| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌKafkaЪЧзюГѕгЩLinkedinЙЋЫОПЊЗЂЃЌЪЧвЛИіЗжВМЪНЁЂжЇГжЗжЧјЕФЃЈpartitionЃЉЁЂЖрИББОЕФЃЈreplicaЃЉЃЌЛљгкzookeeperаЕїЕФЗжВМЪНЯћЯЂЯЕЭГ.
|
|
вЛЁЂ ЧАбд
ЪВУДЪЧЯћЯЂЯЕЭГЃП
дчЦкСНИігІгУГЬађМфНјааЯћЯЂДЋЕнашвЊБЃжЄСНИігІгУГЬађЭЌЪБдкЯпЃЌВЂЧвёюКЯЖШКмИпЁЃЮЊСЫНтОігІгУГЬађВЛдкЯпЕФЧщПіЯТвЕЮёе§ГЃдЫзЊЃЌОЭВњЩњСЫЯћЯЂЯЕЭГЃЌЯћЗбЗЂЫЭепЃЈЩњВњепЃЉНЋЯћЯЂЗЂЫЭжСЯћЯЂЯЕЭГЃЌЯћЯЂНгЪмепЃЈЯћЗбепЃЉДгЯћЯЂЯЕЭГжаЛёШЁЯћЯЂЁЃ
ЬсЕНЯћЯЂЯЕЭГЃЌВЛЕУВЛЫЕвЛЯТJMSМДJavaЯћЯЂЗўЮёЃЈJava Message ServiceЃЉгІгУГЬађНгПкЁЃЪЧвЛИіJavaЦНЬЈжаЙигкУцЯђЯћЯЂжаМфМўЕФAPIЁЃгУгкдкСНИігІгУГЬађжЎМфЛђЗжВМЪНЯЕЭГжаЗЂЫЭЯћЯЂЃЌНјаавьВНЭЈаХЁЃJavaЯћЯЂЗўЮёЪЧвЛИігыОпЬхЦНЬЈЮоЙиЕФAPIЁЃ
ЭЈГЃЯћЯЂДЋЕнгаСНжжРраЭЕФЯћЯЂФЃЪНПЩгУвЛжжЪЧЕуЖдЕуqueueЖгСаФЃЪН(p2p)ЃЌСэвЛжжЪЧtopicЗЂВМ-ЖЉдФФЃЪН(public-subscribe)ЁЃ
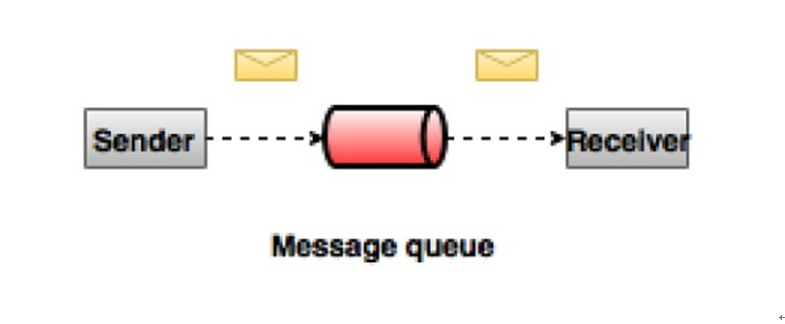
ЕуЖдЕуЯћЯЂЯЕЭГ
дкЕуЖдЕуЯЕЭГжаЃЌЯћЯЂБЛБЃСєдкЖгСажаЁЃ вЛИіЛђЖрИіЯћЗбепПЩвдЯћКФЖгСажаЕФЯћЯЂЃЌЕЋЪЧЬиЖЈЯћЯЂжЛФмгЩзюЖрвЛИіЯћЗбепЯћЗбЁЃвЛЕЉЯћЗбепЖСШЁЖгСажаЕФЯћЯЂЃЌЫќОЭДгИУЖгСажаЯћЪЇЁЃИУЯЕЭГЕФЕфаЭЪОР§ЪЧЖЉЕЅДІРэЯЕЭГЃЌЦфжаУПИіЖЉЕЅНЋгЩвЛИіЖЉЕЅДІРэЦїДІРэЃЌЕЋЖрИіЖЉЕЅДІРэЦївВПЩвдЭЌЪБЙЄзїЁЃЯТЭМУшЪіСЫНсЙЙЁЃ
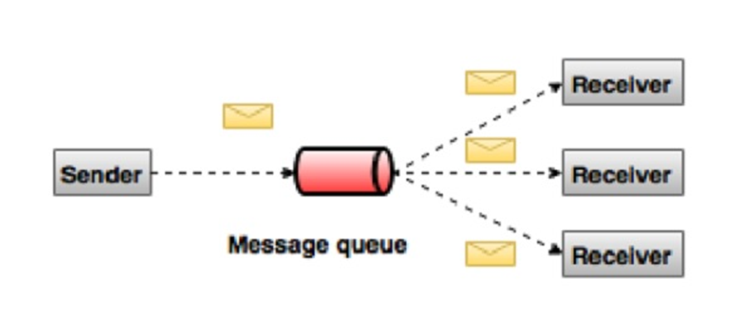
ЗЂВМ - ЖЉдФЯћЯЂЯЕЭГ
дкЗЂВМ-ЖЉдФЯЕЭГжаЃЌЯћЯЂБЛБЃСєдкжїЬтжаЁЃгыЕуЖдЕуЯЕЭГВЛЭЌЃЌЯћЗбепПЩвдЖЉдФвЛИіЛђЖрИіжїЬтВЂЪЙгУИУжїЬтжаЕФЫљгаЯћЯЂЁЃ
дкЗЂВМ - ЖЉдФЯЕЭГжаЃЌЯћЯЂЩњВњепГЦЮЊЗЂВМепЃЌЯћЯЂЪЙгУепГЦЮЊЖЉдФепЁЃвЛИіЯжЪЕЩњЛюЕФР§згЪЧDishЕчЪгЃЌЫќЗЂВМВЛЭЌЕФЧўЕРЃЌШчдЫЖЏЃЌЕчгАЃЌвєРжЕШЃЌШЮКЮШЫЖМПЩвдЖЉдФздМКЕФЦЕЕРМЏЃЌВЂЛёЕУЫћУЧЖЉдФЕФЦЕЕРЪБПЩгУЁЃ
MQЯћЯЂЖгСаЖдБШ
ЯТУцеыЖдRabbitMQгыkafkaНјааЖдБШ
гІгУГЁОАЩЯ
RabbitMQЃКзёбAMQP(Advanced Message
Queuing Protocol)авщЃЌгЩФкдкИпВЂЗЂЕФerlanngгябдПЊЗЂЃЌгУдкЪЕЪБЕФЖдПЩППадвЊЧѓБШНЯИпЕФЯћЯЂДЋЕнЩЯЁЃ
kafkaЃКЪЧLinkedinгк2010Фъ12дТЗнПЊдДЕФЯћЯЂЗЂВМЖЉдФЯЕЭГ,ЫќжївЊгУгкДІРэЛюдОЕФСїЪНЪ§Он,ДѓЪ§ОнСПЕФЪ§ОнДІРэЩЯЁЃ
дкЭЬЭТСПЩЯ
RabbitMQдкЭЬЭТСПЗНУцЩдбЗгкkafkaЃЌЫћУЧЕФГіЗЂЕуВЛвЛбљЃЌrabbitMQжЇГжЖдЯћЯЂЕФПЩППЕФДЋЕнЃЌжЇГжЪТЮёЃЌВЛжЇГжХњСПЕФВйзїЃЛЛљгкДцДЂЕФПЩППадЕФвЊЧѓДцДЂПЩвдВЩгУФкДцЛђепгВХЬЁЃ
kafkaОпгаИпЕФЭЬЭТСПЃЌФкВПВЩгУЯћЯЂЕФХњСПДІРэЃЌЪ§ОнЕФДцДЂКЭЛёШЁЪЧБОЕиДХХЬЫГађХњСПВйзїЃЌЯћЯЂДІРэЕФаЇТЪКмИпЁЃ
дкМЏШКИКдиОљКтЩЯ
RabbitMQЕФИКдиОљКташвЊЕЅЖРЕФloadbalancerНјаажЇГжЁЃ
kafkaВЩгУzookeeperЖдМЏШКжаЕФbrokerЁЂconsumerНјаааЕїЙмРэЁЃ
ЪВУДЪЧKafkaЃП
Apache KafkaЪЧвЛИіЗжВМЪНЗЂВМ-ЖЉдФЯћЯЂЯЕЭГКЭвЛИіЧПДѓЕФЖгСаЃЌЪЕМЪЩЯОЭЪЧJMSЕФвЛИіБфаЮЃЌПЩвдДІРэДѓСПЕФЪ§ОнЃЌВЂЪЙФњФмЙЛНЋЯћЯЂДгвЛИіЖЫЕуДЋЕнЕНСэвЛИіЖЫЕуЁЃKafkaЪЪКЯРыЯпКЭдкЯпЯћЯЂЯћЗбЁЃKafkaЯћЯЂБЃСєдкДХХЬЩЯЃЌВЂдкШКМЏФкИДжЦвдЗРжЙЪ§ОнЖЊЪЇЁЃKafkaЙЙНЈдкZooKeeperЭЌВНЗўЮёжЎЩЯЁЃ
KafkaЕФЬиад
вдЯТЪЧKafkaЕФМИИіКУДІ
ИпЭЬЭТСПЁЂЕЭбгГйЃКkafkaУПУыПЩвдДІРэМИЪЎЭђЬѕЯћЯЂЃЌЫќЕФбгГйзюЕЭжЛгаМИКСУыЃЌУПИіtopicПЩвдЗжЖрИіpartition,
consumer group ЖдpartitionНјааЯћЗбВйзїЁЃ
ПЩРЉеЙадЃКkafkaМЏШКжЇГжШШРЉеЙ
ГжОУадЁЂПЩППадЃКЯћЯЂБЛГжОУЛЏЕНБОЕиДХХЬЃЌВЂЧвжЇГжЪ§ОнБИЗнЗРжЙЪ§ОнЖЊЪЇ
ШнДэадЃКдЪаэМЏШКжаНкЕуЪЇАмЃЈШєИББОЪ§СПЮЊn,дђдЪаэn-1ИіНкЕуЪЇАмЃЉ
ИпВЂЗЂЃКжЇГжЪ§ЧЇИіПЭЛЇЖЫЭЌЪБЖСаД
гІгУГЁОА
KafkaПЩвддкаэЖргУР§жаЪЙгУЁЃ ЦфжавЛаЉСаГіШчЯТЃК
ШежОЪеМЏЃКвЛИіЙЋЫОПЩвдгУKafkaПЩвдЪеМЏИїжжЗўЮёЕФlogЃЌЭЈЙ§kafkaвдЭГвЛНгПкЗўЮёЕФЗНЪНПЊЗХИјИїжжconsumerЃЌР§ШчhadoopЁЂHbaseЁЂSolrЕШЁЃ
ЯћЯЂЯЕЭГЃКНтёюКЭЩњВњепКЭЯћЗбепЁЂЛКДцЯћЯЂЕШЁЃ
гУЛЇЛюЖЏИњзйЃКKafkaОГЃБЛгУРДМЧТМwebгУЛЇЛђепappгУЛЇЕФИїжжЛюЖЏЃЌШчфЏРРЭјвГЁЂЫбЫїЁЂЕуЛїЕШЛюЖЏЃЌетаЉЛюЖЏаХЯЂБЛИїИіЗўЮёЦїЗЂВМЕНkafka
ЕФtopicжаЃЌШЛКѓЖЉдФепЭЈЙ§ЖЉдФетаЉtopicРДзіЪЕЪБЕФМрПиЗжЮіЃЌЛђепзАдиЕНhadoopЁЂЪ§ОнВжПтжазіРыЯпЗжЮіКЭЭкОђЁЃ
дЫгЊжИБъЃКKafkaвВОГЃгУРДМЧТМдЫгЊМрПиЪ§ОнЁЃАќРЈЪеМЏИїжжЗжВМЪНгІгУЕФЪ§ОнЃЌЩњВњИїжжВйзїЕФМЏжаЗДРЁЃЌБШШчБЈОЏКЭБЈИцЁЃ
СїЪНДІРэЃКБШШчspark streamingКЭstorm
ЪТМўдД
KafkaЛљБОИХФю
KafkaжаЗЂВМЖЉдФЕФЖдЯѓЪЧtopicЁЃЮвУЧПЩвдЮЊУПРрЪ§ОнДДНЈвЛИіtopicЃЌАбЯђtopicЗЂВМЯћЯЂЕФПЭЛЇЖЫГЦзїproducerЃЌДгtopicЖЉдФЯћЯЂЕФПЭЛЇЖЫГЦзїconsumerЁЃProducersКЭconsumersПЩвдЭЌЪБДгЖрИіtopicЖСаДЪ§ОнЁЃвЛИіkafkaМЏШКгЩвЛИіЛђЖрИіbrokerЗўЮёЦїзщГЩЃЌЫќИКд№ГжОУЛЏКЭБИЗнОпЬхЕФkafkaЯћЯЂЁЃ
BrokerЃЈОМЭШЫЃЉЃКKafkaНкЕуЃЌвЛИіKafkaНкЕуОЭЪЧвЛИіbrokerЃЌЖрИіbrokerПЩвдзщГЩвЛИіKafkaМЏШКЁЃ
TopicЃЈжїЬтЃЉЃКвЛРрЯћЯЂЃЌЯћЯЂДцЗХЕФФПТММДжїЬтЃЌР§Шчpage viewШежОЁЂclickШежОЕШЖМПЩвдвдtopicЕФаЮЪНДцдкЃЌKafkaМЏШКФмЙЛЭЌЪБИКд№ЖрИіtopicЕФЗжЗЂЁЃ
PartitionЃКtopicЮяРэЩЯЕФЗжзщЃЌвЛИіtopicПЩвдЗжЮЊЖрИіpartitionЃЌУПИіpartitionЪЧвЛИігаађЕФЖгСаЁЃ
SegmentЃКpartitionЮяРэЩЯгЩЖрИіsegmentзщГЩЃЌУПИіSegmentДцзХmessageаХЯЂЁЃ
offsetЃКвЛЬѕЯћЯЂдкЯћЯЂЯЕЭГжаЕФЦЋвЦСПЁЃ
Producer : ЩњВњmessageЗЂЫЭЕНtopicЁЃ
Consumer : ЖЉдФtopicЯћЗбmessage, consumerзїЮЊвЛИіЯпГЬРДЯћЗбЁЃ
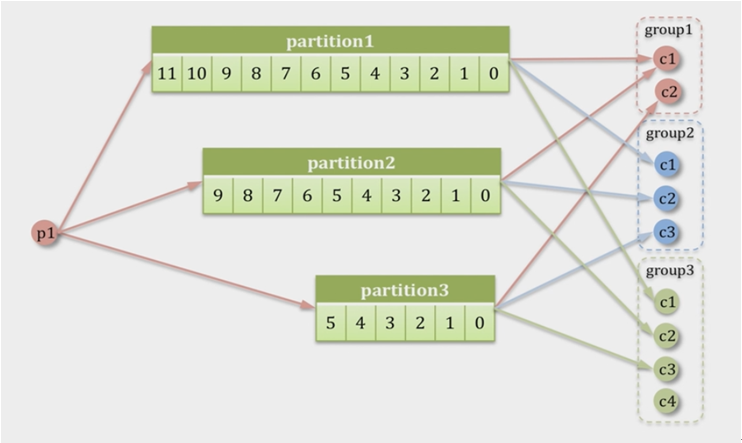
ConsumerGroupЃКвЛИіConsumerGroupАќКЌЖрИіconsumer,етИіЪЧдЄЯШдкХфжУЮФМўжаХфжУКУЕФЁЃИїИіconsumerЃЈconsumerЯпГЬЃЉПЩвдзщГЩвЛИізщЃЈConsumer
groupЃЉЃЌpartitionжаЕФУПИіmessageжЛФмБЛзщЃЈConsumer groupЃЉ жаЕФвЛИіconsumerЃЈconsumer
ЯпГЬЃЉЯћЗбЃЌШчЙћвЛИіmessageПЩвдБЛЖрИіconsumerЃЈconsumer ЯпГЬЃЉ ЯћЗбЕФЛАЃЌФЧУДетаЉconsumerБиаыдкВЛЭЌЕФзщЁЃKafkaВЛжЇГжвЛИіpartitionжаЕФmessageгЩСНИіЛђСНИівдЩЯЕФconsumer
threadРДДІРэЃЌМДБуЪЧРДздВЛЭЌЕФconsumer groupЕФвВВЛааЁЃЫќВЛФмЯёAMQФЧбљПЩвдЖрИіBETзїЮЊconsumerШЅДІРэmessageЃЌетЪЧвђЮЊЖрИіBETШЅЯћЗбвЛИіQueueжаЕФЪ§ОнЕФЪБКђЃЌгЩгквЊБЃжЄВЛФмЖрИіЯпГЬФУЭЌвЛЬѕmessageЃЌЫљвдОЭашвЊааМЖБ№БЏЙлЫјЃЈfor
updateЃЉ,етОЭЕМжТСЫconsumeЕФадФмЯТНЕЃЌЭЬЭТСПВЛЙЛЁЃЖјkafkaЮЊСЫБЃжЄЭЬЭТСПЃЌжЛдЪаэвЛИіconsumerЯпГЬШЅЗУЮЪвЛИіpartitionЁЃШчЙћОѕЕУаЇТЪВЛИпЕФЪБКђЃЌПЩвдМгpartitionЕФЪ§СПРДКсЯђРЉеЙЃЌФЧУДдйМгаТЕФconsumer
threadШЅЯћЗбЁЃетбљУЛгаЫјОКељЃЌГфЗжЗЂЛгСЫКсЯђЕФРЉеЙадЃЌЭЬЭТСПМЋИпЁЃетвВОЭаЮГЩСЫЗжВМЪНЯћЗбЕФИХФюЁЃ

ЩњВњепКЭЯћЗбеп
еыЖдЩњВњепКЭЯћЗбепЃЌашвЊзЂвтвдЯТМИЕу
ЗжЧјдкproducerЖЫНјаа
вЛИіЗжЧјжЛЛсгЩЯћЗбепзщФкЕФвЛИіconsumerЯћЗбЃЌkafkaЛсЭЈЙ§ИКдиОљКтЛњжЦздЖЏЗжХф
offsetгЩconsumerЖЫНјааЮЌЛЄЃЌвЛАуНЛИјzookeeperНјааЮЌЛЄ
жЛФмБЃжЄвЛИіЗжЧјФкЕФЪ§ОнЪЧгаађЕФ
ЖўЁЂ Apache Kafka - АВзАВНжш
зЂЃКАВзАkafkaЧАашвЊЬсЧААВзАJDKгыzookeeper
Step 1: ЯТдиKafkaВЂНтбЙ
> tar -xzfkafka_2.9.2-0.8.1.1.tgz
> cdkafka_2.9.2-0.8.1.1 |
Step 2: ХфжУЛЗОГБфСПЃЈПЩбЁЃЉ
vi/etc/profile
KAFKA_HOME=/opt/kafka_2.9.2-0.8.1.1
PATH=$PATH:$KAFKA_HOME/bin |
Step 3: аоИФХфжУЮФМўжаЕФвдЯТФкШн
cd /opt/kafka_2.9.2-0.8.1.1/config
viserver.properties
broker.id=0 //ЮЊвРДЮдіГЄЕФЃК0ЁЂ1ЁЂ2ЁЂ3ЁЂ4ЃЌМЏШКжаЮЈвЛid
log.dirs=/opt/kafka_2.9.2-0.8.1.1/logs //ШежОЕижЗ
zookeeper.connect=localhost:2181 //zookeeperServersСаБэЃЌИїНкЕувдЖККХЗжПЊ
cd /opt/kafka_2.9.2-0.8.1.1/config
vi zookeeper.properties
dataDir=/usr/local/kafka/zookeeper
dataLogDir=/usr/local/kafka/log/zookeeper |
Step 4: ЦєЖЏЕЅНкЕуЗўЮё
дкkafkaЕФbinжаДцдкКмЖрshЮФМўЃЌЦфжаАќКЌЖдzookeeperЕФЦєЖЏгыЭЃжЙЁЃЪзЯШЦєЖЏzookeeperдйЦєЖЏkafkaЕФbrokerЁЃ
./bin/zookeeper-server-start.shconfig/zookeeper.properties
&
./bin/kafka-server-start.shconfig/server.properties
& |
Step 5: ДДНЈtopic
| ./bin/kafka-topics.sh
--create --zookeeper192.168.2.105:2181 --replication-factor
1 --partitions 1 --topic testlzy |
СаГіЫљгаtopic
| ./bin/kafka-topics.sh
--zookeeper 192.168.2.105:2181--list |
Step 5: ДДНЈЩњВњеп
| ./bin/kafka-console-producer.sh--broker-list
192.168.2.105:9093 --topic testlzy |
Step 6: ДДНЈЯћЗбеп
| ./bin/kafka-console-consumer.sh
--zookeeperlocalhost:2181 --topic testlzy --from-beginning
|
ДЫЪБШчЙћдкЩњВњепПижЦЬЈжаЗЂВМЯћЯЂЃЌЯћЗбепЖЫФмНгЪеЕНЃЌОЭЫуГЩЙІСЫЁЃ
kafkaГЃгУУќСю
вдЯТЪЧkafkaГЃгУУќСюаазмНсЃК
0. ВщПДгаФФаЉжїЬтЃК
| ./kafka-topics.sh
--list --zookeeper192.168.0.201:2181 |
1. ВщПДtopicЕФЯъЯИаХЯЂ
| ./kafka-topics.sh
-zookeeper 127.0.0.1:2181-describe -topic testKJ1
|
2. ЮЊtopicдіМгИББО
| ./kafka-reassign-partitions.sh
-zookeeper127.0.0.1:2181 -reassignment-json-file
json/partitions-to-move.json -execute |
3. ДДНЈtopic
| ./kafka-topics.sh
--create --zookeeperlocalhost:2181 --replication-factor
1 --partitions 1 --topic testKJ1 |
4. ЮЊtopicдіМгpartition
| ./bin/kafka-topics.sh
ЈCzookeeper127.0.0.1:2181 ЈCalter ЈCpartitions 20
ЈCtopic testKJ1 |
5. kafkaЩњВњепПЭЛЇЖЫУќСю
| ./kafka-console-producer.sh
--broker-listlocalhost:9092 --topic testKJ1 |
6. kafkaЯћЗбепПЭЛЇЖЫУќСю
| ./kafka-console-consumer.sh
-zookeeperlocalhost:2181 --from-beginning --topic
testKJ1 |
7. kafkaЗўЮёЦєЖЏ
| ./kafka-server-start.sh
-daemon../config/server.properties |
8. ЯТЯпbroker
./kafka-run-class.shkafka.admin.ShutdownBroker
--zookeeper 127.0.0.1:2181 --broker #brokerId#--num.retries
3 --retry.interval.ms 60
shutdown broker |
9. ЩОГ§topic
./kafka-run-class.shkafka.admin.DeleteTopicCommand
--topic testKJ1 --zookeeper 127.0.0.1:2181
./kafka-topics.sh --zookeeperlocalhost:2181 --delete
--topic testKJ1 |
10. ВщПДconsumerзщФкЯћЗбЕФoffset
./kafka-run-class.shkafka.tools.ConsumerOffsetChecker
--zookeeper localhost:2181 --group test--topic
testKJ1
./kafka-consumer-offset-checker.sh --zookeeper192.168.0.201:2181
--group group1 --topic group1 |
Ш§ЁЂ Apache Kafka ЈC КЫаФдРэ
ИКдиОљКт
ИКдиОљКтЕФСНжжВпТдЃЈЯћЗбЖЫХфжУЃЉ
| partition.assignment.strategy=range|round-robin |
дкkafkaжаpartitionЗжЗЂЯћЯЂИјЯћЗбепВЛЪЧвбЯћЗбЮЊСІЖШНјааЗжХфЕФЃЌЪЧвдЯћЗбепЯпГЬЮЊСІЖШНјааЗжХфЕФЁЃ
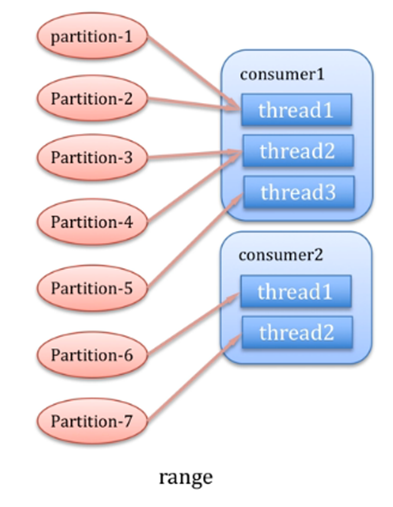
Range
kafkaжаЕФУПИіtopicЕФЗжЧјЪЧЖРСЂНјааЗжХфЕФЃЌtopicМфВЛЪмЕНШЮКЮгАЯьЁЃ
topicжаЯШЪЧЖдpartitionНјааЪ§зжХХађЃЌЯпГЬАДеезжЕфХХађЁЃ
НгЯТРДгУЗжЧјЕФЪ§СПГ§вдЯпГЬЪ§СПОЭЪЧУПИіЯпГЬФмЙЛЗжЕНЕФЯћЯЂЪ§СП
partition_per_thread= ЗжЧјЪ§СП/ЯпГЬЪ§СП
ШчЙћећГ§СЫЃЌФЧУДУПИіЯпГЬвРДЮЗжХфpartition_per_threadИіЗжЧј
ШчЙћВЛећГ§ЃЌЕЭЮЛЕФМИИіthreadЛсЖрЯћЗбЗжЧј
ШчЙћЗжЧјИіЪ§ЩйгкЯпГЬЪ§СПЃЌОЭЛсГіЯжЯпГЬПеЯаЕФЪБКђЃЌвђЮЊkafkaЛсБЃжЄвЛИіЗжЧјжЛФмБЛвЛИіЯћЗбепНјааЯћЗбЁЃЫљвдНЈвщдкХфжУЕФЪБКђЗжЧјЪ§СПКЭЯћЗбепЯпГЬЪ§СПЯрЕШзюКУЁЃ
Round-robin
дкkafkaжавЛИіЯћЗбепзщЪЧПЩвдЖЉдФЖрИіtopicЕФЁЃЕБЖЉдФСЫЖрИіtopicКѓЃЌЫћФкВПЛсАбЫљгаtopicНјааЛьТввдКѓдйАДееrangeВпТдзпвЛБщЃЌЫћЛсБЃжЄУПИіtopicдкconsumerжаЕФЯпГЬЪ§СПБиаыЯрЕШЁЃ
БИзЂ
вЛАугІгУrangeЕФБШНЯЖрЃЌШчЙћconsumerзщжагаИіЯпГЬshutdownСЫЃЌФЧУДkafkaЛсздЖЏЕФжиаТНјааИКдиОљКтЕФЗжХфЁЃетИіИКдиОљКтдіМгСЫЯТгЮЕФЯћЗбФмСІЁЃЖјЧвЗЧГЃЗНБуЕФНјааЯћЗбепЕФРЉеЙЁЃЕБШЛkafkaвВПЩвдШЅГ§етбљЕФИКдиОљКтВпТдЃЌФЌШЯЯћЗбЖЫЗжЮЊhigh
levelЕФПЭЛЇЖЫЃЈЦєгУИКдиОљКтЛњжЦЃЉКЭsimpleЕФПЭЛЇЖЫЃЈВЛЦєгУИКдиОљКтЃЌашвЊздМКОіЖЈЯћЗбФФИіЗжЧјЕФЯћЯЂЃЉЁЃ
жїДгМАИББОЗжВМ
kafkaЕФжїДгжївЊЬсЙЉСЫЗжЧјШнДэЕФФмСІЃЌПЩвдХфжУвЛИіleaderКЭШєИЩfollowerЃЌleaderЪЧДІРэЯћЯЂЃЌЖјfollowerжЛЪЧleaderЕФвЛИіБИЗнЃЌЦНГЃЕФСЌНгЖМЪЧСЌдкleaderЩЯЕФЁЃЕБleaderхДЛњвдКѓЃЌkafkaЛсДгfollowerжабЁОйвЛЬЈleaderРДНјааЗўЮёЁЃ
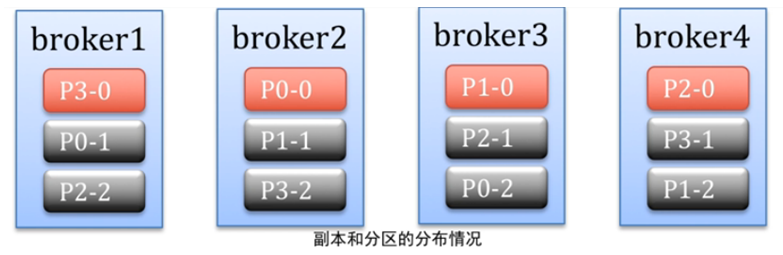
ЖдгкЕкRИіИББОЃЌЯШЫцЛњШЁвЛИіbrokerЗХЗжЧј0ЃЌШЛКѓЫГађЗХЦфЫћЗжЧјЁЃетбљБЃжЄСЫleaderКЭfollowerОљдШЕФЗжВМдкСЫУПИіbrokerЩЯЁЃ
ЭЈЙ§-topicУќСюПЩвдВщПДжИЖЈtopicЕФЗжЧјКЭИББОЕФЗжВМЧщПі

topicЃКtopicУћГЦ
partitionЃКЗжЧјУћГЦ
leaderЃКДЫЗжЧјЕФleaderдкФФИіbrokerЩЯ
replicasЃКЫљгаЕФИББОЗжВМдкФФИіbrokerЩЯ
isrЃКreplicasжаЫљгаin-syncЕФНкЕу
Ждгкin-sync
НкЕуБиаыПЩвдЮЌЛЄКЭzookeeperЕФСЌНгЃЌzookeeperЭЈЙ§аФЬјЛњжЦМьВщУПИіНкЕуЕФСЌНгЁЃ
ШчЙћНкЕуЪЧИіfollowerЁЃЫћБиаыФмМАЪБЕФЭЌВНleaderЕФаДВйзїЃЌбгЪБВЛФмЬЋОУЁЃ
ЩшжУЗНЪН
replica.lag.max.messagesЃКТфКѓЕФЯћЯЂЪ§СП
replica.lag.time.max.msЃКПЈзЁЕФЪБМф
kafkaЪЧЭЈЙ§етСНИіВЮЪ§ШЅХаЖЯЪЧВЛЪЧвЛИігааЇЕФИББОfollowerЁЃЕБleaderхДЛњвдКѓЃЌЪЧДгетаЉгааЇИББОжаНјаабЁОйЕФЁЃЮоаЇЕФЪЧВЛВЮМгбЁОйЕФЁЃ
kafkaЕФГжОУЛЏ
ЯћЯЂИёЪН
kafkaЕФЯћЯЂИёЪНШчЭМ
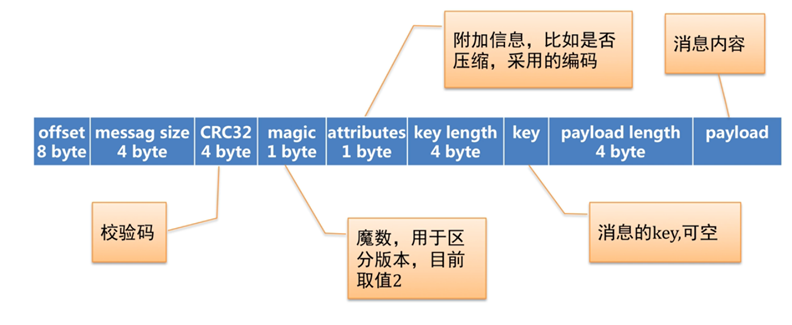
ЮФМўЯЕЭГ
kafkaЛсНЋЯћЯЂзщжЏЕНгВХЬЩЯЃЌдкbrokerЕФЪ§ОнФПТМжаЛсгавдtopicУћГЦ-ЗжЧјКХУќУћЕФЮФМўМаЃЌ
дкЮФМўМажаДцдкГЩЖдГіЯжЕФЮФМўЁЃkafkaВЛЪЧНЋЫљгаЯћЯЂЗХЕНвЛИіДѓЮФМўРяЃЌЖјЪЧИљОнЯћЯЂЕФoffsetНјааСЫЗжЖЮЁЃУПвЛИіЖЮФкЗХЖрЩйЯћЯЂЪЧПЩвдХфжУЕФЁЃЮФМўУћзжДњБэДЫЮФМўжаЕФЕквЛИіЪ§ОнЕФoffsetЁЃindexЮЊЫїв§ЮФМўЃЌlogЮЊЪ§ОнЮФМўЃЌДцЗХЕФЯћЯЂИёЪНМћЩЯЭМЁЃЖдгкindexЮФМўЮЌЛЄЕФЪЧвЛИіЯЁЪшЫїв§ЃЌгЩЯћЯЂЕФБрКХжИЯђЮяРэЦЋвЦЃЌдЫааЪБЛсБЛМгдиЕНФкДцЁЃ

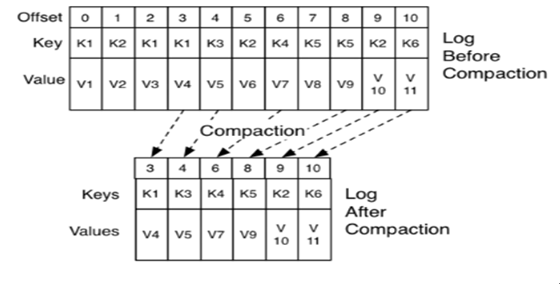
Й§ЦкЪ§ОнЧхРэ
kafkaМШШЛжЇГжСЫГжОУЛЏЃЌЫћЖдДХХЬПеМфЪЧгавЊЧѓЕФЁЃЖдгкЩОГ§Й§ЦкЪ§ОнkafkaЬсЙЉСЫСНжжВпТд
1ЁЂФЌШЯВпТдЮЊжБНгЩОГ§
l ГЌЙ§жИЖЈЕФЪБМфЕФЯћЯЂЃК
log.retention.hours=168
l ГЌЙ§жИЖЈДѓаЁКѓЃЌЩОГ§ОЩЕФЯћЯЂЃК
log.retention.bytes=1073741824
2ЁЂбЙЫѕЃЈжЛдкЬиЖЈЕФвЕЮёГЁОАЯТгавтвхЃЉ
ШЋОжЃКlog.cleaner.enable=true
дкЬиЖЈЕФtopicЩЯЃКlog.cleanup.policy=compact
БЃСєУПИіkeyзюКѓвЛИіАцБОЕФаХЯЂЃЌШєзюКѓвЛИіАцБОЯћЯЂФкШнЮЊПеЃЌетИіkeyБЛЩОГ§
|









