| БрМЭЦМі: |
| БОЮФРДздгкcsdn,StormЪЧвЛИіУтЗбПЊдДЁЂЗжВМЪНЁЂИпШнДэЕФЪЕЪБМЦЫуЯЕЭГЁЃ |
|
1. ЪВУДЪЧStorm
StormЪЧTwitterПЊдДЕФвЛИіЗжВМЪНЕФЪЕЪБМЦЫуЯЕЭГЁЃ
2. StormЕФЩшМЦЫМЯы
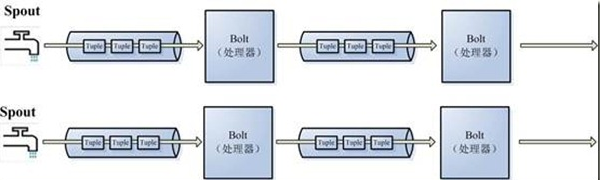
- StormЪЧЖдСїStreamЕФГщЯѓЃЌСїЪЧвЛИіВЛМфЖЯЕФЮоНчЕФСЌајtupleЃЌзЂвтStormдкНЈФЃЪТМўСїЪБЃЌАбСїжаЕФЪТМўГщЯѓЮЊtupleМДдЊзщЁЃ
- StormНЋСїжадЊЫиГщЯѓЮЊTupleЃЌвЛИіtupleОЭЪЧвЛИіжЕСаБэvalue
listЃЌlistжаЕФУПИіvalueЖМгавЛИіnameЃЌВЂЧвИУvalueПЩвдЪЧЛљБОРраЭЃЌзжЗћРраЭЃЌзжНкЪ§зщЕШЃЌЕБШЛвВПЩвдЪЧЦфЫћПЩађСаЛЏЕФРраЭЁЃ
- StormШЯЮЊУПИіstreamЖМгавЛИіstreamдДЃЌвВОЭЪЧдЪМдЊзщЕФдДЭЗЃЌЫљвдЫќНЋетИідДЭЗГЦЮЊSpoutЁЃ
- гаСЫдДЭЗМДspoutвВОЭЪЧгаСЫstreamЃЌФЧУДИУШчКЮДІРэstreamФкЕФtupleФиЁЃНЋСїЕФзДЬЌзЊЛЛГЦЮЊBoltЃЌboltПЩвдЯћЗбШЮвтЪ§СПЕФЪфШыСїЃЌжЛвЊНЋСїЗНЯђЕМЯђИУboltЃЌЭЌЪБЫќвВПЩвдЗЂЫЭаТЕФСїИјЦфЫћboltЪЙгУЃЌетбљвЛРДЃЌжЛвЊДђПЊЬиЖЈЕФspoutЃЈЙмПкЃЉдйНЋspoutжаСїГіЕФtupleЕМЯђЬиЖЈЕФboltЃЌгжboltЖдЕМШыЕФСїзіДІРэКѓдйЕМЯђЦфЫћboltЛђепФПЕФЕиЁЃ
- вдЩЯДІРэЙ§ГЬЭГГЦЮЊTopologyМДЭиЦЫЁЃЭиЦЫЪЧstormжазюИпВуДЮЕФвЛИіГщЯѓИХФюЃЌЫќПЩвдБЛЬсНЛЕНstormМЏШКжДааЃЌвЛИіЭиЦЫОЭЪЧвЛИіСїзЊЛЛЭМЃЌЭМжаУПИіНкЕуЪЧвЛИіspoutЛђепboltЃЌЭМжаЕФБпБэЪОboltЖЉдФСЫФФаЉСїЃЌЕБspoutЛђепboltЗЂЫЭдЊзщЕНСїЪБЃЌЫќОЭЗЂЫЭдЊзщЕНУПИіЖЉдФСЫИУСїЕФboltЃЈетОЭвтЮЖзХВЛашвЊЮвУЧЪжЙЄРЙмЕРЃЌжЛвЊдЄЯШЖЉдФЃЌspoutОЭЛсНЋСїЗЂЕНЪЪЕБboltЩЯЃЉЁЃ
- ЭиЦЫЕФУПИіНкЕуЖМвЊЫЕУїЫќЫљЗЂЩфГіЕФдЊзщЕФзжЖЮЕФnameЃЌЦфЫћНкЕужЛашвЊЖЉдФИУnameОЭПЩвдНгЪеДІРэЁЃ
3.StormМЏШКНсЙЙ
- StormМЏШКБэУцРрЫЦHadoopМЏШКЁЃЕЋдкHadoopЩЯФудЫааЪЧЁБMapReduce
jobsЁБЃЌдкStormЩЯФудЫааЕФЪЧЁБtopologiesЁБЁЃЁБJobsЁБКЭЁБtopologiesЁБЪЧДѓВЛЭЌЕФЃЌвЛИіЙиМќВЛЭЌЪЧвЛИіMapReduceЕФJobзюжеЛсНсЪјЃЌЖјвЛИіtopologyгРдЖДІРэЯћЯЂЃЈЛђжБЕНФуkillЫќЃЉЁЃ
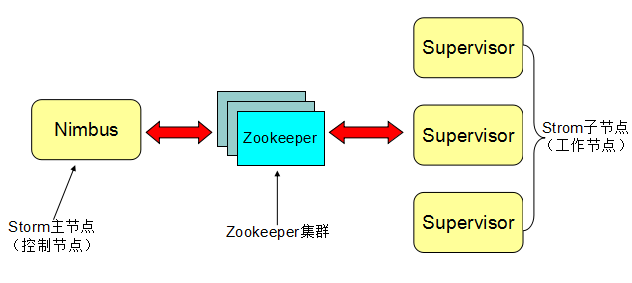
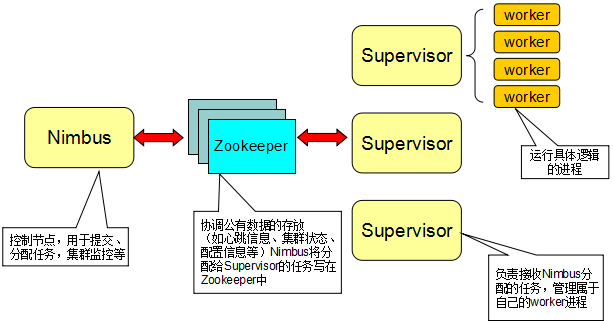
- StormМЏШКгаСНжжНкЕуЃКПижЦЃЈmasterЃЉНкЕуКЭЙЄзїепЃЈworkerЃЉНкЕуЁЃ
- ПижЦНкЕудЫаавЛИіГЦжЎЮЊЁБNimbusЁБЕФКѓЬЈГЬађЃЌЫќРрЫЦгкHaddopЕФЁБJobTrackerЁБЁЃNimbusИКд№дкМЏШКЗЖЮЇФкЗжЗЂДњТыЁЂЮЊworkerЗжХфШЮЮёКЭЙЪеЯМрВтЁЃ
- УПИіЙЄзїепНкЕудЫаавЛИіГЦжЎЁБSupervisorЁБЕФКѓЬЈГЬађЁЃSupervisorМрЬ§ЗжХфИјЫќЫљдкЛњЦїЕФЙЄзїЃЌЛљгкNimbusЗжХфИјЫќЕФЪТЧщРДОіЖЈЦєЖЏЛђЭЃжЙЙЄзїепНјГЬЁЃУПИіЙЄзїепНјГЬжДаавЛИіtopologyЕФзгМЏЃЈвВОЭЪЧвЛИізгЭиЦЫНсЙЙЃЉЃЛвЛИідЫаажаЕФtopologyгЩаэЖрПчЖрИіЛњЦїЕФЙЄзїепНјГЬзщГЩЁЃ
- вЛИіZookeeperМЏШКИКд№NimbusКЭЖрИіSupervisorжЎМфЕФЫљгааЕїЙЄзїЃЈвЛИіЭъећЕФЭиЦЫПЩФмБЛЗжЮЊЖрИізгЭиЦЫВЂгЩЖрИіsupervisorЭъГЩЃЉЁЃ
- ДЫЭтЃЌNimbusКѓЬЈГЬађКЭSupervisorКѓЬЈГЬађЖМЪЧПьЫйЪЇАмЃЈfail-fastЃЉКЭЮозДЬЌЕФЃЛЫљгазДЬЌЮЌГждкZookeeperЛђБОЕиДХХЬЁЃетвтЮЖзХФуПЩвдkill -9ЩБЕєnimbusНјГЬКЭsupervisorНјГЬЃЌШЛКѓжиЦєЃЌЫќУЧНЋЛжИДзДЬЌВЂМЬајЙЄзїЃЌОЭЯёЪВУДвВУЛЗЂЩњЁЃетжжЩшМЦЪЙstormМЋЦфЮШЖЈЁЃетжжЩшМЦжаMasterВЂУЛгажБНгКЭworkerЭЈаХЃЌЖјЪЧНшжњвЛИіжаНщZookeeperЃЌетбљвЛРДПЩвдЗжРыmasterКЭworkerЕФвРРЕЃЌНЋзДЬЌаХЯЂДцЗХдкzookeeperМЏШКФквдПьЫйЛиИДШЮКЮЪЇАмЕФвЛЗНЁЃ
4.StormЕФживЊИХФю
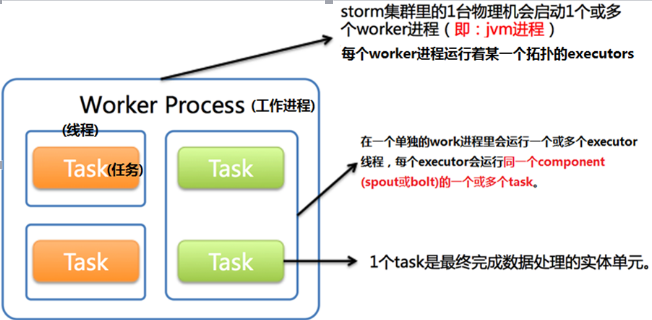
- workerЃК
SupervisorЛсМрЬ§ЗжХфИјЫќФЧЬЈЛњЦїЕФЙЄзїЃЌИљОнашвЊЦєЖЏ/ЙиБеЙЄзїНјГЬЃЌетИіЙЄзїНјГЬОЭЪЧworker
УПвЛИіworkerЖМЛсеМгУЙЄзїНкЕуЕФвЛИіЖЫПкЃЌетИіЖЫПкПЩвддкstorm.yarmжаХфжУЁЃ
вЛИіtopologyПЩФмЛсдквЛИіЛђепЖрИіЙЄзїНјГЬРяУцжДааЃЌУПИіЙЄзїНјГЬжДааећИіtopologyЕФвЛВПЗжЃЌЫљвдвЛИідЫааЕФtopologyгЩдЫаадкКмЖрЛњЦїЩЯЕФКмЖрЙЄзїНјГЬзщГЩЁЃ
- Task:
УПвЛИіSpoutКЭBoltЛсБЛЕБзїКмЖрtaskдкећИіМЏШКРяУцжДааЁЃФЌШЯЧщПіЯТУПвЛИіtaskЖдгІЕНвЛИіЯпГЬЃЈExecutorЃЉЃЌетИіЯпГЬгУРДжДааетИіtaskЃЌЖјstream groupingдђЪЧЖЈвхдѕУДДгвЛЖбtaskЗЂЩфtupleЕНСэЭтвЛЖбtaskЁЃ
- УПЬЈsupervisorдЫаазХШєИЩИіWorkerНјГЬЃЌУПИіWorkerНјГЬдЫаазХШєИЩИіExecutorЯпГЬЃЌУПИіExecutorЯпГЬдЫаазХЭЌвЛИіcomponentЃЈSpoutЛђBoltЃЉЕФвЛИіЛђЖрИіtaskЁЃ
- Config(ХфжУ)ЃК
stormРяУцгавЛЖбВЮЪ§ПЩвдХфжУРДЕїећnimbus, supervisorвдМАе§дкдЫааЕФtopologyЕФааЮЊЃЌ вЛаЉХфжУЪЧЯЕЭГМЖБ№ЕФЃЌ вЛаЉХфжУЪЧtopologyМЖБ№ЕФЁЃЫљгагаФЌШЯжЕЕФХфжУЕФФЌШЯХфжУЪЧХфжУдкdefault.xmlРяУцЕФЁЃФуПЩвдЭЈЙ§ЖЈвхИіstorm.xmlдкФуЕФclasspathРхУзРДИВИЧетаЉФЌШЯХфжУЁЃВЂЧвФувВПЩвддкДњТыРяУцЩшжУвЛаЉtopologyЯрЙиЕФХфжУаХЯЂ ЈC ЪЙгУStormSubmitterЁЃЕБШЛЃЌетаЉХфжУЕФгХЯШМЖЪЧ: default.xml < storm.xml < TOPOLOGY-SPECIFICХфжУЁЃ
- Stream GroupingЃЈЯћЯЂЗжЗЂВпТдЃЉЃК
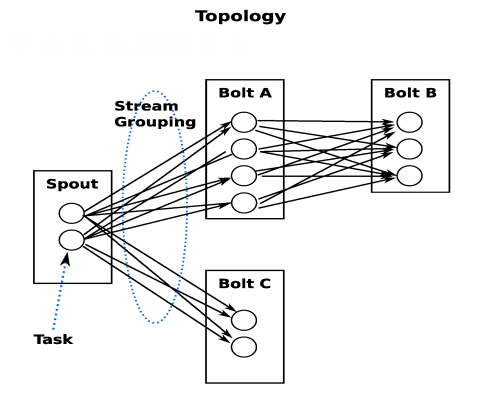
- Shuffle GroupingЃКЫцЛњЗжзщЃЌЫцЛњХЩЗЂstreamРяУцЕФtupleЃЌБЃжЄУПИіboltНгЪеЕНЕФtupleЪ§ФПЯрЭЌЁЃ
- FieldsGroupingЃКАДзжЖЮЗжзщЃЌБШШчАДuseridРДЗжзщЃЌОпгаЭЌбљuseridЕФtupleЛсБЛЗжЕНЯрЭЌЕФBoltsЃЌЖјВЛЭЌЕФuseridдђЛсБЛЗжХфЕНВЛЭЌЕФBoltsЁЃ
- All GroupingЃКЙуВЅЗЂЫЭЃЌЖдгкУПвЛИіtupleЃЌЫљгаЕФBoltsЖМЛсЪеЕНЁЃ
- Global Grouping:ШЋОжЗжзщЃЌетИіtupleБЛЗжХфЕНstormжаЕФвЛИіboltЕФЦфжавЛИіtaskЁЃдйОпЬхвЛЕуОЭЪЧЗжХфИјidжЕзюЕЭЕФФЧИіtaskЁЃ
- NonGroupingЃКВЛЗжзщЃЌетИіЗжзщЕФвтЫМЪЧЫЕstreamВЛЙиаФЕНЕзЫЛсЪеЕНЫќЕФtupleЁЃФПЧАетжжЗжзщКЭShuffle groupingЪЧвЛбљЕФаЇЙћЃЌгавЛЕуВЛЭЌЕФЪЧstormЛсАбетИіboltЗХЕНетИіboltЕФЖЉдФепЭЌвЛИіЯпГЬРяУцШЅжДааЁЃ
- Direct GroupingЃКжБНгЗжзщ,
етЪЧвЛжжБШНЯЬиБ№ЕФЗжзщЗНЗЈЃЌгУетжжЗжзщвтЮЖзХЯћЯЂЕФЗЂЫЭепжИЖЈгЩЯћЯЂНгЪеепЕФФФИіtaskДІРэетИіЯћЯЂЁЃжЛгаБЛЩљУїЮЊDirect StreamЕФЯћЯЂСїПЩвдЩљУїетжжЗжзщЗНЗЈЁЃЖјЧветжжЯћЯЂtupleБиаыЪЙгУemitDirectЗНЗЈРДЗЂЩфЁЃЯћЯЂДІРэепПЩвдЭЈЙ§TopologyContextРДЛёШЁДІРэЫќЕФЯћЯЂЕФtaskid
(OutputCollector.emitЗНЗЈвВЛсЗЕЛиtaskid)ЁЃ
5.StormПЩППадЃК
1ЁЂworkerНјГЬЙвЕє
stormЛсжиаТдйЦєЖЏвЛИіworker
2ЁЂsupervisorНјГЬЙвЕє
ВЛЛсгАЯьжЎЧАвбОЬсНЛЕФtopologyЃЌжЛЪЧКѓЦкВЛЛсдйЯђетИіНкЕуЗжХфШЮЮёСЫЁЃ
3ЁЂnimbusНјГЬЙвЕє
ВЛЛсгАЯьжЎЧАвбОЬсНЛЕФtopologyЃЌжЛЪЧКѓЦкВЛФмдйЯђМЏШКЬсНЛtopologyСЫЁЃ
4ЁЂack/failЯћЯЂШЗШЯЛњжЦ(ШЗБЃвЛИіtupleБЛЭъШЋДІРэ)
дкspoutжаЗЂЩфtupleЕФЪБКђашвЊЭЌЪБЗЂЫЭmessageidЃЌетбљВХЯрЕБгкПЊЦєСЫЯћЯЂШЗШЯЛњжЦ
ШчЙћФуЕФtopologyРяУцЕФtupleБШНЯЖрЕФЛАЃЌ ФЧУДАбackerЕФЪ§СПЩшжУЖрвЛЕу,аЇТЪЛсИпвЛЕуЁЃ
ЭЈЙ§config.setNumAckers(num)РДЩшжУвЛИіtopologyРяУцЕФackerЕФЪ§СПЃЌФЌШЯжЕЪЧ1ЁЃ
зЂвтЃК ackerгУСЫЬиЪтЕФЫуЗЈЃЌЪЙЕУЖдгкзЗзйУПИіspout tupleЕФзДЬЌЫљашвЊЕФФкДцСПЪЧКуЖЈЕФЃЈ20 bytes)
зЂвтЃКШчЙћвЛИіtupleдкжИЖЈЕФtimeout(Config.TOPOLOGY_MESSAGE_TIMEOUT_SECSФЌШЯжЕЮЊ30Уы)ЪБМфФкУЛгаБЛГЩЙІДІРэЃЌФЧУДетИіtupleЛсБЛШЯЮЊДІРэЪЇАмСЫЁЃ
|









