| БрМЭЦМі: |
| БОЮФРДздгкCSDN,БОЮФзмНсСЫElasticsearchЕФЛљДЁжЊЪЖМАР§згЁЂМмЙЙЁЂЪЕЯжЯИНкКЭЦфЫћВЙГфЁЃ |
|
вЛЁЂЛљДЁжЊЪЖ
ElasticsearchЪЧУцЯђЮФЕЕ(document oriented)ЕФЃЌетвтЮЖзХЫќПЩвдДцДЂећИіЖдЯѓЛђЮФЕЕ(document)ЁЃШЛЖјЫќВЛНіНіЪЧДцДЂЃЌЛЙЛсЫїв§(index)УПИіЮФЕЕЕФФкШнЪЙжЎПЩвдБЛЫбЫїЁЃдкElasticsearchжаЃЌФуПЩвдЖдЮФЕЕЃЈЖјЗЧГЩааГЩСаЕФЪ§ОнЃЉНјааЫїв§ЁЂЫбЫїЁЂХХађЁЂЙ§ТЫЁЃетжжРэНтЪ§ОнЕФЗНЪНгывдЭљЭъШЋВЛЭЌЃЌетвВЪЧElasticsearchФмЙЛжДааИДдгЕФШЋЮФЫбЫїЕФдвђжЎвЛЁЃ
1ЁЂР§зг
ЮвУЧРДПДвЛИіЪЕМЪЕФР§згЃЌМйЩшгаШчЯТЕФЪ§ОнЃК
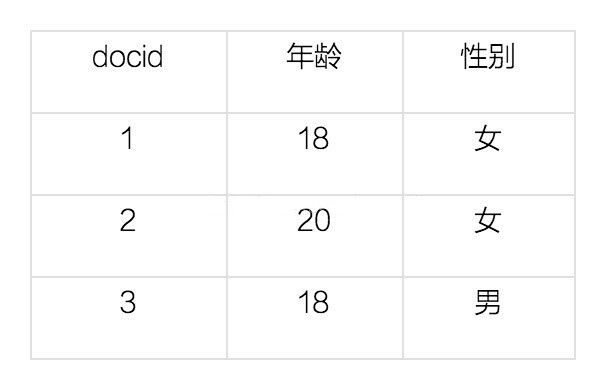
етРяУПвЛааЪЧвЛИіdocumentЁЃУПИіdocumentЖМгавЛИіdocidЁЃФЧУДИјетаЉdocumentНЈСЂЕФЕЙХХЫїв§ОЭЪЧЃК

ПЩвдПДЕНЃЌЕЙХХЫїв§ЪЧper fieldЕФЃЌвЛИізжЖЮгЩвЛИіздМКЕФЕЙХХЫїв§ЁЃ18,20етаЉНазі termЃЌЖј[1,3]ОЭЪЧposting listЁЃPosting listОЭЪЧвЛИіintЕФЪ§зщЃЌДцДЂСЫЫљгаЗћКЯФГИіtermЕФЮФЕЕidЁЃ
2ЁЂИХФю
ПЩвдАбesПДзіЪЧУцЯђЮФЕЕЕФЪ§ОнПтЃЌЫќгыЙиЯЕаЭЪ§ОнПтЕФУћДЪЖдееЙиЯЕШчЯТЃК
Relational DB => Databases => Tables => Rows => Columns
Elasticsearch => Index=> doc Types => Documents => Fields |
2.1ЁЂIndex Ыїв§
Ыїв§ЃЈindexЃЉЪЧElasticsearchЖдТпМЪ§ОнЕФТпМДцДЂЃЌЫљвдЫќПЩвдЗжЮЊИќаЁЕФВПЗжЁЃФуПЩвдАбЫїв§ПДГЩЙиЯЕаЭЪ§ОнПтЕФБэЁЃElasticsearchПЩвдАбЫїв§ДцЗХдквЛЬЈЛњЦїЛђепЗжЩЂдкЖрЬЈЗўЮёЦїЩЯЃЌУПИіЫїв§гавЛЛђЖрИіЗжЦЌЃЈshardЃЉЃЌУПИіЗжЦЌПЩвдгаЖрИіИББОЃЈreplicaЃЉЁЃ
2.2ЁЂdoc Types ЮФЕЕРраЭ
дкElasticsearchжаЃЌвЛИіЫїв§ЖдЯѓПЩвдДцДЂКмЖрВЛЭЌгУЭОЕФЖдЯѓЁЃР§ШчЃЌвЛИіВЉПЭгІгУГЬађПЩвдБЃДцЮФеТКЭЦРТлЁЃЮФЕЕРраЭШУЮвУЧЧсвзЕиЧјЗжЕЅИіЫїв§жаЕФВЛЭЌЖдЯѓЁЃУПИіЮФЕЕПЩвдгаВЛЭЌЕФНсЙЙЃЌЕЋдкЪЕМЪВПЪ№жаЃЌНЋЮФМўАДРраЭЧјЗжЖдЪ§ОнВйзїгаКмДѓАяжњЁЃ
2.3ЁЂ Document ЮФЕЕ
ДцДЂдкElasticsearchжаЕФжївЊЪЕЬхНаЮФЕЕЃЈdocumentЃЉЁЃгУЙиЯЕаЭЪ§ОнПтРДРрБШЕФЛАЃЌвЛИіЮФЕЕЯрЕБгкЪ§ОнПтБэжаЕФвЛааМЧТМЁЃДгПЭЛЇЖЫЕФНЧЖШПДЃЌЮФЕЕЪЧвЛИіJSONЖдЯѓЁЃУПИіЮФЕЕДцДЂдквЛИіЫїв§жаВЂгавЛИіElasticsearchздЖЏЩњГЩЕФЮЈвЛБъЪЖЗћКЭЮФЕЕРраЭЁЃ
2.4ЁЂfield
ЮФЕЕгЩЖрИіfieldзщГЩЃЌДгПЭЛЇЖЫЕФНЧЖШПДЃЌОЭЪЧjsonЖдЯѓжаЕФЖрИіkvНкЕуЁЃ
ЖўЁЂМмЙЙ
1ЁЂshard
ЪЕМЪЩЯЃЌindexНіНіжЛЪЧвЛИіУќУћПеМфРДжИЯђвЛИіЛђЖрИіЪЕМЪЕФЮяРэЗжЦЌ(shard)ЁЃОпЬхЕФЮяРэЗжВМСЃЖШЙиЯЕШчЯТЃК

вЛИіElasticsearch IndexЯрЕБгквЛИіMySQLРяЕФБэЃЌВЛЭЌIndexЕФЪ§ОнЪЧЮяРэЩЯИєРыПЊРДЕФЁЃElasticsearchЕФIndexЛсЗжГЩЖрИіShardДцДЂЃЌвЛВПЗжShardЪЧReplicaБИЗнЁЃвЛИіShardЪЧвЛЗнБОЕиЕФДцДЂЃЈвЛИіБОЕиДХХЬЩЯЕФФПТМЃЉЃЌвВОЭЪЧвЛИіLuceneЕФIndexЁЃВЛЭЌЕФShardПЩФмЛсБЛЗжХфЕНВЛЭЌЕФжїЛњНкЕуЩЯЁЃвЛИіLucene IndexЛсДцДЂКмЖрЕФdocЃЌЮЊСЫКУЙмРэЃЌLuceneАбLucene IndexдйВ№ГЩСЫSegmentДцДЂЃЈзгФПТМЃЉЁЃSegmentФкЕФdocЪ§СПЩЯЯоЪЧ2ЕФ31ДЮЗНЃЌетбљdoc idОЭжЛашвЊвЛИіintОЭПЩвдДцДЂЁЃSegmentЖдгІСЫвЛаЉСаЮФМўДцДЂЫїв§ЃЈЕЙХХБэЕШЃЉКЭжїДцДЂЃЈDocValuesЕШЃЉЃЌетаЉЮФМўФкВПгжЗжЮЊаЁЕФBlockНјаабЙЫѕЁЃ
вЛИіshardЪЕМЪЩЯЪЧвЛИіLuceneЪЕР§ЃЌдкЫќЕФФмСІЗЖЮЇФкгЕгаЭъећЕФЫбЫїЙІФм(дкДІРэЫќздМКгЕгаЕФЪ§ОнЪБгаЫљгаЕФЙІФм)ЁЃЮвУЧЫљгаЮФЕЕЕФЫїв§indexed(ЖЏДЪ)КЭДцДЂЙЄзїЖМЪЧдкshardЩЯЃЌЕЋетЪЧЭИУїЕФЃЌЮвУЧВЛашвЊжБНгКЭshardЭЈаХЃЌЖјЪЧКЭЮвУЧДДНЈЕФindex(УћДЪ)ЭЈаХЁЃ
shardsЪЧESНЋЪ§ОнЗжВМЪНдкФуЕФМЏШКЕФЙиМќЁЃЯыЯѓЯТshardsЪЧЪ§ОнЕФШнЦїЃЌЮФЕЕДцДЂдкshardsРяЃЌЖјshardsБЛЗжХфдкМЏШКЕФУПвЛИіНкЕуNodeРяЁЃЕБФуЕФМЏШКЙцФЃдіГЄКЭНЕЕЭЪБЃЌESЛсздЖЏЕФдкNodesМфЧЈвЦshardsвдБЃГжМЏШКЕФИКдиОљКтЁЃ
2ЁЂБИЗн
shardПЩЗжЮЊprimary shardКЭreplica shardЁЃ дквЛИіindexРяЕФУПвЛИіЮФЕЕЖМЪєгквЛИіЕЅЖРЕФprimary shardЃЌЫљвдprimary shardЕФЪ§СПОіЖЈСЫФузюДѓФмДцДЂЕФЪ§ОнСП(ЖдгІгквЛИіindex)ЁЃ
зЂвтЃКshardЪЧЙщЪєгыindexЕФЃЌЖјВЛЪЧclusterЕФЁЃ
replica shardЪЧprimary shardЕФПНБДЁЃreplicaгаСНИізїгУЃК 1.ШпгрШндж 2.ЬсЙЉЖСЧыЧѓЗўЮёЃЌР§ШчЫбЫїЛђЖСШЁЮФЕЕ
primary shardЕФЪ§СПдкЫїв§ДДНЈЪБШЗЖЈКѓВЛФмаоИФЃЌreplicaПЩвддкШЮКЮЪБКђаоИФЁЃ
3ЁЂShardsЮФЕЕТЗгЩ
ЕБФуЖдвЛИіЮФЕЕНЈСЂЫїв§ЪБЃЌЫќНіДцДЂдквЛИіprimary shardЩЯЁЃESЪЧдѕУДжЊЕРвЛИіЮФЕЕгІИУЪєгкФФИіshardЃПЕБФуДДНЈвЛИіаТЕФЮФЕЕЪБЃЌESЪЧдѕУДжЊЕРгІИУАбЫќДцДЂжСshard1ЛЙЪЧshard2ЃП етИіЙ§ГЬВЛФмЫцЛњЮоЙцТЩЕФЃЌвђЮЊвдКѓЮвУЧЛЙвЊНЋЫќШЁГіРДЁЃЫќЕФТЗгЩЫуЗЈЪЧЃК
shard = hash(routing) % numberofprimary_shards
routingЕФжЕПЩвдЪЧЮФЕЕЕФidЃЌвВПЩвдЪЧгУЛЇздМКЩшжУЕФвЛИіжЕЁЃhashНЋЛсИљОнroutingЫуГівЛИіЪ§жЕШЛКѓ%primaryshardsЕФЪ§СПЁЃетвВЪЧЮЊЪВУДprimary_shardsдкindexДДНЈЪБОЭВЛФмаоИФЕФдвђЁЃ
ЮвУЧПЩвдЯђетИіМЏШКЕФШЮКЮвЛЬЈNODEЗЂЫЭЧыЧѓЃЌУПвЛИіNODEЖМгаФмСІДІРэЧыЧѓЁЃУПвЛИіNODEЖМжЊЕРУПвЛИіЮФЕЕЫљдкЕФЮЛжУЫљвдПЩвджБНгНЋЧыЧѓТЗгЩЙ§ШЅЁЃЯТУцЕФР§згЃЌЮвУЧНЋЫљгаЕФЧыЧѓЖМЗЂЫЭЕНNODE1ЁЃ
4ЁЂаДВйзї
ДДНЈЁЂЫїв§ЁЂЩОГ§ЮФЕЕЖМЪЧаДВйзїЃЌетаЉВйзїБиаыдкprimary shardЭъШЋГЩЙІКѓВХФмПНБДжСЦфЖдгІЕФreplicasЩЯЁЃ
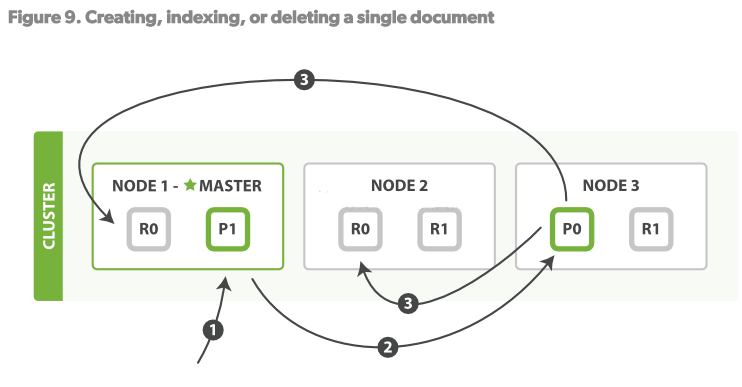
1.ПЭЛЇЖЫЯђNode1ЗЂЫЭаДВйзїЕФЧыЧѓЁЃ
2.Node1ЪЙгУЮФЕЕЕФ_idРДОіЖЈетИіЮФЕЕЪєгкshard0ЃЌШЛКѓНЋЧыЧѓТЗгЩжСNODE3ЃЌP0ЫљдкЕФЮЛжУЁЃ
3.Node3дкP0ЩЯжДааСЫЧыЧѓЁЃШчЙћЧыЧѓГЩЙІЃЌдђНЋЧыЧѓВЂааЕФТЗгЩжСNODE1 NODE2ЕФR0ЩЯЁЃЕБЫљгаЕФreplicasБЈИцГЩЙІКѓЃЌNODE3ЯђЧыЧѓЕФnode(NODE1)ЗЂЫЭГЩЙІБЈИцЃЌNODE1дйБЈИцжСClientЁЃ
ЕБПЭЛЇЖЫЪеЕНжДааГЩЙІКѓЃЌВйзївбОдкPrimary shardКЭЫљгаЕФreplica shardsЩЯжДааГЩЙІСЫЁЃ
ЕБШЛЃЌгавЛаЉЧыЧѓВЮЪ§ПЩвдаоИФетИіТпМЁЃМћдЮФЁЃ
5ЁЂЖСВйзї
вЛИіЮФЕЕПЩвддкprimary shardКЭЫљгаЕФreplica shardЩЯЖСШЁЁЃ
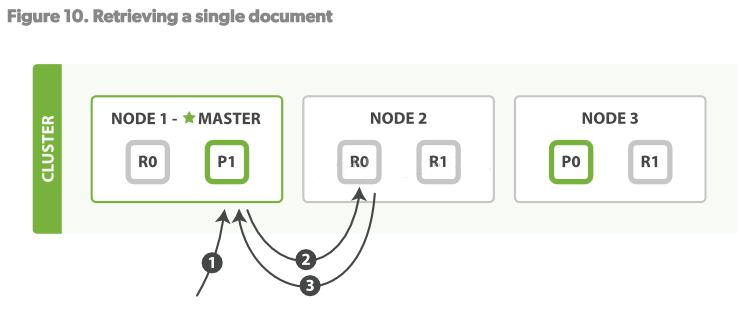
ЖСВйзїВНжшЃК
1.ПЭЛЇЖЫЗЂЫЭGetЧыЧѓЕНNODE1ЁЃ
2.NODE1ЪЙгУЮФЕЕЕФ_idОіЖЈЮФЕЕЪєгкshard 0.shard 0ЕФЫљгаПНБДДцдкгкЫљга3ИіНкЕуЩЯЁЃетДЮЃЌЫќНЋЧыЧѓТЗгЩжСNODE2ЁЃ
3.NODE2НЋЮФЕЕЗЕЛиИјNODE1ЃЌNODE1НЋЮФЕЕЗЕЛиИјПЭЛЇЖЫЁЃ ЖдгкЖСЧыЧѓЃЌЧыЧѓНкЕу(NODE1)НЋдкУПДЮЧыЧѓЕНРДЪБЖМбЁдёвЛИіВЛЭЌЕФreplicaЁЃ
shardРДДяЕНИКдиОљКтЁЃЪЙгУТжбЏВпТдТжбЏЫљгаЕФreplica shardsЁЃ
6ЁЂИќаТВйзї
ИќаТВйзїЃЌНсКЯСЫвдЩЯЕФСНИіВйзїЃКЖСЁЂаДЁЃ
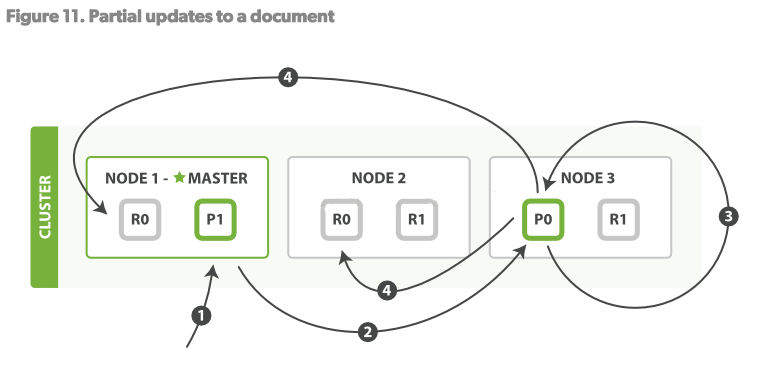
ВНжшЃК
1.ПЭЛЇЖЫЗЂЫЭИќаТВйзїЧыЧѓжСNODE1
2.NODE1НЋЧыЧѓТЗгЩжСNODE3ЃЌPrimary shardЫљдкЕФЮЛжУ
3.NODE3ДгP0ЖСШЁЮФЕЕЃЌИФБфsourceзжЖЮЕФJSONФкШнЃЌШЛКѓЪдЭМжиаТЖдаоИФКѓЕФЪ§ОндкP0зіЫїв§ЁЃШчЙћДЫЪБетИіЮФЕЕвбОБЛЦфЫћЕФНјГЬаоИФСЫЃЌФЧУДЫќНЋжиаТжДаа3ВНжшЃЌетИіЙ§ГЬШчЙћГЌЙ§СЫretryon_conflictЩшжУЕФДЮЪ§ЃЌОЭЗХЦњЁЃ
4.ШчЙћNODE3ГЩЙІИќаТСЫЮФЕЕЃЌЫќНЋВЂааЕФНЋаТАцБОЕФЮФЕЕЭЌВНЕНNODE1КЭNODE2ЕФreplica shardsжиаТНЈСЂЫїв§ЁЃвЛЕЉЫљгаЕФreplica
shardsБЈИцГЩЙІЃЌNODE3ЯђБЛЧыЧѓЕФНкЕу(NODE1)ЗЕЛиГЩЙІЃЌШЛКѓNODE1ЯђПЭЛЇЖЫЗЕЛиГЩЙІЁЃ
7ЁЂВщбЏВйзї
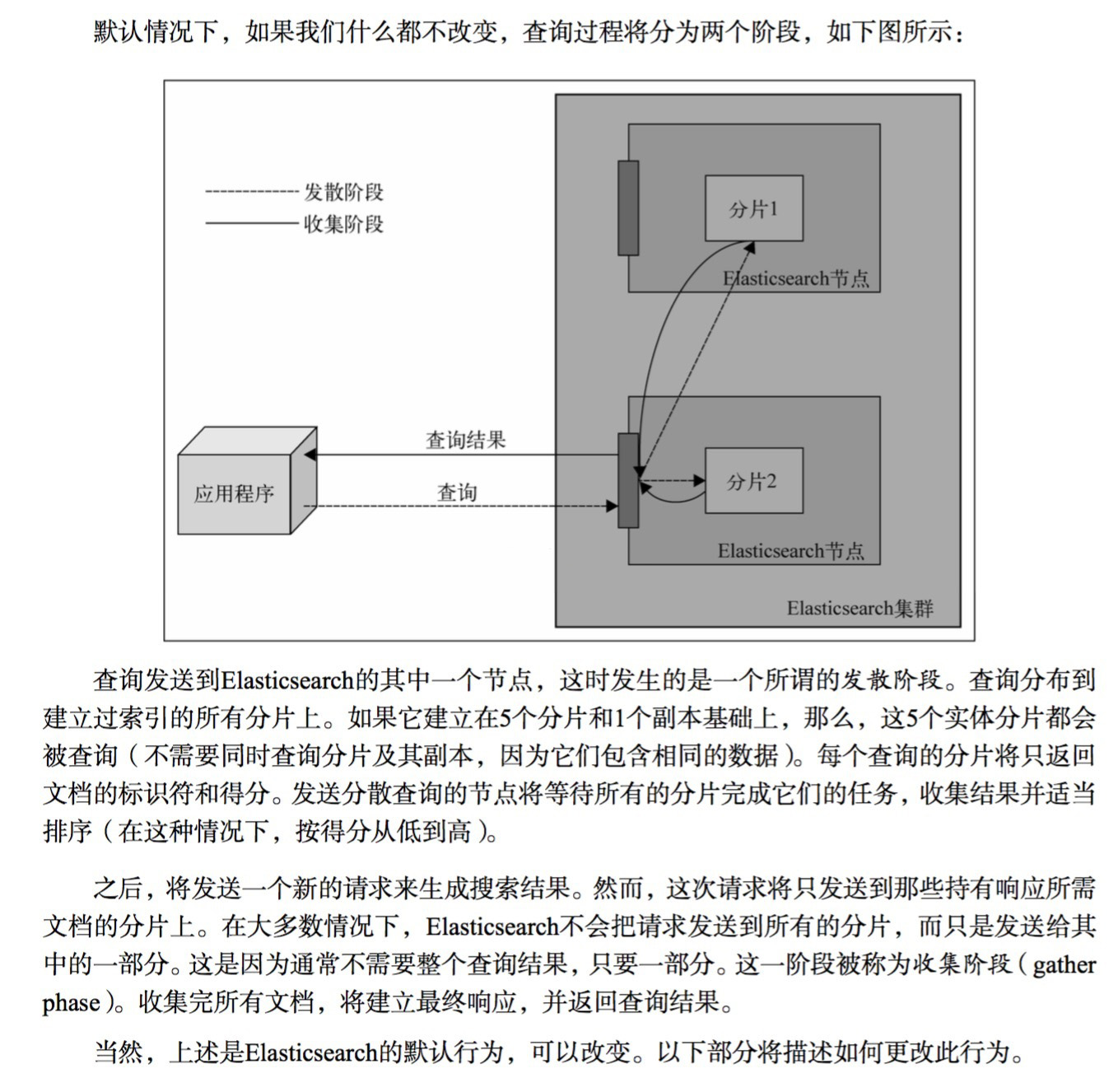
Ш§ЁЂЪЕЯжЯИНк
1ЁЂterm dictionary КЭ term index
ЮЊСЫЪЕЯжtermЕФПьЫйВщбЏЃЌЪЙгУСЫЪВУДбљЕФЪ§ОнНсЙЙФиЃП

МйЩшЮвУЧгаКмЖрИіtermЃЌБШШчЃК
Carla,Sara,Elin,Ada,Patty,Kate,Selena
ШчЙћАДееетбљЕФЫГађХХСаЃЌевГіФГИіЬиЖЈЕФtermвЛЖЈКмТ§ЃЌвђЮЊtermУЛгаХХађЃЌашвЊШЋВПЙ§ТЫвЛБщВХФмевГіЬиЖЈЕФtermЁЃХХађжЎКѓОЭБфГЩСЫЃК
Ada,Carla,Elin,Kate,Patty,Sara,Selena
етбљЮвУЧПЩвдгУЖўЗжВщевЕФЗНЪНЃЌБШШЋБщРњИќПьЕиевГіФПБъЕФtermЁЃетИіОЭЪЧ term dictionaryЁЃгаСЫterm dictionaryжЎКѓЃЌПЩвдгУ logN ДЮДХХЬВщевЕУЕНФПБъЁЃЕЋЪЧДХХЬЕФЫцЛњЖСВйзїШдШЛЪЧЗЧГЃАКЙѓЕФЃЈвЛДЮrandom accessДѓИХашвЊ10msЕФЪБМфЃЉЁЃЫљвдОЁСПЩйЕФЖСДХХЬЃЌгаБивЊАбвЛаЉЪ§ОнЛКДцЕНФкДцРяЁЃЕЋЪЧећИіterm dictionaryБОЩэгжЬЋДѓСЫЃЌЮоЗЈЭъећЕиЗХЕНФкДцРяЁЃгкЪЧОЭгаСЫterm indexЁЃterm indexгаЕуЯёвЛБОзжЕфЕФДѓЕФеТНкБэЁЃБШШчЃК
AПЊЭЗЕФterm ЁЁЁЁЁ. XxxвГ
CПЊЭЗЕФterm ЁЁЁЁЁ. XxxвГ
EПЊЭЗЕФterm ЁЁЁЁЁ. XxxвГ
ШчЙћЫљгаЕФtermЖМЪЧгЂЮФзжЗћЕФЛАЃЌПЩФметИіterm indexОЭецЕФЪЧ26ИігЂЮФзжЗћБэЙЙГЩЕФСЫЁЃЕЋЪЧЪЕМЪЕФЧщПіЪЧЃЌtermЮДБиЖМЪЧгЂЮФзжЗћЃЌtermПЩвдЪЧШЮвтЕФbyteЪ§зщЁЃЖјЧв26ИігЂЮФзжЗћвВЮДБиЪЧУПвЛИізжЗћЖМгаОљЕШЕФtermЃЌБШШчxзжЗћПЊЭЗЕФtermПЩФмвЛИіЖМУЛгаЃЌЖјsПЊЭЗЕФtermгжЬиБ№ЖрЁЃЪЕМЪЕФterm indexЪЧвЛПУtrie ЪїЃК
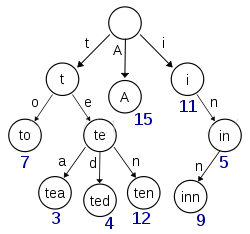
Р§згЪЧвЛИіАќКЌ "A", "to", "tea", "ted", "ten", "i", "in", КЭ "inn" ЕФ trie ЪїЁЃетПУЪїВЛЛсАќКЌЫљгаЕФtermЃЌЫќАќКЌЕФЪЧtermЕФвЛаЉЧАзКЁЃЭЈЙ§term indexПЩвдПьЫйЕиЖЈЮЛЕНterm dictionaryЕФФГИіoffsetЃЌШЛКѓДгетИіЮЛжУдйЭљКѓЫГађВщевЁЃдйМгЩЯвЛаЉбЙЫѕММЪѕЃЈЫбЫї Lucene Finite State TransducersЃЉ term index ЕФГпДчПЩвджЛгаЫљгаtermЕФГпДчЕФМИЪЎЗжжЎвЛЃЌЪЙЕУгУФкДцЛКДцећИіterm indexБфГЩПЩФмЁЃећЬхЩЯРДЫЕОЭЪЧетбљЕФаЇЙћЁЃ
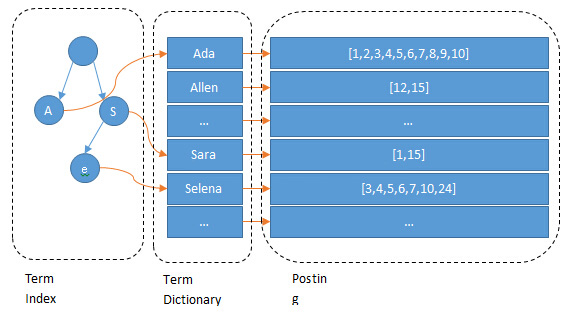
ЯждкЮвУЧПЩвдЛиД№ЁАЮЊЪВУДElasticsearch/LuceneМьЫїПЩвдБШmysqlПьСЫЁЃMysqlжЛгаterm dictionaryетвЛВуЃЌЪЧвдb-treeХХађЕФЗНЪНДцДЂдкДХХЬЩЯЕФЁЃМьЫївЛИіtermашвЊШєИЩДЮЕФrandom accessЕФДХХЬВйзїЁЃЖјLuceneдкterm dictionaryЕФЛљДЁЩЯЬэМгСЫterm indexРДМгЫйМьЫїЃЌterm indexвдЪїЕФаЮЪНЛКДцдкФкДцжаЁЃДгterm indexВщЕНЖдгІЕФterm dictionaryЕФblockЮЛжУжЎКѓЃЌдйШЅДХХЬЩЯевtermЃЌДѓДѓМѕЩйСЫДХХЬЕФrandom accessДЮЪ§ЁЃ
ЖюЭтжЕЕУвЛЬсЕФСНЕуЪЧЃКterm indexдкФкДцжаЪЧвдFSTЃЈfinite state transducersЃЉЕФаЮЪНБЃДцЕФЃЌЦфЬиЕуЪЧЗЧГЃНкЪЁФкДцЁЃTerm dictionaryдкДХХЬЩЯЪЧвдЗжblockЕФЗНЪНБЃДцЕФЃЌвЛИіblockФкВПРћгУЙЋЙВЧАзКбЙЫѕЃЌБШШчЖМЪЧAbПЊЭЗЕФЕЅДЪОЭПЩвдАбAbЪЁШЅЁЃетбљterm dictionaryПЩвдБШb-treeИќНкдМДХХЬПеМфЁЃ
2ЁЂШчКЮСЊКЯЫїв§ВщбЏЃП
ЫљвдИјЖЈВщбЏЙ§ТЫЬѕМў age=18 ЕФЙ§ГЬОЭЪЧЯШДгterm indexевЕН18дкterm dictionaryЕФДѓИХЮЛжУЃЌШЛКѓдйДгterm dictionaryРяОЋШЗЕиевЕН18етИіtermЃЌШЛКѓЕУЕНвЛИіposting listЛђепвЛИіжИЯђposting listЮЛжУЕФжИеыЁЃШЛКѓдйВщбЏ gender=ХЎ ЕФЙ§ГЬвВЪЧРрЫЦЕФЁЃзюКѓЕУГі age=18 AND gender=ХЎ ОЭЪЧАбСНИі posting list зівЛИіЁАгыЁБЕФКЯВЂЁЃ
етИіРэТлЩЯЕФЁАгыЁБКЯВЂЕФВйзїПЩВЛШнвзЁЃЖдгкmysqlРДЫЕЃЌШчЙћФуИјageКЭgenderСНИізжЖЮЖМНЈСЂСЫЫїв§ЃЌВщбЏЕФЪБКђжЛЛсбЁдёЦфжазюselectiveЕФРДгУЃЌШЛКѓСэЭтвЛИіЬѕМўЪЧдкБщРњааЕФЙ§ГЬжадкФкДцжаМЦЫужЎКѓЙ§ТЫЕєЁЃФЧУДвЊШчКЮВХФмСЊКЯЪЙгУСНИіЫїв§ФиЃПгаСНжжАьЗЈЃК
ЪЙгУskip listЪ§ОнНсЙЙЁЃЭЌЪББщРњgenderКЭageЕФposting listЃЌЛЅЯрskipЃЛ
ЪЙгУbitsetЪ§ОнНсЙЙЃЌЖдgenderКЭageСНИіfilterЗжБ№ЧѓГіbitsetЃЌЖдСНИіbitsetзіANВйзїЁЃ
PostgreSQL Дг 8.4 АцБОПЊЪМжЇГжЭЈЙ§bitmapСЊКЯЪЙгУСНИіЫїв§ЃЌОЭЪЧРћгУСЫbitsetЪ§ОнНсЙЙРДзіЕНЕФЁЃЕБШЛвЛаЉЩЬвЕЕФЙиЯЕаЭЪ§ОнПтвВжЇГжРрЫЦЕФСЊКЯЫїв§ЕФЙІФмЁЃElasticsearchжЇГжвдЩЯСНжжЕФСЊКЯЫїв§ЗНЪНЃЌШчЙћВщбЏЕФfilterЛКДцЕНСЫФкДцжаЃЈвдbitsetЕФаЮЪНЃЉЃЌФЧУДКЯВЂОЭЪЧСНИіbitsetЕФANDЁЃШчЙћВщбЏЕФfilterУЛгаЛКДцЃЌФЧУДОЭгУskip listЕФЗНЪНШЅБщРњСНИіon diskЕФposting listЁЃ
1ЁЂРћгУ Skip List КЯВЂ
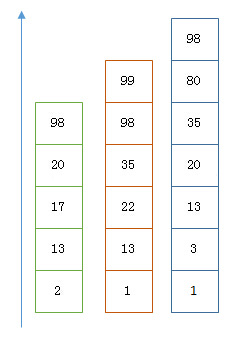
вдЩЯЪЧШ§Иіposting listЁЃЮвУЧЯждкашвЊАбЫќУЧгУANDЕФЙиЯЕКЯВЂЃЌЕУГіposting listЕФНЛМЏЁЃЪзЯШбЁдёзюЖЬЕФposting listЃЌШЛКѓДгаЁЕНДѓБщРњЁЃБщРњЕФЙ§ГЬПЩвдЬјЙ§вЛаЉдЊЫиЃЌБШШчЮвУЧБщРњЕНТЬЩЋЕФ13ЕФЪБКђЃЌОЭПЩвдЬјЙ§РЖЩЋЕФ3СЫЃЌвђЮЊ3БШ13вЊаЁЁЃ
ећИіЙ§ГЬШчЯТ
Next -> 2
Advance(2) -> 13
Advance(13) -> 13
Already on 13
Advance(13) -> 13 MATCH!!!
Next -> 17
Advance(17) -> 22
Advance(22) -> 98
Advance(98) -> 98
Advance(98) -> 98 MATCH!!! |
зюКѓЕУГіЕФНЛМЏЪЧ[13,98]ЃЌЫљашЕФЪБМфБШЭъећБщРњШ§Иіposting listвЊПьЕУЖрЁЃЕЋЪЧЧАЬсЪЧУПИіlistашвЊжИГіAdvanceетИіВйзїЃЌПьЫйвЦЖЏжИЯђЕФЮЛжУЁЃЪВУДбљЕФlistПЩвдетбљAdvanceЭљЧАзіЭмЬјЃПskip listЃК
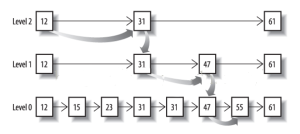
ДгИХФюЩЯРДЫЕЃЌЖдгквЛИіКмГЄЕФposting listЃЌБШШчЃК
[1,3,13,101,105,108,255,256,257]
ЮвУЧПЩвдАбетИіlistЗжГЩШ§ИіblockЃК
[1,3,13] [101,105,108] [255,256,257]
ШЛКѓПЩвдЙЙНЈГіskip listЕФЕкЖўВуЃК
[1,101,255]
1,101,255ЗжБ№жИЯђздМКЖдгІЕФblockЁЃетбљОЭПЩвдКмПьЕиПчblockЕФвЦЖЏжИЯђЮЛжУСЫЁЃ
LuceneздШЛЛсЖдетИіblockдйДЮНјаабЙЫѕЁЃЦфбЙЫѕЗНЪННазіFrame Of ReferenceБрТыЁЃЪОР§ШчЯТЃК
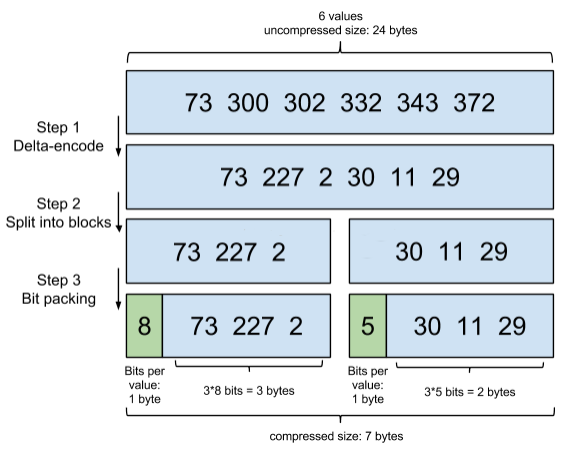
ПМТЧЕНЦЕЗБГіЯжЕФtermЃЈЫљЮНlow cardinalityЕФжЕЃЉЃЌБШШчgenderРяЕФФаЛђепХЎЁЃШчЙћга1АйЭђИіЮФЕЕЃЌФЧУДадБ№ЮЊФаЕФposting listРяОЭЛсга50ЭђИіintжЕЁЃгУFrame of ReferenceБрТыНјаабЙЫѕПЩвдМЋДѓМѕЩйДХХЬеМгУЁЃетИігХЛЏЖдгкМѕЩйЫїв§ГпДчгаЗЧГЃживЊЕФвтвхЁЃЕБШЛmysql b-treeРявВгавЛИіРрЫЦЕФposting listЕФЖЋЮїЃЌЪЧЮДОЙ§етбљбЙЫѕЕФЁЃ
вђЮЊетИіFrame of ReferenceЕФБрТыЪЧгаНтбЙЫѕГЩБОЕФЁЃРћгУskip listЃЌГ§СЫЬјЙ§СЫБщРњЕФГЩБОЃЌвВЬјЙ§СЫНтбЙЫѕетаЉбЙЫѕЙ§ЕФblockЕФЙ§ГЬЃЌДгЖјНкЪЁСЫcpuЁЃ
2ЁЂРћгУbitsetКЯВЂ
BitsetЪЧвЛжжКмжБЙлЕФЪ§ОнНсЙЙЃЌЖдгІposting listШчЃК
[1,3,4,7,10]
ЖдгІЕФbitsetОЭЪЧЃК
[1,0,1,1,0,0,1,0,0,1]
УПИіЮФЕЕАДееЮФЕЕidХХађЖдгІЦфжаЕФвЛИіbitЁЃBitsetздЩэОЭгабЙЫѕЕФЬиЕуЃЌЦфгУвЛИіbyteОЭПЩвдДњБэ8ИіЮФЕЕЁЃЫљвд100ЭђИіЮФЕЕжЛашвЊ12.5ЭђИіbyteЁЃЕЋЪЧПМТЧЕНЮФЕЕПЩФмгаЪ§ЪЎвкжЎЖрЃЌдкФкДцРяБЃДцbitsetШдШЛЪЧКмЩнГоЕФЪТЧщЁЃЖјЧвЖдгкИіУПвЛИіfilterЖМвЊЯћКФвЛИіbitsetЃЌБШШчage=18ЛКДцЦ№РДЕФЛАЪЧвЛИіbitsetЃЌ18<=age<25ЪЧСэЭтвЛИіfilterЛКДцЦ№РДвВвЊвЛИіbitsetЁЃ
ЫљвдУиОїОЭдкгкашвЊгавЛИіЪ§ОнНсЙЙЃК
ПЩвдКмбЙЫѕЕиБЃДцЩЯвкИіbitДњБэЖдгІЕФЮФЕЕЪЧЗёЦЅХфfilterЃЛ
етИібЙЫѕЕФbitsetШдШЛПЩвдКмПьЕиНјааANDКЭ ORЕФТпМВйзїЁЃ
LuceneЪЙгУЕФетИіЪ§ОнНсЙЙНазі Roaring BitmapЁЃ
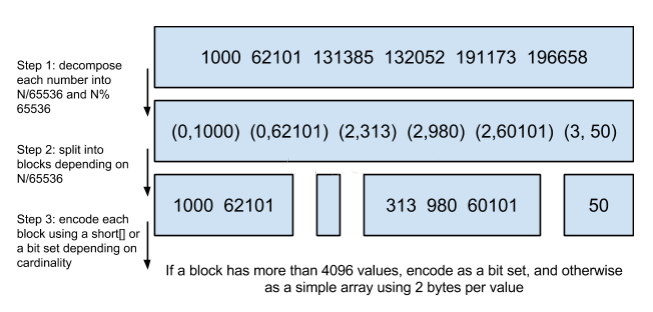
ЦфбЙЫѕЕФЫМТЗЦфЪЕКмМђЕЅЁЃгыЦфБЃДц100Иі0ЃЌеМгУ100ИіbitЁЃЛЙВЛШчБЃДц0вЛДЮЃЌШЛКѓЩљУїетИі0жиИДСЫ100БщЁЃ
етСНжжКЯВЂЪЙгУЫїв§ЕФЗНЪНЖМгаЦфгУЭОЁЃElasticsearchЖдЦфадФмгаЯъЯИЕФЖдБШЃЈhttps://www.elastic.co/blog/frame-of-reference-and-roaring-bitmapsЃЉЁЃМђЕЅЕФНсТлЪЧЃКвђЮЊFrame of ReferenceБрТыЪЧШчДЫ ИпаЇЃЌЖдгкМђЕЅЕФЯрЕШЬѕМўЕФЙ§ТЫЛКДцГЩДПФкДцЕФbitsetЛЙВЛШчашвЊЗУЮЪДХХЬЕФskip listЕФЗНЪНвЊПьЁЃ
3ЁЂШчКЮМѕЩйЮФЕЕЪ§ЃП
вЛжжГЃМћЕФбЙЫѕДцДЂЪБМфађСаЕФЗНЪНЪЧАбЖрИіЪ§ОнЕуКЯВЂГЩвЛааЁЃOpentsdbжЇГжКЃСПЪ§ОнЕФвЛИіОјеаОЭЪЧЖЈЦкАбКмЖрааЪ§ОнКЯВЂГЩвЛааЃЌетИіЙ§ГЬНаcompactionЁЃРрЫЦЕФvivdcortextЪЙгУmysqlДцДЂЕФЪБКђЃЌвВАбвЛЗжжгЕФКмЖрЪ§ОнЕуКЯВЂДцДЂЕНmysqlЕФвЛааРявдМѕЩйааЪ§ЁЃ
етИіЙ§ГЬПЩвдЪОР§ШчЯТЃК
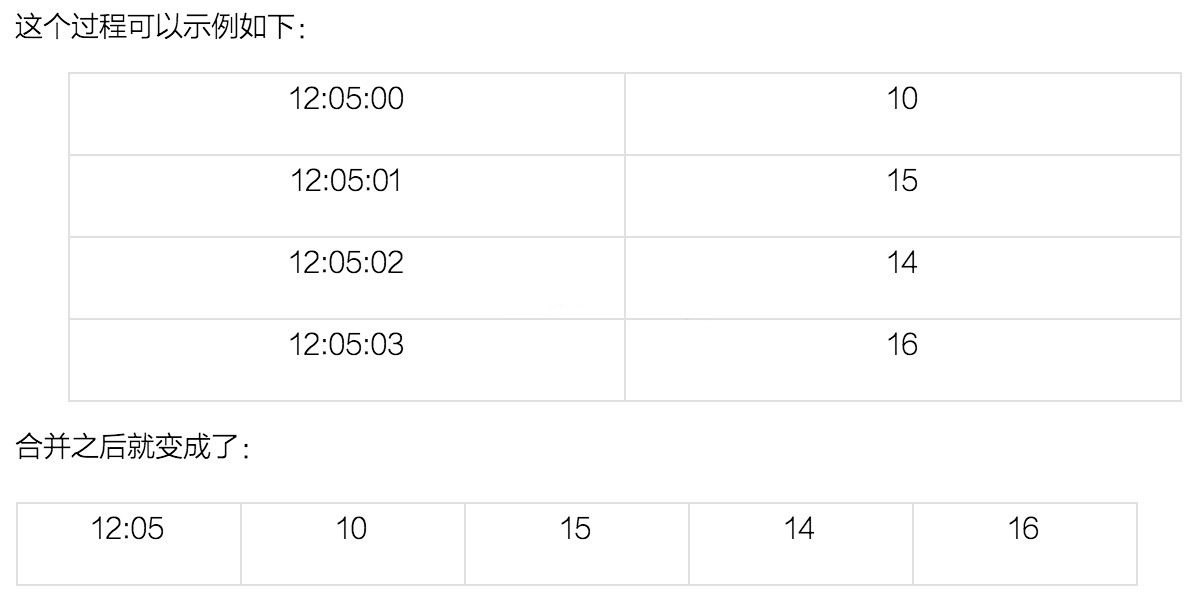
ПЩвдПДЕНЃЌааБфГЩСЫСаСЫЁЃУПвЛСаПЩвдДњБэетвЛЗжжгФквЛУыЕФЪ§ОнЁЃ
ElasticsearchгавЛИіЙІФмПЩвдЪЕЯжРрЫЦЕФгХЛЏаЇЙћЃЌФЧОЭЪЧNested DocumentЁЃЮвУЧПЩвдАбвЛЖЮЪБМфЕФКмЖрИіЪ§ОнЕуДђАќДцДЂЕНвЛИіИИЮФЕЕРяЃЌБфГЩЦфЧЖЬзЕФзгЮФЕЕЁЃЪОР§ШчЯТЃК
{timestamp:12:05:01, idc:sz, value1:10,value2:11}
{timestamp:12:05:02, idc:sz, value1:9,value2:9}
{timestamp:12:05:02, idc:sz, value1:18,value:17} |
ПЩвдДђАќГЩЃК
{
max_timestamp:12:05:02, min_timestamp: 1205:01, idc:sz,
records: [
{timestamp:12:05:01, value1:10,value2:11}
{timestamp:12:05:02, value1:9,value2:9}
{timestamp:12:05:02, value1:18,value:17}
]
} |
етбљПЩвдАбЪ§ОнЕуЙЋЙВЕФЮЌЖШзжЖЮЩЯвЦЕНИИЮФЕЕРяЃЌЖјВЛгУдкУПИізгЮФЕЕРяжиИДДцДЂЃЌДгЖјМѕЩйЫїв§ЕФГпДчЁЃ
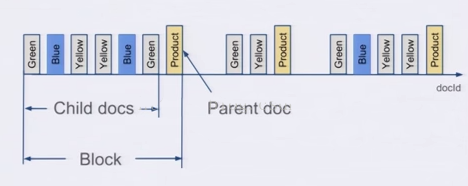
ЃЈЭМЦЌРДдДЃКhttps://www.youtube.com/watch?v=Su5SHc_uJw8ЃЌFaceting with Lucene Block Join QueryЃЉ
дкДцДЂЕФЪБКђЃЌЮоТлИИЮФЕЕЛЙЪЧзгЮФЕЕЃЌЖдгкLuceneРДЫЕЖМЪЧЮФЕЕЃЌЖМЛсгаЮФЕЕIdЁЃЕЋЪЧЖдгкЧЖЬзЮФЕЕРДЫЕЃЌПЩвдБЃДцЦ№згЮФЕЕКЭИИЮФЕЕЕФЮФЕЕidЪЧСЌајЕФЃЌЖјЧвИИЮФЕЕзмЪЧзюКѓвЛИіЁЃгаетбљвЛИіХХађадзїЮЊБЃеЯЃЌФЧУДгавЛИіЫљгаИИЮФЕЕЕФposting listОЭПЩвдИњзйЫљгаЕФИИзгЙиЯЕЁЃвВПЩвдКмШнвзЕидкИИзгЮФЕЕidжЎМфзізЊЛЛЁЃАбИИзгЙиЯЕвВРэНтЮЊвЛИіfilterЃЌФЧУДВщбЏЪБМьЫїЕФЪБКђВЛЙ§ЪЧгжANDСЫСэЭтвЛИіfilterЖјвбЁЃЧАУцЮвУЧвбОПДЕНСЫElasticsearchПЩвдЗЧГЃИпаЇЕиДІРэЖрfilterЕФЧщПіЃЌГфЗжРћгУЕзВуЕФЫїв§ЁЃ
ЪЙгУСЫЧЖЬзЮФЕЕжЎКѓЃЌЖдгкtermЕФposting listжЛашвЊБЃДцИИЮФЕЕЕФdoc idОЭПЩвдСЫЃЌПЩвдБШБЃДцЫљгаЕФЪ§ОнЕуЕФdoc idвЊЩйКмЖрЁЃШчЙћЮвУЧПЩвддквЛИіИИЮФЕЕРяШћШы50ИіЧЖЬзЮФЕЕЃЌФЧУДposting listПЩвдБфГЩжЎЧАЕФ1/50ЁЃ
ЫФЁЂВЙГф

|









