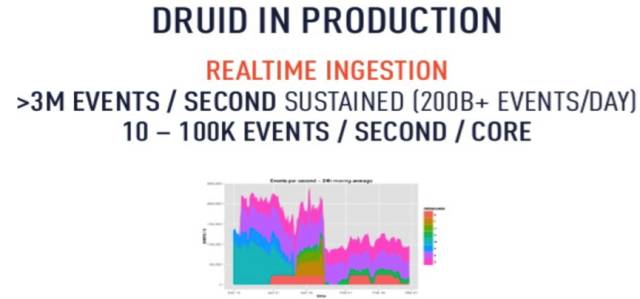
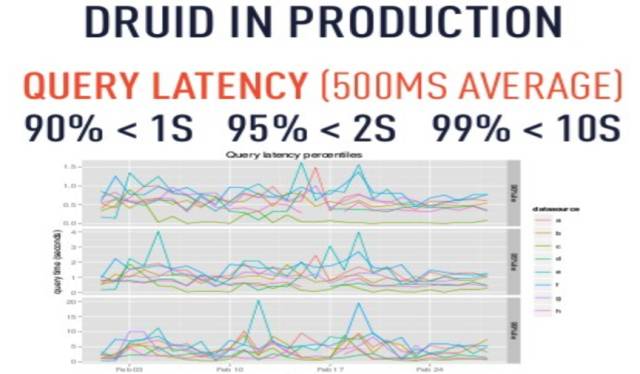
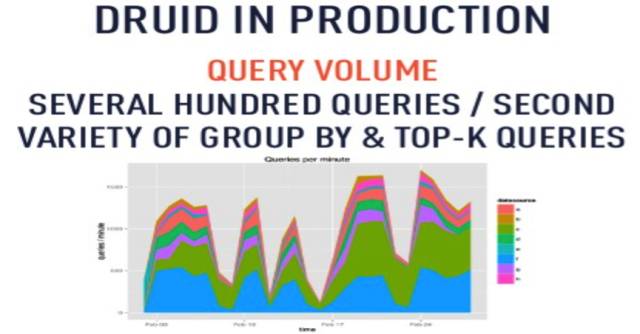
|

DruidЪЧЪВУД
DruidдкДѓЪ§ОнСьгђвбОВЛЪЧаТШЫСЫЃЌвђДЫПЩФмКмЖрЖСепЖМвбОЬ§ЫЕЙ§DruidЃЌЩѕжСгУЙ§DruidЃЌЕЋЪЧЮДБиУПИіШЫЖМеце§ЧхЮњЕиСЫНтDruidЕНЕзЪЧЪВУДЃЌвдМАдкЪВУДЧщПіЯТПЩвдгУDruidЁЃЭЌЪБЃЌЮЊСЫБмУтДѓМвЬ§СЫАыЬьЃЌШДвЛжБЯндкИїжжЯИНкжаЕЋШдШЛВЛжЊЕРЕНЕздкЬ§ЪВУДЖЋЮїЃЌЮвУЧЛЙЪЧгаБивЊдкПЊЪМЕФЪБКђЯШзмЬхЬИвЛЬИDruidЕНЕзЪЧЪВУДЁЃ
МђЕЅРДЫЕЃЌDruid ЪЧвЛИіЗжВМЪНЕФЁЂжЇГжЪЕЪБЖрЮЌOLAPЗжЮіЕФЪ§ОнДІРэЯЕЭГЁЃЫќМШжЇГжИпЫйЕФЪ§ОнЪЕЪБЩуШыДІРэЃЌвВжЇГжЪЕЪБЧвСщЛюЕФЖрЮЌЪ§ОнЗжЮіВщбЏЁЃвђДЫDruidзюГЃгУЕФГЁОАОЭЪЧДѓЪ§ОнБГОАЯТЁЂСщЛюПьЫйЕФЖрЮЌOLAPЗжЮіЁЃ СэЭтЃЌDruidЛЙгавЛИіЙиМќЕФЬиЕуЃКЫќжЇГжИљОнЪБМфДСЖдЪ§ОнНјаадЄОлКЯЩуШыКЭОлКЯЗжЮіЃЌвђДЫвВгагУЛЇОГЃдкгаЪБађЪ§ОнДІРэЗжЮіЕФГЁОАжагУЕНЫќЁЃ
DruidгУЛЇШКФмЙЛбИЫйЗЂеЙЕФвЛИідвђЪЧЫќдкДѓЪ§ОнБГОАЯТМЏШКвРШЛОпБИгХауЕФадФмКЭПЩРЉеЙадЁЃImply.ioЙЋЫОЪЧDruidДДЪМШЫДДАьЕФЙЋЫОЃЌЮвУЧПЩвдЯШЭЈЙ§ЫќЙЋВМЕФвЛаЉМЏШКадФмНщЩмЭМЦЌРДИХРРвЛЯТDruidМЏШКЕФвЛаЉЬиЕуЁЃ
Ъ§ОнЪЕЪБЯћЗбФмСІЃК
МЏШКЕФЪ§ОнЙцФЃЃК

ВщбЏЫйЖШЃК
ВщбЏЕФВЂЗЂСПЃК
ВЛФбПДГіЃЌDruidМЏШКдкДѓЪ§ОнГЁОАЯТБэЯжгХвьЁЃ
НгЯТРДЃЌЮвУЧвВЫГБуСФвЛСФDruidЕФРњЪЗЁЃDruid ЕЅДЪРДдДгкЮїЗНЙХТоТэЕФЩёЛАШЫЮя, жаЮФГЃГЃЗвыГЩЕТТГвСЁЃДЋЫЕ Druid НЬЪПОЋЭЈеМВЗ, ЖдМРьыРёвЧвЛЫПВЛЙЖ,вВЩУГЄгкЬьЮФРњЗЈЁЂвНвЉЁЂЬьЮФКЭЮФбЇЕШЁЃЭЌЪБ, Druid вВ ЪЧжДЗЈепЁЂвїгЮЪЋШЫКЭЬНЯеМвЕФДњУћДЪЁЃУРЙњЙуИцММЪѕЙЋЫО MetaMarkets гк 2011 ФъДДНЈСЫ Druid ЯюФП, ВЂЧвгк 2012 ФъПЊдДСЫ Druid ЯюФПЁЃ Druid ЩшМЦжЎГѕЕФЯыЗЈОЭЪЧЮЊЗжЮіЖјЩњ,ЫќдкДІРэЪ§ОнЕФЙцФЃЁЂЪ§ОнДІРэЕФЪЕЪБадЗНУц, БШДЋЭГЕФ OLAP ЯЕЭГгаСЫЯджјЕФадФмИФНј, ЖјЧвгЕБЇжїСїЕФПЊдДЩњЬЌ, АќРЈ Hadoop ЕШЁЃЖрФъвдРД, Druid вЛжБЪЧЗЧГЃЛюдОЕФПЊдДЯюФПЁЃ СэЭт, АЂРяАЭАЭвВдјДДНЈЙ§вЛИіПЊдДЯюФПНазї Druid(МђГЦАЂРя Druid), ЫќЪЧвЛИіЪ§ОнПтСЌНгГиЕФЯюФПЁЃАЂРя Druid КЭБОЪщЬжТлЕФ Druid УЛгаШЮКЮЙиЯЕ,ЫќУЧНтОіЭъШЋВЛЭЌЕФЮЪЬтЁЃ
Druid ЕФЙйЗНЭјеОЪЧ http://druid.ioЁЃ

ММЪѕбЁаЭЕФЫМПМ
ИїИіЙЋЫОдкММЪѕбЁаЭЕФЪБКђЖМЛсЛѕБШШ§МвЃЌвђДЫдкПМВьDruidЕФЪБКђвВвЛЖЈЛсЮЪЮЊЪВУДашвЊбЁдёDruidЁЃдкБОЖЮТфжаЃЌЮвУЧНЋЛсЖдгУЛЇОГЃЛсФУРДКЭDruidзіБШНЯЕФзщМўжаЕФЦфжаМИИіРДзівЛаЉМђЕЅЕФЫЕУїЁЃЕЋЪЧдкБШНЯжЎЧАЃЌЮвашвЊВћУївЛИіЛљБОЕФЙлЕуЃКетаЉВЛЭЌзщМўЛђММЪѕгаИїздЕФЬиЕуКЭЪЪгУЗЖЮЇЃЌВЂУЛгавЛИіММЪѕОЭФмГЙЕзЬцДњЦфЫќММЪѕетжжЫЕЗЈЃЌЖјБОЮФОЭНіФУЁАДѓЪ§ОнСПЯТЕФЪЕЪБЖрЮЌOLAPЗжЮіЁБетвЛГЁОАРДзіБШНЯЁЃ
ДЋЭГЙиЯЕаЭЪ§ОнПтЃК
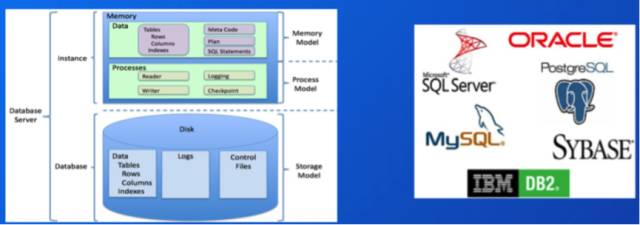
ДЋЭГЙиЯЕаЭЪ§ОнПтЃЈRDBMSЃЉРњЪЗОУдЖЁЂММЪѕГЩЪьЃЌгІгУепЙуЗКЃЌвђДЫВЩгУЕФбЇЯАГЩБОКЭММЪѕЗчЯевВЯрЖдНЯЕЭЁЃЕфаЭЕФRDBMSгаOracleЁЂDB2КЭMySQLЕШЁЃДгРэТлЩЯНВЃЌвђЮЊRDBMSФмБЃжЄЪ§ОнЕФСЂМДвЛжТадЃЌвђДЫЬиБ№ЪЪКЯOLTPЕФГЁОАЁЃШЛЖјгЩгкздЩэЕФЬиЕуЫљЯоЃЌRDBMSдкПЩРЉеЙадЗНУцШДБэЯжЧЗМбЃЌКмФбЧсвзКЭЕЭГЩБОЕЭНјааЯпадРЉеЙвдДІРэИќДѓЕФЪ§ОнСПЁЃМДБуЯждкДѓЖрЪ§ОнПтПЩвдЭЈЙ§ЗжПтЗжБэЕШЗНЗЈРДЪЙздМКПЩвдШнФЩИќЖрЕФЪ§ОнЃЌЕЋЪЧетжжЗНЪНвВДцдкзХЙмРэИДдгКЭГЩБОИпАКЕШУїЯдЖЬАхЃЌвђДЫЪЕМЪгІгУжавВДцдкзХЪ§ОнСПЕФЬьЛЈАхЁЃвђДЫЃЌПМТЧМШЖЈЕФГЁОАЁАДѓЪ§ОнСПЯТЕФЪЕЪБЖрЮЌOLAPЗжЮіЁБЃЌRDBMSЪзЯШОЭКмФбПчЙ§ЁАДѓЪ§ОнСПЁБетвЛЙиЁЃ
Massively Parallel Processing Ъ§ОнПтЃК
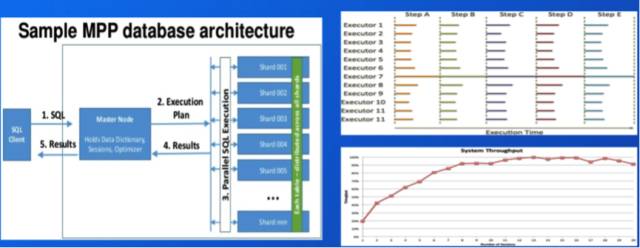
ДѓЙцФЃВЂааДІРэЃЈMPPЃЌmassively parallel processingЃЉЪ§ОнПтЕФДњБэЪЧTeradataЁЂGreenplumЁЂVerticaКЭImpalaЕШЁЃЫќУЧЕФгХЕуЪЧЪЪКЯНЋRDBMSЕФгІгУРЉеЙЕНМЏШКЗЖЮЇЃЌвдДІРэИќДѓЕФЪ§ОнСПЃЌЭЌЪБМЬГаСЫRDBMSЕФКмЖргХЕуЁЃШЛЖјЃЌЫќвРШЛУЛЗЈДгИљБОЩЯТњзуДІРэКЃСПЪ§ОнЕФашЧѓЃЌвђЮЊЫќЕФЯЕЭГадФмКмФбЫцМЏШКЕФРЉеЙвЛжБЯпаддіГЄЃЌЫљвдЦфМЏШКРЉеЙадгаЯоЃЛЖјЧвЫќЕФМЏШКШнДэадвВгаЯоЃЌБШШчЕБЦфRaidДХХЬГіДэКѓПЩФмЛсЕМжТЦфНкЕуЯьгІЫйЖШБфТ§ЁЃ
ElasticSearchЃК
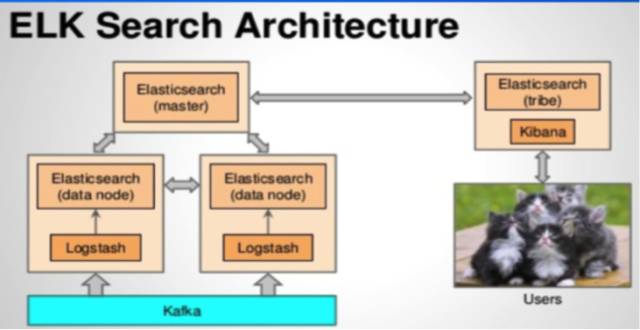
ElasticSearchМИКѕвбОЪЧЕБЯТЪЕЪБЩЯЕФЫбЫїЗўЮёЦїБъзМЃЌЖјЫќгыLogstashКЭKibanaЕФДюХфЃЈМђГЦELKЃЉвВЪЧгІгУКмЙуЕФЬзМўзщКЯЁЃElasticSearchгаКмЧПЕФЮФЕЕЫїв§КЭШЋЮФМьЫїЕФФмСІЃЌвВжЇГжЗсИЛЕФВщбЏЙІФмЃЈАќРЈОлКЯВщбЏЃЉЃЌВЂЧвРЉеЙадКУЃЌвђДЫКмЖргУЛЇвВГЃГЃдкФУElasticsearchКЭDruidзіБШНЯЁЃШЛЖјЃЌдкЮвУЧЕФМШЖЈГЁОАЯТЃЌElasticsearchгазХЦфУїЯдЕФЖЬАхЃКВЛжЇГждЄОлКЯЃЛзщКЯВщбЏадФмЧЗМбЃЛЕШЕШЁЃ
OpenTSDBЃК
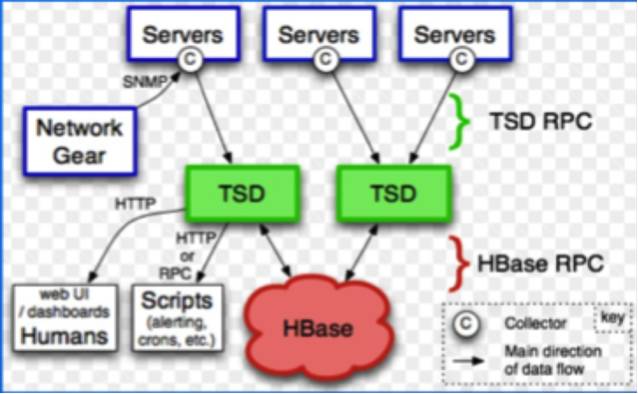
OpenTSDBЪЧвЛПюгХауЕФЪБађЪ§ОнПтЃЌЧвЛљгкгУЛЇЙуЗКЕФHBaseЪ§ОнПтЃЌвђДЫгазХНЯЖрЕФПЭЛЇШКЁЃЫќЕФгХЪЦдкгкВщбЏЫйЖШПьЁЂРЉеЙадКУЃЌЧвschemalessЁЃШЛЖјЃЌЫќвВгавЛаЉШБЕуЃКВщбЏЕФЮЌЖШзщКЯЪ§СПашвЊЬсЧАШЗЖЈКУЃЌМДЭЈЙ§ДцДЂжаЕФtagзщКЯРДШЗЖЈЃЌвђДЫШБЗІСЫСщЛюадЃЛЪ§ОнШпгрЖШДѓЃЛЛљгкHBaseЃЌЖдгкдЫЮЌШЫдБФмСІвЊЧѓНЯИпЃЛЕШЕШЁЃ
KylinЃК
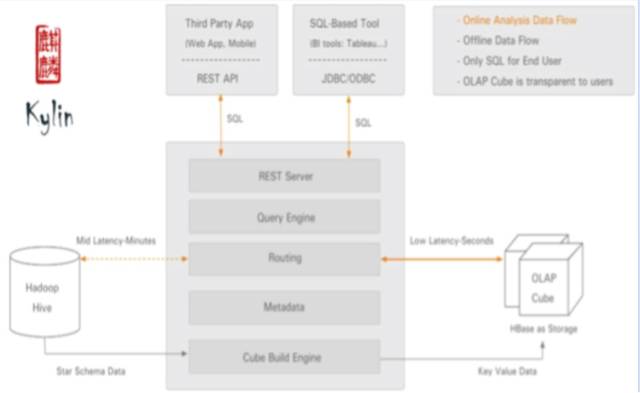
KylinГіздeBayЃЌВЂЧвЪЧApacheЕФаТЖЅМЖЯюФПЃЌЪЧвЛПюЗЧГЃВЛДэЕФЗжВМЪНOLAPЯЕЭГЁЃЫќЕФгХЪЦдкгкЯюФПРДздгкЗсИЛЕФЪЕМљЁЂЗЂеЙЧАОАЙтУїЁЂжБНгРћгУСЫГЩЪьЕФHadoopЬхЯЕЃЈHBaseКЭHiveЕШЃЉЁЂcubeФЃаЭжЇГжНЯКУЁЂВщбЏЫйЖШПьЫйЕШЁЃЕЋЫќвВдквЛаЉЗНУцгазХздМКЕФОжЯоЃЌБШШчЃКВщбЏЕФЮЌЖШзщКЯЪ§СПашвЊЬсЧАШЗЖЈКУЃЌВЛЪЪКЯМДЯЏВщбЏЗжЮіЃЛдЄМЦЫуСПДѓЃЌзЪдДЯћКФЖрЃЛМЏШКвРРЕНЯЖрЃЌШчHBaseКЭHiveЕШЃЌЪєгкжиСПМЖЗНАИЃЌвђДЫдЫЮЌГЩБОвВНЯИпЃЛЕШЕШЁЃ
DruidЛљДЁжЊЪЖ
Ъ§ОнДцДЂИёЪН
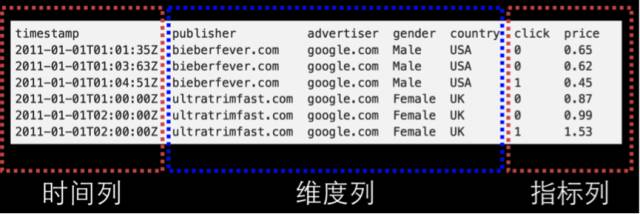
DruidздМКгазХЪ§ОнДцДЂЕФТпМКЭИёЪНЃЈжївЊЪЧDataSourceКЭSegmentЃЉЃЌЖјЧвЦфМмЙЙКЭЪЕЯжвВЪЧЮЇШЦзХЫќУЧЖјНјааЕФЃЌвђДЫЮвУЧгаБивЊЖдЦфЪ§ОнДцДЂИёЪНзівЛаЉНщЩмЁЃ
ЪзЯШЃЌШєгыДЋЭГЕФЙиЯЕаЭЪ§ОнПтЙмРэЯЕЭГ(RDBMS)зіБШНЯЃЌDruid ЕФ DataSource ПЩвдРэНтЮЊ RDBMS жаЕФБэ(Table)ЁЃе§ШчЧАУцеТНкжаЫљНщЩмЕФ,DataSource ЕФНсЙЙАќКЌвдЯТМИИіЗНУцЁЃ
- ЪБМфСа(TimeStamp)ЃКБэУїУПааЪ§ОнЕФЪБМфжЕЃЌФЌШЯЪЙгУ UTC ЪБМфИёЪНЧвОЋШЗЕНКСУыМЖБ№ЁЃетИіСаЪЧЪ§ОнОлКЯгыЗЖЮЇВщбЏЕФживЊЮЌЖШЁЃ
- ЮЌЖШСа(Dimension)ЃК ЖШРДздгкOLAPЕФИХФюЃЌгУРДБъЪЖЪ§ОнааЕФИїИіРрБ№аХЯЂЁЃ
- жИБъСа(Metric)ЃКжИБъЖдгІгкOLAPИХФюжаЕФFactЃЌЪЧгУгкОлКЯКЭМЦЫуЕФСаетаЉжИБъСаЭЈГЃЪЧвЛаЉЪ§зжЃЌМЦЫуВйзїЭЈГЃАќРЈ CountЁЂSum КЭ Mean ЕШЁЃ
ЮоТлЪЧЪЕЪБЪ§ОнЯћЗбЛЙЪЧХњСПЪ§ОнДІРэЃЌDruid дкЛљгк DataSource НсЙЙДцДЂЪ§ОнЪБМДПЩбЁдёЖдШЮвтЕФжИБъСаНјааОлКЯ(Roll Up)ВйзїЁЃЯрЖдгкЦфЫћЪБађЪ§ОнПтЃЌDruid дкЪ§ОнДцДЂЪББуПЩЖдЪ§ОнНјааОлКЯВйзїЪЧЦфвЛДѓЬиЕу, ВЂЧвИУЬиЕуЪЙЕУ Druid ВЛНіФмЙЛНкЪЁДцДЂПеМфЃЌЖјЧвФмЙЛЬсИпОлКЯВщбЏЕФаЇТЪЁЃ
DataSource ЪЧвЛИіТпМИХФюЃЌSegment ШДЪЧЪ§ОнЕФЪЕМЪЮяРэДцДЂИёЪНЃЌDruid е§ЪЧЭЈЙ§ Segment ЪЕЯжСЫЖдЪ§ОнЕФКсзнЯђЧаИю(Slice and Dice)ВйзїЁЃДгЪ§ОнАДЪБМфЗжВМЕФНЧЖШРДПД, ЭЈЙ§ВЮЪ§ segmentGranularity ЕФЩшжУЃЌDruid НЋВЛЭЌЪБМфЗЖЮЇФкЕФЪ§ОнДцДЂдкВЛЭЌЕФ Segment Ъ§ОнПщжаЃЌетБуЪЧЫљЮНЕФЪ§ОнКсЯђЧаИюЁЃетжжЩшМЦЮЊ Druid ДјРДвЛИіЯдЖјвзМћЕФгХЕуЃКАДЪБМфЗЖЮЇВщбЏЪ§ОнЪБЃЌНіашвЊЗУЮЪЖдгІЪБМфЖЮФкЕФетаЉ Segment Ъ§ОнПщ,ЖјВЛашвЊНјааШЋБэЪ§ОнЗЖЮЇВщбЏ,етЪЙаЇТЪЕУЕНСЫМЋДѓЕФЬсИпЁЃ
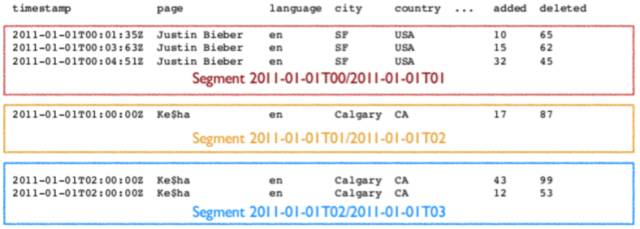
ЭЌЪБЃЌдк Segment жавВУцЯђСаНјааЪ§ОнбЙЫѕДцДЂЃЌетБуЪЧЫљЮНЕФЪ§ОнзнЯђЧаИюЁЃЖјЧвЖдSegment жаЕФЮЌЖШСаЪЙгУСЫ Bitmap ММЪѕЖдЦфЪ§ОнЕФЗУЮЪНјааСЫгХЛЏЁЃЦфжаЃЌDruidЛсЮЊУПвЛЮЌЖШСаДцДЂЫљгаСажЕЁЂДДНЈзжЕфЃЈгУРДДцДЂЫљгаСажЕЖдгІЕФIDЃЉвдМАЮЊУПвЛИіСажЕДДНЈЦфbitmapЫїв§вдАяжњПьЫйЖЈЮЛФФаЉаагЕгаИУСажЕЁЃ
ЛљгкЪЕЪБНкЕуЕФМмЙЙ
DruidзюдчЕФМмЙЙЪЧЛљгкЪЕЪБНкЕуЃЈRealtime NodeЃЉЕФЁЃЫќЕФЬиЕуЪЧгазЈУХЕФЪЕЪБНкЕуРДИКд№ЯћЗбЪ§ОнЁЃ
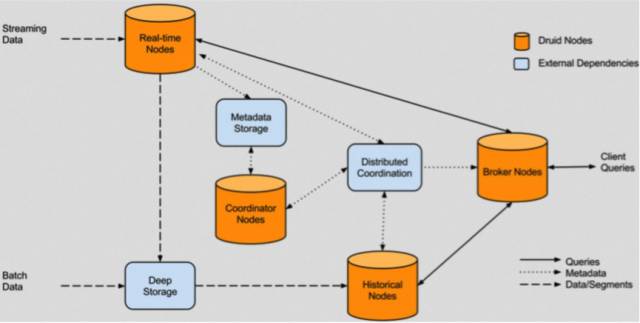
DruidздЩэАќКЌвдЯТ 4 РрНкЕуЁЃ
- ЪЕЪБНкЕу(RealtimeNode)ЃКМДЪБЩуШыЪЕЪБЪ§ОнЃЌвдМАЩњГЩSegmentЪ§ОнЮФМўЁЃ
- РњЪЗНкЕу(HistoricalNode)ЃКМгдивбЩњГЩКУЕФЪ§ОнЮФМўЃЌвдЙЉЪ§ОнВщбЏЁЃ
- ВщбЏНкЕу(Broker Node)ЃКЖдЭтЬсЙЉЪ§ОнВщбЏЗўЮёЃЌВЂЭЌЪБДгЪЕЪБНкЕугыРњЪЗНкЕуВщбЏЪ§Он,КЯВЂКѓЗЕЛиИјЕїгУЗНЁЃ
- аЕїНкЕу(CoordinatorNode)ЃКИКд№РњЪЗНкЕуЕФЪ§ОнИКдиОљКтЃЌвдМАЭЈЙ§Йцдђ(Rule) ЙмРэЪ§ОнЕФЩњУќжмЦкЁЃ
ЭЌЪБЃЌМЏШКЛЙАќКЌвдЯТШ§РрЭтВПвРРЕЁЃ
- дЊЪ§ОнПт(Metastore)ЃКДцДЂDruidМЏШКЕФдЪ§ОнаХЯЂЃЌБШШчSegmentЕФЯрЙиаХЯЂЃЌвЛАугУ MySQL Лђ PostgreSQLЁЃ
- ЗжВМЪНаЕїЗўЮё(Coordination)ЃКЮЊDruidМЏШКЬсЙЉвЛжТадаЕїЗўЮёЕФзщМўЃЌЭЈГЃЮЊZookeeperЁЃ
- Ъ§ОнЮФМўДцДЂПт(DeepStorage)ЃКДцЗХЩњГЩЕФSegmentЪ§ОнЮФМўЃЌВЂЙЉРњЪЗНкЕуЯТди ЖдгкЕЅНкЕуМЏШКПЩвдЪЧБОЕиДХХЬЃЌЖјЖдгкЗжВМЪНМЏШКвЛАуЪЧ HDFS Лђ NFSЁЃ
ДгЪ§ОнСїзЊЕФНЧЖШРДПДЃЌЪ§ОнДгМмЙЙЭМЕФзѓВрНјШыЯЕЭГ,ЗжЮЊЪЕЪБСїЪ§ОнгыХњСПЪ§ОнЁЃЪЕЪБСїЪ§ОнЛсБЛЪЕЪБНкЕуЯћЗб,ШЛКѓЪЕЪБНкЕуНЋЩњГЩЕФ Segment Ъ§ОнЮФМўЩЯДЋЕНЪ§ОнЮФМўДцДЂПтЃЛЖјХњСПЪ§ОнОЙ§ Druid МЏШКЯћЗбКѓЛсБЛжБНгЩЯДЋЕНЪ§ОнЮФМўДцДЂПтЁЃЭЌЪБЃЌВщбЏНкЕуЛсЯьгІЭтВПЕФВщбЏЧыЧѓЃЌВЂНЋЗжБ№ДгЪЕЪБНкЕугыРњЪЗНкЕуВщбЏЕНЕФНсЙћКЯВЂКѓЗЕЛиЁЃ
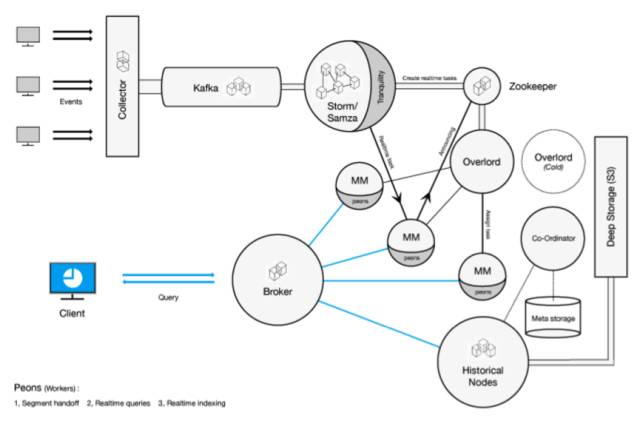
ЛљгкIndexing ServiceЕФМмЙЙ
дкЛљгкIndexing ServiceЕФМмЙЙжаЃЌЪЕЪБНкЕуБЛЗЯЦњЕєСЫЃЌзЊЖјДњжЎЕФOverlordНкЕуКЭMiddleManagerНкЕуЁЃЦфжаЃЌOverlordНкЕузїЮЊЫїв§ЗўЮёЕФжїНкЕу,ЖдЭтИКд№НгЪеШЮЮёЧыЧѓ,ЖдФкИКд№НЋШЮЮёЗжНтВЂЯТЗЂЕНДгНкЕуМДMiddleManagerНкЕуЩЯЁЃЖјMiddleManagerНкЕуОЭЪЧЫїв§ЗўЮёЕФЙЄзїНкЕу,ИКд№НгЪеЭГжЮНкЕуЗжХфЕФШЮЮё,ШЛКѓЦєЖЏЯрЙиПрЙЄЃЈPeonЃЉМДЖРСЂЕФ JVM РДЭъГЩОпЬхЕФШЮЮёЁЃетбљЕФМмЙЙЪЕМЪгы Hadoop Yarn КмЯёЁЃ
НЯжЎЛљгкЪЕЪБНкЕуЕФМмЙЙЃЌЛљгкIndexing ServiceЕФМмЙЙгаВЛЩйгХЕуЃКГ§СЫЖдЪ§ОнФмЙЛгУ pull ЕФЗНЪНЭт,ЛЙжЇГж push ЕФЗНЪНЃЛВЛЭЌгкЪжЙЄБраДЪ§ОнЯћЗбХфжУЮФМўЕФЗНЪНЃЌПЩвдЭЈЙ§ API ЕФБрГЬЗНЪНРДСщЛюЖЈвхШЮЮёХфжУЃЛПЩвдИќСщЛюЕиЙмРэгыЪЙгУЯЕЭГзЪдДЃЛПЩвдЭъГЩ Segment ИББОЪ§СПЕФПижЦЃЛФмЙЛСщЛюЭъГЩИњ Segment Ъ§ОнЮФМўЯрЙиЕФЫљгаВйзїЃЌШчКЯВЂЁЂЩОГ§ Segment Ъ§ОнЮФМўЕШЁЃ
ВщбЏ
DruidЕФФЌШЯЬсЙЉСЫHTTP REST ЗчИёЕФВщбЏНгПкЁЃвЛИіЕфаЭЕФ curl УќСюШчЯТ: curl -X POST ':/druid/v2/?pretty' -H 'Content-Type:application /json' -d @ ЁЃ
ЦфжаЃЌqueryablehost:port ЮЊВщбЏНкЕуЕФ IP ЕижЗКЭЖЫПкЃЛqueryjson_ leЮЊPOSTЕНВщбЏНкЕуЕФВщбЏЧыЧѓЁЃ
ЮЊСЫБугкгУЛЇНјааСщЛюЕФOLAPЗжЮіЃЌDruidЬсЙЉСЫЗсИЛЕФВщбЏНгПкЃЌБШШчЙ§ТЫЦїЁЂОлКЯЦїКЭКѓжУОлКЯЦїЕШЁЃгЩгкетВПЗжФкШнБШНЯКУРэНтЃЌЖјЧвDruidЙйЭјЩЯгаЯъЯИЕФНщЩмЃЌвђДЫБОЮФОЭВЛдйЙ§ЖрЫЕУїЃЌетРяНіОлвЛИіЪЕМЪЕФВщбЏР§згШчЯТЃК
{
"queryType": "timeseries",
"dataSource": "visitor_statistics",
"granularity": "all",
"filter": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "host",
"value": "www.mejia.wang"
},
{
}
]
},
"aggregations": [
{
"type": "longSum",
"name": "pv",
"fieldName": "counbt"
},
{
},
{
"type": "hyperUnique",
"name": "new_visitor_count",
"fieldName": "new_visit_count"
},
{
}
],
"postAggregations": [
{
"type": "arithmetic",
"name": "new_visitor_rate",
"fn": "/",
"fields": [
{
"type": "hyperUniqueCardinality",
"fieldName": "new_visitor_count"
},
{
"fieldName": "visitor_count"
}
]
},
{
"type": "arithmetic",
"name": "click_rate",
"fn": "/",
"fields": [
{
"type": "hyperUniqueCardinality",
"fieldName": "click_visitor_count"
},
{
"type": "hyperUnique",
"name": "click_visitor_count",
"fieldName": "click_visit_count""type": "hyperUniqueCardinality",
"type": "hyperUniqueCardinality",
"fieldName": "visitor_count"
}
]
}
],
"intervals": [
"2016-08-07T00:00:00+08:00/2016-09-05T23:59:59+08:00"
]
} |
ЗЕЛиНсЙћПЩФмШчЯТЃК
["
{
"timestamp": "2016-08-27T16:00:00.000Z",
"result": {
"pv": 30.000000061295435,
"visit_count": 5.006113467958146,
"new_visitor_count": 0,
"click_visitor_count": 5.006113467958146,
"new_visitor_rate": 0,
"click_rate": 1,
}
}
] |
ЗсИЛЕФИЈжњЙІФм
DruidГ§СЫЛљБОЕФКЫаФЪ§ОнЯћЗбКЭВщбЏЙІФмЭтЃЌЛЙЬсЙЉСЫЗсИЛЕФИЈжњЙІФмЃЌвдАяжњгУЛЇИќКУЕиЛљгкDruidЭъГЩЪ§ОнДІРэЙЄзїЁЃБОЮФМђЕЅСаОйМИИіЃК
DataSketches aggregatorЃКНќЫЦМЦЫуCOUNT DISTINCTЕШЮЪЬтЃЌШчPVЁЂСєДцЕШЃЛОЋЖШПЩЕїНкЁЃ
Multi-value dimensionsЃКЖдгкЭЌвЛЮЌЖШСаЃЌдЪаэВЛЭЌаагЕгаВЛЭЌЪ§СПЕФЪ§ОнжЕЃКетЪЙЕУDruidвВФмЙЛгаРрЫЦschemalessЕФЙІФмЁЃ
| {"timestamp": "2011-01-12T00:00:00.000Z", "tags": ["t1","t2","t3"]} #row1 {"timestamp": "2011-01-13T00:00:00.000Z", "tags": ["t3","t4","t5"]} #row2 |
Router NodeЃКажњBroker NodeЪЕЯжИКдиОљКтЁЃ
Query CachingЃКАяжњЬсЩ§ВщбЏадФмЃЌПЩвдгУдкHistorical NodeЛђBroker NodeЩЯЁЃ
ЪЕМљ
зюКѓЃЌНщЩмвЛЯТБЪепФПЧАдкББОЉдЦВтаХЯЂММЪѕгаЯоЙЋЫОЃЈМДTestinЙЋЫОЃЉЕФABВтЪдВњЦЗжаЕФDruidЪЕМљОбщЁЃ
ЯТЭМЪЧЮвУЧABВтЪдВњЦЗЕФМмЙЙЭМЃЌПЩвдПДЕНDruidдкЦфжажївЊИКд№ЖрЮЌЪЕЪБOLAPЗжЮіЁЃ
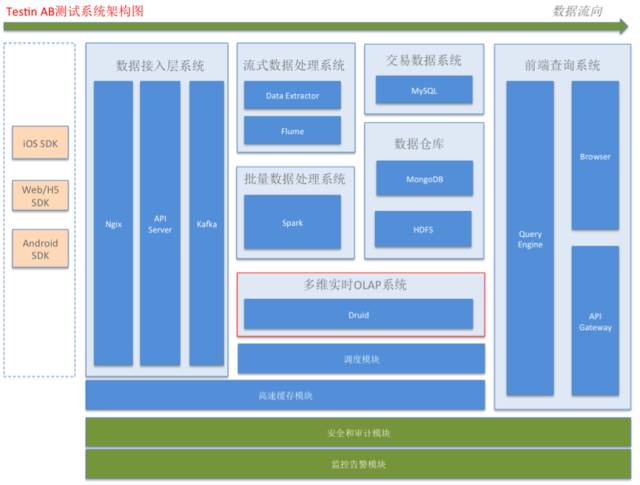
ЮвУЧЪЙгУЕФЪЧDruid Indexing ServiceЕФМмЙЙЃЌЖјЧвЪЙгУСЫKafka Indexing ServiceЕФЙІФмЃЌетЪЙЕУЮвУЧПЩвдКмЗНБуЕиБЃжЄСЫDruidВЛЖЊЦњГЌЙ§ЪБМфДАПкЕФЪ§ОнЁЃ
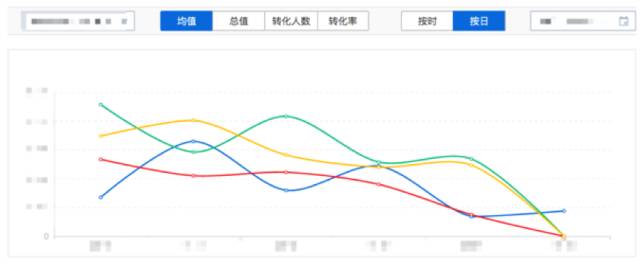
ДгЪЙгУаЇЙћРДПДЃЌDruidИГгшСЫЮвУЧВњЦЗЪЕЪБЕФЪ§ОнЯћЗбКЭВщбЏЃЌЪЙЕУгУЛЇПЩвддкУыМЖБуПДЕНзюаТЕФЪ§ОнЗжЮіНсЙћЃЌШчЯТЭМЃК
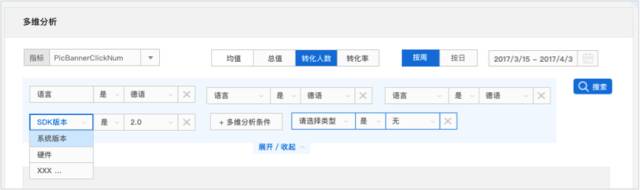
ЭЌЪБЃЌDruidЪЙЕУЮвУЧПЩвдНјааСщЛюЕФЖрЮЌЪЕЪБЗжЮіЃК
|









