| БрМЭЦМі: |
| БОЮФРДздгкжмаёСњ,НщЩмСЫHBaseГіЯжЕФБГОАЁЂHBaseдкHadoopЯюФПжаЕФЮЛжУЁЂЪ§ОнФЃаЭЁЂЯЕЭГМмЙЙЁЃ |
|
HBaseЪЧApache HadoopЕФЪ§ОнПтЃЌФмЙЛЖдДѓаЭЪ§ОнЬсЙЉЫцЛњЁЂЪЕЪБЕФЖСаДЗУЮЪЁЃHBaseЕФФПБъЪЧДцДЂВЂДІРэДѓаЭЕФЪ§ОнЁЃHBaseЪЧвЛИіПЊдДЕФЃЌЗжВМЪНЕФЃЌЖрАцБОЕФЃЌУцЯђСаЕФДцДЂФЃаЭЃЌЫќДцДЂЕФЪЧЫЩЩЂаЭЪ§ОнЁЃ
вЛЁЂHBaseЃКBigTableЕФПЊдДЪЕЯж
1.1 HBaseГіЯжЕФБГОА

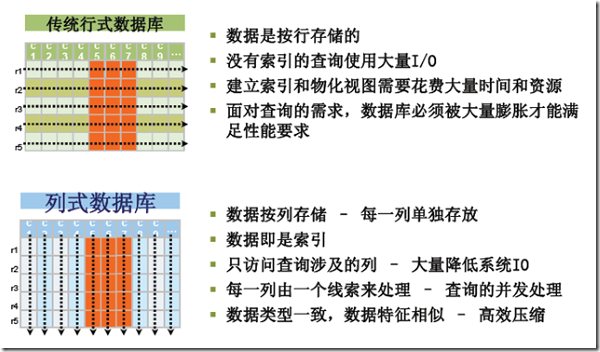
ЃЈ1ЃЉЫцзХЪ§ОнЙцФЃдНРДдНДѓЃЌДѓСПвЕЮёГЁОАПЊЪМПМТЧЪ§ОнДцДЂЫЎЦНРЉеЙЃЌЪЙЕУДцДЂЗўЮёПЩвддіМг/ЩОГ§ЃЌЖјФПЧАЕФЙиЯЕаЭЪ§ОнПтИќзЈзЂгквЛЬЈЛњЦїЁЃ
ЃЈ2ЃЉКЃСПЪ§ОнСПДцДЂГЩЮЊЦПОБЃЌЕЅЬЈЛњЦїЮоЗЈИКдиДѓСПЪ§ОнЁЃ
ЃЈ3ЃЉЕЅЬЈЛњЦїIOЖСаДЧыЧѓГЩЮЊКЃСПЪ§ОнДцДЂЪБКђИпВЂЗЂЃЌДѓЙцФЃЧыЧѓЕФЦПОБЁЃ
ЃЈ4ЃЉЕБЪ§ОнНјааЫЎЦНРЉеЙЪБКђЃЌШчКЮНтОіЪ§ОнIOИпвЛжТадЮЪЬтЁЃНсКЯMap/ReduceМЦЫуПђМмНјааКЃСПЪ§ОнЕФРыЯпЗжЮіЁЃ
1.2 BigTableГЩОЭСЫHBase

GoogleетИіЩёЦцЕФЙЋЫОвдЦфВЛБЃЪиЕФЬЌЖШвдбЇЪѕТлЮФЕФЗНЪНЙЋПЊСЫЦфдЦМЦЫуЕФШ§ДѓЗЈБІЃКGFSЁЂMapReduceКЭBigTableЃЌЦфжаЖдгкBigTableЕФПЊдДЪЕЯжHBaseдђЪЧгЩDoug CuttingЭъГЩЕФЁЃ
HBaseЪЧвЛИіЗжВМЪНЕФЁЂУцЯђСаЕФПЊдДЪ§ОнПтЃЌИУММЪѕРДдДгк Fay Chang ЫљзЋаДЕФGoogleТлЮФЁАBigtableЃКвЛИіНсЙЙЛЏЪ§ОнЕФЗжВМЪНДцДЂЯЕЭГЁБЁЃОЭЯёBigtableРћгУСЫGoogleЮФМўЯЕЭГЃЈFile SystemЃЉЫљЬсЙЉЕФЗжВМЪНЪ§ОнДцДЂвЛбљЃЌHBaseдкHadoopжЎЩЯЬсЙЉСЫРрЫЦгкBigtableЕФФмСІЁЃHBaseЪЧApacheЕФHadoopЯюФПЕФзгЯюФПЁЃHBaseВЛЭЌгквЛАуЕФЙиЯЕЪ§ОнПтЃЌЫќЪЧвЛИіЪЪКЯгкЗЧНсЙЙЛЏЪ§ОнДцДЂЕФЪ§ОнПтЁЃСэвЛИіВЛЭЌЕФЪЧHBaseЛљгкСаЕФЖјВЛЪЧЛљгкааЕФФЃЪНЁЃ
HBaseжаЕФБэвЛАугаетбљЕФЬиЕуЃК
ЃЈ1ЃЉ ДѓЃКвЛИіБэПЩвдгаЩЯвкааЃЌЩЯАйЭђСа
ЃЈ2ЃЉ УцЯђСаЃКУцЯђСа(зх)ЕФДцДЂКЭШЈЯоПижЦЃЌСа(зх)ЖРСЂМьЫїЁЃ
ЃЈ3ЃЉ ЯЁЪшЃКЖдгкЮЊПе(null)ЕФСаЃЌВЂВЛеМгУДцДЂПеМфЃЌвђДЫЃЌБэПЩвдЩшМЦЕФЗЧГЃЯЁЪшЁЃ
PSЃКЪВУДЪЧСаДцДЂЃП
СаДцДЂВЛЭЌгкДЋЭГЕФЙиЯЕаЭЪ§ОнПтЃЌЦфЪ§ОндкБэжаЪЧАДааДцДЂЕФЃЌСаЗНЪНЫљДјРДЕФживЊКУДІжЎвЛОЭЪЧЃЌгЩгкВщбЏжаЕФбЁдёЙцдђЪЧЭЈЙ§СаРДЖЈвхЕФЃЌвђДЫећИіЪ§ОнПтЪЧздЖЏЫїв§ЛЏЕФЁЃАДСаДцДЂУПИізжЖЮЕФЪ§ОнОлМЏДцДЂЃЌдкВщбЏжЛашвЊЩйЪ§МИИізжЖЮЕФЪБКђЃЌФмДѓДѓМѕЩйЖСШЁЕФЪ§ОнСПЃЌвЛИізжЖЮЕФЪ§ОнОлМЏДцДЂЃЌФЧОЭИќШнвзЮЊетжжОлМЏДцДЂЩшМЦИќКУЕФбЙЫѕ/НтбЙЫуЗЈЁЃЯТЭМНВЪіСЫДЋЭГЕФааДцДЂКЭСаДцДЂЕФЧјБ№ЃК
1.3 HBaseдкHadoopЯюФПжаЕФЮЛжУ
гыFUJITSU CliqЕШЩЬгУДѓЪ§ОнВњЦЗВЛЭЌЃЌHBaseЪЧGoogle BigtableЕФПЊдДЪЕЯжЃЌРрЫЦGoogle BigtableРћгУGFSзїЮЊЦфЮФМўДцДЂЯЕЭГЃЌHBaseРћгУHadoop HDFSзїЮЊЦфЮФМўДцДЂЯЕЭГЃЛGoogleдЫааMapReduceРДДІРэBigtableжаЕФКЃСПЪ§ОнЃЌHBaseЭЌбљРћгУHadoop MapReduceРДДІРэHBaseжаЕФКЃСПЪ§ОнЃЛGoogle BigtableРћгУ ChubbyзїЮЊаЭЌЗўЮёЃЌHBaseРћгУZookeeperзїЮЊЖдгІЁЃ
ЯТЭМеЙЪОСЫHBaseдкHadoopЩњЬЌЯЕЭГЬхЯЕНсЙЙжаЫљДІЕФЮЛжУЃК
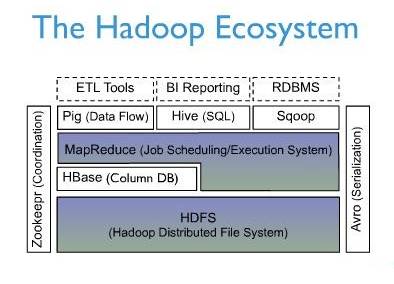
ЩЯЭМУшЪіСЫHadoopЩњЬЌЯЕЭГжаЕФИїВуЯЕЭГЁЃЦфжаЃЌHBaseЮЛгкНсЙЙЛЏДцДЂВуЃЌHadoop HDFSЮЊHBaseЬсЙЉСЫИпПЩППадЕФЕзВуДцДЂжЇГжЃЌHadoop MapReduceЮЊHBaseЬсЙЉСЫИпадФмЕФМЦЫуФмСІЃЌZookeeperЮЊHBaseЬсЙЉСЫЮШЖЈЗўЮёКЭЪЇаЇзЊвЦЃЈFailOverЃЉЛњжЦЁЃ
ДЫЭтЃЌPigКЭHiveЛЙЮЊHBaseЬсЙЉСЫИпВугябджЇГжЃЌЪЙЕУдкHBaseЩЯНјааЪ§ОнЭГМЦДІРэБфЕФЗЧГЃМђЕЅЁЃ SqoopдђЮЊHBaseЬсЙЉСЫЗНБуЕФRDBMSЪ§ОнЕМШыЙІФмЃЌЪЙЕУДЋЭГЪ§ОнПтЪ§ОнЯђHBaseжаЧЈвЦБфЕФЗЧГЃЗНБуЁЃ
ЖўЁЂHBaseЕФЪ§ОнФЃаЭ
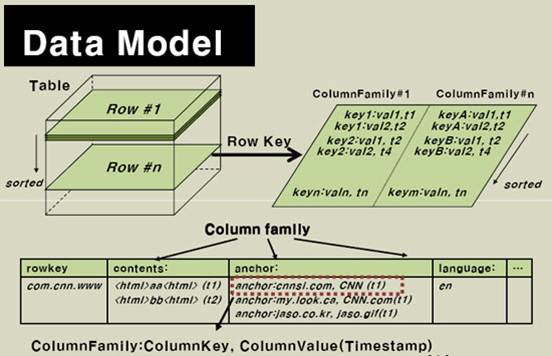
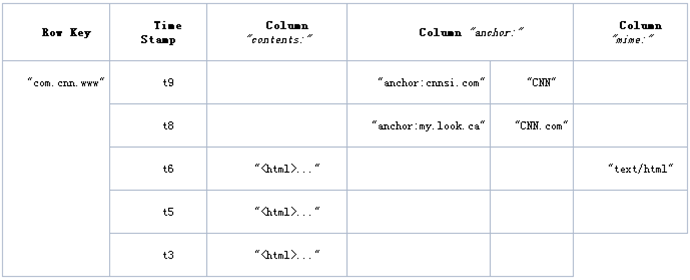
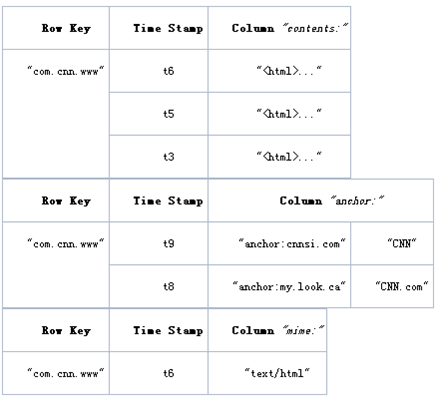
HBASEжаЕФУПвЛеХБэЃЌОЭЪЧЫљЮНЕФBigTableЃЌвЛеХЯЁЪшБэЁЃRowKey КЭ ColumnKey ЪЧЖўНјжЦжЕbyte[]ЃЌАДзжЕфЫГађХХађЃЛTimestamp ЪЧвЛИі 64 ЮЛећЪ§ЃЛvalue ЪЧвЛИіЮДНтЪЭЕФзжНкЪ§зщbyte[]ЁЃБэжаЕФВЛЭЌааПЩвдгЕгаВЛЭЌЪ§СПЕФГЩдБЁЃМДжЇГжЁАЖЏЬЌФЃЪНЁАФЃаЭЁЃ
2.1 ТпМФЃаЭ
Table & Column Family
HBaseвдБэЕФаЮЪНДцДЂЪ§ОнЁЃБэгаааКЭСазщГЩЁЃСаЛЎЗжЮЊШєИЩИіСазх(row family)ЃЌШчЯТЭМЫљЪОЃК
Row Key: ааМќЃЌTableЕФжїМќЃЌTableжаЕФМЧТМАДееRow KeyХХађ
Timestamp: ЪБМфДСЃЌУПДЮЪ§ОнВйзїЖдгІЕФЪБМфДСЃЌПЩвдПДзїЪЧЪ§ОнЕФversion number
Column FamilyЃКСаДиЃЌTableдкЫЎЦНЗНЯђгавЛИіЛђепЖрИіColumn FamilyзщГЩЃЌвЛИіColumn FamilyжаПЩвдгЩШЮвтЖрИіColumnзщГЩЃЌМДColumn FamilyжЇГжЖЏЬЌРЉеЙЃЌЮоашдЄЯШЖЈвхColumnЕФЪ§СПвдМАРраЭЃЌЫљгаColumnОљвдЖўНјжЦИёЪНДцДЂЃЌгУЛЇашвЊздааНјааРраЭзЊЛЛЁЃ
2.2 ЮяРэФЃаЭ
ЃЈ1ЃЉЮяРэДцДЂБэЪО
НЋТпМФЃаЭжаЕФвЛИіRowЗжИюЮЊИљОнColumn familyДцДЂЕФЮяРэФЃаЭЃЌШчЯТЭМЫљЪОЃК
ЃЈ2ЃЉTable & Region
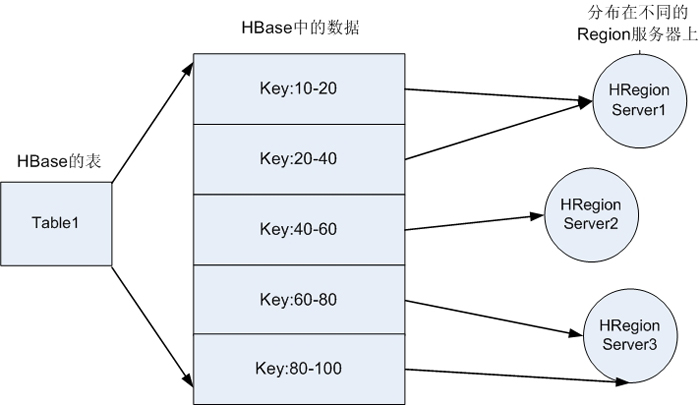
ЕБTableЫцзХМЧТМЪ§ВЛЖЯдіМгЖјБфДѓКѓЃЌЛсж№НЅЗжСбГЩЖрЗнsplitsЃЌГЩЮЊregionsЃЌвЛИіregionгЩ[startkey,endkey)БэЪОЃЌВЛЭЌЕФregionЛсБЛMasterЗжХфИјЯргІЕФRegionServerНјааЙмРэЃЌШчЯТЭМЫљЪОЃК
гЩЩЯПЩжЊЃЌHBaseЕФЩьЫѕаджївЊвРРЕгкЦфПЩЗжСбЕФHRegionМАПЩЩьЫѕЕФЗжВМЪНЮФМўЯЕЭГHDFSЃЌЯТУцНщЩмвЛЯТHBaseШчКЮЪЕЯжЩьЫѕадЃК
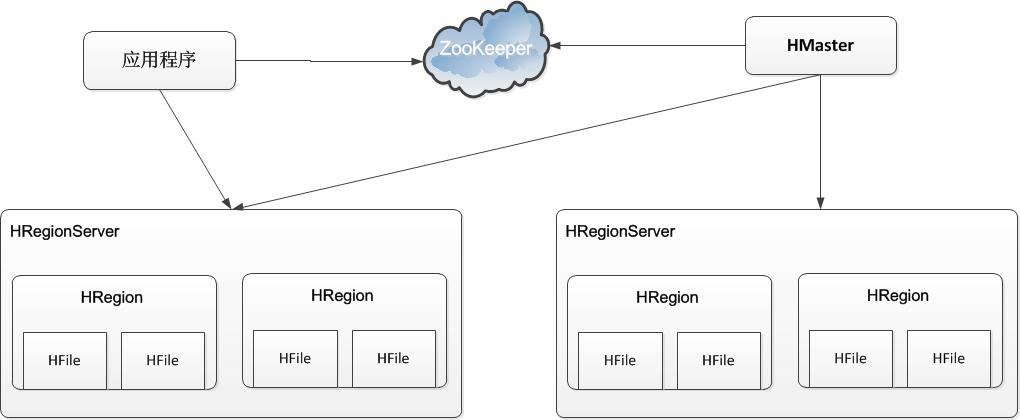
ЂйHBaseжаЪ§ОнвдHRegionЮЊЕЅЮЛНјааЙмРэЃЌвВОЭЪЧЫЕгІгУГЬађШчЙћЯывЊЗУЮЪвЛИіЪ§ОнЃЌБиаыЯШевЕНHRegionЃЌШЛКѓНЋЪ§ОнЖСаДВйзїЬсНЛИјHRegionЃЌгЩHRegionЭъГЩДцДЂВуУцЕФЪ§ОнВйзїЁЃ
ЂкУПИіHRegionжаДцДЂвЛЖЮKeyЧјМфЃЈР§ШчЃК[Key1,Key2)ЃЉЕФЪ§ОнЃЌHRegionServerЪЧЮяРэЗўЮёЦїЃЌУПИіHRegionServerЩЯПЩвдЦєЖЏЖрИіHRegionЪЕР§ЁЃЕБвЛИіHRegionжааДШыЕФЪ§ОнЬЋЖрЃЌДяЕНХфжУЕФЗЇжЕЪБЃЌHRegionЛсЗжСбГЩСНИіHRegionЃЌВЂНЋHRegionдкећИіМЏШКжаНјааЧЈвЦЃЌвдЪЙHRegionServerЕФИКдиОљКтЁЃ
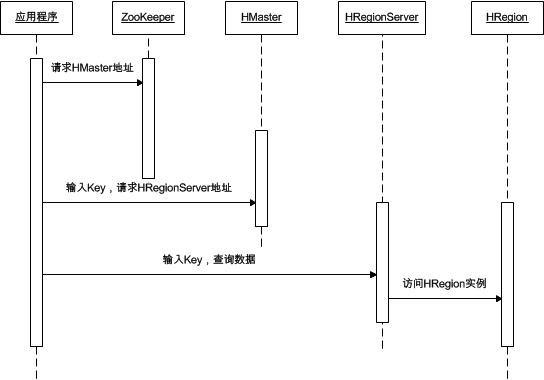
ЂлЫљгаЕФHRegionЕФаХЯЂЖМЃЈР§ШчЃКДцДЂЕФKeyжЕЧјМфЁЂЫљдкHRegionServerЕФIPЕижЗКЭЖЫПкКХЕШЃЉМЧТМдкHMasterЗўЮёЦїЩЯЁЃЭЌЪБЮЊСЫБЃжЄИпПЩгУЃЌHBaseЦєЖЏСЫЖрИіHMasterЃЌВЂЭЈЙ§ZooKeeperЃЈвЛИіжЇГжЗжВМЪНвЛжТадЕФЪ§ОнЙмРэЗўЮёЃЉбЁОйГівЛИіжїЗўЮёЦїЃЌЭЈЙ§етИіжїHMasterЗўЮёЦїЛёЕУKeyжЕЫљдкЕФHRegionServerЃЌзюКѓЧыЧѓИУHRegionServerЩЯЕФHRegionЪЕР§ЃЌЛёЕУашвЊЕФЪ§ОнЁЃЦфОпЬхЕФЪ§ОнбАжЗЗУЮЪСїГЬШчЯТЭМЫљЪОЃК
Ш§ЁЂHBaseЕФЯЕЭГМмЙЙ
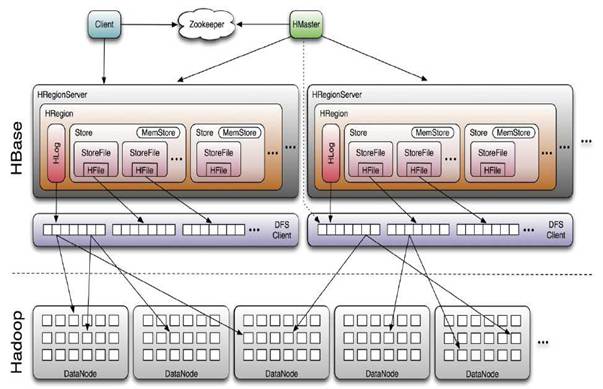
3.1 Client
АќКЌЗУЮЪhbaseЕФНгПкЃЌClientЮЌЛЄзХвЛаЉcacheРДМгПьЖдhbaseЕФЗУЮЪЃЌБШШчregioneЕФЮЛжУаХЯЂЁЃ
3.2 ZooKeeper
ЃЈ1ЃЉ БЃжЄШЮКЮЪБКђЃЌМЏШКжажЛгавЛИіmaster
ЃЈ2ЃЉ ДцжќЫљгаRegionЕФбАжЗШыПкЁЃ
ЃЈ3ЃЉ ЪЕЪБМрПиRegion ServerЕФзДЬЌЃЌНЋRegion serverЕФЩЯЯпКЭЯТЯпаХЯЂЪЕЪБЭЈжЊИјMaster
ЃЈ4ЃЉ ДцДЂHbaseЕФschema,АќРЈгаФФаЉtableЃЌУПИіtableгаФФаЉcolumn family
3.3 HMaster
ЃЈ1ЃЉЮЊRegion ServerЗжХфRegion
ЃЈ2ЃЉИКд№Region ServerЕФИКдиОљКт
ЃЈ3ЃЉЗЂЯжЪЇаЇЕФRegion ServerВЂжиаТЗжХфЦфЩЯЕФRegion
ЃЈ4ЃЉGFSЩЯЕФРЌЛјЮФМўЛиЪе
ЃЈ5ЃЉДІРэSchemaИќаТЧыЧѓ
HMasterжївЊзїгУдкгкЃЌЭЈЙ§HMasterЮЌЛЄЯЕЭГБэ-ROOT-,.META.ЃЌМЧТМregionserverЫљЖдгІregionБфЛЏаХЯЂЁЃДЫЭтЛЙИКд№МрПиДІРэЕБЧАhbase clusterжаregionserverзДЬЌБфЛЏаХЯЂЁЃ
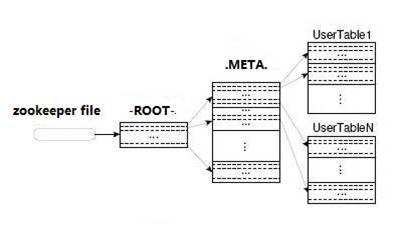
PSЃКСНеХЩёЦцЕФБэЃК-ROOT-КЭ.META
Ђй.META.ЃКМЧТМСЫгУЛЇБэЕФRegionаХЯЂЃЌ.META.ПЩвдгаЖрИіregoin
Ђк-ROOT-ЃКМЧТМСЫ.META.БэЕФRegionаХЯЂЃЌ-ROOT-жЛгавЛИіregion
ZookeeperжаМЧТМСЫ-ROOT-БэЕФlocation
ClientЗУЮЪгУЛЇЪ§ОнжЎЧАашвЊЪзЯШЗУЮЪZookeeperЃЌШЛКѓЗУЮЪ-ROOT-БэЃЌНгзХЗУЮЪ.META.БэЃЌзюКѓВХФмевЕНгУЛЇЪ§ОнЕФЮЛжУШЅЗУЮЪЃК
3.4 Region Server
ЃЈ1ЃЉRegion ServerЮЌЛЄHMasterЗжХфИјЫќЕФRegionЃЌДІРэЖдетаЉRegionЕФIOЧыЧѓ
ЃЈ2ЃЉRegion ServerИКд№ЧаЗждкдЫааЙ§ГЬжаБфЕУЙ§ДѓЕФRegion
ПЩвдПДГіЃЌclient ЗУЮЪhbase ЩЯЪ§ОнЕФЙ§ГЬВЂВЛашвЊmaster ВЮгыЃЌбАжЗЗУЮЪzookeeper КЭregion serverЃЌЪ§ОнЖСаДЗУЮЪregioneserverЁЃHRegionServerжївЊИКд№ЯьгІгУЛЇI/OЧыЧѓЃЌЯђHDFSЮФМўЯЕЭГжаЖСаДЪ§ОнЃЌЪЧHBaseжазюКЫаФЕФФЃПщЁЃ
|









