| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌШчКЮдкетбљЕФГЁОАЯТЭЈЙ§ДѓЪ§ОнЦНЬЈЃЌЮШЖЈжЇГХзЁвЕЮёЕФЗЂеЙЪЧвЛИіВЛаЁЕФЬєеНЁЃБОЮФЗжЯэжївЊЦНЬЈЙЄОпСДЃЌММЪѕЁЂбЁаЭМАМмЙЙЩшМЦЩЯЕФвЛЕуОбщЁЃ
|
|
ДѓЪ§ОнЦНЬЈЯжзД
ЖіСЫУДЕФДѓЪ§ОнЦНЬЈЭХЖгГЩСЂгк2015Фъ5дТЗнзѓгвЃЌдк16Фъ4дТЗнЃЌHadoopМЏШКЙцФЃЛЙжЛдк100+НкЕуЪ§ЃЌЖјдквЛФъЪБМфРяМЏШКЙцФЃПьЫйдіГЄЕН1000+ЕФЫЎЦНЃЌетЛЙЪЧдкв§ШыЪ§ОнЩњУќжмЦкНјааЙмПиЕФЧщПіЯТЕФЙцФЃдіЫйЃЛЭЌбљЃЌСїМЦЫуМЏШКЕФЙцФЃЫфШЛЯрЖдНЯаЁЃЌЕЋвВОРњСЫ10БЖЕФдіГЄЃЌвЛаЉtopicЕФЭЬЭТСПвбГЌЙ§АйЭђУПУыЁЃ
ЕБЧАЦНЬЈВПЗжЕФТпММмЙЙШчЭМ1ЃЌВЂГжајбнНјЁЃ
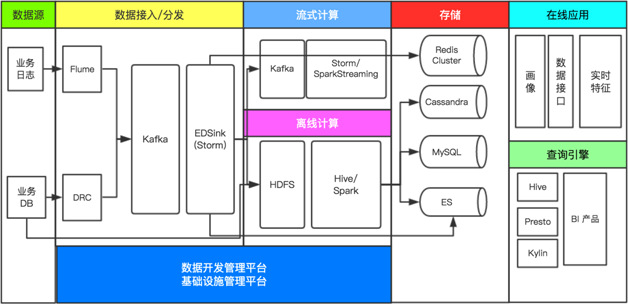
ЭМ1 ЖіСЫУДДѓЪ§ОнЦНЬЈЕФТпММмЙЙЭМ
ЕБГѕУцСйЕФЮЪЬт
ЖіСЫУДвбОГЩСЂ9ФъЪБМфЃЌЯрЖдЖјбдЪ§ОнЦНЬЈЭХЖгЗЧГЃФъЧсЃЌдкМгШыЭХЖгжЎГѕУцСйСЫШчЯТЬєеНЃК
ШЫЩйЛюЖр Л§РлВЛзу
ФкдкжЪСП ЁАВюВЛЖрОЭааЁБ
ЙЪеЯДІРэ ЁАЧЇШЫЧЇУцЁБ
вђДЫЃЌжївЊвдаЇТЪЁЂжЪСПКЭГжајРЉеЙЮЊКЫаФРДНЈЩшЪ§ОнЦНЬЈЁЃ
ММЪѕбЁаЭ
ШчЭМ2ЫљЪОЃЌДѓЪ§ОнЕФММЪѕеЛЗЧГЃЖрбљЛЏЃЌЖдгкЭХЖгКмЖрГѕШыДѓЪ§ОнСьгђЕФГЩдБРДЫЕКмШнвздкГЂаТЙ§ГЬжаЯћКФЭХЖгЕФЩњВњСІЃЌвђДЫдкМгШыЭХЖгГѕЦкЃЌЪзЯШОЭвЊШЗЖЈдкЕБЪБЬѕМўЯТЕФММЪѕбЁаЭЁЃ

ЭМ2 ЖрбљЛЏЕФДѓЪ§ОнММЪѕеЛ
бЁаЭддђ
дкММЪѕбЁаЭЗНУцМсГжЕФддђЪЧЁА3TЁБЃКвЊНтОіЪВУДбљЕФЮЪЬтКЭГЁОАЃЈTroubleЃЉЃЌгаФФаЉММЪѕПЩЙЉбЁдёЃЈTechnologyЃЉЃЌвдМАЭХЖгММЪѕеЛгыФПБъВЩгУММЪѕЕФЦЅХфГЬЖШЛђепЫЕеЦПиФмСІЃЈTeamЃЉЁЃ
ЯТУцОйМИР§згРДПДЃК
МДЯЏВщбЏв§ЧцбЁаЭ
дквдHive on HadoopЮЊжааФЕФРыЯпЪ§ОнВжПтЃЌзюПЊЪМЗжЮіЪІвдМАЪ§ОнЙЄГЬЪІвВЖМЪЧЪЙгУHiveРДзіЪ§ОнЗжЮіКЭЬНЫїЃЌЕЋЪЧHiveБОжЪЩЯЪЧЛљгкMapReduceМмЙЙЕФЃЌВЂВЛЪЧКмЪЪКЯетИіГЁОАЁЃЕБЪБЫљбЁдёЕФФПБъМЏжадкPrestoКЭSparkSQLЩЯЃЌЩчЧјЛюдОЖШSparkЪЧзюИпЕФЃЌВЂЧвДгSQLгяЗЈМцШнадРДПДSparkSQLвВЪЧзюКЯЪЪЕФЃЌгУЛЇЕФЪЙгУГЩБОБШНЯЕЭЃЌЕЋЪЧдкВтЪдЕФЪБКђЗЂЯжЪЇАмТЪИпДя50%ЃЌдкМцШнадКЭЮШЖЈадЗНУцШчЙћЮоЗЈЖдSparkДњТызівЛЖЈЖЈжЦЛЏПЊЗЂЕФЛАДяВЛЕНЮвУЧЕФвЊЧѓЃЌЯрЖдЖјбдPrestoЫфШЛгяЗЈМцШнадВЛШчSparkSQLЃЌЕЋЪЧБШНЯЮШЖЈВЂЧвдкдЫаааЇТЪЩЯвВИпгкSparkSQLЃЌПМТЧЕНЕБЪБЭХЖгЕФSparkСІСПЛ§РлВЛзуЃЌЭЌЪБЭХЖгГЩдБвВгадјЪЙгУКЭЙмРэЙ§PrestoЕФОбщЃЌвђДЫгХЯШПМТЧPrestoзїЮЊAd-hocЕФВщбЏв§ЧцЁЃ
МмЙЙЩшМЦ
ММЪѕбЁаЭШЗЖЈСЫЃЌНгЯТРДашвЊНтОідквЕЮёМБЫйдіГЄЧщПіЯТЕФМмЙЙЩшМЦЮЪЬтЁЃРэЯыЕФМмЙЙЪЧЯЕЭГЩЯЯпКѓОЁСПМѕЩйШЫЕФВЮгыЃЌЛђЭЈЙ§МђЕЅЕФСїГЬМДПЩгІЖдЭтВПБфЛЏЃЌзЗЧѓПЩГжајРЉеЙЕФМмЙЙЩшМЦЃЌетРяЭЈЙ§вЛИіОпЬхАИР§РДБэДяЮвУЧдкЩшМЦЪБЕФЙизЂЕуЁЃ
ШчЭМ5ЃЌСїШыШ§ИідДЪ§ОнСїЃКгУЛЇааЮЊЁЂжїеОЖЉЕЅЁЂвдМАПЊЗХЦНЬЈЖЉЕЅЕФЖЉЕЅЧўЕРЃЌНјааИїжжЪЕЪБжИБъЕФМЦЫуЃЌЦфжаЗжЧўЕРЖЉЕЅЯрЙижИБъЕФМЦЫуКЭЖрЮЌЖШзщКЯЯТЕФUVМЦЫуГЁОАЪЧБШНЯЕфаЭЕФСїМЦЫуЮЪЬтЁЃ
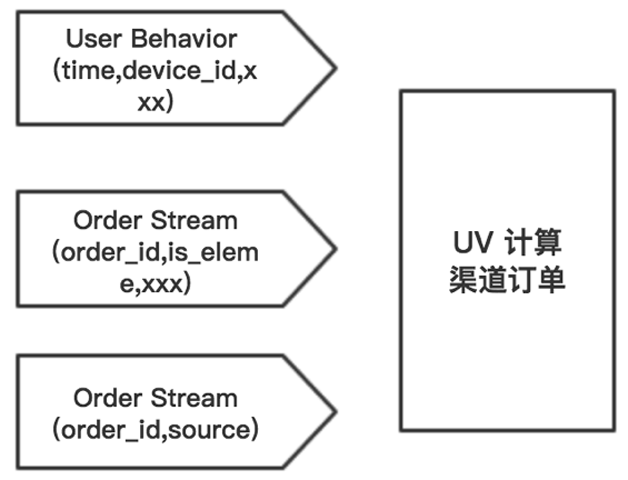
ЭМ5 СїШыШ§ИідДЪ§ОнСїЕФUVМЦЫуЧўЕРЖЉЕЅ
вьВН
ЗжЧўЕРЖЉЕЅжИБъМЦЫуашвЊНЋжїеОЖЉЕЅСїКЭПЊЗЂЦНЬЈЖЉЕЅСїНјааJoinМЦЫуЃЌвђЮЊЪЧЖрЪ§ОнСїЕФКЯВЂМЦЫуЃЌЫљвддкЩшМЦИУМмЙЙЪБЛљгкЕФМйЩшЪЧЃКВЛЭЌдДЪ§ОнСїжЎМфЕФЕНДяЪБМфЮоЗЈаЭЌЃЌЮвУЧНЋЮЪЬтзЊЛЏЮЊЁБдкПЩЕїећЕФЪБМфДАПкФкЭЈЙ§ЦЅХфДЅЗЂJoinМЦЫуЁБЁЃОпЬхТфЕидђЪЧЭЈЙ§RedisЛКДцзЁЛЙУЛгаЦЅХфЕФЖЉЕЅЪ§ОнЃЌв§ШыЪБМфДАПкЪЧЮЊСЫПижЦзЁЛКДцЕФДѓаЁЃЌЖјЪБМфДАПкЕФПижЦгаСНДІЃКдкФУЕНЪ§ОнЪБЛсМьВщЪЧЗёдкЪБМфДАПкФкЃЛСэЭтдкЮДЦЅХфЕФЧщПіЯТаДШыRedisЪБЛсАбЪБМфДАПкЭЈЙ§TTLЕФЗНЪНвЛВЂЮЌЛЄЃЌБмУтЖргрЕФЮЌЛЄШЮЮёЁЃ
ПЩРЉеЙад
UVМЦЫуЪзЯШвЊНтОіЕФОЭЪЧШЅжиЮЪЬтЃЌБШШчХаЖЯФГИіdeviceIDЪЧЗёЪЧЕБЬьЕФЦНЬЈаТЗУПЭЃЌвЛжжзіЗЈЪЧЭЈЙ§RedisЕФМЏКЯРДХаЖЯЃЌОпЬхЪ§ОнНсЙЙШчЯТЃК
key : YYYYMMDD_uv
value : deviceIDЕФМЏКЯ |
етбљЕФЩшМЦЛсДјРДШШЕуЮЪЬтЃЌЫљгаИУЮЌЖШЕФdeviceIDЧыЧѓЖМЛсДђЕНвЛИіНкЕуЩЯВњЩњШШЕуЃЌЕБСїСПдіМгЪБЮоЗЈЭЈЙ§жБНгРЉШнРДНтОіЮЪЬтЃЌФЧУДздШЛОЭЯыЕНШчЯТЕФЪ§ОнНсЙЙЃК
key : _YYYYMMDD
value : еМЮЛЗћ |
ЭЈЙ§ШчДЫзЊЛЏПЩвдКмКУЕиАбЧыЧѓДђЩЂЃЌгаОпИќКУЕФРЉеЙадЁЃ
ЛиЕНЖрЮЌЖШUVМЦЫуЕФГЁОАЯТЃЌЭЈГЃЩцМАЕНЕФзщКЯЮЌЖШПЩвдДяЕН2ЕФNДЮЗНЃЌШчЙћВЩгУЩЯЪіНсЙЙЮоТлЪЧЖСаДЕФЭЬЭТЛЙЪЧПеМфЕФЯћКФЖМЪЧОоДѓЕФЃЌРЉеЙГЩБОЗЧГЃИпЃЌЮвУЧбЁдёЮўЩќвЛЖЈОЋЖШРДДяЕНЕЭГЩБОЕФРЉеЙадЁЃUVМЦЫуБОжЪЪЧЛљЪ§ЙРМЦЮЪЬтЃЌдкИУСьгђЗЧГЃГіУћЕФЪ§ОнНсЙЙОЭЪЧHyperLogLogЃЈвдЯТМђГЦHLLЃЉЃЌЫфШЛRedisБОЩэжЇГжHLLЕЋЪЧЮоЗЈБмУтШШЕуЮЪЬтЃЌЮвУЧбЁдёдкСїМЦЫуЙ§ГЬжаБОЕиМЦЫуHLLЃЌвђЮЊHLLжЇГжmergeВйзїЭЌЪБУнЕШПЩЛиЗХЃЌДѓСПЕФМЦЫуЖМдкМЦЫуШЮЮёНкЕуБОЕиЭъГЩЃЌЮоТлЪЧshuffleЛЙЪЧТфЕиДцДЂЕФДІРэКСЮобЙСІЃЌЭЈЙ§бЙВтЃЌдкВЛРЉШнЕФЧщПіЯТПЩвджЇГХ20БЖЕФбЙСІЁЃ
ЮШЖЈад
ЖдгкЮШЖЈаджївЊЭЈЙ§ЪТЧАЁЂЪТжаКЭЪТКѓШ§ИіЗНУцРДПДЃЌМДжДааМЦЛЎЁЂЙЪеЯДІРэКЭЪТКѓИДХЬЁЃ
жДааМЦЛЎ
ЪзЯШЯпЩЯБфИќЮЊСЫПижЦЗчЯеЃЌгаСНЕуЪЧБиаызёЪиЕФЃКвЛЖЈвЊгаПЩааЕФЛиЙіЗНАИЃЌвЛЖЈвЊЛвЖШЁЃ
ЦфДЮЃЌЖдгкОпЬхЕФЩаЮДздЖЏЛЏжЇГжЕФБфИќСїГЬЛђSOPашвЊПМТЧвьГЃЗжжЇЃЌДѓЖрЪ§ПДЕНЕФSOPЮФЕЕжЛЪЧПМТЧе§ГЃСїГЬвЛВНВНжДааЯТРДЃЌПЩЪЧОГЃгіЕНЕФЮЪЬтЗДЖјЪЧФГИіСїГЬзпВЛЭЈЛђепГіЮЪЬтСЫЁЃ
зюКѓЃЌОЭЪЧБфИќЪБМфЙРЫуКмживЊЃЌЖдБфИќЕФНкзрАбЮеЕФдНЧхГўЗчЯедНДгШнЁЃ
ЙЪеЯДІРэ
ЖдгкЙЪеЯДІРэЮвУЧБШНЯЙизЂЕФвЛИіжИБъОЭЪЧMTTRЃЈMean Time To RecoveryЃЌМДЦНОљЛжИДЪБМфЃЉЁЃ
ЙЪеЯЛжИДЪБМф=ИцОЏЯьгІЪБМф+НщШыДІРэЪБМф
ДгЩЯУцЕФЙЋЪНПЩвдПДГіMTTRжївЊЪЧгЩЯьгІЪБМфКЭДІРэЪБМфЙЙГЩЁЃ
МрПи Ёй ИцОЏ
ЖдгкЮШЖЈадРДЫЕМрПиЪЧЕзЯпЃЌЕЋЪЧЁБМрЁБЖјЮоЁБПиЁБЕФЯжЯѓЗЧГЃЦеБщЃЌДјРДЕФНсЙћЪЧЪеЕНвЛИіИцОЏВЛжЊЕРШчКЮДІРэЃЌЛђепКіТдЕєЃЌЛђепЁАЧЇШЫЧЇУцЁБДІРэЃЌЮЪЬтВЛЭЌГЬЖШЕиБЛвўВиЛђЗХДѓЁЃ
МрПи = metrics+trigger+action
ФЧУДШчКЮЁАПиЁБФи?
МрПиЕФЁБПиЁБ
ЮвУЧМсГжШчЯТДЮађЃКЕЭГЩБОЕФздгњгХЯШгкСїГЬЛђSOPЃЌШчЙћSOPУЛгаИВИЧЕФГЁОАОЭашвЊвЛИіддђРДжИЕМЗНЯђЃЌБШШчЙЪеЯЗЂЩњКѓЪЧгХЯШБЃФФИіЗНУцЃЌвЛжТадЛЙЪЧПЩгУадЁЃж№ВНЕќДњНЋЙЪеЯДІРэЕФЁАЧЇШЫЧЇУцЁБЪеСВЕНДгШнгаађЁЃ
ИДХЬддђ
ЙЪеЯИДХЬЖдгкЯЕЭГЮШЖЈадЕФЬсИпЪЧИіЗЧГЃЗЧГЃгаМлжЕЕФБеЛЗЗДРЁЃЌдкетЗНУцЮвУЧЪЕМљзХFacebookЕФDREPддђЃЌЭЌЪБЛљгкЪЕМљОбщв§ШыСЫW9ЃЈWorkaroundЃЉЃЌЧПЕїПЩГжајЕФЮШЖЈадЁЃ
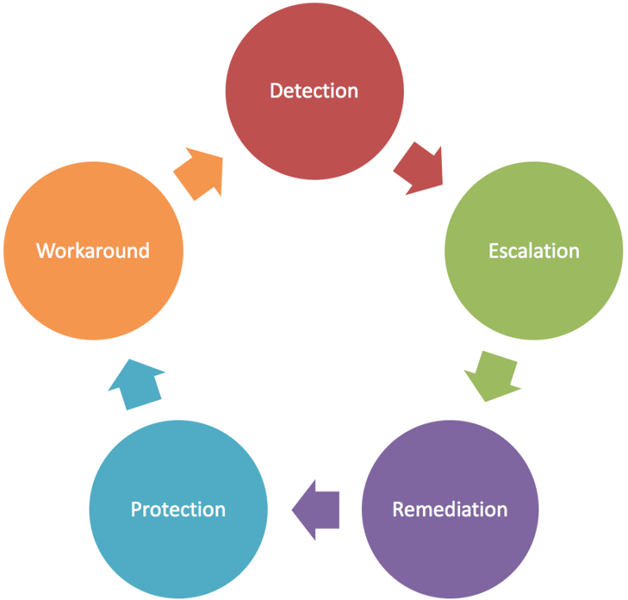
ЭМ6 FacebookЕФDREPддђ
ЙЄОпСД
ЩЯЮФЬсЕНЕФММЪѕбЁаЭМАМмЙЙЩшМЦКЭЮШЖЈадБЃеЯЭЈГЃвРРЕгкШЫЃЌЮвУЧИќЯЃЭћНЋШЫЕФОбщЙЙНЈдкЙЄОпжаЃЌМѕЩйЖдШЫЕФвРРЕЃЌЬсЩ§зщжЏЕФПЩРЉеЙадЁЃЭМ7ЮЊЙЄОпСДЕФМмЙЙЭМЁЃ

ЭМ7 ЙЄОпСДМмЙЙЭМ
ОЁСПРЉДѓЙЄОпдкећИіЪ§ОнЙЄзїЩњУќжмЦкЕФИВИЧЖШЃЌЮЊЪ§ОнЙЄзїШЫдБИГФмЃЌжївЊАќРЈЃК
дЊЪ§ОнЙмРэЃКжИБъЙмРэЃЌЪ§ОнжЪСПМрПиЃЌбЊдЕЙиЯЕзЗЫнЕШЃЛ
ШЈЯоЙмРэМАЪ§ОнАВШЋЃКЪ§ОнЕзВуЕФАВШЋЃЌЛљДЁЩшЪЉШЈЯоЬхЯЕДђЭЈЃЌвдМАЪ§ОнЪЙгУАВШЋЃЛ
Ъ§ОнПЊЗЂЙмРэЃКЪ§ОнБэЙмРэЃЌЪ§ОнЬНВщЃЌРыЯпгыЪЕЪБЪ§ОнПЊЗЂКЭШЮЮёдЫгЊЃЛ
Ъ§ОнгІгУЃКЪ§ОнНгПкПЊЗЂЃЈSQLМДНгПкЃЉЃЌЪ§ОнБЈБэПЊЗЂЃЈSQLМДБЈБэЃЉКЭЙмРэЃЛ
здЖЏЛЏдЫгЊЃКећИіЛљДЁЩшЪЉЕФЙмРэЃЌАќРЈCMDBЁЂЙЄзїСїв§ЧцЁЂШнСПЙцЛЎЁЂадФмЗжЮігыИцОЏЙмПиЕШЁЃ
БОЮФзХжиЗжЯэЪ§ОнПЊЗЂЙмРэКЭЪ§ОнБЈБэПЊЗЂЁЃ

ЭМ8 Ъ§ОнБэЙмРэЯЕЭГЙІФмЪОвтЭМ
Ъ§ОнБэЙмРэ
ЩњВњЪ§ОнБэЪЧЫљгаЪ§ОнПЊЗЂЙЄзїЕФдДЭЗЃЌвђДЫЮвУЧАбЩњВњЪ§ОнБэЕФДДНЈМАЮЌЛЄЙЄзїЭГвЛЪеЕНЪ§ОнБэЙмРэЯЕЭГЃЈвдЯТГЦdtmetaЃЉжаЃЌГ§СЫНЈБэЕФЛљДЁЙІФмЭтЃЌжївЊЙизЂШчЯТаХЯЂЃК
ОВЬЌЪ§ОнЃКБэЫљЪєжїЬтЃЌзжЖЮЪЧЮЌЖШЛЙЪЧЖШСПЃЌЪЧЗёУєИаЛђМгУмзжЖЮЃЌБэЕФЩњУќжмЦкКЭБИЗнжмЦквдМАБэЕФЮяРэНсЙЙаХЯЂЕШЃЛ
ЖЏЬЌЪ§ОнЃКжївЊАќКЌБэЕФЖСаДШШЖШЧщПіЃЌвдМАБэЕФШнСПБфЛЏЧщПіЃЌБугкеыЖдадВпТдгХЛЏКЭЮЪЬтЗжЮіЁЃ
гаСЫетаЉаХЯЂЃЌМѕЩйСЫДѓСПКѓајЮЌЛЄЕФЙЄзїЃЌНЕЕЭНЛЛЅГЩБОЁЃ
Ъ§ОнПЊЗЂМАШЮЮёЙмРэЯЕЭГ
Ъ§ОнПЊЗЂ
ФЃАхЛЏЃКЪ§ОнПЊЗЂЙЄзїепПЩвджБНгдкЯЕЭГжаПЊЗЂETLШЮЮёЃЌжЇГжЖЏЬЌБфСПЃЌЭЌЪБПЩХфжУДЅЗЂЗНЪНЁЂЦкЭћЭъГЩЪБМфЕШЪєадЃЌзїЮЊЬиеїЬсЙЉИјЕїЖШЯЕЭГЃЛ
hookЃКдкШЮЮёЦєЖЏЧАКЭжДааНсЪјКѓПЩвдДЅЗЂЕФactionЃЌБШШчЪ§ОндДЕФбгГйМьВтЃЌЪ§ОнГщШЁКѓЕФЪ§ОнаЃбщЛђепЭЦЫЭКѓСйЪБЪ§ОнзДЬЌЕФЧхРэЃЈДЅЗЂЃЉЕШЃЛ
вРРЕЪЖБ№ЃКЖдгкЛљгквРРЕДЅЗЂЕФШЮЮёРДЫЕЃЌвРРЕЕФздЖЏЛЏЪЖБ№ЗЧГЃБивЊЃЌШЫЙЄХфжУвРРЕЛсгіЕНбЛЗвРРЕвдМАвРРЕвХТЉЃЌДгЖјгАЯьШЮЮёЕФSLAЩѕжСЪ§ОнжЪСПЃЛ
ЖрЪ§ОнДцДЂЭЦЫЭ ЃКHiveЭЈЙ§ЭтВПБэЕФЗНЪНжЇГжЯђESЁЂRedisЁЂCassandraЁЂMongoDBЕШЪ§ОнДцДЂЕФЭЦЫЭвдМАГщШЁЃЌМђЛЏЪ§ОнПЊЗЂЙ§ГЬжаЕФЪ§ОнНЛЛЛЙЄзїЁЃ
ЭМ9 TitanЕїЖШЦНЬЈБрМШЮЮёНиЭМЪОвт
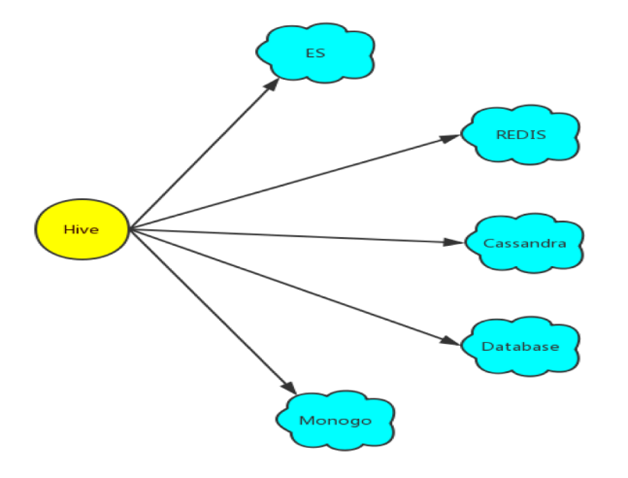
ЭМ10 HiveЕФЖрЪ§ОнДцДЂЭЦЫЭ
ШЮЮёжДаагыЙмРэ
ЖдгкШЮЮёжДааКЭШЮЮёЕФзджњЛЏдЫгЊЙмРэЮвУЧжївЊЙизЂетМИЕуЃК
бЙСІИажЊЃКЛсИаШЮЮёдЫааЕФФПБъЯЕЭГБШШчYarnЕФбЙСІЃЌДяЕНЗДбЙЕФаЇЙћЖјВЛЪЧГжајНЋШЮЮёжБНгЬсНЛИјФПБъЯЕЭГЃЌЭљЭљЛсДЅЗЂЯТгЮЯЕЭГЕФBugЕМжТбЉБРЃЛ
Жрв§ЧцжДааЃКЖдгкHQLЕФШЮЮёЃЌПЩвдЭИУїЧаЛЛЕНHiveКЭSparkжДааЃЌФПЧАаЁЪБЦЕТЪЕФКЫаФШЮЮёвбОЖМЮШЖЈХмдкSparkв§ЧцЩЯЃЛ
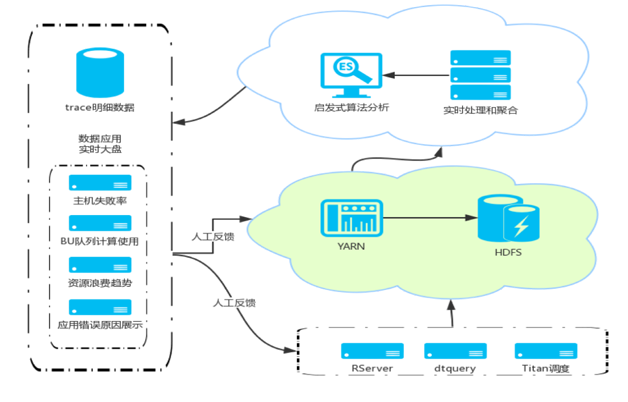
ЭМ11 ДэЮѓШежОЕФГЃМћДІРэВпТд
СДТЗЗжЮі
DAGГіЖШЗжЮіЃЌЦРЙРШЮЮёживЊГЬЖШЃЌЭЌЪБвВЪЧЬсЙЉИјЕїЖШЯЕЭГЕФживЊЬиеїЃЛ
дЫааЧїЪЦЗжЮіЃЌАќРЈЦєЖЏЪБМфЃЌдЫааЪБГЄЃЌДІРэЪ§ОнСПЕФЧїЪЦБфЛЏЃЛ
ЭЈЙ§ТёЕуНЋгУЛЇМЖБ№ЕФШЮЮёКЭЯТгЮЯЕЭГЃЈHadoopЕШЃЉЕФШЮЮёШЋСДТЗДђЭЈЃЌПЩвдзЗЫнЕНШЮКЮвЛИіВуУцжДаазДПіЃЛЭЌЪБЃЌЛсИјШЮЮёДђБъЧЉЃЌБШШчЧуаБЁЂВЮЪ§ВЛКЯРэЕШЬсЙЉИјгУЛЇНјааПьЫйЕФзджњЗжЮіКЭЙмРэЃЛ
ЖдДэЮѓШежОНјааЙщРрДІРэЃЌШЅЕєдывєЃЌВЂИНЩЯГЃМћЕФДІРэВпТдЃЌНјвЛВНЬсЩ§ШЮЮёзджњЛЏЙмРэЁЃ
ИцОЏЃКПЩвдЩшжУСщЛюЕФИцОЏВпТдКЭДЅДяЧўЕРЃЌжївЊЪЧИЈжњШЮЮёИКд№ШЫЛђепжЕАрШЫдБЁЃ
БЈБэПЊЗЂЦНЬЈ
БЈБэПЊЗЂЪЧЪ§ОнгІгУЗЧГЃГЃМћЕФвЛИіГЁОАЃЌдкДѓЪ§ОнВПУХГЩСЂГѕЦкгаДѓСПЕФБЈБэПЊЗЂЙЄзїашвЊЯћКФКмЖрШЫСІЃЌЫфШЛгаКмЖрГЩЪьЕФЩЬвЕВњЦЗЃЌЕЋЪЧДѓЖрзЈзЂгкНЛЛЅПЩЪгЛЏЃЌЖдгквбгаЯЕЭГКЭЛљДЁЩшЪЉЕФНгШыГЩБОКмИпЃЌвђДЫЮвУЧПьЫйПЊЗЂСЫБЈБэПЊЗЂЦНЬЈЃЈEMAЃЉЁЃ
ПЩвдНЋФЃАхЛЏЕФSQLПьЫйзЊГЩБЈБэЧЖШыЕНИїИіЯЕЭГжаЃЌВЂЧвКЭФкВПЯЕЭГДђЭЈЃЌбЊдЕНЈСЂЃЌжЇГжАќРЈMySQL/Preso/Kylin/Hive/SparkЕШИїжжГЃМћЕФЪ§ОндДЛђжДаав§ЧцЃЌЭЌЪБПЩХфжУБЈБэВщбЏЛКДцЪЙЕУДѓМЦЫуСПаЁНсЙћМЏЕФГЁОАЕУЕНКмКУТњзуЁЃEMAЩЯЯпжСНёЃЌгаНгНќАЫГЩЕФБЈБэЖМЪЧГіздИУЯЕЭГЁЃ
ЭМ12 БЈБэПЊЗЂЦНЬЈгІгУ
ЪЕЪБПЊЗЂЦНЬЈ
дкЯпЫуЗЈЕФЪЕЪБЬиеїМЦЫуАќРЈPOIИажЊЁЂЩЯЯТЮФГЁОАИажЊЃЌЖМЪЧКмЕфаЭЕФЪЕЪБМЦЫуГЁОАЁЃЪЕЪБПЊЗЂЙмРэЦНЬЈжївЊАќРЈЪ§ОндДЕФЖЫЕНЖЫНгШыЃЌЗтзАПђМмЕФвЕЮёЮоЙиЯИНкЃЌЬсЙЉПЩХфжУВпТдЃЌСэЭтРћгУfluxНЋШЮЮёХфжУКЭЭиЦЫЙмРэГщЯѓГіРДЁЃШЮЮёЕФЗЂВМПижЦвдМАЩЯЯпКѓздЖЏМрПиСЊЖЏЃЌШУПЊЗЂШЫдБИќЖрЙизЂвЕЮёТпМКЭМмЙЙЩшМЦЃЌМѕЩйЙмРэВуУцЕФЭЖШыЁЃ
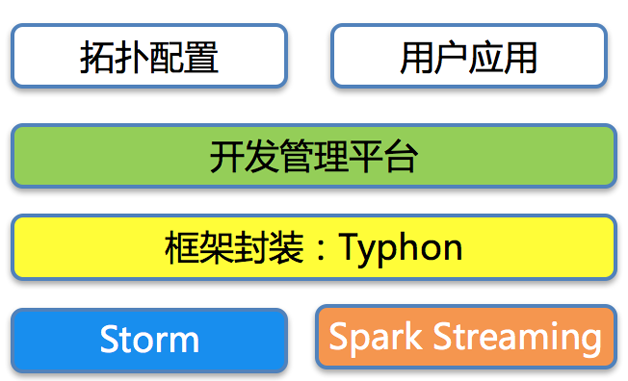
ЭМ13 ЪЕЪБПЊЗЂЦНЬЈЕФМмЙЙЩшМЦ
ЦНЬЈЕФвЛаЉЫМПМ
ЙЕЭЈКЭаЕїЪЧзюДѓЕФГЩБОЃЌDo not take things personally
УцЯђгУЛЇЃКОЁСПЭЦЖЏжњЛЏЃЌКЭВњЦЗЕФздНтЪЭЃЛ
ЗДИДЧПЛЏгУЛЇдЄЦкЃЛ
УцЯђЯЕЭГЃКЭЦЖЏЯЕЭГЕФздЖЏЛЏКЭвЛМќЛЏЃЌзюКѓВХЪЧSOPЁЃ
What gets measured gets fixed
ЩшМЦЗНУц
Less is more
Think about futureЃЌ design with flexibilityЃЌbut only
implement for production
ММЪѕЛђЗНАИбЁаЭ
зюКЯЪЪЕФЃЌЖјВЛЪЧзюЯШНјЕФ
ЧхГўМйЩшЕФБпНч
ММЪѕвЊУцЯђвЕЮёаЇТЪЃЌВњЦЗВЛзуЗўЮёДе
вдЩЯЪЧЮвУЧНижЙЕН17ФъH1ЕФвЛИіЛиЙЫЃЌЖіСЫУДДѓЪ§ОнЦНЬЈЛЙдкГжајПьЫйбнНјжаЃЌЦкД§гаИќЖрЕФИЩЛѕдкНгЯТРДФмЙЛКЭИїЮЛММЪѕЭЌШЪЙВЭЌНЛСїЬНЬжЁЃ |









