| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФНщЩмsolrЕФЙІФмЪЙгУМАЯрЙизЂвтЪТЯю;жївЊАќРЈвдЯТФкШн:ЛЗОГДюНЈМАЕїЪд;СНИіКЫаФХфжУЮФМўНщЩм;ЮЌЛЄЫїв§;ВщбЏЫїв§,КЭдкВщбЏжаПЩвдгІгУЕФИпССЯдЪОЁЂЦДаДМьВщЁЂЫбЫїНЈвщЁЂЗжзщЭГМЦЁЂЦДвєМьЫїЕШЙІФмЕФЪЙгУЗНЗЈЁЃ
|
|
1. Solr ЪЧЪВУДЃП
SolrЫќЪЧвЛжжПЊЗХдДТыЕФЁЂЛљгк Lucene Java ЕФЫбЫїЗўЮёЦїЃЌвзгкМгШыЕН Web гІгУГЬађжаЁЃSolr
ЬсЙЉСЫВуУцЫбЫї(ОЭЪЧЭГМЦ)ЁЂУќжаабФПЯдЪОВЂЧвжЇГжЖржжЪфГіИёЪНЃЈАќРЈXML/XSLT КЭJSONЕШИёЪНЃЉЁЃЫќвзгкАВзАКЭХфжУЃЌЖјЧвИНДјСЫвЛИіЛљгкHTTP
ЕФЙмРэНчУцЁЃПЩвдЪЙгУ Solr ЕФБэЯжгХвьЕФЛљБОЫбЫїЙІФмЃЌвВПЩвдЖдЫќНјааРЉеЙДгЖјТњзуЦѓвЕЕФашвЊЁЃSolrЕФЬиадАќРЈЃК
ИпМЖЕФШЋЮФЫбЫїЙІФм
зЈЮЊИпЭЈСПЕФЭјТчСїСПНјааЕФгХЛЏ
ЛљгкПЊЗХНгПкЃЈXMLКЭHTTPЃЉЕФБъзМ
злКЯЕФHTMLЙмРэНчУц
ПЩЩьЫѕадЃФмЙЛгааЇЕиИДжЦЕНСэЭтвЛИіSolrЫбЫїЗўЮёЦї
ЪЙгУXMLХфжУДяЕНСщЛюадКЭЪЪХфад
ПЩРЉеЙЕФВхМўЬхЯЕ
2. Lucene ЪЧЪВУДЃП
LuceneЪЧвЛИіЛљгкJavaЕФШЋЮФаХЯЂМьЫїЙЄОпАќЃЌЫќВЛЪЧвЛИіЭъећЕФЫбЫїгІгУГЬађЃЌЖјЪЧЮЊФуЕФгІгУГЬађЬсЙЉЫїв§КЭЫбЫїЙІФмЁЃLucene
ФПЧАЪЧ Apache Jakarta(бХМгДя) МвзхжаЕФвЛИіПЊдДЯюФПЁЃвВЪЧФПЧАзюЮЊСїааЕФЛљгкJavaПЊдДШЋЮФМьЫїЙЄОпАќЁЃФПЧАвбОгаКмЖргІгУГЬађЕФЫбЫїЙІФмЪЧЛљгк
Lucene ЃЌБШШчEclipse АяжњЯЕЭГЕФЫбЫїЙІФмЁЃLuceneФмЙЛЮЊЮФБОРраЭЕФЪ§ОнНЈСЂЫїв§ЃЌЫљвдФужЛвЊАбФувЊЫїв§ЕФЪ§ОнИёЪНзЊЛЏЕФЮФБОИёЪНЃЌLucene
ОЭФмЖдФуЕФЮФЕЕНјааЫїв§КЭЫбЫїЁЃ
3. Solr vs Lucene
SolrгыLucene ВЂВЛЪЧОКељЖдСЂЙиЯЕЃЌЧЁЧЁЯрЗДSolr вРДцгкLuceneЃЌвђЮЊSolrЕзВуЕФКЫаФММЪѕЪЧЪЙгУLucene
РДЪЕЯжЕФЃЌSolrКЭLuceneЕФБОжЪЧјБ№гавдЯТШ§ЕуЃКЫбЫїЗўЮёЦїЃЌЦѓвЕМЖКЭЙмРэЁЃLuceneБОжЪЩЯЪЧЫбЫїПтЃЌВЛЪЧЖРСЂЕФгІгУГЬађЃЌЖјSolrЪЧЁЃLuceneзЈзЂгкЫбЫїЕзВуЕФНЈЩшЃЌЖјSolrзЈзЂгкЦѓвЕгІгУЁЃLuceneВЛИКд№жЇГХЫбЫїЗўЮёЫљБиаыЕФЙмРэЃЌЖјSolrИКд№ЁЃЫљвдЫЕЃЌвЛОфЛАИХРЈ
Solr: SolrЪЧLuceneУцЯђЦѓвЕЫбЫїгІгУЕФРЉеЙЁЃ
SolrгыLuceneМмЙЙЭМ:
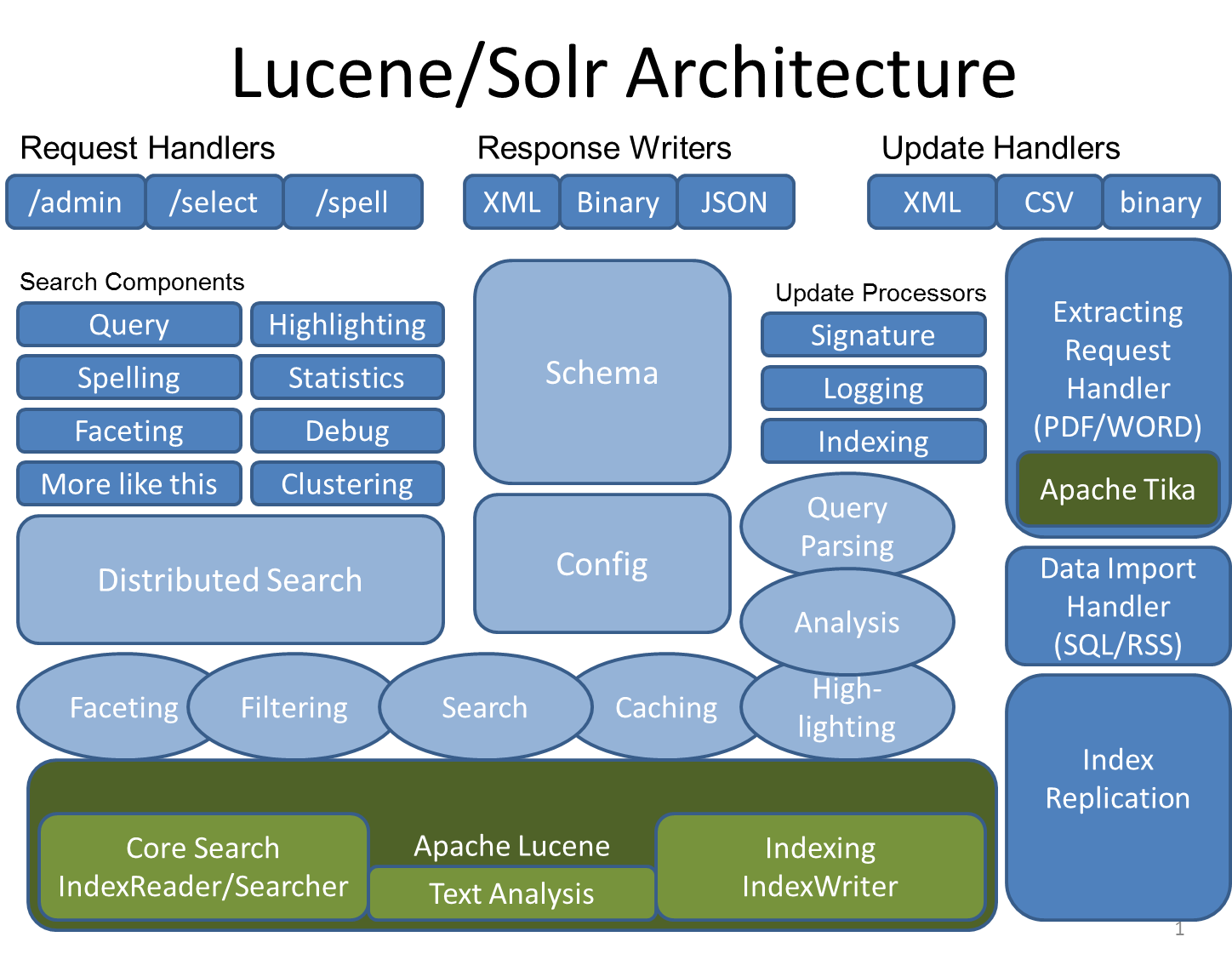
SolrЪЙгУLuceneВЂЧвРЉеЙСЫЫќЃЁ
вЛИіеце§ЕФгЕгаЖЏЬЌзжЖЮ(Dynamic Field)КЭЮЈвЛМќ(Unique Key)ЕФЪ§ОнФЃЪН(Data
Schema)
ЖдLuceneВщбЏгябдЕФЧПДѓРЉеЙЃЁ
жЇГжЖдНсЙћНјааЖЏЬЌЕФЗжзщКЭЙ§ТЫ
ИпМЖЕФЃЌПЩХфжУЕФЮФБОЗжЮі
ИпЖШПЩХфжУКЭПЩРЉеЙЕФЛКДцЛњжЦ
адФмгХЛЏ
жЇГжЭЈЙ§XMLНјааЭтВПХфжУ
гЕгавЛИіЙмРэНчУц
ПЩМрПиЕФШежО
жЇГжИпЫйдіСПЪНИќаТ(Fast incremental Updates)КЭПьееЗЂВМ(Snapshot
Distribution)
4.ДюНЈВЂЕїЪдSolr
4.1 АВзАащФтЛњ
Solr БиаыдЫаадкJava1.6 ЛђИќИпАцБОЕФJava ащФтЛњжаЃЌдЫааБъзМSolr ЗўЮёжЛашвЊАВзАJRE
МДПЩЃЌЕЋШчЙћашвЊРЉеЙЙІФмЛђБрвыдДТыдђашвЊЯТдиJDK РДЭъГЩЁЃПЩвдЭЈЙ§ЯТУцЕФЕижЗЯТдиЫљашJDK ЛђJRE
ЃК
OpenJDK
Sun
IBM
Oracle
АВзА ВНжшЧыВЮПМЯргІЕФАяжњЮФЕЕЁЃ
4.2ЯТдиSolr
БОЮФеыЖдSolr4.2АцБОНјааЕїбаЕФЃЌЯТЮФНщЩмФкШнОљеыЖдSolr4.2АцБОЃЌШчгыSolr
зюаТАцБОгаГіШыЧывдЙйЗНЭјеОФкШнЮЊзМЁЃSolrЙйЗНЭјеОЯТди
4.3ЯТдиВЂЩшжУApache Ant
SolrЪЧЪЙгУAntНјааЙмРэЕФдДТы, AntЪЧвЛжжЛљгкJavaЕФbuildЙЄОпЁЃРэТлЩЯРДЫЕЃЌЫќгааЉРрЫЦгкMaven
ЛђепЪЧ CжаЕФmakeЁЃЯТдиКѓНтбЙГіРДКѓЃЌНјааЛЗОГБфСПЩшжУЁЃ
ANT_HOMEЃКE:\Work\apache-ant\1.9.1 (етРяЮЊФуздМКНтбЙЫѕЕФФПТМ) PATHЃК%ANT_HOME%\bin
ЃЈетИіЩшжУЪЧЮЊСЫЗНБудкdosЛЗОГЯТВйзїЃЉ
ВщПДЪЧЗёАВзАГЩЙІЃЌдкУќСюааДАПкжаЪфШыУќСюantЃЌШєГіЯжНсЙћ:

ЫЕУїantАВзАГЩЙІЃЁвђЮЊantФЌШЯдЫааbuild.xmlЮФМўЃЌетИіЮФМўашвЊЮвУЧНЈСЂЁЃЯждкОЭПЩвдНјааbuild
SolrдДТыСЫЁЃдкУќСюааДАПкжаНјШыЕНФуЕФSolrдДТыФПТМЃЌЪфШыantЛсГіЯжЕБЧАbuild.xmlЪЙгУЬсЪОаХЯЂЁЃ
ЦфЫќЕФЯШВЛгУЙмЫќЃЌЮвУЧжЛвЊеыЖдЮвУЧЪЙгУЕФIDEНјааbuildОЭааСЫЃЌШчЙћЪЙгУeclipseОЭдкУќСюааЪфШыЃКant
eclipse.ШчЙћЪЙгУIntelliJ IDEA ОЭдкУќСюааЪфШыЃКant ideaЁЃетбљОЭФмНјааbuildСЫЁЃ
КкДАПкРяЬсЪОетИіЁЃЁЃЁЃ
ЪЇАмЁЃЁЃЁЃЮЊЪВУДФиЃЌзюКѓЮвЗЂЯжЪЧвђЮЊЯТдиЕФantжаЩйСЫвЛИіjarОЭЪЧетapache-ivyЃЈЯТдиЕижЗЃКhttp://ant.apache.org/ivy/ЃЉетЖЋЖЋУћзгецЙж
ivyЪЧantЙмРэjarвРРЕЙиЯЕЕФЁЃЕБЕквЛДЮbulidЪБivyЛсздЖЏАбbuildжаЕФШБЩйЕФвРРЕНјааЯТдиЁЃЭјЫйТ§ЕФЕквЛДЮbuildвЊКУОУЕФЁЃЁЃЁЃ
ЯТдивЛИіjarОЭааАбjarЗХЕНantЕФlibЯТЃЈE:\Work\apache-ant\1.9.1\libЃЉетбљдйДЮдЫааant
ОЭЛсГЩЙІСЫЁЃЕНЯждкВХПЩвдНјааSolrЕФДњТыЕїЪдЁЃ
4.4ХфжУВЂдЫааSolrДњТы
ВЛЙмгУЪВУДIDEЪзбЁЖМвЊЩшжУSolr HomeдкIDEЕФJVMВЮЪ§ЩшжУVM argumentsаДШы
-Dsolr.solr.home=solr/example/solrвЛАуОЭааСЫ.ВЛаавВПЩвдЪЙгУОјЖдТЗОЖ.
solrЪЙгУStartSolrJettyЮФМўзїЮЊШыПкЮФМўНјааЕїЪдДњТы,дкетРяПЩвдЩшжУЗўЮёЦїЪЙгУЕФЖЫПкКЭsolrЕФwebappsФПТМ.вЛАуЖМВЛгУЩшжУ,ФЌШЯЕФОЭПЩвдНјааЕїЪд.Solr
HomeвВФмПЩдкДњТыжаЩшжУвЛбљКУгУ. System.setProperty("solr.solr.home",
"E:\\Work\\solr-4.2.0-src-idea\\solr\\example\\solr");
ФПЧАЪЧЪЙгУздДјЕФвЛИіexampleзїЮЊsolrХфжУЕФИљФПТМЃЌШчЙћФугаЦфЫћЕФsolrХфжУФПТМЃЌЩшжУжЎМДПЩЁЃЕуЛїrunМДПЩЃЌdebugвВЪЧвЛбљПЩвдгУСЫЁЃУЛгаБ№ЕФЮЪЬтОЭгІИУФмдЫааСЫ.зЂвтservlet
ШнЦїЪЙгУЕФЖЫПк,ШчВщЬсЪО:
FAILED SocketConnector@0.0.0.0:8983:
java.net.BindException: Address already in use: JVM_Bind
ОЭЫЕУїЕБЧАЖЫПкеМгУжа.ИФвЛЯТОЭПЩвдСЫ.ШчЙћУЛгаБЈДэЦєЖЏГЩЙІКѓОЭПЩвддкфЏРРЦїжаЪфШыЕижЗ: http://localhost:8983/solr/
ОЭПЩвдПДЕНШчЯТНчУц
ЕНетРяSolrОЭГЩЙІХфжУВЂдЫааСЫ.вЊЪЧЯыИњДњТыЕїЪддкЦєЖЏЪБдкетИіЗНЗЈРяЕуЖЯЕуОЭПЩвдInitializerЕФinitialize()ЗНЗЈШчЙћЯыДгфЏРРЦїжаевЖЯЕуЕїЪдОЭвЊЕНSolrDispatchFilterЕФdoFilterЗНЗЈжаЕуЖЯЕуСЫ.
зЂЃКIE9дкМцШнФЃЪНЯТгаbugЃЌБиаыЩшжУЮЊЗЧМцШнФЃЪНЁЃ
5.SolrЛљДЁ
вђЮЊ Solr АќзАВЂРЉеЙСЫLuceneЃЌЫљвдЫќУЧЪЙгУКмЖрЯрЭЌЕФЪѕгяЁЃИќживЊЕФЪЧЃЌSolr ДДНЈЕФЫїв§гы
Lucene ЫбЫїв§ЧцПтЭъШЋМцШнЁЃЭЈЙ§Жд Solr НјааЪЪЕБЕФХфжУЃЌФГаЉЧщПіЯТПЩФмашвЊНјааБрТыЃЌSolr
ПЩвддФЖСКЭЪЙгУЙЙНЈЕНЦфЫћ Lucene гІгУГЬађжаЕФЫїв§ЁЃдк Solr КЭ Lucene жаЃЌЪЙгУвЛИіЛђЖрИі
Document РДЙЙНЈЫїв§ЁЃDocument АќРЈвЛИіЛђЖрИі FieldЁЃField АќРЈУћГЦЁЂФкШнвдМАИцЫп
Solr ШчКЮДІРэФкШнЕФдЊЪ§ОнЁЃ
Р§ШчЃЌField ПЩвдАќКЌзжЗћДЎЁЂЪ§зжЁЂВМЖћжЕЛђепШеЦкЃЌвВПЩвдАќКЌФуЯыЬэМгЕФШЮКЮРраЭЃЌжЛашгУдкsolrЕФХфжУЮФМўжаНјааЯргІЕФХфжУМДПЩЁЃField
ПЩвдЪЙгУДѓСПЕФбЁЯюРДУшЪіЃЌетаЉбЁЯюИцЫп Solr дкЫїв§КЭЫбЫїЦкМфШчКЮДІРэФкШнЁЃ
ЯждкЃЌВщПДвЛЯТБэ 1 жаСаГіЕФживЊЪєадЕФзгМЏЃК

5.1ФЃЪНХфжУSchema.xml
schema.xmlетИіХфжУЮФМўПЩвддкФуЯТдиsolrАќЕФАВзАНтбЙФПТМЕФ\solr\example\solr\collection1\confжаевЕНЃЌЫќОЭЪЧsolrФЃЪНЙиСЊЕФЮФМўЁЃДђПЊетИіХфжУЮФМўЃЌФуЛсЗЂЯжгаЯъЯИЕФзЂЪЭЁЃФЃЪНзщжЏжївЊЗжЮЊШ§ИіживЊХфжУ
5.1.1. types ВПЗж
ЪЧвЛаЉГЃМћЕФПЩжигУЖЈвхЃЌЖЈвхСЫ SolrЃЈКЭ LuceneЃЉШчКЮДІРэ FieldЁЃвВОЭЪЧЬэМгЕНЫїв§жаЕФxmlЮФМўЪєаджаЕФРраЭЃЌШчintЁЂtextЁЂdateЕШ.
<fieldType
name="string" class="solr.StrField"
sortMissingLast="true"/>
<fieldType name=" boolean" class="solr.BoolField"
sortMissingLast="true"/>
<fieldType name="int" class="solr.TrieIntField"
precisionStep="0" positionIncrementGap="0"/>
<fieldType name="text_general" class="solr.TextField"
positionIncrementGap="100">
<analyzer type="index">
<tokenizer
class=" solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="stopwords.txt"
enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer
class=" solr.StandardTokenizerFactory"/>
< filter class="solr.StopFilterFactory"
ignoreCase= "true" words="stopwords.txt"
enablePositionIncrements ="true" />
<filter class="solr.SynonymFilterFactory"
synonyms="synonyms.txt" ignoreCase="true"
expand="true"/>
<filter class=" solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType> |
ВЮЪ§ЫЕУї:
| Ъєад |
УшЪі |
| name |
БъЪЖЖјвб |
| class |
КЭЦфЫћЪєадОіЖЈСЫетИіfieldTypeЕФЪЕМЪааЮЊЁЃ |
| sortMissingLast |
ЩшжУГЩtrueУЛгаИУfieldЕФЪ§ОнХХдкгаИУfieldЕФЪ§ОнжЎКѓЃЌЖјВЛЙмЧыЧѓЪБЕФХХађЙцдђ, ФЌШЯЪЧЩшжУГЩfalse |
| sortMissingFirst |
ИњЩЯУцЕЙЙ§РДпТЁЃ ФЌШЯЪЧЩшжУГЩfalse |
| analyzer |
зжЖЮРраЭжИЖЈЕФЗжДЪЦї |
| type |
ЕБЧАЗжДЪгУгУгкЕФВйзї.indexДњБэЩњГЩЫїв§ЪБЪЙгУЕФЗжДЪЦїqueryДњТыдкВщбЏЪБЪЙгУЕФЗжДЪЦї |
| tokenizer |
ЗжДЪЦїРр |
| filter |
ЗжДЪКѓгІгУЕФЙ§ТЫЦї Й§ТЫЦїЕїгУЫГађКЭХфжУЯрЭЌ. |
5.1.2. fileds
ЪЧФуЬэМгЕНЫїв§ЮФМўжаГіЯжЕФЪєадУћГЦЃЌЖјЩљУїРраЭОЭашвЊгУЕНЩЯУцЕФtypes
<field name="id"
type="string" indexed="true"
stored="true" required="true"
multiValued=" false"/>
<field name="path" type="text_smartcn"
indexed="false" stored="true"
multiValued="false" termVector="true"
/>
<field name="content" type="text_smartcn"
indexed="false" stored="true"
multiValued="false" termVector="true"/>
<field name ="text" type ="text_ik"
indexed ="true" stored ="false"
multiValued =" true"/>
<field name =" pinyin" type ="text_pinyin"
indexed ="true" stored ="false"
multiValued =" false"/>
<field name="_version_" type="long"
indexed="true" stored="true"/>
<dynamicField name="*_i" type="int"
indexed="true" stored="true"/>
<dynamicField name="*_l" type="long"
indexed="true" stored="true"/>
<dynamicField name="*_s" type="string"
indexed="true" stored="true"
/> |
field: ЙЬЖЈЕФзжЖЮЩшжУ
dynamicField: ЖЏЬЌЕФзжЖЮЩшжУ,гУгкКѓЦкздЖЈвхзжЖЮ,*КХЭЈХфЗћ.Р§Шч: test_iОЭЪЧintРраЭЕФЖЏЬЌзжЖЮ.
ЛЙгавЛИіЬиЪтЕФзжЖЮcopyField,вЛАугУгкМьЫїЪБгУЕФзжЖЮетбљОЭжЛЖдетвЛИізжЖЮНјааЫїв§ЗжДЪОЭааСЫcopyFieldЕФdestзжЖЮШчЙћгаЖрИіsourceвЛЖЈвЊЩшжУmultiValued=true,ЗёдђЛсБЈДэЕФ
<copyField source="content" dest="pinyin"/>
<copyField source="content" dest="text"/>
<copyField source="pinyin" dest="text"/>
зжЖЮЪєадЫЕУї:
| Ъєад |
УшЪі |
| name |
зжЖЮРраЭУћ |
| class |
javaРрУћ |
| indexed |
ШБЪЁtrueЁЃ ЫЕУїетИіЪ§ОнгІБЛЫбЫїКЭХХађЃЌШчЙћЪ§ОнУЛгаindexedЃЌдђstoredгІЪЧtrueЁЃ |
| stored |
ШБЪЁtrueЁЃЫЕУїетИізжЖЮБЛАќКЌдкЫбЫїНсЙћжаЪЧКЯЪЪЕФЁЃШчЙћЪ§ОнУЛгаstored,дђindexedгІЪЧtrueЁЃ |
| omitNorms |
зжЖЮЕФГЄЖШВЛгАЯьЕУЗжКЭдкЫїв§ЪБВЛзіboostЪБЃЌЩшжУЫќЮЊtrueЁЃ
вЛАуЮФБОзжЖЮВЛЩшжУЮЊtrueЁЃ |
| termVectors |
ШчЙћзжЖЮБЛгУРДзіmore like this КЭhighlightЕФЬиадЪБгІЩшжУЮЊtrueЁЃ |
| compressed |
зжЖЮЪЧбЙЫѕЕФЁЃетПЩФмЕМжТЫїв§КЭЫбЫїБфТ§ЃЌЕЋЛсМѕЩйДцДЂПеМфЃЌжЛгаStrFieldКЭTextFieldЪЧПЩвдбЙЫѕЃЌетЭЈГЃЪЪКЯзжЖЮЕФГЄЖШГЌЙ§200ИізжЗћЁЃ |
| multiValued |
зжЖЮЖргквЛИіжЕЕФЪБКђЃЌПЩЩшжУЮЊtrueЁЃ |
positionIncrementGap
КЭmultiValuedвЛЦ№ЪЙгУЃЌЩшжУЖрИіжЕжЎМфЕФащФтПеАзЕФЪ§СП
зЂвт:_version_ ЪЧвЛИіЬиЪтзжЖЮ,ВЛФмЩОГ§,ЪЧМЧТМЕБЧАЫїв§АцБОКХЕФ.
5.1.3. ЦфЫћХфжУ
uniqueKey: ЮЈвЛМќЃЌетРяХфжУЕФЪЧЩЯУцГіЯжЕФfiledsЃЌвЛАуЪЧidЁЂurlЕШВЛжиИДЕФЁЃдкИќаТЁЂЩОГ§ЕФЪБКђПЩвдгУЕНЁЃ
defaultSearchField:ФЌШЯЫбЫїЪєадЃЌШчq=solrОЭЪЧФЌШЯЕФЫбЫїФЧИізжЖЮ
solrQueryParser:ВщбЏзЊЛЛФЃЪНЃЌЪЧВЂЧвЛЙЪЧЛђепЃЈAND/ORБиаыДѓаДЃЉ
5.2. solrХфжУsolrconfig.xml
solrconfig.xmlетИіХфжУЮФМўПЩвддкФуЯТдиsolrАќЕФАВзАНтбЙФПТМЕФE:\Work\solr-4.2.0-src-idea\solr\example\solr\collection1\confжаевЕНЃЌетИіХфжУЮФМўФкШнгаЕуЖр,жївЊФкШнга:ЪЙгУЕФlibХфжУ,АќКЌвРРЕЕФjarКЭSolrЕФвЛаЉВхМў;зщМўаХЯЂХфжУ;Ыїв§ХфжУКЭВщбЏХфжУ,ЯТУцЯъЯИЫЕвЛЯТЫїв§ХфжУКЭВщбЏХфжУ.
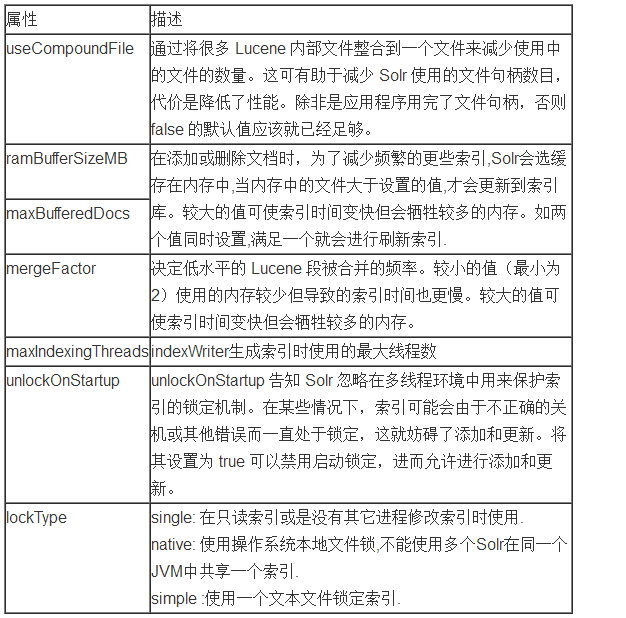
5.2.1Ыїв§indexConfig
Solr адФмвђЫиЃЌРДСЫНтгыИїжжИќИФЯрЙиЕФадФмШЈКтЁЃ Бэ 1 ИХРЈСЫПЩПижЦ Solr Ыїв§ДІРэЕФИїжжвђЫиЃК
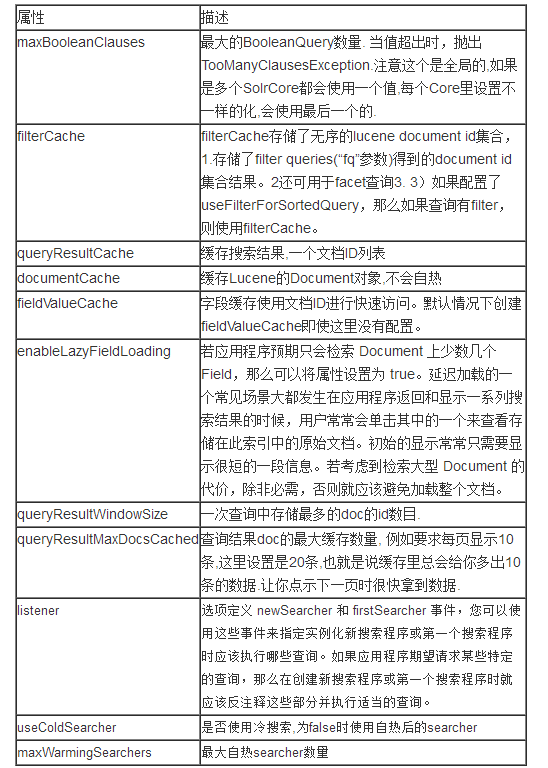
5.2.2 ВщбЏХфжУquery
5.3SolrМгШыжаЮФЗжДЪЦї
жаЮФЗжДЪдкsolrРяУцЪЧУЛгаФЌШЯПЊЦєЕФЃЌашвЊЮвУЧздМКХфжУвЛИіжаЮФЗжДЪЦїЁЃФПЧАПЩгУЕФЗжДЪЦїгаsmartcnЃЌIKЃЌJeasyЃЌтвЖЁЁЃЦфЪЕжївЊЪЧСНжжЃЌвЛжжЪЧЛљгкжаПЦдКICTCLASЕФвўЪНТэЖћПЦЗђHMMЫуЗЈЕФжаЮФЗжДЪЦїЃЌШчsmartcnЃЌictclas4jЃЌгХЕуЪЧЗжДЪзМШЗЖШИпЃЌШБЕуЪЧВЛФмЪЙгУгУЛЇздЖЈвхДЪПтЃЛСэвЛжжЪЧЛљгкзюДѓЦЅХфЕФЗжДЪЦїЃЌШчIK
ЃЌJeasyЃЌтвЖЁЃЌгХЕуЪЧПЩвдздЖЈвхДЪПтЃЌдіМгаТДЪЃЌШБЕуЪЧЗжГіРДЕФРЌЛјДЪНЯЖрЁЃИїгагХШБЕуПДгІгУГЁКЯздМККтСПбЁдёАЩЁЃ
ЯТУцИјГіСНжжЗжДЪЦїЕФАВзАЗНЗЈЃЌШЮбЁЦфвЛМДПЩЃЌЭЦМіЕквЛжжЃЌвђЮЊsmartcnОЭдкsolrЗЂааАќЕФcontrib/analysis-extras/lucene-libs/ЯТЃЌОЭЪЧlucene-analyzers-smartcn-4.2.0.jar,ЪзбЁдкsolrconfig.xmlжаМгвЛОфв§гУanalysis-extrasЕФХфжУ,етбљЮвУЧздМКМгШыЕФЗжДЪЦїВХЛсв§ЕНЕФsolrжа.
<lib dir="../../../contrib/analysis-extras/lib"
regex=".*\.jar" />
5.3.1. smartcn ЗжДЪЦїЕФАВзА
ЪзбЁНЋЗЂааАќЕФcontrib/analysis-extras/lucene-libs/ lucene-analyzers-smartcn-4.2.0.jarИДжЦЕН\solr\contrib\analysis-extras\libЯТ,дкsolrБОЕигІгУЮФМўМаЯТЃЌДђПЊ/solr/conf/scheme.xmlЃЌБрМtextзжЖЮРраЭШчЯТЃЌЬэМгвдЯТДњТыЕНscheme.xmlжаЕФЯргІЮЛжУЃЌОЭЪЧевЕНfieldTypeЖЈвхЕФФЧвЛЖЮЃЌдкЯТУцЖрЬэМгетвЛЖЮОЭКУРВ
<fieldType
name="text_smartcn" class="solr.TextField"
positionIncrementGap="0">
<analyzer
type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
</analyzer>
</fieldType> |
ШчЙћашвЊМьЫїФГИізжЖЮЃЌЛЙашвЊдкscheme.xmlЯТУцЕФfieldжаЃЌЬэМгжИЖЈЕФзжЖЮЃЌгУtext_
smartcnзїЮЊtypeЕФУћзжЃЌРДЭъГЩжаЮФЗжДЪЁЃШч textвЊЪЕЯжжаЮФМьЫїЕФЛАЃЌОЭвЊзіШчЯТЕФХфжУЃК
<field name ="text" type ="text_smartcn"
indexed ="true" stored ="false"
multiValued ="true"/>
5.3.2. IK ЗжДЪЦїЕФАВзА
ЪзбЁвЊШЅЯТдиIKAnalyzerЕФЗЂааАќ.ЯТди
.
ЯТдиКѓНтбЙГіРДЮФМўжаЕФШ§ИіИДжЦЕН\solr\contrib\analysis-extras\libФПТМжа.
| IKAnalyzer2012FF_u1.jar
|
ЗжДЪЦїjarАќ |
| IKAnalyzer.cfg.xml
|
ЗжДЪЦїХфжУЮФМў |
| Stopword.dic |
ЗжДЪЦїЭЃДЪзжЕф,ПЩздЖЈвхЬэМгФкШн |
ИДжЦКѓОЭПЩвдЯёsmartcnвЛбљЕФНјааХфжУscheme.xmlСЫ.
fieldType name="text_ik"
class="solr.TextField">
<analyzer
class= "org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<field name ="text" type ="text_ik"
indexed ="true" stored ="false"
multiValued ="true"/> |
ЯждкРДбщжЄЯТЪЧЗёЬэМгГЩЙІ,ЪзЯШЪЙгУStartSolrJettyРДЦєЖЏsolrЗўЮё,ЦєЖЏЙ§ГЬжаШчЙћХфжУГіДэ,вЛАугаСНИідвђ:вЛЪЧХфжУЕФЗжДЪЦїjarевВЛЕН,вВОЭЪЧФуУЛгаИДжЦjarАќЕН\solr\contrib\analysis-extras\libФПЧАЯТ;ЖўЪЧЗжДЪЦїАцБОВЛЖдЕМжТЕФЗжДЪЦїНгПкAPIВЛвЛбљГіЕФДэ,вЊЪЧетИіДэЕФЛАОЭдкМьВщЗжДЪЦїЕФЯрЙиЮФЕЕ,ПДвЛЯТжЇГжЕФАцБОЪЧЗёвЛбљ.
ШчЙћдкЦєЖЏЙ§ГЬжаУЛгаБЈДэЕФЛАЫЕУїХфжУГЩЙІСЫ.ЮвУЧПЩвдНјШыЕНhttp://localhost:8983/solrЕижЗНјааВтЪдвЛЯТИеМгШыЕФжаЮФЗжДЪЦї.дкЪзвГЕФCore
SelectorжабЁдёФуХфжУЕФCroeКѓЕуЛїЯТУцЕФAnalysis,дкAnalyse Fieldname
/ FieldTypeРябЁдёФуИеВХЩшжУЕФзжЖЮУћГЦЛђЪЧЗжДЪЦїРраЭ,дкField Value(index)жаЪфШы:жаЙњШЫ,ЕуЛїгвУцЕФЗжДЪОЭааСЫ.
6.SolrЙІФмгІгУ
ЮветРяжївЊЪЙгУSolrJНјааНщЩмвЛЯТSolrЕФвЛаЉЛљБОгІгУ,ЪЙгУSolrJМгЩЯEmbeddedSolrServer(ЧЖШыЪНЗўЮёЦї),ЗНБуНјааДњТыИњзйЕїЪд.дкЙІФмЩЯКЭЦфЫќЗўЮёЦїЖМЪЧвЛбљЕФ,ЫќУЧЖМЪЧМЬГаЕФSolrServerРДЬсЙЉЗўЮёAPIЕФ.
EmbeddedSolrServerгХЕуЪЧВЛгУЦ№httpавщ,жБНгМгдиSolrCoreНјааВйзї,адФмЩЯгІИУЪЧзюПьЕФ,ЗНБугУгкАбSolrЕЅНсЕуЗўЮёЧЖШыЕНЯюФПжаЪЙгУ.ЯТУцПЊЪМНщЩмSolrЕФЙІФмЕФгІгУ.EmbeddedSolrServerГѕЪМЛЏ:
System.setProperty ("solr.solr.home",
"E:\\Work\\solr-4.2.0 -src\\solr\\example\\solr");
CoreContainer.Initializer initializer = new CoreContainer.Initializer();
CoreContainer coreContainer = initializer.initialize();
SolrServer server = new EmbeddedSolrServer(coreContainer,
""); |
6.1ЮЌЛЄЫїв§
дквЛАуЯЕЭГжаЮЌЛЄЕФЖМЪЧдіЩОИФ,дкSolrжаЕФЮЌЛЄЙІФмЪЧдіЩОКЭгХЛЏЙІФм,дкSolrжаЕФаоИФВйзїОЭЪЧЯШЩОЕєдйЬэМг.дкзіЫїв§ЮЌЛЄжЎЧА,ЪзЯШвЊзіЕФЪЧХфжУschema.xmlжївЊЪЧАДЩЯУцеТНкжаЕФЫЕУїЩшжУКУзжЖЮаХЯЂ(УћГЦ,РраЭ,Ыїв§,ДцДЂ,ЗжДЪЕШаХЯЂ),ДѓИХОЭЯёдкЪ§ОнПтжааТНЈвЛИіБэвЛбљ.ЩшжУКУschema.xmlОЭПЩвдНјааЫїв§ЯрЙиВйзїСЫ.
6.1.1діМгЫїв§
дкдіМгЫїв§жЎЧАЯШПЩЙЙНЈКУSolrInputDocumentЖдЯѓ.жївЊВйзїОЭЪЧИјЮФЕЕЬэМгзжЖЮКЭжЕ.ДњТыШчЯТ:
SolrInputDocument doc = new SolrInputDocument();
doc.setField ("id", "ABC");
doc.setField ("content", "жаЛЊШЫУёЙВКЭЙњ");
ЙЙНЈКУЮФЕЕКѓЬэМгЕФЩЯУцГѕЪМЛЏКУЕФserverРяОЭааСЫ.
server.add(doc);
server.commit();//етОфвЛАуВЛгУМгвђЮЊЮвУЧПЩвдЭЈЙ§дкХфжУЮФМўжаЕФ
//autoCommitРДЬсИпадФм |
SolrдкaddЮФЕЕЪБ.ШчЙћЮФЕЕВЛДцдкОЭжБНгЬэМг,ШчЙћЮФЕЕДцдкОЭЩОГ§КѓЬэМг,етвВОЭЪЧаоИФЙІФмСЫ.ХаЖЯЮФЕЕЪЧЗёДцдкЕФвРОнЪЧЖЈвхКУЕФuniqueKeyзжЖЮ.
6.1.2ЩОГ§Ыїв§
ЩОГ§Ыїв§ПЩвдЭЈЙ§СНжжЗНЪНВйзї,вЛжжЪЧЭЈЙ§ЮФЕЕIDНјааЩОГ§,Б№вЛжжЪЧЭЈЙ§ВщбЏЕНЕФНсЙћНјааЩОГ§.
ЭЈЙ§IDЩОГ§ЗНЪНДњТы:
server.deleteById(id);
//ЛђЪЧЪЙгУХњСПЩОГ§
server.deleteById(ids);
ЭЈЙ§ВщбЏЩОГ§ЗНЪНДњТы:
server.deleteByQuery("*.*");//етбљОЭЩОГ§СЫЫљгаЮФЕЕЫїв§
//ЁБ*.*ЁБОЭВщбЏЫљгаФкШнЕФ,НщЩмВщбЏЪБЛсЯъЯИЫЕУї. |
6.1.2гХЛЏЫїв§
гХЛЏLucene ЕФЫїв§ЮФМўвдИФНјЫбЫїадФмЁЃЫїв§ЭъГЩКѓжДаавЛЯТгХЛЏЭЈГЃБШНЯКУЁЃШчЙћИќаТБШНЯЦЕЗБЃЌдђгІИУдкЪЙгУТЪНЯЕЭЕФЪБКђАВХХгХЛЏЁЃвЛИіЫїв§ЮоашгХЛЏвВПЩвде§ГЃЕидЫааЁЃгХЛЏЪЧвЛИіКФЪБНЯЖрЕФЙ§ГЬЁЃ
server.optimize();//ВЛвЊЦЕЗБЕФЕїгУ..ОЁСПдкЮоШЫЪЙгУЪБЕїгУ.
6.2ВщбЏЫїв§
SolrдкВЛаоИФШЮЮёХфжУЕФЧщПіЯТОЭПЩвдЪЙгУВщбЏЙІФмЃЌдкwebЯюФПжагІгУПЩвджБНгURLНјааЗУЮЪSolrЗўЮёЦїР§Шч
ЃК
http://localhost:8983/solr/ collection1/select?q=*%3A*&wt=xml&indent=true
ЩЯУцЕФвтЫМОЭЪЧВщбЏУћЮЊcollection1ЕФSolrCoreЕФЫљгаФкШнгУxmlИёЪНЗЕЛиВЂЧвгаЫѕНјЁЃ
ЗЕЛиНсЙћШчЯТ:
<?xml version="1.0"
encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">0</int>
<lst name="params">
<str
name="indent">true</str>
<str name="q">*:*</str>
<str name="wt">xml</str>
</lst>
</lst>
<result name="response" numFound="17971"
start="0">
<doc>
<str
name="path">E:\Reduced\ОќЪТ\1539.txt</str>
<str name="category_s">2</str>
<int name="browseCount_i">-1423701734</int>
<long name="modified_l">1162438568000</long>
<long name="releasedate_l">1162438568000</long> |
[ЖэТоЫЙlentaЭјеО2006Фъ2дТ9ШеБЈЕР]ЖэПеОќИБзмЫОСюБШШШвЎЗђжаНЋГЦЃЌ2006ФъДКЬьЖРСЊЬхЙњМвЗРПеЯЕЭГДђЛїЗЖЮЇЯђЮїЭЦНј150ЧЇУзЃЌеьВьЗЖЮЇЯђЮїЭЦНј400ЧЇУзЁЃЁЁЁЁ2006Фъ3дТАзЖэТоЫЙ4ИіS-300PSЗРПеЕМЕЏгЊЕЃИКеНЖЗШЮЮёЃЌЪЙЖРСЊЬхЗРПеЯЕЭГзїеНЗЖЮЇЕУвдЯђЮїЭЦНјЁЃБШШШвЎЗђжаНЋЛЙаћВМЃЌНќЦкЮкзШБ№ПЫЫЙЬЙПЩФмМгШыЖРСЊЬхЗРПеЯЕЭГЁЃЁЁЁЁЖРСЊЬхЙњМвЗРПеЯЕЭГНЈгк9ФъЧАЃЌЙВга9ИіЙњМвВЮМгИУзщжЏЁЃФПЧАжЛгабЧУРФсбЧЁЂАзЖэТоЫЙЁЂЙўШјПЫЫЙЬЙЁЂМЊЖћМЊЫЙЁЂЖэТоЫЙКЭЫўМЊПЫЫЙЬЙжЇГжИУЬхЯЕЁЃЁЁЁЁЮкПЫРМЁЂЮкзШБ№ПЫЫЙЬЙгыЖэТоЫЙдкЫЋБпЛљДЁЩЯКЯзїЃЌИёТГМЊбЧКЭЭСПтТќзюНќ7ФъВЛВЮМгЖРСЊЬхЙњМвЖдПеЗРгљЁЃ
<str name="id">E3798D82-EAB6
-2BEA-D7E2-79FBD102E845</str>
<long name="_version_"> 1436361868021071872</long></doc>
Ё
</result>
</response> |
ЩЯУцЫљПДЕНЕФОЭЪЧгУxmlИёЪНЗЕЛиЕФВщбЏНсЙћ,ЦфжаЕФdocОЭЪЧвЛИіЮФЕЕ,дкdocРяУцЕФФЧИіОЭЪЧЮвУЧПЊЪМдкschema.xmlжаЖЈвхЕФзжЖЮ.
ШчЙћЪЙгУSolrJНјааЕїгУЕФЛАДњТыШчЯТЃК
SolrQuery query
= new SolrQuery();
query.set("q","*.*");
QueryResponse rsp =server.query(query)
SolrDocumentList list = rsp.getResults(); |
ЗЕЛиНсЙћдкSolrDocumentListжадкетИіЖдЯѓжаБщРњШЁГіжЕРД:
for (int i = 0; i < list.size(); i++) {
SolrDocument sd = list.get(i);
String id = (String) sd.getFieldValue("id");
System.out.println(id);
} |
6.2.1ВщбЏВЮЪ§
| УћГЦ |
УшЪі |
| q |
ВщбЏзжЗћДЎЃЌБиаыЕФЁЃ |
| fq |
filter queryЁЃЪЙгУFilter QueryПЩвдГфЗжРћгУFilter Query
CacheЃЌЬсИпМьЫїадФмЁЃзїгУЃКдкqВщбЏЗћКЯНсЙћжаЭЌЪБЪЧfqВщбЏЗћКЯЕФЃЌР§ШчЃКq=mm&fq=date_time:[20081001
TO 20091031]ЃЌевЙиМќзжmmЃЌВЂЧвdate_timeЪЧ20081001ЕН20091031жЎМфЕФЁЃ |
| fl |
field listЁЃжИЖЈЗЕЛиНсЙћзжЖЮЁЃвдПеИёЁА
ЁБЛђЖККХЁА,ЁБЗжИєЁЃ |
| start |
гУгкЗжвГЖЈвхНсЙћЦ№ЪММЧТМЪ§ЃЌФЌШЯЮЊ0ЁЃ |
| rows |
гУгкЗжвГЖЈвхНсЙћУПвГЗЕЛиМЧТМЪ§ЃЌФЌШЯЮЊ10ЁЃ |
| sort |
<desc|asc>]Ё ЁЃЪОР§ЃКЃЈinStock desc, price
ascЃЉБэЪОЯШ ЁАinStockЁБ НЕађ, дй ЁАpriceЁБ Щ§ађЃЌФЌШЯЪЧЯрЙиадНЕађЁЃ |
| df |
ФЌШЯЕФВщбЏзжЖЮЃЌвЛАуФЌШЯжИЖЈЁЃ |
| q.op |
ИВИЧschema.xmlЕФdefaultOperatorЃЈгаПеИёЪБгУ"AND"ЛЙЪЧгУ"OR"ВйзїТпМЃЉЃЌвЛАуФЌШЯжИЖЈЁЃБиаыДѓаД |
| wt |
ЖЈвхСЫВщбЏЪфГіИёЪНЃКxmlЁЂjsonЁЂpythonЁЂrubyЁЂphpЁЂphpsЁЂcustomЁЃ |
| qt |
query typeЃЌжИЖЈВщбЏЪЙгУЕФQuery HandlerЃЌФЌШЯЮЊЁАstandardЁБЁЃ |
| explainOther |
ЩшжУЕБdebugQuery=trueЪБЃЌЯдЪОЦфЫћЕФВщбЏЫЕУїЁЃ |
| defType |
ЩшжУВщбЏНтЮіЦїУћГЦЁЃ |
| timeAllowed |
ЩшжУВщбЏГЌЪБЪБМфЁЃ |
| omitHeader |
ЩшжУЪЧЗёКіТдВщбЏНсЙћЗЕЛиЭЗаХЯЂЃЌФЌШЯЮЊЁАfalseЁБЁЃ |
| indent |
ЗЕЛиЕФНсЙћЪЧЗёЫѕНјЃЌФЌШЯЙиБеЃЌгУ indent=true|on ПЊЦєЃЌвЛАуЕїЪдjson,php,phps,rubyЪфГіВХгаБивЊгУетИіВЮЪ§ЁЃ |
| version |
ВщбЏгяЗЈЕФАцБОЃЌНЈвщВЛЪЙгУЫќЃЌгЩЗўЮёЦїжИЖЈФЌШЯжЕЁЃ |
| debugQuery |
ЩшжУЗЕЛиНсЙћЪЧЗёЯдЪОDebugаХЯЂЁЃ |
6.2.2ВщбЏгяЗЈ
1.ЦЅХфЫљгаЮФЕЕЃК*:*
2.ЧПжЦЁЂзшжЙКЭПЩбЁВщбЏЃК
1) MandatoryЃКВщбЏНсЙћжаБиаыАќРЈЕФ(for example, only entry name
containing the word make)
Solr/Lucene StatementЃК+make, +make +up ,+make +up
+kiss
2) prohibitedЃК(for example, all documents except those
with word believe)
Solr/Lucene StatementЃК+make +up -kiss
3) optionalЃК
Solr/Lucene StatementЃК+make +up kiss
3.ВМЖћВйзїЃКANDЁЂORКЭNOTВМЖћВйзїЃЈБиаыДѓаДЃЉгыMandatoryЁЂoptionalКЭprohibitedЯрЫЦЁЃ
1) make AND up ЃН +make +up :ANDзѓгвСНБпЕФВйзїЖМЪЧmandatory
2) make || up ЃН make OR upЃНmake up :ORзѓгвСНБпЕФВйзїЖМЪЧoptional
3) +make +up NOT kiss ЃН +make +up ЈCkiss
4) make AND up OR french AND KissВЛПЩвдДяЕНЦкЭћЕФНсЙћЃЌвђЮЊANDСНБпЕФВйзїЖМЪЧmandatoryЕФЁЃ
4. згБэДяЪНВщбЏЃЈзгВщбЏЃЉЃКПЩвдЪЙгУЁА()ЁБЙЙдьзгВщбЏЁЃ
ЪОР§ЃК(make AND up) OR (french AND Kiss)
5.згБэДяЪНВщбЏжазшжЙВщбЏЕФЯожЦЃК
ЪОР§ЃКmake (-up):жЛФмШЁЕУmakeЕФВщбЏНсЙћЃЛвЊЪЙгУmake (-up *:*)ВщбЏmakeЛђепВЛАќРЈupЕФНсЙћЁЃ
6.ЖрзжЖЮfieldsВщбЏЃКЭЈЙ§зжЖЮУћМгЩЯЗжКХЕФЗНЪНЃЈfieldName:queryЃЉРДНјааВщбЏ
ЪОР§ЃКentryNm:make AND entryId:3cdc86e8e0fb4da8ab17caed42f6760c
7.ЭЈХфЗћВщбЏЃЈwildCard QueryЃЉЃК
1) ЭЈХфЗћЃПКЭ*ЃКЁА*ЁББэЪОЦЅХфШЮвтзжЗћЃЛЁАЃПЁББэЪОЦЅХфГіЯжЕФЮЛжУЁЃ
ЪОР§ЃКma?*ЃЈmaКѓУцЕФвЛИіЮЛжУЦЅХфЃЉЃЌma??*(maКѓУцСНИіЮЛжУЖМЦЅХф)
2) ВщбЏзжЗћБиаывЊаЁаД:+Ma +be**ПЩвдЫбЫїЕННсЙћЃЛ+Ma +Be**УЛгаЫбЫїНсЙћ.
3) ВщбЏЫйЖШНЯТ§ЃЌгШЦфЪЧЭЈХфЗћдкЪзЮЛЃКжївЊдвђвЛЪЧашвЊЕќДњВщбЏзжЖЮжаЕФУПИіtermЃЌХаЖЯЪЧЗёЦЅХфЃЛЖўЪЧЦЅХфЩЯЕФtermБЛМгЕНФкВПЕФВщбЏЃЌЕБtermsЪ§СПДяЕН1024ЕФЪБКђЃЌВщбЏЛсЪЇАмЁЃ
4) SolrжаФЌШЯЭЈХфЗћВЛФмГіЯждкЪзЮЛЃЈПЩвдаоИФQueryParserЃЌЩшжУ
setAllowLeadingWildcardЮЊtrueЃЉ
5) set setAllowLeadingWildcard to true.
8.ФЃК§ВщбЏЁЂЯрЫЦВщбЏЃКВЛЪЧОЋШЗЕФВщбЏЃЌЭЈЙ§ЖдВщбЏЕФзжЖЮНјаажиаТВхШыЁЂЩОГ§КЭзЊЛЛРДШЁЕУЕУЗжНЯИпЕФВщбЏНтОіЃЈгЩLevenstein
Distance AlgorithmЫуЗЈжЇГжЃЉЁЃ
1) вЛАуФЃК§ВщбЏЃКЪОР§ЃКmake-believ~
2) УХМїФЃК§ВщбЏЃКЖдФЃК§ВщбЏПЩвдЩшжУВщбЏУХМїЃЌУХМїЪЧ0~1жЎМфЕФЪ§жЕЃЌУХМїдНИпБэУцЯрЫЦЖШдНИпЁЃЪОР§ЃКmake-believ~0.5ЁЂmake-believ~0.8ЁЂmake-believ~0.9
9.ЗЖЮЇВщбЏЃЈRange QueryЃЉЃКLuceneжЇГжЖдЪ§зжЁЂШеЦкЩѕжСЮФБОЕФЗЖЮЇВщбЏЁЃНсЪјЕФЗЖЮЇПЩвдЪЙгУЁА*ЁБЭЈХфЗћЁЃ
ЪОР§ЃК
1) ШеЦкЗЖЮЇЃЈISO-8601 ЪБМфGMTЃЉЃКsa_type:2 AND a_begin_date: [1990-01-01T00:00:00.000Z
TO 1999-12-31T24:59:99.999Z]
2) Ъ§зжЃКsalary:[2000 TO *]
3) ЮФБОЃКentryNm:[a TO a]
10.ШеЦкЦЅХфЃКYEAR, MONTH, DAY, DATE (synonymous
with DAY) HOUR, MINUTE, SECOND, MILLISECOND, and MILLI
(synonymous with MILLISECOND)ПЩвдБЛБъжОГЩШеЦкЁЃ
ЪОР§ЃК
1) r_event_date:[* TO NOW-2YEAR]ЃК2ФъЧАЕФЯждкетИіЪБМф
2) r_event_date:[* TO NOW/DAY-2YEAR]ЃК2ФъЧАЧАвЛЬьЕФетИіЪБМф
6.2.3КЏЪ§ВщбЏЃЈFunction QueryЃЉ
КЏЪ§ВщбЏ ПЩвдРћгУ numericзжЖЮЕФжЕ Лђеп гызжЖЮЯрЙиЕФЕФФГИіЬиЖЈЕФжЕЕФКЏЪ§ЃЌРДЖдЮФЕЕНјааЦРЗжЁЃ
1. ЪЙгУКЏЪ§ВщбЏЕФЗНЗЈ
етРяжївЊгаШ§жжЗНЗЈПЩвдЪЙгУКЏЪ§ВщбЏЃЌетШ§жжsЗНЗЈЖМЪЧЭЈЙ§solr httpНгПкЕФЁЃ
1) ЪЙгУFunctionQParserPluginЁЃie: q={!func}log(foo)
2) ЪЙгУЁА_val_ЁБФкЧЖЗНЗЈ
ФкЧЖдке§ГЃЕФsolrВщбЏБэДяЪНжаЁЃМДЃЌНЋКЏЪ§ВщбЏаДдк qетИіВЮЪ§жаЃЌетЪБКђЃЌЮвУЧЪЙгУЁА_val_ЁБНЋКЏЪ§гыЦфЫћЕФВщбЏМгвдЧјБ№ЁЃ
ieЃКentryNm:make && _val_:ord(entryNm)
3) ЪЙгУdismaxжаЕФbfВЮЪ§
ЪЙгУУїШЗЮЊКЏЪ§ВщбЏЕФВЮЪ§ЃЌБШШчЫЕdismaxжаЕФbfЃЈboost functionЃЉетИіВЮЪ§ЁЃ зЂвтЃКbfетИіВЮЪ§ЪЧПЩвдНгЪмЖрИіКЏЪ§ВщбЏЕФЃЌЫќУЧжЎМфгУПеИёИєПЊЃЌЫќУЧЛЙПЩвдДјЩЯШЈжиЁЃЫљвдЃЌЕБЮвУЧЪЙгУbfетИіВЮЪ§ЕФЪБКђЃЌЮвУЧБиаыБЃжЄЕЅИіКЏЪ§жаЪЧУЛгаПеИёГіЯжЕФЃЌВЛШЛГЬађгаПЩФмЛсвдЮЊЪЧСНИіКЏЪ§ЁЃ
ЪОР§ЃК
q=dismax&bf="ord(popularity)^0.5 recip(rord(price),1,1000,1000)^0.3
2. КЏЪ§ЕФИёЪНЃЈFunction Query Syntax)
ФПЧАЃЌfunction query ВЂВЛжЇГж a+b етбљЕФаЮЪНЃЌЮвУЧЕУАбЫќаДГЩвЛИіЗНЗЈаЮЪНЃЌетОЭЪЧ
sum(a,b).
3. ЪЙгУКЏЪ§ВщбЏзЂвтЪТЯю
1) гУгкКЏЪ§ВщбЏЕФfieldБиаыЪЧБЛЫїв§ЕФЃЛ
2) зжЖЮВЛПЩвдЪЧЖржЕЕФЃЈmulti-valueЃЉ
4. ПЩвдРћгУЕФКЏЪ§ ЃЈavailable functionЃЉ
1) constantЃКжЇГжгааЁЪ§ЕуЕФГЃСПЃЛ Р§ШчЃК1.5 ЃЛSolrQuerySyntax:_val_:1.5
2) fieldvalueЃКетИіКЏЪ§НЋЛсЗЕЛиnumeric fieldЕФжЕЃЌетИізжЖЮБиаыЪЧindexdЕФЃЌЗЧmultiValuedЕФЁЃИёЪНКмМђЕЅЃЌОЭЪЧИУзжЖЮЕФУћзжЁЃШчЙћетИізжЖЮжаУЛгаетбљЕФжЕЃЌФЧУДНЋЛсЗЕЛи0ЁЃ
3) ordЃКЖдгквЛИізжЖЮЃЌЫќЫљгаЕФжЕЖМНЋЛсАДеезжЕфЫГађХХСаЃЌетИіКЏЪ§ЗЕЛиФувЊВщбЏЕФФЧИіЬиЖЈЕФжЕдкетИіЫГађжаЕФХХУћЁЃетИізжЖЮЃЌБиаыЪЧЗЧmultiValuedЕФЃЌЕБУЛгажЕДцдкЕФЪБКђЃЌНЋЗЕЛи0ЁЃР§ШчЃКФГИіЬиЖЈЕФзжЖЮжЛФмШЅШ§ИіжЕЃЌЁАappleЁБЁЂЁАbananaЁБЁЂЁАpearЁБЃЌФЧУДordЃЈЁАappleЁБЃЉ=1ЃЌordЃЈЁАbananaЁБЃЉ=2ЃЌordЃЈЁАpearЁБЃЉ=3.ашвЊзЂвтЕФЪЧЃЌordЃЈЃЉетИіКЏЪ§ЃЌвРРЕгкжЕдкЫїв§жаЕФЮЛжУЃЌЫљвдЕБгаЮФЕЕБЛЩОГ§ЁЂЛђепЬэМгЕФЪБКђЃЌordЃЈЃЉЕФжЕОЭЛсЗЂЩњБфЛЏЁЃЕБФуЪЙгУMultiSearcherЕФЪБКђЃЌетИіжЕвВОЭЪЧВЛЖЈЕФСЫЁЃ
4) rordЃКетИіКЏЪ§НЋЛсЗЕЛигыordЯрЖдгІЕФЕЙХХађЕФХХУћЁЃ
ИёЪН: rord(myIndexedField)ЁЃ
5) sumЃКетИіКЏЪ§ЕФвтЫМОЭЯдЖјвзМћРВЃЌЫќОЭЪЧБэЪОЁАКЭЁБРВЁЃ
ИёЪНЃКsum(x,1) ЁЂsum(x,y)ЁЂ sum(sqrt(x),log(y),z,0.5)
6) productЃКproduct(x,y,...)НЋЛсЗЕЛиЖрИіКЏЪ§ЕФГЫЛ§ЁЃИёЪНЃКproduct(x,2)ЁЂproduct(x,y)
7) divЃКdiv(x,y)БэЪОxГ§вдyЕФжЕЃЌИёЪНЃКdivЃЈ1,xЃЉЁЂdiv(sum(x,100),max(y,1))
8) powЃКpowБэЪОУнжЕЁЃpow(x,y) =x^yЁЃР§ШчЃКpow(x,0.5) БэЪОПЊЗНpow(x,log(y))
9) absЃКabs(x)НЋЗЕЛиБэДяЪНЕФОјЖджЕЁЃИёЪНЃКabs(-5)ЁЂ abs(x)
10) logЃКlog(x)НЋЛсЗЕЛиЛљЪ§ЮЊ10ЃЌxЕФЖдЪ§ЁЃИёЪНЃК log(x)ЁЂ log(sum(x,100))
11) SqrtЃКsqrt(x) ЗЕЛи вЛИіЪ§ЕФЦНЗНИљЁЃИёЪНЃКsqrtЃЈ2ЃЉЁЂsqrt(sum(x,100))
12) MapЃКШчЙћ x>=min,Чвx<=max,ФЧУДmap(x,min,max,target)=target.ШчЙћ
xВЛдк[min,max]етИіЧјМфФкЃЌФЧУДmap(x,min,max,target)=x.
ИёЪНЃКmap(x,0,0,1)
13) ScaleЃКscale(x,minTarget,maxTarget) етИіКЏЪ§НЋЛсАбxЕФжЕЯожЦдк[minTarget,maxTarget]ЗЖЮЇФкЁЃ
14) query ЃКquery(subquery,default)НЋЛсЗЕЛиИјЖЈsubqueryЕФЗжЪ§ЃЌШчЙћsubqueryгыЮФЕЕВЛЦЅХфЃЌФЧУДНЋЛсЗЕЛиФЌШЯжЕЁЃШЮКЮЕФВщбЏРраЭЖМЪЧЪмжЇГжЕФЁЃПЩвдЭЈЙ§в§гУЕФЗНЪНЃЌвВПЩвджБНгжИЖЈВщбЏДЎЁЃ
Р§згЃКq=product(popularity, query({!dismax v='solr rocks'})
НЋЛсЗЕЛиpopularityКЭЭЈЙ§dismax ВщбЏЕУЕНЕФЗжЪ§ЕФГЫЛ§ЁЃ
q=product(popularity, query($qq)&qq={!dismax}solr
rocks ИњЩЯвЛИіР§згЕФаЇЙћЪЧвЛбљЕФЁЃВЛЙ§етРяЪЙгУЕФЪЧв§гУЕФЗНЪН
q=product(popularity, query($qq,0.1)&qq={!dismax}solr
rocks дкЧАвЛИіР§згЕФЛљДЁЩЯгжМгСЫвЛИіФЌШЯжЕЁЃ
15) linearЃК inear(x,m,c)БэЪО m*x+c ,ЦфжаmКЭcЖМЪЧГЃСПЃЌxЪЧвЛИіБфСПвВПЩвдЪЧвЛИіКЏЪ§ЁЃР§ШчЃК
linear(x,2,4)=2*x+4.
16) RecipЃКrecip(x,m,a,b)=a/(m*x+b)ЦфжаЃЌmЁЂaЁЂbЪЧГЃСПЃЌxЪЧБфСПЛђепвЛИіКЏЪ§ЁЃЕБa=bЃЌВЂЧвx>=0ЕФЪБКђЃЌетИіКЏЪ§ЕФзюДѓжЕЪЧ1ЃЌжЕЕФДѓаЁЫцзХxЕФдіДѓЖјМѕаЁЁЃР§ШчЃКrecip(rord(creationDate),1,1000,1000)
17) MaxЃК max(x,c)НЋЛсЗЕЛивЛИіКЏЪ§КЭвЛИіГЃСПжЎМфЕФзюДѓжЕЁЃ
Р§ШчЃКmax(myfield,0)
6.3ИпССЯдЪО
ЮвУЧОГЃЪЙгУЫбЫїв§ЧцЃЌБШШчдкbaidu ЫбЫї java ЃЌЛсГіЯжШчЯТНсЙћЃЌНсЙћжагыЙиМќзжЦЅХфЕФЕиЗНЪЧКьЩЋЯдЪОгыЦфЫћФкШнЧјБ№ПЊРДЁЃ
solr ФЌШЯвбОХфжУСЫhighlight зщМў(ЯъМћ SOLR_HOME/conf/sorlconfig.xml)ЁЃЭЈГЃЮвГіжЛашвЊетбљЧыЧѓhttp://localhost:8983/solr/
collection1 /select? q=%E4%B8%AD%E5%9B%BD& start=0&rows=1&fl =content+path+&wt=xml& indent=true&hl=true&hl.fl=content
ПЩвдПДЕНгыБШвЛАуЕФЧыЧѓЖрСЫСНИіВЮЪ§ "hl=true" КЭ "hl.fl=
content " ЁЃ
"hl=true" ЪЧПЊЦєИпССЃЌ"hl.fl= content "
ЪЧИцЫпsolr Жд name зжЖЮНјааИпСС(ШчЙћФуЯыЖдЖрИізжЖЮНјааИпССЃЌПЩвдМЬајЬэМгзжЖЮЃЌзжЖЮМфгУЖККХИєПЊЃЌШч
"hl.fl=name,name2,name3")ЁЃ ИпССФкШнгыЙиМќЦЅХфЕФЕиЗНЃЌФЌШЯНЋЛсБЛ
"<em>" КЭ "</em>" АќЮЇЁЃЛЙПЩвдЪЙгУhl.simple.pre"
КЭ "hl.simple.post"ВЮЪ§ЩшжУЧАКѓБъЧЉ.
ВщбЏНсЙћШчЯТЃК
<?xml version="1.0"
encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">2</int>
<lst name="params">
<str
name="fl">content path</str>
<str name="indent">true</str>
<str name="start">0</str>
<str name="q">жаЙњ</str>
<str name="hl.simple.pre"><em></str>
<str name="hl.simple.post"></em></str>
<str name="hl.fl">content</str>
<str name="wt">xml</str>
<str name="hl">true</str>
<str name="rows">1</str>
</lst>
</lst>
|
БОБЈбЖ жаЙњвјСЊЙЩЗнгаЯоЙЋЫОКЭжаЙњЕчаХМЏЭХШеЧАдкББОЉЧЉЪ№ШЋУцеНТдКЯзїавщЁЃетБъжОзХжаЙњвјСЊКЭжаЙњЕчаХНЋдкЭЈаХЗўЮёЁЂаХЯЂдіжЕЗўЮёЁЂаТаЭжЇИЖВњЦЗКЯзїПЊЗЂЕШСьгђНЈСЂШЋУцКЯзїЛяАщЙиЯЕЁЃЁЁЁЁОнЯЄЃЌЫЋЗНЧЉЪ№ЕФШЋУцеНТдКЯзїавщжївЊФкШнЪЧЃКжаЙњвјСЊНЋбЁдёжаЙњЕчаХзїЮЊЭЈаХаХЯЂЗўЮёЕФжївЊЬсЙЉЩЬЃЌЫЋЗНЮЇШЦЬсИпжаЙњвјСЊФкВПЭЈаХЕФЫЎЦНКЭЯњЪлЭјТчЕФЗўЮёЫЎЦНПЊеЙШЋУцЁЂЩюШыЕФКЯзїЃЛжаЙњЕчаХбЁдёжаЙњвјСЊзїЮЊвјааПЈзЊНгжЇИЖЗўЮёЕФжївЊЬсЙЉЩЬЃЌВЂЮЇШЦПЊЗЂЁЂЭЦЙуаТаЭжЇИЖжеЖЫВњЦЗКЭдіжЕЗўЮёПЊеЙШЋУцКЯзїЁЃЃЈаСЛЊЃЉ
БОБЈбЖ <em>жаЙњ</em>вјСЊЙЩЗнгаЯоЙЋЫОКЭ<em>жаЙњ</em>ЕчаХМЏЭХШеЧАдкББОЉЧЉЪ№ШЋУцеНТдКЯзїавщЁЃетБъжОзХ<em>жаЙњ</em>вјСЊКЭ<em>жаЙњ</em>ЕчаХНЋдкЭЈаХЗўЮёЁЂаХЯЂдіжЕЗўЮёЁЂаТаЭжЇИЖВњЦЗКЯзїПЊЗЂЕШСьгђНЈСЂШЋУцКЯзїЛяАщЙиЯЕЁЃЁЁЁЁОнЯЄЃЌЫЋЗНЧЉЪ№
ЪЙгУSolrJЗНЗЈЛљБОвЛбљвВЪЧЩшжУетаЉИіВЮЪ§,жЛВЛЙ§ЪЧSolrJЗтзАЦ№РДСЫ,ДњТыШчЯТ:
SolrQuery query
= new SolrQuery();
query.set("q","*.*");
query.setHighlight(true); // ПЊЦєИпССзщМў
query.addHighlightField("content");//
ИпССзжЖЮ
query.setHighlightSimplePre(PRE_TAG);// БъМЧ
query.setHighlightSimplePost(POST_TAG);
QueryResponse rsp =server.query(query)
//ЁЩЯУцШЁНсЙћЕФДњТы
//ШЁГіИпССНсЙћ
if (rsp.getHighlighting() != null) {
if (rsp.getHighlighting().get(id) != null) {//ЯШЭЈЙ§НсЙћжаЕФIDЕНИпССМЏКЯжаШЁГіЮФЕЕИпССаХЯЂ
Map<String, List<String>> map = rsp.getHighlighting().get(id);//ШЁГіИпССЦЌЖЮ
if (map.get(name) != null) {
for (String s : map.get(name)) {
System.out.println(s);
}
}
} |
6.4ЦДаДМьВщ
ЪзЯШХфжУ solrconfig.xmlЃЌЮФМўПЩФмвбОгаетСНИідЊЫи(ШчЙћУЛгаЬэМгМДПЩ)ЃЌашвЊИљОнЮвУЧздМКЕФЯЕЭГЛЗОГзіаЉЪЪЕБЕФаоИФЁЃ
<searchComponent
name="spellcheck" class="solr.SpellCheckComponent">
<str name="queryAnalyzerFieldType">text_spell</str>
<lst name="spellchecker">
<str name="name">direct</str>
<str name="field">spell</str>
<str name="classname">solr.DirectSolrSpellChecker</str>
<str name="distanceMeasure">internal</str>
<float name="accuracy">0.5</float>
<int name="maxEdits">2</int>
<int name="minPrefix">1</int>
<int name="maxInspections">5</int>
<int name="minQueryLength">2</int>
<float name="maxQueryFrequency">0.01</float>
</lst>
</searchComponent>
<requestHandler name="/spell"
class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<str name="spellcheck.dictionary">direct</str>
<str name="spellcheck">on</str>
<str name="spellcheck.collate">true</str>
<str name="spellcheck.collateExtendedResults">true</str>
</lst>
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler> |
ХфжУЭъГЩжЎКѓЃЌЮвУЧНјаавЛЯТВтЪд,жиЦєSolrКѓЃЌЗУЮЪСДНг
<?xml version="1.0"
encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">0</int>
</lst>
<result name="response"
numFound="0" start="0"/>
<lst name="spellcheck">
<lst name="suggestions">
<lst name="beijink">
<int
name="numFound">1</int>
<int name="startOffset">0</int>
<int name="endOffset">3</int>
<arr name="suggestion">
<str>beijing</str>
</arr>
</lst>
</lst>
</lst>
</response> |
ЪЙгУSolrJЪБвВЭЌбљМгШыВЮЪ§ОЭПЩвд
SolrQuery query = new SolrQuery();
query.set("q","*.*");
query.set("qt", "/spell");
QueryResponse rsp =server.query(query)
//ЁЩЯУцШЁНсЙћЕФДњТы
SpellCheckResponse spellCheckResponse = rsp.getSpellCheckResponse();
if (spellCheckResponse != null) {
String collation = spellCheckResponse.getCollatedResult();
} |
6.5МьЫїНЈвщ
МьЫїНЈвщФПЧАЪЧИїДѓЫбЫїЕФБъХфгІгУЃЌжївЊзїгУЪЧБмУтгУЛЇЪфШыДэЮѓЕФЫбЫїДЪЃЌЭЌЪБНЋгУЛЇв§ЕМЕНЯргІЕФЙиМќДЪЫбЫїЩЯЁЃSolrФкжУСЫМьЫїНЈвщЙІФмЃЌЫќдкSolrРяНазіSuggestФЃПщ.ИУФЃПщПЩбЁдёЛљгкЬсЪОДЪЮФБОзіМьЫїНЈвщЃЌЛЙжЇГжЭЈЙ§еыЖдЫїв§ЕФФГИізжЖЮНЈСЂЫїв§ДЪПтзіМьЫїНЈвщЁЃдкжюЖрЮФЕЕжаЖМЭЦМіЪЙгУЛљгкЫїв§РДзіМьЫїНЈвщЃЌвђДЫЮвУЧФПЧАЕФЪЕЯжвВЪЧВЩШЁИУЗНАИЁЃ
ЯждкЮвУЧПЊЪМХфжУSuggestФЃПщ,ЪзЯШдкsolrconfig.xmlЮФМўжаХфжУSuggestвРРЕЕФSpellCheckerФЃПщЃЌШЛКѓдйХфжУSuggestФЃПщ,ЫљвдетСНИіЖМашвЊХфжУЁЃ
<searchComponent
name="suggest" class="solr.SpellCheckComponent">
<str name="queryAnalyzerFieldType">string</str>
<lst name="spellchecker">
<str name="name">suggest</str>
<str name="classname">org.apache.solr.spelling.suggest.Suggester</str>
<str name="lookupImpl">org.apache.solr.spelling.suggest.tst.TSTLookup</str>
<str name="field">text</str>
<float name="threshold">0.0001</float>
<str name="spellcheckIndexDir">spellchecker</str>
<str name="comparatorClass">freq</str>
<str name="buildOnOptimize">true</str>
<!--<str name="buildOnCommit">true</str>-->
</lst>
</searchComponent>
<requestHandler name="/suggest" class="solr.SearchHandler"
startup="lazy">
<lst name="defaults">
<str name="spellcheck">true</str>
<str name="spellcheck.dictionary">suggest</str>
<str name="spellcheck.onlyMorePopular">true</str>
<str name="spellcheck.extendedResults">false</str>
<str name="spellcheck.count">10</str>
<str name="spellcheck.collate">true</str>
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler> |
ХфжУЭъГЩжЎКѓЃЌЮвУЧНјаавЛЯТВтЪд,жиЦєSolrКѓЃЌЗУЮЪШчЯТСДНг
http://localhost:8983/solr/ collection1/suggest?wt=xml&indent=true&spellcheck=true&spellcheck.q=%E4%B8%AD%E5%9B%BD
<?xml version="1.0"
encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">4</int>
</lst>
<lst name="spellcheck">
<lst
name="suggestions">
<lst name="жаЙњ">
<int name="numFound">4</int>
<int name="startOffset">0</int>
<int name="endOffset">2</int>
<arr name="suggestion">
<str>жаЙњЖг</str>
<str>жаЙњжЄМрЛс</str>
<str>жаЙњзуа</str>
<str>жаЙњвјаа</str>
</arr>
</lst>
</lst>
</lst>
</response> |
ЪЙгУSolrJЪБвВЭЌбљМгШыВЮЪ§ОЭПЩвд
SolrQuery query = new SolrQuery();
query.set("q", token);
query.set("qt", "/suggest");
query.set("spellcheck.count", "10");
QueryResponse response = server.query(query);
SpellCheckResponse spellCheckResponse = response.getSpellCheckResponse();
if (spellCheckResponse != null) {
List<SpellCheckResponse.Suggestion> suggestionList
= spellCheckResponse.getSuggestions();
for (SpellCheckResponse.Suggestion suggestion
: suggestionList) {
List<String> suggestedWordList = suggestion.getAlternatives();
for (int i = 0; i < suggestedWordList.size();
i++) {
String word = suggestedWordList.get(i);
}
}
return results;
} |
ЭЈЙ§thresholdВЮЪ§РДЯожЦвЛаЉВЛГЃгУЕФДЪВЛГіЯждкжЧФмЬсЪОСаБэжаЃЌЕБетИіжЕЩшжУЙ§ДѓЪБЃЌПЩФмЕМжТНсЙћЬЋЩйЃЌашвЊв§Ц№зЂвтЁЃФПЧАжївЊДцдкЕФЮЪЬтЪЧЪЙгУfreqХХађЫуЗЈЃЌЗЕЛиЕФНсЙћЭъШЋЛљгкЫїв§жазжЗћЕФГіЯжДЮЪ§ЃЌУЛгаМцЙЫгУЛЇЫбЫїДЪгяЕФЦЕТЪЃЌвђДЫЮоЗЈНЋвЛаЉШШУХДЪХХдкИќППЧАЕФЮЛжУЁЃетПщПЩЖЈжЦSuggestWordScoreComparatorРДЪЕЯжЃЌФПЧАЛЙУЛгазХЪжзіетМўЪТЧщЁЃ
6.6ЗжзщЭГМЦ
ЮветРяЪЕЯжЗжзщЭГМЦЕФЗНЗЈЪЧЪЙгУСЫSolrЕФFacetзщМў, FacetзщМўЪЧSolrФЌШЯМЏГЩЕФвЛИізщМў.
6.6.1 FacetМђНщ
FacetЪЧsolrЕФИпМЖЫбЫїЙІФмжЎвЛ,ПЩвдИјгУЛЇЬсЙЉИќгбКУЕФЫбЫїЬхбщ.дкЫбЫїЙиМќзжЕФЭЌЪБ,ФмЙЛАДееFacetЕФзжЖЮНјааЗжзщВЂЭГМЦ
6.6.2 FacetзжЖЮ
1. ЪЪвЫБЛFacetЕФзжЖЮ
вЛАуДњБэСЫЪЕЬхЕФФГжжЙЋЙВЪєад,ШчЩЬЦЗЕФЗжРр,ЩЬЦЗЕФжЦдьГЇМв,ЪщМЎЕФГіАцЩЬЕШЕШ.
2. FacetзжЖЮЕФвЊЧѓ
FacetЕФзжЖЮБиаыБЛЫїв§.вЛАуРДЫЕИУзжЖЮЮоашЗжДЪ,ЮоашДцДЂ.
ЮоашЗжДЪЪЧвђЮЊИУзжЖЮЕФжЕДњБэСЫвЛИіећЬхИХФю,ШчЕчФдЕФЦЗХЦЁБСЊЯыЁБДњБэСЫвЛИіећ ЬхИХФю,ШчЙћВ№ГЩЁБСЊЁБ,ЁБЯыЁБСНИізжЖМВЛОпгаЪЕМЪвтвх.СэЭтИУзжЖЮЕФжЕЮоашНјааДѓаЁ
аДзЊЛЛЕШДІРэ,БЃГжЦфдУВМДПЩ.
ЮоашДцДЂЪЧвђЮЊвЛАуЖјбдгУЛЇЫљЙиаФЕФВЂВЛЪЧИУзжЖЮЕФОпЬхжЕ,ЖјЪЧзїЮЊЖдВщбЏНсЙћНј ааЗжзщЕФвЛжжЪжЖЮ,гУЛЇвЛАуЛсбизХетИіЗжзщНјвЛВНЩюШыЫбЫї.
3. ЬиЪтЧщПі
ЖдгквЛАуВщбЏЖјбд,ЗжДЪКЭДцДЂЖМЪЧБивЊЕФ.БШШчCPUРраЭЁБIntel ПсюЃ2ЫЋКЫ P7570ЁБ, В№ЗжГЩЁБIntelЁБ,ЁБПсюЃЁБ,ЁБP7570ЁБетбљвЛаЉЙиМќзжВЂЗжБ№Ыїв§,ПЩФмЬсЙЉИќКУЕФЫбЫї
Ьхбщ.ЕЋЪЧШчЙћНЋCPUзїЮЊFacetзжЖЮ,зюКУВЛНјааЗжДЪ.етбљОЭдьГЩСЫУЌЖм,НтОіЗНЗЈЮЊ, НЋCPUзжЖЮЩшжУЮЊВЛЗжДЪВЛДцДЂ,ШЛКѓНЈСЂСэЭтвЛИізжЖЮЮЊЫќЕФCOPY,ЖдетИіCOPYЕФ
зжЖЮНјааЗжДЪКЭДцДЂ.
<types>
<fieldType name="string" class="solr.StrField"
omitNorms="true"/>
<fieldType
name="tokened" class="solr.TextField"
>
<analyzer>
ЁЁ
</analyzer>
</fieldType>
</types>
<fields>
<field name="cpu"
type="string" indexed="true"
stored="false"/>
<field name="cpuCopyЁБ
type=" tokened" indexed="true"
stored="true"/>
</fields>
<copyField source="cpu" dest="cpuCopy"/> |
6.6.2 FacetзщМў
SolrЕФФЌШЯrequestHandlerвбОАќКЌСЫFacetзщМў(solr.FacetComponent).ШчЙћздЖЈвхrequestHandlerЛђепЖдФЌШЯЕФrequestHandlerздЖЈвхзщМўСаБэ,ФЧУДашвЊНЋFacetМгШыЕНзщМўСаБэжаШЅ.
<requestHandler
name="standard" class="solr.SearchHandler"
default="true">
ЁЁ
<arr name="components">
<str>здЖЈвхзщМўУћ</str>
<str>facet</str>
ЁЁ
</arr>
</requestHandler> |
6.6.2 FacetВщбЏ
НјааFacetВщбЏашвЊдкЧыЧѓВЮЪ§жаМгШыfacet=onЛђепfacet=trueжЛгаетбљFacetзщМўВХЦ№зїгУ.
1. Field Facet
FacetзжЖЮЭЈЙ§дкЧыЧѓжаМгШыfacet.fieldВЮЪ§МгвдЩљУї,ШчЙћашвЊЖдЖрИізжЖЮНјааFacetВщбЏ,ФЧУДНЋИУВЮЪ§ЩљУїЖрДЮ.Р§Шч:
http://localhost:8983/solr/ collection1/select?q=*%3A*&start=0&rows=1&wt=xml&indent=true&facet=true&facet.field=category_s&facet.field=modified_l
ЗЕЛиНсЙћ:
<?xml version="1.0"
encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">1</int>
<lst name="params">
<str
name="facet">true</str>
<str name="indent">true</str>
<str name="start">0</str>
<str name="q">*:*</str>
<arr name="facet.field">
<str>category_s</str>
<str>modified_l</str>
</arr>
<str name="wt">xml</str>
<str name="rows">0</str>
</lst>
</lst>
<result name="response" numFound="17971"
start="0">
</result>
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name="category_s">
<int
name="0">5991</int>
<int
name="1">5990</int>
<int
name="2">5990</int>
</lst>
<lst name="modified_l">
<int name="1162438554000">951</int>
<int name="1162438556000">917</int>
<int name="1162438548000">902</int>
<int name="1162438546000">674</int>
</lst>
</lst>
<lst name="facet_dates"/>
<lst name="facet_ranges"/>
</lst>
</response> |
ИїИіFacetзжЖЮЛЅВЛгАЯь,ЧвПЩвдеыЖдУПИіFacetзжЖЮЩшжУВщбЏВЮЪ§.вдЯТНщЩмЕФВЮЪ§МШПЩвдгІгУгкЫљгаЕФFacetзжЖЮ,вВПЩвдгІгУгкУПИіЕЅЖРЕФFacetзжЖЮ.гІгУгкЕЅЖРЕФзжЖЮЪБЭЈЙ§
f.зжЖЮУћ.ВЮЪ§Ућ=ВЮЪ§жЕ
етжжЗНЪНЕїгУ.БШШчfacet.prefixВЮЪ§гІгУгкcpuзжЖЮ,ПЩвдВЩгУШчЯТаЮЪН
f.cpu.facet.prefix=Intel
1.1 facet.prefix
БэЪОFacetзжЖЮжЕЕФЧАзК.БШШчfacet.field=cpu&facet.prefix=Intel,ФЧУДЖдcpuзжЖЮНјааFacetВщбЏ,ЗЕЛиЕФcpuЖМЪЧвдIntelПЊЭЗЕФ,
AMDПЊЭЗЕФcpuаЭКХНЋВЛЛсБЛЭГМЦдкФк.
1.2 facet.sort
БэЪОFacetзжЖЮжЕвдФФжжЫГађЗЕЛи.ПЩНгЪмЕФжЕЮЊtrue(count)|false(index,lex).
true(count)БэЪОАДееcountжЕДгДѓЕНаЁХХСа. false(index,lex)БэЪОАДеезжЖЮжЕЕФздШЛЫГађ(зжФИ,Ъ§зжЕФЫГађ)ХХСа.ФЌШЯЧщПіЯТЮЊtrue(count).ЕБfacet.limitжЕЮЊИКЪ§ЪБ,ФЌШЯfacet.sort=
false(index,lex).
1.3 facet.limit
ЯожЦFacetзжЖЮЗЕЛиЕФНсЙћЬѕЪ§.ФЌШЯжЕЮЊ100.ШчЙћДЫжЕЮЊИКЪ§,БэЪОВЛЯожЦ.
1.4 facet.offset
ЗЕЛиНсЙћМЏЕФЦЋвЦСП,ФЌШЯЮЊ0.Ыќгыfacet.limitХфКЯЪЙгУПЩвдДяЕНЗжвГЕФаЇЙћ.
1.5 facet.mincount
ЯожЦСЫFacetзжЖЮжЕЕФзюаЁcount,ФЌШЯЮЊ0.КЯРэЩшжУИУВЮЪ§ПЩвдНЋгУЛЇЕФЙизЂЕуМЏжадкЩйЪ§БШНЯШШУХЕФСьгђ.
1.6 facet.missing
ФЌШЯЮЊЁБЁБ,ШчЙћЩшжУЮЊtrueЛђепon,ФЧУДНЋЭГМЦФЧаЉИУFacetзжЖЮжЕЮЊnullЕФМЧТМ.
1.7 facet.method
ШЁжЕЮЊenumЛђfc,ФЌШЯЮЊfc.ИУзжЖЮБэЪОСЫСНжжFacetЕФЫуЗЈ,гыжДаааЇТЪЯрЙи.
enumЪЪгУгкзжЖЮжЕБШНЯЩйЕФЧщПі,БШШчзжЖЮРраЭЮЊВМЖћаЭ,ЛђепзжЖЮБэЪОжаЙњЕФЫљгаЪЁЗн.SolrЛсБщРњИУзжЖЮЕФЫљгаШЁжЕ,ВЂДгfilterCacheРяЮЊУПИіжЕЗжХфвЛИіfilter(етРявЊЧѓsolrconfig.xmlРяЖдfilterCacheЕФЩшжУзуЙЛДѓ).ШЛКѓМЦЫуУПИіfilterгыжїВщбЏЕФНЛМЏ.
fc(БэЪОField Cache)ЪЪгУгкзжЖЮШЁжЕБШНЯЖр,ЕЋдкУПИіЮФЕЕРяГіЯжДЮЪ§БШНЯЩйЕФЧщПі.SolrЛсБщРњЫљгаЕФЮФЕЕ,дкУПИіЮФЕЕФкЫбЫїCacheФкЕФжЕ,ШчЙћевЕНОЭНЋCacheФкИУжЕЕФcountМг1.
1.8 facet.enum.cache.minDf
ЕБfacet.method=enumЪБ,ДЫВЮЪ§ЦфзїгУ,minDfБэЪОminimum document
frequency.вВОЭЪЧЮФЕЕФкГіЯжФГИіЙиМќзжЕФзюЩйДЮЪ§.ИУВЮЪ§ФЌШЯжЕЮЊ0.ЩшжУИУВЮЪ§ПЩвдМѕЩйfilterCacheЕФФкДцЯћКФ,ЕЋЛсдіМгзмЕФВщбЏЪБМф(МЦЫуНЛМЏЕФЪБМфдіМгСЫ).ШчЙћЩшжУИУжЕЕФЛА,ЙйЗНЮФЕЕНЈвщгХЯШГЂЪд25-50ФкЕФжЕ.
6.6.3 Date Facet
ШеЦкРраЭЕФзжЖЮдкЮФЕЕжаКмГЃМћ,ШчЩЬЦЗЩЯЪаЪБМф,ЛѕЮяГіВжЪБМф,ЪщМЎЩЯМмЪБМфЕШЕШ.ФГаЉЧщПіЯТашвЊеыЖдетаЉзжЖЮНјааFacet.ВЛЙ§ЪБМфзжЖЮЕФШЁжЕгаЮоЯоад,гУЛЇЭљЭљЙиаФЕФВЛЪЧФГИіЪБМфЕуЖјЪЧФГИіЪБМфЖЮФкЕФВщбЏЭГМЦНсЙћ.
SolrЮЊШеЦкзжЖЮЬсЙЉСЫИќЮЊЗНБуЕФВщбЏЭГМЦЗНЪН.ЕБШЛ,зжЖЮЕФРраЭБиаыЪЧDateField(ЛђЦфзгРраЭ).
ашвЊзЂвтЕФЪЧ,ЪЙгУDate FacetЪБ,зжЖЮУћ,Ц№ЪМЪБМф,НсЪјЪБМф,ЪБМфМфИєет4ИіВЮЪ§ЖМБиаыЬсЙЉ.гыField
FacetРрЫЦ,Date FacetвВПЩвдЖдЖрИізжЖЮНјааFacet.ВЂЧвеыЖдУПИізжЖЮЖМПЩвдЕЅЖРЩшжУВЮЪ§.
facet.date:ИУВЮЪ§БэЪОашвЊНјааDate FacetЕФзжЖЮУћ,гыfacet.fieldвЛбљ,ИУВЮЪ§ПЩвдБЛЩшжУЖрДЮ,БэЪОЖдЖрИізжЖЮНјааDate
Facet.
facet.date.start:Ц№ЪМЪБМф,ЪБМфЕФвЛАуИёЪНЮЊ1995-12-31T23:59:59Z,СэЭтПЩвдЪЙгУNOW\YEAR\
MONTHЕШЕШ,ОпЬхИёЪНПЩвдВЮПМDateFieldЕФjava doc.
facet.date.end:НсЪјЪБМф.
facet.date.gap:ЪБМфМфИє.ШчЙћstartЮЊ2009-1-1,endЮЊ2010-1-1.gapЩшжУЮЊ+1MONTHБэЪОМфИє1ИідТ,ФЧУДНЋЛсАбетЖЮЪБМфЛЎЗжЮЊ12ИіМфИєЖЮ.
зЂвт+вђЮЊЪЧЬиЪтзжЗћЫљвдгІИУгУ%2BДњЬц.
facet.date.hardend:ШЁжЕПЩвдЮЊtrue|false,ФЌШЯЮЊfalse.ЫќБэЪОgapЕќДњЕНendДІВЩгУКЮжжДІРэ.ОйР§ЫЕУїstartЮЊ2009-1-1,endЮЊ2009-12-25,gapЮЊ+1MONTH,
hardendЮЊfalseЕФЛАзюКѓвЛИіЪБМфЖЮЮЊ2009-12-1жС2010-1-1;
hardendЮЊtrueЕФЛАзюКѓвЛИіЪБМфЖЮЮЊ2009-12-1жС2009-12-25.
facet.date.other:ШЁжЕЗЖЮЇЮЊbefore|after|between|none|all,ФЌШЯЮЊnone.beforeЛсЖдstartжЎЧАЕФжЕзіЭГМЦ.afterЛсЖдendжЎКѓЕФжЕзіЭГМЦ.betweenЛсЖдstartжСendжЎМфЫљгажЕзіЭГМЦ.ШчЙћhardendЮЊtrueЕФЛА,ФЧУДИУжЕОЭЪЧИїИіЪБМфЖЮЭГМЦжЕЕФКЭ.noneБэЪОИУЯюНћгУ.allБэЪОbefore,after,allЖМЛсЭГМЦ.
ОйР§:
&facet=on
&facet.date=date
&facet.date.start=2009-1-1T0:0:0Z
&facet.date.end=2010-1-1T0:0:0Z
&facet.date.gap=%2B1MONTH
&facet.date.other=all |
ЗЕЛиНсЙћ:
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields"/>
<lst name="facet_dates">
<int
name="2009-01-01T00:00:00Z">5</int>
<int name="2009-02-01T00:00:00Z">7</int>
<int name="2009-03-01T00:00:00Z">4</int>
<int name="2009-04-01T00:00:00Z">3</int>
<int name="2009-05-01T00:00:00Z">7</int>
<int name="2009-06-01T00:00:00Z">3</int>
<int name="2009-07-01T00:00:00Z">6</int>
<int name="2009-08-01T00:00:00Z">7</int>
<int name="2009-09-01T00:00:00Z">2</int>
<int name="2009-10-01T00:00:00Z">4</int>
<int name="2009-11-01T00:00:00Z">1</int>
<int name="2009-12-01T00:00:00Z">5</int>
<str name="gap">+1MONTH</str>
<date name="end">2010-01-01T00:00:00Z</date>
<int name="before">180</int>
<int name="after">5</int>
<int name="between">54</int>
</lst>
</lst> |
6.6.4 Facet Query
Facet QueryРћгУРрЫЦгкfilter queryЕФгяЗЈЬсЙЉСЫИќЮЊСщЛюЕФFacet.ЭЈЙ§facet.queryВЮЪ§,ПЩвдЖдШЮвтзжЖЮНјааЩИбЁ.
Р§1:
&facet=on
&facet.query=date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]
&facet.query=date:[2009-4-1T0:0:0Z TO 2009-5-1T0:0:0Z] |
ЗЕЛиНсЙћ:
<lst name="facet_counts">
<lst name="facet_queries">
<int name="date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]">5</int>
<int name="date:[2009-4-1T0:0:0Z TO 2009-5-1T0:0:0Z]">3</int>
</lst>
<lst name="facet_fields"/>
<lst name="facet_dates"/>
</lst> |
Р§2:
&facet=on
&facet.query=date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]
&facet.query=price:[* TO 5000] |
ЗЕЛиНсЙћ:
lst name="facet_counts">
<lst name="facet_queries">
<int name="date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]">5</int>
<int name="price:[* TO 5000]">116</int>
</lst>
<lst name="facet_fields"/>
<lst name="facet_dates"/>
</lst> |
Р§3:
&facet=on
&facet.query=cpu:[A TO G] |
ЗЕЛиНсЙћ:
<lst name="facet_counts">
<lst name="facet_queries">
<int name="cpu:[A TO G]">11</int>
</lst>
<lst name="facet_fields"/>
<lst name="facet_dates"/>
</lst> |
6.6.5 keyВйзїЗћ
ПЩвдгУkeyВйзїЗћЮЊFacetзжЖЮШЁвЛИіБ№Ућ.
Р§:
&facet=on
&facet.field={!key=жабыДІРэЦї}cpu
&facet.field={!key=ЯдПЈ}videoCard |
ЗЕЛиНсЙћ:
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name="жабыДІРэЦї">
<int
name="Intel ПсюЃ2ЫЋКЫ T6600">48</int>
<int name="Intel БМЬкЫЋКЫ T4300">28</int>
<int name="Intel ПсюЃ2ЫЋКЫ P8700">18</int>
<int name="Intel ПсюЃ2ЫЋКЫ T6570">11</int>
<int name="Intel ПсюЃ2ЫЋКЫ T6670">11</int>
<int name="Intel БМЬкЫЋКЫ T4400">9</int>
<int name="Intel ПсюЃ2ЫЋКЫ P7450">9</int>
<int name="Intel ПсюЃ2ЫЋКЫ T5870">8</int>
<int name="Intel ШќбяЫЋКЫ T3000">7</int>
<int name="Intel БМЬкЫЋКЫ SU4100">6</int>
<int name="Intel ПсюЃ2ЫЋКЫ P8400">6</int>
<int name="Intel ПсюЃ2ЫЋКЫ SU7300">5</int>
<int name="Intel ПсюЃ i3 330M">4</int>
</lst>
<lst name="ЯдПЈ">
<int name="ATI Mobility Radeon HD 4">63</int>
<int name="NVIDIA GeForce G 105M">24</int>
<int name="NVIDIA GeForce GT 240M">21</int>
<int name="NVIDIA GeForce G 103M">8</int>
<int name="NVIDIA GeForce GT 220M">8</int>
<int name="NVIDIA GeForce 9400M G">7</int>
<int name="NVIDIA GeForce G 210M">6</int>
</lst>
</lst>
<lst name="facet_dates"/>
</lst> |
6.6.6 tagВйзїЗћКЭexВйзїЗћ
ЕБВщбЏЪЙгУfilter queryЕФЪБКђ,ШчЙћfilter queryЕФзжЖЮе§КУЪЧFacetзжЖЮ,ФЧУДВщбЏНсЙћЭљЭљБЛЯожЦдкФГвЛИіжЕФк.
Р§:
&fq=screenSize:14
&facet=on
&facet.field=screenSize |
ЗЕЛиНсЙћ:
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name=" screenSize">
<int
name="14.0">107</int>
<int name="10.2">0</int>
<int name="11.1">0</int>
<int name="11.6">0</int>
<int name="12.1">0</int>
<int name="13.1">0</int>
<int name="13.3">0</int>
<int name="14.1">0</int>
<int name="15.4">0</int>
<int name="15.5">0</int>
<int name="15.6">0</int>
<int name="16.0">0</int>
<int name="17.0">0</int>
<int name="17.3">0</int>
</lst>
</lst>
<lst name="facet_dates"/>
</lst> |
ПЩвдПДЕН,ЦСФЛГпДч(screenSize)ЮЊ14ДчЕФВњЦЗЙВга107Мў,ЦфЫќГпДчЕФВњЦЗЕФЪ§ФПЖМЪЧ0,етЪЧвђЮЊдкfilterРявбОЯожЦСЫscreenSize:14.етбљ,ВщбЏНсЙћжа,Г§СЫscreenSize=14ЕФетвЛЯюжЎЭт,ЦфЫќЯюФПУЛгаЪЕМЪЕФвтвх.гааЉЪБКђ,гУЛЇЯЃЭћАбНсЙћЯожЦдкФГвЛЗЖЮЇФк,гжЯЃЭћВщПДИУЗЖЮЇЭтЕФИХПі.БШШчЩЯЪіЧщПі,МШвЊАбВщбЏНсЙћЯожЦдк14ДчЦСЕФБЪМЧБО,гжЯыВщПДвЛЯТЦфЫќЦСФЛГпДчЕФБЪМЧБОгаЖрЩйВњЦЗ.етИіЪБКђашвЊгУЕНtagКЭexВйзїЗћ.tagОЭЪЧАбвЛИіfilterБъМЧЦ№РД,ex(exclude)ЪЧдкFacetЕФЪБКђАбБъМЧЙ§ЕФfilterХХГ§дкЭт.
Р§:
&fq={!tag=aa}screenSize:14
&facet=on
&facet.field={!ex=aa}screenSize |
ЗЕЛиНсЙћ:
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name=" screenSize">
<int
name="14.0">107</int>
<int name="14.1">40</int>
<int name="13.3">34</int>
<int name="15.6">22</int>
<int name="15.4">8</int>
<int name="11.6">6</int>
<int name="12.1">5</int>
<int name="16.0">5</int>
<int name="15.5">3</int>
<int name="17.0">3</int>
<int name="17.3">3</int>
<int name="10.2">1</int>
<int name="11.1">1</int>
<int name="13.1">1</int>
</lst>
</lst>
<lst name="facet_dates"/>
</lst> |
етбљЦфЫќЦСФЛГпДчЕФЭГМЦаХЯЂОЭгавтвхСЫ.
6.6.7 SolrJЖдFacetЕФжЇГж
//ГѕЪМЛЏВщбЏЖдЯѓ
String q = ЁА*.*ЁБ;
SolrQuery query = new SolrQuery(q);
query.setIncludeScore(false);//ЪЧЗёАДУПзщЪ§СПИпЕЭХХађ
query.setFacet(true);//ЪЧЗёЗжзщВщбЏ
query.setRows(0);//ЩшжУЗЕЛиНсЙћЬѕЪ§ЃЌШчЙћФуЪБЗжзщВщбЏЃЌФуОЭЩшжУЮЊ0
query.addFacetField(ЁАmodified_lЁБ);//діМгЗжзщзжЖЮ q
query.addFacetQuery (ЁАcategory_s[0 TO 1]ЁБ);
QueryResponse rsp = server.query(query);
Ё
//ШЁГіНсЙћ
List<FacetField.Count> list = rsp.getFacetField(ЁАmodified_lЁБ).getValues();
Map<String, Integer> list = rsp.getFacetQuery(); |
6.7здЖЏОлРр
Solr ЪЙгУCarrot2ЭъГЩСЫОлРрЙІФм,ФмЙЛАбМьЫїЕНЕФФкШнздЖЏЗжРр, Carrot2ОлРрЪОР§:
вЊЯыSolrжЇГжОлРрЙІФм,ЪзбЁвЊАбSolrЗЂааАќЕФжаЕФdist/ solr-clustering-4.2.0.jar,
ИДжЦЕН\solr\contrib\analysis-extras\libЯТ.ШЛКѓДђПЊsolrconfig.xmlНјааЬэМгХфжУ:
<searchComponent
name="clustering"
enable="${solr.clustering.enabled:true}"
class="solr.clustering.ClusteringComponent"
>
<lst name="engine">
<str name="name">default</str>
<str name="carrot.algorithm">org.carrot2.clustering.
lingo.LingoClusteringAlgorithm</str>
<str name="LingoClusteringAlgorithm.desiredClusterCountBase">20</str>
</lst>
</searchComponent> |
ХфКУСЫОлРрзщМўКѓ,ЯТУцХфжУrequestHandler:
<requestHandler name="/clustering"
startup="lazy" enable="${solr.clustering.enabled:true}"
class="solr.SearchHandler">
<lst
name="defaults">
<str name="echoParams">explicit</str>
<bool name="clustering">true</bool>
<str name="clustering.engine">default</str>
<bool name="clustering.results">true</bool>
<str name="carrot.title">category_s</str>
<str name="carrot.snippet">content</str>
</lst>
<arr name="last-components">
<str>clustering</str> </arr>
</requestHandler> |
гаСНИіВЮЪ§вЊзЂвтcarrot.title, carrot.snippetЪЧОлРрЕФБШНЯМЦЫузжЖЮ,етСНИіВЮЪ§БиаыЪЧstored="true".carrot.titleЕФШЈживЊИпгкcarrot.snippet,ШчЙћжЛгавЛИізіМЦЫуЕФзжЖЮcarrot.snippetПЩвдШЅЕє(ЪЧШЅЕєВЛЪЧжЕЮЊПе).ЩшЭъСЫгУЯТУцЕФURLОЭПЩвдВщбЏСЫ
http://localhost:8983/skyCore/clustering?q=*%3A*&wt=xml&indent=true
6.8ЯрЫЦЦЅХф
ЁЁЁЁдкЮвУЧЪЙгУЭјвГЫбЫїЪБЃЌЛсзЂвтЕНУПвЛИіНсЙћЖМАќКЌвЛИі ЁАЯрЫЦвГУцЁБ СДНгЃЌЕЅЛїИУСДНгЃЌОЭЛсЗЂВМСэвЛИіЫбЫїЧыЧѓЃЌВщевГігыЦ№ГѕНсЙћРрЫЦЕФЮФЕЕЁЃSolr
ЪЙгУ MoreLikeThisComponentЃЈMLTЃЉКЭ MoreLikeThisHandler
ЪЕЯжСЫвЛбљЕФЙІФмЁЃШчЩЯЫљЪіЃЌMLT ЪЧгыБъзМ SolrRequestHandler МЏГЩдквЛЦ№ЕФЃЛMoreLikeThisHandler
гы MLT НсКЯдквЛЦ№ЃЌВЂЬэМгСЫвЛаЉЦфЫћбЁЯюЃЌЕЋЫќвЊЧѓЗЂВМвЛИіЕЅвЛЕФЧыЧѓЁЃЮвНЋзХжиНВЪі MLTЃЌвђЮЊЪЙгУЫќЕФПЩФмадИќДѓвЛаЉЁЃавдЫЕФЪЧЃЌВЛашвЊШЮКЮЩшжУОЭПЩвдВщбЏЫќЃЌЫљвдФњЯждкОЭПЩвдПЊЪМВщбЏЁЃ
ЁЁЁЁMLT вЊЧѓзжЖЮБЛДЂДцЛђЪЙгУМьЫїДЪЯђСПЃЌМьЫїДЪЯђСПвдвЛжжвдЮФЕЕЮЊжааФЕФЗНЪНДЂДцаХЯЂЁЃMLT ЭЈЙ§ЮФЕЕЕФФкШнРДМЦЫуЮФЕЕжаЙиМќДЪгяЃЌШЛКѓЪЙгУдЪМВщбЏДЪгяКЭетаЉаТДЪгяДДНЈвЛИіаТЕФВщбЏЁЃЬсНЛаТВщбЏОЭЛсЗЕЛиЦфЫћВщбЏНсЙћЁЃЫљгаетаЉЖМПЩвдгУМьЫїДЪЯђСПРДЭъГЩЃКжЛашНЋ
termVectors="true" ЬэМгЕН schema.xml жаЕФ <field>
ЩљУїЁЃ
MoreLikeThisComponent ВЮЪ§ЃК
|
ВЮЪ§ |
ЁЁЫЕУї |
ЁЁжЕгђ |
| mlt |
дкВщбЏЪБЃЌДђПЊ/ЙиБе MoreLikeThisComponent ЕФВМЖћжЕЁЃ |
true|false |
| mlt.count |
ПЩбЁЁЃУПвЛИіНсЙћвЊМьЫїЕФЯрЫЦЮФЕЕЪ§ЁЃ
|
> 0 |
| mlt.fl |
гУгкДДНЈ MLT ВщбЏЕФзжЖЮЁЃ
|
ШЮКЮБЛДЂДцЕФЛђКЌгаМьЫїДЪЯђСПЕФзжЖЮЁЃ |
|
mlt.maxqt |
ЖрЙиМќДЪгяЃЌетбљ MLT
ВщбЏПЩФмЛсКмДѓЃЌДгЖјЕМжТЗДгІЛКТ§ЛђПЩХТЕФ TooManyClausesExceptionЃЌИУВЮЪ§жЛБЃСєЙиМќЕФДЪгяЁЃ |
> 0 |
вЊЯыЪЙгУЦЅХфЯрЫЦЪзЯШдк solrconfig.xml жаХфжУ MoreLikeThisHandler
<requestHandler name="/mlt" class="solr.MoreLikeThisHandler">
</requestHandler>
ШЛКѓЮвОЭПЩвдЧыЧѓ
http://localhost:8983/skyCore/mlt?q=id%3A6F398CCD-2DE0-D3B1-9DD6-D4E532FFC531&mlt.true&mlt.fl=content&wt=xml&indent=true
ЩЯУцЧыЧѓЕФвтЫМВщев id ЮЊ 6F398CCD-2DE0-D3B1-9DD6-D4E532FFC531
ЕФ document ,ШЛКѓЗЕЛигыДЫ document дк name зжЖЮЩЯЯрЫЦЕФЦфЫћ documentЁЃашвЊзЂвтЕФЪЧ
mlt.fl жаЕФ field ЕФ termVector=true ВХгааЇЙћ
<field name="content" type="text_smartcn"
indexed="false" stored="true"
multiValued="false" termVector="true"/>
ЪЙгУSolrJЪБвВЭЌбљМгШыВЮЪ§ОЭПЩвд
SolrQuery query
= new SolrQuery();
query.set("qt", "/mlt");
query.set("mlt.fl","content");
query.set("fl", "id,");
query.set("q", "id: 6F398CCD-2DE0-D3B1-9DD6-D4E532FFC531");
query.setStart(0);
query.setRows(5);
QueryResponse rsp = server.query(query);
SolrDocumentList list = rsp.getResults(); |
6.9ЦДвєМьЫї
ЦДвєМьЫїжаЙњШЫЕФзЈгУМьЫї,Р§Шч:жаЮФФкШнЮЊ жаЙњ ЕФЪфШыzhongguoЁЂzgЁЂzhonggu ШЋЦДЁЂМђЦДЁЂЦДвєЕФЯрСкЕФвЛВПЗнЖМгІИУФмМьЫїГі
жаЙњ РДЁЃ
ЯывЊЪЕЯжЦДвєМьЫїЕквЛИіОЭЪЧЦДвєзЊЛЛЮветРягУЕФЪЧpinyin4jНјааЦДвєзЊЛЛЁЃЕкЖўИіОЭЪЧN-GramЕФЬтФПЃЌЭЦЧУЕНгУЛЇПЩФмЪфШыЕФМШВЛЪЧЧАзКвВВЛЪЧКѓзКЃЌЫљвдДЫДІбЁдёЕФЪЧN-GramММЧЩЃЌЕЋВЛЭЌгкГЃгУЕФN-GramЃЌЮвгІгУЕФДгвЛБпПЊЖЫЕФЕЅЯђЕФN-GramЃЌSolrРяЕФЪЕЯжНаEdgeNGramTokenFilterЃЌЕЋЪЧЗжЕФЗжЕФЬЋЯИСЫЃЌВЛашвЊетУДИДдгEdgeNGramTokenFilter,вВОЭЪЧЫЕЮвУЧгУЕФN-GramВЛЭЌгкДЋЭГЕФN-GramЁЃ
ЭЌбљЕФР§згЪЙгУEdgeNGramTokenFilterДгЧАЭљКѓШЁ2-GramЕФНсЙћЪЧzh, вЛАуЪЧШЁminЈCmaxжЎМфЕФЫљгаgramЃЌЫљвдЪЙгУEdgeNGramTokenFilterШЁ2-20ЕФgramНсЙћОЭЪЧzh,zho,
zhon, zhong, zhongg, zhonggu, zhongguo, ДгетИіР§згвВВЛФбРэНтЮЊЪВУДЮввЊбЁдёЪЙгУEdgeNGramTokenFilterЖјЗЧвЛАувтвхЩЯЕФN-GramЃЌ
ПМТЧЕНгУЛЇПЩФмЪфШыЕФВЛЪЧЧАзКЖјЪЧКѓзКЃЌЫљвдЮЊСЫееЙЫетаЉгУЛЇЃЌЮвбЁдёСЫДгЧАЭљКѓКЭДгКѓЭљЧАЪЙгУСЫСНДЮEdgeNGramTokenFilterЃЌетбљВЛжЛЪЧЧАзКЁЂКѓзКЃЌЖўЪЎШЮвтЕФзжДЎЖМПМТЧНјШЅСЫЃЌЫљвдДѓЗљЖШЕФЬсИпСЫЫбЫїЬхбщ.
ЯждкЫМТЗУїШЗСЫЮвУЧАбЫќНсКЯЕНSolrжаЃЌЮЊСЫЗНБуЪЙгУЯждкаДСЫСНИіFilterНјааДІРэЦДвєЗжДЪЮЪЬтвЛИіЪЧЦДвєзЊЛЛFilterЃЈPinyinTransformTokenFilterЃЉвЛИіЪЧЦДвєN-GramЕФFilter(PinyinNGramTokenFilter),етбљвЛРДЪЙгУЪБОЭВЛгУдкЬэМгЫїв§ЧАзіРЙвєЕФзЊЛЛСЫЁЃЖјЧвPinyinTransformTokenFilterЛЙгаИіКУДІОЭЪЧЫќжЛЪЙгУжаЮФЗжДЪЦїЗжЙ§ЕФДЪЃЌвВОЭЪЧЫЕзізЊЛЛЕФДЪЖМЪЧгагУЕФВЛжиИДЕФЃЌВЛЛсЖдУЛгУЕФЭЃДЪРрЕФзіЦДвєзЊЛЛКЭжиИДЦДвєзЊЛЛЃЌетбљДѓДѓЕФЬсИпСЫЦДвєзЊЛЛЫйЖШЁЃ
ЯывЊSolrжЇГжЦДвєМьЫїОЭвЊЯШАбЦДвєЗжДЪЃЈPinyinAnalyzerЃЉЕФjarИДжЦЕН\solr\contrib\analysis-extras\libЯТЃЌШЛКѓдкschema.xmlжаХфжУвЛИіЦДвєзжЖЮРраЭЃК
<fieldType
name="text_pinyin" class="solr.TextField"
positionIncrementGap="0">
<analyzer
type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory"
minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory"
minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory"
minTermLenght="2" />
<filter
class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory"
minGram="1" maxGram="20" />
</analyzer>
</fieldType> |
minTermLenghtЃКзюаЁжаЮФДЪГЄЖШЃЌвтЫМЪЧаЁгкетИіжЕЕФжаЮФДЪВЛЛсзіЦДвєзЊЛЛЁЃ
minGramЃКзюаЁЦДвєЧаЗжГЄЖШЁЃ
ШчЙћЯыЪЙгУМђЦДЕФЛАдкЦДвєзЊЛЛFilter ЪЙгУетИіВЮЪ§isFirstChar="true"ОЭПЩвдСЫ
дкетИіЦДвєРраЭжаЮвУЧЪЙгУСЫsmartcnЕФжабдгяЗжДЪЦїЃЌШчЙћЯыЪЙгУЦфЫќЕФздМКЛЛЕєОЭааСЫЁЃЯждкЮвУЧдкдРДЫїв§жаМгШывЛИіЦДвєзжЖЮЃЌвђЮЊжЛзіЫїв§,ЮвУЧПЩвдетбљХфжУ:
<field name ="pinyin" type ="text_pinyin"
indexed ="true" stored ="false"
multiValued ="false"/>
МгЭъКѓЮвУЧжиаТЦєЖЏSolrВтЪдвЛЯТПДПД
гЩгкЩЯУцminTermLenghtКЭminGramЩшжУЕФжЕЃЌЯждкГіЯжСЫШЫУЛгаНјааЦДвєзЊЛЛВЂЧвзюаЁЦДвєЧаЗжЪЧДг1ИіПЊЪМЕФЁЃ
ЕНетРяЮвУЧЕФХфжУЛЙгаУЛЭъГЩФиЃЌЛЙвЊМгМИИіcopyFiledЃЌетбљОЭВЛгУЕЅЖРДІРэЮвУЧаТМгЕФЦДвєзжЖЮСЫЁЃЗНБубН~~~
<copyField source="content" dest="pinyin"/>
<copyField source="text" dest="spell"/>
ЕНЯждкОЭПЩвдЪЙгУЦДвєМьЫїСЫЁЃ
ЦДвєЗжДЪЦїjar ЕуЛїВЂИДжЦОЭПЩвдеГГіШЅСЫ.
6.10 SolrCloud
SolrCloudЪЧЛљгкSolrКЭZookeeperЕФЗжВМЪНЫбЫїЗНАИЃЌЪЧе§дкПЊЗЂжаЕФSolr4.0ЕФКЫаФзщМўжЎвЛЃЌЫќЕФжївЊЫМЯыЪЧЪЙгУZookeeperзїЮЊМЏШКЕФХфжУаХЯЂжааФЁЃЫќгаМИИіЬиЩЋЙІФм,МЏжаЪНЕФХфжУаХЯЂЁЂздЖЏШнДэ
ЁЂНќЪЕЪБЫбЫї ЁЂВщбЏЪБздЖЏИКдиОљКтЁЃ
ЛљБОПЩвдгУЩЯУцетЗљЭМРДИХЪіЃЌетЪЧвЛИігЕга4ИіSolrНкЕуЕФМЏШКЃЌЫїв§ЗжВМдкСНИіShardРяУцЃЌУПИіShardАќКЌСНИіSolrНкЕуЃЌвЛИіЪЧLeaderНкЕуЃЌвЛИіЪЧReplicaНкЕуЃЌДЫЭтМЏШКжагавЛИіИКд№ЮЌЛЄМЏШКзДЬЌаХЯЂЕФOverseerНкЕуЃЌЫќЪЧвЛИізмПижЦЦїЁЃМЏШКЕФЫљгазДЬЌаХЯЂЖМЗХдкZookeeperМЏШКжаЭГвЛЮЌЛЄЁЃДгЭМжаЛЙПЩвдПДЕНЃЌШЮКЮвЛИіНкЕуЖМПЩвдНгЪеЫїв§ИќаТЕФЧыЧѓЃЌШЛКѓдйНЋетИіЧыЧѓзЊЗЂЕНЮФЕЕЫљгІИУЪєгкЕФФЧИіShardЕФLeaderНкЕуЃЌLeaderНкЕуИќаТНсЪјЭъГЩЃЌзюКѓНЋАцБОКХКЭЮФЕЕзЊЗЂИјЭЌЪєгквЛИіShardЕФreplicasНкЕуЁЃетРяОЭВЛЖрЫЕSolrCloudСЫЃЌЕШбаОПУїАзКѓдйЕЅаДвЛИіЮФЕЕЁЃ
ИН1ЃКschema.xml
<?xml version="1.0" encoding="UTF-8"
?>
<schema name="example" version="1.5">
<fields>
<field name="id" type="string"
indexed="true" stored="true" required="true"
multiValued="false"/>
<field name="path" type="text_ik"
indexed="false" stored="true"
multiValued="false" termVector="true"
/>
<field name="content" type="text_ik"
indexed="false" stored="true"
multiValued="false" termVector="true"/>
<field name ="text" type ="text_ik"
indexed ="true" stored ="false"
multiValued ="true"/>
<field name ="pinyin" type ="text_pinyin"
indexed ="true" stored ="false"
multiValued ="false"/>
<field name ="py" type ="text_py"
indexed ="true" stored ="false"
multiValued ="false"/>
<field name="spell" type="text_spell"
indexed="true" stored="false"
multiValued="false" termVector="true"/>
<field name="_version_" type="long"
indexed="true" stored="true"/>
<dynamicField name="*_i" type="int"
indexed="true" stored="true"/>
<dynamicField name="*_is" type="int"
indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_s" type="string"
indexed="true" stored="true" />
<dynamicField name="*_ss" type="string"
indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_l" type="long"
indexed="true" stored="true"/>
<dynamicField name="*_ls" type="long"
indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_t" type="text_general"
indexed="true" stored="true"/>
<dynamicField name="*_txt" type="text_general"
indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_en" type="text_en"
indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_b" type="boolean"
indexed="true" stored="true"/>
<dynamicField name="*_bs" type="boolean"
indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_f" type="float"
indexed="true" stored="true"/>
<dynamicField name="*_fs" type="float"
indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_d" type="double"
indexed="true" stored="true"/>
<dynamicField name="*_ds" type="double"
indexed="true" stored="true" multiValued="true"/>
<!-- Type used to index the lat and lon components
for the "location" FieldType -->
<dynamicField name="*_coordinate" type="tdouble"
indexed="true" stored="false"/>
<dynamicField name="*_dt" type="date"
indexed="true" stored="true"/>
<dynamicField name="*_dts" type="date"
indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_p" type="location"
indexed="true" stored="true"/>
<!-- some trie-coded dynamic fields for faster
range queries -->
<dynamicField name="*_ti" type="tint"
indexed="true" stored="true"/>
<dynamicField name="*_tl" type="tlong"
indexed="true" stored="true"/>
<dynamicField name="*_tf" type="tfloat"
indexed="true" stored="true"/>
<dynamicField name="*_td" type="tdouble"
indexed="true" stored="true"/>
<dynamicField name="*_tdt" type="tdate"
indexed="true" stored="true"/>
<dynamicField name="*_pi" type="pint"
indexed="true" stored="true"/>
<dynamicField name="*_c" type="currency"
indexed="true" stored="true"/>
<dynamicField name="ignored_*" type="ignored"
multiValued="true"/>
<dynamicField name="attr_*" type="text_general"
indexed="true" stored="true" multiValued="true"/>
<dynamicField name="random_*" type="random"/>
</fields>
<uniqueKey>id</uniqueKey>
<copyField source="content" dest="spell"/>
<copyField source="content" dest="pinyin"/>
<copyField source="content" dest="py"/>
<copyField source="path" dest="text"/>
<copyField source="content" dest="text"/>
<copyField source="pinyin" dest="text"/>
<copyField source="py" dest="text"/>
<defaultSearchField>text</defaultSearchField>
<types>
<fieldType name="string" class="solr.StrField"
sortMissingLast="true"/>
<fieldType name="boolean" class="solr.BoolField"
sortMissingLast="true"/>
<fieldType name="int" class="solr.TrieIntField"
precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField"
precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField"
precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField"
precisionStep="0" positionIncrementGap="0"/>
<fieldType name="tint" class="solr.TrieIntField"
precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tfloat" class="solr.TrieFloatField"
precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tlong" class="solr.TrieLongField"
precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tdouble" class="solr.TrieDoubleField"
precisionStep="8" positionIncrementGap="0"/>
<fieldType name="date" class="solr.TrieDateField"
precisionStep="0" positionIncrementGap="0"/>
<fieldType name="tdate" class="solr.TrieDateField"
precisionStep="6" positionIncrementGap="0"/>
<fieldtype name="binary" class="solr.BinaryField"/>
<fieldType name="pint" class="solr.IntField"/>
<fieldType name="plong" class="solr.LongField"/>
<fieldType name="pfloat" class="solr.FloatField"/>
<fieldType name="pdouble" class="solr.DoubleField"/>
<fieldType name="pdate" class="solr.DateField"
sortMissingLast="true"/>
<fieldType name="random" class="solr.RandomSortField"
indexed="true"/>
<fieldType name="text_ws" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_general" class="solr.TextField"
positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="stopwords.txt"
enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="stopwords.txt"
enablePositionIncrements="true" />
<filter class="solr.SynonymFilterFactory"
synonyms="synonyms.txt" ignoreCase="true"
expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_spell" class="solr.TextField"
>
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<fieldType name="text_smartcn" class="solr.TextField"
positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_pinyin" class="solr.TextField"
positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory"
minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory"
minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory"
minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory"
minGram="1" maxGram="20" />
</analyzer>
</fieldType>
<fieldType name="text_py" class="solr.TextField"
positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory"
isFirstChar="true" minTermLenght="2"
/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory"
isFirstChar="true" minTermLenght="2"
/>
</analyzer>
</fieldType>
<fieldType name="text_en" class="solr.TextField"
positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- in this example, we will only use synonyms
at query time
<filter class="solr.SynonymFilterFactory"
synonyms="index_synonyms.txt" ignoreCase="true"
expand="false"/>
-->
<!-- Case insensitive stop word removal.
add enablePositionIncrements=true in both the index
and query
analyzers to leave a 'gap' for more accurate phrase
queries.
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
enablePositionIncrements="true"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory"
protected="protwords.txt"/>
<!-- Optionally you may want to use this less aggressive
stemmer instead of PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory"
synonyms="synonyms.txt" ignoreCase="true"
expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
enablePositionIncrements="true"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory"
protected="protwords.txt"/>
<!-- Optionally you may want to use this less aggressive
stemmer instead of PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_en_splitting" class="solr.TextField"
positionIncrementGap="100"
autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<!-- in this example, we will only use synonyms
at query time
<filter class="solr.SynonymFilterFactory"
synonyms="index_synonyms.txt" ignoreCase="true"
expand="false"/>
-->
<!-- Case insensitive stop word removal.
add enablePositionIncrements=true in both the index
and query
analyzers to leave a 'gap' for more accurate phrase
queries.
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
enablePositionIncrements="true"
/>
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1" generateNumberParts="1"
catenateWords="1"
catenateNumbers="1" catenateAll="0"
splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory"
protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory"
synonyms="synonyms.txt" ignoreCase="true"
expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
enablePositionIncrements="true"
/>
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1" generateNumberParts="1"
catenateWords="0"
catenateNumbers="0" catenateAll="0"
splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory"
protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_en_splitting_tight"
class="solr.TextField" positionIncrementGap="100"
autoGeneratePhraseQueries="true">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory"
synonyms="synonyms.txt" ignoreCase="true"
expand="false"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_en.txt"/>
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="0" generateNumberParts="0"
catenateWords="1"
catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory"
protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<!-- this filter can remove any duplicate tokens
that appear at the same position - sometimes
possible with WordDelimiterFilter in conjuncton with
stemming. -->
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_general_rev" class="solr.TextField"
positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="stopwords.txt"
enablePositionIncrements="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ReversedWildcardFilterFactory"
withOriginal="true"
maxPosAsterisk="3" maxPosQuestion="2"
maxFractionAsterisk="0.33"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory"
synonyms="synonyms.txt" ignoreCase="true"
expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="stopwords.txt"
enablePositionIncrements="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="alphaOnlySort" class="solr.TextField"
sortMissingLast="true" omitNorms="true">
<analyzer>
<!-- KeywordTokenizer does no actual tokenizing,
so the entire
input string is preserved as a single token
-->
<tokenizer class="solr.KeywordTokenizerFactory"/>
<!-- The LowerCase TokenFilter does what you expect,
which can be
when you want your sorting to be case insensitive
-->
<filter class="solr.LowerCaseFilterFactory"/>
<!-- The TrimFilter removes any leading or trailing
whitespace -->
<filter class="solr.TrimFilterFactory"/>
<!-- The PatternReplaceFilter gives you the flexibility
to use
Java Regular expression to replace any sequence of
characters
matching a pattern with an arbitrary replacement string,
which may include back references to portions of the
original
string matched by the pattern.
See the Java Regular Expression documentation for
more
information on pattern and replacement string syntax.
http://java.sun.com/j2se/1.6.0/docs/api/java/util/regex/package-summary.html
-->
<filter class="solr.PatternReplaceFilterFactory"
pattern="([^a-z])" replacement=""
replace="all"
/>
</analyzer>
</fieldType>
<fieldtype name="phonetic" stored="false"
indexed="true" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.DoubleMetaphoneFilterFactory"
inject="false"/>
</analyzer>
</fieldtype>
<fieldtype name="payloads" stored="false"
indexed="true" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<!--
The DelimitedPayloadTokenFilter can put payloads on
tokens... for example,
a token of "foo|1.4" would be indexed as
"foo" with a payload of 1.4f
Attributes of the DelimitedPayloadTokenFilterFactory
:
"delimiter" - a one character delimiter.
Default is | (pipe)
"encoder" - how to encode the following
value into a playload
float -> org.apache.lucene.analysis.payloads.FloatEncoder,
integer -> o.a.l.a.p.IntegerEncoder
identity -> o.a.l.a.p.IdentityEncoder
Fully Qualified class name implementing PayloadEncoder,
Encoder must have a no arg constructor.
-->
<filter class="solr.DelimitedPayloadTokenFilterFactory"
encoder="float"/>
</analyzer>
</fieldtype>
<fieldType name="lowercase" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="descendent_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.PathHierarchyTokenizerFactory"
delimiter="/"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="ancestor_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.PathHierarchyTokenizerFactory"
delimiter="/"/>
</analyzer>
</fieldType>
<fieldtype name="ignored" stored="false"
indexed="false" multiValued="true"
class="solr.StrField"/>
<fieldType name="point" class="solr.PointType"
dimension="2" subFieldSuffix="_d"/>
<fieldType name="location" class="solr.LatLonType"
subFieldSuffix="_coordinate"/>
<fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType"
geo="true" distErrPct="0.025"
maxDistErr="0.000009" units="degrees"/>
<fieldType name="currency" class="solr.CurrencyField"
precisionStep="8" defaultCurrency="USD"
currencyConfig="currency.xml"/>
<!-- some examples for different languages (generally
ordered by ISO code) -->
<!-- Arabic -->
<fieldType name="text_ar" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- for any non-arabic -->
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_ar.txt"
enablePositionIncrements="true"/>
<!-- normalizes ? to ?, etc -->
<filter class="solr.ArabicNormalizationFilterFactory"/>
<filter class="solr.ArabicStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Bulgarian -->
<fieldType name="text_bg" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_bg.txt"
enablePositionIncrements="true"/>
<filter class="solr.BulgarianStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Catalan -->
<fieldType name="text_ca" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- removes l', etc -->
<filter class="solr.ElisionFilterFactory"
ignoreCase="true" articles="lang/contractions_ca.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_ca.txt"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Catalan"/>
</analyzer>
</fieldType>
<!-- CJK bigram (see text_ja for a Japanese configuration
using morphological analysis) -->
<fieldType name="text_cjk" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- normalize width before bigram, as e.g. half-width
dakuten combine -->
<filter class="solr.CJKWidthFilterFactory"/>
<!-- for any non-CJK -->
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.CJKBigramFilterFactory"/>
</analyzer>
</fieldType>
<!-- Czech -->
<fieldType name="text_cz" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_cz.txt"
enablePositionIncrements="true"/>
<filter class="solr.CzechStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Danish -->
<fieldType name="text_da" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_da.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Danish"/>
</analyzer>
</fieldType>
<!-- German -->
<fieldType name="text_de" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_de.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.GermanNormalizationFilterFactory"/>
<filter class="solr.GermanLightStemFilterFactory"/>
<!-- less aggressive: <filter class="solr.GermanMinimalStemFilterFactory"/>
-->
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory"
language="German2"/> -->
</analyzer>
</fieldType>
<!-- Greek -->
<fieldType name="text_el" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- greek specific lowercase for sigma -->
<filter class="solr.GreekLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="false" words="lang/stopwords_el.txt"
enablePositionIncrements="true"/>
<filter class="solr.GreekStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Spanish -->
<fieldType name="text_es" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_es.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.SpanishLightStemFilterFactory"/>
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory"
language="Spanish"/> -->
</analyzer>
</fieldType>
<!-- Basque -->
<fieldType name="text_eu" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_eu.txt"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Basque"/>
</analyzer>
</fieldType>
<!-- Persian -->
<fieldType name="text_fa" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<!-- for ZWNJ -->
<charFilter class="solr.PersianCharFilterFactory"/>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ArabicNormalizationFilterFactory"/>
<filter class="solr.PersianNormalizationFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_fa.txt"
enablePositionIncrements="true"/>
</analyzer>
</fieldType>
<!-- Finnish -->
<fieldType name="text_fi" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_fi.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Finnish"/>
<!-- less aggressive: <filter class="solr.FinnishLightStemFilterFactory"/>
-->
</analyzer>
</fieldType>
<!-- French -->
<fieldType name="text_fr" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- removes l', etc -->
<filter class="solr.ElisionFilterFactory"
ignoreCase="true" articles="lang/contractions_fr.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_fr.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.FrenchLightStemFilterFactory"/>
<!-- less aggressive: <filter class="solr.FrenchMinimalStemFilterFactory"/>
-->
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory"
language="French"/> -->
</analyzer>
</fieldType>
<!-- Irish -->
<fieldType name="text_ga" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- removes d', etc -->
<filter class="solr.ElisionFilterFactory"
ignoreCase="true" articles="lang/contractions_ga.txt"/>
<!-- removes n-, etc. position increments is intentionally
false! -->
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/hyphenations_ga.txt"
enablePositionIncrements="false"/>
<filter class="solr.IrishLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_ga.txt"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Irish"/>
</analyzer>
</fieldType>
<!-- Galician -->
<fieldType name="text_gl" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_gl.txt"
enablePositionIncrements="true"/>
<filter class="solr.GalicianStemFilterFactory"/>
<!-- less aggressive: <filter class="solr.GalicianMinimalStemFilterFactory"/>
-->
</analyzer>
</fieldType>
<!-- Hindi -->
<fieldType name="text_hi" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<!-- normalizes unicode representation -->
<filter class="solr.IndicNormalizationFilterFactory"/>
<!-- normalizes variation in spelling -->
<filter class="solr.HindiNormalizationFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_hi.txt"
enablePositionIncrements="true"/>
<filter class="solr.HindiStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Hungarian -->
<fieldType name="text_hu" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_hu.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Hungarian"/>
<!-- less aggressive: <filter class="solr.HungarianLightStemFilterFactory"/>
-->
</analyzer>
</fieldType>
<!-- Armenian -->
<fieldType name="text_hy" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_hy.txt"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Armenian"/>
</analyzer>
</fieldType>
<!-- Indonesian -->
<fieldType name="text_id" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_id.txt"
enablePositionIncrements="true"/>
<!-- for a less aggressive approach (only inflectional
suffixes), set stemDerivational to false -->
<filter class="solr.IndonesianStemFilterFactory"
stemDerivational="true"/>
</analyzer>
</fieldType>
<!-- Italian -->
<fieldType name="text_it" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- removes l', etc -->
<filter class="solr.ElisionFilterFactory"
ignoreCase="true" articles="lang/contractions_it.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_it.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.ItalianLightStemFilterFactory"/>
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory"
language="Italian"/> -->
</analyzer>
</fieldType>
<!-- Japanese using morphological analysis (see
text_cjk for a configuration using bigramming)
NOTE: If you want to optimize search for precision,
use default operator AND in your query
parser config with <solrQueryParser defaultOperator="AND"/>
further down in this file. Use
OR if you would like to optimize for recall (default).
-->
<fieldType name="text_ja" class="solr.TextField"
positionIncrementGap="100" autoGeneratePhraseQueries="false">
<analyzer>
<!-- Kuromoji Japanese morphological analyzer/tokenizer
(JapaneseTokenizer)
Kuromoji has a search mode (default) that does segmentation
useful for search. A heuristic
is used to segment compounds into its parts and the
compound itself is kept as synonym.
Valid values for attribute mode are:
normal: regular segmentation
search: segmentation useful for search with synonyms
compounds (default)
extended: same as search mode, but unigrams unknown
words (experimental)
For some applications it might be good to use search
mode for indexing and normal mode for
queries to reduce recall and prevent parts of compounds
from being matched and highlighted.
Use <analyzer type="index"> and <analyzer
type="query"> for this and mode normal
in query.
Kuromoji also has a convenient user dictionary feature
that allows overriding the statistical
model with your own entries for segmentation, part-of-speech
tags and readings without a need
to specify weights. Notice that user dictionaries
have not been subject to extensive testing.
User dictionary attributes are:
userDictionary: user dictionary filename
userDictionaryEncoding: user dictionary encoding (default
is UTF-8)
See lang/userdict_ja.txt for a sample user dictionary
file.
Punctuation characters are discarded by default. Use
discardPunctuation="false" to keep them.
See http://wiki.apache.org/solr/JapaneseLanguageSupport
for more on Japanese language support.
-->
<tokenizer class="solr.JapaneseTokenizerFactory"
mode="search"/>
<!--<tokenizer class="solr.JapaneseTokenizerFactory"
mode="search" userDictionary="lang/userdict_ja.txt"/>-->
<!-- Reduces inflected verbs and adjectives to
their base/dictionary forms (ДЧјаЮ) -->
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<!-- Removes tokens with certain part-of-speech
tags -->
<filter class="solr.JapanesePartOfSpeechStopFilterFactory"
tags="lang/stoptags_ja.txt"
enablePositionIncrements="true"/>
<!-- Normalizes full-width romaji to half-width
and half-width kana to full-width (Unicode NFKC subset)
-->
<filter class="solr.CJKWidthFilterFactory"/>
<!-- Removes common tokens typically not useful
for search, but have a negative effect on ranking
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_ja.txt"
enablePositionIncrements="true"/>
<!-- Normalizes common katakana spelling variations
by removing any last long sound character (U+30FC)
-->
<filter class="solr.JapaneseKatakanaStemFilterFactory"
minimumLength="4"/>
<!-- Lower-cases romaji characters -->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- Latvian -->
<fieldType name="text_lv" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_lv.txt"
enablePositionIncrements="true"/>
<filter class="solr.LatvianStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Dutch -->
<fieldType name="text_nl" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_nl.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.StemmerOverrideFilterFactory"
dictionary="lang/stemdict_nl.txt" ignoreCase="false"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Dutch"/>
</analyzer>
</fieldType>
<!-- Norwegian -->
<fieldType name="text_no" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_no.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Norwegian"/>
<!-- less aggressive: <filter class="solr.NorwegianLightStemFilterFactory"/>
-->
<!-- singular/plural: <filter class="solr.NorwegianMinimalStemFilterFactory"/>
-->
</analyzer>
</fieldType>
<!-- Portuguese -->
<fieldType name="text_pt" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_pt.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.PortugueseLightStemFilterFactory"/>
<!-- less aggressive: <filter class="solr.PortugueseMinimalStemFilterFactory"/>
-->
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory"
language="Portuguese"/> -->
<!-- most aggressive: <filter class="solr.PortugueseStemFilterFactory"/>
-->
</analyzer>
</fieldType>
<!-- Romanian -->
<fieldType name="text_ro" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_ro.txt"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Romanian"/>
</analyzer>
</fieldType>
<!-- Russian -->
<fieldType name="text_ru" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_ru.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Russian"/>
<!-- less aggressive: <filter class="solr.RussianLightStemFilterFactory"/>
-->
</analyzer>
</fieldType>
<!-- Swedish -->
<fieldType name="text_sv" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_sv.txt"
format="snowball"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Swedish"/>
<!-- less aggressive: <filter class="solr.SwedishLightStemFilterFactory"/>
-->
</analyzer>
</fieldType>
<!-- Thai -->
<fieldType name="text_th" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ThaiWordFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="lang/stopwords_th.txt"
enablePositionIncrements="true"/>
</analyzer>
</fieldType>
<!-- Turkish -->
<fieldType name="text_tr" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.TurkishLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="false" words="lang/stopwords_tr.txt"
enablePositionIncrements="true"/>
<filter class="solr.SnowballPorterFilterFactory"
language="Turkish"/>
</analyzer>
</fieldType>
</types>
</schema>
ИН2ЃКsolrconfig.xml
<?xml version="1.0" encoding="UTF-8"
?>
<config>
<luceneMatchVersion>LUCENE_42</luceneMatchVersion>
<lib dir="../../../lib" regex=".*\.jar"
/>
<lib dir="../../../contrib/extraction/lib"
regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-cell-\d.*\.jar"
/>
<lib dir="../../../contrib/clustering/lib/"
regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-clustering-\d.*\.jar"
/>
<lib dir="../../../contrib/langid/lib/"
regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-langid-\d.*\.jar"
/>
<lib dir="../../../contrib/velocity/lib"
regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-velocity-\d.*\.jar"
/>
<lib dir="/total/crap/dir/ignored" />
<dataDir>${solr.data.dir:}</dataDir>
<directoryFactory name="DirectoryFactory"
class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}"/>
<codecFactory class="solr.SchemaCodecFactory"/>
<indexConfig>
<!-- maxFieldLength was removed in 4.0. To get
similar behavior, include a
LimitTokenCountFilterFactory in your fieldType definition.
E.g.
<filter class="solr.LimitTokenCountFilterFactory"
maxTokenCount="10000"/>
-->
<!-- Maximum time to wait for a write lock (ms)
for an IndexWriter. Default: 1000 -->
<!-- <writeLockTimeout>1000</writeLockTimeout>
-->
<!-- The maximum number of simultaneous threads
that may be
indexing documents at once in IndexWriter; if more
than this
many threads arrive they will wait for others to finish.
Default in Solr/Lucene is 8. -->
<!-- <maxIndexingThreads>8</maxIndexingThreads>
-->
<!-- Expert: Enabling compound file will use less
files for the index,
using fewer file descriptors on the expense of performance
decrease.
Default in Lucene is "true". Default in
Solr is "false" (since 3.6) -->
<!-- <useCompoundFile>false</useCompoundFile>
-->
<!-- ramBufferSizeMB sets the amount of RAM that
may be used by Lucene
indexing for buffering added documents and deletions
before they are
flushed to the Directory.
maxBufferedDocs sets a limit on the number of documents
buffered
before flushing.
If both ramBufferSizeMB and maxBufferedDocs is set,
then
Lucene will flush based on whichever limit is hit
first. -->
<ramBufferSizeMB>100</ramBufferSizeMB>
<maxBufferedDocs>1000</maxBufferedDocs>
<!-- Expert: Merge Policy
The Merge Policy in Lucene controls how merging of
segments is done.
The default since Solr/Lucene 3.3 is TieredMergePolicy.
The default since Lucene 2.3 was the LogByteSizeMergePolicy,
Even older versions of Lucene used LogDocMergePolicy.
<mergePolicy class="org.apache.lucene.index.TieredMergePolicy">
<int name="maxMergeAtOnce">100</int>
<int name="segmentsPerTier">100</int>
</mergePolicy>
-->
<!-- Merge Factor
The merge factor controls how many segments will get
merged at a time.
For TieredMergePolicy, mergeFactor is a convenience
parameter which
will set both MaxMergeAtOnce and SegmentsPerTier at
once.
For LogByteSizeMergePolicy, mergeFactor decides how
many new segments
will be allowed before they are merged into one.
Default is 10 for both merge policies.
-->
<mergeFactor>50</mergeFactor>
<!-- Expert: Merge Scheduler
The Merge Scheduler in Lucene controls how merges
are
performed. The ConcurrentMergeScheduler (Lucene 2.3
default)
can perform merges in the background using separate
threads.
The SerialMergeScheduler (Lucene 2.2 default) does
not.
-->
<!--
<mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler"/>
-->
<!-- LockFactory
This option specifies which Lucene LockFactory implementation
to use.
single = SingleInstanceLockFactory - suggested for
a
read-only index or when there is no possibility of
another process trying to modify the index.
native = NativeFSLockFactory - uses OS native file
locking.
Do not use when multiple solr webapps in the same
JVM are attempting to share a single index.
simple = SimpleFSLockFactory - uses a plain file for
locking
Defaults: 'native' is default for Solr3.6 and later,
otherwise
'simple' is the default
More details on the nuances of each LockFactory...
http://wiki.apache.org/lucene-java/AvailableLockFactories
-->
<lockType>${solr.lock.type:native}</lockType>
<!-- Unlock On Startup
If true, unlock any held write or commit locks on
startup.
This defeats the locking mechanism that allows multiple
processes to safely access a lucene index, and should
be used
with care. Default is "false".
This is not needed if lock type is 'single'
-->
<!--
<unlockOnStartup>false</unlockOnStartup>
-->
<!-- Expert: Controls how often Lucene loads terms
into memory
Default is 128 and is likely good for most everyone.
-->
<!-- <termIndexInterval>128</termIndexInterval>
-->
<!-- If true, IndexReaders will be reopened (often
more efficient)
instead of closed and then opened. Default: true
-->
<!--
<reopenReaders>true</reopenReaders>
-->
<!-- Commit Deletion Policy
Custom deletion policies can be specified here. The
class must
implement org.apache.lucene.index.IndexDeletionPolicy.
The default Solr IndexDeletionPolicy implementation
supports
deleting index commit points on number of commits,
age of
commit point and optimized status.
The latest commit point should always be preserved
regardless
of the criteria.
-->
<!--
<deletionPolicy class="solr.SolrDeletionPolicy">
-->
<!-- The number of commit points to be kept -->
<!-- <str name="maxCommitsToKeep">1</str>
-->
<!-- The number of optimized commit points to be
kept -->
<!-- <str name="maxOptimizedCommitsToKeep">0</str>
-->
<!--
Delete all commit points once they have reached the
given age.
Supports DateMathParser syntax e.g.
-->
<!--
<str name="maxCommitAge">30MINUTES</str>
<str name="maxCommitAge">1DAY</str>
-->
<!--
</deletionPolicy>
-->
<!-- Lucene Infostream
To aid in advanced debugging, Lucene provides an "InfoStream"
of detailed information when indexing.
Setting The value to true will instruct the underlying
Lucene
IndexWriter to write its debugging info the specified
file
-->
<!-- <infoStream file="INFOSTREAM.txt">false</infoStream>
-->
</indexConfig>
<jmx />
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog>
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
<autoCommit>
<maxDocs>1000</maxDocs>
<maxTime>15000</maxTime>
<openSearcher>false</openSearcher>
</autoCommit>
</updateHandler>
<query>
<!-- Max Boolean Clauses
Maximum number of clauses in each BooleanQuery, an
exception
is thrown if exceeded.
** WARNING **
This option actually modifies a global Lucene property
that
will affect all SolrCores. If multiple solrconfig.xml
files
disagree on this property, the value at any given
moment will
be based on the last SolrCore to be initialized.
-->
<maxBooleanClauses>1024</maxBooleanClauses>
<!-- Solr Internal Query Caches
There are two implementations of cache available for
Solr,
LRUCache, based on a synchronized LinkedHashMap, and
FastLRUCache, based on a ConcurrentHashMap.
FastLRUCache has faster gets and slower puts in single
threaded operation and thus is generally faster than
LRUCache
when the hit ratio of the cache is high (> 75%),
and may be
faster under other scenarios on multi-cpu systems.
-->
<!-- Filter Cache
Cache used by SolrIndexSearcher for filters (DocSets),
unordered sets of *all* documents that match a query.
When a
new searcher is opened, its caches may be prepopulated
or
"autowarmed" using data from caches in the
old searcher.
autowarmCount is the number of items to prepopulate.
For
LRUCache, the autowarmed items will be the most recently
accessed items.
Parameters:
class - the SolrCache implementation LRUCache or
(LRUCache or FastLRUCache)
size - the maximum number of entries in the cache
initialSize - the initial capacity (number of entries)
of
the cache. (see java.util.HashMap)
autowarmCount - the number of entries to prepopulate
from
and old cache.
-->
<filterCache class="solr.FastLRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
<!-- Query Result Cache
Caches results of searches - ordered lists of document
ids
(DocList) based on a query, a sort, and the range
of documents requested.
-->
<queryResultCache class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
<!-- Document Cache
Caches Lucene Document objects (the stored fields
for each
document). Since Lucene internal document ids are
transient,
this cache will not be autowarmed.
-->
<documentCache class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
<!-- Field Value Cache
Cache used to hold field values that are quickly accessible
by document id. The fieldValueCache is created by
default
even if not configured here.
-->
<!--
<fieldValueCache class="solr.FastLRUCache"
size="512"
autowarmCount="128"
showItems="32" />
-->
<!-- Custom Cache
Example of a generic cache. These caches may be accessed
by
name through SolrIndexSearcher.getCache(),cacheLookup(),
and
cacheInsert(). The purpose is to enable easy caching
of
user/application level data. The regenerator argument
should
be specified as an implementation of solr.CacheRegenerator
if autowarming is desired.
-->
<!--
<cache name="myUserCache"
class="solr.LRUCache"
size="4096"
initialSize="1024"
autowarmCount="1024"
regenerator="com.mycompany.MyRegenerator"
/>
-->
<!-- Lazy Field Loading
If true, stored fields that are not requested will
be loaded
lazily. This can result in a significant speed improvement
if the usual case is to not load all stored fields,
especially if the skipped fields are large compressed
text
fields.
-->
<enableLazyFieldLoading>true</enableLazyFieldLoading>
<!-- Use Filter For Sorted Query
A possible optimization that attempts to use a filter
to
satisfy a search. If the requested sort does not include
score, then the filterCache will be checked for a
filter
matching the query. If found, the filter will be used
as the
source of document ids, and then the sort will be
applied to
that.
For most situations, this will not be useful unless
you
frequently get the same search repeatedly with different
sort
options, and none of them ever use "score"
-->
<!--
<useFilterForSortedQuery>true</useFilterForSortedQuery>
-->
<!-- Result Window Size
An optimization for use with the queryResultCache.
When a search
is requested, a superset of the requested number of
document ids
are collected. For example, if a search for a particular
query
requests matching documents 10 through 19, and queryWindowSize
is 50,
then documents 0 through 49 will be collected and
cached. Any further
requests in that range can be satisfied via the cache.
-->
<queryResultWindowSize>20</queryResultWindowSize>
<!-- Maximum number of documents to cache for any
entry in the
queryResultCache.
-->
<queryResultMaxDocsCached>200</queryResultMaxDocsCached>
<!-- Query Related Event Listeners
Various IndexSearcher related events can trigger Listeners
to
take actions.
newSearcher - fired whenever a new searcher is being
prepared
and there is a current searcher handling requests
(aka
registered). It can be used to prime certain caches
to
prevent long request times for certain requests.
firstSearcher - fired whenever a new searcher is being
prepared but there is no current registered searcher
to handle
requests or to gain autowarming data from.
-->
<!-- QuerySenderListener takes an array of NamedList
and executes a
local query request for each NamedList in sequence.
-->
<listener event="newSearcher" class="solr.QuerySenderListener">
<arr name="queries">
<!--
<lst><str name="q">solr</str><str
name="sort">price asc</str></lst>
<lst><str name="q">rocks</str><str
name="sort">weight asc</str></lst>
-->
</arr>
</listener>
<listener event="firstSearcher" class="solr.QuerySenderListener">
<arr name="queries">
<lst>
<str name="q">static firstSearcher
warming in solrconfig.xml</str>
</lst>
</arr>
</listener>
<!-- Use Cold Searcher
If a search request comes in and there is no current
registered searcher, then immediately register the
still
warming searcher and use it. If "false"
then all requests
will block until the first searcher is done warming.
-->
<useColdSearcher>false</useColdSearcher>
<!-- Max Warming Searchers
Maximum number of searchers that may be warming in
the
background concurrently. An error is returned if this
limit
is exceeded.
Recommend values of 1-2 for read-only slaves, higher
for
masters w/o cache warming.
-->
<maxWarmingSearchers>2</maxWarmingSearchers>
</query>
<requestDispatcher handleSelect="false"
>
<requestParsers enableRemoteStreaming="true"
multipartUploadLimitInKB="2048000"
formdataUploadLimitInKB="2048"/>
<httpCaching never304="true" />
</requestDispatcher>
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">text</str>
</lst>
</requestHandler>
<requestHandler name="/query" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="wt">json</str>
<str name="indent">true</str>
<str name="df">text</str>
</lst>
</requestHandler>
<requestHandler name="/get" class="solr.RealTimeGetHandler">
<lst name="defaults">
<str name="omitHeader">true</str>
<str name="wt">json</str>
<str name="indent">true</str>
</lst>
</requestHandler>
<requestHandler name="/browse" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<!-- VelocityResponseWriter settings -->
<str name="wt">velocity</str>
<str name="v.template">browse</str>
<str name="v.layout">layout</str>
<str name="title">Solritas</str>
<!-- Query settings -->
<str name="defType">edismax</str>
<str name="qf">
text^0.5 features^1.0 name^1.2 sku^1.5 id^10.0 manu^1.1
cat^1.4
title^10.0 description^5.0 keywords^5.0 author^2.0
resourcename^1.0
</str>
<str name="df">text</str>
<str name="mm">100%</str>
<str name="q.alt">*:*</str>
<str name="rows">10</str>
<str name="fl">*,score</str>
<str name="mlt.qf">
text^0.5 features^1.0 name^1.2 sku^1.5 id^10.0 manu^1.1
cat^1.4
title^10.0 description^5.0 keywords^5.0 author^2.0
resourcename^1.0
</str>
<str name="mlt.fl">text,features,name,sku,id,manu,cat,title,description,keywords,author,resourcename</str>
<int name="mlt.count">3</int>
<!-- Faceting defaults -->
<str name="facet">on</str>
<str name="facet.field">cat</str>
<str name="facet.field">manu_exact</str>
<str name="facet.field">content_type</str>
<str name="facet.field">author_s</str>
<str name="facet.query">ipod</str>
<str name="facet.query">GB</str>
<str name="facet.mincount">1</str>
<str name="facet.pivot">cat,inStock</str>
<str name="facet.range.other">after</str>
<str name="facet.range">price</str>
<int name="f.price.facet.range.start">0</int>
<int name="f.price.facet.range.end">600</int>
<int name="f.price.facet.range.gap">50</int>
<str name="facet.range">popularity</str>
<int name="f.popularity.facet.range.start">0</int>
<int name="f.popularity.facet.range.end">10</int>
<int name="f.popularity.facet.range.gap">3</int>
<str name="facet.range">manufacturedate_dt</str>
<str name="f.manufacturedate_dt.facet.range.start">NOW/YEAR-10YEARS</str>
<str name="f.manufacturedate_dt.facet.range.end">NOW</str>
<str name="f.manufacturedate_dt.facet.range.gap">+1YEAR</str>
<str name="f.manufacturedate_dt.facet.range.other">before</str>
<str name="f.manufacturedate_dt.facet.range.other">after</str>
<!-- Highlighting defaults -->
<str name="hl">on</str>
<str name="hl.fl">content features
title name</str>
<str name="hl.encoder">html</str>
<str name="hl.simple.pre"><b></str>
<str name="hl.simple.post"></b></str>
<str name="f.title.hl.fragsize">0</str>
<str name="f.title.hl.alternateField">title</str>
<str name="f.name.hl.fragsize">0</str>
<str name="f.name.hl.alternateField">name</str>
<str name="f.content.hl.snippets">3</str>
<str name="f.content.hl.fragsize">200</str>
<str name="f.content.hl.alternateField">content</str>
<str name="f.content.hl.maxAlternateFieldLength">750</str>
<!-- Spell checking defaults -->
<str name="spellcheck">on</str>
<str name="spellcheck.extendedResults">false</str>
<str name="spellcheck.count">5</str>
<str name="spellcheck.alternativeTermCount">2</str>
<str name="spellcheck.maxResultsForSuggest">5</str>
<str name="spellcheck.collate">true</str>
<str name="spellcheck.collateExtendedResults">true</str>
<str name="spellcheck.maxCollationTries">5</str>
<str name="spellcheck.maxCollations">3</str>
</lst>
<!-- append spellchecking to our list of components
-->
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>
<requestHandler name="/update" class="solr.UpdateRequestHandler">
</requestHandler>
<requestHandler name="/update/json" class="solr.JsonUpdateRequestHandler">
<lst name="defaults">
<str name="stream.contentType">application/json</str>
</lst>
</requestHandler>
<requestHandler name="/update/csv" class="solr.CSVRequestHandler">
<lst name="defaults">
<str name="stream.contentType">application/csv</str>
</lst>
</requestHandler>
<requestHandler name="/update/extract"
startup="lazy"
class="solr.extraction.ExtractingRequestHandler"
>
<lst name="defaults">
<str name="lowernames">true</str>
<str name="uprefix">ignored_</str>
<!-- capture link hrefs but ignore div attributes
-->
<str name="captureAttr">true</str>
<str name="fmap.a">links</str>
<str name="fmap.div">ignored_</str>
</lst>
</requestHandler>
<requestHandler name="/analysis/field"
startup="lazy"
class="solr.FieldAnalysisRequestHandler"
/>
<requestHandler name="/analysis/document"
class="solr.DocumentAnalysisRequestHandler"
startup="lazy" />
<requestHandler name="/admin/"
class="solr.admin.AdminHandlers" />
<requestHandler name="/admin/ping" class="solr.PingRequestHandler">
<lst name="invariants">
<str name="q">solrpingquery</str>
</lst>
<lst name="defaults">
<str name="echoParams">all</str>
</lst>
</requestHandler>
<!-- Echo the request contents back to the client
-->
<requestHandler name="/debug/dump" class="solr.DumpRequestHandler"
>
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="echoHandler">true</str>
</lst>
</requestHandler>
<requestHandler name="/replication" class="solr.ReplicationHandler"
>
</requestHandler>
<!-- spell -->
<searchComponent name="spellcheck" class="solr.SpellCheckComponent">
<lst name="spellchecker">
<str name="name">direct</str>
<str name="field">spell</str>
<str name="classname">solr.DirectSolrSpellChecker</str>
<str name="distanceMeasure">internal</str>
<float name="accuracy">0.5</float>
<int name="maxEdits">2</int>
<int name="minPrefix">1</int>
<int name="maxInspections">5</int>
<int name="minQueryLength">2</int>
<float name="maxQueryFrequency">0.001</float>
<str name="buildOnCommit">true</str>
</lst>
<lst name="spellchecker">
<!--
Optional, it is required when more than one spellchecker
is configured.
Select non-default name with spellcheck.dictionary
in request handler.
nameЪЧПЩбЁЕФЃЌШчЙћжЛгавЛИіspellcheckerПЩвдВЛаДname
ШчЙћгаЖрИіspellcheckerЃЌашвЊдкRequest HandlerжажИЖЈspellcheck.dictionary
-->
<str name="name">default</str>
<!-- The classname is optional, defaults to IndexBasedSpellChecker
-->
<str name="classname">solr.IndexBasedSpellChecker</str>
<!--
Load tokens from the following field for spell checking,
analyzer for the field's type as defined in schema.xml
are used
ЯТУцетИіfieldУћзжжИЕФЪЧЦДаДМьВщЕФвРОнЃЌвВОЭЪЧЫЕвЊИљОнФФИіFieldРДМьВщгУЛЇЪфШыЁЃ
-->
<str name="field">spell</str>
<!-- Optional, by default use in-memory index (RAMDirectory)
SpellCheckЫїв§ЮФМўЕФДцЗХЮЛжУЃЌЪЧПЩбЁЕФЃЌШчЙћВЛаДФЌШЯЪЙгУФкДцФЃЪНRAMDirectoryЁЃ
./spellchecker1жИЕФЪЧЃКcorex\data\spellchecker1
-->
<str name="spellcheckIndexDir">./spellchecker1</str>
<!-- Set the accuracy (float) to be used for the
suggestions. Default is 0.5 -->
<str name="accuracy">0.7</str>
<!--КЮЪБДДНЈЦДаДЫїв§ЃКbuildOnCommit/buildOnOptimize -->
<str name="buildOnCommit">true</str>
</lst>
<!-- СэвЛИіЦДаДМьВщЦїЃЌЪЙгУJaroWinklerDistanceОрРыЫуЗЈ -->
<lst name="spellchecker">
<str name="name">jarowinkler</str>
<str name="classname">solr.IndexBasedSpellChecker</str>
<str name="field">spell</str>
<str name="distanceMeasure">org.apache.lucene.search.spell.JaroWinklerDistance</str>
<str name="spellcheckIndexDir">./spellchecker2</str>
<str name="buildOnCommit">true</str>
</lst>
<!-- СэвЛИіЦДаДМьВщЦїЃЌЪЙгУЮФМўФкШнЮЊМьВщвРОн
<lst name="spellchecker">
<str name="classname">solr.FileBasedSpellChecker</str>
<str name="name">file</str>
<str name="sourceLocation">spellings.txt</str>
<str name="characterEncoding">UTF-8</str>
<str name="spellcheckIndexDir">./spellcheckerFile</str>
<str name="buildOnCommit">true</str>
</lst>-->
<str name="queryAnalyzerFieldType">text_spell</str>
</searchComponent>
<queryConverter name="queryConverter"
class="solr.SpellingQueryConverter"/>
<requestHandler name="/spell" class="solr.SearchHandler">
<lst name="defaults">
<str name="spellcheck.dictionary">default</str>
<str name="spellcheck.collate">true</str>
<str name="spellcheck.onlyMorePopular">true</str>
<str name="spellcheck.extendedResults">false</str>
<str name="spellcheck.count">10</str>
</lst>
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>
<searchComponent name="suggest" class="solr.SpellCheckComponent">
<str name="queryAnalyzerFieldType">string</str>
<lst name="spellchecker">
<str name="name">suggest</str>
<str name="classname">org.apache.solr.spelling.suggest.Suggester</str>
<str name="lookupImpl">org.apache.solr.spelling.suggest.tst.TSTLookup</str>
<str name="field">text</str>
<float name="threshold">0.0001</float>
<str name="comparatorClass">freq</str>
<str name="buildOnOptimize">true</str>
<!--<str name="buildOnCommit">true</str>-->
</lst>
</searchComponent>
<requestHandler name="/suggest" class="solr.SearchHandler"
startup="lazy">
<lst name="defaults">
<str name="spellcheck">true</str>
<str name="spellcheck.dictionary">suggest</str>
<str name="spellcheck.onlyMorePopular">true</str>
<str name="spellcheck.extendedResults">false</str>
<str name="spellcheck.count">10</str>
<!--<str name="spellcheck.collate">true</str>-->
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler>
<requestHandler name="/mlt" class="solr.MoreLikeThisHandler">
</requestHandler>
<searchComponent name="tvComponent" class="solr.TermVectorComponent"/>
<requestHandler name="/tvrh" class="solr.SearchHandler"
startup="lazy">
<lst name="defaults">
<str name="df">text</str>
<bool name="tv">true</bool>
</lst>
<arr name="last-components">
<str>tvComponent</str>
</arr>
</requestHandler>
<searchComponent name="clustering"
enable="${solr.clustering.enabled:true}"
class="solr.clustering.ClusteringComponent"
>
<!-- Declare an engine -->
<lst name="engine">
<str name="name">default</str>
<str name="carrot.algorithm">org.carrot2.clustering.lingo.LingoClusteringAlgorithm</str>
<!-- Engine-specific parameters -->
<str name="LingoClusteringAlgorithm.desiredClusterCountBase">20</str>
</lst>
</searchComponent>
<requestHandler name="/clustering"
startup="lazy"
enable="${solr.clustering.enabled:true}"
class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<bool name="clustering">true</bool>
<str name="clustering.engine">default</str>
<bool name="clustering.results">true</bool>
<str name="carrot.title">category_s</str>
<str name="carrot.snippet">content</str>
<str name="carrot.produceSummary">true</str>
</lst>
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>
<searchComponent name="terms" class="solr.TermsComponent"/>
<!-- A request handler for demonstrating the terms
component -->
<requestHandler name="/terms" class="solr.SearchHandler"
startup="lazy">
<lst name="defaults">
<bool name="terms">true</bool>
<bool name="distrib">false</bool>
</lst>
<arr name="components">
<str>terms</str>
</arr>
</requestHandler>
<searchComponent name="elevator" class="solr.QueryElevationComponent"
>
<!-- pick a fieldType to analyze queries -->
<str name="queryFieldType">string</str>
<str name="config-file">elevate.xml</str>
</searchComponent>
<!-- A request handler for demonstrating the elevator
component -->
<requestHandler name="/elevate" class="solr.SearchHandler"
startup="lazy">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="df">text</str>
</lst>
<arr name="last-components">
<str>elevator</str>
</arr>
</requestHandler>
<searchComponent class="solr.HighlightComponent"
name="highlight">
<highlighting>
<!-- Configure the standard fragmenter -->
<!-- This could most likely be commented out in
the "default" case -->
<fragmenter name="gap"
default="true"
class="solr.highlight.GapFragmenter">
<lst name="defaults">
<int name="hl.fragsize">100</int>
</lst>
</fragmenter>
<!-- A regular-expression-based fragmenter
(for sentence extraction)
-->
<fragmenter name="regex"
class="solr.highlight.RegexFragmenter">
<lst name="defaults">
<!-- slightly smaller fragsizes work better because
of slop -->
<int name="hl.fragsize">70</int>
<!-- allow 50% slop on fragment sizes -->
<float name="hl.regex.slop">0.5</float>
<!-- a basic sentence pattern -->
<str name="hl.regex.pattern">[-\w
,/\n\"']{20,200}</str>
</lst>
</fragmenter>
<!-- Configure the standard formatter -->
<formatter name="html"
default="true"
class="solr.highlight.HtmlFormatter">
<lst name="defaults">
<str name="hl.simple.pre"><![CDATA[<em>]]></str>
<str name="hl.simple.post"><![CDATA[</em>]]></str>
</lst>
</formatter>
<!-- Configure the standard encoder -->
<encoder name="html"
class="solr.highlight.HtmlEncoder" />
<!-- Configure the standard fragListBuilder -->
<fragListBuilder name="simple"
class="solr.highlight.SimpleFragListBuilder"/>
<!-- Configure the single fragListBuilder -->
<fragListBuilder name="single"
class="solr.highlight.SingleFragListBuilder"/>
<!-- Configure the weighted fragListBuilder -->
<fragListBuilder name="weighted"
default="true"
class="solr.highlight.WeightedFragListBuilder"/>
<!-- default tag FragmentsBuilder -->
<fragmentsBuilder name="default"
default="true"
class="solr.highlight.ScoreOrderFragmentsBuilder">
</fragmentsBuilder>
<!-- multi-colored tag FragmentsBuilder -->
<fragmentsBuilder name="colored"
class="solr.highlight.ScoreOrderFragmentsBuilder">
<lst name="defaults">
<str name="hl.tag.pre"><![CDATA[
<b style="background:yellow">,<b
style="background:lawgreen">,
<b style="background:aquamarine">,<b
style="background:magenta">,
<b style="background:palegreen">,<b
style="background:coral">,
<b style="background:wheat">,<b
style="background:khaki">,
<b style="background:lime">,<b
style="background:deepskyblue">]]></str>
<str name="hl.tag.post"><![CDATA[</b>]]></str>
</lst>
</fragmentsBuilder>
<boundaryScanner name="default"
default="true"
class="solr.highlight.SimpleBoundaryScanner">
<lst name="defaults">
<str name="hl.bs.maxScan">10</str>
<str name="hl.bs.chars">.,!? 	 </str>
</lst>
</boundaryScanner>
<boundaryScanner name="breakIterator"
class="solr.highlight.BreakIteratorBoundaryScanner">
<lst name="defaults">
<!-- type should be one of CHARACTER, WORD(default),
LINE and SENTENCE -->
<str name="hl.bs.type">WORD</str>
<!-- language and country are used when constructing
Locale object. -->
<!-- And the Locale object will be used when getting
instance of BreakIterator -->
<str name="hl.bs.language">en</str>
<str name="hl.bs.country">US</str>
</lst>
</boundaryScanner>
</highlighting>
</searchComponent>
<queryResponseWriter name="json" class="solr.JSONResponseWriter">
<str name="content-type">text/plain;
charset=UTF-8</str>
</queryResponseWriter>
<!--
Custom response writers can be declared as needed...
-->
<queryResponseWriter name="velocity"
class="solr.VelocityResponseWriter" startup="lazy"/>
<queryResponseWriter name="xslt" class="solr.XSLTResponseWriter">
<int name="xsltCacheLifetimeSeconds">5</int>
</queryResponseWriter>
<admin>
<defaultQuery>*:*</defaultQuery>
</admin>
</config> |









