| БрМЭЦМі: |
БОЮФРДздгкВЉПЭдА,БОЮФЭЈЙ§БОЕиВтЪдДњТыЃЌМђЕЅЕФНщЩмСЫstormЕФбЇЯАЃЌЯЃЭћЖдФњЕФбЇЯАгаАяжњЁЃ
|
|
1.HADOOPгыSTORMБШНЯ
Ъ§ОнРДдДЃКHADOOPДІРэЕФЪЧHDFSЩЯTBМЖБ№ЕФЪ§Он(РњЪЗЪ§Он)ЃЌSTORMЪЧДІРэЕФЪЧЪЕЪБаТдіЕФФГвЛБЪЪ§Он(ЪЕЪБЪ§Он)ЃЌДІРэвЛаЉМђЕЅЕФвЕЮёТпМЃЛ
ДІРэЙ§ГЬЃКHADOOPЪЧЗжMAPНзЖЮЕНREDUCEНзЖЮЃЌSTORMЪЧгЩгУЛЇЖЈвхДІРэСїГЬЃЌСїГЬжаПЩвдАќКЌЖрИіВНжшЃЌУПИіВНжшПЩвдЪЧЪ§ОндД(SPOUT)ЛђДІРэТпМ(BOLT)ЃЛ
ЪЧЗёНсЪјЃКHADOOPзюКѓЪЧвЊНсЪјЕФЃЌSTORMЪЧУЛгаНсЪјзДЬЌЃЌЕНзюКѓвЛВНЪБЃЌОЭЭЃдкФЧЃЌжБЕНгааТЪ§ОнНјШыЪБдйДгЭЗПЊЪМЃЌЃЈSPOUTвЛжБбЛЗnextTuple()ЗНЗЈЃЌBOLTЕБгаНгЪмЕНЯћЯЂОЭЕїгУexecute(Tuple
inputЃЉЗНЗЈЃЉЃЛ
ДІРэЫйЖШЃКHADOOPЪЧвдДІРэHDFSЩЯTBМЖБ№Ъ§ОнЮЊФПЕФЃЌДІРэЫйЖШТ§ЃЌSTORMЪЧжЛвЊДІРэаТдіЕФФГвЛБЪЪ§ОнМДПЩЃЌПЩвдзіЕНКмПьЃЛ
ЪЪгУГЁОАЃКHADOOPЪЧдквЊДІРэХњСПЪ§ОнЪБгУЕФЃЌВЛНВОПЪБаЇадЃЌSTORMЪЧвЊДІРэФГвЛаТдіЪ§ОнЪБгУЕФЃЌвЊНВЪБаЇадЃЛ
2.StormЕФЩшМЦЫМЯы
StormЪЧЖдСїStreamЕФГщЯѓЃЌСїЪЧвЛИіВЛМфЖЯЕФЮоНчЕФСЌајtupleЃЌзЂвтStormдкНЈФЃЪТМўСїЪБЃЌАбСїжаЕФЪТМўГщЯѓЮЊtupleМДдЊзщЁЃ
StormНЋСїжадЊЫиГщЯѓЮЊTupleЃЌвЛИіtupleОЭЪЧвЛИіжЕСаБэvalue listЃЌlistжаЕФУПИіvalueЖМгавЛИіnameЃЌВЂЧвИУvalueПЩвдЪЧЛљБОРраЭЃЌзжЗћРраЭЃЌзжНкЪ§зщЕШЃЌЕБШЛвВПЩвдЪЧЦфЫћПЩађСаЛЏЕФРраЭЁЃ
StormШЯЮЊУПИіstreamЖМгавЛИіstreamдДЃЌвВОЭЪЧдЪМдЊзщЕФдДЭЗЃЌЫљвдЫќНЋетИідДЭЗГЦЮЊSpoutЁЃ
гаСЫдДЭЗМДspoutвВОЭЪЧгаСЫstreamЃЌФЧУДИУШчКЮДІРэstreamФкЕФtupleФиЁЃНЋСїЕФзДЬЌзЊЛЛГЦЮЊBoltЃЌboltПЩвдЯћЗбШЮвтЪ§СПЕФЪфШыСїЃЌжЛвЊНЋСїЗНЯђЕМЯђИУboltЃЌЭЌЪБЫќвВПЩвдЗЂЫЭаТЕФСїИјЦфЫћboltЪЙгУЃЌетбљвЛРДЃЌжЛвЊДђПЊЬиЖЈЕФspoutЃЈЙмПкЃЉдйНЋspoutжаСїГіЕФtupleЕМЯђЬиЖЈЕФboltЃЌгжboltЖдЕМШыЕФСїзіДІРэКѓдйЕМЯђЦфЫћboltЛђепФПЕФЕиЁЃ
вдЩЯДІРэЙ§ГЬЭГГЦЮЊTopologyМДЭиЦЫЁЃЭиЦЫЪЧstormжазюИпВуДЮЕФвЛИіГщЯѓИХФюЃЌЫќПЩвдБЛЬсНЛЕНstormМЏШКжДааЃЌвЛИіЭиЦЫОЭЪЧвЛИіСїзЊЛЛЭМЃЌЭМжаУПИіНкЕуЪЧвЛИіspoutЛђепboltЃЌЭМжаЕФБпБэЪОboltЖЉдФСЫФФаЉСїЃЌЕБspoutЛђепboltЗЂЫЭдЊзщЕНСїЪБЃЌЫќОЭЗЂЫЭдЊзщЕНУПИіЖЉдФСЫИУСїЕФboltЃЈетОЭвтЮЖзХВЛашвЊЮвУЧЪжЙЄРЙмЕРЃЌжЛвЊдЄЯШЖЉдФЃЌspoutОЭЛсНЋСїЗЂЕНЪЪЕБboltЩЯЃЉЁЃ
ЭиЦЫЕФУПИіНкЕуЖМвЊЫЕУїЫќЫљЗЂЩфГіЕФдЊзщЕФзжЖЮЕФnameЃЌЦфЫћНкЕужЛашвЊЖЉдФИУnameОЭПЩвдНгЪеДІРэЁЃ
3.СїДІРэЙ§ГЬ
4.StormЕФЛљДЁИХФю
Topology : ЯрЕБгквЛИівЕЮёСїГЬЯюФПЃЌЯрЕБгкhadoopжаMapperReduceжаЕФjob
Stream:ЯћЯЂСїЃЌЪЧвЛИіУЛгаБпНчЕФtupleађСаЃЌетаЉtuplesЛсБЛвдвЛжжЗжВМЪНЕФЗНЪНВЂааЕиДДНЈКЭДІРэ
tuple:ОЭЪЧЪ§ОнЕФЕЅЮЛЃЌашвЊУПвЛИіашвЊДІРэЕФЪ§ОнЕФЗтзАдкtupleжа
Spouts ЯћЯЂдДЃЌЪЧЯћЯЂЩњВњепЃЌЫћЛсДгвЛИіЭтВПдДЖСШЁЪ§ОнВЂЯђtopologyРяУцУцЗЂГіЯћЯЂЃКtuple
Bolts ЯћЯЂДІРэепЃЌЫљгаЕФЯћЯЂДІРэТпМБЛЗтзАдкboltsРяУцЃЌДІРэЪфШыЕФЪ§ОнСїВЂВњЩњаТЕФЪфГіЪ§ОнСї,ПЩжДааЙ§ТЫЃЌОлКЯЃЌВщбЏЪ§ОнПтЕШВйзї
Task УПвЛИіSpoutКЭBoltЛсБЛЕБзїКмЖрtaskдкећИіМЏШКРяУцжДаа,УПвЛИіtaskЖдгІЕНвЛИіЯпГЬ.
Stream groupings ЯћЯЂЗжЗЂВпТд,ЖЈвхвЛИіTopologyЕФЦфжавЛВНЪЧЖЈвхУПИіtupleНгЪмЪВУДбљЕФСїзїЮЊЪфШы,stream
groupingОЭЪЧгУРДЖЈвхвЛИіstreamгІИУШчКЮЗжХфИјBoltsУЧ.
5.БОЕиВтЪдДњТы
| package
stormNew;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class LocalTopology {
public static void main(String[] args) {
//зщзАTopology
TopologyBuilder build = new TopologyBuilder();
//ЖЈвхspoutЕФid
build.setSpout("spout", new Spout());
//ЖЈвхboltЕФid,ЪЙгУnew Fields("field")зжЖЮНјааЗжзщ
build.setBolt("bolt", new Bolt()).fieldsGrouping("spout",
new Fields("field"));
try {
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalTopology",
conf, build.createTopology());
// Config stormConf = new Config();
// stormConf.setNumWorkers(2);
// StormSubmitter.submitTopology("luluTology",
stormConf,build.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
public static class Spout extends BaseRichSpout{
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
private int i;
private HashMap<Integer,Integer> map =
new HashMap<Integer,Integer>();
//spoutжабЛЗетИіЗНЗЈЃЌНјааЯћЯЂЛёШЁгыЗЂЫЭ
public void nextTuple() {
// System.err.println("Spout:"+i);
//зїЮЊУПвЛЬѕЯћЯЂЕФЮЈвЛБъЪЖЃЌгУгкackЕФЯћЯЂШЗШЯЛњжЦ
int mgsid = i;
//ЗЂЫЭtupleЯћЯЂЕНboltжаДІРэ
this.collector.emit(new Values(i++,i%3),mgsid);
//spoutздЩэЮЌЛЄзХЯћЯЂгыБъЪЖжЎМфЕФЙиЯЕ
map.put(mgsid, i);
try {
//анУпвЛЯТЃЌЧхЮњПДГіаЇЙћ
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
public void declareOutputFields(OutputFieldsDeclarer
outputFieldsDeclarer) {
//ЖЈвхЗЂЫЭзжЖЮЕФУћГЦ
outputFieldsDeclarer.declare(new Fields("num","field"));
}
@Override
//ЕБboltЕїгУЕФackЗНУцЪБЃЌЛиЕїspoutжаЕФackЗНЗЈ
public void ack(Object msgId) {
System.out.println("ШЗШЯаХЯЂ-----------");
}
@Override
//ЕБboltЕїгУЕФfailЗНУцЪБЃЌЛиЕїspoutжаЕФfailЗНЗЈ
public void fail(Object msgId) {
System.out.println("ЯћЯЂЪЇАм-----------"+map.get(msgId));
}
}
public static class Bolt extends BaseRichBolt{
private Map conf;
private TopologyContext context;
private OutputCollector collector;
private int sum = 0;
//boltНгЪмЖЏspoutЗЂЫЭЙ§РДЕФЯћЯЂОЭЕїexecute
public void execute(Tuple input) {
// TODO Auto-generated method stub
//ЭЈЙ§зжЖЮУћГЦРДЛёШЁЪ§Он
int num = input.getIntegerByField("num");
System.err.println("--------------------num:"+(num));
/**
* ЮЊСЫИќКУЕФПДЪщackЯћЯЂШЗШЯЛњжЦЕФаЇЙћЃЌЫљвджБНгЕїгУackгыfailЗНЗЈ
*
* ФЌШЯИУЗНЗЈЪЧетбљНјааackЕФЕїгУ
* try{
* вЕЮёТпМ
* this.collector.ack(input);
*}catch(){
* this.collector.fail(input);
*}
*/
if(num >=10 && num <=20){
//System.err.println("sum:"+(sum+=num));
this.collector.ack(input);
}else{
this.collector.fail(input);
}
}
public void prepare(Map conf, TopologyContext
context, OutputCollector collector) {
// TODO Auto-generated method stub
this.conf = conf;
this.context = context;
this.collector = collector;
}
public void declareOutputFields(OutputFieldsDeclarer
outputFieldsDeclarer) {
// TODO Auto-generated method stub
}
}
} |
6.StormМЏШКНсЙЙ
жїНкЕуЃЈNimbusЃЉ:NimbusИКд№дкМЏШКЗЖЮЇФкЗжЗЂДњТыЁЂЮЊworkerЗжХфШЮЮёКЭЙЪеЯМрВт
ДгНкЕуЃЈSupervisorЃЉ:SupervisorМрЬ§ЗжХфИјЫќЫљдкЛњЦїЕФЙЄзїЃЌЛљгкNimbusЗжХфИјЫќЕФЪТЧщРДОіЖЈЦєЖЏЛђЭЃжЙЙЄзїепНјГЬЁЃУПИіЙЄзїепНјГЬжДаавЛИіtopologyЕФзгМЏЃЈвВОЭЪЧвЛИізгЭиЦЫНсЙЙЃЉЃЛвЛИідЫаажаЕФtopologyгЩаэЖрПчЖрИіЛњЦїЕФЙЄзїепНјГЬзщГЩЁЃ
ЦєЖЏМЏШК
дкnimbusНкЕужДаа"nohup bin/storm nimbus >/dev/null
2>&1 &"ЦєЖЏNimbusКѓЬЈГЬађЃЌВЂЗХЕНКѓЬЈжДаа
дкsupervisorНкЕужДаа"nohup bin/storm supervisor >/dev/null
2>&1 &"ЦєЖЏSupervisorКѓЬЈГЬађЃЌВЂЗХЕНКѓЬЈжДааЃЛ
дкnimbusНкЕужДаа"nohup bin/storm ui >/dev/null
2>&1 &"ЦєЖЏUIКѓЬЈГЬађЃЌВЂЗХЕНКѓЬЈжДааЃЌЦєЖЏКѓПЩвдЭЈЙ§http://{nimbus
host}:8080ЙлВьМЏШКЕФworkerзЪдДЪЙгУЧщПіЁЂTopologiesЕФдЫаазДЬЌЕШаХЯЂЁЃ
дкЫљгаНкЕужДаа"nohup bin/storm logviewer >/dev/null
2>&1 &"ЦєЖЏlogКѓЬЈГЬађЃЌВЂЗХЕНКѓЬЈжДааЃЌЦєЖЏКѓПЩвдЭЈЙ§http://{host}:8000ЙлВьШежОаХЯЂЁЃ(nimbusНкЕуПЩвдВЛгУЦєЖЏlogviewerНјГЬЃЌвђЮЊlogviewerНјГЬжївЊЪЧЮЊСЫЗНБуВщПДШЮЮёЕФжДааШежОЃЌетаЉжДааШежОЖМдкsupervisorНкЕуЩЯЁЃ)
ЭЃжЙзївЕ
ЯШВщбЏзївЕСаБэstorm list
УќСюааЯТжДааstorm kill TopologyName
дкstorm uiЩЯЕуЛїkillАДХЅ
7.ВЂааЖШ
вЛИіНкЕуЩЯзюЖрФмЙЛдЫааЫФИіworkerЃЌЪЧЫФИіslots
1ИіworkerНјГЬжДааЕФЪЧ1ИіtopologyЕФзгМЏЃЈзЂЃКВЛЛсГіЯж1ИіworkerЮЊЖрИіtopologyЗўЮёЃЉЁЃ1ИіworkerНјГЬЛсЦєЖЏ1ИіЛђЖрИіexecutorЯпГЬРДжДаа1ИіtopologyЕФcomponent(spoutЛђbolt)ЁЃвђДЫЃЌ1ИідЫаажаЕФtopologyОЭЪЧгЩМЏШКжаЖрЬЈЮяРэЛњЩЯЕФЖрИіworkerНјГЬзщГЩЕФЁЃ
executorЪЧ1ИіБЛworkerНјГЬЦєЖЏЕФЕЅЖРЯпГЬЁЃУПИіexecutorжЛЛсдЫаа1ИіtopologyЕФ1Иіcomponent(spoutЛђbolt)ЕФtaskЃЈзЂЃКtaskПЩвдЪЧ1ИіЛђЖрИіЃЌstormФЌШЯЪЧ1ИіcomponentжЛЩњГЩ1ИіtaskЃЌexecutorЯпГЬЛсдкУПДЮбЛЗРяЫГађЕїгУЫљгаtaskЪЕР§ЃЉЁЃ
taskЪЧзюжедЫааspoutЛђboltжаДњТыЕФжДааЕЅдЊЃЈзЂЃК1ИіtaskМДЮЊspoutЛђboltЕФ1ИіЪЕР§ЃЌexecutorЯпГЬдкжДааЦкМфЛсЕїгУИУtaskЕФnextTupleЛђexecuteЗНЗЈЃЉЁЃtopologyЦєЖЏКѓЃЌ1Иіcomponent(spoutЛђbolt)ЕФtaskЪ§ФПЪЧЙЬЖЈВЛБфЕФЃЌЕЋИУcomponentЪЙгУЕФexecutorЯпГЬЪ§ПЩвдЖЏЬЌЕїећЃЈР§ШчЃК1ИіexecutorЯпГЬПЩвджДааИУcomponentЕФ1ИіЛђЖрИіtaskЪЕР§ЃЉЁЃетвтЮЖзХЃЌЖдгк1ИіcomponentДцдкетбљЕФЬѕМўЃК#threads<=#tasksЃЈМДЃКЯпГЬЪ§аЁгкЕШгкtaskЪ§ФПЃЉЁЃФЌШЯЧщПіЯТtaskЕФЪ§ФПЕШгкexecutorЯпГЬЪ§ФПЃЌМД1ИіexecutorЯпГЬжЛдЫаа1ИіtaskЁЃ
ФЌШЯЧщПіЯТЃЌвЛИіsupervisorНкЕуЛсЦєЖЏ4ИіworkerНјГЬЁЃУПИіworkerНјГЬЛсЦєЖЏ1ИіexecutorЃЌУПИіexecutorЦєЖЏ1Иіtask
ЬсИпВЂааЖШ
worker(slots)
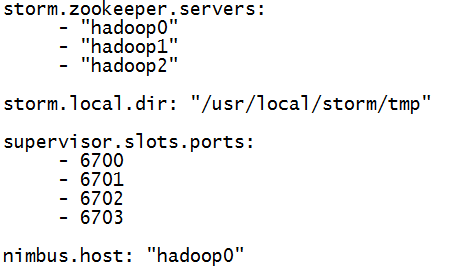
ФЌШЯвЛИіДгНкЕуЩЯУцПЩвдЦєЖЏ4ИіworkerНјГЬЃЌВЮЪ§ЪЧsupervisor.slots.portЁЃдкstormХфжУЮФМўжавбОХфжУЙ§СЫЃЌФЌШЯЪЧдкstrom-core.jarАќжаЕФdefaults.yamlжаХфжУЕФгаЁЃ
ФЌШЯвЛИіstromЯюФПжЛЪЙгУвЛИіworkerНјГЬЃЌПЩвдЭЈЙ§ДњТыРДЩшжУЪЙгУЖрИіworkerНјГЬЁЃ
ЭЈЙ§config.setNumWorkers(workers)ЩшжУ
ЭЈЙ§conf.setNumAckers(0);ПЩвдШЁЯћackerШЮЮё
зюКУвЛЬЈЛњЦїЩЯЕФвЛИіtopologyжЛЪЙгУвЛИіworker,жївЊдвђЪЧМѕЩйСЫworkerжЎМфЕФЪ§ОнДЋЪф
ШчЙћworkerЪЙгУЭъЕФЛАдйЬсНЛtopologyОЭВЛЛсжДааЃЌЛсДІгкЕШД§зДЬЌ
executor
ФЌШЯЧщПіЯТвЛИіexecutorдЫаавЛИіtaskЃЌПЩвдЭЈЙ§дкДњТыжаЩшжУ
builder.setSpout(id, spout, parallelism_hint);
builder.setBolt(id, bolt, parallelism_hint);
task
ЭЈЙ§boltDeclarer.setNumTasks(num);РДЩшжУЪЕР§ЕФИіЪ§
executorЕФЪ§СПЛсаЁгкЕШгкtaskЕФЪ§СП(ЮЊСЫrebalance)
ЕЏадМЦЫу
ЭЈЙ§ДњТыЕїећ
| ЭЈЙ§ДњТыЕїећ
topologyBuilder.setBolt("green-bolt",
new GreenBolt(),2)
.setNumTasks(4).shuffleGrouping("blue-spout);
ЭЈЙ§shellЕїећ
# 10УыжЎКѓПЊЪМЕїећ
# Reconfigure the topology "mytopology"
to use 5 worker processes,
# the spout "blue-spout" to use 3
executors and
# the bolt "yellow-bolt" to use 10
executors.
storm rebalance mytopology -w 10 -n 5 -e blue-spout=3
-e yellow-bolt=10 |
-w ДњБэМИУыКѓПЊЪМжДаа
-n ДњБэМИИіworker
-e ДњБэМИИіexcutor
stream groupingЗжРр
Shuffle Grouping: ЫцЛњЗжзщЃЌ ЫцЛњХЩЗЂstreamРяУцЕФtupleЃЌ БЃжЄboltжаЕФУПИіШЮЮёНгЪеЕНЕФtupleЪ§ФПЯрЭЌ.(ЫќФмЪЕЯжНЯКУЕФИКдиОљКт)
Fields GroupingЃКАДзжЖЮЗжзщЃЌ БШШчАДuseridРДЗжзщЃЌ ОпгаЭЌбљuseridЕФtupleЛсБЛЗжЕНЭЌвЛШЮЮёЃЌ
ЖјВЛЭЌЕФuseridдђЛсБЛЗжХфЕНВЛЭЌЕФШЮЮё
All GroupingЃК ЙуВЅЗЂЫЭ,ЖдгкУПвЛИіtuple,BoltsжаЕФЫљгаШЮЮёЖМЛсЪеЕН. |









