KSQLЪЧвЛИігУгкApache katkatmЕФСїЪНSQLв§ЧцЁЃKSQLНЕЕЭСЫНјШыСїДІРэЕФУХМїЃЌЬсЙЉСЫвЛИіМђЕЅЕФЁЂЭъШЋНЛЛЅЪНЕФSQLНгПкЃЌгУгкДІРэKafkaЕФЪ§ОнЁЃФуВЛдйашвЊгУJavaЛђPythonетбљЕФБрГЬгябдБраДДњТыСЫЃЁKSQLЪЧПЊдДЕФ(Apache 2.0аэПЩ)ЁЂЗжВМЪНЕФЁЂПЩРЉеЙЕФЁЂПЩППЕФКЭЪЕЪБЕФЁЃЫќжЇГжЙуЗКЕФЧПДѓЕФСїДІРэВйзїЃЌАќРЈОлКЯЁЂСЌНгЁЂДАПкЁЂЛсЛАЃЌЕШЕШЁЃ
вЛИіМђЕЅЕФР§зг
ВщбЏСїЪ§ОнЪЧЪВУДвтЫМЃЌетгыSQLЪ§ОнПтгаЪВУДЧјБ№Фи?
ЪЕМЪЩЯЃЌЫќгыSQLЪ§ОнПтгаКмДѓЕФВЛЭЌЁЃДѓЖрЪ§Ъ§ОнПтЖМгУгкЖдДцДЂЪ§ОнНјааАДашВщевКЭаоИФЁЃKSQLВЛНјааВщев(ЕЋЪЧ)ЃЌЫќЫљзіЕФЪЧСЌајЕФзЊЛЛЁЊЁЊвВОЭЪЧЃЌСїДІРэЁЃР§ШчЃЌМйЩшЮвгавЛИіРДздгУЛЇЕФЕуЛїСїЃЌвдМАвЛИіЙигкетаЉгУЛЇВЛЖЯИќаТЕФеЪЛЇаХЯЂЕФБэЁЃKSQLдЪаэЮвЖдетвЛДЎЕЅЛїКЭгУЛЇБэНјааНЈФЃЃЌВЂНЋСНепНсКЯдквЛЦ№ЁЃМДЪЙетСНМўЪТжЎвЛЪЧЮоЯоЕФЁЃ
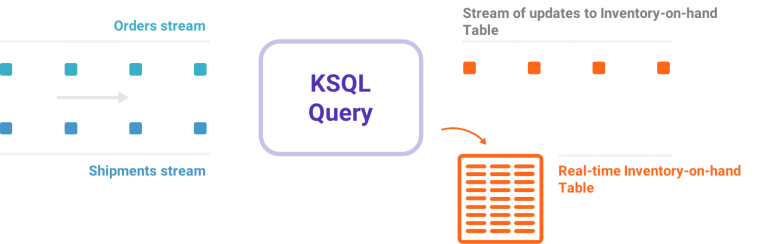
вђДЫЃЌKSQLЫљдЫааЕФЪЧСЌајВщбЏЁЊЁЊдкKafkaжїЬтЕФЪ§ОнСїжаЃЌСЌајВЛЖЯЕидЫаааТЪ§ОнЁЃЯрЗДЃЌДЋЭГЪ§ОнПтЖдЙиЯЕЪ§ОнПтЕФВщбЏЪЧвЛДЮадВщбЏЁЊЁЊдкЪ§ОнПтжадЫаавЛДЮSELECTгяОфЛёШЁгаЯоааЕФЪ§ОнМЏЁЃ
KSQLЕФКУДІЪЧЪВУД?
КмКУЃЌЫљвдФуПЩвдВЛЖЯЕиВщбЏЮоЯоЕФЪ§ОнСїЁЃетгаЪВУДКУДІ?
1 ЪЕЪБМрПиЪЕЪБЗжЮі
CREATE TABLE error_counts AS
SELECT error_code, count(*)FROM monitoring_stream
WINDOW TUMBLING (SIZE 1 MINUTE)
WHERE type = 'ERROR' |
ЦфжаЕФвЛИігУЭОЪЧЖЈвхЖЈжЦЕФвЕЮёМЖЖШСПЃЌетаЉЖШСПЪЧЪЕЪБМЦЫуЕФЃЌФњПЩвдМрЪгКЭОЏБЈЃЌОЭЯёФњЕФCPUИКдивЛбљЁЃСэвЛИігУЭОЪЧдкKSQLжаЖЈвхгІгУГЬађЕФе§ШЗадЕФИХФюЃЌВЂМьВщЫќдкЩњВњЙ§ГЬжаЪЧЗёЛсгіЕНетИіЮЪЬтЁЃЭЈГЃЃЌЕБЮвУЧЯыЕНМрПиЪБЃЌЮвУЧЛсЯыЕНМЦЪ§ЦїКЭвЧБэИњзйЕЭЫЎЦНЕФадФмЭГМЦЁЃетаЉРраЭЕФВтСПЦїЭЈГЃПЩвдИцЫпФуCPUИКдиКмИпЃЌЕЋЪЧЫќУЧВЛФмеце§ИцЫпФуФуЕФгІгУГЬађЪЧЗёдкзіЫќгІИУзіЕФЪТЧщЁЃKSQLдЪаэДггІгУГЬађЩњГЩЕФдЪМЪТМўСїжаЖЈвхЖЈжЦжИБъЃЌЮоТлЫќУЧЪЧШежОЪТМўЁЂЪ§ОнПтИќаТЛЙЪЧЦфЫћРраЭЕФЪТМўЁЃ
Р§ШчЃЌвЛИіwebгІгУГЬађПЩФмашвЊМьВщЃЌУПДЮаТПЭЛЇзЂВсвЛИіЪмЛЖгЕФЕчзггЪМўЃЌДДНЈвЛИіаТЕФгУЛЇМЧТМЃЌВЂЧвЫћУЧЕФаХгУПЈБЛМЦЗбЁЃетаЉЙІФмПЩФмЗжВМдкВЛЭЌЕФЗўЮёЛђгІгУГЬађжаЃЌФњПЩФмЯЃЭћМрЪгУПИіаТПЭЛЇдкSLAжаЗЂЩњЕФУПвЛМўЪТЃЌБШШч30УыЁЃ
2 АВШЋадКЭвьГЃМьВт
CREATE STREAM possible_fraud AS
SELECT card_number, count(*)
FROM authorization_attempts
WINDOW TUMBLING (SIZE 5 SECONDS)
GROUP BY card_number
HAVING count(*) > 3; |
етЪЧФњдкЩЯУцЕФбнЪОжаПДЕНЕФвЛИіМђЕЅЕФАцБО:KSQLВщбЏЃЌЫќНЋЪТМўСїзЊЛЛЮЊЪ§жЕЪБМфађСаЃЌЪЙгУKafka-ElasticСЌНгЦїНЋЦфзЂШыЕНЕЏаджаЃЌВЂдкGrafana UIжаПЩЪгЛЏЁЃАВШЋгУР§ЭЈГЃПДЦ№РДКмЯёМрЪгКЭЗжЮіЁЃЖјВЛЪЧМрЪггІгУГЬађЕФааЮЊЛђвЕЮёааЮЊЃЌФње§дкбАевЦлеЉЁЂРФгУЁЂРЌЛјгЪМўЁЂШыЧжЛђЦфЫћВЛСМааЮЊЕФФЃЪНЁЃKSQLЬсЙЉСЫвЛжжМђЕЅЁЂИДдгКЭЪЕЪБЕФЗНЪНРДЖЈвхетаЉФЃЪНКЭВщбЏЪЕЪБСїЁЃ
3 дкЯпЪ§ОнМЏГЩ
CREATE STREAM vip_users AS
SELECT userid, page, action
FROM clickstream c
LEFT JOIN users u ON c.userid = u.user_id
WHERE u.level = 'Platinum'; |
дкЙЋЫОжаЭъГЩЕФДѓВПЗжЪ§ОнДІРэЖМЪєгкЪ§ОнЗсИЛЕФСьгђ:ДгМИИіЪ§ОнПтжаЬсШЁЪ§ОнЃЌзЊЛЛЫќЃЌНЋЦфСЌНгЕНвЛИіМќжЕДцДЂЁЂЫбЫїЫїв§ЁЂЛКДцЛђЦфЫћЪ§ОнЗўЮёЯЕЭГжаЁЃдкКмГЄвЛЖЮЪБМфФкЃЌгУгкЪ§ОнМЏГЩЕФETL-ЬсШЁЁЂзЊЛЛКЭМгди-зїЮЊжмЦкадЕФХњДІРэзївЕжДааЁЃР§ШчЃЌЪЕЪБзЊДЂдЪМЪ§ОнЃЌШЛКѓУПИєМИИіаЁЪБзЊЛЛвЛДЮЃЌвдЪЕЯжИпаЇЕФВщбЏЁЃЖдгкаэЖргУР§РДЫЕЃЌетжжбгГйЪЧВЛПЩНгЪмЕФЁЃKSQLгыKafkaЕФСЌНгЦївЛЦ№ЪЙгУЪБЃЌПЩвдДгХњДІРэЪ§ОнМЏГЩЕНдкЯпЪ§ОнМЏГЩЁЃФњПЩвдЪЙгУСї-БэСЌНгДцДЂдкБэжаЕФдЊЪ§ОнРДЗсИЛЪ§ОнСїЃЌЛђепдкНЋСїМгдиЕНСэвЛИіЯЕЭГжЎЧАЖдPII(ИіШЫПЩЪЖБ№ЕФаХЯЂ)НјааМђЕЅЕФЙ§ТЫЁЃ
4 гІгУГЬађПЊЗЂ
аэЖргІгУГЬађНЋЪфШыСїзЊЛЛЮЊЪфГіСїЁЃ Р§ШчЃЌИКд№жиаТХХађдкЯпЩЬЕъПтДцВЛзуЕФВњЦЗЕФСїГЬПЩФмЛсВњЩњЯњЪлКЭГіЛѕСїЃЌвдМЦЫуГіЖЉЕЅСїЁЃ
ЖдгкгУJavaБраДЕФИќИДдгЕФгІгУГЬађРДЫЕЃЌKafkaЕФдЩњСїAPIПЩФмАяжњВЛДѓЁЃЕЋЪЧЖдгкМђЕЅЕФгІгУГЬађЃЌЛђепЖдJavaБрГЬВЛИааЫШЄЕФЭХЖгРДЫЕЃЌвЛИіМђЕЅЕФSQLНгПкПЩФмОЭЪЧЫћУЧЯывЊЕФЁЃ
KSQLжаЕФКЫаФГщЯѓ
KSQLдкФкВПЪЙгУKafkaЕФStreams APIЃЌВЂЧвЫќУЧЙВЯэгыKafkaСїДІРэЯрЭЌЕФКЫаФГщЯѓЁЃ KSQLгаСНИіКЫаФГщЯѓЃЌЫќУЧгГЩфЕНKafka StreamsжаЕФСНИіКЫаФГщЯѓЃЌВЂдЪаэФњВйзнKafkaжїЬтЃК
1.СїЃКСїЪЧЮоЯожЦЕФНсЙЙЛЏЪ§ОнађСаЃЈЁАЪТЪЕЁБЃЉЁЃ Р§ШчЃЌЮвУЧПЩвдгавЛИіН№ШкНЛвзСїЃЌР§ШчЁАAliceЯђBobЗЂЫЭСЫ100УРдЊЃЌШЛКѓВщРэЯђБЋВЊЗЂЫЭСЫ50УРдЊЁБЁЃ СїжаЕФЪТЪЕЪЧВЛПЩБфЕФЃЌетвтЮЖзХПЩвдНЋаТЪТЪЕВхШыЕНСїжаЃЌЕЋЪЧЯжгаЪТЪЕгРдЖВЛЛсБЛИќаТЛђЩОГ§ЁЃ СїПЩвдДгKafkaжїЬтДДНЈЃЌЛђепДгЯжгаЕФСїКЭБэжаХЩЩњЁЃ
CREATE STREAM pageviews (viewtime BIGINT, userid VARCHAR, pageid VARCHAR)
WITH (kafka_topic='pageviews', value_format=ЁЏJSONЁЏ); |
2ЁЃБэ:вЛИіБэЪЧвЛИіСїЛђСэвЛИіБэЕФЪгЭМЃЌЫќДњБэСЫвЛИіВЛЖЯБфЛЏЕФЪТЪЕЕФМЏКЯЁЃР§ШчЃЌЮвУЧПЩвдгЕгавЛИіАќКЌзюаТВЦЮёаХЯЂЕФБэЃЌР§ШчЁАBobЕФОГЃеЪЛЇгрЖюЮЊ$150ЁБЁЃЫќЯрЕБгкДЋЭГЕФЪ§ОнПтБэЃЌЕЋЭЈЙ§СїЛЏЕШСїгявхРДЗсИЛЁЃБэжаЕФЪТЪЕЪЧПЩБфЕФЃЌетвтЮЖзХПЩвдНЋаТЕФЪТЪЕВхШыЕНБэжаЃЌЯжгаЕФЪТЪЕПЩвдБЛИќаТЛђЩОГ§ЁЃПЩвдДгKafkaжїЬтжаДДНЈБэЃЌвВПЩвдДгЯжгаЕФСїКЭБэжаХЩЩњБэЁЃ
CREATE TABLE users (registertime BIGINT, gender VARCHAR, regionid VARCHAR, userid VARCHAR)
WITH (kafka_topic='users', value_format='DELIMITED'); |
KSQLМђЛЏСЫСїгІгУГЬађЃЌвђЮЊЫќЭъШЋМЏГЩСЫБэКЭСїЕФИХФюЃЌдЪаэЪЙгУБэЪОЯждкЗЂЩњЕФЪТМўЕФСїРДСЌНгБэЪОЕБЧАзДЬЌЕФБэЁЃ Apache KafkaжаЕФвЛИіжїЬтПЩвдБэЪОЮЊKSQLжаЕФSTREAMЛђTABLEЃЌОпЬхШЁОігкжїЬтДІРэЕФдЄЦкгявхЁЃ Р§ШчЃЌШчЙћвЊНЋжїЬтжаЕФЪ§ОнзїЮЊвЛЯЕСаЖРСЂжЕЖСШЁЃЌдђПЩвдЪЙгУCREATE STREAMЁЃДЫРрСїЕФвЛИіР§згЪЧВЖЛёвГУцЪгЭМЪТМўЃЌЦфжаУПИівГУцЪгЭМЪТМўЖМВЛЯрЙиЧвЖРСЂгкСэвЛИівГУцЪгЭМЪТМўЁЃСэвЛЗНУцЃЌШчЙћФњЯЃЭћНЋФГИіжїЬтжаЕФЪ§ОнЖСШЁЮЊПЩИќаТЕФжЕЕФМЏКЯЃЌФЧУДФњНЋЪЙгУCREATE TABLEЁЃдкKSQLжагІИУЖСШЁвЛИіжїЬтЕФЪОР§ЃЌЫќВЖЛёгУЛЇдЊЪ§ОнЃЌЦфжаУПИіЪТМўДњБэЬиЖЈгУЛЇidЕФзюаТдЊЪ§ОнЃЌШчгУЛЇЕФаеУћЁЂЕижЗЛђЪзбЁЯюЁЃ
KSQL:ЪЕЪБЕуЛїСїЗжЮіКЭвьГЃМьВт
ШУЮвУЧРДПДвЛИіеце§ЕФР§згЁЃетИіР§згеЙЪОШчКЮЪЙгУKSQLНјааЪЕЪБМрЪгЁЂвьГЃМьВтКЭОЏБЈЁЃЖдclickstreamЪ§ОнЕФЪЕЪБШежОЗжЮіПЩвдВЩШЁЖржжаЮЪНЁЃдкБОР§жаЃЌЮвУЧНЋБъМЧдкwebЗўЮёЦїЩЯЯћКФЙ§ЖрДјПэЕФЖёвтгУЛЇЛсЛАЁЃМрЪгЖёвтгУЛЇЛсЛАЪЧЛсЛАЛЏЕФжкЖргІгУжЎвЛЁЃЕЋДгЙувхЩЯЫЕЃЌЛсЛАЪЧгУЛЇааЮЊЗжЮіЕФЛљДЁЁЃвЛЕЉФњНЋгУЛЇКЭЪТМўЙиСЊЕНвЛИіЬиЖЈЕФЛсЛАБъЪЖЗћЃЌФњОЭПЩвдЙЙНЈаэЖрРраЭЕФЗжЮіЃЌДгМђЕЅЕФЖШСПЃЌР§ШчЗУЮЪМЦЪ§ЁЃЮвУЧЭЈЙ§еЙЪОШчКЮдкElasticжЇГжЕФGrafanaвЧБэАхЩЯЪЕЪБЯдЪОKSQLВщбЏЕФЪфГіЃЌРДНсЪјетИіР§згЁЃ
ФњвВПЩвдАДееЮвУЧЕФжИЪОЃЌЧзздЭъГЩР§згЃЌВЂВщПДДњТыЁЃ
ПДПДРяУц
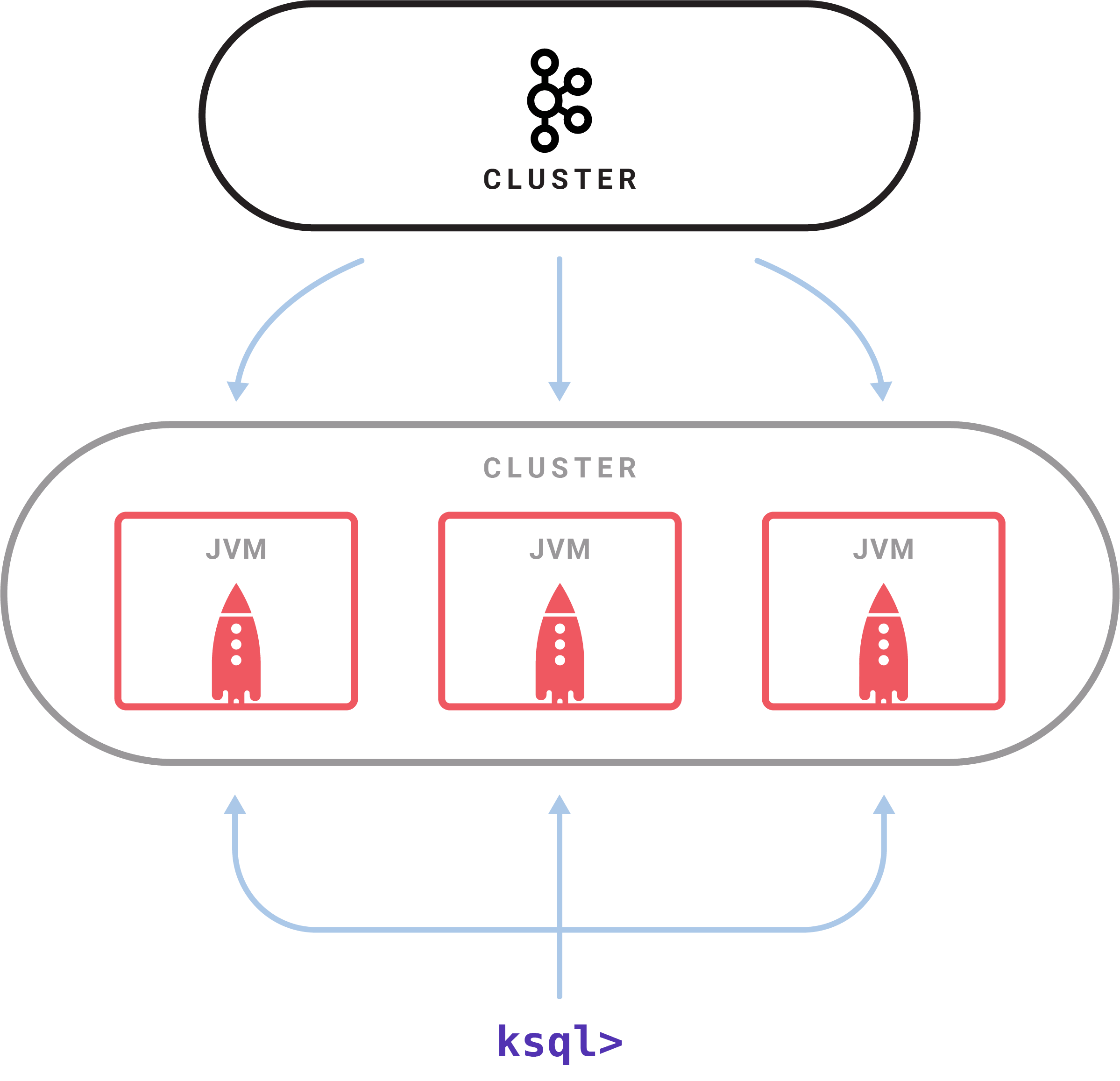
гавЛИіKSQLЗўЮёЦїНјГЬжДааВщбЏЁЃвЛзщKSQLНјГЬзїЮЊМЏШКдЫааЁЃФњПЩвдЭЈЙ§ЦєЖЏИќЖрЕФKSQL serverЪЕР§РДЖЏЬЌЬэМгИќЖрЕФДІРэФмСІЁЃетаЉЪЕР§ЪЧШнДэЕФ:ШчЙћвЛИіЪЇАмСЫЃЌЦфЫћЕФОЭЛсНгЙмЫќЕФЙЄзїЁЃВщбЏЪЧЪЙгУНЛЛЅЪНЕФKSQLУќСюааПЭЛЇЖЫЦєЖЏЕФЃЌИУПЭЛЇЖЫЭЈЙ§REST APIЯђМЏШКЗЂЫЭУќСюЁЃУќСюаадЪаэМьВщПЩгУЕФСїКЭБэЃЌЗЂГіаТЕФВщбЏЃЌМьВщзДЬЌВЂжежЙе§дкдЫааЕФВщбЏЁЃKSQLФкВПЪЧЪЙгУKafkaЕФСїAPIЙЙНЈЕФ;ЫќМЬГаСЫЫќЕФЕЏадПЩЩьЫѕадЁЂЯШНјЕФзДЬЌЙмРэКЭШнДэЙІФмЃЌВЂжЇГжKafkaзюНќв§ШыЕФвЛДЮадДІРэгявхЁЃKSQLЗўЮёЦїНЋДЫЧЖШыЕНвЛИіЗжВМЪНSQLв§Чцжа(АќРЈвЛаЉгУгкВщбЏадФмЕФздЖЏзжНкДњТыЩњГЩ)КЭвЛИігУгкВщбЏКЭПижЦЕФREST APIЁЃ
Kafka + KSQLНЋЪ§ОнПтзЊГіРД
Й§ШЅЮвУЧвбОЬжТлЙ§НЋЪ§ОнПтзЊШыФкВПЃЌЯждкЮвУЧЭЈЙ§ЯђФкЯђЭтЕФDBЬэМгвЛИіSQLВуРДЪЕЯжЁЃ
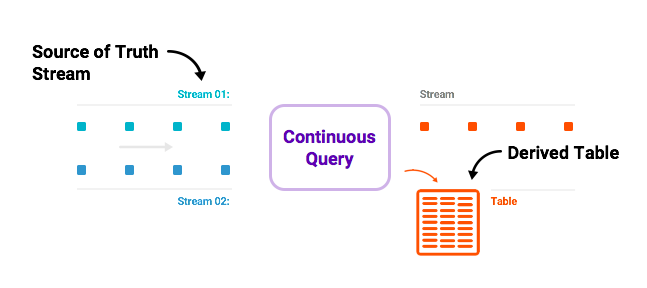
дкЙиЯЕЪ§ОнПтжаЃЌБэЪЧКЫаФГщЯѓЃЌШежОЪЧвЛИіЪЕЯжЯИНкЁЃ дквдЪ§ОнПтЮЊжааФЕФЪТМўЪРНчжаЃЌКЫаФГщЯѓВЛЪЧБэ; ЫќЪЧШежОЁЃ етаЉБэжЛЪЧДгШежОЕМГіЕФЃЌВЂЫцзХаТЪ§ОнЕНДяШежОЖјВЛЖЯИќаТЁЃ жабыШежОЪЧKafkaЃЌKSQLЪЧв§ЧцЃЌдЪаэФњДДНЈЫљашЕФЮяЛЏЪгЭМЃЌВЂНЋЦфБэЪОЮЊВЛЖЯИќаТЕФБэЁЃ
ШЛКѓЃЌФњПЩвдвдетжжСїЪНБэИёЗНЪНдЫааМДЪБВщбЏЃЈМДНЋдкKSQLжаЃЉЃЌвдБувдГжајЕФЗНЪНЛёШЁШежОжаУПИіМќЕФзюаТжЕЁЃ
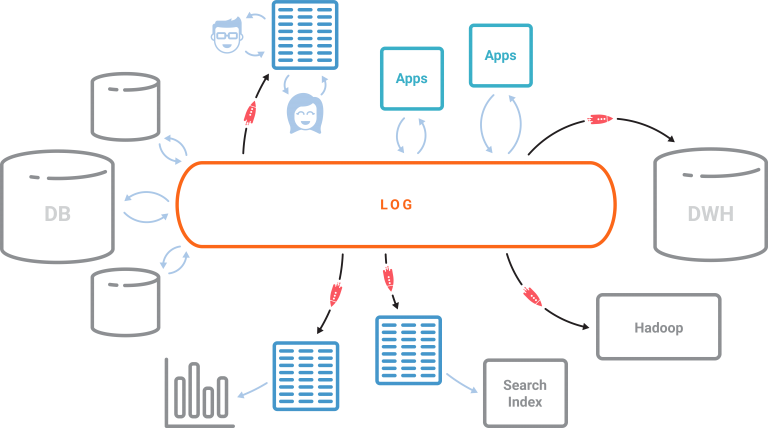
ЪЙгУKafkaКЭKSQLНЋЪ§ОнПтзЊГіЃЌЖдвЛМвЙЋЫОЕФЫљгаЪ§ОнЖМгаКмДѓЕФгАЯьЃЌетаЉЪ§ОнПЩвдздШЛЕивдСїУНЬхЗНЪННјааБэЪОКЭДІРэЁЃKafkaШежОЪЧСїЪ§ОнЕФКЫаФДцДЂГщЯѓЃЌдЪаэНјШыФњЕФРыЯпЪ§ОнВжПтЕФЯрЭЌЪ§ОнЯждкПЩвдгУгкСїДІРэЁЃЦфЫћвЛЧаЖМЪЧдкШежОЩЯЕФвЛИіСїЛЏЕФЮяЛЏЪгЭМЃЌЫќЪЧИїжжЪ§ОнПтЁЂЫбЫїЫїв§ЃЌЛђепЪЧЙЋЫОЕФЦфЫћЪ§ОнЗўЮёЯЕЭГЁЃДДНЈетаЉХЩЩњЪгЭМЫљашЕФЫљгаЪ§ОнКЭETLЃЌЯждкЖМПЩвдЪЙгУKSQLвдСїУНЬхЗНЪНЭъГЩЁЃМрПиЁЂАВШЋЁЂвьГЃКЭЭўаВМьВтЁЂЗжЮіКЭЖдЙЪеЯЕФЯьгІЖМПЩвдЪЕЪБНјааЃЌЖјЕБЪБМфЬЋЭэСЫЁЃЫљгаетаЉЖМПЩвдЭЈЙ§вЛИіМђЕЅЖјгжЪьЯЄЕФSQLНгПкРДЪЙгУЫљгаKafkaЕФЪ§Он:KSQLЁЃ
KSQLЕФЯТвЛВНЪЧЪВУДЃП
ЮвУЧе§дкЗЂВМKSQLзїЮЊПЊЗЂепдЄРРЃЌПЊЪМЙЙНЈЩчЧјЃЌЪеМЏЗДРЁЁЃЮвУЧМЦЛЎдкПЊдДЩчЧјЙЄзїЪБдіМгИќЖрЕФЙІФмЃЌНЋЦфДгжЪСПЃЌЮШЖЈадКЭKSQLЕФПЩВйзїадзЊБфЮЊЩњВњОЭаїЯЕЭГЃЌвджЇГжИќЗсИЛЕФSQLгяЗЈЃЌАќРЈНјвЛВНЕФОлКЯЙІФмКЭЪБМфЕуSELECTдкСЌајЕФБэЩЯ - МДЃЌЮЊСЫФмЙЛПьЫйВщевЕНФПЧАЮЊжЙЫљМЦЫуЕФФкШнЃЌвдМАСЌајМЦЫуСїНсЙћЕФЕБЧАЙІФмЁЃ |









