| БрМЭЦМі: |
БОЮФРДздгкМђЪщЃЌБОЮФЪЧвЛЦЊЛљДЁЮФеТЃЌЯъЯИНщЩмСЫSolrЪЧЪВУДЃЌМАЩцМАЕНЕФВуУцЁЃ
|
|
вЛ ЛљБОЫЕУї
МђЕЅРДЫЕSolrЪЧЛљгкLuceneЕФИпадФмЕФЃЌПЊдДЕФJavaЦѓвЕЫбЫїЗўЮёЦїЁЃSolrПЩвдПДзївЛИіWeb
appЃЌдЫаадкtomcatЛђJettyетРрHTTPЗўЮёЦїЩЯЃЌ
ЕзВуЪЧвЛИіЛљгкLuceneЕФЫбЫїв§ЧцЃЌЛЙИНМгвЛИіSolrЕФЛљБОЙмРэНчУцЁЃSolrЬсЙЉHTTPЗўЮёЃЌЭЈЙ§GetЗНЗЈНјааВщбЏ,ЭЈЙ§PostЗНЗЈНјааЫїв§ЕФЬэМг/ЩОГ§ЙмРэЁЃ
вЛАуРДЫЕSolrЕФВщбЏЪБЭЈЙ§GetЗНЗЈЧыЧѓЕНHTTPЗўЮёЦїЕФsolrетИіappЯТЕФ/selectЖдгІЕФservletЩЯШЅЃЌЖјЬэМгЕШВйзїЪБЭЈЙ§POSTЗНЗЈЕНHTTPЗўЮёЦїЕФ
SolrетИіappЯТЕФ/updateЖдгІЕФservletЗНЗЈЩЯШЅЁЃ
SolrзїЮЊЫбЫїв§ЧцЃЌЬсЙЉЛљгкЧаУц/ИпСС/ЖржжЪфГіИёЪН/ИДдгЕФгяЗЈЫбЫїЙцдђЕШЙІФмЁЃ
гыLuceneЕФЧјБ№ЪЧЃКLuceneЪЧвЛаЉРрAPIЪЧИіЙЄОпАќЃЌЭЈЙ§етаЉAPIЮвУЧПЩвдДДНЈЫїв§/ЭЈЙ§Ыїв§ВщбЏЃЛЖјSolrЪЧдкДЫЛљДЁЩЯЕФЗтзАЃЌЭЈЙ§МђЕЅЕФХфжУ
ОЭПЩвджБНгЪЙгУЕФПЊдДЫбЫїЗўЮёЦїЁЃ
Жў ЛљБОИХФю
дкSolrбЇЯАвЛжаСЫНтЕНЫбЫїв§ЧцЕФКЫаФЪЧНЈСЂЫїв§ЃЌШЛКѓРћгУЫїв§НјааЫбЫїЁЃ
дкSolrжаЫїв§ЩцМАЕНЕФИХФюгаЃК
1 ЁЂCoreЃК дкSolrЕФЕЅНкЕуВПЪ№ЛђепMaster-SalveЗНЪНВПЪ№ЯТБъЪОвЛИіЭъећЫїв§ЁЃCoreЖМЪЧгЩЖрИіЮФМўзщГЩЃЌНЈСЂЫїв§ЕФЪБКђЪЧЯШЗжЖЮЃЌШЛКѓдйКЯВЂЕФЗНЪНЁЃ
вЛИіSolrПЩвдАќКЌвЛИіЛђЖрИіCoreЃЌУПИіCoreЕФХфжУПЩвдВЛЭЌЃЛдкSolrCoudВПЪ№ЯТБъЪОЫїв§ЕФвЛВПЗжЁЃ
2ЁЂCollectionЃК дкSolrCouldВПЪ№ФЃЪНЯТЃЌжИЕФЪЧвЛИіЫїв§ЕФТпМИХФюЁЃПЩвдАбSolrжаЕФCoreЛђCollectionПДзівЛИіOracleЕФЪЕР§ЁЃвЛИіSolrCouldПЩвдАќКЌЖрИіCollectionЁЃ
вЛИіCollectionПЩвдЧаЗжГЩЖрИіShardЃЌЧаЗжЕФЪ§СПДѓаЁКЭЛњЦїНкЕуЪ§КЭИББОЪ§гаЙиЯЕЃЌвЊЧѓshardЪ§СП*ИББОЪ§<НкЕуЪ§*numShards?ЁЃзЂвтвЛИіНкЕуБъЪОЦєЖЏвЛИіHTTPЗўЮёЦїЃЌ
вЛЬЈЛњЦїПЩвдЦ№ЖрИіSolrНкЕуЃЈетжжЧщПіБиаыЩшжУВЛЭЌЕФЖЫПкЃЉЃЌвЛИіCollectionЕФФкШнЪЧгЩУПИіshardжаЕФаХЯЂзщГЩЁЃвЛИіshardЕФаХЯЂЖдгІзщГЩЫќЕФвЛИіИББОЕФаХЯЂЁЃ
3ЁЂShardЃК БъЪОЧаЦЌЃЌдкSolrColud ВПЪ№ФЃЪНЯТЃЌНЋвЛИіТпМЫїв§CollectionЧаИюГЩЖрИіЗжЦЌЃЌ
УПИіShardЪЧгЩЖрИіИББОReplicaзщГЩЁЃ
4ЁЂReplicaЃК ИББОЁЃЖрИіИББОзщГЩвЛИіShardЁЂзЂвтвЛИіShardжаЕФreplica АќКЌЕФФкШнТпМЩЯгІИУЪЧвЛбљЕФЃЌShardЕФЪ§ОнжЛЪЧЦфжавЛЗнReplicaЃЌВЛЪЧетаЉИББОЕФзщКЯЁЃ
етаЉИББОжагавЛИіИББОЛсБЛбЁдёЮЊLeaderЃЌИКд№аДЫїв§ЁЃ
5ЁЂZookeeperЃКСэЭтвЛИіПЊдДЕФШэМўЃЌдкsolrCloudВПЪ№ФЃЪНЯТЪЧБиаыЕФЃЌжївЊзїгУЪЧЃК
1ЃЉХфжУЕФЭГвЛДцДЂКЭЗжЗЂЃЛ2ЃЉshardжаИББОЕФLeaderЕФбЁШЁЃЛ3ЃЉИКд№МрПиМЏШКзДЬЌЃЌЗЂЩњИФБфЪБКђЭЈжЊЯрЙиЕФМрЬ§ЦїЃЌБШШчЙвСЫвЛЬЈЛњЦїЃЌетЬЈЛњЦїЩЯШчЙћгаshardЕФleaderНкЕуЃЌЪЃгрЕФЭЌвЛИіshardЕФЦфЫћИББОЛсОКбЁLeaderЃЌЧвsolrColudЛсжЊЕРетЬЈЛњЦїЙвЕєЃЌдкДІРэЧыЧѓЕФЪБКђОЭВЛЗЂЧыЧѓИјетЬЈЛњЦїЁЃ
6ЁЂConfig Set:ХфжУзщЃЌДцДЂХфжУаХЯЂЃЌУПИіCollectionЖМгаЃЌжСЩйАќКЌsolrconfig.xmlетИіЪЧХфжУетИіcollectionЛљБОХфжУЃЌБШШчЪЙгУЕФLuceneЕФАцБОЁЂЪЙгУЕФВщбЏзщМўЁЂЛКДцЯрЙиаХЯЂЕШЃЛЛЙБиаыАќКЌSchema.Xml
етИіХфжУЮФМўХфжУЕФЪЧCollectionДцдкЕФЮФЕЕЕФзжЖЮЃЌАќРЈзжЖЮЕФРраЭЃЌЪЧЗёашвЊДцДЂЃЌЪЧЗёашвЊЗжДЪЕШЁЃ
7ЁЂЮФЕЕЃК дкSolrжаНЈСЂЫїв§ЪЧЭЈЙ§ЮФЕЕЬэМгЕФЗНЪННјааЃЌШчЙћНЋЫїв§ПДГЩвЛеХБэЃЌФЧУДЮФЕЕПЩвдПДГЩЪЧвЛЬѕМЧТМЃЌФЧУДSchema.xmlПЩвдПДГЩетИіБэЕФЖЈвхЁЃ
вЛИіЮФЕЕгЩЖрИізжЖЮЖЈвхЃЌетаЉЪЧдкSchema.xmlжаЖЈвхЕФЃЌВЛЪЧЫљгаЖЈвхЕФзжЖЮЮФЕЕжаЖМБиаыгаЃЌЕЋЪЧЗДЙ§РДЮФЕЕжагаЕФзжЖЮБиаыдкSchema.xmlжаЖЈвхЃЌ
БШШчЃК БъЪОЖЈвхвЛИізжЖЮЮЊstringРраЭЃЌУћГЦЮЊЃКsubAcctName
ЪЧБЛЫїв§ЕФЃЌЖјЧвЪЧДцДЂЕФЁЃЕБШЛвВПЩвдЭЈЙ§вЛжжНаЖЏЬЌЖЈвхЕФЗНЗЈНјаазжЖЮЕФФЃК§ЦЅХфЃЌБШШч?ОЭБэЪОЫљгавд_iНсЮВЕФзжЖЮЖМЕБГЩintРДДІРэЁЃ
зЂвтетРяУцЕФРраЭВЛЭЌгкjavaЕФРраЭЃЌжЛЪЧЯрЫЦЃЌЖдгкУПИіРраЭЃЌsolrЛсЖЈвхЦфЯрЙиЕФДІРэЙцдђЕШЁЃБШШчЃК
БъЪОstringРраЭЃЌЖдгІЕФРрЮЊStrFieldРрЃЌШчЙћШБЪЇетИізжЖЮЃЌФЌШЯдкЫбЫїЕФЪБКђЪЧХХдкзюКѓЕФЁЃ
Schema.xml дкЖЈвхЮФЕЕЕФзжЖЮЪБКђЛсЖЈвхвЛИіЮЈвЛжЕзжЖЮЃЌЫЦгкБэЕФжїМќЃЌаЮШчЃК?idЃЌзїгУЪЧгУгкдкsolrCloud
ФЃЪНЯТНјааТЗгЩЃЌSolrЭЈЙ§вЛЖЈЕФЫуЗЈЖдУПИіЮФЕЕЕФIDНјааМЦЫуЃЌЕУЕНЕФвЛИіHashжЕЃЌШЛКѓПДЯТетИіHashжЕЪЧЪєгкФФИіshardЃЌОЭАбЮФЕЕЗЂЕНФФИіshardЩЯШЅЁЃ
ЭЈЙ§етИіЫуЗЈПЩвдБЃжЄshardжЎМфЪ§СПЕФОљКтЃЌдкНЈЫїв§ПЩвдЦ№ЕНИКдиОљКтЕФзїгУЁЃ
ШчЙћФувЊжЦЖЈЮФЕЕДцДЂЕФshardЃЌгаШ§ИіАьЗЈЃК
1ЃЉЭЈЙ§ЬиЪтЕФIDЃЌетИіIDБиаыгаСНВПЗжзщГЩЃЌСНВПЗжжЎМфгУЃЁКХЗжИєЃЌsolrдкМЦЫуhashЕФЪБКђЃЌЛсРћгУЃЁЧАУцЕФ16bitзіhashЃЌВЂЧвРћгУКѓУц16ИіbitзіhashЃЌ
ШЛКѓАбЫќзщКЯЦ№РДЃЌетбљПЩвдБЃжЄетРрЮФЕЕЖМЗЂЕНЬиЖЈЕФshardЩЯЃЌзЂвтетИіЬиЖЈЕФshardЩЯЃЌЖјВЛжЊЕРЪЧОпЬхЪЧФФвЛИіshardЩЯЁЃ
2ЃЉЭЈЙ§_shard_зжЖЮРДжИЖЈОпЬхЕФshardЩЯЃЌетИізжЖЮЩшжУЮЊshard1ЁЂshard2ЕШЁЃ
3ЃЉ дкНЈcollectionЕФЪБКђТЗгЩЦїЩшжУЮЊЃКimplicitЗНЪНЃЌдкНЈЫїв§ЕФЪБКђЃЌЮФЕЕЬэМгвЛИі_route_зжЖЮЃЌжЕЮЊЃКshard1ЁЂshard2ЕШЁЃ
ОпЬхЕФгяОфОйР§ЃК?http://x.x.x.x:xxx/solr -5.0.0-web/admin/collections?action =CREATE&name =testimplicit&router.name =implicit&shards= shard1,shard2,shard3
ЮФЕЕдкЬэМгЪБКђЃЌШчЙћвдxmlИёЪНЬэМгЃЌФкШнРрЫЦЃК
05991
Peter Parker
Spider-Man
superhero
agility
spider-sense
8ЁЂгђЃЈFieldЃЉЃКРрЫЦгкЪ§ОнПтБэЕФзжЖЮЃЌгаРраЭЃЌгаДІРэЗНЪНЁЃзЂвтЮвдкSolrбЇЯАжЎвЛНВЕФЕЙХХЫїв§жаЕФДЪЕфжаЕФДЪВЛЭЌгкзжЖЮЁЃ
гђжЛгажИУїБЛЫїв§КѓЃЌШЛКѓБЛЗжДЪЦїНјааЗжДЪЃЈдкsolrжаstringЕШЛљБОРраЭЪЧВЛЛсБЛЗжДЪЕФЃЌtextРраЭБъЪОИДдгРраЭЃЌашвЊЗжДЪЃЉЃЌжЎКѓВХЛсДцДЂдкДЪЕфжа
гђгаМИИіЗЧГЃживЊЕФЪєадЃК
indexedЃК БъЪОЪЧЗёБЛЫїв§ЃЌМђЕЅРДЫЕЃЌжЛгаБЛЫїв§ЕФзжЖЮЃЌдкВщбЏЪБКђВХПЩвдЭЈЙ§етИізжЖЮЕФжЕНјааЦЅХфВщбЏЁЃ
storedЃК ? ШчЙћетИіЩшжУЮЊtrueБъЪОдкЫїв§жавВДцДЂетИізжЖЮаХЯЂЃЛШчЙћВЛДцдкетИіаХЯЂЃЌетВщбЏЕФНсЙћжаВЛЛсЯдЪОЃЌетЪЪгУгкФкШнЗЧГЃЖрЕФГЁОАЃЌ
ЮвУЧЭЈЙ§ВщбЏЕНЕФIDЃЌдйЕНЦфЫћДцДЂжаЃЌБШШчЪ§ОнПтжаАбЖдгІЕФетИізжЖЮаХЯЂдйГщГіРДЁЃ
гђжагаИіЬиЪтЕФгђНаПНБДгђЃЌЫќЕФзїгУЪЧЃЌПЩвдНЋЦфЫћгђЕФжЕПНБДЕНетИігђжаЃЌЫбЫїЕФЪБКђжЛвЊЫбЫїетИігђОЭПЩвдСЫЁЃНЋгђtitleКЭcontentФкШнПНБДЕНtextгђРяУцЁЃ
9ЁЂЖЮЃЈSegmentЃЉ
ЖрИіЖЮзщГЩЫїв§ЃЌвЛИіЖЮгЩЖрИіЮФМўзщГЩЃЌаТЬэМгЕФЮФЕЕПЩвдЩњВњаТЕФЖЮЃЌВЛЭЌЕФЖЮжЎМфПЩвдКЯВЂЁЃ
дкindexФПТМЯТвдЯрЭЌЪ§зжЕФЮФМўПЊЭЗЕФЪєгквЛИіЖЮ.
segments.genКЭsegments_* ЪєгкЖЮЕФдЊЪ§ОнаХЯЂЃЌБЃДцЖЮЕФЛљБОЪєадЁЃ
10ЁЂДЪ(Term)
ЕквЛВПЗжНщЩмзщГЩДЪЕфЕФВПЗжЃЌЪЧДЪЗЈЗжЮігяЗЈЗжЮіКѓЕУЕНЕФзжЗћДЎЁЃ
termгЩвЛЖджЕзщГЩЃКfield name(string)КЭfield value(bytes)ЃЌЭЌвЛИіvalueдкВЛЭЌЕФfieldжагаВЛЭЌЕФКЌвхЁЃ
ЮФЕЕЁЂЫїв§ЁЂзжЖЮЁЂДЪжЎМфЕФЙиЯЕПЩвдгУЯТЭМУшЪіЃК
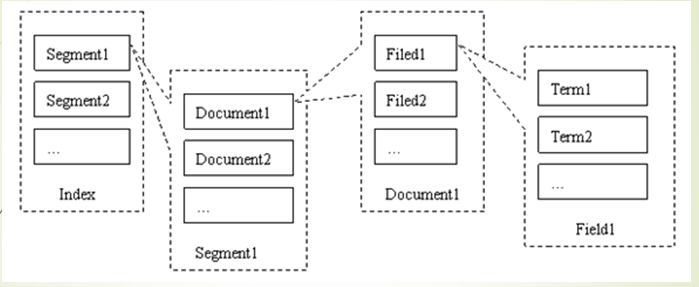
ЁЖЭјЩЯНшРДЕФЭМЁЗ
вЛИіЫїв§ЪЧгЩЖрИіЖЮзщГЩЃЌдкЪЕМЪжаЖЮЪЧвЛаЉСаЮФМўЃЌвЛИіЖЮгжЪЧгЩЖрИіЮФЕЕзщГЩЕФЃЌвЛИіЮФЕЕгжЪЧгЩЖрИізжЖЮзщГЩЁЃ
ЖЮЖРСЂДцдкЃЌзїЮЊвЛИізгЫїв§ЃЌПЩвдБЛЕЅЖРЫбЫїЁЃ
вЛИізжЖЮжаЕФФкШнОЙ§ЗжДЪБфГЩTeam ДцДЂдкЕЙХХЫїв§жаЁЃ
LuceneБЃДцЕФЫїв§аХЯЂЃЌМШАќРЈе§ЯђаХЯЂгжАќКЌЗДЯђаХЯЂЁЃ
е§ЯђаХЯЂЃКАДееДгЪєЙиЯЕЃКЫїв§(Index) ЈC> ЖЮ(segment) ЈC> ЮФЕЕ(Document)
ЈC> гђ(Field) ЈC> ДЪ(Term)
вЛАуЩЯВуВЛЙтАќКЌздМКЕФаХЯЂЛЙАќКЌВПЗжЕФЯТВуаХЯЂЁЃ
БЃДце§ЯђаХЯЂЕФЮФМўга:
| segments_N |
БЃДцСЫДЫЫїв§АќКЌЖрЩйИіЖЮЃЌУПИіЖЮАќКЌЖрЩйЦЊЮФЕЕЁЃ |
|
XXX.fnm |
БЃДцСЫДЫЖЮАќКЌСЫЖрЩйИігђЃЌУПИігђЕФУћГЦМАЫїв§ЗНЪНЁЃ |
|
XXX.fdxЃЌXXX.fdt |
БЃДцСЫДЫЖЮАќКЌЕФЫљгаЮФЕЕЃЌУПЦЊЮФЕЕАќКЌСЫЖрЩйгђЃЌУПИігђБЃДцСЫФЧаЉаХЯЂЁЃ |
XXX.tvxЃЌXXX.tvdЃЌXXX.tvf БЃДцСЫДЫЖЮАќКЌЖрЩйЮФЕЕЃЌУПЦЊЮФЕЕАќКЌСЫЖрЩйгђЃЌУПИігђАќКЌСЫЖрЩйДЪЃЌУПИіДЪЕФзжЗћДЎЃЌЮЛжУЕШаХЯЂЁЃ
ЗДЯђаХЯЂЃК
ДЪЕфЕНЫїв§ЕФгГЩфЃЌвВМДЮвУЧЫЕЕФЕЙХХЫїв§ЁЃ
|
XXX.tisЃЌXXX.tii |
БЃДцСЫДЪЕф(Term Dictionary)ЃЌвВМДДЫЖЮАќКЌЕФЫљгаЕФДЪАДзжЕфЫГађЕФХХађЁЃ |
| XXX.frq |
БЃДцСЫЕЙХХБэЃЌвВМДАќКЌУПИіДЪЕФЮФЕЕIDСаБэЁЃ |
|
XXX.prx |
БЃДцСЫЕЙХХБэжаУПИіДЪдкАќКЌДЫДЪЕФЮФЕЕжаЕФЮЛжУЁЃ |
|









