| 编辑推荐: |
本文来自于csdn,Kafka一个开源流处理平台,本文主要来讲述Kafka的三个版本的消息格式的演变,希望对大家的学习能有帮助。
|
|
摘要
对于一个成熟的消息中间件而言,消息格式不仅关系到功能维度的扩展,还牵涉到性能维度的优化。随着Kafka的迅猛发展,其消息格式也在不断的升级改进,从0.8.x版本开始到现在的1.1.x版本,Kafka的消息格式也经历了3个版本。本文这里主要来讲述Kafka的三个版本的消息格式的演变,文章偏长,建议先关注后鉴定。
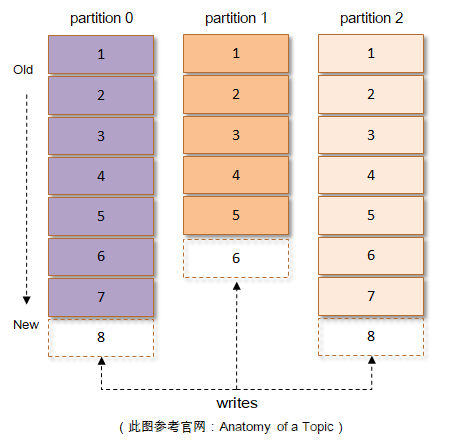
每一条消息被发送到Kafka中,其会根据一定的规则选择被存储到哪一个partition中。如果规则设置的合理,所有的消息可以均匀分布到不同的partition里,这样就实现了水平扩展。如上图,每个partition由其上附着的每一条消息组成,如果消息格式设计的不够精炼,那么其功能和性能都会大打折扣。比如有冗余字段,势必会使得partition不必要的增大,进而不仅使得存储的开销变大、网络传输的开销变大,也会使得Kafka的性能下降;又比如缺少字段,在最初的Kafka消息版本中没有timestamp字段,对内部而言,其影响了日志保存、切分策略,对外部而言,其影响了消息审计、端到端延迟等功能的扩展,虽然可以在消息体内部添加一个时间戳,但是解析变长的消息体会带来额外的开销,而存储在消息体(参考下图中的value字段)前面可以通过指针偏量获取其值而容易解析,进而减少了开销(可以查看v1版本),虽然相比于没有timestamp字段的开销会差一点。如此分析,仅在一个字段的一增一减之间就有这么多门道,那么Kafka具体是怎么做的呢?本文只针对Kafka 0.8.x版本开始做相应说明,对于之前的版本不做陈述。
v0版本
对于Kafka消息格式的第一个版本,我们把它称之为v0,在Kafka 0.10.0版本之前都是采用的这个消息格式。注意如无特殊说明,我们只讨论消息未压缩的情形。
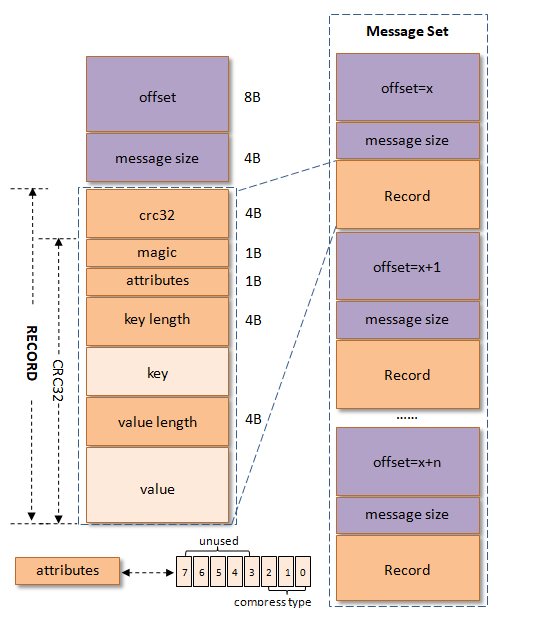
上左图中的“RECORD”部分就是v0版本的消息格式,大多数人会把左图中的整体,即包括offset和message size字段都都看成是消息,因为每个Record(v0和v1版)必定对应一个offset和message size。每条消息都一个offset用来标志它在partition中的偏移量,这个offset是逻辑值,而非实际物理偏移值,message size表示消息的大小,这两者的一起被称之为日志头部(LOG_OVERHEAD),固定为12B。LOG_OVERHEAD和RECORD一起用来描述一条消息。与消息对应的还有消息集的概念,消息集中包含一条或者多条消息,消息集不仅是存储于磁盘以及在网络上传输(Produce & Fetch)的基本形式,而且是kafka中压缩的基本单元,详细结构参考上右图。
下面来具体陈述一下消息(Record)格式中的各个字段,从crc32开始算起,各个字段的解释如下:
1.crc32(4B):crc32校验值。校验范围为magic至value之间。
2.magic(1B):消息格式版本号,此版本的magic值为0。
3.attributes(1B):消息的属性。总共占1个字节,低3位表示压缩类型:0表示NONE、1表示GZIP、2表示SNAPPY、3表示LZ4(LZ4自Kafka 0.9.x引入),其余位保留。
4.key length(4B):表示消息的key的长度。如果为-1,则表示没有设置key,即key=null。
5.key:可选,如果没有key则无此字段。
6.value length(4B):实际消息体的长度。如果为-1,则表示消息为空。
7.value:消息体。可以为空,比如tomnstone消息。
v0版本中一个消息的最小长度(RECORD_OVERHEAD_V0)为crc32 + magic + attributes + key length + value length = 4B + 1B + 1B + 4B + 4B =14B,也就是说v0版本中一条消息的最小长度为14B,如果小于这个值,那么这就是一条破损的消息而不被接受。
这里我们来做一个测试,首先创建一个partition数和副本数都为1的topic,名称为“msg_format_v0”,然后往msg_format_v0中发送一条key=”key”,value=”value”的消息,之后查看对应的日志:
[root@node1
kafka_2.10-0.8.2.1]# bin/kafka-run-class.sh kafka.tools.DumpLogSegments
--files /tmp/kafka-logs/msg_format_v0-0/00000000000000000000.log
Dumping /tmp/kafka-logs-08/msg_format_v0-0/00000000000000000000.log
Starting offset: 0
offset: 0 position: 0 isvalid:
true payloadsize: 5 magic: 0 compresscodec: NoCompressionCodec
crc: 592888119 keysize: 3 |
查看消息的大小,即00000000000000000000.log文件的大小为34B,其值正好等于LOG_OVERHEAD+RECORD_OVERHEAD_V0 + 3B的key + 5B的value = 12B + 14B + 3B + 5B = 34B。
[root@node1 msg_format_v0-0]# ll *.log
-rw-r--r-- 1 root root 34 Apr 26 02:52 00000000000000000000.log |
我们再发送一条key=null, value=”value”的消息,之后查看日志的大小:
[root@node3 msg_format_v0-0]# ll *.log
-rw-r--r-- 1 root root 65 Apr 26 02:56 00000000000000000000.log |
日志大小为65B,减去上一条34B的消息,可以得知本条消息的大小为31B,正好等于LOG_OVERHEAD+RECORD_OVERHEAD_V0 + 5B的value = 12B + 14B+ 5B = 31B。
v1版本
kafka从0.10.0版本开始到0.11.0版本之前所使用的消息格式版本为v1,其比v0版本就多了一个timestamp字段,表示消息的时间戳。v1版本的消息结构图如下所示:
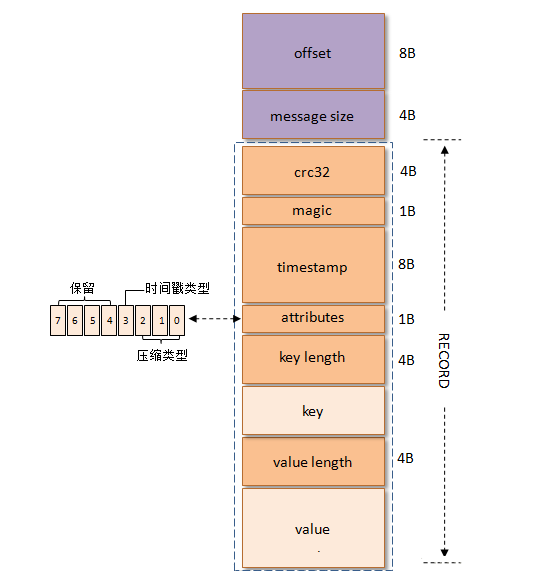
v1版本的magic字段值为1。v1版本的attributes字段中的低3位和v0版本的一样,还是表示压缩类型,而第4个bit也被利用了起来:0表示timestamp类型为CreateTime,而1表示tImestamp类型为LogAppendTime,其他位保留。v1版本的最小消息(RECORD_OVERHEAD_V1)大小要比v0版本的要大8个字节,即22B。如果像v0版本介绍的一样发送一条key=”key”,value=”value”的消息,那么此条消息在v1版本中会占用42B,具体测试步骤参考v0版的相关介绍。
消息压缩
常见的压缩算法是数据量越大压缩效果越好,一条消息通常不会太大,这就导致压缩效果并不太好。而kafka实现的压缩方式是将多条消息一起进行压缩,这样可以保证较好的压缩效果。而且在一般情况下,生产者发送的压缩数据在kafka broker中也是保持压缩状态进行存储,消费者从服务端获取也是压缩的消息,消费者在处理消息之前才会解压消息,这样保持了端到端的压缩。
压缩率是压缩后的大小与压缩前的对比。例如:把100MB的文件压缩后是90MB,压缩率为90/100*100%=90%,压缩率一般是越小压缩效果越好。一般口语化陈述时会误描述为压缩率越高越好,为了避免混淆,本文不引入学术上的压缩率而引入压缩效果,这样容易达成共识。
讲解到这里都是针对消息未压缩的情况,而当消息压缩时是将整个消息集进行压缩而作为内层消息(inner message),内层消息整体作为外层(wrapper message)的value,其结构图如下所示:
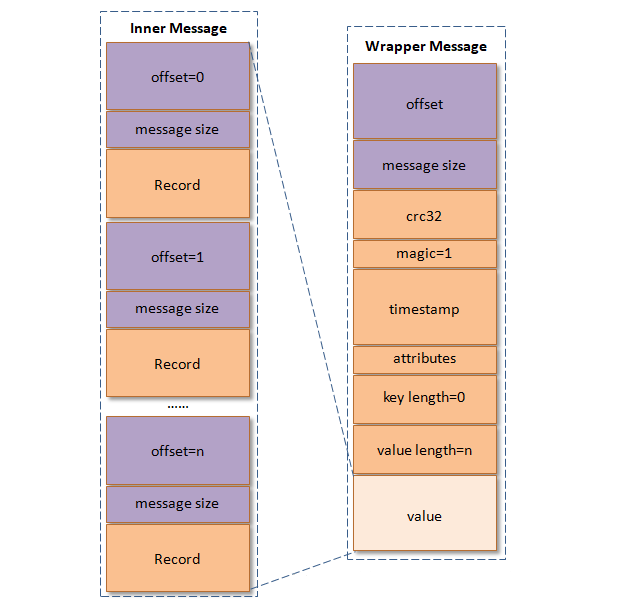
压缩后的外层消息(wrapper message)中的key为null,所以图右部分没有画出key这一部分。当生产者创建压缩消息的时候,对内部压缩消息设置的offset是从0开始为每个内部消息分配offset,详细可以参考下图右部:
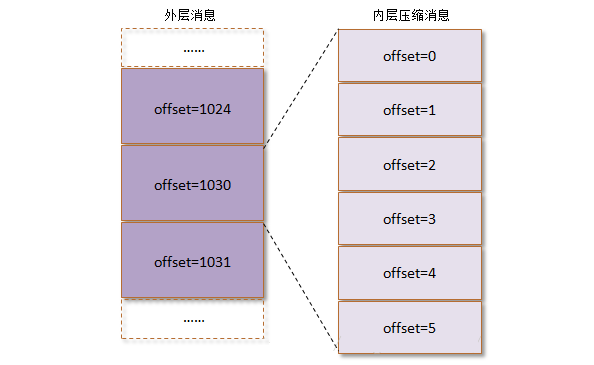
其实每个从生产者发出的消息集中的消息offset都是从0开始的,当然这个offset不能直接存储在日志文件中,对offset进行转换时在服务端进行的,客户端不需要做这个工作。外层消息保存了内层消息中最后一条消息的绝对位移(absolute offset),绝对位移是指相对于整个partition而言的。参考上图,对于未压缩的情形,图右内层消息最后一条的offset理应是1030,但是被压缩之后就变成了5,而这个1030被赋予给了外层的offset。当消费者消费这个消息集的时候,首先解压缩整个消息集,然后找到内层消息中最后一条消息的inner offset,然后根据如下公式找到内层消息中最后一条消息前面的消息的absolute offset(RO表示Relative Offset,IO表示Inner Offset,而AO表示Absolute Offset):
RO = IO_of_a_message - IO_of_the_last_message
AO = AO_Of_Last_Inner_Message + RO |
注意这里RO是前面的消息相对于最后一条消息的IO而言的,所以其值小于等于0,0表示最后一条消息自身。
压缩消息,英文是compress message,Kafka中还有一个compact message,常常也会被人们直译成压缩消息,需要注意两者的区别。compact message是针对日志清理策略而言的(cleanup.policy=compact),是指日志压缩(log compaction)后的消息,这个后续的系列文章中会有介绍。本文中的压缩消息单指compress message,即采用GZIP、LZ4等压缩工具压缩的消息。
在讲述v1版本的消息时,我们了解到v1版本比v0版的消息多了个timestamp的字段。对于压缩的情形,外层消息的timestamp设置为:
1.如果timestamp类型是CreateTime,那么设置的是内层消息中最大的时间戳(the max timestampof inner messages if CreateTime is used)。
2.如果timestamp类型是LogAppendTime,那么设置的是kafka服务器当前的时间戳;
内层消息的timestamp设置为:
1.如果外层消息的timestamp类型是CreateTime,那么设置的是生产者创建消息时的时间戳。
2.如果外层消息的timestamp类型是LogAppendTime,那么所有的内层消息的时间戳都将被忽略。
对于attributes字段而言,它的timestamp位只在外层消息(wrapper message)中设置,内层消息(inner message)中的timestamp类型一直都是CreateTime。
v2版本
kafka从0.11.0版本开始所使用的消息格式版本为v2,这个版本的消息相比于v0和v1的版本而言改动很大,同时还参考了Protocol Buffer而引入了变长整型(Varints)和ZigZag编码。Varints是使用一个或多个字节来序列化整数的一种方法,数值越小,其所占用的字节数就越少。ZigZag编码以一种锯齿形(zig-zags)的方式来回穿梭于正负整数之间,以使得带符号整数映射为无符号整数,这样可以使得绝对值较小的负数仍然享有较小的Varints编码值,比如-1编码为1,1编码为2,-2编码为3。详细可以参考:https://developers.google.com/protocol-buffers/docs/encoding。
回顾一下kafka v0和v1版本的消息格式,如果消息本身没有key,那么key length字段为-1,int类型的需要4个字节来保存,而如果采用Varints来编码则只需要一个字节。根据Varints的规则可以推导出0-63之间的数字占1个字节,64-8191之间的数字占2个字节,8192-1048575之间的数字占3个字节。而kafka broker的配置message.max.bytes的默认大小为1000012(Varints编码占3个字节),如果消息格式中与长度有关的字段采用Varints的编码的话,绝大多数情况下都会节省空间,而v2版本的消息格式也正是这样做的。不过需要注意的是Varints并非一直会省空间,一个int32最长会占用5个字节(大于默认的4字节),一个int64最长会占用10字节(大于默认的8字节)。
v2版本中消息集谓之为Record Batch,而不是先前的Message Set了,其内部也包含了一条或者多条消息,消息的格式参见下图中部和右部。在消息压缩的情形下,Record Batch Header部分(参见下图左部,从first offset到records count字段)是不被压缩的,而被压缩的是records字段中的所有内容。
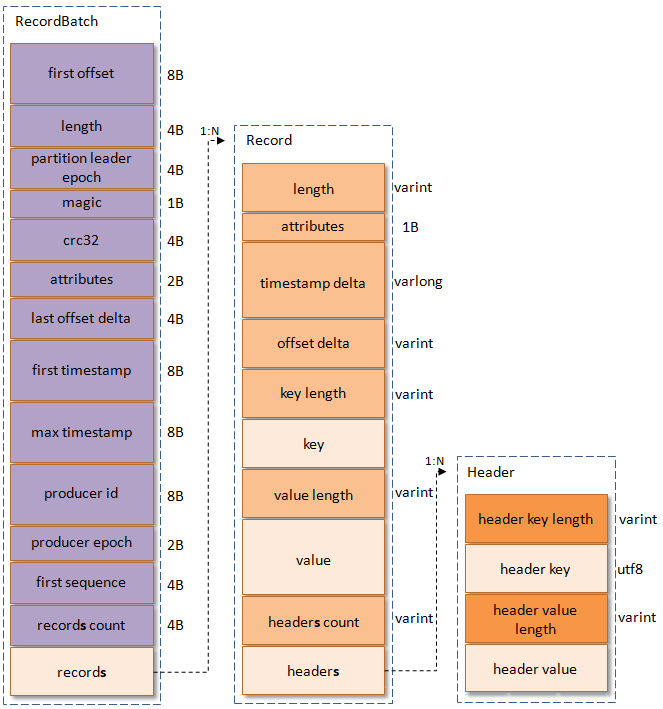
先来讲述一下消息格式Record的关键字段,可以看到内部字段大量采用了Varints,这样Kafka可以根据具体的值来确定需要几个字节来保存。v2版本的消息格式去掉了crc字段,另外增加了length(消息总长度)、timestamp delta(时间戳增量)、offset delta(位移增量)和headers信息,并且attributes被弃用了,笔者对此做如下分析(对于key、key length、value、value length字段和v0以及v1版本的一样,这里不再赘述):
下面来具体陈述一下消息(Record)格式中的各个字段,从crc32开始算起,各个字段的解释如下:
1.length:消息总长度。
2.attributes:弃用,但是还是在消息格式中占据1B的大小,以备未来的格式扩展。
3.timestamp delta:时间戳增量。通常一个timestamp需要占用8个字节,如果像这里保存与RecordBatch的其实时间戳的差值的话可以进一步的节省占用的字节数。
4.offset delta:位移增量。保存与RecordBatch起始位移的差值,可以节省占用的字节数。
5.headers:这个字段用来支持应用级别的扩展,而不需要像v0和v1版本一样不得不将一些应用级别的属性值嵌入在消息体里面。Header的格式如上图最有,包含key和value,一个Record里面可以包含0至多个Header。具体可以参考以下KIP-82。
如果对于v1版本的消息,如果用户指定的timestamp类型是LogAppendTime而不是CreateTime,那么消息从发送端(Producer)进入broker端之后timestamp字段会被更新,那么此时消息的crc值将会被重新计算,而此值在Producer端已经被计算过一次;再者,broker端在进行消息格式转换时(比如v1版转成v0版的消息格式)也会重新计算crc的值。在这些类似的情况下,消息从发送端到消费端(Consumer)之间流动时,crc的值是变动的,需要计算两次crc的值,所以这个字段的设计在v0和v1版本中显得比较鸡肋。在v2版本中将crc的字段从Record中转移到了RecordBatch中。
v2版本对于消息集(RecordBatch)做了彻底的修改,参考上图左部,除了刚刚提及的crc字段,还多了如下字段:
1.first offset:表示当前RecordBatch的起始位移。
2.length:计算partition leader epoch到headers之间的长度。
3.partition leader epoch:用来确保数据可靠性,详细可以参考KIP-101
4.magic:消息格式的版本号,对于v2版本而言,magic等于2。
5.attributes:消息属性,注意这里占用了两个字节。低3位表示压缩格式,可以参考v0和v1;第4位表示时间戳类型;第5位表示此RecordBatch是否处于事务中,0表示非事务,1表示事务。第6位表示是否是Control消息,0表示非Control消息,而1表示是Control消息,Control消息用来支持事务功能。
6.last offset delta:RecordBatch中最后一个Record的offset与first offset的差值。主要被broker用来确认RecordBatch中Records的组装正确性。
7.first timestamp:RecordBatch中第一条Record的时间戳。
8.max timestamp:RecordBatch中最大的时间戳,一般情况下是指最后一个Record的时间戳,和last offset delta的作用一样,用来确保消息组装的正确性。
9.producer id:用来支持幂等性,详细可以参考KIP-98。
10.producer epoch:和producer id一样,用来支持幂等性。
11.first sequence:和producer id、producer epoch一样,用来支持幂等性。
12.records count:RecordBatch中Record的个数。
这里我们再来做一个测试,在1.0.0的kafka中创建一个partition数和副本数都为1的topic,名称为“msg_format_v2”。然后同样插入一条key=”key”,value=”value”的消息,查看日志结果如下:
[root@node1 kafka_2.12-1.0.0]# bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/msg_format_v2-0/00000000000000000000.log --print-data-log
Dumping /tmp/kafka-logs/msg_format_v2-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false position: 0 CreateTime: 1524709879130 isvalid: true size: 76 magic: 2 compresscodec: NONE crc: 2857248333
|
可以看到size字段为76,我们根据上图中的v2版本的日志格式来验证一下,Record Batch Header部分共61B。Record部分中attributes占1B;timestamp delta值为0,占1B;offset delta值为0,占1B;key length值为3,占1B,key占3B;value length值为5,占1B,value占5B;headers count值为0,占1B, 无headers。Record部分的总长度=1B+1B+1B+1B+3B+1B+5B+1B=14B,所以Record的length字段值为14,编码为变长整型占1B。最后推到出这条消息的占用字节数=61B+14B+1B=76B,符合测试结果。同样再发一条key=null,value=”value”的消息的话,可以计算出这条消息占73B。
这么看上去好像v2版本的消息比之前版本的消息占用空间要大很多,的确对于单条消息而言是这样的,如果我们连续往msg_format_v2中再发送10条value长度为6,key为null的消息,可以得到:
| baseOffset: 2 lastOffset: 11 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false position: 149 CreateTime: 1524712213771 isvalid: true size: 191 magic: 2 compresscodec: NONE crc: 820363253 |
本来应该占用740B大小的空间,实际上只占用了191B,如果在v0版本中这10条消息则需要占用320B的空间,v1版本则需要占用400B的空间,这样看来v2版本又节省了很多的空间,因为其将多个消息(Record)打包存放到单个RecordBatch中,又通过Varints编码极大的节省了空间。
就以v1和v2版本对比而立,至于哪个消息格式占用空间大是不确定的,要根据具体情况具体分析。比如每条消息的大小为16KB,那么一个消息集中只能包含有一条消息(参数batch.size默认大小为16384),所以v1版本的消息集大小为12B+22B+16384B=16418B。而对于v2版本而言,其消息集大小为61B+11B+16384B=17086B(length值为16384+,占用3B,value length值为16384,占用大小为3B,其余数值型的字段都可以只占用1B的空间)。可以看到v1版本又会比v2版本节省些许空间。
其实可以思考一下:当消息体越小,v2版本中的Record字段的占用会比v1版本的LogHeader+Record占用越小,以至于某个临界点可以完全忽略到v2版本中Record Batch Header的61B大小的影响。就算消息体很大,v2版本的空间占用也不会比v1版本的空间占用大太多,几十个字节内,反观对于这种大消息体的大小而言,这几十个字节的大小从某种程度上又可以忽略。
由此可见,v2版本的消息不仅提供了类似事务、幂等等更多的功能,还对空间占用提供了足够的优化,总体提升很大。也由此体现一个优秀的设计是多么的重要,虽然说我们不要过度的设计和优化,那么是否可以着眼于前来思考一下?kafka为我们做了一个很好的榜样。
| 








