| БрМЭЦМі: |
БОЮФРДздгкcnblogs
,ЮФжаНщЩмСЫKafkaМмЙЙжаЯрЛЅжЎМфЕФЙиЯЕЃЌдѕУДЗжВМЕФЁЃ
|
|
ЯћЯЂжаМфМўMessageQuene НтёюЧвПЩРЉеЙЃКвЕЮёИДдгЖШЕФЬсЩ§ДјРДЕФвВЪЧёюКЯЖШЕФЬсИпЃЌЯћЯЂЖгСадкДІРэЙ§ГЬжаМфВхШыСЫвЛИівўКЌЕФЁЂЛљгкЪ§ОнЕФНгПкВуЃЌСНБпЕФДІРэЙ§ГЬЖМвЊЪЕЯжетвЛНгПкЁЃетдЪаэФуЖРСЂЕФРЉеЙЛђаоИФСНБпЕФДІРэЙ§ГЬЃЌжЛвЊШЗБЃЫќУЧзёЪиЭЌбљЕФНгПкдМЪјЁЃ ШпгрЃКгааЉвЕЮёдкДІРэЙ§ГЬжаШчЙћЪЇАмСЫЃЌЪ§ОндкЮДНјааГжОУЛЏЕФЪБКђОЭвбОЯћЪЇЃЌЯћЯЂЖгСаАбЪ§ОнГжОУЛЏжБЕНЫћУЧБЛДІРэЃЌБмУтСЫЪ§ОнЕФЖЊЪЇ ДІРэВЂЗЂЃКДѓЪ§ОнСПЗУЮЪЕФЪБКђЮвУЧПЩвдНЋЯћЯЂЗХШыЖгСажаЃЌШЛКѓдкЖгСаРяУцАДееЯЕЭГЕФЭЬЭТФмСІРДНјааЮШЖЈЕФГщШЁЪ§ОнВЂНјаавЕЮёДІРэЁЃ ПЩЛжИДЃКвЛВПЗжЯЕЭГГіЯжЮЪЬтЃЌПЩФмгАЯьећИіГЬађЮШЖЈЃЌЯћЯЂЖгСагЩгкНЋЪ§ОнГжОУЛЏЃЌЫљвддкГіЯжЮЪЬтЕФЪБКђПЩвдЦ№ЕНвЛИіБИЗнЕФзїгУЃЌЯЕЭГЮШЖЈжЎКѓПЩвдНјааЪ§ОнжиаТЯћЗбЁЃ ЫЭДяБЃжЄЃКДѓЖрЪ§ЯћЯЂЖгСаЖМгавЛЬзздМКЕФЯћЯЂДІРэЛњжЦЃЌвЛАуЗжЮЊЯћЯЂДІРэЖрДЮЃЌЯћЯЂжСЩйБЛДІРэвЛДЮЕШЧщПіЃЌетЪЙЕУЮвУЧДІРэвЕЮёМѕЩйСЫЪ§ОнЖЊЪЇЧщПіЕФЗЂЩњЁЃ ЫГађДІРэЃКАДеевЛЖЈЕФЫГађЗЂЫЭЯћЯЂЃЌЪЙЕУЯћЯЂдкЖгСажаЪЧгаађДцдкЕФЃЌЫљвддкЯћЗбЪ§ОнЕФЪБКђЮвУЧвВЪЧгаађДІРэЕФЃЈЯШНјЯШГіЃЉЁЃ вьВНЭЈаХЃККмЖрЪБКђЃЌФуВЛЯывВВЛашвЊСЂМДДІРэЯћЯЂЁЃЯћЯЂЖгСаЬсЙЉСЫвьВНДІРэЛњжЦЃЌдЪаэФуАбвЛИіЯћЯЂЗХШыЖгСаЃЌЕЋВЂВЛСЂМДДІРэЫќЁЃФуЯыЯђЖгСажаЗХШыЖрЩйЯћЯЂОЭЗХЖрЩйЃЌШЛКѓдкФуРжвтЕФЪБКђдйШЅДІРэЫќУЧЁЃ
ГЃгУMQЖдБШ
RedisMQЃКRedisЪЧЛљгкKey-ValueЕФNoSqlЪ§ОнПтЃЌБОЩэжЇГжMQЖгСаВйзїЃЌЪЧвЛИіЧсСПМЖЕФЖгСаЗўЮёЃЌдкЪЙгУRedisзїЮЊЛКДцЕФЯюФПжаЃЌПЩвдгХЯШЪЙгУRedisMQзїЮЊЯћЯЂЖгСаНјаавЕЮёДІРэЁЃгХЕуЃКЧсСПМЖЃЌШнвзПЊЗЂЁЃШБЕуЃКЪ§ОнДѓЕФЪБКђШыЖгЫйЖШНЯТ§ ActiveMQЃКApacheЕФвЛИіПЊдДзгЯюФПЃЌжЇГжЖржжгябдвдМАЭјТчавщЁЃгХЕуЃКШнвзПЊЗЂЃЌВЂЧвгаздДјжиСЌЛњжЦЁЃШБЕуЃКДЋШыЮФМўВЛЗНБуЃЌЪ§ОнДѓЕФЪБКђаЇТЪвЛАуЃЌЯћЗбЪЇАмЕФЪ§ОнНЋЛсЖЊЪЇЁЃ KafkaЃКApacheЕФвЛИіПЊдДзгЯюФПЃЌИпадФмДѓЭЬЭТСПВЂЧвФмЙЛТњзуПчгябдЦНЬЈЗжВМЪНЁЃгХЕуЃКПьЫйГжОУЛЏЃЌДѓЭЬЭТСПЃЌжЇГжhadoopЪ§ОнВЂааМгдиЃЌПЩвдНјааРыЯпЯћЯЂДІРэЁЃШБЕуЃКПЊЗЂРЇФбЃЌХфжУЮФМўИДдгЃЌПЊдДДњТыНЯЩйЁЃ
KafkaдЊЫиНщЩм
brokerЃКkafkaДюНЈЕФМЏШКЗўЮёЦїГЦЮЊbrokerЃЌМЏШКжавЛЬЈЗўЮёЦїПЩвдДюдиЖрИіbrokerЁЃ TopicЃКУПЬѕЗЂВМЕНKafkaМЏШКЕФЯћЯЂЖМгавЛИіРрБ№ЃЌетИіРрБ№БЛГЦЮЊtopicЁЃЮвУЧПЩвдШЯЮЊЭЌвЛжжРраЭЕФЯћЯЂДцЕНЭЌвЛИіtopicЯТЃЌетЕуКЭMapЕФkeyжЕгаЯрЫЦжЎДІЁЃ PartitonЃКparitionЪЧЮяРэЩЯЕФИХФюЃЌУПИіtopicАќКЌвЛИіЛђЖрИіpartitionЃЌДДНЈtopicЕФЪБКђПЩвджИЖЈpartitonЕФЪ§СПЁЃУПвЛИіpartitionЖдгІвЛИіЮФМўМаЁЃЮФМўМаРяУцДцЗХЫїв§ЮФМўвдМАЪ§ОнЮФМўЁЃ ProducerЃКИКд№ЗЂВМЯћЯЂЕНBrokerжа ConsumerЃКУПИіЯћЗбепЪєгкЬиЖЈЕФЯћЗбепзщЃЌУПИіЯћЗбепзщжЛФмЯћЗбвЛИіpartitionЕФЪ§ОнЃЌЖрИізщПЩвдЭЌЪБЯћЗбЭЌвЛИіpartitionЕФЪ§ОнЁЃ
KafkaЕФМмЙЙ
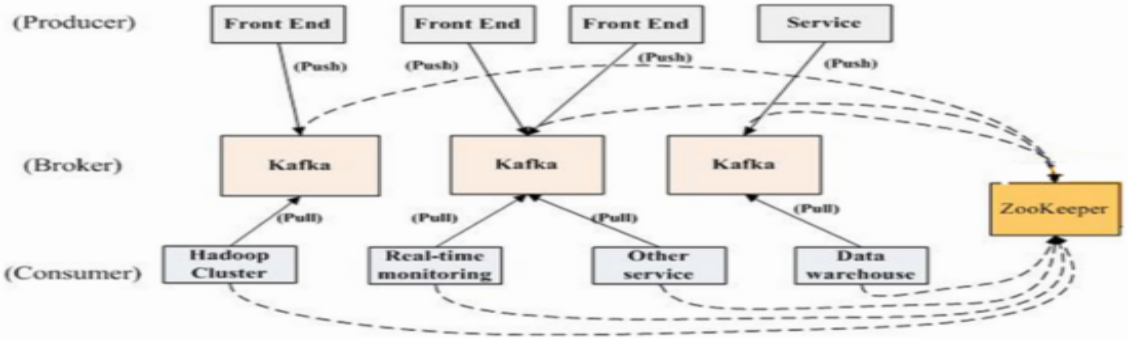
вЛИіЕфаЭЕФkafkaМЏШКжаАќКЌШєИЩproducerЃЌШєИЩbrokerЃЈKafkaжЇГжЫЎЦНРЉеЙЃЌвЛАуbrokerЪ§СПдНЖрЃЌМЏШКЭЬЭТТЪдНИпЃЉЃЌ
ШєИЩconsumer groupЃЌвдМАвЛИі Zookeeper МЏШКЁЃKafkaЭЈЙ§ZookeeperЙмРэМЏШКХфжУЃЌбЁОйleaderЃЌвдМАдкconsumer
groupЗЂЩњБфЛЏЪБНјааrebalanceЁЃproducerЪЙгУpushФЃЪННЋЯћЯЂЗЂВМЕНbrokerЃЌconsumerЪЙгУpullФЃЪНДг
brokerЖЉдФВЂЯћЗбЯћЯЂЁЃ
KafkaДІРэЯћЯЂЕФЛњжЦ
producerЃКProducerЯђBrokerЭЦЫЭЯћЯЂЃЈpushЃЉ consumerЃКconsumerДгbrokerРШЁЯћЯЂЃЈpullЃЉ pushФЃЪНЯТКмФбЪЪгІВЛЭЌЯћЗбЫйТЪЕФЯћЗбепДІРэЯћЯЂЃЌвђЮЊЗЂЫЭЯћЯЂЕФЫйЖШЪЧгЩbrokerОіЖЈЕФЁЃpushФЃЪНЕФФПЕФЪЧЮЊСЫОЁПьЕФЯћЗбЃЌЕЋЪЧетбљШнвздьГЩconsumerРДВЛМАДІРэЯћЯЂЁЃЕфаЭЕФБэЯжОЭЪЧЭјТчзшШћКЭОмОјЗўЮёЁЃ pullФЃЪНПЩвдИљОнЯћЗбепЯћЗбЫйТЪЖјзЅШЁЯћЯЂЃЌетбљБмУтСЫЭјТчзшШћЕФЧщПіЗЂЩњЁЃ
TopicгыPartitionШЯЪЖЁЊЁЊМђЕЅЗжВМ
PartitionЗжВМЮвУЧжївЊЗжГЩЕЅBrokerКЭЖрИіBrokerЃК
ЕЅИіBrokerЃК
ДДНЈвЛИіpartitionЮЊ3ЃЌReplicaЮЊ1ЃЌTopicУћзжЮЊorderЕФtopicЁЃЮвУЧЕУЕНЕФЗжВМЪНдкХфжУКУЕФLOGЮФМўМажаЩњГЩШ§ИіЗжБ№ЮЊЃКorder-0ЁЂorder-1ЁЂorder-2ЕФЮФМўМагУРДДцДЂPartitionЯТЕФаХЯЂЕФ.indexЮФМў.logЮФМўКЭ.timeindexЮФМўЁЃ
ЖрИіBrokerЃК
ДДНЈвЛИіpartitionЮЊ3ЃЌReplicaЮЊ1ЃЌTopicУћзжЮЊorderЕФtopicЁЃЮвУЧдкBroker0жаЖдгІЕФLOGЮФМўМажажЛЪЧЗЂЯжСЫorder-0ЕФЮФМўМаЃЌдкЦфЫћBrokerжаЗжБ№ЗЂЯжСЫPartitionЕФЮФМўМаЁЃШчЙћBrokerЪ§ДѓгкPartitionЪ§ЃЌФЧУДгаBrokerжаУЛгаЖдгІЕФPartitionЃЛШчЙћBrokerаЁгкPartitionЪ§ЃЌBrokerжаЛсДцдкЖрИіPartitionЁЃ
ЯТУцвдвЛИіKafkaМЏШКжа4ИіBrokerОйР§ЃЌДДНЈ1ИіtopicАќКЌ4ИіPartitionЃЌ2Иі
ReplicationЃК
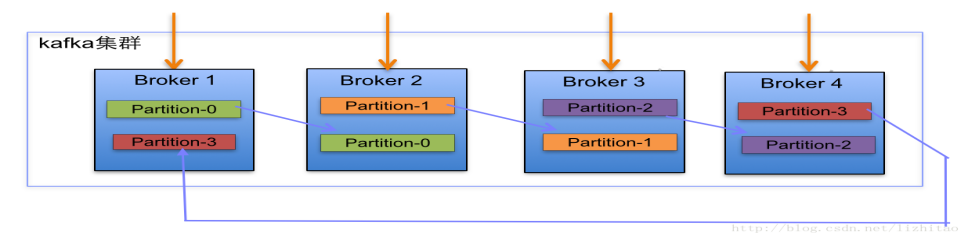
ЕБМЏШКжааТді2НкЕуЃЌPartitionдіМгЕН6ИіЪБЗжВМЧщПіЃК
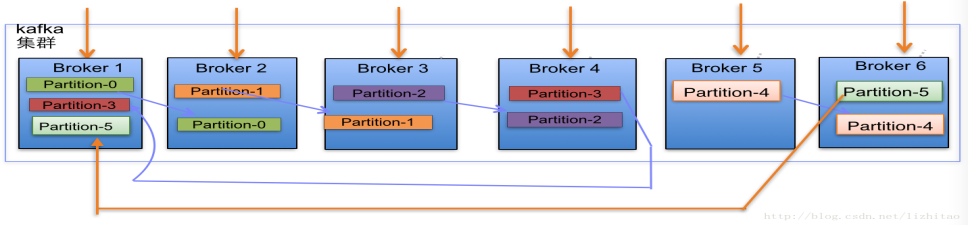
TopicгыPartitionШЯЪЖЁЊЁЊЗжВМТпМ ИББОЗжХфТпМЃК
дкkafkaМЏШКжаЃЌУПИіBrokerЗжХфPartitionЕФleaderЛњЛсЪЧОљЕШЕФ УПИіBrokerЃЈАДееbrokeridгаађЃЉвРДЮЗжХфleaderЕФPartitionЃЌЯТвЛИіBrokerЮЊИББОЃЌШчДЫбЛЗЕќДњЗжХфЃЌЖрИББОвВзёбДЫЙцдђЁЃ ИББОЗжХфЫуЗЈЃК
НЋЫљгаЕФBrokerКЭД§ЗжХфЕФPartitionНјааХХађ НЋЕкiИіPartitionЗжХфЕНЕк(i mod n)ИіBrokerЩЯ НЋЕкiИіPartitionЕФЕкjИіИББОЗжХфЕНЕк((i + j) mod n)ИіBrokerЩЯ.
PartitionЁЊЁЊLeaderгыFollower
LeaderКЭFollowerЃК
opicЕФReplicationВЛЪЧБибЁ ШчЙћReplicationжаЕФLeaderхДЛњСЫЃЌФЧУДИББОFollowerНЋзїЮЊLeader FollowerЕФЪ§ОнЪЧДгLeaderжаРШЁЕФЃЌЖјВЛЪЧLeaderЗЂЫЭЕФ ХаЖЯНкЕуЪЧЗёaliveЃКЪзЯШНкЕуБиаыПЩвдЮЌЛЄКЭzookeeperЕФСЌНгЃЌzookeeperЭЈЙ§аФЬјЛњжЦМьВщУПИіНкЕуЕФСДНгЃЛЦфДЮЪЧШчЙћетИіНкЕуЪЧfollowerЃЌБиаыФмЙЛЭЌВНleaderЕФаДВйзїЃЌбгЪБВЛФмЬЋОУЁЃЃЈЗћКЯЬѕМўЕФНкЕуЮЊЭЌВНжазДЬЌЃЌШчЙћГіЯжЩЯЪіЮЪЬтЕФНкЕуЃЌleaderНЋЛсАбНкЕувЦГ§ЃЌЪБМфгЩreplica.lag.time.max.msОіЖЈЃЌЯћЯЂгЩreplica.lag.max.messagesОіЖЈЃЉ ШчЙћгаИББОЃЌФЧУДЕБЫљгаИББОЖММгШыШежОжаВХЫуетЬѕаХЯЂcommitedЃЌжЛгаЯћЯЂЪЧcommitedзДЬЌЕФВХФмБЛЯћЗбепЯћЗбЁЃЃЈProducerПЩвдИљОнacksВЮЪ§РДОіЖЈЪЧЗёЕШД§ЯћЯЂЬсНЛЭЈжЊЗДРЁЃЉ KafkaжЛвЊБЃжЄгавЛИіНкЕуЪЧЭЌВНжаЕФЃЌвбОcommitedЕФЯћЯЂОЭВЛЛсЖЊЪЇЁЃ
PartitionЁЊЁЊLeaderбЁОй
ЗжВМЪНLeaderбЁОйЛњжЦгаFollowerЭЖЦБЃЌвдМАFollowerУќжаТЪЛњжЦРДЕШЃЌетСНжжЛњжЦЖМЪЧИљОнИББОНкЕуЕФзДЬЌРДЖЏЬЌбЁдёЕФЁЃЖјkafkaВЂВЛЪЙгУетСНжжЁЃ ЫфШЛkafkaЪЙгУzookeeperНјааleaderбЁдёЃЌЕЋЪЧЫќВЩгУFastLeaderElectionЕФЗНЪНКЭДЋЭГЗНЪНгаЫљВЛЭЌЁЃ kafkaздМКЮЌЛЄЭЌВНзДЬЌЕФИББОМЏКЯЃЈISRЃЉЃЌетИіРяУцЕФНкЕуЖМЪЧКЭLeaderЪ§ОнБЃГжИпЖШвЛжТЕФЃЌШЮКЮвЛЬѕЯћЯЂБЃжЄУПИіНкЕуЕФЯћЯЂзЗМгЕНШежОжаВХЛсИцЫпLeaderетИіЯћЯЂвбОcommitedЃЌЫљвдШЮКЮFollowerНкЕудкLeaderхДЕєжЎКђЖМПЩФмБЛбЁдёЮЊLeaderЃЌВЂЧветаЉНкЕуЖМЪЧЭЈЙ§zookeeperЙмРэЮЌЛЄЁЃ FollowerНкЕуЮЊNЃЌШчЙћN-1ИіНкЕуЖМхДЃЌkafkaвРШЛПЩвде§ГЃЙЄзїЃЌШчЙћФГвЛИіхДЕєНкЕугжжиаТaliveЃЌгЩЛсБЛжиаТМгШыЕНISRжаЁЃ ШчЙћNИіНкЕуЖМхДЕєСЫЃЌОЭЛсЕШД§ISRжаШЮКЮвЛИіжиаТaliveЕФНкЕузїЮЊLeaderЃЌЛђепбЁдёЫљгаНкЕужажиаТaliveЕФНкЕузїЮЊLeaderЃЈУВЫЦаТАцБОkafkaжаПЩвдХфжУLeaderбЁОйЕФетжжЧщПіЕФбЁдёЗНЪНЃЉ
PartitionЁЊЁЊЮФМўДцДЂЗНЪН
УПИіpartion(ФПТМ)ЯрЕБгквЛИіОоаЭЮФМўБЛЦНОљЗжХфЕНЖрИіДѓаЁЯрЕШsegment(ЖЮ)Ъ§ОнЮФМўжаЁЃЕЋУПИіЖЮsegment
fileЯћЯЂЪ§СПВЛвЛЖЈЯрЕШЃЌетжжЬиадЗНБуold segment fileПьЫйБЛЩОГ§ЁЃ УПИіpartitonжЛашвЊжЇГжЫГађЖСаДОЭааСЫЃЌsegmentЮФМўЩњУќжмЦкгЩЗўЮёЖЫХфжУВЮЪ§ОіЖЈЁЃ ДХХЬдкНјааЗЧЯпадаДШыЕФаЇТЪКмЕЭЃЌдкжЊЕРЖСаДЫГађЕФЧщПіЯТаЇТЪКмИпЃЌетЪЧkafkaаЇТЪИпЃЌТњзуИпЭЬЭТСПЕФЬѕМўЁЃ
PartitionЁЊЁЊЮФМў
ЖЮТфЮФМўгЩШ§ВПЗжзщГЩЃК.indexЮФМўЁЂ.logЮФМўвдМА.timeindexЮФМўЁЃЃЈ0.8АцБОжЎЧАЕФkafkaУЛгаtimeindexЮФМўЃЉ indexЮФМўЮЊЫїв§ЮФМўЃЌУќУћЙцдђЮЊДг0ПЊЪМЕНЃЌКѓајЕФгЩЩЯвЛИіЮФМўЕФзюДѓЕФoffsetЦЋвЦСПРДПЊЭЗЃЈ19ЮЛЪ§зжзжЗћГЄЖШЃЉ .logЮФМўЮЊЪ§ОнЮФМўЃЌДцЗХОпЬхЯћЯЂЪ§Он .timeindexЮФМўЃЌЪЧkafkaЕФОпЬхЪБМфШежО ШчЙћЩшжУlogЪЇаЇЪБМфБШНЯЖЬЃЌОЭЛсГіЯжЯТУцетжжзДПі

PartitionЁЊЁЊindexКЭlogЕФЦЅХфЙиЯЕ
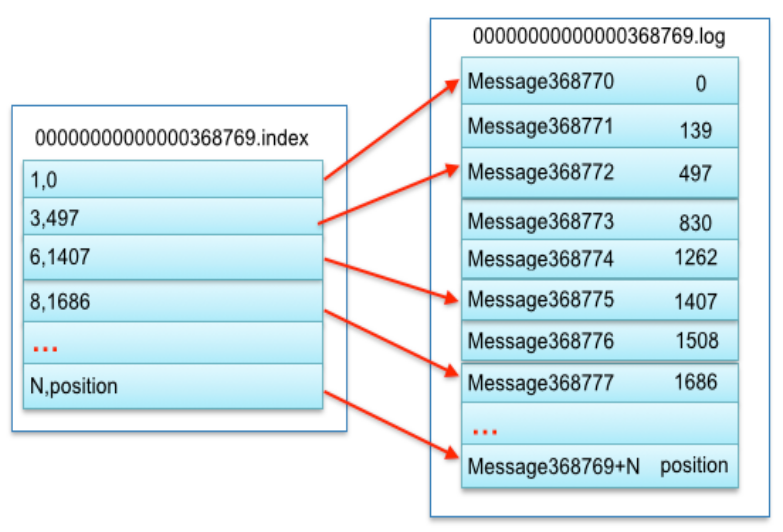
Ыїв§ЮФМўДцДЂДѓСПдЊЪ§ОнЃЌЪ§ОнЮФМўДцДЂДѓСПЯћЯЂЃЌЫїв§ЮФМўжадЊЪ§ОнжИЯђЖдгІЪ§ОнЮФМўжаmessageЕФЮяРэЦЋвЦЕижЗЁЃЦфжавдЫїв§ЮФМўжа
дЊЪ§Он3,497ЮЊР§ЃЌвРДЮдкЪ§ОнЮФМўжаБэЪОЕк3Иіmessage(дкШЋОжpartitonБэЪОЕк368772Иіmessage)ЁЂвдМАИУЯћЯЂЕФЮяРэЦЋвЦ
ЕижЗЮЊ497ЁЃ
PartitionЁЊЁЊMessageЕФЮяРэНсЙЙ


PartitionЁЊЁЊЭЈЙ§OffsetВщевMessage ЖСШЁOffsetЮЊ368776ЕФMessageЃК
1.ВщбЏЖЮТфЮФМўЃК
МйЩшpartitionгаСНИіindexЮФМўЃЌЗжБ№ЮЊ:0...0.indexЮФМўКЭ0...383562.indexЮФМўЃЌгЩгкЮвУЧЕкЖўИіЕФЦЋвЦСПГѕЪМжЕЮЊ383562+1ЃЌЖјвЊВщбЏЕФЮФМўЮЊ368776ЃЌЫљвдЮвУЧВщбЏЕФMessageдкЕквЛИі0...0.logжаЁЃЪЙгУoffset
**ЖўЗжВщев**ЮФМўСаБэЃЌОЭПЩвдПьЫйЖЈЮЛЕНОпЬхЮФМўЁЃ
2.ЖЮТфЮФМўЫїв§гыMessageЮФМўНјааЦЅХфЃК
ЭЈЙ§segment fileВщевmessageЭЈЙ§ЕквЛВНЖЈЮЛЕНsegment fileЃЌЕБoffset=368776ЪБЃЌвРДЮЖЈЮЛЕН0...000.indexЕФдЊЪ§ОнЮяРэЮЛжУКЭ
0..000.logЕФЮяРэЦЋвЦЕижЗЃЌШЛКѓдйЭЈЙ§0...0.logЫГађВщевжБЕН offset=368776ЮЊжЙ
ConsumerЁЊЁЊHigh Level КмЖрЪБКђЃЌПЭЛЇГЬађжЛЪЧЯЃЭћДгKafkaЖСШЁЪ§ОнЃЌВЛЬЋЙиаФЯћЯЂoffsetЕФДІРэЁЃЭЌЪБвВЯЃЭћЬсЙЉвЛаЉгявхЃЌР§ШчЭЌвЛЬѕЯћЯЂжЛБЛФГвЛИіConsumerЯћЗбЃЈЕЅВЅЃЉЛђБЛЫљгаConsumerЯћЗбЃЈЙуВЅЃЉЁЃвђДЫЃЌKafka
Hight Level ConsumerЬсЙЉСЫвЛИіДгKafkaЯћЗбЪ§ОнЕФИпВуГщЯѓЃЌДгЖјЦСБЮЕєЦфжаЕФЯИНкВЂЬсЙЉЗсИЛЕФгявхЁЃ
ConsumerЁЊЁЊConsumer Group УПвЛИіconsumerЪЕР§ЖМЪєгквЛИіconsumer groupЃЌУПвЛЬѕЯћЯЂжЛЛсБЛЭЌвЛИіconsumer
groupРяЕФвЛИіconsumerЪЕР§ЯћЗбЁЃЃЈВЛЭЌconsumer groupПЩвдЭЌЪБЯћЗбЭЌвЛЬѕЯћЯЂЃЉ
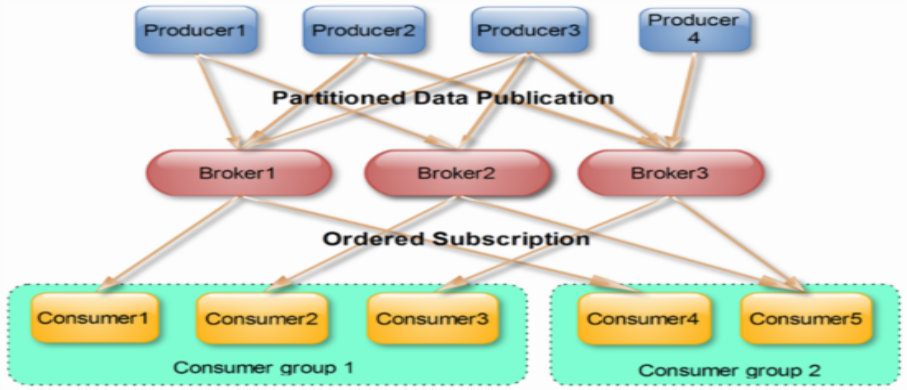
ConsumerЁЊЁЊRebalance KafkaБЃжЄЭЌвЛConsumer GroupжажЛгавЛИіConsumerЛсЯћЗбФГЬѕЯћЯЂЃЌЪЕМЪЩЯЃЌKafkaБЃжЄЕФЪЧЮШЖЈзДЬЌЯТУПвЛИіConsumerЪЕР§жЛЛсЯћЗбФГвЛИіЛђЖрИіЬиЖЈPartitionЕФЪ§ОнЃЌЖјФГИіPartitionЕФЪ§ОнжЛЛсБЛФГвЛИіЬиЖЈЕФConsumerЪЕР§ЫљЯћЗбЁЃ
KafkaЖдЯћЯЂЕФЗжХфЪЧвдPartitionЮЊЕЅЮЛЗжХфЕФЁЃетбљЩшМЦЕФСгЪЦЪЧЮоЗЈБЃжЄЭЌвЛИіЯћЗбепзщРяЕФConsumerОљдШЯћЗбЪ§ОнЃЌгХЪЦЪЧУПИіConsumerВЛгУЖМИњДѓСПЕФBrokerЭЈаХЃЌМѕЩйЭЈаХПЊЯњЃЌЭЌЪБвВНЕЕЭСЫЗжХфФбЖШЃЌЪЕЯжвВИќМђЕЅЁЃСэЭтЃЌвђЮЊЭЌвЛИіPartitionРяЕФЪ§ОнЪЧгаађЕФЃЌетжжЩшМЦПЩвдБЃжЄУПИіPartitionРяЕФЪ§ОнПЩвдБЛгаађЯћЗбЁЃ
ШчЙћФГConsumer GroupжаConsumerЪ§СПЩйгкPartitionЪ§СПЃЌдђжСЩйгавЛИіConsumerЛсЯћЗбЖрИіPartitionЕФЪ§ОнЃЌШчЙћConsumerЕФЪ§СПгыPartitionЪ§СПЯрЭЌЃЌдђе§КУвЛИіConsumerЯћЗбвЛИіPartitionЕФЪ§ОнЁЃЖјШчЙћConsumerЕФЪ§СПЖргкPartitionЕФЪ§СПЪБЃЌЛсгаВПЗжConsumerЮоЗЈЯћЗбИУTopicЯТШЮКЮвЛЬѕЯћЯЂЁЃ
kafkarЕФRebalanceЕФЫуЗЈЃК
НЋФПБъTopicЯТЕФЫљгаPartirtionХХађЃЌДцгкPT ЖдФГConsumer GroupЯТЫљгаConsumerХХађЃЌДцгкCG ЕкiИіConsumerМЧЮЊCi N=size(PT)/size(CG)ЃЌЯђЩЯШЁећ НтГ§CiЖддРДЗжХфЕФPartitionЕФЯћЗбШЈЃЈiДг0ПЊЪМЃЉ НЋЕкi?NЕНЃЈi+1ЃЉ?N?1ИіPartitionЗжХфИјCi ЗжЧјЕФЫуЗЈЃК
ЗжЧјЪ§=Tt/Max(Tp,Tc)
Tp:producerЭЬЭТСП Tc:consumerЭЬЭТСП TtФПБъЕФЭЬЭТСП
ConsumerЁЊЁЊLow Level ЪЙгУLow LevelЃЈSimple ConsumerЃЉдвђЪЧгУЛЇЯЃЭћБШConsumerGroupИќКУЕФПижЦЪ§ОнЕФЯћЗбЃК
ЭЌвЛЬѕЯћЯЂЯћЗбЖрДЮ жЛЖСФГвЛИіtopicЯТЕФЙЬЖЈЗжЧјЪ§Он ЙмРэЪТЮёЃЌФГвЛЬѕЯћЯЂНіБЛЯћЗбвЛДЮ ЖюЭтЙЄзїЃК
БиаыдкгІгУГЬађжаИњзйoffsetЃЌДгЖјШЗЖЈЯТвЛЬѕгІИУЯћЗбФФЬѕЯћЯЂ гІгУГЬађашвЊЭЈЙ§ГЬађЛёжЊУПИіPartitionЕФLeaderЪЧЫ БиаыДІРэLeaderЕФБфЛЏ гЩгкВйзїБШНЯИДдгЃЌЫљвдЮвУЧдкТњзуашЧѓЕФЭЌЪБбЁдёЪЙгУHigh Level Consumer |









