| 1.
SQL On Hadoop ЗжРр
1.1 ВщбЏбгЪБЗжРр
AtScale дк 2016 ФъЕФвЛЦЊУћЮЊ [15]The Business Intelligence
for Hadoop Benchmark ЕФ SQL On Hadoop адФмВтЦРБЈИцжажИГіЃКЪмВщбЏЪ§ОнСПДѓаЁЃЌВщбЏРраЭ
(join БэИіЪ§ЃЌБэДѓаЁЃЌЪЧЗёОлКЯ)ЃЌВЂЗЂгУЛЇСПЕШвђЫигАЯьЃЌУЛгавЛИі SQL On Hadoop
ЯЕЭГФмЙЛдкЫљгаГЁОАЯТЪЄГіЁЃ БШШч Impala КЭ Presto дкВЂЗЂГЁОАЯТадФмБШНЯгХдНЃЌSpark
SQL ДѓБэ Join адФмБШНЯКУЁЃШЛЖјЖдгкЫљга SQL On Hadoop ЖјбдЃЌДѓБэ Join
ЖМБШНЯТ§ЁЃ
дкжкЖрЕФ SQL On Hadoop ЯЕЭГжаЃЌгаБивЊЖдЦфНјаавЛИіЗжРрЁЃвЛАуЖјбдЃЌгУЛЇИќЙиаФЕФЪЧВщбЏЪБбгЃЌИљОнгУЛЇЬсНЛВщбЏЕННсЙћЗЕЛиЕФЪБМфГЄЖЬЃЌНЋ
SQL ВщбЏЗжЮЊШчЯТШ§РрЃКbatch SQLЃЌinteractive SQLЃЌoperation SQL,
ШчЭМ 1ЁЃ
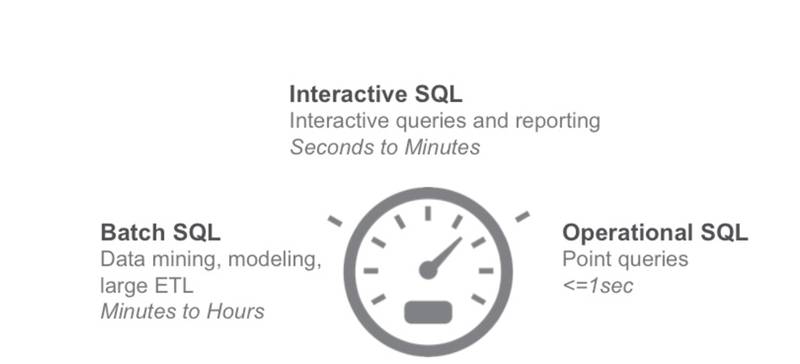
ЭМ 1 SQL On Hadoop ЗжРр,
еЊздЮФЯз [14]
Batch SQLЃЌBatch SQL ЕФВщбЏЪБМфЭЈГЃдкЗжжгЃЌаЁЪБМЖБ№ЃЌвЛАугУгкИДдгЕФ ETL ДІРэЃЌЪ§ОнЭкОђЃЌИпМЖЗжЮіЁЃгЩгк
Batch SQL ЕФВщбЏбгЪББШНЯИпЃЌвђДЫжЇГжВщбЏФк (Intra-query) ШнДэЪЧИУРрЯЕЭГБиаыОпБИЕФЪєадЃЌВщбЏФкШнДэЪЧжИЃЌЕБНкЕухДЛњЛђепВщбЏФкВПФГИі
Task ЪЇАмЪБЃЌЯЕЭГБиаыФмЙЛжиаТЬсНЛИУ task ЖјВЛЪЧжиаТЬсНЛећИіВщбЏРДНјааШнДэЁЃBatch SQL
жазюЕфаЭЕФЯЕЭГЪЧ HiveЁЃSpark SQL вВПЩвдЙщРрЕНИУЯЕЭГЁЃ
Interactive SQLЃЌInteractive SQL вВНазіНЛЛЅЪН SQL ВщбЏЃЌгУЛЇЭЈГЃдкЭЌвЛИіБэЩЯЗДИДЕФжДааВЛЭЌЕФВщбЏЃЌInteractive
SQL ЕФВщбЏЪБМфЭЈГЃдкКСУыМЖЛђепУыМЖвдФкЃЌвЛАуВЛГЌЙ§ЗжжгМЖБ№ЁЃгЩгкИУРрЯЕЭГжївЊзЗЧѓЕЭбгГйЃЌЖјВЛЙ§ЗжЧПЕїВщбЏФкВПШнДэЃЌЫљвдЕБФГИі
task ЪЇАмЪБЃЌПЩвджиаТЬсНЛИУВщбЏвдБуНјааШнДэЃЌвђЮЊжиаТЬсНЛвЛИі SQL ВщбЏЕФжДааЪБМфЭЈГЃКмЖЬЁЃInteractive
SQL дкЪЕЯжЩЯЭЈГЃВЩгУ MPP МмЙЙЃЌВЂЧвНЋШШЕуЪ§ОнЛКДцЕНФкДцжаЃЌБШШч PrestoЃЌImpalaЃЌDrillЃЌHAWQЁЃМјгк
Spark SQL вВОпгаЗЧГЃИпаЇЕФВщбЏЫйЖШЃЌSpark SQL вВПЩвдЙщРрЕН Interactive
SQL жаЁЃ
Operation SQL, ЭЈГЃЪЧЕЅЕуВщбЏЃЌбгЪБвЊЧѓаЁгк 1 УыЃЌИУРрЯЕЭГжївЊЪЧ HBaseЁЃ
1.2 МмЙЙЗжРр
1.2.1 MPP МмЙЙ
MPP МмЙЙЕФгХЕуЪЧВщбЏЫйЖШПьЃЌЭЈГЃдкУыМЦЩѕжСКСУыМЖвдФкОЭПЩвдЗЕЛиВщбЏНсЙћЃЌетвВЪЧЮЊКЮКмЖрЧПЕїЕЭбгГйЕФЯЕЭГВЩгУ
MPP МмЙЙЕФдвђЁЃ
ЯТУцжиЕуПДЯТ MPP МмЙЙЕФШБЕуЃЌMPP МмЙЙзюжївЊЕФШБЕуЪЧВЛжЇГжЯИСЃЖШЕФШнДэЃЌМЏШКНкЕуЪ§СПКмФбРЉеЙЕН
100 ИівдЩЯЃЌШчЙћМЏШКГіЯжТфКѓНкЕуЃЌФЧУДНЋгАЯьећИіЯЕЭГЕФВщбЏадФмЃЌДЫЭтВЛЙм MPP НкЕуЪ§СПЕФЖрЩйЃЌВЂЗЂВщбЏЕФЪ§СПЭЈГЃжЛФмДяЕН
20 ИізѓгвЁЃ
ШнДэЃЌMPP МмЙЙЕФШнДэЬиЕуЪЧДжСЃЖШШнДэЃЌВЛФмДІРэТфКѓНкЕу (Straggler node)ЁЃДжСЃЖШШнДэЪЧжИЃЌФГИі
task жДааЪЇАмНЋЕМжТећИіВщбЏЪЇАмЃЌШЛКѓЯЕЭГжиаТЬсНЛећИіВщбЏРДЛёШЁНсЙћЁЃетжжШнДэЗНЪНжЛЪЪгУгк Iterative
SQL етжжЕЭбгГйЕФЙЄзїИКдиЃЌЖјВЛЪЪКЯ Batch SQL ГЁОАЃЌвђЮЊ Batch SQL ВщбЏЪБМфЭЈГЃдкЗжжгаЁЪБМЖБ№ЃЌжиаТЬсМлвЛИіВщбЏДњМлЬЋИпЁЃ
ТфКѓНкЕуЃЌЕБвЛИіНкЕужДааЫйЖШТ§гкЦфЫћНкЕуЪБЃЌНЋЕМжТећИіЯЕЭГЕФВщбЏадФмЯТНЕЁЃ
РЉеЙадЃКЪмТфКѓНкЕуЕФгАЯьЃЌMPP МмЙЙКмФбРЉеЙЕН 100 ИіНкЕувдЩЯЁЃШчЙћФГИіНкЕуТ§гкЦфЫћНкЕуЃЌФЧУДећИіЯЕЭГЕФВщбЏадФмНЋЪмЯогкетИізюТ§ЕФНкЕуЃЌЖјгыМЏШКНкЕуЪ§СПЮоЙиЁЃашвЊзЂвтЕФЪЧЃЌдкДѓаЭМЏШКжаТфКѓНкЕуЪЧЦеБщДцдкЕФЃЌЫцзХМЏШКНкЕуЪ§СПЕФдіМгЃЌТфКѓНкЕуГіЯжЕФИХТЪвВдіМгЃЌ[13]
еыЖдДХХЬЙЪеЯИХТЪЕФЭГМЦШчЯТЃК
ШчЙћМЏШКАќКЌ 1000 ИіЮДЪЙгУвЛФъЕФДХХЬЃЌФЧУДУПФъНЋгаДѓдМ 20 ДХХЬГіЯжЙЪеЯЃЌЦНОљУПСНжмОЭЛсГіЯжвЛИіЙЪеЯЁЃЕБДХХЬЪЙгУГЌЙ§вЛФъКѓЃЌУПФъДХХЬЙЪеЯГіЯжЕФИХТЪНЋДяЕН
8% зѓгвЃЌЦНОљУПжмНЋГіЯжДѓдМСНДЮЙЪеЯЁЃгЩгкетИідвђЃЌMPP МмЙЙКмФбРЉеЙЕН 100 ИіНкЕувдЩЯЃЌвЛАудк
50 ИіНкЕузѓгвЁЃ
ВЂЗЂЃЌMPP МмЙЙЕФВЂЗЂВщбЏЪ§СПКЭМЏШКНкЕуЪ§СПЮоЙиЁЃMPP ЪЧЖдГЦНсЙЙЃЌЕБжДаавЛИіВщбЏЪБЃЌИУВщбЏНЋБЛЕїЖШЕНМЏШКжаЕФУПвЛИіНкЕужДааЃЌетвтЮЖзХвЛИіАќКЌ
4 ИіНкЕуЕФ MPP МЏШККЭвЛИіАќКЌ 400 ИіНкЕуЕФ MPP МЏШКЫљжЇГжЕФВЂЗЂВщбЏЪ§СПЪЧЯрЭЌЕФЃЌвВОЭЪЧЫЕЃЌВЂЗЂВщбЏЪ§СПКЭМЏШКНкЕуЪ§СПЮоЙиЃЌвЛАуЖјбдЃЌЕБВЂЗЂВщбЏИіЪ§ДяЕН
20 зѓгвЪБЃЌећИіЯЕЭГЕФЭЬЭТвбОДяЕНТњИККЩзДЬЌЁЃ
злЩЯЫљЪіЃЌMPP МмЙЙВЛЪЪКЯДѓЙцФЃВПЪ№ЃЌШчЙћашвЊДѓЙцФЃВПЪ№ЃЌПЩвдПМТЧ Spark Sql етбљЕФЯЕЭГЁЃ
1.2.2 ЗЧ MPP МмЙЙ
ЕфаЭЕФЗЧ MPP МмЙЙга HiveЃЌSpark SqlЁЃЫћУЧЗжБ№ЙЙНЈдк MR КЭ Spark жЎЩЯЃЌгХЕуЪЧМЏШКНкЕуЪ§СППЩвдРЉеЙЕНМИАйЩѕжСЩЯЧЇИіЃЌжЇГжЯИСЃЖШШнДэЁЃШБЕуЪЧВщбЏЫйЖШПЩФмВЛШч
MPP МмЙЙЁЃ
2. дЫаав§ЧцЕФЩшМЦ
2.1. гХЛЏЦї
ФПЧА SQL On Hadoop ЕФВщбЏгХЛЏЦїжївЊгаСНжжЃКЛљгкЙцдђЕФ (Rule-Based Optimizer)
КЭЛљгкДњМлЕФ (Cost-Based Optimizer CBO)ЁЃЛљгкЙцдђЕФгХЛЏЦїМђЕЅЃЌвзгкЪЕЯжЃЌЭЈЙ§ФкжУЕФвЛзщЙцдђРДОіЖЈШчКЮжДааВщбЏМЦЛЎЃЌетРяВЛзіНщЩмЁЃ
ЩшМЦвЛИіКУЕФ CBO гХЛЏЦїЗЧГЃОпгаЬєеНадЃЌвЛИіКУЕФ CBO вРРЕгкЯъЯИПЩППЕФЭГМЦаХЯЂЃЌБШШчУПИіСаЕФзюДѓжЕЃЌзюаЁжЕЃЌБэДѓаЁЃЌБэЗжЧјаХЯЂЃЌЭАаХЯЂЃЌШЛЖјдк
SQL On Hadoop жаЃЌЭЈГЃШБЗІПЩППЕФЭГМЦНсЙћЃЌДњМлЙРМЦДњЪ§ЃЌетЪЙЕУдк SQL On Hadoop
жав§Шы CBO КмРЇФбЁЃОЁЙмШчДЫЃЌМјгк CBO дкдЫааПЩвдИќМгжЧФмЕФНјааВщбЏгХЛЏЃЌШдШЛгадНРДдНЖрЕФ
SQL On Hadoop ПЊЪМжЇГж CBOЃЌБШШч HiveЃЌSpark SQL(МЦЛЎжа)ЁЃ
CBO жївЊгУРДгХЛЏ shuffleЃЌjoinЃЌШчКЮОЁПЩФмЕФБмУт shuffleЃЌЬсИп join
жДааЫйЖШЪЧ CBO жївЊЙизЂЕФЮЪЬтЃЌЦфжа Join ЕФЪЕЯжЗНЪНКЭ Join ЫГађЪЧжиЕуПМТЧЕФЁЃдк SQL
On Hadoop жївЊгаЫФжж join ЪЕЯжЗНЪНЃКshuffle hash join,broadcast
join,Bucket joinЃЌcartesian joinЃК
shuffle hash joinЃЌдк map НзЖЮАДее join key ЖдСНИіБэжДаа hash
shuffleЃЌетбљгЕгаЯрЭЌ join key ЕФдЊзщНЋ shuffle ЕНЭЌвЛИіНкЕуЃЌдк reduce
НзЖЮЖдБэНјаа joinЁЃ
broadcast joinЃЌЕБвЛИіДѓБэ join вЛИіаЁБэЪБЃЌВЂЧваЁБэПЩвдЭъШЋЗХЕНФкДцжаЃЌДЫЪБПЩвдНЋаЁБэЙуВЅЕНДѓБэЫљдкЕФУПвЛИіМЦЫуНкЕуЃЌШЛКѓжДаа
joinЁЃетжж join ЗНЪННазі broadcast join Лђеп map joinЁЃBroadcast
join гХЕуЪЧБмУтСЫ shuffleЃЌЬсИп join адФмЁЃ
Bucket join, МйЩшБэ A КЭБэ B ЪЙгУ bucket ЗжЧјВпТдДцДЂЃЌВЂЧвБэ A КЭБэ
B ЕФ bucket ИіЪ§ЮЊ nЃЌДЫЪБПЩвдАДееШчЯТЗНЪН join:bucket 1 of A join
bucet 1 of B,......,bucket n of A join bucket n of
BЁЃ
Bucket join гХЕуЪЧПЩвдЖдСНИіДѓБэжДаа joinЃЌВЂЧвВЛашвЊНЋЪ§ОнЗХЕНФкДцжаЃЌдк Hive
КЭ Spark2.0 жаЖМжЇГж Bucket joinЁЃ
cartesian joinЃЌвВНазіЕбПЈЖљЛ§ joinЃЌЖдСНИіБэжДааЕбПЈЖљЛ§ joinЃЌНсЙћМЏжадЊЫиЕФЪ§СПЪЧСНИіБэДѓаЁЕФГЫЛ§ЁЃБШШчБэ
A га 10 ЭђааЃЌБэ B га 10 ЭђааЃЌФЧУДЕбПЈЖљЛ§ join жЎКѓЕФБэДѓаЁНЋДяЕН 100 ЭђЬѕЪ§ОнЁЃвђДЫГ§ЗЧЕНЭђВЛЕУвбЃЌЗёдђВЛЛсЪЙгУЕбПЈЖљЛ§
joinЁЃ
БэЕФ join ЫГађ (Join order) жївЊгаСНжжЃКleft-deep treeЃЈЯТЭМзѓЃЉ,bushy
tree(ЯТЭМгв)ЁЃвЛИіКУЕФ CBO гІИУФмЙЛИљОн SQL гяОфЕФЬиЕуЃЌРДздЖЏбЁдёЪЙгУ Left-deep
tree ЛЙЪЧ bushy tree жДаа joinЁЃ
Left-deep tree, ШчЙћЖд AЃЌBЃЌCЃЌD жДаа joinЃЌФЧУДЪзЯШ A join B
ЕУЕНвЛИіСйЪББэ AB ВЂ AB ЮяЛЏЕНДХХЬЃЌШЛКѓ AB join C ЕУЕНжаМфСйЪББэ ABC ВЂЮяЛЏЕНДХХЬЃЌзюКѓ
ABC joinD ЕУЕНзюжеНсЙћЁЃПЩвдЗЂЯжЃЌетжж join ЫГађЗЧГЃМђЕЅЃЌШБЕуЪЧжЛФмДЎаа joinЃЌВЂЧвгЩгкВњЩњСЫДѓСПЕФжаМфСйЪББэЃЌвђДЫВЛЬЋЪЪКЯ
OLAP жаЕФаЧаЭКЭбЉЛЈФЃаЭЁЃ
bushy tree, ВЩгУ bushy tree ЗНЪНЃЌПЩвдВЂаажДаа A join B КЭ C
joinDЁЃШЛКѓНЋЖўепЕФНсЙћ AB КЭ CD Нјаа join ЕУЕНзюжеНсЙћЁЃBushy tree гХЕуЪЧПЩвдВЂаа
joinЃЌВЂЧвФмЙЛКмКУЕФДІРэаЧаЭФЃаЭКЭбЉЛЈФЃаЭЁЃ
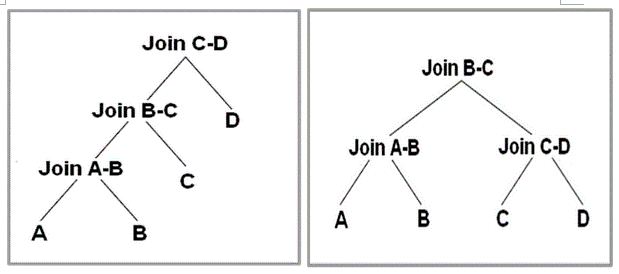
ЭМ 2left-deep tree КЭ
bushy tree, еЊздЮФЯз [16]
2.2. ВщбЏжДаав§Чц
ВщбЏжДаав§Чц (query execution engine) ЪЧ SQL On Hadoop ЕФКЫаФзщМўЁЃВщбЏжДаав§ЧцЕФКУЛЕЖдВщбЏадФмЕФгАЯьЗЧГЃДѓЁЃФПЧАжївЊгаСНжжВщбЏжДааЃКЛ№ЩНжДааФЃаЭКЭЯђСПЛЏжДаав§ЧцЁЃдкКѓУцЕФЯђСПЛЏжДаав§ЧцеТНкжагаЯъЯИЕФНщЩмЁЃ
3. адФмгХЛЏ
ДггВМўзЪдДНЧЖШНЋадФмгХЛЏЗжЮЊ 3 ИіВПЗжЃК
ДХХЬгХЛЏЃКЪ§ОнБОЕиЛЏЃЌМѕЩйжаМфНсЙћЕФЮяЛЏЃЌЪ§ОнбЙЫѕЃЌСаДцДЂЮФМўЃЌЗжЧјЃЌПщМЖЫїв§
CPU гХЛЏЃКЯђСПЛЏжДаав§ЧцЃЌЖЏЬЌДњТыЩњГЩЃЌЧсСПМЖбЙЫѕЫуЗЈЃЌШЮЮёЦєЖЏгХЛЏ
ФкДцКЭ CPU ЛКДцЃКФкДцбЙЫѕСаДцДЂЃЌЖбЭтДцДЂЃЌЛКДцУєИаЪ§ОнНсЙЙКЭЫуЗЈ
3.1 Ъ§ОнБОЕиЛЏ
SQL On Hadoop ЩшМЦЕФвЛИіЛљБОддђЪЧЃКНЋМЦЫуШЮЮёвЦЖЏЕНЪ§ОнЫљдкЕФНкЕуЖјВЛЪЧЗДЙ§РДЁЃетжївЊГігкЭјТчгХЛЏЕФФПЕФЃЌвђЮЊЪ§ОнЗжВМдкВЛЭЌЕФНкЕуЃЌШчЙћвЦЖЏЪ§ОнФЧУДНЋЛсВњЩњДѓСПЕФЕЭаЇЕФЭјТчЪ§ОнДЋЪфЁЃЪ§ОнБОЕиЛЏвЛАуЗжЮЊШ§жжЃКНкЕуОжВПад
(Node Locality), ЛњМмОжВПад (Rack Locality) КЭШЋОжОжВПад (Global
Locality)ЁЃНкЕуОжВПадЪЧжИНЋМЦЫуШЮЮёЗжХфЕНЪ§ОнЫљдкЕФНкЕуЩЯЃЌДЫЪБЮоашШЮКЮЪ§ОнДЋЪфЃЌаЇТЪзюМбЁЃЛњМмОжВПадЪЧжИНЋМЦЫуШЮЮёвЦЖЏЕНЪ§ОнЫљдкЕФЛњМмЃЌЫфШЛМЦЫуШЮЮёКЭЪ§ОнЗжЪєВЛЭЌЕФМЦЫуНкЕуЃЌЕЋЪЧвђЮЊЛњМмФкВПЭјТчДЋЪфЫйЖШУїЯдИпгкЛњМмМфЭјТчДЋЪфЃЌЫљвдЛњМмОжВПадвВЪЧвЛжжВЛДэЕФЗНЪНЁЃЦфЫћЕФЧщПіЪєгкШЋОжОжВПадЃЌДЫЪБашвЊПчЛњМмНјааЭјТчДЋЪфЃЌЛсВњЩњЗЧГЃДѓЕФЭјТчДЋЪфПЊЯњЁЃ
ЕїЖШЯЕЭГдкНјааШЮЮёЕїЖШЪБЃЌгІИУОЁПЩФмЕФБЃжЄНкЕуОжВПадЃЌШЛКѓЪЧЛњМмОжВПадЃЌШчЙћвдЩЯСНепЖМВЛФмТњзуЃЌЕїЖШЯЕЭГвВЛсЭЈЙ§ЭјТчДЋЪфНЋЪ§ОнвЦЖЏЕНМЦЫуШЮЮёЫљдкЕФНкЕуЃЌЫфШЛадФмЯрЖдЕЭаЇЃЌЕЋвВБШзЪдДПежУБШНЯКУЁЃ
ЮЊСЫЪЕЯжЪ§ОнБОЕиЛЏЕїЖШЃЌЕїЖШЯЕЭГЛсНсКЯбгГйЕїЖШЫуЗЈРДНјааШЮЮёЕїЖШЁЃКЫаФЫМЯыЪЧгХЯШНЋМЦЫуШЮЮёЕїЖШЕНЪ§ОнЫљдкЕФНкЕу
iЃЌШчЙћНкЕу i УЛгазуЙЛЕФМЦЫузЪдДЃЌФЧУДЕШД§МИУыжгКѓШчЙћНкЕу i вРШЛУЛгаМЦЫузЪдДПЩгУЃЌФЧУДОЭЗХЦњЪ§ОнБОЕиЛЏНЋИУМЦЫуШЮЮёЕїЖШЕНЦфЫћМЦЫуНкЕуЁЃ
3.2 МѕЩйжаМфНсЙћЕФЮяЛЏ
дквЛИізЗЧѓЕЭбгГйЕФ SQL On Hadoop ЯЕЭГжаЃЌОЁПЩФмЕФМѕЩйжаМфНсЙћЕФДХХЬЮяЛЏПЩвдМЋДѓЕФЬсИпВщбЏадФмЁЃ
ШчЯТЭМЃЌHive жДаав§ЧцВЩгУ pull ЛёШЁЪ§ОнЃЌЦфгХЕуЪЧПЩвдНјааЯИСЃЖШЕФШнДэЃЌШБЕуЪЧЯТгЮЕФ MapReduce
БиаыЕШД§ЩЯгЮ MapReduce ЭъШЋНЋЪ§ОнаДШыЕНДХХЬКѓВХФмПЊЪМ pull Ъ§ОнЁЃPresto ВЩгУ
push ЗНЪНЛёШЁЪ§ОнЃЌЪ§ОнЭъШЋвдСїЕФЗНЪНдкВЛЭЌ stage жЎМфНјааДЋЪфЃЌжаМфНсЙћВЛашвЊЮяЛЏЕНДХХЬЃЌДгЖјЪЙЕУ
presto ОпгаЗЧГЃИпаЇЕФжДааЫйЖШЃЌШБЕуЪЧВЛФмжЇГжЯИСЃЖШЕФШнДэЁЃ
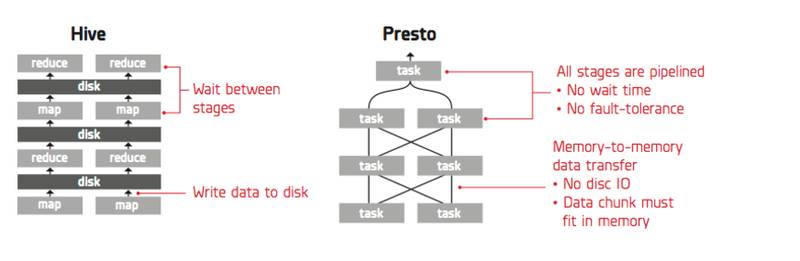
ЭМ 3push КЭ pull
3.3 СаДцДЂ
ДЋЭГЕФЙиЯЕДцДЂФЃаЭНЋвЛИідЊзщЕФСаСЌајДцДЂЃЌМДЪЙжЛВщбЏвЛИіСаЃЌвВашвЊНЋећИідЊзщЖСШЁГіРДЃЌПЩвдЗЂЯжЃЌЕБВщбЏжЛгаЩйСПСаЪБЃЌадФмЗЧГЃЕЭЁЃ
СаДцДЂЕФЫМЯыЪЧНЋдЊзщДЙжБЛЎЗжЮЊСазхМЏКЯЃЌУПвЛИіСазхЖРСЂДцДЂЃЌСазхПЩвдЭЫЛЏЮЊжЛНіАќКЌвЛИіСаЕФЦНЗВСазхЁЃЕБВщбЏЩйСПСаЪБЃЌСаДцДЂФЃаЭПЩвдМЋДѓЕФМѕЩйДХХЬ
IO ВйзїЃЌЬсИпВщбЏадФмЁЃЕБВщбЏЕФСаПчдНЖрИіСазхЪБЃЌашвЊНЋДцДЂдкВЛЭЌСазхжаСаЪ§ОнЦДНгГЩдЪМЪ§ОнЃЌгЩгкВЛЭЌСазхДцДЂдкВЛЭЌЕФ
HDFS НкЕуЩЯЃЌЕМжТДѓСПЕФЪ§ОнПчдНЭјТчДЋЪфЃЌДгЖјНЕЕЭВщбЏадФмЁЃвђДЫдкЪЕМЪЪЙгУСазхЪБЃЌЭЈГЃИљОнвЕЮёВщбЏЬиЕуЃЌНЋЦЕЗБЗУЮЪЕФСаЗХдквЛИіСазхжаЁЃ
дкДЋЭГЕФЪ§ОнПтСьгђжаЃЌШЫУЧвбОЖдСаДцДЂНјааСЫЗЧГЃЩюПЬЕФбаОПЃЌВЂЧвКмЖрбаОПГЩЙћвбОБЛгІгУЕНЙЄвЕСьгђЃЌЦфжаАќРЈЧсСПМЖбЙЫѕЫуЗЈЃЌжБНгВйзїбЙЫѕЪ§ОнЃЌбгГйЮяЛЏЃЌЯђСПЛЏжДаав§ЧцЁЃПЩЪЧзнЙлФПЧА
SQL On Hadoop ЯЕЭГЃЌетаЉММЪѕЕФгІгУШдШЛдЖдЖЕФТфКѓгкДЋЭГЪ§ОнПтЃЌдкзюНќЕФвЛаЉ SQL On
Hadoop жавбОЬэМгСЫЯђСПЛЏжДаав§ЧцЃЌЧсСПМЖбЙЫѕЫуЗЈЃЌЕЋЪЧжюШчжБНгВйзїбЙЫѕЪ§ОнЃЌбгГйНтбЙЕШММЪѕЛЙУЛгаБЛгІгУЕН
SQL on Hadop ЯЕЭГЁЃЙигкСаДцДЂЕФИќЖрФкШнПЩвдВЮМћ [20]ЁЃ
СаДцДЂбЙЫѕ
СаДцДЂбЙЫѕЫуЗЈОпгаШчЯТЬиЕуЃК
бЙЫѕБШ СаДцДЂФЃаЭОпгаЗЧГЃИпЕФбЙЫѕБШЃЌЭЈГЃПЩвдДяЕН 10ЃК1ЃЌЖјааДцДЂбЙЫѕБШЭЈГЃжЛга
4ЃК1ЁЃШчЭМ 4ЃК
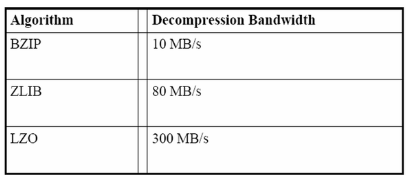
ЭМ 4 жиСПМЖбЙЫѕЫуЗЈ
ЧсСПМЖбЙЫѕЫуЗЈ (Leight-Weight Compression) ЧсСПМЖбЙЫѕЫуЗЈЪЧ CPU
гбКУЕФЁЃааДцДЂФЃаЭжЛФмЪЙгУ zipЃЌlzoЃЌsnappy ЕШжиСПМЖбЙЫѕЫуЗЈЃЌетаЉЫуЗЈзюДѓЕФШБЕуЪЧбЙЫѕКЭНтбЙЫѕЫйЖШБШНЯТ§ЃЌЭЈГЃУПУыжЛФмНтбЙжСЖрМИАйезЪ§ОнЁЃЯрЗДЃЌСаДцДЂФЃаЭВЛНіПЩвдЪЙгУжиСПМЖбЙЫѕЫуЗЈЃЌЛЙПЩвдЪЙгУвЛаЉЗЧГЃЧсСПМЖЕФбЙЫѕЫуЗЈЃЌБШШч
Run-length encodeЃЌBit VectorЁЃЧсСПМЖбЙЫѕЫуЗЈВЛНіОпгаНЯКУЕФбЙЫѕБШЃЌЖјЧвЛЙОпгаЗЧГЃИпЕФбЙЫѕКЭНтбЙЫйЖШЁЃФПЧАдк
ORC File КЭ Parquet ДцДЂжаЃЌвбОжЇГж Bit packing,Run-length
enode,Dictionary encode ЕШЧсСПМЖбЙЫѕЫуЗЈЁЃ
жБНгВйзїбЙЫѕЪ§Он (Operating Directly on Compressed Data)
ЕБЪЙгУЧсСПМЖбЙЫѕЫуЗЈЪБЃЌПЩФмЮоашНтбЙМДПЩжБНгЛёШЁМЦЫуНсЙћЁЃР§Шч:Run Length Encode
ЫуЗЈНЋСЌајжиИДЕФзжЗћбЙЫѕЮЊзжЗћИіЪ§КЭзжЗћЃЌБШШч aaaaaabbccccaaaa НЋБЛбЙЫѕЮЊ 6a2b4c4aЃЌЦфжа
6a БэЪОгаСЌај 6 ИізжЗћ aЁЃЯждкМйЩшвЛИіФГСаАќКЌЩЯЪібЙЫѕЕФзжЗћДЎЃЌЕБжДаа select count(*)
from table where columnA=ЁЏaЁЏЪБЃЌВЛашвЊНтбЙ 6a2b4c4aЃЌОЭФмЙЛжЊЕР
a ЕФИіЪ§ЪЧ 10ЁЃ
ашвЊзЂвтЕФЪЧЃЌгЩгкааДцДЂжЛФмЪЙгУжиСПМЖбЙЫѕЫуЗЈЃЌЫљвджБНгВйзїбЙЫѕЪ§ОнВЛФмБЛгІгУЕНааДцДЂЁЃ
бгГйНтбЙ parquet жаЕФЪ§ОнАДПщДцДЂЃЌУПИіПщДцДЂСЫзюаЁжЕЃЌзюДѓжЕЕШЧсСПМЖЫїв§ЃЌБШШчФГИіПщЕФзюаЁжЕзюДѓжЕЗжБ№ЪЧ
100 КЭ 120ЃЌетБэУїИУПщжаЕФШЮвтвЛЬѕЪ§ОнЖМНщгк 100 ЕН 120 жЎМфЃЌвђДЫЕБЮвУЧжДаа select
column a from table where v>120 ЪБЃЌжДаав§ЧцПЩвдЬјЙ§етИіЪ§ОнПщЃЌЖјВЛБиНЋЦфНтбЙдйНјааЪ§ОнЙ§ТЫЁЃЯрЗДЃЌдкааДцДЂжаЃЌБиаыНЋЪ§ОнПщЭъећЕФЖСШЁЕНФкДцжаЃЌНтбЙЃЌШЛКѓдйНјааЪ§ОнЙ§ТЫЃЌЕМжТВЛБивЊЕФДХХЬЖСШЁВйзїЁЃ
3.4 ПщМЖЫїв§
ДЋЭГЪ§ОнПтЪЙгУЫїв§РДгХЛЏВщбЏадФмЃЌШЛЖјЪмЯогк HDFS block ЕФЗХжУВпТдЃЌЪЙгУЫїв§РДгХЛЏ SQL
On Hadoop ВЛЪЧвЛМўШнвзЕФЪТЧщЁЃФПЧАДѓВПЗж SQL On Hadoop ЯЕЭГЖМВЛжЇГжШЋОжЫїв§ЃЌШЁЖјДњжЎЪЙгУЕФЪЧПщМЖЫїв§ЃЌБШШч
Hive IndexЃЌORC FileЃЌParquetЁЃПщМЖЫїв§ЕФЫМЯыЪЧдкУПвЛИіЪ§ОнПщжаЬэМгвЛаЉжюШчзюДѓжЕЃЌзюаЁжЕЕФЧсСПМЖЫїв§ЃЌЕБ
SQL в§ЧцЩЈУш HDFS ЮФМўЪБЃЌПЩвдЬјЙ§ВЛЗћКЯЬѕМўЕФ BlockЃЌДгЖјМѕЩйДХХЬ IO ЬсИпВщбЏадФмЁЃШчЯТЭМЃЌдк
ORC File жаЃЌУПвЛИі Stripe ЖМАќКЌвЛИі Index Data,Index Data
жаДцДЂСЫСаЕФзюДѓжЕЃЌзюаЁжЕЁЃЕБжДаав§ЧцжДаа filter етжжВщбЏЪБЃЌжЛашвЊЖСШЁ Index Data
ОЭааЃЌШчЙћЗћКЯЬѕМўОЭЖСШЁ Row DataЃЌЗёдђПЩвджБНгЬјЙ§ Row Data ЕФЖСШЁЃЌДгЖјМѕЩйДХХЬ
IOЃЌЬсИпВщбЏадФмЁЃ
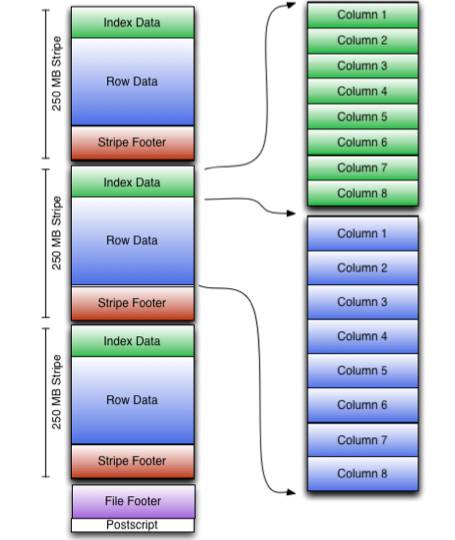
ЭМ 3-3 ORC Storage
зюДѓжЕЃЌзюаЁжЕетбљЕФЭГМЦЫїв§жївЊгУгкгХЛЏЗЖЮЇВщбЏадФмЃЌЖдгкЕЅЕуВщбЏЭЈГЃПЩвдЪЙгУВМТЁЙ§ТЫЦїзїЮЊЫїв§ЃЌВМТЁЙ§ТЫЦїПЩвддкЪ§ОнСПЗЧГЃДѓЕФЧщПіЯТПьЫйЕФВщбЏЪ§ОнЁЃ
3.5 ЗжЧј
MPP Ъ§ОнПтИљОнЗжЧјВпТдНЋвЛИіБэЫЎЦНЛђепДЙжБЧаЗжЮЊвЛИізгБэМЏКЯЃЌВЛЭЌЕФзгБэДцДЂдкВЛЭЌЕФНкЕуЃЌетбљПЩвдВЂааЕФДІРэВЛЭЌЕФзгБэЁЃЕфаЭЕФЗжЧјВпТдгаЙўЯЃЃЌЗЖЮЇЁЃ
SQL On Hadoop жавВДцдкБэЗжЧјЕФИХФюЃЌвЛИіБэЗжЧјДцДЂдквЛИі HDFS ЮФМўФПТМЯТЃЌЮФМўФПТМвдСаУћ
= СажЕЗНЪНДцДЂЁЃБШШчЮвУЧдк Hive жажДааШчЯТ SQLЃК
| CREATE
TABLE test_table(id string,name int) PARTITION
BY(ds string)ЁЃ |
ЕБЯђ test_table жаВхШыШчЯТдЊзщЪБЃК
| (id=ЁЎ10010ЁЏЃЌname=ЁЎsql
on hadoopЁЏ,ds=ЁЎ2017-05-31ЁЏ)
(id=ЁЎ10010ЁЏЃЌname=ЁЎsql on hadoopЁЏ,ds=ЁЎ2017-05-32ЁЏ) |
HDFS жаНЋДДНЈШчЯТФПТМ:
| /user/hive/warehouse/test_table/ds=2017-05-31
/user/hive/warehouse/test_table/ds=2017-05-32 |
ЕБжДаа SELECT * FROM test_table WHERE ds=ЁЏ2017-05-31ЁЏЪБЃЌжЛашвЊЩЈУш
ds=2017-05-31ФПТММДПЩЃЌетбљПЩвдЬјЙ§ДѓСПЮоЙиЪ§ОнЕФЩЈУшЃЌДгЖјМгПьЪ§ОнВщбЏЫйЖШЁЃ
ФПЧАДѓВПЗж SQL On Hadoop ЖМжЇГжЗжЧјЙІФмЃЌБШШч HiveЃЌPrestoЃЌImpalaЃЌSpark
SQLЁЃ
3.6 бЙЫѕ
вЛАуЧщПіЯТЃЌбЙЫѕ HDFS жаЕФЮФМўПЩвдМЋДѓЕФЬсИпВщбЏадФмЁЃбЙЫѕФмЙЛМѕЩйЪ§ОнЫљеМгУЕФДцДЂПеМфЃЌМѕЩйДХХЬ
IO ЕФЖСаДЃЌЬсИпЪ§ОнДІРэЫйЖШЃЌДЫЭтЃЌбЙЫѕЛЙФмЙЛМѕЩйЭјТчДЋЪфСПЃЌЬсИпЭјТчДЋЪфЫйЖШЁЃдк SQL On
Hadoop жаЃЌбЙЫѕжївЊгІгУдк HDFS жаЕФЪ§ОндДЃЌshuffle Ъ§ОнЃЌзюжеМЦЫуНсЙћЁЃ
ШчЙћгІгУГЬађЪЧ io-bound ЕФЃЌФЧУДбЙЫѕЪ§ОнПЩвдЬсИпЪ§ОнДІРэЫйЖШЃЌвђЮЊбЙЫѕКѓЕФЪ§ОнБфаЁСЫЃЌЫљвдПЩвддіМгЪ§ОнЖСаДЫйЖШЁЃашвЊжївЊЕФЪЧЃЌбЙЫѕЫуЗЈВЂВЛЪЧбЙЫѕБШдНИпдНКУЃЌбЙЫѕТЪдНИпЕФЫуЗЈбЙЫѕКЭНтбЙЫѕЫйЖШОЭдНТ§ЃЌгУЛЇашвЊдк
cpu КЭ io жЎМфШЁЕУвЛИіСМКУЕФЦНКтЁЃР§Шч gzip2 гЕгаЗЧГЃИпЕФбЙЫѕБШЃЌЕЋЪЧЦфбЙЫѕКЭНтбЙЫѕЫйЖШШДЗЧГЃТ§ЃЌЩѕжСПЩФмГЌЙ§Ъ§ОнЮДбЙЫѕЪБЕФЖСаДЪБМфЃЌвђДЫУЛга
SQL On Hadooop ЯЕЭГЪЙгУ gzip2 ЫуЗЈЃЌФПЧАдк SQL On Hadoop ЯЕЭГжаБШНЯСїааЕФбЙЫѕЫуЗЈжївЊгаЃКSnappyЃЌLzoЃЌGlibЁЃ
ШчЙћгІгУГЬађЪЧ cpu-bound ЕФЃЌФЧУДбЁдёвЛИіПЩвд splittable ЕФбЙЫѕЫуЗЈЪЧКмживЊЕФЃЌШчЙћвЛИіЮФМўЪЧ
splittabe ЕФЃЌФЧУДетИіЮФМўПЩвдБЛЧаЗжЮЊЖрИіПЩвдВЂааЖСШЁЕФЪ§ОнПщЃЌетбљ MR Лђеп Spark
дкЖСШЁЮФМўЪБЃЌЛсЮЊУПвЛИіЪ§ОнПщЗжХфвЛИі task РДЖСШЁЪ§ОнЃЌДгЖјЬсИпЪ§ОнВщбЏЫйЖШЁЃ
3.7 ЯђСПЛЏжДаав§Чц
ВщбЏжДаав§Чц (query execution engine) ЪЧЪ§ОнПтжаЕФвЛИіКЫаФзщМўЃЌгУгкНЋВщбЏМЦЛЎзЊЛЛЮЊЮяРэМЦЛЎЃЌВЂЖдЦфЧѓжЕЗЕЛиНсЙћЁЃВщбЏжДаав§ЧцЖдЪ§ОнПтЯЕЭГадФмгАЯьКмДѓЃЌФПЧАжївЊЕФжДаав§ЧцгаШчЯТЫФРрЃКVolcano-styleЃЌBlock-oriented
processingЃЌColumn-at-a-timeЃЌVectored iterator modelЁЃЯТУцЗжБ№НщЩметЫФжжжДаав§ЧцЁЃ
Volcano-style, зюдчЕФВщбЏжДаав§ЧцЪЧ Volcano-style execution
engine(Л№ЩНжДаав§ЧцЃЌЛ№ЩНФЃаЭ)ЃЌвВНазіЕќДњФЃаЭ (iterator model)ЃЌЛђеп one-tuple-at-a-timeЁЃдкетжжФЃаЭжаЃЌВщбЏМЦЛЎЪЧвЛИігЩ
operator зщГЩЕФ tree Лђеп DAGЃЌЦфжаУПвЛИі operator АќКЌШ§ИіКЏЪ§ЃКopenЃЌnextЃЌcloseЁЃOpen
гУгкЩъЧызЪдДЃЌБШШчЗжХфФкДцЃЌДђПЊЮФМўЃЌclose гУгкЪЭЗХзЪдДЃЌnext ЗНЗЈЕнЙщЕФЕїгУзг operator
ЕФ next ЗНЗЈЩњГЩвЛИідЊзщЁЃЭМ 1 УшЪіСЫ select id,name,age from people
where age >30 ЕФЛ№ЩНФЃаЭЕФВщбЏМЦЛЎЃЌИУВщбЏМЦЛЎАќКЌ UserЃЌProjectЃЌSelectЃЌScan
ЫФИі operatorЃЌУПИі operator ЕФ next ЗНЗЈЕнЙщЕїгУзгНкЕуЕФ nextЃЌвЛжБЕнЙщЕїгУЕНвЖзгНкЕу
Scan operatoЃЌScan Operator ЕФ next ДгЮФМўжаЗЕЛивЛИідЊзщЁЃ
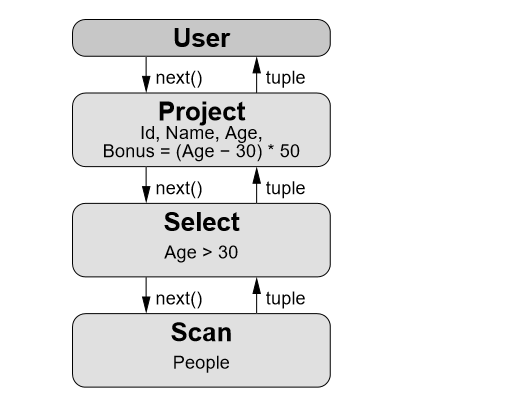
ЭМ 3-4 Л№ЩНФЃаЭ еЊздЮФЯз [2,page
39]
Л№ЩНФЃаЭЕФжївЊШБЕуЪЧАКЙѓЕФНтЪЭПЊЯњ (interpretation overhead) КЭЕЭЯТЕФ
CPU Cache УќжаТЪЁЃЪзЯШЃЌЛ№ЩНФЃаЭЕФ next ЗНЗЈЭЈГЃЪЕЯжЮЊвЛИіащКЏЪ§ЃЌдкБрвыЦїжаЃЌащКЏЪ§ЕїгУашвЊВщеващКЏЪ§Бэ,
ВЂЧващКЏЪ§ЕїгУЪЧвЛИіЗЧжБНгЬјзЊ (indirect jump), ЛсЕМжТвЛДЮДэЮѓЕФ CPU ЗжжЇдЄВт
(brance misprediction), вЛДЮДэЮѓЕФЗжжЇдЄВташвЊЪЎМИИіжмЦкЕФПЊЯњЁЃЛ№ЩНФЃаЭЮЊСЫЗЕЛивЛИідЊзщЃЌашвЊЕїгУЖрДЮ
next ЗНЗЈЃЌЕМжТАКЙѓЕФКЏЪ§ЕїгУПЊЯњЁЃ[] баОПБэУїЃЌдкВЩгУЛ№ЩНжДааФЃаЭЕФ MySQL жажДаа TPC-H
Q1 ВщбЏЃЌНіга 10% ЕФЪБМфгУгкеце§ЕФВщбЏМЦЫуЃЌЦфгрЕФ 90% ЪБМфЖМРЫЗбдкНтЪЭПЊЯњ (interpretation
overhead)ЁЃЦфДЮЃЌnext ЗНЗЈвЛДЮжЛЗЕЛивЛИідЊзщЃЌдЊзщЭЈГЃВЩгУааДцДЂЃЌШчЭМ 3-5 Row
FormatЃЌШчЙћЫГађЗУЮЪЕквЛСа 1ЃЌ2ЃЌ3ЃЌФЧУДУПДЮЗУЮЪЖМНЋЕМжТ CPU Cache УќжаЪЇАм (МйЩшИУааВЛФмЭъШЋЗХШы
CPU Cache жа)ЁЃШчЙћВЩгУ Column FormatЃЌФЧУДжЛгадкЗУЮЪЕквЛИіжЕЪБВХГіЯжЛКДцУќжаЪЇАмЃЌКѓајЗУЮЪ
2 КЭ 3 ЪБЖМНЋЛКДцУќжаГЩЙІ, ДгЖјМЋДѓЕФЬсИпВщбЏадФмЁЃ
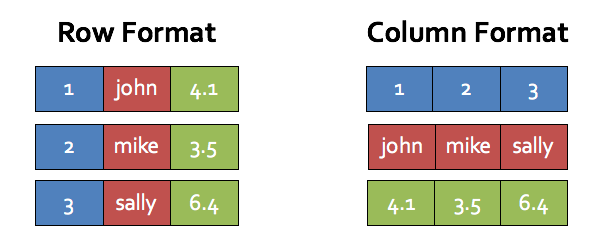
ЭМ 3-6 ааДцДЂКЭСаДцДЂ
Block-oriented processingЃЌBlock-oriented processing
ФЃаЭЪЧЖдЛ№ЩНФЃаЭЕФвЛИіИФНјЃЌИУФЃаЭвЛДЮ next ЕїгУЗЕЛивЛХњдЊзщ, дЊзщИіЪ§дк 100-1000
ВЛЕШЃЌnext ФкВПЪЙгУвЛИібЛЗРДДІРэетХњдЊзщЁЃдкЭМ 1 ЕФЛ№ЩНФЃаЭжаЃЌSelect operator
next ЗНЗЈПЩвдШчЯТЪЕЯж:
| def
next():Array[Tuple]={
// ЕїгУзгНкЕуЕФ next ЗНЗЈЃЌЗЕЛивЛИідЊзщЯђСПЃЌИУЯђСПАќКЌ 1024 ИідЊзщ
val tuples=child.next()
val result=new ArrayBuffer[Tuple]
for(i=0;i30) result.append(tuples(i))
}
result// ЗЕЛиНсЙћ
} |
Block-oriented processing ФЃаЭЕФгХЕуЪЧвЛДЮ next ЗЕЛиЖрИідЊзщЃЌМѕЩйСЫНтЪЭПЊЯњЃЌЭЌЪБвВБЛжЄУїдіМгСЫ
CPU Cache ЕФУќжаТЪЃЌЕБ CPU ЗУЮЪдЊзщжаЕФФГИіСаЪБЛсНЋИУдЊзщМгдиЕН CPU Cache(ШчЙћИУдЊзщДѓаЁаЁгк
CPU Cache ЛКДцааЕФДѓаЁ), ЗУЮЪКѓМЬЕФСаНЋжБНгДг CPU Cache жаЛёШЁЃЌДгЖјОпгаНЯИпЕФ
CPU Cache УќжаТЪЃЌШЛЖјШчЙћжЎЗУЮЪвЛИіСаЛђепЩйЪ§МИИіСаЪБ CPU УќжаТЪШдШЛВЛРэЯыЁЃИУФЃаЭзюДѓЕФвЛИіШБЕуЪЧВЛФмГфЗжРћгУЯжДњБрвыЦїММЪѕЃЌБШШчдкЩЯУцЕФбЛЗжаЃЌКмФбЪЙгУ
SIMD жИСюДІРэЪ§ОнЁЃ
Column-at-a-time ФЃаЭЃЌЯђСПЛЏжДааЕФзюдчРњЪЗПЩвдзЗЫЗЕН MonetDB[], дк
MonetDB ЬсГіСЫвЛИіНазі Column-at-a-time ЕФВщбЏжДааФЃаЭЃЌИУФЃаЭжаУПвЛДЮ next
ЕїгУЗЕЛивЛИіЛђепЖрИіСаЃЌУПИіСавдЪ§зщаЮЪНЗЕЛиЁЃИУФЃаЭгХЕуЪЧОпгаЗЧГЃИпЕФВщбЏаЇТЪЃЌШБЕуЪЧвЛИіСаЪ§ОнашвЊБЛЮяЛЏЕНФкДцЩѕжСДХХЬЃЌЕМжТКмИпЕФФкДцеМгУКЭ
io ПЊЯњЃЌЭЌЪБЪ§ОнВЛФмЗХЕН CPU Cache жаЃЌЕМжТНЯЕЭЕФ CPU Cache УќжаТЪЁЃ
Vectored iterator model,VectorWise ЬсГіСЫ Vectored iterator
model ФЃаЭЃЌИУФЃаЭЪЧЖд Column-at-a-time ЕФИФНјЃЌnext ЕїгУВЛЪЧЗЕЛиЭъећЕФвЛИіСаЃЌЖјЪЧЗЕЛивЛИіПЩвдЗХЕН
CPU Cache ЕФЯђСПЁЃИУФЃаЭБмУтСЫ Column-at-a-tim CPU Cache УќжаТЪЕЭЕФШБЕуЁЃVectored
iterator model зюДѓЕФгХЕуЪЧПЩвдЪЙгУдЫааЪББрвыЦї (JIT) ЖЏЬЌЕФЩњГЩИќЪЪКЯЯжДњДІРэЦїЕФжИСюЃЌБШШч
JIT ПЩвдЩњГЩ SIMD жИСюРДДІРэЯђСПЁЃПМТЧ TPC-H Q1 ВщбЏЃКSELECT l_extprice*(1-l_discount)*(1+l_tax)
FROM lineitemЁЃИУ SQL ВщбЏЕФжДааМЦЛЎШчЯТЃК
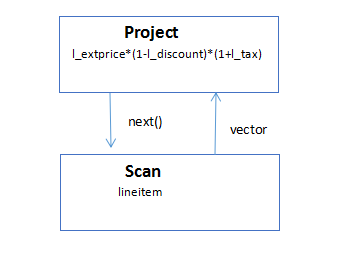
Цфжа Project operator ЕФ next ЗНЗЈПЩвдШчЯТЪЕЯж (scala ЮБДњТы):
| def
next():Array[Tuple]={
val tuples=child.next()
var result=new ArrayBuffer[Int]
for(i=0;i |
НќМИФъЃЌвЛаЉ SQL On Hadoop ЯЕЭГв§ШыСЫЯђСПЛЏжДаав§ЧцЃЌБШШч HiveЃЌImpalaЃЌPrestoЃЌSpark
ЕШЃЌОЁЙмЦфЪЕЯжЯИНкВЛЭЌЃЌЕЋКЫаФЫМЯыЪЧвЛжТЕФЃКОЁПЩФмЕФдквЛДЮ next ЗНЗЈЕїгУЗЕЛиЖрЬѕЪ§ОнЃЌШЛКѓЪЙгУЖЏЬЌДњТыЩњГЩММЪѕРДгХЛЏбЛЗЃЌБэДяЪНМЦЫуДгЖјМѕЩйНтЪЭПЊЯњЃЌЬсИп
CPU Cache УќжаТЪЃЌМѕЩйЗжжЇдЄВтЁЃ
Impala жаЕФЯђСПЛЏжДаав§ЧцБОжЪЩЯЪєгк Block-oriented processingЃЌimapla
ЕФУПДЮ next ЕїгУЗЕЛивЛХњдЊзщЃЌетжжФЃаЭШдШЛОпгаНЯЕЭЕФ CPU Cache УќжаТЪЃЌЭЌЪБвВКмФбЪЙгУ
SIMD ЕШжИСюНјаагХЛЏЃЌЮЊСЫЛКНтетИіЮЪЬтЃЌImpala ЪЙгУЖЏЬЌДњТыЩњГЩММЪѕЃЌЖдгкДѓбЛЗЃЌБэДяЪНМЦЫуЕШНјааЪЙгУЖЏЬЌДњТыЩњГЩРДНјаагХЛЏЁЃ
дк Spark2.0 жаЃЌЪЕЯжСЫЛљгк Parquet ЕФЯђСПЛЏжДаав§Чц [12]ЃЌИУжДаав§ЧцЪєгк
Vectored iterator modelЃЌв§ЧцдкЕїгУ next ЗНЗЈЪБвдСаДцДЂИёЪНЗЕЛивЛХњдЊзщЃЌПЩвдЪЙгУбЛЗРДДІРэИУХњдЊзщЁЃДЫЭтЮЊСЫИќГфЗжЕФРћгУЯжДњ
CPU ЬиадЃЌSpark ЛЙжЇГжећНзЖЮДњТыЩњГЩММЪѕЃЌКЫаФЫМЯыЪЧНЋЖрИі operator БрвыЕНвЛИіЗНЗЈжаЃЌДгЖјМѕЩйНтЪЭПЊЯњЁЃ
3.8 ЖЏЬЌДњТыЩњГЩ
ЖЏЬЌДњТыЩњГЩвЛАуКЭЯђСПЛЏжДаав§ЧцНсКЯЪЙгУЃЌвђЮЊЯђСПжДаав§ЧцЕФ next ЗНЗЈФкВППЩвдЪЙгУ for
бЛЗРДДІРэдЊзщЯђСПЛђепСаЯђСПЃЌЪЙгУЖЏЬЌДњТыЩњГЩММЪѕПЩвддкдЫааЪБЖд next ЗНЗЈЩњГЩИќИпаЇЕФжДааДњТыЁЃбаОПжЄУїЯђСПЛЏжДаав§ЧцКЭЖЏЬЌДњТыЩњГЩПЩвдМѕЩйНтЪЭПЊЯњ
(interpretation overhead), МћЮФЯз [18]ЃЌжївЊгАЯьвдЯТШ§ИіЗНУцЃК
Select, ЕБ select гяОфжаАќКЌИДдгЕФБэДяЪНМЦЫуЪБЃЌБШШч avgЃЌsumЃЌcountЃЌselect
ЕФМЦЫуадФмжївЊЪм CPU Cache КЭ SIMD жИСюгАЯьЁЃЕБЪ§ОнВЛФмЗХЕН CPU Cache ЪБЃЌCPU
ДѓВПЗжЪБМфЖМдкЕШД§Ъ§ОнДгФкДцМгдиЕН CPU CacheЃЌвђДЫЕБ CPU жДааМЦЫуЫљашЕФЪ§Ондк CPU
Cache жаЪБПЩвдМЋДѓЕФЬсИпМЦЫуадФмЁЃвЛЬѕ SIMD жИСюПЩвдЭЌЪБМЦЫуЖрИіЪ§ОнЃЌвђДЫЪЙгУ SIMD
жИСюжДааБэДяЪНМЦЫуПЩвдЬсИпМЦЫуадФмЁЃ
whereЃЌгы Select гяОфВЛЭЌЕФЪЧ Where гяОфвЛАуВЛашвЊИДдгЕФМЦЫуЃЌгАЯь where
адФмИќЖрЕФЪЧЗжжЇдЄВтЁЃШчЙћ CPU ЗжжЇдЄВтДэЮѓЃЌФЧУДжЎЧАЕФ CPU СїЫЎЯпНЋШЋБЛЧхЯДЃЌвЛДЮ CPU
ЗжжЇдЄВтДэЮѓПЩФмжСЩйРЫЗбЪЎМИИіжИСюжмЦкЕФПЊЯњЁЃЭЈЙ§ЪЙгУЖЏЬЌДњТыЩњГЩММЪѕЃЌJIT БрвыЦїФмЙЛздЖЏЕФЩњГЩЗжжЇдЄВтгбКУЕФжИСюЁЃ
HashЃЌhash ЫуЗЈгАЯь equal-joinЃЌgroup ЕФВщбЏадФмЃЌhash ЫуЗЈЕФ CPU
Cache УќжаТЪКмЕЭЁЃ[18] УшЪіСЫвЛжжЛКДцгбКУЕФ hash ЫуЗЈЃЌПЩвдЯджјЕФЬсИп hash МЦЫуадФмЁЃ
ЖЏЬЌДњТыЩњГЩгаСНжжЃКC++ ЯЕКЭ java ЯЕЁЃЦфжа C++ ЯЕПЩвджБНгЩњГЩБОЛњПЩжДааЖўНјжЦДњТыЃЌВЂЧвФмЙЛЩњГЩИпаЇЕФ
SIMD жИСюЃЌР§Шч Impala ЪЙгУ C++ ЪЕЯжВщбЏжДаав§ЧцЃЌЭЌЪБЪЙгУ LLVM БрвыЦїЖЏЬЌЕФЩњГЩБОЛњПЩжДааЖўНјжЦДњТыЃЌLLVM
ПЩвдЩњГЩ SIMD жИСюЖдБэДяЪНжДааМЦЫуЁЃJava ЯЕРћгУЗДЩфЛњжЦЖЏЬЌЕФЩњГЩ java зжНкТыЃЌвЛАуЖјбдЃЌВЛФмГфЗжРћгУ
SIMD жИСюНјаагХЛЏ,Spark ЪЙгУЗДЩфЛњжЦЖЏЬЌЕФЩњГЩ java зжНкТыЃЌЭЈГЃКмФбжБНгРћгУ SIMD
НјааБэДяЪНгХЛЏЁЃДЫЭтдк Spark2.0 жаЫљЬсЙЉЕФећНзЖЮДњТыЩњГЩ (Whole-Stage Code
Generation) ММЪѕвВЪЧЖЏЬЌДњТыЩњГЩММЪѕНЋЖрИі Operator БрвыГЩвЛИіЗНЗЈНјаагХЛЏЁЃ
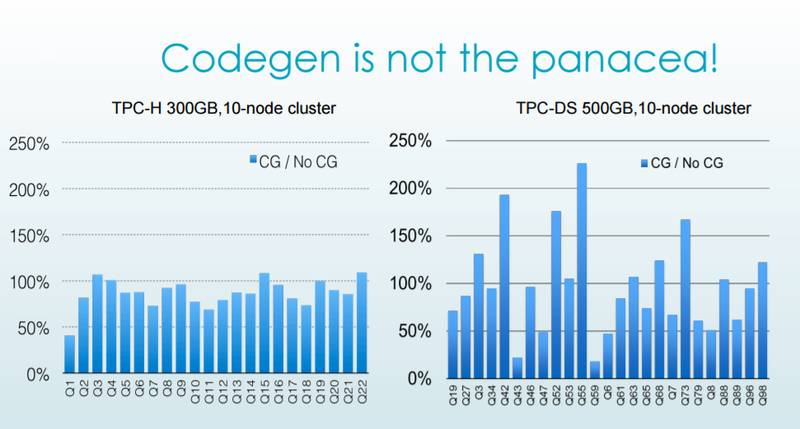
ашвЊзЂвтЕФЪЧЃЌЖЏЬЌДњТыЩњГЩММЪѕВЂВЛзмЪЧЭђФмвЉЃЌдкЯТЭМжаЃЌimpala ЕФЖЏЬЌДњТыЩњГЩММЪѕВЂУЛгаЬсИп
TPC-DS Q42ЃЌQ52ЃЌQ55 ЕФВщбЏЫйЖШЃЌжївЊдвђетаЉ SQL гяОфЕФ SELECT гяОфжаВЂУЛгаЪВУДИДдгЕФМЦЫуЁЃ
3.9 ЖбЭтДцДЂ
ЪЙгУ JVM ЪЕЯжЕФВщбЏжДаав§ЧцвРРЕгк GC ЛиЪеФкДцЃЌУПвЛДЮ Full GC ЛсднЭЃЫљгаЙЄзїЯпГЬЃЌвЛДЮ
GC ЭЈГЃдкЗжжгМЖБ№вдЩЯЃЌЕМжТЫљга SQL ВщбЏМЦЫуЭЃжЙЃЌДгЖјбЯжиЕФгАЯьВщбЏадФмВЂЧвПЩФмЛсЕМжТвЛаЉЗЧГЃЦцЙжЕФвьГЃГіЯжЃЌБШШчЭјТчГЌЪБЃЌshuffle
ЛёШЁЪ§ОнЪ§ОнЪЇАмЁЃЮЊСЫМѕЩй GC ЖдГЬађадФмЕФгАЯьЃЌаэЖр SQL On Hadoop ЪЙгУЖбЭтДцДЂ
(off heap) РДДцДЂЪ§ОнЁЃ
ЖбЭтДцДЂЫљашЕФФкДцгЩВйзїЯЕЭГЙмРэЖјВЛЪЧ Java GCЃЌjava.nio ЬсЙЉСЫвЛаЉгУгкЖСаДЖбЭтДцДЂЕФРрЃЌПЩвддкЖбЭтДцДЂжаДцДЂ
IntЃЌDouble етжжЛљдЊРраЭЃЌвВПЩвдДцДЂ mapЃЌstruct етжжИДКЯЖдЯѓЃЌЕБДцДЂИДКЯЖдЯѓЪБашвЊНЋИДКЯЖдЯѓађСаЛЏДцДЂЕНЖбЭтДцДЂЃЌдкЖСШЁЪБвВашНјааЗДађСаЛЏЁЃвђЮЊађСаЛЏ
/ ЗДађСаЛЏЛсЯћКФДѓСПЕФ CPU МЦЫуЃЌвђДЫдкЪЙгУЖбЭтДцДЂЪБашвЊдк GC КЭ cpu жЎМфНјаавЛИіКЯРэЕФЦНКтЁЃ
3.10 ФкДцбЙЫѕСаДцДЂ
дкФкДцжаЛКДцШШЕуЪ§ОнЪЧЬсИпВщбЏадФмЕФвЛИіЛљБОгХЛЏЪжЖЮЁЃдкФкДцжаЛКДцШШЕуЪ§ОнашвЊПМТЧжСЩйПМТЧШ§ИіЮЪЬт:
ЕквЛЃЌШчКЮМѕЩйЪ§ОнЕФФкДцеМгУЃЌЕкЖўЃЌШчКЮЬсИп CPU Cache УќжаТЪЃЌЕкШ§ЃЌШчЙћЪЙгУ JVM ЯЕЭГЃЌЛЙвЊПМТЧШчКЮМѕЩй
GC ДЮЪ§КЭ GC ЪБМфЁЃетРяашвЊжиЕуЙизЂЕФЪЧШчКЮЬсИп CPU Cache ЕФУќжаТЪЁЃ
етШ§ИіЮЪЬтПЩвдЭЈЙ§ЪЙгУФкДцбЙЫѕСаДцДЂРДНтОіЃК
МѕЩйФкДцеМгУЃЌдкФкДцСаДцДЂжаЃЌШчЙћСадЊЫиРраЭЪЧЛљдЊРраЭ (Int,Double,Long ЕШ)ЃЌФЧУДУПвЛИіСаДцДЂЮЊвЛИіЪ§зщЃЌШчЙћСадЊЫиЪЧ
MapЃЌStruct етжжИКд№ЖдЯѓЃЌПЩвдНЋЦфађСаЛЏЮЊвЛИізжНкЪ§ОнНјааДцДЂЁЃЪ§зщПЩвдБЛбЙЫѕДцДЂЃЌашвЊзЂвтЕФЪЧЃЌдкбЁдёбЙЫѕЫуЗЈЪБЃЌвЛАуВЛЛсбЁдёжиСПМЖбЙЫѕЫуЗЈЃЌЫфШЛжиСПМЖбЙЫѕЫуЗЈОпгаНЯИпЕФбЙЫѕТЪЃЌЕЋЪЧЫќдкбЙЫѕКЭНтбЙЫѕЪБЗЧГЃТ§ЃЌетНЋбЯжиЕФгАЯьВщбЏадФмЁЃдкФкДцбЙЫѕСаДцДЂжаЃЌЧсСПМЖбЙЫѕЫуЗЈОпгаИќИпжДаааЇТЪЃЌетЪЧвђЮЊЧсСПМЖбЙЫѕЫуЗЈдкНјаабЙЫѕКЭНтбЙЪБМИКѕВЛашвЊЬЋЖрЕФ
CPU МЦЫуЁЃдк Spark SQL ЕФФкДцбЙЫѕСаДцДЂжа [10]ЃЌЪЙгУЕФОЭЪЧ Run length
encodeЃЌdictionary encode ЕШЧсСПМЖбЙЫѕЫуЗЈЁЃ
ЬсИп CPU Cache УќжаТЪЃЌФкДцСаДцДЂОпгаНЯКУЕФ CPU Cache УќжаТЪЃЌвђЮЊСаЪ§ОнСЌајДцДЂЃЌЫљвдЕБ
CPU ЗУЮЪЪ§зщжаФГИідЊЫиЪБПЩвдНЋИУдЊЫиСйНќЕФЪ§ОнвЛЦ№МгдиЕН CPU Cache ЛКДцаажаЃЌетбљ CPU
ЗУЮЪИУдЊЫиЕФЯТвЛИідЊЫиЪБОЭВЛашвЊЗУЮЪФкДцСЫЃЌДгЖјЬсИп CPU Cache УќжаТЪЃЌЬсИпВщбЏМЦЫуадФмЁЃ
МѕЩй GC ЪБМфЃЌзюКѓЃЌФкДцСаДцДЂЖдгк JVM ЯЕЭГвВЪЧгбКУЕФЁЃЪзЯШЃЌJVM жаУПИіЖдЯѓЖМАќКЌвЛИіЖдЯѓЭЗЃЌетИіЖдЯѓЭЗЕФПЊЯњЭЈГЃашвЊ
12 ИізжНкЃЌШчЙћЮвУЧНЋ Int АДааДцДЂЃЌФЧУДУПИі Int ЖМНЋжСЩйРЫЗб 12 ИізжНкЕФДцДЂПеМфеМгУЁЃЯрЗДЃЌШчЙћНЋ
Int ДцДЂЮЊвЛИіЪ§зщЃЌФЧУДУПИі Int жЛашвЊ 4 ИізжНкЃЌПЩвдМѕЩй 3 БЖЕФДцДЂПеМфеМгУЁЃФкДцСаДцДЂЛЙПЩвдМѕЩй
GC ЪБМфЃЌGC ЪБМфжївЊКЭЖдЯѓЪ§СПГЪе§ЯрЙиЃЌЭЈЙ§ВЩгУФкДцСаДцДЂЃЌУПИіСазїЮЊвЛИіЪ§зщЖдЯѓДцДЂЃЌПЩвдМЋДѓЕФМѕЩйЖдЯѓЪ§СПЃЌМѕЩй
GC ЪБМфЁЃ
3.11 ЛКДцУєИаЫуЗЈ
здДг CPU Cache ГіЯжвдРДЃЌШЫУЧЖдгкЛКДцУєИаЫуЗЈЕФбаОПОЭДгЮДЭЃжЙЁЃЫљЮНЕФЛКДцУєИаЫуЗЈЃЌОЭЪЧБраД
CPU Cache УќжаТЪИпЕФЫуЗЈЁЃдкетИіСьгђвбОгаСЫДѓСПЕФбаОПЃЌБШШчДХХЬЫїв§ B-tree ЕФЛКДцУєИаЪЕЯжЃЌФкДцЫїв§
T-tree ЕФЛКДцУєИаЪЕЯжЃЌСДБэЃЌЙўЯЃБэЕШЕШЁЃ
ЛКДцУєИаЫуЗЈЭЈГЃБШНЯИДдгЃЌВЂЧвВЛвзРэНтЃЌвђДЫНЋЫљгаЫуЗЈЖМЩшМЦГЩЛКДцУєИаЕФЪЧВЛУїжЧЕФЃЌЪТЪЕЩЯДѓВПЗж
SQL МЦЫужївЊЮЊХХађЃЌОлКЯЃЌjoinЃЌжЛашЖдетаЉЫуЗЈНјаагХЛЏМДПЩЁЃдк Spark SQL ЪЕЯжСЫЛКДцУєИаЕФ
Sort ЫуЗЈЃЌИУЫуЗЈгІгУдкЛљгк sort ЕФ shuffleЃЌХХађКЭ joinЃЌгХЛЏКѓЕФ Sort
адФмжСЩйЬсИпСЫ 3 БЖЁЃ
4. ЦфЫћ
ФПЧАдк SQL On Hadoop СьгђжаДцдкжжРрЗБдгЕФПЊдДШэМўЃЌОЁЙмЦфОпЬхЕФЪЕЯжЯИНкКЭгІгУГЁОАВЛЭЌЃЌЕЋЪЧШдШЛгавЛаЉЙВЭЌЕФММЪѕБЛЙуЗКВЩгУЃКСаДцДЂЃЌЯђСПЛЏжДаав§ЧцЃЌЛКДцШШЕуЪ§ОнЃЌФкДцбЙЫѕСаДцДЂЕШЁЃ
гЩгкЩшМЦОіВпЃЌМмЙЙЕФВЛЭЌЃЌВЛЭЌ SQL On Hadoop ШдШЛгааэЖрВЛЭЌЕФЕиЗНЃК
ЭГвЛзЪдДЙмРэЃЌвЛИіжЇГжЭГвЛзЪдДЕїЖШЕФ SQL On Hadoop ЯЕЭГЗЧГЃОпгабаОПМлжЕЃЌвђЮЊдквЛИіДѓаЭИДдгЕФЗжВМЪНМЏШКжаЃЌВЛПЩФмжЛгавЛжжМЦЫуПђМмгЕгаЪ§ОнЃЌИќЖрЕФЪЧЖржжЙЄзїИКдиВЛЭЌЕФМЦЫуПђМмЭЌЪБВПЪ№дкЭЌвЛМЏШКЃЌБШШч
SparkЃЌMRЃЌHiveЃЌSparkSqlЃЌImpalaЃЌЮЊСЫБмУтВЛЭЌМЦЫуПђМмжЎМфЕФзЪдДОКељЃЌашвЊЪЙгУЭГвЛЕФзЪдДЕїЖШПђМмНјаазЪдДЙмРэЃЌЪЙгУЭГвЛзЪдДЙмРэПЩвдБмУтМЦЫуПђМмЩъЧыЙ§ЖрЕФзЪдДЕМжТМЏШКЃЌВйзїЯЕЭГЕШГіЯжВЛЮШЖЈзДЬЌЃЌYarn
КЭ Mesos ЪЧСНИізюСїааЕФПЊдДзЪдДЙмРэПђМмЁЃImpalaЃЌSparkSql ЕШЖМжЇГж Yarn
НјааЭГвЛзЪдДЕїЖШЃЌpresto ФПЧАВЛжЇГж yarnЁЃ
ШнДэСЃЖШЃЌImpalaЃЌPrestoЃЌdrill етаЉВЩгУ MPP МмЙЙЕФЯЕЭГВЛжЇГжЯИСЃЖШЕФШнДэЁЃSpark
SqlЃЌHive етаЉЯЕЭГЭЈЙ§НшМјЕзВуЯЕЭГ MR КЭ Spark ЕФШнДэЛњжЦЃЌвВЪЕЯжСЫЯИСЃЖШЕФШнДэЁЃ
JVMЃЌ ДѓВПЗж SQL On Hadoop ЖМВЩгУ JVM гябдРДЪЕЯжЃЌВПЗжЯЕЭГВЩгУЗЧ JvmЃЌБШШч
Impala ЪЙгУ C++ ЪЕЯжВщбЏжДаав§ЧцЁЃ
зюКѓЃЌЫљгаЕФ SQL On Hadoop ЖМгІИУОЁПЩФмЕФзЗЧѓПьЫйЃЌвзЪЙгУЁЃВщбЏЫйЖШдНПьЃЌОЭдНФмЪЪгІИќЖрЕФГЁОАЁЃжЇГж
ANSI SQL ЖјВЛЪЧЦфЫћЗНбдПЩвдМѕЩйгУЛЇбЇЯАЧњЯпЃЌБмУтгУЛЇЯнШыЕНЙ§ЖрЕФгябдЬиаджаЁЃ
|









