| ЧАбдЃКДѓЪ§Он
2.0 ЪБДњВЛЦкЖјжС
ЫцзХДѓЪ§Он 2.0 ЪБДњЧФШЛЕНРДЃЌДѓЪ§ОнДгМђЕЅЕФХњДІРэРЉеЙЕНСЫЪЕЪБДІРэЁЂСїДІРэЁЂНЛЛЅЪНВщбЏКЭЛњЦїбЇЯАгІгУЁЃдчЦкЕФДІРэФЃаЭ
(Map/Reduce) дчвбОСІВЛДгаФЃЌЖјЧввВКмФбгІгУЕНДІРэСїГЬГЄЧвИДдгЕФЪ§ОнСїЫЎЯпЩЯЁЃСэЭтЃЌНќФъРДгПЯжГіжюЖрДѓЪ§ОнгІгУзщМўЃЌШч
HBaseЁЂHiveЁЂKafkaЁЂSparkЁЂFlink ЕШЁЃПЊЗЂепОГЃвЊгУЕНВЛЭЌЕФММЪѕЁЂПђМмЁЂAPIЁЂПЊЗЂгябдКЭ
SDK РДгІЖдИДдггІгУЕФПЊЗЂЁЃетДѓДѓдіМгСЫбЁдёКЯЪЪЙЄОпКЭПђМмЕФФбЖШЃЌПЊЗЂепЯывЊНЋЫљгаЕФДѓЪ§ОнзщМўЪьСЗдЫгУМИКѕЪЧвЛЯюВЛПЩФмЭъГЩЕФШЮЮёЁЃ
УцЖдетжжЧщПіЃЌGoogle дк 2016 Фъ 2 дТаћВМНЋДѓЪ§ОнСїЫЎЯпВњЦЗЃЈGoogle DataFlowЃЉЙБЯзИј
Apache ЛљН№ЛсЗѕЛЏЃЌ2017 Фъ 1 дТ Apache ЖдЭтаћВМПЊдД Apache BeamЃЌ2017
Фъ 5 дТгРДСЫЫќЕФЕквЛИіЮШЖЈАцБО 2.0.0ЁЃдкЙњФкЃЌДѓВПЗжПЊЗЂепЖдгк Beam ЛЙШБЗІСЫНтЃЌЩчЧјжаЮФзЪСЯвВБШНЯЩйЁЃInfoQ
ЦкЭћЭЈЙ§ Apache Beam ЪЕеНжИФЯЯЕСаЮФеТ ЭЦЖЏ Apache Beam дкЙњФкЕФЦеМАЁЃ
БОЮФНЋМђвЊНщЩм Apache Beam ЕФЗЂеЙРњЪЗЁЂгІгУГЁОАЁЂФЃаЭКЭдЫааСїГЬЁЂSDKs КЭ Beam
ЕФгІгУЪОР§ЁЃЛЖгМгШы Beam жаЮФЩчЧјЩюШыЬжТлКЭНЛСїЁЃ
ИХЪі
ДѓЪ§ОнДІРэСьгђЕФвЛДѓЮЪЬтЪЧЃКПЊЗЂепОГЃвЊгУЕНКмЖрВЛЭЌЕФММЪѕЁЂПђМмЁЂAPIЁЂПЊЗЂгябдКЭ SDKЁЃШЁОігкашвЊЭъГЩЕФЪЧЪВУДШЮЮёЃЌвдМАдкЪВУДЧщПіЯТНјааЃЌПЊЗЂепКмПЩФмЛсгУ
MapReduce НјааХњДІРэЃЌгУ Apache Spark SQL НјааНЛЛЅЧыЧѓЃЈinteractive
queriesЃЉЃЌгУ Apache Flink НјааЪЕЪБСїДІРэЃЌЛЙгаПЩФмгУЕНЛљгкдЦЖЫЕФЛњЦїбЇЯАПђМмЁЃ
НќСНФъгПЯжЕФПЊдДДѓГБЃЌЮЊДѓЪ§ОнПЊЗЂепЬсЙЉСЫЪЎЗжИЛгрЕФЙЄОпЁЃЕЋетЭЌЪБвВдіМгСЫПЊЗЂепбЁдёКЯЪЪЙЄОпЕФФбЖШЃЌгШЦфЖдгкаТШыааЕФПЊЗЂепРДЫЕЁЃетКмПЩФмЭЯТ§ЁЂЩѕжСзшАПЊдДЙЄОпЕФЗЂеЙЃКАбИїжжПЊдДПђМмЁЂЙЄОпЁЂПтЁЂЦНЬЈШЫЙЄећКЯЕНвЛЦ№ЫљашЙЄзїжЎИДдгЃЌЪЧДѓЪ§ОнПЊЗЂепГЃгаЕФБЇдЙжЎвЛЃЌвВЪЧЫћУЧжЇГжзЈгаДѓЪ§ОнЦНЬЈЕФЪзвЊдвђЁЃ
Apache Beam ЗЂеЙРњЪЗ
Beam дк 2016 Фъ 2 дТГЩЮЊ Apache ЗѕЛЏЦїЯюФПЃЌВЂдк 2016 Фъ 12 дТЩ§МЖГЩЮЊ
Apache ЛљН№ЛсЕФЖЅМЖЯюФПЁЃЭЈЙ§ЪЎЮхИідТЕФХЌСІЃЌвЛИіЩдЯдЛьТвЕФДњТыПтЃЌДгЖрИізщжЏКЯВЂЃЌвбЗЂеЙГЩЮЊЪ§ОнДІРэЕФЭЈгУв§ЧцЃЌМЏГЩЖрИіДІРэЪ§ОнПђМмЃЌПЩвдзіЕНПчЛЗОГЁЃ
Beam ОЙ§Ш§ИіЗѕЛЏЦїАцБОКЭШ§ИіКѓЗѕЛЏЦїАцБОЕФбнЛЏКЭИФНјЃЌзюжедк 2017 Фъ 5 дТ 17 ШегРДСЫЫќЕФЕквЛИіЮШЖЈАц
2.0.0ЁЃЗЂВМЮШЖЈАцБО 3 ИідТвдРДЃЌApache Beam вбОГіЯжУїЯдЕФдіГЄЃЌЮоТлЪЧЭЈЙ§ЙйЗНЛЙЪЧЩчЧјЕФЙБЯзЪ§СПЁЃApache
Beam дкЙШИшдЦЗНУцвВвбОеЙЪОГіСЫЁАВХИЩЁБЁЃ
Beam 2.0.0 ИФНјСЫгУЛЇЬхбщЃЌжиЕудкгкПђМмПчЛЗОГЕФЮоЗьвЦжВФмСІЃЌетаЉжДааЛЗОГАќРЈжДаав§ЧцЁЂВйзїЯЕЭГЁЂБОЕиМЏШКЁЂдЦЖЫвдМАЪ§ОнДцДЂЯЕЭГЁЃBeam
ЕФЦфЫћЬиадЛЙАќРЈШчЯТМИЕуЃК
API ЮШЖЈадКЭЖдЮДРДАцБОЕФМцШнадЁЃ
газДЬЌЕФЪ§ОнДІРэФЃЪНЃЌИпаЇЕФжЇГжвРРЕгкЪ§ОнЕФМЦЫуЁЃ
жЇГжгУЛЇРЉеЙЕФЮФМўЯЕЭГЃЌжЇГж Hadoop ЗжВМЪНЗЂЮФМўЯЕЭГМАЦфЫћЁЃ
ЬсЙЉСЫвЛИіЖШСПжИБъЯЕЭГЃЌПЩгУгкИњзйЙмЕРЕФжДаазДПіЁЃ
ЭјЩЯвбОгаКмЖрШЫаДЙ§ Beam 2.0.0 АцБОжЎЧАЕФзЪСЯЃЌЕЋЪЧ 2.0.0 АцБОКѓ API КмЖраДЗЈБфЖЏНЯДѓЃЌБОЮФНЋДјзХДѓМвДгСуЛљДЁЕН
Apache Beam ШыУХЁЃ
Apache Beam гІгУГЁОА
Google CloudЁЂPayPalЁЂTalend ЕШЙЋЫОЖМдкЪЙгУ BeamЃЌЙњФкАќРЈАЂРяАЭАЭЁЂАйЖШЁЂН№ЩНЁЂЫеФўЁЂОХДЮЗНДѓЪ§ОнЁЂ360ЁЂЛлОлЪ§ЭЈаХЯЂММЪѕгаЯоЙЋЫОЕШвВдкЪЙгУ
BeamЃЌЭЌЪБЛЙгавЛаЉДѓЪ§ОнЙЋЫОЕФМмЙЙЪІЛђбаЗЂШЫдБе§дквЛЦ№НјаабаОПЁЃApache Beam жаЮФЩчЧје§дкМЏГЩвЛаЉЙЄзїжаЕФ
runners КЭ sdk IOЃЌАќРЈШЫЙЄжЧФмЁЂЛњЦїбЇЯАКЭЪБађЪ§ОнПтЕШвЛаЉЙІФмЁЃ
вдЯТЮЊгІгУГЁОАЕФМИИіР§згЃК
Beam ПЩвдгУгк ETL Job ШЮЮё
Beam ЕФЪ§ОнПЩвдЭЈЙ§ SDKs ЕФ IO НгШыЃЌЭЈЙ§ЙмЕРПЩвдгУКѓУцЕФ Runners зіЧхЯДЁЃ
Beam Ъ§ОнВжПтПьЫйЧаЛЛЁЂПчВжПт
гЩгк Beam ЕФЪ§ОндДЪЧЖрбљ IOЃЌЫљвдгУ Beam ПЩвдПьЫйЧаЛЛШЮКЮЪ§ОнВжПтЁЃ
Beam МЦЫуДІРэЦНЬЈЧаЛЛЁЂПчЦНЬЈ
Runners ФПЧАЬсЙЉСЫ 3-4 жжПЩвдЧаЛЛЕФЦНЬЈЃЌЫцзХ Beam ЕФЧПДѓгІИУЛсгаИќЖрЕФЦНЬЈЬсЙЉИјДѓМвЪЙгУЁЃ
Apache Beam дЫааСїГЬ
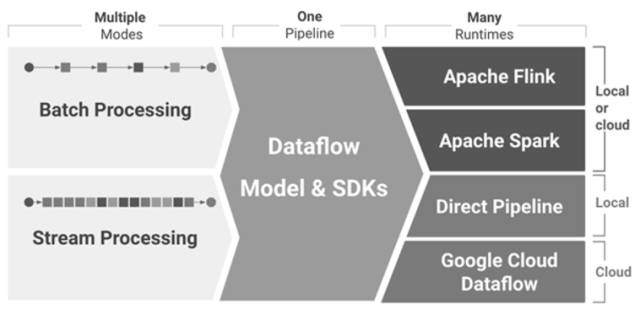
4-1 Ъ§ОнДІРэСїГЬ
ШчЭМ 4-1 ЫљЪОЃЌApache Beam ДѓЬхдЫааСїГЬЗжГЩШ§ДѓВПЗжЃК
Modes
Modes ЪЧ Beam ЕФФЃаЭЛђНаЪ§ОнРДдДЕФ IOЃЌЫќЪЧгЩЖржжЪ§ОндДЛђВжПтЕФ IO зщГЩЃЌЪ§ОндДжЇГжХњДІРэКЭСїДІРэЁЃ
Pipeline
Pipeline ЪЧ Beam ЕФЙмЕРЃЌЫљгаЕФХњДІРэЛђСїДІРэЖМвЊЭЈЙ§етИіЙмЕРАбЪ§ОнДЋЪфЕНКѓЖЫЕФМЦЫуЦНЬЈЁЃетИіЙмЕРЯждкЪЧЮЈвЛЕФЁЃЪ§ОндДПЩвдЧаЛЛЖржжЃЌМЦЫуЦНЬЈЛђДІРэЦНЬЈвВжЇГжЖржжЁЃашвЊзЂвтЕФЪЧЃЌЙмЕРжЛгавЛЬѕЃЌЫќЕФзїгУЪЧСЌНгЪ§ОнКЭ
Runtimes ЦНЬЈЁЃ
Runtimes
Runtimes ЪЧДѓЪ§ОнМЦЫуЛђДІРэЦНЬЈЃЌФПЧАжЇГж Apache FlinkЁЂApache SparkЁЂDirect
Pipeline КЭ Google Clound Dataflow ЫФжжЁЃЦфжа Apache Flink
КЭ Apache Spark ЭЌЪБжЇГжБОЕиКЭдЦЖЫЁЃDirect Pipeline НіжЇГжБОЕиЃЌGoogle
Clound Dataflow НіжЇГждЦЖЫЁЃГ§ДЫжЎЭтЃЌКѓЦк Beam ЙњЭтбаЗЂЭХЖгЛЙЛсМЏГЩЦфЫћДѓЪ§ОнМЦЫуЦНЬЈЁЃгЩгкЙШИшЮДНјШыжаЙњЃЌФПЧАЙњФкПЊЗЂШЫдБдкЙЄзїжаЖдЙШИшдЦЕФЪЙгУгІИУВЛЪЧКмЖрЃЌжївЊвдЧАСНжжЮЊжїЁЃЮЊСЫЪЙЖСепЖСЭъЮФеТКѓФмПьЫйбЇЯАЧвИќЬљНќЪЕМЪЙЄзїЛЗОГЃЌКѓајЮФеТжаЮвЛсвдЧАСНжжзїЮЊДѓЪ§ОнМЦЫуЛђДІРэЦНЬЈНјаабнЪОЁЃ
Beam Model МАЦфЙЄзїСїГЬ
Beam Model жИЕФЪЧ Beam ЕФБрГЬЗЖЪНЃЌМД Beam SDK БГКѓЕФЩшМЦЫМЯыЁЃдкНщЩм Beam
Model жЎЧАЃЌЯШМђвЊНщЩмвЛЯТ Beam Model вЊДІРэЕФЮЪЬтгђгывЛаЉЛљБОИХФюЁЃ
Ъ§ОндДРраЭЁЃЗжВМЪНЪ§ОнРДдДРраЭвЛАуПЩвдЗжЮЊСНРрЃЌгаНчЕФЪ§ОнМЏКЭЮоНчЕФЪ§ОнСїЁЃгаНчЕФЪ§ОнМЏЃЌБШШчвЛИі
Ceph жаЕФЮФМўЃЌвЛИі Mongodb БэЕШЃЌЬиЕуЪЧЪ§ОнвбОДцдкЃЌЪ§ОнМЏгавбжЊЕФЁЂЙЬЖЈЕФДѓаЁЃЌвЛАуДцдкДХХЬЩЯЃЌВЛЛсЭЛШЛЯћЪЇЁЃЖјЮоНчЕФЪ§ОнСїЃЌБШШч
Kafka жаСїЙ§РДЕФЪ§ОнСїЃЌетжжЪ§ОнЕФЬиЕуЪЧЪ§ОнЖЏЬЌСїШыЁЂУЛгаБпНчЁЂЮоЗЈШЋВПГжОУЛЏЕНДХХЬЩЯЁЃBeam
ПђМмЩшМЦЪБашвЊеыЖдетСНжжЪ§ОнЕФДІРэНјааПМТЧЃЌМДХњДІРэКЭСїДІРэЁЃ
ЪБМфЁЃЗжВМЪНПђМмЕФЪБМфДІРэгаСНжжЃЌвЛжжЪЧШЋСПМЦЫуЃЌСэвЛжжЪЧВПЗждіСПМЦЫуЁЃЮвИјДѓМвОйИіР§згЃКР§ШчЮвУЧЭцЁАЭѕепХЉвЉЁБгЮЯЗЃЌгЮЯЗЕФЪ§ОнашвЊЪЕЪБЕиСїЯђЗўЮёЦїЃЌЕєбЊЧщПіЛсЫцзХЪБМфЪЕЪББфЛЏЃЌЕЋЪЧХХааАёЕФЪ§ОндђЪЧШЋВПЭцМвдквЛЖЈЪБМфФкЕФХХУћЃЌР§ШчвЛжмЛђвЛИідТЁЃBeam
еыЖдетСНжжЧщПіЖМЩшМЦСЫЖдгІЕФДІРэЗНЪНЁЃ
ТвађЁЃЖдгкСїДІРэПђМмДІРэЕФЪ§ОнСїРДЫЕЃЌЪ§ОнЕНДяДѓЬхЗжСНжжЃЌвЛжжЪЧАДее Process Time ЖЈвхЪБМфДАПкЃЌетжжВЛгУПМТЧТвађЮЪЬтЃЌвђЮЊЖМЪЧЙиБеЕБЧАДАПкКѓВХНјааЯТвЛИіДАПкВйзїЃЌашвЊЕШД§ЃЌЫљвджДааЖМЪЧгаађЕФЁЃЖјСэвЛжжЃЌEvent
Time ЖЈвхЕФЪБМфДАПкдђВЛашвЊЕШД§ЃЌПЩФмЕБЧАВйзїЛЙУЛгаДІРэЭъЃЌОЭжБНгжДааЯТвЛИіВйзїЃЌдьГЩЯћЯЂЫГађДІРэЕЋНсЙћВЛЪЧАДЫГађХХађСЫЁЃР§ШчЮвУЧЕФЖЉЕЅЯћЯЂЃЌВЩгУСЫЗжВМЪНДІРэЃЌШчЙћЯТЕЅВйзїЫљЪєЗўЮёЦїДІРэЫйЖШБШНЯТ§ЃЌЖјгУЛЇжЇИЖЕФЗўЮёЦїЫйЖШЗЧГЃПьЃЌетЪБзюКѓЕФЖЉЕЅВйзїЪБМфжсОЭЛсГіЯжвЛжжЧщПіЃЌЯТЕЅдкжЇИЖЕФКѓУцЁЃЖдгкетжжЧщПіЃЌШчКЮШЗЖЈГйЕНЪ§ОнЃЌвдМАЖдгкГйЕНЪ§ОнШчКЮДІРэЭЈГЃЪЧКмТщЗГЕФЪТЧщЁЃ
Beam Model ДІРэЕФФПБъЪ§ОнЪЧЮоНчЕФЪБМфТвађЪ§ОнСїЃЌВЛПМТЧЪБМфЫГађЛђгаНчЕФЪ§ОнМЏПЩПДзіЪЧЮоНчТвађЪ§ОнСїЕФвЛИіЬиР§ЁЃBeam
Model ДгЯТУцЫФИіЮЌЖШЙщФЩСЫгУЛЇдкНјааЪ§ОнДІРэЕФЪБКђашвЊПМТЧЕФЮЪЬтЃК
WhatЁЃШчКЮЖдЪ§ОнНјааМЦЫуЃПР§ШчЃЌЛњЦїбЇЯАжабЕСЗбЇЯАФЃаЭПЩвдгУ Sum Лђеп Join ЕШЁЃдк
Beam SDK жагЩ Pipeline жаЕФВйзїЗћжИЖЈЁЃ
WhereЁЃЪ§ОндкЪВУДЗЖЮЇжаМЦЫуЃПР§ШчЃЌЛљгк Process-Time ЕФЪБМфДАПкЁЂЛљгк Event-Time
ЕФЪБМфДАПкЁЂЛЌЖЏДАПкЕШЕШЁЃдк Beam SDK жагЩ Pipeline ЕФДАПкжИЖЈЁЃ
WhenЁЃКЮЪБЪфГіМЦЫуНсЙћЃПР§ШчЃЌдк 1 аЁЪБЕФ Event-Time ЪБМфДАПкжаЃЌУПИє 1 ЗжжгНЋЕБЧАДАПкМЦЫуНсЙћЪфГіЁЃдк
Beam SDK жагЩ Pipeline ЕФ Watermark КЭДЅЗЂЦїжИЖЈЁЃ
HowЁЃГйЕНЪ§ОнШчКЮДІРэЃПР§ШчЃЌНЋГйЕНЪ§ОнМЦЫудіСПНсЙћЪфГіЃЌЛђЪЧНЋГйЕНЪ§ОнМЦЫуНсЙћКЭДАПкФкЪ§ОнМЦЫуНсЙћКЯВЂГЩШЋСПНсЙћЪфГіЁЃдк
Beam SDK жагЩ Accumulation жИЖЈЁЃ
Beam Model НЋЁАWWWHЁБЫФИіЮЌЖШГщЯѓГіРДзщГЩСЫ Beam SDKЃЌгУЛЇдкЛљгк Beam
SDK ЙЙНЈЪ§ОнДІРэвЕЮёТпМЪБЃЌУПвЛВНжЛашвЊИљОнвЕЮёашЧѓАДееетЫФИіЮЌЖШЕїгУОпЬхЕФ APIЃЌМДПЩЩњГЩЗжВМЪНЪ§ОнДІРэ
PipelineЃЌВЂЬсНЛЕНОпЬхжДаав§ЧцЩЯжДааЁЃЁАWWWHЁБЫФИіЮЌЖШжЛЪЧДгвЕЮёЕФНЧЖШПДД§ЮЪЬтЃЌВЂВЛЪЧШЋВПЪЪгУгкздМКЕФвЕЮёЁЃзіММЪѕМмЙЙвЛЖЈвЊНсКЯздМКЕФвЕЮёЪЙгУЯргІЕФММЪѕЬиадЛђПђМмЁЃBeam
зіЮЊЁАвЛЭГЁБЕФПђМмЃЌЮЊПЊЗЂепДјРДСЫЗНБуЁЃ
Beam SDKs
Beam SDK ИјЩЯВугІгУЕФПЊЗЂепЬсЙЉСЫвЛИіЭГвЛЕФБрГЬНгПкЃЌПЊЗЂепВЛашвЊСЫНтЕзВуЕФОпЬхЕФДѓЪ§ОнЦНЬЈЕФПЊЗЂНгПкЪЧЪВУДЃЌжБНгЭЈЙ§
Beam SDK ЕФНгПкОЭПЩвдПЊЗЂЪ§ОнДІРэЕФМгЙЄСїГЬЃЌВЛЙмЪфШыЪЧгУгкХњДІРэЕФгаНчЪ§ОнМЏЃЌЛЙЪЧСїЪНЕФЮоНчЪ§ОнМЏЁЃЖдгкетСНРрЪфШыЪ§ОнЃЌBeam
SDK ЖМЪЙгУЯрЭЌЕФРрРДБэЯжЃЌВЂЧвЪЙгУЯрЭЌЕФзЊЛЛВйзїНјааДІРэЁЃBeam SDK гЕгаВЛЭЌБрГЬгябдЕФЪЕЯжЃЌФПЧАвбОЭъећЕиЬсЙЉСЫ
Java ЕФ SDKЃЌPython ЕФ SDK ЛЙдкПЊЗЂжаЃЌЯраХЮДРДЛсЗЂВМИќЖрВЛЭЌБрГЬгябдЕФ SDKЁЃ
Beam 2.0 ЕФ SDKs ФПЧАгаЃК
AmqpЃКИпМЖЯћЯЂЖгСаавщЁЃ
CassandraЃКCassandra ЪЧвЛИі NoSQL СазхЃЈcolumn familyЃЉЪЕЯжЃЌЪЙгУгЩ
Amazon Dynamo в§ШыЕФМмЙЙЗНУцЕФЬиадРДжЇГж Big Table Ъ§ОнФЃаЭЁЃCassandra
ЕФвЛаЉгХЪЦШчЯТЫљЪОЃК
ИпЖШПЩРЉеЙадКЭИпЖШПЩгУадЃЌУЛгаЕЅЕуЙЪеЯ
NoSQL СазхЪЕЯж
ЗЧГЃИпЕФаДШыЭЬЭТСПКЭСМКУЕФЖСШЁЭЬЭТСП
РрЫЦ SQL ЕФВщбЏгябдЃЈДг 0.8 АцБОЦ№ЃЉЃЌВЂЭЈЙ§ЖўМЖЫїв§жЇГжЫбЫї
ПЩЕїНкЕФвЛжТадКЭЖдИДжЦЕФжЇГжСщЛюЕФФЃЪН
ElasticesarchЃКвЛИіЪЕЪБЕФЗжВМЪНЫбЫїв§ЧцЁЃ
Google-cloud-platformЃКЙШИшдЦ IOЁЃ
Hadoop-file-systemЃКВйзї Hadoop ЮФМўЯЕЭГЕФ IOЁЃ
Hadoop-hbaseЃКВйзї Hadoop ЩЯЕФ Hbase ЕФНгПк IOЁЃ
HcatalogЃКHcatalog ЪЧ Apache ПЊдДЕФЖдгкБэКЭЕзВуЪ§ОнЙмРэЭГвЛЗўЮёЦНЬЈЁЃ
JdbcЃКСЌНгИїжжЪ§ОнПтЕФЪ§ОнПтСЌНгЦїЁЃ
JmsЃКJava ЯћЯЂЗўЮёЃЈJava Message ServiceЃЌМђГЦ JMSЃЉЪЧгУгкЗУЮЪЦѓвЕЯћЯЂЯЕЭГЕФПЊЗЂЩЬжаСЂЕФ
APIЁЃЦѓвЕЯћЯЂЯЕЭГПЩвдажњгІгУШэМўЭЈЙ§ЭјТчНјааЯћЯЂНЛЛЅЁЃJMS дкЦфжаАчбнЕФНЧЩЋгы JDBC КмЯрЫЦЃЌе§Шч
JDBC ЬсЙЉСЫвЛЬзгУгкЗУЮЪИїжжВЛЭЌЙиЯЕЪ§ОнПтЕФЙЋЙВ APIЃЌJMS вВЬсЙЉСЫЖРСЂгкЬиЖЈГЇЩЬЕФЦѓвЕЯћЯЂЯЕЭГЗУЮЪЗНЪНЁЃ
KafkaЃКДІРэСїЪ§ОнЕФЧсСПМЖДѓЪ§ОнЯћЯЂЯЕЭГЃЌЛђНаЯћЯЂзмЯпЁЃ
KinesisЃКЖдНгбЧТэбЗЕФЗўЮёЃЌПЩвдЙЙНЈгУгкДІРэЛђЗжЮіСїЪ§ОнЕФздЖЈвхгІгУГЬађЃЌвдТњзуЬиЖЈашЧѓЁЃ
MongodbЃКMongoDB ЪЧвЛИіЛљгкЗжВМЪНЮФМўДцДЂЕФЪ§ОнПтЁЃ
MqttЃКIBM ПЊЗЂЕФвЛИіМДЪБЭЈбЖавщЁЃ
SolrЃКбЧЪЕЪБЕФЗжВМЪНЫбЫїв§ЧцММЪѕЁЃ
xmlЃКвЛжжЪ§ОнИёЪНЁЃ
Beam Pipeline Runners
Beam Pipeline Runner НЋгУЛЇгУ Beam ФЃаЭЖЈвхПЊЗЂЕФДІРэСїГЬЗвыГЩЕзВуЕФЗжВМЪНЪ§ОнДІРэЦНЬЈжЇГжЕФдЫааЪБЛЗОГЁЃдкдЫаа
Beam ГЬађЪБЃЌашвЊжИУїЕзВуЕФе§ШЗ Runner РраЭЃЌеыЖдВЛЭЌЕФДѓЪ§ОнЦНЬЈЃЌЛсгаВЛЭЌЕФ RunnerЁЃФПЧА
FlinkЁЂSparkЁЂApex вдМАЙШИшЕФ Cloud DataFlow ЖМгажЇГж Beam ЕФ
RunnerЁЃ
ашвЊзЂвтЕФЪЧЃЌЫфШЛ Apache Beam ЩчЧјЗЧГЃЯЃЭћЫљгаЕФ Beam жДаав§ЧцЖМФмЙЛжЇГж Beam
SDK ЖЈвхЕФЙІФмШЋМЏЃЌЕЋЪЧдкЪЕМЪЪЕЯжжаПЩФмЮоЗЈДяЕНетвЛЦкЭћЁЃР§ШчЃЌЛљгк MapReduce ЕФ Runner
ЯдШЛКмФбЪЕЯжКЭСїДІРэЯрЙиЕФЙІФмЬиадЁЃОЭФПЧАзДЬЌЖјбдЃЌЖд Beam ФЃаЭжЇГжзюКУЕФОЭЪЧдЫаагкЙШИшдЦЦНЬЈжЎЩЯЕФ
Cloud DataflowЃЌвдМАПЩвдгУгкздНЈЛђВПЪ№дкЗЧЙШИшдЦжЎЩЯЕФ Apache FlinkЁЃЕБШЛЃЌЦфЫќЕФ
Runner вВе§дкгЭЗИЯЩЯЃЌећИіаавЕвВдкГЏзХжЇГж Beam ФЃаЭЕФЗНЯђЗЂеЙЁЃ
Beam 2.0 ЕФ Runners ПђМмШчЯТЃК
Apex
ЕЎЩњгк 2015 Фъ 6 дТЕФ Apache ApexЃЌЦфЭЌбљдДзд DataTorrent МАЦфСюШЫгЁЯѓЩюПЬЕФ
RTS ЦНЬЈЃЌЦфжаАќКЌвЛЬзКЫаФДІРэв§ЧцЁЂвЧБэАхЁЂеяЖЯгыМрПиЙЄОпЬзМўЭтМгзЈУХУцЯђЪ§ОнПЦбЇМвгУЛЇЕФЭМаЮСїБрГЬЯЕЭГ
dtAssembleЁЃжївЊгУгкСїДІРэЃЌГЃгУгкЮяСЊЭјЕШГЁОАЁЃ
Direct-java
БОЕиДІРэКЭдЫаа runnerЁЃ
Flink_2.10
Flink ЪЧвЛИіеыЖдСїЪ§ОнКЭХњЪ§ОнЕФЗжВМЪНДІРэв§ЧцЁЃ
Gearpump
Gearpump ЪЧвЛИіЛљгк Akka Actor ЕФЧсСПМЖЕФЪЕЪБСїМЦЫув§ЧцЁЃШчНёСїЦНЬЈашвЊДІРэРДздИїжжвЦЖЏЖЫКЭЮяСЊЭјЩшБИЕФКЃСПЪ§ОнЃЌЯЕЭГвЊФмВЛМфЖЯЕиЬсЙЉЗўЮёЃЌЖдЪ§ОнЕФДІРэвЊФмзіЕНВЛЖЊЪЇВЛжиИДЃЌЖдИїжжШэгВМўДэЮѓФмЦНЛЌДІРэЃЌЖдгУЛЇЕФЪфШывЊФмЪЕЪБЯьгІЁЃГ§СЫетаЉЯЕЭГВуУцЕФашЧѓЭтЃЌгУЛЇВуУцЕФНгПкЛЙвЊФмзіЕНЗсИЛЖјСщЛюЃЌвЛЗНУцЃЌЦНЬЈвЊЬсЙЉзуЙЛЗсИЛЕФЛљДЁЩшЪЉЃЌФмзюМђЛЏгІгУГЬађЕФБраДЃЛСэвЛЗНУцЃЌетИіЦНЬЈгІЬсЙЉОпгаБэЯжСІЕФБрГЬ
APIЃЌШУгУЛЇФмСщЛюБэДяИїжжМЦЫуЃЌВЂЧвећИіЯЕЭГПЩвдЖЈжЦЃЌдЪаэгУЛЇбЁдёЕїЖШВпТдКЭВПЪ№ЛЗОГЃЌдЪаэгУЛЇдкВЛЭЌЕФжИБъМфзіелжаШЁЩсЃЌвдТњзуЬиЖЈЕФашЧѓЁЃAkka
Actor ЬсЙЉСЫЭЈаХЁЂВЂЗЂЁЂИєРыЁЂШнДэЕФЛљДЁЩшЪЉЃЌGearpump ЭЈЙ§АбГщЯѓВуДЮЬсЩ§ЕН Actor
етвЛВуЃЌЦСБЮСЫЕзВуЕФЯИНкЃЌзЈзЂгкСїДІРэашЧѓБОЩэЃЌФмИќМђЕЅЖјгжИпаЇЕиНтОіЩЯЪіЮЪЬтЁЃ
Dataflow
2016 Фъ 2 дТЗнЃЌЙШИшМАЦфКЯзїЛяАщЯђ Apache ОшдљСЫвЛДѓХњДњТыЃЌДДСЂСЫЗѕЛЏжаЕФ Beam
ЯюФПЃЈзюГѕНа Apache DataflowЃЉЁЃетаЉДњТыжаЕФДѓВПЗжРДздгкЙШИш Cloud Dataflow
SDKЁЊЁЊПЊЗЂепгУРДаДСїДІРэКЭХњДІРэЙмЕРЃЈpipelinesЃЉЕФПтЃЌПЩдкШЮКЮжЇГжЕФжДаав§ЧцЩЯдЫааЁЃЕБЪБЃЌжЇГжЕФжївЊв§ЧцЪЧЙШИш
Cloud DataflowЁЃ
Spark
Apache Spark ЪЧвЛИіе§дкПьЫйГЩГЄЕФПЊдДМЏШКМЦЫуЯЕЭГЁЃApache Spark ЩњЬЌЯЕЭГжаЕФАќКЭПђМмШевцЗсИЛЃЌЪЙЕУ
Spark ФмЙЛжДааИпМЖЪ§ОнЗжЮіЁЃApache Spark ЕФПьЫйГЩЙІЕУвцгкЫќЕФЧПДѓЙІФмКЭвзгУадЁЃЯрБШгкДЋЭГЕФ
MapReduce ДѓЪ§ОнЗжЮіЃЌSpark аЇТЪИќИпЁЂдЫааЪБЫйЖШИќПьЁЃApache Spark ЬсЙЉСЫФкДцжаЕФЗжВМЪНМЦЫуФмСІЃЌОпга
JavaЁЂScalaЁЂPythonЁЂR ЫФжжБрГЬгябдЕФ API БрГЬНгПкЁЃ
ЪЕеНЃКПЊЗЂЕквЛИі Beam ГЬађ
8.1 ПЊЗЂЛЗОГ
ЯТдиАВзА JDK 7 ЛђИќаТЕФАцБОЃЌМьВт JAVA_HOME ЛЗОГБфСПЁЃБОЮФЪОР§ЪЙгУЕФЪЧ JDK
1.8ЁЃ
ЯТди maven ВЂХфжУЃЌБОЮФЪОР§ЪЙгУЕФЪЧ maven-3.3.3ЁЃ
ПЊЗЂЛЗОГ myeclipseЁЂSpring Tool Suite ЁЂIntelliJ IDEAЃЌетИіПЩвдАДееИіШЫЯВКУЃЌБОЮФЪОР§гУЕФЪЧ
STSЁЃ
8.2 ПЊЗЂЕквЛИі wordCount ГЬађВЂЧвдЫаа
1 аТНЈвЛИі maven ЯюФП
2 дк pom.xml ЮФМўжаЬэМгСНИі jar Аќ
3 аТНЈвЛИі txtIOTest.java

аДШывдЯТДњТыЃК

4 вђЮЊ Windows ЩЯЕФ Beam2.0.0 ВЛжЇГжБОЕиТЗОЖЃЌашвЊВПЪ№ЕН Linux ЩЯЃЌашвЊДђАќШчЭМЃЌДЫДІзЂвтвЊАбвРРЕ
jar ЖМДђАќНјШЅЁЃ

5 ВПЪ№ beam.jar ЕН Linux ЛЗОГжа
ЪЙгУ Xshell 5 ЕЧТМащФтЛњЛђеп Linux ЯЕЭГЁЃгУ rz УќСюАбИеВХДђАќЕФЮФМўЩЯДЋЩЯШЅЁЃЦфжаащФтЛњвЊАВзАЩЯ
jdk ВЂХфжУКУЛЗОГБфСПЁЃ
ЮвУЧПЩвдгУЪфШы javac УќСюВтЪдвЛЯТЁЃ

ЮвУЧАб beam.jar ЩЯДЋЕН /usr/local/ ФПТМЯТУцЃЌШЛКѓаТНЈвЛИіЮФМўЃЌвВОЭЪЧдДЮФМўЁЃУќСюЃКtouch
text.txtЁЁУќСюЃКchmod o+rwxЁЁtext.txt
аоИФ text.txt ВЂЬэМгЪ§ОнЁЃЁЁУќСюЃКvi text.txt
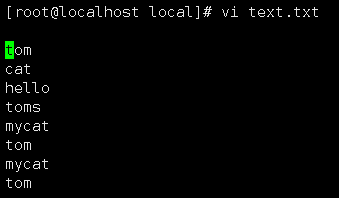
дЫааУќСюЃКjava -jar beam.jarЃЌЩњГЩЮФМўЁЃ
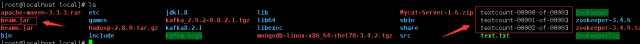
гУ cat УќСюВщПДЮФМўФкШнЃЌРяУцОЭЪЧЭГМЦЕФНсЙћЁЃ

8.3 ЪЕеНЦЪЮі
ЮвУЧПЩвдЭЈЙ§вдЩЯЪЕеНДњТыНјвЛВНСЫНт Beam ЕФдЫгУдРэЁЃ
ЕквЛМўЪТЧщЪЧДюНЈвЛИіЙмЕРЃЈPipelineЃЉЃЌР§ШчЮвУЧаЁЪБКђМвРяННЕигУЕФЁАЫЎЙмЁБЁЃЫќОЭЪЧСЌНгЫЎдДКЭДІРэЕФЧХСКЁЃ
| PipelineOptions
pipelineOptions = PipelineOptionsFactory.create();//
ДДНЈЙмЕР |
ЕкЖўМўЪТЧщЪЧШУЮвУЧЕФЙмЕРгавЛИіДІРэПђМмЃЌвВОЭЪЧЮвУЧЕФ Runtimes ЁЃР§ШчЮвУЧНгЕНЫЎвЊдѕУДДІРэЃЌЪЧЪфЫЭИјЮвУЧГЧЪаЕФЮлЫЎДІРэГЇЃЌЛЙЪЧЦфЫћЁЃетИіЮлЫЎДІРэГЇОЭЯрЕБгкЮвУЧЕФДІРэПђМмЃЌР§ШчЯждкСїааЕФ
Apache Spark Лђ Apache FlinkЁЃетИівЊИљОнздМКЕФвЕЮёжИЖЈЃЌШчЯТДњТыжаЮвжИЖЈСЫБОЕиЕФДІРэПђМмЁЃ
| pipelineOptions.setRunner(DirectRunner.class); |
ЕкШ§МўЪТЧщвВЪЧ Beam зюКѓвЛИіживЊЕФЕиЗНЃЌОЭЪЧФЃаЭ (Model)ЃЌЭЈЫзЕуНВОЭЪЧЮвУЧЕФЪ§ОнРДдДЁЃШчЙћНсКЯвдЩЯЕквЛМўКЭЕкЖўМўЕФЪТЧщЫЕОЭЪЧЫЎДгФФРяРДЃЌЫЎЕФРДдДПЩФмЪЧКгРяЁЂПЩФмЪЧЮлЫЎЭЈЕРЕШЕШЁЃБОЪЕР§гУЕФЪЧгаНчЙЬЖЈДѓаЁЕФЮФБОЮФМўЁЃЕБШЛ
Model ЛЙАќКЌЮоНчЪ§ОнЃЌР§Шч kafka ЕШЕШЃЌПЩвдИљОнЕФашЧѓСщЛюдЫгУЁЃ
pipeline.apply
(TextIO.read(). from ("/usr/local/text.txt")).
apply
(" ExtractWords", ParDo.of (new DoFn<String,
String>() //КѓЪЁТд |
зюКѓвЛВНЪЧДІРэНсЙћЃЌетИіБШНЯМђЕЅЃЌПЩвдИљОнздМКЕФашЧѓДІРэЁЃЯЃЭћЭЈЙ§ДњТыЕФЪЕеННсКЯдРэЦЪЮіПЩвдАяжњДѓМвИќПьЕиЪьЯЄ
Beam ВЂФмЙЛМђЕЅЕидЫгУ BeamЁЃ
змНс
Apache Beam ЪЧМЏГЩСЫКмЖрЪ§ОнФЃаЭЕФвЛИіЭГвЛЛЏЦНЬЈЃЌЫќЮЊДѓЪ§ОнПЊЗЂЙЄГЬЪІЦЕЗБЛЛЪ§ОндДЛђЖрЪ§ОндДЁЂЖрМЦЫуПђМмЬсЙЉСЫМЏГЩЭГвЛПђМмЦНЬЈЁЃApache
Beam ЩчЧјЯждквбОМЏГЩСЫЪ§ОнПтЕФЧаЛЛ IOЃЌЮДРД Beam жаЮФЩчЧјЛЙНЋЮЊ Beam МЏГЩИќЖрЕФ
Model КЭМЦЫуПђМмЃЌЮЊДѓМвЬсЙЉЗНБуЁЃ |









