| БрМЭЦМі: |
БОЮФРДздгкВЉПЭдАЃЌApache
Spark ЪЧзЈЮЊДѓЙцФЃЪ§ОнДІРэЖјЩшМЦЕФПьЫйЭЈгУЕФМЦЫув§ЧцЁЃ
|
|
Spark:
Apache Spark ЪЧзЈЮЊДѓЙцФЃЪ§ОнДІРэЖјЩшМЦЕФПьЫйЭЈгУЕФМЦЫув§ЧцЁЃ
SparkЪЧUC Berkeley AMP lab (МгжнДѓбЇВЎПЫРћЗжаЃЕФAMPЪЕбщЪв)ЫљПЊдДЕФРрHadoop
MapReduceЕФЭЈгУВЂааПђМмЃЌSparkЃЌгЕгаHadoop MapReduceЫљОпгаЕФгХЕуЃЛЕЋВЛЭЌгкMapReduceЕФЪЧJobжаМфЪфГіНсЙћПЩвдБЃДцдкФкДцжаЃЌДгЖјВЛдйашвЊЖСаДHDFSЃЌвђДЫSparkФмИќКУЕиЪЪгУгкЪ§ОнЭкОђгыЛњЦїбЇЯАЕШашвЊЕќДњЕФMapReduceЕФЫуЗЈЁЃ
Spark ЪЧвЛжжгы Hadoop ЯрЫЦЕФПЊдДМЏШКМЦЫуЛЗОГЃЌЕЋЪЧСНепжЎМфЛЙДцдквЛаЉВЛЭЌжЎДІЃЌетаЉгагУЕФВЛЭЌжЎДІЪЙ
Spark дкФГаЉЙЄзїИКдиЗНУцБэЯжЕУИќМггХдНЃЌЛЛОфЛАЫЕЃЌSpark ЦєгУСЫФкДцЗжВМЪ§ОнМЏЃЌГ§СЫФмЙЛЬсЙЉНЛЛЅЪНВщбЏЭтЃЌЫќЛЙПЩвдгХЛЏЕќДњЙЄзїИКдиЁЃ
Spark ЪЧдк Scala гябджаЪЕЯжЕФЃЌЫќНЋ Scala гУзїЦфгІгУГЬађПђМмЁЃгы
Hadoop ВЛЭЌЃЌSpark КЭ Scala ФмЙЛНєУмМЏГЩЃЌЦфжаЕФ Scala ПЩвдЯёВйзїБОЕиМЏКЯЖдЯѓвЛбљЧсЫЩЕиВйзїЗжВМЪНЪ§ОнМЏЁЃ
ОЁЙмДДНЈ Spark ЪЧЮЊСЫжЇГжЗжВМЪНЪ§ОнМЏЩЯЕФЕќДњзївЕЃЌЕЋЪЧЪЕМЪЩЯЫќЪЧЖд Hadoop ЕФВЙГфЃЌПЩвддк
Hadoop ЮФМўЯЕЭГжаВЂаадЫааЁЃЭЈЙ§УћЮЊ Mesos ЕФЕкШ§ЗНМЏШКПђМмПЩвджЇГжДЫааЮЊЁЃSpark
гЩМгжнДѓбЇВЎПЫРћЗжаЃ AMP ЪЕбщЪв (Algorithms, Machines, and People
Lab) ПЊЗЂЃЌПЩгУРДЙЙНЈДѓаЭЕФЁЂЕЭбгГйЕФЪ§ОнЗжЮігІгУГЬађЁЃ
SparkЕФадФмЬиЕуЃК
1.ИќПьЕФЫйЖШЃКФкДцМЦЫуЯТЃЌSpark БШ Hadoop Пь100БЖЁЃ
1.ФкДцМЦЫув§ЧцЃЌЬсЙЉCacheЛњжЦРДжЇГжашвЊЗДИДЕќДњМЦЫуЛђепЖрДЮЪ§ОнЙВЯэЃЌМѕЩйЪ§ОнЖСШЁЕФI/OПЊЯњ
2.DAGв§ЧцЃЌМѕЩйЖрДЮМЦЫужЎМфжаМфНсЙћаДЕНHDFSЕФПЊЯњЃЛ3.ЪЙгУЖрЯпГЬГиФЃаЭРДМѕЩйtaskЦєЖЏПЊЯњЃЌshuffleЙ§ГЬжаБмУтВЛБивЊЕФsortВйзївбОМѕЩйДХХЬI/OВйзїЃЛ
2.взгУадЃК
1.Spark ЬсЙЉСЫ80ЖрИіИпМЖдЫЫуЗћЁЃ
2.ЬсЙЉСЫЗсИЛЕФAPIЃЌжЇГжJAVA,Scala,PythonКЭRЫФжжгябдЃЛ
3.ДњТыСПБШMapReduceЩй2~5БЖЃЛ
3.ЭЈгУадЃКSpark ЬсЙЉСЫДѓСПЕФПтЃЌАќРЈSQLЁЂDataFramesЁЂMLlibЁЂGraphXЁЂSpark
StreamingЁЃ ПЊЗЂепПЩвддкЭЌвЛИігІгУГЬађжаЮоЗьзщКЯЪЙгУетаЉПтЁЃ
4.жЇГжЖржжзЪдДЙмРэЦїЃКSpark жЇГж Hadoop YARNЃЌApache MesosЃЌМАЦфздДјЕФЖРСЂМЏШКЙмРэЦї
SparkЛљБОдРэЃК
Spark StreamingЃКЙЙНЈдкSparkЩЯДІРэStreamЪ§ОнЕФПђМмЃЌЛљБОЕФдРэЪЧНЋStreamЪ§ОнЗжГЩаЁЕФЪБМфЦЌЖЯЃЈМИУыЃЉЃЌвдРрЫЦbatchХњСПДІРэЕФЗНЪНРДДІРэетаЁВПЗжЪ§ОнЁЃSpark
StreamingЙЙНЈдкSparkЩЯЃЌвЛЗНУцЪЧвђЮЊSparkЕФЕЭбгГйжДаав§ЧцЃЈ100ms+ЃЉЃЌЫфШЛБШВЛЩЯзЈУХЕФСїЪНЪ§ОнДІРэШэМўЃЌвВПЩвдгУгкЪЕЪБМЦЫуЃЌСэвЛЗНУцЯрБШЛљгкRecordЕФЦфЫќДІРэПђМмЃЈШчStormЃЉЃЌвЛВПЗжевРРЕЕФRDDЪ§ОнМЏПЩвдДгдДЪ§ОнжиаТМЦЫуДяЕНШнДэДІРэФПЕФЁЃДЫЭтаЁХњСПДІРэЕФЗНЪНЪЙЕУЫќПЩвдЭЌЪБМцШнХњСПКЭЪЕЪБЪ§ОнДІРэЕФТпМКЭЫуЗЈЁЃЗНБуСЫвЛаЉашвЊРњЪЗЪ§ОнКЭЪЕЪБЪ§ОнСЊКЯЗжЮіЕФЬиЖЈгІгУГЁКЯЁЃ
SparkБГОАЃК
1.MapReduceОжЯоад:
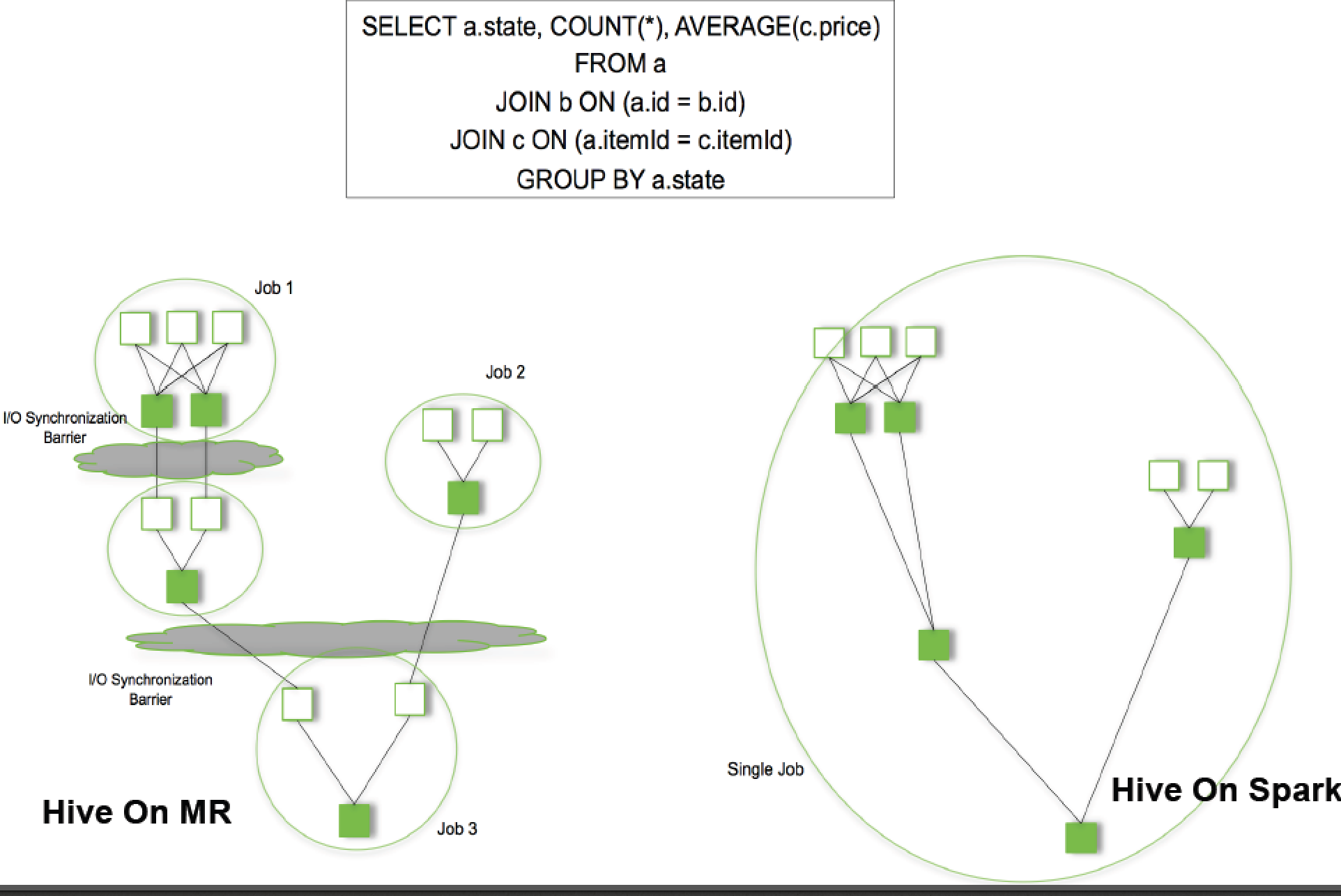
1.НіжЇГжMapКЭReduceСНжжВйзїЃЛ2.ДІРэаЇТЪЕЭаЇЃЛВЛЪЪКЯЕќДњМЦЫуЃЈШчЛњЦїбЇЯАЁЂЭММЦЫуЕШЃЉЃЌНЛЛЅЪНДІРэЃЈЪ§ОнЭкОђЃЉКЭСїЪЇДІРэЃЈШежОЗжЮіЃЉ
3.MapжаМфНсЙћашвЊаДДХХЬЃЌReduceаДHDFSЃЌЖрИіMRжЎМфЭЈЙ§HDFSНЛЛЛЪ§ОнЃЛ
4.ШЮЮёЕїЖШКЭЦєЖЏПЊЯњДѓЃЛ
5.ЮоЗЈГфЗжРћгУФкДцЃЛЃЈгыMRВњЩњЪБДњгаЙиЃЌMRГіЯжЪБФкДцМлИёБШНЯИпЃЌВЩгУДХХЬДцДЂДњМлаЁЃЉ
6.MapЖЫКЭReduceЖЫОљашвЊХХађЃЛ
2.MapReduceБрГЬВЛЙЛСщЛюЁЃЃЈБШНЯScalaКЏЪ§ЪНБрГЬЖјбдЃЉ3.ПђМмЖрбљЛЏ[ВЩгУвЛжжПђМмММЪѕ(Spark)ЭЌЪБЪЕЯжХњДІРэЁЂСїЪНМЦЫуЁЂНЛЛЅЪНМЦЫу]ЃК
1.ХњДІРэЃКMapReduceЁЂHiveЁЂPig;
2.СїЪНМЦЫу:Storm
3.НЛЛЅЪНМЦЫу:ImpalaЁЁЁЁ
SparkКЫаФИХФюЃК
1.RDDЃКResilient Distributed Datasets,ЕЏадЗжВМЪНЪ§ОнМЏ
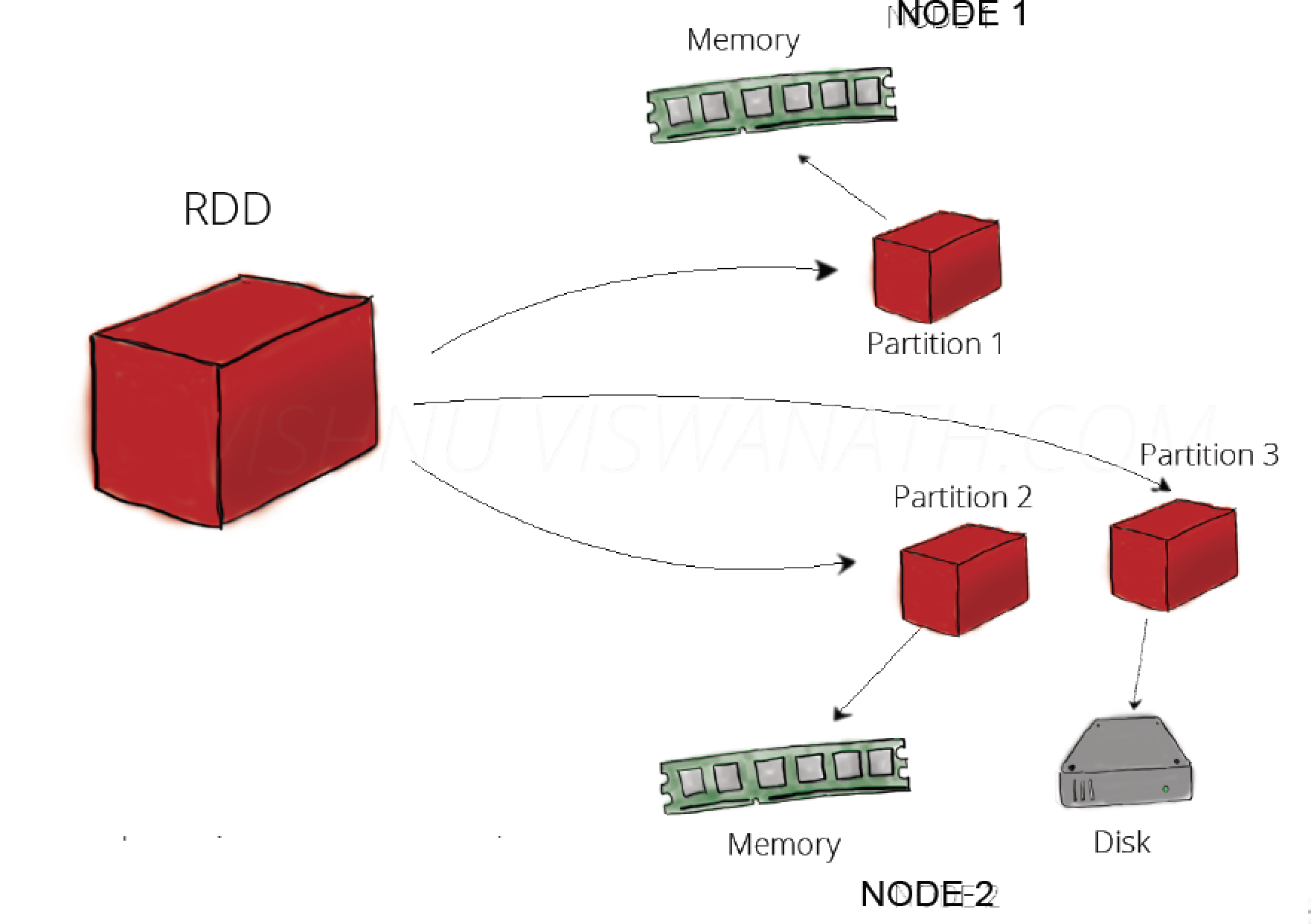
1.ЗжВМдкМЏШКжаЕФжЛЖСЖдЯѓМЏКЯЃЈгЩЖрИіPartitionЁЁЙЙГЩЃЉЃЛ
2.ПЩвдДцДЂдкДХХЬЛђФкДцжаЃЈЖржжДцДЂМЖБ№ЃЉЃЛ
3.ЭЈЙ§ВЂааЁАзЊЛЛЁБВйзїЙЙдьЃЛ
4.ЪЇаЇКѓздЖЏжиЙЙЃЛ
5.RDDЛљБОВйзїЃЈoperatorЃЉ
TransformationОпЬхФкШн
map(func) :ЗЕЛивЛИіаТЕФЗжВМЪНЪ§ОнМЏЃЌгЩУПИіддЊЫиОЙ§funcКЏЪ§зЊЛЛКѓзщГЩ
filter(func) : ЗЕЛивЛИіаТЕФЪ§ОнМЏЃЌгЩОЙ§funcКЏЪ§КѓЗЕЛижЕЮЊtrueЕФддЊЫизщГЩ
*flatMap(func) : РрЫЦгкmapЃЌЕЋЪЧУПвЛИіЪфШыдЊЫиЃЌЛсБЛгГЩфЮЊ0ЕНЖрИіЪфГідЊЫиЃЈвђДЫЃЌfuncКЏЪ§ЕФЗЕЛижЕЪЧвЛИіSeqЃЌЖјВЛЪЧЕЅвЛдЊЫиЃЉ
flatMap(func) : РрЫЦгкmapЃЌЕЋЪЧУПвЛИіЪфШыдЊЫиЃЌЛсБЛгГЩфЮЊ0ЕНЖрИіЪфГідЊЫиЃЈвђДЫЃЌfuncКЏЪ§ЕФЗЕЛижЕЪЧвЛИіSeqЃЌЖјВЛЪЧЕЅвЛдЊЫиЃЉ
sample(withReplacement, frac, seed) :
ИљОнИјЖЈЕФЫцЛњжжзгseedЃЌЫцЛњГщбљГіЪ§СПЮЊfracЕФЪ§Он
union(otherDataset) : ЗЕЛивЛИіаТЕФЪ§ОнМЏЃЌгЩдЪ§ОнМЏКЭВЮЪ§СЊКЯЖјГЩ
groupByKey([numTasks]) :
дквЛИігЩЃЈK,VЃЉЖдзщГЩЕФЪ§ОнМЏЩЯЕїгУЃЌЗЕЛивЛИіЃЈKЃЌSeq[V])ЖдЕФЪ§ОнМЏЁЃзЂвтЃКФЌШЯЧщПіЯТЃЌЪЙгУ8ИіВЂааШЮЮёНјааЗжзщЃЌФуПЩвдДЋШыnumTaskПЩбЁВЮЪ§ЃЌИљОнЪ§ОнСПЩшжУВЛЭЌЪ§ФПЕФTask
reduceByKey(func, [numTasks]) : дквЛИіЃЈKЃЌV)ЖдЕФЪ§ОнМЏЩЯЪЙгУЃЌЗЕЛивЛИіЃЈKЃЌVЃЉЖдЕФЪ§ОнМЏЃЌkeyЯрЭЌЕФжЕЃЌЖМБЛЪЙгУжИЖЈЕФreduceКЏЪ§ОлКЯЕНвЛЦ№ЁЃКЭgroupbykeyРрЫЦЃЌШЮЮёЕФИіЪ§ЪЧПЩвдЭЈЙ§ЕкЖўИіПЩбЁВЮЪ§РДХфжУЕФЁЃ
join(otherDataset, [numTasks]) :
дкРраЭЮЊЃЈK,V)КЭЃЈK,W)РраЭЕФЪ§ОнМЏЩЯЕїгУЃЌЗЕЛивЛИіЃЈK,(V,W))ЖдЃЌУПИіkeyжаЕФЫљгадЊЫиЖМдквЛЦ№ЕФЪ§ОнМЏ
groupWith(otherDataset, [numTasks]) : дкРраЭЮЊЃЈK,V)КЭ(K,W)РраЭЕФЪ§ОнМЏЩЯЕїгУЃЌЗЕЛивЛИіЪ§ОнМЏЃЌзщГЩдЊЫиЮЊЃЈK,
Seq[V], Seq[W]) TuplesЁЃетИіВйзїдкЦфЫќПђМмЃЌГЦЮЊCoGroup
cartesian(otherDataset) : ЕбПЈЖћЛ§ЁЃЕЋдкЪ§ОнМЏTКЭUЩЯЕїгУЪБЃЌЗЕЛивЛИі(TЃЌUЃЉЖдЕФЪ§ОнМЏЃЌЫљгадЊЫиНЛЛЅНјааЕбПЈЖћЛ§ЁЃ
flatMap(func) :
РрЫЦгкmapЃЌЕЋЪЧУПвЛИіЪфШыдЊЫиЃЌЛсБЛгГЩфЮЊ0ЕНЖрИіЪфГідЊЫиЃЈвђДЫЃЌfuncКЏЪ§ЕФЗЕЛижЕЪЧвЛИіSeqЃЌЖјВЛЪЧЕЅвЛдЊЫиЃЉ
ActionsОпЬхФкШн
reduce(func) : ЭЈЙ§КЏЪ§funcОлМЏЪ§ОнМЏжаЕФЫљгадЊЫиЁЃFuncКЏЪ§НгЪм2ИіВЮЪ§ЃЌЗЕЛивЛИіжЕЁЃетИіКЏЪ§БиаыЪЧЙиСЊадЕФЃЌШЗБЃПЩвдБЛе§ШЗЕФВЂЗЂжДаа
collect() : дкDriverЕФГЬађжаЃЌвдЪ§зщЕФаЮЪНЃЌЗЕЛиЪ§ОнМЏЕФЫљгадЊЫиЁЃетЭЈГЃЛсдкЪЙгУfilterЛђепЦфЫќВйзїКѓЃЌЗЕЛивЛИізуЙЛаЁЕФЪ§ОнзгМЏдйЪЙгУЃЌжБНгНЋећИіRDDМЏCollectЗЕЛиЃЌКмПЩФмЛсШУDriverГЬађOOM
count() : ЗЕЛиЪ§ОнМЏЕФдЊЫиИіЪ§
take(n) : ЗЕЛивЛИіЪ§зщЃЌгЩЪ§ОнМЏЕФЧАnИідЊЫизщГЩЁЃзЂвтЃЌетИіВйзїФПЧАВЂЗЧдкЖрИіНкЕуЩЯЃЌВЂаажДааЃЌЖјЪЧDriverГЬађЫљдкЛњЦїЃЌЕЅЛњМЦЫуЫљгаЕФдЊЫи(GatewayЕФФкДцбЙСІЛсдіДѓЃЌашвЊНїЩїЪЙгУЃЉ
first() : ЗЕЛиЪ§ОнМЏЕФЕквЛИідЊЫиЃЈРрЫЦгкtake(1)ЃЉ
saveAsTextFile(path) : НЋЪ§ОнМЏЕФдЊЫиЃЌвдtextfileЕФаЮЪНЃЌБЃДцЕНБОЕиЮФМўЯЕЭГЃЌhdfsЛђепШЮКЮЦфЫќhadoopжЇГжЕФЮФМўЯЕЭГЁЃSparkНЋЛсЕїгУУПИідЊЫиЕФtoStringЗНЗЈЃЌВЂНЋЫќзЊЛЛЮЊЮФМўжаЕФвЛааЮФБО
saveAsSequenceFile(path) : НЋЪ§ОнМЏЕФдЊЫиЃЌвдsequencefileЕФИёЪНЃЌБЃДцЕНжИЖЈЕФФПТМЯТЃЌБОЕиЯЕЭГЃЌhdfsЛђепШЮКЮЦфЫќhadoopжЇГжЕФЮФМўЯЕЭГЁЃRDDЕФдЊЫиБиаыгЩkey-valueЖдзщГЩЃЌВЂЖМЪЕЯжСЫHadoopЕФWritableНгПкЃЌЛђвўЪНПЩвдзЊЛЛЮЊWritableЃЈSparkАќРЈСЫЛљБОРраЭЕФзЊЛЛЃЌР§ШчIntЃЌDoubleЃЌStringЕШЕШЃЉ
foreach(func) : дкЪ§ОнМЏЕФУПвЛИідЊЫиЩЯЃЌдЫааКЏЪ§funcЁЃетЭЈГЃгУгкИќаТвЛИіРлМгЦїБфСПЃЌЛђепКЭЭтВПДцДЂЯЕЭГзіНЛЛЅ
ЫузгЗжРр
ДѓжТПЩвдЗжЮЊШ§ДѓРрЫузг:
ValueЪ§ОнРраЭЕФTransformationЫузгЃЌетжжБфЛЛВЂВЛДЅЗЂЬсНЛзївЕЃЌеыЖдДІРэЕФЪ§ОнЯюЪЧValueаЭЕФЪ§ОнЁЃ
Key-ValueЪ§ОнРраЭЕФTransfromationЫузгЃЌетжжБфЛЛВЂВЛДЅЗЂЬсНЛзївЕЃЌеыЖдДІРэЕФЪ§ОнЯюЪЧKey-ValueаЭЕФЪ§ОнЖдЁЃ
ActionЫузгЃЌетРрЫузгЛсДЅЗЂSparkContextЬсНЛJobзївЕЁЃ
3.ЪОР§ЃК
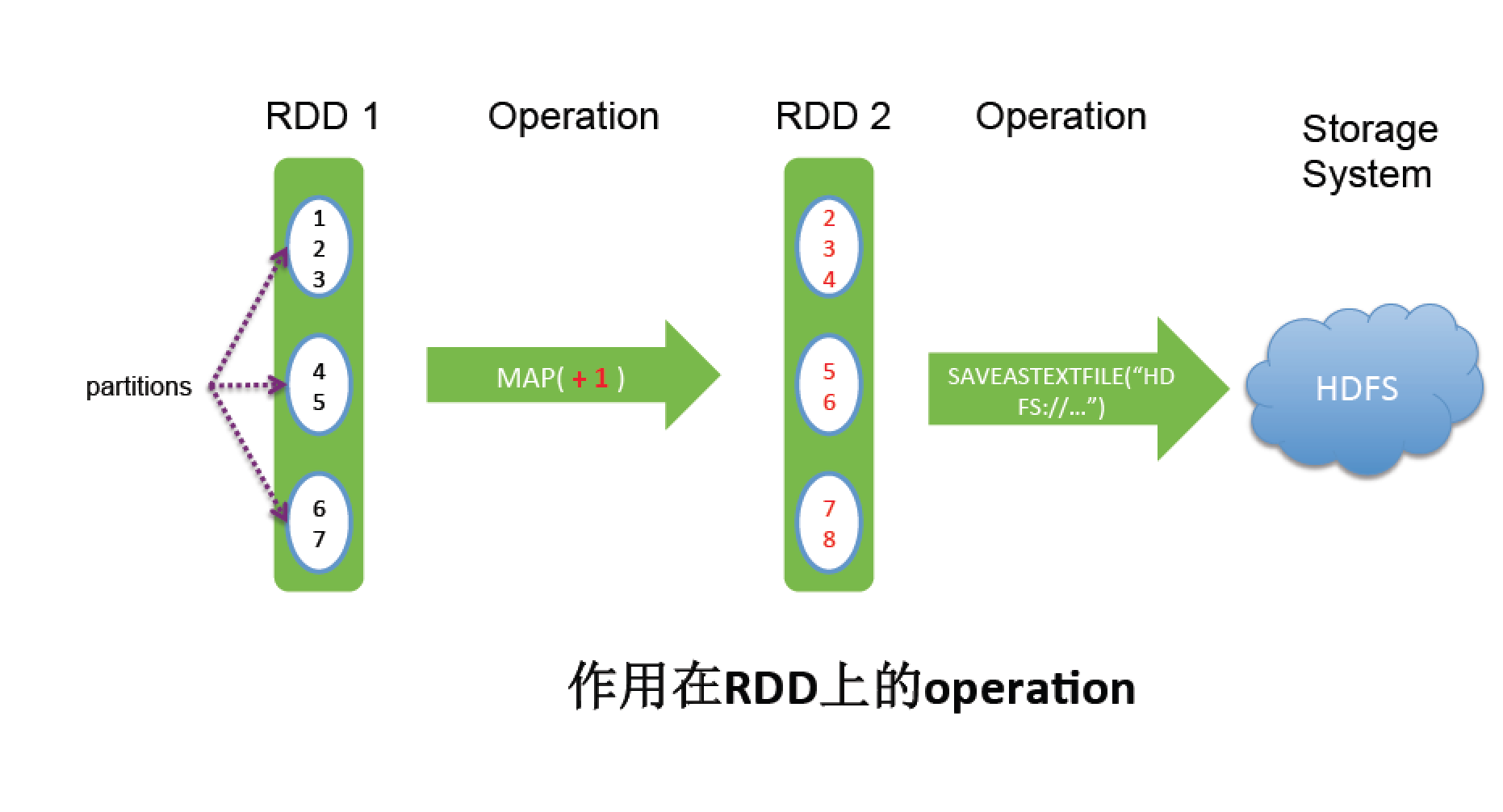
4.Spark RDD cache/persist
1.Spark RDD cache
1.дЪаэНЋRDDЛКДцЕНФкДцжаЛђДХХЬЩЯЃЌвдБугкжигУ
2.ЬсЙЉСЫЖржжЛКДцМЖБ№ЃЌвдБугкгУЛЇИљОнЪЕМЪашЧѓНјааЕїећ

3.cacheЪЙгУ

2.жЎЧАгУMapReduceЪЕЯжЙ§WordCountЃЌЯждкЮвУЧгУScalaЪЕЯжЯТwordCount.ЪЧВЛЪЧКмМђНрФиЃПЃЁ
3.ЙигкRDDЕФTransformationгыActionЕФЬиЕуЮвУЧНщЩмЯТЃЛ
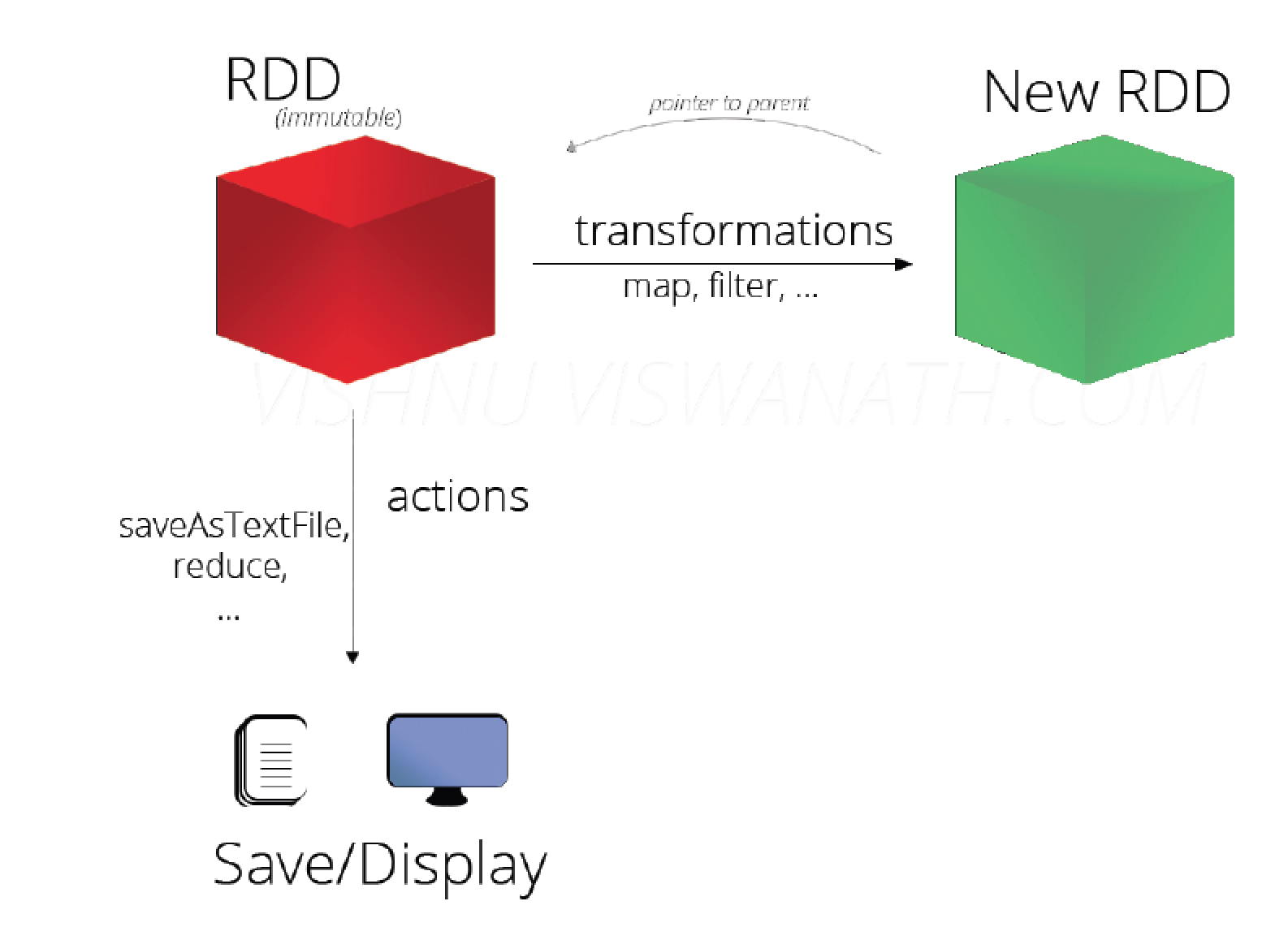
1.НгПкЖЈвхЗНЪНВЛЭЌЃК
Transformation: RDD[X]-->RDD[y]
Action:RDD[x]-->Z (ZВЛЪЧвЛИіRDDЃЌПЩФмЪЧвЛИіЛљБОРраЭЃЌЪ§зщЕШЃЉ
2.ЖшаджДааЃК
TransformationЃКжЛЛсМЧТМRDDзЊЛЏЙиЯЕЃЌВЂВЛЛсДЅЗЂМЦЫу
Action:ЪЧДЅЗЂГЬађжДааЃЈЗжВМЪН)ЕФЫузгЁЃ
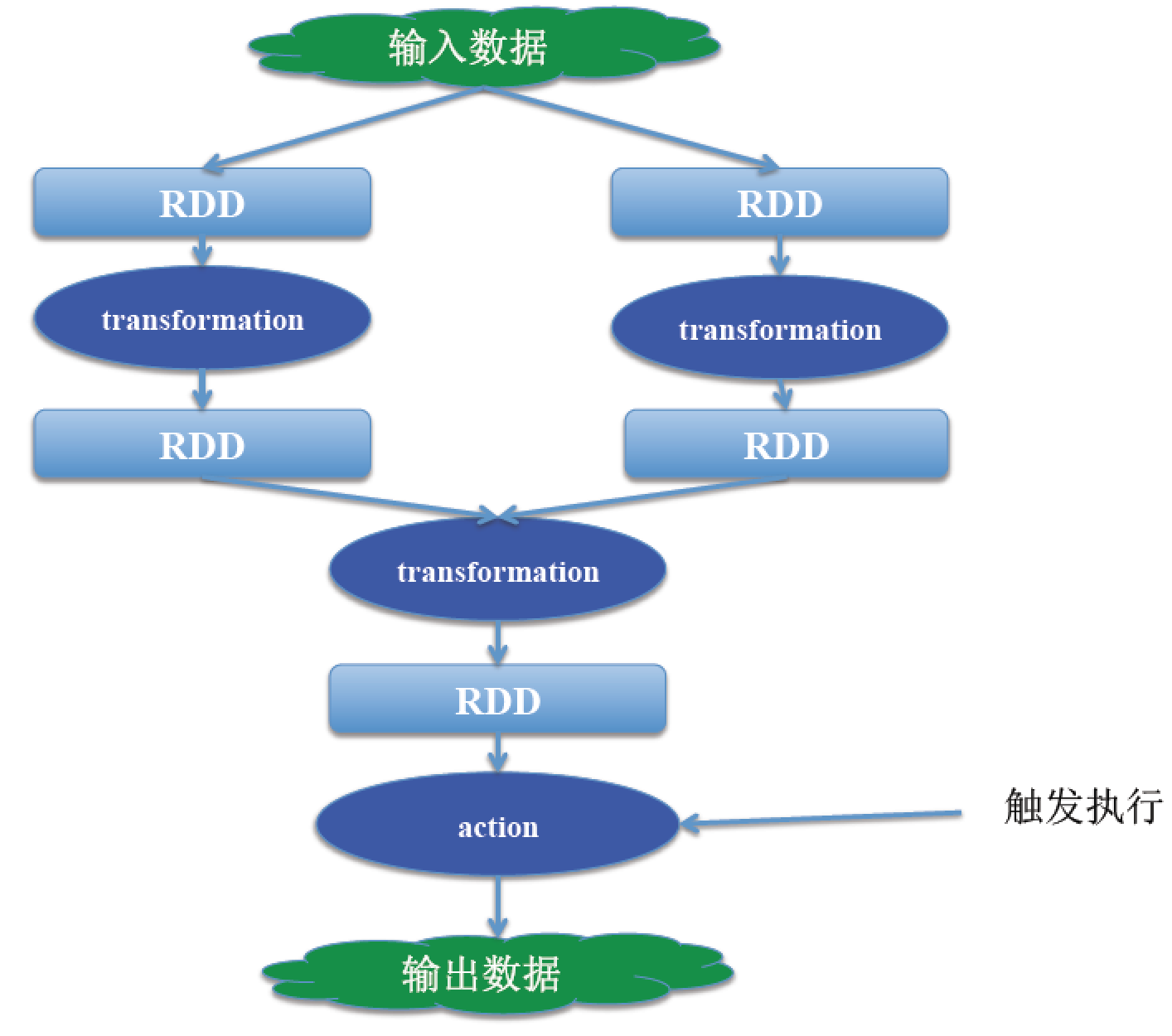
ГЬађЕФжДааСїГЬЃК
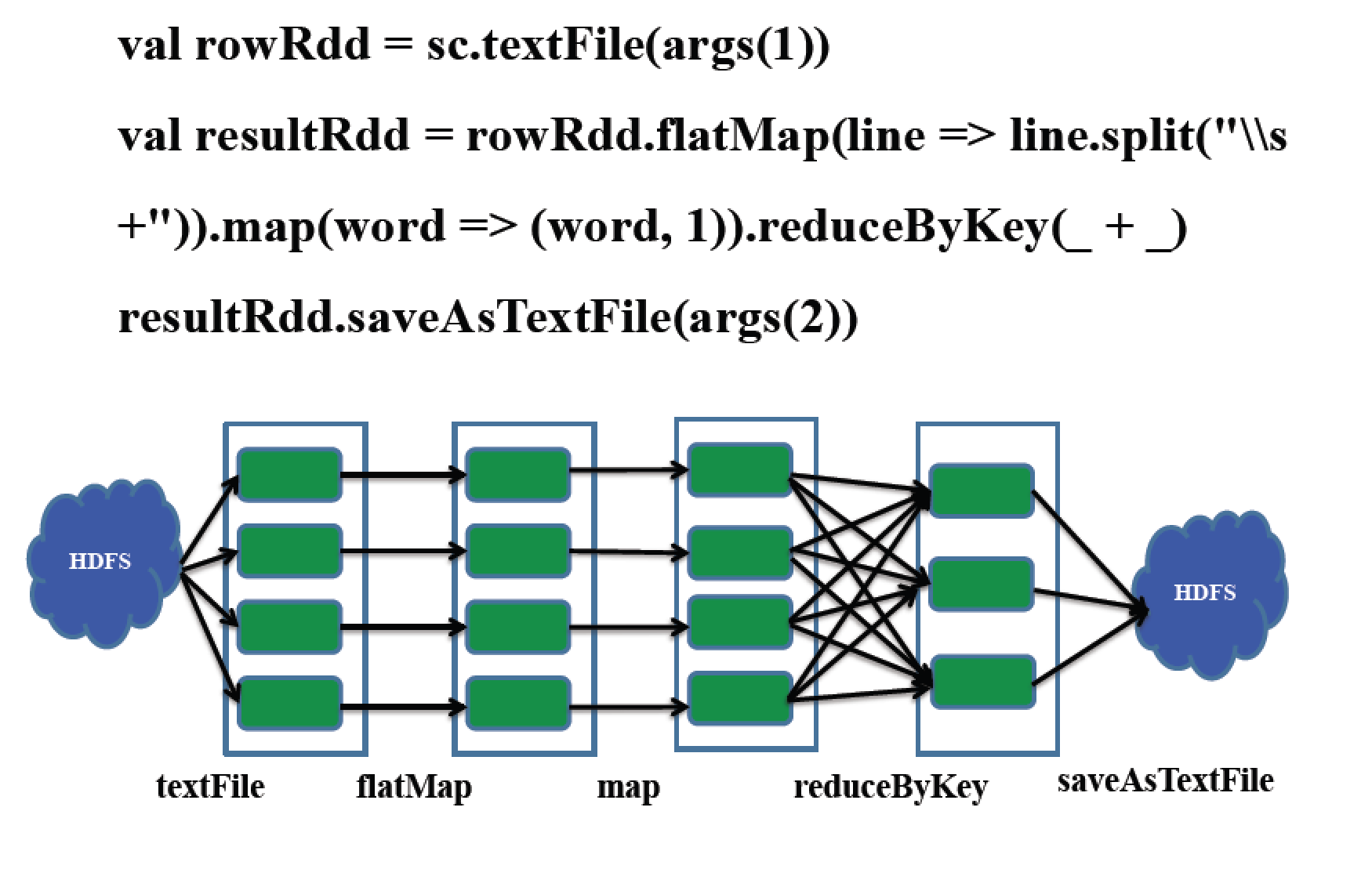
SparkдЫааФЃЪНЃК
1.Local(БОЕиФЃЪНЃЉЃК
1.ЕЅЛњдЫааЃЌЭЈГЃгУгкВтЪдЃЛ
1.local:жЛЦєЖЏвЛИіexecutor
2.local[k]:ЦєЖЏkИіexecutor
3.local[*]:ЦєЖЏИњcpuЪ§ФПЯрЭЌЕФexecutor
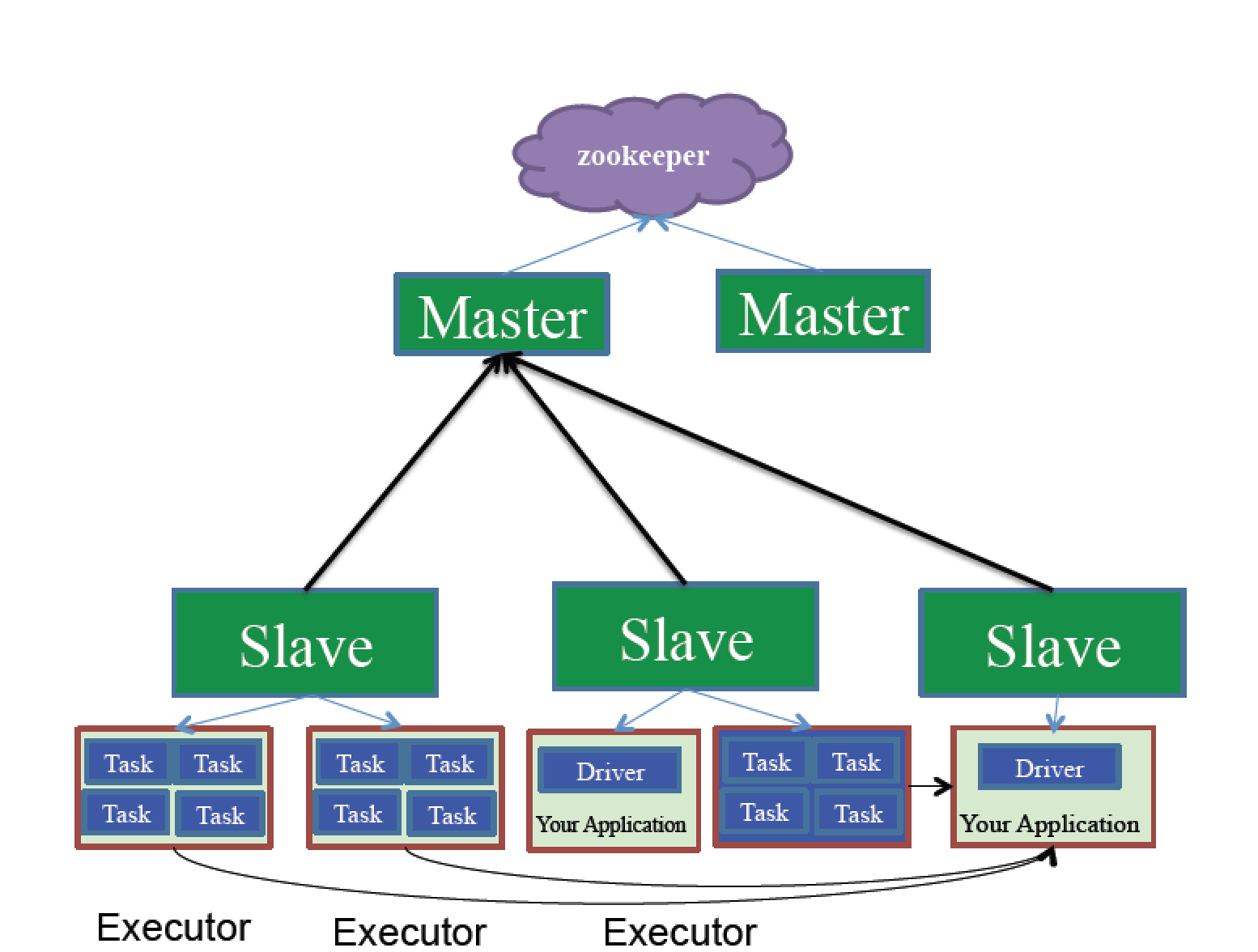
2.standalone(ЖРСЂФЃЪНЃЉ
1.ЖРСЂдЫаадквЛИіМЏШКжа
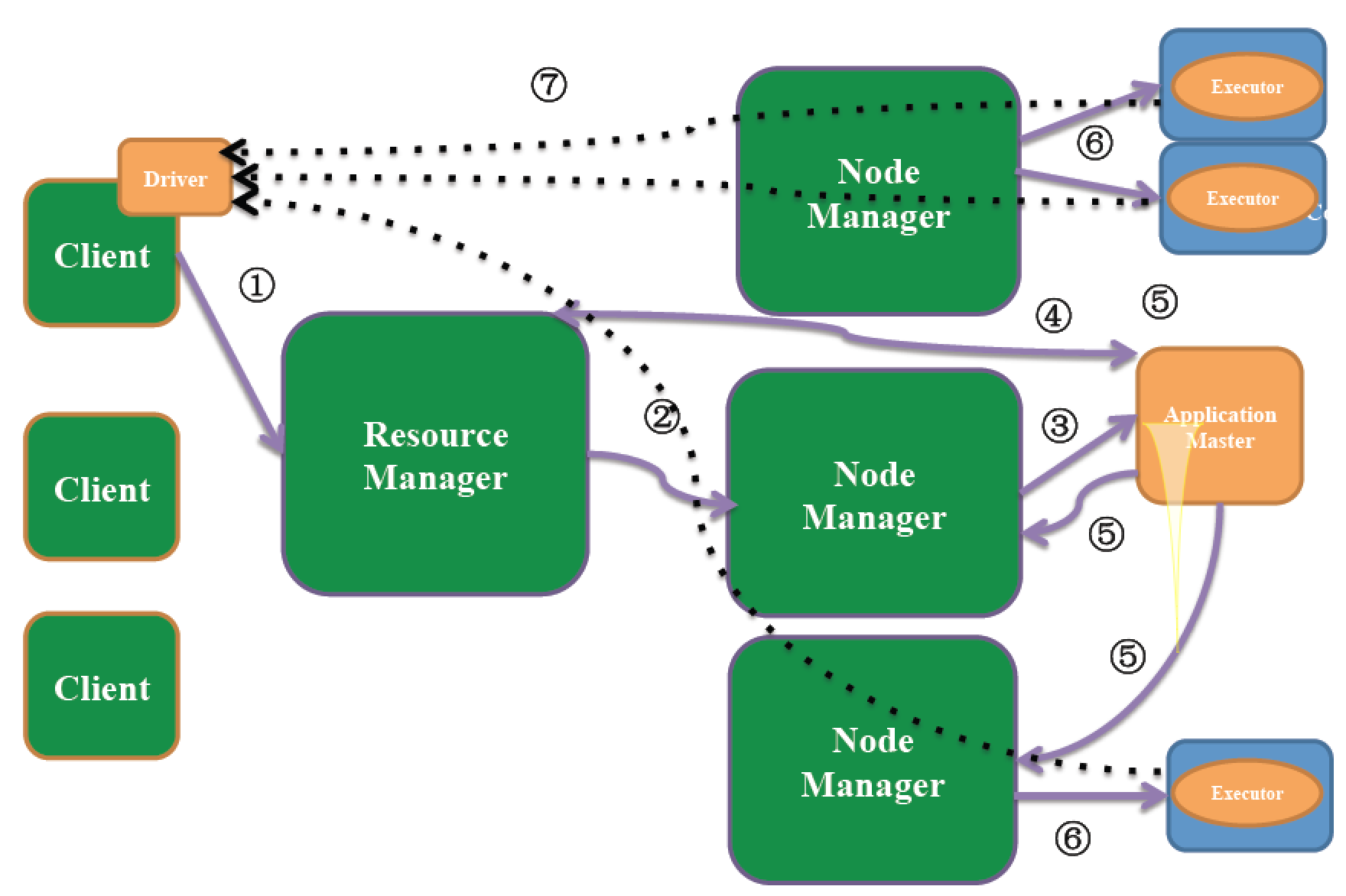
3.Yarn/mesos
1.дЫаадкзЪдДЙмРэЯЕЭГЩЯЃЌБШШчYarnЛђmesos
2.Spark On YarnДцдкСНжжФЃЪН
1.yarn-client
2.yanr-cluster
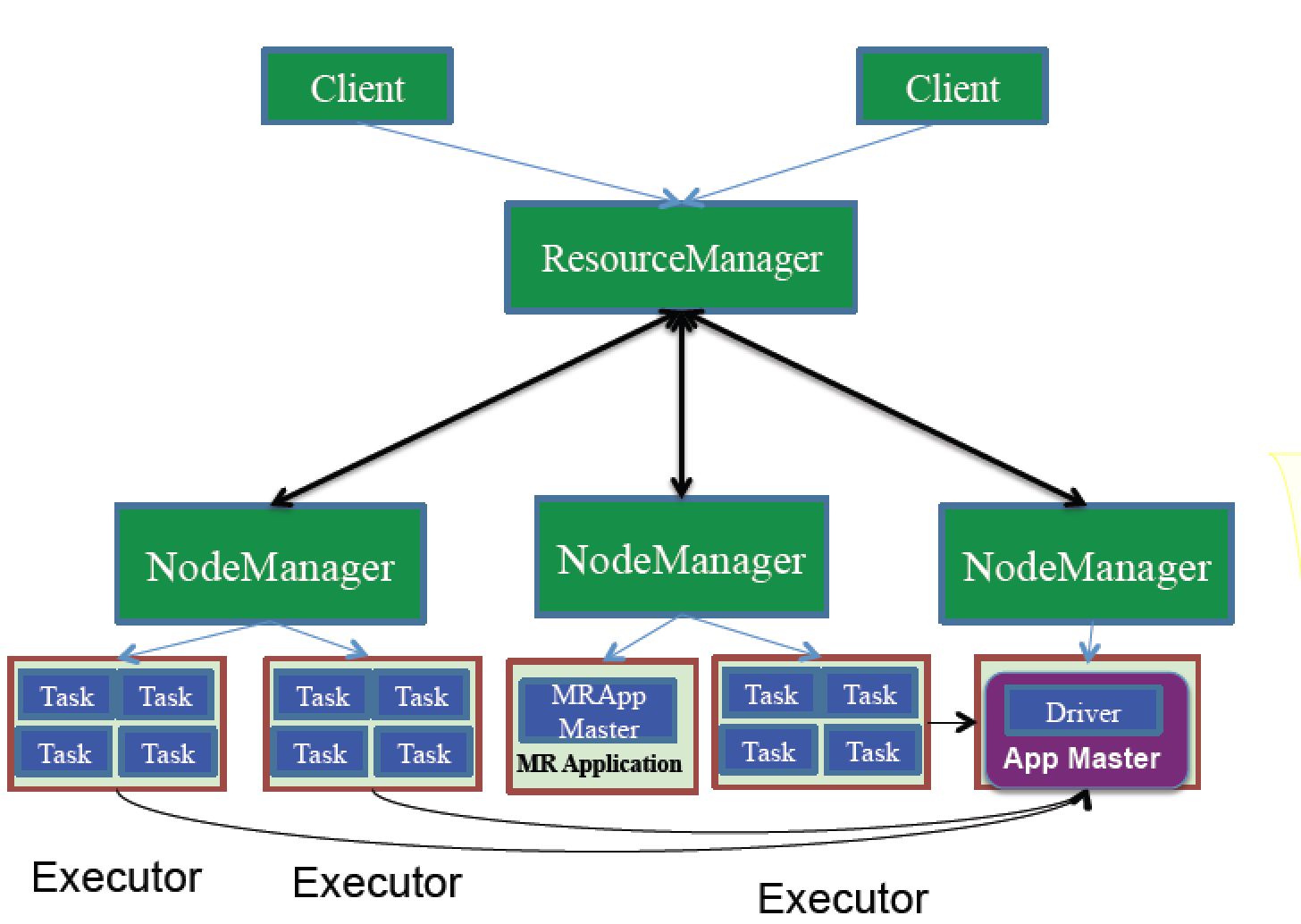
3.БШНЯСНжжЗНЪНЧјБ№ЃК
SparkдкЦѓвЕжаЕФгІгУГЁОА
1.ЛљгкШежОЪ§ОнЕФПьЫйВщбЏЯЕЭГвЕЮёЃЛ
1.ЙЙНЈгкSparkжЎЩЯЕФSparkSQL ,РћгУЦфПьЫйвдМАФкДцБэЕШгХЪЦЃЌГаЕЃСЫШежОЪ§ОнЕФМДЯЏВщбЏЙЄзїЁЃ
2.ЕфаЭЫуЗЈЕФSparkЪЕЯж
1.дЄВтгУЛЇЕФЙуИцЕуЛїИХТЪЃЛ
2.МЦЫуСНИіКУгбМфЕФЙВЭЌКУгбЪ§ЃЛ
3.гУгкETLЕФSparkSQLКЭDAGШЮЮёЃЛ |









