|
ИХЪі
баОПSparkзївЕЕїЖШЃЌЪЧЮЊСЫКЯРэЪЙгУМЏШКЕФзЪдДЁЃИќОпЬхвЛЕуЃЌЪЧПДПДЪЧЗёЬсЙЉСЫПЩвдИіадЛЏХфжУЕФЕуЃЌШЛКѓИљОнгІгУЕФОпЬхЧщПіжЦЖЈХфжУЛђепЪЙгУЗНАИЁЃ
ПчгІгУЕїЖШ
ПчгІгУЕФЕїЖШЪЧгЩЕзВуЕФМЏШКЙмРэЦїИКд№ЕФЃЌгаСНжжзЪдДЗжХфВпТдЁЃ
вЛжжЪЧОВЬЌзЪдДЗжИєЃЌМДвЛИігІгУвЛПЊЪМОЭЩъЧыЫљгаЕФзЪдДЃЌВЂдкГЬађдЫааЦкМфЪЙгУГжгаетаЉзЪдДЁЃ
вЛжжЪЧЖЏЬЌзЪдДЗжХфЃЌгІгУИљОнздМКЕФИКдиЧщПіЖЏЬЌЧыЧѓЛђЪЭЗХзЪдДЁЃетжжВпТдФЌШЯЪЧВЛПЊЦєЕФЁЃ
ОВЬЌзЪдДЗжИє
ЫљгаЕФМЏШКЙмРэЦїЖМжЇГжОВЬЌзЪдДЗжИєЃЌжЛЪЧОпЬхЕФХфжУВпТдВЛЭЌЃК
Standalone mode
ЬсНЛЕНStandalone modeМЏШКЕФгІгУЛсвдFIFOЕФЫГађдЫааЃЌУПвЛИіе§дкдЫааЕФгІгУЖМЛсГЂЪдеМгУЫљгаЕФПЩгУзЪдДЁЃЪЙгУЯТУцЕФХфжУЯюПЩвдЯожЦУПИігІгУЩъЧыЕФзЪдДЃК
гІгУПЩвдЩъЧыЕФзюДѓЪ§СПЕФCPUКЫЕФЪ§СПЃЌШчЙћУЛгаЩшжУЃЌШЁspark.deploy.defaultCoresЕФжЕЁЃ
ЗжХфИјУПИіexecutorНјГЬЕФФкДцзЪдДЁЃ
Mesos
ЮЊСЫЪЙгУОВЬЌзЪдДИєРыЃЌашвЊЩшжУspark.mesos.coarseЮЊtrueЃЌетГЦЮЊДжСЃЖШЕФMesosФЃЪНЁЃ
СэЭтЃЌspark.cores.maxКЭspark.executor.memoryдкMesosФЃЪНЯТЭЌбљгааЇЁЃ
YARN
дкЪЙгУspark-submitЬсНЛзївЕЪБЃЌПЩвдЪЙгУ--num-executorsбЁЯюЧыЧѓжИЖЈЕФexecutorИіЪ§ЁЃ
дкГЬађФкВПЃЌПЩвдЭЈЙ§ЩшжУspark.executor.instancesЪєадДяЕНЭЌбљЕФФПЕФЁЃ
дкЪЙгУspark-submitЬсНЛзївЕЪБЃЌПЩвдЪЙгУ--executor-memoryбЁЯюЩшжУУПИіexecutorЩъЧыЕФФкДцЁЃ
дкГЬађФкВПЃЌПЩвдЭЈЙ§ЩшжУspark.executor.memoryЪєадДяЕНЭЌбљЕФФПЕФЁЃ
дкЪЙгУspark-submitЬсНЛзївЕЪБЃЌПЩвдЪЙгУ--executor-coresбЁЯюЩшжУУПИіexecutorЩъЧыЕФCPUКЫЁЃ
дкГЬађФкВПЃЌПЩвдЭЈЙ§ЩшжУspark.executor.coresЪєадДяЕНЭЌбљЕФФПЕФЁЃ
ЖЏЬЌзЪдДЗжХф
sparkЕФдЫааФЃаЭЪЧЛљгкexecutorЕФЃЌexecutorЪЧзЪдДЕФЪЕМЪГжгаепЁЃЫљвдЖЏЬЌзЪдДЗжХфЃЌЪЧЭЈЙ§ЖЏЬЌЕФЩъЧыexecutorКЭЪЭЗХexecutorРДЪЕЯжЕФЁЃ
ЖЏЬЌзЪдДЗжХфЩцМАЕНСНИіЗНУцЃЌШчКЮдкашвЊЕФЪБКђЖЏЬЌЩъЧызЪдДЃЌвдМАШчКЮдкПеЯаЕФЪБКђЖЏЬЌЪЭЗХзЪдДЁЃ
ЖЏЬЌЧыЧѓВпТдЃКШчЙћвЛИігІгУгаtasksдкЕШД§ЃЌГЌЙ§вЛЖЈЕФЪБМфЃЈspark.dynamicAllocation.schedulerBacklogTimeoutУыЃЉОЭЛсЩъЧы1ИіexecutorЁЃДЫКѓУПИєвЛЖЈЕФЪБМфЃЈspark.dynamicAllocation.sustainedSchedulerBacklogTimeoutУыЃЉОЭМьВтгІгУЪЧЗёгаtasksдкЕШД§ЃЌгаОЭМЬајЩъЧыexecutorЁЃ
ЖЏЬЌЧыЧѓзЪдДЕФЪ§СПЪЧжИЪ§МЖЕФЃЌЕквЛДЮЩъЧы1ИіЃЌЕкЖўДЮЩъЧы2ИіЃЌНгзХЪЧ4,
8 ...етжжПМТЧЪЧЮЊСЫдкНїЩїЩъЧызЪдДЕФЭЌЪБЃЌгжПЩвддкдЪаэЕФЪБМфЗЖЮЇФкЛёЕУеце§ашвЊЕФзЪдДСПЁЃ
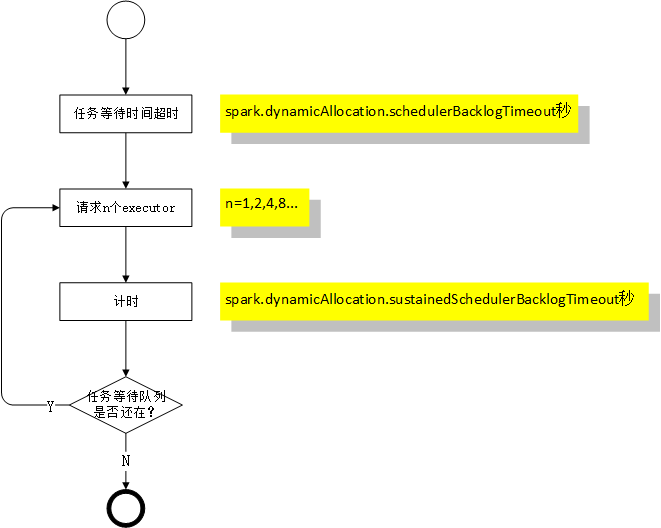
ЖЏЬЌЪЭЗХзЪдДЃКЪЧЭЈЙ§МьВщгІгУеМОнЕФexecutorЪЧЗёГЌЙ§СЫжИЖЈЕФЪБМфЃЈspark.dynamicAllocation.executorIdleTimeoutУыЃЉРДОіЖЈЕФЃЌГЌЙ§СЫОЭЪЭЗХЁЃ
ЪЭЗХзЪдДЕФЬѕМўКЭЧыЧѓзЪдДЕФЬѕМўЪЧЛЅГтЕФЃЌМДШчЙћвЛИігІгУгаtasksдкХХЖгЃЌОЭВЛгІИУЛсгаПеЯаЕФexecutorЁЃ
how to do
ЮЊСЫЪЙгУЖЏЬЌзЪдДЗжХфЃЌашвЊзіСНМўЪТЃК
1.ЩшжУspark.dynamicAllocation.enabledжЕЮЊtrue
2.дкУПвЛИіЙЄзїНкЕуЦєЖЏexternal shuffle serviceЃЌВЂЩшжУspark.shuffle.service.enabledЮЊtrue
external shuffle serviceЕФзїгУдкКѓУцЛсНщЩмЃЌВЛЭЌМЏШКФЃЪНЯТЦєЖЏexternal
shuffle serviceЕФЗНЪНВЛЭЌЃК
дкStandaloneФЃЪНЃЌВЛашвЊЖюЭтЕФЙЄзїРДЦєЖЏexternal shuffle serviceЃЌжЛашвЊЩшжУspark.shuffle.service.enabledЮЊtrueМДПЩЁЃ
дкMesosДжСЃЖШФЃЪНЃЌдкУПвЛИіslave nodesдЫааНХБО$SPARK_HOME/sbin/start-mesos-shuffle-service.shРДЦєЖЏexternal
shuffle serviceЁЃ
дкYARNФЃЪНЃЌВЮПМConfiguring the External Shuffle Service
On YarnЁЃ
ЖЏЬЌвЦГ§executorУцЖдЕФЮЪЬт
ЖЏЬЌЪЭЗХзЪдДашвЊЖюЭтЕФжЇГжЃЌвђЮЊexecutorПЩФмЛсВњЩњжаМфНсЙћВЂЪфГіЕНБОЕиЃЌдкашвЊЕФЪБКђашвЊЭЈЙ§етИіexecutorЛёШЁЫќЕФжаМфНсЙћЁЃУАШЛвЦГ§executorЛсЖЊЪЇЫќМЦЫуЕФжаМфНсЙћЃЌЕМжТдкеце§ашвЊЕФЪБКђгжвЊжиаТМЦЫуЁЃ
БШШчдкmapНзЖЮexecutorЪфГіmapНсЙћЃЌдкshuffleНзЖЮетаЉmapНсЙћгжашвЊЭЈЙ§executorЖСГіРДДЋЫЭЕНИКд№reduceЕФexecutorЁЃ
sparkЭЈЙ§external shuffle serviceРДНтОіетИіЮЪЬтЁЃexternal shuffle
serviceЪЧжИдкУПвЛИіnodeЖМдЫааЕФвЛИіГЄЦкНјГЬЃЌетИіНјГЬЖРСЂгкгІгУКЭexecutorЃЌИКд№ЬсЙЉexecutorЕФЪфГіЪ§ОнЕФЛёШЁЗўЮёЁЃдРДexecutorжЎМфЯрЛЅЧыЧѓРДЛёШЁЖдЗНЕФЪфГіНсЙћЃЌБфГЩСЫЭГвЛДгexternal
shuffle serviceЛёШЁНсЙћЁЃ
МДЪЙexecutorвбОБЛвЦГ§СЫЃЌЫќЫљЪфГіЕФЪ§ОнвРШЛПЩвдЭЈЙ§external
shuffle serviceРДЛёШЁЁЃ
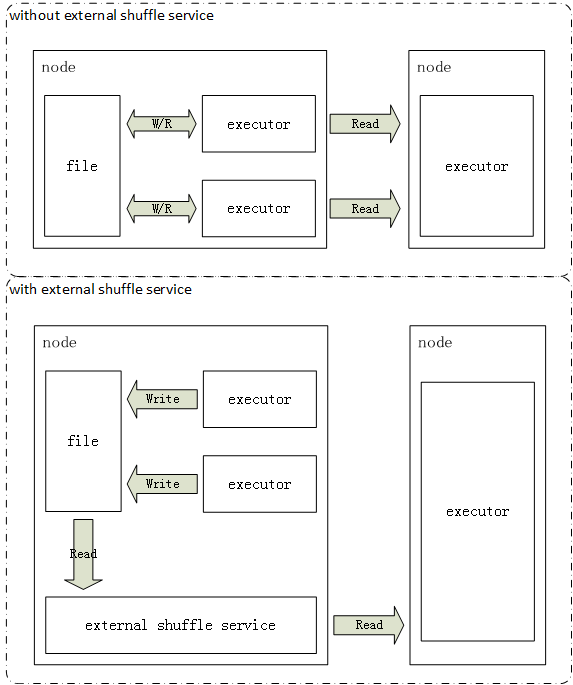
СэЭтЃЌexecutorЛЙПЩФмЛсАбжаМфНсЙћЛКДцЕНФкДцЃЌФПЧАЕФВпТдЪЧВЛвЦГ§ДЫРрЕФexecutorЁЃЮДРДПЩФмВЩШЁНЋЛКДцГжОУЛЏЕФЗНЪНЃЌНјЖјЪЭЗХexecutorЁЃ
гІгУФкВПЕїЖШ
вЛИіsparkгІгУПЩвджЇГжЖрИіВЛЭЌЯпГЬЕФjobЭЌЪБЬсНЛЃЌетГЃМћгкsparkгІгУЬсЙЉЭјТчЗўЮёЕФГЁОАЁЃ
sparkФЌШЯЕФЕїЖШВпТдЪЧFIFOЃЌШчЙћЖгСаЭЗВПЕФjobБШНЯДѓЃЌеМгУСЫМЏШКЕФЫљгазЪдДЃЌКѓУцЕФаЁШЮЮёНЋГйГйЕУВЛЕНдЫааЕФЛњЛсЁЃ
СэЭтЃЌsparkЛЙжЇГжХфжУFAIRЕїЖШЃЌsparkбЛЗЕїЖШУПИіjobЕФtaskЁЃетбљМДЪЙгаДѓjobдкдЫааЃЌИеЬсНЛЕФаЁjobвВПЩвдМАЪБЛёЕУзЪдДЃЌЖјВЛашвЊЕШЕНДѓjobНсЪјЁЃ
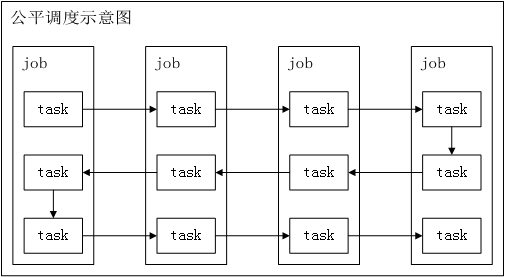
ЭЈЙ§ЩшжУЪєадspark.scheduler.modeРДЦєгУЙЋЦНЕїЖШЃК
| val
conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.scheduler.mode", "FAIR")
val sc = new SparkContext(conf) |
ЙЋЦНЕїЖШГи
sparkжЇГжЙЋЦНЕїЖШГиЕФИХФюЃЌУПИіЯпГЬПЩвджИЖЈНЋjobsЬсНЛЕНФФИіГизгЃЌзюЯИСЃЖШЕФГЁОАЯТЪЧУПИіЯпГЬЖдгІвЛИіГиЃЌвВПЩвдЖрИіЯпГЬЪЙгУЭЌвЛИіГиЁЃ
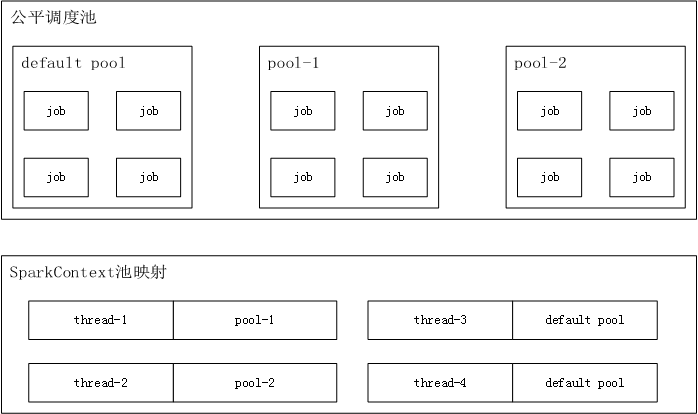
УПИіЯпГЬФЌШЯЪЙгУЕФГиЪЧdefaultЃЌвВПЩвдЭЈЙ§ЩшжУВЮЪ§РДУїШЗжИЖЈГиЁЃ
| //
Assuming sc is your SparkContext variable
sc.setLocalProperty("spark.scheduler.pool",
"pool1") |
ШчЙћЯыжижУЕБЧАЯпГЬАѓЖЈЕФГизгЃЌЕїгУsc.setLocalProperty("spark.scheduler.pool",
null)ЁЃ
ПЩвдЭЈЙ§ХфжУЮФМўНЋзЪдДАДеевЛЖЈЕФБШжиЗжХфЕНГиЃЌХфжУЮФМўЕФФЃАхЃКconf/fairscheduler.xml.templateЁЃ
ЭЈЙ§conf.set("spark.scheduler.allocation.file",
"/path/to/file")жИЖЈХфжУЮФМўЁЃ
УПИіГиПЩжЇГжЕФВЮЪ§гаШ§ИіЃК
1.schedulingModeЃКFIFO Лђ FAIRЃЌFIFOЪЧФЌШЯЕФВпТдЁЃ
2.weightЃКУПИіГизгЗжХфзЪдДЕФШЈжиЃЌФЌШЯЧщПіЯТЫљгаЕФШЈжиЮЊ1ЁЃ
3.minShareЃКзюаЁзЪдДЃЌCPUКЫЕФЪ§СПЃЌФЌШЯЮЊ0ЁЃдкНјаазЪдДЗжХфЪБЃЌзмЪЧзюЯШТњзуЫљгаГиЕФminShareЃЌдйИљОнweightЗжХфЪЃЯТЕФзЪдДЁЃ
ХфжУЮФМўЪОР§ЃК
| <?xml
version="1.0"?>
<allocations>
<pool name="production">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>2</minShare>
</pool>
<pool name="test">
<schedulingMode>FIFO</schedulingMode>
<weight>2</weight>
<minShare>3</minShare>
</pool>
</allocations> |
УЛгаГіЯждкХфжУЮФМўжаЕФГиЃЌЫљгаВЮЪ§ШЁФЌШЯжЕЃЈschedulingMode=FIFOЃЌweight=1ЃЌminShare=0ЃЉЁЃ
ИХФюГЮЧх
executorЕНЕзжИЪВУДЃПКЭШнЦїЁЂJVMЕФЙиЯЕЪЧдѕбљЕФЃП
executorЪЧИКд№вЛЖЈжАд№ЕФГЬађзщМўЃЌПЩвддквбгаЕФJVMжадЫааЃЈБШШчlocal modeЃЉЃЌвВПЩвддкаТЕФJVMжадЫааЁЃЪЙгУYARNЪБЃЌexecutorЪЧдкYARNШнЦїжадЫааЕФЁЃ
sparkЕФjob - stage - taskЕФЛЎЗжЪЧдѕУДбљЕФЃП
sparkЕФjobПЩвдЛЎЗжЮЊЖрИіstageЃЌетаЉstageЙЙГЩСЫDAGЁЃУПвЛИіstageгжПЩвдЛЎЗжЮЊЖрИіtasksЁЃstageЕФЛЎЗжЪЧИљОнshuffle
map taskРДЕФЃЌетвЛРрЕФtaskЯрЕБгкMapReduceжаshuffleЕФmapЖЫЃЌИКд№дкБОЕиRDDЗжЧјНјааМЦЫуЃЌВЂНЋНсЙћЪфГіЕНаТЕФЗжЧјЃЌЙЉКѓајЕФЪЙгУЁЃдкЛЎЗжstageЪБЃЌshuffle
mapШЮЮёзїЮЊНзЖЮЕФНсЪјЕФБпНчЁЃ
|









