| БрМЭЦМі: |
БОЮФРДздгкЭјТчЃЌНщЩмСЫMapperЖЫЃЌЛЗаЮBufferЪ§ОнНсЙЙЃЌSpillЃЌКЯВЂSpillЮФМўЃЌReducerЖЫЃЌКЯВЂЃЌадФмЕїгХЕШЁЃ
|
|
MapReduceМђНщ
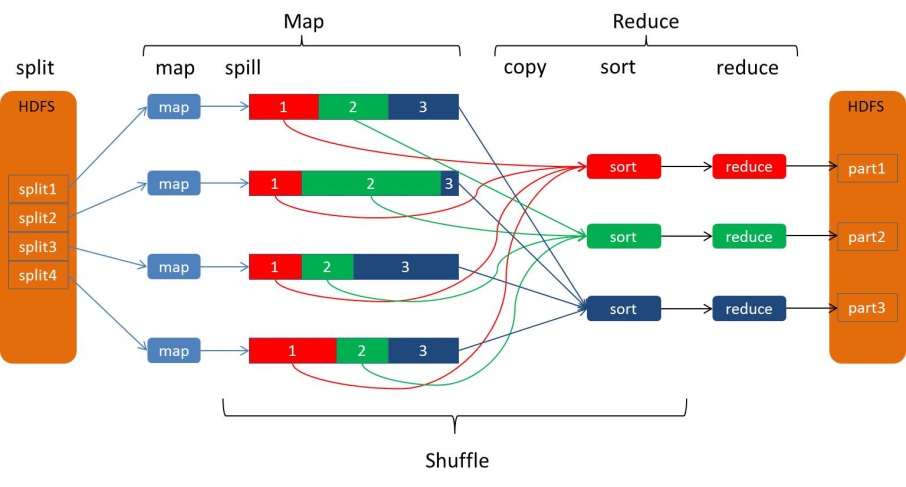
дкHadoop MapReduceжаЃЌПђМмЛсШЗБЃreduceЪеЕНЕФЪфШыЪ§ОнЪЧИљОнkeyХХађЙ§ЕФЁЃЪ§ОнДгMapperЪфГіЕНReducerНгЪеЃЌЪЧвЛИіКмИДдгЕФЙ§ГЬЃЌПђМмДІРэСЫЫљгаЮЪЬтЃЌВЂЬсЙЉСЫКмЖрХфжУЯюМАРЉеЙЕуЁЃвЛИіMapReduceЕФДѓжТЪ§ОнСїШчЯТЭМЃК
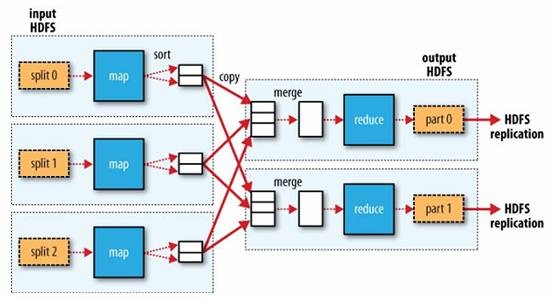
MapperЕФЪфГіХХађЁЂШЛКѓДЋЫЭЕНReducerЕФЙ§ГЬЃЌГЦЮЊshuffleЁЃБОЮФЯъЯИЕиНтЮіshuffleЙ§ГЬЃЌЩюШыРэНтетИіЙ§ГЬЖдгкMapReduceЕїгХжСЙиживЊЃЌФГжжГЬЖШЩЯЫЕЃЌshuffleЙ§ГЬЪЧMapReduceЕФКЫаФФкШнЁЃ
MapperЖЫ
ЕБmapКЏЪ§ЭЈЙ§context.write()ПЊЪМЪфГіЪ§ОнЪБЃЌВЛЪЧЕЅДПЕиНЋЪ§ОнаДШыЕНДХХЬЁЃЮЊСЫадФмЃЌmapЪфГіЕФЪ§ОнЛсаДШыЕНЛКГхЧјЃЌВЂНјаадЄХХађЕФвЛаЉЙЄзїЃЌећИіЙ§ГЬШчЯТЭМЃК
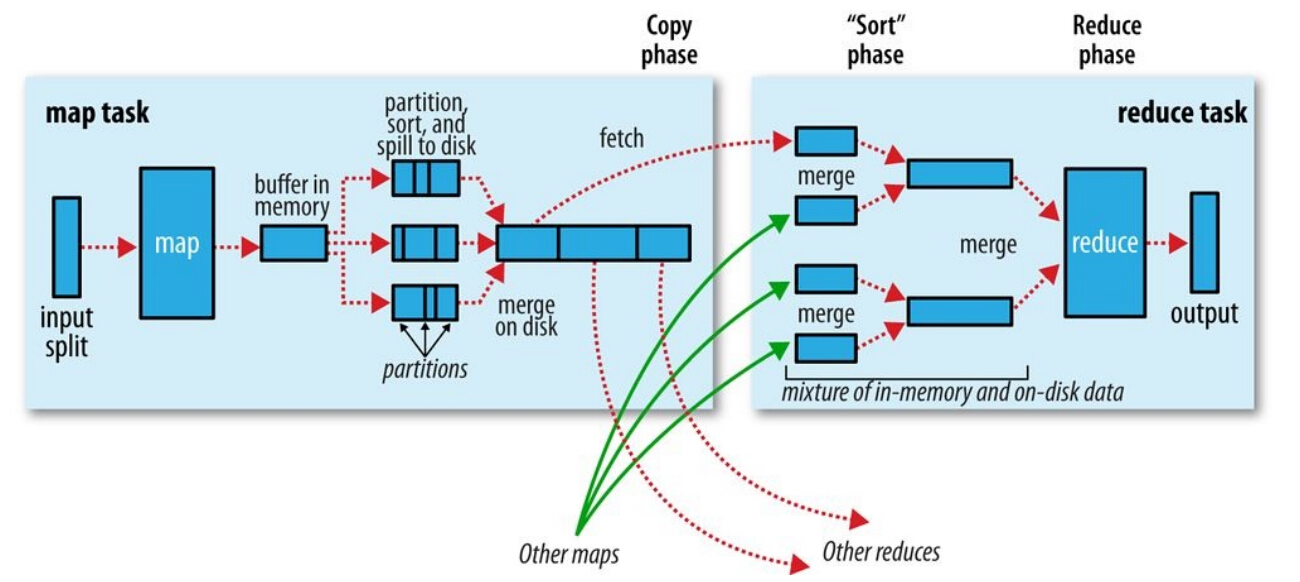
ЛЗаЮBufferЪ§ОнНсЙЙ
УПвЛИіmapШЮЮёгавЛИіЛЗаЮBufferЃЌmapНЋЪфГіаДШыЕНетИіBufferЁЃЛЗаЮBufferЪЧФкДцжаЕФвЛжжЪзЮВЯрСЌЕФЪ§ОнНсЙЙЃЌзЈУХгУРДДцДЂKey-ValueИёЪНЕФЪ§ОнЃК
HadoopжаЃЌЛЗаЮЛКГхЦфЪЕОЭЪЧвЛИізжНкЪ§зщЃК
// MapTask.java
private byte [] kvbuffer; // main output buffer
kvbuffer = new byte [ maxMemUsage - recordCapacity
] ; |
kvbufferАќКЌЪ§ОнЧјКЭЫїв§ЧјЃЌетСНИіЧјЪЧЯрСкВЛжиЕўЕФЧјгђЃЌгУвЛИіЗжНчЕуРДБъЪЖЁЃЗжНчЕуВЛЪЧгРКуВЛБфЕФЃЌУПДЮSpillжЎКѓЖМЛсИќаТвЛДЮЁЃГѕЪМЗжНчЕуЮЊ0ЃЌЪ§ОнДцДЂЗНЯђЮЊЯђЩЯдіГЄЃЌЫїв§ДцДЂЗНЯђЯђЯТЃК
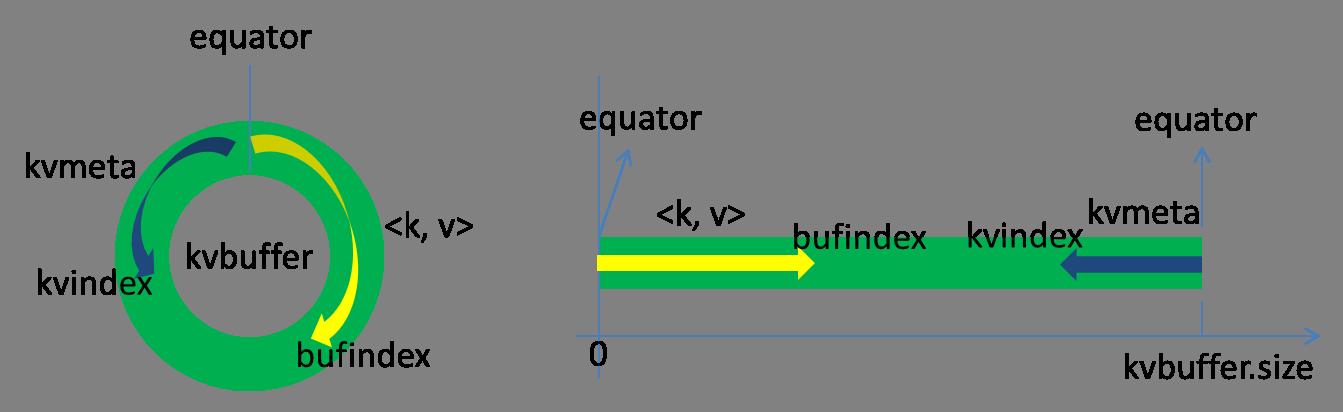
bufferindexвЛжБЭљЩЯдіГЄЃЌР§ШчзюГѕЮЊ0ЃЌаДШывЛИіintРраЭЕФkeyжЎКѓБфЮЊ4ЃЌаДШывЛИіintРраЭЕФvalueжЎКѓБфГЩ8ЁЃ
Ыїв§ЪЧЖдkey-valueдкkvbufferжаЕФЫїв§ЃЌЪЧИіЫФдЊзщЃЌеМгУЫФИіIntГЄЖШЃЌАќРЈЃК
valueЕФЦ№ЪМЮЛжУ
keyЕФЦ№ЪМЮЛжУ
partitionжЕ
valueЕФГЄЖШ
private static
final int VALSTART = 0; // val offset in acct
private static final int KEYSTART = 1; // key
offset in acct
private static final int PARTITION = 2; // partition
offset in acct
private static final int VALLEN = 3; // length
of value
private static final int NMETA = 4; // num meta
ints
private static final int METASIZE = NMETA * 4;
// size in bytes
// write accounting info
kvmeta.put (kvindex + PARTITION , partition);
kvmeta.put (kvindex + KEYSTART , keystart);
kvmeta.put (kvindex + VALSTART , valstart);
kvmeta.put (kvindex + VALLEN, distanceTo (valstart
, valend) ); |
kvmetaЕФДцЗХжИеыkvindexУПДЮЖМЪЧЯђЯТЬјЫФИіЁАИёзгЁБЃЌШЛКѓдйЯђЩЯвЛИіИёзгвЛИіИёзгЕиЬюГфЫФдЊзщЕФЪ§ОнЁЃБШШчkvindexГѕЪМЮЛжУЪЧ-4ЃЌЕБЕквЛИіkey-valueаДЭъжЎКѓЃЌ(kvindex+0)ЕФЮЛжУДцЗХvalueЕФЦ№ЪМЮЛжУЁЂ(kvindex+1)ЕФЮЛжУДцЗХkeyЕФЦ№ЪМЮЛжУЁЂ(kvindex+2)ЕФЮЛжУДцЗХpartitionЕФжЕЁЂ(kvindex+3)ЕФЮЛжУДцЗХvalueЕФГЄЖШЃЌШЛКѓkvindexЬјЕН-8ЮЛжУЁЃ
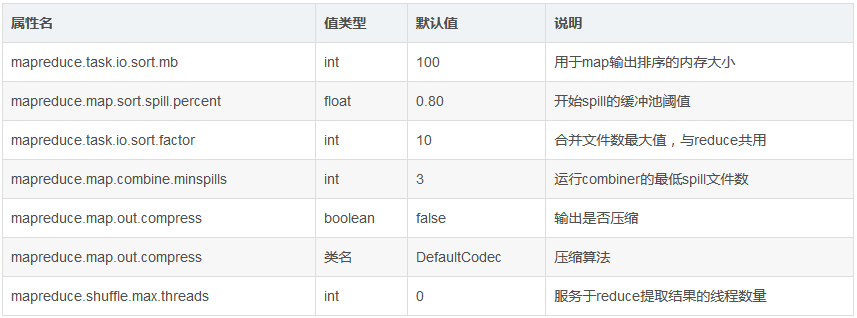
ЛКГхЧјЕФДѓаЁФЌШЯЮЊ100MЃЌЕЋЪЧПЩвдЭЈЙ§mapreduce.task.io.sort.mbетИіЪєадРДХфжУЁЃ
Spill
mapНЋЪфГіВЛЖЯаДШыЕНетИіЛКГхЧјжаЃЌЕБЛКГхЧјЪЙгУСПДяЕНвЛЖЈБШР§жЎКѓЃЌвЛИіКѓЬЈЯпГЬПЊЪМАбЛКГхЧјЕФЪ§ОнаДШыДХХЬЃЌетИіаДШыЕФЙ§ГЬНаspillЁЃПЊЪМspillЕФBufferБШР§ФЌШЯЮЊ0.80ЃЌПЩвдЭЈЙ§mapreduce.map.sort.spill.percentХфжУЁЃдкКѓЬЈЯпГЬаДШыЕФЭЌЪБЃЌmapМЬајНЋЪфГіаДШыетИіЛЗаЮЛКГхЃЌШчЙћЛКГхГиаДТњСЫЃЌmapЛсзшШћжБЕНspillЙ§ГЬЭъГЩЃЌЖјВЛЛсИВИЧЛКГхГижаЕФвбгаЕФЪ§ОнЁЃ
дкаДШыжЎЧАЃЌКѓЬЈЯпГЬАбЪ§ОнАДееЫћУЧНЋЫЭЭљЕФreducerНјааЛЎЗжЃЌЭЈЙ§ЕїгУPartitionerЕФgetPartition()ЗНЗЈОЭФмжЊЕРИУЪфГівЊЫЭЭљФФИіReducerЁЃФЌШЯЕФPartitionerЪЙгУHashЫуЗЈРДЗжЧјЃЌМДЭЈЙ§key.hashCode()
mode RРДМЦЫуЃЌRЮЊReducerЕФИіЪ§ЁЃgetPartitionЗЕЛиPartitionЪТЪЕЩЯЪЧИіећЪ§ЃЌР§Шчга10ИіReducerЃЌдђЗЕЛи0-9ЕФећЪ§ЃЌУПИіReducerЛсЖдгІЕНвЛИіPartitionЁЃmapЪфГіЕФМќжЕЖдЃЌгыpartitionвЛЦ№ДцдкЛКГхжаЃЈМДЧАУцЬсЕНЕФkvmetaжаЃЉЁЃМйЩшзївЕга2ИіreduceШЮЮёЃЌдђЪ§ОндкФкДцжаБЛЛЎЗжЮЊreduce1КЭreduce2ЃК

ВЂЧвеыЖдУПВПЗжЪ§ОнЃЌЪЙгУПьЫйХХађЫуЗЈЃЈQuickSortЃЉЖдkeyХХађЁЃ
ШчЙћЩшжУСЫCombinerЃЌдђдкХХађЕФНсЙћЩЯдЫааcombineЁЃ
ХХађКѓЕФЪ§ОнБЛаДШыЕНmapreduce.cluster.local.dirХфжУЕФФПТМжаЕФЦфжавЛИіЃЌЪЙгУround
robin fashionЕФЗНЪНТжСїЁЃзЂвтаДШыЕФЪЧБОЕиЮФМўФПТМЃЌЖјВЛЪЧHDFSЁЃSpillЮФМўУћЯёsipll0.outЃЌspill1.outЕШЁЃ
ВЛЭЌPartitionЕФЪ§ОнЖМЗХдкЭЌвЛИіЮФМўЃЌЭЈЙ§Ыїв§РДЧјЗжpartitionЕФБпНчКЭЦ№ЪМЮЛжУЁЃЫїв§ЪЧвЛИіШ§дЊзщНсЙЙЃЌАќРЈЦ№ЪМЮЛжУЁЂЪ§ОнГЄЖШЁЂбЙЫѕКѓЕФЪ§ОнГЄЖШЃЌЖдгІIndexRecordРрЃК
public class
IndexRecord {
public long startOffset;
public long rawLength;
public long partLength;
public IndexRecord() { }
public IndexRecord(long startOffset , long rawLength
, long partLength ) {
this.startOffset = startOffset;
this.rawLength = rawLength;
this.partLength = partLength;
}
} |
УПИіmapperвВгаЖдгІЕФвЛИіЫїв§ЛЗаЮBufferЃЌФЌШЯЮЊ1KBЃЌПЩвдЭЈЙ§mapreduce
.task .index .cache .limit .bytes РДХфжУЃЌЫїв§ШчЙћзуЙЛаЁдђДцдкФкДцжаЃЌШчЙћФкДцЗХВЛЯТЃЌашвЊаДШыДХХЬЁЃ
SpillЮФМўЫїв§УћГЦРрЫЦетбљ spill110 .out.index
, spill111.out .indexЁЃ
SpillЮФМўЕФЫїв§ЪТЪЕЩЯЪЧ org.apache .hadoop
.mapred .SpillRecord ЕФвЛИіЪ§зщЃЌУПИіMapШЮЮёЃЈдДТыжаЕФMapTask .javaРрЃЉЮЌЛЄвЛИіетбљЕФСаБэЃК
| final ArrayList
<SpillRecord> indexCacheList = new ArrayList
<SpillRecord> (); |
ДДНЈвЛИіSpillRecordЪБЃЌЛсЗжХфЃЈNumber_Of_Reducers
* 24ЃЉBytesЛКГх:
public SpillRecord
(int numPartitions) {
buf = ByteBuffer.allocate (
numPartitions * MapTask.MAP_ OUTPUT_INDEX_ RECORD_
LENGTH );
entries = buf.asLongBuffer ();
} |
numPartitionsЪЧPartitionЕФИіЪ§ЃЌЦфЪЕвВОЭЪЧReducerЕФИіЪ§ЃК
public static
final int MAP_OUTPUT_ INDEX_RECORD_ LENGTH = 24;
// ---
partitions = jobContext .getNumReduceTasks ();
final SpillRecord spillRec = new SpillRecord (
partitions ); |
ФЌШЯЕФЫїв§ЛКГхЮЊ1KBЃЌМД1024*1024 BytesЃЌМйЩшга2ИіReducerЃЌдђУПИіSpillЮФМўЕФЫїв§ДѓаЁЮЊ2*24=48
BytesЃЌЕБSpillЮФМўГЌЙ§21845.3ЪБЃЌЫїв§ЮФМўОЭашвЊаДШыДХХЬЁЃ
Ыїв§МАspillЮФМўШчЯТЭМЪОвтЃК
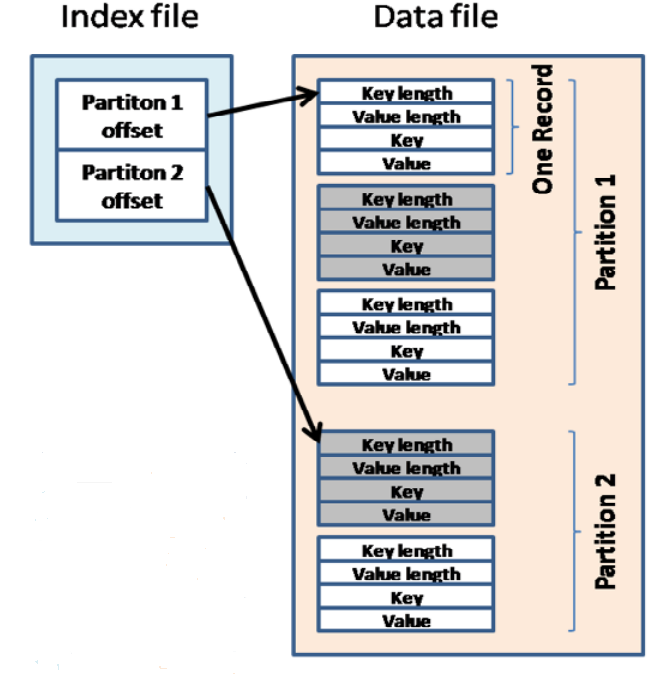
SpillЕФЙ§ГЬжСЩйашвЊдЫаавЛДЮЃЌвђЮЊMapperЕФЪфГіНсЙћБиаывЊаДШыДХХЬЃЌЙЉReducerНјвЛВНДІРэЁЃ
КЯВЂSpillЮФМў
дкећИіmapШЮЮёжаЃЌвЛЕЉЛКГхДяЕНЩшЖЈЕФуажЕЃЌОЭЛсДЅЗЂspillВйзїЃЌаДШыspillЮФМўЕНДХХЬЃЌвђДЫзюКѓПЩФмгаЖрИіspillЮФМўЁЃдкmapШЮЮёНсЪјжЎЧАЃЌетаЉЮФМўЛсИљОнЧщПіКЯВЂЕНвЛИіДѓЕФЗжЧјЕФЁЂХХађЕФЮФМўжаЃЌХХађЪЧдкФкДцХХађЕФЛљДЁЩЯНјааШЋОжХХађЁЃЯТЭМЪЧКЯВЂЙ§ГЬЕФМђЕЅЪОвтЃК
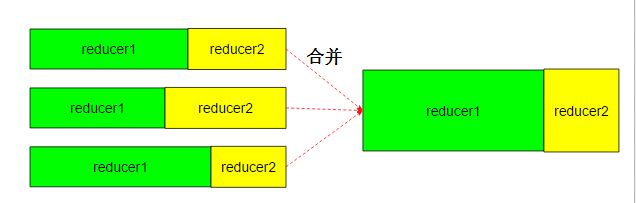
ЯрЖдгІЕФЫїв§ЮФМўвВЛсБЛКЯВЂЃЌвдБудкReducerЧыЧѓЖдгІPartitionЕФЪ§ОнЕФЪБКђФмЙЛПьЫйЖСШЁЁЃ
СэЭтЃЌШчЙћspillЮФМўЪ§СПДѓгкmapreduce.map.combiner.minspillsХфжУЕФЪ§ЃЌдђдкКЯВЂЮФМўаДШыжЎЧАЃЌЛсдйДЮдЫааcombinerЁЃШчЙћspillЮФМўЪ§СПЬЋЩйЃЌдЫааcombinerЕФЪевцПЩФмаЁгкЕїгУЕФДњМлЁЃ
mapreduce.task.io.sort.factorЪєадХфжУУПДЮзюЖрКЯВЂЖрЩйИіЮФМўЃЌФЌШЯЮЊ10ЃЌМДвЛДЮзюЖрКЯВЂ10ИіspillЮФМўЁЃзюКѓЃЌЖрТжКЯВЂжЎКѓЃЌЫљгаЕФЪфГіЮФМўБЛКЯВЂЮЊЮЈвЛвЛИіДѓЮФМўЃЌвдМАЯргІЕФЫїв§ЮФМўЃЈПЩФмжЛдкФкДцжаДцдкЃЉЁЃ
бЙЫѕ
дкЪ§ОнСПДѓЕФЪБКђЃЌЖдmapЪфГіНјаабЙЫѕЭЈГЃЪЧИіКУжївтЁЃвЊЦєгУбЙЫѕЃЌНЋmapreduce.
map. output. compress ЩшЮЊ trueЃЌВЂЪЙгУmapreduce .map.output
.compress .codecЩшжУЪЙгУЕФбЙЫѕЫуЗЈЁЃ
ЭЈЙ§HTTPБЉТЖЪфГіНсЙћ
mapЪфГіЪ§ОнЭъГЩжЎКѓЃЌЭЈЙ§дЫаавЛИіHTTP ServerБЉТЖГіРДЃЌЙЉreduceЖЫЛёШЁЁЃгУРДЯргІreduceЪ§ОнЧыЧѓЕФЯпГЬЪ§СППЩвдХфжУЃЌФЌШЯЧщПіЯТЮЊЛњЦїФкКЫЪ§СПЕФСНБЖЃЌШчашздМКХфжУЃЌЭЈЙ§mapreduce.shuffle.max.threadsЪєадРДХфжУЃЌзЂвтИУХфжУЪЧеыЖдNodeManagerХфжУЕФЃЌЖјВЛЪЧУПИізївЕХфжУЁЃ
ЭЌЪБЃЌMapШЮЮёЭъГЩКѓЃЌвВЛсЭЈжЊApplication MasterЃЌвдБуReducerФмЙЛМАЪБРДРШЁЪ§ОнЁЃ
ЭЈЙ§ЛКГхЁЂЛЎЗжЃЈpartitionЃЉЁЂХХађЁЂcombinerЁЂКЯВЂЁЂбЙЫѕЕШЙ§ГЬжЎКѓЃЌmapЖЫЕФЙЄзїОЭЫуЭъБЯЃК
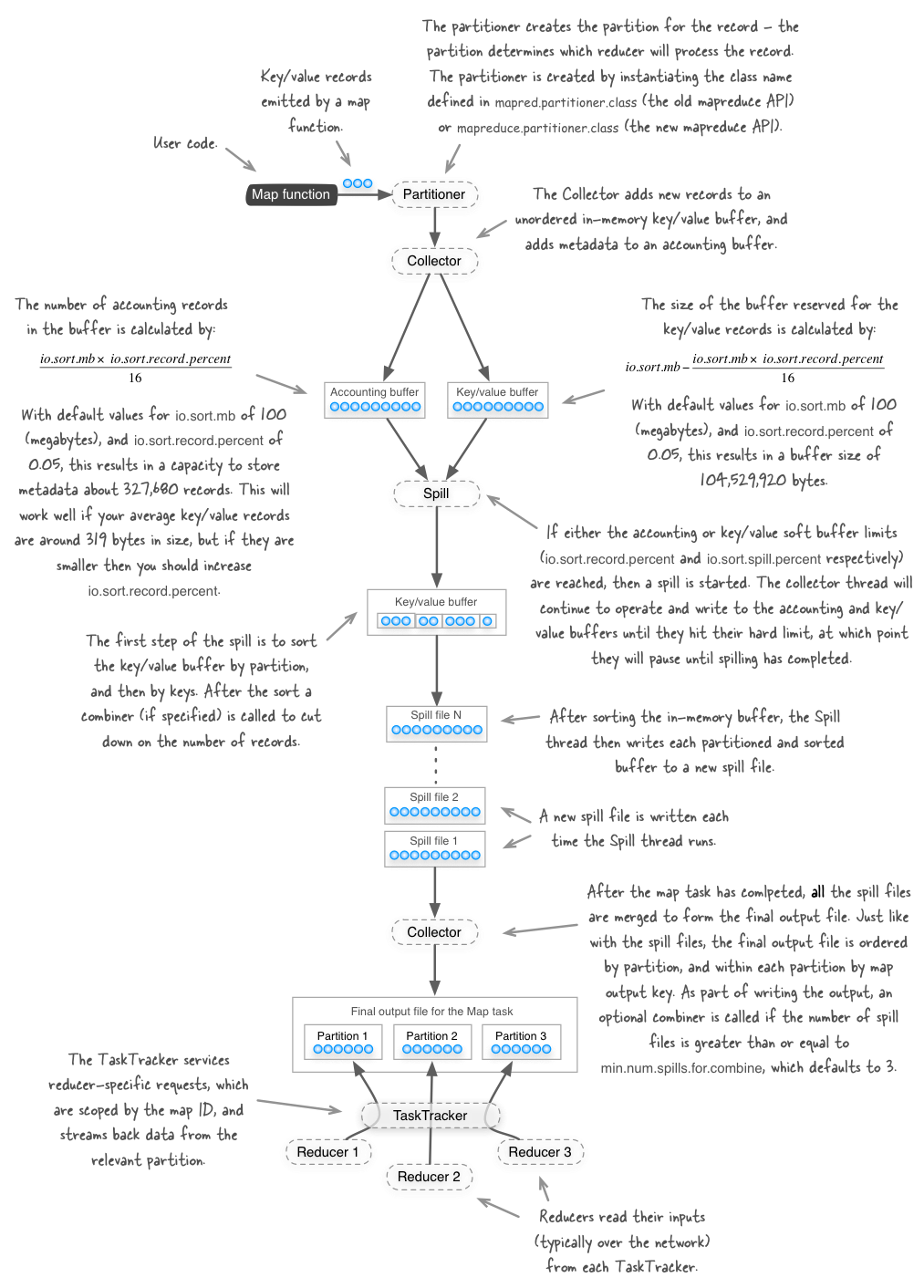
ReducerЖЫ
ИїИіmapШЮЮёдЫааЭъжЎКѓЃЌЪфГіаДШыдЫааШЮЮёЕФЛњЦїДХХЬжаЁЃReducerашвЊДгИїmapШЮЮёжаЬсШЁздМКЕФФЧвЛВПЗжЪ§ОнЃЈЖдгІЕФpartitionЃЉЁЃУПИіmapШЮЮёЕФЭъГЩЪБМфПЩФмЪЧВЛвЛбљЕФЃЌreduceШЮЮёдкmapШЮЮёНсЪјжЎКѓЛсОЁПьШЁзпЪфГіНсЙћЃЌетИіНзЖЮНаcopyЁЃ
ReducerЪЧШчКЮжЊЕРвЊШЅФФаЉЛњЦїШЅЪ§ОнФиЃПвЛЕЉmapШЮЮёЭъГЩжЎКѓЃЌОЭЛсЭЈЙ§ГЃЙцаФЬјЭЈжЊгІгУГЬађЕФApplication
MasterЁЃreduceЕФвЛИіЯпГЬЛсжмЦкадЕиЯђmasterбЏЮЪЃЌжБЕНЬсШЁЭъЫљгаЪ§ОнЃЈШчКЮжЊЕРЬсШЁЭъЃПЃЉЁЃ
Ъ§ОнБЛreduceЬсзпжЎКѓЃЌmapЛњЦїВЛЛсСЂПЬЩОГ§Ъ§ОнЃЌетЪЧЮЊСЫдЄЗРreduceШЮЮёЪЇАмашвЊжизіЁЃвђДЫmapЪфГіЪ§ОнЪЧдкећИізївЕЭъГЩжЎКѓВХБЛЩОГ§ЕєЕФЁЃ
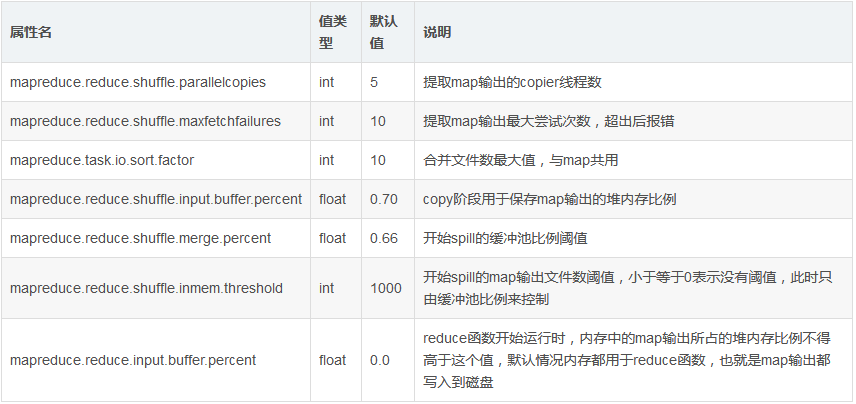
reduceЮЌЛЄМИИіcopierЯпГЬЃЌВЂааЕиДгmapШЮЮёЛњЦїЬсШЁЪ§ОнЁЃФЌШЯЧщПіЯТга5Иіcopy
ЯпГЬЃЌПЩвдЭЈЙ§mapreduce .reduce .shuffle .parallelcopies
ХфжУЁЃ
ШчЙћmapЪфГіЕФЪ§ОнзуЙЛаЁЃЌдђЛсБЛПНБДЕНreduceШЮЮёЕФJVMФкДцжаЁЃmapreduce
.reduce .shuffle .input .buffer .percent ХфжУJVM ЖбФкДцЕФЖрЩйБШР§ПЩвдгУгкДцЗХmap
ШЮЮёЕФЪфГіНсЙћЁЃШчЙћЪ§ОнЬЋДѓШнВЛЯТЃЌдђБЛПНБДЕНreduce ЕФЛњЦїДХХЬЩЯЁЃ
ФкДцжаКЯВЂ
ЕБЛКГхжаЪ§ОнДяЕНХфжУЕФуажЕЪБЃЌетаЉЪ§ОндкФкДцжаБЛКЯВЂЁЂаДШыЛњЦїДХХЬЁЃуажЕга2жжХфжУЗНЪНЃК
ХфжУФкДцБШР§ЃК ЧАУцЬсЕНreduce JVMЖбФкДцЕФвЛВПЗжгУгкДцЗХРДздmapШЮЮёЕФЪфШыЃЌдкетЛљДЁжЎЩЯХфжУвЛИіПЊЪМКЯВЂЪ§ОнЕФБШР§ЁЃМйЩшгУгкДцЗХmap
ЪфГіЕФФкДцЮЊ500MЃЌmapreduce .reduce .shuffle .merger .percent
ХфжУЮЊ0.80ЃЌдђЕБФкДцжаЕФЪ§ОнДяЕН400MЕФЪБКђЃЌЛсДЅЗЂКЯВЂаДШыЁЃ
ХфжУmapЪфГіЪ§СПЃК ЭЈЙ§mapreduce .reduce.merge .inmem .thresholdХфжУЁЃ
дкКЯВЂЕФЙ§ГЬжаЃЌЛсЖдБЛКЯВЂЕФЮФМўзіШЋОжЕФХХађЁЃШчЙћзївЕХфжУСЫCombinerЃЌдђЛсдЫааcombineКЏЪ§ЃЌМѕЩйаДШыДХХЬЕФЪ§ОнСПЁЃ
CopyЙ§ГЬжаДХХЬКЯВЂ
дкcopyЙ§РДЕФЪ§ОнВЛЖЯаДШыДХХЬЕФЙ§ГЬжаЃЌвЛИіКѓЬЈЯпГЬЛсАбетаЉЮФМўКЯВЂЮЊИќДѓЕФЁЂгаађЕФЮФМўЁЃШчЙћmapЕФЪфГіНсЙћНјааСЫбЙЫѕЃЌдђдкКЯВЂЙ§ГЬжаЃЌашвЊдкФкДцжаНтбЙКѓВХФмИјНјааКЯВЂЁЃетРяЕФКЯВЂжЛЪЧЮЊСЫМѕЩйзюжеКЯВЂЕФЙЄзїСПЃЌвВОЭЪЧдкmapЪфГіЛЙдкПНБДЪБЃЌОЭПЊЪМНјаавЛВПЗжКЯВЂЙЄзїЁЃКЯВЂЕФЙ§ГЬвЛбљЛсНјааШЋОжХХађЁЃ
зюжеДХХЬжаКЯВЂ
ЕБЫљгаmapЪфГіЖМПНБДЭъБЯжЎКѓЃЌЫљгаЪ§ОнБЛзюКѓКЯВЂГЩвЛИіХХађЕФЮФМўЃЌзїЮЊreduceШЮЮёЕФЪфШыЁЃетИіКЯВЂЙ§ГЬЪЧвЛТжвЛТжНјааЕФЃЌзюКѓвЛТжЕФКЯВЂНсЙћжБНгЭЦЫЭИјreduceзїЮЊЪфШыЃЌНкЪЁСЫДХХЬВйзїЕФвЛИіРДЛиЁЃзюКѓЃЈЫљвдmapЪфГіЖМПНБДЕНreduceжЎКѓЃЉНјааКЯВЂЕФmapЪфГіПЩФмРДздКЯВЂКѓаДШыДХХЬЕФЮФМўЃЌвВПЩФмРДМАФкДцЛКГхЃЌдкзюКѓаДШыФкДцЕФmapЪфГіПЩФмУЛгаДяЕНуажЕДЅЗЂКЯВЂЃЌЫљвдЛЙСєдкФкДцжаЁЃ
УПвЛТжКЯВЂВЂВЛвЛЖЈКЯВЂЦНОљЪ§СПЕФЮФМўЪ§ЃЌжИЕМддђЪЧЪЙгУећИіКЯВЂЙ§ГЬжааДШыДХХЬЕФЪ§ОнСПзюаЁЃЌЮЊСЫДяЕНетИіФПЕФЃЌдђашвЊзюжеЕФвЛТжКЯВЂжаКЯВЂОЁПЩФмЖрЕФЪ§ОнЃЌвђЮЊзюКѓвЛТжЕФЪ§ОнжБНгзїЮЊreduceЕФЪфШыЃЌЮоашаДШыДХХЬдйЖСГіЁЃвђДЫЮвУЧШУзюжеЕФвЛТжКЯВЂЕФЮФМўЪ§ДяЕНзюДѓЃЌМДКЯВЂвђзгЕФжЕЃЌЭЈЙ§mapreduce.task.io.sort.factorРДХфжУЁЃ
МйЩшЯждкга50ИіmapЪфГіЮФМўЃЌКЯВЂвђзгХфжУЮЊ10ЃЌдђашвЊ5ТжЕФКЯВЂЁЃзюжеЕФвЛТжШЗБЃКЯВЂ10ИіЮФМўЃЌЦфжаАќРЈ4ИіРДздЧА4ТжЕФКЯВЂНсЙћЃЌвђДЫдЪМЕФ50ИіжаЃЌдйСєГі6ИіИјзюжевЛТжЁЃЫљвдзюКѓЕФ5ТжКЯВЂПЩФмЧщПіШчЯТЃК
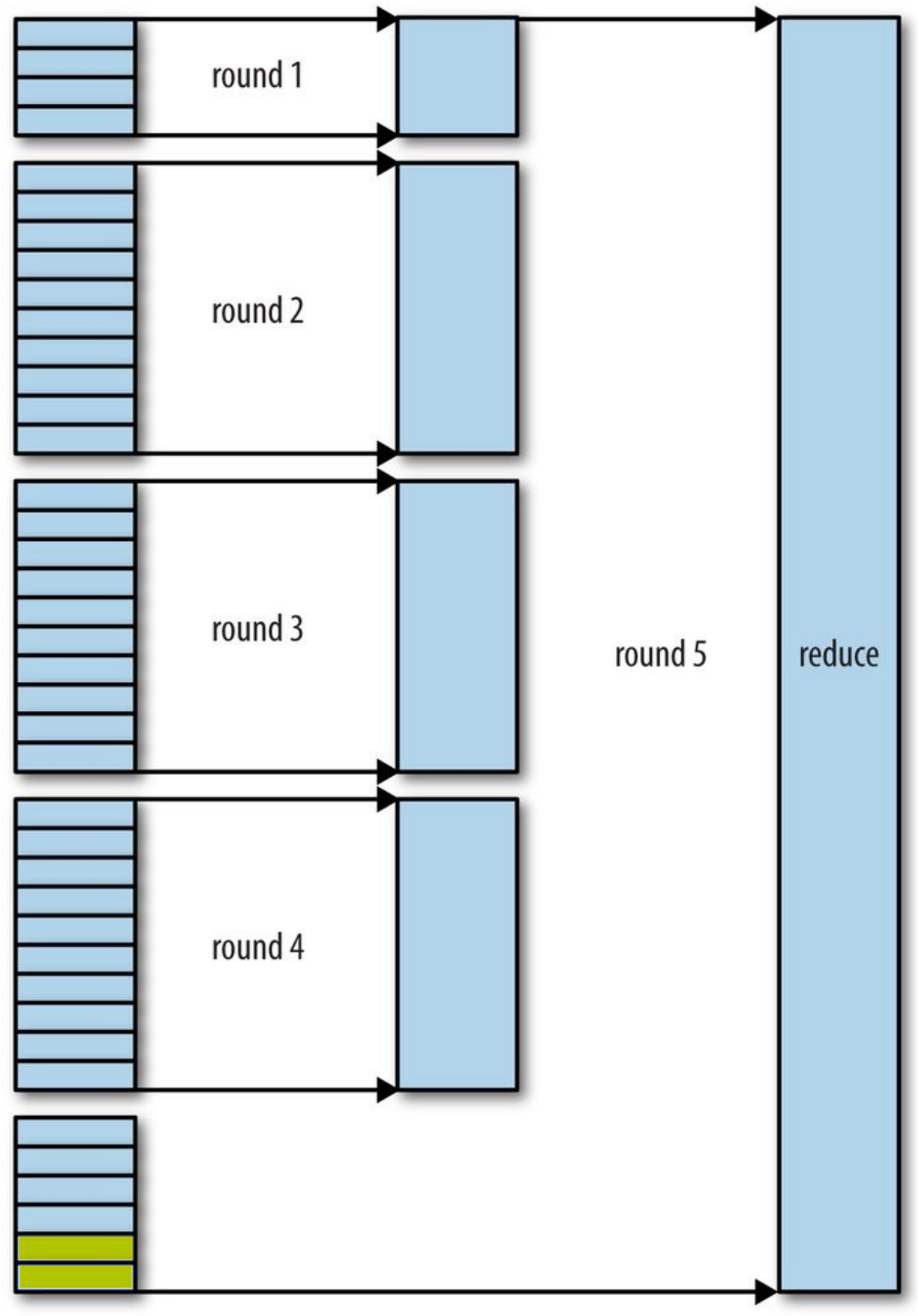
ЧА4ТжКЯВЂКѓЕФЪ§ОнЖМЪЧаДШыЕНДХХЬжаЕФЃЌзЂвтЕНзюКѓЕФ2ИёбеЩЋВЛвЛбљЃЌЪЧЮЊСЫБъУїетаЉЪ§ОнПЩФмжБНгРДздгкФкДцЁЃ
MemToMemКЯВЂ
Г§СЫФкДцжаКЯВЂКЭДХХЬжаКЯВЂЭтЃЌHadoopЛЙЖЈвхСЫвЛжжMemToMemКЯВЂЃЌетжжКЯВЂНЋФкДцжаЕФmapЪфГіКЯВЂЃЌШЛКѓдйаДШыФкДцЁЃетжжКЯВЂФЌШЯЙиБеЃЌПЩвдЭЈЙ§reduce.merge
.memtomem .enabledДђПЊЃЌЕБmapЪфГіЮФМўДяЕНreduce .merge .memtomem
.thresholdЪБЃЌДЅЗЂетжжКЯВЂЁЃ
зюКѓвЛДЮКЯВЂКѓДЋЕнИјreduceЗНЗЈ
КЯВЂКѓЕФЮФМўзїЮЊЪфШыДЋЕнИјReducerЃЌReducerеыЖдУПИіkeyМАЦфХХађЕФЪ§ОнЕїгУreduceКЏЪ§ЁЃВњЩњЕФreduceЪфГівЛАуаДШыЕНHDFSЃЌreduceЪфГіЕФЮФМўЕквЛИіИББОаДШыЕНЕБЧАдЫааreduceЕФЛњЦїЃЌЦфЫћИББОбЁжЗддђАДееГЃЙцЕФHDFSЪ§ОнаДШыддђРДНјааЃЌЯъЯИаХЯЂЧыВЮПМетРяЁЃ
ЭЈЙ§ДгmapЛњЦїЬсШЁНсЙћЃЌКЯВЂЃЌcombineжЎКѓЃЌДЋЕнИјreduceЭъГЩзюКѓЙЄзїЃЌећИіЙ§ГЬвВОЭВюВЛЖрЭъГЩЁЃзюКѓдйИаЪмвЛЯТЯТУцетеХЭМЃК
адФмЕїгХ
ШчЙћФмЙЛИљОнЧщПіЖдshuffleЙ§ГЬНјааЕїгХЃЌЖдгкЬсЙЉMapReduceадФмКмгаАяжњЁЃЯрЙиЕФВЮЪ§ХфжУСадкКѓУцЕФБэИёжаЁЃ
вЛИіЭЈгУЕФддђЪЧИјshuffleЙ§ГЬЗжХфОЁПЩФмДѓЕФФкДцЃЌЕБШЛФуашвЊШЗБЃmapКЭreduceгазуЙЛЕФФкДцРДдЫаавЕЮёТпМЁЃвђДЫдкЪЕЯжMapperКЭReducerЪБЃЌгІИУОЁСПМѕЩйФкДцЕФЪЙгУЃЌР§ШчБмУтдкMapжаВЛЖЯЕиЕўМгЁЃ
дЫааmapКЭreduceШЮЮёЕФJVMЃЌФкДцЭЈЙ§mapred .child
.java.optsЪєадРДЩшжУЃЌОЁПЩФмЩшДѓФкДцЁЃШнЦїЕФФкДцДѓаЁЭЈЙ§mapreduce .map .memory
.mb КЭmapreduce .reduce .memory .mbРДЩшжУЃЌФЌШЯЖМЪЧ1024MЁЃ
mapгХЛЏ
дкmapЖЫЃЌБмУтаДШыЖрИіspillЮФМўПЩФмДяЕНзюКУЕФадФмЃЌвЛИіspillЮФМўЪЧзюКУЕФЁЃЭЈЙ§ЙРМЦmapЕФЪфГіДѓаЁЃЌЩшжУКЯРэЕФmapreduce.task.io.sort.*ЪєадЃЌЪЙЕУspillЮФМўЪ§СПзюаЁЁЃР§ШчОЁПЩФмЕїДѓmapreduce.task.io.sort.mbЁЃ
mapЖЫЯрЙиЕФЪєадШчЯТБэЃК
reduceгХЛЏ
дкreduceЖЫЃЌШчЙћФмЙЛШУЫљгаЪ§ОнЖМБЃДцдкФкДцжаЃЌПЩвдДяЕНзюМбЕФадФмЁЃЭЈГЃЧщПіЯТЃЌФкДцЖМБЃСєИјreduceКЏЪ§ЃЌЕЋЪЧШчЙћreduceКЏЪ§ЖдФкДцашЧѓВЛЪЧКмИпЃЌНЋmapreduce.reduce.merge.inmem.thresholdЃЈДЅЗЂКЯВЂЕФmapЪфГіЮФМўЪ§ЃЉЩшЮЊ0ЃЌmapreduce.reduce.input.buffer.percentЃЈгУгкБЃДцmapЪфГіЮФМўЕФЖбФкДцБШР§ЃЉЩшЮЊ1.0ЃЌПЩвдДяЕНКмКУЕФадФмЬсЩ§ЁЃдк2008ФъЕФTBМЖБ№Ъ§ОнХХађадФмВтЪджаЃЌHadoopОЭЪЧЭЈЙ§НЋreduceЕФжаМфЪ§ОнЖМБЃДцдкФкДцжаЪЄРћЕФЁЃ
reduceЖЫЯрЙиЪєадЃК
ЭЈгУгХЛЏ
HadoopФЌШЯЪЙгУ4KBзїЮЊЛКГхЃЌетИіЫуЪЧКмаЁЕФЃЌПЩвдЭЈЙ§io .file
.buffer .sizeРДЕїИпЛКГхГиДѓаЁЁЃ |









