| БрМЭЦМі: |
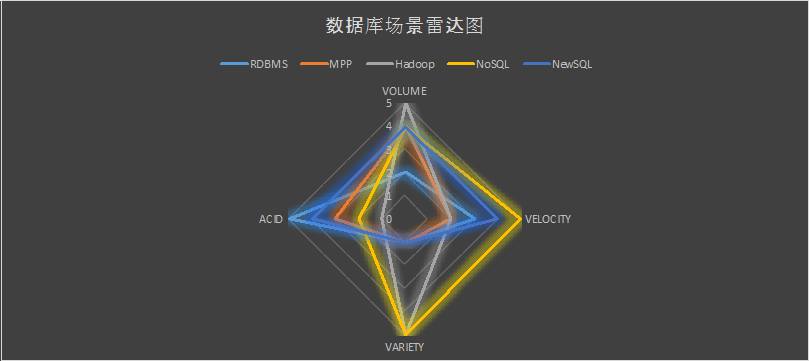
БОЮФРДздгкЭјТчДѓЪ§ОнЃЌHadoopДѓЪ§ОнЪЧдѕУДСЫФи?ЮвУЧДгDBMSЪ§ОнПтЙмРэЯЕЭГЕФНЧЖШЃЌРДЦЪЮіЯТГЃМћВњЦЗЕФФмСІЃКRDBMSЃЌMPPЃЌHadoopЃЌNoSQLвдМАNewSQLЁЃ
етМИРрВњЦЗЖдЪ§ОнДІРэЕФФмСІИїгаЪВУДбљЕФЬиЕу?
|
|
1. Hadoop ЕФЩёЛАе§дкЦЦУ№
IBM leads BigInsights for Hadoop out behind barn.
Shots heard
IBM has announced the retirement of the basic plan
for its data analytics software platform, BigInsights
for Hadoop.
The basic plan of the service will be retired in a
month, on December 7 of this year.
ЁАIBMАбBigInsights for HadoopЧЃЕНФСХяКѓУцЃЌжЛЬ§вЛЩљЧЙЯьЁЁБ
етИіЪЧЧАВЛОУгЂЙњжЊУћУНЬхThe RegisterЖдIBM ВњЦЗBigInsightsВњЦЗЯТЯпЕФБЈЕРЁЃ
BigInsights ЪЧIBMдкApache HadoopЩЯдіМгСЫВЛЩйIBMЗжЮіММЪѕФмСІКѓаЮГЩЕФвЛИіДѓЪ§ОнЗжЮіВњЦЗЁЃ
дкУцСйНќКѕ2ФъЕФЧАЭОЮДВЗЕФОНОГжЎКѓЃЌIBMжегкОіЖЈНЋЦфЙиБеЁЃ
ЮоЖРгаХМЃЌЧАВЛОУGartnerЕФвЛЦЊЮФеТвВжИГі ЁА70%вдЩЯЕФHadoopВПЪ№ЮДФмЬьЯпЕФвЕЮёМлжЕЁЁБ
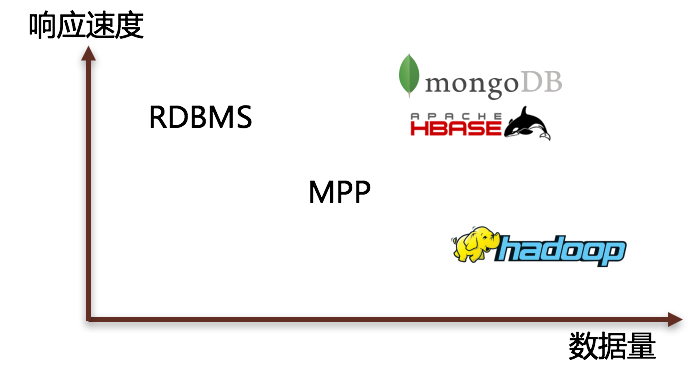
HadoopДѓЪ§ОнЪЧдѕУДСЫФи?
ЮвУЧДгDBMSЪ§ОнПтЙмРэЯЕЭГЕФНЧЖШЃЌРДЦЪЮіЯТГЃМћВњЦЗЕФФмСІЃКRDBMSЃЌMPPЃЌHadoopЃЌNoSQLвдМАNewSQLЁЃ
етМИРрВњЦЗЖдЪ§ОнДІРэЕФФмСІИїгаЪВУДбљЕФЬиЕу?
2. ГЃМћМИжжЪ§ОнММЪѕБШНЯ
ЮвУЧЪзЯШЪдЭМЖдДѓЪ§ОнетИіБЛЕквЛРФгУЕФУћДЪРДЭГвЛвЛЯТИХФюЁЃАДееGartnerЕФЫЕЗЈЃЌДѓЪ§ОнОпБИвдЯТМИИіЬиеї(3ИіV)ЃК
VolumeЃК Ъ§ОнСПЙЛДѓ
Velocity: Ъ§ОнЗУЮЪВЂЗЂЙЛИпЃЌЙЛЪЕЪБ
VarietyЃК Ъ§ОнЕФРраЭЖр
ДгСэвЛЗНУцНВЃЌДѓЪ§ОнвВЪЧЪ§ОнЃЌЖдГЃЙцЪ§ОнЕФЙмРэРыВЛПЊЮвУЧЪьЯЄЕФACIDЪТЮёадРДБЃжЄЖдЪ§ОнВйзїЪБКђЕФдзгадЃЌвЛжТадЃЌИєРыадКЭГжОУадЁЃгаСЫетИіМИИіКтСПБъзМвдКѓЃЌЮвУЧПЩвдРДЖдЩЯЪіМИИіВњЦЗСаБэБШНЯвЛЯТЁЃ
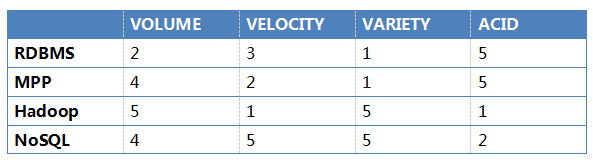
дкетРяИљОн4ИіЮЌЖШИјМИжжСїааЕФЪ§ОнПтЙмРэММЪѕДђЗжЃЌвд5ЗжжЦЮЊР§ЃЌ5ЗжМДзюИпЗжЃЌБэУїОпБИзюМбФмСІЁЃ1ЗжЮЊзюЕЭЗжЃЌБэУїЯрЖдЖјбдФмСІзюШѕЁЃЦфЪЕзюНќвбОгаРрЫЦгкTiDBЛђепCockroachDBЕФNewSQLВњЦЗГіЯжЃЌЕЋЪЧЪ§ОнПтШэМўЪЧзюЮЊИДдгЕФШэМўжЎвЛЃЌ
вђЮЊЫќвЊТњзуИїжжгІгУЕФЪЙгУГЁОАЁЃШчЙћРњЪЗЪЧУцОЕзгЃЌФЧУДзюЩйЛЙвЊ3ФъзѓгветаЉNewSQLЕФБэЯжВХФмБЛзуЙЛЕФЦРВтЁЃЫљвдетРяЮвУЧднЪБТдЙ§ЁЃ
ЯТУцЮвУЧРДНтЖСвЛЯТИїжжЪ§ОнПтЕФЕУЗждвђЁЃ
3. ЙиЯЕаЭЪ§ОнПт
RDBMSШЋГЦЙиЯЕаЭЪ§ОнПт(Relational Database Management System)ЪЧРњЪЗзюгЦОУЕФЪ§ОнПтРраЭЁЃЙиЯЕаЭЪ§ОнПтвдOracleЃЌSQLServerЃЌMySQLЃЌPostgreSQLЕШЮЊДњБэЃЌЪЧЮвУЧзюЪьЯЄЕФЪ§ОнПтЁЃЬиЕуЪЧЃК
ЕЅЛњМмЙЙЯожЦЃЌДІРэЪ§ОнСПгаЯо, ЭЈГЃдкаЁМИИіTBвдЯТ(ЕУЗж2)
ЪмЪТЮёжЎРлЃЌВЂЗЂВЛИпЃЌЕЋЪЧЭЈГЃЪЧКСУыМЖЯьгІ(ЕУЗж3)
бЯНїЕФЙиЯЕФЃаЭЃЌЮоЗЈДІРэЗЧНсЙЙЛЏЪ§Он(ЕУЗж1)
ЪТЮёадЧПЃЌЮогыТзБШ(ЕУЗж5)
4. MPP Ъ§Вж
MPPЃЌШЋГЦMassive Parallel ProcessingЪ§ОнПтЃЌЭЈГЃБЛгУРДЪЕЯжЦѓвЕЕФЪ§ОнВжПтКЭODSЕШашЧѓЁЃMPPЕФВњЩњжївЊЪЧгУРДНтОіЙиЯЕаЭЪ§ОнПтЕФЪ§ОнСПЙмРэФмСІЕФЮЪЬтЁЃMPPЪ§ОнПтЭЈЙ§АбЪ§ОнНјааЗжЧјЗжЦЌЃЌВЂЗжВМЕНИїИіКсЯђРЉеЙНкЕуЃЌВЂгЩЕїЖШНкЕуНјааЭГвЛЙмРэМЦЫуЁЃУПвЛДЮФужДааВщбЏЕФЪБКђЃЌИУВщбЏЛсБЛЗжНтЮЊЖрИізгВщбЏВЂНЛИЖИјУПвЛИіМЦЫуНкЕуШЅзіВЂааЕФВщбЏЁЃетИіМмЙЙПЩвдЭЈЙ§діМгНкЕуЕФЗНЪНРДРЉеЙШнСПЁЃЪ§ОндкMPPЯЕЭГРяЪЧЗжЦЌЕФ(Sharded),
УПИіНкЕуЛсДцШЁздМКБОЕиЕФвЛВПЗжЪ§ОнЁЃетИіНЯжЎЙВЯэДцДЂ(ШчOracle RAC)ЗНАИРДЫЕгжгаВЛЩйадФмЩЯЕФгХЪЦЁЃвђДЫДѓВПЗжMPPЯЕЭГЃЌШчTeradataЃЌGreenplumЃЌVerticaЕШЖМВЩгУСЫетжжshared
nothingМАDAS жБЙвДцДЂЕФМмЙЙЁЃвЛАуРДЫЕMPPЯЕЭГЖМОпБИЭъБИЧвГЩЪьЕФSQLгХЛЏЦїЃЌжЇГжжїСїЕФSQLБъзМЃЌАќРЈЕиРэЗжЮіЃЌШЋЮФМьЫївдМАЪ§ОнЭкОђЙІФмЁЃГ§СЫGPжЎЭтЃЌМИКѕЫљгаЕФMPPЯЕЭГЖМЪЧБедДЯЕЭГЃЌВЂЧввЛАуЖМЪЧКЭАКЙѓЁЂИДдгетаЉДЪСЊЯЕдквЛЦ№ЕФЁЃ
ЭМЦЌРДдДЃК Gregory Kesden
MPPРэТлЩЯЪЧПЩвдЮоЯоКсЯђРЉеЙЕФЃЌЕЋЪЧЪЕМЪЩЯгЩгкПижЦНкЕуЛђаЕїНкЕуЕФдвђЃЌЭљЭљКмФбГЌГівЛАйзѓгвЕФНкЕуЪ§СПЁЃЫљвдVOLUMEЕУЗжЮЊ4ЗжЖјВЛЪЧТњЗжЁЃMPPЯЕЭГЩЯжївЊдЫааЕФЪЧЗжЮіаЭЕФгІгУГЁОАЃЌВЂЗЂЪ§ЭљЭљНЯЕЭЃЌЪЧЮЊЖрНкЕуВЂааЗжЮіФмСІЖјВЛЪЧИпВЂЗЂФмСІгХЛЏЕФЃЌвђДЫVELOCITYЩЯЕУЗжЮЊ2ЗжЁЃMPPДѓжТвВЪЧЛљгкЙиЯЕФЃаЭЕФЃЌЖдЗЧНсЙЙЛЏЪ§ОнЕФДІРэЩЯКЭRDBMSЛљБОвЛбљЮоФмЮЊСІЃЌвђДЫЕУЗжЮЊ1ЁЃ
5. Hadoop
ЯТвЛИіГіГЁЕФЪЧHadoopЃЌАДЪБМфЫГађРДХХЕФЛАЁЃ Apache HadoopЪЧ2007ФъЗЂВМЕФПЊдДШэМўЁЃHadoopЪЧЛљгкGoogle
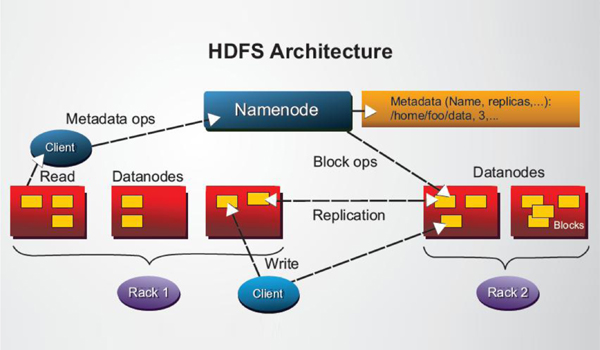
ЙЋПЊЕФMapReduceКЭHDFSММЪѕбаЗЂЖјГЩЕФЁЃЫќЕФзюЮАДѓжЎДІОЭЪЧШУЦѓвЕФмЙЛвдЗЧГЃСЎМлЕФx86ЗўЮёЦїАбДѓСПЕФЪ§ОнЙмРэЦ№РДЁЃдкФЧжЎЧАЃЌЛњЙЙашвЊЙКТђЛњЦїАКЙѓЕФЦѓвЕМЖДцДЂЩшБИРДЙмРэКЃСПЪ§ОнЁЃОЭДгетвЛЕуЩЯЃЌHadoopММЪѕвбОЮЊЦѓвЕДјРДСЫКмДѓЕФМлжЕЁЃетИіШЗЪЕЪЧHadoopЕФЧПДІЫљдкЁЃШЛЖјЃЌHadoopЕФШѕЕувВЪЧвЛТсП№ЃКАВШЋЃЌЪ§ОнЙмРэЃЌВщбЏЫйЖШЃЌИДдгЕШЕШЁЃ10ФъЕФЗЂеЙЃЌКмЖретаЉЕиЗНЖМвбОгаСЫБШНЯВЛДэЕФНтОіЃЌЮЈгаетИіЪ§ОнВщбЏЫйЖШвРШЛЪЧКмЖрHadoopВПЪ№ЕФЭДжажЎЭДЁЃетИіадФмЕЭЯТЕФдвђЃЌЪЧКЭHDFSЃЌHadoopгУРДДцДЂЮФМўЕФЛњжЦЃЌHDFSЃЌЗжВЛПЊЕФЁЃHDFSВЛжЇГжЫїв§ЃЌОйИіР§згРДЫЕЃЌФуЯывЊдкДЪЕфРяеввЛИіВЛШЯЪЖЕФЩњЦЇДЪЕФЗЂвєКЭЪЭвхЃЌЮЊСЫевЕНетИіЩњЦЇДЪЃЌФуПЩФмашвЊЗБщећБОДЪЕфЃЌвђЮЊФуЮоЗЈЪЙгУЦДвєРДМьЫїЁЃдкHDFSРяУцевФкШнЖМЪЧЭЈЙ§ЩЈУш(SCAN)ЕФЗНЪНЃЌвВМДЪЧДгЭЗЖСЕНЮВРДевЕНФуЯывЊЕФЪ§ОнЁЃПЩвдЯыЯѓетжжВйзїЕФадФмШчКЮЁЃ
HadoopЕФДђЗжЧщПіЃК
Лљгкx86СЎМлЗўЮёЦїМАЕЭЖЫДцДЂКЃСПРЉеЙЃЌЧсЫЩжЇГж TB/PBМЖЪ§ОнСПЃЌVOLUMEЕУЗж5Зж
HDFSЮФМўДцДЂЯЕЭГЖдЫљгаИёЪНЕФЪ§ОнееЕЅШЋЪеЃЌдкVARIETYЩЯУцвВОЁЕУИпЗж5ЗжЁЃ
адФмЗНУцHadoopКСВЛПЭЦјЕФеМСЫЕЙЪ§ЕквЛЃЌЕЋЪЧВЂЗЂНгШыФмСІЛЙЪЧokayЃЌЫљвдИј2Зж
ACIDЪТЮёадИќЪЧАЫИЫзгДђВЛзХЃЌЕУ1ЗжЁЃ
6. NoSQLЪ§ОнПт
NoSQLЪ§ОнПтЪЧвЛИіељвщЦФЖрЕФЛАЬтЁЃЪзЯШЪЧNoSQLеѓгЊВЮВюВЛЦыЃЌгавдRedisЮЊДњБэЕФKeyValueРраЭЃЌзЈГЄгкМЋЖЬЯьгІЪБМфМАКмИпЕФЕЅЛњВЂЗЂФмСІЃЌЪЪКЯгкЛКДцЁЂгУЛЇЛсЛАЕШГЁОАЁЃ
гавдПэБэСазхЮЊФЃаЭЕФHBaseЁЂCassandraЃЌЖдIoTКЃСПЪ§ОнГжајаДШыГЁОАгаВЛДэжЇГжЃЌЕЋЪЧЪЙгУЦ№РДБШНЯВЛгбКУЁЃгавдЭМЙиЯЕФЃаЭЕФNeo4JЃЌзЈзЂгкИДдгЙиЯЕЫбЫїЁЃElasticSearch
дђвдЫбЫїЦ№МвЃЌдкЕьЖЈСЫЫбЫїЪаГЁКѓвВЪгЭМаЁъяЪ§ОнПтЕФДѓЕАИтЁЃЖјОпгаJSONЮФЕЕФЃаЭЕФMongoDBПЩвдЫЕЪЧNoSQLРяУцЕФВЛелВЛПлЕФСњЭЗРЯДѓЁЃJSONЯёXMLвЛбљИЛгаБэДяадЃЌЭЌЪБгжВЛЯёXMLФЧбљЗБЫіЃЌгУЙ§ЕФГЬађдБЛљБОЖМЫЕКУЁЃгЩгкИїжжNoSQLЪ§ОнПтВювьЬЋДѓЃЌКмФбФУГівЛИіГщЯѓФЃаЭРДДњБэNoSQLЃЌЮвУЧЯТУцОЭгУDBEnginesЩЯУцГжајЖрФъХХУћNoSQLЕквЛЕФMongoDBРДЫЕЪТЁЃ

MongoDB дкКмЖрЗНУцКЭHadoopгаЯрЫЦжЎДІЃКЖМЪЧЛљгкx86ЕФЗжВМЪНЪ§ОнПтЃЌЖМЪЧschema-on-readЃЌжЇГжНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнРраЭЕШЕШЁЃвджСгкКмЖрШЫЖМвдЮЊMongoDBОЭЪЧКЭHadoopвЛбљгУРДзіДѓЪ§ОнЗжЮіГЁОАЁЃЪТЪЕЩЯMongoDBЕФвЛЙсЖЈЮЛЖМЪЧOLTPЪ§ОнПтЃЌвдСЊЛњНЛвзЮЊжївЊЪЪгУГЁОАЃЌШчIoTЃЌCMSЃЌCustomer
dataЃЌвдМАMobile/WebЕШЕЭбгГйНЛЛЅЪНгІгУЁЃMongoDBЕФРЉеЙФмСІПЩвджЇГжPBМЖБ№ЕФЪ§ОнСП(АйЖШдЦ)вдМАУПУыАйЭђ+ЕФЛьКЯЖСаДВЂЗЂДІРэФмСІ(Adobe)ЁЃ
е§вђЮЊШчДЫЫќдкVOLUMEЁЂVELOCITYЁЂМАVARIETYЩЯУцЖМЛёЕУСЫНЯИпЕФЕУЗж(ЗжБ№ЮЊ4ЃЌ5ЃЌ5Зж)ЁЃЫќЕФЖЬАхОЭЪЧЪТЮёадЃЌACIDЫФЯюжаЃЌAtomicity
ФПЧАПЩвджЇГжЮФЕЕМЖБ№ЕФЕФдзгадЁЃвЛИіЮФЕЕПЩвдКмИДдгЃЌЕЋЪЧеыЖдЕЅИіЮФЕЕФкЫљгааДВйзїЃЌАќРЈзгЮФЕЕЃЌПЩвдЯэЪмдзгадЕФБЃжЄЁЃMongoDBВЛжЇГжЖрЮФЕЕЛђепЖрМЏКЯжЎМфЕФдзгадЃЌЕЋЪЧгЩгкЮФЕЕФЃаЭЯТЖрБэВйзївбОзЊЛЛГЩЮЊЕЅБэВйзїЃЌЫљвдЖдЖрБэдзгадЕФашЧѓвбОДѓДѓНЕЕЭЁЃConsistencyвЛжТадЗНУцЃЌMongoDBФЌШЯжЛЪЙгУжїНкЕузіЖСКЭаДРДБЃжЄЪ§ОнЕФЖСаДвЛжТадЁЃIsolation
ЩЯMongoDBжЇГжЕНСЫЕкЖўМЖБ№ЃКЬсНЛЖС(Read Committed)ЁЃ DurabilityГжОУадЗДЖјЪЧMongoDBЕФЧПЯюЃЌвЛЗнЪ§ОнЛсБЛзМЪЕЪБЕФЭЌВНЕНЦфЫћНкЕуЩЯЃЌДгЖјКмДѓЯоЖШЩЯБЃжЄСЫЪ§ОнЕФВЛЖЊЪЇадЁЃЫљвддкЪТЮёЩЯИјСЫMongoDB
2ЗжЁЃ
7. HadoopЃКОжЯогкДѓЪ§ОнЗжЮіГЁОА
ШчЙћЮвУЧгУвЛИіРзДяЭМРДБэЪОИїРрЪ§ОнПтЕФФмСІЃЌЮвУЧПЩвджБЙлЕФПДЕНИїжжММЪѕЕФИВИЧУцЁЃУцЛ§дНДѓЃЌБэЪОПЩвдЪЪгУЕФГЁОАдНЖрЁЃ
ЮвУЧЗЂЯжHadoopЦфЪЕИВИЧЕФУцЛ§ВЂВЛЪЧзюДѓЕФЃЌЫфШЛДѓМвжЎЧАЖМБЛНЬг§Й§етИіХгДѓЕФЩњЬЌЯЕЭГПЩвдАќжЮАйВЁЁЃЯждкЮвУЧПЩвдПЊЪМРэНтвЛаЉЮЊЪВУДGartnerЛсЫЕга70%
HadoopгУЛЇИаОѕЕНВЂУЛгаЛёЕУЦкЭћМлжЕЁЃHadoopЦфЪЕЩУГЄЕФОЭЪЧЖдКЃСПЪ§ОнЕФРыЯпЗжЮі(Offline
Analytical)ЃЌHDFSетИіЮФМўЯЕЭГЕФЩшМЦОЭОіЖЈСЫетвЛЕуЁЃетжжММЪѕЬиадЪЪКЯгУРДзіЧїЪЦЗжЮіЃЌгУЛЇааЮЊЭкОђЃЌЛњЦїбЇЯАЃЌЗчЯеПижЦЃЌРњЪЗЪ§ОнСєДцЕШвЛЯЕСаЗжЮіГЁОАЃЌгУРДИЈжњЩЬвЕОіВпЁЃ
ЕЋЪЧЦѓвЕНёЬьЖдЪ§ОнЕФашЧѓЃЌКЮжЙЪЧЗжЮіаЭвЛжж?
8. NoSQLЃК ВйзїаЭДѓЪ§ОнжЎЪзбЁ
ЮвУЧЫЕДѓЪ§ОнЕФМлжЕЬхЯжЗНЪНгаВЛНіНіЪЧЗжЮіаЭЃЌЛЙгавЛжжЭЌбљживЊЕФОЭЪЧдкЯпВйзїаЭ(Online Operational)ЁЃ
дкЯпВйзїаЭ(Online Operational)Ъ§ОнГЁОАдђЪЧЮвУЧЖњЪьФмЯъЕФЦѓвЕЛњЙЙШеГЃЩњВњЕФНЛвзЪ§ОнЃЌШчгУЛЇЃЌБэЕЅЃЌЖЉЕЅЃЌПтДцЃЌПЭЗўЃЌгЊЯњЕШЁЃетаЉЪ§ОнЪЙгУЕФЬиЕуОЭЪЧНЛЛЅаЭЃЌЕЭЯьгІбгГйЁЃдРДетаЉЯЕЭГЪ§ОнИїздЮЊгЊЕФЪБКђЦеЭЈЙиЯЕаЭЪ§ОнПтПЩвдДІРэЃЌЕЋЪЧдкДѓЪ§ОнЪБДњЕБЮвУЧашвЊАбетаЉВйзїаЭЪ§ОнЃЌЩѕжСАќРЈ5ФъФкЫљгаЪ§ОнЖМвЊЬсЙЉГіРДЙЉгУЛЇПьЫйЗУЮЪЕФЪБКђЃЌЛђепЕБДЋЭГДѓаЭЦѓвЕЭЛШЛвЊУцЯђЪ§АйЩЯЧЇЭђзюжегУЛЇЕФвЦЖЏAPPЗУЮЪашЧѓЕФЪБКђ(ШчвјаавЕЃЌКНПевЕЕШ)ЃЌетаЉОЭашвЊвЛИідкЯпДѓЪ§ОнНтОіЗНАИРДЪЕЯжСЫЁЃ
ЖјHadoopДѓЩњЬЌЯЕЭГКХГЦЪЧДѓЪ§ОнЮЪЬтДѓАќДѓРПЃЌ ЕЋЪЧЖЏЕННЛЛЅЪНВщбЏЛђепИќаТЕФЪБКђОЭзННѓМћжтСЫЁЃHiveЃЌ
HbasЃЌ ImpalaЕШвЛЯЕСаНтОіЗНАИвВЖМЮДФмгааЇНтОіЖдЪ§ОнЛюгУЕФЦШЧаашЧѓЁЃ
ВйзїаЭДѓЪ§ОнЕФСНДѓЙиМќММЪѕашЧѓЃКЪ§ОнСПДѓЃЌЯьгІбИЫйМАЪБЁЃ
ДгетСНИіЮЌЖШПЩвдПДГіЃЌвдMongoDBЛђепHBaseжЎРрЕФ NoSQLИќМгЪЪКЯгУРДзіВйзїаЭДѓЪ§ОнЦНЬЈЕФГЁОАЁЃ
9. MongoDB vs. HBase
ЪТЪЕЩЯHBaseе§ЪНзїЮЊвЛИіNoSQLЭЈГЃЪЧHadoopЩњЬЌЯЕЭГРягУРДжЇГжВйзїаЭДѓЪ§ОнЕФЪЕЪБЖСаДашЧѓЕФЁЃПЩЯЇHBase
ЪЧИіЗіВЛЦ№ЕФСѕАЂЖЗЃЌИњзХHadoopЕФДѓЦьеДСЫВЛЩйЙтЃЌгУЦ№РДЮЪЬтвЛЖбЃК
дЩњВЛжЇГжЖўМЖЫїв§ЃЌжЛФмЭЈЙ§жїМќЗУЮЪЁЃЩчЧјЪЕЯжЕФЖўМЖЫїв§ЙІФмжЇГжКЭЪ§ОнИќаТгаЪБбгЃЌЕМжТЭЗЬлЕФвЛжТадЮЪЬт
ПэБэФЃаЭИХФюожПМЃЌФбгкРэНтВЂЧввЊЧѓЪЕЯжНЈФЃЃЌВЛЙЛСщЛю
Ъ§ОнРраЭЕЭМЖЃЌжЛжЇГжБШЬиСїЃЌПЊЗЂКмВЛгбКУ
жЇГжГЬађгябджжРрЩй(Java,Thrift, RESTful API)
МЏШКНсЙЙИДдгЃЌга8жжВЛЭЌРраЭНкЕу
ЮовЛжТадПьееЙІФм
ашвЊЖЈЪБcompactЃЌЖдГжајЖСаДГЁОАгАЯьКмДѓ
вђЮЊетаЉдвђЃЌHBaseжЛФмдкецЕФЪЧГЌМЖДѓСПЪ§ОнЕФГЁОАЯТВХжЕЕУШЅШЬЪмзХжжжжВЛБуШЅЪЙгУЁЃ
КЭHBaseЯрБШЃЌMongoDBвВгавЛаЉздМКЕФВЛзуЃК
ЖрБэЪТЮёЛЙдкбаЗЂжаЃЌЕМжТЖддзгадвЊЧѓНЯИпашвЊЛиЙіЕФЪБКђжЛФмЭЈЙ§БфЭЈЪжЖЮРДЪЕЯжЃЌдіМгСЫПЊЗЂИДдгЖШ(ЫљгаNoSQLЛљБОЖМВЛжЇГжЪТЮё)
ГЃЮЊЖСадФмгХЛЏЖјЙФРјШпгрЃЌЕЋЪЧгжВЛЬсЙЉетаЉШпгрЪ§ОнБфЛЏЪБКђЕФздЖЏЭЌВН
ЕЋЪЧMongoDBдкШЁдУПЊЗЂепЃЌЬсИпПЊЗЂаЇТЪЩЯПЩЪЧзіЕФСмРьОЁжТЃК
жЇГжЪ§ЪЎжжГЬађгябд
газюДѓЕФПЊЗЂЩчЧј
JSONЮФЕЕФЃаЭЪЧИіГЬађдБЖМЖЎЃЌAPIЪНЙмРэЪ§ОнПтЃЌЗЧГЃздШЛ
жЇГжЖўМЖЫїв§ЃЌЙиЯЕаЭЪ§ОнПтЕФИДдгВщбЏЛљБОЖМФмжЇГж
MEAN stackЃЌШЋJSПЊЗЂ
ЮоаыORMЃЌМѕЩйЗўЮёВуКЭГжОУЛЏВуЕФФІВС
ЖЏЬЌФЃаЭЃЌЮоаыЯдЪННЈФЃЃЌЪЪКЯПьЫйПЊЗЂ
ЩЕЙЯЪНЫЎЦНРЉеЙ
е§ЪЧетаЉдвђЃЌDBTA 2017ФъЕФЁАЖСепзюЯВЛЖЕФЪ§ОнПтЁБРяУцЃЌMongoDBАСЪгШКалЃЌЖсЕУСЫЙ№ЙкЁЃ

10. КѓHadoopЪБДњЃК Ъ§ОнМДЗўЮё
НёЬьЕФЦѓвЕдкЦфЪ§зжЛЏзЊаЭЁЂЫЋФЃITМАЦѓвЕЩЯдЦВпТдЯТЃЌЗзЗздкжиаТЩѓЪгЦѓвЕЕФЦНЬЈМЖЪ§ОнПтВњЦЗВпТдЁЃЦѓвЕвбОДѓЪжБЪЭЖШыСЫДѓСПЕФзЪдДЙЙНЈЛљгкHadoopЕФЪ§ОнКўЃЌЕЋЪЧгЩгкHadoopБОЩэЬиадЫљЯоЃЌКмЖрВПЪ№БфГЩСЫ
ЁАЪ§ОнРЌЛјЖбЁБ(Data Dump)ЃЌПегаЪ§ОнЃЌЕЋЮоЗЈЪЕЯжМлжЕЁЃЦѓвЕеце§ашвЊЕФЪЧвЛЬздкЯпВйзїаЭДѓЪ§ОнНтОіЗНАИПЩвдТњзуЃК
ЛуОлРДздИїИіЖРСЂИєРыЯЕЭГЕФПЭЛЇЁЂааЯњЁЂЩњВњЕШЪ§ОнЃЌЬсЙЉ360ЖШЭГвЛЪгЭМ
КЃСПЕФадФмРЉеЙРДгІИЖШевцдіМгЕФЪ§ОнСПМАвЕЮёашЧѓ
ЬсЙЉУыМЖЪ§ОнAPI ЗўЮёРДЧ§ЖЏЪЕЪБУцАхКЭПьЫйгІгУПЊЗЂ
ДѓЙцФЃМѕЩйETLСїГЬЃЌНЕЕЭГЩБО
етжжЗНАИгІИУГфЗжЦѓвЕвбОЭЖШыЕФHadoopЬхЯЕМмЙЙЃЌЕЋЪЧдкДЫжЎЩЯЦЬЩшвЛИівдЕЭбгГйИпВЂЗЂжЇГжСщЛюAPIЮЊЬиЩЋЕФDaaS(Data
as a Service)Ъ§ОнМДЗўЮёВуЁЃ
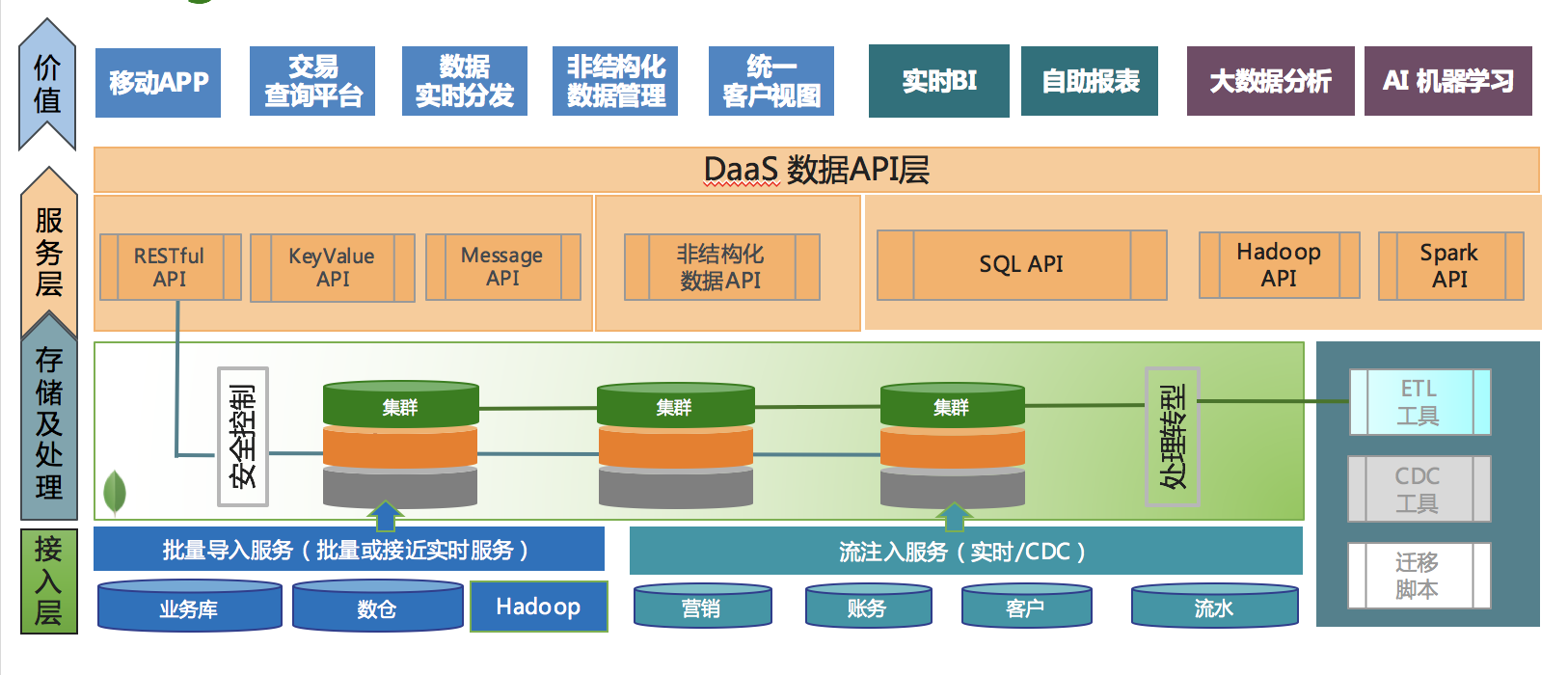
Ъ§ОнМДЗўЮёОЭЪЧвЛжжВйзїаЭДѓЪ§ОнЦНЬЈЕФОпЬхЬхЯжЁЃетжжЛљгкMongoDBЕФМмЙЙЕФгХЪЦдкгкЃК

Г§ЩЯЪіжЎЭтЃЌЛљгкЗжЦЌЛњжЦЕФздЖЏРЉШнЕФЛњжЦИќПЩвджЇГжЪ§вдАйTBМЖЕФвЕЮёЪ§ОнСП;вьЙЙЪ§ОнПтЪЕЪБЭЌВНЙЄОпПЩвдАбРДздгкЪ§ЪЎИівЕЮёЯЕЭГПтФкЕФЪ§ОнЭЌВНЕНЪ§ОнЗўЮёВуЃЌВЂЬсЙЉУыМЖЕФЪ§ОнвЛжТ;дкЭЌВНЙ§ГЬжаЪЕЯжЪ§ОнФЃаЭзЊЛЛЃЌПьЫйДюНЈЗўЮё;ХњСПЗНЪНЛђепСЌНгЦїЗНЪНжБНгНгЪмРДздHadoopМЏШКЕФЗжЮіНсЙћЃЌШчИіадЛЏБъЧЉМАЭЦМіаХЯЂЕШЃЌЬсИпHadoopЕФПЩВйзїад
ЕШЕШгХЪЦЁЃ
RBSвјаадк2015ФъОЭПЊЪМЪЕЪЉСЫетбљЕФDaaSМмЙЙЃЌЖЬЖЬСНФъЪБМфЃЌRBSЩљГЦвбОЛёЕУСЫвдЯТЕФМлжЕЃК
НЕЕЭЕФГЩБОЃКЪ§АйЭђХЗдЊЕФCoherenceМАOracleЩЬвЕЪкШЈЕФНкЪЁ
МђЛЏЕФММЪѕеЛЃКвЛЬзЗНАИвбОжЇГжСЫЪ§ЪЎИіЪ§ОнгІгУ
ПЊЗЂМгЫйЃКаТгІгУЩЯЯпЪБМфДг12ИідТЕНЪ§ИіаЧЦк
гыДЫРрЫЦЕФГЩЙІАИР§ЛЙгаАЭПЫРГвјааЃЌVodafoneЕчаХЙЋЫОЕШЃЌОљЪЧдкЦфЪ§зжЛЏзЊаЭжаОЙ§ЩѓЩїЦРЙРЃЌбЁдёСЫВйзїадЧПЃЌвзгУадИпЃЌЗжВМЪНФмСІПЩППЕФMongoDBзїЮЊЦфаТвЛДњЪ§ОнЗўЮёЦНЬЈЁЃ
11. Нсгя
УПвЛжжММЪѕЖМгаЫќЕФгІгУГЁОАЃЌдкетЦЊЮФеТРяЮвУЧЯывЊЬжТлЕФЪЧвЛжжВйзїаЭДѓЪ§ОнНтОіЗНАИЃЌЫљвдЮвУЧЛЈСЫВЛЩйБЪФЋдкNoSQLВЂШЯЮЊMongoDBЪЧвЛИіЗЧГЃВЛДэЕФбЁдёЁЃNewSQLЛђаэЛсЪЧвЛИіЧБдкЕФбЁдёЃЌШчЙћВЛЪЧвђЮЊЯждкЫќЛЙУЛЗЂеЙГЩЪьЁЃПіЧвЃЌNewSQLЖдАыНсЙЙЛЏЁЂЗЧНсЙЙЛЏЪ§ОнЕФашЧѓжЇГжЙРМЦвВЛЙЪЧЮоЗЈКмКУТњзуЃЌ
ЫљвдЮвУЧЪУФПвдД§ЁЃ
зюКѓЃЌдкзівЛИіДѓаЭОіВпЕФЪБКђЃЌЮвУЧвЊГфЗжПМТЧЕНЦѓвЕЖдММЪѕФмСІЕФашЧѓЃЌАбашЧѓСаГіРДЃЌШЛКѓЖдееЪ§ОнВњЦЗИїздЕФГЄЖЬАхЃЌгаРэТлгаЗНЗЈЕФНјаабЁаЭЃЌВЂЖдзюКѓ2-3ИібЁдёНјааPOCбщжЄЃЌзюжеШЗЖЈКЯЪЪЕФЗНАИЁЃ
|









