| БрМЭЦМі: |
БОЮФРДздгкЗЖаРаР
,ЮФеТжївЊДгдРэЪЕМљМАГЁОАНщЩмЕФЃЌЭМЮФЫЕУїЯъЯИЃЌЯЃЭћЖдДѓМвгаАяжњЁЃ
|
|
HBaseДггУЗЈЕФНЧЖШРДНВЦфЪЕЗІГТПЩЩЦЃЌЫљгаИќаТВхШыЩОГ§ЛљБОвЛСНИіAPIОЭПЩвдИуЖЈЃЌвЊЫЕЩдЮЂгаЕуИДдгЕФЛАЃЌScanЕФгУЗЈПЩФмЛсЖрвЛаЉЫЕЭЗЁЃЖјЧвОЙ§БЪепЙлВьЃЌКмЖрвЕЮёЖдScanЕФгУЗЈПЩФмДцдквЛаЉЮѓЧјЃЈЖдгкетаЉЮѓЧјЃЌБЪепвВЛсдкЯТЮФжИГіЃЉЃЌвђДЫгаСЫБОЦЊЮФеТЕФаДзїЖЏЛњЁЃвВЫуЪЧScanЯЕСаЕФЦфжавЛЦЊАЩЃЌКѓУцЖдгкScanЛЙЛсгавЛЦЊНсКЯHDFSЗжЮіHBaseЪ§ОнЖСШЁдкHDFSВуУцЪЧдѕУДвЛИіСїГЬЃЌОДЧыЦкД§ЁЃ
HBaseжаScanДгДѓЕФВуУцРДПДжївЊгаШ§жжГЃМћгУЗЈЃКScanAPIЁЂTableScanMRвдМАSnapshotScanMRЁЃШ§жжгУЗЈЕФдРэВЛОЁЯрЭЌЃЌЩЈУшаЇТЪвВЕБШЛЯрВюЩѕЖрЃЌзюживЊЕФЪЧетМИжжгУЗЈЪЪгУгкВЛЭЌЕФгІгУГЁОАЃЌвЕЮёашвЊИљОнздМКЕФЪЙгУГЁОАбЁдёКЯЪЪЕФЩЈУшЗНЪНЁЃНгЯТРДЗжБ№ЖдетШ§жжгУЗЈДгЙЄзїдРэЁЂзюМбЪЕМљСНИіВуУцНјааНтЮіЃЌзюКѓдйзнЯђЖдШ§жжгУЗЈНјаавЛЯТЖдБШЃЌЯЃЭћДѓМвФмЙЛДггУЗЈВуУцЖдScanгаИќЖрСЫНтЁЃ
ScanAPI
scanПЭЛЇЖЫЩшМЦдРэ
зюГЃМћЕФscanгУЗЈЃЌМћЙйЗНAPIЮФЕЕЁЃscanЕФдРэжЎЧАдкЖрЦЊЮФеТжаЖМгаЬсМАЃЌЮЊСЫБэЪіЗНБуЃЌгаБивЊдкДЫМђЕЅИХЪівЛЗЌЁЃHBaseжаscanВЂВЛЯёДѓМвЯыЯѓЕФвЛбљжБНгЗЂЫЭвЛИіУќСюЙ§ШЅЃЌЗўЮёЦїОЭНЋТњзуЩЈУшЬѕМўЕФЫљгаЪ§ОнвЛДЮадЗЕЛиИјПЭЛЇЖЫЁЃЖјЪЕМЪЩЯЫќЕФЙЄзїдРэШчЯТЭМЫљЪОЃК
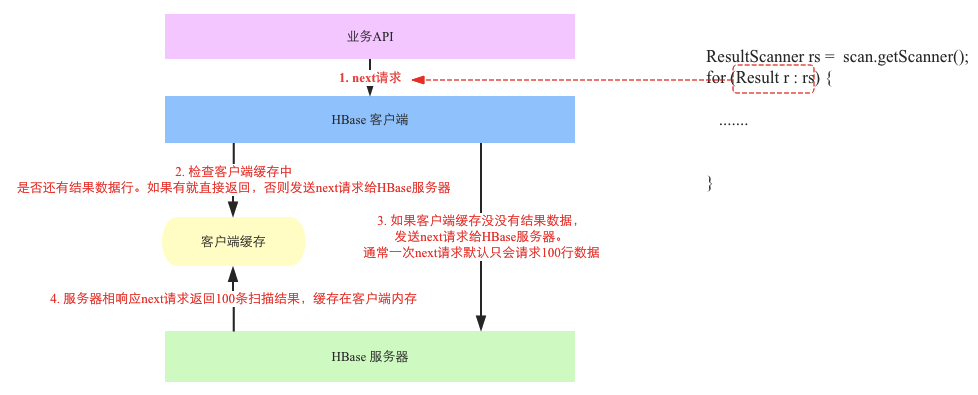
ЩЯЭМгвВрЪЧHBase scanЕФПЭЛЇЖЫДњТыЃЌЦфжаforбЛЗжаУПДЮБщРњResultScannerЖдЯѓЛёШЁвЛааМЧТМЃЌЪЕМЪЩЯдкПЭЛЇЖЫВуУцЖМЛсЕїгУвЛДЮnextЧыЧѓЁЃnextЧыЧѓећИіСїГЬПЩвдЗжЮЊШчЯТМИИіВНжшЃК
nextЧыЧѓЪзЯШЛсМьВщПЭЛЇЖЫЛКДцжаЪЧЗёДцдкЛЙУЛгаЖСШЁЕФЪ§ОнааЃЌШчЙћгаОЭжБНгЗЕЛиЃЌЗёдђашвЊНЋnextЧыЧѓИјHBaseЗўЮёЦїЖЫЃЈRegionServerЃЉЁЃ
ШчЙћПЭЛЇЖЫЛКДцвбОУЛгаЩЈУшНсЙћЃЌОЭЛсНЋnextЧыЧѓЗЂЫЭИјHBaseЗўЮёЦїЖЫЁЃФЌШЯЧщПіЯТЃЌвЛДЮnextЧыЧѓНіПЩвдЧыЧѓ100ааЪ§ОнЃЈЛђепЗЕЛиНсЙћМЏзмДѓаЁВЛГЌЙ§2MЃЉ
ЗўЮёЦїЖЫНгЪеЕНnextЧыЧѓжЎКѓОЭПЊЪМДгBlockCacheЁЂHFileвдМАmemcacheжавЛаавЛааНјааЩЈУшЃЌЩЈУшЕФааЪ§ДяЕН100аажЎКѓОЭЗЕЛиИјПЭЛЇЖЫЃЌПЭЛЇЖЫНЋет100ЬѕЪ§ОнЛКДцЕНФкДцВЂЗЕЛивЛЬѕИјЩЯВувЕЮёЁЃ
ЩЯВувЕЮёВЛЖЯвЛЬѕвЛЬѕЛёШЁЩЈУшЪ§ОнЃЌдкЪ§ОнСПДѓЕФЧщПіЯТЪЕМЪЩЯHBaseПЭЛЇЖЫЛсВЛЖЯЗЂЫЭnextЧыЧѓЕНHBaseЗўЮёЦїЁЃгаЕФХѓгбПЩФмЛсЮЪЮЊЪВУДscanашвЊЩшМЦЮЊЖрДЮnextЧыЧѓЕФФЃЪНЃПИіШЫШЯЮЊетЪЧЛљгкЖрИіВуУцЕФПМТЧЃК
HBaseБОЩэДцДЂСЫКЃСПЪ§ОнЃЌЫљвдКмЖрГЁОАЯТвЛДЮscanЧыЧѓЕФЪ§ОнСПЖМЛсБШНЯДѓЁЃШчЙћВЛЯожЦУПДЮЧыЧѓЕФЪ§ОнМЏДѓаЁЃЌКмПЩФмЛсЕМжТЯЕЭГДјПэГдНєДгЖјдьГЩећИіМЏШКЕФВЛЮШЖЈЁЃ
ШчЙћВЛЯожЦУПДЮЧыЧѓЕФЪ§ОнМЏДѓаЁЃЌКмЖрЧщПіЯТПЩФмЛсдьГЩПЭЛЇЖЫЛКДцOOMЕєЁЃ
ШчЙћВЛЯожЦУПДЮЧыЧѓЕФЪ§ОнМЏДѓаЁЃЌКмПЩФмЗўЮёЦїЖЫЩЈУшДѓСПЪ§ОнЛсЛЈЗбДѓСПЪБМфЃЌПЭЛЇЖЫКЭЗўЮёЦїЖЫЕФСЌНгОЭЛсtimeoutЁЃ
етбљЕФЩшМЦгаУЛгашІДУЃП
nextВпТдПЩвдБмУтдкДѓЪ§ОнСПЕФЧщПіЯТЗЂЩњИїжжвьГЃЧщПіЃЌЕЋетбљЕФЩшМЦЖдгкЩЈУшаЇТЪЫЦКѕВЂВЛгбКУЃЌетРяОйСНИіР§згЃК
scanВЂУЛгаВЂЗЂжДааЁЃетРяПЩФмКмЖрПДЙйЛсЮЪЃКЩЈУшЪ§ОнЗжВМдкВЛЭЌЕФregionФбЕРвВВЛЛсВЂаажДааЩЈУшТ№ЃПЪЧЕФЃЌШЗЪЕВЛЛсЃЌжСЩйдкЯждкЕФАцБОжаУЛгаЪЕЯжЁЃетЕувЛЖЈГіКѕКмЖрЖСепЕФвтСЯЃЌЮвУЧжЊЕРgetЕФХњСПЖСЧыЧѓЛсНЋЫљгаЕФЧыЧѓАДееФПБъregionНјааЗжзщЃЌВЛЭЌЗжзщЕФgetЧыЧѓЛсВЂЗЂжДааЖСШЁЁЃШЛЖјscanВЂУЛгаетбљЪЕЯжЁЃ
ДѓМвгаУЛгазЂвтЕНЩЯЭМжаВНжш3КЭВНжш4жЎМфHBaseЗўЮёЦїЖЫЩЈУшЪ§ОнЕФЪБКђHBaseПЭЛЇЖЫдкИЩЪВУДЃПзшШћЕШД§ЪЧАЩЁЃШЗЪЕЃЌЫљвдДгПЭЛЇЖЫЪгНЧРДПДећИіЩЈУшЪБМфЃНПЭЛЇЖЫДІРэЪ§ОнЪБМфЃЋЗўЮёЦїЖЫЩЈУшЪ§ОнЪБМфЃЌетФмВЛФмгХЛЏЃП
ScanAPIгІгУГЁОА
ИљОнЩЯУцЕФЗжЮіЃЌscan APIЕФаЇТЪКмДѓГЬЖШЩЯШЁОігкЩЈУшЕФЪ§ОнСПЁЃЭЈГЃНЈвщOLTPвЕЮёжаЩйСПЪ§ОнСПЩЈУшЕФscanПЩвдЪЙгУscan
APIЃЌДѓСПЪ§ОнЕФЩЈУшЪЙгУscan APIЃЌЩЈУшадФмгаЪБКђВЂВЛФмЙЛЕУЕНгааЇБЃжЄЁЃ
ScanAPIзюМбЪЕМљ
ХњСПOLAPЩЈУшвЕЮёНЈвщВЛвЊЪЙгУScanAPIЃЌScanAPIЪЪгУгкЩйСПЪ§ОнЩЈУшГЁОАЃЈOLTPГЁОАЃЉ
НЈвщЫљгаscanОЁПЩФмЖМЩшжУstartkeyвдМАstopkeyМѕЩйЩЈУшЗЖЮЇ
НЈвщЫљгаНіашвЊЩЈУшВПЗжСаЕФscanОЁПЩФмЭЈЙ§НгПкsetFamilyMapЩшжУСазхвдМАСа
TableScanMR
ScanAPIНіЪЪгУгкOLTPГЁОАЃЌФЧOLAPГЁОАЯТашвЊДгHBaseжаЩЈУшДѓСПЪ§ОнНјааЗжЮідѕУДАьФиЃПЯждкгаКмЖрвЕЮёашЧѓЖМашвЊДгHBaseЩЈУшДѓСПЪ§ОнНјааЗжЮіЃЌБШШчзюГЃМћЕФгУЛЇааЮЊЗжЮівЕЮёЃЌЭЈГЃашвЊЩЈУшФГаЉгУЛЇзюНќвЛЖЮЪБМфЕФЭјТчааЮЊЪ§ОнНјааЗжЮіЁЃ
ЖдгкетРрвЕЮёЃЌHBaseФПЧАЬсЙЉСЫСНжжЛљгкMRЩЈУшЕФгУЗЈЃЌЗжБ№ЮЊTableScanMRвдМАSnapshotScanMRЁЃЪзЯШРДНщЩмTableScanMRЃЌОпЬхгУЗЈПЩвдВЮПМЙйЗНЮФЕЕЁЃTableScanMRЕФЙЄзїдРэЦфЪЕКмМђЕЅЃЌЫЕАзСЫОЭЪЧScanAPIЕФВЂааЛЏЁЃШчЯТЭМЫљЪОЃК
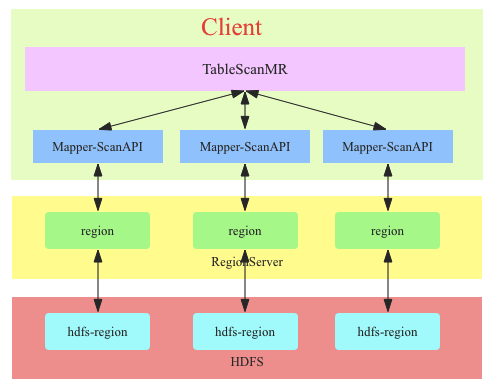
TableScanMRЛсНЋscanЧыЧѓИљОнФПБъregionЕФЗжНчНјааЗжНтЃЌЗжНтГЩЖрИіsub-scanЃЌУПИіsub-scanБОжЪЩЯОЭЪЧвЛИіScanAPIЁЃМйШчscanЪЧШЋБэЩЈУшЃЌФЧетеХБэгаЖрЩйregionЃЌОЭЛсНЋетИіscanЗжНтГЩЖрИіsub-scanЃЌУПИіsub-scanЕФstartkeyКЭstopkeyОЭЪЧregionЕФstartkeyКЭstopkeyЁЃ
TableScanMRзюМбЪЕМљ
TableScanMRЩшМЦЮЊOLAPГЁОАЪЙгУЃЌвђДЫдкРыЯпЩЈУшЪБОЁПЩФмЪЙгУИУжаЗНЪН
TableScanMRдРэЩЯжївЊЪЕЯжСЫScanAPIЕФВЂааЛЏЃЌНЋscanАДееregionБпНчНјааЧаЗжЁЃетжжГЁОАЯТећИіscanЕФЪБМфЛљБОЕШгкзюДѓregionЩЈУшЕФЪБМфЁЃдкФГаЉгаЪ§ОнЧуаБЕФГЁОАЯТПЩФмГіЯжФГвЛИіregionЩЯгаДѓСПД§ЩЈУшЪ§ОнЃЌЖјЦфЫћДѓСПregionЩЯЖМНігаКмЩйЕФД§ЩЈУшЪ§ОнЁЃетбљВЂааЛЏаЇЙћВЂВЛКУЁЃеыЖдетжжЪ§ОнЧуаБЕФГЁОАTableScanMRзіСЫЦНКтДІРэЃЌЫќЛсНЋДѓregionЩЯЕФscanЧаЗжГЩЖрИіаЁЕФscanЪЙЕУЫљгаЗжНтКѓЕФscanЩЈУшЕФЪ§ОнСПЛљБОЯрЕБЁЃетИігХЛЏФЌШЯЪЧЙиБеЕФЃЌашвЊЩшжУВЮЪ§ЁБhbase.mapreduce.input.autobalanceЁБЮЊtrueЁЃвђДЫНЈвщДѓМвЪЙгУTableScanMRЪБНЋИУВЮЪ§ЩшжУЮЊtrueЁЃ
ОЁСПНЋЩЈУшБэжаЯрСкЕФаЁregionКЯВЂГЩДѓregionЃЌЖјНЋДѓregionЧаЗжГЩЩдЮЂаЁЕуЕФregion
TableScanMRжаScanашвЊзЂвтШчЯТСНИіВЮЪ§ЩшжУЃК
Scan scan = new
Scan();
scan.setCaching(500); // 1 is the default in Scan,
which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true
for MR jobs |
SnapshotScanMR
SnapshotScanMRгыTableScanMRЯрЭЌЖМЪЧЪЙгУMRВЂааЛЏЖдЪ§ОнНјааЩЈУшЃЌСНепгУЗЈвВЛљБОЯрЭЌЃЌжБНгЪЙгУTableScanMRЕФгУЗЈЃЌдкДЫЛљДЁЩЯзіВПЗжаоИФМДПЩЃЌШчЯТЫљЪОЃК
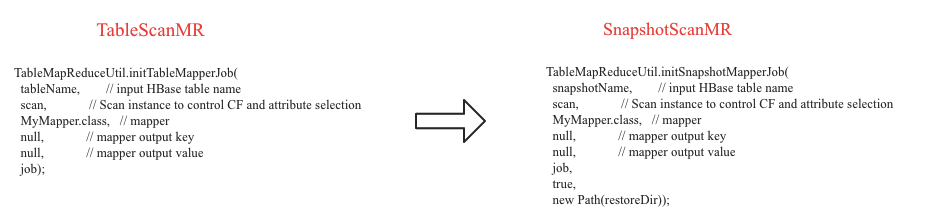
ЕЋСНепдкЪЕЯжЩЯШДгаЖрИіЗЧГЃДѓЕФЧјБ№ЃК
ДгУќУћРДПДОЭжЊЕРЃЌSnapshotScanMRЩЈУшгкдЪМБэЖдгІЕФsnapshotжЎЩЯЃЈИќзМШЗРДЫЕИљОнsnapshot
restoreГіРДЕФhfileЃЉЃЌЖјTableScanMRЩЈУшгкдЪМБэЁЃ
SnapshotScanMRжБНгЛсдкПЭЛЇЖЫДђПЊregionЩЈУшHDFSЩЯЕФЮФМўЃЌВЛашвЊЗЂЫЭScanЧыЧѓИјRegionServerЃЌдйгаRegionServerЩЈУшHDFSЩЯЕФЮФМўЁЃЪЧЕФЃЌФуУЛПДДэЃЌЪЧдкПЭЛЇЖЫжБНгЩЈУшHDFSЩЯЕФЮФМўЃЌетРрscannerГЦжЎЮЊClientSideRegionScannerЁЃ
ЯТЭМЪЧSnapshotScanMRЕФЙЄзїдРэЭМЃЈзЂвтКЭTableScanMRЙЄзїдРэЭМЖдБШЃЉЃК
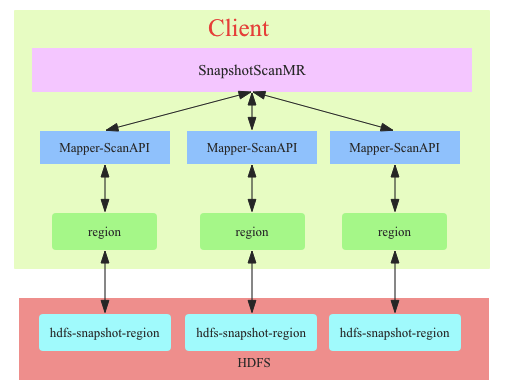
етЪЧвЛИіЯрЖдМђЕЅЕФЪОвтЭМЃЌЦфжаЪЁТдСЫКмЖрДІРэsnapshotЕФЙ§ГЬвдМАЧаЗжscanЕФЙ§ГЬЁЃзмЬхРДПДКЭTableScanMRЙЄзїСїГЬЛљБОвЛжТЃЌзюДѓЕФВЛЭЌРДздregionЩЈУшHDFSетИіФЃПщЃЌTableScanMRжаетИіФЃПщРДздгкregionserverЃЌЖјSnapshotScanMRжаПЭЛЇЖЫжБНгШЦЙ§regionserverдкПЭЛЇЖЫНшгУregionжаЕФЩЈУшЛњжЦжБНгЩЈУшhdfsжаЪ§ОнЁЃ
гааЉХѓгбПЩФмвЊЮЪСЫЃЌЮЊЪВУДвЊетУДЭцЃПзмНсЦ№РДЃЌжЎЫљвдетУДЭцжївЊгаСНИідвђЃК
МѕаЁЖдRegionServerЕФгАЯьЁЃКмЯдШЛЃЌSnapshotScanMRетжжШЦЙ§RegionServerЕФЪЕЯжЗНЪНзюДѓЯоЖШЕФМѕаЁСЫЖдМЏШКжаЦфЫћвЕЮёЕФгАЯьЁЃ
МЋДѓЕФЬсЩ§СЫЩЈУшаЇТЪЁЃSnapshotScanMRЯрБШTableScanMRдкЩЈУшаЇТЪЩЯЛсга2БЖЁЋNБЖЕФадФмЬсЩ§ЃЈЯТвЛаЁНкЖдИїжжЩЈУшгУЗЈадФмзіИіЖдБШЦРЙРЃЉЁЃгаШЫгжвЊЮЪСЫЃЌЮЊЪВУДЛсгаетУДДѓЕФадФмЬсЩ§ЃПИіШЫШЯЮЊжївЊгаШчЯТСНИіЗНУцЕФдвђЃК
ЩЈУшЕФЙ§ГЬЩйСЫвЛДЮЭјТчДЋЪфЃЌЖдгкДѓЪ§ОнСПЕФЩЈУшЃЌЭјТчДЋЪфЛЈЗбЕФЪБМфЪЧЗЧГЃХгДѓЕФЃЌетжївЊПЩФмЧЃГЖЕНЪ§ОнЕФађСаЛЏвдМАЗДађСаЛЏПЊЯњЁЃ
TableScanMRЩЈУшжаRegionServerКмПЩФмЛсГЩЮЊЦПОБЃЌЖјSnapshotScanMRЩЈУшВЂУЛгаетИіЦПОБЕуЁЃ
дкзюКѓЫЕвЛИіTableScanMRКЭSnapshotScanMRЖМДцдкЕФЮЪЬтЃЌСНепЪЕМЪЩЯЖМЪЧАДееregionЖдscanНјааЧаЗжЃЌШЛЖјЖдгкКмЖрДѓregionЃЈДѓгк30gЃЉЃЌЕЅИіregionЕФЩЈУшСЃЖШЛЙЪЧЬЋДѓЁЃСэЭтЃЌКмЖрscanЩЈУшПЩФмВЂУЛгаЩцМАЖрИіregionЃЌЖјЪЧМЏжадкФГвЛИіregionЩЯЃЌОйИіР§згЃЌЩЈУшФГИігУЛЇзюНќвЛИідТЕФааЮЊМЧТМЃЌШчЙћrowkeyЩшМЦЮЊusername+timestampЕФЛАЃЌД§ЩЈУшЪ§ОнЭЈГЃЛсМЏжаДцДЂдквЛИіregionЩЯЃЌетжжЩЈУшШчЙћЪЙгУMRЕФЛАЃЌдкЕБЧАЕФВпТдЯТжЛЛсЩњГЩвЛИіMapperЁЃвђДЫгаБивЊЬсЙЉвЛаЉЦфЫћВпТдПЩвдНЋscanЗжНтЕФСЃЖШзіЕФИќЯИЁЃ
ЛљБОадФмЖдБШ
еыЖдTableScanMRКЭSnapshotScanMRСНжжЩЈУшЗНЪНЃЌБЪепзіЙ§вЛИіМђЕЅВтЪдЃЌЭЌбљЩЈУш1вкЬѕЕЅаа1KЕФМЧТМЃЈregionга15ИіЃЉЃЌSnapshotScanMRЫљашвЊЕФЪБМфЛљБОЪЧTableScanMRЕФвЛАыЁЃЧАаЉЬьБЪепИеКУПДЕНвЛИіЗжЯэЃЌРяУцгаЖдЪЙгУScanAPIЁЂClientSideRegionScannerAPIЁЂTableScannMRвдМАSnapshotScanMRНјааСЫадФмЖдБШЃЌШчЯТЭМЫљЪОЃК

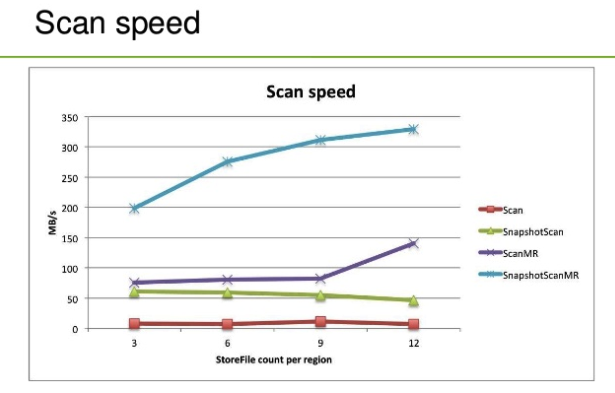
ДгЩЯЭМжаПЩвдПДГіЃЌЪЙгУScanAPIЕФадФмзюВюЃЌSnapshotScanMRЕФадФмзюКУЁЃSnapshotScanMRЕФадФмЯрБШTableScanMR(ScanMR)вВга3БЖЕФадФмЬсЩ§ЁЃШЛЖјдкЪЕМЪгІгУжаЃЌКЭаЁУзcommitterељЩёжЎЧАСФЙ§ЃЌSnapshotScanMRФПЧАПЩФмЛЙгаКмЖрВЛЪЧКмЭъЩЦЕФЕиЗНЃЌЫћУЧвВдкВЛЖЯЕФаоИДЃЌЯраХдкжЎКѓЕФАцБОжаSnapshotScanMRЛсИќМгГЩЪьЁЃ |









