for parallel
processing of large data sets.
ЮвУЧЦНГЃНгДЅБШНЯЖрЕФвВЪЧ HDFSЁЂYARNЁЂMapReduceЃЛ
ОпЬхЕФГЁОАЃЌHDFSЃЌБШШчЭЈЙ§ПЭЛЇЖЫЗУЮЪМЏШКЃЌ YARNЃЌMapReduceЃЌЮвУЧПДЬсНЛЕФШЮЮёЕФжДааЧщПіЁЃ
3. HadoopМмЙЙ
HadoopЕФЗЂеЙ Hadoop1.0 vs Hadoop 2.0
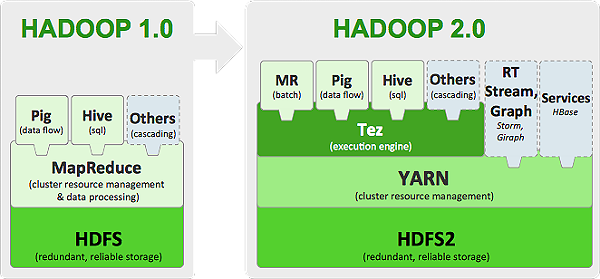

дк Hadoop 1.0 ЪБДњЃЌHadoop ЕФСНДѓКЫаФзщМў HDFS NameNode КЭ JobTrackerЖМДцдкзХЕЅЕуЮЪЬтЃЌетЦфжавдNameNodeЕФЕЅЕуЮЪЬтгШЮЊбЯжиЁЃвђЮЊNameNodeБЃДцСЫећИіHDFSЕФдЊЪ§ОнаХЯЂЃЌвЛЕЉNameNodeЙвЕєЃЌећИіHDFSОЭЮоЗЈЗУЮЪЃЌЭЌЪБHadoopЩњЬЌЯЕЭГжавРРЕгкHDFSЕФИїИізщМўЃЌАќРЈMapReduceЁЂHiveЁЂPigвдМАHBaseЕШвВЖМЮоЗЈе§ГЃЙЄзїЃЌВЂЧвжиаТЦєЖЏNameNodeКЭНјааЪ§ОнЛжИДЕФЙ§ГЬвВЛсБШНЯКФЪБЁЃетаЉЮЪЬтдкИјHadoopЕФЪЙгУепДјРДРЇШХЕФЭЌЪБЃЌвВМЋДѓЕиЯожЦСЫHadoopЕФЪЙгУГЁОАЃЌЪЙЕУHadoopдкКмГЄЕФЪБМфФкНіФмгУзїРыЯпДцДЂКЭРыЯпМЦЫуЃЌЮоЗЈгІгУЕНЖдПЩгУадКЭЪ§ОнвЛжТадвЊЧѓКмИпЕФдкЯпгІгУГЁОАжаЁЃ
Hadoop1.0HDFSгЩвЛИіNameNodeКЭЖрИіDataNode зщГЩЃЌ MapReduceЕФжДааЙ§ГЬгЩвЛИіJobTrackerКЭЖрИіTaskTracker
зщГЩЁЃ
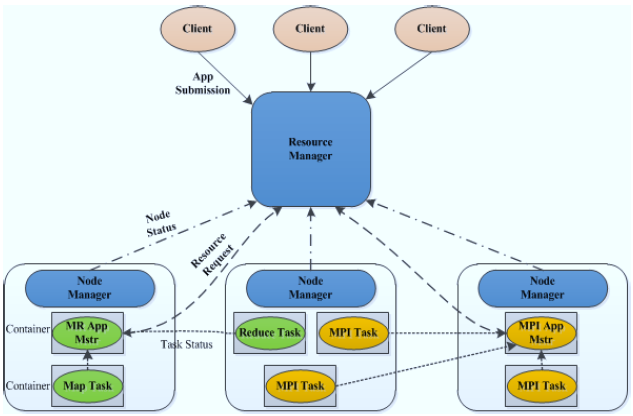
Hadoop2.0еыЖдHadoop1.0жаЕФЕЅNameNodeжЦдМHDFSЕФРЉеЙадЮЪЬтЃЌЬсГіСЫHDFSFederationЃЈСЊУЫЃЉЃЌЫќШУЖрИіNameNodeЗжЙмВЛЭЌЕФФПТМНјЖјЪЕЯжЗУЮЪИєРыКЭКсЯђРЉеЙЃЌЭЌЪБЫќГЙЕзНтОіСЫNameNodeЕЅЕуЙЪеЯЮЪЬтЁЃЫќНЋJobTrackerжаЕФзЪдДЙмРэКЭзївЕПижЦЙІФмЗжПЊЃЌЗжБ№гЩзщМўResourceManagerКЭApplicationMasterЪЕЯжЃЌЦфжаЃЌResourceManagerИКд№ЫљгагІгУГЬађЕФзЪдДЗжХфЃЌЖјApplicationMasterНіИКд№ЙмРэвЛИігІгУГЬађЃЌНјЖјЕЎЩњСЫШЋаТЕФЭЈгУзЪдДЙмРэПђМмYARNЁЃЛљгкYARNЃЌгУЛЇПЩвддЫааИїжжРраЭЕФгІгУГЬађЃЈВЛдйЯё1.0ФЧбљНіОжЯогкMapReduceвЛРргІгУЃЉЃЌДгРыЯпМЦЫуЕФMapReduceЕНдкЯпМЦЫуЃЈСїЪНДІРэЃЉЕФStormЕШYARNВЛНіЯогкMapReduceвЛжжПђМмЪЙгУЃЌвВПЩвдЙЉЦфЫћПђМмЪЙгУЃЌБШШчTezЁЂSparkЁЂStormЁЃ
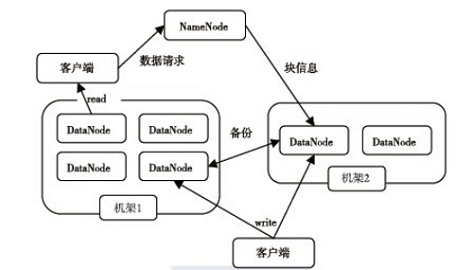
ЭМ HDFS1.0
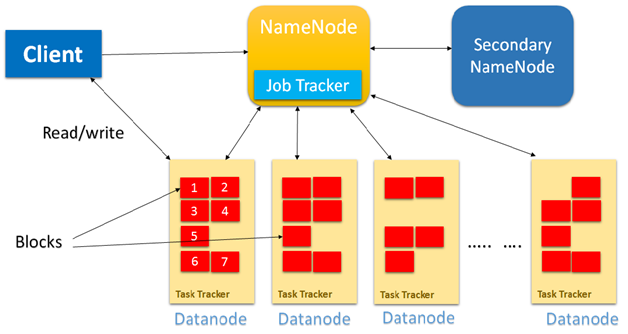
ЭМ HDFS2.0
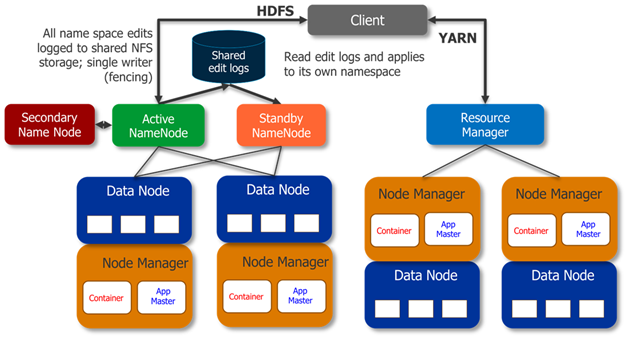
Hadoop 1.0
Hadoop 2.0
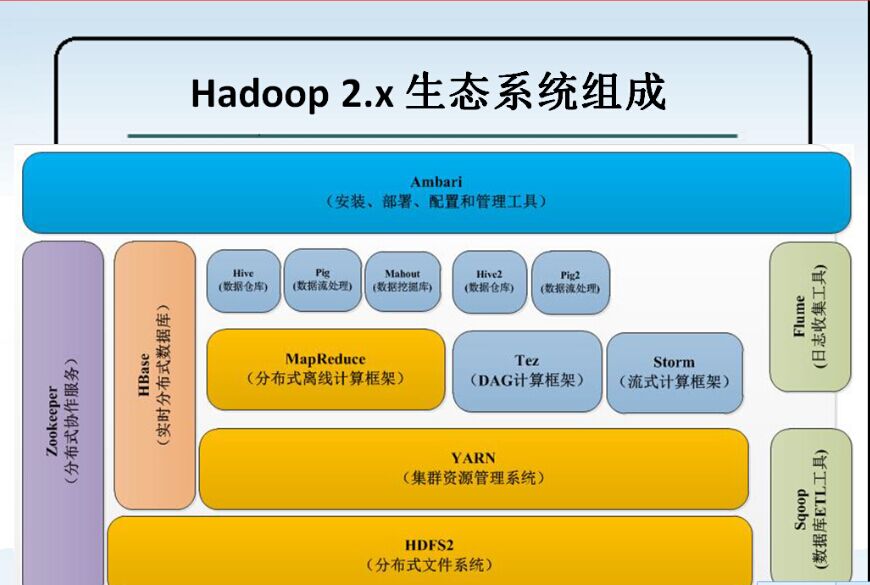
етИіЭМРяУцгаHadoopЕФЙЙГЩЃЌвдМАHadoopЯрЙиЯюФПЕФвЛаЉЙЙГЩЃЌБШШчHiveЁЂPig,SparkЁЃЫќУЧЖМЪЧвРРЕгкMapReduceжЎЩЯЕФЃЌБШШчHive
Sql ЛсзЊЛЛГЩ MapReduceГЬађШЅжДааЁЃ
4. MapReduceдРэМАЙ§ГЬ
ДЋЭГЕФЗжВМЪНГЬађЩшМЦЃЈШчMPIЃЉЗЧГЃИДдгЃЌгУЛЇашвЊЙизЂЕФЯИНкЗЧГЃЖрЃЌБШШчЪ§ОнЗжЦЌЁЂЪ§ОнДЋЪфЁЂНкЕуМфЭЈаХЕШЃЌвђЖјЩшМЦЗжВМЪНГЬађЕФУХМїЗЧГЃИпЁЃ
HadoopЕФвЛИіживЊЩшМЦФПБъБуЪЧМђЛЏЗжВМЪНГЬађЩшМЦЃЌНЋЫљгаВЂааГЬађОљашвЊЙизЂЕФЩшМЦЯИНкГщЯѓГЩЙЋЙВФЃПщВЂНЛгЩЯЕЭГЪЕЯжЃЌЖјгУЛЇжЛашзЈзЂгкздМКЕФгІгУГЬађТпМЪЕЯжЃЌетбљМђЛЏСЫЗжВМЪНГЬађЩшМЦЧвЬсИпСЫПЊЗЂаЇТЪЁЃ
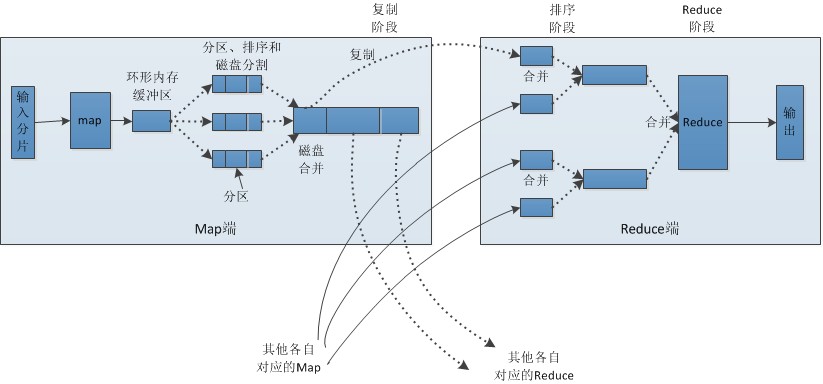
Map Task ЯШНЋЖдгІЕФ split ЕќДњНтЮіГЩвЛИіИі key/value ЖдЃЌвРДЮЕїгУгУЛЇздЖЈвхЕФmap()КЏЪ§НјааДІРэЃЌзюжеНЋСйЪБНсЙћДцЗХЕНБОЕиДХХЬЩЯЃЌЦфжаСйЪБЪ§ОнБЛЗжГЩШєИЩИіpartitionЃЌУПИі
partition НЋБЛвЛИі Reduce Task ДІРэЁЃ
Reduce Task жДааЙ§ГЬШчЭМ2-8ЫљЪОЁЃИУЙ§ГЬЗжЮЊШ§ИіНзЖЮЂйДгдЖГЬНкЕуЩЯЖСШЁMapTaskжаМфНсЙћЃЈГЦЮЊЁАShuffleНзЖЮЁБЃЉЃЛЂкАДее
key Ждkey/valueЖдНјааХХађЃЈГЦЮЊЁАSortНзЖЮЁБЃЉЃЛЂлвРДЮЖСШЁ <key, valuelist>ЃЌЕїгУгУЛЇздЖЈвхЕФ
reduce() КЏЪ§ДІРэЃЌВЂНЋзюжеНсЙћДцЕНHDFSЩЯЃЈГЦЮЊЁАReduce НзЖЮЁБЃЉЁЃ
вЛАуЕФГЁОАЪЧашвЊЖрИіMapReduceНјааЕќДњМЦЫуЃЈШчHiveSQLЃЉЃЌMap ReduceЙ§ГЬЖМЛсгааДДХХЬЕФВйзїЃЌЖјЧвСНИіMapReduceжЎМфЛЙашвЊЗУЮЪHDFSЁЃ
ШЮЮёЬсНЛ
Hadoop 1.0
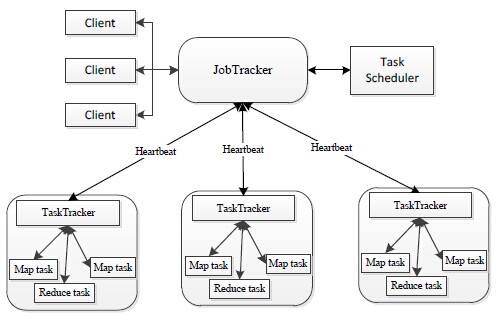
Yarn
5. Hive HQL дРэ
ДѓМввђЮЊЯрЛЅбЁдёзпЕНСЫвЛЦ№ЃЌШЛКѓГЩОЭСЫБЫДЫЁЃЕЋВЛЪЧЬьЩњОЭЪЧЮЊСЫБЫДЫЁЃ
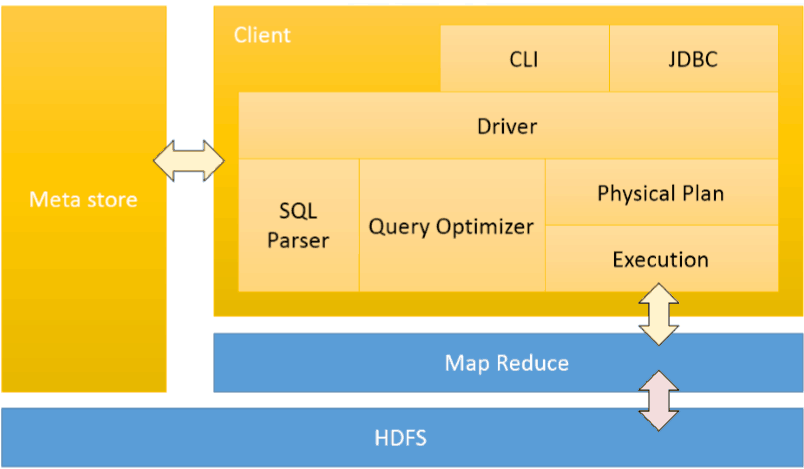
HiveQLЭЈЙ§CLI/webUIЛђепthriftЁЂodbcЛђjdbcНгПкЕФЭтВПНгПкЬсНЛЃЌОЙ§complierБрвыЦїЃЌдЫгУMetastoreжаЕФдЦЪ§ОнНјааРраЭМьВтКЭгяЗЈЗжЮіЃЌЩњГЩвЛИіТпМЗНАИ(logicalplan),ШЛКѓЭЈЙ§МђЕЅЕФгХЛЏДІРэЃЌВњЩњвЛИівдгаЯђЮоЛЗЭМDAGЪ§ОнНсЙЙаЮЪНеЙЯжЕФmap-reduceШЮЮё
ећИіБрвыЙ§ГЬЗжЮЊСљИіНзЖЮЃК
1ЁЂAntlrЖЈвхSQLЕФгяЗЈЙцдђЃЌЭъГЩSQLДЪЗЈЃЌгяЗЈНтЮіЃЌНЋSQLзЊЛЏЮЊГщЯѓгяЗЈЪїAST TreeЃЛ
2ЁЂБщРњAST TreeЃЌГщЯѓГіВщбЏЕФЛљБОзщГЩЕЅдЊQueryBlockЃЛ
3ЁЂБщРњQueryBlockЃЌЗвыЮЊжДааВйзїЪїOperatorTreeЃЛ
4ЁЂТпМВугХЛЏЦїНјааOperatorTreeБфЛЛЃЌКЯВЂВЛБивЊЕФReduceSinkOperatorЃЌМѕЩйshuffleЪ§ОнСПЃЛ
5ЁЂБщРњOperatorTreeЃЌЗвыЮЊMapReduceШЮЮёЃЛ
6ЁЂЮяРэВугХЛЏЦїНјааMapReduceШЮЮёЕФБфЛЛЃЌЩњГЩзюжеЕФжДааМЦЛЎЁЃ
TDW Hive зЊЛЛЮЊ MapReduceОйР§ЃК
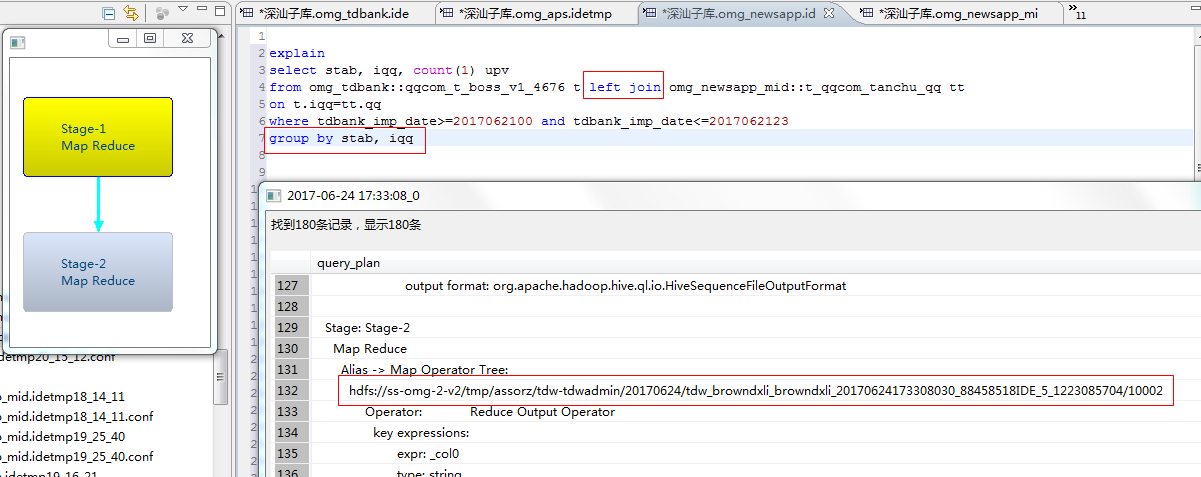
TDW Hive Sql зЊЛЏЮЊ MapReduceЃЌПЩвддкIDEРяЯШПДЯТSQLЕФжДааМЦЛЎЃЌУПИіStageЖМЪЧгЩвЛИіMapReduceзщГЩЃЌЕБШЛЃЌвЛИіStageвВПЩФмУЛгаReduceЁЃ
СНИіStageжЎМфЃЌЩЯвЛИіreduceЕФЪ§ОнЛсаДЕНHDFSЩЯЁЃ
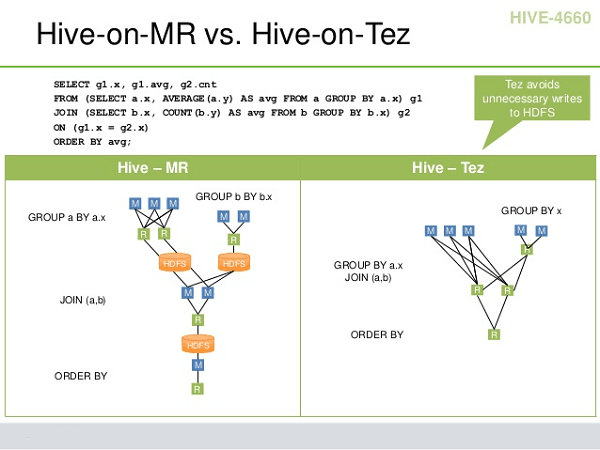
6ЁЂDAGМЦЫуПђМм Tez
ЖдгкашвЊЖрИіMapReduceзївЕЕќДњМЦЫуЕФГЁОАЃЌвђЮЊУПИіMapReduceЖМвЊЖСаДHDFSЛсдьГЩДХХЬКЭЭјТчIOЕФРЫЗбЃЌЖјTezзїЮЊвЛИіDAGПђМмЃЌПЩвдНЋЖрИігавРРЕЕФMapReduceзївЕзЊЛЏЮЊвЛИізївЕЃЌДгЖјЬсИпадФмЁЃ
Spark ЛљгкФкДцЕФМЦЫуПђМм
1ЁЂКЫаФИХФю RDD
RDD ЕЏадЗжВМЪНЪ§ОнМЏЃЈRDDЃЌResilient Distributed DatasetsЃЉЃЌЪЧвЛИіШнДэЕФЁЂВЂааЕФЪ§ОнНсЙЙЃЌПЩвдШУгУЛЇЯдЪНЕиНЋЪ§ОнДцДЂЕНДХХЬКЭФкДцжаЃЌВЂФмПижЦЪ§ОнЕФЗжЧјЁЃRDDЛЙЬсЙЉСЫвЛзщЗсИЛЕФВйзїРДВйзїетаЉЪ§ОнЁЃSparkЖдгкЪ§ОнЕФДІРэЃЌЖМЪЧЮЇШЦзХRDDНјааЕФЁЃ
RDDжЛФмЭЈЙ§дкЮШЖЈЕФДцДЂЦїЛђЦфЫћRDDЕФЪ§ОнЩЯЕФШЗЖЈадВйзїРДДДНЈЁЃ
val hdfsURL=
"hdfs://** /**/** /**/ds= 20170101 /*gz"
val hdfsRdd = sparkSession .sparkContext .textFile
(hdfsURL) |
2ЁЂRDDЕФВйзїЃКRDDзЊЛЛКЭЖЏзї
Transformation ВйзїЪЧбгГйМЦЫуЕФЃЌвВОЭЪЧЫЕДгвЛИіRDD зЊЛЛЩњГЩСэвЛИі RDD ЕФзЊЛЛВйзїВЛЪЧТэЩЯжДааЃЌашвЊЕШЕНга
Action ВйзїЕФЪБКђВХЛсеце§ДЅЗЂдЫЫуЁЃ
Action ааЖЏЫузгЃКетРрЫузгЛсДЅЗЂ SparkContext ЬсНЛ Job зївЕЁЃ
3ЁЂжДааЙ§ГЬ
ПэевРРЕ
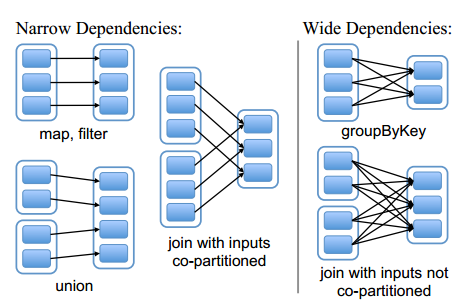
евРРЕдЪаэдквЛИіМЏШКНкЕуЩЯвдСїЫЎЯпЕФЗНЪНЃЈpipelineЃЉМЦЫуЫљгаИИЗжЧјЁЃР§ШчЃЌж№ИідЊЫиЕижДааmapЁЂШЛКѓfilterВйзїЃЛЖјПэвРРЕдђашвЊЪзЯШМЦЫуКУЫљгаИИЗжЧјЪ§ОнЃЌШЛКѓдкНкЕужЎМфНјааShuffleЃЌетгыMapReduceРрЫЦЁЃЕкЖўЃЌевРРЕФмЙЛИќгааЇЕиНјааЪЇаЇНкЕуЕФЛжИДЃЌМДжЛашжиаТМЦЫуЖЊЪЇRDDЗжЧјЕФИИЗжЧјЃЌЖјЧвВЛЭЌНкЕужЎМфПЩвдВЂааМЦЫуЃЛЖјЖдгквЛИіПэвРРЕЙиЯЕЕФLineageЭМЃЌЕЅИіНкЕуЪЇаЇПЩФмЕМжТетИіRDDЕФЫљгазцЯШЖЊЪЇВПЗжЗжЧјЃЌвђЖјашвЊећЬхжиаТМЦЫуЁЃ
4ЁЂ гыMapReduceЖдБШЃЌЬсЩ§аЇТЪЕФЕиЗН
MapReduceЪЧвЛИіMapКЭвЛИіReduceзщГЩвЛИіstageЃЌЕБШЛвВгаУЛгаreduceЕФstageЃЌЃЈШчМђЕЅЕФВЛЩцМАЕНreduceЕФВщбЏЃЉ
SparkвВРрЫЦЃЌУПвЛИіПэвРРЕЃЈашвЊshuffleЃЌРрЫЦReduceЃЉЕФЕиЗНОЭЪЧСНИіStageЕФЗжНчЯпЁЃ
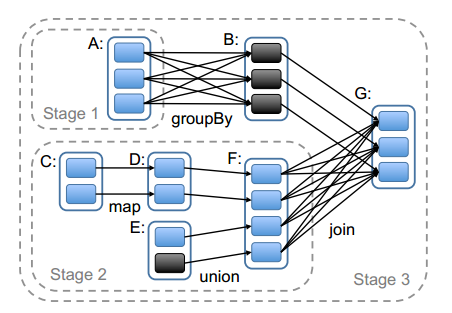
ПЩвдПДЕН SparkЕФstageЫМЯыИњ TezЕФКмЯёЃЌВЛЯёMapReduceФЧбљБиаыГЩЖдЕФMapReduceвЛЦ№ГіЯжЃЌПЩвддкmapНзЖЮзіКмЖрЪТЧщЃЌМѕЩйВЛБивЊЕФЭјТчIOКЭаДHDFSЕФЪБМфЁЃЭЌЪБвЛИіStageФкЃЌЪ§ОнЕФДІРэвВЪЧЛљгкФкДцЕФЃЌМѕЩйСЫБОЕиДХХЬЕФIOЁЃ
5ЁЂ DataSet НсЙЙЛЏЕФRDD
дкSparkжаЃЌDataFrameЪЧвЛжжвдRDDЮЊЛљДЁЕФЗжВМЪНЪ§ОнМЏЃЌРрЫЦгкДЋЭГЪ§ОнПтжаЕФЖўЮЌБэИёЁЃDataFrameгыRDDЕФжївЊЧјБ№дкгкЃЌЧАепДјгаschemaдЊаХЯЂЃЌМДDataFrameЫљБэЪОЕФЖўЮЌБэЪ§ОнМЏЕФУПвЛСаЖМДјгаУћГЦКЭРраЭЁЃетЪЙЕУSpark
SQLЕУвдЖДВьИќЖрЕФНсЙЙаХЯЂЃЌДгЖјЖдВигкDataFrameБГКѓЕФЪ§ОндДвдМАзїгУгкDataFrameжЎЩЯЕФБфЛЛНјааСЫеыЖдадЕФгХЛЏЃЌзюжеДяЕНДѓЗљЬсЩ§дЫааЪБаЇТЪЕФФПБъЁЃЗДЙлRDDЃЌгЩгкЮоДгЕУжЊЫљДцЪ§ОндЊЫиЕФОпЬхФкВПНсЙЙЃЌSparkCoreжЛФмдкstageВуУцНјааМђЕЅЁЂЭЈгУЕФСїЫЎЯпгХЛЏЁЃ
6ЁЂSpark ЪЙгУ
SparkSQLЕФЧАЩэЪЧSharkЃЌЖјSharkЕФЧАЩэЪЧHadoopжаЕФhiveЁЃ
ЪмЯогкТчзгЃЌФПЧАКУЯёжЛФмгУScalaПЊЗЂЁЃ
Python SqlЕФШЮЮёЃЌШчЙћSQLжЇГжSpark SQLЕФгяЗЈЃЌЛсЪЙгУSparkв§ЧцжДааШЮЮёЁЃ |









