Spark
ApplicationŅ…“‘÷ĪĹ”‘ň––‘ŕYARNľĮ»ļ…Ō£¨’‚÷÷‘ň––ń£ Ĺ£¨ĽŠĹę◊ ‘īĶńĻ‹ņŪ”Ž–≠ĶųÕ≥“ĽĹĽłÝYARNľĮ»ļ»•ī¶ņŪ£¨’‚—ýń‹ĻĽ ĶŌ÷ĻĻĹ®”ŕYARNľĮ»ļ÷ģ…ŌApplicationĶń∂ŗ—ý–‘£¨Ī»»ÁŅ…“‘‘ň––MapReduc≥Ő–Ú£¨Ņ…“‘‘ň––HBaseľĮ»ļ£¨“≤Ņ…“‘‘ň––StormľĮ»ļ£¨ĽĻŅ…“‘‘ň–– Ļ”√PythonŅ™∑ĘĽķ∆ų—ßŌį”¶”√≥Ő–Ú£¨Ķ»Ķ»°£
ő“√«÷™Ķņ£¨Spark on YARN”÷∑÷ő™clientń£ ĹļÕclusterń£ Ĺ£ļ‘ŕclientń£ ĹŌ¬£¨Spark
Application‘ň––ĶńDriverĽŠ‘ŕŐŠĹĽ≥Ő–ÚĶńĹŕĶ„…Ō£¨∂Ýł√ĹŕĶ„Ņ…ń‹ «YARNľĮ»ļńŕ≤ŅĹŕĶ„£¨“≤Ņ…ń‹≤Ľ «£¨“Ľį„ņīňĶŐŠĹĽSpark
ApplicationĶńŅÕĽß∂ňĹŕĶ„≤Ľ «YARNľĮ»ļńŕ≤ŅĶńĹŕĶ„£¨ń«√ī‘ŕŅÕĽß∂ňĹŕĶ„…ŌŅ…“‘łýĺ›◊‘ľļĶń–Ť“™į≤◊įłų÷÷–Ť“™Ķń»ŪľĢļÕĽ∑ĺ≥£¨“‘÷ß≥ŇSpark
Application’ż≥£‘ň––°£‘ŕclusterń£ ĹŌ¬£¨Spark Application‘ň–– ĪĶńňý”–ĹÝ≥Ő∂ľ‘ŕYARNľĮ»ļĶńNodeManagerĹŕĶ„…Ō£¨∂Ý«“ĺŖŐŚ‘ŕńń–©NodeManager…Ō‘ň–– «”…YARNĶńĶų∂»≤Ŗ¬‘ňýĺŲ∂®Ķń°£
∂‘Ī»’‚ŃĹ÷÷ń£ Ĺ£¨◊ÓĻōľŁĶń «Spark Application‘ň–– ĪDriverňý‘ŕĶńĹŕĶ„≤ĽÕ¨£¨∂Ý«“£¨»ÁĻŻŌŽ“™∂‘Driverňý‘ŕĹŕĶ„Ķń‘ň––Ľ∑ĺ≥ĹÝ––Ňš÷√£¨«ÝĪūļ‹īů£¨Ķę’‚∂‘”ŕPySpark
Application‘ň––ņīňĶ «∑«≥£ĻōľŁĶń°£
PySpark «Sparkő™ Ļ”√Python≥Ő–ÚĪŗ–īSpark Application∂Ý ĶŌ÷ĶńŅÕĽß∂ňŅ‚£¨Õ®ĻżPySpark“≤Ņ…“‘Īŗ–īSpark
Application≤Ę‘ŕSparkľĮ»ļ…Ō‘ň––°£PythonĺŖ”–∑«≥£∑ŠłĽĶńŅ∆—ßľ∆ň„°ĘĽķ∆ų—ßŌįī¶ņŪŅ‚£¨»Ánumpy°Ępandas°ĘscipyĶ»Ķ»°£ő™Ńňń‹ĻĽ≥š∑÷ņŻ”√’‚–©łŖ–ßĶńPythonń£Ņť£¨ļ‹∂ŗĽķ∆ų—ßŌį≥Ő–Ú∂ľĽŠ Ļ”√Python ĶŌ÷£¨Õ¨ Ī“≤Ō£ÕŻń‹ĻĽ‘ŕSparkľĮ»ļ…Ō‘ň––°£
PySpark Application‘ň––‘≠ņŪ
ņŪĹ‚PySpark ApplicationĶń‘ň––‘≠ņŪ£¨”–÷ķ”ŕő“√« Ļ”√PythonĪŗ–īSpark Application£¨≤Ęń‹ĻĽ∂‘PySpark
ApplicationĹÝ––łų÷÷Ķų”Ň°£PySparkĻĻĹ®”ŕSparkĶńJava API÷ģ…Ō£¨ żĺ›‘ŕPythonĹŇĪĺņÔ√śĹÝ––ī¶ņŪ£¨∂Ý‘ŕJVM÷–ĽļīśļÕShuffle żĺ›£¨ żĺ›ī¶ņŪŃų≥Ő»ÁŌ¬Õľňý ĺ£®ņī◊‘Apache
Spark Wiki£©£ļ
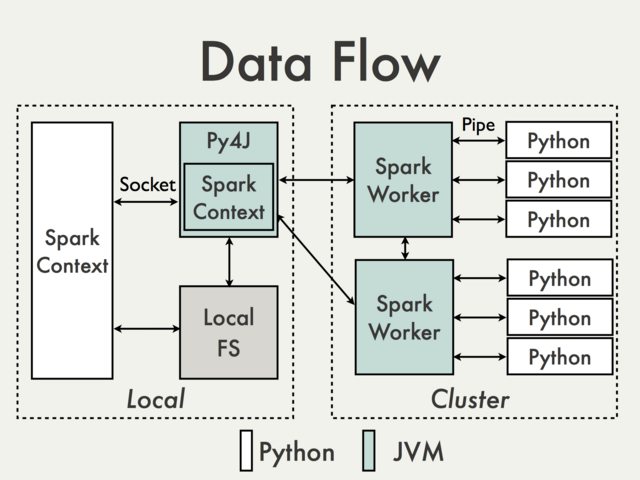
Spark ApplicationĽŠ‘ŕDriver÷–īīĹ®pyspark.SparkContext∂‘Ōů£¨ļů–ÝÕ®Ļżpyspark.SparkContext∂‘ŌůņīĻĻĹ®Job
DAG≤ĘŐŠĹĽDAG‘ň––°£ Ļ”√PythonĪŗ–īPySpark Application£¨‘ŕPythonĪŗ–īĶńDriver÷–“≤”–“ĽłŲpyspark.SparkContext∂‘Ōů£¨ł√pyspark.SparkContext∂‘ŌůĽŠÕ®ĻżPy4Jń£Ņť∆Ű∂Į“ĽłŲJVM Ķņż£¨īīĹ®“ĽłŲJavaSparkContext∂‘Ōů°£PY4J÷Ľ”√‘ŕDriver…Ō£¨ļů–Ý‘ŕPython≥Ő–Ú”ŽJavaSparkContext∂‘Ōů÷ģľšĶńÕ®–Ň£¨∂ľĽŠÕ®ĻżPY4Jń£Ņťņī ĶŌ÷£¨∂Ý«“∂ľ «ĪĺĶōÕ®–Ň°£
PySpark Application÷–“≤”–RDD£¨∂‘Python RDDĶńTransformation≤Ŕ◊ų£¨∂ľĽŠĪĽ”≥…šĶĹJava÷–ĶńPythonRDD∂‘Ōů…Ō°£∂‘”ŕ‘∂≥ŐĹŕĶ„…ŌĶńPython
RDD≤Ŕ◊ų£¨Java PythonRDD∂‘ŌůĽŠīīĹ®“ĽłŲPython◊”ĹÝ≥Ő£¨≤ĘĽý”ŕPipeĶń∑Ĺ Ĺ”Žł√Python◊”ĹÝ≥ŐÕ®–Ň£¨Ĺę”√ĽßĪŗ–īPythonī¶ņŪīķ¬ŽļÕ żĺ›∑ĘňÕĶĹPython◊”ĹÝ≥Ő÷–ĹÝ––ī¶ņŪ°£
Ō¬√ś£¨ő“√«Ľý”ŕSpark on YARNń£ Ĺ£¨≤Ęłýĺ›ĶĪ«į∆ů“ĶňýĺŖ”–Ķń Ķľ ľĮ»ļ‘ň––Ľ∑ĺ≥«ťŅŲ£¨ņīňĶ√ų»Áļő‘ŕSparkľĮ»ļ…Ō‘ň––PySpark
Application£¨īů÷¬∑÷ő™»ÁŌ¬3÷÷«ťŅŲ£ļ
YARNľĮ»ļŇš÷√PythonĽ∑ĺ≥
’‚÷÷«ťŅŲ£¨»ÁĻŻ «≥ű ľį≤◊įYARN°ĘSparkľĮ»ļ£¨≤ĘŅľ¬«ĶĹŃňĶĪ«į”¶”√≥°ĺį–Ť“™÷ß≥÷Python≥Ő–Ú‘ň––‘ŕSparkľĮ»ļ÷ģ…Ō£¨’‚ ĪŅ…“‘◊ľĪłļ√∂‘”¶Python»ŪľĢįŁ°Ę“ņņĶń£Ņť£¨‘ŕYARNľĮ»ļ÷–Ķń√ŅłŲĹŕĶ„…ŌĹÝ––į≤◊į°£’‚—ý£¨YARNľĮ»ļĶń√ŅłŲNodeManager…Ō∂ľĺŖ”–PythonĽ∑ĺ≥£¨Ņ…“‘Īŗ–īPySpark
Application≤Ę‘ŕľĮ»ļ…Ō‘ň––°£ńŅ«įĪ»ĹŌŃų––Ķń «÷ĪĹ”į≤◊įPython–ťń‚Ľ∑ĺ≥£¨ Ļ”√AnacondaĶ»»ŪľĢ£¨Ņ…“‘ľęīůĶōľÚĽĮPythonĽ∑ĺ≥ĶńĻ‹ņŪĻ§◊ų°£
’‚÷÷∑Ĺ ĹĶń»ĪĶ„ «£¨»ÁĻŻļů–Ý Ļ”√PythonĪŗ–īSpark Application£¨–Ť“™‘Ųľ”–¬Ķń“ņņĶń£Ņť£¨ń«√īĺÕ–Ť“™‘ŕYARNľĮ»ļĶń√ŅłŲĹŕĶ„…Ō∂ľĹÝ––ł√–¬‘Ųń£ŅťĶńį≤◊į°£∂Ý«“£¨»ÁĻŻ“ņņĶPythonĶńįśĪĺ£¨Ņ…ń‹ĽĻ–Ť“™Ļ‹ņŪ≤ĽÕ¨įśĪĺPythonĽ∑ĺ≥°£“Úő™ŐŠĹĽPySpark
Application‘ň––£¨ĺŖŐŚ‘ŕńń–©NodeManager…Ō‘ň––ł√Application£¨ «”…YARNĶńĶų∂»∆ųĺŲ∂®Ķń£¨Īō–ŽĪ£÷§√ŅłŲNodeManager…Ō∂ľĺŖ”–PythonĽ∑ĺ≥£®Ľýī°Ľ∑ĺ≥+“ņņĶń£Ņť£©°£
YARNľĮ»ļ≤ĽŇš÷√PythonĽ∑ĺ≥
’‚÷÷«ťŅŲ£¨łŁ ļŌ∆ů“Ķ“—ĺ≠į≤◊įŃňĻśń£ĹŌīůĶńYARNľĮ»ļ£¨≤Ę‘ŕŅ™ ľ Ļ”√ Ī≤ĘőīŅľ¬«ĶĹļů–ÝĽŠ Ļ”√Ľý”ŕPythonņīĪŗ–īSpark
Application£¨≤Ę«“≤ĽŌŽ‘ŕYARNľĮ»ļĶńNodeManager…Ōį≤◊įPythonĽ∑ĺ≥“ņņĶ“ņņĶń£Ņť°£ő“√«≤őŅľŃňBenjamin
ZaitlenĶń≤©őń£®ŌÍľŻļů√ś≤őŅľŃīĹ”£©£¨≤ĘĽý”ŕAnaconda»ŪľĢĽ∑ĺ≥ĹÝ––Ńň ĶľýļÕ—ť÷§£¨ĺŖŐŚ ĶŌ÷ňľ¬∑»ÁŌ¬ňý ĺ£ļ
‘ŕ»ő“‚“ĽłŲLInux OSĶńĹŕĶ„…Ō£¨į≤◊įAnaconda»ŪľĢ
Õ®ĻżAnacondaīīĹ®–ťń‚PythonĽ∑ĺ≥
‘ŕīīĹ®ļ√ĶńPythonĽ∑ĺ≥÷–Ō¬‘ōį≤◊į“ņņĶĶńPythonń£Ņť
Ĺę’ŻłŲPythonĽ∑ĺ≥īÚ≥…zipįŁ
ŐŠĹĽPySpark Application Ī£¨≤ĘÕ®Ļż®Carchives—°ŌÓ÷ł∂®zipįŁ¬∑ĺ∂
Ō¬√śĹÝ––ŌÍŌłňĶ√ų£ļ
◊Ō»£¨ő“√«‘ŕCentOS 7.2…Ō£¨Ľý”ŕPython 2.7£¨Ō¬‘ōŃňAnaconda2-5.0.0.1-Linux-x86_64.shį≤◊į»ŪľĢ£¨≤ĘĹÝ––Ńňį≤◊į°£AnacondaĶńį≤◊į¬∑ĺ∂ő™/root/anaconda2°£
»Ľļů£¨īīĹ®“ĽłŲPython–ťń‚Ľ∑ĺ≥£¨÷ī––»ÁŌ¬√ŁŃÓ£ļ
| conda create -n
mlpy_env --copy -y -q python= 2 numpy pandas scipy |
…Ō Ų√ŁŃÓīīĹ®Ńň“ĽłŲ√Ż≥∆ő™mlpy_envĶńPythonĽ∑ĺ≥£¨®Ccopy—°ŌÓĹę∂‘”¶Ķń»ŪľĢįŁ∂ľį≤◊įĶĹł√Ľ∑ĺ≥÷–£¨įŁņ®“Ľ–©CĶń∂ĮŐ¨ŃīĹ”Ņ‚őńľĢ°£Õ¨ Ī£¨Ō¬‘ōnumpy°Ępandas°Ęscipy’‚»żłŲ“ņņĶń£ŅťĶĹł√Ľ∑ĺ≥÷–°£
Ĺ”◊Ň£¨Ĺęł√PythonĽ∑ĺ≥īÚįŁ£¨÷ī––»ÁŌ¬√ŁŃÓ£ļ
cd /root/anaconda2/envs
zip -r mlpy_env.zip mlpy_env
|
ł√zipőńľĢīůłŇ”–400MB◊ů”“£¨Ĺęł√zip—ĻňűįŁŅĹĪīĶĹ÷ł∂®ńŅ¬ľ÷–£¨∑ĹĪ„ļů–ÝŐŠĹĽPySpark Application£ļ
◊Óļů£¨ő“√«Ņ…“‘ŐŠĹĽő“√«ĶńPySpark Application£¨÷ī––»ÁŌ¬√ŁŃÓ£ļ
PYSPARK_PYTHON= ./ANACONDA/mlpy_env/ bin/python
spark-submit \
--conf spark.yarn.appMasterEnv .PYSPARK_PYTHON =./ANACONDA/mlpy_env/ bin/python
\
--master yarn-cluster \
--archives /tmp/ mlpy_env.zip #ANACONDA \
/var/lib/hadoop-hdfs/ pyspark/test_pyspark_dependencies.py
|
…Ō√śĶńtest_pyspark_dependencies.pyőńľĢ÷–£¨ Ļ”√Ńňnumpy°Ępandas°Ęscipy’‚»żłŲ“ņņĶįŁĶńļĮ ż£¨Õ®Ļż…Ō√śŐŠĶĹĶńYARNľĮ»ļĶńclusterń£ ĹŅ…“‘‘ň––‘ŕSparkľĮ»ļ…Ō°£
Ņ…“‘ŅīĶĹ£¨…Ō√śĶń“ņņĶzip—ĻňűįŁĹę’ŻłŲPythonĶń‘ň––Ľ∑ĺ≥∂ľįŁļ¨‘ŕņÔ√ś£¨‘ŕŐŠĹĽPySpark
Application ĪĽŠĹęł√Ľ∑ĺ≥zipįŁ…ŌīęĶĹ‘ň––ApplicationĶńňý‘ŕĶń√ŅłŲĹŕĶ„…Ō£¨≤ĘĹ‚—Ļňűļůő™Pythonīķ¬ŽŐŠĻ©‘ň–– ĪĽ∑ĺ≥°£»ÁĻŻ≤ĽŌŽ√Ņīő∂ľī”ŅÕĽß∂ňĹęł√Ľ∑ĺ≥őńľĢ…ŌīęĶĹľĮ»ļ÷–‘ň––PySpark
ApplicationĶńĹŕĶ„…Ō£¨“≤Ņ…“‘ĹęzipįŁ…ŌīęĶĹHDFS…Ō£¨≤Ę–řłń®Carchives≤ő żĶń÷Ķő™hdfs:///tmp/mlpy_env.zip
#ANACONDA£¨“≤ «Ņ…“‘Ķń°£
ŃŪÕ‚£¨–Ť“™ňĶ√ųĶń «£¨»ÁĻŻő“√«Ņ™∑ĘĶń/var/lib/hadoop-hdfs/pyspark
/test_pyspark_dependencies.pyőńľĢ÷–£¨“≤“ņņĶĶń“Ľ–©ő“√«◊‘ľļ ĶŌ÷Ķńī¶ņŪļĮ ż£¨ĺŖ”–∂ŗłŲPython“ņņĶĶńőńľĢ£¨ŌŽ“™Õ®Ļż…Ō√śĶń∑Ĺ Ĺ‘ň––£¨Īō–ŽĹę’‚–©“ņņĶĶńPythonőńľĢŅĹĪīĶĹő“√«īīĹ®ĶńĽ∑ĺ≥÷–£¨∂‘”¶ĶńńŅ¬ľő™mlpy_env/lib/python2.7/site-packages/Ō¬√ś°£
Ľý”༞ļŌĪŗ≥Ő”Ô—‘Ľ∑ĺ≥
ľŔ»Áő“√«ĽĻ «Ō£ÕŻ Ļ”√Spark on YARNń£ Ĺņī‘ň––PySpark Application£¨Ķę≤Ę≤ĽĹęPython≥Ő–ÚŐŠĹĽĶĹYARNľĮ»ļ…Ō‘ň––°£’‚ Ī£¨ő“√«Ņ…“‘Ņľ¬« Ļ”√ĽžļŌĪŗ≥Ő”Ô—‘Ķń∑Ĺ Ĺ£¨ņīī¶ņŪ żĺ›»őőŮ°£Ī»»Á£¨Ľķ∆ų—ßŌįApplicationĺŖ”–ĶŁīķľ∆ň„ĶńŐō–‘£¨łŁ ļŌ‘ŕ“ĽłŲłŖŇšĶńĹŕĶ„…Ō‘ň––£Ľ∂Ý∆’Õ®ĶńETL żĺ›ī¶ņŪĺŖ”–∂ŗĽķ≤Ę––ī¶ņŪĶńŐōĶ„£¨ ļŌ∑ŇĶĹľĮ»ļ…ŌĹÝ––∑÷≤ľ Ĺī¶ņŪ°£
“ĽłŲÕÍ’ŻĶńĽķ∆ų—ßŌįApplicationĶń…Ťľ∆”ŽĻĻĹ®£¨Ņ…“‘Ĺęň„∑®≤Ņ∑÷ļÕ żĺ›◊ľĪł≤Ņ∑÷∑÷ņŽ≥Ųņī£¨ Ļ”√Scala/JavaĹÝ–– żĺ›‘§ī¶ņŪ£¨ š≥Ų“ĽłŲĽķ∆ų—ßŌįň„∑®ňý–Ť“™£®łŁĪ„”ŕĶŁīķ°Ę—į”Ňľ∆ň„£©Ķń š»Ž żĺ›łŮ Ĺ£¨’‚ĽŠľęīůĶō—Ļňűň„∑® š»Ž żĺ›ĶńĻśń££¨ī”∂Ý Ļň„∑®ĶŁīķľ∆ň„≥š∑÷ņŻ”√Ķ•ĽķĪĺĶōĶń◊ ‘ī£®ńŕīś°ĘCPU°ĘÕݬÁ£©£¨’‚Ņ…ń‹ĽŠĪ»÷ĪĹ”∑ŇĶĹľĮ»ļ÷–ľ∆ň„“™ŅžĶ√∂ŗ°£
“Úīň£¨ő“√«‘ŕ∂‘Ľķ∆ų—ßŌįApplication◊ľĪł żĺ› Ī£¨ Ļ”√‘≠…ķĶńScalaĪŗ≥Ő”Ô—‘ ĶŌ÷Spark
Applicationņīī¶ņŪ żĺ›£¨įŁņ®◊™ĽĽ°ĘÕ≥ľ∆°Ę—ĻňűĶ»Ķ»£¨Ĺę¬ķ◊„ň„∑® š»ŽłŮ ĹĶń żĺ› š≥ŲĶĹHDFS÷ł∂®ńŅ¬ľ÷–°£‘ŕ–‘ń‹∑Ĺ√ś£¨∂‘ żĺ›Ļśń£ĹŌīůĶń«ťŅŲŌ¬£¨‘ŕSparkľĮ»ļ…Ōī¶ņŪ żĺ›£¨Scala/Java ĶŌ÷ĶńSpark
Application‘ň–––‘ń‹“™ļ√“Ľ–©°£»Ľļů£¨ň„∑®ĶŁīķ≤Ņ∑÷£¨Ľý”ŕ∑ŠłĽ°ĘłŖ–‘ń‹ĶńPythonŅ∆—ßľ∆ň„ń£Ņť£¨ Ļ”√Python”Ô—‘ ĶŌ÷£¨∆š Ķ÷ĪĹ” Ļ”√PySpark
API ĶŌ÷“ĽłŲĽķ∆ų—ßŌįPySpark Application£¨‘ň––ń£ Ĺő™YARN clientń£ Ĺ°£’‚ Ī£¨ĺÕ–Ť“™‘ŕň„∑®‘ň––ĶńĹŕĶ„…Ōį≤◊įļ√PythonĽ∑ĺ≥ľį∆š“ņņĶń£Ņť£®∂Ý≤Ľ–Ť“™‘ŕYARNľĮ»ļĶńĹŕĶ„…Ōį≤◊į£©£¨Driver≥Ő–Úī”HDFS÷–∂Ń»° š»Ž żĺ›£®ĽļīśĶĹĪĺĶō£©£¨»Ľļů‘ŕĪĺĶōĹÝ––ň„∑®ĶńĶŁīķľ∆ň„£¨◊Óļů š≥Ųń£–Õ°£
◊‹ĹŠ
∂‘”ŕ÷ō∂» Ļ”√PySparkĶń«ťŅŲ£¨Ī»»Á∆ęŌÚĽķ∆ų—ßŌį£¨Ņ…“‘Ņľ¬«‘ŕ’ŻłŲľĮ»ļ÷–∂ľį≤◊įļ√PythonĽ∑ĺ≥£¨≤Ęłýĺ›≤ĽÕ¨Ķń–Ť“™ĹÝ––“ņņĶń£ŅťĶńÕ≥“ĽĻ‹ņŪ£¨ń‹ĻĽ=ľęīůĶō∑ĹĪ„PySpark
ApplicationĶń‘ň––°£
≤Ľ‘ŕYARNľĮ»ļ…Ōį≤◊įPythonĽ∑ĺ≥Ķń∑Ĺįł£¨ĽŠ ĻŐŠĹĽĶńPythonĽ∑ĺ≥zipįŁ‘ŕYARNľĮ»ļ÷–īę šīÝņī“Ľ∂®Ņ™Ōķ£¨∂Ý«“√ŅīőŐŠĹĽ“ĽłŲPySpark
Application∂ľ–Ť“™īÚįŁ“ĽłŲĽ∑ĺ≥zipőńľĢ£¨»ÁĻŻ”–īůŃŅĶńPython ĶŌ÷ĶńPySpark Application–Ť“™‘ŕSparkľĮ»ļ…Ō‘ň––£¨Ņ™ŌķĽŠ‘Ĺņī‘Ĺīů°£ŃŪÕ‚£¨»ÁĻŻPySpark”¶”√≥Ő–Ú–řłń£¨Ņ…ń‹–Ť“™÷ō–¬īÚįŁĽ∑ĺ≥°£Ķę «’‚—ý◊Ų»∑ Ķ≤Ľ‘ŕ–Ť“™Ņľ¬«YARNľĮ»ļľĮ»ļĹŕĶ„…ŌĶńPythonĽ∑ĺ≥Ńň£¨»őļőįśĪĺPythonĪŗ–īĶńPySpark
Application∂ľŅ…“‘ Ļ”√ľĮ»ļ◊ ‘ī‘ň––°£
Ļō”ŕł√ő Ő‚£¨SPARK-13587£®ŌÍľŻŌ¬√ś≤őŅľŃīĹ”£©“≤‘ŕŐ÷¬Ř»ÁĻŻ”ŇĽĮł√ő Ő‚£¨ļů–Ý”¶ł√ĽŠ”–“ĽłŲĪ»ĹŌļŌ ĶńĹ‚ĺŲ∑Ĺįł°£ |









