| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌЮФжаНщЩмСЫConceptsЃЌKafka
КЫаФдРэЃЌUse Cases ЃЌDevelopment with Kafka ЃЌAdministration
ЃЌCluster Planning ЃЌCompare ЕШЁЃ |
|
вЛ. Concepts
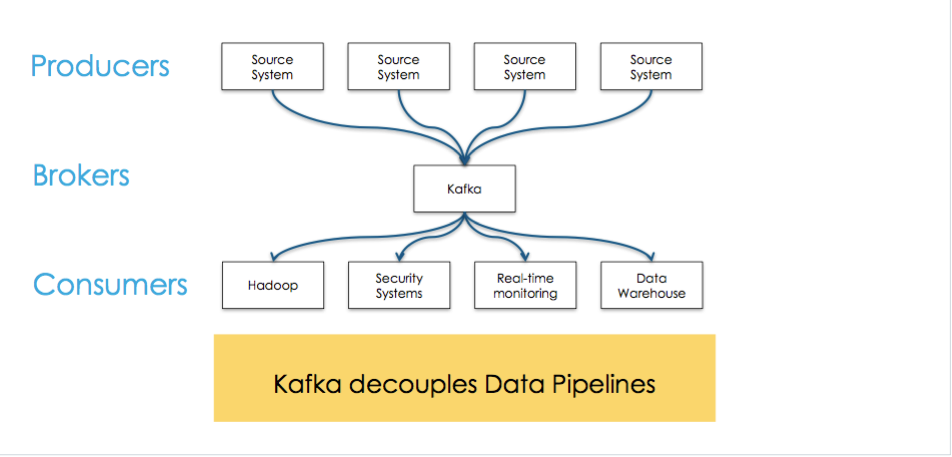
Kafka is used for building real-time data pipelines
and streaming apps
ЗжВМЪНЯћЯЂДЋЕн
ЭјеОЛюдОЪ§ОнИњзй
ШежООлКЯ
СїЪНЪ§ОнДІРэ
Ъ§ОнДцДЂ
ЪТМўдД
ЁЁ
Kafka terminology Ъѕгя
1.Topics
Kafka maintains feeds of messages in categories called
topics.
ЯћЯЂЖМЙщЪєгквЛИіРрБ№ГЩЮЊtopic,дкЮяРэЩЯВЛЭЌTopicЕФЯћЯЂЗжПЊДцДЂ,ТпМЩЯвЛИіTopicЕФЯћЯЂЖдЪЙгУепЭИУї
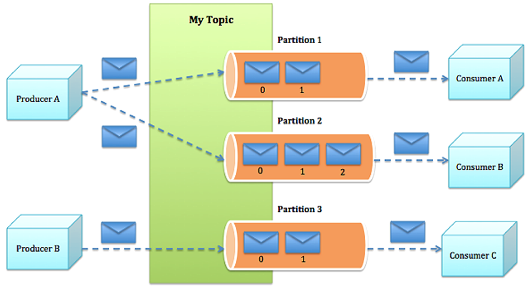
2.Partitions
Topics are broken up into ordered commit logs called
partitions
УПИіTopicsЛЎЗжЮЊвЛИіЛђепЖрИіPartition,ВЂЧвPartitionжаЕФУПЬѕЯћЯЂЖМБЛБъМЧСЫвЛИіsequential
id ,вВОЭЪЧoffset,ВЂЧвДцДЂЕФЪ§ОнЪЧПЩХфжУДцДЂЪБМфЕФ
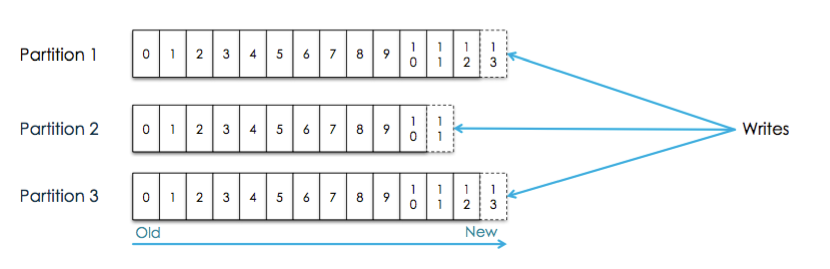
3.Message Ordering
ЯћЯЂжЛБЃжЄдкЭЌвЛИіPartitionжагаађ,Ыљвд,ШчЙћвЊБЃжЄДгTopicжаФУЕНЕФЪ§Онгаађ,дђашвЊзіЕН:
Group messages in a partition by key(producer)
Configure exactly one consumer instance per partition
within a consumer group
kafkaФмБЃжЄЕФЪЧ:
Message sent by a producer to a particular topic
partition will be appended in the order they are sent
A consumer instance sees messages in the order they
are stored in the log
For a topic with replication factor N, kafka can tolerate
up to N-1 server failures without ЁАlosingЁБ any messages
committed to the log
4.Log
PartitionЖдгІТпМЩЯЕФLog
5.Replication ИББО
Topics can (and should) be replicated
The unit of replication is the partition
Each partition in a topic has 1 leader and 0 or more
replicas
A replica is deemed to be ЁАin-syncЁБ if
The replica can communicate with Zookeeper
The replica is not ЁАtoo farЁБ behind the leader(configurable)
The group of in-sync replicas for a partition is
called the ISR(In-Sync-Replicas)
The Replication factor cannot be lowered
6.kafka durability ПЩППад
Durability can be configured with the producer configuration
request.required.acks
0 : The producer never waits for an ack
1 : The producer gets an ack after the leader replica
has received the data
-1 : The producer gets an ack after all ISRs receive
the data
Minimum available ISR can also be configured such
that an error is returned if enough replicas are not
available to replicate data
Ыљвд,kafkaПЩвдбЁдёВЛЭЌЕФdurabilityРДЛЛШЁВЛЭЌЕФЭЬЭТСП

ЭЈгУ,kafkaПЩвдЭЈЙ§діМгИќЖрЕФBrokerРДЬсЩ§ЭЬЭТСП
вЛИіЭЦМіЕФХфжУ:

7.Broker
Kafka is run as a cluster comparised of one or more
servers each of which is called broker

8.Producer
Processes that publish messages to a kafka topic
are called producers
Producers publish to a topic of their choosing(push)
Ъ§ОндиШыkafkaПЩвдЪЧЗжВМЪНЕФ,ЭЈГЃЪЧЭЈЙ§ЁБRound-RobinЁБЫуЗЈВпТд,вВПЩвдИљОнmessageжаЕФkeyРДНјаагявхЗжИюЁБsemantic
partitioningЁБРДЗжВМЪНдиШы,Brokers ЭЈЙ§ЗжЧјРДОљКтдиШы
kafkaжЇГжвьВНЗЂЫЭasync,вьВНЗЂЫЭЯћЯЂЪЧless durableЕФ,ЕЋЪЧЪЧИпЭЬЭТЕФ
ProducerЕФдиШыЦНКтКЭISRs
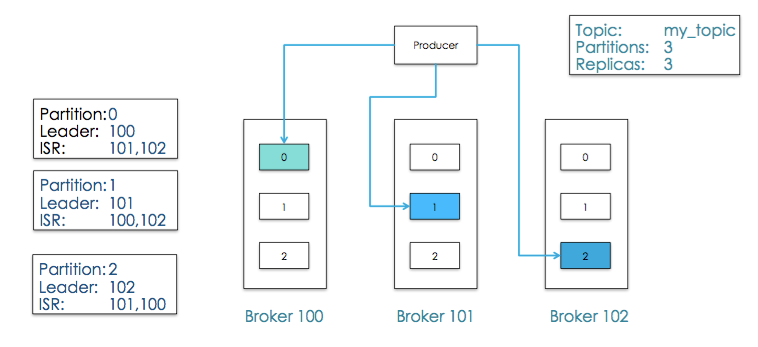
9.Consumer
Processes that subscribe(ЖЉдФ) to tpics and process
the feed of published messages are called consumers
Multiple Consumer can read from the same topic
Each Consumer is responsible for managing itЁЏs own
offset
Message stay on kafkaЁ they are not removed after
they consumed
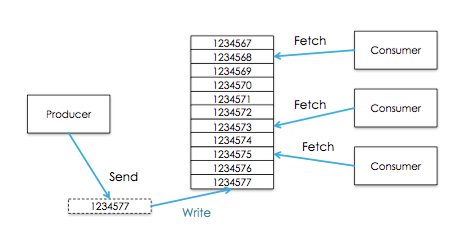
ConsumerПЩвдДгШЮвЛЕиЗНПЊЪМЯћЗб,ШЛКѓгжЛиЕНзюДѓЦЋвЦСПДІ,ConsumersгжПЩвдБЛЛЎЗжЮЊConsumer
Group
10.Consumer Group
Consumer GroupЪЧЯдЪНЗжВМЪН,ЖрИіConsumerЙЙГЩзщНсЙЙ,MessageжЛФмДЋЪфИјФГИіGroupжаЕФФГвЛИіConsumer
ГЃгУЕФConsumer GroupФЃЪН:
All consumer instances in one group
Acts like a traditional queue with load balancing
All consumer instances in different groups
All messages are broadcast to all consumer instances
ЁАLogical SubscriberЁБ - Many consumer instances in
a group
Consumers are added for scalability and fault tolerance,Each
consumer instance reads from one or more partitions
for a topic ,There cannot be more consumer instances
than partitions
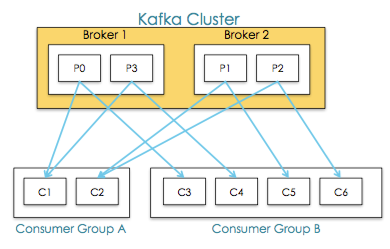
Consumer Groups ЬсЙЉСЫtopicsКЭpartitionsЕФИєРы
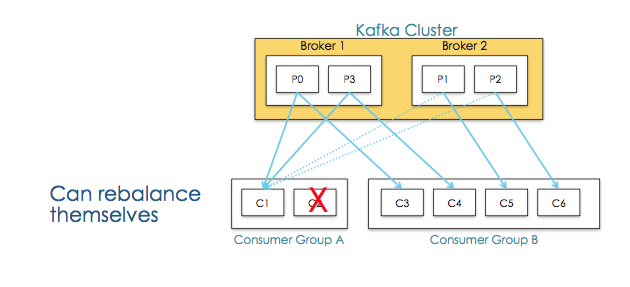
ВЂЧвЕБФГИіConsumerЙвЕєКѓФмЙЛжиаТЦНКт
Consumer GroupЕФгІгУГЁОА
ЕуЖдЕу
НЋЫљгаЯћЗбепЗХЕНвЛИіConsumer Group
ЙуВЅ
НЋУПИіЯћЗбепЕЅЖРЗХЕНвЛИіConsumer Group
ЫЎЦНРЉеЙ
ЯђConsumer GroupжаЬэМгЯћЗбепВЂНјааRebalance
ЙЪеЯзЊвЦ
ЕБФГИіConsumerЗЂЩњЙЪеЯЪБ,Consumer GroupжиаТЗжХфЗжЧј
Жў. Kafka КЫаФдРэ
KafkaЩшМЦЫМЯы
ПЩГжОУЛЏMessage
ГжОУЛЏБОЕиЮФМўЯЕЭГ,ЩшжУгааЇЦк
жЇГжИпСїСПДІРэ
УцЯђЬиЖЈЕФЪЙгУГЁОАЖјВЛЪЧЭЈгУЙІФм
ЯћЗбзДЬЌБЃДцдкЯћЗбЖЫЖјВЛЪЧЗўЮёЖЫ
МѕЧсЗўЮёЦїИКЕЃКЭНЛЛЅ
жЇГжЗжВМЪН
ЩњВњеп/ЯћЗбепЭИУївьВН
вРРЕДХХЬЮФМўЯЕЭГзіЯћЯЂЛКДц
ВЛЯћКФФкДц
ИпаЇЕФДХХЬДцШЁ
ИДдгЖШЮЊO(1)
ЧПЕїМѕЩйЪ§ОнЕФађСаЛЏКЭПНБДПЊЯњ
ХњСПДцДЂКЭЗЂЫЭЁЂzero-copy
жЇГжЪ§ОнВЂааМгдиЕНHadoop
МЏГЩHadoop
KafkaдРэЗжЮі
1.ДцДЂ
Partition
topicЮяРэЩЯЕФЗжзщЃЌвЛИіtopicПЩвдЗжЮЊЖрИіpartitionЃЌУПИіpartitionЪЧвЛИігаађЕФЖгСаЁЃ
дкKafkaЮФМўДцДЂжаЃЌЭЌвЛИіtopicЯТгаЖрИіВЛЭЌpartitionЃЌУПИіpartitionЮЊвЛИіФПТМЃЌpartitonУќУћЙцдђЮЊtopicУћГЦ+гаађађКХЃЌЕквЛИіpartitonађКХДг0ПЊЪМЃЌађКХзюДѓжЕЮЊpartitionsЪ§СПМѕ1

УПИіpartion(ФПТМ)ЯрЕБгквЛИіОоаЭЮФМўБЛЦНОљЗжХфЕНЖрИіДѓаЁЯрЕШsegment(ЖЮ)Ъ§ОнЮФМўжаЁЃЕЋУПИіЖЮsegment
fileЯћЯЂЪ§СПВЛвЛЖЈЯрЕШЃЌетжжЬиадЗНБуold segment fileПьЫйБЛЩОГ§ЁЃ
УПИіpartitonжЛашвЊжЇГжЫГађЖСаДОЭааСЫЃЌsegmentЮФМўЩњУќжмЦкгЩЗўЮёЖЫХфжУВЮЪ§ОіЖЈЁЃ
етбљзіЕФКУДІОЭЪЧФмПьЫйЩОГ§ЮогУЮФМўЃЌгааЇЬсИпДХХЬРћгУТЪЁЃ
segment file
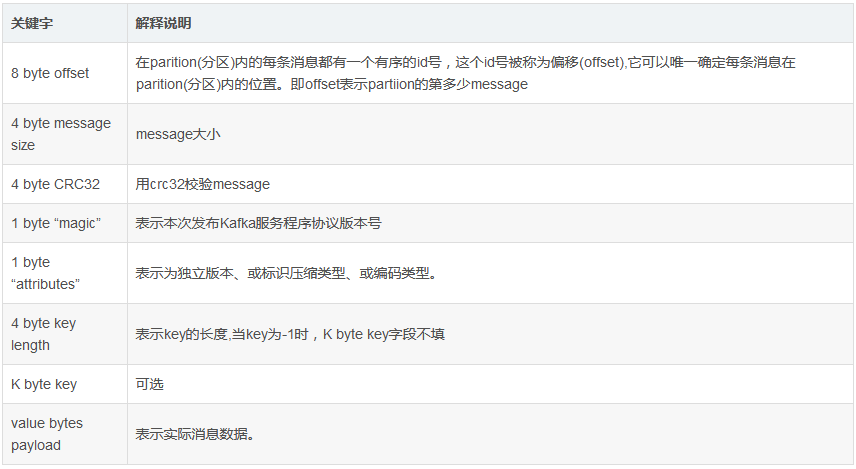
segment fileзщГЩЃКгЩ2ДѓВПЗжзщГЩЃЌЗжБ№ЮЊindex fileКЭdata fileЃЌДЫ2ИіЮФМўвЛвЛЖдгІЃЌГЩЖдГіЯжЃЌКѓзКЁБ.indexЁБКЭЁА.logЁБЗжБ№БэЪОЮЊsegmentЫїв§ЮФМўЁЂЪ§ОнЮФМў.
segmentЮФМўУќУћЙцдђЃКpartionШЋОжЕФЕквЛИіsegmentДг0ПЊЪМЃЌКѓајУПИіsegmentЮФМўУћЮЊЩЯвЛИіsegmentЮФМўзюКѓвЛЬѕЯћЯЂЕФoffsetжЕЁЃЪ§жЕзюДѓЮЊ64ЮЛlongДѓаЁЃЌ19ЮЛЪ§зжзжЗћГЄЖШЃЌУЛгаЪ§зжгУ0ЬюГфЁЃ

Цфжа.indexЫїв§ЮФМўДцДЂДѓСПдЊЪ§ОнЃЌ.logЪ§ОнЮФМўДцДЂДѓСПЯћЯЂЃЌЫїв§ЮФМўжадЊЪ§ОнжИЯђЖдгІЪ§ОнЮФМўжаmessageЕФЮяРэЦЋвЦЕижЗЁЃЫћУЧСНИіЪЧвЛвЛЖдгІЕФ,ЖдгІЙиЯЕШчЯТ

Message
segment data fileгЩаэЖрmessageзщГЩЃЌmessageЮяРэНсЙЙШчЯТ

ВЮЪ§ЫЕУї:
2. Consumer
High Level Consumer
ЯћЗбепБЃДцЯћЗбзДЬЌЃКНЋДгФГИіPartitionЖСШЁЕФзюКѓвЛЬѕЯћЯЂЕФoffsetДцгкZooKeeperжа
Low Level ConsumerЃКИќКУЕФПижЦЪ§ОнЕФЯћЗб
ЭЌвЛЬѕЯћЯЂЖСЖрДЮ
жЛЖСШЁФГИіTopicЕФВПЗжPartition
ЙмРэЪТЮёЃЌДгЖјШЗБЃУПЬѕЯћЯЂБЛДІРэвЛДЮЃЌЧвНіБЛДІРэвЛДЮ
ДѓСПЖюЭтЙЄзї
БиаыдкгІгУГЬађжаИњзйoffsetЃЌДгЖјШЗЖЈЯТвЛЬѕгІИУЯћЗбФФЬѕЯћЯЂ
гІгУГЬађашвЊЭЈЙ§ГЬађЛёжЊУПИіPartitionЕФLeaderЪЧЫ
БиаыДІРэLeaderЕФБфЛЏ
3.ЯћЯЂДЋЕнгявхDelivery Semantics
At least once
kafkaЕФФЌШЯЩшжУ
Messages are never lost but maybe redelivered
At most once
Messages are lost but never redelivered
Exactly once
БШНЯФбЪЕЯж
Messages are delivered once and only once
ЪЕЯжExactly OnceашвЊПМТЧ:
Must consider two components
Durability guarantees when publishing a message
Durability guarantees when consuming a message
Producer
What happens when a produce request was sent but a
network error returned before an ack ?
RE:Use a single writer per partition and check the
latest committed value after network errors
Consumer
include a unique ID(e.g.UUID) and de-duplicate
Consider storing offsets with data
НтЪЭ:
ЯћЯЂДЋЕнгявх: Producer НЧЖШ
ЕБProducerЯђbrokerЗЂЫЭЯћЯЂЪБЃЌвЛЕЉетЬѕЯћЯЂБЛcommitЃЌвђЮЊreplicationЕФДцдкЃЌЫќОЭВЛЛсЖЊ,ЕЋЪЧШчЙћProducerЗЂЫЭЪ§ОнИјbrokerКѓЃЌгіЕНЭјТчЮЪЬтЖјдьГЩЭЈаХжаЖЯЃЌФЧProducerОЭЮоЗЈХаЖЯИУЬѕЯћЯЂЪЧЗёвбОcommit
РэЯыЕФНтОіЗНАИЃКProducerПЩвдЩњГЩвЛжжРрЫЦгкжїМќЕФЖЋЮїЃЌЗЂЩњЙЪеЯЪБУнЕШадЕФжиЪдЖрДЮЃЌетбљОЭзіЕНСЫExactly
once,ФПЧАФЌШЯЧщПіЯТвЛЬѕЯћЯЂДгProducerЕНbrokerЪЧШЗБЃСЫAt least once
ЯћЯЂДЋЕнгявх: Consumer : High Level API
ConsumerдкДгbrokerЖСШЁЯћЯЂКѓЃЌПЩвдбЁдёcommitЃЌИУВйзїЛсдкZookeeperжаБЃДцИУConsumerдкИУPartitionжаЖСШЁЕФЯћЯЂЕФoffset
ИУConsumerЯТвЛДЮдйЖСИУPartitionЪБЛсДгЯТвЛЬѕПЊЪМЖСШЁЃЛШчЮДcommitЃЌЯТвЛДЮЖСШЁЕФПЊЪМЮЛжУЛсИњЩЯвЛДЮcommitжЎКѓЕФПЊЪМЮЛжУЯрЭЌ
ЯжЪЕЕФЮЪЬтЃКЕНЕзЪЧЯШДІРэЯћЯЂдйcommitЃЌЛЙЪЧЯШcommitдйДІРэЯћЯЂЃП
ЯШДІРэЯћЯЂдйcommit
ШчЙћдкДІРэЭъЯћЯЂдйНјааcommitжЎЧАConsumerЗЂЩњхДЛњЃЌЯТДЮжиаТПЊЪМЙЄзїЪБЛЙЛсДІРэИеИеЮДcommitЕФЯћЯЂЃЌЪЕМЪЩЯИУЯћЯЂвбОБЛДІРэЙ§СЫЁЃетОЭЖдгІгкAt
least once
вЕЮёГЁОАЪЙгУУнЕШадЃКЯћЯЂЖМгавЛИіжїМќЃЌЫљвдЯћЯЂЕФДІРэЭљЭљОпгаУнЕШадЃЌМДЖрДЮДІРэетвЛЬѕЯћЯЂИњжЛДІРэвЛДЮЪЧЕШаЇЕФЃЌФЧОЭПЩвдШЯЮЊЪЧExactly
onceЁЃ
ЯШcommitдйДІРэЯћЯЂ
ШчЙћConsumerдкcommitКѓЛЙУЛРДЕУМАДІРэЯћЯЂОЭхДЛњСЫЃЌЯТДЮжиаТПЊЪМЙЄзїКѓОЭЮоЗЈЖСЕНИеИевбЬсНЛЖјЮДДІРэЕФЯћЯЂЃЌетОЭЖдгІгкAt
most once
ЯћЯЂДЋЕнгявх: Consumer : Lower Level API
Exactly onceЕФЪЕЯжЫМЯыЃКаЕїoffsetКЭЯћЯЂЪ§Он
ОЕфзіЗЈЪЧв§ШыСННзЖЮЬсНЛ
offsetКЭЯћЯЂЪ§ОнЗХдкЭЌвЛИіЕиЗНЃКConsumerФУЕНЪ§ОнКѓПЩФмАбЪ§ОнЗХЕНЙВЯэПеМфжаЃЌШчЙћАбзюаТЕФoffsetКЭЪ§ОнБОЩэвЛЦ№аДЕНЙВЯэПеМфЃЌФЧОЭПЩвдБЃжЄЪ§ОнЕФЪфГіКЭoffsetЕФИќаТвЊУДЖМЭъГЩЃЌвЊУДЖМВЛЭъГЩЃЌМфНгЪЕЯжExactly
once
High level APIЖјбдЃЌoffsetЪЧДцгкZookeeperжаЕФЃЌЮоЗЈЛёШЁЃЌЖјLow level
APIЕФoffsetЪЧгЩздМКШЅЮЌЛЄЕФЃЌПЩвдЪЕЯжвдЩЯЗНАИ
4.ИпПЩгУад
ЭЌвЛИіPartitionПЩФмЛсгаЖрИіReplicaЃЌашвЊБЃжЄЭЌвЛИіPartitionЕФЖрИіReplicaжЎМфЕФЪ§ОнвЛжТад
ЖјетЪБашвЊдкетаЉReplicationжЎМфбЁГівЛИіLeaderЃЌProducerКЭConsumerжЛгыетИіLeaderНЛЛЅЃЌЦфЫќReplicaзїЮЊFollowerДгLeaderжаИДжЦЪ§Он
ИББОгыИпПЩгУадЃКИББОLeader ElectionЫуЗЈ
ZookeeperжаЕФбЁОйЫуЗЈЛиЙЫ
ЩйЪ§ЗўДгЖрЪ§ЃКШЗБЃМЏШКжавЛАывдЩЯЕФЛњЦїЕУЕНЭЌВН
ЪЪКЯЙВЯэМЏШКХфжУЕФЯЕЭГжаЃЌЖјВЂВЛЪЪКЯашвЊДцДЂДѓСПЪ§ОнЕФЯЕЭГЃЌвђЮЊашвЊДѓСПИББОМЏЁЃfИіReplicaЪЇАмЧщПіЯТашвЊ2f+1ИіИББО
KafkaЕФзіЗЈ
ISR(in-sync replicas)ЃЌетИіISRРяЕФЫљгаИББОЖМИњЩЯСЫLeaderЃЌжЛгаISRРяЕФГЩдБВХгаБЛбЁЮЊLeaderЕФПЩФм
дкетжжФЃЪНЯТЃЌЖдгкf+1ИіИББОЃЌвЛИіPartitionФмдкБЃжЄВЛЖЊЪЇвбОcommitЕФЯћЯЂЕФЧАЬсЯТШнШЬfИіИББОЕФЪЇАм
ISRашвЊЕФзмЕФИББОЕФИіЪ§МИКѕЪЧЁАЩйЪ§ЗўДгЖрЪ§ЁБЕФвЛАы
ИББОгыИпПЩгУадЃКReplicaЗжХфЫуЗЈ
НЋЫљгаReplicaОљдШЗжВМЕНећИіМЏШК
НЋЫљгаnИіBrokerКЭД§ЗжХфЕФPartitionХХађ
НЋЕкiИіPartitionЗжХфЕНЕк(i mod n)ИіBrokerЩЯ
НЋЕкiИіPartitionЕФЕкjИіReplicaЗжХфЕНЕк((i + j) mode n)ИіBrokerЩЯ
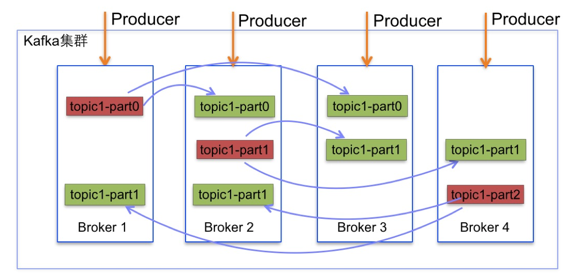
5. СуПНБД
KafkaЭЈЙ§MessageЗжзщКЭSendfileЯЕЭГЕїгУЪЕЯжСЫzero-copy
ДЋЭГЕФsocketЗЂЫЭЮФМўПНБД
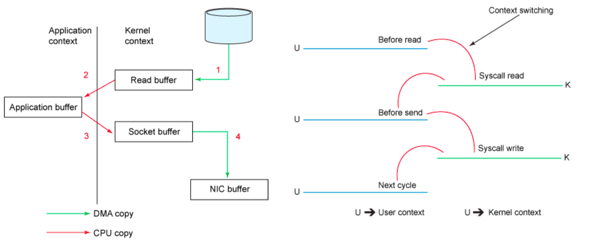
1.ФкКЫЬЌ
2.гУЛЇЬЌ
3.ФкКЫЬЌ
4.ЭјПЈЛКДц
ОРњСЫФкКЫЬЌКЭгУЛЇЬЌЕФПНБД
sendfileЯЕЭГЕїгУ
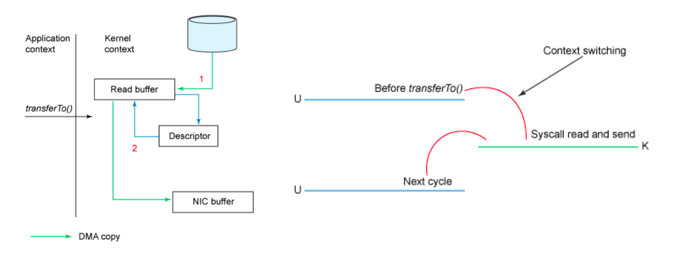
БмУтСЫФкКЫЬЌгыгУЛЇЬЌЕФЩЯЯТЮФЧаЛЛЖЏзї
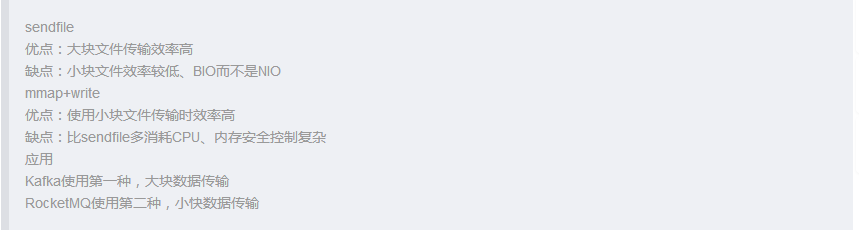
Ш§. Use Cases
Real-Time Stream Processing(combined with Spark
Streaming)
General purpose Message Bus
Collecting User Activity Data
Collecting Operational Metrics from applications,servers
or devices
Log Aggregation
Change Data Capture
Commit Log for distributed systems
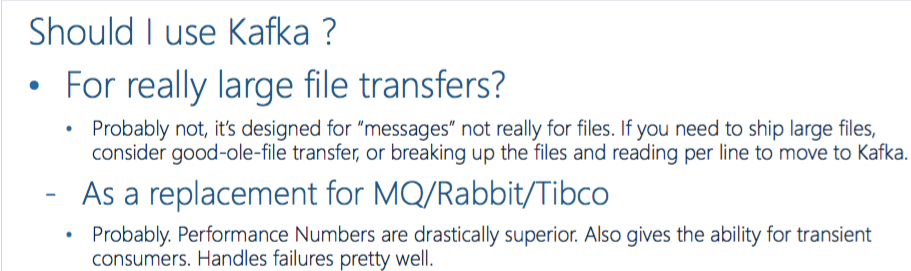
ЫФ. Development with Kafka
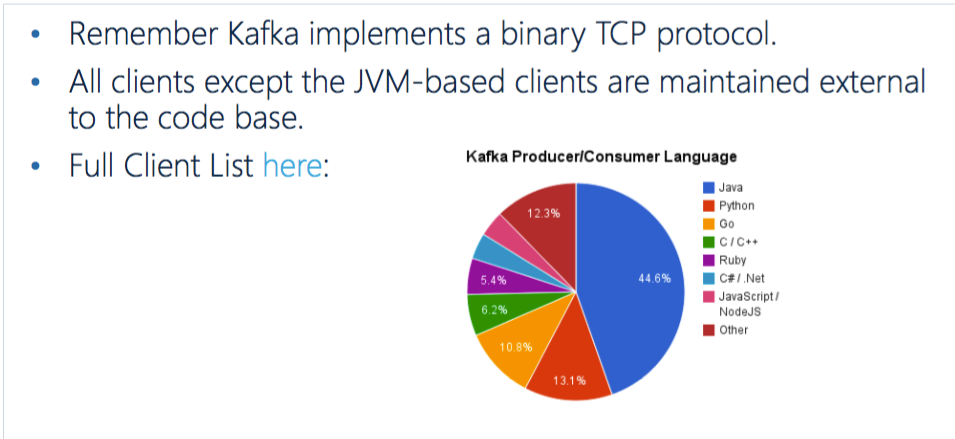
Юх. Administration
list && describe
echo "ДЫKafkaМЏШКЫљгаЕФTopic
: "
kafka-topics -- list -- zookeeper dc226. dooioo.cn:2181,
dc227.dooioo.cn:2181, dc229. dooioo.cn:2181 /kafka
echo " ФњвЊВщПДЕФTopicЯъЯИ : "
kafka- topics - -describe -- zookeeper dc226.
dooioo.cn: 2181, dc227.dooioo.cn: 2181,dc229.
dooioo.cn:2181 /kafka --topic $ topicName |
create topic
kafka-topics
--create -- zookeeper dc226.dooioo.cn:2181,dc227.
dooioo.cn:2181,dc229. dooioo.cn:2181 /kafka --
replication- factor 1 --pa
rtitions 1 --topic $topicName |
open producer
| kafka-console-
producer -- broker- list 10.22. 253.227:9092 --topic
$topicName |
open consumer
| kafka-console-consumer
--zookeeper 10.22.253.226: 2181, 10.22. 253 .227:
2181,10.22. 253.229:2181 /kafka -- topic $topicName
-- from- beginning |
Сљ. Cluster Planning
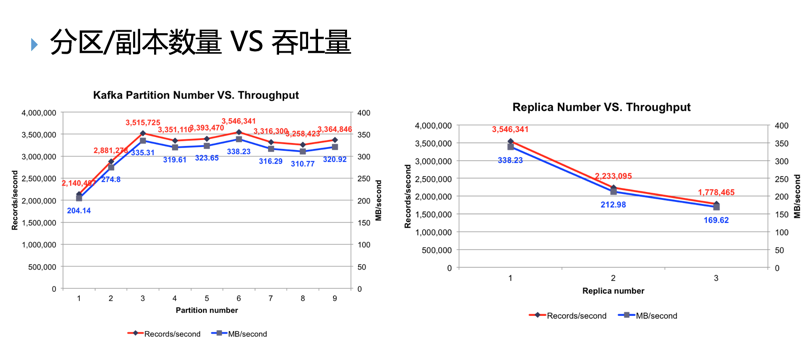
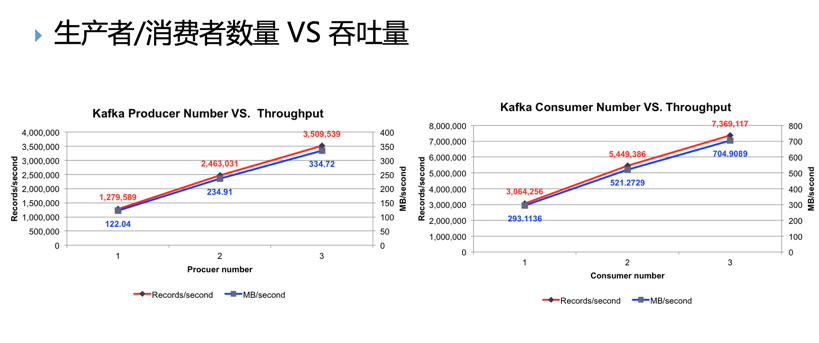
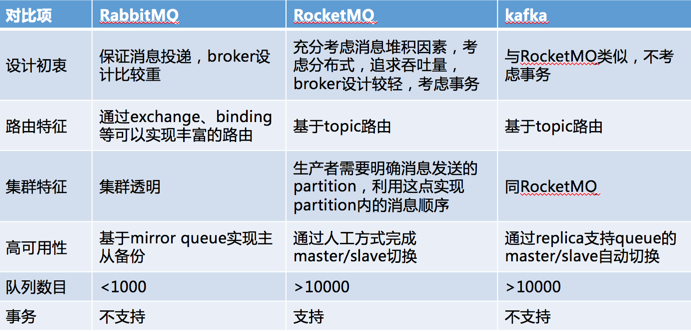
Цп. Compare
|









