|
БОЮФЪЧЯЕСаЮФеТЕФЕкШ§ЦЊЃЌЕквЛЦЊ
"KafkaЩшМЦНтЮіЃЈвЛЃЉ- KafkaБГОАМАМмЙЙНщЩм"ЁЃЕкЖўЦЊ
KafkaЩшМЦНтЮіЃЈЖўЃЉ- Kafka High Availability ЃЈЩЯЃЉ
БОЮФдкЩЯЦЊЮФеТЛљДЁЩЯЃЌИќМгЩюШыНВНтСЫKafkaЕФHAЛњжЦЃЌжївЊВћЪіСЫHAЯрЙиИїжжГЁОАЃЌШчBroker
failoverЃЌController failoverЃЌTopicДДНЈ/ЩОГ§ЃЌBrokerЦєЖЏЃЌFollowerДгLeader
fetchЪ§ОнЕШЯъЯИДІРэЙ§ГЬЁЃ
ControllerЖдBroker FailureЕФДІРэЙ§ГЬ
ControllerдкZookeeperЕФ/brokers/idsНкЕуЩЯзЂВсWatchЁЃвЛЕЉгаBrokerхДЛњЃЈБОЮФгУхДЛњДњБэШЮКЮШУKafkaШЯЮЊЦфBroker
dieЕФЧщОАЃЌАќРЈЕЋВЛЯогкЛњЦїЖЯЕчЃЌЭјТчВЛПЩгУЃЌGCЕМжТЕФStop The WorldЃЌНјГЬcrashЕШЃЉЃЌЦфдкZookeeperЖдгІЕФZnodeЛсздЖЏБЛЩОГ§ЃЌZookeeperЛсfire
ControllerзЂВсЕФWatchЃЌControllerМДПЩЛёШЁзюаТЕФавДцЕФBrokerСаБэЁЃ ControllerОіЖЈset_pЃЌИУМЏКЯАќКЌСЫхДЛњЕФЫљгаBrokerЩЯЕФЫљгаPartitionЁЃ Ждset_pжаЕФУПвЛИіPartitionЃК Дг/brokers/topics/[topic]/partitions/[partition]/stateЖСШЁИУPartitionЕБЧАЕФISRЁЃ ОіЖЈИУPartitionЕФаТLeaderЁЃШчЙћЕБЧАISRжагажСЩйвЛИіReplicaЛЙавДцЃЌдђбЁдёЦфжавЛИізїЮЊаТLeaderЃЌаТЕФISRдђАќКЌЕБЧАISRжаЫљгаавДцЕФReplicaЁЃЗёдђбЁдёИУPartitionжаШЮвтвЛИіавДцЕФReplicaзїЮЊаТЕФLeaderвдМАISRЃЈИУГЁОАЯТПЩФмЛсгаЧБдкЕФЪ§ОнЖЊЪЇЃЉЁЃШчЙћИУPartitionЕФЫљгаReplicaЖМхДЛњСЫЃЌдђНЋаТЕФLeaderЩшжУЮЊ-1ЁЃ НЋаТЕФLeaderЃЌISRКЭаТЕФleader_epochМАcontroller_epochаДШы/brokers/topics/[topic]/partitions/[partition]/stateЁЃзЂвтЃЌИУВйзїжЛгаControllerАцБОдк3.1жС3.3ЕФЙ§ГЬжаЮоБфЛЏЪБВХЛсжДааЃЌЗёдђЬјзЊЕН3.1ЁЃ жБНгЭЈЙ§RPCЯђset_pЯрЙиЕФBrokerЗЂЫЭLeaderAndISRRequestУќСюЁЃControllerПЩвддквЛИіRPCВйзїжаЗЂЫЭЖрИіУќСюДгЖјЬсИпаЇТЪЁЃ Broker failoverЫГађЭМШчЯТЫљЪОЁЃ
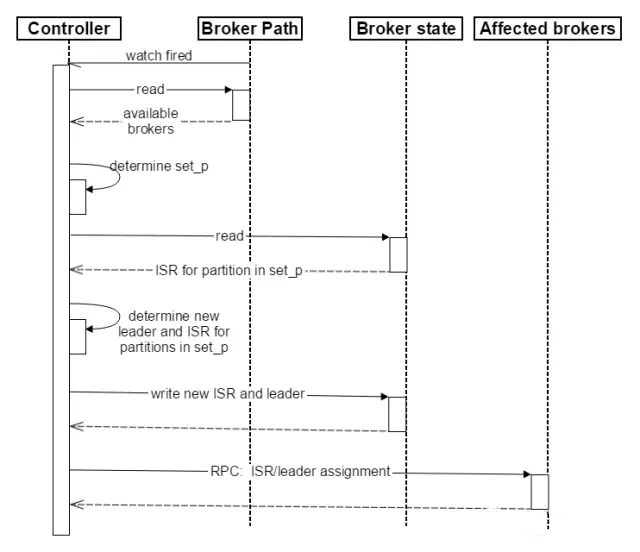
LeaderAndIsrRequestНсЙЙШчЯТ

LeaderAndIsrResponseНсЙЙШчЯТ

ДДНЈ/ЩОГ§Topic
ControllerдкZookeeperЕФ/brokers/topicsНкЕуЩЯзЂВсWatchЃЌвЛЕЉФГИіTopicБЛДДНЈЛђЩОГ§ЃЌдђControllerЛсЭЈЙ§WatchЕУЕНаТДДНЈ/ЩОГ§ЕФTopicЕФPartition/ReplicaЗжХфЁЃ ЖдгкЩОГ§TopicВйзїЃЌTopicЙЄОпЛсНЋИУTopicУћзжДцгк/admin/delete_topicsЁЃШєdelete.topic.enableЮЊtrueЃЌдђControllerзЂВсдк/admin/delete_topicsЩЯЕФWatchБЛfireЃЌControllerЭЈЙ§ЛиЕїЯђЖдгІЕФBrokerЗЂЫЭStopReplicaRequestЃЛШєЮЊfalseдђControllerВЛЛсдк/admin/delete_topicsЩЯзЂВсWatchЃЌвВОЭВЛЛсЖдИУЪТМўзїГіЗДгІЃЌДЫЪБTopicВйзїжЛБЛМЧТМЖјВЛЛсБЛжДааЁЃ ЖдгкДДНЈTopicВйзїЃЌControllerДг/brokers/idsЖСШЁЕБЧАЫљгаПЩгУЕФBrokerСаБэЃЌЖдгкset_pжаЕФУПвЛИіPartitionЃК ДгЗжХфИјИУPartitionЕФЫљгаReplicaЃЈГЦЮЊARЃЉжаШЮбЁвЛИіПЩгУЕФBrokerзїЮЊаТЕФLeaderЃЌВЂНЋARЩшжУЮЊаТЕФISRЃЈвђЮЊИУTopicЪЧаТДДНЈЕФЃЌЫљвдARжаЫљгаЕФReplicaЖМУЛгаЪ§ОнЃЌПЩШЯЮЊЫќУЧЖМЪЧЭЌВНЕФЃЌвВМДЖМдкISRжаЃЌШЮвтвЛИіReplicaЖМПЩзїЮЊLeaderЃЉ НЋаТЕФLeaderКЭISRаДШы/brokers/topics/[topic]/partitions/[partition] жБНгЭЈЙ§RPCЯђЯрЙиЕФBrokerЗЂЫЭLeaderAndISRRequestЁЃ ДДНЈTopicЫГађЭМШчЯТЫљЪОЁЃ
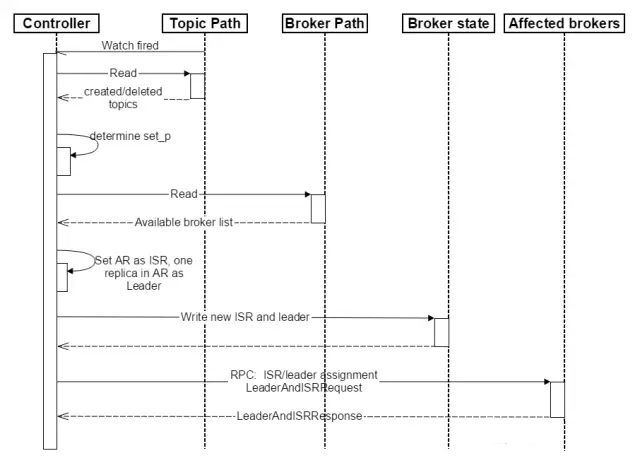
BrokerЯьгІЧыЧѓСїГЬ
BrokerЭЈЙ§kafka.network.SocketServerМАЯрЙиФЃПщНгЪмИїжжЧыЧѓВЂзїГіЯьгІЁЃећИіЭјТчЭЈаХФЃПщЛљгкJava
NIOПЊЗЂЃЌВЂВЩгУReactorФЃЪНЃЌЦфжаАќКЌ1ИіAcceptorИКд№НгЪмПЭЛЇЧыЧѓЃЌNИіProcessorИКд№ЖСаДЪ§ОнЃЌMИіHandlerДІРэвЕЮёТпМЁЃ AcceptorЕФжївЊжАд№ЪЧМрЬ§ВЂНгЪмПЭЛЇЖЫЃЈЧыЧѓЗЂЦ№ЗНЃЌАќРЈЕЋВЛЯогкProducerЃЌConsumerЃЌControllerЃЌAdmin
ToolЃЉЕФСЌНгЧыЧѓЃЌВЂНЈСЂКЭПЭЛЇЖЫЕФЪ§ОнДЋЪфЭЈЕРЃЌШЛКѓЮЊИУПЭЛЇЖЫжИЖЈвЛИіProcessorЃЌжСДЫЫќЖдИУПЭЛЇЖЫИУДЮЧыЧѓЕФШЮЮёОЭНсЪјСЫЃЌЫќПЩвдШЅЯьгІЯТвЛИіПЭЛЇЖЫЕФСЌНгЧыЧѓСЫЁЃЦфКЫаФДњТыШчЯТЁЃ
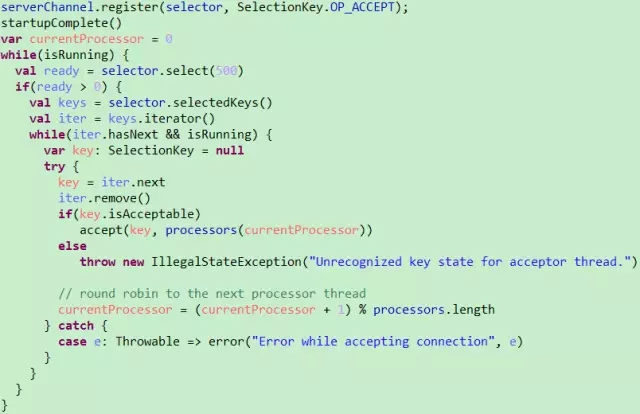
ProcessorжївЊИКд№ДгПЭЛЇЖЫЖСШЁЪ§ОнВЂНЋЯьгІЗЕЛиИјПЭЛЇЖЫЃЌЫќБОЩэВЂВЛДІРэОпЬхЕФвЕЮёТпМЃЌВЂЧвЦфФкВПЮЌЛЄСЫвЛИіЖгСаРДБЃДцЗжХфИјЫќЕФЫљгаSocketChannelЁЃProcessorЕФrunЗНЗЈЛсбЛЗДгЖгСажаШЁГіаТЕФSocketChannelВЂНЋЦфSelectionKey.OP_READзЂВсЕНselectorЩЯЃЌШЛКѓбЛЗДІРэвбОЭаїЕФЖСЃЈЧыЧѓЃЉКЭаДЃЈЯьгІЃЉЁЃProcessorЖСШЁЭъЪ§ОнКѓЃЌНЋЦфЗтзАГЩRequestЖдЯѓВЂНЋЦфНЛИјRequestChannelЁЃ RequestChannelЪЧProcessorКЭKafkaRequestHandlerНЛЛЛЪ§ОнЕФЕиЗНЃЌЫќАќКЌвЛИіЖгСаrequestQueueгУРДДцЗХProcessorМгШыЕФRequestЃЌKafkaRequestHandlerЛсДгРяУцШЁГіRequestРДДІРэЃЛЭЌЪБЫќЛЙАќКЌвЛИіrespondQueueЃЌгУРДДцЗХKafkaRequestHandlerДІРэЭъRequestКѓЗЕЛЙИјПЭЛЇЖЫЕФResponseЁЃ ProcessorЛсЭЈЙ§processNewResponsesЗНЗЈвРДЮНЋrequestChannelжаresponseQueueБЃДцЕФResponseШЁГіЃЌВЂНЋЖдгІЕФSelectionKey.OP_WRITEЪТМўзЂВсЕНselectorЩЯЁЃЕБselectorЕФselectЗНЗЈЗЕЛиЪБЃЌЖдМьВтЕНЕФПЩаДЭЈЕРЃЌЕїгУwriteЗНЗЈНЋResponseЗЕЛиИјПЭЛЇЖЫЁЃ KafkaRequestHandlerбЛЗДгRequestChannelжаШЁRequestВЂНЛИјkafka.server.KafkaApisДІРэОпЬхЕФвЕЮёТпМЁЃ
LeaderAndIsrRequestЯьгІЙ§ГЬ
ЖдгкЪеЕНЕФLeaderAndIsrRequestЃЌBrokerжївЊЭЈЙ§ReplicaManagerЕФbecomeLeaderOrFollowerДІРэЃЌСїГЬШчЯТЃК ШєЧыЧѓжаcontrollerEpochаЁгкЕБЧАзюаТЕФcontrollerEpochЃЌдђжБНгЗЕЛиErrorMapping.StaleControllerEpochCodeЁЃ ЖдгкЧыЧѓжаpartitionStateInfosжаЕФУПвЛИідЊЫиЃЌМД((topic, partitionId),
partitionStateInfo)ЃК ШєpartitionStateInfoжаЕФleader epochДѓгкЕБЧАReplicManagerжаДцДЂЕФ(topic,
partitionId)ЖдгІЕФpartitionЕФleader epochЃЌдђЃК ШєЕБЧАbrokeridЃЈЛђепЫЕreplica idЃЉдкpartitionStateInfoжаЃЌдђНЋИУpartitionМАpartitionStateInfoДцШывЛИіУћЮЊpartitionStateЕФHashMapжа ЗёдђЫЕУїИУBrokerВЛдкИУPartitionЗжХфЕФReplica listжаЃЌНЋИУаХЯЂМЧТМгкlogжа ЗёдђНЋЯргІЕФError codeЃЈErrorMapping.StaleLeaderEpochCodeЃЉДцШыResponseжа ЩИбЁГіpartitionStateжаLeaderгыЕБЧАBroker IDЯрЕШЕФЫљгаМЧТМДцШыpartitionsTobeLeaderжаЃЌЦфЫќМЧТМДцШыpartitionsToBeFollowerжаЁЃ ШєpartitionsTobeLeaderВЛЮЊПеЃЌдђЖдЦфжДааmakeLeadersЗНЁЃ ШєpartitionsToBeFollowerВЛЮЊПеЃЌдђЖдЦфжДааmakeFollowersЗНЗЈЁЃ ШєhighwatermakЯпГЬЛЙЮДЦєЖЏЃЌдђНЋЦфЦєЖЏЃЌВЂНЋhwThreadInitializedЩшЮЊtrueЁЃ ЙиБеЫљгаIdleзДЬЌЕФFetcherЁЃ LeaderAndIsrRequestДІРэЙ§ГЬШчЯТЭМЫљЪО
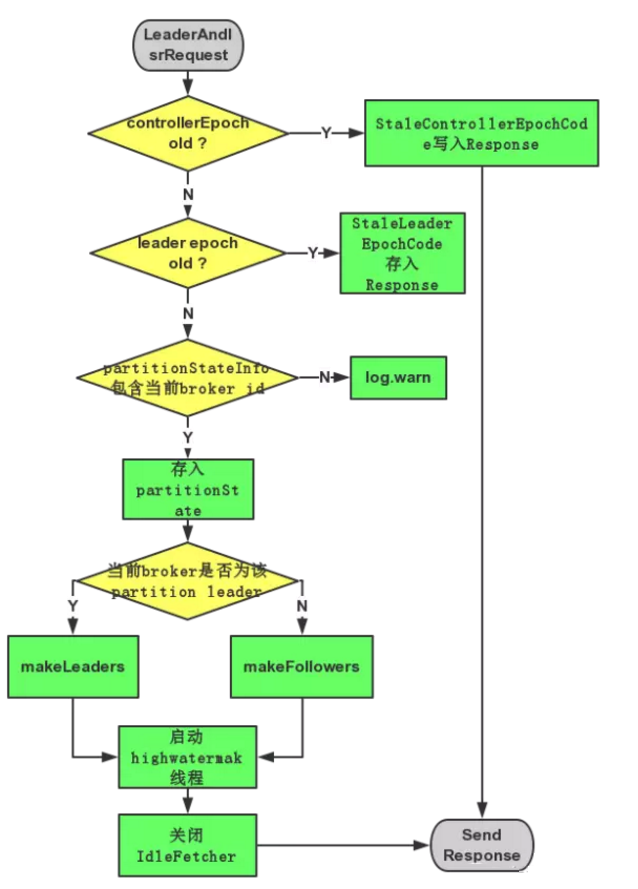
BrokerЦєЖЏЙ§ГЬ
BrokerЦєЖЏКѓЪзЯШИљОнЦфIDдкZookeeperЕФ/brokers/idszondeЯТДДНЈСйЪБзгНкЕуЃЈEphemeral
nodeЃЉЃЌДДНЈГЩЙІКѓControllerЕФReplicaStateMachineзЂВсЦфЩЯЕФBroker
Change WatchЛсБЛfireЃЌДгЖјЭЈЙ§ЛиЕїKafkaController.onBrokerStartupЗНЗЈЭъГЩвдЯТВНжшЃК 1. ЯђЫљгааТЦєЖЏЕФBrokerЗЂЫЭUpdateMetadataRequestЃЌЦфЖЈвхШчЯТ

2. НЋаТЦєЖЏЕФBrokerЩЯЕФЫљгаReplicaЩшжУЮЊOnlineReplicaзДЬЌЃЌЭЌЪБетаЉBrokerЛсЮЊетаЉPartitionЦєЖЏhigh
watermarkЯпГЬЁЃ 3. ЭЈЙ§partitionStateMachineДЅЗЂOnlinePartitionStateChangeЁЃ
Controller Failover
ControllerвВашвЊFailoverЁЃУПИіBrokerЖМЛсдкController Path
(/controller)ЩЯзЂВсвЛИіWatchЁЃЕБЧАControllerЪЇАмЪБЃЌЖдгІЕФController
PathЛсздЖЏЯћЪЇЃЈвђЮЊЫќЪЧEphemeral NodeЃЉЃЌДЫЪБИУWatchБЛfireЃЌЫљгаЁАЛюЁБзХЕФBrokerЖМЛсШЅОКбЁГЩЮЊаТЕФControllerЃЈДДНЈаТЕФController
PathЃЉЃЌЕЋЪЧжЛЛсгавЛИіОКбЁГЩЙІЃЈетЕугЩZookeeperБЃжЄЃЉЁЃОКбЁГЩЙІепМДЮЊаТЕФLeaderЃЌОКбЁЪЇАмепдђжиаТдкаТЕФController
PathЩЯзЂВсWatchЁЃвђЮЊZookeeperЕФWatchЪЧвЛДЮадЕФЃЌБЛfireвЛДЮжЎКѓМДЪЇаЇЃЌЫљвдашвЊжиаТзЂВсЁЃ BrokerГЩЙІОКбЁЮЊаТControllerКѓЛсДЅЗЂKafkaController.onControllerFailoverЗНЗЈЃЌВЂдкИУЗНЗЈжаЭъГЩШчЯТВйзїЃК ЖСШЁВЂдіМгController EpochЁЃ дкReassignedPartitions Patch (/admin/reassign_partitions)ЩЯзЂВсWatchЁЃ дкPreferredReplicaElection Path (/admin/preferred_replica_election)ЩЯзЂВсWatchЁЃ ЭЈЙ§partitionStateMachineдкBroker Topics Patch (/brokers/topics)ЩЯзЂВсWatchЁЃ Шєdelete.topic.enableЩшжУЮЊtrueЃЈФЌШЯжЕЪЧfalseЃЉЃЌдђpartitionStateMachineдкDelete
Topic Patch (/admin/delete_topics)ЩЯзЂВсWatchЁЃ ЭЈЙ§replicaStateMachineдкBroker Ids Patch (/brokers/ids)ЩЯзЂВсWatchЁЃ ГѕЪМЛЏControllerContextЖдЯѓЃЌЩшжУЕБЧАЫљгаTopicЃЌЁАЛюЁБзХЕФBrokerСаБэЃЌЫљгаPartitionЕФLeaderМАISRЕШЁЃ ЦєЖЏreplicaStateMachineКЭpartitionStateMachineЁЃ НЋbrokerStateзДЬЌЩшжУЮЊRunningAsControllerЁЃ НЋУПИіPartitionЕФLeadershipаХЯЂЗЂЫЭИјЫљгаЁАЛюЁБзХЕФBrokerЁЃ Шєauto.leader.rebalance.enableХфжУЮЊtrueЃЈФЌШЯжЕЪЧtrueЃЉЃЌдђЦєЖЏpartition-rebalanceЯпГЬЁЃ Шєdelete.topic.enableЩшжУЮЊtrueЧвDelete Topic Patch(/admin/delete_topics)жагажЕЃЌдђЩОГ§ЯргІЕФTopicЁЃ
PartitionжиаТЗжХф
ЙмРэЙЄОпЗЂГіжиаТЗжХфPartitionЧыЧѓКѓЃЌЛсНЋЯргІаХЯЂаДЕН/admin/reassign_partitionsЩЯЃЌЖјИУВйзїЛсДЅЗЂReassignedPartitionsIsrChangeListenerЃЌДгЖјЭЈЙ§жДааЛиЕїКЏЪ§KafkaController.onPartitionReassignmentРДЭъГЩвдЯТВйзїЃК НЋZookeeperжаЕФARЃЈCurrent Assigned ReplicasЃЉИќаТЮЊOARЃЈOriginal
list of replicas for partitionЃЉ + RARЃЈReassigned replicasЃЉЁЃ ЧПжЦИќаТZookeeperжаЕФleader epochЃЌЯђARжаЕФУПИіReplicaЗЂЫЭLeaderAndIsrRequestЁЃ НЋRAR - OARжаЕФReplicaЩшжУЮЊNewReplicaзДЬЌЁЃ ЕШД§жБЕНRARжаЫљгаЕФReplicaЖМгыЦфLeaderЭЌВНЁЃ НЋRARжаЫљгаЕФReplicaЖМЩшжУЮЊOnlineReplicaзДЬЌЁЃ НЋCacheжаЕФARЩшжУЮЊRARЁЃ ШєLeaderВЛдкRARжаЃЌдђДгRARжажиаТбЁОйГівЛИіаТЕФLeaderВЂЗЂЫЭLeaderAndIsrRequestЁЃШєаТЕФLeaderВЛЪЧДгRARжабЁОйЖјГіЃЌдђЛЙвЊдіМгZookeeperжаЕФleader
epochЁЃ НЋOAR - RARжаЕФЫљгаReplicaЩшжУЮЊOfflineReplicaзДЬЌЃЌИУЙ§ГЬАќКЌСНВПЗжЁЃЕквЛЃЌНЋZookeeperЩЯISRжаЕФOAR
- RARвЦç€ߐLeaderЗЂЫЭLeaderAndIsrRequestДгЖјЭЈжЊетаЉReplicaвбОДгISRжавЦГ§ЃЛЕкЖўЃЌЯђOAR
- RARжаЕФReplicaЗЂЫЭStopReplicaRequestДгЖјЭЃжЙВЛдйЗжХфИјИУPartitionЕФReplicaЁЃ НЋOAR - RARжаЕФЫљгаReplicaЩшжУЮЊNonExistentReplicaзДЬЌДгЖјНЋЦфДгДХХЬЩЯЩОГ§ЁЃ НЋZookeeperжаЕФARЩшжУЮЊRARЁЃ ЩОГ§/admin/reassign_partitionЁЃ зЂвтЃКзюКѓвЛВНВХНЋZookeeperжаЕФARИќаТЃЌвђЮЊетЪЧЮЈвЛвЛИіГжОУДцДЂARЕФЕиЗНЃЌШчЙћControllerдкетвЛВНжЎЧАcrashЃЌаТЕФControllerШдШЛФмЙЛМЬајЭъГЩИУЙ§ГЬЁЃ
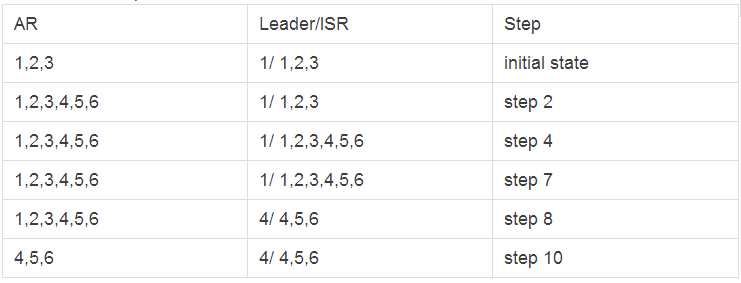
вдЯТЪЧPartitionжиаТЗжХфЕФАИР§ЃЌOAR = {1ЃЌ2ЃЌ3}ЃЌRAR = {4ЃЌ5ЃЌ6}ЃЌPartitionжиаТЗжХфЙ§ГЬжаZookeeperжаЕФARКЭLeader/ISRТЗОЖШчЯТ
FollowerДгLeader FetchЪ§Он
FollowerЭЈЙ§ЯђLeaderЗЂЫЭFetchRequestЛёШЁЯћЯЂЃЌFetchRequestНсЙЙШчЯТ

ДгFetchRequestЕФНсЙЙПЩвдПДГіЃЌУПИіFetchЧыЧѓЖМвЊжИЖЈзюДѓЕШД§ЪБМфКЭзюаЁЛёШЁзжНкЪ§ЃЌвдМАгЩTopicAndPartitionКЭPartitionFetchInfoЙЙГЩЕФMapЁЃЪЕМЪЩЯЃЌFollowerДгLeaderЪ§ОнКЭConsumerДгBroker
FetchЪ§ОнЃЌЖМЪЧЭЈЙ§FetchRequestЧыЧѓЭъГЩЃЌЫљвддкFetchRequestНсЙЙжаЃЌЦфжавЛИізжЖЮЪЧclientIDЃЌВЂЧвЦфФЌШЯжЕЪЧConsumerConfig.DefaultClientIdЁЃ LeaderЪеЕНFetchЧыЧѓКѓЃЌKafkaЭЈЙ§KafkaApis.handleFetchRequestЯьгІИУЧыЧѓЃЌЯьгІЙ§ГЬШчЯТЃК replicaManagerИљОнЧыЧѓЖСГіЪ§ОнДцШыdataReadжаЁЃ ШчЙћИУЧыЧѓРДздFollowerдђИќаТЦфЯргІЕФLEOЃЈlog end offsetЃЉвдМАЯргІPartitionЕФHigh
Watermark ИљОнdataReadЫуГіПЩЖСЯћЯЂГЄЖШЃЈЕЅЮЛЮЊзжНкЃЉВЂДцШыbytesReadableжаЁЃ ТњзуЯТУц4ИіЬѕМўжаЕФ1ИіЃЌдђСЂМДНЋЯргІЕФЪ§ОнЗЕЛи FetchЧыЧѓВЛЯЃЭћЕШД§ЃЌМДfetchRequest.macWait <= 0 FetchЧыЧѓВЛвЊЧѓвЛЖЈФмШЁЕНЯћЯЂЃЌМДfetchRequest.numPartitions <=
0ЃЌвВМДrequestInfoЮЊПе газуЙЛЕФЪ§ОнПЩЙЉЗЕЛиЃЌМДbytesReadable >= fetchRequest.minBytes ЖСШЁЪ§ОнЪБЗЂЩњвьГЃ ШєВЛТњзувдЩЯ4ИіЬѕМўЃЌFetchRequestНЋВЛЛсСЂМДЗЕЛиЃЌВЂНЋИУЧыЧѓЗтзАГЩDelayedFetchЁЃМьВщИУDeplayedFetchЪЧЗёТњзуЃЌШєТњзудђЗЕЛиЧыЧѓЃЌЗёдђНЋИУЧыЧѓМгШыWatchСаБэ
LeaderЭЈЙ§вдFetchResponseЕФаЮЪННЋЯћЯЂЗЕЛиИјFollowerЃЌFetchResponseНсЙЙШчЯТ

|








