| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌApache
SparkЪЧвЛИіЮЇШЦЫйЖШЁЂвзгУадКЭИДдгЗжЮіЙЙНЈЕФДѓЪ§ОнДІРэПђМм,БОЮФНщЩмСЫSparkЛљБОМмЙЙМАдРэЁЃ |
|
Apache SparkЪЧвЛИіЮЇШЦЫйЖШЁЂвзгУадКЭИДдгЗжЮіЙЙНЈЕФДѓЪ§ОнДІРэПђМмЃЌзюГѕдк2009ФъгЩМгжнДѓбЇВЎПЫРћЗжаЃЕФAMPLabПЊЗЂЃЌВЂгк2010ФъГЩЮЊApacheЕФПЊдДЯюФПжЎвЛЃЌгыHadoopКЭStormЕШЦфЫћДѓЪ§ОнКЭMapReduceММЪѕЯрБШЃЌSparkгаШчЯТгХЪЦЃК
SparkЬсЙЉСЫвЛИіШЋУцЁЂЭГвЛЕФПђМмгУгкЙмРэИїжжгазХВЛЭЌаджЪЃЈЮФБОЪ§ОнЁЂЭМБэЪ§ОнЕШЃЉЕФЪ§ОнМЏКЭЪ§ОндДЃЈХњСПЪ§ОнЛђЪЕЪБЕФСїЪ§ОнЃЉЕФДѓЪ§ОнДІРэЕФашЧѓ
ЙйЗНзЪСЯНщЩмSparkПЩвдНЋHadoopМЏШКжаЕФгІгУдкФкДцжаЕФдЫааЫйЖШЬсЩ§100БЖЃЌЩѕжСФмЙЛНЋгІгУдкДХХЬЩЯЕФдЫааЫйЖШЬсЩ§10БЖ
ФПБъЃК
1.МмЙЙМАЩњЬЌ
2.spark гы hadoop
3.дЫааСїГЬМАЬиЕу
4.ГЃгУЪѕгя
5.standaloneФЃЪН
6.yarnМЏШК
7.RDDдЫааСїГЬ
МмЙЙМАЩњЬЌЃК
ЭЈГЃЕБашвЊДІРэЕФЪ§ОнСПГЌЙ§СЫЕЅЛњГпЖШ(БШШчЮвУЧЕФМЦЫуЛњга4GBЕФФкДцЃЌЖјЮвУЧашвЊДІРэ100GBвдЩЯЕФЪ§Он)етЪБЮвУЧПЩвдбЁдёsparkМЏШКНјааМЦЫуЃЌгаЪБЮвУЧПЩФмашвЊДІРэЕФЪ§ОнСПВЂВЛДѓЃЌЕЋЪЧМЦЫуКмИДдгЃЌашвЊДѓСПЕФЪБМфЃЌетЪБЮвУЧвВПЩвдбЁдёРћгУsparkМЏШКЧПДѓЕФМЦЫузЪдДЃЌВЂааЛЏЕиМЦЫуЃЌЦфМмЙЙЪОвтЭМШчЯТЃК
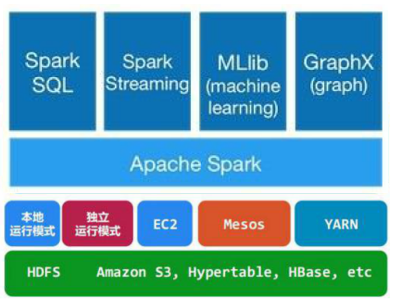
Spark CoreЃКАќКЌSparkЕФЛљБОЙІФмЃЛгШЦфЪЧЖЈвхRDDЕФAPIЁЂВйзївдМАетСНепЩЯЕФЖЏзїЁЃЦфЫћSparkЕФПтЖМЪЧЙЙНЈдкRDDКЭSpark
CoreжЎЩЯЕФ
Spark SQLЃКЬсЙЉЭЈЙ§Apache HiveЕФSQLБфЬхHiveВщбЏгябдЃЈHiveQLЃЉгыSparkНјааНЛЛЅЕФAPIЁЃУПИіЪ§ОнПтБэБЛЕБзівЛИіRDDЃЌSpark
SQLВщбЏБЛзЊЛЛЮЊSparkВйзїЁЃ
Spark StreamingЃКЖдЪЕЪБЪ§ОнСїНјааДІРэКЭПижЦЁЃSpark StreamingдЪаэГЬађФмЙЛЯёЦеЭЈRDDвЛбљДІРэЪЕЪБЪ§Он
MLlibЃКвЛИіГЃгУЛњЦїбЇЯАЫуЗЈПтЃЌЫуЗЈБЛЪЕЯжЮЊЖдRDDЕФSparkВйзїЁЃетИіПтАќКЌПЩРЉеЙЕФбЇЯАЫуЗЈЃЌБШШчЗжРрЁЂЛиЙщЕШашвЊЖдДѓСПЪ§ОнМЏНјааЕќДњЕФВйзїЁЃ
GraphXЃКПижЦЭМЁЂВЂааЭМВйзїКЭМЦЫуЕФвЛзщЫуЗЈКЭЙЄОпЕФМЏКЯЁЃGraphXРЉеЙСЫRDD APIЃЌАќКЌПижЦЭМЁЂДДНЈзгЭМЁЂЗУЮЪТЗОЖЩЯЫљгаЖЅЕуЕФВйзї
SparkМмЙЙЕФзщГЩЭМШчЯТЃК

Cluster ManagerЃКдкstandaloneФЃЪНжаМДЮЊMasterжїНкЕуЃЌПижЦећИіМЏШКЃЌМрПиworkerЁЃдкYARNФЃЪНжаЮЊзЪдДЙмРэЦї
WorkerНкЕуЃКДгНкЕуЃЌИКд№ПижЦМЦЫуНкЕуЃЌЦєЖЏExecutorЛђепDriverЁЃ
DriverЃК дЫааApplication ЕФmain()КЏЪ§
ExecutorЃКжДааЦїЃЌЪЧЮЊФГИіApplicationдЫаадкworker nodeЩЯЕФвЛИіНјГЬ
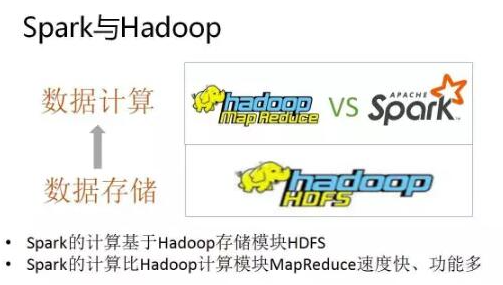
Sparkгыhadoop:
HadoopгаСНИіКЫаФФЃПщЃЌЗжВМЪНДцДЂФЃПщHDFSКЭЗжВМЪНМЦЫуФЃПщMapreduce
sparkБОЩэВЂУЛгаЬсЙЉЗжВМЪНЮФМўЯЕЭГЃЌвђДЫsparkЕФЗжЮіДѓЖрвРРЕгкHadoopЕФЗжВМЪНЮФМўЯЕЭГHDFS
HadoopЕФMapreduceгыsparkЖМПЩвдНјааЪ§ОнМЦЫуЃЌЖјЯрБШгкMapreduceЃЌsparkЕФЫйЖШИќПьВЂЧвЬсЙЉЕФЙІФмИќМгЗсИЛ
ЙиЯЕЭМШчЯТЃК
дЫааСїГЬМАЬиЕуЃК
sparkдЫааСїГЬЭМШчЯТЃК
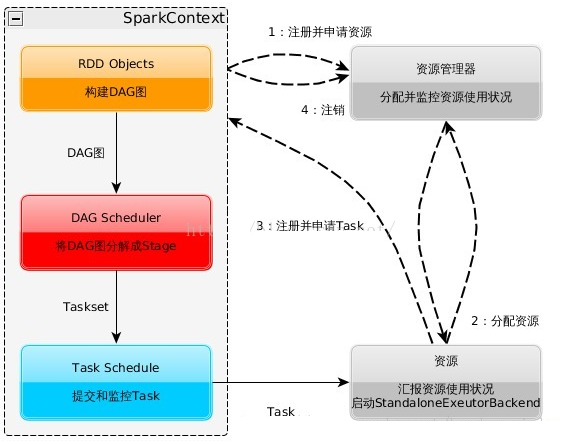
ЙЙНЈSpark ApplicationЕФдЫааЛЗОГЃЌЦєЖЏSparkContext
SparkContextЯђзЪдДЙмРэЦїЃЈПЩвдЪЧStandaloneЃЌMesosЃЌYarnЃЉЩъЧыдЫааExecutorзЪдДЃЌВЂЦєЖЏStandaloneExecutorbackendЃЌ
ExecutorЯђSparkContextЩъЧыTask
SparkContextНЋгІгУГЬађЗжЗЂИјExecutor
SparkContextЙЙНЈГЩDAGЭМЃЌНЋDAGЭМЗжНтГЩStageЁЂНЋTasksetЗЂЫЭИјTask
SchedulerЃЌзюКѓгЩTask SchedulerНЋTaskЗЂЫЭИјExecutorдЫаа
TaskдкExecutorЩЯдЫааЃЌдЫааЭъЪЭЗХЫљгазЪдД
SparkдЫааЬиЕуЃК
УПИіApplicationЛёШЁзЈЪєЕФexecutorНјГЬЃЌИУНјГЬдкApplicationЦкМфвЛжБзЄСєЃЌВЂвдЖрЯпГЬЗНЪНдЫааTaskЁЃетжжApplicationИєРыЛњжЦЪЧгагХЪЦЕФЃЌЮоТлЪЧДгЕїЖШНЧЖШПДЃЈУПИіDriverЕїЖШЫћздМКЕФШЮЮёЃЉЃЌЛЙЪЧДгдЫааНЧЖШПДЃЈРДздВЛЭЌApplicationЕФTaskдЫаадкВЛЭЌJVMжаЃЉЃЌЕБШЛетбљвтЮЖзХSpark
ApplicationВЛФмПчгІгУГЬађЙВЯэЪ§ОнЃЌГ§ЗЧНЋЪ§ОнаДШыЭтВПДцДЂЯЕЭГ
SparkгызЪдДЙмРэЦїЮоЙиЃЌжЛвЊФмЙЛЛёШЁexecutorНјГЬЃЌВЂФмБЃГжЯрЛЅЭЈаХОЭПЩвдСЫ
ЬсНЛSparkContextЕФClientгІИУППНќWorkerНкЕуЃЈдЫааExecutorЕФНкЕуЃЉЃЌзюКУЪЧдкЭЌвЛИіRackРяЃЌвђЮЊSpark
ApplicationдЫааЙ§ГЬжаSparkContextКЭExecutorжЎМфгаДѓСПЕФаХЯЂНЛЛЛ
TaskВЩгУСЫЪ§ОнБОЕиадКЭЭЦВтжДааЕФгХЛЏЛњжЦ
ГЃгУЪѕгя:
Application: ApplictionЖМЪЧжИгУЛЇБраДЕФSparkгІгУГЬађЃЌЦфжаАќРЈвЛИіDriverЙІФмЕФДњТыКЭЗжВМдкМЏШКжаЖрИіНкЕуЩЯдЫааЕФExecutorДњТы
Driver: SparkжаЕФDriverМДдЫааЩЯЪіApplicationЕФmainКЏЪ§ВЂДДНЈSparkContextЃЌДДНЈSparkContextЕФФПЕФЪЧЮЊСЫзМБИSparkгІгУГЬађЕФдЫааЛЗОГЃЌдкSparkжагаSparkContextИКд№гыClusterManagerЭЈаХЃЌНјаазЪдДЩъЧыЁЂШЮЮёЕФЗжХфКЭМрПиЕШЃЌЕБExecutorВПЗждЫааЭъБЯКѓЃЌDriverЭЌЪБИКд№НЋSparkContextЙиБеЃЌЭЈГЃгУSparkContextДњБэDriver
Executor: ФГИіApplicationдЫаадкworkerНкЕуЩЯЕФвЛИіНјГЬЃЌ ИУНјГЬИКд№дЫааФГаЉTaskЃЌ
ВЂЧвИКд№НЋЪ§ОнДцЕНФкДцЛђДХХЬЩЯЃЌУПИіApplicationЖМгаИїздЖРСЂЕФвЛХњExecutorЃЌ дкSpark
on YarnФЃЪНЯТЃЌЦфНјГЬУћГЦЮЊCoarseGrainedExecutor BackendЁЃвЛИіCoarseGrainedExecutor
BackendгаЧвНігавЛИіExecutorЖдЯѓЃЌ ИКд№НЋTaskАќзАГЩtaskRunner,ВЂДгЯпГЬГижаГщШЁвЛИіПеЯаЯпГЬдЫааTaskЃЌ
етИіУПвЛИіoarseGrainedExecutor BackendФмВЂаадЫааTaskЕФЪ§СПШЁОігыЗжХфИјЫќЕФcpuИіЪ§
Cluter ManagerЃКжИЕФЪЧдкМЏШКЩЯЛёШЁзЪдДЕФЭтВПЗўЮёЁЃФПЧАгаШ§жжРраЭ
Standalon : sparkдЩњЕФзЪдДЙмРэЃЌгЩMasterИКд№зЪдДЕФЗжХф
Apache Mesos:гыhadoop MRМцШнадСМКУЕФвЛжжзЪдДЕїЖШПђМм
Hadoop Yarn: жївЊЪЧжИYarnжаЕФResourceManager
Worker: МЏШКжаШЮКЮПЩвддЫааApplicationДњТыЕФНкЕуЃЌдкStandaloneФЃЪНжажИЕФЪЧЭЈЙ§slaveЮФМўХфжУЕФWorkerНкЕуЃЌдкSpark
on YarnФЃЪНЯТОЭЪЧNoteManagerНкЕу
Task: БЛЫЭЕНФГИіExecutorЩЯЕФЙЄзїЕЅдЊЃЌЕЋhadoopMRжаЕФMapTaskКЭReduceTaskИХФювЛбљЃЌЪЧдЫааApplicationЕФЛљБОЕЅЮЛЃЌЖрИіTaskзщГЩвЛИіStageЃЌЖјTaskЕФЕїЖШКЭЙмРэЕШЪЧгЩTaskSchedulerИКд№
Job: АќКЌЖрИіTaskзщГЩЕФВЂааМЦЫуЃЌЭљЭљгЩSpark ActionДЅЗЂЩњГЩЃЌ вЛИіApplicationжаЭљЭљЛсВњЩњЖрИіJob
Stage: УПИіJobЛсБЛВ№ЗжГЩЖрзщTaskЃЌ зїЮЊвЛИіTaskSetЃЌ ЦфУћГЦЮЊStageЃЌStageЕФЛЎЗжКЭЕїЖШЪЧгаDAGSchedulerРДИКд№ЕФЃЌStageгаЗЧзюжеЕФStageЃЈShuffle
Map StageЃЉКЭзюжеЕФStageЃЈResult StageЃЉСНжжЃЌStageЕФБпНчОЭЪЧЗЂЩњshuffleЕФЕиЗН
DAGScheduler: ИљОнJobЙЙНЈЛљгкStageЕФDAGЃЈDirected
Acyclic GraphгаЯђЮоЛЗЭМ)ЃЌВЂЬсНЛStageИјTASkSchedulerЁЃ ЦфЛЎЗжStageЕФвРОнЪЧRDDжЎМфЕФвРРЕЕФЙиЯЕевГіПЊЯњзюаЁЕФЕїЖШЗНЗЈЃЌШчЯТЭМ
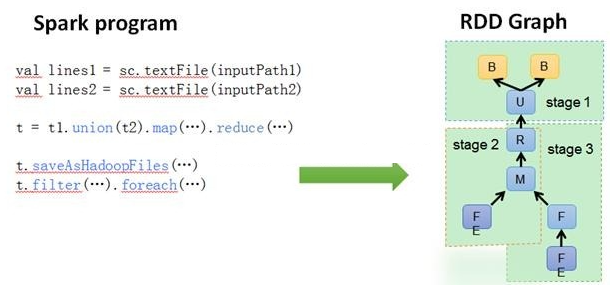
TASKSedulter: НЋTaskSETЬсНЛИјworkerдЫааЃЌУПИіExecutorдЫааЪВУДTaskОЭЪЧдкДЫДІЗжХфЕФ.
TaskSchedulerЮЌЛЄЫљгаTaskSetЃЌЕБExecutorЯђDriverЗЂЩњаФЬјЪБЃЌTaskSchedulerЛсИљОнзЪдДЪЃгрЧщПіЗжХфЯргІЕФTaskЁЃСэЭтTaskSchedulerЛЙЮЌЛЄзХЫљгаTaskЕФдЫааБъЧЉЃЌжиЪдЪЇАмЕФTaskЁЃЯТЭМеЙЪОСЫTaskSchedulerЕФзїгУ
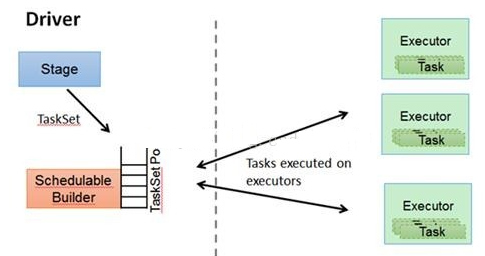
дкВЛЭЌдЫааФЃЪНжаШЮЮёЕїЖШЦїОпЬхЮЊЃК
1.Spark on StandaloneФЃЪНЮЊTaskScheduler
2.YARN-ClientФЃЪНЮЊYarnClientClusterScheduler
3.YARN-ClusterФЃЪНЮЊYarnClusterScheduler
НЋетаЉЪѕгяДЎЦ№РДЕФдЫааВуДЮЭМШчЯТЃК
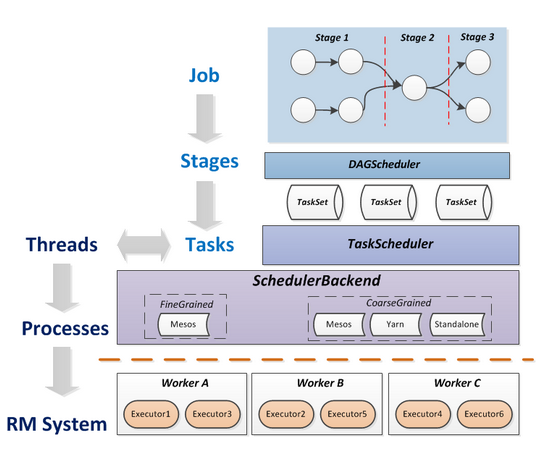
Job=ЖрИіstageЃЌStage=ЖрИіЭЌжжtask, TaskЗжЮЊShuffleMapTaskКЭResultTaskЃЌDependencyЗжЮЊShuffleDependencyКЭNarrowDependency
SparkдЫааФЃЪНЃК
SparkЕФдЫааФЃЪНЖржжЖрбљЃЌСщЛюЖрБфЃЌВПЪ№дкЕЅЛњЩЯЪБЃЌМШПЩвдгУБОЕиФЃЪНдЫааЃЌвВПЩвдгУЮБЗжВМФЃЪНдЫааЃЌЖјЕБвдЗжВМЪНМЏШКЕФЗНЪНВПЪ№ЪБЃЌвВгажкЖрЕФдЫааФЃЪНПЩЙЉбЁдёЃЌетШЁОігкМЏШКЕФЪЕМЪЧщПіЃЌЕзВуЕФзЪдДЕїЖШМДПЩвдвРРЕЭтВПзЪдДЕїЖШПђМмЃЌвВПЩвдЪЙгУSparkФкНЈЕФStandaloneФЃЪНЁЃ
ЖдгкЭтВПзЪдДЕїЖШПђМмЕФжЇГжЃЌФПЧАЕФЪЕЯжАќРЈЯрЖдЮШЖЈЕФMesosФЃЪНЃЌвдМАhadoop YARNФЃЪН
БОЕиФЃЪНЃКГЃгУгкБОЕиПЊЗЂВтЪдЃЌБОЕиЛЙЗжБ№ local КЭ local cluster
standalone: ЖРСЂМЏШКдЫааФЃЪН
StandaloneФЃЪНЪЙгУSparkздДјЕФзЪдДЕїЖШПђМм
ВЩгУMaster/SlavesЕФЕфаЭМмЙЙЃЌбЁгУZooKeeperРДЪЕЯжMasterЕФHA
ПђМмНсЙЙЭМШчЯТ:
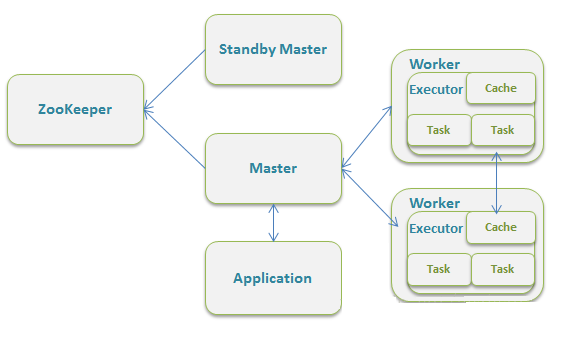
ИУФЃЪНжївЊЕФНкЕугаClientНкЕуЁЂMasterНкЕуКЭWorkerНкЕуЁЃЦфжаDriverМШПЩвддЫаадкMasterНкЕуЩЯжаЃЌвВПЩвддЫаадкБОЕиClientЖЫЁЃЕБгУspark-shellНЛЛЅЪНЙЄОпЬсНЛSparkЕФJobЪБЃЌDriverдкMasterНкЕуЩЯдЫааЃЛЕБЪЙгУspark-submitЙЄОпЬсНЛJobЛђепдкEclipsЁЂIDEAЕШПЊЗЂЦНЬЈЩЯЪЙгУЁБnew
SparkConf.setManager(ЁАspark://master:7077ЁБ)ЁБЗНЪНдЫааSparkШЮЮёЪБЃЌDriverЪЧдЫаадкБОЕиClientЖЫЩЯЕФ
дЫааЙ§ГЬШчЯТЭМЃК
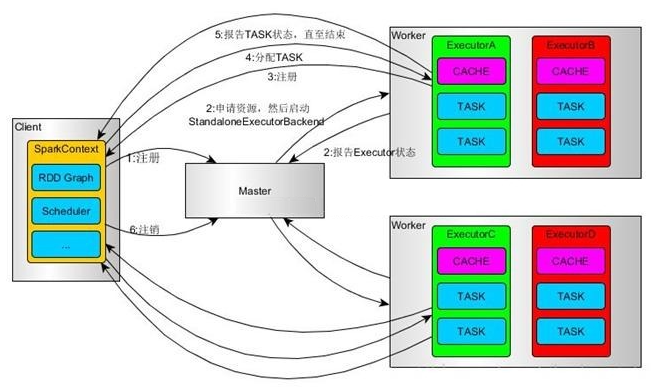
SparkContextСЌНгЕНMasterЃЌЯђMasterзЂВсВЂЩъЧызЪдДЃЈCPU Core КЭMemoryЃЉ
MasterИљОнSparkContextЕФзЪдДЩъЧывЊЧѓКЭWorkerаФЬјжмЦкФкБЈИцЕФаХЯЂОіЖЈдкФФИіWorkerЩЯЗжХфзЪдДЃЌШЛКѓдкИУWorkerЩЯЛёШЁзЪдДЃЌШЛКѓЦєЖЏStandaloneExecutorBackendЃЛ
StandaloneExecutorBackendЯђSparkContextзЂВсЃЛ
SparkContextНЋApplicaitonДњТыЗЂЫЭИјStandaloneExecutorBackendЃЛВЂЧвSparkContextНтЮіApplicaitonДњТыЃЌЙЙНЈDAGЭМЃЌВЂЬсНЛИјDAG
SchedulerЗжНтГЩStageЃЈЕБХіЕНActionВйзїЪБЃЌОЭЛсДпЩњJobЃЛУПИіJobжаКЌга1ИіЛђЖрИіStageЃЌStageвЛАудкЛёШЁЭтВПЪ§ОнКЭshuffleжЎЧАВњЩњЃЉЃЌШЛКѓвдStageЃЈЛђепГЦЮЊTaskSetЃЉЬсНЛИјTask
SchedulerЃЌTask SchedulerИКд№НЋTaskЗжХфЕНЯргІЕФWorkerЃЌзюКѓЬсНЛИјStandaloneExecutorBackendжДааЃЛ
StandaloneExecutorBackendЛсНЈСЂExecutorЯпГЬГиЃЌПЊЪМжДааTaskЃЌВЂЯђSparkContextБЈИцЃЌжБжСTaskЭъГЩ
ЫљгаTaskЭъГЩКѓЃЌSparkContextЯђMasterзЂЯњЃЌЪЭЗХзЪдД
yarn: ЃЈВЮПМЃКhttp://blog.csdn.net/gamer_gyt/article/details/51833681ЃЉ
Spark on YARNФЃЪНИљОнDriverдкМЏШКжаЕФЮЛжУЗжЮЊСНжжФЃЪНЃКвЛжжЪЧYARN-ClientФЃЪНЃЌСэвЛжжЪЧYARN-ClusterЃЈЛђГЦЮЊYARN-StandaloneФЃЪНЃЉ
Yarn-ClientФЃЪНжаЃЌDriverдкПЭЛЇЖЫБОЕидЫааЃЌетжжФЃЪНПЩвдЪЙЕУSpark ApplicationКЭПЭЛЇЖЫНјааНЛЛЅЃЌвђЮЊDriverдкПЭЛЇЖЫЃЌЫљвдПЩвдЭЈЙ§webUIЗУЮЪDriverЕФзДЬЌЃЌФЌШЯЪЧhttp://hadoop1:4040ЗУЮЪЃЌЖјYARNЭЈЙ§http://
hadoop1:8088ЗУЮЪ
YARN-clientЕФЙЄзїСїГЬВНжшЮЊЃК
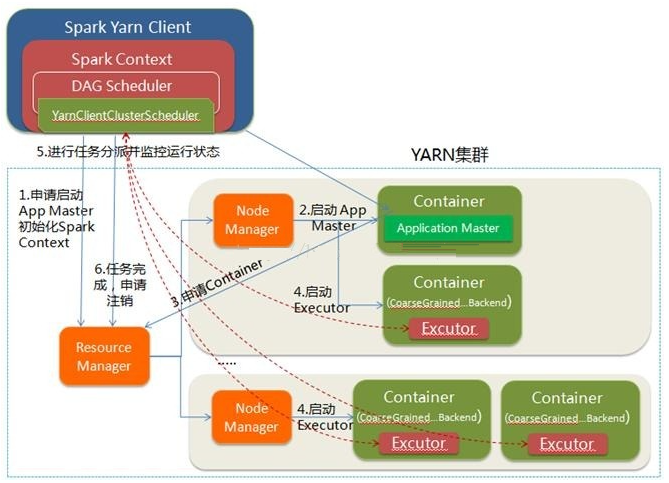
Spark Yarn ClientЯђYARNЕФResourceManagerЩъЧыЦєЖЏApplication
MasterЁЃЭЌЪБдкSparkContentГѕЪМЛЏжаНЋДДНЈDAGSchedulerКЭTASKSchedulerЕШЃЌгЩгкЮвУЧбЁдёЕФЪЧYarn-ClientФЃЪНЃЌГЬађЛсбЁдёYarnClientClusterSchedulerКЭYarnClientSchedulerBackend
ResourceManagerЪеЕНЧыЧѓКѓЃЌдкМЏШКжабЁдёвЛИіNodeManagerЃЌЮЊИУгІгУГЬађЗжХфЕквЛИіContainerЃЌвЊЧѓЫќдкетИіContainerжаЦєЖЏгІгУГЬађЕФApplicationMasterЃЌгыYARN-ClusterЧјБ№ЕФЪЧдкИУApplicationMasterВЛдЫааSparkContextЃЌжЛгыSparkContextНјааСЊЯЕНјаазЪдДЕФЗжХЩ
ClientжаЕФSparkContextГѕЪМЛЏЭъБЯКѓЃЌгыApplicationMasterНЈСЂЭЈбЖЃЌЯђResourceManagerзЂВсЃЌИљОнШЮЮёаХЯЂЯђResourceManagerЩъЧызЪдДЃЈContainerЃЉ
вЛЕЉApplicationMasterЩъЧыЕНзЪдДЃЈвВОЭЪЧContainerЃЉКѓЃЌБугыЖдгІЕФNodeManagerЭЈаХЃЌвЊЧѓЫќдкЛёЕУЕФContainerжаЦєЖЏCoarseGrainedExecutorBackendЃЌCoarseGrainedExecutorBackendЦєЖЏКѓЛсЯђClientжаЕФSparkContextзЂВсВЂЩъЧыTask
clientжаЕФSparkContextЗжХфTaskИјCoarseGrainedExecutorBackendжДааЃЌCoarseGrainedExecutorBackendдЫааTaskВЂЯђDriverЛуБЈдЫааЕФзДЬЌКЭНјЖШЃЌвдШУClientЫцЪБеЦЮеИїИіШЮЮёЕФдЫаазДЬЌЃЌДгЖјПЩвддкШЮЮёЪЇАмЪБжиаТЦєЖЏШЮЮё
гІгУГЬађдЫааЭъГЩКѓЃЌClientЕФSparkContextЯђResourceManagerЩъЧызЂЯњВЂЙиБездМК
Spark ClusterФЃЪН:
дкYARN-ClusterФЃЪНжаЃЌЕБгУЛЇЯђYARNжаЬсНЛвЛИігІгУГЬађКѓЃЌYARNНЋЗжСНИіНзЖЮдЫааИУгІгУГЬађЃК
ЕквЛИіНзЖЮЪЧАбSparkЕФDriverзїЮЊвЛИіApplicationMasterдкYARNМЏШКжаЯШЦєЖЏЃЛ
ЕкЖўИіНзЖЮЪЧгЩApplicationMasterДДНЈгІгУГЬађЃЌШЛКѓЮЊЫќЯђResourceManagerЩъЧызЪдДЃЌВЂЦєЖЏExecutorРДдЫааTaskЃЌЭЌЪБМрПиЫќЕФећИідЫааЙ§ГЬЃЌжБЕНдЫааЭъГЩ
YARN-clusterЕФЙЄзїСїГЬЗжЮЊвдЯТМИИіВНжш
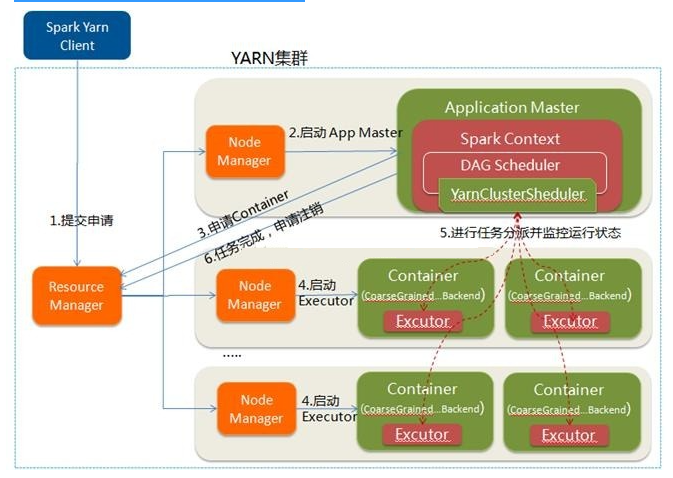
Spark Yarn ClientЯђYARNжаЬсНЛгІгУГЬађЃЌАќРЈApplicationMasterГЬађЁЂЦєЖЏApplicationMasterЕФУќСюЁЂашвЊдкExecutorжадЫааЕФГЬађЕШ
ResourceManagerЪеЕНЧыЧѓКѓЃЌдкМЏШКжабЁдёвЛИіNodeManagerЃЌЮЊИУгІгУГЬађЗжХфЕквЛИіContainerЃЌвЊЧѓЫќдкетИіContainerжаЦєЖЏгІгУГЬађЕФApplicationMasterЃЌЦфжаApplicationMasterНјааSparkContextЕШЕФГѕЪМЛЏ
ApplicationMasterЯђResourceManagerзЂВсЃЌетбљгУЛЇПЩвджБНгЭЈЙ§ResourceManageВщПДгІгУГЬађЕФдЫаазДЬЌЃЌШЛКѓЫќНЋВЩгУТжбЏЕФЗНЪНЭЈЙ§RPCавщЮЊИїИіШЮЮёЩъЧызЪдДЃЌВЂМрПиЫќУЧЕФдЫаазДЬЌжБЕНдЫааНсЪј
вЛЕЉApplicationMasterЩъЧыЕНзЪдДЃЈвВОЭЪЧContainerЃЉКѓЃЌБугыЖдгІЕФNodeManagerЭЈаХЃЌвЊЧѓЫќдкЛёЕУЕФContainerжаЦєЖЏCoarseGrainedExecutorBackendЃЌCoarseGrainedExecutorBackendЦєЖЏКѓЛсЯђApplicationMasterжаЕФSparkContextзЂВсВЂЩъЧыTaskЁЃетвЛЕуКЭStandaloneФЃЪНвЛбљЃЌжЛВЛЙ§SparkContextдкSpark
ApplicationжаГѕЪМЛЏЪБЃЌЪЙгУCoarseGrainedSchedulerBackendХфКЯYarnClusterSchedulerНјааШЮЮёЕФЕїЖШЃЌЦфжаYarnClusterSchedulerжЛЪЧЖдTaskSchedulerImplЕФвЛИіМђЕЅАќзАЃЌдіМгСЫЖдExecutorЕФЕШД§ТпМЕШ
ApplicationMasterжаЕФSparkContextЗжХфTaskИјCoarseGrainedExecutorBackendжДааЃЌCoarseGrainedExecutorBackendдЫааTaskВЂЯђApplicationMasterЛуБЈдЫааЕФзДЬЌКЭНјЖШЃЌвдШУApplicationMasterЫцЪБеЦЮеИїИіШЮЮёЕФдЫаазДЬЌЃЌДгЖјПЩвддкШЮЮёЪЇАмЪБжиаТЦєЖЏШЮЮё
гІгУГЬађдЫааЭъГЩКѓЃЌApplicationMasterЯђResourceManagerЩъЧызЂЯњВЂЙиБездМК
Spark Client КЭ Spark ClusterЕФЧјБ№:
РэНтYARN-ClientКЭYARN-ClusterЩюВуДЮЕФЧјБ№жЎЧАЯШЧхГўвЛИіИХФюЃКApplication
MasterЁЃдкYARNжаЃЌУПИіApplicationЪЕР§ЖМгавЛИіApplicationMasterНјГЬЃЌЫќЪЧApplicationЦєЖЏЕФЕквЛИіШнЦїЁЃЫќИКд№КЭResourceManagerДђНЛЕРВЂЧыЧѓзЪдДЃЌЛёШЁзЪдДжЎКѓИцЫпNodeManagerЮЊЦфЦєЖЏContainerЁЃДгЩюВуДЮЕФКЌвхНВYARN-ClusterКЭYARN-ClientФЃЪНЕФЧјБ№ЦфЪЕОЭЪЧApplicationMasterНјГЬЕФЧјБ№
YARN-ClusterФЃЪНЯТЃЌDriverдЫаадкAM(Application Master)жаЃЌЫќИКд№ЯђYARNЩъЧызЪдДЃЌВЂМрЖНзївЕЕФдЫаазДПіЁЃЕБгУЛЇЬсНЛСЫзївЕжЎКѓЃЌОЭПЩвдЙиЕєClientЃЌзївЕЛсМЬајдкYARNЩЯдЫааЃЌвђЖјYARN-ClusterФЃЪНВЛЪЪКЯдЫааНЛЛЅРраЭЕФзївЕ
YARN-ClientФЃЪНЯТЃЌApplication MasterНіНіЯђYARNЧыЧѓExecutorЃЌClientЛсКЭЧыЧѓЕФContainerЭЈаХРДЕїЖШЫћУЧЙЄзїЃЌвВОЭЪЧЫЕClientВЛФмРыПЊ
ЫМПМЃК ЮвУЧдкЪЙгУSparkЬсНЛjobЪБЪЙгУЕФФФжжФЃЪНЃП
RDDдЫааСїГЬЃК
RDDдкSparkжадЫааДѓИХЗжЮЊвдЯТШ§ВНЃК
1.ДДНЈRDDЖдЯѓ
2.DAGSchedulerФЃПщНщШыдЫЫуЃЌМЦЫуRDDжЎМфЕФвРРЕЙиЯЕЃЌRDDжЎМфЕФвРРЕЙиЯЕОЭаЮГЩСЫDAG
3.УПвЛИіJobБЛЗжЮЊЖрИіStageЁЃЛЎЗжStageЕФвЛИіжївЊвРОнЪЧЕБЧАМЦЫувђзгЕФЪфШыЪЧЗёЪЧШЗЖЈЕФЃЌШчЙћЪЧдђНЋЦфЗждкЭЌвЛИіStageЃЌБмУтЖрИіStageжЎМфЕФЯћЯЂДЋЕнПЊЯњ
ЪОР§ЭМШчЯТЃК
вдЯТУцвЛИіАД A-Z ЪззжФИЗжРрЃЌВщевЯрЭЌЪззжФИЯТВЛЭЌаеУћзмИіЪ§ЕФР§згРДПДвЛЯТ
RDD ЪЧШчКЮдЫааЦ№РДЕФ
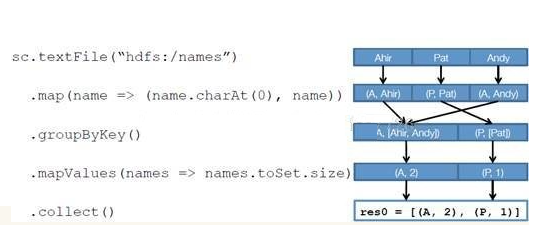
ДДНЈ RDD ЩЯУцЕФР§згГ§ШЅзюКѓвЛИі collect ЪЧИіЖЏзїЃЌВЛЛсДДНЈ RDD жЎЭтЃЌЧАУцЫФИізЊЛЛЖМЛсДДНЈГіаТЕФ
RDD ЁЃвђДЫЕквЛВНОЭЪЧДДНЈКУЫљга RDD( ФкВПЕФЮхЯюаХЯЂ )ЃП
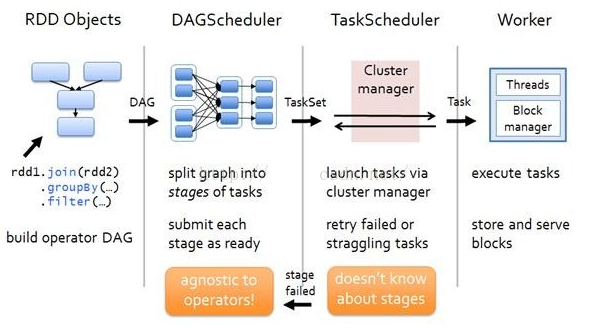
ДДНЈжДааМЦЛЎ Spark ЛсОЁПЩФмЕиЙмЕРЛЏЃЌВЂЛљгкЪЧЗёвЊжиаТзщжЏЪ§ОнРДЛЎЗж
НзЖЮ (stage) ЃЌР§ШчБОР§жаЕФ groupBy() зЊЛЛОЭЛсНЋећИіжДааМЦЛЎЛЎЗжГЩСННзЖЮжДааЁЃзюжеЛсВњЩњвЛИі
DAG(directed acyclic graph ЃЌгаЯђЮоЛЗЭМ ) зїЮЊТпМжДааМЦЛЎ
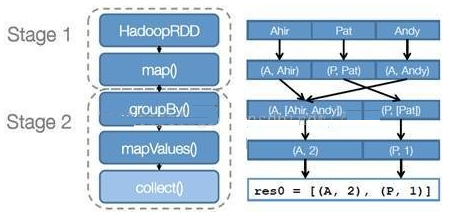
ЕїЖШШЮЮё НЋИїНзЖЮЛЎЗжГЩВЛЭЌЕФ ШЮЮё (task) ЃЌУПИіШЮЮёЖМЪЧЪ§ОнКЭМЦЫуЕФКЯЬхЁЃдкНјааЯТвЛНзЖЮЧАЃЌЕБЧАНзЖЮЕФЫљгаШЮЮёЖМвЊжДааЭъГЩЁЃвђЮЊЯТвЛНзЖЮЕФЕквЛИізЊЛЛвЛЖЈЪЧжиаТзщжЏЪ§ОнЕФЃЌЫљвдБиаыЕШЕБЧАНзЖЮЫљгаНсЙћЪ§ОнЖММЦЫуГіРДСЫВХФмМЬај
|









