| БрМЭЦМі: |
БОЮФРДздгкcsdn
,БОЮФНщЩм2жжЛёШЁСаЕФЖрАцБОЪ§ОнЕФЗНЪНЃКshellКЭspring data
hadoopЁЃ |
|
дкЫЕHBaseжЎЧАЃЌЮвЯыдйпыпЖМИОфЁЃзіЛЅСЊЭјгІгУЕФИчУЧЖљгІИУЖМЧхГўЃЌЛЅСЊЭјгІгУетЖЋЮїЃЌФуУЛАьЗЈдЄВтФуЕФЯЕЭГЪВУДЪБКђЛсБЛЖрЩйШЫЗУЮЪЃЌФуУцСйЕФгУЛЇЕНЕзгаЖрЩйЃЌЫЕВЛЖЈНёЬьФуЕФгУЛЇЛЙЩйЃЌУїЬьЯЕЭГгУЛЇОЭБфЖрСЫЃЌНсЙћФњЕФЯЕЭГгІИЖВЛЙ§РДСЫСЫЃЌВЛИЩСЫЃЌетЦёВЛЪЧдлИчМИИіЕФБЏАЇЃЌЫЕЪБїжЕуОЭНаЁАБОпАЁЁБЁЃ
ЦфЪЕЫЕАзСЫЃЌетаЉОЭЪЧЪТЯШУЛгаШЯЧхГўЛЅСЊЭјгІгУЪВУДВХЪЧзюживЊЕФЁЃДгЯЕЭГМмЙЙЕФНЧЖШРДЫЕЃЌЛЅСЊЭјгІгУИќМгПДжиЯЕЭГадФмвдМАЩьЫѕадЃЌЖјДЋЭГЦѓвЕМЖгІгУЖМЪЧБШНЯПДжиЪ§ОнЭъећадКЭЪ§ОнАВШЋадЁЃФЧУДЮвУЧОЭРДЫЕЫЕЛЅСЊЭјгІгУЩьЫѕадетЪТЖљ.ЖдгкЩьЫѕадетЪТЖљЃЌИчУЧЖљЮввВаДСЫМИЦЊВЉЮФЃЌЯыПДЕФажЕмПЩвдВЮПМЮввдЧАЕФВЉЮФЃЌЖдгкweb
server,app serverЕФЩьЫѕадЃЌЮвдкетРяЯШВЛЫЕСЫЃЌвђЮЊетВПЗжЕФЩьЫѕадЯрЖдРДЫЕБШНЯШнвзвЛЕуЃЌЮвжївЊРДЛиЙЫвЛаЉвЛИіТ§Т§БфДѓЕФЛЅСЊЭјгІгУШчКЮгІЖдЪ§ОнПтетвЛВуЕФЩьЫѕЁЃ
ЪзЯШИеПЊЪМЃЌШЫВЛЖрЃЌбЙСІвВВЛДѓ,ИувЛЬЈЪ§ОнПтЗўЮёЦїОЭИуЖЈСЫЃЌДЫЪБЫљгаЕФЖЋЖЋЖМШћНјвЛИіServerРяЃЌАќРЈweb
server,app server,db server,ЕЋЪЧЫцзХШЫдНРДдНЖрЃЌЯЕЭГбЙСІдНРДдНЖрЃЌетИіЪБКђПЩФмФуАбweb
server,app serverКЭdb serverЗжРыСЫЃЌКУДѕетбљПЩвдгІИЖвЛеѓзгЃЌЕЋЪЧЫцзХгУЛЇСПЕФВЛЖЯдіМгЃЌФуЛсЗЂЯжЃЌЪ§ОнПтетИчУЧВЛааСЫЃЌЫйЖШРЯТ§СЫЃЌгаЪБКђЛЙЛсхДЕєЃЌЫљвдетИіЪБКђЃЌФуЕУИјЪ§ОнПтетИчУЧевМИИіАщЃЌетИіЪБКђMaster-SalveОЭГіЯжСЫЃЌетИіЪБКђгавЛИіMaster
ServerзЈУХИКд№НгЪеаДВйзїЃЌСэЭтЕФМИИіSalve ServerзЈУХНјааЖСШЁЃЌетбљMasterетИчУЧжегкВЛБЇдЙСЫЃЌзмЫуЖСаДЗжРыСЫЃЌбЙСІзмЫуЧсЕуСЫ,етИіЪБКђЦфЪЕжївЊЪЧЖдЖСШЁВйзїНјааСЫЫЎЦНРЉеХЃЌЭЈЙ§діМгЖрИіSalveРДПЫЗўВщбЏЪБCPUЦПОБЁЃвЛАуетбљЯТРДЃЌФуЕФЯЕЭГПЩвдгІИЖвЛЖЈЕФбЙСІЃЌЕЋЪЧЫцзХгУЛЇЪ§СПЕФдіЖрЃЌбЙСІЕФВЛЖЯдіМгЃЌФуЛсЗЂЯжMaster
serverетИчУЧЕФаДбЙСІЛЙЪЧБфЕФЬЋДѓЃЌУЛАьЗЈЃЌетИіЪБКђдѕУДАьФиЃПФуОЭЕУЧаЗжАЁЃЌЫзЛАЫЕЁАжЛгаЧаЗжСЫЃЌВХЛсгаЩьЫѕадТяЁБЃЌЫљвдАЁЃЌетИіЪБКђжЛФмЗжПтСЫЃЌетвВЪЧЮвУЧГЃЫЕЕФЪ§ОнПтЁАДЙжБЧаЗжЁБЃЌБШШчНЋвЛаЉВЛЙиСЊЕФЪ§ОнДцЗХЕНВЛЭЌЕФПтжаЃЌЗжПЊВПЪ№ЃЌетбљжегкПЩвдДјзпвЛВПЗжЕФЖСШЁКЭаДШыбЙСІСЫЃЌMasterгжПЩвдЧсЫЩвЛЕуСЫЃЌЕЋЪЧЫцзХЪ§ОнЕФВЛЖЯдіЖрЃЌФуЕФЪ§ОнПтБэжаЕФЪ§ОнгжБфЕФЗЧГЃЕФДѓЃЌетбљВщбЏаЇТЪЗЧГЃЕЭЃЌетИіЪБКђОЭашвЊНјааЁАЫЎЦНЗжЧјЁБСЫЃЌБШШчЭЈЙ§НЋUserБэжаЕФЪ§ОнАДее10WРДЛЎЗжЃЌетбљУПеХБэВЛЛсГЌЙ§10WСЫЁЃ
злЩЯЫљЪіЃЌвЛАувЛИіСїааЕФwebеОЕуЖМЛсОРњвЛИіДгЕЅЬЈDBЃЌЕНжїДгИДжЦЃЌЕНДЙжБЗжЧјдйЕНЫЎЦНЗжЧјЕФЭДПрЕФЙ§ГЬЁЃЦфЪЕЪ§ОнПтЧаЗжетЪТЖљЃЌПДЦ№РДдРэУВЫЦКмМђЕЅЃЌШчЙћеце§зіЦ№РДЃЌЮвЯыЗВЪЧshardingЙ§Ъ§ОнПтЕФИчУЧЖљЖМЩюЪмЦфПрАЁЁЃЖдгкЪ§ОнПтЩьЫѕЕФЮФеТЃЌИчУЧЖљПЩвдПДПДКѓУцЕФВЮПМзЪСЯНщЩмЁЃ
КУСЫЃЌДгЩЯУцЕФФЧвЛЖбЗЯЛАжаЃЌЮвУЧвВЗЂЯжЪ§ОнПтДцДЂЫЎЦНРЉеХscale outЪЧЖрУДЭДПрЕФвЛМўЪТЧщЃЌВЛЙ§авКУММЪѕдкНјВНЃЌвЕНчЕФЦфЫќЕмажвВдкХЌСІЃЌ09ФъетвЛФъГіЯжСЫЗЧГЃЖрЕФNoSQLЪ§ОнПтЃЌИќзМШЗЕФгІИУЫЕЪЧNo
relationЪ§ОнПтЃЌетаЉЪ§ОнПтЖрЪ§ЖМЛсЖдЗЧНсЙЙЛЏЕФЪ§ОнЬсЙЉЭИУїЕФЫЎЦНРЉеХФмСІЃЌДѓДѓМѕЧсСЫИчУЧЖљЩшМЦЪБКђЕФбЙСІЁЃЯТУцЮвОЭФУHbaseетЗжВМЪНСаДцДЂЯЕЭГРДЫЕЫЕЁЃ
вЛ HbaseЪЧИіЩЖЖЋЖЋЃП
дкЫЕHaseЪЧИіЩЖМвЛяжЎЧАЃЌЪзЯШЮвУЧРДПДПДСНИіИХФюЃЌУцЯђааДцДЂКЭУцЯђСаДцДЂЁЃУцЯђааДцДЂЃЌЮвЯраХДѓЛяЖљгІИУЖМЧхГўЃЌЮвУЧЪьЯЄЕФRDBMSОЭЪЧДЫжжРраЭЕФЃЌУцЯђааДцДЂЕФЪ§ОнПтжївЊЪЪКЯгкЪТЮёадвЊЧѓбЯИёГЁКЯЃЌЛђепЫЕУцЯђааДцДЂЕФДцДЂЯЕЭГЪЪКЯOLTPЃЌЕЋЪЧИљОнCAPРэТлЃЌДЋЭГЕФRDBMSЃЌЮЊСЫЪЕЯжЧПвЛжТадЃЌЭЈЙ§бЯИёЕФACIDЪТЮёРДНјааЭЌВНЃЌетОЭдьГЩСЫЯЕЭГЕФПЩгУадКЭЩьЫѕадЗНУцДѓДѓелПлЃЌЖјФПЧАЕФКмЖрNoSQLВњЦЗЃЌАќРЈHbaseЃЌЫќУЧЖМЪЧвЛжжзюжевЛжТадЕФЯЕЭГЃЌЫќУЧЮЊСЫИпЕФПЩгУадЮўЩќСЫвЛВПЗжЕФвЛжТадЁЃКУЯёЃЌЮвЩЯУцЫЕСЫУцЯђСаДцДЂЃЌФЧУДЕНЕзЪВУДЪЧУцЯђСаДцДЂФиЃПHbase,Casandra,BigtableЖМЪєгкУцЯђСаДцДЂЕФЗжВМЪНДцДЂЯЕЭГЁЃПДЕНетРяЃЌШчЙћФњВЛУїАзHbaseЪЧИіЩЖЖЋЖЋЃЌВЛвЊНєЃЌЮвдйзмНсвЛЯТЯТЃК
HbaseЪЧвЛИіУцЯђСаДцДЂЕФЗжВМЪНДцДЂЯЕЭГЃЌЫќЕФгХЕудкгкПЩвдЪЕЯжИпадФмЕФВЂЗЂЖСаДВйзїЃЌЭЌЪБHbaseЛЙЛсЖдЪ§ОнНјааЭИУїЕФЧаЗжЃЌетбљОЭЪЙЕУДцДЂБОЩэОпгаСЫЫЎЦНЩьЫѕадЁЃ
Жў HbaseЪ§ОнФЃаЭ
HBase,CassandraЕФЪ§ОнФЃаЭЗЧГЃРрЫЦЃЌЫћУЧЕФЫМЯыЖМЪЧРДдДгкGoogleЕФBigtableЃЌвђДЫетШ§епЕФЪ§ОнФЃаЭЗЧГЃРрЫЦЃЌЮЈвЛВЛЭЌЕФОЭЪЧCassandraОпгаSuper
cloumn familyЕФИХФюЃЌЖјHbaseФПЧАЮвУЛЗЂЯжЁЃКУСЫЃЌЗЯЛАЩйЫЕЃЌЮвУЧРДПДПДHbaseЕФЪ§ОнФЃаЭЕНЕзЪЧИіЩЖЖЋЖЋЁЃ
дкHbaseРяУцгавдЯТСНИіжївЊЕФИХФюЃЌRow key,Column FamilyЃЌЮвУЧЪзЯШРДПДПДColumn
family,Column familyжаЮФгжУћЁАСазхЁБЃЌColumn familyЪЧдкЯЕЭГЦєЖЏжЎЧАдЄЯШЖЈвхКУЕФЃЌУПвЛИіColumn
FamilyЖМПЩвдИљОнЁАЯоЖЈЗћЁБгаЖрИіcolumn.ЯТУцЮвУЧРДОйИіР§згОЭЛсЗЧГЃЕФЧхЮњСЫЁЃ
МйШчЯЕЭГжагавЛИіUserБэЃЌШчЙћАДееДЋЭГЕФRDBMSЕФЛАЃЌUserБэжаЕФСаЪЧЙЬЖЈЕФЃЌБШШчschema
ЖЈвхСЫname,age,sexЕШЪєадЃЌUserЕФЪєадЪЧВЛФмЖЏЬЌдіМгЕФЁЃЕЋЪЧШчЙћВЩгУСаДцДЂЯЕЭГЃЌБШШчHbaseЃЌФЧУДЮвУЧПЩвдЖЈвхUserБэЃЌШЛКѓЖЈвхinfo
СазхЃЌUserЕФЪ§ОнПЩвдЗжЮЊЃКinfo:name = zhangsan,info:age=30,info:sex=maleЕШЃЌШчЙћКѓРДФугжЯыдіМгСэЭтЕФЪєадЃЌетбљКмЗНБужЛашвЊinfo:newPropertyОЭПЩвдСЫЁЃ
вВаэЧАУцЕФетИіР§згЛЙВЛЙЛЧхЮњЃЌЮвУЧдйОйИіР§згРДНтЪЭвЛЯТЃЌЪьЯЄSNSЕФХѓгбЃЌгІИУЖМжЊЕРгаКУгбFeedЃЌвЛАуЩшМЦFeedЃЌЮвУЧЖМЪЧАДееЁАФГШЫдкФГЪБзіСЫБъЬтЮЊФГФГЕФЪТЧщЁБЃЌЕЋЪЧЭЌЪБвЛАуЮвУЧвВЛсдЄСєвЛЯТЙиМќзжЃЌБШШчгаЪБКђfeedвВаэашвЊurlЃЌfeedашвЊimageЪєадЕШЃЌетбљРДЫЕЃЌfeedБОЩэЕФЪєадЪЧВЛШЗЖЈЕФЃЌвђДЫШчЙћВЩгУДЋЭГЕФЙиЯЕЪ§ОнПтНЋЗЧГЃТщЗГЃЌПіЧвЙиЯЕЪ§ОнПтЛсдьГЩвЛаЉЮЊnullЕФЕЅдЊРЫЗбЃЌЖјСаДцДЂОЭВЛЛсГіЯжетИіЮЪЬтЃЌдкHbaseРяЃЌШчЙћУПвЛИіcolumn
ЕЅдЊУЛгажЕЃЌФЧУДЪЧеМгУПеМфЕФЁЃЯТУцЮвУЧЭЈЙ§СНеХЭМРДаЮЯѓЕФБэЪОетжжЙиЯЕЃК

ЩЯЭМЪЧДЋЭГЕФRDBMSЩшМЦЕФFeedБэЃЌЮвУЧПЩвдПДГіfeedгаЖрЩйСаЪЧЙЬЖЈЕФЃЌВЛФмдіМгЃЌВЂЧвЮЊnullЕФСаРЫЗбСЫПеМфЁЃЕЋЪЧЮвУЧдйПДПДЯТЭМЃЌЯТЭМЮЊHbaseЃЌCassandra,BigtableЕФЪ§ОнФЃаЭЭМЃЌДгЯТЭМПЩвдПДГіЃЌFeedБэЕФСаПЩвдЖЏЬЌЕФдіМгЃЌВЂЧвЮЊПеЕФСаЪЧВЛДцДЂЕФЃЌетОЭДѓДѓНкдМСЫПеМфЃЌЙиМќЪЧFeedетЖЋЮїЫцзХЯЕЭГЕФдЫааЃЌИїжжИїбљЕФFeedЛсГіЯжЃЌЮвУЧЪТЯШУЛАьЗЈдЄВтгаЖрЩйжжFeedЃЌФЧУДЮвУЧвВОЭУЛгаАьЗЈШЗЖЈFeedБэгаЖрЩйСаЃЌвђДЫHbase,Cassandra,BigtableЕФЛљгкСаДцДЂЕФЪ§ОнФЃаЭОЭЗЧГЃЪЪКЯДЫГЁОАЁЃЫЕЕНетРяЃЌВЩгУHbaseЕФетжжЗНЪНЃЌЛЙгавЛИіЗЧГЃживЊЕФКУДІОЭЪЧFeedЛсздЖЏЧаЗжЃЌЕБFeedБэжаЕФЪ§ОнГЌЙ§ФГвЛИіЗЇжЕвдКѓЃЌHbaseЛсздЖЏЮЊЮвУЧЧаЗжЪ§ОнЃЌетбљЕФЛАЃЌВщбЏОЭОпгаСЫЩьЫѕадЃЌЖјдйМгЩЯHbaseЕФШѕЪТЮёадЕФЬиадЃЌЖдHbaseЕФаДШыВйзївВНЋБфЕУЗЧГЃПьЁЃ
ЩЯУцЫЕСЫColumn familyЃЌФЧУДЮвжЎЧАЫЕЕФRow keyЪЧЩЖЖЋЖЋЃЌЦфЪЕФуПЩвдРэНтrow keyЮЊRDBMSжаЕФФГвЛИіааЕФжїМќЃЌЕЋЪЧвђЮЊHbaseВЛжЇГжЬѕМўВщбЏвдМАOrder
byЕШВщбЏЃЌвђДЫRow keyЕФЩшМЦОЭвЊИљОнФуЯЕЭГЕФВщбЏашЧѓРДЩшМЦСЫЖюЁЃЮвЛЙФУИеВХФЧИіFeedЕФСазгРДЫЕЃЌЮвУЧвЛАуЪЧВщбЏФГИіШЫзюаТЕФвЛаЉFeedЃЌвђДЫЮвУЧFeedЕФRow
keyПЩвдгавдЯТШ§ИіВПЗжЙЙГЩ<userId><timestamp><feedId>ЃЌетбљвдРДЕБЮвУЧвЊВщбЏФГИіШЫЕФзюНјЕФFeedОЭПЩвджИЖЈStart
RowkeyЮЊ<userId><0><0>ЃЌEnd RowkeyЮЊ<userId><Long.MAX_VALUE><Long.MAX_VALUE>РДВщбЏСЫЃЌЭЌЪБвђЮЊHbaseжаЕФМЧТМЪЧАДееrowkeyРДХХађЕФЃЌетбљОЭЪЙЕУВщбЏБфЕУЗЧГЃПьЁЃ
Ш§ HbaseЕФгХШБЕу
1 СаЕФПЩвдЖЏЬЌдіМгЃЌВЂЧвСаЮЊПеОЭВЛДцДЂЪ§Он,НкЪЁДцДЂПеМф.
2 HbaseздЖЏЧаЗжЪ§ОнЃЌЪЙЕУЪ§ОнДцДЂздЖЏОпгаЫЎЦНscalability.
3 HbaseПЩвдЬсЙЉИпВЂЗЂЖСаДВйзїЕФжЇГж
HbaseЕФШБЕуЃК
1 ВЛФмжЇГжЬѕМўВщбЏЃЌжЛжЇГжАДееRow keyРДВщбЏ.
2 днЪБВЛФмжЇГжMaster serverЕФЙЪеЯЧаЛЛ,ЕБMasterхДЛњКѓ,ећИіДцДЂЯЕЭГОЭЛсЙвЕє.
ЫФ.ВЙГф
1.Ъ§ОнРраЭЃЌHBaseжЛгаМђЕЅЕФзжЗћРраЭЃЌЫљгаЕФРраЭЖМЪЧНЛгЩгУЛЇздМКДІРэЃЌЫќжЛБЃДцзжЗћДЎЁЃЖјЙиЯЕЪ§ОнПтгаЗсИЛЕФРраЭКЭДцДЂЗНЪНЁЃ
2.Ъ§ОнВйзїЃКHBaseжЛгаКмМђЕЅЕФВхШыЁЂВщбЏЁЂЩОГ§ЁЂЧхПеЕШВйзїЃЌБэКЭБэжЎМфЪЧЗжРыЕФЃЌУЛгаИДдгЕФБэКЭБэжЎМфЕФЙиЯЕЃЌЖјДЋЭГЪ§ОнПтЭЈГЃгаИїЪНИїбљЕФКЏЪ§КЭСЌНгВйзїЁЃ
3.ДцДЂФЃЪНЃКHBaseЪЧЛљгкСаДцДЂЕФЃЌУПИіСазхЖМгЩМИИіЮФМўБЃДцЃЌВЛЭЌЕФСазхЕФЮФМўЪБЗжРыЕФЁЃЖјДЋЭГЕФЙиЯЕаЭЪ§ОнПтЪЧЛљгкБэИёНсЙЙКЭааФЃЪНБЃДцЕФ
4.Ъ§ОнЮЌЛЄЃЌHBaseЕФИќаТВйзїВЛгІИУНаИќаТЃЌЫќЪЕМЪЩЯЪЧВхШыСЫаТЕФЪ§ОнЃЌЖјДЋЭГЪ§ОнПтЪЧЬцЛЛаоИФ
5.ПЩЩьЫѕадЃЌHbaseетРрЗжВМЪНЪ§ОнПтОЭЪЧЮЊСЫетИіФПЕФЖјПЊЗЂГіРДЕФЃЌЫљвдЫќФмЙЛЧсЫЩдіМгЛђМѕЩйгВМўЕФЪ§СПЃЌВЂЧвЖдДэЮѓЕФМцШнадБШНЯИпЁЃЖјДЋЭГЪ§ОнПтЭЈГЃашвЊдіМгжаМфВуВХФмЪЕЯжРрЫЦЕФЙІФм
ЯТУцЪЧгУЯъЯИЪЕМЪВйзїНиЭМБШНЯЧјБ№
1.nosqlЪ§ОнПтФмЗёЩОГ§Са
2.nosqlЪ§ОнПтШчКЮЩОГ§вЛЬѕМЧТМ
3.nosqlЪ§ОнПтСазхКЭliederЧјБ№ЪЧЪВУДЃП
4.nosqlВйзїгыДЋЭГЪ§ОнПтЕФВйзїЧјБ№дкЪВУДЕиЗНЃП
ЖдгкДѓЖрЪ§зіММЪѕЕФШЫдБЃЌЖМжЊЕРЮвУЧДЋЭГЪ§ОнПтЪЧЪВУДбљзгЕФЃЌФЧУДШчЯТЭМЫљЪОЃЌЮвУЧВйзїЕФЖдЯѓЪЧааЁЃ
вВОЭЪЧдіЩОИФВщЃЌЖМЪЧвдЮЊЖдЯѓЁЃ
1.ДЋЭГЪ§ОнПтдіМгЩОГ§НщЩм

ЭМ1
ЯТУцЮвУЧвдmysqlЮЊР§ЃК
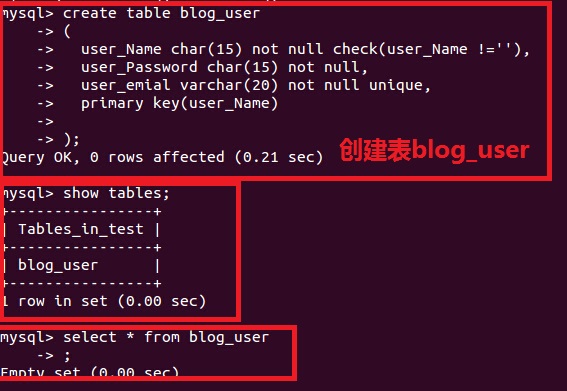
ВхШыЪ§Он
| mysql>INSERT
INTO blog_user (`user_Name`,`user_Password`,`user_emial`)VALUES
('aboutyun','aboutyun', 'aboutyun@sina.com'); |

ЩОГ§Ъ§ОнЃК
| mysql> delete
from blog_user where user_name="aboutyun"; |

2.NosqlЪ§ОнПтдіМгЩОГ§НщЩм
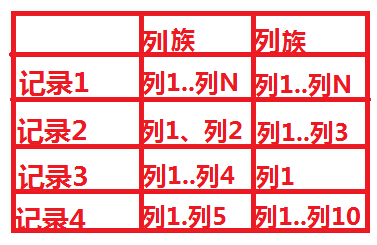
ЭМ2
вдhbaseЮЊР§ЃК
ДДНЈБэЃК
| create 'blog_user','userInfo' |
ИДжЦДњТы

ВхШыЪ§Он
етРяЪЧЙиМќЕуЃЌвВЪЧКмЖрШЫВЛШнвзРэНтЕФЕиЗН
hbase(main):012:0>
put'blog_user', 'www.aboutyun.com', 'userInfo:user_Name', 'aboutyun'
0 row(s) in 1.7530 seconds |

ЩЯУцЮвУЧПДЕНСЫ
1ЫљЪОЪЧЪВУДЃЌЮвУЧдкДЋЭГЪ§ОнПщРяУцИљБОУЛгаЃЌетЪЧnosqlЫљЬигаЕФЃЌЪЧвЛИіrowkeyЃЌЪЧЯЕЭГздДјЕФЃЌвВЪЧnosqlжавЛЬѕМЧТМЕФЮЈвЛБъЪЖЁЃЕЋЪЧетИіЮЈвЛБъЪЖЃЌгаИњЮвУЧЕФДЋЭГЪ§ОнПтЪЧгаЫљВюБ№ЕФЁЃШчЭМ1ЫљЪОЃЌЁАМЧТМ1ЁББуЪЧrowkey.
2ЫљЪОЪЧЮвУЧВхШыЕФСаuser_NameЃЌетвВЪЧзюФбвдРэНтЕФЕиЗНЃЌСаОЙШЛПЩвдВхШыЁЃВЂЧвЦфЁЏvalueЁЎЮЊ3МД'aboutyun'
ЮвУЧВхШыСЫСаЃЌЯТУцЮвУЧРДВщПДвЛЯТаЇЙћЃК

ЯТУцРДНтЪЭвЛЯТЩЯУцЕФКЌвхЃК
ЮвУЧЛсПДЕН
1ЮЊrowkeyЃЌВхШыЪ§ОнЁЏwww.aboutyun.comЁЎЃЌ
2ЮЊСазхЯТУцСаЕФУћзжuser_Name
3ЮвУЧВЂУЛгадкЩшМЦЕФЬэМгетИіСазхЃЌЫљвдетИіЪЧЯЕЭГздДјЕФЃЌетИіЪЧМЧТМЕФВйзїЪБМфЃЌвдЪБМфДСЕФаЮЪНЗХЕНhbaseРяУцЁЃ
4ЪЧЮвУЧВхШыЕФuser_NameЕФжЕ
ЯТУцЮвУЧдкВхШыpasswordЃК
| hbase(main):015:0>
put'blog_user', 'www.aboutyun.com', 'userInfo:user_Password', 'aboutyun' |

дйДЮВщбЏНсЙћЃК
hbase(main):016:0>
scan 'blog_user'
ROW COLUMN+CELL
www.aboutyun.com column=userInfo:user_Name, timestamp=1400663775901,
value=aboutyun
www.aboutyun.com column=userInfo:user_Password,
timestamp=1400665203430, value=aboutyun
1 row(s) in 0.0390 seconds |

ЕНетРяЃЌЮвУЧПДЕНСНааМЧТМЃЌДЋЭГЪ§ОнПщШЯЮЊетЪЧСНааЪ§ОнЃЌЖдгкnosqlЃЌетЪЧвЛЬѕМЧТМЁЃ
ЩОГ§СаЪ§Он
ЩОГ§Ъ§ОнЗжЮЊЩОГ§СаКЭЩОГ§МЧТМ
1.ЩОГ§Са
етРяУцЕФЩОГ§ЃЌУЛгаЩОГ§
delete 'blog_user', 'www.aboutyun.com',
'userInfo:user_Password'

ДгЩЯУцЮвУЧПДГіСаБЛЩОГ§СЫ
2.ЩОГ§МЧТМЃК
| deleteall 'blog_user','www.aboutyun.com' |
етЪЧЩОГ§жЎЧАЯдЪОНсЙћЃЌетРявбОЪЧ

ЩОГ§КѓНсЙћ
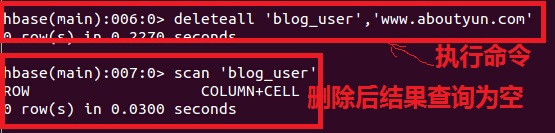
змНс
ЖдгкДЋЭГЪ§ОнПтЃЌдіМгСаЖдгквЛИіЯюФПРДНВЃЌИФБфЪЧЗЧГЃДѓЕФЁЃЕЋЪЧЖдгкnosqlЃЌВхШыСаКЭЩОГ§СаЃЌИњДЋЭГЪ§ОнПтРяУцЕФдіМгМЧТМКЭЩОГ§МЧТМРрЫЦ
|









