|
БОЮФЪЧЯЕСаЮФеТЕФЕк4ЦЊЃЌ
ЕквЛЦЊ
"KafkaЩшМЦНтЮіЃЈвЛЃЉ- KafkaБГОАМАМмЙЙНщЩм"
ЕкЖўЦЊ
KafkaЩшМЦНтЮіЃЈЖўЃЉ- Kafka High Availability ЃЈЩЯЃЉ
ЕкШ§ЦЊ
KafkaЩшМЦНтЮіЃЈШ§ЃЉ- Kafka High Availability ЃЈжаЃЉ
БОЮФдкЧАСНЦЊЕФЛљДЁЩЯЃЌНщЩмСЫKafkaЬсЙЉЕФгыReplicationЯрЙиЕФЙЄОпЃЌШчжиаТЗжХфPartitionЕШЁЃ
Topic Tool
$KAFKA_HOME/bin/kafka-topics.shЃЌИУЙЄОпПЩгУгкДДНЈЁЂЩОГ§ЁЂаоИФЁЂВщПДФГИіTopicЃЌвВПЩгУгкСаГіЫљгаTopicЁЃСэЭтЃЌИУЙЄОпЛЙПЩаоИФвдЯТХфжУЁЃ unclean.leader.election.enable delete.retention.ms segment.jitter.ms retention.ms flush.ms segment.bytes flush.messages segment.ms retention.bytes cleanup.policy segment.index.bytes min.cleanable.dirty.ratio max.message.bytes file.delete.delay.ms min.insync.replicas index.interval.bytes
Replica Verification Tool
$KAFKA_HOME/bin/kafka-replica-verification.shЃЌИУЙЄОпгУРДбщжЄЫљжИЖЈЕФвЛИіЛђЖрИіTopicЯТУПИіPartitionЖдгІЕФЫљгаReplicaЪЧЗёЖМЭЌВНЁЃПЩЭЈЙ§topic-white-listетвЛВЮЪ§жИЖЈЫљашвЊбщжЄЕФЫљгаTopicЃЌжЇГже§дђБэДяЪНЁЃ
Preferred Replica Leader Election Tool
гУЭО гаСЫReplicationЛњжЦКѓЃЌУПИіPartitionПЩФмгаЖрИіБИЗнЁЃФГИіPartitionЕФReplicaСаБэНазїARЃЈAssigned
ReplicasЃЉЃЌARжаЕФЕквЛИіReplicaМДЮЊЁАPreferred ReplicaЁБЁЃДДНЈвЛИіаТЕФTopicЛђепИјвбгаTopicдіМгPartitionЪБЃЌKafkaБЃжЄPreferred
ReplicaБЛОљдШЗжВМЕНМЏШКжаЕФЫљгаBrokerЩЯЁЃРэЯыЧщПіЯТЃЌPreferred ReplicaЛсБЛбЁЮЊLeaderЁЃвдЩЯСНЕуБЃжЄСЫЫљгаPartitionЕФLeaderБЛОљдШЗжВМЕНСЫМЏШКЕБжаЃЌетвЛЕуЗЧГЃживЊЃЌвђЮЊЫљгаЕФЖСаДВйзїЖМгЩLeaderЭъГЩЃЌШєLeaderЗжВМЙ§гкМЏжаЃЌЛсдьГЩМЏШКИКдиВЛОљКтЁЃЕЋЪЧЃЌЫцзХМЏШКЕФдЫааЃЌИУЦНКтПЩФмЛсвђЮЊBrokerЕФхДЛњЖјБЛДђЦЦЃЌИУЙЄОпОЭЪЧгУРДАяжњЛжИДLeaderЗжХфЕФЦНКтЁЃ ЪТЪЕЩЯЃЌУПИіTopicДгЪЇАмжаЛжИДЙ§РДКѓЃЌЫќФЌШЯЛсБЛЩшжУЮЊFollowerНЧЩЋЃЌГ§ЗЧФГИіPartitionЕФReplicaШЋВПхДЛњЃЌЖјЕБЧАBrokerЪЧИУPartitionЕФARжаЕквЛИіЛжИДЛиРДЕФReplicaЁЃвђДЫЃЌФГИіPartitionЕФLeaderЃЈPreferred
ReplicaЃЉхДЛњВЂЛжИДКѓЃЌЫќКмПЩФмВЛдйЪЧИУPartitionЕФLeaderЃЌЕЋШдШЛЪЧPreferred
ReplicaЁЃ
дРэ дкZookeeperЩЯДДНЈ/admin/preferred_replica_electionНкЕуЃЌВЂДцШыашвЊЕїећPreferred
ReplicaЕФPartitionаХЯЂЁЃ ControllerвЛжБWatchИУНкЕуЃЌвЛЕЉИУНкЕуБЛДДНЈЃЌControllerЛсЪеЕНЭЈжЊЃЌВЂЛёШЁИУФкШнЁЃ ControllerЖСШЁPreferred ReplicaЃЌШчЙћЗЂЯжИУReplicaЕБЧАВЂЗЧЪЧLeaderВЂЧвЫќдкИУPartitionЕФISRжаЃЌControllerЯђИУReplicaЗЂЫЭLeaderAndIsrRequestЃЌЪЙИУReplicaГЩЮЊLeaderЁЃШчЙћИУReplicaЕБЧАВЂЗЧЪЧLeaderЃЌЧвВЛдкISRжаЃЌControllerЮЊСЫБЃжЄУЛгаЪ§ОнЖЊЪЇЃЌВЂВЛЛсНЋЦфЩшжУЮЊLeaderЁЃ
гУЗЈ $KAFKA_HOME/bin/kafka-preferred-replica-election.sh
ЁЊzookeeper localhost:2181 дкАќКЌ8ИіBrokerЕФKafkaМЏШКЩЯЃЌДДНЈ1ИіУћЮЊtopic1ЃЌreplication-factorЮЊ3ЃЌPartitionЪ§ЮЊ8ЕФTopicЃЌЪЙгУШчЯТУќСю$KAFKA_HOME/bin/kafka-topics.sh
--describe --topic topic1 --zookeeper localhost:2181ВщПДЦфPartition/ReplicaЗжВМЁЃ ВщбЏНсЙћШчЯТЭМЫљЪОЃЌДгЭМжаПЩвдПДЕНЃЌKafkaНЋЫљгаReplicaОљдШЗжВМЕНСЫећИіМЏШКЃЌВЂЧвLeaderвВОљдШЗжВМЁЃ
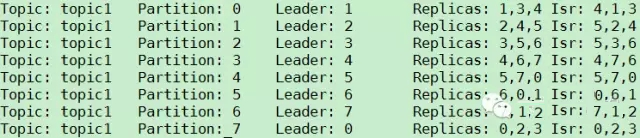
ЪжЖЏЭЃжЙВПЗжBrokerЃЌtopic1ЕФPartition/ReplicaЗжВМШчЯТЭМЫљЪОЁЃДгЭМжаПЩвдПДЕНЃЌгЩгкBroker
1/2/4ЖМБЛЭЃжЙЃЌPartition 0ЕФLeaderгЩдРДЕФ1БфЮЊ3ЃЌPartition 1ЕФLeaderгЩдРДЕФ2БфЮЊ5ЃЌPartition
2ЕФLeaderгЩдРДЕФ3БфЮЊ6ЃЌPartition 3ЕФLeaderгЩдРДЕФ4БфЮЊ7ЁЃ
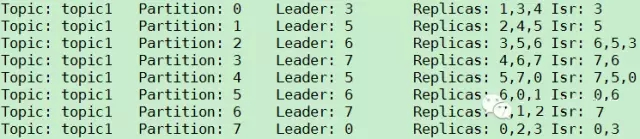
дйжиаТЦєЖЏIDЮЊ1ЕФBrokerЃЌtopic1ЕФPartition/ReplicaЗжВМШчЯТЁЃПЩвдПДЕНЃЌЫфШЛBroker
1вбОЦєЖЏЃЈPartition 0КЭPartition5ЕФISRжага1ЃЉЃЌЕЋЪЧ1ВЂВЛЪЧШЮКЮвЛИіParititonЕФLeaderЃЌЖјBroker
5/6/7ЖМЪЧ2ИіPartitionЕФLeaderЃЌМДLeaderЕФЗжВМВЛОљКтЁЊЁЊвЛИіBrokerзюЖрЪЧ2ИіPartitionЕФLeaderЃЌЖјзюЩйЪЧ0ИіPartitionЕФLeaderЁЃ
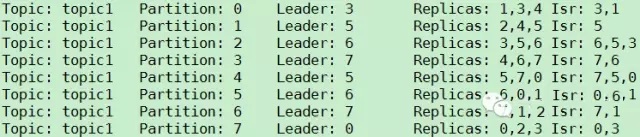
дЫааИУЙЄОпКѓЃЌtopic1ЕФPartition/ReplicaЗжВМШчЯТЭМЫљЪОЁЃгЩЭМПЩМћЃЌГ§СЫPartition
1КЭPartition 3гЩгкBroker 2КЭBroker 4ЛЙЮДЦєЖЏЃЌЫљвдЦфLeaderВЛЪЧЦфPreferred
RepliacЭтЃЌЦфЫќЫљгаPartitionЕФLeaderЖМЪЧЦфPreferred ReplicaЁЃЭЌЪБЃЌгыдЫааИУЙЄОпЧАЯрБШЃЌLeaderЕФЗжХфИќОљдШЁЊЁЊвЛИіBrokerзюЖрЪЧ2ИіParittionЕФLeaderЃЌзюЩйЪЧ1ИіPartitionЕФLeaderЁЃ

ЦєЖЏBroker 2КЭBroker 4ЃЌLeaderЗжВМгыЩЯвЛВНЯрБШВЂЮДБфЛЏЃЌШчЯТЭМЫљЪОЁЃ

дйДЮдЫааИУЙЄОпЃЌЫљгаPartitionЕФLeaderЖМгЩЦфPreferred ReplicaГаЕЃЃЌLeaderЗжВМИќОљдШЁЊЁЊУПИіBrokerГаЕЃ1ИіPartitionЕФLeaderНЧЩЋЁЃ
Г§СЫЪжЖЏдЫааИУЙЄОпЪЙLeaderЗжХфОљдШЭтЃЌKafkaЛЙЬсЙЉСЫздЖЏЦНКтLeaderЗжХфЕФЙІФмЃЌИУЙІФмПЩЭЈЙ§НЋauto.leader.rebalance.enableЩшжУЮЊtrueПЊЦєЃЌЫќНЋжмЦкадМьВщLeaderЗжХфЪЧЗёЦНКтЃЌШєВЛЦНКтЖШГЌЙ§вЛЖЈуажЕдђздЖЏгЩControllerГЂЪдНЋИїPartitionЕФLeaderЩшжУЮЊЦфPreferred
ReplicaЁЃМьВщжмЦкгЩleader.imbalance.check.interval.secondsжИЖЈЃЌВЛЦНКтЖШуажЕгЩleader.imbalance.per.broker.percentageжИЖЈЁЃ
Reassign Partitions Tool
гУЭО ИУЙЄОпЕФЩшМЦФПБъгыPreferred Replica Leader Election ToolгааЉРрЫЦЃЌЖМжМдкДйНјKafkaМЏШКЕФИКдиОљКтЁЃВЛЭЌЕФЪЧЃЌPreferred
Replica Leader ElectionжЛФмдкPartitionЕФARЗЖЮЇФкЕїећЦфLeaderЃЌЪЙLeaderЗжВМОљдШЃЌЖјИУЙЄОпЛЙПЩвдЕїећPartitionЕФARЁЃ FollowerашвЊДгLeader FetchЪ§ОнвдБЃГжгыLeaderЭЌВНЃЌЫљвдНіНіБЃГжLeaderЗжВМЕФЦНКтЖдећИіМЏШКЕФИКдиОљКтРДЫЕЪЧВЛЙЛЕФЁЃСэЭтЃЌЩњВњЛЗОГЯТЃЌЫцзХИКдиЕФдіДѓЃЌПЩФмашвЊИјKafkaМЏШКРЉШнЁЃЯђKafkaМЏШКжадіМгBrokerЗЧГЃМђЕЅЗНБуЃЌЕЋЪЧЖдгквбгаЕФTopicЃЌВЂВЛЛсздЖЏНЋЦфPartitionЧЈвЦЕНаТМгШыЕФBrokerЩЯЃЌДЫЪБПЩгУИУЙЄОпДяЕНДЫФПЕФЁЃФГаЉГЁОАЯТЃЌЪЕМЪИКдиПЩФмдЖаЁгкзюГѕдЄЦкИКдиЃЌДЫЪБПЩгУИУЙЄОпНЋЗжВМдкећИіМЏШКЩЯЕФPartitionжизАЗжХфЕНФГаЉЛњЦїЩЯЃЌШЛКѓПЩвдЭЃжЙВЛашвЊЕФBrokerДгЖјЪЕЯжНкдМзЪдДЕФФПЕФЁЃ ашвЊЫЕУїЕФЪЧЃЌИУЙЄОпВЛНіПЩвдЕїећPartitionЕФARЮЛжУЃЌЛЙПЩЕїећЦфARЪ§СПЃЌМДИФБфИУTopicЕФreplication
factorЁЃ
дРэ ИУЙЄОпжЛИКд№НЋЫљашаХЯЂДцШыZookeeperжаЯргІНкЕуЃЌШЛКѓЭЫГіЃЌВЛИКд№ЯрЙиЕФОпЬхВйзїЃЌЫљгаЕїећЖМгЩControllerЭъГЩЁЃ
дкZookeeperЩЯДДНЈ/admin/reassign_partitionsНкЕуЃЌВЂДцШыФПБъPartitionСаБэМАЦфЖдгІЕФФПБъARСаБэЁЃ ControllerзЂВсдк/admin/reassign_partitionsЩЯЕФWatchБЛfireЃЌControllerЛёШЁИУСаБэЁЃ ЖдСаБэжаЕФЫљгаPartitionЃЌControllerЛсзіШчЯТВйзїЃК ЦєЖЏRAR - ARжаЕФReplicaЃЌМДаТЗжХфЕФReplicaЁЃЃЈRAR = Reassigned
ReplicasЃЌ AR = Assigned ReplicasЃЉ ЕШД§аТЕФReplicaгыLeaderЭЌВН ШчЙћLeaderВЛдкRARжаЃЌДгRARжабЁГіаТЕФLeader ЭЃжЙВЂЩОГ§AR - RARжаЕФReplicaЃЌМДВЛдйашвЊЕФReplica ЩОГ§/admin/reassign_partitionsНкЕу
гУЗЈ ИУЙЄОпгаШ§жжЪЙгУФЃЪН generateФЃЪНЃЌИјЖЈашвЊжиаТЗжХфЕФTopicЃЌздЖЏЩњГЩreassign planЃЈВЂВЛжДааЃЉ executeФЃЪНЃЌИљОнжИЖЈЕФreassign planжиаТЗжХфPartition verifyФЃЪНЃЌбщжЄжиаТЗжХфPartitionЪЧЗёГЩЙІ ЯТУцетИіР§згНЋЪЙгУИУЙЄОпНЋTopicЕФЫљгаPartitionжиаТЗжХфЕНBroker 4/5/6/7ЩЯЃЌВНжшШчЯТЃК 1. ЪЙгУgenerateФЃЪНЃЌЩњГЩreassign planЁЃжИЖЈашвЊжиаТЗжХфЕФTopic ЃЈ{ЁАtopicsЁБ:[{ЁАtopicЁБ:ЁБtopic1ЁБ}],ЁБversionЁБ:1}ЃЉЃЌВЂДцШы/tmp/topics-to-move.jsonЮФМўжаЃЌШЛКѓжДааУќСю$KAFKA_HOME/bin/kafka-reassign-partitions.sh
--zookeeper localhost:2181 --topics-to-move-json-file
/tmp/topics-to-move.json --broker-list "4,5,6,7"
--generateЃЌНсЙћШчЯТЭМЫљЪО
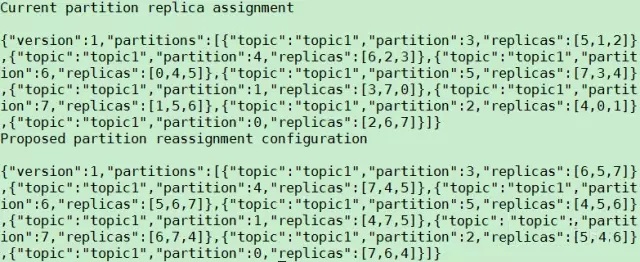
2. ЪЙгУexecuteФЃЪНЃЌжДааreassign planЁЃНЋЩЯвЛВНЩњГЩЕФreassignment
planДцШы/tmp/reassign-plan.jsonЮФМўжаЃЌВЂжДаа$KAFKA_HOME/bin/kafka-reassign-partitions.sh
--zookeeper localhost:2181 --reassignment-json-file
/tmp/reassign-plan.json --execute
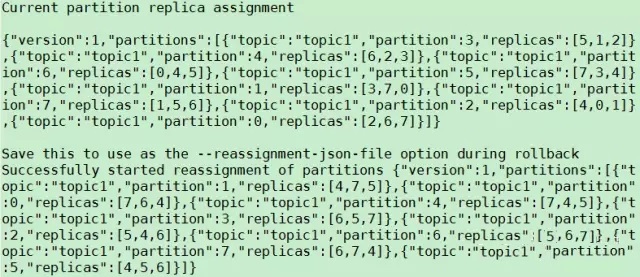
ДЫЪБЃЌZookeeperЩЯ/admin/reassign_partitionsНкЕуБЛДДНЈЃЌЧвЦфжЕгы/tmp/reassign-plan.jsonЮФМўЕФФкШнвЛжТЁЃ

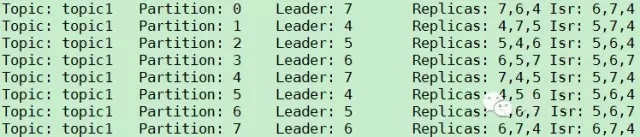
3. ЪЙгУverifyФЃЪНЃЌбщжЄreassignЪЧЗёЭъГЩЁЃжДааverifyУќСюЃЌ$KAFKA_HOME/bin/kafka-reassign-partitions.sh
--zookeeper localhost:2181 --reassignment-json-file
/tmp/reassign-plan.json --verifyЁЃНсЙћШчЯТЫљЪОЃЌДгЭМжаПЩПДГіtopic1ЕФЫљгаPartititonЖМжиаТЗжХфГЩЙІЁЃ
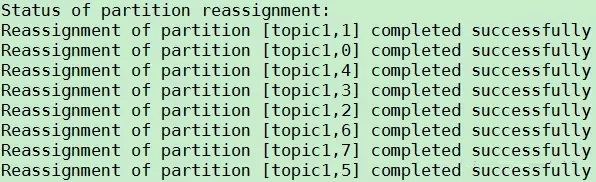
4. гУTopic ToolдйДЮбщжЄЁЃbin/kafka-topics.sh --zookeeper
localhost:2181 --describe --topic topic1ЁЃНсЙћШчЯТЭМЫљЪОЃЌДгЭМжаПЩПДГіtopic1ЕФЫљгаPartitionЖМБЛжиаТЗжХфЕНBroker
4/5/6/7ЃЌЧвУПИіPartitionЕФARгыreassign planвЛжТЁЃ
ашвЊЫЕУїЕФЪЧЃЌдкЪЙгУexecuteжЎЧАЃЌВЂВЛвЛЖЈвЊЪЙгУgenerateФЃЪНздЖЏЩњГЩreassign
planЃЌЪЙгУgenerateФЃЪНжЛЪЧЮЊСЫЗНБуЁЃЪТЪЕЩЯЃЌФГаЉГЁОАЯТЃЌgenerateФЃЪНЩњГЩЕФreassign
planВЂВЛвЛЖЈФмТњзуашЧѓЃЌДЫЪБгУЛЇПЩвдздМКЩшжУreassign planЁЃ
State Change Log Merge Tool
гУЭО ИУЙЄОпжМдкДгећИіМЏШКЕФBrokerЩЯЪеМЏзДЬЌИФБфШежОЃЌВЂЩњГЩвЛИіМЏжаЕФИёЪНЛЏЕФШежОвдАяжњеяЖЯзДЬЌИФБфЯрЙиЕФЙЪеЯЁЃУПИіBrokerЖМЛсНЋЦфЪеЕНЕФзДЬЌИФБфЯрЙиЕФЕФжИСюДцгкУћЮЊstate-change.logЕФШежОЮФМўжаЁЃФГаЉЧщПіЯТЃЌPartitionЕФLeader
ElectionПЩФмЛсГіЯжЮЪЬтЃЌДЫЪБЮвУЧашвЊЖдећИіМЏШКЕФзДЬЌИФБфгаИіШЋОжЕФСЫНтДгЖјеяЖЯЙЪеЯВЂНтОіЮЪЬтЁЃИУЙЄОпНЋМЏШКжаЯрЙиЕФstate-change.logШежОАДЪБМфЫГађКЯВЂЃЌЭЌЪБжЇГжгУЛЇЪфШыЪБМфЗЖЮЇКЭФПБъTopicМАPartitionзїЮЊЙ§ТЫЬѕМўЃЌзюжеНЋИёЪНЛЏЕФНсЙћЪфГіЁЃ
гУЗЈ bin/kafka-run-class.sh kafka.tools.StateChangeLogMerger
--logs /opt/kafka_2.11-0.8.2.1/logs/state-change.log
--topic topic1 --partitions 0,1,2,3,4,5,6,7 |









