| БрМЭЦМі: |
| БОЮФРДздгкДѓЪ§ОнМмЙЙЃЌБОЮФЯъЯИЗжЮіСЫKafkaЪТЮёЛњжЦЕФЪЕЯждРэЃЌВЂНщЩмСЫKafkaШчКЮДІРэЪТЮёЯрЙиЕФвьГЃЧщПіЃЌШчTransaction
CoordinatorхДЛњЁЃ |
|
аДдкЧАУцЕФЛА
БОЮФЫљгаKafkaдРэадЕФУшЪіГ§ЬиЪтЫЕУїЭтОљЛљгк Kafka 1.0.0
АцБОЁЃ
ЮЊЪВУДвЊЬсЙЉЪТЮёЛњжЦ
KafkaЪТЮёЛњжЦЕФЪЕЯжжївЊЪЧЮЊСЫжЇГж
1.Exactly OnceМДе§КУвЛДЮгявх
2.ВйзїЕФдзгад
3.газДЬЌВйзїЕФПЩЛжИДад
Exactly Once
ЁЖKafkaБГОАМАМмЙЙНщЩмЁЗвЛЮФжагаЫЕУїKafkaдк0.11.0.0жЎЧАЕФАцБОжажЛжЇГжAt
Least Once КЭ At Most OnceгявхЃЌЩаВЛжЇГжExactly OnceгявхЁЃ
ЕЋЪЧдкКмЖрвЊЧѓбЯИёЕФГЁОАЯТЃЌШчЪЙгУKafkaДІРэНЛвзЪ§ОнЃЌExactly OnceгявхЪЧБиаыЕФЁЃЮвУЧПЩвдЭЈЙ§ШУЯТгЮЯЕЭГОпгаУнЕШадРДХфКЯKafkaЕФAt
Least OnceгявхРДМфНгЪЕЯжExactly OnceЁЃЕЋЪЧЃК
1.ИУЗНАИвЊЧѓЯТгЮЯЕЭГжЇГжУнЕШВйзїЃЌЯожЦСЫKafkaЕФЪЪгУГЁОА
2.ЪЕЯжУХМїЯрЖдНЯИпЃЌашвЊгУЛЇЖдKafkaЕФЙЄзїЛњжЦЗЧГЃСЫНт
3.ЖдгкKafka StreamЖјбдЃЌKafkaБОЩэМДЪЧздМКЕФЯТгЮЯЕЭГЃЌЕЋKafkaдк0.11.0.0АцБОжЎЧАВЛОпгаУнЕШЗЂЫЭФмСІ
вђДЫЃЌKafkaБОЩэЖдExactly OnceгявхЕФжЇГжОЭЗЧГЃБивЊЁЃ
ЁЃЁЃЁЃЁЃЁЃЁЃ
Вйзїдзгад
ВйзїЕФдзгадЪЧжИЃЌЖрИіВйзївЊУДШЋВПГЩЙІвЊУДШЋВПЪЇАмЃЌВЛДцдкВПЗжГЩЙІВПЗжЪЇАмЕФПЩФмЁЃ
ЪЕЯждзгадВйзїЕФвтвхдкгкЃК
1.ВйзїНсЙћИќПЩПиЃЌгажњгкЬсЩ§Ъ§ОнвЛжТад
2.БугкЙЪеЯЛжИДЁЃвђЮЊВйзїЪЧдзгЕФЃЌДгЙЪеЯжаЛжИДЪБжЛашвЊжиЪдИУВйзїЃЈШчЙћдВйзїЪЇАмЃЉЛђепжБНгЬјЙ§ИУВйзїЃЈШчЙћдВйзїГЩЙІЃЉЃЌЖјВЛашвЊМЧТМжаМфзДЬЌЃЌИќВЛашвЊеыЖджаМфзДЬЌзїЬиЪтДІРэ
ЪЕЯжЪТЮёЛњжЦЕФМИИіНзЖЮ
УнЕШадЗЂЫЭ
ЩЯЮФЬсЕНЃЌЪЕЯжExactly OnceЕФвЛжжЗНЗЈЪЧШУЯТгЮЯЕЭГОпгаУнЕШДІРэЬиадЃЌЖјдкKafka StreamжаЃЌKafka
PRODUCER БОЩэОЭЪЧЁАЯТгЮЁБЯЕЭГЃЌвђДЫШчЙћФмШУ PRODUCER ОпгаУнЕШДІРэЬиадЃЌФЧОЭПЩвдШУKafka
StreamдквЛЖЈГЬЖШЩЯжЇГжExactly onceгявхЁЃ
ЮЊСЫЪЕЯж PRODUCER ЕФУнЕШгявхЃЌKafkaв§ШыСЫ PRODUCER IDЃЈМДPIDЃЉКЭSequence
NumberЁЃУПИіаТЕФ PRODUCER дкГѕЪМЛЏЕФЪБКђЛсБЛЗжХфвЛИіЮЈвЛЕФPIDЃЌИУPIDЖдгУЛЇЭъШЋЭИУїЖјВЛЛсБЉТЖИјгУЛЇЁЃ
ЖдгкУПИіPIDЃЌИУ PRODUCER ЗЂЫЭЪ§ОнЕФУПИі<Topic, Partition>ЖМЖдгІвЛИіДг0ПЊЪМЕЅЕїЕндіЕФSequence
NumberЁЃ
РрЫЦЕиЃЌBrokerЖЫвВЛсЮЊУПИі<PID, Topic, Partition>ЮЌЛЄвЛИіађКХЃЌВЂЧвУПДЮCommitвЛЬѕЯћЯЂЪБНЋЦфЖдгІађКХЕндіЁЃЖдгкНгЪеЕФУПЬѕЯћЯЂЃЌШчЙћЦфађКХБШBrokerЮЌЛЄЕФађКХЃЈМДзюКѓвЛДЮCommitЕФЯћЯЂЕФађКХЃЉДѓвЛЃЌдђBrokerЛсНгЪмЫќЃЌЗёдђНЋЦфЖЊЦњЃК
1.ШчЙћЯћЯЂађКХБШBrokerЮЌЛЄЕФађКХДѓвЛвдЩЯЃЌЫЕУїжаМфгаЪ§ОнЩаЮДаДШыЃЌвВМДТвађЃЌДЫЪБBrokerОмОјИУЯћЯЂЃЌ PRODUCER ХзГіInvalidSequenceNumber
2.ШчЙћЯћЯЂађКХаЁгкЕШгкBrokerЮЌЛЄЕФађКХЃЌЫЕУїИУЯћЯЂвбБЛБЃДцЃЌМДЮЊжиИДЯћЯЂЃЌBrokerжБНгЖЊЦњИУЯћЯЂЃЌ PRODUCER ХзГіDuplicateSequenceNumber
ЩЯЪіЩшМЦНтОіСЫ0.11.0.0жЎЧААцБОжаЕФСНИіЮЪЬтЃК
1.BrokerБЃДцЯћЯЂКѓЃЌЗЂЫЭACKЧАхДЛњЃЌ PRODUCER ШЯЮЊЯћЯЂЮДЗЂЫЭГЩЙІВЂжиЪдЃЌдьГЩЪ§ОнжиИД
2.ЧАвЛЬѕЯћЯЂЗЂЫЭЪЇАмЃЌКѓвЛЬѕЯћЯЂЗЂЫЭГЩЙІЃЌЧАвЛЬѕЯћЯЂжиЪдКѓГЩЙІЃЌдьГЩЪ§ОнТвађ
ЪТЮёадБЃжЄ
ЩЯЪіУнЕШЩшМЦжЛФмБЃжЄЕЅИі PRODUCER ЖдгкЭЌвЛИі <Topic,
Partition> ЕФ Exactly Once гявхЁЃ
СэЭтЃЌЫќВЂВЛФмБЃжЄаДВйзїЕФдзгадЁЊЁЊМДЖрИіаДВйзїЃЌвЊУДШЋВПБЛCommitвЊУДШЋВПВЛБЛCommitЁЃ
ИќВЛФмБЃжЄЖрИіЖСаДВйзїЕФЕФдзгадЁЃгШЦфЖдгкKafka StreamгІгУЖјбдЃЌЕфаЭЕФВйзїМДЪЧДгФГИіTopicЯћЗбЪ§ОнЃЌОЙ§вЛЯЕСазЊЛЛКѓаДЛиСэвЛИіTopicЃЌБЃжЄДгдДTopicЕФЖСШЁгыЯђФПБъTopicЕФаДШыЕФдзгадгажњгкДгЙЪеЯжаЛжИДЁЃ
ЪТЮёБЃжЄПЩЪЙЕУгІгУГЬађНЋЩњВњЪ§ОнКЭЯћЗбЪ§ОнЕБзївЛИідзгЕЅдЊРДДІРэЃЌвЊУДШЋВПГЩЙІЃЌвЊУДШЋВПЪЇАмЃЌМДЪЙИУЩњВњЛђЯћЗбПчЖрИі<Topic,
Partition>ЁЃ
СэЭтЃЌгазДЬЌЕФгІгУвВПЩвдБЃжЄжиЦєКѓДгЖЯЕуДІМЬајДІРэЃЌвВМДЪТЮёЛжИДЁЃ
ЮЊСЫЪЕЯжетжжаЇЙћЃЌгІгУГЬађБиаыЬсЙЉвЛИіЮШЖЈЕФЃЈжиЦєКѓВЛБфЃЉЮЈвЛЕФIDЃЌвВМДTransaction
IDЁЃTransactin IDгыPIDПЩФмвЛвЛЖдгІЁЃЧјБ№дкгкTransaction IDгЩгУЛЇЬсЙЉЃЌЖјPIDЪЧФкВПЕФЪЕЯжЖдгУЛЇЭИУїЁЃ
СэЭтЃЌЮЊСЫБЃжЄаТЕФ PRODUCER ЦєЖЏКѓЃЌОЩЕФОпгаЯрЭЌ Transaction
IDЕФ PRODUCER МДЪЇаЇЃЌУПДЮ PRODUCER ЭЈЙ§Transaction IDФУЕНPIDЕФЭЌЪБЃЌЛЙЛсЛёШЁвЛИіЕЅЕїЕндіЕФepochЁЃгЩгкОЩЕФ
PRODUCER ЕФ epoch БШаТ PRODUCER ЕФepochаЁЃЌKafkaПЩвдКмШнвзЪЖБ№ГіИУ PRODUCER ЪЧРЯЕФ PRODUCER ВЂОмОјЦфЧыЧѓЁЃ
гаСЫTransaction IDКѓЃЌKafkaПЩБЃжЄЃК
1.ПчSessionЕФЪ§ОнУнЕШЗЂЫЭЁЃЕБОпгаЯрЭЌ Transaction
IDЕФаТЕФ PRODUCER ЪЕР§БЛДДНЈЧвЙЄзїЪБЃЌОЩЕФЧвгЕгаЯрЭЌTransaction IDЕФ PRODUCER НЋВЛдйЙЄзїЁЃ
2.ПчSessionЕФЪТЮёЛжИДЁЃШчЙћФГИігІгУЪЕР§хДЛњЃЌаТЕФЪЕР§ПЩвдБЃжЄШЮКЮЮДЭъГЩЕФОЩЕФЪТЮёвЊУДCommitвЊУДAbortЃЌЪЙЕУаТЪЕР§ДгвЛИіе§ГЃзДЬЌПЊЪМЙЄзїЁЃ
ашвЊзЂвтЕФЪЧЃЌЩЯЪіЕФЪТЮёБЃжЄЪЧДг PRODUCER ЕФНЧЖШШЅПМТЧЕФЁЃДгConsumerЕФНЧЖШРДПДЃЌИУБЃжЄЛсЯрЖдШѕвЛаЉЁЃгШЦфЪЧВЛФмБЃжЄЫљгаБЛФГЪТЮёCommitЙ§ЕФЫљгаЯћЯЂЖМБЛвЛЦ№ЯћЗбЃЌвђЮЊЃК
1.ЖдгкбЙЫѕЕФTopicЖјбдЃЌЭЌвЛЪТЮёЕФФГаЉЯћЯЂПЩФмБЛЦфЫќАцБОИВИЧ
2.ЪТЮёАќКЌЕФЯћЯЂПЩФмЗжВМдкЖрИіSegmentжаЃЈМДЪЙдкЭЌвЛИіPartitionФкЃЉЃЌЕБРЯЕФSegmentБЛЩОГ§ЪБЃЌИУЪТЮёЕФВПЗжЪ§ОнПЩФмЛсЖЊЪЇ
3.ConsumerдквЛИіЪТЮёФкПЩФмЭЈЙ§seekЗНЗЈЗУЮЪШЮвтOffsetЕФЯћЯЂЃЌДгЖјПЩФмЖЊЪЇВПЗжЯћЯЂ
4.ConsumerПЩФмВЂВЛашвЊЯћЗбФГвЛЪТЮёФкЕФЫљгаPartitionЃЌвђДЫЫќНЋгРдЖВЛЛсЖСШЁзщГЩИУЪТЮёЕФЫљгаЯћЯЂ
ЪТЮёЛњжЦдРэ
ЪТЮёадЯћЯЂДЋЕн
етвЛНкЫљЫЕЕФЪТЮёжївЊжИдзгадЃЌвВМД PRODUCER НЋЖрЬѕЯћЯЂзїЮЊвЛИіЪТЮёХњСПЗЂЫЭЃЌвЊУДШЋВПГЩЙІвЊУДШЋВПЪЇАмЁЃ
ЮЊСЫЪЕЯжетвЛЕуЃЌKafka 0.11.0.0в§ШыСЫвЛИіЗўЮёЦїЖЫЕФФЃПщЃЌУћЮЊ Transaction
Coordinator ЃЌгУгкЙмРэ PRODUCER ЗЂЫЭЕФЯћЯЂЕФЪТЮёадЁЃ
ИУ Transaction CoordinatorЮЌЛЄ Transaction LogЃЌИУlogДцгквЛИіФкВПЕФTopicФкЁЃгЩгкTopicЪ§ОнОпгаГжОУадЃЌвђДЫЪТЮёЕФзДЬЌвВОпгаГжОУадЁЃ
PRODUCER ВЂВЛжБНгЖСаД Transaction LogЃЌЫќгы Transaction CoordinatorЭЈаХЃЌШЛКѓгЩTransaction
CoordinatorНЋИУЪТЮёЕФзДЬЌВхШыЯргІЕФ Transaction LogЁЃ
Transaction LogЕФЩшМЦгыOffset LogгУгкБЃДцConsumerЕФOffsetРрЫЦЁЃ
ЪТЮёжаOffsetЕФЬсНЛ
аэЖрЛљгкKafkaЕФгІгУЃЌгШЦфЪЧKafka StreamгІгУжаЭЌЪБАќКЌConsumerКЭ PRODUCER ЃЌЧАепИКд№ДгKafkaжаЛёШЁЯћЯЂЃЌКѓепИКд№НЋДІРэЭъЕФЪ§ОнаДЛиKafkaЕФЦфЫќTopicжаЁЃ
ЮЊСЫЪЕЯжИУГЁОАЯТЕФЪТЮёЕФдзгадЃЌKafkaашвЊБЃжЄЖдConsumer OffsetЕФCommitгы PRODUCER ЖдЗЂЫЭЯћЯЂЕФCommitАќКЌдкЭЌвЛИіЪТЮёжаЁЃЗёдђЃЌШчЙћдкЖўепCommitжаМфЗЂЩњвьГЃЃЌИљОнЖўепCommitЕФЫГађПЩФмЛсдьГЩЪ§ОнЖЊЪЇКЭЪ§ОнжиИДЃК
1.ШчЙћЯШCommit PRODUCER ЗЂЫЭЪ§ОнЕФЪТЮёдйCommit
ConsumerЕФOffsetЃЌМДAt Least OnceгявхЃЌПЩФмдьГЩЪ§ОнжиИДЁЃ
2.ШчЙћЯШCommit ConsumerЕФOffsetЃЌдйCommit
PRODUCER Ъ§ОнЗЂЫЭЪТЮёЃЌМДAt Most OnceгявхЃЌПЩФмдьГЩЪ§ОнЖЊЪЇЁЃ
гУгкЪТЮёЬиадЕФПижЦаЭЯћЯЂ
ЮЊСЫЧјЗжаДШыPartitionЕФЯћЯЂБЛCommitЛЙЪЧAbortЃЌKafkaв§ШыСЫвЛжжЬиЪтРраЭЕФЯћЯЂЃЌМДControl
MessageЁЃИУРрЯћЯЂЕФValueФкВЛАќКЌШЮКЮгІгУЯрЙиЕФЪ§ОнЃЌВЂЧвВЛЛсБЉТЖИјгІгУГЬађЁЃЫќжЛгУгкBrokerгыClientМфЕФФкВПЭЈаХЁЃ
Ждгк PRODUCER ЖЫЪТЮёЃЌKafkaвдControl MessageЕФаЮЪНв§ШывЛЯЕСаЕФ Transaction
MarkerЁЃConsumerМДПЩЭЈЙ§ИУБъМЧХаЖЈЖдгІЕФЯћЯЂБЛCommitСЫЛЙЪЧAbortСЫЃЌШЛКѓНсКЯИУConsumerХфжУЕФИєРыМЖБ№ОіЖЈЪЧЗёгІИУНЋИУЯћЯЂЗЕЛиИјгІгУГЬађЁЃ
ЪТЮёДІРэбљР§ДњТы
| PRODUCER <String,
String> PRODUCER = new Kafka PRODUCER <String,
String>(props);
// ГѕЪМЛЏЪТЮёЃЌАќРЈНсЪјИУ Transaction IDЖдгІЕФЮДЭъГЩЕФЪТЮёЃЈШчЙћгаЃЉ
// БЃжЄаТЕФЪТЮёдквЛИіе§ШЗЕФзДЬЌЯТЦєЖЏ
PRODUCER .init Transactions ();
// ПЊЪМЪТЮё
PRODUCER .begin Transaction ();
// ЯћЗбЪ§Он
ConsumerRecords<String, String> records
= consumer.poll(100);
try{
// ЗЂЫЭЪ§Он
PRODUCER .send(new PRODUCER Record<String,
String>("Topic", "Key",
"Value"));
// ЗЂЫЭЯћЗбЪ§ОнЕФOffsetЃЌНЋЩЯЪіЪ§ОнЯћЗбгыЪ§ОнЗЂЫЭФЩШыЭЌвЛИі Transaction Фк
PRODUCER . sendOffsetsTo Transaction(offsets, "group1");
// Ъ§ОнЗЂЫЭМАOffsetЗЂЫЭОљГЩЙІЕФЧщПіЯТЃЌЬсНЛЪТЮё
PRODUCER .commit Transaction ();
} catch ( PRODUCER FencedException | OutOfOrderSequenceException
| AuthorizationException e) {
// Ъ§ОнЗЂЫЭЛђепOffsetЗЂЫЭГіЯжвьГЃЪБЃЌжежЙЪТЮё
PRODUCER .abort Transaction();
} finally {
// ЙиБе PRODUCER КЭConsumer
PRODUCER .close();
consumer.close();
} |
ЭъећЪТЮёЙ§ГЬ
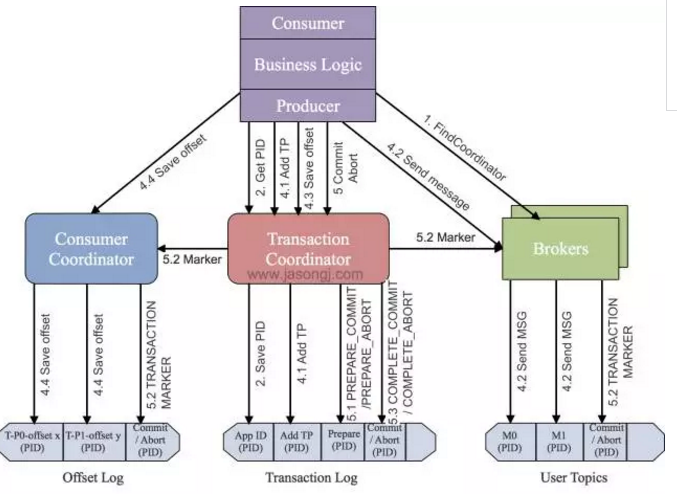
1. евЕН Transaction Coordinator
гЩгк Transaction CoordinatorЪЧЗжХфPIDКЭЙмРэЪТЮёЕФКЫаФЃЌвђДЫ PRODUCER вЊзіЕФЕквЛМўЪТЧщОЭЪЧЭЈЙ§ЯђШЮвтвЛИіBrokerЗЂЫЭFindCoordinatorЧыЧѓевЕН Transaction
CoordinatorЕФЮЛжУЁЃ
зЂвтЃКжЛгагІгУГЬађЮЊ PRODUCER ХфжУСЫ Transaction IDЪБВХПЩЪЙгУЪТЮёЬиадЃЌвВВХашвЊетвЛВНЁЃСэЭтЃЌгЩгкЪТЮёадвЊЧѓ PRODUCER ПЊЦєУнЕШЬиадЃЌвђДЫЭЈЙ§НЋ transactional.idЩшжУЮЊЗЧПеДгЖјПЊЦєЪТЮёЬиадЕФЭЌЪБвВашвЊЭЈЙ§НЋenable.idempotenceЩшжУЮЊtrueРДПЊЦєУнЕШЬиадЁЃ
2. ЛёШЁPID
евЕН Transaction CoordinatorКѓЃЌОпгаУнЕШЬиадЕФ PRODUCER БиаыЗЂЦ№InitPidRequestЧыЧѓвдЛёШЁPIDЁЃ
зЂвтЃКжЛвЊПЊЦєСЫУнЕШЬиадМДБиаыжДааИУВйзїЃЌЖјЮоаыПМТЧИУ PRODUCER ЪЧЗёПЊЦєСЫЪТЮёЬиадЁЃ
ШчЙћЪТЮёЬиадБЛПЊЦєЃЌInitPidRequestЛсЗЂЫЭИј Transaction
Coordinator ЁЃШчЙћ Transaction Coordinator ЪЧЕквЛДЮЪеЕНАќКЌгаИУ
Transaction IDЕФInitPidRequestЧыЧѓЃЌЫќНЋЛсАбИУ<TransactionID,
PID>ДцШы Transaction LogЃЌШчЩЯЭМжаВНжш2.1ЫљЪОЁЃетбљПЩБЃжЄИУЖдгІЙиЯЕБЛГжОУЛЏЃЌДгЖјБЃжЄМДЪЙTransaction
CoordinatorхДЛњИУЖдгІЙиЯЕвВВЛЛсЖЊЪЇЁЃ
Г§СЫЗЕЛиPIDЭтЃЌInitPidRequestЛЙЛсжДааШчЯТШЮЮёЃК
діМгИУPIDЖдгІЕФepochЁЃОпгаЯрЭЌPIDЕЋepochаЁгкИУepochЕФЦфЫќ PRODUCER ЃЈШчЙћгаЃЉаТПЊЦєЕФЪТЮёНЋБЛОмОјЁЃ
ЛжИДЃЈCommitЛђAbortЃЉжЎЧАЕФ PRODUCER ЮДЭъГЩЕФЪТЮёЃЈШчЙћгаЃЉЁЃ
зЂвтЃКInitPidRequestЕФДІРэЙ§ГЬЪЧЭЌВНзшШћЕФЁЃвЛЕЉИУЕїгУе§ШЗЗЕЛиЃЌ PRODUCER МДПЩПЊЪМаТЕФЪТЮёЁЃ
СэЭтЃЌШчЙћЪТЮёЬиадЮДПЊЦєЃЌInitPidRequestПЩЗЂЫЭжСШЮвтBrokerЃЌВЂЧвЛсЕУЕНвЛИіШЋаТЕФЮЈвЛЕФPIDЁЃИУ PRODUCER НЋжЛФмЪЙгУУнЕШЬиадвдМАЕЅвЛSessionФкЕФЪТЮёЬиадЃЌЖјВЛФмЪЙгУПчSessionЕФЪТЮёЬиадЁЃ
3. ПЊЦєЪТЮё
KafkaДг0.11.0.0АцБОПЊЪМЃЌЬсЙЉ beginTransaction() ЗНЗЈгУгкПЊЦєвЛИіЪТЮёЁЃЕїгУИУЗНЗЈКѓЃЌ PRODUCER БОЕиЛсМЧТМвбОПЊЦєСЫЪТЮёЃЌЕЋTransaction
CoordinatorжЛгадк PRODUCER ЗЂЫЭЕквЛЬѕЯћЯЂКѓВХШЯЮЊЪТЮёвбОПЊЦєЁЃ
4. Consume-Transform-Produce
етвЛНзЖЮЃЌАќКЌСЫећИіЪТЮёЕФЪ§ОнДІРэЙ§ГЬЃЌВЂЧвАќКЌСЫЖржжЧыЧѓЁЃ
AddPartitionsToTxnRequest
вЛИі PRODUCER ПЩФмЛсИјЖрИі<Topic, Partition>ЗЂЫЭЪ§ОнЃЌИјвЛИіаТЕФ<Topic,
Partition>ЗЂЫЭЪ§ОнЧАЃЌЫќашвЊЯШЯђ Transaction CoordinatorЗЂЫЭAddPartitionsToTxnRequestЁЃ
Transaction CoordinatorЛсНЋИУ< Transaction , Topic,
Partition>Дцгк Transaction LogФкЃЌВЂНЋЦфзДЬЌжУЮЊBEGINЃЌШчЩЯЭМжаВНжш4.1ЫљЪОЁЃгаСЫИУаХЯЂКѓЃЌЮвУЧВХПЩвддкКѓајВНжшжаЮЊУПИіTopic,
Partition>ЩшжУCOMMITЛђепABORTБъМЧЃЈШчЩЯЭМжаВНжш5.2ЫљЪОЃЉЁЃ
СэЭтЃЌШчЙћИУ<Topic, Partition>ЮЊИУЪТЮёжаЕквЛИі<Topic,
Partition>ЃЌ Transaction CoordinatorЛЙЛсЦєЖЏЖдИУЪТЮёЕФМЦЪБЃЈУПИіЪТЮёЖМгаздМКЕФГЌЪБЪБМфЃЉЁЃ
PRODUCER equest
PRODUCER ЭЈЙ§вЛИіЛђЖрИі PRODUCER equestЗЂЫЭвЛЯЕСаЯћЯЂЁЃГ§СЫгІгУЪ§ОнЭтЃЌИУЧыЧѓЛЙАќКЌСЫPIDЃЌepochЃЌКЭSequence
NumberЁЃИУЙ§ГЬШчЩЯЭМжаВНжш4.2ЫљЪОЁЃ
AddOffsetsToTxnRequest
ЮЊСЫЬсЙЉЪТЮёадЃЌ PRODUCER аТдіСЫsendOffsetsTo TransactionЗНЗЈЃЌИУЗНЗЈНЋЖрзщЯћЯЂЕФЗЂЫЭКЭЯћЗбЗХШыЭЌвЛХњДІРэФкЁЃ
ИУЗНЗЈЯШХаЖЯдкЕБЧАЪТЮёжаИУЗНЗЈЪЧЗёвбОБЛЕїгУВЂДЋШыСЫЯрЭЌЕФGroup IDЁЃШєЪЧЃЌжБНгЬјЕНЯТвЛВНЃЛШєВЛЪЧЃЌдђЯђ Transaction
CoordinatorЗЂЫЭAddOffsetsToTxnRequestsЧыЧѓЃЌTransaction
CoordinatorНЋЖдгІЕФЫљга<Topic, Partition>ДцгкTransaction
LogжаЃЌВЂНЋЦфзДЬЌМЧЮЊBEGINЃЌШчЩЯЭМжаВНжш4.3ЫљЪОЁЃИУЗНЗЈЛсзшШћжБЕНЪеЕНЯьгІЁЃ
TxnOffsetCommitRequest
зїЮЊsendOffsetsToTransactionЗНЗЈЕФвЛВПЗжЃЌдкДІРэЭъAddOffsetsToTxnRequestКѓЃЌ PRODUCER вВЛсЗЂЫЭTxnOffsetCommitЧыЧѓИјConsumer
CoordinatorДгЖјНЋБОЪТЮёАќКЌЕФгыЖСВйзїЯрЙиЕФИї<Topic, Partition>ЕФOffsetГжОУЛЏЕНФкВПЕФ__consumer_offsetsжаЃЌШчЩЯЭМВНжш4.4ЫљЪОЁЃ
дкДЫЙ§ГЬжаЃЌConsumer CoordinatorЛсЭЈЙ§PIDКЭЖдгІЕФepochРДбщжЄЪЧЗёгІИУдЪаэИУ PRODUCER ЕФИУЧыЧѓЁЃ
етРяашвЊзЂвтЃК
аДШы__consumer_offsetsЕФOffsetаХЯЂдкЕБЧАЪТЮёCommitЧАЖдЭтЪЧВЛПЩМћЕФЁЃвВМДдкЕБЧАЪТЮёБЛCommitЧАЃЌПЩШЯЮЊИУOffsetЩаЮДCommitЃЌвВМДЖдгІЕФЯћЯЂЩаЮДБЛЭъГЩДІРэЁЃ
Consumer CoordinatorВЂВЛЛсСЂМДИќаТЛКДцжаЯргІ<Topic, Partition>ЕФOffsetЃЌвђЮЊДЫЪБетаЉИќаТВйзїЩаЮДБЛCOMMITЛђABORTЁЃ
5. CommitЛђAbortЪТЮё
вЛЕЉЩЯЪіЪ§ОнаДШыВйзїЭъГЩЃЌгІгУГЬађБиаыЕїгУ Kafka PRODUCER ЕФ commitTransaction ЗНЗЈЛђепabortTransactionЗНЗЈвдНсЪјЕБЧАЪТЮёЁЃ
EndTxnRequest
commitTransactionЗНЗЈЪЙЕУ PRODUCER аДШыЕФЪ§ОнЖдЯТгЮ Consumer ПЩМћЁЃabortTransaction ЗНЗЈЭЈЙ§Transaction
MarkerНЋ PRODUCER аДШыЕФЪ§ОнБъМЧЮЊAbortedзДЬЌЁЃЯТгЮЕФConsumerШчЙћНЋisolation.levelЩшжУЮЊREAD_COMMITTEDЃЌдђЫќЖСЕНБЛAbortЕФЯћЯЂКѓжБНгНЋЦфЖЊЦњЖјВЛЛсЗЕЛиИјПЭЛЇГЬађЃЌвВМДБЛAbortЕФЯћЯЂЖдгІгУГЬађВЛПЩМћЁЃ
ЮоТлЪЧCommitЛЙЪЧAbortЃЌ PRODUCER ЖМЛсЗЂЫЭEndTxnRequestЧыЧѓИј Transaction
CoordinatorЃЌВЂЭЈЙ§БъжОЮЛБъЪЖЪЧгІИУCommitЛЙЪЧAbortЁЃ
ЪеЕНИУЧыЧѓКѓЃЌTransaction CoordinatorЛсНјааШчЯТВйзї
1.НЋPREPARE_COMMITЛђPREPARE_ABORTЯћЯЂаДШы Transaction
LogЃЌШчЩЯЭМжаВНжш5.1ЫљЪО
2.ЭЈЙ§WriteTxnMarkerЧыЧѓвд Transaction
MarkerЕФаЮЪННЋCOMMITЛђABORTаХЯЂаДШыгУЛЇЪ§ОнШежОвдМАOffset LogжаЃЌШчЩЯЭМжаВНжш5.2ЫљЪО
3.зюКѓНЋCOMPLETE_COMMITЛђCOMPLETE_ABORTаХЯЂаДШы Transaction
LogжаЃЌШчЩЯЭМжаВНжш5.3ЫљЪО
ВЙГфЫЕУїЃКЖдгкcommit TransactionЗНЗЈЃЌЫќЛсдкЗЂЫЭEndTxnRequestжЎЧАЯШЕїгУflushЗНЗЈвдШЗБЃЫљгаЗЂЫЭГіШЅЕФЪ§ОнЖМЕУЕНЯргІЕФACKЁЃЖдгкabortTransactionЗНЗЈЃЌдкЗЂЫЭEndTxnRequestжЎЧАжБНгНЋЕБЧАBufferжаЕФЪТЮёадЯћЯЂЃЈШчЙћгаЃЉШЋВПЖЊЦњЃЌЕЋБиаыЕШД§ЫљгаБЛЗЂЫЭЕЋЩаЮДЪеЕНACKЕФЯћЯЂЗЂЫЭЭъГЩЁЃ
ЩЯЪіЕкЖўВНЪЧЪЕЯжНЋвЛзщЖСВйзїгыаДВйзїзїЮЊвЛИіЪТЮёДІРэЕФЙиМќЁЃвђЮЊ PRODUCER аДШыЕФЪ§ОнTopicвдМАМЧТМComsumer
OffsetЕФTopicЛсБЛаДШыЯрЭЌЕФTransactin MarkerЃЌЫљвдетвЛзщЖСВйзїгыаДВйзївЊУДШЋВПCOMMITвЊУДШЋВПABORTЁЃ
WriteTxnMarkerRequest
ЩЯУцЬсЕНЕФWriteTxnMarkerRequestгЩ Transaction CoordinatorЗЂЫЭИјЕБЧАЪТЮёЩцМАЕНЕФУПИі<Topic,
Partition>ЕФLeaderЁЃЪеЕНИУЧыЧѓКѓЃЌЖдгІЕФLeaderЛсНЋЖдгІЕФCOMMIT(PID)ЛђепABORT(PID)ПижЦаХЯЂаДШыШежОЃЌШчЩЯЭМжаВНжш5.2ЫљЪОЁЃ
ИУПижЦЯћЯЂЯђBrokerвдМАConsumerБэУїЖдгІPIDЕФЯћЯЂБЛCommitСЫЛЙЪЧБЛAbortСЫЁЃ
етРявЊзЂвтЃЌШчЙћЪТЮёвВЩцМАЕН__consumer_offsetsЃЌМДИУЪТЮёжагаЯћЗбЪ§ОнЕФВйзїЧвНЋИУЯћЗбЕФOffsetДцгк__consumer_offsetsжаЃЌTransaction
CoordinatorвВашвЊЯђИУФкВПTopicЕФИїPartitionЕФLeaderЗЂЫЭWriteTxnMarkerRequestДгЖјаДШыCOMMIT(PID)ЛђCOMMIT(PID)ПижЦаХЯЂЁЃ
аДШызюжеЕФCOMPLETE_COMMITЛђCOMPLETE_ABORTЯћЯЂ
аДЭъЫљгаЕФ Transaction MarkerКѓЃЌTransaction CoordinatorЛсНЋзюжеЕФCOMPLETE_COMMITЛђCOMPLETE_ABORTЯћЯЂаДШыTransaction
LogжавдБъУїИУЪТЮёНсЪјЃЌШчЩЯЭМжаВНжш5.3ЫљЪОЁЃ
ДЫЪБЃЌTransaction LogжаЫљгаЙигкИУЪТЮёЕФЯћЯЂШЋВППЩвдвЦГ§ЁЃЕБШЛЃЌгЩгкKafkaФкЪ§ОнЪЧAppend
OnlyЕФЃЌВЛПЩжБНгИќаТКЭЩОГ§ЃЌетРяЫЕЕФвЦГ§жЛЪЧНЋЦфБъМЧЮЊnullДгЖјдкLog CompactЪБВЛдйБЃСєЁЃ
СэЭтЃЌCOMPLETE_COMMITЛђCOMPLETE_ABORTЕФаДШыВЂВЛашвЊЕУЕНЫљгаRreplicaЕФACKЃЌвђЮЊШчЙћИУЯћЯЂЖЊЪЇЃЌПЩвдИљОнЪТЮёавщжиЗЂЁЃ
ВЙГфЫЕУїЃЌШчЙћВЮгыИУЪТЮёЕФФГаЉ<Topic, Partition>дкБЛаДШы Transaction
MarkerЧАВЛПЩгУЃЌЫќЖдREAD_COMMITTEDЕФConsumerВЛПЩМћЃЌЕЋВЛгАЯьЦфЫќПЩгУ<Topic,
Partition>ЕФCOMMITЛђABORTЁЃдкИУ<Topic, Partition>ЛжИДПЩгУКѓЃЌTransaction
CoordinatorЛсжиаТИљОнPREPARE_COMMITЛђPREPARE_ABORTЯђИУ<Topic,
Partition>ЗЂЫЭ Transaction MarkerЁЃ
змНс
1.PIDгыSequence NumberЕФв§ШыЪЕЯжСЫаДВйзїЕФУнЕШад
2.аДВйзїЕФУнЕШадНсКЯAt Least OnceгявхЪЕЯжСЫЕЅвЛSessionФкЕФExactly
Onceгявх
3.Transaction MarkerгыPIDЬсЙЉСЫЪЖБ№ЯћЯЂЪЧЗёгІИУБЛЖСШЁЕФФмСІЃЌДгЖјЪЕЯжСЫЪТЮёЕФИєРыад
4.OffsetЕФИќаТБъМЧСЫЯћЯЂЪЧЗёБЛЖСШЁЃЌДгЖјНЋЖдЖСВйзїЕФЪТЮёДІРэзЊЛЛГЩСЫЖдаДЃЈOffsetЃЉВйзїЕФЪТЮёДІРэ
5.KafkaЪТЮёЕФБОжЪЪЧЃЌНЋвЛзщаДВйзїЃЈШчЙћгаЃЉЖдгІЕФЯћЯЂгывЛзщЖСВйзїЃЈШчЙћгаЃЉЖдгІЕФOffsetЕФИќаТНјааЭЌбљЕФБъМЧЃЈМДTransaction
MarkerЃЉРДЪЕЯжЪТЮёжаЩцМАЕФЫљгаЖСаДВйзїЭЌЪБЖдЭтПЩМћЛђЭЌЪБЖдЭтВЛПЩМћ
6.KafkaжЛЬсЙЉЖдKafkaБОЩэЕФЖСаДВйзїЕФЪТЮёадЃЌВЛЬсЙЉАќКЌЭтВПЯЕЭГЕФЪТЮёад
ExceptionДІРэ
Invalid PRODUCER Epoch
етЪЧвЛжжFatal ErrorЃЌЫќЫЕУїЕБЧА PRODUCER ЪЧвЛИіЙ§ЦкЕФЪЕР§ЃЌгаTransaction
IDЯрЭЌЕЋepochИќаТЕФ PRODUCER ЪЕР§БЛДДНЈВЂЪЙгУЁЃДЫЪБ PRODUCER ЛсЭЃжЙВЂХзГіExceptionЁЃ
InvalidPidMapping
Transaction CoordinatorУЛгагыИУ Transaction IDЖдгІЕФPIDЁЃДЫЪБ PRODUCER ЛсЭЈЙ§АќКЌгаTransaction
IDЕФInitPidRequestЧыЧѓДДНЈвЛИіаТЕФPIDЁЃ
NotCorrdinatorForGTransactionalId
ИУTransaction CoordinatorВЛИКд№ИУЕБЧАЪТЮёЁЃ PRODUCER ЛсЭЈЙ§FindCoordinatorRequestЧыЧѓжиаТбАевЖдгІЕФTransaction
CoordinatorЁЃ
InvalidTxnRequest
ЮЅЗДСЫЪТЮёавщЁЃе§ШЗЕФClientЪЕЯжВЛгІИУГіЯжетжжExceptionЁЃШчЙћИУвьГЃЗЂЩњСЫЃЌгУЛЇашвЊМьВщздМКЕФПЭЛЇЖЫЪЕЯжЪЧЗёгаЮЪЬтЁЃ
CoordinatorNotAvailable
Transaction CoordinatorШддкГѕЪМЛЏжаЁЃ PRODUCER жЛашвЊжиЪдМДПЩЁЃ
DuplicateSequenceNumber
ЗЂЫЭЕФЯћЯЂЕФађКХЕЭгкBrokerдЄЦкЁЃИУвьГЃЫЕУїИУЯћЯЂвбОБЛГЩЙІДІРэЙ§ЃЌ PRODUCER ПЩвджБНгКіТдИУвьГЃВЂДІРэЯТвЛЬѕЯћЯЂ
InvalidSequenceNumber
етЪЧвЛИіFatal ErrorЃЌЫќЫЕУїЗЂЫЭЕФЯћЯЂжаЕФађКХДѓгкBrokerдЄЦкЁЃДЫЪБгаСНжжПЩФм
Ъ§ОнТвађЁЃБШШчЧАУцЕФЯћЯЂЗЂЫЭЪЇАмКѓжиЪдЦкМфЃЌаТЕФЯћЯЂБЛНгЪеЁЃе§ГЃЧщПіЯТВЛгІИУГіЯжИУЮЪЬтЃЌвђЮЊЕБУнЕШЗЂЫЭЦєгУЪБЃЌmax.inflight.requests.per.connectionБЛЧПжЦЩшжУЮЊ1ЃЌЖјacksБЛЧПжЦЩшжУЮЊallЁЃЙЪЧАУцЯћЯЂжиЪдЦкМфЃЌКѓајЯћЯЂВЛЛсБЛЗЂЫЭЃЌвВМДВЛЛсЗЂЩњТвађЁЃВЂЧвжЛгаISRжаЫљгаReplicaЖМACKЃЌ PRODUCER ВХЛсШЯЮЊЯћЯЂвбОБЛЗЂЫЭЃЌвВМДВЛДцдкBrokerЖЫЪ§ОнЖЊЪЇЮЪЬтЁЃ
ЗўЮёЦїгЩгкШежОБЛTruncateЖјдьГЩЪ§ОнЖЊЪЇЁЃДЫЪБгІИУЭЃжЙ PRODUCER ВЂНЋДЫFatal ErrorБЈИцИјгУЛЇЁЃ
InvalidTransactionTimeout
InitPidRequestЕїгУГіЯжЕФFatal ErrorЁЃЫќБэУї PRODUCER ДЋШыЕФtimeoutЪБМфВЛдкПЩНгЪмЗЖЮЇФкЃЌгІИУЭЃжЙ PRODUCER ВЂБЈИцИјгУЛЇЁЃ
ДІРэTransaction CoordinatorЪЇАм
аДPREPARE_COMMIT/PREPARE_ABORTЧАЪЇАм
PRODUCER ЭЈЙ§FindCoordinatorRequestевЕНаТЕФTransaction CoordinatorЃЌВЂЭЈЙ§EndTxnRequestЧыЧѓЗЂЦ№COMMITЛђABORTСїГЬЃЌаТЕФTransaction
CoordinatorМЬајДІРэEndTxnRequestЧыЧѓЁЊЁЊаДPREPARE_COMMITЛђPREPARE_ABORTЃЌаДTransaction
MarkerЃЌаДCOMPLETE_COMMITЛђCOMPLETE_ABORTЁЃ
аДЭъPREPARE_COMMIT/PREPARE_ABORTКѓЪЇАм
ДЫЪБОЩЕФTransaction CoordinatorПЩФмвбОГЩЙІаДШыВПЗжTransaction MarkerЁЃаТЕФTransaction
CoordinatorЛсжиИДетаЉВйзїЃЌЫљвдВПЗжPartitionжаПЩФмЛсДцдкжиИДЕФCOMMITЛђABORTЃЌЕЋжЛвЊИУ PRODUCER дкДЫЦкМфУЛгаЗЂЦ№аТЕФЪТЮёЃЌетаЉжиИДЕФTransaction
MarkerОЭВЛЪЧЮЪЬтЁЃ
аДЭъCOMPLETE_COMMIT/ABORTКѓЪЇАм
ОЩЕФTransaction CoordinatorПЩФмвбОаДЭъСЫCOMPLETE_COMMITЛђCOMPLETE_ABORTЕЋдкЗЕЛиEndTxnRequestжЎЧАЪЇАмЁЃИУГЁОАЯТЃЌаТЕФTransaction
CoordinatorЛсжБНгИј PRODUCER ЗЕЛиГЩЙІЁЃ
ЪТЮёЙ§ЦкЛњжЦ
ЪТЮёГЌЪБ
transaction.timeout.ms
жежЙЙ§ЦкЪТЮё
ЕБ PRODUCER ЪЇАмЪБЃЌTransaction CoordinatorБиаыФмЙЛжїЖЏЕФШУФГаЉНјаажаЕФЪТЮёЙ§ЦкЁЃЗёдђУЛга PRODUCER ЕФВЮгыЃЌTransaction
CoordinatorЮоЗЈХаЖЯетаЉЪТЮёгІИУШчКЮДІРэЃЌетЛсдьГЩЃК
1.ШчЙћетжжНјаажаЪТЮёЬЋЖрЃЌЛсдьГЩTransaction CoordinatorашвЊЮЌЛЄДѓСПЕФЪТЮёзДЬЌЃЌДѓСПеМгУФкДц
2.Transaction LogФквВЛсДцдкДѓСПЪ§ОнЃЌдьГЩаТЕФTransaction
CoordinatorЦєЖЏЛКТ§
3.READ_COMMITTEDЕФConsumerашвЊЛКДцДѓСПЕФЯћЯЂЃЌдьГЩВЛБивЊЕФФкДцРЫЗбЩѕжСЪЧOOM
ШчЙћЖрИіTransaction IDВЛЭЌЕФ PRODUCER НЛВцаДЭЌвЛИіPartitionЃЌЕБвЛИі PRODUCER ЕФЪТЮёзДЬЌВЛИќаТЪБЃЌREAD_COMMITTEDЕФConsumerЮЊСЫБЃжЄЫГађЯћЗбЖјБЛзшШћ
5.ЮЊСЫБмУтЩЯЪіЮЪЬтЃЌTransaction CoordinatorЛсжмЦкадБщРњФкДцжаЕФЪТЮёзДЬЌMapЃЌВЂжДааШчЯТВйзї
1.ШчЙћзДЬЌЪЧBEGINВЂЧвЦфзюКѓИќаТЪБМфгыЕБЧАЪБМфВюДѓгкtransaction.remove.expired.transaction.cleanup.interval.msЃЈФЌШЯжЕЮЊ1аЁЪБЃЉЃЌдђжїЖЏНЋЦфжежЙЃК1ЃЉЮДБмУтд PRODUCER СйЪБЛжИДгыЕБЧАжежЙСїГЬГхЭЛЃЌдіМгИУ PRODUCER ЖдгІЕФPIDЕФepochЃЌВЂШЗБЃНЋИУИќаТЕФаХЯЂаДШыTransaction
LogЃЛ2ЃЉвдИќаТКѓЕФepochЛиЙіЪТЮёЃЌДгЖјЪЙЕУИУЪТЮёЯрЙиЕФЫљгаBrokerЖМИќаТЦфЛКДцЕФИУPIDЕФepochДгЖјОмОјОЩ PRODUCER ЕФаДВйзї
2.ШчЙћзДЬЌЪЧPREPARE_COMMITЃЌЭъГЩКѓајЕФCOMMITСїГЬЁЊЁЊЁЊЁЊЯђИї<Topic,
Partition>аДШыTransaction MarkerЃЌдкTransaction LogФкаДШыCOMPLETE_COMMIT
3.ШчЙћзДЬЌЪЧPREPARE_ABORTЃЌЭъГЩКѓајABORTСїГЬ
жежЙTransaction ID
ФГTransaction IDЕФ PRODUCER ПЩФмКмГЄЪБМфВЛдйЗЂЫЭЪ§ОнЃЌTransaction CoordinatorУЛБивЊдйБЃДцИУTransaction
IDгыPIDЕШЕФгГЩфЃЌЗёдђПЩФмЛсдьГЩДѓСПЕФзЪдДРЫЗбЁЃвђДЫашвЊгавЛИіЛњжЦЬНВтВЛдйЛюдОЕФTransaction
IDВЂНЋЦфаХЯЂЩОГ§ЁЃ
Transaction CoordinatorЛсжмЦкадБщРњФкДцжаЕФTransaction IDгыPIDгГЩфЃЌШчЙћФГTransaction
IDУЛгаЖдгІЕФе§дкНјаажаЕФЪТЮёВЂЧвЫќЖдгІЕФзюКѓвЛИіЪТЮёЕФНсЪјЪБМфгыЕБЧАЪБМфВюДѓгкtransactional.id.expiration.msЃЈФЌШЯжЕЪЧ7ЬьЃЉЃЌдђНЋЦфДгФкДцжаЩОç€дкTransaction
LogжаНЋЦфЖдгІЕФШежОЕФжЕЩшжУЮЊnullДгЖјЪЙЕУLog CompactПЩНЋЦфМЧТМЩОГ§ЁЃ
гыЦфЫќЯЕЭГЪТЮёЛњжЦЖдБШ
PostgreSQL MVCC
KafkaЕФЪТЮёЛњжЦгыЁЖMVCC PostgreSQLЪЕЯжЪТЮёКЭЖрАцБОВЂЗЂПижЦЕФОЋЛЊЁЗвЛЮФжаНщЩмЕФPostgreSQLЭЈЙ§MVCCЪЕЯжЪТЮёЕФЛњжЦЗЧГЃРрЫЦЃЌЖдгкЪТЮёЕФЛиЙіЃЌВЂВЛашвЊЩОГ§вбаДШыЕФЪ§ОнЃЌЖМЪЧНЋаДШыЪ§ОнЕФЪТЮёБъМЧЮЊRollback/AbortДгЖјдкЖСЪ§ОнЪБЙ§ТЫИУЪ§ОнЁЃ
СННзЖЮЬсНЛ
KafkaЕФЪТЮёЛњжЦгыЁЖЗжВМЪНЪТЮёЃЈвЛЃЉСННзЖЮЬсНЛМАJTAЁЗвЛЮФжаЫљНщЩмЕФСННзЖЮЬсНЛЛњжЦПДЫЦЯрЫЦЃЌЖМЗжPREPAREНзЖЮКЭзюжеCOMMITНзЖЮЃЌЕЋгжгаКмДѓВЛЭЌ
1.KafkaЪТЮёЛњжЦжаЃЌPREPAREЪБМДвЊжИУїЪЧPREPARE_COMMITЛЙЪЧPREPARE_ABORTЃЌВЂЧвжЛаыдкTransaction
LogжаБъМЧМДПЩЃЌЮоаыЦфЫќзщМўВЮгыЁЃЖјСННзЖЮЬсНЛЕФPREPAREашвЊЗЂЫЭИјЫљгаЕФЗжВМЪНЪТЮёВЮгыЗНЃЌВЂЧвЪТЮёВЮгыЗНашвЊОЁПЩФмзМБИКУЃЌВЂИљОнзМБИЧщПіЗЕЛиPreparedЛђNon-PreparedзДЬЌИјЪТЮёЙмРэЦїЁЃ
2.KafkaЪТЮёжаЃЌвЛЕЋЗЂЦ№PREPARE_COMMITЛђPREPARE_ABORTЃЌдђШЗЖЈИУЪТЮёзюжеЕФНсЙћгІИУЪЧБЛCOMMITЛђABORTЁЃЖјЗжВМЪНЪТЮёжаЃЌPREPAREКѓгЩИїЪТЮёВЮгыЗНЗЕЛизДЬЌЃЌжЛгаЫљгаВЮгыЗНОљЗЕЛиPreparedзДЬЌВХЛсеце§жДааCOMMITЃЌЗёдђжДааROLLBACK
3.KafkaЪТЮёЛњжЦжаЃЌФГМИИіPartitionдкCOMMITЛђABORTЙ§ГЬжаБфЮЊВЛПЩгУЃЌжЛгАЯьИУPartitionВЛгАЯьЦфЫќPartitionЁЃСННзЖЮЬсНЛжаЃЌШєЮЈвЛЪеЕНCOMMITУќСюВЮгыепCrashЃЌЦфЫќЪТЮёВЮгыЗНЮоЗЈХаЖЯЪТЮёзДЬЌДгЖјЪЙЕУећИіЪТЮёзшШћ
4.KafkaЪТЮёЛњжЦв§ШыЪТЮёГЌЪБЛњжЦЃЌгааЇБмУтСЫЙвЦ№ЕФЪТЮёгАЯьЦфЫќЪТЮёЕФЮЪЬт
5.KafkaЪТЮёЛњжЦжаДцдкЖрИіTransaction CoordinatorЪЕР§ЃЌЖјЗжВМЪНЪТЮёжажЛгавЛИіЪТЮёЙмРэЦї
Zookeeper
ZookeeperЕФдзгЙуВЅавщгыСННзЖЮЬсНЛвдМАKafkaЪТЮёЛњжЦгаЯрЫЦжЎДІЃЌЕЋгжгаИїздЕФЬиЕу
1.KafkaЪТЮёПЩCOMMITвВПЩABORTЁЃЖјZookeeperдзгЙуВЅавщжЛгаCOMMITУЛгаABORTЁЃЕБШЛЃЌZookeeperВЛCOMMITФГЯћЯЂвВМДЕШаЇгкABORTИУЯћЯЂЕФИќаТЁЃ
2.KafkaДцдкЖрИіTransaction CoordinatorЪЕР§ЃЌРЉеЙадНЯКУЁЃЖјZookeeperаДВйзїжЛФмдкLeaderНкЕуНјааЃЌЫљвдЦфаДадФмдЖЕЭгкЖСадФмЁЃ
3.KafkaЪТЮёЪЧCOMMITЛЙЪЧABORTЭъШЋШЁОігк PRODUCER МДПЭЛЇЖЫЁЃЖјZookeeperдзгЙуВЅавщжаФГЬѕЯћЯЂЪЧЗёБЛCOMMITШЁОігкЪЧЗёгавЛДѓАыFOLLOWER
ACKИУЯћЯЂЁЃ
|









