| БрМЭЦМі: |
| БОЮФРДздгкЭѕЧхХр,ЯждкдНРДдНЖрЕФЗжВМЪНЯЕЭГЖМашвЊгУЕНElasticSearchРДНтОіЮЪЬт,гаЪВУДРэгЩВЛШЅбЇЯАКЭЪЙгУЫќРДЬсИпЯЕЭГЕФећЬхЗўЮёЫЎЦН?БОЦЊЮФеТЪЧзїепбЇЯАЪБЕФОбщзмНсЁЃ |
|
1.БГОА
СНФъЧАгаЛњЛсНгДЅЙ§elasticsearchЃЌЕЋЪЧЮДзіЩюШыбЇЯАЃЌжЛЪЧЙЄзїжагУЕНСЫЁЃдНРДдНЗЂЯжesЪЧИіВЛДэЕФКУЖЋЮїЃЌЫљвдЛЈСЫЕуЪБМфКУКУбЇЯАСЫЯТЁЃдкбЇЯАЙ§ГЬжавВЗЂЯжСЫвЛаЉЮЪЬтЃЌЭјЩЯДѓЖрзЪСЯЖМКмСуЩЂЃЌДѓВПЗжЖМЪЧЪЕбщадЕФdemoЃЌКмЖрЮЪЬтВЂУЛгаНВЧхГўвВВЂУЛгаЯЕЭГЕФНВЭъећвЛећЬзЗНАИЃЌЫљвдФЭаФЕФУўЫїКЭзмНсСЫвЛаЉЖЋЮїЗжЯэГіРДЁЃ
БЯОЙЕБФугУЩњВњЪЙгУЕФБъзМРДЪЙгУesЪБЛсгаКмЖрЮЪЬтЃЌетЖдФуЕФбЇЯАЬсГіРДСЫаТЕФБъзМЁЃ
БШШчЃЌЪЙгУelasticsearch servicewrapperНјааздЦєЖЏЕФЪБКђФбЕРОЭУЛЗЂЯжЫќЕФХфжУжагавЛИіаЁbugЕМжТloadВЛСЫelasticsearch jarАќжаЕФclassТ№ЁЃ
ЛЙгаesВЛЭЌАцБОжЎМфЕФВювьОоДѓЃЌБШШчЃЌ1.0жаЕФЗжВМЪНroutingдк2.0жаНјааСЫОоДѓВювьЕФаоИФЁЃдБОroutingЪЧИњзХmappingвЛЦ№ХфжУЕФЃЌЕНСЫ2.0ШДИњзХindexЖЏЬЌзпСЫЁЃетИіЕїећЕФБОжЪФПЕФЪЧКУЕФЃЌШУЭЌвЛИіindexЕФВЛЭЌtypeЖМгаЛњЛсбЁдёshardЕФЦЌМќЁЃШчЙћЪЧИњзХmappingзпЕФЛАОЭжЛФмЯоЖЈгкЕБЧАindexЕФЫљгаtypeЁЃ
esЪЧИіКУЖЋЮїЃЌЯждкдНРДдНЖрЕФЗжВМЪНЯЕЭГЖМашвЊгУЕНЫќРДНтОіЮЪЬтЁЃДгELKетжжЯЕЭГВуЕФЙЄОпЕНЕчЩЬЦНЬЈЕФКЫаФвЕЮёНЛвзЯЕЭГЕФЩшМЦЖМашвЊЫќРДжЇГХЪЕЪБДѓЪ§ОнЫбЫїЗжЮіЁЃБШШчЃЌЩЬЦЗжааФЕФЩЯЧЇЭђЕФskuашвЊЪЕЪБЫбЫїЃЌдйЕНКЃСПЕФдкЯпЖЉЕЅЪЕЪБВщбЏЖМашвЊгУЕНЫбЫїЁЃ
дквЛаЉDevOpsЕФЙЄОпжаЖМашвЊesРДЬсЙЉЧПДѓЕФЪЕЪБЫбЫїЙІФмЁЃжЕЕУЛЈЕуЪБМфКУКУбаОПбЇЯАЯТЁЃ
зїЮЊЕчЩЬМмЙЙЪІЃЌЫљвдУЛгаЪВУДРэгЩВЛШЅбЇЯАКЭЪЙгУЫќРДЬсИпЯЕЭГЕФећЬхЗўЮёЫЎЦНЁЃБОЦЊЮФеТНЋздМКетЖЮЪБМфбЇЯАЕФОбщзмНсГіРДЗжЯэИјДѓМвЁЃ
2.АВзА
ЪзЯШФуашвЊМИЬЈlinuxЛњЦїЃЌФуХмащЛњвВааЁЃФуПЩвддквЛЬЈащФтЛњЩЯЭъГЩАВзАКЭХфжУЃЌШЛКѓНЋЕБЧАащФтЛњcloneГіЖрЗнаоИФЯТIPЁЂHWaddrЁЂUUIDМДгУЃЌетбљЗНБуФуЪЙгУЃЌЖјВЛашвЊдйжиИДЕФАВзАХфжУЁЃ
1.ЮвБОЕиЪЧШ§ЬЈLinux centos6.5ЃЌIPЗжБ№ЪЧЃЌ192.168.0.10ЁЂ192.168.0.20ЁЂ192.168.0.30ЁЃ
(ЮвУЧЯШдк192.168.0.10ЩЯжДааАВзАХфжУЃЌШЛКѓвЛЧаОЭаїжЎКѓЮвУЧНЋетИіНкЕуcloneГіРДаоИФХфжУЃЌШЛКѓдйХфжУМЏШКВЮЪ§ЃЌзюКѓаЮГЩПЩвдЙЄзїЕФвдШ§ИіnodeзщГЩЕФМЏШКЪЕР§ЁЃЃЉ
2.гЩгкElasticSearchЪЧjavaгябдПЊЗЂЕФЃЌЫљвдЮвУЧашвЊдЄЯШАВзАКУjavaЯрЙиЛЗОГЁЃЮвЪЙгУЕФЪЧJDK8ЃЌжБНгЪЙгУyumАВзАМДПЩЃЌyumВжПтгазюаТЕФдДЁЃ
ЯШВщПДФуЕБЧАЛњЦїЪЧЗёАВзАСЫjavaЛЗОГЃК
yum info installed |grep java*
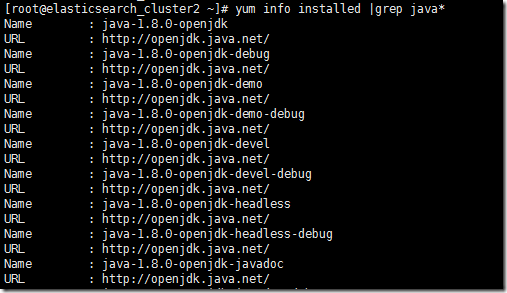
ШчЙћвбОДцдкjavaЛЗОГЧветИіЛЗОГВЛЪЧФуЯывЊЕФЃЌФуПЩвдаЖдиШЛКѓжиаТАВзАФуЯывЊЕФАцБОЁЃ(yum ЈCy remove xxx)ШчЙћаЖдиВЛИЩОЛЃЌФуПЩвджБНгfind ВщевЯрЙиЮФМўЃЌШЛКѓжБНгЮяРэЩОГ§ЁЃlinuxЕФЯЕЭГЖМЪЧЛљгкЮФМўЕФЃЌжЛвЊФмевЕНЛљБОЩЯЖМПЩвдЩОГ§ЁЃ
ЯШПДЯТгаФФаЉАцБОЃК
yum search java
java-1.8.0-openjdk.x86_64 : OpenJDK Runtime EnvironmentЃЈевЕНетИідДЃЉ
ШЛКѓжДааАВзАЃК
yum ЈCy install java-1.8.0-openjdk.x86_64
АВзАКУжЎКѓВщПДjava ЯрЙиВЮЪ§ЃК
java ЈCversion

дЄБИЙЄзїЮвУЧвбОзіКУЃЌНгЯТРДЮвУЧНЋжДааElasticSearchЕФЛЗОГАВзАКЭХфжУЁЃ
2.1.ВщевЁЂЯТдиrpmАќЁЂжДааrpmАќАВзА
ФуПЩвдгаМИжжЗНЪНАВзАЁЃЪЙгУyum repositoryЪЧзюПьзюБуНнЕФЃЌЕЋЪЧвЛАуетРяУцЕФАцБОгІИУЪЧБШНЯжЭКѓЕФЁЃЫљвдЮвЪЧжБНгЕНЙйЭјЯТдиrpmАќАВзАЕФЁЃ
elasticsearchЙйЗНЯТдиЕижЗЃК https://www.elastic.co/downloads/elasticsearch
евЕНФуЖдгІЕФЯЕЭГРраЭЮФМўЃЌЕБШЛШчЙћФуЪЧwindowsЯЕЭГФЧОЭжБНгЯТдиzipАќЪЙгУОЭааСЫЁЃетРяЮвашвЊrpmЮФМўЁЃ
ФувВПЩвдАВзАБОЕиyum дДЃЌШЛКѓЛЙЪЧЪЙгУyumУќСюАВзАЁЃ
ЮвЪЧЪЙгУwget ЙЄОпжБНгЯТдиRPMЮФМўЕНБОЕиЕФЁЃЃЈШчЙћФуЕФАќгавРРЕНЈвщЛЙЪЧyumЗНЪНАВзАЁЃЃЉ
ЃЈШчЙћФуЕФwgetУќСюВЛЦ№зїгУЃЌМЧЕУЯШАВзАЃКyum -y install wgetЃЉ
wget https://download.elastic.co /elasticsearch/release/org /elasticsearch/distribution/rpm/elasticsearch/ 2.4.0/elasticsearch-2.4.0.rpm
ШЛКѓЕШД§ЯТдиЭъГЩЁЃ
етРягаИіЖЋЮїашвЊЬсабЯТЃЌОЭЪЧФуЪЧЗёвЊАВзАзюаТАцБОЕФelasticsearchЃЌИіШЫНЈвщЛЙЪЧАВзАЩдЮЂЕЭвЛИіАцБОЕФЃЌЮвБОЕиАВзАЕФЪЧ2.3.4ЕФАцБОЁЃЮЊЪВУДвЊетбљЧПЕїФсЃЌвђЮЊЕБФуАВзАСЫКмИпЕФАцБОжЎКѓгавЛИіКмДѓЕФЮЪЬтОЭЪЧжаЮФЗжДЪЦїФмЗёжЇГжЕНетИіАцБОЁЃДг2.3.5жЎКѓОЭжБНгЕН2.4.0ЕФАцБОСЫЃЌЮвЕБЪБАВзАЕФЪЧ2.3.5ЕФАцБОКѓРДЗЂЯжвЛИіЮЪЬтОЭЪЧikжаЮФЗжДЪЦїЮвЕУgit cloneЯТРДБрвыКѓВХФмгаЪфГіВПЪ№ЮФМўЁЃЫљвдНЈвщДѓМвАВзА2.3.4ЕФАцБОЃЌ2.3.4ЕФАцБОжаЮФЗжДЪЦїОЭПЩвджБНгдкlinuxЗўЮёЦїРяЯТдиВПЪ№ЃЌКмЗНБуЁЃ
жДааАВзАЃК
rpm -iv elasticsearch-2.3.4.rpm
ШЛКѓЕШД§АВзАЭъГЩЁЃ
ВЛГіЪВУДвтЭтЃЌАВзАОЭгІИУЭъГЩСЫЁЃЮвУЧНјааЯТЛљБОЕФАВзАаХЯЂВщПДЃЌЪЧЗёАВзАжЎКѓШБЩйЪВУДЮФМўЁЃвђЮЊгааЉАќРяУцЛсШБЩйвЛаЉconfigХфжУЁЃШчЙћШБЩйЮвУЧЛЙЕУВЙГфЭъећЁЃ
ЮЊСЫЗНБуВщПДАВзАЩцМАЕНЕФЮФМўЃЌФуПЩвдЕМКНЕНИљФПТМЯТ findЁЃ
cd /
find . ЈCname elasticsearch
./var/lib/elasticsearch
./var/log/elasticsearch
./var/run/elasticsearch
./etc/rc.d/init.d/elasticsearch
./etc/sysconfig/elasticsearch
./etc/elasticsearch
./usr/share/elasticsearch
./usr/share/elasticsearch/bin/elasticsearch |
ЛљБОЩЯВюВЛЖрСЫЃЌФуЛЙЕУПДЯТЪЧЗёШБЩйconfigЃЌвђЮЊЮвАВзАЕФЪБКђЪЧШБЩйЕФЁЃ
cd /usr/share/elasticsearch/
ll
drwxr-xr-x. 2 root root 4096 9дТ 4 01:10 bin
drwxr-xr-x. 2 root root 4096 9дТ 4 01:10 lib
-rw-r--r--. 1 root root 11358 6дТ 30 19:22 LICENSE.txt
drwxr-xr-x. 5 root root 4096 9дТ 4 01:10 modules
-rw-r--r--. 1 root root 150 6дТ 30 19:22 NOTICE.txt
drwxr-xr-x. 2 elasticsearch elasticsearch 4096 6дТ 30 19:32 plugins
-rw-r--r--. 1 root root 8700 6дТ 30 19:22 README.textile |
ДѓИХПДЯТФугІИУвВЪЧШБЩйconfigЮФМўМаЕФЁЃЮвУЧЛЙЕУАбетИіЮФМўМаНЈКУЃЌЭЌЪБЛЙашвЊвЛИіelasticsearch.ymlХфжУЮФМўЁЃвЊВЛШЛЦєЖЏЕФЪБКђПЯЖЈЪЧБЈДэЕФЁЃ
mkdir config
cd config
vim elasticsearch.yml |
еввЛЯТelasticsearch.ymlХфжУЬљЩЯШЅЃЌЛђепФугУЮФМўЕФЗНЪНДЋЫЭвВааЁЃетаЉХфжУЖМЪЧЛљБОЕФЃЌЛиЭЗЛЙашвЊИљОнЧщПіЕїећХфжУЕФЁЃгааЉХфжУдкХфжУЮФМўжаЪЧУЛгаЕФЃЌЛЙашвЊЕНЙйЗНЩЯШЅВщевЕФЁЃЫљвдетРяЮоЫљЮНХфжУЮФМўЕФШЋЛђепВЛШЋЁЃЙигкХфжУЯюЭјЩЯгаКмЖрзЪСЯЃЌЫљвдетИіЮоЫљЮНЕФЁЃ
БЃДцЯТelasticsearch.ymlЮФМўЁЃ
ФуЛЙашвЊвЛИіlogging.ymlШежОХфжУЮФМўЁЃesзїЮЊЗўЮёЦїКѓЬЈдЫааЕФЗўЮёЪЧПЯЖЈашвЊШежОЮФМўЕФЁЃетВПЗжШежОЛсБЛФуЕФШежОЦНЬЈЪеМЏКЭМрПиЃЌгУРДзіЮЊдЫЮЌНЁПЕМьВщЁЃlogging.ymlБОжЪЩЯЪЧвЛИіlog4jЕФХфжУЮФМўЃЌетИігІИУДѓМвЖМБШНЯЪьЯЄСЫЁЃИњelasticsearch.ymlРрЫЦЃЌвЊУДИДжЦеГЬљвЊУДЮФМўДЋЫЭЁЃ
ШежОЕФЪфГідкlogsФПТМЯТЃЌетИіФПТМЛсБЛздЖЏДДНЈЁЃЕЋЪЧЮвЛЙЪЧЯВЛЖДДНЈКУЃЌВЛЯВЛЖгаВЛШЗЖЈвђЫиЃЌвВаэЫќОЭВЛЛсздЖЏДДНЈЁЃ
mkdir logs
зюКѓашвЊЩшжУЯТИеВХЮвУЧЬэМгЕФЮФМўЕФжДааШЈЯоЁЃвЊВЛШЛФуЕФЮФМўУћзжгІИУЪЧАзЩЋЕФЃЌЪЧВЛдЪаэБЛжДааЁЃ

cd ..
chmod ЈCR u+x config/

ЯждкЛљБОЩЯАВзАЫуЪЧЭъГЩСЫЃЌЪдзХcdЕНЮФМўЕФЦєЖЏФПТМЯТЦєЖЏesЃЌРДМьВщЯТЪЧЗёФме§ГЃЦєЖЏЁЃ
ВЛГівтЭтФуЛсЪеЕНвЛИі ЁАjava.lang.RuntimeException: don't run elasticsearch as rootЁБвьГЃЁЃетЫЕУїЮвУЧЭъГЩСЫЕквЛВНАВзАЙ§ГЬЃЌЯТНкЮвУЧРДПДгаЙиЦєЖЏеЫЛЇЕФЮЪЬтЁЃ

2.2.ХфжУelasticsearchзЈЪєеЫЛЇКЭзщ
ФЌШЯЧщПіЯТesЪЧВЛдЪаэrootеЫЛЇЦєЖЏЕФЃЌетЪЧЮЊСЫАВШЋЦ№МћЁЃesФЌШЯФкЧЖСЫgroovyНХБОв§ЧцЕФЙІФмЃЌЛЙгаКмЖрpluginНХБОв§ЧцВхМўЃЌШЗЪЕВЛЬЋАВШЋЁЃesИеГіРДЕФЪБКђЛЙгаgroovyТЉЖДЃЌЫљвдНЈвщдкВњЯпЕФes instance ЙиЕєетИіНХБОЙІФмЁЃЫфШЛФЌШЯВЛЪЧПЊЦєЕФЃЌАВШЋЦ№МћЛЙЪЧМьВщвЛЯТФуЕФХфжУЁЃ
ЫљвдЮвУЧашвЊЮЊesХфжУЖРСЂЕФеЫЛЇКЭзщЁЃдкДДНЈesзЈгУеЫЛЇжЎЧАЯШВщПДЯТЯЕЭГРяУцЪЧЗёвбОгаСЫesзЈгУеЫЛЇЁЃвђЮЊдкЮвУЧЧАУцrpmАВзАЕФЪБКђЛсздЖЏАВзАelasticsearchзщКЭгУЛЇЁЃЯШВщПДЯТЃЌШчЙћФуЕФАВзАУЛгаДјЩЯзЈгУзщКЭгУЛЇШЛКѓФудкДДНЈЁЃетбљвдУтФуздМКдіМгЕФКЭЯЕЭГДДНЈЕФИуЛьЯ§ЁЃ
ВщПДЯТзщ:
cat /etc/group
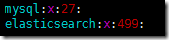
ВщПДЯТгУЛЇЃК
cat /etc/passwd

ЛљБОЩЯЖМДДНЈКУСЫЁЃ499ЕФgroupдкpasswdжавВДДНЈСЫЖдгІЕФelasticsearchеЫКХЁЃ
ШчЙћФуЯЕЭГРяУЛгаздЖЏДДНЈЖдгІЕФзщКЭеЫКХЃЌФуОЭЖЏЪжздМКДДНЈЃЌШчЯТЃК
ДДНЈзщЃК
groupadd elasticsearch_group
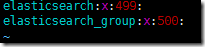
ДДНЈгУЛЇЃК
useradd elasticsearch_user -g elasticsearch_group -s /sbin/nologin

зЂвтЃКДЫеЫЛЇЪЧВЛОпгаЕЧТМШЈЯоЕФЁЃЫќЕФshellЪЧдк/sbin/nologinЁЃ
ЮЊСЫбнЪОЃЌдкЮвЕФЕчФдЩЯгаСНзщelasticsearchзЈгУеЫЛЇЃЌЮвНЋЩОГ§ЁА_groupЁБКЭЁА_userЁБНсЮВЕФеЫКХЃЌвдrpmздЖЏАВзАЕФЮЊesЕФЦєЖЏеЫКХЃЈelasticsearchЃЉЁЃ
2.3.ЩшжУelasticsearchЮФМўЫљгаеп
НгЯТРДЮвУЧашвЊзіЕФОЭЪЧЙиСЊesЮФМўКЭelasticsearchеЫКХЃЌНЋesЯрЙиЕФЮФМўЩшжУГЩelasticsearchгУЛЇЮЊЫљгаепЃЌетбљelasticsearchгУЛЇОЭПЩвдУЛгаШЮКЮШЈЯоЯожЦЕФЪЙгУesЫљгаЮФМўЁЃ
ЕМКНЕНelasticsearchЩЯМЖФПТМЃК
cd /usr/share
ll

chown -R elasticsearch:elasticsearch elasticsearch/

ДЫЪБЃЌФуЕФelasticsearchЮФМўЕФownerЪЧelasticsearchЁЃ
2.4.ЧаЛЛЕНelasticsearchзЈЪєеЫЛЇВтЪдФмЗёГЩЙІЦєЖЏ
ЮЊСЫВтЪдЦєЖЏesЪЕР§ЃЌЮвУЧашвЊднЪБЕФНЋelasticsearchЕФгУЛЇЧаЛЛЕН/bin/bashЁЃетбљЮвУЧОЭПЩвдsu elasticsearchЃЌШЛКѓЦєЖЏesЪЕР§ЁЃ
su elasticsearch
cd /usr/share/elasticsearch/bin
./elasticsearch

ЦєЖЏЭъГЩЃЌДЫЪБгІИУУЛЗЂЩњШЮКЮвьГЃЁЃПДЯТЯЕЭГЖЫПкЪЧЗёЦєЖЏГЩГЄЁЃ
netstat ЈCtnl

МЬајВщПДЯТHTTPЗўЮёЪЧЗёЦєЖЏе§ГЃЁЃ
curl ЈCget http://192.168.0.103:9200/_cat
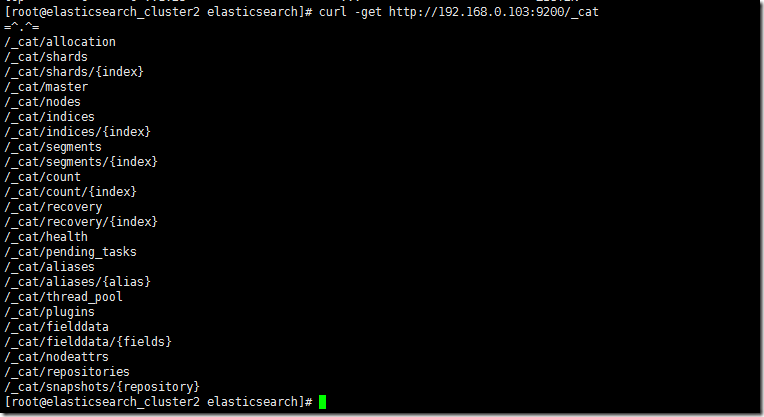
гЩгкДЫЪБЮвУЧВЂУЛгаАВзАШЮКЮИЈжњЙмРэЙЄОпЃЌШчЃЌplugin/headЁЃЫљвдгУФкжУЕФ_cat rest endpoitЛЙЪЧЭІЗНБуЕФЁЃ
curl -get http://192.168.0.103:9200/_cat/nodes
192.168.0.103 192.168.0.103 4 64 0.00 d * node-1
ПЩвдПДМћЃЌФПЧАжЛгавЛИіНкЕудкЙЄзїЃЌ192.168.0.103ЃЌЧвЫќЪЧвЛИіdata nodeЁЃ
ЃЈБИзЂЃКЮЊСЫНкЪЁЪБМфЃЌЮвднЪБЯШЪЙгУвЛЬЈ103ЕФИЩОЛЛЗОГзїЮЊАВзАКЭЛЗОГДюНЈбнЪОЃЌЕБДюНЈМЏШКЕФЪБКђЮвЛсcloneГіРДКЭаоИФIPЁЃ)
2.5.АВзАздЦєЖЏelasticsearch servicewrapperАќ
esЕФЯЕЭГздЦєЖЏгавЛИіПЊдДЕФwrapperАќПЩвдЪЙгУЁЃШчЙћФуВЛЪЙгУетИіwrapperвВПЩвдздМКШЅаДshellНХБОЃЌЕЋЪЧРяУцЕФКмЖрВЮЪ§ашвЊФуИуЕФЗЧГЃЧхГўВХааЃЌдкМгЩЯгааЉЙиМќВЮЪ§ашвЊЩшжУЁЃЫљвдЛЙЪЧНЈвщдкelasticsearchwrapperАќЕФЛљДЁЩЯНјаааоИФаЇТЪЛсИпЕуЃЌЖјЧвФуЛЙФмдкelasticsearch shellжаПДМћвЛаЉesЩюВуДЮЕФХфжУКЭдРэЁЃ
(БИзЂЃКШчЙћФуЪЧ.neterЃЌФуПЩвдНЋservicewrapperРэНтГЩЪЧПЊдД.net topshelfЁЃБОжЪОЭЪЧНЋГЬађАќзАГЩОпгаЯЕЭГЗўЮёЙІФмЃЌФуПЩвдАВзАЁЂаЖдиЃЌвВПЩвджБНгЦєЖЏЁЂЭЃжЙЃЌЛђепИЩДржБНгЧАЬЈдЫааЁЃЃЉ
2.5.1.ЯТдиelasticsearch servicewrapper Аќ
elasticsearchwrapper githubЪзвГЃЌ https://github.com/elastic/ elasticsearch-servicewrapper
ИДжЦ git repository ЕижЗЕНМєЬљАхЃЌШЛКѓжБНгcloneЕНБОЕиЁЃ
git clone https://github.com/elastic/ elasticsearch-servicewrapper.git
(ФуашвЊдкЕБЧАlinuxЛњЦїЩЯАВзАgitПЭЛЇЖЫЃКyum ЈCy install gitЃЌЮвАВзАЕФЪЧФЌШЯ1.7ЕФАцБОЁЃЃЉ
ШЛКѓЕШД§cloneЭъГЩЁЃ

ВщПДЯТcloneЯТРДЕФБОЕиВжПтЮФМўЧщПіЁЃНјШыelasticsearchwrapperЃЌВщПДЕБЧАgit ЗжжЇЁЃ
cd /root/elasticsearch-servicewrapper
git branch
*master
ll |
вЛЧаЖМКме§ГЃЃЌЫЕУїЮвУЧcloneЯТРДУЛЮЪЬтЃЌАќРЈЗжжЇвВЪЧКмЧхЮњЕФЁЃserviceЮФМўОЭЪЧЮвУЧвЊАВзАЕФАВзАЮФМўЁЃ

ЮвУЧашвЊНЋserviceЮФМўcopyЕНelasticsearch/binФПТМЯТЁЃ
cp -R service/ /usr/share/elasticsearch/bin/
cd /usr/share/elasticsearch/bin/

serviceРяЕФАВзАЮФМўашвЊдкelasticsearch/binФПТМЯТЙЄзїЁЃ
cd service/
ll
./elasticsearch
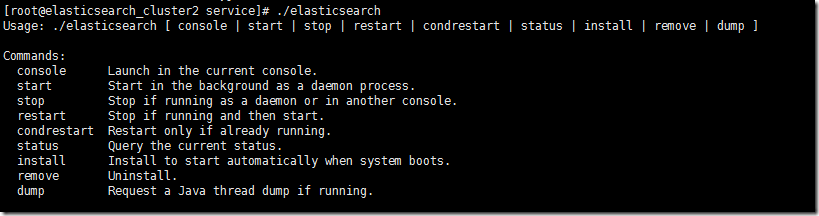
ВЮПМgithubЩЯelasticsearchwrapperЪЙгУЫЕУїЁЃelasticsearch servicewrapperЕФЙІФмЛЙЪЧТљЖрЕФЃЌstatusЁЂdumpЖМЪЧКмКУЕФМьВщКЭЕїЪдЙЄОпЁЃ
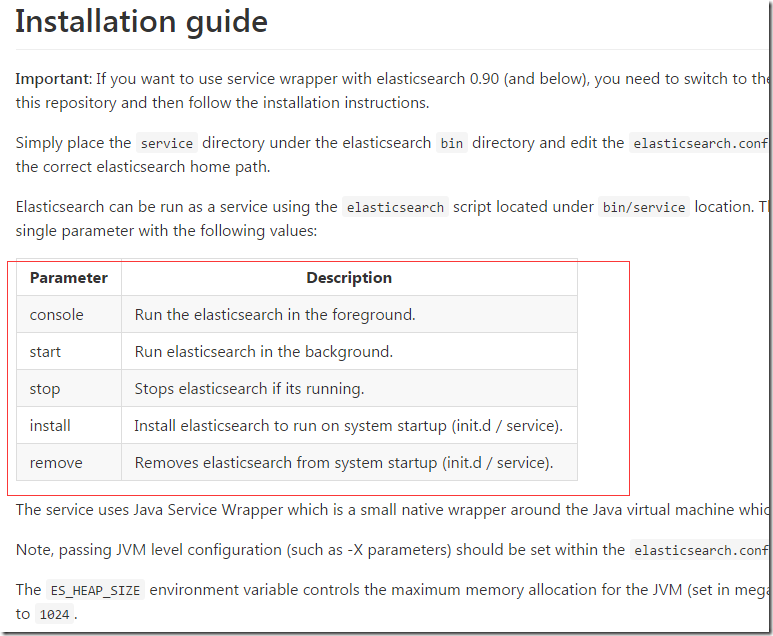
дкАВзАжЎЧАЃЌЮвУЧашвЊднЪБдкЧАЬЈдЫааesЪЕР§ЃЌетбљПЩвдВщПДвЛаЉlogЪЧЗёгавьГЃЧщПіЁЃParameterЕФИїИіВЮЪ§аДЕФКмЧхГўЃЌЮвУЧетРяЪЙгУconsoleПижЦЬЈЪфГіЦєЖЏesЪЕР§ЁЃ
./elasticsearch console
2.5.2 elasticsearch servicewrapperПЊдДАќЕФХфжУаЁbug
ДЫЪБФугІИУЛсЪеЕНвЛИіErrorЕФЬсЪОЃК
WrapperSimpleApp Error: Unable to locate the class org.elasticsearch.bootstrap.ElasticsearchF : java.lang.ClassNotFoundException: org.elasticsearch.bootstrap.ElasticsearchF
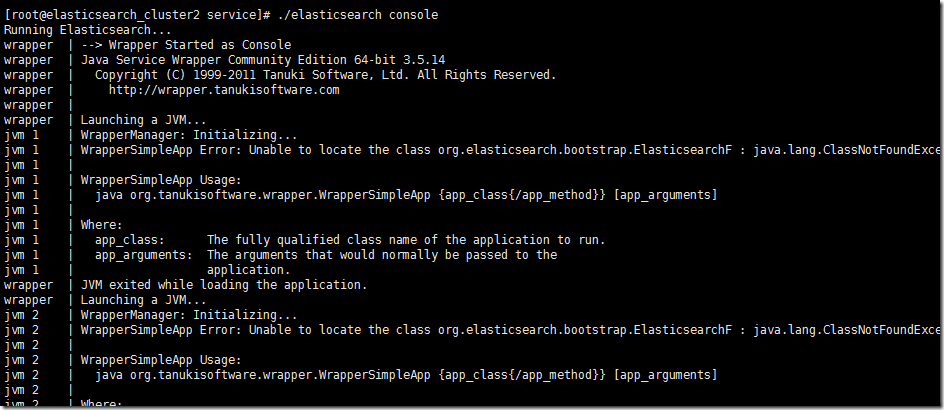
ЕквЛДЮПДЕНетИіЮвгаЕуУЩЃЌетИіElasticsearchFЪЧИіЪВУДЖдЯѓЁЃУќУћгаЕуЬиЪтЃЌдйНјвЛВНВщПДExceptionЕФаХЯЂЃЌЦфЪЕЪЧвЛИіClassNotFoundExceptionвьГЃЁЃЫЕУїевВЛЕНетИіElasticSearchFРрЁЃ
СНжжПЩФмадЃЌЕквЛОЭЪЧjava elasticsearchЯрЙиАќЕФЮЪЬтЃЌШЗЪЕШБЩйетИіРрЁЃЕЋЪЧетИіПЩФмадКмаЁЃЌвђЮЊЮвУЧжЎЧАжБНгдЫааelasticsearchЪЧГЩЙІЕФЁЃЮвЕБЪБгУjd-guiЗСЫЯТesЕФАќЃЌШЗЪЕУЛгаетИіРрЁЃ
ЕкЖўОЭЪЧетРяЕФХфжУДэЮѓЃЌгІИУОЭИіЪжЮѓЃЌШЗЪЕУЛгаElasticsearchFетИіРрЁЃ
ЮвУЧВщПДЯТservice/elasticsearch.confХфжУЮФМўРяЪЧВЛЪЧгаетИіЁЎelasticsearchFЁЏзжЗћДЎЁЃЃЈwrapperАќЪЧЪЙгУЕБЧАФПТМЯТЕФelasticsearch.confзїЮЊХфжУЮФМўЪЙгУЕФЃЉ
grep ЈCi elasticsearchf elasticsearch.conf

ШЗЪЕгаетИізжЗћДЎЃЌЮвУЧНјааБрМБЃДцЃЌШЅЕєзюКѓЕФЁЎFЁЏЁЃ

ШЛКѓЮвУЧдкНјааЦєЖЏГЂЪдЁЃ
./elasticsearch console
ЮвВЛжЊЕРФуЪЧВЛЪЧЛсКЭЮвЕФЧщПівЛбљЃЌЬсЪОЯрЙиУќСюЖМЪЧВЛЙцЗЖЕФЁЃ
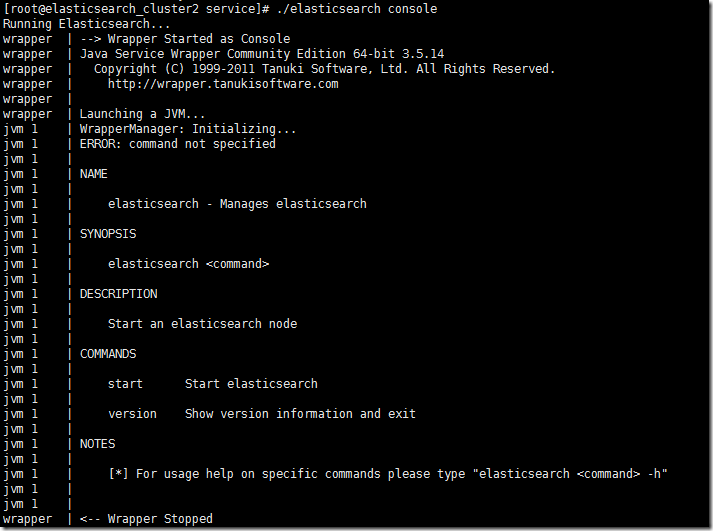
етИідЫааСДТЗЛљБОЩЯОЙ§Ш§ИіТЗОЖЃЌЕквЛИіОЭЪЧservice/elasticsearch shellЦєЖЏНХБОЃЌШЛКѓЛёШЁУќСюЗжЮіУќСюдйЦєЖЏexecЯТЕФЯрЙиjava servicewrapperГЬађЁЃ
етИіjava servicewrapperГЬађЃЌАцБОЪЧ3.5.14ЁЃИљОнЩЯЪіЫМТЗЃЌЭЈЙ§ВщПДelasticsearch shellГЬађЃЌЫќдкНгЪеЕНЭтВПЕФУќСюжЎКѓЛсЦєЖЏexecЯТЕФjava servicewrapperГЬађЁЃЮвЯыЪдзХБрМСЫЯТelasticsearch shellЮФМўЃЌЪфГівЛаЉаХЯЂГіРДЃЌВщПДЯТЪЧВЛЪЧЛёШЁЯрЙиТЗОЖЛђепВЮЪ§жЎРрЕФЕМжТДэЮѓЁЃЃЈгіЕНЮЪЬтВЛХТЃЌжСЩйЮвУЧвЊвЛТЗИњЯТШЅЃЌПДЯТОПОЙЪЧдѕУДЛиЪТЁЃЃЉ
vim ./elasticsearch
esc
:/console
евЯТconsoleдкФФРяЃЌШЛКѓМгЩЯЕїЪдЮФБОаХЯЂЃЌЪфГіЕННчУцЩЯЁЃ
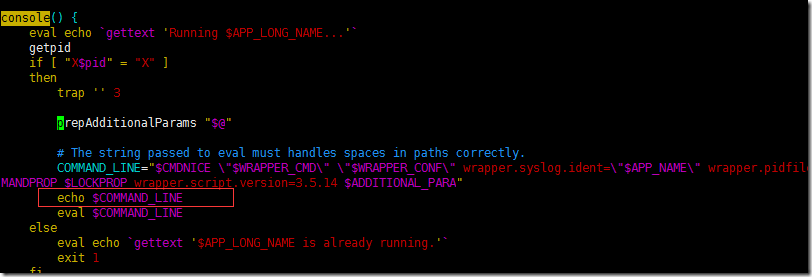
дйдЫааЃЌВщПДУќСюВЮЪ§ЪЧЗёгаЮЪЬтЁЃ

ВщПДСЫЯТЃЌЪфГіЕФВЮЪ§ЛљБОЖМУЛгаЮЪЬтЁЃвЛЪБЮоНтЁЃКУЦцаФзїЙжЃЌБОЯыдйНјвЛВНПДЯТexec/elasticsearch-linux-x86-64.soЮФМўЕФЃЌКѓРДЗЂЯжДђПЊИљБООЭПДВЛЖЎЁЃЫљвдОЭСэбАЦфЫћЗНЗЈЃЌЮвевСЫwindowsАцБОservicewrapperЃЌЗЂЯжwindowsЕФelasticsearchservicewrapperЪЧУЛга32ЮЛЕФservicewrapperЕФЁЃЮвЪдзХдЫааЦ№РДЛљБОЩЯвВЪЧБЈЯрЭЌЕФДэЮѓЃЌЕЋЪЧwindowsЕФwrapperЕФerrorаХЯЂБШНЯЖрЕуЃЌЬсЪОГіДэЕФдвђдкФФРяЁЃ
ЮвЯыаоИФЯТШежОЕФЪфГіМЖБ№ЃЌПДФмЗёЪфГівЛаЉПЩвдгУЕФаХЯЂЁЃБрМservice/elasticsearch.conf wrapperАќзЈгУХфжУЁЃ
# Log Level for console output.? (See docs for log levels)
wrapper.console.loglevel=TRACE
# Log Level for console output.? (See docs for log levels)
wrapper.console.loglevel=TRACE |
ЮвУЧНЋШежОЪфГіМЖБ№ЩшжУГЩtraceЃЌгаСНДІашвЊЩшжУЃЌЮвУЧдйПДЪфГіаХЯЂЁЃ
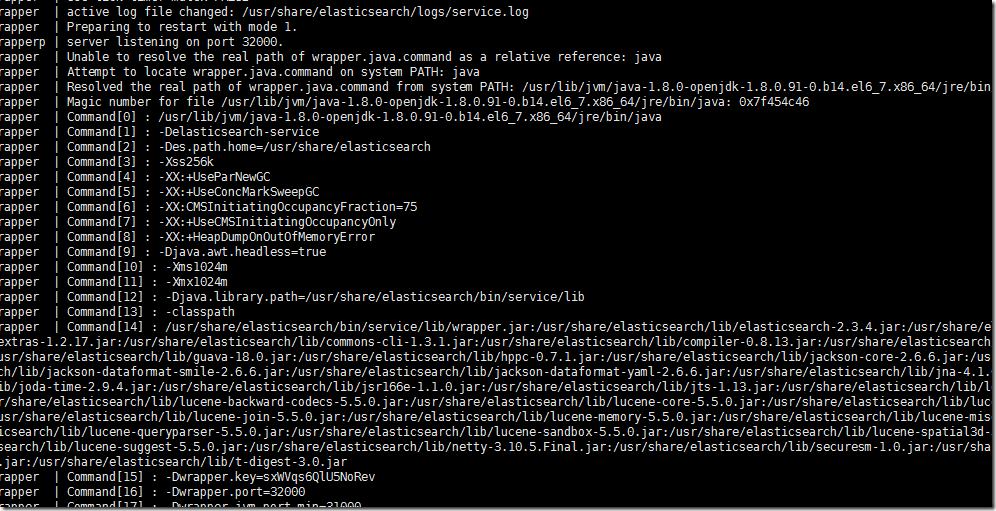
ЪЧЪфГіСЫвЛаЉгагУЕФаХЯЂЃЌПЩвдВщПДlogЮФМўЯъЧщЁЃ
WrapperManager Debug: Received a packet LOGFILE : /usr/share/elasticsearch/logs/service.log
ЕЋЪЧгаЙигкerrorЕФаХЯЂЛЙЪЧжЛгавЛЬѕЁЃ
етРяОЭИцвЛЖЮТфЁЃЮвУЧЕФФПЕФЪЧЮЊСЫЪЙгУconsoleРДдЫааЃЌЯыВщПДЯТвЛаЉдЫааШежОЃЌЕЋЪЧХмВЛЦ№РДвВЮоЫљЮНЃЌЮвУЧМЬајжДааАВзАВйзїЁЃ
ЃЈФФЮЛВЉгбШчЙћжЊЕРЮЪЬтдкФФРяЕФПЩвдЗжЯэГіРДЃЌЮвОѕЕУетИіЮЪЬтВЛЪЧвЛИіХМЗЂадЮЪЬтЃЌгІИУЖМЛсгіЕНЁЃЮвЯШХзГіЮЪЬтЃЌжСЩйПЩвдЗўЮёНЋРДЕФЪЙгУепЁЃетРяЯШаЛаЛСЫЁЃЃЉ
ЦфЪЕЃЌШчЙћФуВЛЪЙгУelasticsearch servicewrapperРДАќзАЖјЪЧздМКШЅЯТдиjava serivcewrapperРДАќзАelasticsearchвВЪЧПЩвдЕФЃЌЪЕЯжЦ№РДвВКмЗНБуЁЃ
ЮвУЧЛиЕНжїЬтЃЌМШШЛЮвУЧЮоЗЈconsoleдЫааЃЌвВПДВЛСЫвЛаЉwrapper consoleжДааЪБЕФЧщПіЃЌФЧЮвУЧОЭжЛФмНјааАВзАСЫЁЃ
2.5.3 servicewrapperАВзА (elasticsearch init.d ЦєЖЏЮФМўЩшжУuserЁЂopenfileЁЂconfigpath)
АДееelasticsearch servicewrapper parameterВЮЪ§жИЪОЃЌЮвУЧжДааАВзАЁЃ
./elasticsearch install
Installing the Elasticsearch daemon..
ЪиЛЄНјГЬАВзАЭъГЩЁЃЮвУЧЛЙЪЧЧАШЅЯЕЭГФПТМЯТВщПДЪЧВЛЪЧАВзАГЩЙІЃЈММЪѕШЫдБЪМжеБЃГжвЛИібЯНїЕФаФЬЌЪЧгаБивЊЕФЁЃЃЉЧАЭљ/etc/init.d/ФПТМЯТВщПДЁЃ
ll /etc/init.d/
-rwxrwxr--. 1 root root? 4496 10дТ? 4 01:43 elasticsearch
ЮветРяЩшжУЙ§chmod u+x ./elasticsearchЁЃБ№ЭќМЧЩшжУЮФМўЕФжДааШЈЯоЃЌетдкЮвУЧЁО2.1НкЁПРяНЋНсЙћЃЌетРяОЭВЛжиИДСЫЁЃ
ЮвУЧПЊЪМБрМelasticsearchЦєЖЏЮФМўЁЃ

жївЊОЭЪЧетЖЮЃЌЬюаДКУХфжУЕФesЕФзЈгУеЫЛЇЃЈelasticsearchЁО2.2.НкЁПЃЉЃЌЛЙгаЯргІЕФЮФМўТЗОЖЁЃетРяЯШКіТдMAX_OPEN_FILESЁЂMAX_MAP_COUNTСНИіХфжУЯюЃЌдкКѓУцЁО3.3.НкЁПХфжУВПЗжЛсНВНтЕНЁЃ
2.5.4 chkconfig -add МгШыlinuxЦєЖЏЗўЮёСаБэ
НЋЦфЬэМгЕНЯЕЭГЗўЮёжаЃЌвдБуБЛЯЕЭГздЖЏЦєЖЏЁЃ
chkconfig --add elasticsearch
chkconfig ЈClist |
вбОЬэМгКУЯЕЭГздЦєЖЏЗўЮёСаБэжаЁЃ
| service elasticsearch start |
ЦєЖЏesЪЕР§ЃЌЕШД§ЖЫПкЦєЖЏЭъГЩЃЌЩдЕШЦЌПЬВщПДЖЫПкЧщПіЁЃ
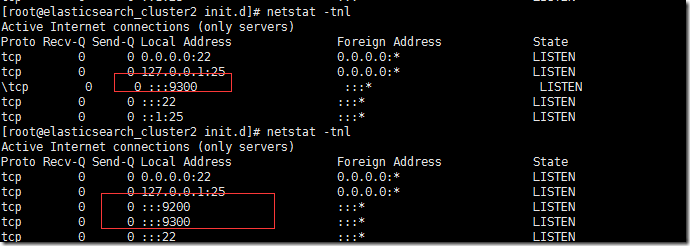
9300ЖЫПкБШ9200ЖЫПкЯШЦєЖЏЃЌвђЮЊ9300ЖЫПкЪЧ clusterФкВПЙмРэЖЫПкЁЃ9200ЪЧrest endpoint ЗўЮёЖЫПкЁЃЕБШЛЃЌетИіЪБМфбгГЄВЛЛсКмГЄЁЃ
ЖЫПкЖМЦєЖЏГЩЙІжЎКѓЃЌЮвУЧВщПДЯТФмЗёе§ГЃЗУЮЪesЪЕР§ЁЃ
curl -get http://192.168.0.103:9200/
{
"name" : "node-1",
"cluster_name" : "orderSearch_cluster",
"version" : {
"number" : "2.3.4",
"build_hash" : "e455fd0c13dceca8dbbdbb1665d068ae55dabe3f",
"build_timestamp" : "2016-06-30T11:24:31Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
} |
ЮвУЧЛЙЪЧЪЙгУ_cat rest endpointРДВщПДЁЃ
curl -get http://192.168.0.103:9200/_cat/nodes
192.168.0.103 192.168.0.103 4 61 0.00 d * node-1 |
ШчЙћФуПЩвддкБОЛњЗУЮЪЃЌЕЋЪЧдкЭтВПфЏРРЦїжаЮоЗЈЗУЮЪЃЌКмПЩФмЪЧЗРЛ№ЧНЕФЩшжУЮЪЬтЃЌФуПЩвдШЅЩшжУЯТЗРЛ№ЧНЁЃ
vim /etc/sysconfig/iptables
жиЦєЭјТчЗўЮёЃЌвдБуМгдиЗРЛ№ЧНЩшжУЯюЁЃ
service network restart
ШЛКѓдйГЂЪдПДФмЗёЭтВПЗУЮЪЃЌШчЙћВЛааФуОЭtelnetЖЫПкЯТЁЃ
вђЮЊЗУЮЪВЛСЫЛЙгавЛИідвђЪЧКЭelasticsearch.ymlвЛИіХфжУЯюгаЙиЯЕЁЃМћЁО3.1.1НкЁПЁЃ
жиЦєЛњЦїЃЌВщПДesЪЕР§ЪЧЗёЛсздЖЏЦєЖЏЁЃ
shutdown ЈCr now
ЩдЕШЦЌПЬЃЌШЛКѓГЂЪдСЌНгЛњЦїЁЃ
ШчЙћУЛГіЪВУДвтЭтЃЌЖМгІИУе§ГЃЕФЃЌЖЫПквВЦєЖЏГЩЙІСЫЁЃЫЕУїЮвУЧЭъГЩСЫesЪЕР§здЦєЖЏЙІФмЃЌЫќЯждкзїЮЊlinuxЯЕЭГЗўЮёБЛздЖЏЙмРэЁЃ
АВзАГЩЗўЮёжЎКѓЃЌelasticsearch servicewrapperКЭЮвУЧОЭУЛгаЬЋЖрЙиЯЕСЫЁЃвђЮЊЫќЕФparameterЖМЪЧЮЇШЦепЮвУЧЛљгкservicewrapperРДЪЙгУЕФЁЃ
2.6.АВзА_plugin/headЙмРэВхМўЃЈИЈжњЙмРэЃЉ
ЮЊСЫКмКУЕФЙмРэМЏШКЃЌЮвУЧашвЊЯргІЕФЙЄОпЃЌheadЪЧБШНЯСїааКЭЭЈгУЕФЃЌЖјЧвЪЧУтЗбЕФЁЃЕБШЛЛЙгаКмЖрКУгУЕФЦфЫћЙЄОпЃЌШчЃЌBigdeskЁЂMarvelЃЈЩЬгУЪеЗбЃЉЁЃpluginЕФАВзАЖМДѓЭЌаЁвьЃЌЮвУЧетРяОЭЪЙгУЭЈгУЕФheadЙЄОпЁЃ
ЯШПДЯТЃЌheadИјЮвУЧДјРДЕФЧхЮњЕФМЏШКНкЕуЙмРэЪгЭМЁЃ
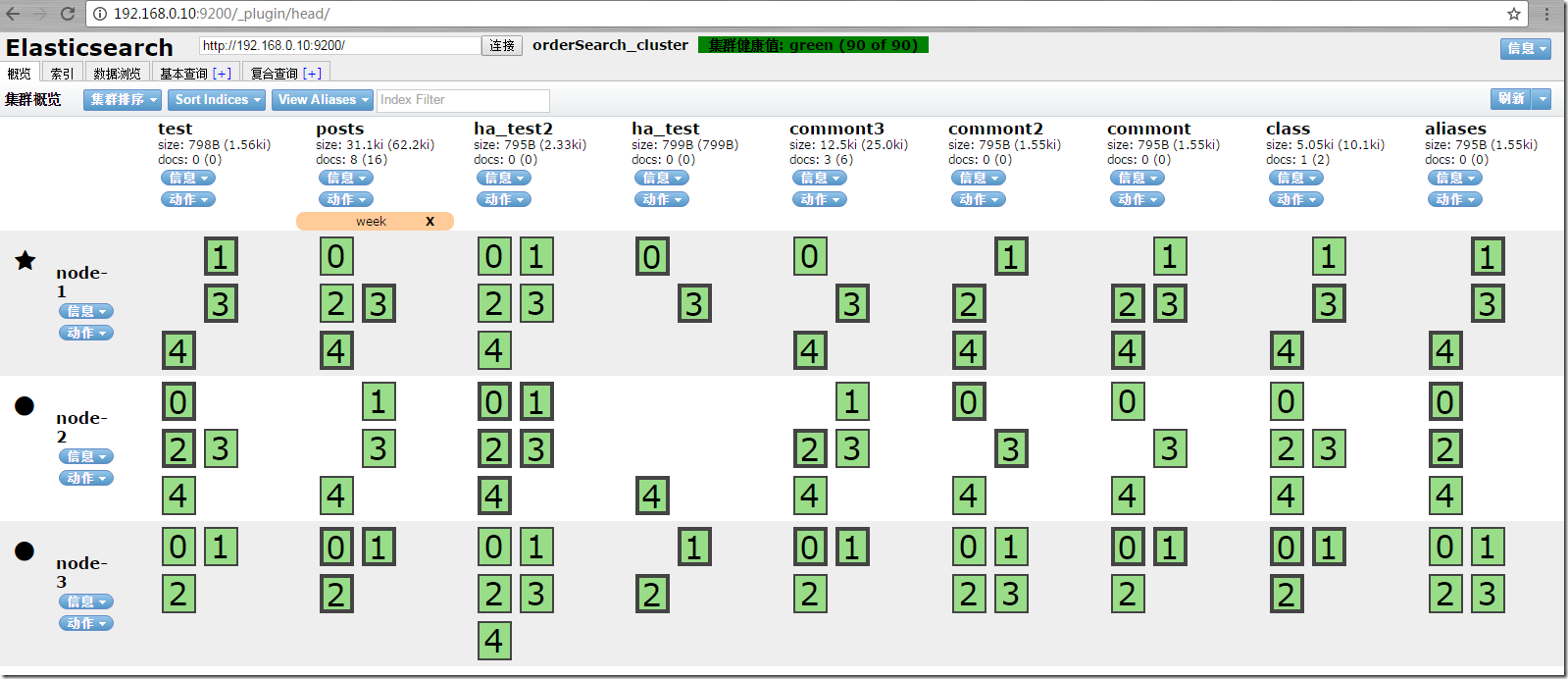
етЪЧгаШ§ИіНкЕуЕФesМЏШКЪЕР§ЁЃЫќЪЧвЛИіЖўЮЌОиеѓХХСаЃЌзюЩЯУцКсЯђЪЧЫїв§ЃЌзюзѓБпЪЧНкЕуЃЌНЛВцЕФЕиЗНЪЧЫїв§ЕФЗжЦЌаХЯЂКЭЗжЦЌБШР§ЁЃ
АВзАheadВхМўЛЙЪЧБШНЯЗНБуЕФЃЌФувВПЩвджБНгcopyЮФМўЕФЗНЪНЪЙгУЁЃдкelasticsearchЕФhomeФПТМЯТгавЛИіpluginsФПТМЃЌЫќЪЧЫљгаВхМўЕФФПТМЃЌЫљгаЕФВхМўЖМЛсдкетИіЮФМўМаВщевКЭМгдиЁЃ
ЮвУЧПДЯТАВзАheadВхМўЗНЗЈЁЃдкelasticsearch/bin ФПТМЯТгавЛИіpluginПЩжДааЮФМўЃЌЫќЪЧзЈУХгУРДАВзАВхМўгУЕФГЬађЁЃ
| ./plugin -install mobz/elasticsearch-head |
ВхМўЕФВщевТЗОЖгаМИИіelasticsearchЙйЭјЪЧвЛИіЃЌgithubЪЧвЛИіЁЃетРяЛсЯШГЂЪддкgithubЩЯВщевЃЌЩдЕШЦЌПЬЃЌЕШД§АВзАЭъГЩЁЃЮвУЧГЂЪдЗУЮЪheadВхМўЕижЗrestЕижЗ/_plugin/headЁЃ
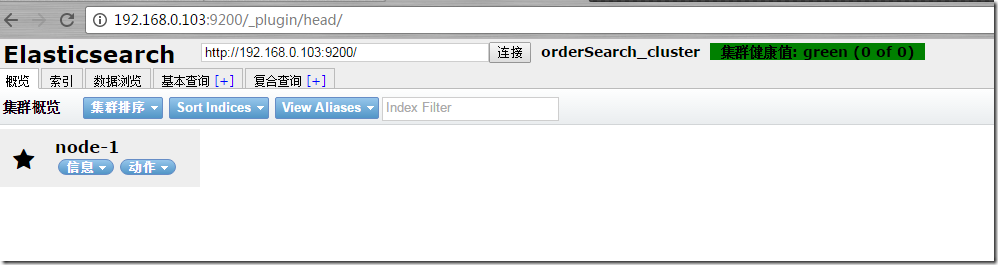
ПДЕНетИіНчУцЛљБОАВзАГЩЙІСЫЃЌnode-1ФЌШЯЪЧmasterНкЕуЁЃ
2.7.АВзАchromжаЕФelasticsearchПЭЛЇЖЫВхМў
chromжагаКмЖрПЩвдЪЙгУЕФelasticsearchПЭЛЇЖЫВхМўЃЌБугкПЊЗЂКЭЮЌЛЄЃЌНЈвщжБНгЪЙгУchromжаЕФВхМўЁЃжЛвЊЫбЫїЯТelasticsearchЙиМќзжОЭЛсГіРДКмЖрЁЃ

гаСНИіБШНЯГЃгУЃЌвВБШНЯКУгУЃЌEalsticSearch ToolboxЁЂSense(здЖЏЬсЪОdslБрМЙЄОпЃЉЁЃchromВхМўЖМЪЧФЧУДЕФПсЃЌЪЙгУЦ№РДЖМКмЩЭаФдУФПЁЃ
elasticsearch toolbox ПЩвдКмЗНБуЕФВщбЏКЭЕМГіЪ§ОнЁЃ
senseПЩвдШУФуБрМelasticsearch dsl ЬиЖЈгябдЛсгаЦєЖЏЬсЪОАяжњЃЌетбљБраДЦ№ИДдгЕФdslаЇТЪЛсИпЖјЧвВЛвзГіДэЁЃЦфЫћЕФЙЄОпЮввВУЛгУЙ§ЃЌИаОѕЖМПЩвдГЂЪдгУгУПДЁЃ
ЃЈБИзЂЃКШчЙћФуЮоЗЈЗУЮЪchromЩЬЕъжааФОЭашвЊЬиЪтДІРэЯТЃЌетРяОЭВЛНтЪЭСЫЁЃЃЉ
2.8.ЪЙгУelasticsearchздДјЕФ_catЙЄОп
дквЛаЉЬиЪтЕФЧщПіЯТФуПЩФмЮоЗЈжБНгЪЙгУpluginРДАяФуЙмРэЛђепВщПДМЏШКЧщПіЁЃДЫЪБФуПЩвджБНгЪЙгУelasticsearchздДјЕФrest _catВщПДМЏШКЧщПіЃЌБШШчЃЌФуПЩФмЗЂЯж_plugin/headгавЛаЉНкЕуУЛгаЩЯРДЃЌЕЋЪЧФугжВЛШЗЖЈЗЂЩњСЫЪВУДЧщПіЃЌФуОЭПЩвдЪЙгУ/_cat/nodesРДВщПДЫљгаnodeЕФЧщПіЁЃгаЪБКђШЗЪЕгаЕФНкЕуУЛгаЦєЖЏЦ№РДЃЌЕЋЪЧДѓЖрЪ§ЧщПіЯТЖМЪЧИїздЮЊеўЃЈФдСбЃЉЃЌФуПЩФмашвЊШУЫћУЧжиаТбЁОйЛђепМгПьЕФбЁОйЙ§ГЬЁЃ
http://192.168.0.20:9200/_cat/nodes?v (ВщПДnodesЧщПіЃЉ
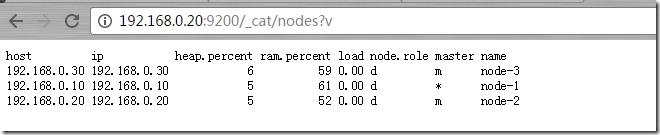
_cat restЖЫЕуДјгавЛИіvЕФВЮЪ§ЃЌетИіВЮЪ§ЪЧАяжњФудФЖСЕФВЮЪ§ЁЃ_search restЖЫЕуДјгаprettyВЮЪ§ЃЌетИіВЮЪ§ЪЧАяжњВщбЏЪ§ОндФЖСЕФЁЃУПвЛИіЖЫЕуЛљБОЩЯЖМгаИїздЕФИЈжњдФЖСВЮЪ§ЁЃ
http://192.168.0.20:9200/_cat/shards?v ЃЈВщПДshardsЧщПіЃЉ
http://192.168.0.20:9200/_cat/ ЃЈВщПДЫљгаПЩвдcatЕФЙІФмЃЉ
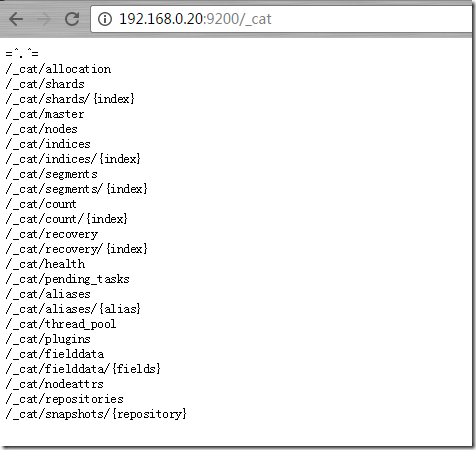
ФуПЩвдВщПДЯЕЭГ aliasesБ№УћЁЂsegmentsЦЌЖЮЃЈПДЯТУПИіЦЌЖЮЕФЬсНЛАцБОвЛжТадЃЉЁЂindicesЫїв§МЏКЯЕШЕШЁЃ
2.9.clone ащЛњЃЈаоИФIPЁЂHWaddrЁЂUUIDХфжУЃЌзюКѓаоИФЯТЯЕЭГЪБМфЃЉ
ЕБЮвУЧЭъГЩСЫЖдвЛЬЈЛњЦїЕФАВзАжЎКѓЃЌНгЯТРДОЭашвЊДюНЈЗжВМЪНЯЕЭГЁЃЗжВМЪНЯЕЭГОЭашвЊЖрНкЕуЛњЦїЃЌАДееesЗжВМЪНМЏШКДюНЈзюМбЪЕМљЃЌФужСЩйашвЊШ§ИіНкЕуЁЃЫљвдЮвУЧНЋвбОАВзАЭъГЩЕФетИіЛњЦїcloneГіРДСНЬЈЃЌвЛЙВШ§ЬЈзщГЩПЩвдЙЄзїЕФШ§ИіНкЕуЕФЗжВМЪНЯЕЭГЁЃ
ЪзЯШcloneЕБЧААВзАЭъГЩЕФЛњЦїЃЌ192.168.0.103ЃЌcloneКУжЎКѓЦєЖЏЦ№РДаоИФМИИіХфжУМДПЩЁЃЃЈвђЮЊФуЪЧcloneГіРДЕФЃЌЫљвдХфжУвбОжиИДЃЌБШШчЃЌЭјПЈЕижЗЁЂIPЕижЗЃЉ
БрМЭјПЈХфжУЮФМўЃК
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth3
HWADDR=00:0C:29:CF:48:23
TYPE=Ethernet
UUID=b848e750-d491-4c9d-b2ca-c853f21bf40b
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
BROADCAST=192.168.233.255
IPADDR=192.168.0.103
NETMASK=255.255.255.0
GATEWAY=192.168.0.1 |
DEVICE ЪЧЭјПЈБъЪОЃЌИљОнФуБОЕиЕФЭјПЈБъЪЖаоИФГЩЖдгІЕФМДПЩЃЌПЩвдЭЈЙ§ifconfigВщПДЁЃHWADDRЭјПЈЕижЗЃЌЫцвтаоИФЯТЃЌБЃжЄдкФуЕФЭјЖЮФкВЛжиИДМДПЩЁЃUUIDвВЪЧКЭHWADDRвЛбљаоИФЁЃ
IPЕижЗаоИФГЩФуздМКОѕЕУКЯЪЪЕФIPЃЌзюКУВЮПМФуЕБЧАЮяРэЛњЦїЕФЯрЙиХфжУЁЃGATEWAYЭјЙиЕижЗвЊВЮПМФуЮяРэЛњЦїЕФЭјЙиЕижЗЃЌШчЙћФуЕФащФтЛњЪЙгУЕФЪЧЧХНгФЃЪНЕФЭјТчСЌНгЃЌетРяОЭашвЊЩшжУЃЌвЊВЛШЛЭјТчОЭСЌНгВЛЩЯЁЃ
жиЦєЭјТчЗўЮёЃК
service network restart
ЩдЕШЦЌПЬЃЌsshжиаТСЌНгЃЌШЛКѓifconfigПДЯТЭјТчЯрЙиВЮЪ§ЪЧЗёе§ШЗЃЌзюКѓдйpingвЛЯТЭтВПЭјжЗКЭФуЕБЧАЮяРэЛњЦїЕФIPЃЌБЃжЄЭјТчЖМЪЧЭЈГЉЕФЁЃ
зюКѓЮвУЧашвЊаоИФЯТlinuxЕФЯЕЭГЪБМфЃЌетЪЧЮЊСЫЗРжЙЗўЮёЦїЪБМфВЛвЛжТЃЌЕМжТКмЖрЯИЮЂЕФЮЪЬтЃЌБШШчЃЌesМЏШКmasterбЁОйЕФЪБМфДСЮЪЬтЁЂlog4jЪфГіЕФШежОЕФМЧТМЮЪЬтЕШЕШЁЃдкЗжВМЪНЯЕЭГжаЃЌЪБжгЗЧГЃживЊЁЃ
date -s '20161008 20:47:00'
ЪБЧјЕФЛАШчЙћФуашвЊвВПЩвдЩшжУЃЌетРяднЪБВЛашвЊЁЃ
ИљОнФуздМКЕФашвЊЃЌФуcloneМИЬЈЛњЦїЁЃАДееФЌШЯЕФЗНЪНЮвУЧДѓИХдМЖЈЮЊЃЌ192.168.0.10ЁЂ192.168.0.20ЁЂ192.168.0.30ЃЌетШ§ЬЈЛњЦїНЋзщГЩвЛИіesЗжВМЪНМЏШКЁЃ
3.ХфжУ
МЏШКЕФИїИіНкЕуЮвУЧвбОзМБИКУСЫЃЌЮвУЧНгЯТРДзМБИХфжУМЏШКЃЌШУетШ§ИіНкЕуПЩвдСЌНгдквЛЦ№ЁЃетРяЩцМАЕФХфжУБШНЯМђЕЅЃЌжЛЪЧЭъГЩМЏШКЕФвЛИіЛљБОГЃгУЙІФмЃЌШчгаЬиЪтЕФашЧѓПЩвдздааВщПДelasticsearchЙйЭјЛђепАйЖШЃЌетЗНУцЕФзЪСЯвбОКмЗсИЛСЫЁЃ
етРяЕФвЛаЉХфжУЮвУЧЦфЪЕвбОЪмвцгкelasticsearch servicewrapperМђЛЏСЫКмЖрЁЃ
ДгетРяПЊЪМЃЌЮвУЧНЋЖдШ§ЬЈЛњЦїНјааХфжУЃЌ192.168.160.10ЁЂ192.168.160.20ЁЂ192.168.160.30ЁЃ
3.1.elasticsearch.ymlХфжУ
дкelasticsearchЕФconfigФПТМЯТЖМЪЧХфжУЮФМўЁЃЕМКНЕН cd /usr/share/elasticsearch/configФПТМЁЃ
3.1.1.IPЗУЮЪЯожЦЁЂФЌШЯЖЫПкаоИФ9200
етРягаСНИіашвЊЬсабЯТЃЌЕквЛИіОЭЪЧIPЗУЮЪЯожЦЃЌЕкЖўИіОЭЪЧesЪЕР§ЕФФЌШЯЖЫПкКХ9200ЁЃIPЗУЮЪЯожЦПЩвдЯоЖЈОпЬхЕФIPЗУЮЪЗўЮёЦїЃЌетгавЛЖЈЕФАВШЋЙ§ТЫзїгУЁЃ
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0 |
ШчЙћЩшжУГЩ0.0.0.0дђЪЧВЛЯожЦШЮКЮIPЗУЮЪЁЃвЛАудкЩњВњЕФЗўЮёЦїПЩФмЛсЯоЖЈМИЬЈIPЃЌЭЈГЃгУгкЙмРэЪЙгУЁЃ
ФЌШЯЕФЖЫПк9200дквЛАуЧщПіЯТвВгаЕуЗчЯеЃЌПЩвдНЋФЌШЯЕФЖЫПкаоИФГЩСэЭтвЛИіЃЌетЛЙгавЛИідвђОЭЪЧХТПЊЗЂШЫдБЮѓВйзїЃЌСЌНгЩЯМЏШКЁЃЕБШЛЃЌШчЙћФуЕФЙЋЫОЭјТчИєРызіЕФКмКУвВЮоЫљЮНЁЃ
#
# Set a custom port for HTTP:
#
http.port: 9200
transport.tcp.port: 9300 |
етРяЕФ9300ЪЧМЏШКФкВПЭЈбЖЪЙгУЕФЖЫПкЃЌетИівВПЩвдаоИФЕєЁЃвђЮЊСЌНгМЏШКЕФЗНЪНгаСНжжЃЌЭЈЙ§АчбнМЏШКnodeвВЪЧПЩвдНјШыМЏШКЕФЃЌЫљвдЛЙЪЧАВШЋЦ№МћЃЌаоИФЕєФЌШЯЕФЖЫПкЁЃ
ЃЈБИзЂЃКМЧЕУаоИФШ§ИіНкЕуЕФЯрЭЌХфжУЃЌвЊВЛШЛНкЕужЎМфЮоЗЈНЈСЂСЌНгЙЄзїЃЌвВЛсБЈДэЁЃЃЉ
3.1.2.МЏШКЗЂЯжIPСаБэЁЂnodeЁЂclusterУћГЦ
НєНгзХаоИФМЏШКНкЕуIPЕижЗЃЌетбљПЩвдШУМЏШКдкЙцЖЈЕФМИИіНкЕужЎМфЙЄзїЁЃelasticsearchЃЌФЌШЯЪЧЪЙгУздЖЏЗЂЯжIPЛњжЦЁЃОЭЪЧдкЕБЧАЭјЖЮФкЃЌжЛвЊФмБЛздЖЏИажЊЕНЕФIPОЭФмздЖЏМгШыЕНМЏШКжаЁЃетгаКУДІвВгаЛЕДІЁЃКУДІОЭЪЧздЖЏЛЏСЫЃЌЕБФуЕФesМЏШКашвЊдЦЛЏЕФЪБКђОЭЛсЗЧГЃЗНБуЁЃЕЋЪЧвВЛсДјРДвЛаЉВЛЮШЖЈЕФЧщПіЃЌШчЃЌmasterЕФбЁОйЮЪЬтЁЂЪ§ОнИДжЦЮЪЬтЁЃ
ЕМжТmasterбЁОйЕФвђЫижЎвЛОЭЪЧМЏШКгаНкЕуНјШыЁЃЕБЪ§ОнИДжЦЗЂЩњЕФЪБКђвВЛсгАЯьМЏШКЃЌвђЮЊвЊзіЪ§ОнЦНКтИДжЦКЭШпгрЁЃетРяУцПЩвдЖРСЂmasterМЏШКЃЌЬоГ§masterМЏШКЕФЪ§ОнНкЕуФмСІЁЃ
ЙЬЖЈСаБэЕФIPЗЂЯжгаСНжжХфжУЗНЪНЃЌвЛжжЪЧЛЅЯрвРРЕЗЂЯжЃЌвЛжжЪЧШЋСПЗЂЯжЁЃИїгагХЪЦАЩЃЌЮвЪЧЪЙгУЕФвРРЕЗЂЯжРДзіЕФЁЃетгаИіКмживЊЕФВЮПМБъзМЃЌОЭЪЧФуЕФМЏШКРЉеЙЫйЖШгаЖрПьЁЃвђЮЊетгаИіЮЪЬтОЭЪЧЃЌЕБШЋСПЗЂЯжЕФЪБКђЃЌШчЙћЪЧГѕЪМЛЏМЏШКЛсгаКмДѓЕФЮЪЬтЃЌОЭЪЧmasterШЋОжЛсКмГЄЃЌШЛКѓНкЕужЎМфЕФЦєЖЏЫйЖШИїВЛвЛбљЁЃЫљвдЮвВЩгУСЫППЦзЕуЕФвРРЕЗЂЯжЁЃ
ФуашвЊдк192.168.0.20ЕФelasticsearchжаХфжУГЩЃК
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: [ "192.168.0.10:9300" ] |
ШУЫћШЅЗЂЯж10ЕФЛњЦїЃЌвдДЫФкЭЦЃЌЭъГЩЪЃЯТЕФ30ЕФХфжУЁЃ
ЃЈБИзЂЃКЭјЩЯгаКмЖреыЖдВЛЭЌГЁОАЕФЗЂЯжХфжУЃЌДѓМвПЩвдОЭДЫХззЉв§гёЃЌЖдетИіжїЬтИааЫШЄЕФПЩвдАйЖШКмЖрзЪСЯЕФЁЃЃЉ
ШЛКѓФуашвЊХфжУЯТМЏШКУћГЦЃЌОЭЪЧФуЕБЧАНкЕуЫљдкМЏШКЕФУћГЦЃЌетгажњгкФуЙцЛЎФуЕФМЏШКЁЃжЛгаМЏШКУћГЦвЛбљВХФмзщГЩвЛИіТпММЏШКЁЃ
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: orderSearch_cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-2 |
вдДЫРрЭЦЃЌЭъГЩСэЭтСНИіНкЕуЕФХфжУЁЃcluster.nameЕФУћГЦБиаыБЃГжвЛбљЁЃШЛКѓЗжБ№ЩшжУnode.nameЁЃ
3.1.3.master node ЦєЖЏЧаЛЛ
етРягавЛИіаЁаЁЕФОбщЗжЯэЯТЃЌОЭЪЧЮвдкЪЙгУМЏШКЕФЪБКђЃЌвђЮЊЮвЪЧащФтЛЏГіРДЕФЛњЦїЫљвдОГЃЛсЙиБеКЭжиЦєМЏШКЁЃгаЪБКђЗЂЯжМЏШКmasterаћОЦЛсгавЛИіЮЪЬтОЭЪЧЃЌШчЙћФуЕФМЏШКЙиБеЕФЗНЪНВЛЖдЃЌЛсжБНггАЯьЯТИіmasterбЁОйЕФТпМЁЃ
ЮвВщСЫЯТбЁОйЕФДѓИХТпМЃЌЫќЛсИљОнЗжЦЌЕФЪ§ОнЕФЧАКѓаТЯЪГЬЖШРДзїЮЊбЁОйЕФвЛИіживЊТпМЁЃЃЈШежОЁЂЪ§ОнЁЂЪБМфЖМЛсзїЮЊМЏШКmasterШЋОжЕФживЊжИБъЃЉ
вђЮЊПМТЧЕНЪ§ОнвЛжТадЮЪЬтЃЌЕБШЛЪЧгУзюаТЕФЪ§ОнНкЕузїЮЊmasterЃЌШЛКѓНјаааТЪ§ОнЕФИДжЦКЭЫЂаТЦфЫћnodeЁЃ
ШчЙћФуЗЂЯжгавЛИіНкЕуГйГйНјВЛСЫМЏШКЃЌПЩвдГЂЪджиЦєЯТesЗўЮёЃЌШУМЏШКmasterжиаТШЋОжЁЃ
3.2.linux ДђПЊзюДѓЮФМўЪ§ЩшжУЃЈгУзїindexЪБКђЕФЯЕЭГЗЇжЕЃЉ
дкlinuxЯЕЭГжаЃЌвЊЯыЪЙгУзюДѓЛЏЕФЯЕЭГзЪдДашвЊЯђВйзїЯЕЭГШЅЩъЧыЁЃгЩгкelasticsearchашвЊдкindexЕФЪБКђгУЕНДѓСПЕФЮФМўОфБњзЪдДЃЌдкдРДlinuxФЌШЯЕФзЪдДЯТПЩФмЛсВЛЙЛгУЁЃЫљвдетРяОЭашвЊЮвУЧдкЪЙгУЕФЪБКђЪТЯШЩшжУКУЁЃ
етИіХфжУдкЁЖElasticSearch ПЩРЉеЙЕФПЊдДЕЏадЫбЫїНтОіЗНАИЁЗвЛЪщжазїЮЊжиЕуХфжУНщЩмЃЌПЩЯыЖјжЊЛЙЪЧгаВЛЩйШЫВШЕНЙ§ЕФПгЁЃ
етИіХфжУдкelasticsearch service wrapperжаАяЮвУЧХфжУКУСЫЁЃ
vim /etc/init.d/elasticsearch

етИіХфжУЛсБЛЦєЖЏЕФЪБКђЩшжУЕНesЪЕР§жаШЅЁЃ
етИіЪБКђЪдзХжиЦєШ§ЬЈЛњЦїЕФesЪЕР§ЃЌПДФмВЛФмдк_plugin/headжаВщПДЕНШ§ЬЈЛњЦїЕФМЏШКзДЬЌЁЃЃЈМЧЕУЗУЮЪАВзАСЫheadВхМўЕФФЧЬЈЛњЦїЃЌЮветРяЪЧдк10ЛњЦїЩЯАВзАЕФЃЉ
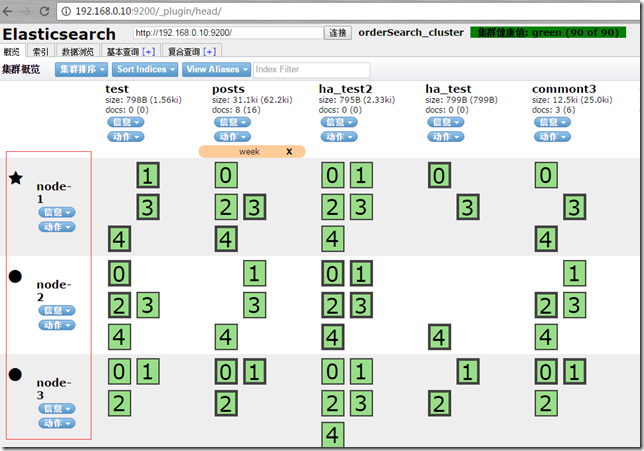
КьЩЋЕФОЭЪЧФуЩшжУЕФnode.nameНкЕуУћГЦЃЌЫћУЧдквЛИіМЏШКРяЙЄзїЁЃ
3.3.АВзАжаЮФЗжДЪЦїikЃЈзЂвтЖдгІАцБОЮЪЬтЃЉ
ДЫЪБМЏШКгІИУПЩвдЙЄзїСЫЃЌЮвУЧЛЙашвЊХфжУжаЮФЗжДЪЦїЃЌБЯОЙЮвУЧЪЙгУЕФжаЮФЃЌelasticsearchЕФздДјЕФЗжДЪЦїЖджаЮФЗжДЪжЇГжЕФВЛЬЋЪЪКЯБОЭСЁЃ
ЮвЪЧЪЙгУЕФikЗжДЪЦїЃЌдкgithubЩЯЕФЕижЗЃК https://github.com/medcl/elasticsearch-analysis-ik
ЯШБ№МБЕФcloneЃЌЮвУЧЯШРДПДЯТikЗжДЪЦїЫљжЇГжЕФelasticsearchЖдгІЕФАцБОЁЃ
ЮвУЧЪЙгУЕФelasticsearchАцБОЮЊ2.3.4ЁЃЫљвдЮвУЧвЊевЖдгІЕФikАцБОЃЌвЊВЛШЛЦєЖЏЕФЪБКђОЭжБНгБЈМгдиВЛСЫЖдгІАцБОЕФikВхМўЁЃЧаЛЛЕНreleaseАцБОСаБэЃЌевЕНЖдгІЕФАцБОШЛКѓЯТдиЯТРДЁЃ
ФуПЩвджБНгЯТдиЕНLinuxЛњЦїЩЯЃЌвВПЩвдЯТдиЕНФуЕФЫожїЛњЦїЩЯШЛКѓИДжЦЕНащФтЛњЩЯЁЃШчЙћФуЕФelasticsearchАцБОЪЧзюаТЕФЃЌФуПЩФмОЭашвЊЯТдиikдДТыЯТРДБрвыжЎКѓдйВПЪ№ЁЃ
ЕБШЛФуПЩвдЪЙгУgit+mavenЕФЗНЪНАВзАЃЌЯъЯИЕФАВзАВНжшПЩвдВЮМћЃК https://github.com/medcl/elasticsearch-analysis-ik
етвВБШНЯМђЕЅЃЌЮветРяОЭВЛжиИДСЫЁЃАВзАКУжЎКѓжиЦєesЪЕР§ЁЃ
3.4.elasticsearchМЏШКЙцЛЎЃЈmasterОЁСПВЛвЊзїЮЊdataНкЕуЃЌЖРСЂmasterЮЊcommanderЃЉ
ПЩвдетбљЙцЛЎвЛИіМЏШКЁЃmasterПЩвдСНЬЈЃЌетСНИіНкЕуЖМЪЧзїЮЊcommanderЭГГяМЏШКВуУцЕФЪТЮёЃЌШЁЯћетСНЬЈЕФdataШЈРћЁЃШЛКѓдкЙцЛЎГіШ§ИіНкЕуЕФdataМЏШКЃЌШЁЯћетШ§ИіНкЕуЕФmasterШЈРћЁЃШУЫћУЧАВаФЕФзіКУЪ§ОнДцДЂКЭМьЫїЗўЮёЁЃетЪЧзюаЁЕФСЃЖШМЏШКНсЙЙЃЌПЩвдЛљгкетИіНсЙЙНјааРЉеЙЁЃ
етбљзігавЛИіКУДІЃЌОЭЪЧжАд№ЗжУїЃЌПЩвдзюДѓЯоЖШЕФЗРжЙmasterНкЕугаЪТdataНкЕуЃЌЕМжТВЛЮШЖЈвђЫиЗЂЩњЁЃБШШчЃЌdataНкЕуЕФЪ§ОнИДжЦЃЌЪ§ОнЦНКтЃЌТЗгЩЕШЕШЃЌжБНггАЯьmasterЕФЮШЖЈадЁЃНјЖјПЩФмЛсЗЂЩњФдСбЮЪЬтЁЃ
4.ПЊЗЂ
ЮвУЧНјШызюКѓвЛИіЛЗНкЃЌЫљгаЕФЖЋЮїЖМзМБИКУСЫЃЌЮвУЧЪЧВЛЪЧгІИУВйзїВйзїетИіЧПДѓЕФЫбЫїв§ЧцСЫЁЃcome onЁЃ
4.1.НгШыМЏШКЗНЪН
ЫЕЕНМЏШКЃЌОЭЛсгаЯргІЕФЮЪЬтЫцжЎЖјРДЃЌИпПЩгУЁЂИпВЂЗЂЁЂДѓЪ§ОнЁЂКсЯђРЉеЙЕШЕШЁЃФЧУДelasticsearhЕФМЏШКДѓИХЪЧИіЪВУДдРэЁЃ
ЪзЯШclientЕФдкНгШыМЏШКЕФЪБКђЮЊСЫБЃжЄИпПЩгУВЛЪЧВЩгУ vipЦЏвЦЪЕЯжИпПЩгУЃЌРрЫЦkeepalived етжжЁЃelasticserachдкПЭЛЇЖЫСЌНгЕФЪБКђЪЙгУХфжУЖрИіIPЕФЗНЪНРДЪзЯШПЭЛЇЖЫsdkЕФИКдиЁЃетвбОЪЧЗжВМЪНЯЕЭГГЃМћЕФзіЗЈСЫЁЃжЛгаРрЫЦDBЁЂcacheетбљжааФЛЏЕФМЏШКашвЊЪЙгУЃЌвдЮЊЪЧЫќУЧЕФЪЙгУЬиЕуОіЖЈСЫЁЃЃЈЪ§ОнвЛжТадЃЉ
elasticsearchЕФЫљгаНкЕуЖМПЩвдДІРэЧыЧѓЃЌНкЕудНЖрВЂЗЂQPSдНИпЃЌЯргІЕФTPSЛсЯТНЕЃЌЕЋЪЧЯТНЕЕФадФмВЛЪЧИљОнНкЕуЕФе§БШР§РДЕФЁЃЃЈЫќЪЙгУquorumЃЈЗЈЖЈШЫЪ§ЃЉЫуЗЈЃЌБЃжЄПЩгУадЁЃЃЉЫљвдНкЕуЕФИДжЦВЛЪЧЮвУЧЯыЕБШЛЕФФЧбљЁЃ
СЌНгesМЏШКЕФЗНЪНгаСНжжЃЌадФмИпЕуЕФОЭЪЧжБНгНЋclientАчбнГЩcluster nodeНјШЅМЏШКЃЌЭЌЪБШЁЯћздМКЕФdataШЈРћЁЃетЭЈГЃЖМЪЧгУРДзіЖўДЮПЊЗЂгУЕФЃЌФуПЩвдgithub cloneЯТРДдДТыЬэМгздМКЕФГЁОАШЛКѓНјШыМЏШКЃЌПЩФмФуЛсИЩдЄбЁОйЃЌвВПЩФмЛсИЩдЄshardingЃЌвВПЩФмЛсИЩдЄМЏШКЦНКтЁЃ
elasticsearch ЪЙгУздМКЖЈвхЕФвЛЬзDSLгябдЃЌЪЙгУrestfulЗНЪНЪЙгУЃЌИљОнВЛЭЌЕФrest end pointРДЪЙгУЁЃБШШчЃЌ_searchЁЂ_catЁЂ_queryЕШЕШЁЃетаЉЖМЪЧжИЕуЕФrestЖЫЕуЁЃШЛКѓФуПЩвдpost dslЕНelasticsearchЗўЮёЦїДІРэЁЃ
elasticsearch search dslЃК https://www.elastic.co/guide/en/elasticsearch /reference/current/search.html
elasticsearch dsl apiЃК http://elasticsearch-dsl. readthedocs.io/en/latest/
Р§ЃК
POST _search
{
"query": {
"bool" : {
"must" : {
"query_string" : {
"query" : "query some test"
}
},
"filter" : {
"term" : { "user" : "plen" }
}
}
}
} |
ПЩЖСадКмЧПЃЌдкЭЈЙ§chromeВхМўSenseИЈжњБраДЃЌЛсБШНЯЗНБуЁЃ
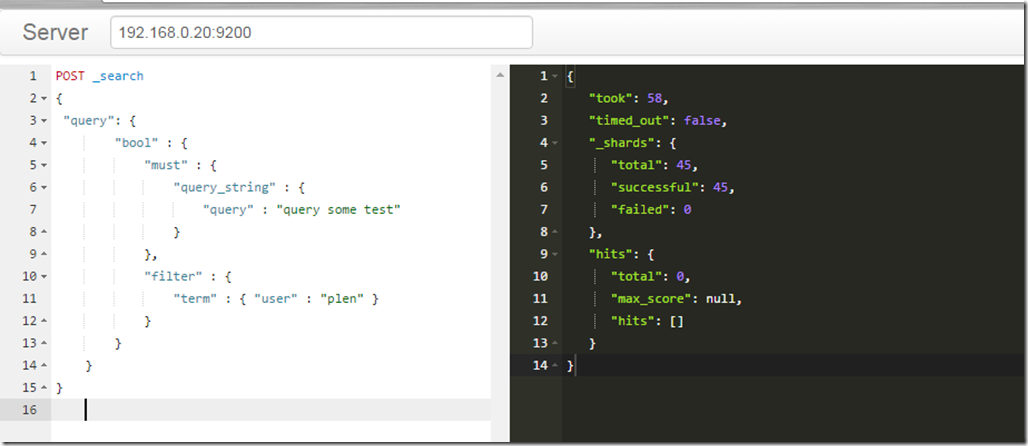
ЕЋЪЧвЛАуЖМВЛЛсетУДзіЃЌвЛАуЖМЪЧЪЙгУsdkСЌНгМЏШКЁЃжБНгЪЙгУdslЕФДѓЖрЪЧдкВтЪдЪ§ОнЕФЪБКђЛђепдкЕїЪдЕФЪБКђЁЃПДsdkЪфГіЕФdslЪЧЗёе§ШЗЁЃОЭИњЕїЪдSQLВюВЛЖрЁЃ
4.1.1.net nestЪЙгУЃЈЪЙгУpoolСЌНгesМЏШКЃЉ
.NETГЬађгаПЊдДАќnestЃЌжБНгдкNugetЩЯЫбЫїАВзАМДПЩЁЃ
ЙйЭјЕижЗЃК https://www.elastic.co/guide/en/ elasticsearch/client/net-api/1.x/ nest-connecting.html
ЪЙгУpoolИпПЩгУЕФЗНЪНСЌНгМЏШКЁЃ
var node1 = new Uri("http://192.168.0.10:9200");
var node2 = new Uri("http://192.168.0.20:9200");
var node3 = new Uri("http://192.168.0.30:9200");
var connectionPool = new SniffingConnectionPool(new[] { node1, node2, node3 });
var settings = new ConnectionSettings(connectionPool);
var client = new ElasticClient(settings); |
ДЫЪБЪЙгУclientЖдЯѓОЭЪЧШэИКдиЕФЃЌЫќЛсИљОнвЛЖЈЕФВпТдРДОљКтЕФСЌНгКѓЬЈШ§ИіnodeЁЃЃЈПЩФмЪЧЦНОљЕФЁЂПЩФмЪЧШЈжиЕФЃЌОпЬхУЛбаОПЃЉ
4.1.2.java jestЪЙгУ
java ЕФЛАЮвЪЧЪЙгУjestЁЃЮвУЧДДНЈвЛИіmavenЯюФПЃЌШЛКѓЬэМгjest ЯргІЕФjarАќmavenв§гУЁЃ
<dependencies>
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>2.0.3</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.3.5</version>
</dependency>
</dependencies> |
JestClientFactory factory = new JestClientFactory();
List<String> nodes = new LinkedList<String>();
nodes.add("http://192.168.0.10:9200");
nodes.add("http://192.168.0.20:9200");
nodes.add("http://192.168.0.30:9200");
HttpClientConfig config = new HttpClientConfig.Builder(nodes).multiThreaded(true).build();
factory.setHttpClientConfig(config);
JestHttpClient client = (JestHttpClient) factory.getObject();
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.queryStringQuery("жаЛЊШЫУћЙВКЭЙњ"));
searchSourceBuilder.field("name");
Search search = new Search.Builder(searchSourceBuilder.toString()).build();
JestResult rs = client.execute(search);
System.out.println(rs.getJsonString()); |
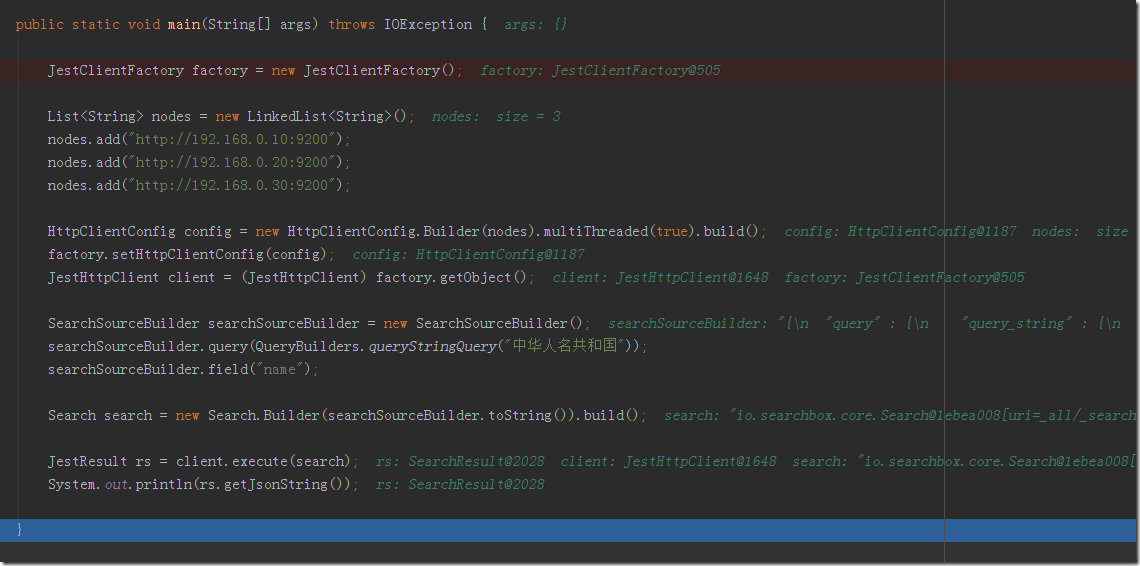
{
"took": 71,
"timed_out": false,
"_shards": {
"total": 45,
"successful": 45,
"failed": 0
},
"hits": {
"total": 6,
"max_score": 0.6614378,
"hits": [
{
"_index": "posts",
"_type": "post",
"_id": "1",
"_score": 0.6614378,
"fields": {
"name": [
"ЭѕЧхХр"
]
}
},
{
"_index": "posts",
"_type": "post",
"_id": "5",
"_score": 0.57875806,
"fields": {
"name": [
"ЭѕЧхХр"
]
}
},
{
"_index": "posts",
"_type": "post",
"_id": "2",
"_score": 0.57875806,
"fields": {
"name": [
"ЭѕЧхХр"
]
}
},
{
"_index": "posts",
"_type": "post",
"_id": "AVaKENIckgl39nrAi9V5",
"_score": 0.57875806,
"fields": {
"name": [
"ЭѕЧхХр"
]
}
},
{
"_index": "class",
"_type": "student",
"_id": "1",
"_score": 0.17759356
},
{
"_index": "posts",
"_type": "post",
"_id": "3",
"_score": 0.17759356,
"fields": {
"name": [
"ЭѕЧхХр"
]
}
}
]
}
} |
ЗЕЛиЕФЪ§ОнКсПчЖрИіЫїв§ЁЃФуПЩвдЭЈЙ§ВЛЖЯЕФdebugРДВщПДСДНгIPЪЧВЛЪЧЛсЦєЖЏЧаЛЛЃЌЪЧВЛЪЧЛсЦ№ЕНПЩгУадЕФзїгУЁЃ
4.2.indexПЊЗЂ
Ыїв§ПЊЗЂвЛАуВНжшБШНЯМђЕЅЃЌЪзЯШНЈСЂЖдгІЕФmappingгГЩфЃЌХфжУКУИїИіtypeжаЕФfieldЕФЬиадЁЃ
4.2.1.mapping ХфжУ
mappingЪЧesЪЕР§гУРДдкindexЕФЪБКђЃЌзїЮЊИїИізжЖЮЕФВйзївРОнЁЃБШШчЃЌusernameЃЌетИізжЖЮЪЧЗёвЊЫїв§ЁЂЪЧЗёвЊДцДЂЁЂГЄЖШДѓаЁЕШЕШЁЃЫфШЛelasticsearchПЩвдЖЏЬЌЕФДІРэетаЉЃЌЕЋЪЧГігкЙмРэКЭдЫЮЌЕФФПЕФЛЙЪЧНЈвщНЈСЂЖдгІЕФЫїв§гГЩфЃЌетИігГЩфПЩвдБЃДцдкЮФМўРяЃЌвдБуНЋРДжиНЈЫїв§гУЁЃ
POST /demoindex
{
"mappings": {
"demotype": {
"properties": {
"contents": {
"type": "string",
"index": "analyzed"
},
"name": {
"store": true,
"type": "string",
"index": "analyzed"
},
"id": {
"store": true,
"type": "long"
},
"userId": {
"store": true,
"type": "long"
}
}
}
}
} |
етЪЧвЛИізюМђЕЅЕФmappingЃЌЖЈвхСЫЫїв§УћГЦЮЊdemoindexЃЌРраЭЮЊdemotypeЕФmappingЁЃИїИізжЖЮЗжБ№ЪЧвЛИіjsonЖдЯѓЃЌРяУцгаРраЭгаЫїв§ЪЧЗёашвЊЁЃ
етИідкsenseРяБрМЃЌШЛКѓжБНгpostЬсНЛЁЃ
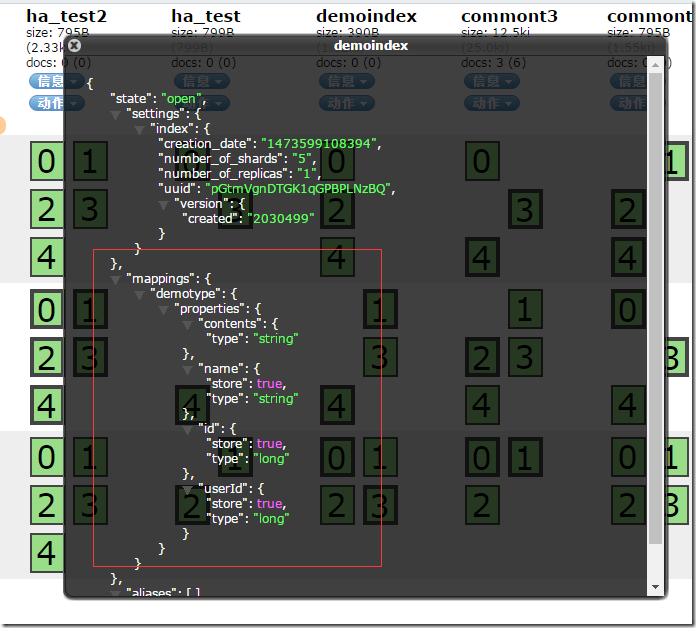
ЭЈЙ§ВщПДДДНЈКУЕФЫїв§аХЯЂШЗШЯЪЧЗёЪЧФуЬсНЛЕФmappingЩшжУЁЃ
4.2.2.mapping templateХфжУ
УПДЮЖМЭЈЙ§ЪжЖЏЕФДДНЈРрЫЦЕФmappingЪМжеЪЧИіЕЭаЇТЪЕФЪТЧщЃЌelasticserachжЇГжНЈСЂmappingФЃАхЃЌШЛКѓШУФЃАхздЖЏЦЅХфЪЙгУФФИіmappingЖЈвхЁЃ
PUT log_template
{
"order": 10,
"template": "log_*",
"settings": {
"index": {
"number_of_replicas": "2",
"number_of_shards": "5"
}
},
"mappings": {
"_default_": {
"_source_": {
"enable": false
}
}
}
} |
ДДНЈвЛИіlogРраЭЕФЫїв§mappingЁЃЮвУЧЩшжУСЫСНИіЛљБОЕФЪєадЃЌ "number_of_replicas": "2" ИДжЦЗжЪ§, "number_of_shards": "5" ЗжЦЌИіЪ§ЁЃmappingsРяУцЩшжУСЫsourceзжЖЮФЌШЯВЛПЊЦєЁЃ
ЕБЮвУЧЬсНЛЫљгавдЁАlog_xxxЁБУћзжИёЪНЕФЫїв§ЪБНЋздЖЏУќжаетИіmappingФЃАхЁЃ
ПЩвдЭЈЙ§_template restЖЫЕуВщПДвбОДцдкЕФmappingФЃАхЃЌЛђепЭЈЙ§headВхМўЕФгвЩЯНЧЕФЁБаХЯЂЁБРяУцЕФЁБФЃАхЁБВЫЕЅВщПДЁЃ
{
"mq_template" : {
"order" : 10,
"template" : "mq*",
"settings" : {
"index" : {
"number_of_shards" : "5",
"number_of_replicas" : "2"
}
},
"mappings" : {
"_default_" : {
"_source_" : {
"enable" : false
}
}
},
"aliases" : { }
},
"log_template" : {
"order" : 10,
"template" : "log_*",
"settings" : {
"index" : {
"number_of_shards" : "5",
"number_of_replicas" : "2"
}
},
"mappings" : {
"_default_" : {
"_source_" : {
"enable" : false
}
}
},
"aliases" : { }
},
"error_template" : {
"order" : 10,
"template" : "error_*",
"settings" : {
"index" : {
"number_of_shards" : "5",
"number_of_replicas" : "2"
}
},
"mappings" : {
"_default_" : {
"_source_" : {
"enable" : false
}
}
},
"aliases" : { }
}
} |
етЭЈГЃгУгквЛаЉвЕЮёВЛЯыЙиЕФДцДЂжаЃЌБШШчШежОЁЂЯћЯЂЁЂжиДѓДэЮѓдЄОЏЕШЕШЖМПЩвдЩшжУЃЌжЛвЊетаЉжиИДЕФmappingЪЧгаЙцТЩЕФЁЃ
4.2.3.index routingЫїв§ТЗгЩХфжУ
дкesЖдЪ§ОнНјааЗжЦЌЕФЪБКђЪЧВЩгУhashШЁгрЕФЗНЪННјааЕФЃЌЫљвдФуПЩвдДЋЕнвЛИіЙЬЖЈЕФkeyЃЌФЧУДетИіkeyНЋзїЮЊФуЙЬЖЈЕФТЗгЩЙцдђЁЃдкДДНЈmappingsЕФЪБКђПЩвдЩшжУетИі_routingВЮЪ§ЁЃетдк1.0ЕФАцБОжаЪЧетбљЕФЩшжУЕФЃЌвВОЭЪЧЫЕФуЕБЧАtypeЯТЕФЫљгаdocumentЖМЪЧжЛФмгУзХетИіТЗгЩkeyНјааЁЃЕЋЪЧдкes2.0жЎКѓroutingИњзХindexдЊЪ§ОнзпЃЌетбљПЩвдПижЦЕЅИіindexЕФТЗгЩЙцдђЃЌдкЬсНЛindexЕФЪБКђПЩвдЕЅЖРжЦЖЈ_routingВЮЪ§ЃЌЖјВЛЪЧжБНгЩшжУmappingsЩЯЁЃ
дк2.0жЎКѓвбОВЛдйжЇГжmappingsХфжУ_routingВЮЪ§СЫЁЃ
https://www.elastic.co/guide/ en/elasticsearch/reference/ current/breaking_20_mapping_changes. html#migration-meta-fields
дк1.0РяЃЌБШШчЃЌФуПЩвдНЋuseridзїЮЊrouting keyЃЌетбљОЭПЩвдНЋЕБЧАгУЛЇЕФЫљгаЪ§ОнЖМдквЛИіЗжЦЌЩЯЃЌЕБВщбЏЕФЪБКђОЭЛсМгПьВщбЏЫйЖШЁЃ
{
"mappings": {
"post": {
"_routing": {
"required": true,
"path":"userid"
},
"properties": {
"contents": {
"type": "string"
},
"name": {
"store": true,
"type": "string"
},
"id": {
"store": true,
"type": "long"
},
"userId": {
"store": true,
"type": "long"
}
}
}
}
} |
етИі_routingЪЧЩшжУдкmappingЩЯЕФЃЌзїгУгкЫљгаtypeЁЃЛсЪЙгУuseridзїЮЊshardingЕФkeyЁЃЕЋЪЧдк2.0РяЃЌЪЧБиаыУїШЗжИЖЈrouting pathЕФЁЃ
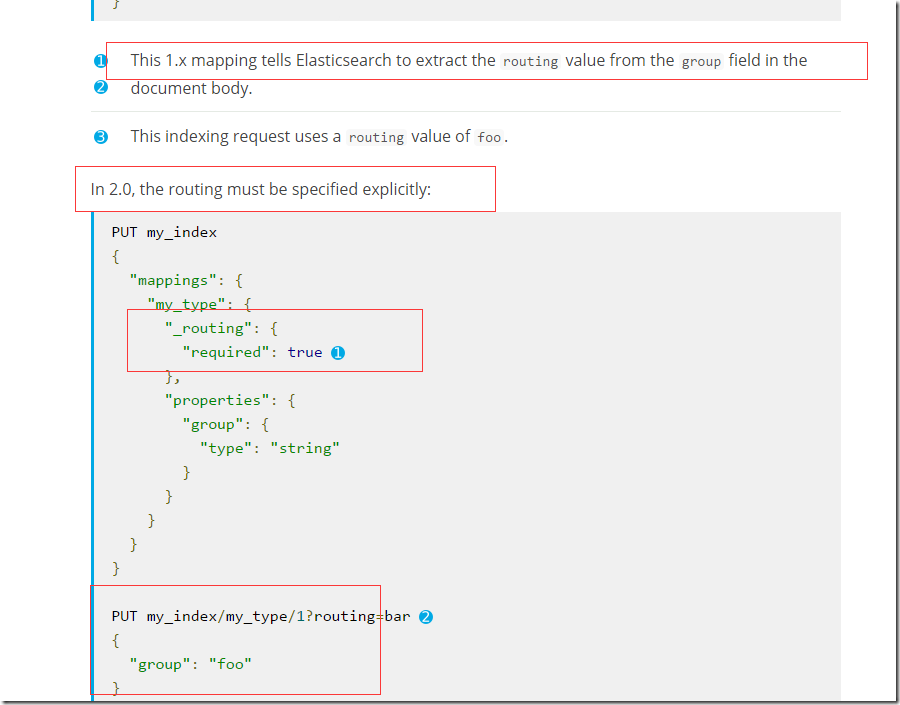
дкФуЬэМгКУmappingsжЎКѓЃЌДДНЈЕБЧАЫїв§ЕФЪБКђБиаыжИЖЈ&routing=xxxЃЌВЮЪ§ЁЃетгаИіКмДѓЕФКУДІОЭЪЧФуПЩвдИљОнВЛЭЌЕФвЕЮёЮЌЖШздгЩЕїећЗжЦЌВпТдЁЃ
5.змНс
ЪыФмЩњЧЩЃЌЗжВМЪНЕФЖЋЮїЛЙЪЧгаКмЖрБШНЯЬиЪтКЭЬєеНЕФЕиЗНЃЌгШЦфЪЧЫћЕФЗжВМадЃЌЭЌЪБЛЙвЊНтОіКмЖрвЛжТадЮЪЬтЁЂПЩгУадЮЪЬтЕШЕШЁЃЮвЖдelasticsearchЕФЪЙгУвВжЛЪЧИіМђЕЅЕФЦЄУЋЖјвбЃЌЫќЕФЗжВМЪНЬиадЩюЩюЕФЮќв§СЫЮвЃЌЦкД§ЯТЦЊЮФеТИќМгЩюШыЕФЗжЯэЁЃБШШчЃЌroutingЕФФкВПдРэЃЌИДжЦЦНКтЫуЗЈЕШЕШЁЃетЦЊЮФеТЪЧЮвЖдelasticsearchЪЙгУЕФвЛИіМђЕЅЕФзмНсЃЌЯЃЭћФмЖдИїЮЛВЉгбгаЕуАяжњЃЌаЛаЛдФЖСЃЌаЛаЛжЇГжЁЃ
ВЮПМЪщМЎЁЖElasticSearch ПЩРЉеЙЕФПЊдДЕЏадЫбЫїНтОіЗНАИЁЗЁЂЁЖElastcSearchШЈЭўжИФЯЁЗЁЃ
|









