| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌЮФеТжївЊМЧТМ
Elasticsearch КЭ Kibana ЛЗОГЕФХфжУЃЌвдМАВЩМЏЗўЮёзЗзйЪ§ОнЕФЯдГіДІРэЁЃ |
|
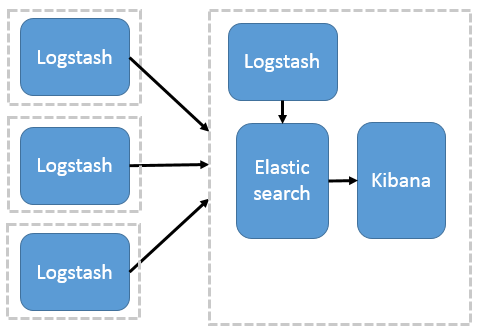
1. ELK Stack МђНщ
ELK ЪЧШ§ИіПЊдДШэМўЕФЫѕаДЃЌЗжБ№ЮЊЃКElasticsearchЁЂLogstash вдМА KibanaЃЌЫќУЧЖМЪЧПЊдДШэМўЁЃВЛЙ§ЯждкЛЙаТдіСЫвЛИі
BeatsЃЌЫќЪЧвЛИіЧсСПМЖЕФШежОЪеМЏДІРэЙЄОпЃЈAgentЃЉЃЌBeats еМгУзЪдДЩйЃЌЪЪКЯгкдкИїИіЗўЮёЦїЩЯЫбМЏШежОКѓДЋЪфИј
LogstashЃЌЙйЗНвВЭЦМіДЫЙЄОпЃЌФПЧАгЩгкдБОЕФ ELK Stack ГЩдБжаМгШыСЫ Beats ЙЄОпЫљвдвбИФУћЮЊ
Elastic StackЁЃ
ИљОн Google Trend ЕФаХЯЂЯдЪОЃЌElastic Stack вбОГЩЮЊФПЧАзюСїааЕФМЏжаЪНШежОНтОіЗНАИЁЃ
Elastic Stack АќКЌЃК
Elasticsearch ЪЧИіПЊдДЗжВМЪНЫбЫїв§ЧцЃЌЬсЙЉЫбМЏЁЂЗжЮіЁЂДцДЂЪ§ОнШ§ДѓЙІФмЁЃЫќЕФЬиЕугаЃКЗжВМЪНЃЌСуХфжУЃЌздЖЏЗЂЯжЃЌЫїв§здЖЏЗжЦЌЃЌЫїв§ИББОЛњжЦЃЌrestful
ЗчИёНгПкЃЌЖрЪ§ОндДЃЌздЖЏЫбЫїИКдиЕШЁЃЯъЯИПЩВЮПМ Elasticsearch ШЈЭўжИФЯ
Logstash жївЊЪЧгУРДШежОЕФЫбМЏЁЂЗжЮіЁЂЙ§ТЫШежОЕФЙЄОпЃЌжЇГжДѓСПЕФЪ§ОнЛёШЁЗНЪНЁЃвЛАуЙЄзїЗНЪНЮЊ
c/s МмЙЙЃЌclient ЖЫАВзАдкашвЊЪеМЏШежОЕФжїЛњЩЯЃЌserver ЖЫИКд№НЋЪеЕНЕФИїНкЕуШежОНјааЙ§ТЫЁЂаоИФЕШВйзїдквЛВЂЗЂЭљ
Elasticsearch ЩЯШЅЁЃ
Kibana вВЪЧвЛИіПЊдДКЭУтЗбЕФЙЄОпЃЌKibana ПЩвдЮЊ Logstash КЭ ElasticSearch
ЬсЙЉЕФШежОЗжЮігбКУЕФ Web НчУцЃЌПЩвдАяжњЛузмЁЂЗжЮіКЭЫбЫїживЊЪ§ОнШежОЁЃ
Beats дкетРяЪЧвЛИіЧсСПМЖШежОВЩМЏЦїЃЌЦфЪЕ Beats Мвзхга 6 ИіГЩдБЃЌдчЦкЕФ ELK МмЙЙжаЪЙгУ
Logstash ЪеМЏЁЂНтЮіШежОЃЌЕЋЪЧ Logstash ЖдФкДцЁЂcpuЁЂio ЕШзЪдДЯћКФБШНЯИпЁЃЯрБШ
LogstashЃЌBeats ЫљеМЯЕЭГЕФ CPU КЭФкДцМИКѕПЩвдКіТдВЛМЦЁЃ
ELK Stack ЃЈ5.0АцБОжЎКѓЃЉ--> Elastic Stack == ЃЈELK Stack
+ BeatsЃЉЁЃ
ФПЧА Beats АќКЌСљжжЙЄОпЃК
PacketbeatЃК ЭјТчЪ§ОнЃЈЪеМЏЭјТчСїСПЪ§ОнЃЉ
MetricbeatЃК жИБъЃЈЪеМЏЯЕЭГЁЂНјГЬКЭЮФМўЯЕЭГМЖБ№ЕФ CPU КЭФкДцЪЙгУЧщПіЕШЪ§ОнЃЉ
FilebeatЃК ШежОЮФМўЃЈЪеМЏЮФМўЪ§ОнЃЉ
WinlogbeatЃК windows ЪТМўШежОЃЈЪеМЏ Windows ЪТМўШежОЪ§ОнЃЉ
AuditbeatЃКЩѓМЦЪ§ОнЃЈЪеМЏЩѓМЦШежОЃЉ
HeartbeatЃКдЫааЪБМфМрПиЃЈЪеМЏЯЕЭГдЫааЪБЕФЪ§ОнЃЉ
ELK МђЕЅМмЙЙЭМЃК
2. ЛЗОГзМБИ
ЗўЮёЦїЛЗОГЃКCentos 7.0ЃЈФПЧАЕЅЛњЃЌКѓајдйВПЪ№МЏШКЃЉ
Elasticsearch КЭ Logstash ашвЊ Java ЛЗОГЃЌElasticsearch
ЭЦМіЕФАцБОЮЊ Java 8ЃЌАВзАНЬГЬЃКШЗЖЈЮШЖЈЕФ Spring Cloud ЯрЙиЛЗОГАцБО
СэЭтЃЌЮвУЧашвЊаоИФЯТЗўЮёЦїжїЛњаХЯЂЃК
[root@node1
~]# vi /etc/hostname
node1
[root@node1 ~]# vi /etc/hosts
192.168.0.11 node1
127.0.0.1 node1 localhost localhost.localdomain
localhost4 localhost4.localdomain4
::1 node1 localhost localhost.localdomain local
host6 localhost6.localdomain6 |
зЂвтЃКЮвжЎЧААВзА Elasticsearch КЭ Kibana ЖМЪЧзюаТАцБОЃЈ6.xЃЉЃЌЕЋКЭ Spring
Cloud МЏГЩгааЉЮЪЬтЃЌЫљвдОЭВЩгУСЫ 5.x АцБОЃЈОпЬх 5.6.9 АцБОЃЉ
3. АВзА Elasticsearch
дЫаавдЯТУќСюНЋ Elasticsearch ЙЋЙВ GPG УмдПЕМШы
rpmЃК
| [root@node1
~]# rpm --import https: // artifacts . elastic
.co /GPG - KEY - elasticsearch |
дк/etc/yum.repos.d/ФПТМжаЃЌДДНЈвЛИіУћЮЊelasticsearch.repoЕФЮФМўЃЌЬэМгЯТУцХфжУЃК
[elasticsearch-5.x]
name=Elasticsearch repository for 5.x packages
baseurl = https: // artifacts . elastic . co /
packages /5.x /yum
gpgcheck = 1
gpgkey = https: // artifacts.elastic.co /GPG -
KEY - elasticsearch
enabled = 1
autorefresh = 1
type = rpm - md |
Elasticsearch дДДДНЈЭъГЩжЎКѓЃЌЭЈЙ§ makecache
ВщПДдДЪЧЗёПЩгУЃЌШЛКѓЭЈЙ§ yum АВзА ElasticsearchЃК
| [root@node1
~] # yum makecache && yum install elasticsearch
- y |
аоИФХфжУЃЈЦєЖЏЕижЗКЭЖЫПкЃЉЃК
[root@node1
~]# vi / etc / elasticsearch / elasticsearch .yml
network.host: node1 # ФЌШЯlocalhostЃЌздЖЈвхЮЊip
http .port : 9200 |
вЊНЋ Elasticsearch ХфжУЮЊдкЯЕЭГв§ЕМЪБздЖЏЦєЖЏЃЌдЫаавдЯТУќСюЃК
[root@node1
~]# sudo / bin /systemctl daemon - reload
[root@node1 ~]# sudo / bin /systemctl enable elasticsearch
.service |
Elasticsearch ПЩвдАДШчЯТЗНЪНЦєЖЏКЭЭЃжЙЃК
[root@node1
~]# sudo systemctl start elastic search .service
[root@node1 ~]# sudo systemctl stop elastic search
.service |
СаГі Elasticsearch ЗўЮёЕФШежОЃК
[root@node1
~]# sudo journalctl --unit elastic search
-- Logs begin at Ш§ 2018-05-09 10:13:46 CEST, end
at Ш§ 2018-05-09 10:53:53 CEST. --
5дТ 09 10:53:43 node1 systemd [1]: [/ usr /lib
/ systemd / system / elasticsearch.service : 8
] Unknown lvalue 'RuntimeDirectory' in section
' Service '
5дТ 09 10:53:43 node1 systemd [1]: [/usr /lib /systemd
/system / elasticsearch.service : 8 ] Unknown
lvalue 'RuntimeDirectory' in section ' Service
'
5дТ 09 10:53:48 node1 systemd [1]: Starting Elastic
search...
5дТ 09 10:53:48 node1 systemd [1]: Started Elastic
search.
5дТ 09 10:53:48 node1 elasticsearch[2908]: which:
no java in (/usr /local /sbin: /usr/ local/ bin:/
usr /sbin :/usr /bin )
5дТ 09 10:53:48 node1 elasticsearch[2908]: could
not find java; set JAVA_HOME or ensure java is
in PATH
5дТ 09 10:53:48 node1 systemd [1]: elasticsearch.
service : main process exited, code = exited ,
status = 1 / FAILURE
5дТ 09 10:53:48 node1 systemd [1]: Unit elastic
search .service entered failed state. |
ГіЯжСЫДэЮѓЃЌОпЬхаХЯЂЪЧЮДевЕНJAVA_HOMEЛЗОГБфСПЃЌЕЋЮвУЧУїУївбОХфжУЙ§СЫЁЃ
НтОіЗНЪНЃЈВЮПМзЪСЯЃКhttps://segmentfault.com/q/1010000004715131ЃЉЃК
[root@node1
~]# vi / etc / sysconfig / elastic search
JAVA _ HOME = /usr/ local /java |
жиаТЦєЖЏЃК
| sudo systemctl
restart elasticsearch .service |
ЛђепЭЈЙ§systemctlУќСюЃЌВщПД Elasticsearch ЦєЖЏзДЬЌЃК
[root@node1
~]# systemctl status elasticsearch.service
elasticsearch.service - Elasticsearch
Loaded: loaded (/usr/lib/ systemd/system /elasticsearch.
service ; enabled )
Active: active (running) since вЛ 2018- 05- 14
05:13:45 CEST; 4h 5min ago
Docs: http: // www.elastic.co
Process: 951 ExecStartPre= /usr/share /elasticsearch
/bin / elasticsearch - systemd-pre-exec (code
= exited, status = 0/SUCCESS)
Main PID: 953 (java)
CGroup: /system.slice /elasticsearch .service
ЉИЉЄ 953 /usr /local/java/bin/java - Xms2g - Xmx2g
-XX: + UseConcMarkSweepGC - XX : CMSInitiatingO...
5дТ 14 05:13:45 node1 systemd[1]: Started Elasticsearch. |
ЗЂЯж Elasticsearch вбОГЩЙІЦєЖЏЁЃ
ВщПД Elasticsearch аХЯЂЃК
[root@node1
~]# curl - XGET 'http: // node1: 9200 / ?pretty
'
{
"name" : "AKmrtMm",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "r7lG3UBXQ-uTLHInJxbOJA",
"version" : {
"number"
: "5.6.9",
"build _ hash" : "877a590",
"build _ date" : "2018- 04- 12T16:
25:14.838Z",
"build _ snapshot" : false,
"lucene _ version" : "6.6.1"
},
"tagline" : "You Know, for
Search"
} |
4. АВзА Kibana
дЫаавдЯТУќСюНЋ Elasticsearch ЙЋЙВ GPG УмдПЕМШы
rpmЃК
| [root@node1
~]# rpm -- import https: //artifacts .elastic
.co /GPG-KEY-elasticsearch |
дк/etc/yum.repos.d/ФПТМжаЃЌДДНЈвЛИіУћЮЊkibana.repoЕФЮФМўЃЌЬэМгЯТУцХфжУЃК
[kibana-5.x]
name = Kibana repository for 5.x packages
baseurl = https: //artifacts .elastic.co /packages
/ 5.x /yum
gpgcheck = 1
gpgkey = https://artifacts.elastic.co/GPG-KEY-elastic
search
enabled = 1
autorefresh = 1
type = rpm - md |
АВзА KibanaЃК
| [root@node1
~]# yum makecache && yum install kibana
- y |
аоИФХфжУЃЈЕижЗКЭЖЫПкЃЌвдМА Elasticsearch ЕФЕижЗЃЌзЂвтserver.hostжЛФмЬюаДЗўЮёЦїЕФ
IP ЕижЗЃЉЃК
[root@node1
~]# vi /etc/ kibana / kibana.yml
# Kibana is served by a back end server. This
setting specifies the port to use.
server.port : 5601
# Specifies the address to which the Kibana
server will bind. IP addresses and host names
are both valid values.
# The default is 'localhost', which usually
means remote machines will not be able to connect.
# To allow connections from remote users, set
this parameter to a non-loopback address.
server.host: "192.168.0.11"
# The Kibana server's name. This is used for
display purposes.
server . name : "kibana - server"
# The URL of the Elasticsearch instance to
use for all your queries.
elasticsearch.url : "http: //node1:9200"
# ХфжУkibanaЕФШежОЮФМўТЗОЖЃЌВЛШЛФЌШЯЪЧ messages РяМЧТМШежО
logging.dest: /var /log /kibana.log |
ДДНЈШежОЮФМўЃК
| [root@node1
~]# touch / var /log / kibana.log ; chmod 777
/var /log/ kibana.log |
вЊНЋ Kibana ХфжУЮЊдкЯЕЭГв§ЕМЪБздЖЏЦєЖЏЃЌдЫаавдЯТУќСюЃК
[root@node1
~]# sudo / bin / systemctl daemon - reload
[root@node1 ~]# sudo / bin / systemctl enable
kibana .service |
Kibana ПЩвдШчЯТЦєЖЏКЭЭЃжЙ
[root@node1
~]# sudo systemctl start kibana . service
[root@node1 ~]# sudo systemctl stop kibana . service |
ВщПДЦєЖЏШежОЃК
[root@node1
~]# sudo journalctl -- unit kibana
5дТ 09 11:14:48 node1 systemd [1]: Starting Kibana...
5дТ 09 11:14:48 node1 systemd [1]: Started Kibana. |
ШЛКѓфЏРРЦїЗУЮЪЃКhttp://node1:5601
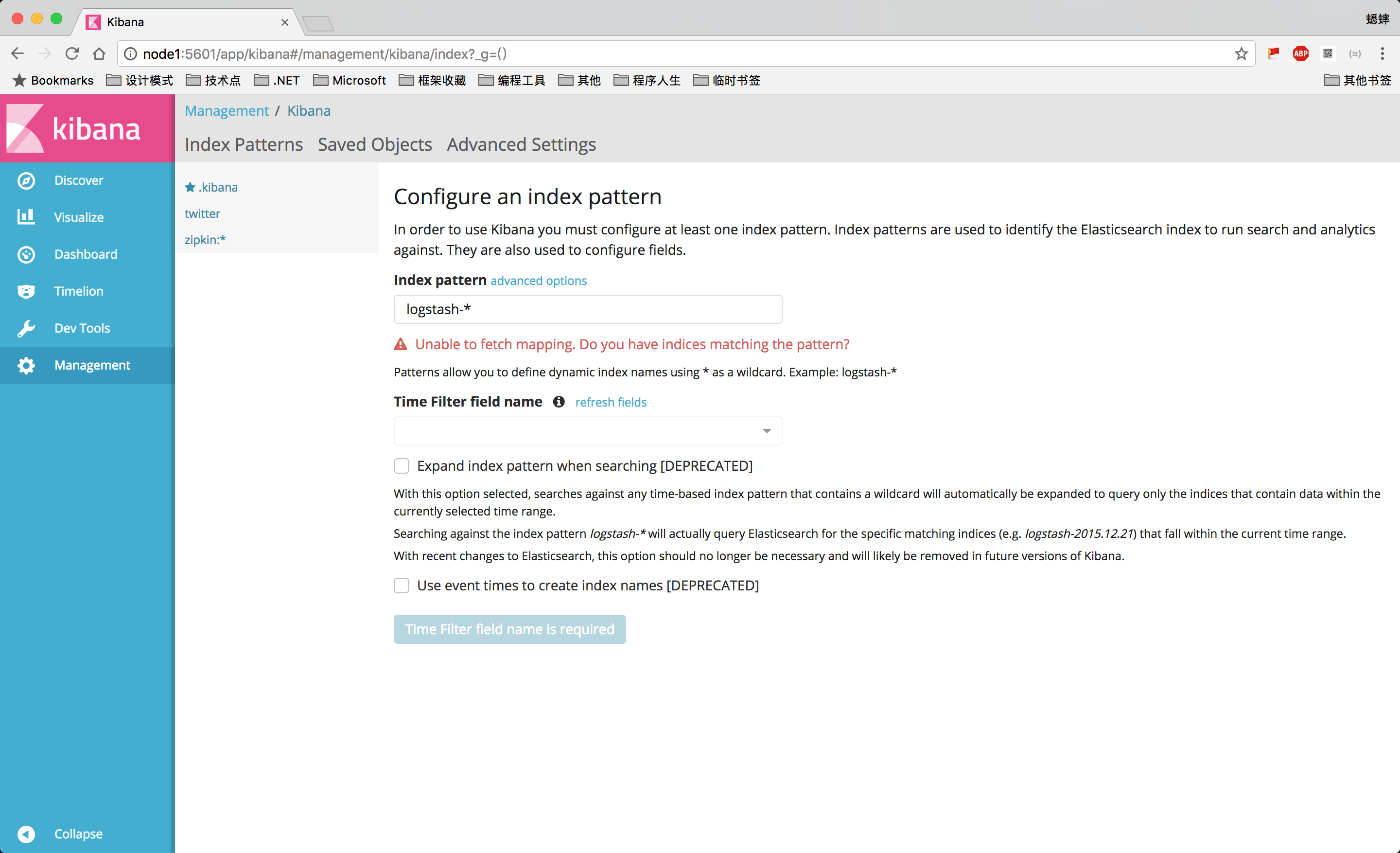
ГѕДЮЪЙгУЪБЃЌЛсШУФуХфжУвЛИіФЌШЯЕФ indexЃЌвВОЭЪЧФужСЩйашвЊЙиСЊвЛИі Elasticsearch
РяЕФ IndexЃЌПЩвдЪЙгУ pattern е§дђЦЅХфЁЃ
зЂвтЃКШчЙћ Elasticsearch жаУЛгаЪ§ОнЕФЛАЃЌФуЪЧЮоЗЈДДНЈ Index ЕФЁЃ
ШчЙћ Spring Cloud Sleuth Zipkin + Stream + RabbitMQ
ХфжУе§ШЗЕФЛАЃЈвдКѓдйЯъЯИЫЕУїЃЉЃЌЗўЮёзЗзйЕФЪ§ОнОЭвбОДцДЂдк Elasticsearch жаСЫЁЃ
5. Kibana ЪЙгУ
ДДНЈzipkin:*Ыїв§ЃЈ*ЦЅХфКѓУцЫљгазжЗћЃЉЃК
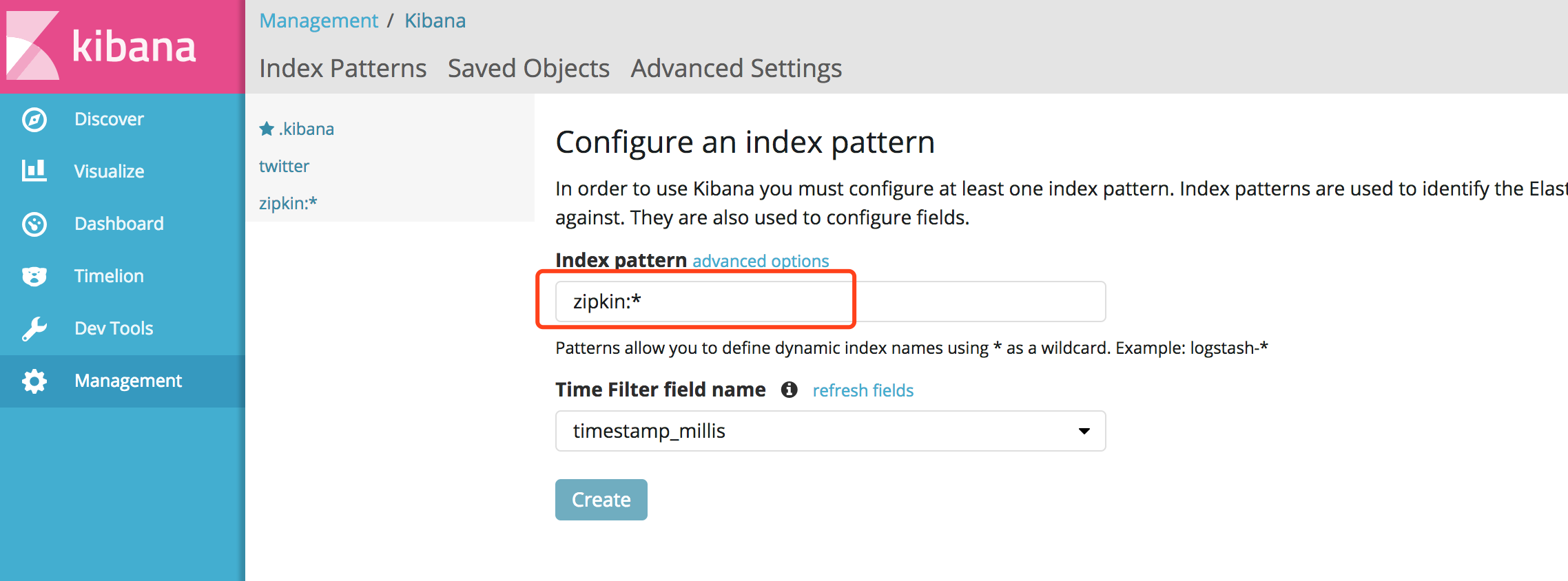
ШЛКѓОЭПЩвдВщПДЗўЮёзЗзйЕФЪ§ОнСЫЃК
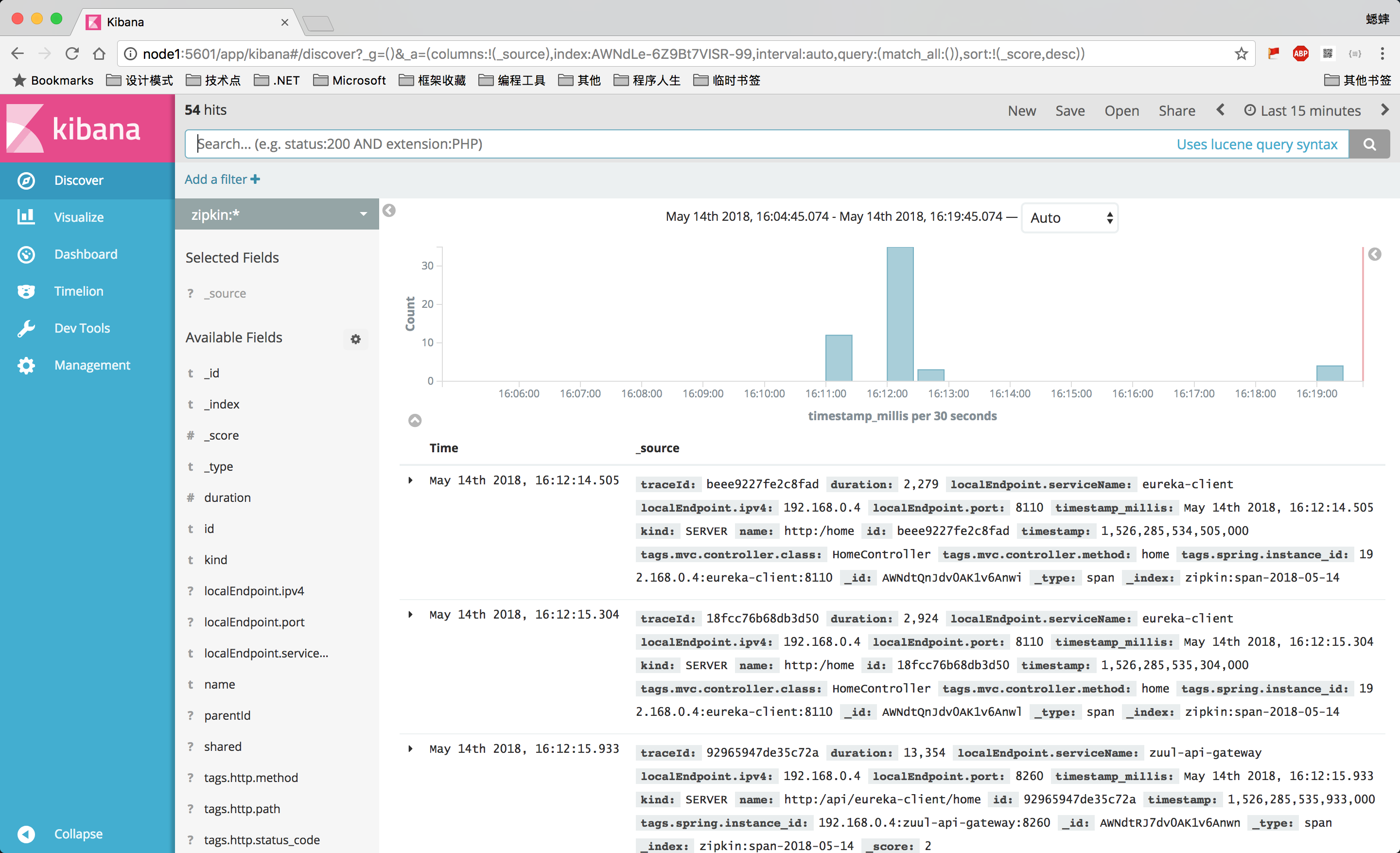
вВПЩвдДДНЈздЖЈвхвЧБэХЬЃК
6. Elasticsearch УќСю
ДДНЈЫїв§ЃК
| $ curl -XPUT
'http: // node1:9200 / twitter' |
ВщПД Index Ыїв§СаБэЃК
$ curl -XGET
http: //node1:9200/_ cat /indices
yellow open twitter k1KnzWyYRDeckjt7GASh8w 5 1
1 0 5.1kb 5.1kb
yellow open .kibana 8zJGQkq8TwC4s3JJLMX44g 1 1
1 0 4kb 4kb
yellow open student iZPqPcwrQbifGOfE9DQYvg 5 1
0 0 955b 955b |
ЬэМг Document Ъ§ОнЃК
$ curl -XPUT
'http: //node1:9200/ twitter/ tweet / 1' - d '{
" user " : " kimchy ",
" post_date " : "2009- 11- 15T14:12:12
",
"message" : " trying out Elastic
Search "
} ' |
ЛёШЁ Document Ъ§ОнЃК
$ curl -XGET
'http: //node1:9200 /twitter /tweet /1'
{"_index" : "twitter","_
type":"tweet","_ id"
: "1" ," _ version " :1 ,
"found" : true,"_ source "
: {
"user" : "kimchy",
"post_date" : "2009- 11- 15T14
:12: 12",
"message"
: "trying out Elastic Search"
}}% |
ВщбЏzipkinЫїв§ЯТУцЕФЪ§ОнЃК
| $ curl - XGET
'http : // node1:9200 /zipkin:* /_ search' |
|









