ЧАбд
дкWeTestгпЧщЯюФПжаЃЌашвЊЖдУПЬьЧЇЭђМЖЕФгЮЯЗЦРТлаХЯЂНјааДЪЦЕЭГМЦЃЌдкЩњВњепвЛЖЫЃЌЮвУЧНЋЪ§ОнАДееУПЬьЕФРШЁЪБМфДцШыСЫKafkaЕБжаЃЌЖјдкЯћЗбепвЛЖЫЃЌЮвУЧРћгУСЫspark streamingДгkafkaжаВЛЖЯРШЁЪ§ОнНјааДЪЦЕЭГМЦЁЃБОЮФЪзЯШЖдspark streamingЧЖШыkafkaЕФЗНЪННјааЙщФЩзмНсЃЌжЎКѓМђЕЅВћЪіSpark streaming+kafkaдкгпЧщЯюФПжаЕФгІгУЃЌзюКѓНЋздМКдкSpark Streaming+kafkaЕФЪЕМЪгХЛЏжаЕФвЛаЉОбщНјааЙщФЩзмНсЁЃЃЈШчгаШЮКЮчЂТЉЛЖгВЙГфРДВШЃЌЮвЛсЕквЛЪБМфИФе§^v^ЃЉ
Spark streamingНгЪеKafkaЪ§Он
гУspark streamingСїЪНДІРэkafkaжаЕФЪ§ОнЃЌЕквЛВНЕБШЛЪЧЯШАбЪ§ОнНгЪеЙ§РДЃЌзЊЛЛЮЊspark streamingжаЕФЪ§ОнНсЙЙDstreamЁЃНгЪеЪ§ОнЕФЗНЪНгаСНжжЃК1.РћгУReceiverНгЪеЪ§ОнЃЌ2.жБНгДгkafkaЖСШЁЪ§ОнЁЃ
ЛљгкReceiverЕФЗНЪН
етжжЗНЪНРћгУНгЪеЦїЃЈReceiverЃЉРДНгЪеkafkaжаЕФЪ§ОнЃЌЦфзюЛљБОЪЧЪЙгУKafkaИпНзгУЛЇAPIНгПкЁЃЖдгкЫљгаЕФНгЪеЦїЃЌДгkafkaНгЪеРДЕФЪ§ОнЛсДцДЂдкsparkЕФexecutorжаЃЌжЎКѓspark streamingЬсНЛЕФjobЛсДІРэетаЉЪ§ОнЁЃШчЯТЭМЃК
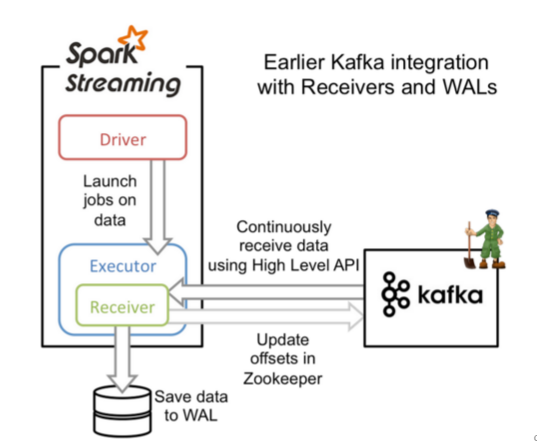
дкЪЙгУЪБЃЌЮвУЧашвЊЬэМгЯргІЕФвРРЕАќЃК
| <dependency><!-- Spark Streaming Kafka --> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.6.3</version> </dependency> |
ЖјЖдгкScalaЕФЛљБОЪЙгУЗНЪНШчЯТЃК
| import org.apache.spark.streaming.kafka._ val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume]) |
ЛЙгаМИИіашвЊзЂвтЕФЕуЃК
- дкReceiverЕФЗНЪНжаЃЌSparkжаЕФpartitionКЭkafkaжаЕФpartitionВЂВЛЪЧЯрЙиЕФЃЌЫљвдШчЙћЮвУЧМгДѓУПИіtopicЕФpartitionЪ§СПЃЌНіНіЪЧдіМгЯпГЬРДДІРэгЩЕЅвЛReceiverЯћЗбЕФжїЬтЁЃЕЋЪЧетВЂУЛгадіМгSparkдкДІРэЪ§ОнЩЯЕФВЂааЖШЁЃ
- ЖдгкВЛЭЌЕФGroupКЭtopicЮвУЧПЩвдЪЙгУЖрИіReceiverДДНЈВЛЭЌЕФDstreamРДВЂааНгЪеЪ§ОнЃЌжЎКѓПЩвдРћгУunionРДЭГвЛГЩвЛИіDstreamЁЃ
- ШчЙћЮвУЧЦєгУСЫWrite Ahead LogsИДжЦЕНЮФМўЯЕЭГШчHDFSЃЌФЧУДstorage levelашвЊЩшжУГЩ StorageLevel.MEMORY_AND_DISK_SERЃЌвВОЭЪЧKafkaUtils.createStream(..., StorageLevel.MEMORY_AND_DISK_SER)
жБНгЖСШЁЗНЪН
дкspark1.3жЎКѓЃЌв§ШыСЫDirectЗНЪНЁЃВЛЭЌгкReceiverЕФЗНЪНЃЌDirectЗНЪНУЛгаreceiverетвЛВуЃЌЦфЛсжмЦкадЕФЛёШЁKafkaжаУПИіtopicЕФУПИіpartitionжаЕФзюаТoffsetsЃЌжЎКѓИљОнЩшЖЈЕФmaxRatePerPartitionРДДІРэУПИіbatchЁЃЦфаЮЪНШчЯТЭМЃК
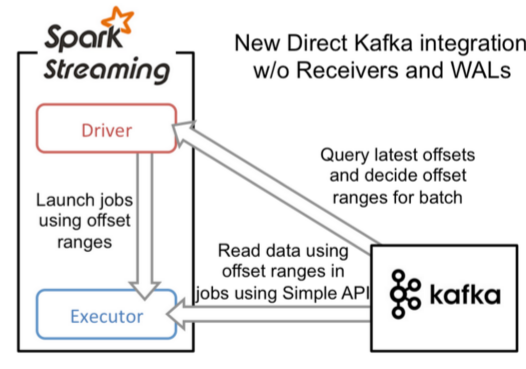
етжжЗНЗЈЯрНЯгкReceiverЗНЪНЕФгХЪЦдкгкЃК
- МђЛЏЕФВЂааЃКдкReceiverЕФЗНЪНжаЮвУЧЬсЕНДДНЈЖрИіReceiverжЎКѓРћгУunionРДКЯВЂГЩвЛИіDstreamЕФЗНЪНЬсИпЪ§ОнДЋЪфВЂааЖШЁЃЖјдкDirectЗНЪНжаЃЌKafkaжаЕФpartitionгыRDDжаЕФpartitionЪЧвЛвЛЖдгІЕФВЂааЖСШЁKafkaЪ§ОнЃЌетжжгГЩфЙиЯЕвВИќРћгкРэНтКЭгХЛЏЁЃ
- ИпаЇЃКдкReceiverЕФЗНЪНжаЃЌЮЊСЫДяЕН0Ъ§ОнЖЊЪЇашвЊНЋЪ§ОнДцШыWrite Ahead LogжаЃЌетбљдкKafkaКЭШежОжаОЭБЃДцСЫСНЗнЪ§ОнЃЌРЫЗбЃЁЖјЕкЖўжжЗНЪНВЛДцдкетИіЮЪЬтЃЌжЛвЊЮвУЧKafkaЕФЪ§ОнБЃСєЪБМфзуЙЛГЄЃЌЮвУЧЖМФмЙЛДгKafkaНјааЪ§ОнЛжИДЁЃ
- ОЋШЗвЛДЮЃКдкReceiverЕФЗНЪНжаЃЌЪЙгУЕФЪЧKafkaЕФИпНзAPIНгПкДгZookeeperжаЛёШЁoffsetжЕЃЌетвВЪЧДЋЭГЕФДгKafkaжаЖСШЁЪ§ОнЕФЗНЪНЃЌЕЋгЩгкSpark StreamingЯћЗбЕФЪ§ОнКЭZookeeperжаМЧТМЕФoffsetВЛЭЌВНЃЌетжжЗНЪНХМЖћЛсдьГЩЪ§ОнжиИДЯћЗбЁЃЖјЕкЖўжжЗНЪНЃЌжБНгЪЙгУСЫМђЕЅЕФЕЭНзKafka APIЃЌOffsetsдђРћгУSpark StreamingЕФcheckpointsНјааМЧТМЃЌЯћГ§СЫетжжВЛвЛжТадЁЃ
вдЩЯжївЊЪЧЖдЙйЗНЮФЕЕ[1]ЕФвЛИіМђЕЅЗвыЃЌЯъЯИФкШнДѓМвПЩвджБНгПДЯТЙйЗНЮФЕЕетРяВЛдйзИЪіЁЃ
ВЛЭЌгкReceiverЕФЗНЪНЃЌЪЧДгZookeeperжаЖСШЁoffsetжЕЃЌФЧУДздШЛzookeeperОЭБЃДцСЫЕБЧАЯћЗбЕФoffsetжЕЃЌФЧУДШчЙћжиаТЦєЖЏПЊЪМЯћЗбОЭЛсНгзХЩЯвЛДЮoffsetжЕМЬајЯћЗбЁЃЖјдкDirectЕФЗНЪНжаЃЌЮвУЧЪЧжБНгДгkafkaРДЖСЪ§ОнЃЌФЧУДoffsetашвЊздМКМЧТМЃЌПЩвдРћгУcheckpointЁЂЪ§ОнПтЛђЮФМўМЧТМЛђепЛиаДЕНzookeeperжаНјааМЧТМЁЃетРяЮвУЧИјГіРћгУKafkaЕзВуAPIНгПкЃЌНЋoffsetМАЪБЭЌВНЕНzookeeperжаЕФЭЈгУРрЃЌЮвНЋЦфЗХдкСЫgithubЩЯЃК
Spark streaming+Kafka https:// github.com/xlturing /MySpark/tree/ master/SparkStreamingKafka
ЪОР§жаKafkaManagerЪЧвЛИіЭЈгУРрЃЌЖјKafkaClusterЪЧkafkaдДТыжаЕФвЛИіРрЃЌгЩгкАќУћШЈЯоЕФдвђЮвАбЫќЕЅЖРЬсГіРДЃЌComsumerMainМђЕЅеЙЪОСЫЭЈгУРрЕФЪЙгУЗНЗЈЃЌдкУПДЮДДНЈKafkaStreamЪБЃЌЖМЛсЯШДгzookerжаВщПДЩЯДЮЕФЯћЗбМЧТМoffsetsЃЌЖјУПИіbatchДІРэЭъГЩКѓЃЌЛсЭЌВНoffsetsЕНzookeeperжаЁЃ
SparkЯђkafkaжааДШыЪ§Он
ЩЯЮФВћЪіСЫSparkШчКЮДгKafkaжаСїЪНЕФЖСШЁЪ§ОнЃЌЯТУцЮвећРэЯђKafkaжааДЪ§ОнЁЃгыЖСЪ§ОнВЛЭЌЃЌSparkВЂУЛгаЬсЙЉЭГвЛЕФНгПкгУгкаДШыKafkaЃЌЫљвдЮвУЧашвЊЪЙгУЕзВуKafkaНгПкНјааАќзАЁЃ
зюжБНгЕФзіЗЈЮвУЧПЩвдЯыЕНШчЯТетжжЗНЪНЃК
| input.foreachRDD(rdd =>
// ВЛФмдкетРяДДНЈKafkaProducer
rdd.foreachPartition(partition =>
partition.foreach{
case x:String=>{
val props = new HashMap[String, Object]()
props.put( ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put( ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put( ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
println(x)
val producer = new KafkaProducer[String,String](props)
val message=new ProducerRecord[String, String]("output",null,x)
producer.send(message)
}
}
)
) |
ЕЋЪЧетжжЗНЪНШБЕуКмУїЯдЃЌЖдгкУПИіpartitionЕФУПЬѕМЧТМЃЌЮвУЧЖМашвЊДДНЈKafkaProducerЃЌШЛКѓРћгУproducerНјааЪфГіВйзїЃЌзЂвтетРяЮвУЧВЂВЛФмНЋKafkaProducerЕФаТНЈШЮЮёЗХдкforeachPartitionЭтБпЃЌвђЮЊKafkaProducerЪЧВЛПЩађСаЛЏЕФЃЈnot serializableЃЉЁЃЯдШЛетжжзіЗЈЪЧВЛСщЛюЧвЕЭаЇЕФЃЌвђЮЊУПЬѕМЧТМЖМашвЊНЈСЂвЛДЮСЌНгЁЃШчКЮНтОіФиЃП
- ЪзЯШЃЌЮвУЧашвЊНЋKafkaProducerРћгУlazy valЕФЗНЪННјааАќзАШчЯТЃК
import java.util.concurrent.Future
import org.apache.kafka.clients.producer.{ KafkaProducer, ProducerRecord, RecordMetadata }
class KafkaSink[K, V](createProducer: () => KafkaProducer[K, V]) extends Serializable {
/* This is the key idea that allows us to work around running into
NotSerializableExceptions. */
lazy val producer = createProducer()
def send(topic: String, key: K, value: V): Future[RecordMetadata] =
producer.send(new ProducerRecord[K, V](topic, key, value))
def send(topic: String, value: V): Future[RecordMetadata] =
producer.send(new ProducerRecord[K, V](topic, value))
}
object KafkaSink {
import scala.collection.JavaConversions._
def apply[K, V](config: Map[String, Object]): KafkaSink[K, V] = {
val createProducerFunc = () => {
val producer = new KafkaProducer[K, V](config)
sys.addShutdownHook {
// Ensure that, on executor JVM shutdown, the Kafka producer sends
// any buffered messages to Kafka before shutting down.
producer.close()
}
producer
}
new KafkaSink(createProducerFunc)
}
def apply[K, V](config: java.util.Properties): KafkaSink[K, V] = apply(config.toMap)
} |
- жЎКѓЮвУЧРћгУЙуВЅБфСПЕФаЮЪНЃЌНЋKafkaProducerЙуВЅЕНУПвЛИіexecutorЃЌШчЯТЃК
// ЙуВЅKafkaSink
val kafkaProducer: Broadcast[KafkaSink[String, String]] = {
val kafkaProducerConfig = {
val p = new Properties()
p.setProperty("bootstrap.servers", Conf.brokers)
p.setProperty("key.serializer", classOf[StringSerializer].getName)
p.setProperty("value.serializer", classOf[StringSerializer].getName)
p
}
log.warn("kafka producer init done!")
ssc.sparkContext.broadcast(KafkaSink[String, String](kafkaProducerConfig))
} |
етбљЮвУЧОЭФмдкУПИіexecutorжагфПьЕФНЋЪ§ОнЪфШыЕНkafkaЕБжаЃК
//ЪфГіЕНkafka
segmentedStream.foreachRDD(rdd => {
if (!rdd.isEmpty) {
rdd.foreach(record => {
kafkaProducer.value.send(Conf.outTopics, record._1.toString, record._2)
// do something else
})
}
}) |
Spark streaming+KafkaгІгУ
WeTestгпЧщМрПиЖдгкУПЬьХРШЁЕФЧЇЭђМЖгЮЯЗЭцМвЦРТлаХЯЂЖМвЊЪЕЪБЕФНјааДЪЦЕЭГМЦЃЌЖдгкХРШЁЕНЕФгЮЯЗЭцМвЦРТлЪ§ОнЃЌЮвУЧЛсЩњВњЕНKafkaжаЃЌЖјСэвЛЖЫЕФЯћЗбепЮвУЧВЩгУСЫSpark StreamingРДНјааСїЪНДІРэЃЌЪзЯШРћгУЩЯЮФЮвУЧВћЪіЕФDirectЗНЪНДгKafkaРШЁbatchЃЌжЎКѓОЙ§ЗжДЪЁЂЭГМЦЕШЯрЙиДІРэЃЌЛиаДЕНDBЩЯЃЈжСгкSparkжаDBЕФЛиаДЗНЪНПЩВЮПМЮвжЎЧАзмНсЕФВЉЮФЃКSparkВШПгМЧЁЊЁЊЪ§ОнПтЃЈHbase+MysqlЃЉЃЉЃЌгЩДЫИпаЇЪЕЪБЕФЭъГЩУПЬьДѓСПЪ§ОнЕФДЪЦЕЭГМЦШЮЮёЁЃ
Spark streaming+KafkaЕїгХ
Spark streaming+KafkaЕФЪЙгУжаЃЌЕБЪ§ОнСПНЯаЁЃЌКмЖрЪБКђФЌШЯХфжУКЭЪЙгУБуФмЙЛТњзуЧщПіЃЌЕЋЪЧЕБЪ§ОнСПДѓЕФЪБКђЃЌОЭашвЊНјаавЛЖЈЕФЕїећКЭгХЛЏЃЌЖјетжжЕїећКЭгХЛЏБОЩэвВЪЧВЛЭЌЕФГЁОАашвЊВЛЭЌЕФХфжУЁЃ
КЯРэЕФХњДІРэЪБМфЃЈbatchDurationЃЉ
МИКѕЫљгаЕФSpark StreamingЕїгХЮФЕЕЖМЛсЬсМАХњДІРэЪБМфЕФЕїећЃЌдкStreamingContextГѕЪМЛЏЕФЪБКђЃЌгавЛИіВЮЪ§БуЪЧХњДІРэЪБМфЕФЩшЖЈЁЃШчЙћетИіжЕЩшжУЕФЙ§ЖЬЃЌМДИіbatchDurationЫљВњЩњЕФJobВЂВЛФмдкетЦкМфЭъГЩДІРэЃЌФЧУДОЭЛсдьГЩЪ§ОнВЛЖЯЖбЛ§ЃЌзюжеЕМжТSpark StreamingЗЂЩњзшШћЁЃЖјЧвЃЌвЛАуЖдгкbatchDurationЕФЩшжУВЛЛсаЁгк500msЃЌвђЮЊЙ§аЁЛсЕМжТSparkStreamingЦЕЗБЕФЬсНЛзївЕЃЌЖдећИіstreamingдьГЩЖюЭтЕФИКЕЃЁЃдкЦНЪБЕФгІгУжаЃЌИљОнВЛЭЌЕФгІгУГЁОАКЭгВМўХфжУЃЌЮвЩшдк1~10sжЎМфЃЌЮвУЧПЩвдИљОнSparkStreamingЕФПЩЪгЛЏМрПиНчУцЃЌЙлВьTotal DelayРДНјааbatchDurationЕФЕїећЃЌШчЯТЭМЃК

КЯРэЕФKafkaРШЁСПЃЈmaxRatePerPartitionживЊЃЉ
ЖдгкSpark StreamingЯћЗбkafkaжаЪ§ОнЕФгІгУГЁОАЃЌетИіХфжУЪЧЗЧГЃЙиМќЕФЃЌХфжУВЮЪ§ЮЊЃКspark.streaming.kafka.maxRatePerPartitionЁЃетИіВЮЪ§ФЌШЯЪЧУЛгаЩЯЯпЕФЃЌМДkafkaЕБжагаЖрЩйЪ§ОнЫќОЭЛсжБНгШЋВПРГіЁЃЖјИљОнЩњВњепаДШыKafkaЕФЫйТЪвдМАЯћЗбепБОЩэДІРэЪ§ОнЕФЫйЖШЃЌЭЌЪБетИіВЮЪ§ашвЊНсКЯЩЯУцЕФbatchDurationЃЌЪЙЕУУПИіpartitionРШЁдкУПИіbatchDurationЦкМфРШЁЕФЪ§ОнФмЙЛЫГРћЕФДІРэЭъБЯЃЌзіЕНОЁПЩФмИпЕФЭЬЭТСПЃЌЖјетИіВЮЪ§ЕФЕїећПЩвдВЮПМПЩЪгЛЏМрПиНчУцжаЕФInput RateКЭProcessing TimeЃЌШчЯТЭМЃК
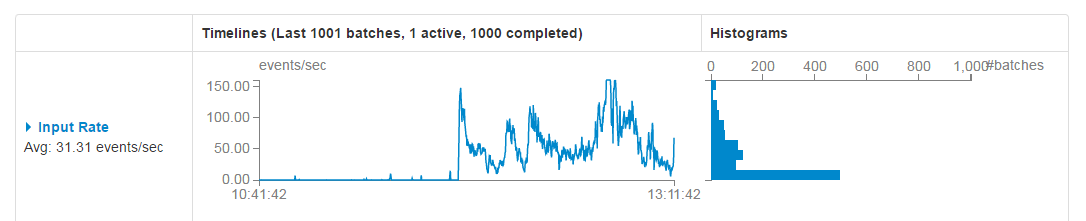

ЛКДцЗДИДЪЙгУЕФDstreamЃЈRDDЃЉ
SparkжаЕФRDDКЭSparkStreamingжаЕФDstreamЃЌШчЙћБЛЗДИДЕФЪЙгУЃЌзюКУРћгУcache()ЃЌНЋИУЪ§ОнСїЛКДцЦ№РДЃЌЗРжЙЙ§ЖШЕФЕїЖШзЪдДдьГЩЕФЭјТчПЊЯњЁЃПЩвдВЮПМЙлВьScheduling DelayВЮЪ§ЃЌШчЯТЭМЃК

ЩшжУКЯРэЕФGC
ГЄЦкЪЙгУJavaЕФаЁЛяАщЖМжЊЕРЃЌJVMжаЕФРЌЛјЛиЪеЛњжЦЃЌПЩвдШУЮвУЧВЛЙ§ЖрЕФЙизЂгыФкДцЕФЗжХфЛиЪеЃЌИќМгзЈзЂгквЕЮёТпМЃЌJVMЖМЛсЮЊЮвУЧИуЖЈЁЃЖдJVMгааЉСЫНтЕФаЁЛяАщгІИУжЊЕРЃЌдкJavaащФтЛњжаЃЌНЋФкДцЗжЮЊСЫГѕЩњДњЃЈeden generationЃЉЁЂФъЧсДњЃЈyoung generationЃЉЁЂРЯФъДњЃЈold generationЃЉвдМАгРОУДњЃЈpermanent generationЃЉЃЌЦфжаУПДЮGCЖМЪЧашвЊКФЗбвЛЖЈЪБМфЕФЃЌгШЦфЪЧРЯФъДњЕФGCЛиЪеЃЌашвЊЖдФкДцЫщЦЌНјааећРэЃЌЭЈГЃВЩгУБъМЧ-ЧхГўЕФзіЗЈЁЃЭЌбљЕФдкSparkГЬађжаЃЌJVM GCЕФЦЕТЪКЭЪБМфвВЪЧгАЯьећИіSparkаЇТЪЕФЙиМќвђЫиЁЃдкЭЈГЃЕФЪЙгУжаНЈвщЃК
| --conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC" |
ЩшжУКЯРэЕФCPUзЪдДЪ§
CPUЕФcoreЪ§СПЃЌУПИіexecutorПЩвдеМгУвЛИіЛђЖрИіcoreЃЌПЩвдЭЈЙ§ЙлВьCPUЕФЪЙгУТЪБфЛЏРДСЫНтМЦЫузЪдДЕФЪЙгУЧщПіЃЌР§ШчЃЌКмГЃМћЕФвЛжжРЫЗбЪЧвЛИіexecutorеМгУСЫЖрИіcoreЃЌЕЋЪЧзмЕФCPUЪЙгУТЪШДВЛИпЃЈвђЮЊвЛИіexecutorВЂВЛзмФмГфЗжРћгУЖрКЫЕФФмСІЃЉЃЌетИіЪБКђПЩвдПМТЧШУУДИіexecutorеМгУИќЩйЕФcoreЃЌЭЌЪБworkerЯТУцдіМгИќЖрЕФexecutorЃЌЛђепвЛЬЈhostЩЯУцдіМгИќЖрЕФworkerРДдіМгВЂаажДааЕФexecutorЕФЪ§СПЃЌДгЖјдіМгCPUРћгУТЪЁЃЕЋЪЧдіМгexecutorЕФЪБКђашвЊПМТЧКУФкДцЯћКФЃЌвђЮЊвЛЬЈЛњЦїЕФФкДцЗжХфИјдНЖрЕФexecutorЃЌУПИіexecutorЕФФкДцОЭдНаЁЃЌвджТГіЯжЙ§ЖрЕФЪ§Онspill overЩѕжСout of memoryЕФЧщПіЁЃ
ЩшжУКЯРэЕФparallelism
partitionКЭparallelismЃЌpartitionжИЕФОЭЪЧЪ§ОнЗжЦЌЕФЪ§СПЃЌУПвЛДЮtaskжЛФмДІРэвЛИіpartitionЕФЪ§ОнЃЌетИіжЕЬЋаЁСЫЛсЕМжТУПЦЌЪ§ОнСПЬЋДѓЃЌЕМжТФкДцбЙСІЃЌЛђепжюЖрexecutorЕФМЦЫуФмСІЮоЗЈРћгУГфЗжЃЛЕЋЪЧШчЙћЬЋДѓСЫдђЛсЕМжТЗжЦЌЬЋЖрЃЌжДаааЇТЪНЕЕЭЁЃдкжДааactionРраЭВйзїЕФЪБКђЃЈБШШчИїжжreduceВйзїЃЉЃЌpartitionЕФЪ§СПЛсбЁдёparent RDDжазюДѓЕФФЧвЛИіЁЃЖјparallelismдђжИЕФЪЧдкRDDНјааreduceРрВйзїЕФЪБКђЃЌФЌШЯЗЕЛиЪ§ОнЕФparititionЪ§СПЃЈЖјдкНјааmapРрВйзїЕФЪБКђЃЌpartitionЪ§СПЭЈГЃШЁздparent RDDжаНЯДѓЕФвЛИіЃЌЖјЧввВВЛЛсЩцМАshuffleЃЌвђДЫетИіparallelismЕФВЮЪ§УЛгагАЯьЃЉЁЃЫљвдЫЕЃЌетСНИіИХФюУмЧаЯрЙиЃЌЖМЪЧЩцМАЕНЪ§ОнЗжЦЌЕФЃЌзїгУЗНЪНЦфЪЕЪЧЭГвЛЕФЁЃЭЈЙ§spark.default.parallelismПЩвдЩшжУФЌШЯЕФЗжЦЌЪ§СПЃЌЖјКмЖрRDDЕФВйзїЖМПЩвджИЖЈвЛИіpartitionВЮЪ§РДЯдЪНПижЦОпЬхЕФЗжЦЌЪ§СПЁЃ
дкSparkStreaming+kafkaЕФЪЙгУжаЃЌЮвУЧВЩгУСЫDirectСЌНгЗНЪНЃЌЧАЮФВћЪіЙ§SparkжаЕФpartitionКЭKafkaжаЕФPartitionЪЧвЛвЛЖдгІЕФЃЌЮвУЧвЛАуФЌШЯЩшжУЮЊKafkaжаPartitionЕФЪ§СПЁЃ
ЪЙгУИпадФмЕФЫузг
етРяВЮПМСЫУРЭХММЪѕЭХЖгЕФВЉЮФЃЌВЂУЛгазіЙ§ОпЬхЕФадФмВтЪдЃЌЦфНЈвщШчЯТЃК
- ЪЙгУreduceByKey/aggregateByKeyЬцДњgroupByKey
- ЪЙгУmapPartitionsЬцДњЦеЭЈmap
- ЪЙгУforeachPartitionsЬцДњforeach
- ЪЙгУfilterжЎКѓНјааcoalesceВйзї
- ЪЙгУrepartitionAndSortWithinPartitionsЬцДњrepartitionгыsortРрВйзї
ЪЙгУKryoгХЛЏађСаЛЏадФм
етИігХЛЏддђЮвБОЩэвВУЛгаОЙ§ВтЪдЃЌЕЋЪЧКУЖргХЛЏЮФЕЕгаЬсЕНЃЌетРявВМЧТМЯТРДЁЃ
дкSparkжаЃЌжївЊгаШ§ИіЕиЗНЩцМАЕНСЫађСаЛЏЃК
- дкЫузгКЏЪ§жаЪЙгУЕНЭтВПБфСПЪБЃЌИУБфСПЛсБЛађСаЛЏКѓНјааЭјТчДЋЪфЃЈМћЁАддђЦпЃКЙуВЅДѓБфСПЁБжаЕФНВНтЃЉЁЃ
- НЋздЖЈвхЕФРраЭзїЮЊRDDЕФЗКаЭРраЭЪБЃЈБШШчJavaRDDЃЌStudentЪЧздЖЈвхРраЭЃЉЃЌЫљгаздЖЈвхРраЭЖдЯѓЃЌЖМЛсНјааађСаЛЏЁЃвђДЫетжжЧщПіЯТЃЌвВвЊЧѓздЖЈвхЕФРрБиаыЪЕЯжSerializableНгПкЁЃ
- ЪЙгУПЩађСаЛЏЕФГжОУЛЏВпТдЪБЃЈБШШчMEMORY_ONLY_SERЃЉЃЌSparkЛсНЋRDDжаЕФУПИіpartitionЖМађСаЛЏГЩвЛИіДѓЕФзжНкЪ§зщЁЃ
ЖдгкетШ§жжГіЯжађСаЛЏЕФЕиЗНЃЌЮвУЧЖМПЩвдЭЈЙ§ЪЙгУKryoађСаЛЏРрПтЃЌРДгХЛЏађСаЛЏКЭЗДађСаЛЏЕФадФмЁЃSparkФЌШЯЪЙгУЕФЪЧJavaЕФађСаЛЏЛњжЦЃЌвВОЭЪЧObjectOutputStream/ObjectInputStream APIРДНјааађСаЛЏКЭЗДађСаЛЏЁЃЕЋЪЧSparkЭЌЪБжЇГжЪЙгУKryoађСаЛЏПтЃЌKryoађСаЛЏРрПтЕФадФмБШJavaађСаЛЏРрПтЕФадФмвЊИпКмЖрЁЃЙйЗННщЩмЃЌKryoађСаЛЏЛњжЦБШJavaађСаЛЏЛњжЦЃЌадФмИп10БЖзѓгвЁЃSparkжЎЫљвдФЌШЯУЛгаЪЙгУKryoзїЮЊађСаЛЏРрПтЃЌЪЧвђЮЊKryoвЊЧѓзюКУвЊзЂВсЫљгаашвЊНјааађСаЛЏЕФздЖЈвхРраЭЃЌвђДЫЖдгкПЊЗЂепРДЫЕЃЌетжжЗНЪНБШНЯТщЗГЁЃ
вдЯТЪЧЪЙгУKryoЕФДњТыЪОР§ЃЌЮвУЧжЛвЊЩшжУађСаЛЏРрЃЌдйзЂВсвЊађСаЛЏЕФздЖЈвхРраЭМДПЩЃЈБШШчЫузгКЏЪ§жаЪЙгУЕНЕФЭтВПБфСПРраЭЁЂзїЮЊRDDЗКаЭРраЭЕФздЖЈвхРраЭЕШЃЉЃК
// ДДНЈSparkConfЖдЯѓЁЃ
val conf = new SparkConf().setMaster(...).setAppName(...)
// ЩшжУађСаЛЏЦїЮЊKryoSerializerЁЃ
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// зЂВсвЊађСаЛЏЕФздЖЈвхРраЭЁЃ
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2])) |
НсЙћ
ОЙ§жжжжЕїЪдгХЛЏЃЌЮвУЧзюжевЊДяЕНЕФФПЕФЪЧЃЌSpark StreamingФмЙЛЪЕЪБЕФРШЁKafkaЕБжаЕФЪ§ОнЃЌВЂЧвФмЙЛБЃГжЮШЖЈЃЌШчЯТЭМЫљЪОЃК
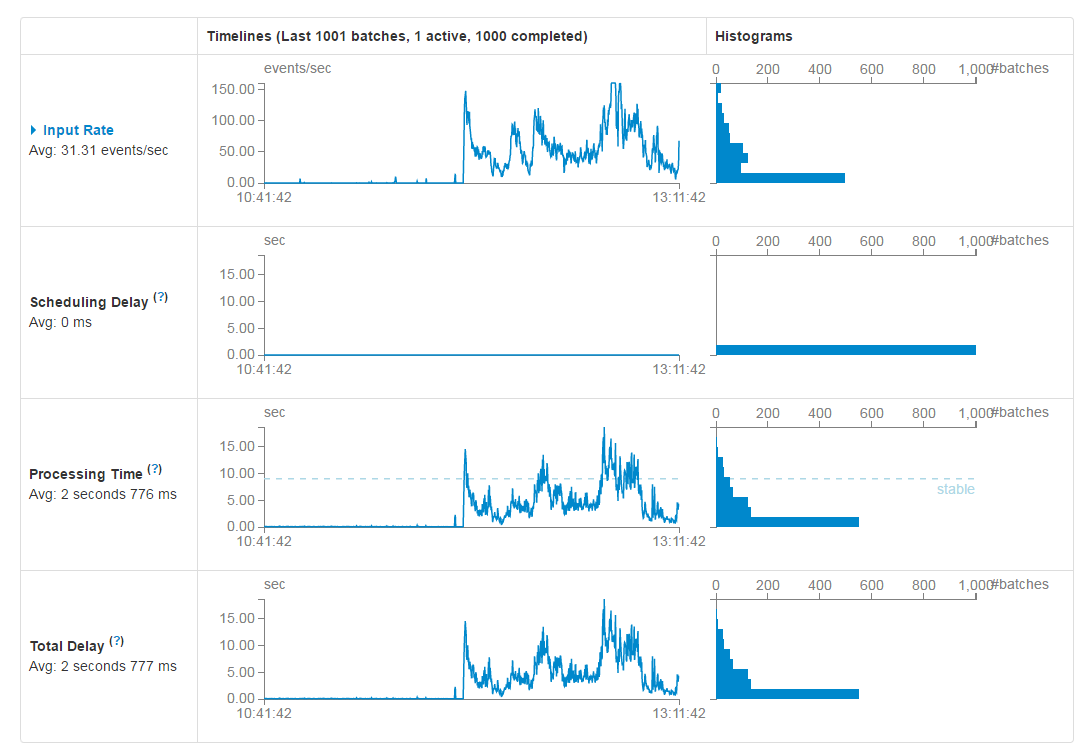
ЕБШЛВЛЭЌЕФгІгУГЁОАЛсгаВЛЭЌЕФЭМаЮЃЌетЪЧБОЮФДЪЦЕЭГМЦгХЛЏЮШЖЈКѓЕФМрПиЭМЃЌЮвУЧПЩвдПДЕНProcessing TimeетвЛжљаЮЭМжагавЛStableЕФащЯпЃЌЖјДѓЖрЪ§BatchЖМФмЙЛдкетвЛащЯпЯТДІРэЭъБЯЃЌЫЕУїећЬхSpark StreamingЪЧдЫааЮШЖЈЕФЁЃ |









