| БрМЭЦМі: |
БОЮФРДздгкKobi
Hikri ЃЌЮФДгМЦЫуЛњСьгђЕФЁАзцЪІвЏЁБАЌТзЁЄЭМСщЬсГіЕФЭМСщЛњИХФюПЊЪМЃЌНщЩмСЫЭМаЮМЦЫуЕФИХФюЃЌВЂвдЪОР§НщЩмСЫapache
stormЃЌЛљгкapache stormШчКЮНјааЗжВМЪНЭМаЮМЦЫуЁЃ
|
|
НщЩм
МЦЫуПЩФмКмИДдгЁЃЖдЮвУЧРДЫЕЃЌетжжИДдгжївЊОЭЪЧШэМўЪРНчЕФШЫРрЧ§ЖЏСІЁЃЩѕжСгавЛИібЇПЦећИіЖМЮЇШЦзХЮЪЬтНтОіКЭМЦЫуЁЊЁЊМЦЫуЛњПЦбЇЁЃ
ЕБвЛИіШЫПЊЪМбЇЯАМЦЫуЛњПЦбЇЪБЃЌЛсБЛНщЩмвЛаЉЪѕгяКЭИХФюЃЌетаЉЪѕгяКЭИХФюЖМЪЧЮЇШЦзХЪдЭМвдПЩжЄУїЃЌЧЁЕБЕФЗНЪНЖдЮЪЬтЕФНтОіЗНАИНјааНЈФЃКЭБэДяЖјаЮГЩЕФЁЃ

АЌТзЁЄЭМСщ
АЌТзЁЄЭМСщЬьВХЕиЬсГіСЫЭМСщЛњЕФИХФюЁЃетаЉЁАЛњЦїЁБЪЙЮвУЧФмЙЛвдЪ§бЇжЄУїЕФЗНЪНЧЁШчЦфЗжЕиУшЪіНтОіЗНАИЃЌЭЌбљвВЪЪгУгкНтОіМЦЫуЛњПЦбЇСьгђгіЕНЕФЮЪЬтЁЃ

ЭМЦЌгЩЮЌЛљБОПЦЬсЙЉЁЃ
ДгФЧЪБЦ№ЃЌЮЇШЦГщЯѓМЦЫуЛњЃЈАќРЈЭМСщЛњЃЉЕФећИібаОПЗЂеЙЦ№РДЃЌУћЮЊздЖЏЛњРэТлЕФбаОПЁЃ
здЖЏЛњРэТлЕФСьгђЪЧЙуЗКЕФЃЌвВЪЧдкВЛЖЯдіГЄКЭзюСїааЕФ ЁЊ вђЮЊЫќПЩвдЩњГЩФмЙЛНтОіЯжЪЕЩњЛюжаЮЪЬтЕФФЃаЭЁЃ
ЭМЦЌгЩЮЌЛљБОПЦЬсЙЉЁЃ
дквЛЖЈГЬЖШЩЯЃЌздЖЏЛњРэТлгыЭМТлЪЧУмЧаЯрЙиЕФЁЃ
НсКЯетСНжжРэТлЕФгХЕуЃЌЮвУЧФмЙЛЩшМЦГіПЩжЄУїЕФЁЂЗжВМЪНЕФЁЂгааЇЕФНтОіЮЪЬтЕФЗНАИЃЌЗёдђетаЉЮЪЬтНЋЛсЬЋЙ§гкИДдгЃЌФбвдБэДяКЭНтОіЁЃ
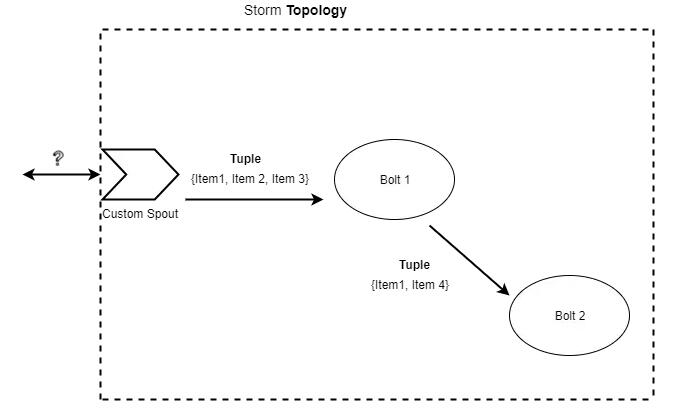
дкБОЮФжаЃЌНЋНщЩмApache StormЃЈДгЯждкПЊЪМЪЙгУЪѕгяЁАStormЁБ ЈC ЭЈГЃЪЧжИApacheЕФStormАцБОЁЃstormжаЕФspoutвыЮЊЁАХчзьЁБЃЌboltвыЮЊЁАТнЫЈЁБЃЉЃЌзїЮЊЗжВМЪНЭМаЮМЦЫуЛљДЁМмЙЙЕФЪЕЯжЁЃ
ЭМаЮМЦЫузїЮЊНЕЕЭЯЕЭГИДдгЖШЕФвЛжжЗНЪН
дкНщЩмСЫЭМСщЛњЁЂздЖЏЛњРэТлКЭЭМТлжЎКѓЃЌЭМаЮМЦЫуПЩвдзїЮЊвЛжжНЕЕЭЯЕЭГИДдгЖШЕФЗНЪНТ№ЃП
Д№АИЪЧПЯЖЈЕФЁЃ
вРППвЛИіОЙ§ВтЪдКЭжЄУїЕФФЃаЭЃЌВЂВЛвЛЖЈвтЮЖзХЪЙгУетИіФЃаЭКЭжЄУїЫќвЛбљИДдгЁЃ
Р§ШчЯТУцЕФБэДяЪНЃК
1 + 1 = 2
ДѓМвЖМЁАжЊЕРЁБЫќЪЧе§ШЗЕФЃЌВЂЧвФмЙЛЪЙгУЫќЃЌвђЮЊвбОгаШЫжЄУїЫќЪЧе§ШЗЕФЁЃ
дкБОЮФЕФР§згжаЃЌЪдЭМНЋвЛИівбжЊЕФЮЪЬтзЊЛЏЮЊвЛИіЭМаЮМЦЫуЃЌЦфжаУПИіЖЅЕуЖМЪЧвЛИіМЦЫуЕЅдЊЁЃИљОнСЌНгЫќУЧЕФБпЃЌдкЖЅЕужЎМфЁАвЦЖЏЁБЁЃ
НгЯТРДПДЯТУцЕФР§згЃК
ЯывЊЪЕЯжвЛИігІгУГЬађжДаавдЯТШЮЮёЃК
ЫќНгЪевЛИіЖЉЕЅЧыЧѓзїЮЊЪфШыЁЃ
ШчЙћЖЉЕЅгааЇЃЌОЭЛсЯђВжПтЗЂЫЭАќзАКЭдЫЪфЧыЧѓЃЌВЂЭЈжЊПЭЛЇЖЉЕЅГЩЙІЁЃ
ШчЙћЖЉЕЅЮоаЇЃЌдђЭЈжЊПЭЛЇЁЃ
АбЪжЭЗЕФШЮЮёПДзїЪЧвЛИіЭМаЮМЦЫуЃЌПЩвдНЋЦфУшЪіШчЯТЃК
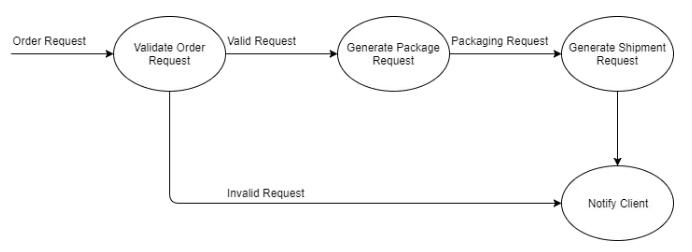
вдЭМаЮЕФЗНЪНЫМПМЮЪЬтгавЛаЉКУДІЁЃ
ЪзЯШЃЌгаСЫЭМаЮвдКѓЃЌШЫРрЕФЫМЮЌИќШнвзРэНтЃЌВЛжСгкФЧУДГщЯѓСЫЁЃ
ЦфДЮЃЌЙФРјЮвУЧзёбСМКУЮёЪЕЕФШэМўЩшМЦддђЃЌШчЙизЂЕуЗжРыддђЁЃУПИіЖЅЕужЛзівЛМўЪТЁЃ
дйДЮЃЌЫќЪЙЮвУЧПДЕНУПИіЖЅЕуЫљзіЕФЪТЃЌВЂНЋЦфЭтАќИјЛљДЁМмЙЙЁЃ
Р§ШчЃЌУПИіЖЅЕуНгЪеВЂПЩФмЗЂЫЭЯћЯЂЁЃвдШнДэЕФЗНЪНИКд№ЭтАќДІРэДЋШыКЭДЋГіЯћЯЂЪЧЗЧГЃПЩШЁЕФЁЃ
ВПЪ№вВПЩвдЭЈЙ§етжжЗНЪНБфЕУИќМгСщЛю ЁЊ Р§ШчЃЌПЩвдВПЪ№вЛЬЈЕЅЖРМЦЫуЛњЕФУПИіМЦЫуЕЅдЊЃЌВЂШУЛљДЁМмЙЙШЅИКд№ЙЬгаЕФЯћЯЂДЋЕнКЭЗжЗЂЁЃ
ИКдиОљКтКЭПЩРЉеЙадШчКЮЃППЩвдвРППЁАЭтВПЁБЯћЯЂДЋЕнЯЕЭГРДЙмРэЭЌвЛМЦЫуЕЅдЊЕФЖрИіЪЕР§Т№ЃПД№АИЪЧПЯЖЈЕФЃЁ
ШчЙћдкЖЉЕЅбщжЄЙ§ГЬжагіЕНЦПОБЃЌЪЧЗёПЩвдЪЕР§ЛЏвЛИіЖюЭтЕФбщжЄМЦЫуЕЅдЊВЂШУЫќДІРэвЛаЉЙЄзїФиЃППЩвдЕФЁЃ
ЯждкЧыМЧзЁЃЌЮвУЧвбОдкЭМжаУшЪіСЫгІИУШчКЮДІРэУПИіЪфШыЯћЯЂЁЃЛЙУЛгаУшЪіЙ§ШчКЮВПЪ№ЫќЁЃ
ЫљвдЮвУЧвВЗжПЊПМТЧСЫШэМўЕФе§ШЗадКЭШэМўЕФВПЪ№ЮЪЬтЁЃ
ПЩФмЕФЧщПіЪЧЃЌГ§СЫНЋЪЕР§ЛЏСНИіМЦЫуЕЅдЊЕФбщжЄЖЅЕужЎЭтЃЌЛЙЮЊУПИіЁАТпМЁБЭМаЮЖЅЕуЪЕР§ЛЏвЛИіЮяРэМЦЫуЕЅдЊЃЌШчЯТЭМЫљЪОЃК
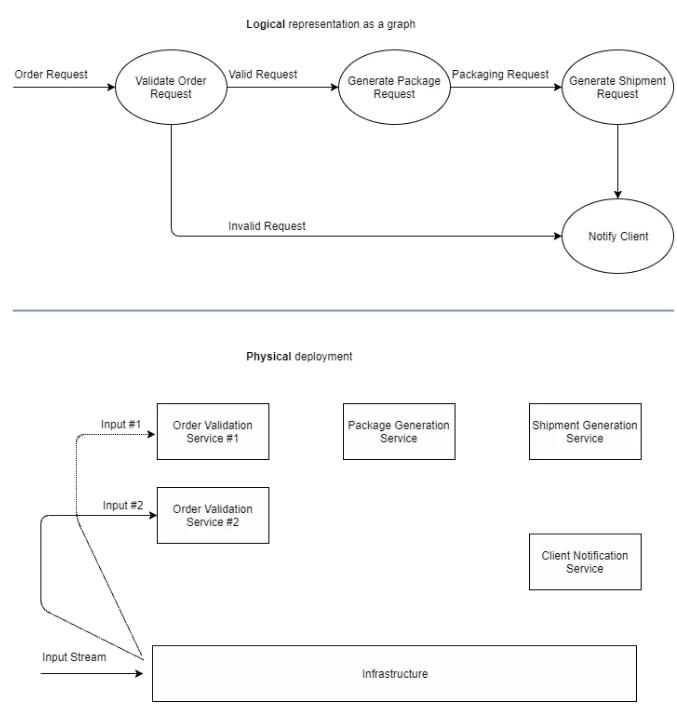
ЧАУцЬсЕНЕФЙигкЙизЂЕуЗжРыЕФЬсЪОЃЌРћгУЪЪЕБЕФЛљДЁМмЙЙЃЌПЩвдДІРэНјГЬМфЕФЭЈаХЃЌИјГіВЛЭЌЕФВПЪ№ашЧѓЃЈУПИізщжЏ/ИіШЫЃЉЃЌвдШнДэКЭПЩРЉеЙЕФЗНЪНЃЌжМдкевзМЮЪЬтЁЃ
ЭМаЮМЦЫуШЗЪЕЪЧгагУЕФЃЌАяжњЮвУЧПМТЧШэМўНтОіЗНАИЃЌЭЌЪБАбШэМўВПЪ№ХХГ§дкЭт ЁЊжЛвЊгаЪЪЕБЕФЛљДЁМмЙЙЃЌОЭПЩвдзіЕНетвЛЕуЁЃ
Apache StormЬсЙЉСЫвдЭМаЮЗНЪНБраДМЦЫуЕФФмСІЃЌЭЌЪБЬсЙЉСЫвЛИіЙЬгаЕФЛљДЁМмЙЙЃЌЪЙЮвУЧФмЙЛПЩППИпаЇЕиЭъГЩетаЉМЦЫуЁЃ
Apache StormЕФЗНЪН
Apache StormжаЃЌжївЊгІгУГЬађБЛГЦЮЊЭиЦЫЃЈtopologyЃЉЃЌвВОЭЪЧStormЭиЦЫЁЃ

УПИіЭиЦЫДњБэвЛИігРдЖдкЯпЕФгІгУГЬађЃЌЫќПЩвдНгЪеРДздБЛГЦЮЊХчзьЃЈspoutЃЉЕФЪ§ОндДЕФЪфШыЁЃ

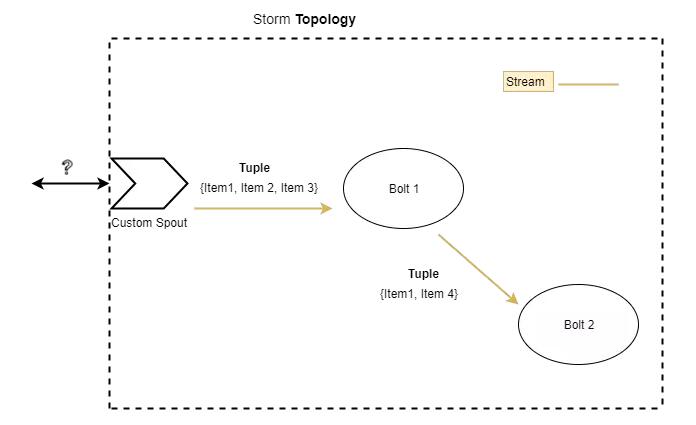
ХчзьЪЧЪфШыЯћЯЂЕФРДдДЃЌГЦЮЊдЊзщЁЃдЊзщЪЧЖЏЬЌРраЭЕФЃЌЫќЕФГЩдБПЩвдЪЧШЮКЮРраЭ ЁЊжЛвЊStormЁАжЊЕРЁБШчКЮађСаЛЏКЭЗДађСаЛЏетаЉРраЭЁЃ
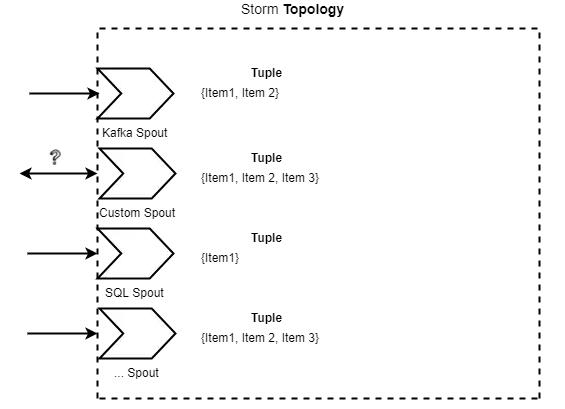
дЊзще§дкАДееЭиЦЫЕФЖЈвхдкТнЫЈЃЈ boltЃЉжЎМфДЋЕнЁЃУПИіТнЫЈЖМПЩвдДЋЕндЊзщЕНЦфЫќТнЫЈЃЌжЛвЊЫќУЧСЌНгЕНЫќЁЃвЛИіТнЫЈПЩвдаоИФвЛИідЊзщЛђепДДНЈвЛИіаТЕФдЊзщЁЃЫќвВПЩвдАДдбљДЋЕнДЋШыЕФдЊзщЃЌЛђепИљБОВЛДЋЕнШЮКЮЖЋЮїЁЃ
дЊзщЭЈЙ§ХчзьЕФдЊзщСїЯђБЛГЦЮЊСїЁЃЖрИіСїПЩвдЙВДцгквЛИіЭиЦЫжаЁЃУПИіЪ§ОнСїЖМгыЦфЫќЪ§ОнСїВЂааДІРэЁЃЩдКѓНЋЛсдйНВЕНетвЛЕуЁЃ
StormМЋОпШкКЯадЃЌВЂгыЦфЫќММЪѕКмКУЕиМЏГЩЁЃЫќФмЙЛЪЙгУElasticsearchЃЌMongodbЃЌKafkaЃЌRedisЃЌKinesisЕШЛљДЁМмЙЙЁЃШчЙћашвЊздЖЈвхЕФЖЋЮїЃЌетвВЪЧПЩФмЕФЃЌStormгавЛИіКмДѓЕФВЂдкВЛЖЯЗЂеЙЕФПтЩњЬЌЯЕЭГЁЃ
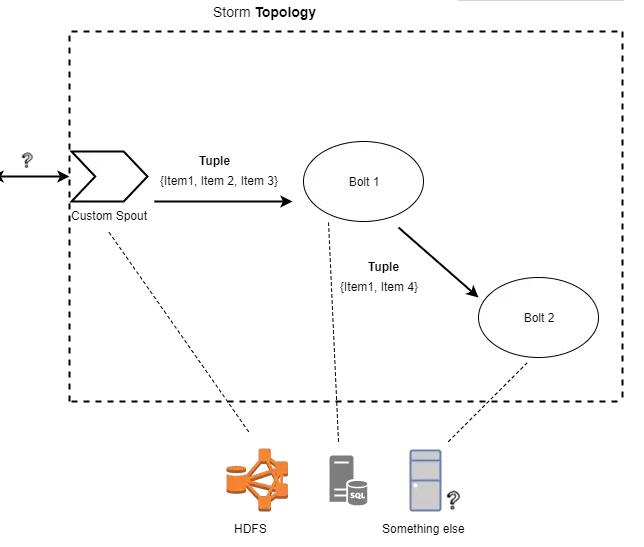
ЫљвдЃЌШчЙћЯыгУвЛОфЛАзмНсвЛЯТЁАStormЗНЪНЁБЕФЛАЃЌЮвЛсЫЕЃК
Apache StormЪЧвЛжжЗжВМЪНММЪѕЃЌжМдкдЪаэПЊЗЂШЫдБРћгУЭМаЮМЦЫуФЃаЭЮЊЮЪЬтЭЌЪБЬсЙЉЁАЕзВуЁБЃЈР§ШчЯћЯЂИКдиОљКтЃЉКЭЁАЖЅВуЁАЃЈР§ШчзМБИЪЙгУKafka
Spout - жЛашХфжУКЭЪЙгУРДздKafkaЕФЪ§ОнЃЉЕФТпМНтОіЗНАИЁЃ
Apache StormИХЪі
ЮЊСЫИќКУЕиСЫНтStormШчКЮЙЄзїЃЌашвЊднЪБЫѕаЁЗЖЮЇЁЃ
БОЮФВЛЛсЖдММЪѕБОЩэНјааЩюШыЕибаОПЁЃЕЋЪЧЃЌШчЙћЯыИќКУЕиСЫНтИУММЪѕЃЌАќРЈВПЪ№ЕФбнЪОЃЌгыЦфЫќММЪѕЕФМЏГЩКЭМрПиЃЌЧыВЮдФЮвЕФПЮГЬЃЌдкетРяЁЃ
ДгКъЙлЩЯПДПДStormМЏШКЪЧШчКЮНЈСЂЕФЁЃетНЋгажњгкСЫНтЫќЪЧШчКЮЬсЙЉЩЯЪіЛљДЁМмЙЙЕФЃЌБШШчМЦЫуЭМаЮВПЗжжЎМфЕФПЩППЯћЯЂДЋЕнЃЌвдМАФГжжГЬЖШЕФВЂааадЃЌЮФеТНЋдкКѓУцзїНјвЛВННтЪЭЁЃ
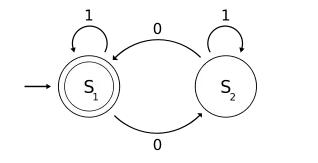
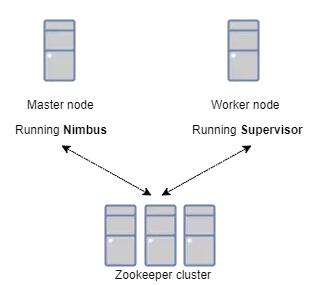
ЪзЯШЃЌstormМЏШКЪЧгЩЃЈВЛзуЮЊЦцЃЉЁНкЕуЙЙНЈЖјГЩЕФЁЃетаЉНкЕуПЩвдВЩгУШЮКЮвЛИіжїНкЕуЕФаЮЪНдЫааNimbusЪиЛЄНјГЬЛђепВЩгУЙЄзїНјГЬЃЈworkerЃЉНкЕуЕФаЮЪНЁЊдЫааSupervisorЪиЛЄНјГЬЁЃЫќВЩгУжїДгМмЙЙЗНЪНЃЌжїНкЕуЪЧNimbusЃЌДгНкЕуЪЧSupervisorЃЌгаЙиЕїЖШЯрЙиЕФаХЯЂДцДЂдкZookeeperМЏШКжаЁЃ
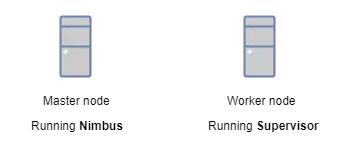
жїНкЕуИКд№дкЙЄзїНкЕужЎМфЗжХфЙЄзїЁЃЗжХфЪВУДЙЄзїФиЃПЪЕЯжЭМаЮМЦЫуЕФЪЕМЪДњТызїЮЊЭиЦЫДЋЕнИјStormМЏШКЁЃ
жїНкЕуКЭЙЄзїНкЕуШчКЮЯрЛЅШЯжЊЃПЭЈЙ§ZookeeperЁЃZookeeperЪЧвЛИіЗжВМЪНЗўЮёЃЌзїЮЊвЛИіПЩППЕФХфжУКЭЭЌВНЬсЙЉепЁЃвЊСЫНтИќЖрЙигкZookeeperЕФаХЯЂЃЌАќРЈАВзАКЭМЏГЩбнЪОЃЌЧыПДПДетРяЁЃ
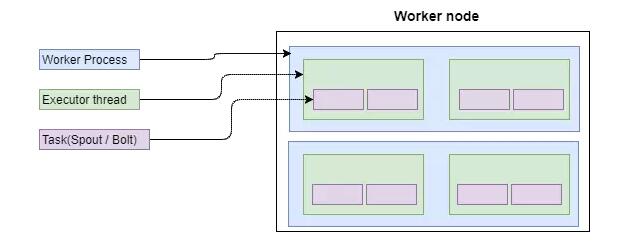
ЫљвдЫЕжїНкЕуИКд№НЋДњТыЗжЗЂИјЙЄзїНкЕуЁЃЕЋЪЧЃЌетРяЛЙгавЛИіЖюЭтЕФГщЯѓВуЃКЙЄзїНјГЬЁЃ
вЛИіЙЄзїНјГЬИКд№жДааЭиЦЫЕФвЛИізгМЏЁЃУПИіЙЄзїНјГЬНЋЪЕР§ЛЏжДааШЮЮёЪЕР§ЕФжДааЦїЯпГЬЁЃетаЉШЮЮёПЩвдЪЧХчзьЛђТнЫЈЁЃ
ЫфШЛРэНтЦ№РДПЩФмЯрЕБРЇФбЃЌЕЋЪЧетжжНсЙЙШЗЪЕОпгадкИїжжЮяРэЛњЦїЃЌНјГЬКЭЯпГЬжЎМфЗжХфТпММЦЫуЭМаЮЕФФмСІЃЌДгЖјЪЙstormМЏШКдкгВМўЙЪеЯЕФЧщПіЯТБЃГжТпММЦЫуЭъећадЁЃ
вЛИіЙЄзїНјГЬЙвСЫЃПУЛЮЪЬт ЁЊжїНкЕуЛсНЋЦфЙЄзїЗжХфИјСэвЛИіЙЄзїНкЕуЁЃ
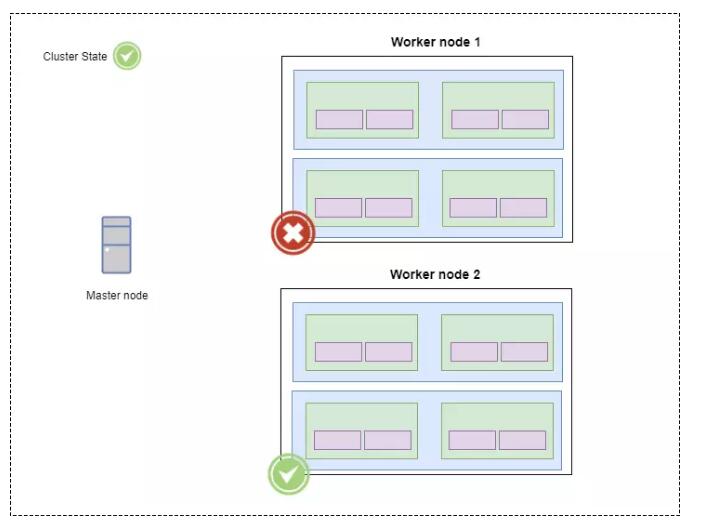
ЧызЂвтЃЌПДЦ№РДжїНкЕуЫЦКѕЪЧвЛИіЕЅЕуЙЪеЯЕуЁЃЪТЪЕВЂВЛЪЧетбљЁЃМДЪЙжїНкЕуЗЂЩњЙЪеЯЛђБРРЃЃЌЭиЦЫШдНЋМЬајжДааЁЃЯдШЛЃЌЮвУЧНЋЮоЗЈЯђМЏШКЬсНЛаТЭиЦЫЃЌвђЮЊжїНкЕугад№ШЮдкЙЄзїНкЕужЎМфНјааДњТыЙВЯэЃЌЕЋЪЧдкЯпМЦЫуНЋМЬајЯТШЅЁЃ
етжжВЛЯЃЭћЗЂЩњЕФЧщПіПЩвдЭЈЙ§дкStormМЏШКЃЈгжУћNimbus H / AЃЉжаЖЈвхЖрИіжїНкЕуРДУжВЙЁЃетбљЕФЛАЃЌвЛИіЪЇАмЕФжїНкЕуНЋЛсБЛвЛИіНЁПЕЕФжїНкЕуЬцЛЛЁЃ
ЯждкгІИУФмЙЛИќКУЕиРэНтStormЪЧШчКЮНЋМЦЫуЭМаЮКЭЮяРэгВМўВуЃЈжїНкЕуКЭЙЄзїНкЕуЃЌzookeeperЃЌжДааНјГЬжаЕФЙЄзїНјГЬКЭШЮЮёЃЉЕФТпМИХФюЭъШЋЗжРыПЊРДЕФЃЈЭиЦЫНсЙЙЪЧгЩХчзьКЭТнЫЈгыдЊзщжЎМфЕФСїЖЏНЈСЂЦ№РДЕФЃЉЁЃ
етжжМмЙЙЪЧЭХЖгжЎМфЙизЂЕуЗжРыЕФЭЦЖЏепЁЃПЩвдНЋДІРэТпМВуЕФШЮЮёЗжХфИјПЊЗЂШЫдБЃЌвВПЩвдНЋДІРэЮяРэВуЕФШЮЮёЗжХфИјDevOpsЙЄГЬЪІЁЃ
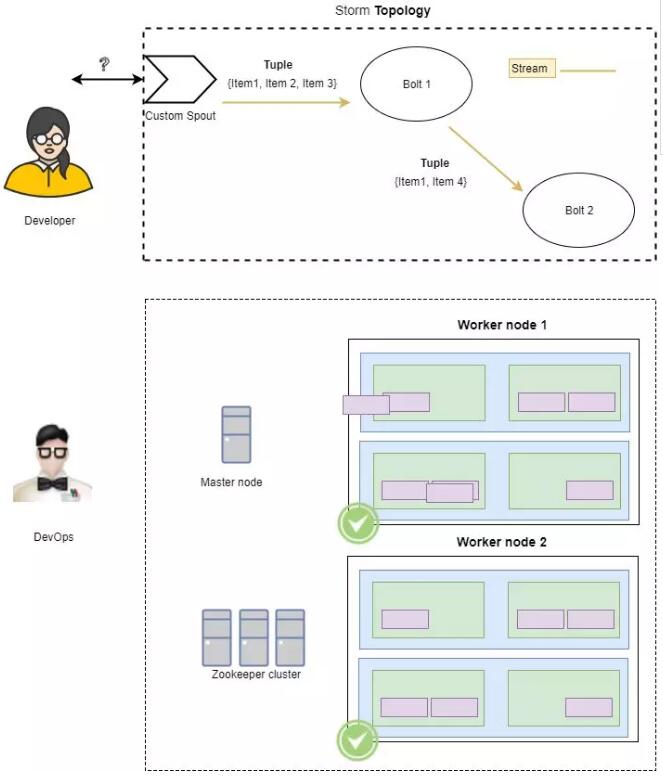
ПЊЗЂStormЕФЙЄГЬЪІПМТЧСЫЩЯЪіЙизЂЕуЗжРыЕФИХФюЃЌВЂЯђПЊЗЂШЫдБЬсЙЉСЫдкПЊЗЂШЫдБЕФЛњЦїЩЯБОЕидЫааЭиЦЫЕФЫМТЗЁЃ
ЬИТлПЊЗЂШЫдБЁЊВЛШчПДвЛаЉДњТыЃП
ЪОР§ЭиЦЫЁЊШУЮвУЧПДвЛаЉДњТы
КУАЩЃЌгааЉШЫПЩФмвдЮЊдкНјааЖЉЕЅбщжЄЃЌАќзАКЭзАдЫЪБЃЌетИіР§згВЂВЛЬЋЪЪКЯбнЪОЭМаЮМЦЫуЁЃ
ЮвВЛетУДШЯЮЊЁЃЭМаЮМЦЫуЃЌОЭЯёШЮКЮЦфЫќФЃаЭвЛбљЖМЪЧвЛИіЙЄОпЁЃзїЮЊПЊЗЂШЫдБЃЌШэМўМмЙЙЪІКЭ/ЛђбаЗЂИБзмВУЃЌЖМашвЊОіЖЈетИіЙЄОпЪЧЗёЪЪКЯЪжЭЗЩЯЕФШЮЮёЁЃЮвШЯЮЊЖдгкИпЭЬЭТСПЕФЕчзгЩЬЮёЭјеОЃЌStormЪЕМЪЩЯЗЧГЃЪЪКЯзїЮЊвЛИіЮШЖЈЕФКѓЬЈЁЃ
НгЯТРДПДПДШчКЮНЋЩЯЪігУР§зїЮЊвЛИіStormЕФЭиЦЫЪЕЯжЁЃ
ЪзЯШЃЌашвЊНЈСЂвЛИіаТЕФЯюФПЃЌОЭгУвЛИіMavenЯюФПРДеЙЪОЁЃвбОНЋвдЯТвРРЕЯюЬэМгЕНpom.xmlЮФМўжаЃК
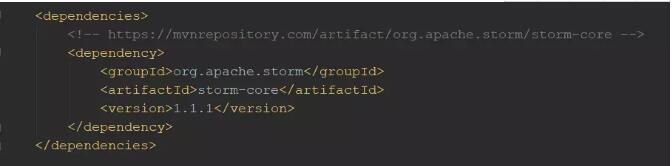
ЪзЯШДДНЈвЛИіЪЙгУгЩStormЬсЙЉЕФTopologyBuilderЕФЭиЦЫЃК

ЮЊСЫЩшжУЭиЦЫХчзьЃЌЕїгУTopologyBuilderЪЕР§ЩЯЕФsetSpoutЗНЗЈЃЌДЋЕнвЛИіХчзьIDКЭвЛИіХчзьЪЕР§ЁЃ

етЪЧНјШыЭМаЮМЦЫуЕФЧаШыЕуЁЃетвВПЩФмЪЧвЛИіKafkaSpoutЁЃ
ЯждкгааХЯЂНјШыЯЕЭГЃЌОЭЯыЯћЛЏЫќЁЃгаЪБМфдкЭиЦЫжаЬэМгвЛаЉТнЫЈЁЃ
АбУПвЛИіТнЫЈСЌНгЕНЭиЦЫЃЌНЋЬсЙЉШчЯТаХЯЂЃК
дкЭиЦЫжаЮЈвЛБъЪЖЫќЕФТнЫЈIDЁЃ
ЫќдкЭиЦЫжаЕФЧАЩэЃЌвдМАЪзбЁЕФЗжзщЗНЗЈЁЃ
вЛИіПЩбЁЕФСїIDЁЃ
2КЭ3КмПьОЭЛсЬсЕНЁЃ
ФЧУДНгЯТРДПДПДДјгаЫљгаТнЫЈЕФЭиЦЫЃК
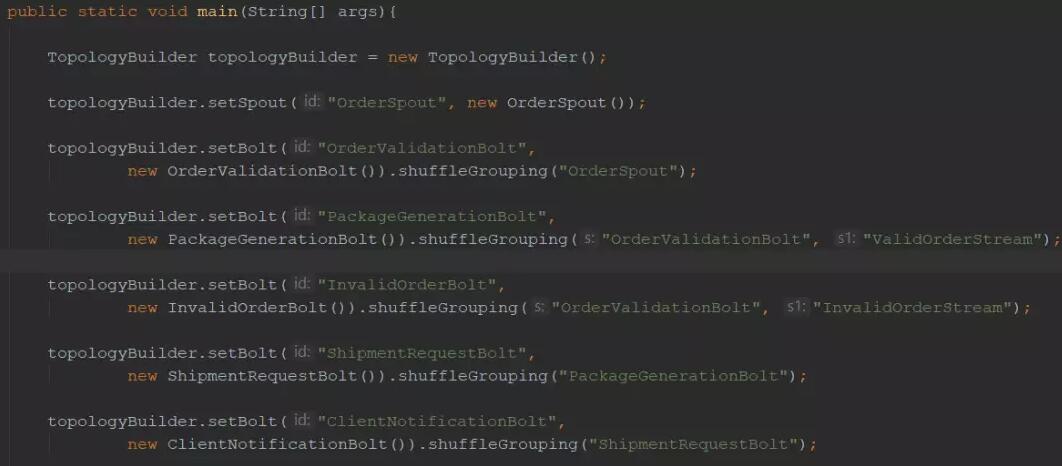
УПвЛДЮЬэМгвЛИіТнЫЈЕНЭиЦЫЃЌЖМЕїгУsetBoltЁЃ

ШЛКѓЃЌИјТнЫЈУќУћЃЌВЂЮЊИУТнЫЈЬсЙЉвЛИіЪЕР§ЁЃИУЪЕР§ЪЧИљОнУПИіТнЫЈЫљашТпМЪЕЯжЕФРрЁЃНгЯТРДПДвЛЯТетбљЕФТнЫЈЁЃ

УПИіТнЫЈЃЌвбОСЌНгЕНСэвЛИіТнЫЈЛђХчзьЃЌВЂЬсЙЉЪфШыЁЃ

дкбщжЄТнЫЈЕФЧщПіЯТЃЌгаСНжжПЩФмЕФНсЙћЃЈгааЇЕФЛђЮоаЇЕФЃЉЃЌИљОнУПИіПЩФмЕФНсЙћЃЌвбОДДНЈСЫвЛИіжЛдкЬиЖЈСїЃЈбщжЄТнЫЈе§дкЯђЦфЗЂЫЭЯћЯЂЃЉЩЯеьЬ§ЯћЯЂЕФТнЫЈЁЃ


ЯждкРДЙлВьвЛИіТнЫЈЕФЪЕЯжЁЃЮЊСЫЗћКЯStormЕФМмЙЙЃЌашвЊжДааЪВУДЃП
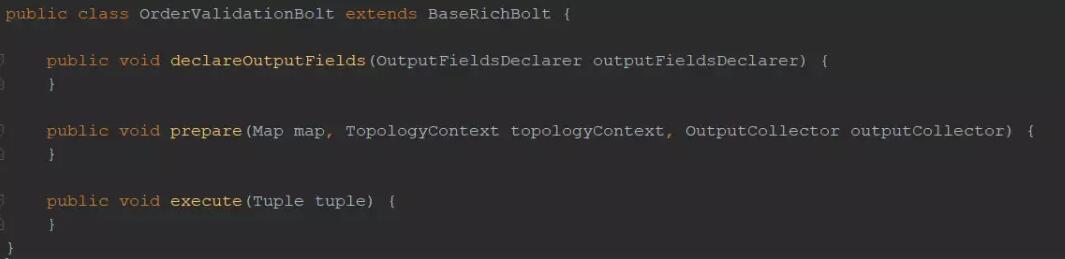
етРяПЩвдПДЕНвбОРЉеЙСЫBaseRichBoltРрЁЃЮЊСЫЗћКЯЦфЖЈвхЃЌБиаыЪЕЯжШ§жжЗНЗЈЁЃ
е§ШчЫќУћзжАЕЪОЕФФЧбљЃЌетИіprepareЗНЗЈЪЧвЛИіеМЮЛЗћЃЌвЛЕЉдЊзщЕНДяЫќЃЌОЭПЩвджДааТнЫЈЫљашЕФШЮКЮБивЊЕФГѕЪМЛЏЃЌвдЪЕЯжЧЁЕБЕФЙІФмЁЃдкДѓЖрЪ§ЧщПіЯТЃЌжСЩйЛсНЋЪфГіЪеМЏЦїв§гУБЃДцЕНОжВПБфСПжаЁЃЪфГіЪеМЏЦїдЪаэЗЂГіаТЕФдЊзщЕНЯТУцЕФТнЫЈЁЃ
ЫќвВдЪаэШЗШЯвЛИідЊзщЁЃStormЛсНЋШЮКЮЮДШЗШЯЕФдЊзщЪгЮЊвЛИіЮДДІРэЕФЪ§ОнНсЙЙЃЌвдБужиаТДІРэЁЃ
executeЗНЗЈдкУПИідЊзщДЋЕнЪБЃЈгЩStormЛљДЁНсЙЙЃЉЕїгУвЛДЮЁЃдкexecuteЗНЗЈжаНЋЪЙгУдЊзщЃЌдкашвЊЕФЧщПіЯТЗЂГіШЮКЮаТЕФдЊзщЃЌзюКѓЃЌШЗШЯДЋШыЕФдЊзщЁЃ
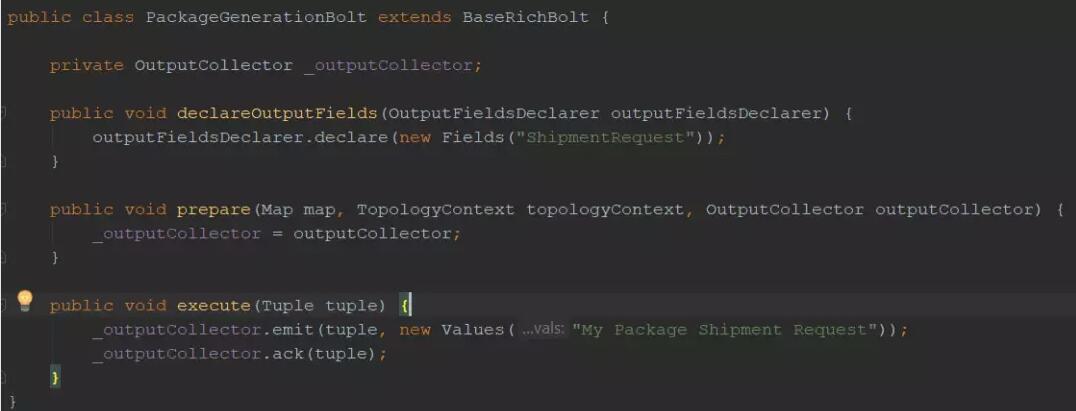
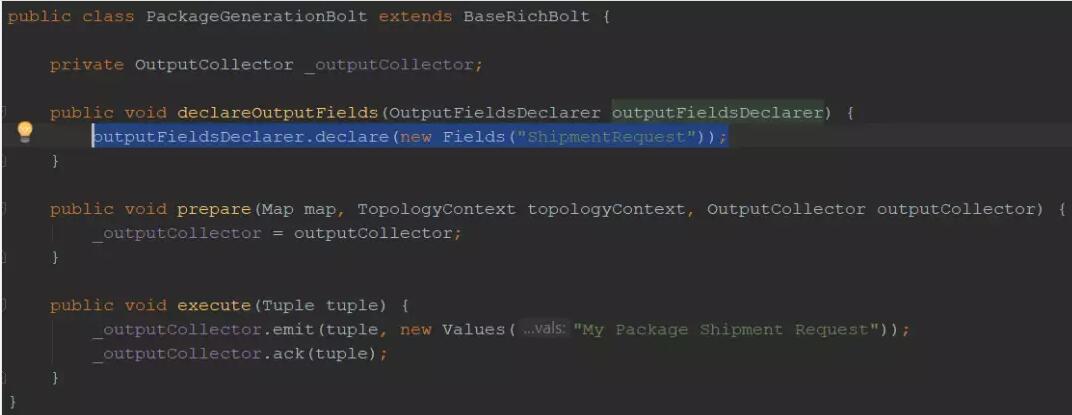
ЕБЯывЊДЋЕнвЛИіЬиЖЈЕФзжЖЮЕНЯТвЛИіТнЫЈЪБЃЌdeclareOutputFieldsЗНЗЈЪЧБиашЕФЁЃР§ШчЃЌPackageGenerationBolt
ДЋЕнвдвЛИізжЖЮУћЮЊЁАShipmentRequestЁБЕФзАдЫЧыЧѓЕНЯТвЛИіТнЫЈЃЈShipmentRequestBoltЃЉЪБЃЌвЊжЊЕРШчКЮв§гУЃК
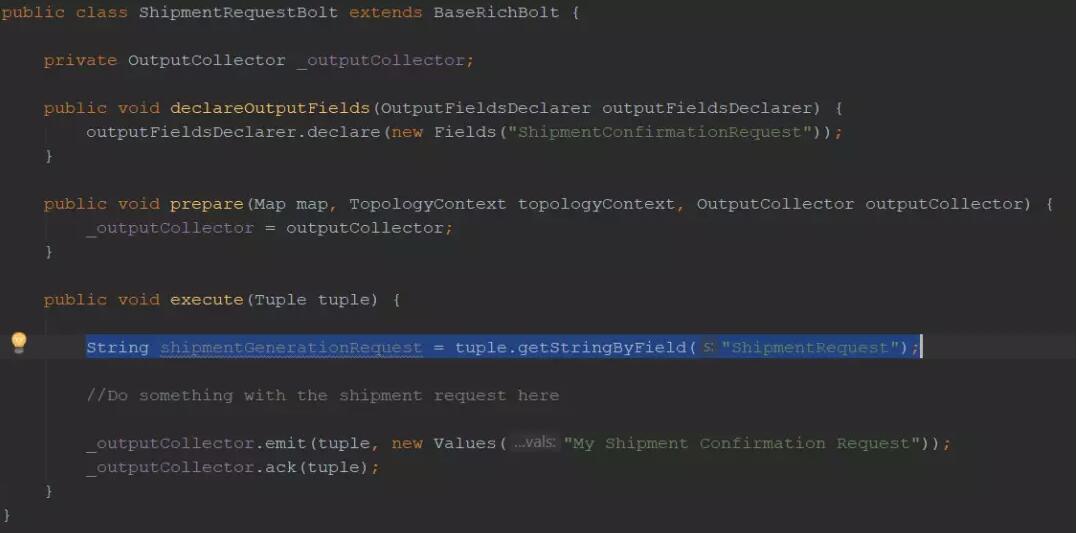
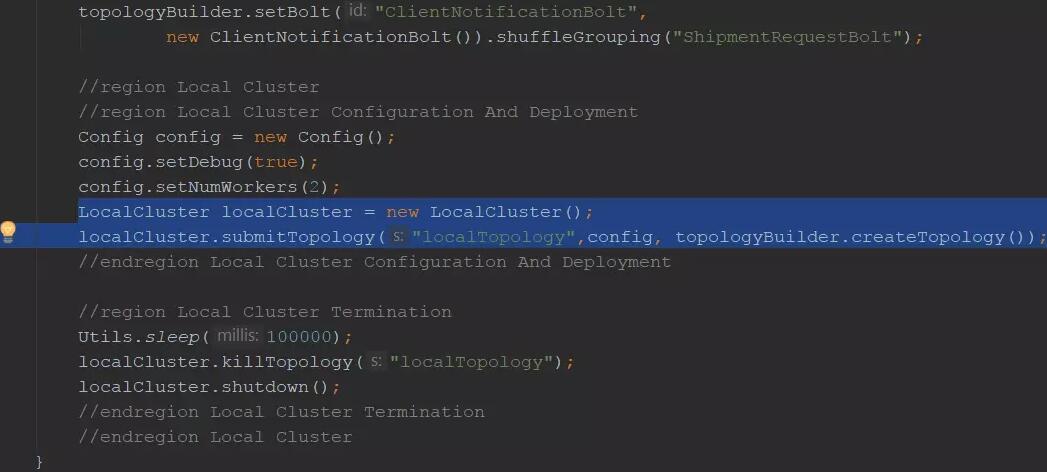
зюКѓЃЌНЋЭиЦЫЬсНЛЕНМЏШКВЂдЫааЫќЁЃдкетИіР§згжаЃЌЬсНЛИјвЛИізЈУХЮЊЕїЪдЖјПЊЗЂЕФБОЕиМЏШКЃК
вЛЕЉЭиЦЫОЙ§ВтЪдКЭЕїЪдЃЌОЭПЩвдАВШЋЕиНЋЦфВПЪ№ЕН ЁАецЪЕЁБЕФStormМЏШКЁЃ
етПЩвдЭЈЙ§МИжжЗНЪНРДЭъГЩЁЃ
вЛАуРДЫЕЃЌашвЊНЋЭиЦЫСЌЭЌЫљгаЯрЙиЕФвРРЕЯюДђАќЕНjarЮФМўжаЃЌВЂНЋЦфДЋЕнИјStormМЏШКЁЃЭЈЙ§ЪЙгУУќСюааРДЭъГЩИќМђЕЅЁЃ
ШчЙћЯыПДЕНвЛИіЁАецЪЕЕФЁБЕФdemoЃЌЧыВщПДетРяЁЃ
ШчКЮНјааЗжВМЪНМЦЫуЃП
ЬЋЩёЦцСЫЃЁЯждкУїАзСЫЃЌАбаэЖрМЦЫуЗжНтГЩЭМаЮЕФТпМКЭЮяРэаЮЪНВЂВЛЪЧКмФбЃЌвђЮЊЖЅЕувдЁАБъзМЁБаЮЪНЃЈађСаЛЏдЊзщЃЉНјааЭЈаХЁЃ
ЯждквВжЊЕРДњТыЪЧШчКЮдкStormМЏШКЩЯжДааЕФЁЃ
дкНЋЭиЦЫЬсНЛИјМЏШККѓЃЌДђАќГЩвЛИіjarЮФМўЃЌЭиЦЫзщМўЃЈМДspoutsКЭboltЃЉБЛВПЪ№ЕНИїИіstormЙЄзїНкЕуЃЈгЩжїНкЕуОіЖЈЃЉЃЌВЂдкЙЄзїНкЕужаЪЕР§ЛЏЁЊЁЊЗтзАдкШЮЮёЯпГЬжаЃЌДцдкжДааЙ§ГЬжаЁЃ
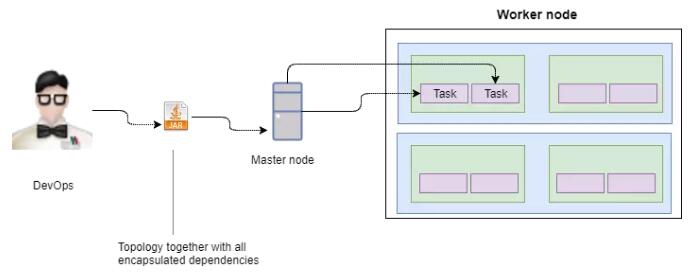
StormЛљДЁМмЙЙжЊЕРЭиЦЫФкСїЖЏЕФЪ§ОнСїЁЃетИіЛљДЁМмЙЙЛЙЭЈЙ§ТнЫЈИњзйдЊзщШЗШЯЃЌЮЊЮвУЧЬсЙЉСЫПЩППЕФЯћЯЂДЋЕнЯЕЭГЁЃ
ФкдкЕФВЂааадЃКзїЮЊВЂааЖШЕФСї
ЭМаЮМЦЫуЕФКУДІжЎвЛЪЧЃЌПЩвддкгІгУГЬађжаЧхЮњЕиЯдЪОЕЅЖРЕФМЦЫуТЗОЖЁЃ
ПДПДетРяЃК
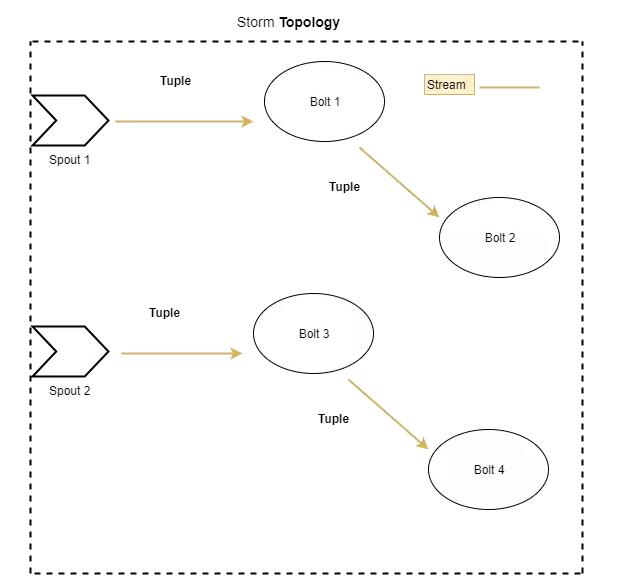
гаЪВУДЖЋЮїзшжЙВЂааДІРэСНжжВЛЭЌЕФЪ§ОнСїТ№ЃПЕБШЛУЛгаЃЌетЪЧStormЕФЭъУРШЮЮёЃЁ
СїЪЧ StormжаЕФвЛжжВЂааЕФГЬЖШЁЃЫљгаЕФСїдЊзщЖМНЋСїОЯрЙиЕФТнЫЈЃЈШчЭиЦЫЫљУшЪіЕФФЧбљЃЉЃЌЖјВЛжЊЕРЭиЦЫжаЕФЦфЫќСїЁЃ
ТнЫЈЃЈboltЃЉЕФЪЕР§
етЪЧвЛИіКУЕФПЊЪМЃЌЪЧВЛЪЧЃПВЛЭЌЕФСїПЩвдЗжБ№ЕЅЖРДІРэЁЃШЛЖјЃЌЛЙгаСэЭтвЛжжВЂааЖШЁЊдкШЮЮёВуУцЕФВЂааЖШЁЃзїЮЊвЛИігХауЕФбЇЩњЃЌгІИУМЧзЁШЮЮёПЩвдЪЧХчзьЛђТнЫЈЕФаЮЪНЁЃ
ЖЈвхЭиЦЫЪБЃЌПЩвдЩљУїУПИіХчзьЛђТнЫЈЫљашЕФВЂааЖШЁЃ

ЧызЂвтЃЌВЛЯЃЭћШЮЮёУЛгаПижЦЕФАДашВњЩњЃЁЬЋЖрЕФШЮЮёЃЈМДЯпГЬЃЉЛсв§ШыЙ§ЖШВЂааЃЌВЂПЩФмЕМжТМЏШКЁАТ§ЯТРДЁБЃЌзюжеШУгІгУГЬађБфЕУЮоЗЈЯьгІЁЃ
дкЪЙгУStormЕФВЂааЖШЙІФмжЎЧАЃЌЧыПМТЧЯыДяЕНЕФВЂааЖШЃЌВЂЬсЙЉПЩгУЕФзЪдДЁЃ
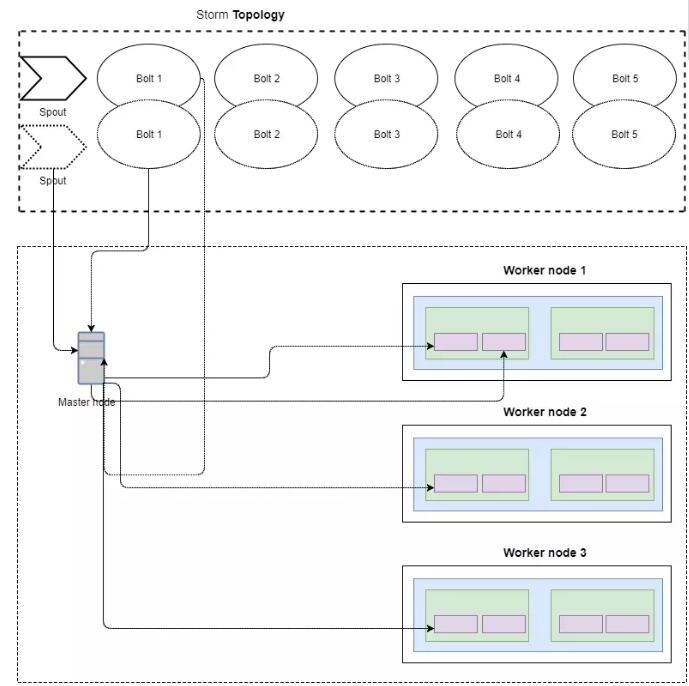
МйЩшга3ИіStormЙЄзїНјГЬНкЕуЃЌВЂЧвВПЪ№СЫвЛИіОпгавЛИіВЂааЖШЩшжУЮЊ2ЕФЕЅИіХчзьЕФЭиЦЫЃЌвдМА5ИіВЂааЖШЩшжУЮЊ2ЕФТнЫЈ
ЁЊ stormНЋЮЊХчзьЩњГЩ2ИіШЮЮёЃЌУПИіТнЫЈЩњГЩ5 * 2 = 10 ИіШЮЮёЁЃ
етвтЮЖзХНЋга12ИіШЮЮёЃЌstormМЏШКНЋЪдЭМОљдШЕиЗжВМдк3ИіЙЄзїНкЕуЩЯЃЈЯТЭМУЛгаЛГіЫљгаЕФЯпвдБмУтЛьТвЃЉЁЃ
зїЮЊФкВПЁАжШађепЁБЕФЗжзщ
ЛЙЪЧЛиЕНЗжзщЕФИХФюЁЃ
жЎЧАвбОПДЕНЃЌЕБДДНЈвЛИіТнЫЈЪБЃЌвбОжИЖЈСЫЫќЕФЁАЪфШыЁБТнЫЈЃК

ЕЋЪЧетбљзіЕФЗНЪНЛЙВЛЧхГўЃЌе§ШчЮвУЧЫљЫЕЕФФЧбљЃЌашвЊвЛИіЁАЫцЛњЗжзщЁБ

ЦцЙжЃЌВЛЪЧТ№ЃПЗжзщгыжЎЧАНЈСЂЕФЭМаЮЭиЦЫгаЪВУДЙиЯЕЃПФбЕРВЛЪЧЫљгаЕФСїдЊзщЖМжЛЪЧДгвЛИіТнЫЈСїЕНСэвЛИіТнЫЈТ№ЃП
ФЧУДЧыМЧзЁЃЌХчзьКЭТнЫЈПЩвдгаЖрИіЪЕР§ЃЌвдБуНјааЗжВМЪНВЂааМЦЫуЁЃ
ЫфШЛХчзьЛђТнЫЈдкТпМЩЯЪЧвЛИідзгМЦЫуЕЅдЊЃЌЕЋЫќЕФЮяРэЪЕЯжВЂВЛвЛЖЈЁЃ
ЗжзщЪЧЖЈвхСНИіВЛЭЌЭиЦЫдЊЫижЎМфЕФдЊзщСїЕФЗНЪНЁЃЫќНЋЖЈвхЪфШыЪЕЬхКЭФПБъЪЕЬхЕФЪЕР§ЃЈШЮЮёЃЉжЎМфЕФдЊзщЪЧШчКЮСїЖЏЕФЁЃ
Р§ШчЃЌЁАshuffleGroupingЁБНЋЫцЛњЗЂЫЭдЊзщЕНТнЫЈЪЕР§ЁЃ
ЬсабвЛЯТЃЌдкЬжТлЗжзщЪБЃЌЬжТлЕФЪЧСНИіЪЕЬхжЎМфЕФЪ§ОнСїЃЌВЂЧвжЛгаСНИіЪЕЬхЁЃ
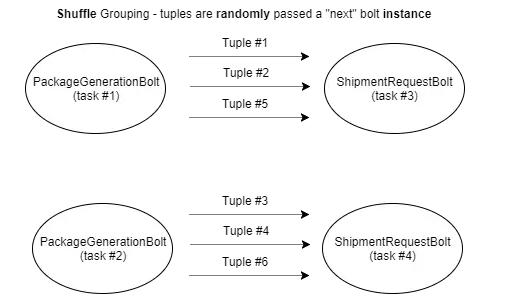
дкетРяЃЌПЩвдПДЕНУПИідЊзщЪЧШчКЮЫцЛњЕизЊвЦЕНвЛИіТнЫЈЪЕР§ЃЈШЮЮёЃЉЃЌДгPackageGenerationBoltЕНShipmentRequestBoltЁЃ
вЛИізюгаШЄЕФЗжзщбЁЯюЪЧЁАзжЖЮЁБЗжзщЃЌдкетИіЗжзщжажИЖЈвЊНЋдЊзщЗжзщЕФЬиЖЈзжЖЮЁЃР§ШчЃЌЗжзщShipmentRequestBoltЕНЛљгкзжЖЮЁАWarehouseIdЁБЕФPackageGenerationRequestЁЃгЩгкетжжЁАзжЖЮЁБЕФЗжзщВпТдЃЌЫљгаДјгаЯрЭЌWarehouseIdжЕЕФдЊзщЃЌдкЪфШыдЊзщЪБЪМжеБЛЖЈЯђЕНЯрЭЌЕФShipmentRequestBoltШЮЮёЪЕР§ЁЃ
ЛЙгаЦфЫќгаШЄЕФЗжзщЗНЗЈПЩвддкетРяВщПДЁЃ
НсТл
ИааЛДѓМвгыЮввЛЦ№ЖШЙ§етЖЮЖЬднЕФТУГЬЃЌзмЬхЕиЛиЙЫСЫЭМаЮМЦЫуЕФИХФюКЭApache StormИќОпЬхЕФЯИНкЁЃдкаДетЦЊЮФеТЕФЪБКђЃЌЮввЛжБРЮМЧЁАБЃГжМђЕЅЁБЃЌМйЩшвЛЕЉЁАРэНтСЫЁБетИіЯыЗЈВЂРэНтСЫетИіЙЄОпЃЌНЋФмЙЛОіЖЈФуЪЧЗёашвЊЖдStormНјааИќЩюШыЕФбаОПЁЃетвВЪЧЮвЬсЕНЖюЭтЕФдФЖСКЭЮвЕФPluralsightПЮГЬЕФдвђЁЃ
ЮвУЧДгРэНтЭМаЮМЦЫуЪЧЪВУДвдМАЫќЦ№дДгкКЮДІПЊЪМСЫетвЛТУГЬЁЃЬиБ№ЪЧРэНтСЫЫќдкМЦЫуЛњПЦбЇСьгђЪЧЖрУДЩюАТЕФИХФюЁЃ
вЛЕЉШЗаХЃЈЯЃЭћЃЉЃЌЮвУЧвбОПЊЪМЬжТлжЇГжЛљДЁМмЙЙЕФКУДІЃЌвдБуПЩППЕиНЋгІгУГЬађзїЮЊЭМаЮМЦЫуЪЕЯжЁЃ
ЮвУЧНщЩмСЫApache StormетбљвЛжжММЪѕЁЃ
stormдкТпМВуЁЂЭиЦЫВуКЭЮяРэВуЁЊЁЊЮяРэМЏШКБОЩэНјааСЫЛиЙЫЁЃ
РэНтСЫЭиЦЫШчКЮдкећИіМЏШКжаДЋВЅЃЌВЂдкЮяРэВуЕФзюжеГщЯѓВуЃЈШЮЮёЃЉжажДааЁЃ
ШЛКѓЬжТлСЫStormШчКЮЬсЙЉВЂааЖШЁЊ ЮоТлЪЧдкСїМЖБ№КЭЛЙЪЧдкЬиЖЈШЮЮёМЖБ№ЃЈХчзьЛђТнЫЈЃЉЁЃ
ПДвЛаЉДњТыЃЌЮвЪдЭМДЋЕнЪЙгУstormЕФМђЕЅКЭУРРіЁЃЯЃЭћвбОГЩЙІЕиЮќв§СЫФуЁЃ
|









