| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФжївЊДгSolrЯЕЭГВуУцКЭЫїв§зжЖЮгХЛЏСНИіЗНУцНјаагХЛЏвдМАеЙПЊвЛЯТЕФАИР§ЗжЮіЁЃ
|
|
ЫцзХumcНгШыжїЛњЕФЪ§СПдНРДдНЖрЃЌУПЬьВњЩњЕФsyslogШежОЪ§СПвВдкОчдіЃЌ
жЎЧАвЛЬьВњЩњsyslogЪ§СПВХВЛЕН1WЃЌЫцзХећИіМЏЭХЕФЭјТчЩшБИВЛЖЫНгШыЃЌЕМжТЯждкУПЬьВњЩњЕФsyslogЪ§СПДѓИХ180wзѓгвЃЌЖјетаЉsyslogЖдЭјТчКЭPEЭЌбЇХХВщЯпЩЯЭјТчЩшБИЮЪЬтгжЪЧЪЎЗжживЊЕФЃЌЫћУЧЕФвЊЧѓЪЧПЩвдЬсЙЉВщбЏзюНќ3ИідТЕФsyslogЃЌ
БЃДцвЛФъЕФsyslogЃЌдк7дТЗнЕФЪБКђЃЌеыЖдСПВЛЖрЕФЧщПіЃЌеыЖдmysqlЕЅБэзіСЫЫїв§ЃЌКѓРДгжзіСЫЕЅБэБИЗнЃЌЕЋЪЧВщбЏЕФЫйЖШЛЙЪЧЮоЗЈШУШЫНгЪмЃЌКѓУцгжНсКЯвГУцеыЖдmysqlcount(*)гяОфзіСЫгХЛЏЃК
ЪЙгУcount(*)гяОфжЛЪЧдкЕквЛДЮВщбЏЕФЪБКђВщбЏвЛДЮЃЌКѓУцБЃДцЯТРДЃЌдкКѓУцЗжвГВщбЏЕФЪБКђЃЌВЛдйашвЊдйВщбЏзмЪ§СПЃЌМДВЛЕїгУcount(*)жЎРрЕФsqlгяОфЃЌНсЙћдкЗвГЪБЃЌЫйЖШЛЙЪЧБШНЯПьЃЌЕЋЪзДЮВщбЏЕФЪБКђЃЌЛЙЪЧЗЧГЃЗЧГЃТ§ЃЌЕЋетБЯОЙжЛЪЧвЛИіСйЪБЕФНтОіЗНАИЃЛКѓУцНсКЯsyslogЫбЫїЕФвЕЮёЧщПіЃЌНсКЯИїжжММЪѕВЮПМЃЌзюжебЁдёСЫЪЙгУSolrЫбЫїв§ЧцРДНтОіsyslogВщевТ§ЕФЮЪЬтЃЛ
дкзібЙСІВтЪдЕФЪБКђЃЌЗЂЯжадФмЮЪЬтЃКдкЪ§ОнСПВЛДѓ(<1000W)ЕФЪБКђЃЌгУSolrЫбЫїЪЧБШНЯПьЃЌЕЋЫцзХзХ
syslogЪ§ОнСПЕФВЛЖЯдіЖрЃЌаДЫїв§КЭЫбЫїЕФЫйЖШдНРДдНВЛФмШУШЫНгЪмЃЌвђДЫВЛЕУВЛПМТЧЖдSolrНјаагХЛЏЃЛ
ЭјЩЯСЫЫбСЫвЛЯТSolrгХЛЏЕФДѓЬхЗНАИЃЌжївЊДгШчЯТСНИіВНжшРДНјаагХЛЏЃК
1. SolrЯЕЭГВуУцЃЛ
2. Ыїв§зжЖЮгХЛЏЃЛ
еыЖдSolrЯЕЭГВуЕФгХЛЏЃЌжївЊгаШчЯТЕФЗНЗЈЃК
1. ЪЪЕБЕїДѓSolrВщбЏЛКДцЃЛ
2.ЪЪЕБдіМгSolrМЏШКЕФЧаЦЌЃЛ
3ИљОнВщбЏЕФвЕЮёГЁОАЃЌЪЪЕБЕї
ећЫїв§КЯВЂЕФЪБМфЃЌЕШЕШвЛЯЕСаЭЈгУЕФзіЗЈЃЌеыЖдетаЉаоИФвдКѓЃЌЗЂЯжаоИФЧАКѓЃЌЖдВщбЏЕФадФмУЛгаБОжЪЕФЬсИпЃЛ
еыЖдЫїв§зжЖЮЕФгХЛЏЃЌОЭЪЧеыЖдЬэМгЕНLucenceжаЮФЕЕИїЫїв§зжЖЮЕФгХЛЏЃЌ syslogЫїв§зжЖЮжївЊЕФзжЖЮгаЃК
|
id(Integer),
ip(String),
log_level(String),
log_value(String)
syslog_time(Date), |
вЊеыЖдетаЉзжЖЮгХЫїв§гХЛЏЃЌОЭвЊЪзЯШЗжЮіЫїв§ВщевЕФЙ§ГЬЃЌвЊзіЕНзжЖЮгХЛЏЫїв§ЃЌПЩвдДгСНЗНУцПМТЧЃЌ
1. МѕЩйзжЖЮЫїв§ДцДЂСПЃЌ
2. ЬсИпВщбЏЫїв§БШНЯЕФЪБМфЃЌ еыЖдетСНЕуЃЌ
ПЩвдКСВЛгЬдЅЕФПМТЧАбStringРраЭЕФзжЖЮЯђIntegerЛђLongРраЭжЎРрЕФећаЭзжЖЮгГЩфзЊЛЛ(ећаЭЕФЫїв§ДцДЂПеМфвЛАуБШзжЖЮДЎЫљеМЕФДцДЂЫїв§ПеМфвЊаЁЃЛећаЭЕФВщевБШНЯЫйЖШБШзжЖЮДЎРраЭвЊПьЃЌЦфЪЕетвВЪЧЪ§ОнПтВщевгХЛЏЕФвЛИіЗНУц)ЃЛЛљгкетбљЕФПМТЧЃЌipЁЂlog_levelКЭsyslog_timeПЩвдЯђЯргІЕФећаЭгГЩфЃЌИїИізжЖЮОпЬхЕФгГЩфЗНЗЈШчЯТЃК
1. ip ЕижЗЯђећаЮгГЩфЃЌетИіЮЪЬтБШНЯКУНтОіЃЌдкМЦЫуЛњЭјТчавщжаЃЌдкЕзВуЪЧЛсАбipЕижЗзЊЛЛГЩЖдгІЕФЮоЗћКХГЄећаЭЃЌЕЋгЩгкjavaУЛгаЮоЗћКХетИіИХФюЃЌвђДЫПЩвдПМТЧАбipЕижЗЯђећаЭЛђГЄећаЭзіЯрЛЅгГЩфзЊЛЛ,ЕЋвђЮЊећаЭБШГЄећаЭеМгУЕФзжНкИќЩйЃЌвђДЫВЩгУећаЭЃЌОпЬхзЊЛЛДњТыШчЯТЃК
| public
static Long ipToInteger(String ip) {
String[] ips = StringUtils.split(ip,'.');
if (ips == null || ips.length < 4){
throw newRuntimeException("ipЕижЗЗЧЗЈ!");
}
Integer integerIP = 0;
Integer ip0= Integer.parseInteger(ips[0]);
Integer ip1= Integer.parseInteger(ips[1]);
Integer ip2= Integer.parseInteger(ips[2]);
Integer ip3= Integer.parseInteger(ips[3]);
if (ip0 > 255) {
throw newRuntimeException("ip0ЕижЗЗЧЗЈ:"
+ ip0);
}
if (ip1 > 255) {
throw newRuntimeException("ip1ЕижЗЗЧЗЈ:"
+ ip1);
}
if (ip2 > 255) {
throw newRuntimeException("ip2ЕижЗЗЧЗЈ:"
+ ip2);
}
if (ip3 > 255) {
throw newRuntimeException("ip3ЕижЗЗЧЗЈ:"
+ ip3);
}
integerIP |=( ip0 << 24) & (0xff000000);
integerIP |=( ip1 << 16) & (0x00ff0000);
integerIP |=( ip2 << 8) & (0x0000ff00);
integerIP |=( ip3 << 0) & (0x000000ff);
return integerIP ;
} |
| /**
* intРраЭЕНipзЊЛЛ
* @param integerIP
* @return
*/
public static String integerToIP(IntegerintegerIP)
{
String ip = "";
Integer ip0= (integerIP & 0xff000000) >>>
24;
Integer ip1= (integerIP & 0x00ff0000) >>
16 ;
Integer ip2= (integerIP & 0x0000ff00) >>
8;
Integer ip3= (integerIP & 0x000000ff) >>
0;
ip = ip0 + "." + ip1 +"."
+ ip2 + "." + ip3;
return ip;
} |
2. log_level жЛга8жжжЕЃЌЗжБ№ЪЧЃКEmergencyЃЌ
AlertЃЌ CriticalЃЌ ErrorЃЌ WarningЃЌNoticeЃЌInformationalЃЌDebugЃЛ
етИіКУзЊЛЛЃЌжБНгАДЯТБэЕФЗНЪНзіЯрЛЅгГЩфМДПЩ
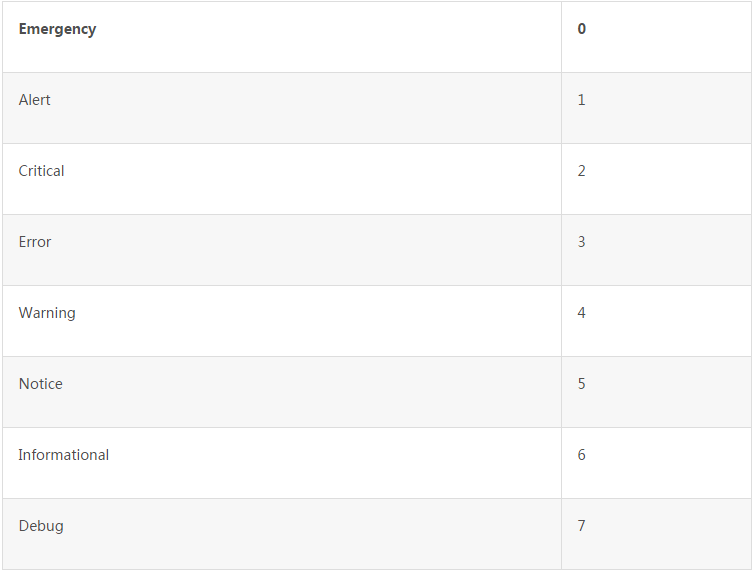
3. Абsyslog_timeзЊЛЛГЩLongРраЭЃЌетИіИќШнвзЃЌjavaжаDateРраЭгавЛИіgetTime()ЗНЗЈОЙ§АбетШ§ИізжЖЮЖМзЊЛЛГЩећаЭвдКѓЃЌЫїв§ВхШыКЭЫбЫїЫйЖШЖМЬсИпВЛЩйЃЌЬиБ№ЪЧЫбЫїЫйЖШгаЗЧГЃЗЧГЃУїЯдЕФЬсЩ§ЃЌЬиБ№ЪЧдкЪ§ОнСПГЌЙ§2вкЕФЪБМфЃЌаЇЙћИќУїЯдЕНДЫЃЌзжЖЮгХЛЏЭъБЯЃЛЕЋДЫЪБЛЙЗЂЯжвЛИіЮЪЬтЃКвЛДЮВщевЗЕЛиЕФЪ§ОнСПЬЋЖрЃЌЕМжТДцдкЗвГТ§ЕФЮЪЬтЃЌР§ШчЃКвЛДЮЗЕЛи10WвГЪ§ОнЃЌШчЙћвЛЯТЗЕНЕк10WвГЃЌВщбЏЕФЫйЖШЛсЗЧГЃЗЧГЃТ§ЩѕжСПЩФмГіЯжSolrМЏШКШЋВПхДЛњЕФЧщПіЃЌетЪЧВЛФмНгЪмЕФЃЌвђЮЊЮвУЧвГУцЩЯЬсЙЉСЫЗЕНзюКѓвЛУцЕФЙІФмЃЌ
ЫфШЛгУЛЇвЛАуЧщПіЯТВЛЛсетУДзіЃЌЕЋЭђвЛВЛаЁЕуДэСЫЃЌећИіЯпЩЯSorlМЏШКОЭШЋВПЙвСЫЃЌдѕУДАьЃПетИіЮЪЬтЃЌШУЮвЯыЦ№СЫmysqlРяЕФЗвГЕФЮЪЬтЃЌЯТУцСНЬѕSQLгяОфЃК
| select
* from umc_syslog where syslog_time between
date1 and date2 order by id limit 0, 10;
select * from umc_syslog where syslog_time between
date1 and date2 order by id limit 10000, 10; |
ЮвУЧжЊЕРЃЌЕквЛЬѕSQLгяОфВщбЏЕФЫйЖШЗЧГЃПьЃЌЕкЖўSQLгяОфВщбЏЕФЫйЖШЗЧГЃТ§ЃЌдкЯЕЭГбЙСІНЯДѓЕФЧщПіЯТЃЌПЩФмЛсАбmysqlЗўЮёХЊЙвЃЌИљБОдвђдкгкlimitstart,
rowsгяОфЃЌmysqlЛсдкЩЈУшЪБЃЌЛсЩЈЙ§ТњзуНсЙћЕФЧАstartааЕФМЧТМЃЌШЛКѓВХЖСШЁlenааЕФЪ§ОнЃЌШчЙћstartЬиБ№ДѓЃЌЛсЗЧГЃТ§ЃЌдкИпадФмmysqlетБОЪщжаНщЩмСЫИїжжНтОіЗжвГЮЪЬтЕФгХЛЏЃЌШчбгГйЙиСЊЁЂНзЕнЗжвГЕШЃЌЦфжаНзЕнЗжвГПЩвддкSolrжаЪЕЯжЃЌЕЋЮвУЧвГУцВЛдЪаэетУДзіЃЌВЛШЛдчОЭгУHbaseРДНтОіСЫЃЌдѕУДАьЃЌдкЮоНтОіЕФЧщПіЯТЃЌЭЛШЛЗЂЯжЃЌSolrВщбЏжагаorder
byХХађЕФЮЪЬтЃЌЪЪЕБгУorder byПЩвдКмКУРДНтОіlimit ЗжвГТ§ЕФЮЪЬтЃК
МйЩш вЛИіSolrВщбЏАДid НЕађХХађЗЕЛиЃЌМйЩшЗЕЛи10WааМЧТМЃЌЧА5WЬѕМЧТМПЩвдЫцЛњЗжвГВщбЏЕНЃЌЕЋКѓУц5WЬѕМЧТМКмФбЫцЛњЗжвГВщбЏЕНЃЌдьГЩетИіЮЪЬтЕФдвђЪЧАДidНЕађЗЕЛиЃЌШчЙћЪЪЕБаоИФвЛЯТВщбЏгяОфЃЌЫйЖШПЩФмЛсгаЫљЬсИпЃЌвђЮЊSolrВщбЏУПДЮЖМЛсЗЕЛизмЕФМЧТМЬѕЪ§ЃЌетИізмЕФМЧТМЬѕЪ§ЪЧвбжЊЕФЃЌ
МЧЮЊtotal, зїШчЯТДІРэЃКШчЙћstart аЁгкЕШгк ЃЈtotal >> 1ЃЉ,дђДгЧАЭљКѓЖСЃЛЗёдђОЭДгКѓЭљЧАЖСЃЌШЛКѓЃЌдйАбЗЕЛиЕФНсЙћФцађЃЌЯдЪОМДПЩЃЌЮБДњТыШчЯТЃЛ
| if
start <= (total >> 1)
query order by id desc limit start, rows;
else
calculate new start as start';
calculate new rows as rows';
query order by asc limit start', rows';
reverse the return data;
end |
ГЬађжаЯрЙиДњТыЃК
| //
ЪЧЗёЪЧАДidЩ§ађВщбЏ, ФЌШЯЪЧfalse
boolean isAscend = false;
// Щ§ађЛђНЕађВщбЏХаЖЯ
if (totalCount == 0) {
isAscend = false;
} else {
if (start >= (totalCount >> 1) ) {
isAscend = true;
}
}
if (!isAscend) {
realStart = start;
realRows = rows;
} else {
Integer count = totalCount.intValue();
realStart = (start + rows)>= count? 0 : (count
- (start +rows));
realRows = (start + rows)>= count? (count
- start + 1) : rows;
}
solrQuery.setStart(realStart);
solrQuery.setRows(realRows);
if (!isAscend) {// idНЕађ
solrQuery.setSort("id", ORDER.desc);
} else { // id Щ§ађ
solrQuery.setSort("id", ORDER.asc);
}
// ФцађДІРэ
if (isAscend) {
int size = syslogVOList.size();
int left = 0;
int right = size - 1;
while (left < right) {
SyslogVO leftSyslogVO =syslogVOList.get(left);
SyslogVO rightSyslogVO =syslogVOList.get(right);
syslogVOList.set(left, rightSyslogVO);
syslogVOList.set(right, leftSyslogVO);
left ++;
right --;
}
} |
ОЙ§етИіЙ§ГЬЕФДІРэжЎКѓЃЌЯђКѓЗвГВщбЏЕФЫйЖШПьСЫКмЖрЃЌжСЩйВЛЛсГіЯжхДЛњЕФЯжЯѓЃЛ
ВщбЏвГУцШчЯТЃК
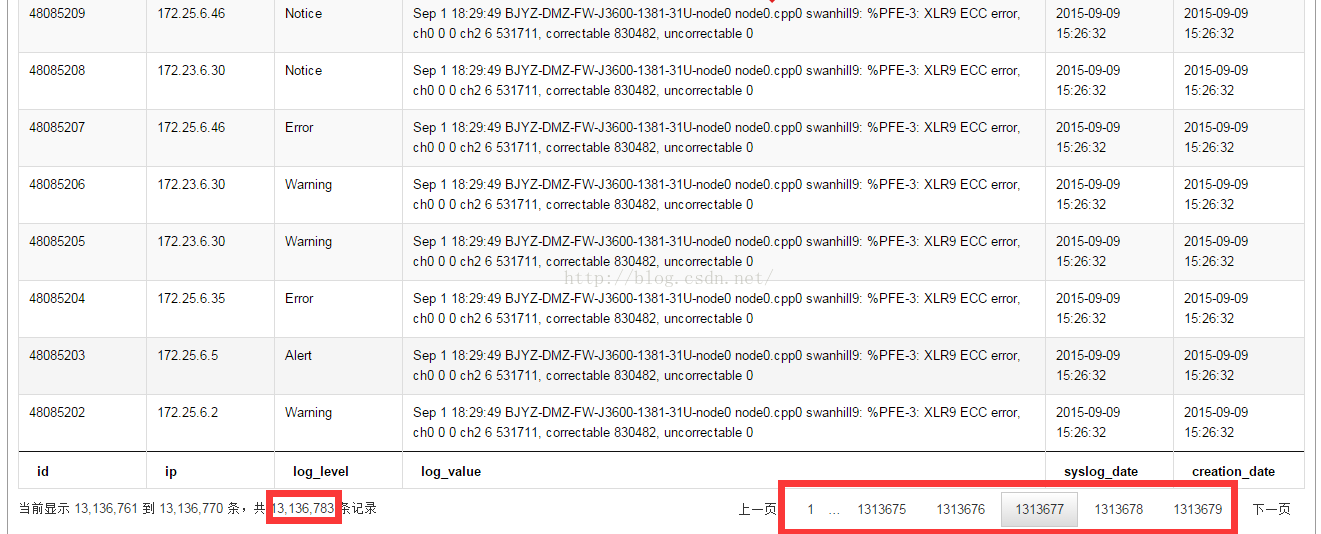
дкЯрЭЌЕФЬѕМўЯТЃК
гХЛЏКѓSolrВщбЏЕФЪБМфЃК
гХЛЏЧАmysqlЕФВщбЏЪБМфЃК
ЦфЪЕетИіММЧЩдкmysqlЗжвГВщбЏЃЌЪ§ОнСПЗЧГЃДѓЕФЪБКђвВЪЪгУЃЛ |









