| БрМЭЦМі: |
БОЮФРДздгкzhanshi258.iteye.com/blog,НщЩмСЫЗЂеЙЪЗЃЌЖЈвхАВзАЃЌЬиЕуМАећЬхМмЙЙЁЃ |
|
ШежОЪЧЯЕЭГЪ§ОнЕФЛљЪЏЃЌЖдгкЯЕЭГЕФАВШЋРДЫЕЗЧГЃживЊЃЌЫќМЧТМСЫЯЕЭГУПЬьЗЂЩњЕФИїжжИїбљЕФЪТЧщЃЌгУЛЇПЩвдЭЈЙ§ЫќРДМьВщДэЮѓЗЂЩњЕФдвђЃЌЛђепбАевЪмЕНЙЅЛїЪБЙЅЛїепСєЯТЕФКлМЃЁЃШежОжївЊЕФЙІФмЪЧЩѓМЦКЭМрВтЁЃЫќЛЙПЩвдЪЕЪБЕиМрВтЯЕЭГзДЬЌЃЌМрВтКЭзЗзйЧжШыепЁЃЯждкЛЅСЊЭјЩЯДцдкЕФШежОзщМўИїжжИїбљЃЌЮвУЧетРяжївЊНВЕФЪЧFlumeЁЃ
Flume ЗЂеЙРњЪЗ
Cloudera ПЊЗЂЕФЗжВМЪНШежОЪеМЏЯЕЭГ FlumeЃЌЪЧ hadoop жмБпзщМўжЎвЛЁЃЦфПЩвдЪЕЪБЕФНЋЗжВМдкВЛЭЌНкЕуЁЂЛњЦїЩЯЕФШежОЪеМЏЕН
hdfs жаЁЃFlume ГѕЪМЕФЗЂааАцБОФПЧАБЛЭГГЦЮЊ Flume OGЃЈoriginal generationЃЉЃЌЪєгк
clouderaЁЃЕЋЫцзХ FLume ЙІФмЕФРЉеЙЃЌFlume OG ДњТыЙЄГЬгЗжзЁЂКЫаФзщМўЩшМЦВЛКЯРэЁЂКЫаФХфжУВЛБъзМЕШШБЕуБЉТЖГіРДЃЌгШЦфЪЧдк
Flume OG ЕФзюКѓвЛИіЗЂааАцБО 0.94.0 жаЃЌШежОДЋЪфВЛЮШЖЈЕФЯжЯѓгШЮЊбЯжиЃЌетЕуПЩвддк BigInsights
ВњЦЗЮФЕЕЕФ troubleshooting АхПщЗЂЯжЁЃЮЊСЫНтОіетаЉЮЪЬтЃЌ2011 Фъ 10 дТ 22
КХЃЌcloudera ЭъГЩСЫ Flume-728ЃЌЖд Flume НјааСЫРяГЬБЎЪНЕФИФЖЏЃКжиЙЙКЫаФзщМўЁЂКЫаФХфжУвдМАДњТыМмЙЙЃЌжиЙЙКѓЕФАцБОЭГГЦЮЊ
Flume NGЃЈnext generationЃЉЃЛИФЖЏЕФСэвЛдвђЪЧНЋ Flume ФЩШы apache
ЦьЯТЃЌcloudera Flume ИФУћЮЊ Apache FlumeЁЃЕБШЛЮвУЧЯждкгУЕФЪЧFlume
NGЃЌЫљвдВЛдйНВFlume OGЕФФкШнЁЃ
FlumeЖЈвх
FlumeЪЧвЛИіИпПЩгУЃЌИпПЩППЃЌЗжВМЪНКЃСПШежОВЩМЏЁЂОлКЯКЭДЋЪфЯЕЭГЃЌFlumeжЇГждкШежОЯЕЭГжаЖЈжЦИїРрЪ§ОнЗЂЫЭЗНЃЌгУгкЪеМЏЪ§ОнЃЛЭЌЪБЃЌFlumeЬсЙЉЖдЪ§ОнНјааМђЕЅДІРэЃЌВЂаДЕНИїжжЪ§ОнНгЪмЗНЃЈПЩЖЈжЦЃЉЕФФмСІЁЃ
FlumeМмЙЙНщЩм
FlumeШежОЪеМЏНсЙЙЭМ
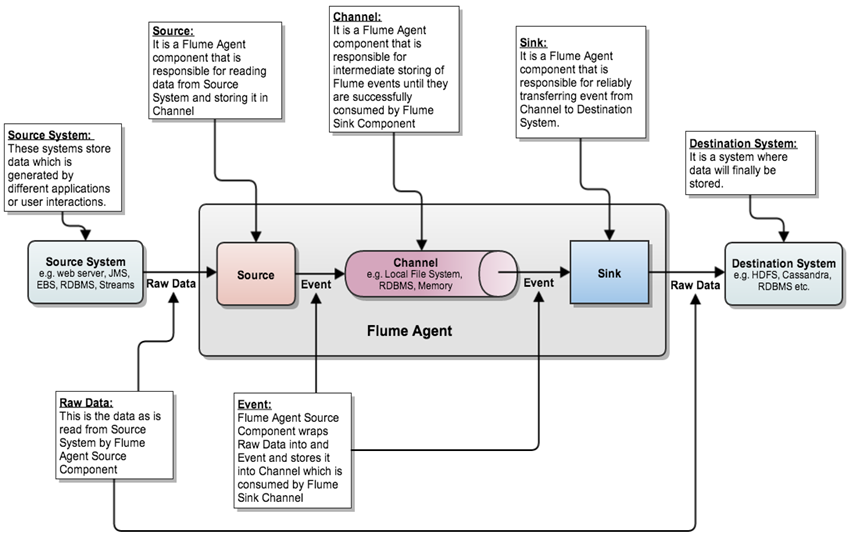
Flume ЕФКЫаФЪЧАбЪ§ОнДгЪ§ОндДЪеМЏЙ§РДЃЌдйЫЭЕНФПЕФЕиЁЃ
ЮЊСЫБЃжЄЪфЫЭвЛЖЈГЩЙІЃЌдкЫЭЕНФПЕФЕижЎЧАЃЌЛсЯШЛКДцЪ§ОнЃЌД§Ъ§Онеце§ЕНДяФПЕФЕиКѓЃЌЩОГ§здМКЛКДцЕФЪ§ОнЁЃ
Flume ДЋЪфЕФЪ§ОнЕФЛљБОЕЅЮЛЪЧ EventЃЌШчЙћЪЧЮФБОЮФМўЃЌЭЈГЃЪЧвЛааМЧТМЃЌетвВЪЧЪТЮёЕФЛљБОЕЅЮЛЁЃ
Event Дг SourceЃЌСїЯђ ChannelЃЌдйЕН SinkЃЌБОЩэЮЊвЛИі byte Ъ§зщЃЌВЂПЩаЏДј
headers аХЯЂЁЃ
Event ДњБэзХвЛИіЪ§ОнСїЕФзюаЁЭъећЕЅдЊЃЌДгЭтВПЪ§ОндДРДЃЌЯђЭтВПЕФФПЕФЕиШЅЁЃ
Flume дЫааЕФКЫаФЪЧ AgentЁЃЫќЪЧвЛИіЭъећЕФЪ§ОнЪеМЏЙЄОпЃЌКЌгаШ§ИіКЫаФзщМўЃЌЗжБ№ЪЧ SourceЁЂChannelЁЂSinkЁЃ
Source ПЩвдНгЪеЭтВПдДЗЂЫЭЙ§РДЕФЪ§ОнЁЃВЛЭЌЕФ SourceЃЌПЩвдНгЪмВЛЭЌЕФЪ§ОнИёЪНЁЃБШШчгаФПТМГи(spooling
directory)Ъ§ОндДЃЌПЩвдМрПижИЖЈЮФМўМажаЕФаТЮФМўБфЛЏЃЌШчЙћФПТМжагаЮФМўВњЩњЃЌОЭЛсСЂПЬЖСШЁЦфФкШнЁЃ
Channel ЪЧвЛИіДцДЂЕиЃЌНгЪе Source ЕФЪфГіЃЌжБЕНга Sink ЯћЗбЕє Channel
жаЕФЪ§ОнЁЃ
Channel жаЕФЪ§ОнжБЕННјШыЕНЯТвЛИіChannelжаЛђепНјШыжеЖЫВХЛсБЛЩОГ§ЁЃ
ЕБ Sink аДШыЪЇАмКѓЃЌПЩвдздЖЏжиЦєЃЌВЛЛсдьГЩЪ§ОнЖЊЪЇЃЌвђДЫКмПЩППЁЃ
Sink ЛсЯћЗб Channel жаЕФЪ§ОнЃЌШЛКѓЫЭИјЭтВПдДЛђепЦфЫћ SourceЁЃШчЪ§ОнПЩвдаДШыЕН
HDFS Лђеп HBase жаЁЃ
Flume КЫаФИХФюећРэ
Agent AgentжаАќКЌЖрИіsourcesКЭsinksЁЃ
Client ЩњВњЪ§ОнЃЌдЫаадквЛИіЖРСЂЕФЯпГЬЁЃ
Source ДгClientЪеМЏЪ§ОнЃЌДЋЕнИјChannelЁЃгУРДЯћЗбДЋЕнЕНИУзщМўЕФEventЁЃ
Sink ДгChannelЪеМЏЪ§ОнЃЌНЋEventДЋЕнЕНFlow PipelineжаЕФЯТвЛИіAgentЁЃ
Channel жазЊEventСйЪБДцДЂЃЌБЃДцSourceДЋЕнЙ§РДEventЃЌСЌНг sources КЭ
sinks ЁЃ
Events вЛИіЪ§ОнЕЅдЊЃЌДјгавЛИіПЩбЁЕФЯћЯЂЭЗЁЃПЩвдЪЧШежОМЧТМЁЂ avro ЖдЯѓЕШЁЃ
Flume ЬиЕу
flumeЕФЪ§ОнСїгЩЪТМў(Event)ЙсДЉЪМжеЁЃЪТМўЪЧFlumeЕФЛљБОЪ§ОнЕЅЮЛЃЌЫќаЏДјШежОЪ§Он(зжНкЪ§зщаЮЪН)ВЂЧваЏДјгаЭЗаХЯЂЃЌетаЉEventгЩAgentЭтВПЕФSourceЩњГЩЃЌЕБSourceВЖЛёЪТМўКѓЛсНјааЬиЖЈЕФИёЪНЛЏЃЌШЛКѓSourceЛсАбЪТМўЭЦШы(ЕЅИіЛђЖрИі)ChannelжаЁЃФуПЩвдАбChannelПДзїЪЧвЛИіЛКГхЧјЃЌЫќНЋБЃДцЪТМўжБЕНSinkДІРэЭъИУЪТМўЁЃSinkИКд№ГжОУЛЏШежОЛђепАбЪТМўЭЦЯђСэвЛИіSourceЁЃ
AgentЪЧFlumeжазюаЁЕФдЫааЕЅЮЛЃЌвЛИіAgentжагЩSourceЁЂSinkКЭChannelШ§ИізщМўЙЙГЩЁЃ
EventЪЧFlumeжаЛљБОЪ§ОнЕЅЮЛЃЌEventжаАќКЌгаДЋЪфЪ§ОнМАЪ§ОнЭЗЪ§ОнАќ
ШчЯТЭМЫљЪОЃК
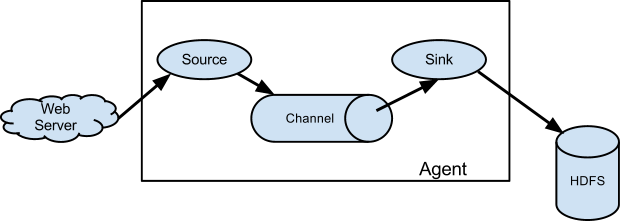
жЕЕУзЂвтЕФЪЧЃЌFlumeЬсЙЉСЫДѓСПФкжУЕФSourceЁЂChannelКЭSinkРраЭЁЃВЛЭЌРраЭЕФSource,ChannelКЭSinkПЩвдздгЩзщКЯЁЃзщКЯЗНЪНЛљгкгУЛЇЩшжУЕФХфжУЮФМўЃЌЗЧГЃСщЛюЁЃ
БШШчЃКChannelПЩвдАбЪТМўднДцдкФкДцРяЃЌвВПЩвдГжОУЛЏЕНБОЕигВХЬЩЯЁЃSinkПЩвдАбШежОаДШыHDFS,
HBaseЃЌЩѕжСЪЧСэЭтвЛИіSourceЕШЕШЁЃFlumeжЇГжгУЛЇНЈСЂЖрМЖСїЃЌвВОЭЪЧЫЕЃЌЖрИіagentПЩвдаЭЌЙЄзїЃЌВЂЧвжЇГжFan-inЁЂFan-outЁЂContextual
RoutingЁЂBackup RoutesЃЌетвВе§ЪЧNBжЎДІЁЃ
ШчЯТЭМЫљЪО:
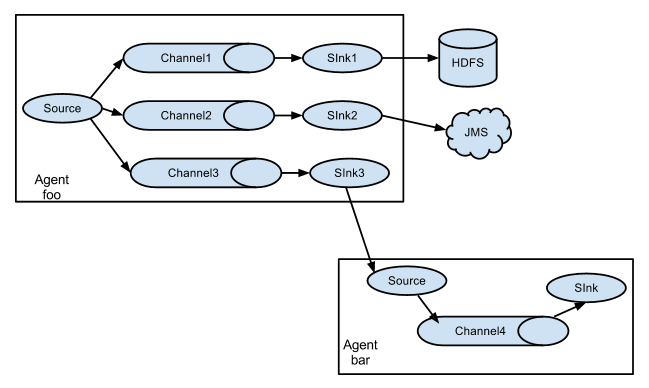
Flume ећЬхМмЙЙзмНс
FlumeМмЙЙећЬхЩЯПДОЭЪЧ source-->channel-->sink ЕФШ§ВуМмЙЙЃЌРрЫЦЩњГЩепКЭЯћЗбепЕФМмЙЙЃЌЫћУЧжЎМфЭЈЙ§queueЃЈchannelЃЉДЋЪфЃЌНтёюЁЃ
Source:ЭъГЩЖдШежОЪ§ОнЕФЪеМЏЃЌЗжГЩ transtion КЭ event ДђШыЕНchannelжЎжаЁЃ
Channel:жївЊЬсЙЉвЛИіЖгСаЕФЙІФмЃЌЖдsourceЬсЙЉжаЕФЪ§ОнНјааМђЕЅЕФЛКДцЁЃ
Sink:ШЁГіChannelжаЕФЪ§ОнЃЌНјааЯргІЕФДцДЂЮФМўЯЕЭГЃЌЪ§ОнПтЃЌЛђепЬсНЛЕНдЖГЬЗўЮёЦїЁЃ
ЖдЯжгаГЬађИФЖЏзюаЁЕФЪЙгУЗНЪНЪЧЪЙгУЪЧжБНгЖСШЁГЬађдРДМЧТМЕФШежОЮФМўЃЌЛљБОПЩвдЪЕЯжЮоЗьНгШыЃЌВЛашвЊЖдЯжгаГЬађНјааШЮКЮИФЖЏЁЃ
Flume ЯТдиЁЂАВзА
АВзАJDK
1.НЋЯТдиКУЕФJDKАќНтбЙЃЌБШШчЮвЕФНтбЙЕН /home/liuqing/jdk1.7.0_72 ФПТМЯТ
2.ХфжУЛЗОГБфСП
дк/etc/profile ЮФМўжаЬэМг
JavaДњТы
export JAVA_HOME=/home/liuqing/jdk1.7.0_72
export PATH=$JAVA_HOME/bin:$PATH
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar: $JAVA_HOME/lib/tools.jar: $CLASS_PATH
|
3.жДааsource profile
4.дкУќСюааЪфШы java -version
ГіЯжЃК
java version "1.7.0_72"
Java(TM) SE Runtime Environment (build 1.7.0_72-b14)
Java HotSpot(TM) 64-Bit Server VM (build 24.72-b04,
mixed mode)
БэЪОАВзАГЩЙІ
АВзАFlume
1. ДгЙйЭј http://flume.apache.org/download.html ЯТдизюаТЕФАВзААќ
2. НтбЙЫѕЃЌБШШчЮвЕФНтбЙЕН /home/liuqing/hadoop/flumeФПТМ
3. аоИФ flume-env.sh ХфжУЮФМў,жївЊЪЧJAVA_HOMEБфСПЩшжУ
JAVA_HOME=/home/liuqing/jdk1.7.0_72
4. бщжЄЪЧЗёАВзАГЩЙІ
root@ubuntu:/home/liuqing/hadoop/flume/bin# ./flume-ng
version
ГіЯжЃК
Flume 1.6.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
БэЪОАВзАГЩЙІ
АИР§
АИР§1. ЕЅНкЕу FlumeХфжУ
1. аТНЈХфжУЮФМўЃЌХфжУЮФМўЪОР§
JavaДњТы
# example.conf:
A single-node Flume configuration
# agentзщМўУћГЦ
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source ХфжУ
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# sink ХфжУ
a1.sinks.k1.type = logger
# ЪЙгУФкДцжаBuffer Event Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# АѓЖЈ source КЭ sink ЕНchannel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 |
НЋЩЯЪіХфжУДцЮЊЃК/home/liuqing/hadoop/flume/conf/example.conf
2. ШЛКѓЮвУЧОЭПЩвдЦєЖЏ Flume СЫЃК
дк/home/liuqing/hadoop/flumeТЗОЖЯТдЫааЃК
JavaДњТы
| bin/flume-ngagent
--conf conf --conf-file conf/example.conf --name
a1 -Dflume.root.logger=INFO,console |
Цфжа -c/--conf КѓИњХфжУФПТМЃЌ-f/--conf-file КѓИњОпЬхЕФХфжУЮФМўЃЌ-n/--name
жИЖЈagentЕФУћГЦ
3. ШЛКѓЮвУЧдйПЊвЛИі shell жеЖЫДАПкЃЌtelnet ЩЯХфжУжаеьЬ§ЕФЖЫПкЃЌОЭПЩвдЗЂЯћЯЂПДЕНаЇЙћСЫЃК
JavaДњТы
$ telnet localhost
44444
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
Hello world! <ENTER>
OK |
4.Flume жеЖЫДАПкДЫЪБЛсДђгЁГіШчЯТаХЯЂЃЌОЭБэЪОГЩЙІСЫ
JavaДњТы
12/06/1915: 32:19
INFO source.NetcatSource: Source starting
12/06/1915:32: 19 INFO source.NetcatSource: Created
serverSocket: sun.nio.ch.ServerSocketChannelImpl [/127.0.0.1:44444]
12/06/1915:32:34 INFO sink.LoggerSink: Event:
{ headers:{} body: 48 65 6C 6C 6F 20 77 6F 72
6C 64 21 0D Hello world!. } |
жСДЫЃЌдлУЧЕФЕквЛИі Flume Agent ЫуЪЧВПЪ№ГЩЙІСЫЃЁ
АИР§2. НсКЯЪЕМЪЯюФП
ВЮПМЃКhttps://github.com/gilt/logback-flume-appender
1. дк/home/liuqing/hadoop/flume/conf/ЯТаТНЈХфжУЮФМў test.conf
JavaДњТы
agent1.sources
= source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure source1
agent1.sources.source1.type = avro
agent1.sources.source1.bind = 0.0.0.0
agent1.sources.source1.port = 44444
# Describe sink1
#ШежОЮФМўАДЪБМфЩњГЩ
#agent1.sinks.sink1.type = FILE_ROLL
#agent1.sinks.sink1.sink.directory = /home/liuqing/hadoop/flume/flume-out
#agent1.sinks.sink1.sink.rollInterval = 1800
#agent1.sinks.sink1.batchSize = 5
#ШежОЮФМўИљОнДѓаЁЩњГЩ
#ЩњГЩФПТМдкconfЮФМўМаЯТЕФlog4j.propertiesПЩвдХфжУ
agent1.sinks.sink1.type = logger
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.capacity = 1000
agent1.channels.channel1.transactionCapactiy =
100
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1 |
2. ЯюФПвбОХфКУСЫlogback.xml ЮФМў
дкlogback.xmlЮФМўжаЬэМг
XmlДњТы
<appender name="flumeApplender"
class= "com.xxx.hd.extended.log.flume. FlumeLogstashV1Appender">
<flumeAgents>
192.168.23.235:44444,
</flumeAgents>
<flumeProperties>
connect-timeout=4000;
request-timeout=8000
</flumeProperties>
<batchSize>2048</batchSize>
<reportingWindow>20480</reportingWindow>
<additionalAvroHeaders>
myHeader=myValue
</additionalAvroHeaders>
<application>ProjectName</application>
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%d{HH:mm:ss.SSS} %-5level %logger{36}
- \(%file:%line\) - %msg%n%ex< /pattern>
</layout>
</appender> |
3. ШЛКѓЮвУЧОЭПЩвдЦєЖЏ Flume СЫЃК
дк/home/liuqing/hadoop/flumeТЗОЖЯТдЫааЃК
JavaДњТы
| bin/flume-ng agent
--conf ./conf/ -f conf/lqtest.conf -n agent1 |
4. ЯждкШежОЛсДђгЁЕН/home/liuqing/hadoop/flume/logsФПТМЯТ
ШежОЮФМўТњ128MОЭЛсздЖЏНЈвЛИіаТЕФ |









