| БрМЭЦМі: |
БОЮФРДздгкВЉПЭдАЃЌБОЮФЪзЯШНщЩмСЫStormЕФЛљБОИХФюКЭЪ§ОнСїФЃаЭЃЌШЛКѓНсКЯвЛИіЕфаЭгІгУГЁОАРДЫЕУїStormжЇГжTopologyжЎМфЪ§ОнСїЖЉдФЕФБивЊадЃЌзюКѓЖдБШСЫStormгыСэвЛИіСїДІРэЯЕЭГдкЪ§ОнСїФЃаЭЩЯЕФЧјБ№жЎДІЁЃ
|
|
StormЛљБОИХФю
StormЪЧвЛИіПЊдДЕФЪЕЪБМЦЫуЯЕЭГЃЌЫќЬсЙЉСЫвЛЯЕСаЕФЛљБОдЊЫигУгкНјааМЦЫуЃКTopologyЁЂStreamЁЂSpoutЁЂBoltЕШЕШЁЃ
дкStormжаЃЌвЛИіЪЕЪБгІгУЕФМЦЫуШЮЮёБЛДђАќзїЮЊTopologyЗЂВМЃЌетЭЌHadoopЕФMapReduceШЮЮёЯрЫЦЁЃЕЋЪЧгавЛЕуВЛЭЌЕФЪЧЃКдкHadoopжаЃЌMapReduceШЮЮёзюжеЛсжДааЭъГЩКѓНсЪјЃЛЖјдкStormжаЃЌTopologyШЮЮёвЛЕЉЬсНЛКѓгРдЖВЛЛсНсЪјЃЌГ§ЗЧФуЯдЪОШЅЭЃжЙШЮЮёЁЃ
МЦЫуШЮЮёTopologyЪЧгЩВЛЭЌЕФSpoutsКЭBoltsЃЌЭЈЙ§Ъ§ОнСїЃЈStreamЃЉСЌНгЦ№РДЕФЭМЁЃЯТУцЪЧвЛИіTopologyЕФНсЙЙЪОвтЭМЃК

ЦфжаАќКЌгаЃК
SpoutЃКStormжаЕФЯћЯЂдДЃЌгУгкЮЊTopologyЩњВњЯћЯЂЃЈЪ§ОнЃЉЃЌвЛАуЪЧДгЭтВПЪ§ОндДЃЈШчMessage
QueueЁЂRDBMSЁЂNoSQLЁЂRealtime LogЃЉВЛМфЖЯЕиЖСШЁЪ§ОнВЂЗЂЫЭИјTopologyЯћЯЂЃЈtupleдЊзщЃЉЁЃ
BoltЃКStormжаЕФЯћЯЂДІРэепЃЌгУгкЮЊTopologyНјааЯћЯЂЕФДІРэЃЌBoltПЩвджДааЙ§ТЫЃЌ ОлКЯЃЌ
ВщбЏЪ§ОнПтЕШВйзїЃЌЖјЧвПЩвдвЛМЖвЛМЖЕФНјааДІРэЁЃ
зюжеЃЌTopologyЛсБЛЬсНЛЕНstormМЏШКжадЫааЃЛвВПЩвдЭЈЙ§УќСюЭЃжЙTopologyЕФдЫааЃЌНЋTopologyеМгУЕФМЦЫузЪдДЙщЛЙИјStormМЏШКЁЃ
StormЪ§ОнСїФЃаЭ
Ъ§ОнСїЃЈStreamЃЉЪЧStormжаЖдЪ§ОнНјааЕФГщЯѓЃЌЫќЪЧЪБМфЩЯЮоНчЕФtupleдЊзщађСаЁЃдкTopologyжаЃЌSpoutЪЧStreamЕФдДЭЗЃЌИКд№ЮЊTopologyДгЬиЖЈЪ§ОндДЗЂЩфStreamЃЛBoltПЩвдНгЪеШЮвтЖрИіStreamзїЮЊЪфШыЃЌШЛКѓНјааЪ§ОнЕФМгЙЄДІРэЙ§ГЬЃЌШчЙћашвЊЃЌBoltЛЙПЩвдЗЂЩфГіаТЕФStreamИјЯТМЖBoltНјааДІРэЁЃ
ЯТУцЪЧвЛИіTopologyФкВПSpoutКЭBoltжЎМфЕФЪ§ОнСїЙиЯЕЃК
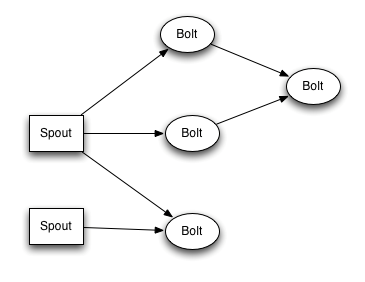
TopologyжаУПвЛИіМЦЫузщМўЃЈSpoutКЭBoltЃЉЖМгавЛИіВЂаажДааЖШЃЌдкДДНЈTopologyЪБПЩвдНјаажИЖЈЃЌStormЛсдкМЏШКФкЗжХфЖдгІВЂааЖШИіЪ§ЕФЯпГЬРДЭЌЪБжДааетвЛзщМўЁЃ
ФЧУДЃЌгавЛИіЮЪЬтЃКМШШЛЖдгквЛИіSpoutЛђBoltЃЌЖМЛсгаЖрИіtaskЯпГЬРДдЫааЃЌФЧУДШчКЮдкСНИізщМўЃЈSpoutКЭBoltЃЉжЎМфЗЂЫЭtupleдЊзщФиЃП
StormЬсЙЉСЫШєИЩжжЪ§ОнСїЗжЗЂЃЈStream GroupingЃЉВпТдгУРДНтОіетвЛЮЪЬтЁЃдкTopologyЖЈвхЪБЃЌашвЊЮЊУПИіBoltжИЖЈНгЪеЪВУДбљЕФStreamзїЮЊЦфЪфШыЃЈзЂЃКSpoutВЂВЛашвЊНгЪеStreamЃЌжЛЛсЗЂЩфStreamЃЉЁЃ
ФПЧАStormжаЬсЙЉСЫвдЯТ7жжStream GroupingВпТдЃКShuffle GroupingЁЂFields
GroupingЁЂAll GroupingЁЂGlobal GroupingЁЂNon GroupingЁЂDirect
GroupingЁЂLocal or shuffle groupingЃЌОпЬхВпТдПЩвдВЮПМетРяЁЃ
вЛжжStormВЛФмжЇГжЕФГЁОА
вдЩЯНщЩмСЫвЛаЉStormжаЕФЛљБОИХФюЃЌПЩвдПДГіЃЌStormжаStreamЕФИХФюЪЧTopologyФкЮЈвЛЕФЃЌжЛФмдкTopologyФкАДееЁАЗЂВМ-ЖЉдФЁБЗНЪНдкВЛЭЌЕФМЦЫузщМўЃЈSpoutКЭBoltЃЉжЎМфНјааЪ§ОнЕФСїЖЏЃЌЖјStreamдкTopologyжЎМфЪЧЮоЗЈСїЖЏЕФЁЃ
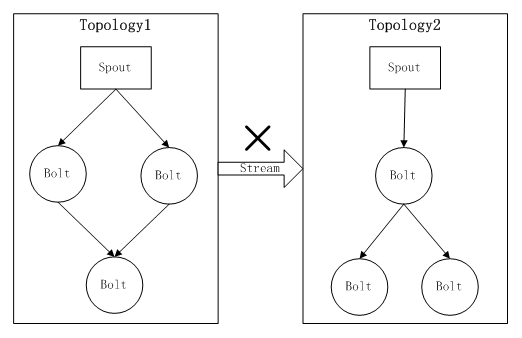
етвЛЕуЯожЦСЫStormдквЛаЉГЁОАЯТЕФгІгУЃЌЯТУцЭЈЙ§вЛИіМђЕЅЕФЪЕР§РДЫЕУїЁЃ
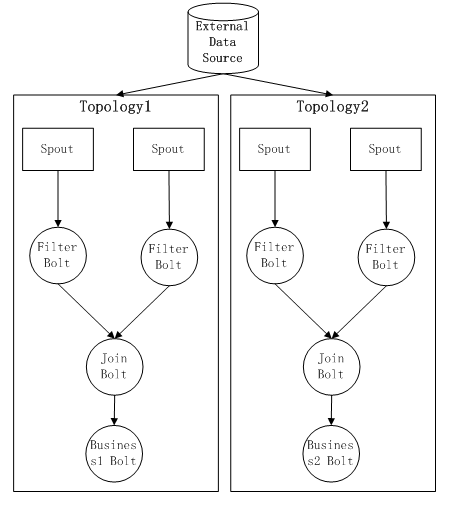
МйЩшЯждкгавЛИіTopology1ЕФНсЙЙШчЯТЃКЭЈЙ§SpoutВњЩњЪ§ОнСїКѓЃЌвРДЮашвЊОЙ§Filter
BoltЃЌJoin BoltЃЌBusiness1 BoltЁЃЦфжаЃЌFilter BoltгУгкЖдЪ§ОнНјааЙ§ТЫЃЌJoin
BoltгУгкЪ§ОнСїЕФОлКЯЃЌBusiness1 BoltгУгкНјаавЛИіЪЕМЪвЕЮёЕФМЦЫуТпМЁЃ
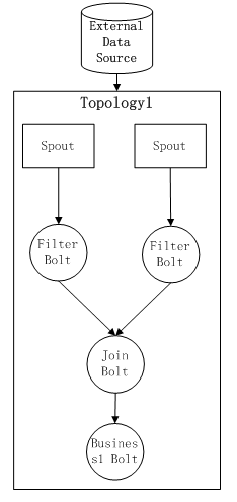
ФПЧАетИіTopology1вбОБЛЬсНЛЕНStormМЏШКдЫааЃЌЖјЯждкЮвУЧгжгаСЫаТЕФашЧѓЃЌашвЊМЦЫувЛИіаТЕФвЕЮёТпМЃЌЖјетИіTopologyЕФЬиЕуЪЧКЭTopology1ЙЋгУЭЌбљЕФЪ§ОндДЃЌЖјЧвЧАЦкЕФдЄДІРэЙ§ГЬЭъШЋвЛбљЃЈвРДЮОРњFilter
BoltКЭJoin BoltЃЉЃЌФЧУДетЪБКђStormдѕУДРДТњзуетвЛашЧѓЃПОнИіШЫСЫНтЃЌгавдЯТМИжжЁАЧњелЁБЕФЪЕЯжЗНЪНЃК
1ЃЉ ЕквЛжжЗНЪНЃКЪзЯШkillЕєвбОдкМЏШКжадЫааЕФTopology1МЦЫуШЮЮёЃЌШЛКѓЪЕЯжBusiness2
BoltЕФМЦЫуТпМЃЌВЂжиаТДђАќаЮГЩвЛИіаТЕФTopologyМЦЫуШЮЮёjarАќКѓЃЌЬсНЛЕНStormМЏШКжажиаТдЫааЃЌетЪБКђStormФкЕФећЬхTopologyНсЙЙШчЯТЃК
етжжЗНЪНЕФШБЕудкгкЃКгЩгквЊжиЦєTopologyЃЌЫљвдШчЙћSpoutЛђBoltгазДЬЌдђЛсЖЊЪЇЕєЃЛЭЌЪБгЩгкTopologyНсЙЙЗЂЩњСЫБфЛЏЃЌвђДЫжиаТдЫааTopologyЧАашвЊЖдГЬађЕФЮШЖЈадЁЂе§ШЗадНјаабщжЄЃЛСэЭтTopologyНсЙЙЕФБфЛЏвВЛсДјРДЖюЭтЕФдЫЮЌПЊЯњЁЃ
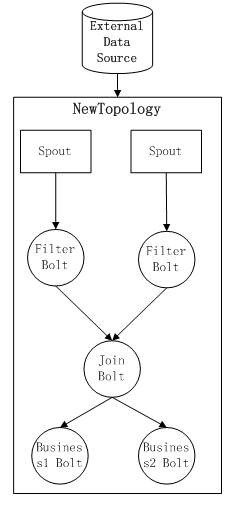
2ЃЉ ЕкЖўжжЗНЪНЃКЭъШЋПЊЗЂВПЪ№вЛЬзаТЕФTopologyЃЌЦфжаЧАУцЕФЙЋЙВВПЗжЕФSpoutКЭBoltПЩвджБНгИДгУЃЌжЛашвЊжиаТПЊЗЂаТЕФМЦЫуТпМBusiness2
BoltРДЬцЛЛдгаЕФBusiness1 BoltМДПЩЁЃШЛКѓжиаТЬсНЛаТЕФTopologyдЫааЁЃетЪБКђStormФкЕФећЬхTopologyНсЙЙШчЯТЃК
етжжЗНЪНЕФШБЕудкгкЃКгЩгкСНИіTopologyЖМЛсДгExternal Data SourceЖСШЁЭЌвЛЗнЪ§ОнЃЌЮовЩдіМгСЫExternal
Data SourceЕФИКдибЙСІЃЛЖјЧвЛсЕМжТЭЌбљЕФЪ§ОндкStormМЏШКФкБЛДЋЪфЯрЭЌЕФСНЗнЃЌБЛЭЌбљЕФМЦЫуЕЅдЊBoltНјааДІРэЃЌРЫЗбСЫStormЕФМЦЫузЪдДКЭЭјТчДЋЪфДјПэЁЃМйЩшЯждкВЛжЙгаСНИіетбљЕФTopologyМЦЫуШЮЮёЃЌЖјЪЧгаNИіЃЌФЧУДЖдStormЕФМЦЫуSlotЕФРЫЗбКмбЯжиЁЃ
зЂвтЃКЩЯЪіСНжжЗНЪНЛЙгавЛИіЙЋЙВЕФШБЕуЁЊЁЊЯЕЭГПЩРЉеЙадВЛКУЃЌетвтЮЖзХВЛЙмФФжжЗНЪНЃЌжЛвЊвдКѓгаетжжаТдівЕЮёТпМЕФашЧѓЃЌЖМашвЊНјааИДдгЕФШЫЙЄВйзїЛђЯпадЕФзЪдДРЫЗбЯжЯѓЁЃ
3ЃЉ ЕкШ§жжЗНЪНЃКOKЃЌПДСЫвдЩЯСНжжЗНЪНКѓЃЌвВаэФуЛсЬсГіЯТУцЕФНтОіЗНАИЃКЭЈЙ§KafkaетбљЕФЯћЯЂжаМфМўЃЌЪЕЯжВЛЭЌTopologyЕФSpoutЙВЯэЪ§ОндДЃЌЖјЧветбљПЩвдзіЕНЯћЯЂПЩППДЋЪфЁЂЯћЯЂrewindЛиДЋЕШЃЌКУДІЪЧЖдгкStormРДЫЕЃЌвбОгаСЫstorm-kafkaВхМўЕФжЇГжЁЃетЪБКђStormФкЕФећЬхTopologyНсЙЙШчЯТЃК
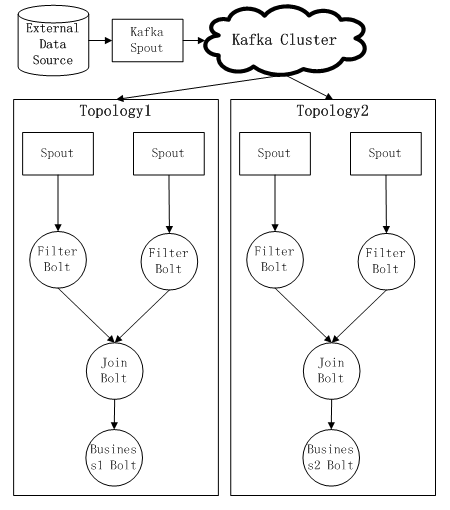
етжжЪЕЯжЗНЪНПЩвдЭЈЙ§в§ШывЛВуЯћЯЂжаМфМўМѕЩйЖдExternal Data SourceЕФжиИДЗУЮЪЕФбЙСІЃЌЖјЧвПЩвдЭЈЙ§ЯћЯЂжаМфМўВуЃЌЦСБЮЕєExternal
Data SourceЕФЯИНкЃЌШчЙћашвЊРЉеЙаТЕФвЕЮёТпМЃЌжЛашвЊжиаТВПЪ№дЫаааТЕФTopologyЃЌгІИУЫЕЪЧЯжгаStormАцБОЯТКмКУЕФЪЕЯжЗНЪНСЫЁЃВЛЙ§ЯћЯЂжаМфМўЕФв§ШыЃЌЮовЩНЋИјЯЕЭГДјРДСЫвЛЖЈЕФИДдгадЃЌетЖдгкStormЩЯЕФгІгУПЊЗЂРДЫЕЬсИпСЫУХМїЁЃ
жЕЕУзЂвтЕФЪЧЃЌЗНАИШ§жаШдвХСєгавЛЕуЮЪЬтУЛгаНтОіЃКЖдгкStormМЏШКРДЫЕЃЌетжжЗНЪНЛЙЪЧУЛгаФмЙЛДгИљБОЩЯБмУтЪ§ОндкStormВЛЭЌTopologyФкЕФжиИДЗЂЫЭгыДІРэЁЃетЪЧгЩгкStormЕФЪ§ОнСїФЃаЭЩЯЕФЯожЦЫљЕМжТЕФЃЌШчЙћStormЪЕЯжСЫВЛЭЌTopologyжЎМфStreamЕФЙВЯэЃЌФЧУДетвЛЮЪЬтвВОЭгШаЖјНтСЫЁЃ
вЛИіСїДІРэЯЕЭГЕФЪ§ОнСїФЃаЭ
ИіШЫЙЄзїжагаавВЮгыЙ§вЛИіСїДІРэПђМмЕФПЊЗЂгыгІгУЁЃЯТУцЮвУЧРДМђЕЅПДПДЦфжаЫљВЩгУЕФЪ§ОнСїФЃаЭЁЃ
ЪзЯШЃЌЯШРДПДвЛЯТИУСїДІРэЯЕЭГФкЕФМИИіЛљБОИХФюЃК
1ЃЉЪ§ОнСїЃЈdata streamЃЉЃКЪБМфЗжВМКЭЪ§СПЩЯЮоЯоЕФвЛЯЕСаЪ§ОнМЧТМЕФМЏКЯЬхЃЛ
2ЃЉЪ§ОнМЧТМЃЈdata recordЃЉЃКЪ§ОнСїЕФзюаЁзщГЩЕЅдЊЃЌУПЬѕЪ§ОнМЧТМАќРЈ 3 РрЪ§ОнЃКЫљЪєЪ§ОнСїУћГЦЃЈstream
nameЃЉЁЂгУгкТЗгЩЕФЪ§ОнЃЈkeysЃЉКЭОпЬхЪ§ОнДІРэТпМЫљашЕФЪ§ОнЃЈvalueЃЉЃЛ
3ЃЉЪ§ОнДІРэШЮЮёЖЈвхЃЈtask definitionЃЉЃКЖЈвхвЛИіЪ§ОнДІРэШЮЮёЕФЛљБОЪєадЃЌЮоЗЈжБНгБЛжДааЃЌБиаыЬиЛЏЮЊОпЬхЕФШЮЮёЪЕР§ЁЃЦфЛљБОЪєадАќРЈЃК
ЃЈПЩбЁЃЉЪфШыСїЃЈinput streamЃЉЃКУшЪіИУШЮЮёвРРЕФФаЉЪ§ОнСїзїЮЊЪфШыЃЌЪЧвЛИіЪ§ОнСїУћГЦСаБэЃЛЪ§ОнСїВњЩњдДВЛЛсвРРЕЦфЫћЪ§ОнСїЃЌПЩКіТдИУХфжУЃЛ
Ъ§ОнДІРэТпМЃЈprocess logicЃЉЃКУшЪіИУШЮЮёОпЬхЕФДІРэТпМЃЌР§ШчгЩЖРСЂНјГЬНјааЕФЭтВПДІРэТпМЃЛ
ЃЈПЩбЁЃЉЪфГіСїЃЈoutput streamЃЉЃКУшЪіИУШЮЮёВњЩњФФИіЪ§ОнСїЃЌЪЧвЛИіЪ§ОнСїУћГЦЃЛЪ§ОнСїДІРэСДФЉМЖШЮЮёВЛЛсВњЩњаТЕФЪ§ОнСїЃЌПЩКіТдИУХфжУЃЛ
4ЃЉЪ§ОнДІРэШЮЮёЪЕР§ЃЈtask instanceЃЉЃКЖдвЛИіЪ§ОнДІРэШЮЮёЖЈвхНјааОпЬхдМЪјКѓЃЌПЩЭЦЫЭЕНФГИіДІРэНсЕуЩЯдЫааЕФТпМЪЕЬхЁЃИНМгЯТСаЪєадЃК
Ъ§ОнДІРэШЮЮёЖЈвхЃКжИЯђИУШЮЮёЪЕР§ЖдгІЕФЪ§ОнДІРэШЮЮёЖЈвхЪЕЬхЃЛ
ЪфШыСїЙ§ТЫЬѕМўЃЈinput filting conditionЃЉЃКвЛИі boolean БэДяЪНСаБэЃЌУшЪіУПИіЪфШыСїжаЗћКЯЪВУДЬѕМўЕФЪ§ОнМЧТМПЩвдзїЮЊгааЇЪ§ОнНЛИјДІРэТпМЃЛШєФГИіЪфШыСїжаЫљгаЪ§ОнМЧТМЖМЪЧгааЇЪ§ОнЃЌдђПЩжБНггУ
true БэЪОЃЛ
ЃЈПЩбЁЃЉЧПжЦЪфГіжмЦкЃЈoutput intervalЃЉЃКУшЪівдЪВУДЦЕТЪЧПжЦИУШЮЮёЪЕЧœٜЪфГіСїМЧТМЃЌПЩвдгУЪфШыСїМЧТМИіЪ§ЛђМфИєЪБМфзїЮЊжмЦкЃЛКіТдИУХфжУЪБЃЌЪфГіСїМЧТМВњЩњжмЦкЭъШЋгЩДІРэТпМздЩэОіЖЈЃЌВЛЪмПђМмдМЪјЃЛ
5ЃЉЪ§ОнДІРэНсЕуЃЈnodeЃЉЃКПЩШнФЩЖрИіЪ§ОнДІРэШЮЮёЪЕР§дЫааЕФЪЕЬхЛњЦїЃЌУПИіЪ§ОнДІРэНсЕуЕФIPv4ЕижЗБиаыБЃжЄЮЈвЛЁЃ
ИУСїДІРэЯЕЭГЃЌВЩгУЗжВМЪНВпТдЃЌгЩЖрИіЪ§ОнДІРэНсЕуНјааЪ§ОнЕФДІРэЙ§ГЬЃЛНЋСїЪНЪ§ОнЕФДІРэЙ§ГЬЛЎЗжЮЊВЛЭЌЕФНзЖЮЃЌУПИіНзЖЮАщЫцЪ§ОнСїЕФСїШыЁЂШЮЮёЕФДІРэМАЪ§ОнСїЕФСїГіЃЛИїИіНзЖЮЛсгаШєИЩИіДІРэНсЕуВЮгыЭъГЩЃЌЦфжаЃЌУПИіДІРэНсЕуЩЯЛсгаШєИЩИіЪ§ОнДІРэШЮЮёЪЕР§дЫааЃЌУПИіЪ§ОнДІРэШЮЮёЪЕР§дђЪЧЖдвЛИіЪ§ОнДІРэШЮЮёЖЈвхНјааОпЬхдМЪјКѓЃЌПЩЭЦЫЭЕНФГИіДІРэНсЕуЩЯдЫааЕФТпМЪЕЬхЁЃдкВЛЭЌЕФДІРэНсЕужЎМфЃЌЪ§ОнСїИљОнХфжУаХЯЂНјааДЋЪфЃЛдкДІРэНсЕуФкВПЃЌНсЕуИљОнХфжУаХЯЂЖдСїОИУНсЕуЕФЪ§ОнНјааДІРэЁЃ
ЯТЭМЮЊЯЕЭГЖдгкСїЪНЪ§ОнЕФЛљБОДІРэСїГЬЃК
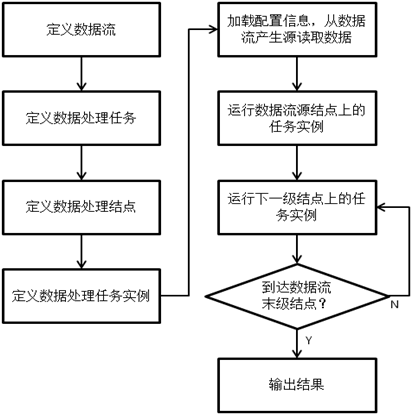
1ЃЉЖЈвхЪ§ОнСїЃКНЋСїЪНЪ§ОнЕФДІРэЙ§ГЬЛЎЗжГЩВЛЭЌЕФНзЖЮЃЌЖЈвхГіВЛЭЌЕФЪ§ОнСїУћГЦЃЛ
2ЃЉЖЈвхЪ§ОнДІРэШЮЮёЃКЮЊЪ§ОнСїЕФДІРэЙ§ГЬЖЈвхЯргІЕФЪ§ОнДІРэШЮЮёЃЌЦфжаЃЌИїИіДІРэШЮЮёЖЈвхСЫЭтВПДІРэТпМЃЌЧвЦфЪфШы/ЪфГіЪ§ОнСїаыДг1ЃЉжадЄЖЈвхЕФЪ§ОнСїСаБэжабЁШЁЃЛ
3ЃЉЖЈвхЪ§ОнДІРэНсЕуЃКЖЈвхИїИіЪ§ОнДІРэНсЕуЕФУћГЦМАЦфIPv4ЕижЗаХЯЂЃЛ
4ЃЉЖЈвхЪ§ОнДІРэШЮЮёЪЕР§ЃКЮЊ3ЃЉжаЖЈвхКУЕФУПИіДІРэНсЕуЃЌЗжБ№ЖЈвхдЫаадкЦфЩЯЕФЪ§ОнДІРэШЮЮёЪЕР§ЃЌЦфжаЃЌУПИіШЮЮёЪЕР§ЫљЖдгІЕФЪ§ОнДІРэШЮЮёЪЕЬхаыДг2ЃЉжадЄЖЈвхЕФДІРэШЮЮёСаБэжабЁШЁЃЛ
5ЃЉМгдиЪ§ОнСїЕФЯрЙиХфжУаХЯЂМАЖЉдФаХЯЂЃЈОпЬхИёЪНМћЁАИНТМЃКХфжУаХЯЂИёЪНЁБЃЉЃЌШЛКѓПЊЪМДгЪ§ОнСїВњЩњдДЖСШЁЪ§ОнЃЛ
6ЃЉдЫааЪ§ОнСїдДНсЕуЩЯЕФШЮЮёЪЕР§ЃКЪ§ОнСїДІРэСДдДНсЕуЩЯЕФДІРэШЮЮёЪЕР§жБНгЖдЪ§ОнСїВњЩњдДЕФЪ§ОнНјааДІРэЃЌШЛКѓВњЩњаТЕФЪфГіЪ§ОнСїЃЛ
7ЃЉдЫааЯТвЛМЖНсЕуЩЯЕФШЮЮёЪЕР§ЃКжаМфЕФДІРэНсЕуЩЯЕФДІРэШЮЮёЪЕР§вРРЕгкЩЯвЛМЖДІРэНсЕуЕФЪфГіЪ§ОнСїзїЮЊЪфШыЪ§ОнСїЃЌДгжаЖСШЁЪ§ОнЃЌНјааДІРэЃЌВњЩњЪфГіЪ§ОнСїЃЌВЂДЋЕнЕНЯТвЛМЖДІРэНсЕуЃЛ
8ЃЉХаЖЯЪЧЗёЕНДяЪ§ОнСїФЉМЖНсЕуЃК
ШчЙћВЛЪЧЃЌдђМЬајЗЕЛиВНжш7ЃЉЃЌАДееЪ§ОнСїЕФСїЖЏЙиЯЕЃЌМЬајдЫааЯТвЛМЖНсЕуЩЯЕФШЮЮёЪЕР§ЃЛ
ЗёдђЮЊЪ§ОнСїФЉМЖНсЕуЃЌдђНјааВНжш9ЃЉЁЃ
9ЃЉЪфГіНсЙћЃКЪ§ОнСїДІРэСДФЉМЖНсЕуЩЯЕФДІРэШЮЮёВЛЛсВњЩњаТЕФЪ§ОнСїЃЌЭъГЩзюжеЕФЪ§ОнДІРэШЮЮёКѓНЋНсЙћНјааЪфГіЁЃ
вдЩЯЪЧЪ§ОнСїдкВЛЭЌДІРэНсЕужЎМфЕФДІРэСїГЬЁЃУПИіДІРэНсЕузїЮЊСїДІРэЕФвЛИіЛЗНкЃЌЦфНсЕуФкВПЕФДІРэСїГЬШчЯТЭМЫљЪОЃК
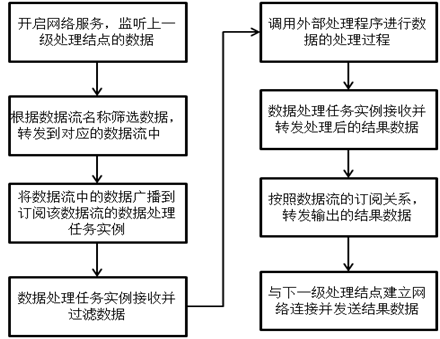
1ЃЉУПИіДІРэНсЕуЦєЖЏСїДІРэЙ§ГЬКѓЃЌПЊЦєЭјТчЗўЮёЃЌМрЬ§ДгЩЯвЛМЖДІРэНсЕуЗЂГіЕФTCPСЌНгЧыЧѓЃЌНгЪеДгЩЯвЛМЖНсЕуЗЂРДЕФЪ§ОнЃЛ
2ЃЉДІРэНсЕуВЛМфЖЯЕиНгЪеДгЩЯвЛМЖДІРэНсЕуЗЂРДЕФЪ§ОнЃЌЖдгкУПЬѕЪ§ОнМЧТМЃЌИљОнЪ§ОнСїУћНјааЩИбЁЃЌНЋЦфЗжЗЂЕНИУЪ§ОнСїЫљЖдгІЕФДІРэНјГЬжаЃЛ
3ЃЉНЋДгУПИіЬиЖЈЪ§ОнСїЗЂРДЕФЪ§ОнЃЌЙуВЅЕНЫљгавдИУЪ§ОнСїзїЮЊЪфШыЪ§ОнСїЕФЪ§ОнДІРэШЮЮёЪЕР§жаЃЛ
4ЃЉЪ§ОнДІРэШЮЮёЪЕР§ДгЦфЪфШыЪ§ОнСїжаНгЪеЪ§ОнЃЌАДееЙ§ТЫЬѕМўНјааЩИбЁЃЌШЛКѓНЋЗћКЯЙ§ТЫЬѕМўЕФЪ§ОнМЧТМЗЂЫЭИјЭтВПгІгУГЬађНјааДІРэЃЛ
5ЃЉЭтВПгІгУГЬађЦєЖЏЭтВПДІРэНјГЬЃЌЖдЪ§ОнНјааЪЕМЪДІРэЙ§ГЬЃЌВЂНЋУПЬѕЪ§ОнМЧТМЕФДІРэНсЙћЗЕЛиИјЯргІЕФЪ§ОнДІРэШЮЮёЪЕР§ЃЛ
6ЃЉЪ§ОнДІРэШЮЮёЪЕР§ДгЭтВПгІгУГЬађЪеМЏДІРэКѓЕФНсЙћЪ§ОнЃЌВЂвРДЮНЋЦфзЊЗЂЕНЖдгІЕФЪфГіЪ§ОнСїжаЃЛ
7ЃЉЪфГіЪ§ОнСїНјГЬНгЪеЗЂЯђИУЪ§ОнСїЕФЪ§ОнЃЌШЛКѓАДееЪ§ОнСїЕФЖЉдФЙиЯЕЃЌНЋЪ§ОнЗЂЫЭЕНЫљгаЖЉдФСЫИУЪ§ОнСїЕФЯТвЛМЖДІРэНсЕуЃЛ
8ЃЉИљОнЯТвЛМЖДІРэНсЕуЕФIPЕижЗКЭЖЫПкКХЃЌЭЈЙ§TCPЧыЧѓгыЯТвЛМЖДІРэНсЕуНЈСЂЭјТчСЌНгЃЌШЛКѓНЋЪ§ОнАДађДЋЪфЕНЯТвЛМЖДІРэНсЕуЁЃ
ЖўепдкЪ§ОнСїФЃаЭЩЯЕФВЛЭЌжЎДІ
жСгкСНИіЯЕЭГЕФЪЕЯжЯИНкЃЌЮвУЧЯШВЛШЅзіОпЬхБШНЯЃЌЯТУцНіСаГіЖўепдкЪ§ОнСїФЃаЭЩЯЕФвЛаЉВЛЭЌжЎДІЃЈетРяВЂВЛЪЧЮЊСЫШЋУцЖдБШЖўепЕФВЛЭЌжЎДІЃЌжЛЪЧСаГіЦфжаЕФЙиМќВПЗжЃЉЃК
1ЃЉ дкStormжаЃЌЪ§ОнСїStreamЪЧдкTopologyФкНјааЖЈвхЃЌВЂдкTopologyФкНјааДЋЪфЕФЃЛЖјдкЩЯУцЬсЕНЕФСїДІРэЯЕЭГжаЃЌЪ§ОнСїStreamЪЧдкећИіЯЕЭГФкШЋОжЮЈвЛЕФЃЌПЩвддкећИіМЏШКФкБЛЖЉдФЁЃ
2ЃЉ дкStormжаЃЌЪ§ОнСїStreamЕФЗЂВМКЭЖЉдФЖМЪЧОВЬЌЕФЃЌЫљЮНОВЬЌЪЧжИЪ§ОнСїЕФЗЂВМгыЖЉдФЙиЯЕдкЯђStormМЏШКЬсНЛTopologyМЦЫуШЮЮёЪБЃЌБЛвЛДЮадЩњГЩЕФЃЌетвЛЙиЯЕдкTopologyЕФдЫааЙ§ГЬжаЪЧВЛФмБЛИФБфЕФЃЛЖјдкЩЯУцЬсЕНЕФСїДІРэЯЕЭГжаЃЌЪ§ОнСїStreamЕФЗЂВМКЭЖЉдФЖМЪЧЖЏЬЌЕФЃЌМДЪ§ОнДІРэШЮЮёtaskПЩвдЖЏЬЌЕФЗЂВМStreamЃЌвВПЩвдЖЏЬЌЕФЖЉдФЯЕЭГФквбОЩњГЩЕФШЮвтStreamЃЌЪ§ОнСїЕФЖЉдФЙигкЭЈЙ§ЗжВМЪНгІгУГЬађаЕїЗўЮёZooKeeperМЏШКЕФЖЏЬЌНкЕуРДЮЌЛЄЙмРэЁЃ
КУСЫЃЌгаСЫвдЩЯЕФЖдБШЃЌЮвУЧВЛФбЗЂЯжЃЌЖдгкБОЮФЫљОйЕФгІгУГЁОАЪЕР§ЃЌStormЕФЪ§ОнСїФЃЪНЩаВЛФмКмЗНБуЕФжЇГжЃЌЖјдкетРяЬсЕНЕФетИіСїДІРэЯЕЭГЕФШЋОжЪ§ОнСїФЃаЭЯТЃЌетвЛгІгУГЁОАЕФашЧѓПЩвдКмЗНБуЕФТњзуЁЃ
змНсЕФЛА
ИіШЫОѕЕУЃЌStormгаБивЊЪЕЯжВЛЭЌTopologyжЎМфStreamЕФЙВЯэЃЌетИіжСЩйПЩвддкВЛЫ№ЪЇStormЯжгаЙІФмЕФЧАЬсЯТЃЌЪЙЕУStormдкДІРэЪЕМЪЩњВњЛЗОГЯТЕФвЛаЉгІгУГЁОАЪБИќМгДгШнгІЖдЁЃ
жСгкШчКЮдкЯжгаStormЕФЛљДЁЩЯЪЕЯжетвЛашЧѓЃЌПЩФмЕФЗНЪНКмЖрЁЃвЛжжМђЕЅЕФЗНЪНЪЧЭЈЙ§ZookeeperРДМЏжаДцДЂЁЂЖЏЬЌИажЊTopologyжЎМфStreamЕФЁАЗЂВМ-ЖЉдФЁБЙиЯЕЃЌЭЌЪБдкStormЕФЯћЯЂЗжЗЂЙ§ГЬжаЖдетжжЧщПіМгвдДІРэЁЃ
|









