| БОЮФЪЧЯЕСаЮФеТЕФЕк4ЦЊЃЌ
ЕквЛЦЊ
"KafkaЩшМЦНтЮіЃЈвЛЃЉ- KafkaБГОАМАМмЙЙНщЩм"
ЕкЖўЦЊ
"KafkaЩшМЦНтЮіЃЈЖўЃЉ- Kafka High Availability ЃЈЩЯЃЉ
ЕкШ§ЦЊ
KafkaЩшМЦНтЮіЃЈШ§ЃЉ- Kafka High Availability ЃЈжаЃЉ
ЕкЫФЦЊ
KafkaЩшМЦНтЮіЃЈЫФЃЉ- Kafka High Availability ЃЈЯТЃЉ
ЕкЮхЦЊ
KafkaЩшМЦНтЮіЃЈЮхЃЉ- Kafka ConsumerЩшМЦНтЮі
ЕкСљЦЊ KafkaЩшМЦНтЮіЃЈСљЃЉ-
KafkaадФмВтЪдЗНЗЈМАBenchmarkБЈИц
ЁЖKafkaЩшМЦНтЮіЁЗЯЕСаЩЯвЛЦЊЁЖKafkaИпадФмМмЙЙжЎЕРЁЊЁЊKafkaЩшМЦНтЮіЃЈСљЃЉЁЗДгКъЙлМмЙЙЕНОпЬхЪЕЯжЗжЮіСЫKafkaЪЕЯжИпадФмЕФдРэЁЃБОЮФНщЩмСЫKafka
StreamЕФМмЙЙКЭВЂЗЂФЃаЭЃЌЭЌЪБЗжЮіСЫKafka StreamШчКЮНтОіСїЪНМЦЫуЕФЙиМќЮЪЬтЁЃ
ЪВУДЪЧСїЪНМЦЫу
вЛАуСїЪНМЦЫуЛсгыХњСПМЦЫуЯрБШНЯ
дкСїЪНМЦЫуФЃаЭжаЃЌЪфШыЪЧГжајЕФЃЌдкЪБМфЩЯЪЧЮоНчЕФЁЃетвВОЭвтЮЖзХЃЌгРдЖФУВЛЕНШЋСПЪ§ОнМЏНјааМЦЫуЁЃЭЌЪБЃЌМЦЫуНсЙћЛсГжајЪфГіЃЌвВМДМЦЫуНсЙћдкЪБМфЩЯвВЪЧЮоНчЕФЁЃ
СїЪНМЦЫувЛАуЖдЪЕЪБадвЊЧѓБШНЯИпЃЌЭЌЪБвЛАуЪЧЯШЖЈвхФПБъМЦЫуЃЌШЛКѓЪ§ОнЕНДяКѓНЋМЦЫуТпМгІгУгкЪ§ОнжЎЩЯЁЃЭЌЪБЮЊСЫЬсИпМЦЫуаЇТЪЃЌвЛАуОЁПЩФмЃЈЖдгкПЩКЯВЂЕФМЦЫуЃЉВЩгУдіСПМЦЫуДњЬцШЋСПМЦЫуЁЃ
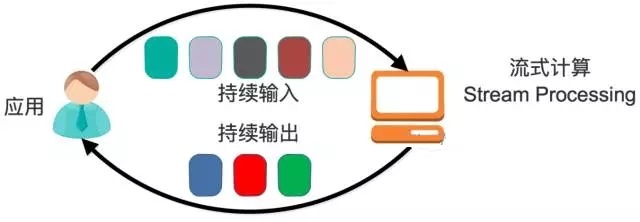
ХњСПДІРэФЃаЭжаЃЌвЛАуЯШгаШЋСПЪ§ОнМЏЃЌШЛКѓНЋМЦЫуТпМгІгУгкИУШЋСПЪ§ОнМЏЁЃЬиЕуЪЧШЋСПМЦЫуЃЌВЂЧвМЦЫуНсЙћвЛДЮадШЋСПЪфГіЃЌдкЪБМфЩЯЪЧгаНчЕФЁЃ
Kafka StreamЪЧЪВУД
Kafka StreamЪЧKafkaДг0.10.*в§ШыЕФвЛИіаТЕФЬиадЁЃЫќЬсЙЉСЫЖдДцгкKafkaФкЕФЪ§ОнНјааЗжВМЪНСїЪНДІРэвдКЭЗжЮіЕФФмСІЁЃ
Kafka StreamЕФЬиЕуШчЯТЃК
Г§СЫKafkaЭтЃЌВЛвРРЕгкШЮКЮЭтВПЯЕЭГ
Kafka StreamЪЧвЛИіЗЧГЃМђЕЅВЂЧвЧсСПМЖЕФРрПтЃЌПЩвдЗЧГЃЗНБуЕиНЋЫќЧЖШыШЮвтJavaГЬађжаЃЌвВПЩвдШЮвтЗНЪННјааДђАќвдМАВПЪ№
ЭЌЪБЬсЙЉЕзВуЕФДІРэЕЅдЊProcessorЃЈРрЫЦгкStormЬсЙЉЕФboltКЭspoutЃЉЃЌвдМАИпВуГщЯѓЕФDSLЃЈРрЫЦгкSparkЕФgroup/reduce/mapЃЉ
ЭЈЙ§ОпгаШнДэадЕФstate storeЪЕЯжПЩППЕФзДЬЌВйзїЃЈШчwindowed joinКЭaggregationЃЉ
жЇГжExactly OnceЃЈе§КУвЛДЮЃЉДІРэгявх
ОпБИМЧТММЖЃЈвВМДааМЖЃЉЕФЪ§ОнДІРэФмСІЃЌДгЖјНЋбгГйНЕЕЭЕНКСУыМЖБ№
ГфЗжРћгУKafkaЗжЧјЛњжЦвдЪЕЯжScale OutЃЈЫЎЦНРЉеЙЃЉВЂЬсЙЉЫГађадБЃжЄ
жЇГжЛљгкЪТМўЪБМфЕФДАПкВйзїЃЈSpark StreamingднВЛжЇГжЪТМўЪБМфЃЉЃЌВЂЧвПЩДІРэЭэЕНЕФЪ§ОнЃЈlate
arrival of recordsЃЉ
Kafka StreamЖЈЮЛМАгХЪЦ
ЕБЧАвбОгаЖржжЗжВМЪНСїЪНДІРэЯЕЭГЃЌзюжЊУћЧвгІгУзюЖрЕФПЊдДСїЪНДІРэЯЕЭГЕБЪєTwitterПЊдДЕФApache
StormКЭUC berkeleyЕФSpark StreamingЁЃЁЃЁЃЁЃ
Apache StormОЙ§ЖрФъЗЂеЙЃЌгІгУЙуЗКЃЌВЂЧвЭЌбљЬсЙЉМЧТММЖЃЈааМЖЃЉЕФДІРэФмСІЃЌбгГйвВдкКСУыМЖЁЃФПЧАвбжЇГжSQL
on StreamЁЃ
Spark StreamingЛљгкApache SparkЃЌЧвЗЧГЃБугкгыSQLДІРэКЭЭММЦЫуЕШМЏГЩЃЌЙІФмЧПДѓЃЌЖдгкЪьЯЄЦфЫќSparkгІгУПЊЗЂЕФгУЛЇЖјбдЪЙгУУХМїЗЧГЃЕЭ
СэЭтЃЌФПЧАжїСїЕФHadoopЗЂааАцЃЌШчClouderaЃЌHortonworksКЭMapRЃЌЖММЏГЩСЫSparkКЭStormЃЌЪЙЕУВПЪ№гыдЫЮЌетаЉЯЕЭГЗЧГЃЗНБуЁЃЁЃЁЃЁЃЁЃЁЃЁЃ
МШШЛApache StormгыApache SparkгЕгУШчДЫЖргХЕуЃЌФЧЮЊКЮЛЙашвЊKafka StreamФиЃПБЪепШЯЮЊжївЊгаШчЯТдвђЁЃЁЃЁЃЁЃЁЃЁЃЁЃ
ЕквЛЃЌSparkКЭStormЖМЪЧСїЪНДІРэПђМмЃЌЖјKafka StreamЬсЙЉЕФЪЧвЛИіЛљгкKafkaЕФСїЪНДІРэРрПтЁЃПђМмвЊЧѓПЊЗЂепАДеежИЖЈЕФЗНЪНШЅПЊЗЂТпМВПЗжЃЌВЂАДеежИЖЈЕФЗНЗЈВПЪ№ЁЃПЊЗЂепКмФбСЫНтПђМмЕФФкВПДІРэЗНЪНЃЌДгЖјЪЙЕУЕїЪдКЭдЫЮЌГЩБОНЯИпЃЌЧвЪЙгУЪмЯоЁЃЖјKafka
StreamзїЮЊСїЪНДІРэРрПтЃЌжБНгЬсЙЉОпЬхЕФРрИјПЊЗЂепЕїгУЃЌећИігІгУЕФдЫааКЭВПЪ№ЗНЪНЭъГЩгЩПЊЗЂепОіЖЈЃЌМЋДѓЕиЗНБуСЫЪЙгУКЭЕїЪдЁЃгІгУГЬађгыРрПтМАПђМмЕФЙиЯЕШчЯТЭМЫљЪОЁЃ
ЕкЖўЃЌжїСїЕФЗжВМЪНСїЪНДІРэЯЕЭГЃЌЛљБОЖМжЇГжвдKafkaзїЮЊЦфЪ§ОндДЁЃР§ШчSparkЬсЙЉзЈУХЕФspark-streaming-kafkaФЃПщЃЌЖјStormвВОпгазЈУХЕФkafka-spoutЁЃЪТЪЕЩЯЃЌKafkaПЩвдЫЕЪЧЕБЧАвЕНчжїСїЕФЗжВМЪНСїЪНДІРэЯЕЭГЕФБъзМЪ§ОндДЃЌДѓВПЗжЕфаЭЕФСїЪНЯЕЭГжаЖМвбВПЪ№СЫKafkaЃЌДЫЪБЪЙгУKafka
StreamЕФЪЙгУКЭЮЌЛЄГЩБОЗЧГЃЕЭЁЃЁЃЁЃЁЃЁЃЁЃЁЃ
ЕкШ§ЃЌЫфШЛHortonworksгыClouderaЗНБуСЫSparkКЭStormЕФВПЪ№ЃЌЕЋетаЉПђМмЕФВПЪ№КЭдЫЮЌШдЯрЖдИДдгЁЃЯрЗДЃЌKafka
StreamзїЮЊРрПтЃЌПЩвдЗЧГЃЗНБуЕиБЛЧЖШыЕНвбгаЕФгІгУГЬађжаЃЌЫќЖдгІгУЕФДђАќЗНЪНМАВПЪ№ЗНЪНЛљБОЩЯУЛгаШЮКЮвЊЧѓЁЃЁЃЁЃЁЃЁЃЁЃ
ЕкЫФЃЌгЩгкKafkaБОЩэЬсЙЉЪ§ОнГжОУЛЏЃЌвђДЫKafka StreamОпгадкЯпЙіЖЏЩ§МЖКЭЙіЖЏВПЪ№МАжиаТМЦЫуЕФФмСІЁЃЁЃ
ЕкЮхЃЌKafka StreamГфЗжРћгУСЫConsumerЕФRebalanceЛњжЦКЭKafkaЕФЗжЧјЛњжЦЃЌЪЙЕУKafka
StreamПЩвдЗЧГЃЗНБуЕиНјааЫЎЦНРЉеЙЁЃОпЬхРДЫЕЃЌУПИідЫааKafka StreamЕФгІгУЪЕР§ЖМАќКЌСЫвЛИіKafka
ConsumerЪЕР§ЃЌЖрИіЭЌвЛгІгУЕФВЛЭЌЪЕР§МфВЂааДІРэФПБъЪ§ОнМЏЁЃЖјВЛЭЌЪЕР§жЎМфЕФВПЪ№ЗНЪНВЂВЛБиЭъШЋвЛжТЃЌБШШчВПЗжЪЕР§дЫаадкWebШнЦїжаЃЌВПЗжЪЕР§ПЩвддЫаадкDockerЛђKubernetesЕШащФтЛЏШнЦїжаЁЃ
ЕкСљЃЌKafkaОпгаConsumer RebalanceЛњжЦЃЌвђДЫПЩдкЯпЖЏЬЌЕїећВЂааЖШЖјВЛашвЊжиЦє
ЕкСљЃЌЪЙгУSpark StreamingЛђStormЪБЃЌашвЊЮЊПђМмБОЩэЕФНјГЬдЄСєзЪдДЃЌШчSpark
on YARNЕФnode managerКЭStormЕФsupervisorЁЃЖдгІгУГЬађЃЌПђМмБОЩэвВЛсеМгУВПЗжзЪдДЃЌШчSpark
StreamingашвЊЮЊshuffleКЭstorageдЄСєФкДцЁЃЁЃЁЃЁЃЁЃЁЃЁЃ
Kafka StreamећЬхМмЙЙ
Kafka StreamЕФећЬхМмЙЙЭМШчЯТЁЃ
ФПЧАЃЈKafka 0.11.0.0ЃЉKafka StreamЕФЪ§ОндДжЛФмЪЧKafkaЃЈШчЩЯЭМЫљЪОЃЉЁЃЕЋЪЧДІРэНсЙћВЂВЛвЛЖЈвЊШчЩЯЭМЫљЪОЪфГіЕНKafkaЁЃЪЕМЪЩЯGlobalKTableКЭKTableМАKStreamЕФЪЕР§ЛЏЖМаыжИЖЈTopicЃЈШчЯТЫљЪОЃЉЁЃ

СэЭтЃЌЩЯЭМжаЕФProducerКЭConsumerВЛашгЩПЊЗЂепдкKafka StreamгІгУжаЯдЪОЕиЪЕР§ЛЏЃЌЖјЪЧгЩKafka
StreamИљОнВЮЪ§вўЪНЪЕР§ЛЏЃЌДгЖјНЕЕЭСЫЪЙгУKafkaЕФУХМїЁЃПЊЗЂепжЛашзЈзЂгкПЊЗЂКЫаФвЕЮёТпМЃЌвВМДЩЯЭМжаTaskФкЕФВПЗжЁЃ
Processor Topology
ЛљгкKafka StreamЕФСїЪНгІгУЕФвЕЮёТпМШЋВПгЩвЛИіБЛГЦЮЊProcessor TopologyЕФзщМўжДааЁЃЫќгыSpark
StreamingЕФDAGКЭStormЕФTopologyРрЫЦЃЌЖМЖЈвхСЫЪ§ОндкИїИіДІРэЕЅдЊЃЈдкKafka
StreamжаБЛГЦзїProcessorЃЉМфЕФСїЖЏЗНЪНЃЌвВМДЖЈвхСЫЪ§ОнЕФДІРэТпМ
ЯТУцЪЧвЛИіProcessorЕФЪОР§ЃЌИУProcessorЪЕЯжСЫWord CountЙІФмЃЌЧвУПУыЪфГівЛДЮМЦЫуНсЙћЁЃ

гЩЩЯЪіДњТыПЩМћ
context.getStateStoreЬсЙЉЕФзДЬЌДцДЂЮЊгазДЬЌМЦЫуЃЈШчОлКЯВйзїЃЌДАПкВйзїЃЉЬсЙЉСЫПЩФмад
processЖЈвхСЫЖдУПЬѕМЧТМЕФДІРэТпМЃЌвВгЁжЄСЫKafkaОпгаМЧТММЖЕФЪ§ОнДІРэФмСІ
context.schedulerЖЈвхСЫpunctuateБЛжДааЕФжмЦкЃЌДгЖјЬсЙЉСЫЪЕЯжДАПкВйзїЕФФмСІ
Kafka StreamВЂааФЃаЭ
Kafka StreamЕФВЂааФЃаЭжаЃЌзюаЁСЃЖШЮЊTaskЃЌУПИіTaskАќКЌвЛИіЬиЖЈзгTopologyЕФЫљгаProcessorЁЃвђДЫУПИіTaskЫљжДааЕФДњТыЭъШЋвЛбљЃЌЮЈвЛЕФВЛЭЌдкгкЫљДІРэЕФЪ§ОнМЏЛЅВЙЁЃ
етвЛЕуИњStormЕФTopologyЭъШЋВЛвЛбљЁЃStormЕФTopologyЕФУПвЛИіTaskжЛАќКЌвЛИіSpoutЛђBoltЕФЪЕР§ЁЃвђДЫStormЕФвЛИіTopologyФкЕФВЛЭЌTaskжЎМфашвЊЭЈЙ§ЭјТчЭЈаХДЋЕнЪ§ОнЃЌЖјKafka
StreamЕФTaskАќКЌСЫЭъећЕФзгTopologyЃЌЫљвдTaskжЎМфВЛашвЊДЋЕнЪ§ОнЃЌвВОЭВЛашвЊЭјТчЭЈаХЁЃетвЛЕуНЕЕЭСЫЯЕЭГИДдгЖШЃЌвВЬсИпСЫДІРэаЇТЪЁЃ
ШчЙћФГИіStreamЕФЪфШыTopicгаЖрИі(БШШч2ИіTopicЃЌ1ИіPartitionЪ§ЮЊ5ЃЌСэвЛИіPartitionЪ§ЮЊ6)ЃЌдђзмЕФTaskЪ§ЕШгкPartitionЪ§зюЖрЕФФЧИіTopicЕФPartitionЪ§ЃЈmax(5,6)=6ЃЉЁЃетЪЧвђЮЊKafka
StreamЪЙгУСЫConsumerЕФRebalanceЛњжЦЃЌУПИіPartitionЖдгІвЛИіTaskЁЃ
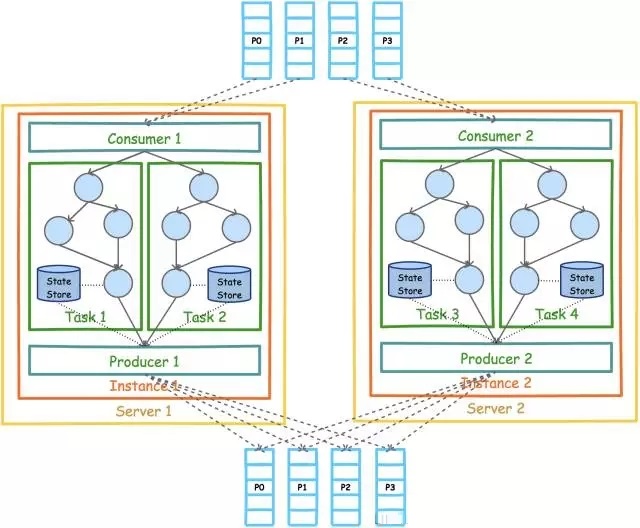
ЯТЭМеЙЪОСЫдквЛИіНјГЬЃЈInstanceЃЉжавд2ИіTopicЃЈPartitionЪ§ОљЮЊ4ЃЉЮЊЪ§ОндДЕФKafka
StreamгІгУЕФВЂааФЃаЭЁЃДгЭМжаПЩвдПДЕНЃЌгЩгкKafka StreamгІгУЕФФЌШЯЯпГЬЪ§ЮЊ1ЃЌЫљвд4ИіTaskШЋВПдквЛИіЯпГЬжадЫааЁЃ
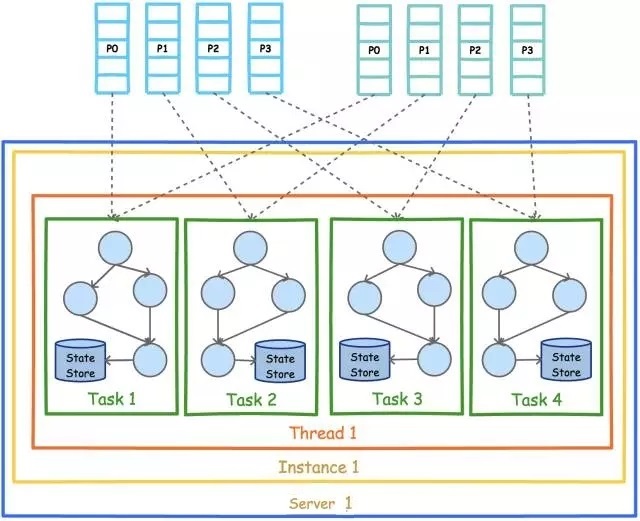
ЮЊСЫГфЗжРћгУЖрЯпГЬЕФВЂааДІРэгХЪЦЃЌKafka StreamгІгУГЬађПЩЩшжУЯпГЬЪ§ЃЈФЌШЯЮЊ1ЃЉЁЃЯТЭМеЙЪОСЫЯпГЬЪ§ЮЊ2ЪБЕФВЂааФЃаЭЁЃ
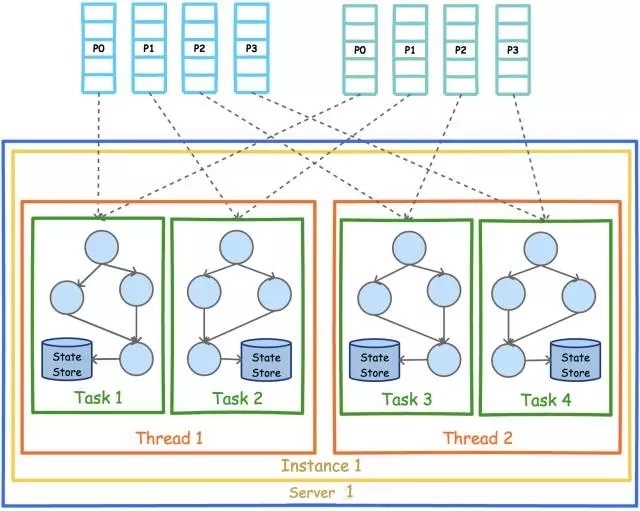
ДгЩЯЭМПЩМћЃЌУПИіЯпГЬЗжБ№ИКд№жДааСНИіTaskЁЃ
ЧАЮФгаЬсЕНЃЌKafka StreamПЩБЛЧЖШыЕНШЮвтJavaгІгУЃЈРэТлЩЯЛљгкJVMЕФгІгУЖМПЩвдЃЉжаЁЃЯТЭМеЙЪОСЫдкЭЌвЛЬЈЛњЦїЕФВЛЭЌНјГЬжаЭЌЪБЦєЖЏЭЌвЛИіKafka
StreamгІгУЪБЕФВЂааФЃаЭЁЃЁЃЁЃ
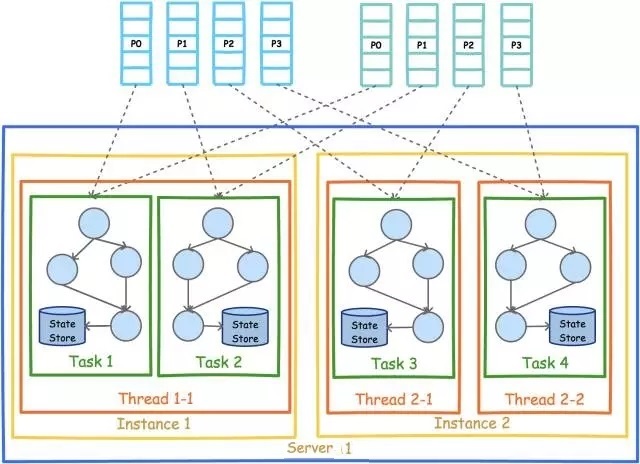
зЂвтЃЌетРявЊБЃжЄСНИіНјГЬЕФStreamsConfig.APPLICATION_ID_CONFIGЭъШЋвЛбљЁЃвђЮЊKafka
StreamНЋAPPLICATION_ID_CONFIGзїЮЊвўЪНЦєЖЏЕФConsumerЕФGroup
IDЁЃжЛгаБЃжЄAPPLICATION_ID_CONFIGЯрЭЌЃЌВХФмБЃжЄетСНИіНјГЬЕФConsumerЪєгкЭЌвЛИіGroupЃЌДгЖјПЩвдЭЈЙ§Consumer
RebalanceЛњжЦФУЕНЛЅВЙЕФЪ§ОнМЏЁЃ
МШШЛЪЕЯжСЫЖрНјГЬВПЪ№ЃЌПЩвдвдЭЌбљЕФЗНЪНЪЕЯжЖрЛњЦїВПЪ№ЁЃИУВПЪ№ЗНЪНвВвЊЧѓЫљгаНјГЬЕФAPPLICATION_ID_CONFIGЭъШЋвЛбљЁЃДгЭМЩЯвВПЩвдПДЕНЃЌУПИіЪЕР§жаЕФЯпГЬЪ§ВЂВЛвЊЧѓвЛбљЁЃЕЋЪЧЮоТлШчКЮВПЪ№ЃЌTaskзмЪ§змЛсБЃжЄвЛжТЁЃ
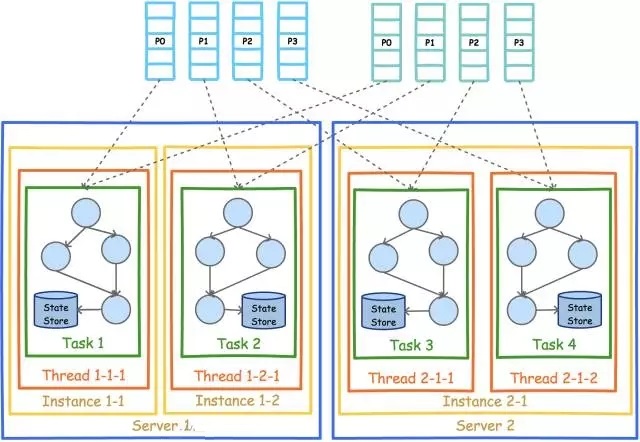
зЂвтЃКKafka StreamЕФВЂааФЃаЭЃЌЗЧГЃвРРЕгкЁЖKafkaЩшМЦНтЮіЃЈЫФЃЉ- Kafka ConsumerЩшМЦНтЮіЁЗвЛЮФжаНщЩмЕФConsumerЕФRebalanceЛњжЦКЭЁЖKafkaЩшМЦНтЮіЃЈвЛЃЉ-
KafkaБГОАМАМмЙЙНщЩмЁЗвЛЮФжаНщЩмЕФKafkaЗжЧјЛњжЦЁЃЧПСвНЈвщВЛЬЋЪьЯЄетСНжжЛњжЦЕФХѓгбЃЌЯШаадФЖСетСНЦЊЮФеТЁЃ
етРяЖдБШвЛЯТStormЕФTopologyКЭKafka StreamЕФProcessor TopologyЁЃ
StormЕФTopologyгЩSpoutКЭBoltзщГЩЃЌSpoutЬсЙЉЪ§ОндДЃЌЖјBoltЬсЙЉМЦЫуКЭЪ§ОнЕМГіЁЃKafka
StreamЕФProcessor TopologyЭъШЋгЩProcessorзщГЩЃЌвђЮЊЫќЕФЪ§ОнЙЬЖЈгЩKafkaЕФConsumerДгKafkaЕФвЛИіЛђЖрИіTopicжаЛёШЁ
StormЕФTopologyПЩвдЭЌЪБАќКЌShuffleВПЗжКЭЗЧShuffleВПЗжЃЌВЂЧвЭљЭљвЛИіTopologyОЭЪЧвЛИіЭъећЕФгІгУЁЃЖјKafka
StreamЕФвЛИіЮяРэTopologyжЛАќКЌЗЧShuffleВПЗжЃЌЖјShuffleВПЗжашвЊЭЈЙ§throughВйзїЯдЪОЭъГЩЃЌИУВйзїНЋвЛИіДѓЕФTopologyЗжГЩСЫ2ИізгTopology
StormЕФВЛЭЌBoltдЫаадкВЛЭЌЕФExecutorжаЃЌКмПЩФмЮЛгкВЛЭЌЕФЛњЦїЃЌашвЊЭЈЙ§ЭјТчЭЈаХДЋЪфЪ§ОнЁЃЖјKafka
StreamЕФProcessor TopologyЕФВЛЭЌProcessorЭъШЋдЫаагкЭЌвЛИіTaskжаЃЌвВОЭЭъШЋДІгкЭЌвЛИіЯпГЬЃЌЮоашЭјТчЭЈаХ
StormЕФвЛИіTaskжЛАќКЌвЛИіSpoutЛђепBoltЕФЪЕР§ЃЌЖјKafka StreamЕФвЛИіTaskАќКЌСЫвЛИізгTopologyЕФЫљгаProcessor
StormЕФTopologyФкЃЌВЛЭЌBolt/SpoutЕФВЂааЖШПЩвдВЛвЛбљЃЌЖјKafka StreamЕФзгTopologyФкЃЌЫљгаProcessorЕФВЂааЖШЭъШЋвЛбљ
StormШчЙћвЊаоИФФГИіSpoutЛђBoltЕФВЂааЖШЃЌашвЊжиЦєTopologyЁЃЖјKafka StreamПЩРћгУConsumer
RebalanceЛњжЦЗЧГЃЗНБуЕидкЯпЖЏЬЌЕїећВЂааЖШ
State store
СїЪНДІРэжаЃЌВПЗжВйзїЪЧЮозДЬЌЕФЃЌР§ШчЙ§ТЫВйзїЃЈKafka Stream DSLжагУfilerЗНЗЈЪЕЯжЃЉЁЃЖјВПЗжВйзїЪЧгазДЬЌЕФЃЌашвЊМЧТМжаМфзДЬЌЃЌШчWindowВйзїКЭОлКЯМЦЫуЁЃState
storeБЛгУРДДцДЂжаМфзДЬЌЁЃЫќПЩвдЪЧвЛИіГжОУЛЏЕФKey-ValueДцДЂЃЌвВПЩвдЪЧФкДцжаЕФHashMapЃЌЛђепЪЧЪ§ОнПтЁЃKafkaЬсЙЉСЫЛљгкTopicЕФзДЬЌДцДЂЁЃ
TopicжаДцДЂЕФЪ§ОнМЧТМБОЩэЪЧKey-ValueаЮЪНЕФЃЌЭЌЪБKafkaЕФlog compactionЛњжЦПЩЖдРњЪЗЪ§ОнзіcompactВйзїЃЌБЃСєУПИіKeyЖдгІЕФзюКѓвЛИіValueЃЌДгЖјдкБЃжЄKeyВЛЖЊЪЇЕФЧАЬсЯТЃЌМѕЩйзмЪ§ОнСПЃЌДгЖјЬсИпВщбЏаЇТЪЁЃ
ЙЙдьKTableЪБЃЌашвЊжИЖЈЦфstate store nameЁЃФЌШЯЧщПіЯТЃЌИУУћзжвВМДгУгкДцДЂИУKTableЕФзДЬЌЕФTopicЕФУћзжЃЌБщРњKTableЕФЙ§ГЬЃЌЪЕМЪОЭЪЧБщРњЫќЖдгІЕФstate
storeЃЌЛђепЫЕБщРњTopicЕФЫљгаkeyЃЌВЂШЁУПИіKeyзюаТжЕЕФЙ§ГЬЁЃЮЊСЫЪЙЕУИУЙ§ГЬИќМгИпаЇЃЌФЌШЯЧщПіЯТЛсЖдИУTopicНјааcompactВйзїЁЃ
СэЭтЃЌГ§СЫKTableЃЌЫљгазДЬЌМЦЫуЃЌЖМашвЊжИЖЈstate store nameЃЌДгЖјМЧТМжаМфзДЬЌЁЃ
KStream vs. KTable
KTableКЭKStreamЪЧKafka StreamжаЗЧГЃживЊЕФСНИіИХФюЃЌЫќУЧЪЧKafkaЪЕЯжИїжжгявхЕФЛљДЁЁЃвђДЫетРягаБивЊЗжЮіЯТЖўепЕФЧјБ№ЁЃ
KStreamЪЧвЛИіЪ§ОнСїЃЌПЩвдШЯЮЊЫљгаМЧТМЖМЭЈЙ§Insert onlyЕФЗНЪНВхШыНјетИіЪ§ОнСїРяЁЃЖјKTableДњБэвЛИіЭъећЕФЪ§ОнМЏЃЌПЩвдРэНтЮЊЪ§ОнПтжаЕФБэЁЃгЩгкУПЬѕМЧТМЖМЪЧKey-ValueЖдЃЌетРяПЩвдНЋKeyРэНтЮЊЪ§ОнПтжаЕФPrimary
KeyЃЌЖјValueПЩвдРэНтЮЊвЛааМЧТМЁЃПЩвдШЯЮЊKTableжаЕФЪ§ОнЖМЪЧЭЈЙ§Update onlyЕФЗНЪННјШыЕФЁЃвВОЭвтЮЖзХЃЌШчЙћKTableЖдгІЕФTopicжааТНјШыЕФЪ§ОнЕФKeyвбОДцдкЃЌФЧУДДгKTableжЛЛсШЁГіЭЌвЛKeyЖдгІЕФзюКѓвЛЬѕЪ§ОнЃЌЯрЕБгкаТЕФЪ§ОнИќаТСЫОЩЕФЪ§ОнЁЃ
вдЯТЭМЮЊР§ЃЌМйЩшгавЛИіKStreamКЭKTableЃЌЛљгкЭЌвЛИіTopicДДНЈЃЌВЂЧвИУTopicжаАќКЌШчЯТЭМЫљЪО5ЬѕЪ§ОнЁЃДЫЪББщРњKStreamНЋЕУЕНгыTopicФкЪ§ОнЭъШЋвЛбљЕФЫљга5ЬѕЪ§ОнЃЌЧвЫГађВЛБфЁЃЖјДЫЪББщРњKTableЪБЃЌвђЮЊет5ЬѕМЧТМжага3ИіВЛЭЌЕФKeyЃЌЫљвдНЋЕУЕН3ЬѕМЧТМЃЌУПИіKeyЖдгІзюаТЕФжЕЃЌВЂЧветШ§ЬѕЪ§ОнжЎМфЕФЫГађгыдРДдкTopicжаЕФЫГађБЃГжвЛжТЁЃетвЛЕугыKafkaЕФШежОcompactЯрЭЌЁЃ
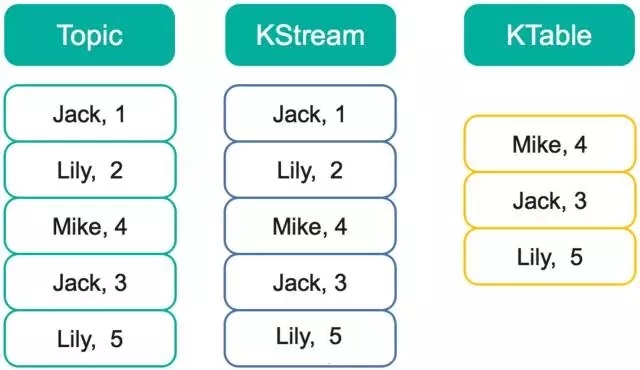
ДЫЪБШчЙћЖдИУKStreamКЭKTableЗжБ№ЛљгкkeyзіGroupЃЌЖдValueНјааSumЃЌЕУЕНЕФНсЙћНЋЛсВЛЭЌЁЃЖдKtableЕФМЦЫуНсЙћЪЧ<MikeЃЌ4>ЃЌ<JackЃЌ3>ЃЌ<LilyЃЌ5>ЁЃЖјЖдKStreamЕФМЦЫуНсЙћНЋЪЧ<JackЃЌ4>ЃЌ<LilyЃЌ7>ЃЌ<MikeЃЌ4>ЁЃ
ЪБМф
дкСїЪНЪ§ОнДІРэжаЃЌЪБМфЪЧЪ§ОнЕФвЛИіЗЧГЃживЊЕФЪєадЁЃДгKafka 0.10ПЊЪМЃЌУПЬѕМЧТМГ§СЫKeyКЭValueЭтЃЌЛЙдіМгСЫtimestampЪєадЁЃФПЧАKafka
StreamжЇГжШ§жжЪБМф
ЪТМўЗЂЩњЪБМфЁЃЪТМўЗЂЩњЕФЪБМфЃЌАќКЌдкЪ§ОнМЧТМжаЁЃЗЂЩњЪБМфгЩProducerдкЙЙдьProducerRecordЪБжИЖЈЁЃВЂЧвашвЊBrokerЛђепTopicНЋmessage.timestamp.typeЩшжУЮЊCreateTimeЃЈФЌШЯжЕЃЉВХФмЩњаЇЁЃ
ЯћЯЂНгЪеЪБМфЃЌвВМДЯћЯЂДцШыBrokerЕФЪБМфЁЃЕБBrokerЛђTopicНЋmessage.timestamp.typeЩшжУЮЊLogAppendTimeЪБЩњаЇЁЃДЫЪБBrokerЛсдкНгЪеЕНЯћЯЂКѓЃЌДцШыДХХЬЧАЃЌНЋЦфtimestampЪєаджЕЩшжУЮЊЕБЧАЛњЦїЪБМфЁЃвЛАуЯћЯЂНгЪеЪБМфБШНЯНгНќгкЪТМўЗЂЩњЪБМфЃЌВПЗжГЁОАЯТПЩДњЬцЪТМўЗЂЩњЪБМфЁЃ
ЯћЯЂДІРэЪБМфЃЌвВМДKafka StreamДІРэЯћЯЂЪБЕФЪБМфЁЃ
зЂЃКKafka StreamдЪаэЭЈЙ§ЪЕЯжorg.apache.kafka.streams.processor.TimestampExtractorНгПкздЖЈвхМЧТМЪБМфЁЃ
ДАПк
ЧАЮФЬсЕНЃЌСїЪНЪ§ОнЪЧдкЪБМфЩЯЮоНчЕФЪ§ОнЁЃЖјОлКЯВйзїжЛФмзїгУдкЬиЖЈЕФЪ§ОнМЏЃЌвВМДгаНчЕФЪ§ОнМЏЩЯЁЃвђДЫашвЊЭЈЙ§ФГжжЗНЪНДгЮоНчЕФЪ§ОнМЏЩЯАДЬиЖЈЕФгявхбЁШЁГігаНчЕФЪ§ОнЁЃДАПкЪЧвЛжжЗЧГЃГЃгУЕФЩшЖЈМЦЫуБпНчЕФЗНЪНЁЃВЛЭЌЕФСїЪНДІРэЯЕЭГжЇГжЕФДАПкРрЫЦЃЌЕЋВЛОЁЯрЭЌЁЃ
Kafka StreamжЇГжЕФДАПкШчЯТЁЃ
Hopping Time Window ИУДАПкЖЈвхШчЯТЭМЫљЪОЁЃЫќгаСНИіЪєадЃЌвЛИіЪЧAdvance intervalЃЌвЛИіЪЧWindow
sizeЁЃAdvance intervalЖЈвхЪфГіЕФЪБМфМфИєЃЌЖјWindow sizeжИЖЈСЫДАПкЕФДѓаЁЃЌвВМДУПДЮМЦЫуЕФЪ§ОнМЏЕФДѓаЁЁЃЖјЁЃвЛИіЕфаЭЕФгІгУГЁОАЪЧЃЌУПИє5УыжгЪфГівЛДЮЙ§ШЅ1ИіаЁЪБФкЭјеОЕФPVЛђепUV

Tumbling Time Window ИУДАПкЖЈвхШчЯТЭМЫљЪОЁЃПЩвдШЯЮЊЫќЪЧHopping Time
WindowЕФвЛжжЬиР§ЃЌвВМДWindow sizeКЭAdvance intervalЯрЕШЁЃЫќЕФЬиЕуЪЧИїИіWindowжЎМфЭъШЋВЛЯрНЛЁЃ

Session Window ИУДАПкгУгкЖдKeyзіGroupКѓЕФОлКЯВйзїжаЁЃЫќашвЊЖдKeyзіЗжзщЃЌШЛКѓЖдзщФкЕФЪ§ОнИљОнвЕЮёашЧѓЖЈвхвЛИіДАПкЕФЦ№ЪМЕуКЭНсЪјЕуЁЃвЛИіЕфаЭЕФАИР§ЪЧЃЌЯЃЭћЭЈЙ§Session
WindowМЦЫуФГИігУЛЇЗУЮЪЭјеОЕФЪБМфЁЃЖдгквЛИіЬиЖЈЕФгУЛЇЃЈгУKeyБэЪОЃЉЖјбдЃЌЕБЗЂЩњЕЧТМВйзїЪБЃЌИУгУЛЇЃЈKeyЃЉЕФДАПкМДПЊЪМЃЌЕБЗЂЩњЭЫГіВйзїЛђепГЌЪБЪБЃЌИУгУЛЇЃЈKeyЃЉЕФДАПкМДНсЪјЁЃДАПкНсЪјЪБЃЌПЩМЦЫуИУгУЛЇЕФЗУЮЪЪБМфЛђепЕуЛїДЮЪ§ЕШЁЃ
Sliding Window ИУДАПкжЛгУгк2ИіKStreamНјааJoinМЦЫуЪБЁЃИУДАПкЕФДѓаЁЖЈвхСЫJoinСНВрKStreamЕФЪ§ОнМЧТМБЛШЯЮЊдкЭЌвЛИіДАПкЕФзюДѓЪБМфВюЁЃМйЩшИУДАПкЕФДѓаЁЮЊ5УыЃЌдђВЮгыJoinЕФ2ИіKStreamжаЃЌМЧТМЪБМфВюаЁгк5ЕФМЧТМБЛШЯЮЊдкЭЌвЛИіДАПкжаЃЌПЩвдНјааJoinМЦЫуЁЃ
Join
Kafka StreamгЩгкАќКЌKtableКЭKStreamСНжжЪ§ОнМЏЃЌвђДЫЬсЙЉШчЯТJoinМЦЫу
KTable Join KTable НсЙћШдЮЊKTableЁЃШЮвтвЛБпгаИќаТЃЌНсЙћKTableЖМЛсИќаТЁЃ
KStream Join KStream НсЙћЮЊKStreamЁЃБиаыДјДАПкВйзїЃЌЗёдђЛсдьГЩJoinВйзївЛжБВЛНсЪјЁЃ
KStream Join KTable / GlobalKTable НсЙћЮЊKStreamЁЃжЛгаЕБKStreamжагааТЪ§ОнЪБЃЌВХЛсДЅЗЂJoinМЦЫуВЂЪфГіНсЙћЁЃKStreamЮоаТЪ§ОнЪБЃЌKTableЕФИќаТВЂВЛЛсДЅЗЂJoinМЦЫуЃЌвВВЛЛсЪфГіЪ§ОнЁЃВЂЧвИУИќаТжЛЖдЯТДЮJoinЩњаЇЁЃвЛИіЕфаЭЕФЪЙгУГЁОАЪЧЃЌKStreamжаЕФЖЉЕЅаХЯЂгыKTableжаЕФгУЛЇаХЯЂзіЙиСЊМЦЫуЁЃ
ЖдгкJoinВйзїЃЌШчЙћвЊЕУЕНе§ШЗЕФМЦЫуНсЙћЃЌашвЊБЃжЄВЮгыJoinЕФKTableЛђKStreamжаKeyЯрЭЌЕФЪ§ОнБЛЗжХфЕНЭЌвЛИіTaskЁЃОпЬхЗНЗЈЪЧ
ВЮгыJoinЕФKTableЛђKStreamЖдгІЕФTopicЕФPartitionЪ§ЯрЭЌ
ВЮгыJoinЕФKTableЛђKStreamЕФKeyРраЭЯрЭЌЃЈЪЕМЪЩЯЃЌвЕЮёКЌвтвВгІИУЯрЭЌЃЉ
PartitionerВпТдЕФзюжеНсЙћЕШаЇЃЈЪЕЯжВЛашвЊЭъШЋвЛбљЃЌЕЋаЇЙћБиаывЛжТЃЉЃЌвВМДKeyЯрЭЌЕФЧщПіЯТЃЌБЛЗжХфЕНIDЯрЭЌЕФPartitionФк
ШчЙћЩЯЪіЬѕМўВЛТњзуЃЌПЩЭЈЙ§ЕїгУШчЯТЗНЗЈЪЙЕУЫќТњзуЩЯЪіЬѕМўЁЃ
KStream<K, V> through(Serde<K> keySerde,
Serde<V> valSerde, StreamPartitioner<K, V>
partitioner, String topic)
ЭЈЙ§throughЗНЗЈЃЌНјааJoinВйзїЕФЙ§ГЬШчЯТЭМЫљЪО
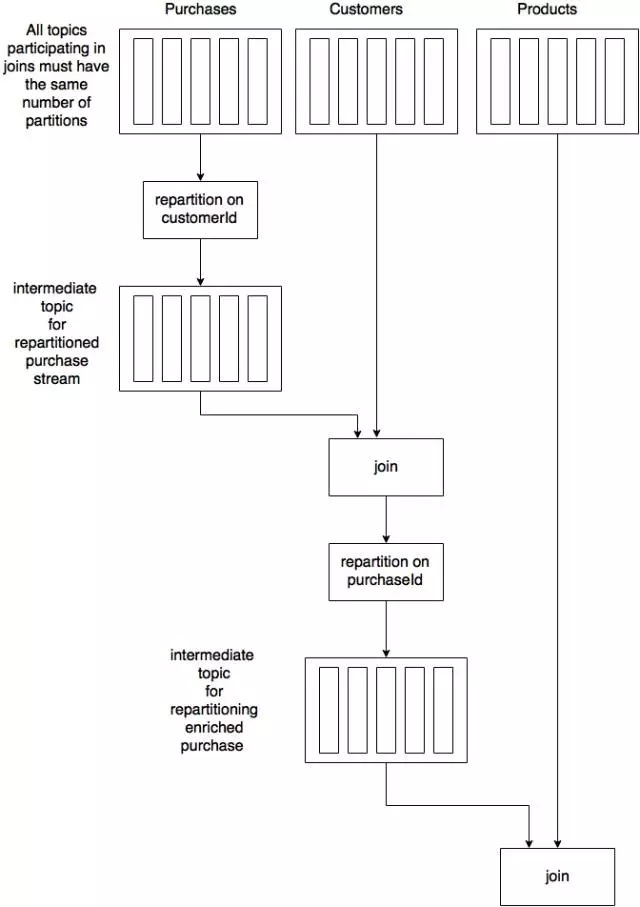
ДгЩЯЭМПЩвдПДГіЃЌЮЊСЫТњзуJoinЬѕМўЃЌашвЊЭЈЙ§throughЕШЗНЗЈЖдВЮгыJoinЕФФГвЛЗННјаажиаТЗжЧјЃЌЯрЕБгкStormЕФField
GroupingКЭSparkЕФShuffleЁЃ
ЮЊСЫЬсИпJoinЕФаЇТЪЃЌ0.10.2.0жав§ШыСЫGlobalKTableЁЃЕБKStreamгывЛИіGlobalKTable
JoinЪБЃЌGlobalKTableЕФЫљгаЪ§ОнЛсБЛИДжЦЕНЫљгаKafka StreamгІгУЪЕР§ЃЌвђДЫKStreamПЩдкTaskФкжБНггыЦфЫљдкЪЕР§жаЕФGlobalKTableИББОНјааJoinЃЌВЛашвЊЭЈЙ§throughЕШЗНЗЈНјаажиаТЗжЧјЃЌМЋДѓЬсИпСЫJoinЪБЕФаЇТЪЁЃгыGlobalKTableЕФJoinЙ§ГЬШчЯТЭМЫљЪОЁЃ
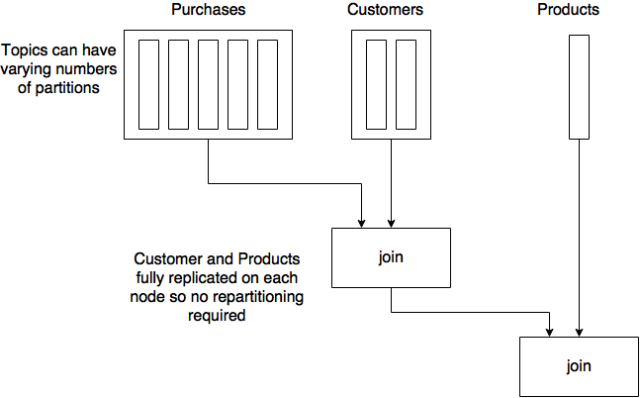
вЛИіЕфаЭЕФЪЪгУГЁОАЪЧЃЌдкРрЪ§ОнВжПтЕФгІгУжаЃЌНЋАќКЌДѓСПдіСПЪ§ОнЕФTopicЭЈЙ§KStreamв§гУЃЌЖјНЋАќКЌЩйСПЃЌПЩФмИќаТЕФЪ§ОнЃЌжУгкGlobalKTableжаЁЃГфЗжРћгУGlobalKTableЕФЪ§ОнИДжЦЬиадЃЌНЕЕЭJoinПЊЯњЃЌЬсИпадФмЁЃ
ЕЋашвЊзЂвтЕФЪЧЃЌGlobalKTableашвЊНЋЫљгаЪ§ОнИДжЦЕНУПвЛИіЪЕР§ЃЌвђДЫБиаыБЃжЄЪЕР§ФкДцжСЩйзуЙЛБЃДцИУGlobalKTableФкШЋВПЪ§ОнЁЃ
ОлКЯгыТвађДІРэ
ОлКЯВйзїПЩгІгУгкKStreamКЭKTableЁЃЕБОлКЯЗЂЩњдкKStreamЩЯЪББиаыжИЖЈДАПкЃЌДгЖјЯоЖЈМЦЫуЕФФПБъЪ§ОнМЏЁЃ
ашвЊЫЕУїЕФЪЧЃЌОлКЯВйзїЕФНсЙћПЯЖЈЪЧKTableЁЃвђЮЊKTableЪЧПЩИќаТЕФЃЌПЩвддкЭэЕНЕФЪ§ОнЕНРДЪБЃЈвВМДЗЂЩњЪ§ОнТвађЪБЃЉИќаТНсЙћKTableЁЃ
етРяОйР§ЫЕУїЁЃМйЩшЖдKStreamвд5УыЮЊДАПкДѓаЁЃЌНјааTumbling Time WindowЩЯЕФCountВйзїЁЃВЂЧвKStreamЯШКѓГіЯжЪБМфЮЊ1Уы,
3Уы, 5УыЕФЪ§ОнЃЌДЫЪБ5УыЕФДАПквбДяЩЯЯоЃЌKafka StreamЙиБеИУДАПкЃЌДЅЗЂCountВйзїВЂНЋНсЙћ3ЪфГіЕНKTableжаЃЈМйЩшИУНсЙћБэЪОЮЊ<1-5,3>ЃЉЁЃШє1УыКѓЃЌгжЪеЕНСЫЪБМфЮЊ2УыЕФМЧТМЃЌгЩгк1-5УыЕФДАПквбЙиБеЃЌШєжБНгХзЦњИУЪ§ОнЃЌдђПЩШЯЮЊжЎЧАЕФНсЙћ<1-5,3>ВЛзМШЗЁЃЖјШчЙћжБНгНЋЭъећЕФНсЙћ<1-5,4>ЪфГіЕНKStreamжаЃЌдђKStreamжаНЋЛсАќКЌИУДАПкЕФ2ЬѕМЧТМЃЌ<1-5,3>,
<1-5,4>ЃЌвВЛсДцдкАЙЪ§ОнЁЃвђДЫKafka StreamбЁдёНЋОлКЯНсЙћДцгкKTableжаЃЌДЫЪБаТЕФНсЙћ<1-5,4>ЛсЬцДњОЩЕФНсЙћ<1-5,3>ЁЃгУЛЇПЩЕУЕНЭъећЕФе§ШЗЕФНсЙћЁЃ
етжжЗНЪНБЃжЄСЫЪ§ОнзМШЗадЃЌЭЌЪБвВЬсИпСЫШнДэадЁЃ
ЕЋашвЊЫЕУїЕФЪЧЃЌKafka StreamВЂВЛЛсЖдЫљгаЭэЕНЕФЪ§ОнЖМжиаТМЦЫуВЂИќаТНсЙћМЏЃЌЖјЪЧШУгУЛЇЩшжУвЛИіretention
periodЃЌНЋУПИіДАПкЕФНсЙћМЏдкФкДцжаБЃСєвЛЖЈЪБМфЃЌИУДАПкФкЕФЪ§ОнЭэЕНЪБЃЌжБНгКЯВЂМЦЫуЃЌВЂИќаТНсЙћKTableЁЃГЌЙ§retention
periodКѓЃЌИУДАПкНсЙћНЋДгФкДцжаЩОГ§ЃЌВЂЧвЭэЕНЕФЪ§ОнМДЪЙТфШыДАПкЃЌвВЛсБЛжБНгЖЊЦњЁЃ
ШнДэ
Kafka StreamДгШчЯТМИИіЗНУцНјааШнДэ
ИпПЩгУЕФPartitionБЃжЄЮоЪ§ОнЖЊЪЇЁЃУПИіTaskМЦЫувЛИіPartitionЃЌЖјKafkaЪ§ОнИДжЦЛњжЦБЃжЄСЫPartitionФкЪ§ОнЕФИпПЩгУадЃЌЙЪЮоЪ§ОнЖЊЪЇЗчЯеЁЃЭЌЪБгЩгкЪ§ОнЪЧГжОУЛЏЕФЃЌМДЪЙШЮЮёЪЇАмЃЌвРШЛПЩвджиаТМЦЫуЁЃ
зДЬЌДцДЂЪЕЯжПьЫйЙЪеЯЛжИДКЭДгЙЪеЯЕуМЬајДІРэЁЃЖдгкJoinКЭОлКЯМАДАПкЕШгазДЬЌМЦЫуЃЌзДЬЌДцДЂПЩБЃДцжаМфзДЬЌЁЃМДЪЙЗЂЩњFailoverЛђConsumer
RebalanceЃЌШдШЛПЩвдЭЈЙ§зДЬЌДцДЂЛжИДжаМфзДЬЌЃЌДгЖјПЩвдМЬајДгFailoverЛђConsumer
RebalanceЧАЕФЕуМЬајМЦЫуЁЃ
KTableгыretention periodЬсЙЉСЫЖдТвађЪ§ОнЕФДІРэФмСІЁЃ
Kafka StreamгІгУЪОР§
ЯТУцНсКЯвЛИіАИР§РДНВНтШчКЮПЊЗЂKafka StreamгІгУЁЃБОР§ЭъећДњТыПЩДгзїепGithubЛёШЁЁЃhttps://github.com/habren/KafkaExample
ЖЉЕЅKStreamЃЈУћЮЊorderStreamЃЉЃЌЕзВуTopicЕФPartitionЪ§ЮЊ3ЃЌKeyЮЊгУЛЇУћЃЌValueАќКЌгУЛЇУћЃЌЩЬЦЗУћЃЌЖЉЕЅЪБМфЃЌЪ§СПЁЃгУЛЇKTableЃЈУћЮЊuserTableЃЉЃЌЕзВуTopicЕФPartitionЪ§ЮЊ3ЃЌKeyЮЊгУЛЇУћЃЌValueАќКЌадБ№ЃЌЕижЗКЭФъСфЁЃЩЬЦЗKTableЃЈУћЮЊitemTableЃЉЃЌЕзВуTopicЕФPartitionЪ§ЮЊ6ЃЌKeyЮЊЩЬЦЗУћЃЌМлИёЃЌжжРрКЭВњЕиЁЃЯждкЯЃЭћМЦЫуУПаЁЪБЙКТђВњЕигыздМКЫљдкЕиЯрЭЌЕФгУЛЇзмЪ§ЁЃ
ЪзЯШгЩгкЯЃЭћЪЙгУЖЉЕЅЪБМфЃЌЖјЫќАќКЌдкorderStreamЕФValueжаЃЌашвЊЭЈЙ§ЬсЙЉвЛИіЪЕЯжTimestampExtractorНгПкЕФРрДгorderStreamЖдгІЕФTopicжаГщШЁГіЖЉЕЅЪБМфЁЃ
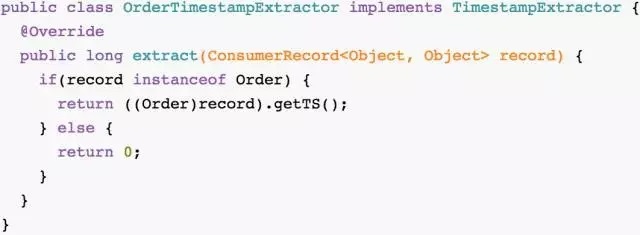
НгзХЭЈЙ§НЋorderStreamгыuserTableНјааJoinЃЌРДЛёШЁЖЉЕЅгУЛЇЫљдкЕиЁЃгЩгкЖўепЖдгІЕФTopicЕФPartitionЪ§ЯрЭЌЃЌЧвKeyЖМЮЊгУЛЇУћЃЌдйМйЩшProducerЭљетСНИіTopicаДЪ§ОнЪБЫљгУЕФPartitionerЪЕЯжЯрЭЌЃЌдђДЫЪБЩЯЮФЫљЪіJoinЬѕМўТњзуЃЌПЩжБНгНјааJoinЁЃ
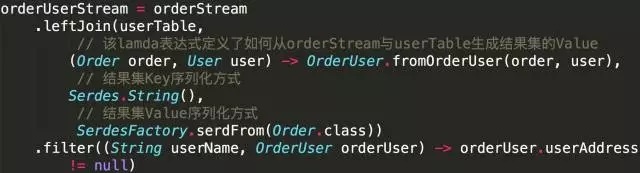
ДгЩЯЪіДњТыжаЃЌПЩвдПДЕНЃЌJoinЪБашвЊжИЖЈШчКЮДгВЮгыJoinЫЋЗНЕФМЧТМЩњГЩНсЙћМЧТМЕФValueЁЃKeyВЛашвЊжИЖЈЃЌвђЮЊНсЙћМЧТМЕФKeyгыJoin
KeyЯрЭЌЃЌЙЪЮоаыжИЖЈЁЃJoinНсЙћДцгкУћЮЊorderUserStreamЕФKStreamжаЁЃ
НгЯТРДашвЊНЋorderUserStreamгыitemTableНјааJoinЃЌДгЖјЛёШЁЩЬЦЗВњЕиЁЃДЫЪБorderUserStreamЕФKeyШдЮЊгУЛЇУћЃЌЖјitemTableЖдгІЕФTopicЕФKeyЮЊВњЦЗУћЃЌВЂЧвЖўепЕФPartitionЪ§ВЛвЛбљЃЌвђДЫЮоЗЈжБНгJoinЁЃДЫЪБашвЊЭЈЙ§throughЗНЗЈЃЌЖдЦфжавЛЗНЛђЫЋЗННјаажиаТЗжЧјЃЌЪЙЕУЖўепТњзуJoinЬѕМўЁЃетвЛЙ§ГЬЯрЕБгкSparkЕФShuffleЙ§ГЬКЭStormЕФFieldGroupingЁЃ
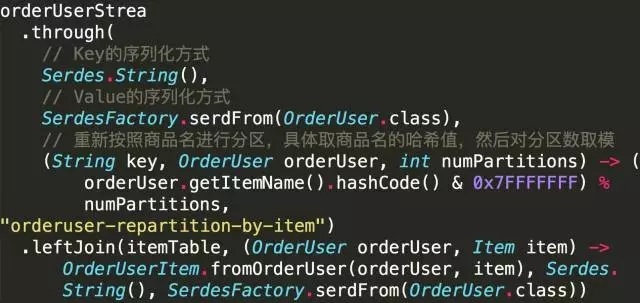
ДгЩЯЪіДњТыПЩМћЃЌthroughЪБашвЊжИЖЈKeyЕФађСаЛЏЦїЃЌValueЕФађСаЛЏЦїЃЌвдМАЗжЧјЗНЪНКЭНсЙћМЏЫљдкЕФTopicЁЃетРявЊзЂвтЃЌИУTopicЃЈorderuser-repartition-by-itemЃЉЕФPartitionЪ§БиаыгыitemTableЖдгІTopicЕФPartitionЪ§ЯрЭЌЃЌВЂЧвthroughЪЙгУЕФЗжЧјЗНЗЈБиаыгыiteamTableЖдгІTopicЕФЗжЧјЗНЪНвЛбљЁЃОЙ§етжжthroughВйзїЃЌorderUserStreamгыitemTableТњзуСЫJoinЬѕМўЃЌПЩжБНгНјааJoinЁЃ
змНс
Kafka StreamЕФВЂааФЃаЭЭъШЋЛљгкKafkaЕФЗжЧјЛњжЦКЭRebalanceЛњжЦЃЌЪЕЯжСЫдкЯпЖЏЬЌЕїећВЂааЖШ
ЭЌвЛTaskАќКЌСЫвЛИізгTopologyЕФЫљгаProcessorЃЌЪЙЕУЫљгаДІРэТпМЖМдкЭЌвЛЯпГЬФкЭъГЩЃЌБмУтСЫВЛБиЕФЭјТчЭЈаХПЊЯњЃЌДгЖјЬсИпСЫаЇТЪЁЃ
throughЗНЗЈЬсЙЉСЫРрЫЦSparkЕФShuffleЛњжЦЃЌЮЊЪЙгУВЛЭЌЗжЧјВпТдЕФЪ§ОнЬсЙЉСЫJoinЕФПЩФм
log compactЬсИпСЫЛљгкKafkaЕФstate storeЕФМгдиаЇТЪ
state storeЮЊзДЬЌМЦЫуЬсЙЉСЫПЩФм
ЛљгкoffsetЕФМЦЫуНјЖШЙмРэвдМАЛљгкstate storeЕФжаМфзДЬЌЙмРэЮЊЗЂЩњConsumer rebalanceЛђFailoverЪБДгЖЯЕуДІМЬајДІРэЬсЙЉСЫПЩФмЃЌВЂЮЊЯЕЭГШнДэадЬсЙЉСЫБЃеЯ
KTableЕФв§ШыЃЌЪЙЕУОлКЯМЦЫугЕгУСЫДІРэТвађЮЪЬтЕФФмСІ |









