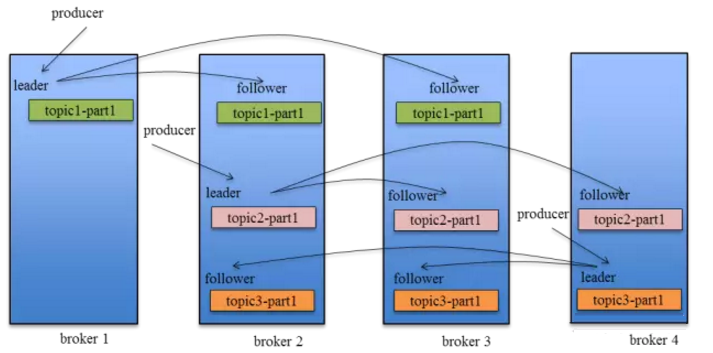
|
БОЮФЪЧЯЕСаЮФеТЕФЕкЖўЦЊЃЌЕквЛЦЊ
"KafkaЩшМЦНтЮіЃЈвЛЃЉ- KafkaБГОАМАМмЙЙНщЩм"ЁЃ
еЊвЊ Kafkaдк0.8вдЧАЕФАцБОжаЃЌВЂВЛЬсЙЉHigh AvailablityЛњжЦЃЌвЛЕЉвЛИіЛђЖрИіBrokerхДЛњЃЌдђхДЛњЦкМфЦфЩЯЫљгаPartitionЖМЮоЗЈМЬајЬсЙЉЗўЮёЁЃШєИУBrokerгРдЖВЛФмдйЛжИДЃЌврЛђДХХЬЙЪеЯЃЌдђЦфЩЯЪ§ОнНЋЖЊЪЇЁЃЖјKafkaЕФЩшМЦФПБъжЎвЛМДЪЧЬсЙЉЪ§ОнГжОУЛЏЃЌЭЌЪБЖдгкЗжВМЪНЯЕЭГРДЫЕЃЌгШЦфЕБМЏШКЙцФЃЩЯЩ§ЕНвЛЖЈГЬЖШКѓЃЌвЛЬЈЛђепЖрЬЈЛњЦїхДЛњЕФПЩФмадДѓДѓЬсИпЃЌЖдгкFailoverЛњжЦЕФашЧѓЗЧГЃИпЁЃвђДЫЃЌKafkaДг0.8ПЊЪМЬсЙЉHigh
AvailabilityЛњжЦЁЃБОЮФДгData ReplicationКЭLeader ElectionСНЗНУцНщЩмСЫKafkaЕФHAЛњжЦЁЃ
ЮЊКЮашвЊReplication
дкKafkaдк0.8вдЧАЕФАцБОжаЃЌЪЧУЛгаReplicationЕФЃЌвЛЕЉФГвЛИіBrokerхДЛњЃЌдђЦфЩЯЫљгаЕФPartitionЪ§ОнЖМВЛПЩБЛЯћЗбЃЌетгыKafkaЪ§ОнГжОУадМАDelivery
GuaranteeЕФЩшМЦФПБъЯруЃЁЃЭЌЪБProducerЖМВЛФмдйНЋЪ§ОнДцгкетаЉPartitionжаЁЃ ШчЙћProducerЪЙгУЭЌВНФЃЪНдђProducerЛсдкГЂЪджиаТЗЂЫЭmessage.send.max.retriesЃЈФЌШЯжЕЮЊ3ЃЉДЮКѓХзГіExceptionЃЌгУЛЇПЩвдбЁдёЭЃжЙЗЂЫЭКѓајЪ§ОнвВПЩбЁдёМЬајбЁдёЗЂЫЭЁЃЖјЧАепЛсдьГЩЪ§ОнЕФзшШћЃЌКѓепЛсдьГЩБОгІЗЂЭљИУBrokerЕФЪ§ОнЕФЖЊЪЇЁЃ ШчЙћProducerЪЙгУвьВНФЃЪНЃЌдђProducerЛсГЂЪджиаТЗЂЫЭmessage.send.max.retriesЃЈФЌШЯжЕЮЊ3ЃЉДЮКѓМЧТМИУвьГЃВЂМЬајЗЂЫЭКѓајЪ§ОнЃЌетЛсдьГЩЪ§ОнЖЊЪЇВЂЧвгУЛЇжЛФмЭЈЙ§ШежОЗЂЯжИУЮЪЬтЁЃ гЩДЫПЩМћЃЌдкУЛгаReplicationЕФЧщПіЯТЃЌвЛЕЉФГЛњЦїхДЛњЛђепФГИіBrokerЭЃжЙЙЄзїдђЛсдьГЩећИіЯЕЭГЕФПЩгУадНЕЕЭЁЃЫцзХМЏШКЙцФЃЕФдіМгЃЌећИіМЏШКжаГіЯжИУРрвьГЃЕФМИТЪДѓДѓдіМгЃЌвђДЫЖдгкЩњВњЯЕЭГЖјбдReplicationЛњжЦЕФв§ШыЗЧГЃживЊЁЃ
ЮЊКЮашвЊLeader Election
ЃЈБОЮФЫљЪіLeader ElectionжївЊжИReplicaжЎМфЕФЃЈLeader ElectionЃЉ
в§ШыReplicationжЎКѓЃЌЭЌвЛИіPartitionПЩФмЛсгаЖрИіReplicaЃЌЖјетЪБашвЊдкетаЉReplicationжЎМфбЁГівЛИіLeaderЃЌProducerКЭConsumerжЛгыетИіLeaderНЛЛЅЃЌЦфЫќReplicaзїЮЊFollowerДгLeaderжаИДжЦЪ§ОнЁЃ вђЮЊашвЊБЃжЄЭЌвЛИіPartitionЕФЖрИіReplicaжЎМфЕФЪ§ОнвЛжТадЃЈЦфжавЛИіхДЛњКѓЦфЫќReplicaБиаывЊФмМЬајЗўЮёВЂЧвМДВЛФмдьГЩЪ§ОнжиИДвВВЛФмдьГЩЪ§ОнЖЊЪЇЃЉЁЃШчЙћУЛгавЛИіLeaderЃЌЫљгаReplicaЖМПЩЭЌЪБЖС/аДЪ§ОнЃЌФЧОЭашвЊБЃжЄЖрИіReplicaжЎМфЛЅЯрЃЈNЁСNЬѕЭЈТЗЃЉЭЌВНЪ§ОнЃЌЪ§ОнЕФвЛжТадКЭгаађадЗЧГЃФбБЃжЄЃЌДѓДѓдіМгСЫReplicationЪЕЯжЕФИДдгадЃЌЭЌЪБвВдіМгСЫГіЯжвьГЃЕФМИТЪЁЃЖјв§ШыLeaderКѓЃЌжЛгаLeaderИКд№Ъ§ОнЖСаДЃЌFollowerжЛЯђLeaderЫГађFetchЪ§ОнЃЈNЬѕЭЈТЗЃЉЃЌЯЕЭГИќМгМђЕЅЧвИпаЇЁЃ
ШчКЮНЋReplicaОљдШЗжВМЕНећИіМЏШК
ЮЊСЫИќКУЕФзіИКдиОљКтЃЌKafkaОЁСПНЋЫљгаЕФPartitionОљдШЗжХфЕНећИіМЏШКЩЯЁЃвЛИіЕфаЭЕФВПЪ№ЗНЪНЪЧвЛИіTopicЕФPartitionЪ§СПДѓгкBrokerЕФЪ§СПЁЃЭЌЪБЮЊСЫЬсИпKafkaЕФШнДэФмСІЃЌвВашвЊНЋЭЌвЛИіPartitionЕФReplicaОЁСПЗжЩЂЕНВЛЭЌЕФЛњЦїЁЃЪЕМЪЩЯЃЌШчЙћЫљгаЕФReplicaЖМдкЭЌвЛИіBrokerЩЯЃЌФЧвЛЕЉИУBrokerхДЛњЃЌИУPartitionЕФЫљгаReplicaЖМЮоЗЈЙЄзїЃЌвВОЭДяВЛЕНHAЕФаЇЙћЁЃЭЌЪБЃЌШчЙћФГИіBrokerхДЛњСЫЃЌашвЊБЃжЄЫќЩЯУцЕФИКдиПЩвдБЛОљдШЕФЗжХфЕНЦфЫќавДцЕФЫљгаBrokerЩЯЁЃ KafkaЗжХфReplicaЕФЫуЗЈШчЯТЃК НЋЫљгаBrokerЃЈМйЩшЙВnИіBrokerЃЉКЭД§ЗжХфЕФPartitionХХађ НЋЕкiИіPartitionЗжХфЕНЕкЃЈi mod nЃЉИіBrokerЩЯ НЋЕкiИіPartitionЕФЕкjИіReplicaЗжХфЕНЕкЃЈ(i + j) mode nЃЉИіBrokerЩЯ
Data Replication
KafkaЕФData ReplicationашвЊНтОіШчЯТЮЪЬтЃК дѕбљPropagateЯћЯЂ дкЯђProducerЗЂЫЭACKЧАашвЊБЃжЄгаЖрЩйИіReplicaвбОЪеЕНИУЯћЯЂ дѕбљДІРэФГИіReplicaВЛЙЄзїЕФЧщПі дѕбљДІРэFailed ReplicaЛжИДЛиРДЕФЧщПі
PropagateЯћЯЂ
ProducerдкЗЂВМЯћЯЂЕНФГИіPartitionЪБЃЌЯШЭЈЙ§ZookeeperевЕНИУPartitionЕФLeaderЃЌШЛКѓЮоТлИУTopicЕФReplication
FactorЮЊЖрЩйЃЈвВМДИУPartitionгаЖрЩйИіReplicaЃЉЃЌProducerжЛНЋИУЯћЯЂЗЂЫЭЕНИУPartitionЕФLeaderЁЃLeaderЛсНЋИУЯћЯЂаДШыЦфБОЕиLogЁЃУПИіFollowerЖМДгLeader
pullЪ§ОнЁЃетжжЗНЪНЩЯЃЌFollowerДцДЂЕФЪ§ОнЫГађгыLeaderБЃГжвЛжТЁЃFollowerдкЪеЕНИУЯћЯЂВЂаДШыЦфLogКѓЃЌЯђLeaderЗЂЫЭACKЁЃвЛЕЉLeaderЪеЕНСЫISRжаЕФЫљгаReplicaЕФACKЃЌИУЯћЯЂОЭБЛШЯЮЊвбОcommitСЫЃЌLeaderНЋдіМгHWВЂЧвЯђProducerЗЂЫЭACKЁЃ ЮЊСЫЬсИпадФмЃЌУПИіFollowerдкНгЪеЕНЪ§ОнКѓОЭСЂТэЯђLeaderЗЂЫЭACKЃЌЖјЗЧЕШЕНЪ§ОнаДШыLogжаЁЃвђДЫЃЌЖдгквбОcommitЕФЯћЯЂЃЌKafkaжЛФмБЃжЄЫќБЛДцгкЖрИіReplicaЕФФкДцжаЃЌЖјВЛФмБЃжЄЫќУЧБЛГжОУЛЏЕНДХХЬжаЃЌвВОЭВЛФмЭъШЋБЃжЄвьГЃЗЂЩњКѓИУЬѕЯћЯЂвЛЖЈФмБЛConsumerЯћЗбЁЃЕЋПМТЧЕНетжжГЁОАЗЧГЃЩйМћЃЌПЩвдШЯЮЊетжжЗНЪНдкадФмКЭЪ§ОнГжОУЛЏЩЯзіСЫвЛИіБШНЯКУЕФЦНКтЁЃдкНЋРДЕФАцБОжаЃЌKafkaЛсПМТЧЬсЙЉИќИпЕФГжОУадЁЃ ConsumerЖСЯћЯЂвВЪЧДгLeaderЖСШЁЃЌжЛгаБЛcommitЙ§ЕФЯћЯЂЃЈoffsetЕЭгкHWЕФЯћЯЂЃЉВХЛсБЉТЖИјConsumerЁЃKafka
ReplicationЕФЪ§ОнСїШчЯТЭМЫљЪО
ACKЧАашвЊБЃжЄгаЖрЩйИіБИЗн
КЭДѓВПЗжЗжВМЪНЯЕЭГвЛбљЃЌKafkaДІРэЪЇАмашвЊУїШЗЖЈвхвЛИіBrokerЪЧЗёЁАЛюзХЁБЁЃЖдгкKafkaЖјбдЃЌKafkaДцЛюАќКЌСНИіЬѕМўЃЌвЛЪЧЫќБиаыЮЌЛЄгыZookeeperЕФsession(етИіЭЈЙ§ZookeeperЕФHeartbeatЛњжЦРДЪЕЯж)ЁЃЖўЪЧFollowerБиаыФмЙЛМАЪБНЋLeaderЕФЯћЯЂИДжЦЙ§РДЃЌВЛФмЁАТфКѓЬЋЖрЁБЁЃ LeaderЛсИњзйгыЦфБЃГжЭЌВНЕФReplicaСаБэЃЌИУСаБэГЦЮЊISRЃЈМДin-sync ReplicaЃЉЁЃШчЙћвЛИіFollowerхДЛњЃЌЛђепТфКѓЬЋЖрЃЌLeaderНЋАбЫќДгISRжавЦГ§ЁЃетРяЫљУшЪіЕФЁАТфКѓЬЋЖрЁБжИFollowerИДжЦЕФЯћЯЂТфКѓгкLeaderКѓЕФЬѕЪ§ГЌЙ§дЄЖЈжЕЃЈИУжЕПЩдк$KAFKA_HOME/config/server.propertiesжаЭЈЙ§replica.lag.max.messagesХфжУЃЌЦфФЌШЯжЕЪЧ4000ЃЉЛђепFollowerГЌЙ§вЛЖЈЪБМфЃЈИУжЕПЩдк$KAFKA_HOME/config/server.propertiesжаЭЈЙ§replica.lag.time.max.msРДХфжУЃЌЦфФЌШЯжЕЪЧ10000ЃЉЮДЯђLeaderЗЂЫЭfetchЧыЧѓЁЃЁЃ KafkaЕФИДжЦЛњжЦМШВЛЪЧЭъШЋЕФЭЌВНИДжЦЃЌвВВЛЪЧЕЅДПЕФвьВНИДжЦЁЃЪТЪЕЩЯЃЌЭЌВНИДжЦвЊЧѓЫљгаФмЙЄзїЕФFollowerЖМИДжЦЭъЃЌетЬѕЯћЯЂВХЛсБЛШЯЮЊcommitЃЌетжжИДжЦЗНЪНМЋДѓЕФгАЯьСЫЭЬЭТТЪЃЈИпЭЬЭТТЪЪЧKafkaЗЧГЃживЊЕФвЛИіЬиадЃЉЁЃЖјвьВНИДжЦЗНЪНЯТЃЌFollowerвьВНЕФДгLeaderИДжЦЪ§ОнЃЌЪ§ОнжЛвЊБЛLeaderаДШыlogОЭБЛШЯЮЊвбОcommitЃЌетжжЧщПіЯТШчЙћFollowerЖМИДжЦЭъЖМТфКѓгкLeaderЃЌЖјШчЙћLeaderЭЛШЛхДЛњЃЌдђЛсЖЊЪЇЪ§ОнЁЃЖјKafkaЕФетжжЪЙгУISRЕФЗНЪНдђКмКУЕФОљКтСЫШЗБЃЪ§ОнВЛЖЊЪЇвдМАЭЬЭТТЪЁЃFollowerПЩвдХњСПЕФДгLeaderИДжЦЪ§ОнЃЌетбљМЋДѓЕФЬсИпИДжЦадФмЃЈХњСПаДДХХЬЃЉЃЌМЋДѓМѕЩйСЫFollowerгыLeaderЕФВюОрЁЃ ашвЊЫЕУїЕФЪЧЃЌKafkaжЛНтОіfail/recoverЃЌВЛДІРэЁАByzantineЁБЃЈЁААнеМЭЅЁБЃЉЮЪЬтЁЃвЛЬѕЯћЯЂжЛгаБЛISRРяЕФЫљгаFollowerЖМДгLeaderИДжЦЙ§ШЅВХЛсБЛШЯЮЊвбЬсНЛЁЃетбљОЭБмУтСЫВПЗжЪ§ОнБЛаДНјСЫLeaderЃЌЛЙУЛРДЕУМАБЛШЮКЮFollowerИДжЦОЭхДЛњСЫЃЌЖјдьГЩЪ§ОнЖЊЪЇЃЈConsumerЮоЗЈЯћЗбетаЉЪ§ОнЃЉЁЃЖјЖдгкProducerЖјбдЃЌЫќПЩвдбЁдёЪЧЗёЕШД§ЯћЯЂcommitЃЌетПЩвдЭЈЙ§request.required.acksРДЩшжУЁЃетжжЛњжЦШЗБЃСЫжЛвЊISRгавЛИіЛђвдЩЯЕФFollowerЃЌвЛЬѕБЛcommitЕФЯћЯЂОЭВЛЛсЖЊЪЇЁЃ
ЁЁЁЁ
Leader ElectionЫуЗЈ
ЩЯЮФЫЕУїСЫKafkaЪЧШчКЮзіReplicationЕФЃЌСэЭтвЛИіКмживЊЕФЮЪЬтЪЧЕБLeaderхДЛњСЫЃЌдѕбљдкFollowerжабЁОйГіаТЕФLeaderЁЃвђЮЊFollowerПЩФмТфКѓаэЖрЛђепcrashСЫЃЌЫљвдБиаыШЗБЃбЁдёЁАзюаТЁБЕФFollowerзїЮЊаТЕФLeaderЁЃвЛИіЛљБОЕФддђОЭЪЧЃЌШчЙћLeaderВЛдкСЫЃЌаТЕФLeaderБиаыгЕгадРДЕФLeader
commitЙ§ЕФЫљгаЯћЯЂЁЃетОЭашвЊзївЛИіелждЃЌШчЙћLeaderдкБъУївЛЬѕЯћЯЂБЛcommitЧАЕШД§ИќЖрЕФFollowerШЗШЯЃЌФЧдкЫќхДЛњжЎКѓОЭгаИќЖрЕФFollowerПЩвдзїЮЊаТЕФLeaderЃЌЕЋетвВЛсдьГЩЭЬЭТТЪЕФЯТНЕЁЃ вЛжжЗЧГЃГЃгУЕФLeader ElectionЕФЗНЪНЪЧЁАMajority VoteЁБЃЈЁАЩйЪ§ЗўДгЖрЪ§ЁБЃЉЃЌЕЋKafkaВЂЮДВЩгУетжжЗНЪНЁЃетжжФЃЪНЯТЃЌШчЙћЮвУЧга2f+1ИіReplicaЃЈАќКЌLeaderКЭFollowerЃЉЃЌФЧдкcommitжЎЧАБиаыБЃжЄгаf+1ИіReplicaИДжЦЭъЯћЯЂЃЌЮЊСЫБЃжЄе§ШЗбЁГіаТЕФLeaderЃЌfailЕФReplicaВЛФмГЌЙ§fИіЁЃвђЮЊдкЪЃЯТЕФШЮвтf+1ИіReplicaРяЃЌжСЩйгавЛИіReplicaАќКЌгазюаТЕФЫљгаЯћЯЂЁЃетжжЗНЪНгаИіКмДѓЕФгХЪЦЃЌЯЕЭГЕФlatencyжЛШЁОігкзюПьЕФМИИіBrokerЃЌЖјЗЧзюТ§ФЧИіЁЃMajority
VoteвВгавЛаЉСгЪЦЃЌЮЊСЫБЃжЄLeader ElectionЕФе§ГЃНјааЃЌЫќЫљФмШнШЬЕФfailЕФfollowerИіЪ§БШНЯЩйЁЃШчЙћвЊШнШЬ1ИіfollowerЙвЕєЃЌБиаывЊга3ИівдЩЯЕФReplicaЃЌШчЙћвЊШнШЬ2ИіFollowerЙвЕєЃЌБиаывЊга5ИівдЩЯЕФReplicaЁЃвВОЭЪЧЫЕЃЌдкЩњВњЛЗОГЯТЮЊСЫБЃжЄНЯИпЕФШнДэГЬЖШЃЌБиаывЊгаДѓСПЕФReplicaЃЌЖјДѓСПЕФReplicaгжЛсдкДѓЪ§ОнСПЯТЕМжТадФмЕФМБОчЯТНЕЁЃетОЭЪЧетжжЫуЗЈИќЖргУдкZookeeperетжжЙВЯэМЏШКХфжУЕФЯЕЭГжаЖјКмЩйдкашвЊДцДЂДѓСПЪ§ОнЕФЯЕЭГжаЪЙгУЕФдвђЁЃР§ШчHDFSЕФHA
FeatureЪЧЛљгкmajority-vote-based journalЃЌЕЋЪЧЫќЕФЪ§ОнДцДЂВЂУЛгаЪЙгУетжжЗНЪНЁЃ ЪЕМЪЩЯЃЌLeader ElectionЫуЗЈЗЧГЃЖрЃЌБШШчZookeeperЕФZab, RaftКЭViewstamped
ReplicationЁЃЖјKafkaЫљЪЙгУЕФLeader ElectionЫуЗЈИќЯёЮЂШэЕФPacificAЫуЗЈЁЃ KafkaдкZookeeperжаЖЏЬЌЮЌЛЄСЫвЛИіISRЃЈin-sync replicasЃЉЃЌетИіISRРяЕФЫљгаReplicaЖМИњЩЯСЫleaderЃЌжЛгаISRРяЕФГЩдБВХгаБЛбЁЮЊLeaderЕФПЩФмЁЃдкетжжФЃЪНЯТЃЌЖдгкf+1ИіReplicaЃЌвЛИіPartitionФмдкБЃжЄВЛЖЊЪЇвбОcommitЕФЯћЯЂЕФЧАЬсЯТШнШЬfИіReplicaЕФЪЇАмЁЃдкДѓЖрЪ§ЪЙгУГЁОАжаЃЌетжжФЃЪНЪЧЗЧГЃгаРћЕФЁЃЪТЪЕЩЯЃЌЮЊСЫШнШЬfИіReplicaЕФЪЇАмЃЌMajority
VoteКЭISRдкcommitЧАашвЊЕШД§ЕФReplicaЪ§СПЪЧвЛбљЕФЃЌЕЋЪЧISRашвЊЕФзмЕФReplicaЕФИіЪ§МИКѕЪЧMajority
VoteЕФвЛАыЁЃ ЫфШЛMajority VoteгыISRЯрБШгаВЛашЕШД§зюТ§ЕФBrokerетвЛгХЪЦЃЌЕЋЪЧKafkaзїепШЯЮЊKafkaПЩвдЭЈЙ§ProducerбЁдёЪЧЗёБЛcommitзшШћРДИФЩЦетвЛЮЪЬтЃЌВЂЧвНкЪЁЯТРДЕФReplicaКЭДХХЬЪЙЕУISRФЃЪНШдШЛжЕЕУЁЃ
ЁЁ
ШчКЮДІРэЫљгаReplicaЖМВЛЙЄзї
ЩЯЮФЬсЕНЃЌдкISRжажСЩйгавЛИіfollowerЪБЃЌKafkaПЩвдШЗБЃвбОcommitЕФЪ§ОнВЛЖЊЪЇЃЌЕЋШчЙћФГИіPartitionЕФЫљгаReplicaЖМхДЛњСЫЃЌОЭЮоЗЈБЃжЄЪ§ОнВЛЖЊЪЇСЫЁЃетжжЧщПіЯТгаСНжжПЩааЕФЗНАИЃК ЕШД§ISRжаЕФШЮвЛИіReplicaЁАЛюЁБЙ§РДЃЌВЂЧвбЁЫќзїЮЊLeader бЁдёЕквЛИіЁАЛюЁБЙ§РДЕФReplicaЃЈВЛвЛЖЈЪЧISRжаЕФЃЉзїЮЊLeader етОЭашвЊдкПЩгУадКЭвЛжТадЕБжазїГівЛИіМђЕЅЕФелждЁЃШчЙћвЛЖЈвЊЕШД§ISRжаЕФReplicaЁАЛюЁБЙ§РДЃЌФЧВЛПЩгУЕФЪБМфОЭПЩФмЛсЯрЖдНЯГЄЁЃЖјЧвШчЙћISRжаЕФЫљгаReplicaЖМЮоЗЈЁАЛюЁБЙ§РДСЫЃЌЛђепЪ§ОнЖМЖЊЪЇСЫЃЌетИіPartitionНЋгРдЖВЛПЩгУЁЃбЁдёЕквЛИіЁАЛюЁБЙ§РДЕФReplicaзїЮЊLeaderЃЌЖјетИіReplicaВЛЪЧISRжаЕФReplicaЃЌФЧМДЪЙЫќВЂВЛБЃжЄвбОАќКЌСЫЫљгавбcommitЕФЯћЯЂЃЌЫќвВЛсГЩЮЊLeaderЖјзїЮЊconsumerЕФЪ§ОндДЃЈЧАЮФгаЫЕУїЃЌЫљгаЖСаДЖМгЩLeaderЭъГЩЃЉЁЃKafka0.8.*ЪЙгУСЫЕкЖўжжЗНЪНЁЃИљОнKafkaЕФЮФЕЕЃЌдквдКѓЕФАцБОжаЃЌKafkaжЇГжгУЛЇЭЈЙ§ХфжУбЁдёетСНжжЗНЪНжаЕФвЛжжЃЌДгЖјИљОнВЛЭЌЕФЪЙгУГЁОАбЁдёИпПЩгУадЛЙЪЧЧПвЛжТадЁЃ
ЁЁЁЁ
ШчКЮбЁОйLeader
зюМђЕЅзюжБЙлЕФЗНАИЪЧЃЌЫљгаFollowerЖМдкZookeeperЩЯЩшжУвЛИіWatchЃЌвЛЕЉLeaderхДЛњЃЌЦфЖдгІЕФephemeral
znodeЛсздЖЏЩОГ§ЃЌДЫЪБЫљгаFollowerЖМГЂЪдДДНЈИУНкЕуЃЌЖјДДНЈГЩЙІепЃЈZookeeperБЃжЄжЛгавЛИіФмДДНЈГЩЙІЃЉМДЪЧаТЕФLeaderЃЌЦфЫќReplicaМДЮЊFollowerЁЃ ЕЋЪЧИУЗНЗЈЛсга3ИіЮЪЬтЃК ЁЁЁЁ split-brain етЪЧгЩZookeeperЕФЬиадв§Ц№ЕФЃЌЫфШЛZookeeperФмБЃжЄЫљгаWatchАДЫГађДЅЗЂЃЌЕЋВЂВЛФмБЃжЄЭЌвЛЪБПЬЫљгаReplicaЁАПДЁБЕНЕФзДЬЌЪЧвЛбљЕФЃЌетОЭПЩФмдьГЩВЛЭЌReplicaЕФЯьгІВЛвЛжТ herd effect ШчЙћхДЛњЕФФЧИіBrokerЩЯЕФPartitionБШНЯЖрЃЌЛсдьГЩЖрИіWatchБЛДЅЗЂЃЌдьГЩМЏШКФкДѓСПЕФЕїећ ZookeeperИКдиЙ§жи УПИіReplicaЖМвЊЮЊДЫдкZookeeperЩЯзЂВсвЛИіWatchЃЌЕБМЏШКЙцФЃдіМгЕНМИЧЇИіPartitionЪБZookeeperИКдиЛсЙ§жиЁЃ
Kafka 0.8.*ЕФLeader ElectionЗНАИНтОіСЫЩЯЪіЮЪЬтЃЌЫќдкЫљгаbrokerжабЁГівЛИіcontrollerЃЌЫљгаPartitionЕФLeaderбЁОйЖМгЩcontrollerОіЖЈЁЃcontrollerЛсНЋLeaderЕФИФБфжБНгЭЈЙ§RPCЕФЗНЪНЃЈБШZookeeper
QueueЕФЗНЪНИќИпаЇЃЉЭЈжЊашЮЊДЫзїГіЯьгІЕФBrokerЁЃЭЌЪБcontrollerвВИКд№діЩОTopicвдМАReplicaЕФжиаТЗжХфЁЃ
HAЯрЙиZookeeperНсЙЙ
ЃЈБОНкЫљЪОZookeeperНсЙЙжаЃЌЪЕЯпПђДњБэТЗОЖУћЪЧЙЬЖЈЕФЃЌЖјащЯпПђДњБэТЗОЖУћгывЕЮёЯрЙиЃЉ admin ЃЈИУФПТМЯТznodeжЛгадкгаЯрЙиВйзїЪБВХЛсДцдкЃЌВйзїНсЪјЪБЛсНЋЦфЩОГ§ЃЉ
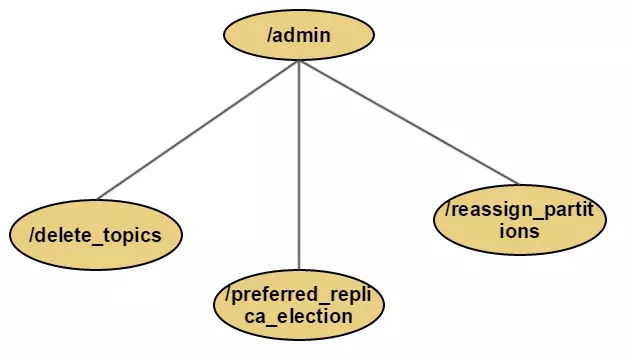
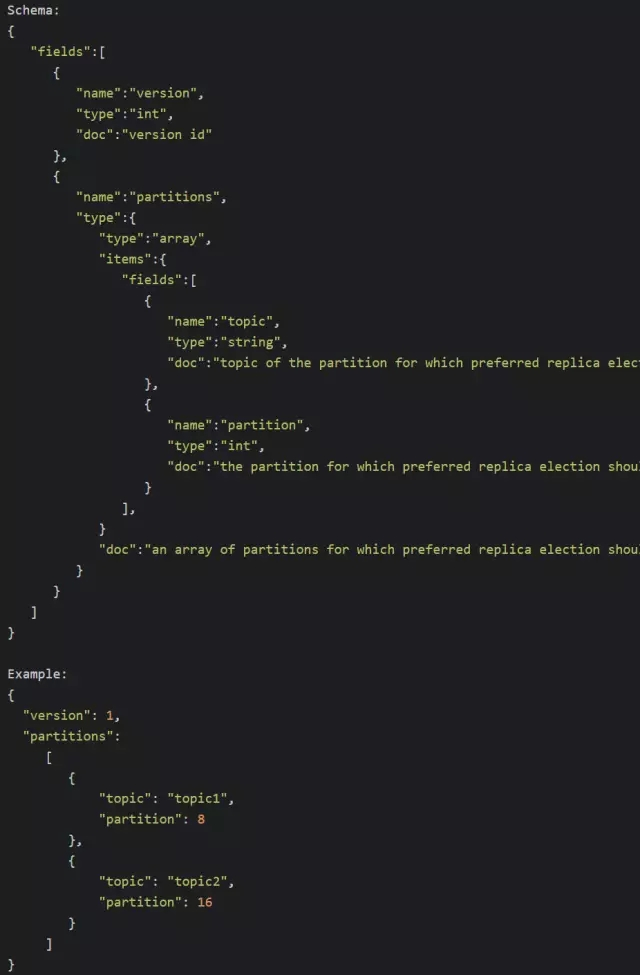
/admin/preferred_replica_election
Ъ§ОнНсЙЙ
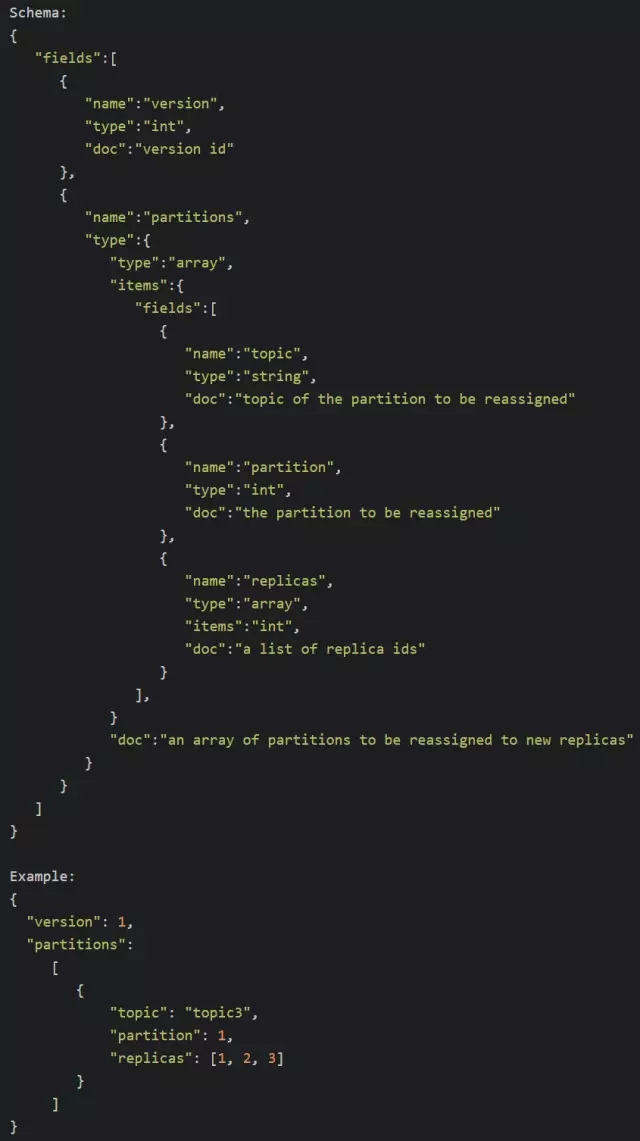
/admin/reassign_partitionsгУгкНЋвЛаЉPartitionЗжХфЕНВЛЭЌЕФbrokerМЏКЯЩЯЁЃЖдгкУПИіД§жиаТЗжХфЕФPartitionЃЌKafkaЛсдкИУznodeЩЯДцДЂЦфЫљгаЕФReplicaКЭЯргІЕФBroker
idЁЃИУznodeгЩЙмРэНјГЬДДНЈВЂЧввЛЕЉжиаТЗжХфГЩЙІЫќНЋЛсБЛздЖЏвЦГ§ЁЃЦфЪ§ОнНсЙЙШчЯТ
/admin/delete_topicsЪ§ОнНсЙЙ
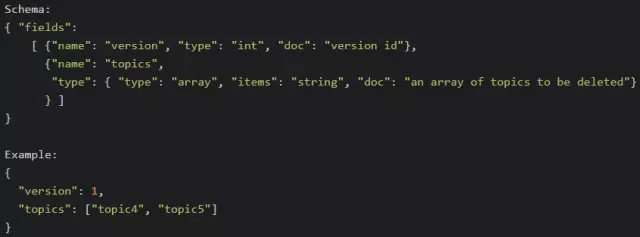
brokers
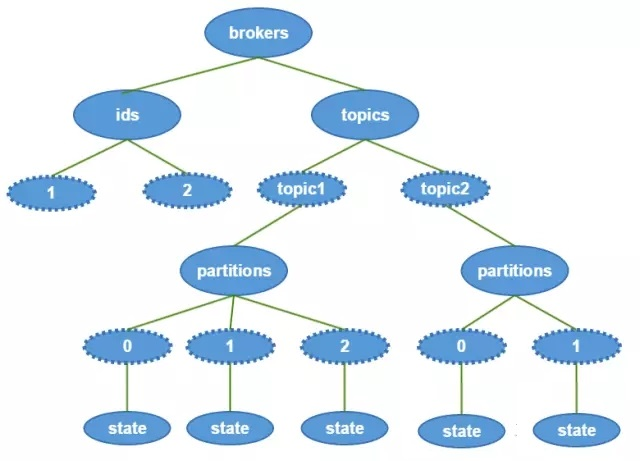
brokerЃЈМД/brokers/ids/[brokerId]ЃЉДцДЂЁАЛюзХЁБЕФBrokerаХЯЂЁЃЪ§ОнНсЙЙШчЯТ
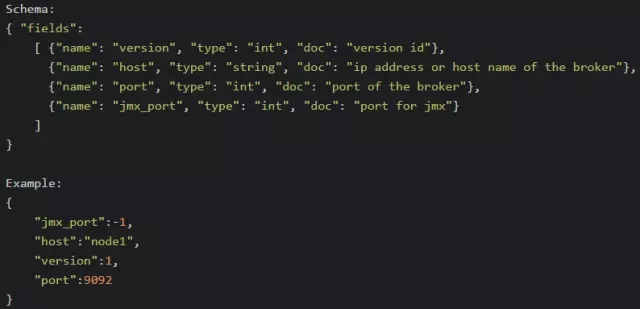
topicзЂВсаХЯЂЃЈ/brokers/topics/[topic]ЃЉЃЌДцДЂИУTopicЕФЫљгаPartitionЕФЫљгаReplicaЫљдкЕФBroker
idЃЌЕквЛИіReplicaМДЮЊPreferred ReplicaЃЌЖдвЛИіИјЖЈЕФPartitionЃЌЫќдкЭЌвЛИіBrokerЩЯзюЖржЛгавЛИіReplica,вђДЫBroker
idПЩзїЮЊReplica idЁЃЪ§ОнНсЙЙШчЯТ
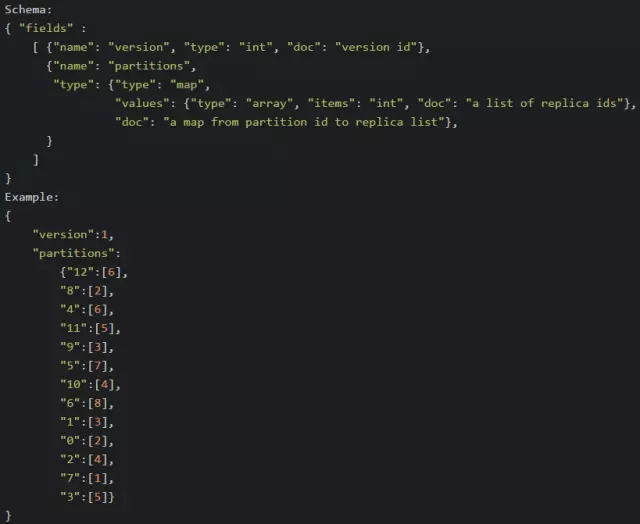
partition state ЃЈ/brokers/topics/[topic] /partitions/ [partitionId]/stateЃЉ
НсЙЙШчЯТ
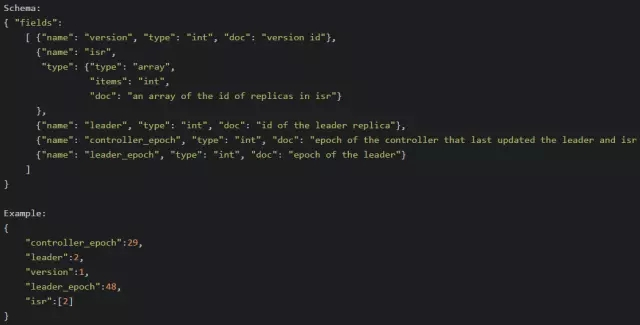
controller
/controller -> int (broker id of
the controller)ДцДЂЕБЧАcontrollerЕФаХЯЂ
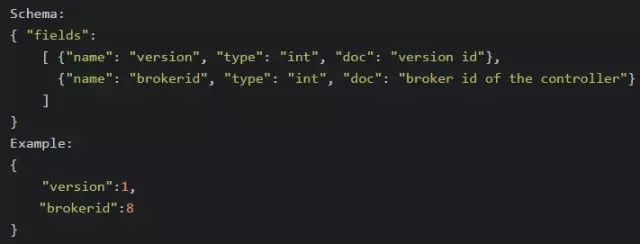
/controller_epoch -> int (epoch)жБНгвдећЪ§аЮЪНДцДЂcontroller epochЃЌЖјЗЧЯёЦфЫќznodeвЛбљвдJSONзжЗћДЎаЮЪНДцДЂЁЃ
ЁЁЁЁ
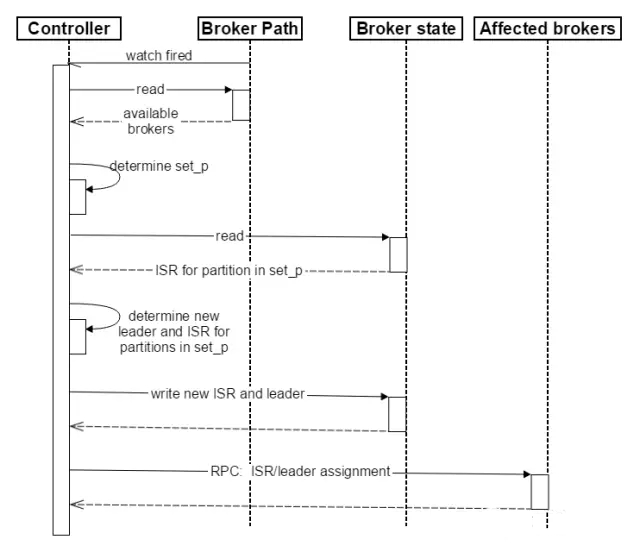
Broker failoverЙ§ГЬМђНщ
1.ControllerдкZookeeperзЂВсWatchЃЌвЛЕЉгаBrokerхДЛњЃЈетЪЧгУхДЛњДњБэШЮКЮШУЯЕЭГШЯЮЊЦфdieЕФЧщОАЃЌАќРЈЕЋВЛЯогкЛњЦїЖЯЕчЃЌЭјТчВЛПЩгУЃЌGCЕМжТЕФStop
The WorldЃЌНјГЬcrashЕШЃЉЃЌЦфдкZookeeperЖдгІЕФznodeЛсздЖЏБЛЩОГ§ЃЌZookeeperЛсfire
ControllerзЂВсЕФwatchЃЌControllerЖСШЁзюаТЕФавДцЕФBroker 2.ControllerОіЖЈset_pЃЌИУМЏКЯАќКЌСЫхДЛњЕФЫљгаBrokerЩЯЕФЫљгаPartition 3.Ждset_pжаЕФУПвЛИіPartition
3.1 Дг/brokers/topics/[topic] /partitions/[partition]/stateЖСШЁИУPartitionЕБЧАЕФISR
3.2 ОіЖЈИУPartitionЕФаТLeaderЁЃШчЙћЕБЧАISRжагажСЩйвЛИіReplicaЛЙавДцЃЌдђбЁдёЦфжавЛИізїЮЊаТLeaderЃЌаТЕФISRдђАќКЌЕБЧАISRжаЫљгаавДцЕФReplicaЁЃЗёдђбЁдёИУPartitionжаШЮвтвЛИіавДцЕФReplicaзїЮЊаТЕФLeaderвдМАISRЃЈИУГЁОАЯТПЩФмЛсгаЧБдкЕФЪ§ОнЖЊЪЇЃЉЁЃШчЙћИУPartitionЕФЫљгаReplicaЖМхДЛњСЫЃЌдђНЋаТЕФLeaderЩшжУЮЊ-1ЁЃ
3.3 НЋаТЕФLeaderЃЌISRКЭаТЕФleader_epochМАcontroller_epochаДШы/brokers/topics/[topic]
/partitions/[partition]/stateЁЃзЂвтЃЌИУВйзїжЛгаЦфversionдк3.1жС3.3ЕФЙ§ГЬжаЮоБфЛЏЪБВХЛсжДааЃЌЗёдђЬјзЊЕН3.1
4.жБНгЭЈЙ§RPCЯђset_pЯрЙиЕФBrokerЗЂЫЭLeaderAndISRRequestУќСюЁЃControllerПЩвддквЛИіRPCВйзїжаЗЂЫЭЖрИіУќСюДгЖјЬсИпаЇТЪЁЃ Broker failoverЫГађЭМШчЯТЫљЪОЁЃ
ЯТЦЊдЄИц
ЯТЦЊЮФеТНЋЯъЯИНщЩмKafka HAЯрЙиЕФвьГЃЧщПіДІРэЃЌР§ШчЃЌдѕбљДІРэBroker failoverЃЌFollowerШчКЮДгLeader
fetchЯћЯЂЃЌШчКЮжиаТЗжХфReplicaЃЌШчКЮДІРэController failureЕШЁЃ |









