| Spark的核心概念是RDD,而RDD的关键特性之一是其不可变性,来规避分布式环境下复杂的各种并行问题。这个抽象,在数据分析的领域是没有问题的,它能最大化的解决分布式问题,简化各种算子的复杂度,并提供高性能的分布式数据处理运算能力。
然而在机器学习领域,RDD的弱点很快也暴露了。机器学习的核心是迭代和参数更新。RDD凭借着逻辑上不落地的内存计算特性,可以很好的解决迭代的问题,然而RDD的不可变性,却非常不适合参数反复多次更新的需求。这本质上的不匹配性,导致了Spark的MLlib库,发展一直非常缓慢,从2015年开始就没有实质性的创新,性能也不好。
为此,Angel在设计生态圈的时候,优先考虑了Spark。在V1.0.0推出的时候,就已经具备了Spark
on Angel的功能,基于Angel为Spark加上了PS功能,在不变中加入了变化的因素,可谓如虎添翼。
我们将以L-BFGS为例,来分析Spark在机器学习算法的实现上的问题,以及Spark on Angel是如何解决Spark在机器学习任务中的遇到的瓶颈,让Spark的机器学习更加强大。
1. L-BFGS算法说明

2.L-BFGS的Spark实现


3.L-BFGS的Spark on Angel实现
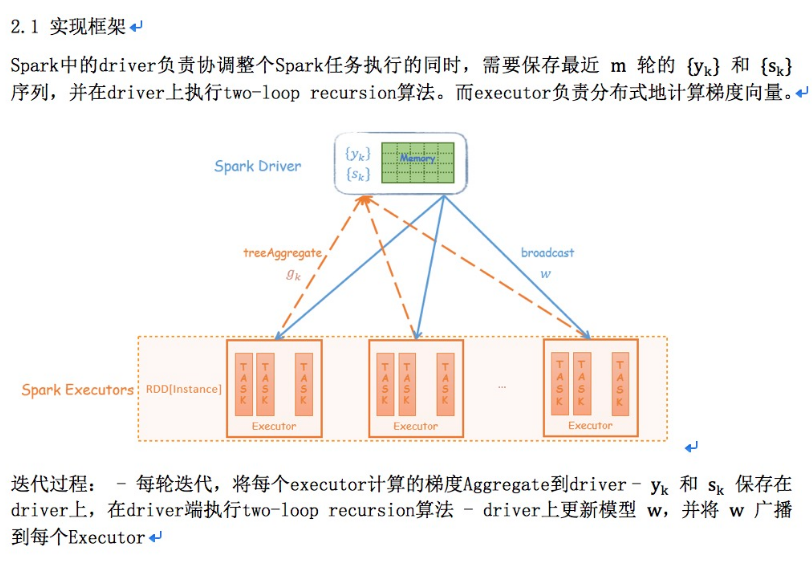
3.1 实现框架
Spark on Angel借助Angel PS-Service的功能为Spark引入PS的角色,减轻整个算法流程对driver的依赖。two-loop
recursion算法的运算交给PS,而driver只负责任务的调度,大大减轻的对driver性能的依赖。
Angel PS由一组分布式节点组成,每个vector、matrix被切分成多个partition保存到不同的节点上,同时支持vector和matrix之间的运算;
3.2 性能分析
整个算法过程,driver只负责任务调度,而复杂的two-loop recursion运算在PS上运行,梯度的Aggregate和模型的同步是executor和PS之间进行,所有运算都变成分布式。在网络传输中,高维度的PSVector会被切成小的数据块再发送到目标节点,这种节点之间多对多的传输大大提高了梯度聚合和模型同步的速度。
这样Spark on Angel完全避开了Spark中driver单点的瓶颈,以及网络传输高维度向量的问题。
4.“轻易强快”的Spark on Angel
Spark on Angel是Angel为解决Spark在机器学习模型训练中的缺陷而设计的“插件”,没有对Spark做“侵入式”的修改,是一个独立的框架。可以用
“轻”、“易”、“强”、“快” 来概括Spark on Angel的特点。
4.1 轻 — “插件式”的框架
Spark on Angel是Angel为解决Spark在机器学习模型训练中的缺陷而设计的“插件”。Spark
on Angel没有对Spark中的RDD做侵入式的修改,Spark on Angel是依赖于Spark和Angel的框架,同时其逻辑又独立于Spark和Angel。
因此,Spark用户使用Spark on Angel非常简单,只需在Spark的提交脚本里做三处改动即可,详情可见Angel的Github
Spark on Angel Quick Start文档
可以看到提交的Spark on Angel任务,其本质上依然是一个Spark任务,整个任务的执行过程与Spark一样的。
source ${Angel_HOME}/bin/spark-on-angel-env.sh
$SPARK_HOME/bin/spark-submit \
--master yarn-cluster \
--conf spark.ps.jars=$SONA_ANGEL_JARS \
--conf spark.ps.instances=20 \
--conf spark.ps.cores=4 \
--conf spark.ps.memory=10g \
--jars $SONA_SPARK_JARS \
....
Spark on Angel能够成为如此轻量级的框架,得益于Angel对PS-Service的封装,使Spark的driver和executor可以通过PsAgent、PSClient与Angel
PS做数据交互。
4.2 强 — 功能强大,支持breeze库
breeze库是scala实现的面向机器学习的数值运算库。Spark MLlib的大部分数值优化算法都是通过调用breeze来完成的。如下所示,Spark和Spark
on Angel两种实现都是通过调用breeze.optimize.LBFGS实现的。Spark的实现是---BreezePSVector。-----
BreezePSVector是指Angel PS上的Vector,该Vector实现了breeze
NumericOps下的方法,如常用的 dot,scale,axpy,add等运算,因此在LBFGS[BreezePSVector]
two-loop recursion算法中的高维度向量运算是BreezePSVector之间的运算,而BreezePSVector之间全部在Angel
PS上分布式完成。
Spark的L-BFGS实现

4.3 易 — 编程接口简单
Spark能够在大数据领域这么流行的另外一个原因是:其编程方式简单、容易理解,Spark on Angel同样继承了这个特性。
Spark on Angel本质是一个Spark任务,整个代码实现逻辑跟Spark是一致的;当需要与PSVector做运算时,调用相应的接口即可。
如下代码所示,LBFGS在Spark和Spark on Angel上的实现,二者代码的整体思路是一样的,主要的区别是梯度向量的Aggregate和模型
的pull/push。 因此,如果将Spark的算法改造成Spark on Angel的任务,只需要修改少量的代码即可。
L-BFGS需要用户实现DiffFunction,DiffFunction的calculte接口输入参数是
,遍历训练数据并返回 loss 和 gradient。
其完整代码,请前往Github SparseLogistic
Spark的DiffFunction实现
4.4 快 — 性能强劲
我们分别实现了SGD、LBFGS、OWLQN三种优化方法的LR,并在Spark和Spark on
Angel上做了实验对比。 该实验代码请前往Github SparseLRWithX.scala .
数据集:腾讯内部某业务的一份数据集,2.3亿样本,5千万维度
实验设置:
说明1:三组对比实验的资源配置如下,我们尽可能保证所有任务在资源充足的情况下执行,因此配置的资源比实际需要的偏多;
说明2:执行Spark任务时,需要加大spark.driver.maxResultSize参数;而Spark
on Angel就不用配置此参数。
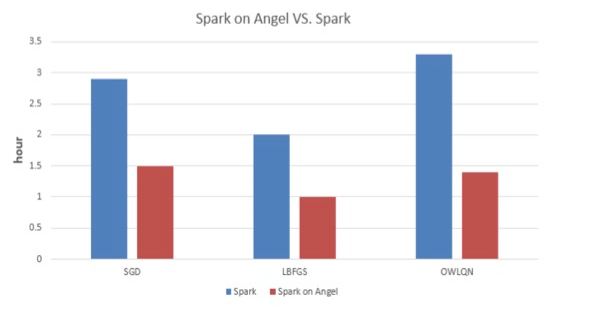
如上数据所示,Spark on Angel相较于Spark在训练LR模型时有50%以上的加速;对于越复杂的模型,其加速的比例越大。
5.结语
Spark on Angel的出现可以高效、低成本地克服Spark在机器学习领域遇到的瓶颈;我们将继续优化Spark
on Angel,并提高其性能。也欢迎大家在Github上一起参与我们的改进。
|









