| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФНщЩмСЫHBaseЬхЯЕНсЙЙМАЦфдкNoSQLЪ§ОнДцДЂНтОіЗНАИЗНУцЕФжївЊгХЪЦЁЃ |
|
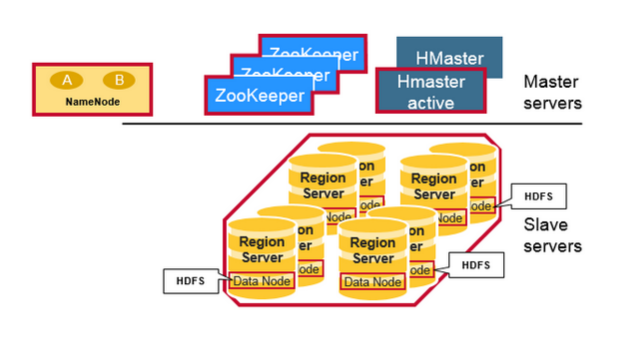
HBaseМмЙЙзщМў
ДгЮяРэНсЙЙЩЯНВЃЌHBaseгЩШ§жжРраЭЕФЗўЮёЦїЙЙГЩжїДгЪНМмЙЙЁЃRegion ServersЮЊЪ§ОнЕФЖСШЁКЭаДШыЬсЙЉЗўЮёЁЃЕБЗУЮЪЪ§ОнЪБЃЌПЭЛЇЖЫжБНгКЭRegion
ServersЭЈаХЁЃRegionЕФЗжХфЃЌDDL (create, delete tables)ВйзїгаHBase
MasterНјГЬДІРэЁЃZookeeperЪЧHDFSЕФвЛВПЗжЃЌЮЌЛЄзХвЛИіЛюЖЏЕФМЏШКЁЃ
Hadoop DataNode ДцДЂзХRegion ServerЫљЙмРэЕФЪ§ОнЁЃЫљгаЕФHBaseЪ§ОнДцДЂдкHDFSЕФЮФМўжаЁЃRegion
ServerКЭHDfs DataNodeВЂжУдквЛЦ№ЃЌетЪЙЕУRegionServersЫљЗўЮёЕФЪ§ОнОпгаЪ§ОнОжВПадЃЈЪЙЪ§ОнНгНќашвЊЕФЮЛжУЃЉЁЃHBaseЪ§ОндкаДШыЪБЪЧБОЕиЪ§ОнЃЌЕЋЪЧЕБRegionвЦЖЏЪБЃЌдкбЙЪЕжЎЧАЫќВЛЪЧБОЕиЪ§ОнЁЃ
NameNodeЮЌЛЄЙЙГЩЮФМўЕФЫљгаЮяРэЪ§ОнПщЕФдЊЪ§ОнаХЯЂЁЃ
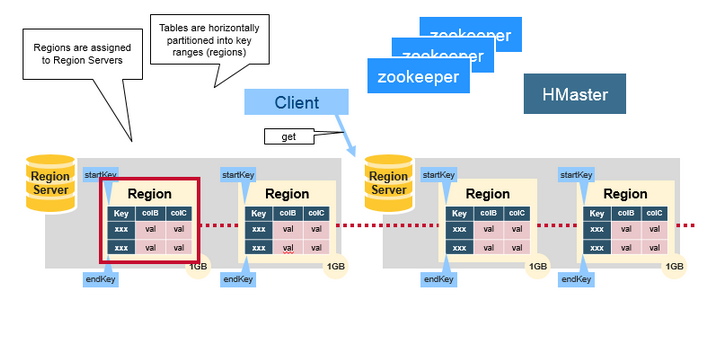
Regions
HBaseБэЪЧАДееrowkeyЗЖЮЇЫЎЦНЛЎЗжЮЊЁАRegionsЁБ.RegionАќКЌБэжаstart keyКЭend
keyжЎМфЕФЫљгаааЁЃRegion ServerНЋRegionsЗжХфЕНМЏШКЕФНкЕужаЃЌВЂЖдЪ§ОнЕФЖСШЁКЭаДШыЬсЙЉЗўЮёЁЃЕЅИіRedion
ServerПЩЗўЮёДѓдМ1000ИіregionЁЃ
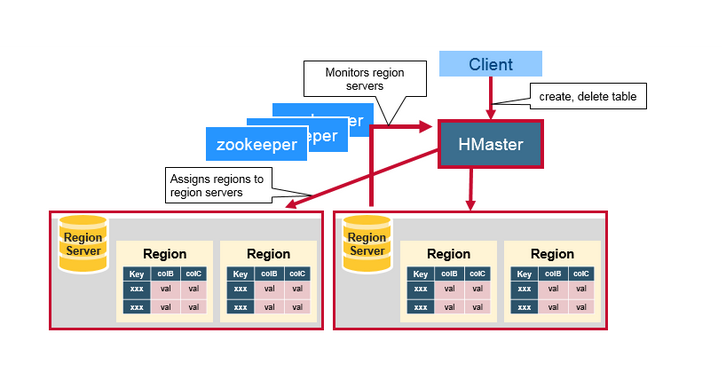
HBase HMaster
RegionЗжХфЃЌDDL(create, delete tables)ВйзїгЩHBase MasterДІРэЁЃ
MaterЕФжївЊжАд№ЃК
аЕїRegion Servers
ЦєЖЏЪБЗжХфRegionЃЌЛЙдЪБжиаТЗжХфRegionЛђепИКдиОљКт
МрПиМЏШКжаЫљгаRegionServerЪЕР§ЃЈМрЬ§ZookeeperЕФЯћЯЂЃЉ
ЙмРэдБЗНЗЈ
ЬсЙЉДДНЈЃЌЩОГ§ЃЌИќаТБэЕФНгПкЁЃ
ZooKeeper: The Coordinator
HBaseЪЙгУZookeeperзіЮЊЗжВМЪНаЕїЗўЮёРДЮЌЛЄМАШКжкserverЕФзДЬЌЁЃZookeeperЮЌЛЄДІгкЛюзДЬЌВЂПЩЪЙгУЕФSeversЃЌВЂЬсЙЉServerЙЪеЯЭЈжЊЁЃZookeeperЪЙгУЙВЪЖРДБЃжЄЙВЭЌЙВЯэЕФзДЬЌЁЃЧызЂвтЃЌгІИУгаШ§ЕНЮхЬЈЛњЦїДяГЩЙВЪЖЁЃ
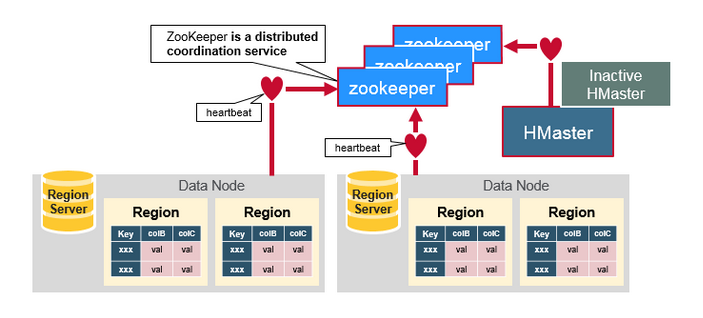
How the Components Work TogetherЃЈзщНЈШчКЮаЕїЙЄзїЃЉ
ZookeeperгУгкаЕїЗжВМЪНЯЕЭГГЩдБЕФЙВЯэзДЬЌаХЯЂЁЃRegion ServerКЭactive
HMasterЭЈЙ§ЛсЛАСДНгЕНZookeeper.ZooKeeperЭЈЙ§аФЬјЮЌЛЄЛсЛАЛюЖЏЕФСйЪБНкЕуЁЃ
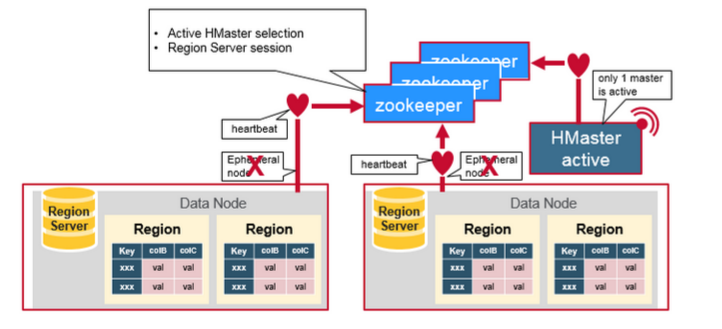
УПИіRegion ServerДДНЈвЛИіСйЪБНкЕуЁЃHMasterМрПиетаЉНкЕувдЗЂЯжПЩгУЕФregion
serversЃЌВЂМрПиетаЉНкЕуЕФЗўЮёЦїЙЪеЯЁЃ
HMasterМрПиетаЉНкЕувдЗЂЯжПЩгУЕФЧјгђЗўЮёЦїЃЌВЂМрПиетаЉНкЕуЕФЗўЮёЦїЙЪеЯЁЃHMastersељЖсДДдьвЛИіЖЬднЕФНкЕуЁЃZookeeperШЗЖЈЕквЛИіВЂЪЙгУЫќРДШЗБЃжЛгавЛИіжїеОДІгкЛюЖЏзДЬЌЁЃ
ЛюЖЏHMasterНЋаФЬјЗЂЫЭЕНZookeeperЃЌЗЧЛюЖЏHMasterНЋМрЬ§ЛюЖЏHMasterЙЪеЯЕФЭЈжЊЁЃШчЙћregion
serverЛђепactice HMasterЮДФмЗЂЫЭаФЬјаХКХЃЌдђЛсЛАЙ§ЦкВЂЩОГ§ЯргІЕФСйЪБНкЕуЁЃListenersЕФИќаТдкЪеЕННкЕуЩОГ§ЕФЭЈжЊКѓЁЃActive
HMasterМрЬ§region serversЃЌВЂдкregion serversГіЯжЙЪеЯЪБНјааЛжИДЁЃInactive
HMasterМрЬ§active HMasterЙЪеЯЃЌВЂЧвШчЙћactive HMasterЙЪеЯЪБЃЌinactive
HMasterБрГЬactiveзДЬЌЁЃ
Base First Read or Write
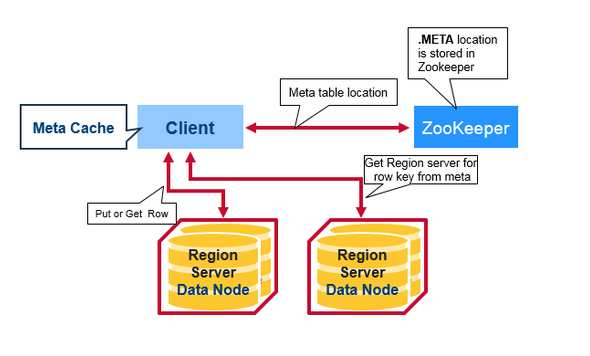
HBaseгавЛИіНазіMETAЕФЬиЪтЕФФПТМБэЃЌгУгкБЃДцМЏШКжаregionsЕФЮЛжУаХЯЂЁЃZookeeperДцДЂзХMETAБэЕФЮЛжУЁЃ
вдЯТЪЧПЭЛЇЖЫЕквЛДЮЖСШЁКЭаДШыHBaseЪБЗЂЩњЕФЧщПіЃК
1.ПЭЛЇЖЫДгzookeeperжаMETA TableЕФЮЛжУ.
2.ПЭЛЇЖЫВщбЏ.METAЁЃЗўЮёЦїЛёШЁПЭЛЇЖЫЯывЊЗУЮЪЕФВЂЧвЪЧrowkeyЫљЯрЖдгІRegion
ServerЕФаХЯЂЁЃПЭЛЇЖЫЛсНЋMETAЛКДцДјБОЕиЁЃ
3.ДгЯргІЕФRegion ServerЛёШЁаа
дкЮДРДЕФЖСШЁВйзїЙ§ГЬжаЃЌПЭЛЇЖЫЪЙгУMeta CacheРДМьЫїMETA TableЕФЮЛжУКЭжЎЧАЖСШЁЕФRow
KeysЁЃЫцзХЪБМфЕФЭЦвЦЃЌВЛдйашвЊВщбЏMETA tableСЫЃЌГ§ЗЧгІЮЊвЛИіregionзЊвЦЖјДэЙ§,ФЧУДЫќНЋжиаТВщбЏВЂИќаТMeta
CacheЁЃ
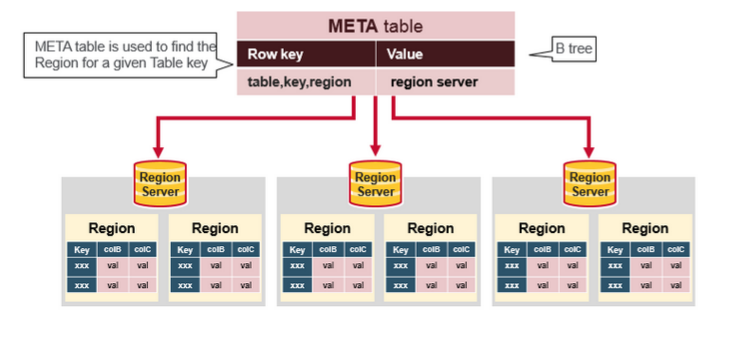
HBase Meta Table
1.METAБэЪЧвЛИіБЃДцЕФСЫЯЕЭГжаЫљгаregionСаБэЕФHBaseБэЁЃ
2.METAБэОЭЯёвЛПХBЁЊtree
3.METaЕФНсЙЙШчЯТЃК
Key: region start key,region id
Values: RegionServer
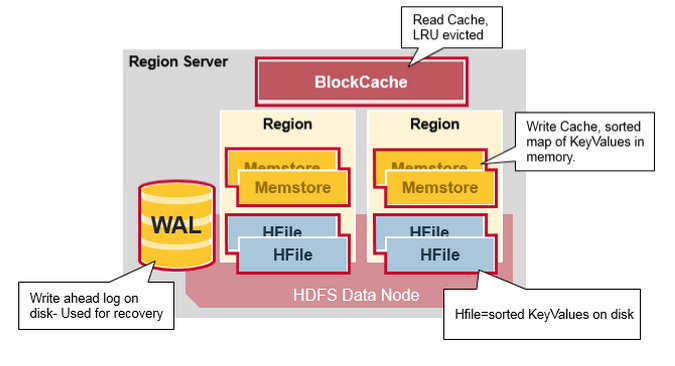
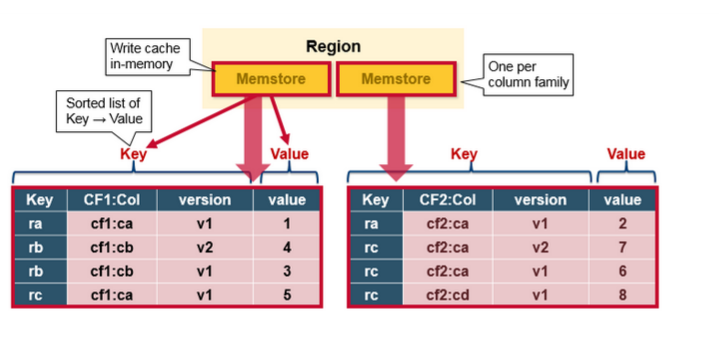
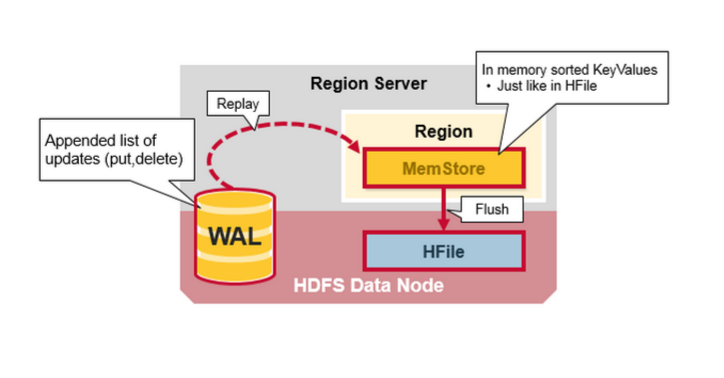
Region Server Components
Region ServerдЫаадкHDFSЕФDataNode,ВЂЧвОпБИвдЯТзщМўЃК
1.WALЃКдЄаДШежОЪЧЗжВМЪНЮФМўЯЕЭГЩЯЕФЮФМўЁЃWALгУгкДцДЂЩаЮДБЛгРОУБЃДцЕФаТЪ§ОнЃЌгУгкЙЪеЯЧщПіЯТЕФЛжИДЁЃ
2.BlockCache: ЪЧЖСШЁЛКДцЁЃдкФкДцжаДцДЂЦЕЗБЖСШЁЕФЪ§ОнЃЌНќЦкзюЩйЪЙгУЕФЪ§ОндкТњЪББЛЩОГ§ЁЃ
3.MemStore:ЪЧаДШыЛКДцЁЃДцДЂЩаЮДаДШыДХХЬЕФЪ§ОнЁЃдкаДШыДХХЬжЎЧАНјааХХађЃЌУПИіregionЕФУПИіcolumn
familyгавЛИіMemStoreЁЃ
4.дкДХХЬЩЯЃЌHfilesНЋааДцДЂЮЊвбХХађЕФKeyValuesЁЃ
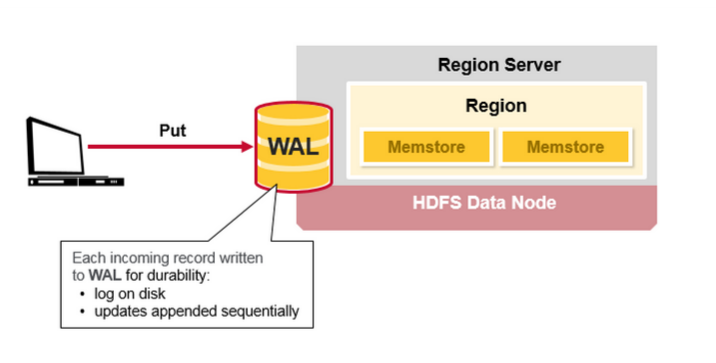
HBase Write Steps (1)
ЕБПЭЛЇЖЫЗЂЦ№PutЧыЧѓЪБЃЌЕквЛВНЪЧНЋЪ§ОнаДШыгкаДШежОЃЌWALЃК
1.ЗЂВМЕФФкШнНЋБЛЬэМгЕНДцДЂдкДХХЬЩЯЕФWALЮФМўФЉЮВЁЃ
2.WALгУгкдкЗўЮёЦїБРРЃЕФЧщПіЯТЛжИДЩаЮДБЃДцЕФЪ§ОнЁЃ
HBase Write Steps (2)
вЛЕЉЪ§ОнаДШыWALЃЌНЋЛсБЛаДШыMemStoreжаЃЌШЛКѓЗХШыPutЧыЧѓШЗШЯаХЯЂЗЕЛиИјПЭЛЇЖЫЁЃ
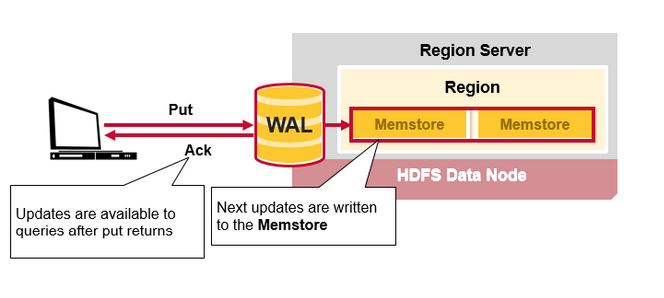
HBase MemStore
MemStore НЋИќаТЕФФкШнХХађВЂвдKeyValuesЕФаЮЪНДцДЂЕНФкДцжаЃЌгыНЋЦфДцДЂдкHFileжаЯрЭЌЁЃУПИіСазхжЛгавЛИіMenStorreЃЌИќаТФкШнАДееСазхХХађЁЃ
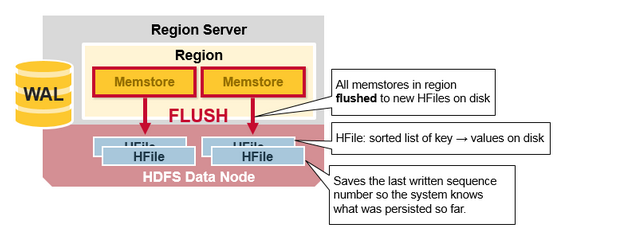
HBase Region Flush
ЕБMemStroreЛ§ОлСЫзуЙЛЕФЪ§ОнЃЌећИігаађМЏКЯБЛаДШыЕНHDFSЕФHFileжаЁЃHBaseУПИіСазхЪЙгУЖрИіHFileЃЌЦфжаАќКЌеце§ЕФCellЛђепKeyValueЪЕР§ЁЃЫцзХЪБМфЕФЭЦвЦЃЌдкMenStoreжаИњОнKeyValueХХађЃЌзюжеЫЂаТЕНДХХЬHFileЮФМўжаЁЃ
зЂвтетвВЪЧHBaseЮЊЪВУДЯожЦСазхЪ§СПЕФвЛИідвђЁЃУПИіСазхжЛгавЛИіMemStoreЃЛЕБвЛИіMemStoreЪ§ОнТњСЫЃЌЛсЫЂаТЕНДХХЬЮФМўжаЁЃЫќЛЙБЃДцСЫзюНќаДШыЕФађСаКХЃЌвдБуШУЯЕЭГжЊЕРЕНФПЧАЮЊжЙГжОУЛЏЕФЧщПіЁЃ
ИпЮЛађСаКХзїЮЊдЊзжЖЮДцДЂдкУПИіHFileжаЃЌвдЗДгГГжОУЛЏНсЪјЮЛжУвдМАМЬајжДааЕФЮЛжУЁЃдкregionЦєЖЏЪБЃЌађСаКХБЛЖСШЁКѓЃЌШЛКѓзюИпЮЛзіЮЊаТБрМФкШнЕФађСаКХЁЃ
HBase HFile
Ъ§ОнДцДЂдкHFileжаЃЌЦфжаАќКЌХХађЕФKey/ValueЁЃЕБMemStoreРлЛ§зуЙЛЕФЪ§ОнЪБЃЌећИівбХХађЕФKeyValueМЏНЋБЛаДШыHDFSжаЕФаТHFileЁЃетЪЧвЛИіЫГађаДШыЁЃЫќЫйЖШЗЧГЃПьЃЌвђЮЊЫќБмУтСЫвЦЖЏДХХЬЧ§ЖЏЦїДХЭЗЁЃ
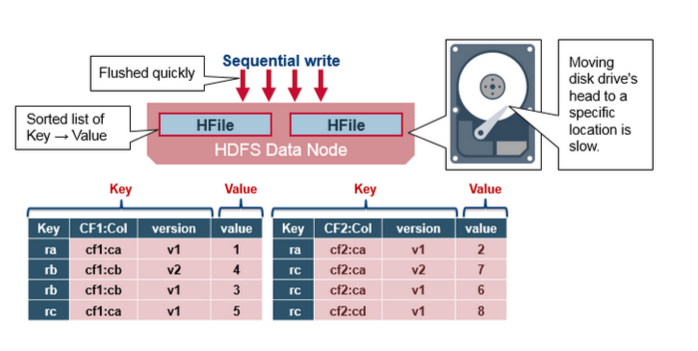
HBase HFile Structure
HBaseАќКЌвЛИіЖрВуЫїв§ЃЌЪЧHBaseВЛБиЖСШЁећИіЮФМўЕФЧщПіЯТВщевЖЈЮЛЪ§ОнЁЃЖрМЖЫїв§ОЭЯёвЛПХb+tree:
1.МќжЕЖдАДееЩ§ађДцДЂ
2.Ыїв§ЭЈЙ§RowKeyжИЯђФкШнЮЊkey/valueЕФ64kbДѓаЁЕФblockжаЁЃ
3.УПИіblockЖМгаздМКвЖзгЫїв§
4.УПИіblockЕФзюКѓЕФkeyЗХНјintermediate indexЃЈжаМфЫїв§ЃЉ
5.ИљЫїв§жИЯђжаМфЫїв§
trailerжИЯђдЊЪ§ОнПщЃЌЫќаДдкЮФМўжаГжОУЛЏЪ§ОнЕФФЉЮВЁЃtrailerвВАќКЌВМТЁЙ§ТЫЦїКЭЪБМфЗЖЮЇаХЯЂЁЃВМТЁЙ§ТЫЦїгажњгкЬјЙ§ВЛАќКЌФГИіrow
keyЕФЮФМўЁЃШчЙћЪБМфЗЖЮЇаХЯЂВЛдкЖСШЁЕФЪБМфЗЖЮЇФкЃЌдђЪБМфЗЖЮЇаХЯЂЖдгкЬјЙ§ИУЮФМўЗЧГЃгагУЁЃ
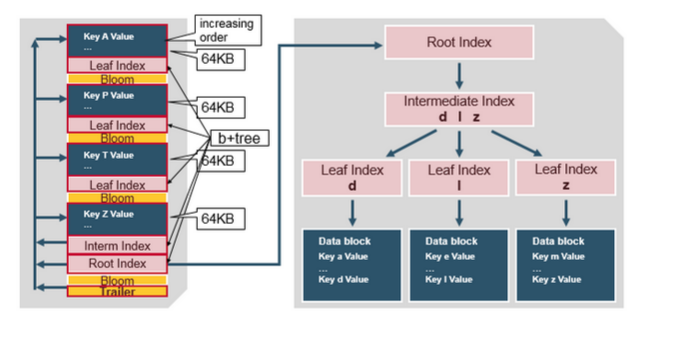
HFile Index
ЮвУЧИеВХЬжТлЕФЫїв§ЪЧдкHFileДђПЊВЂБЃДцдкФкДцжаЪБМгдиЕФЁЃетдЪаэВщевЭЈЙ§ЕЅИіДХХЬбАЕРРДжДааЁЃ
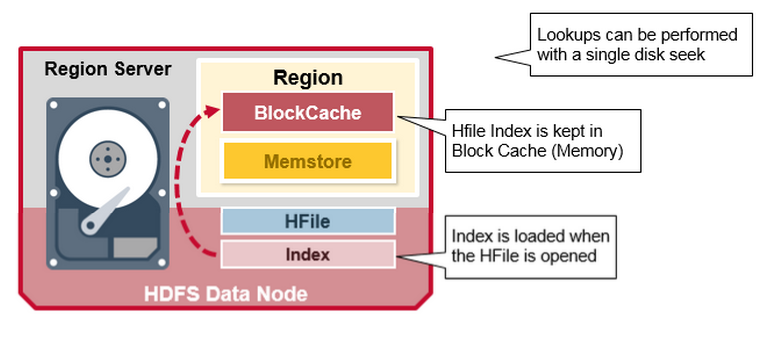
HBase Read Merge
ЮвУЧвбОПДЕНЃЌrowЖдгІЕФKeyValue cellПЩвддкЖрИіЮЛжУЃЌrow cellвбОГжОУЛЏЕНHfileжаЃЌзюНќИќаТЕФcellдкMemStoreжаЃЌзюНќЖСШЁЕФcellдкBlock
CacheжаЁЃвђДЫЃЌЕБЖСШЁвЛааЪ§ОнЪБЃЌЯЕЭГЪЧШчКЮЛёЕУЯргІЕФcellВЂЗЕЛиЕФЃПЖСШЁВйзїАДеевдЯТВНжшДгBlockCacheЃЌMemStoreКЭHFileКЯВЂЙиМќжЕЃК
ЪзЯШЃЌЩЈУшЦїдкBlockCacheЃЈЖСШЁЛКДцЃЉжаЃЌВщевRow CellsЁЃзюНќЖСШЁЕФKey ValuesБЛЛКДцдкетРяЃЌВЂЧвЕБашвЊФкДцЪБЃЌзюНќзюЩйЪЙгУЕФБЛЧхГ§ЁЃ
ЦфДЮЃЌЩЈУшЦїдкMemStoreжаВщевЃЌФкДцаДШыЛКДцАќКЌзюНќЕФаДШыЁЃ
ШчЙћЩЈУшЦїдкMenStoreКЭBlockCacheжаУЛгаевЕНRow
cellsЃЌШЛКѓHBaseЪЙгУBLock CacheЕФHFileЫїв§КЭВМТЁЙ§ТЫЦїАбПЩФмДцдкФПБъRow
cellsЕФHFileМгдиЕНФкДцжаЁЃ
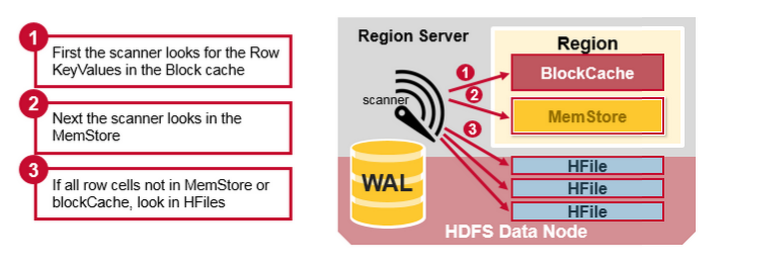
HBase Read Merge
е§ШчЧАУцЫљЬжТлЕФЃЌУПИіMemStoreПЩФмгааэЖрHFileЃЌетвтЮЖзХЖСШЁЪБПЩФмашвЊМьВщЖрИіHFileЮФМўЃЌетПЩФмЛсгАЯьадФмЁЃетБЛГЦЮЊЖСШЁЗХДѓЁЃ
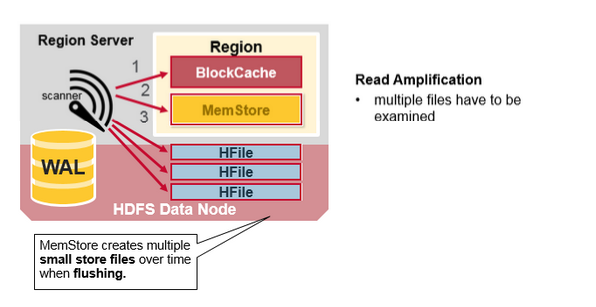
HBase Minor Compaction
HBaseЛсздЖЏбЁдёвЛаЉНЯаЁЕФHFileЃЌВЂНЋЫќУЧжиаДГЩИќЩйЧвИќДѓЕФHfilesЁЃетИіЙ§ГЬГЦЮЊMinor
CompactionЁЃMinor CompactionЭЈЙ§НЋНЯаЁЕФЮФМўжиаДЮЊНЯЩйЕЋНЯДѓЕФЮФМўРДМѕЩйДцДЂЮФМўЕФЪ§СПЃЌжДааКЯВЂХХађЁЃ
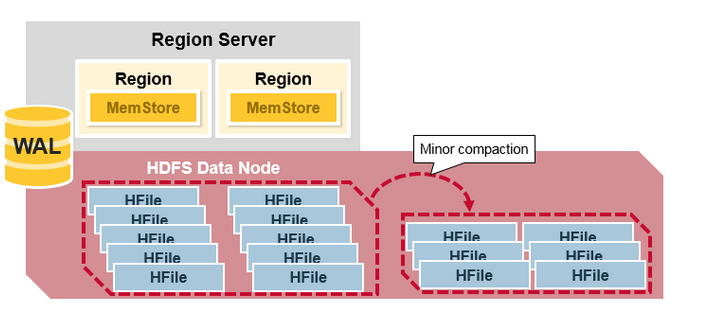
HBase Major Compaction
Major compactionНЋregionЫљгаЕФHFileКЯВЂВЂжиаДЕНвЛИіHFileжаЃЌУПИіСазхЖдгІетбљЕФвЛИіHFileЁЃВЂдкДЫЙ§ГЬжаЃЌЩОГ§вбЩОГ§ЛђЙ§ЦкЕФCellЁЃетбљЬсЩ§СЫЖСШЁадФмЃЌгЩгкMajor
compactionжиаДСЫЫљгаHFileЮФМўЃЌвђДЫдкДЫЙ§ГЬжаПЩФмЛсЗЂЩњДѓСПДХХЬI/OКЭЭјТчСїСПЁЃетБЛГЦЮЊаДШыЗХДѓЁЃ
Major compactionжДааМЦЛЎПЩвдздЖЏдЫааЁЃгЩгкаДШыЗХДѓЃЌЭЈГЃМЦЛЎдкжмФЉЛђЭэЩЯНјааMajor
compactionЁЃгЩгкЗўЮёЦїЙЪеЯЛђИКдиЦНКтЃЌMajor compactionЛЙЛсЪЙШЮКЮдЖГЬЪ§ОнЮФМўГЩЮЊБОЕиЗўЮёЦїЕФБОЕиЪ§ОнЮФМўЁЃ
Region = Contiguous Keys
ПьЫйЛиЙЫвЛЯТregion:
БэИёПЩвдЫЎЦНЛЎЗжЮЊвЛИіЛђепЖрИіregionЁЃдчstart keyКЭend keyжЎМфАќКЌСЌајЕФЃЌХХађЕФааЗЖЮЇЁЃ
УПИіregionаЁЮЊ1GBЃЈФЌШЯЃЉ
БэЕФregionЭЈЙ§RegionServerЮЊПЭЛЇЖЫЬсЙЉЗўЮёЁЃ
RegionServerПЩвдЬсЙЉДѓдМ1,000ИіregionЃЈПЩФмЪєгкЭЌвЛИіБэЛђВЛЭЌЕФБэЃЉ
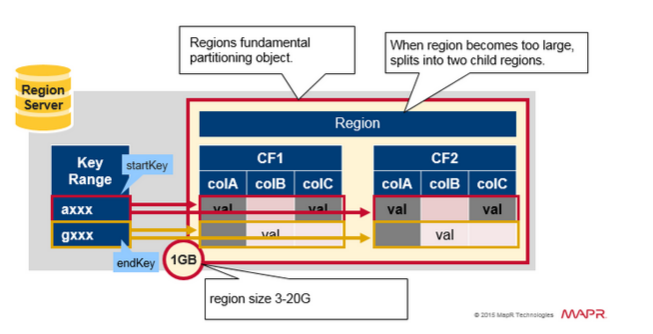
Region Split
зюГѕУПИіБэИёгавЛИіЧјгђЁЃЕБвЛИіregionБфЕУЬЋДѓЪБЃЌЫќЛсЗжСбГЩСНИізгregionЁЃДњБэдregionЕФвЛАыЕФСНИізгregionЃЌдкЯрЭЌЕФRegionServerЩЯВЂааДђПЊЃЌШЛКѓНЋЗжЧјБЈИцИјHMasterЁЃгЩгкИКдиЦНКтЕФдвђЃЌHMasterПЩвдАВХХНЋаТregionвЦЖЏЕНЦфЫћЗўЮёЦїЁЃ
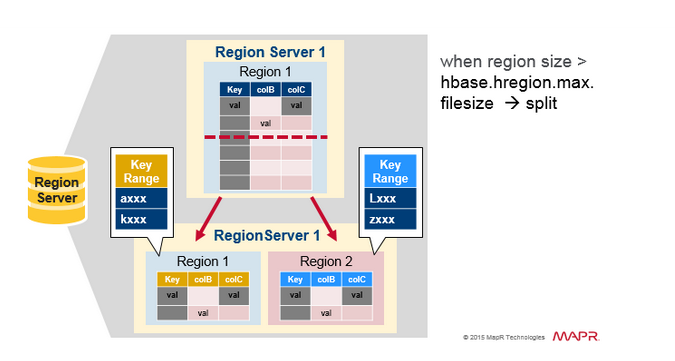
Read Load Balancing
ЗжСбзюГѕЗЂЩњдкЭЌвЛИіRegionServerЩЯЃЌгЩгкИКдиЦНКтЕФдвђЃЌHMasterПЩвдАВХХНЋаТregionвЦЖЏЕНЦфЫћЗўЮёЦїЁЃетЕМжТаТRegionServerЬсЙЉЗўЮёЕФЪ§ОнРДзддЖГЬHDFSНкЕуЃЌжБЕНMajor
compactionНЋЪ§ОнЮФМўвЦЖЏЕНRegionServerЕФБОЕиНкЕуЁЃHBaseЪ§ОндкаДШыЪБЪЧБОЕиЪ§ОнЃЌЕЋЕБФГИіЧјгђБЛвЦЖЏЪБЃЈЮЊСЫИКдиЦНКтЛђЛжИДЃЉЃЌдкMajor
compactionжЎЧАЫќВЛЪЧБОЕиЪ§ОнЁЃ
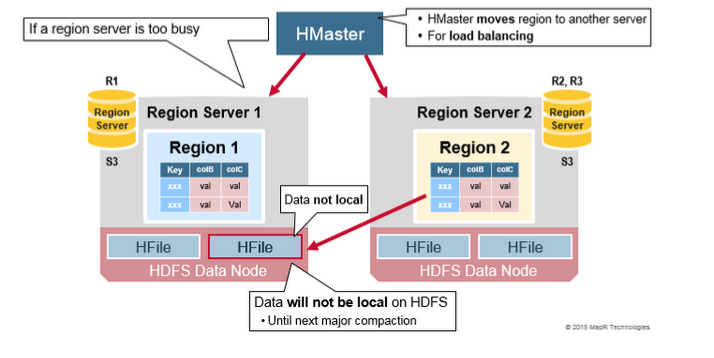
HDFS Data Replication
ЫљгаЕФаДШыКЭЖСШЁЖМРДзджїНкЕуЁЃHDFSИДжЦWALКЭHFileПщЁЃHFileПщИДжЦздЖЏЗЂЩњЁЃHBaseвРППHDFSдкДцДЂЮФМўЪБЬсЙЉЕФЪ§ОнАВШЋадЁЃдкHDFSжааДШыЪ§ОнЪБЃЌБОЕиаДШывЛИіИББОЃЌШЛКѓНЋЦфИДжЦЕНЕкЖўИіНкЕуЃЌВЂНЋЕкШ§ИіИББОаДШыЕкШ§ИіНкЕуЁЃ
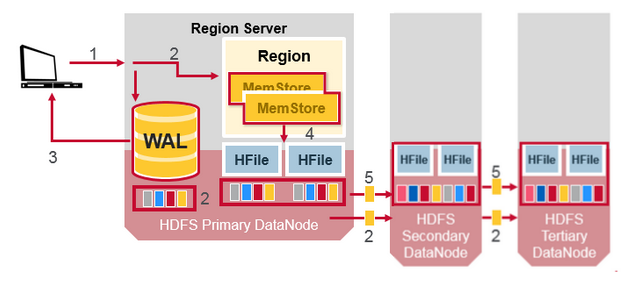
HDFS Data Replication (2)
WALЮФМўКЭHFilesЮФМўБЛГжОУЛЏЕНДХХЬВЂИДжЦЃЌФЧУДHBaseШчКЮЛжИДУЛгаБЈГжОУЛЏЕНHFileЕФMemStoreИќаТФиЃПЧыВЮдФЯТвЛНкбАевД№АИЁЃ
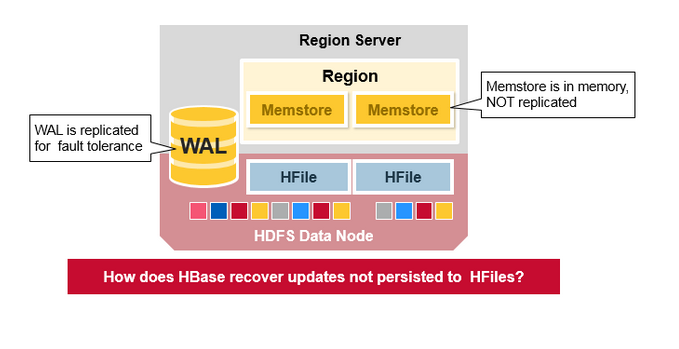
HBase Crash Recovery
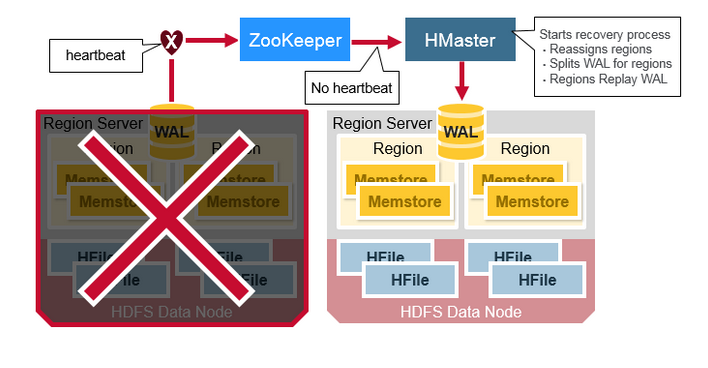
ЕБRegionServerЪЇАмЪБЃЌБРРЃЕФregionНЋВЛПЩгУЃЌжБЕНМьВтКЭЛжИДВНжшЗЂЩњЁЃ ZookeeperЛсдкЪЇШЅгыRegionServerаФЬјаХКХЪБШЗЖЈНкЕуЙЪеЯЁЃ
HMasterНЋЛсБЛЭЈжЊRegion ServerЪЇАмЁЃHMasterНЋЛсБЛЭЈжЊRegion ServerЪЇАмЁЃ
ЕБHMasterШЗЖЈRegionServerхДЛњЪБЃЌHMasterжиаТЗжХфхДЛњЗўЮёЦїЕФRegionЕНЛюЖЏЕФЗўЮёЦїЁЃЮЊСЫЛжИДхДЛњЗўЮёЦїЮДЫЂаТЕНДХХЬЕФmemstoreЪ§ОнЃЌHMasterНЋЪєгкхДЛњRegionServerЕФWALВ№ЗжГЩЕЅЖРЕФЮФМўВЂНЋетаЉЮФМўДцДЂдкаТRegionServerЕФЪ§ОнНкЕужаЁЃУПИіRegion
ServerШЛКѓНјаажиВЅWALЃЌДгЯргІЕФWALВ№ЗжЮФМўЃЌЮЊregionжиНЈMemStoreЁЃ
WALЕФЮФМўАќКЌБрМСаБэЃЌЦфжавЛИіБрМБэЪОЕЅИіЗХжУЛђЩОГ§ЁЃвЛИіБрМБэЪОвЛИіЗХжУЛђЩОГ§ЁЃБрМАДЪБМфЫГађБраДЃЌвђДЫЃЌЖдгкГжОУЛЏЃЌЬэМгФкШнНЋИНМгЕНДцДЂдкДХХЬЩЯЕФWALЮФМўЕФФЉЮВЁЃ
ШчЙћЪ§ОнШддкФкДцжаВЂЧвЮДБЃДцЕНHFileЪБЗЂЩњЙЪеЯЛсЗЂЩњЪВУДЃПWALжиВЅЃЌжиВЅWALЕФЙ§ГЬЪЧЭЈЙ§ЖСШЁWALЃЌЬэМгЛђепХХађвбжЊЕФБрМЕНЕБЧАMemStoreЁЃзюКѓЃЌMemtoreНЋБфЛЏЫЂаТЕНHFileЁЃ
Data Recovery
Apache HBase Architecture Benefits
HBase гХЕу:
1.ЧПвЛжТадФЃаЭ
ЕБаДШыЗЕЛиЪБЃЌЫљгаЖСепНЋПДЕНЯрЭЌЕФжЕ
2.здЖЏРЉеЙ
Ъ§ОндіГЄЙ§ДѓЪБЗжИюregion
ЪЙгУHDFSДЋВЅКЭИДжЦЪ§Он
3.ФкжУЛжИДЛњжЦ
ЪЙгУдЄаДШежО (гыЮФМўЯЕЭГЩЯЕФШеМЧРрЫЦ)
4.МЏГЩHadoop
MHBaseЩЯЕФMapReduceКмМђЕЅ
Apache HBase Has Problems TooЁ
Business continuity reliability:
1.WAL жиВЅЛКТ§
2.втЭтЛжИДЛКТ§
3.Major Compaction I/O ЗчБЉ
|









