| НгЯТРДЮвЛсИњДѓМвЗжЯэвЛЯТ58ДѓЪ§ОнЦНЬЈдкзюНќвЛФъАыЕФЪБМфФкММЪѕбнНјЕФЙ§ГЬЁЃжївЊФкШнЗжЮЊШ§ЗНУцЃК58ДѓЪ§ОнЦНЬЈФПЧАЕФећЬхМмЙЙЪЧдѕУДбљЕФЃЛзюНќвЛФъАыЕФЪБМфФкЮвУЧУцСйЕФЮЪЬтЁЂЬєеНвдМАММЪѕбнНјЙ§ГЬЃЛвдМАЮДРДЕФЙцЛЎЁЃ
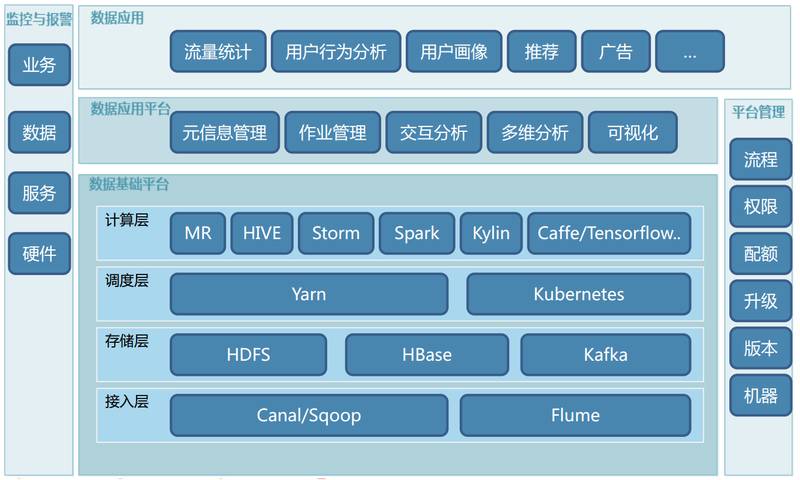
ЪзЯШПДвЛЯТ58ДѓЪ§ОнЦНЬЈМмЙЙЁЃДѓЕФЗНУцРДЫЕЗжЮЊШ§ВуЃКЪ§ОнЛљДЁЦНЬЈВуЁЂЪ§ОнгІгУЦНЬЈВуЁЂЪ§ОнгІгУВуЃЌЛЙгаСНСаМрПигыБЈОЏКЭЦНЬЈЙмРэЁЃ
Ъ§ОнЛљДЁЦНЬЈВугжЗжЮЊЫФИізгВуЃК
1.НгШыВуЃЌАќРЈСЫCanal/SqoopЃЈжївЊНтОіЪ§ОнПтЪ§ОнНгШыЮЪЬтЃЉЁЂЛЙгаДѓСПЕФЪ§ОнВЩгУFlumeНтОіЗНАИЃЛ
2.ДцДЂВуЃЌЕфаЭЕФЯЕЭГHDFSЃЈЮФМўДцДЂЃЉЁЂHBaseЃЈKVДцДЂЃЉЁЂKafkaЃЈЯћЯЂЛКДцЃЉЃЛ
3.дйЭљЩЯОЭЪЧЕїЖШВуЃЌетИіВуДЮЩЯЮвУЧВЩгУСЫYarnЕФЭГвЛЕїЖШвдМАKubernetesЕФЛљгкШнЦїЕФЙмРэКЭЕїЖШЕФММЪѕЃЛ
4.дйЭљЩЯЪЧМЦЫуВуЃЌАќКЌСЫЕфаЭЕФЫљгаМЦЫуФЃаЭЕФМЦЫув§ЧцЃЌАќКЌСЫMRЁЂHIVEЁЂStormЁЂSparkЁЂKylinвдМАЩюЖШбЇЯАЦНЬЈБШШчCaffeЁЂTensorflowЕШЕШЁЃ
Ъ§ОнгІгУЦНЬЈжївЊАќРЈвдЯТЙІФмЃК
1.дЊаХЯЂЙмРэЃЌЛЙгаеыЖдЫљгаМЦЫув§ЧцЁЂМЦЫув§ЧцjobЕФзївЕЙмРэЃЌжЎКѓОЭЪЧНЛЛЅЗжЮіЁЂЖрЮЌЗжЮівдМАЪ§ОнПЩЪгЛЏЕФЙІФмЁЃ
2.дйЭљЩЯЪЧжЇГХ58МЏЭХЕФЪ§ОнвЕЮёЃЌБШШчЫЕСїСПЭГМЦЁЂгУЛЇааЮЊЗжЮіЁЂгУЛЇЛЯёЁЂЫбЫїЁЂЙуИцЕШЕШЁЃ
3.еыЖдвЕЮёЁЂЪ§ОнЁЂЗўЮёЁЂгВМўвЊгаЭъБИЕФМьВтгыБЈОЏЬхЯЕЁЃ
4.ЦНЬЈЙмРэЗНУцЃЌашвЊЖдСїГЬЁЂШЈЯоЁЂХфЖюЁЂЩ§МЖЁЂАцБОЁЂЛњЦївЊгаКмШЋУцЕФЙмРэЦНЬЈЁЃ
етИіОЭЪЧФПЧА58ДѓЪ§ОнЦНЬЈЕФећЬхМмЙЙЭМЁЃ

етИіЭМеЙЪОЕФЪЧМмЙЙЭМжаЫљАќКЌЕФЯЕЭГЪ§ОнСїЖЏЕФЧщПіЁЃЗжЮЊСНИіВПЗжЃК
ЪзЯШЪЧЪЕЪБСїЃЌОЭЪЧЛЦЩЋМ§ЭЗБъЪЖЕФетИіТЗОЖЁЃЪ§ОнЪЕЪБВЩМЏЙ§РДжЎКѓЪзЯШЛсНјШыЕНKafkaЦНЬЈЃЌЯШзіЛКДцЁЃЪЕЪБМЦЫув§ЧцБШШчSpark
streamingЛђstormЛсЪЕЪБЕФДгKafkaжаШЁГіЫќУЧЯывЊМЦЫуЕФЪ§ОнЁЃОЙ§ЪЕЪБЕФДІРэжЎКѓНсЙћПЩФмЛсаДЛиЕНKafkaЛђепЪЧаЮГЩзюжеЕФЪ§ОнДцЕНMySQLЛђепHBaseЃЌЬсЙЉИјвЕЮёЯЕЭГЃЌетЪЧвЛИіЪЕЪБТЗОЖЁЃ
ЖдгкРыЯпТЗОЖЃЌЭЈЙ§НгШыВуЕФВЩМЏКЭЪеМЏЃЌЪ§ОнзюКѓЛсТфЕНHDFSЩЯЃЌШЛКѓОЙ§SparkЁЂMRХњСПМЦЫув§ЧцДІРэЩѕжСЪЧЛњЦїбЇЯАв§ЧцЕФДІРэЁЃЦфжаДѓВПЗжЕФЪ§ОнвЊНјШЅЪ§ОнВжПтжаЃЌдкЪ§ОнВжПтетВПЗжЪЧвЊОЙ§Ъ§ОнГщШЁЁЂЧхЯДЁЂЙ§ТЫЁЂгГЩфЁЂКЯВЂЛузмЃЌзюКѓОлКЯНЈФЃЕШЕШМИВПЗжЕФДІРэЃЌаЮГЩЪ§ОнВжПтЕФЪ§ОнЁЃШЛКѓЭЈЙ§HIVEЁЂKylinЁЂSparkSQLетжжНгПкНЋЪ§ОнЬсЙЉИјИїИівЕЮёЯЕЭГЛђепЮвУЧФкВПЕФЪ§ОнВњЦЗЃЌгавЛВПЗжЛЙЛсСїЯђMySQLЁЃвдЩЯЪЧЪ§ОндкДѓЪ§ОнЦНЬЈЩЯЕФСїЖЏЧщПіЁЃ
дкЪ§ОнСїжЎЭтЛЙгавЛЬзЙмРэЦНЬЈЁЃАќРЈдЊаХЯЂЙмРэЃЈдЦДАЃЉЁЂзївЕЙмРэЦНЬЈЃЈ58dpЃЉЁЂШЈЯоЩѓХњКЭСїГЬздЖЏЛЏЙмРэЦНЬЈЃЈNightFuryЃЉЁЃ

ЮвУЧЕФЙцФЃПЩФмВЛЫуДѓЃЌИњBATБШЦ№РДгааЉаЁЃЌЕЋЪЧвВЙ§СЫвЛЧЇЬЈЃЌФПЧАга1200ЬЈЕФЛњЦїЁЃЮвУЧЕФЪ§ОнЙцФЃФПЧАга27PBЃЌУПЬьдіСПга50TBЁЃзївЕЙцФЃУПЬьДѓИХга80000ИіjobЃЌКЫаФjobЃЈВњЩњЙЋЫОКЫаФжИБъЕФjobЃЉга20000ИіЃЌУПЬь80000ИіjobвЊДІРэЪ§ОнСПЪЧ2.5PBЁЃ
ММЪѕЦНЬЈММЪѕбнНјгыЪЕЯж
НгЯТРДЮвЛсжиЕуНщЩмвЛЯТдкзюНќвЛФъАыЪБМфФкЮвУЧДѓЪ§ОнЦНЬЈЕФММЪѕбнНјЙ§ГЬЃЌЙВЗжЫФИіВПЗжЃКЮШЖЈадЁЂЦНЬЈжЮРэЁЂадФмвдМАвьЙЙМЦЫуЁЃЕквЛИіВПЗжЙигкЮШЖЈадЕФИФНјЃЌЮШЖЈадЪЧзюЛљДЁЕФЙЄзїЃЌЮвУЧзіСЫБШНЯЖрЕФЙЄзїЁЃЕкЖўИіВПЗжЪЧдкЦНЬЈжЮРэЗНУцЕФФкШнЁЃЕкШ§ИіЗНУцЮвУЧеыЖдадФмвВзіСЫвЛаЉгХЛЏЁЃЕкЫФИіЗНУцЃЌЮвУЧеыЖдвьЙЙЛЗОГЃЌБШШчЫЕЛњЦїЕФвьЙЙЁЂзївЕЕФвьЙЙЃЌдкетжжЛЗОГЯТдѕУДКЯРэЕиЪЙгУзЪдДЁЃ
ЮШЖЈадИФНј
ЪзЯШПДвЛЯТЮШЖЈадЕФИФНјЁЃетПщЮвЛсОйвЛаЉР§згНјааЫЕУїЁЃЮШЖЈадАќКЌСЫМИИіЗНУцЃЌЦфжаЕквЛИіЗНУцОЭЪЧЯЕЭГЕФПЩгУадЃЌДѓМвПЩвдВЩгУЩчЧјЬсЙЉЕФHDFS
HAЁЂYarn HAЃЌStorm HAРДНтОіЁЃСэЭтвЛИіЗНУцЪЧЙигкРЉеЙадЃЌР§ШчFlumeЁЂHDFSЃЌYarnЃЌStormЕФРЉеЙадЁЃетРяжївЊНщЩмЯТFlumeКЭHDFSЕФРЉеЙадЯрЙиЕФвЛаЉПМТЧЁЃДЫЭтЃЌгаСЫПЩгУадКЭРЉеЙадЃЌЯЕЭГОЭЮШЖЈСЫТ№ЃПЪЕМЪЩЯВЛЪЧетбљЁЃвђЮЊЛЙгаКмЖрЕФЭЛЗЂЮЪЬтЁЃМДЪЙНтОіСЫПЩгУадКЭРЉеЙадЃЌЕЋЭЛЗЂЮЪЬтЛЙЪЧПЩФмЛсдьГЩЯЕЭГВЛПЩгУЃЌР§ШчгЩгквЛаЉЮЪЬтдьГЩСНЬЈNameNodeШЋВПхДЛњЁЃ
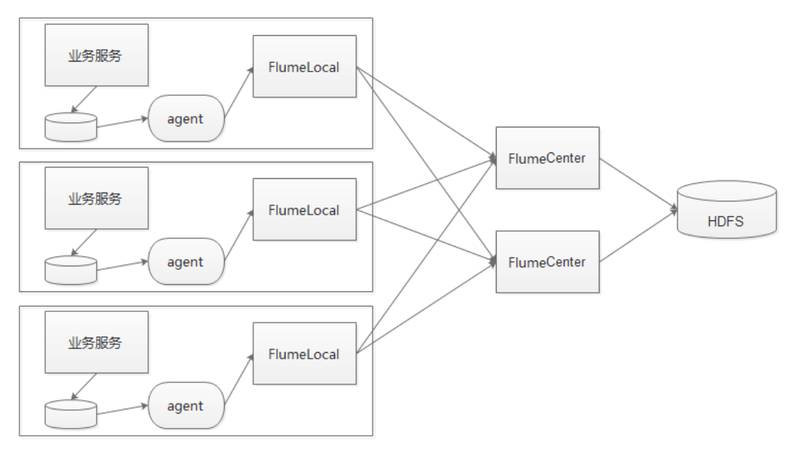
ЪзЯШПДвЛЯТFlumeЕФРЉеЙадЁЃЮвУЧШЫЮЊЕФАбЫќЖЈвхСЫСНВуЁЃвЛИіЪЧFlumeLocalЃЈжївЊНтОівЛЬЈЛњЦїЕФШежОВЩМЏЮЪЬтЃЌМђГЦLocalЃЉЃЌвЛИіЪЧFlumeCenterЃЈжївЊДгLocalЩЯЪеМЏЪ§ОнЃЌШЛКѓАбЪ§ОнаДЕНHDFSЩЯЃЌМђГЦCenterЃЉЃЌLocalКЭCenterжЎМфЪЧгавЛИіHAЕФПМТЧЕФЃЌОЭЪЧLocalашвЊдкХфжУЮФМўРяжИЖЈСНИіCenterШЅаДШыЃЌвЛЕЉвЛИіCenterГіЯжЮЪЬтЃЌЪ§ОнПЩвдТэЩЯДгСэвЛИіCenterСїЯђHDFSЁЃДЫЭтЃЌЮвУЧЛЙПЊЗЂСЫвЛИіИпПЩППЕФAgentЁЃвЕЮёЯЕЭГжаЛсАбЪ§ОнВњЩњШежОаДЕНДХХЬЩЯЃЌAgentБЃжЄЪ§ОнДгДХХЬЩЯЪЕЪБПЩППЕФЪеМЏИјБОЕиЕФLocalЃЌЦфжаЮвУЧВЩгУСЫМьВщЕуЕФММЪѕРДНтОіЪ§ОнПЩППадЕФЮЪЬтЁЃ

етЪЧFlumeЕФЕфаЭМмЙЙЁЃLocalашвЊдкХфжУЮФМўРяУцжИЖЈЫРвЊСЌЕНФФМИИіCenterЩЯЁЃШчЙћЫЕ10ЬЈЃЌПЩФмЛЙOKЃЌ100ЬЈвВOKЃЌШчЙћвЛЧЇЬЈФиЃПШчЙћЗЂЯжСНЬЈFlume
CenterвбОДяЕНЛњЦїзЪдДЕФЩЯЯоЃЌШчКЮзіНєМБЕФРЉШнФиЃПЫљвдДгетИіНЧЖШПДFlumeЕФРЉеЙадЪЧгаЮЪЬтЕФЁЃ
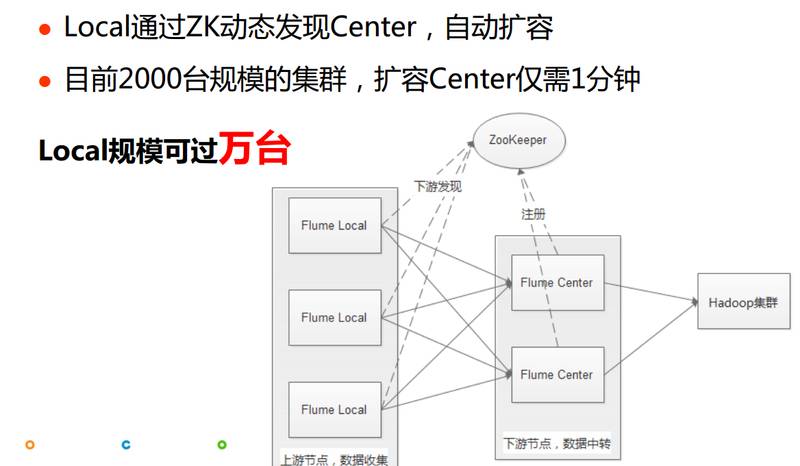
ЮвУЧЕФНтОіЗНЗЈЪЧдкLocalКЭCenterжаМфМгСЫвЛИіZooKeeperЃЌLocalЭЈЙ§ZKЖЏЬЌЗЂЯжCenterЃЌЖЏЬЌЕФЗЂЯжЯТгЮгаЪВУДЃЌОЭПЩвдДяЕНCenterздЖЏРЉШнЕФФПБъСЫЁЃЮвУЧЙЋЫОLocalгаСНЧЇЖрЬЈЃЌРЉШнвЛЬЈCenterНіашвЛЗжжгЃЌетжжМмЙЙЪЕМЪЩЯПЩвджЇГжДяЕНЭђЬЈЙцФЃЕФЃЌетЪЧFlumeРЉеЙадЕФвЛаЉИФНјЁЃ

НгЯТРДПДвЛЯТHDFSРЉеЙадЕФЮЪЬтЁЃЩЯУцетеХЭМеЙЪОСЫhdfs federationЕФМмЙЙЃЌзѓВрЪЧвЛИіЕЅnamespaceМмЙЙЃЌМДећИіФПТМЪїдквЛИіnamespaceжаЃЌећИіМЏШКЕФЮФМўЪ§ЙцФЃЪмЯожЦгкЕЅЛњФкДцЕФЯожЦЁЃfederationЕФЫМЯыЪЧАбФПТМЪїВ№ЗжЃЌаЮГЩВЛЭЌЕФnamespaceЃЌВЛЭЌnamespaceгЩВЛЭЌnamenodeЙмРэЃЌетбљОЭДђЦЦСЫЕЅЛњзЪдДЯожЦЃЌДгЖјДяЕНСЫПЩРЉеЙЕФФПБъЃЌШчгвВрЭМЁЃ
ЕЋетИіЗНАИгавЛаЉвўВиЕФЮЪЬтЃЌВЛжЊЕРДѓМвгаУЛгазЂвтЕНЃЌБШШчетРяУПИіDatanodeЖМЛсгыЫљгаЕФNameNodeШЅаФЬјЃЌШчЙћDataNodeЪ§СПЩЯЭђЬЈЃЌФЧУДОЭПЩФмЛсГіЯжСНИіЮЪЬтЃКЕквЛЃЌДгжїНкЕужЎМфЕФаФЬјЁЂПщЛуБЈГЩЮЊЦПОБЃЌЕкЖўЃЌШчЙћЕЅИіВПУХЕФЪ§ОнЙцФЃЙ§ДѓФЧИУдѕУДАьЃП
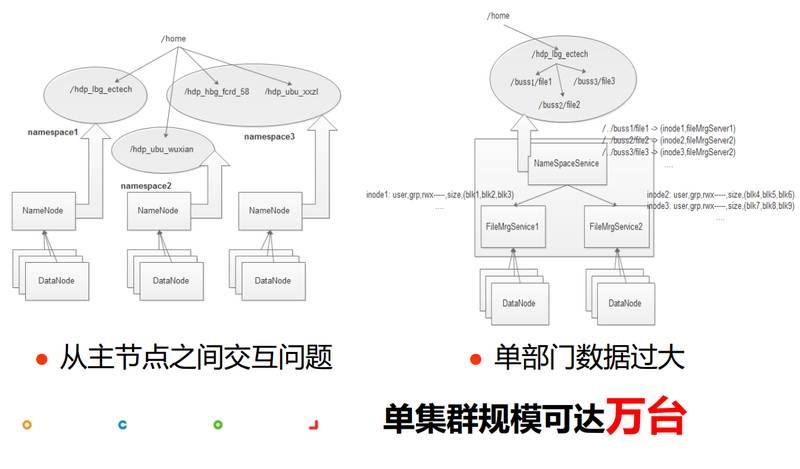
еыЖдДгжїНкЕужЎМфНЛЛЅЕФЮЪЬтЃЌЮвУЧПЩвдНјааВ№ЗжЃЌПижЦвЛИіNameNodeЙмРэЕФDateNodeЕФЪ§СПЃЌетбљОЭПЩвдБмУтжїДгНкЕуНЛЛЅПЊЯњЙ§ДѓЕФЮЪЬтЁЃеыЖдЕЅВПУХЪ§ОнЙ§ДѓЕФЛАПЩвдеыЖдВПУХФкЪ§ОнНјааНјвЛВНЯИВ№ЃЌОЭOKСЫЁЃЛђепПЩвдПМТЧАйЖШжЎЧАЬсЙЉЕФвЛИіЗНАИЃЌМДАбФПТМЪїКЭinodeаХЯЂНјааГщЯѓЃЌШЛКѓЗжВуЙмРэКЭДцДЂЁЃЕБШЛЮвУЧФПЧАВЩгУЩчЧјfederationЕФЗНАИЁЃШчЙћКУКУЙцЛЎЕФЛАЃЌвВЪЧПЩвдЕНЭђЬЈСЫЁЃ
ВЛжЊЕРДѓМвгаУЛгадкздМКдЫгЊМЏШКЙ§ГЬжагіЕНЙ§вЛаЉЮЪЬтЃЌФуУЧЪЧдѕУДНтОіЕФЃЌгааЉЮЪЬтПЩФмЯрЕБЕФМЌЪжЁЃЭЛЗЂЮЪЬтЪЧЗЧГЃНєМБЖјЧвживЊЕФЃЌашвЊдкЖЬЪБМфФкИуЖЈЁЃНгЯТРДЮвЛсЗжЯэШ§ИіР§згЁЃ
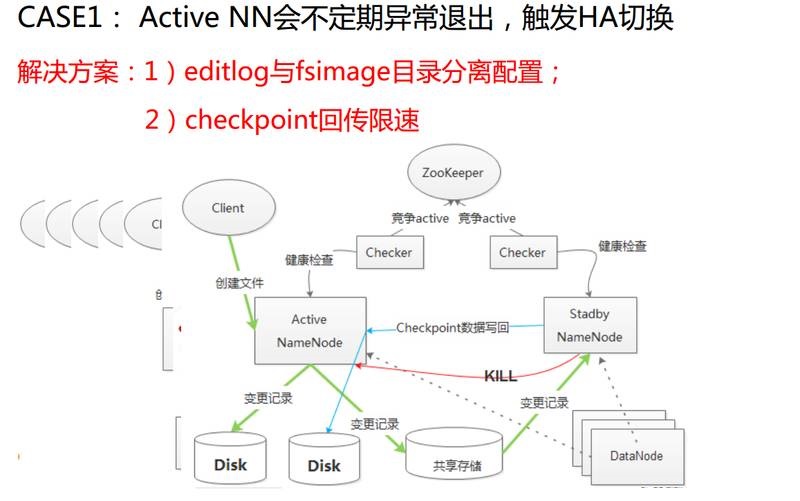
ЕквЛИіР§згЪЧHDFSЕФActive NNЛсВЛЖЈЦквьГЃЭЫГіЃЌДЅЗЂHAЧаЛЛЃЌетОЭКУЯёвЛИіВЛЖЈЪБеЈЕЏвЛбљЁЃетИіЭМеЙЪОСЫHDFSЕФHAЕФМмЙЙЭМЃЌПЭЛЇЖЫНјааБфИќВйзїЃЈШчДДНЈЮФМўЃЉЕФЛАЛсЗЂГіЧыЧѓИјnamenodeЃЌnamenodeЧыЧѓДІРэЭъжЎКѓЛсНјааГжОУЛЏЙЄзїЃЌЛсдкБОЕиДХХЬДцвЛЗнЃЌЭЌЪБЛсдкЙВЯэДцДЂДцвЛЗнЃЌЙВЯэДцДЂЪЧЮЊСЫactiveКЭstandbyжЎМфЭЌВНзДЬЌЕФЃЌstandbyЛсжмЦкДгЙВЯэДцДЂжаРШЁИќаТЕФЪ§ОнгІгУЕНздМКЕФФкДцКЭФПТМЪїЕБжаЃЌЫљгаЕФDataNodeЖМЪЧЫЋЛуБЈЕФЃЌетбљСНИіnamenodeЖМЛсгазюаТЕФПщаХЯЂЁЃзюЩЯУцЕФЪЧСНИіCheckerЃЌЪЧЮЊСЫжйВУОПОЙЫЪЧActiveЕФЁЃ
ЛЙгавЛИіЙ§ГЬЃЌStandby NameNodeЛсЖЈЦкзіcheckpointЙЄзїЃЌШЛКѓдкcheckpointзіЭъжЎКѓЛсЛиДЋзюаТЕФfsimageИјactiveЃЌзюжеБЃДцдкactiveЕФДХХЬжаЃЌФЌШЯЧщПіЯТдкЛиДЋЙ§ГЬЛсдьГЩДѓСПЕФЭјТчКЭДХХЬЕФбЙСІЃЌЕМжТactiveЕФБОЕиДХХЬЕФUtilДяЕН100%ЃЌДЫЪБгУЛЇБфИќЧыЧѓбгГйОЭЛсБфИпЁЃШчЙћДХХЬЕФUtil100%ГжајЪБМфКмГЄОЭЛсЕМжТгУЛЇЧыЧѓГЌЪБЃЌЩѕжСChecherЕФМьВтЧыЧѓвВвђХХЖгЙ§ГЄЖјГЌЪБЃЌзюжеШЛКѓДЅЗЂCheckerжйВУHAЧаЛЛЁЃ
ЧаЛЛЕФЙ§ГЬжадкЩшМЦЩЯгаКмживЊвЛЕуПМТЧЃЌВЛФмЭЌЪБгаСНИіActiveЃЌЫљвдвЊГЩЮЊаТActive NameNodeЃЌвЊАбдРДЕФActive
NameNodeЭЃжЙЕєЁЃЯШЛсКмгбКУЕиЭЃжЙЃЌЪВУДЪЧгбКУФиЃПОЭЪЧЗЂвЛИіRPCЃЌШчЙћГЩЙІСЫОЭЪЧгбКУЕФЃЌШчЙћЪЇАмСЫЃЌОЭЛсsshЙ§ШЅЃЌАбдРДactive
namenodeНјГЬkillЕєЃЌетОЭЪЧActive NameNodeвьГЃЭЫЕФдвђЁЃ
ЕБетИідвђСЫНтСЫжЎКѓЃЌЦфЪЕвЊНтОіетИіЮЪЬтвВЗЧГЃМђЕЅЁЃ
ЕквЛЕувЊАбeditlogгыfsimageБЃДцЕФБОЕиФПТМЗжРыХфжУЃЌетжжЗжРыЪЧДХХЬЩЯЕФЗжРыЃЌЮяРэЗжРыЁЃ
ЕкЖўЪЧcheckpointжЎКѓfsimageЛиДЋЯоЫйЁЃАбeditlogгыfsimageСНИіДХХЬЗжРыЃЌfsimageЛиДЋЕФioбЙСІВЛЛсЖдПЭЛЇЖЫЧыЧѓдьГЩгАЯьЃЌСэЭтЃЌЛиДЋЯоЫйКѓЃЌвВФмЯожЦioбЙСІЁЃетЪЧБШНЯМЌЪжЕФЮЪЬтЁЃдвђПДЦ№РДКмМђЕЅЃЌЕЋЪЧДгЯжЯѓевЕНдвђЃЌетИіЙ§ГЬВЂУЛгаФЧУДШнвзЁЃ

ЕкЖўИіАИР§вВЪЧвЛбљЃЌActive NNгжГіЯжвьГЃЭЫГіЃЌВњЩњHAЧаЛЛЁЃетДЮКЭЭјТчСЌНгЪ§гаЙиЃЌетеХЭМЪЧActive
NameNodeЕФЫљдкЛњЦїЕФЭјТчСЌНгЪ§ЃЌЦНЪБЖМЭІе§ГЃЃЌ20000ЕН30000жЎМфЃЌКіШЛгавЛИіЕувЛЯТДђЕН60000ЖрЃЌШЛКѓОЭДђЦНСЫЃЌзюКѓНЕЯТРДЃЌНЕЯТРДЕФдвђКмУїЯдЃЌЪЧЗўЮёНјГЬЭЫСЫЁЃ
ЮЊЪВУДЛсГіЯжетИіЧщПіФиЃПдкКѓајЗжЮіЕФЙ§ГЬжаЮвУЧЗЂЯжСЫвЛИіЯпЫїЃЌдкNameNodeШежОРяБЈСЫвЛИіПежИеыЕФвьГЃЁЃОЭЫГЬйУўЙЯЗЂЯжСЫвЛИіJDK1.7ЕФBUGЃЌВЮМћЩЯУцЭМЦЌЫљЪОЃЌдкjava
selectПтКЏЪ§ЕїЖШТЗОЖЙ§ГЬжазюжеЛсЕїгУетИіКЏЪ§ЃЈsetUpdateEventsЃЉЃЌДѓМвПЩвдПДЕНЃЌШчЙћfdЕФИіЪ§ГЌЙ§СЫMAX_UPDATE_ARRAY_SIZEЃЈ65535ЃЉетИіЪ§ЕФЛАЃЌНЋЛсзпЕНelseТЗОЖЃЌетИіТЗОЖдкifНјааВЛЕШБэДяЪНХаЖЯЪБЃЌНЋЛсГіЗЂПежИеывьГЃЁЃ
НгЯТРДЕФЮЪЬтЪЧЃЌЮЊЪВУДЛсВњЩњетУДЖрЕФСДНгФиЃПОЙ§ЗжЮіЮвУЧЗЂЯжЃЌдкЮЪЬтГіЯжЕФЪБКђЃЌДцдквЛДЮДѓФПТМЕФDUВйзїЃЌЖјDUЛсЫјзЁећИіnamespaceЃЌетбљОЭЕМжТКѓајЕФаДЧыЧѓБЛзшШћЃЌзюжеЕМжТЧыЧѓЕФЖбЛ§ЃЌЧыЧѓЕФЖбЛ§ЕМжТСЫСЌНгЪ§ДѓСПЖбЛ§ЃЌСЌНгЪ§ЖбЛ§ЕНвЛЖЈГЬЖШОЭДЅЗЂJDK1.7ЕФетИіBUGЁЃетИіЮЪЬтЕФНтОіЃЌДгСНИіЗНУцПДЃЌЪзЯШЮвУЧЯШАбJDKЩ§МЖЕН1.8ЁЃЦфДЮЃЌЕїећВЮЪ§dfs.content-summary.limitЃЌЯожЦduВйзїЕФГжЫјЪБМфЁЃИУВЮЪ§ФЌШЯВЮЪ§ЪЧ0ЁЃЮвУЧЯждкЪЧЩшГЩ10000СЫЃЌДѓМвПЩвдВЮПМЁЃетЪЧЕкЖўИіЗЧГЃМЌЪжЕФЮЪЬтЁЃ
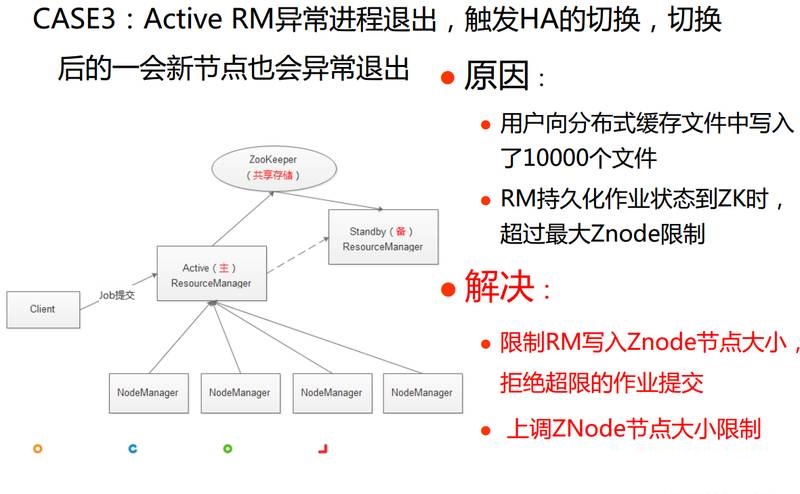
ЕкШ§ИіАИР§ЙигкYARNжїНкЕуЕФЃЌгавЛЬьжаЮчЃЌЮвУЧЪеЕНБЈОЏЃЌЗЂЯжActive RMвьГЃНјГЬЭЫГіЃЌДЅЗЂHAЕФЧаЛЛЃЌШЛЖјЧаЛЛКѓвЛЛсаТЕФActive
RMНкЕувВЛсвьГЃЭЫГіЃЌетОЭБШНЯБЏОчЃЌЮвУЧЯШНјааСЫЛжИДЁЃжЎКѓЮвУЧДгЕБЪБЕФШежОжаЗЂЯжСЫдвђЃКвЛИігУЛЇаДСЫвЛЭђИіЮФМўЕНЗжВМЪНЛКДцРяЃЌЗжВМЪНЛКДцРяЪ§ОнЛсЭЌВНЕНZKЩЯЃЌRMГжОУЛЏзївЕзДЬЌЕНZKЪБГЌЙ§ZnodeЕЅНкЕузюДѓЩЯЯоЃЌХзГівьГЃЃЌзюжеЕМжТResourceManagerНјГЬЕФвьГЃЭЫГіЁЃЦфЪЕЮЪЬтЕФНтОіЗНЗЈвВЗЧГЃМђЕЅЃЌЮвУЧдіМгСЫЯожЦТпМЃЌЖдгкађСаЛЏЪ§ОнСПДѓгкZnodeНкЕуДѓаЁЕФJobЃЌжБНгХзвьГЃДЅЗЂJobЕФЪЇАмЁЃСэЭтЮвУЧЛЙЪЪЕБЬсЩ§ZnodeНкЕуДѓаЁЁЃ
вдЩЯЪЧдкЮШЖЈадЗНУцЕФвЛаЉЙЄзїЃЌетШ§ИіАИР§ИњДѓМвЗжЯэвЛЯТЃЌШчЙћгаРрЫЦЕФЮЪЬтНЈвщДѓМвПЩвдГЂЪдвЛЯТЃЌетаЉЗНАИЪЧБЛЮвУЧбщжЄOKЕФЁЃ
ЦНЬЈжЮРэ
НгЯТРДНщЩмвЛЯТЦНЬЈжЮРэетПщЁЃАќКЌМИИіЮЪЬтЃЌЦфжаЕквЛЮЪЬтЪЧЙигкЪ§ОнЕФЃЌвЛЗНУцЃЌОЭЪЧДѓМвПЊЗЂСЫЪ§ОнжЎКѓЃЌОГЃевВЛЕНЃЌвЊППКАЃЌБШШчЫЕдкШКРяКАвЛЯТЪВУДЪ§ОндкФФЃЌЫФмИцЫпЮввЛЯТЃЌетИіаЇТЪКмЕЭЯТЁЃСэЭтвЛЗНУцЪЧжЎЧАЕФЙмРэЪ§ОнЪЧЙВЯэЕФЃЌВЛАВШЋЃЌШЮКЮШЫЖМПЩвдЗУЮЪЦфЫћШЫЕФЪ§ОнЁЃ
ЕкЖўИіЮЪЬтЪЧЙигкзЪдДЃЌжЎЧАЪЧЁАДѓЙјЗЙЁБФЃЪНЃЌДѓМвЙВЯэМЦЫузЪдДЃЌЯрЛЅОКељЃЌетбљЁАФмГдЕФЁАПЯЖЈЪЧМЗЖвЁБВЛФмГдЕФЁАЃЌОГЃГіЯжКЫаФШЮЮёВЛФмАДЪБАДЕуЭъГЩЃЌРЯАхПДВЛЕНЪ§ОнЃЌетЕуКмПЩХТЁЃЛЙгаЪЧећИіМЏШКзЪдДЪЙгУЧщПіУЛгаИажЊЃЌетбљИљБОВЛжЊЕРзЪдДвЊдѕУДЗжХфЃЌЪЧЗёЙЛгУЁЃ
ЕкШ§ИіЮЪЬтЪЧЙигкзївЕЕФЃЌПЊЗЂШЫдБПЊЗЂДѓСПЕФзївЕжЎКѓЃЌетаЉзївЕвЊдѕУДЙмРэЃЌЪЕМЪЩЯЫћУЧПЩФмЖМВЛжЊЕРЁЃЛЙгаОЭЪЧЙигкзївЕжЎМфвРРЕЃЌОГЃвЛИіжИБъМЦЫуГіРДвЊОРњЖрИізївЕЃЌзївЕжЎМфвРРЕЪЧдѕУДПМТЧЕФЃЌЕЅДПППЪБМфЩЯЕФвРРЕЪЧЗЧГЃДрШѕЕФЃЌШчЙћЧАЦкЕФjobбгГйВњЩњСЫЃЌКѓајЕФjobБиШЛЪЇАмЁЃзюКѓвЛИіЮЪЬтЪЧЪ§ОнПЊЗЂШЫдБЕФаЇТЪВЛИпЃЌЫљашвЊзіЕФВНжшЙ§ЖрЁЃ
еыЖдетЫФИіЮЪЬтЮвУЧзіСЫвЛаЉИФНјЃЌЪзЯШЪЧЪ§ОнгызЪдДжЮРэЁЃЪ§ОнЗНУцвЊв§ШыАВШЋВпТдЁЂдЊаХЯЂЙмРэгыЛљДЁЪ§ВжНЈЩшЁЃЮвУЧздМКПЊЗЂСЫвЛЬзАВШЋПижЦВпТдЃЌжївЊдіМгСЫАзУћЕЅКЭШЈЯоПижЦВпТдЁЃвЛИіHDFSЕФЧыЧѓЕФСїГЬЃЌЪзЯШПЭЛЇЖЫЛсЯђNameNodeЗЂЧыЧѓЃЌNameNodeНгЕНЧыЧѓжЎКѓЪзЯШвЊзіСЌНгНтЮіЃЌЖСШЁГіЧыЧѓЯрЙиФкШнзіЧыЧѓДІРэЃЌдйАбНсЙћЗДРЁЛиРДЃЌжЎКѓПЭЛЇЖЫЯђЯргІЕФDataNodeНјаааДШыЪ§ОнЛђепЖСШЁЪ§ОнЁЃДгЩЯЪіСїГЬПЩвдПДГіЃЌЫљгаHDFSВйзїШЋВПвЊОЙ§NameNodeетвЛВуЁЃ
ФЧУДАВШЋВпТджЛвЊдкNameNodeЕФСНИіЕузіЯТПижЦМШПЩЭъГЩЃКдкСЌНгНтЮіКѓЃЌЮвУЧЛсбщжЄЧыЧѓЗНЕФIPЃЌвдМАгУЛЇЪЧВЛЪЧдкКЯЗЈХфжУЯТУцЕФЁЃШчЙћбщжЄЪЇАмЃЌдђОмОјЧыЧѓЁЃШчЙћбщжЄЭЈЙ§ЃЌЮвУЧЛсНјвЛВНдкЧыЧѓДІРэЙ§ГЬжабщжЄгУЛЇЗУЮЪЕФФПТМКЭгУЛЇдкЗёдкКЯЗЈЕФХфжУЯТЁЃБШШчЫЕгУЛЇAЯыЗУЮЪгУЛЇBЕФЪ§ОнЃЌШчЙћУЛдкдЪаэЕФЧщПіЯТЛсАбСЌНгЙиЕєЃЌЭЈЙ§МђЕЅЕФВпТдЕїећОЭФмДяЕНСщЛюЕФЪ§ОнЕФАВШЋПижЦКЭЪ§ОнЙВЯэЕФЗНЪНЁЃНгЯТРДеыЖдЪ§ОневВЛЕНЕФЮЪЬтЃЌЮвУЧПЊЗЂСЫШЋЙЋЫОВуУцЕФЛљДЁЪ§ОнВжПтвдМАеыЖдШЋЙЋЫОВуУцдЊЪ§ОнЙмРэЦНЬЈЁЃ
етеХЭМеЙЪОСЫЛљДЁЪ§ОнВжПтИВИЧЖШЃЌЫќИВИЧСЫМЏЭХИїИіЙЋЫОЃЌгжИВИЧСЫЖрИіЦНЬЈЃЌБШШчЫЕЪжЛњЁЂAppЖЫЁЂPCЖЫЁЂЮЂаХЖЫЕШЕШЁЃЪ§ОнВуДЮЃЌЪЧЪ§ОнВжПтВуЁЂЪ§ОнМЏЪаВуЛЙЪЧЪ§ОнгІгУВуЃЌЫљЪєФФИіЪТвЕШКЃЌзюКѓеыЖдЪ§ОнНјааЗжРрБъЧЉЃЌБШШчЫЕЬћзгЪ§ОнЁЂгУЛЇЪ§ОнЕШЕШЖМПЩвдЭЈЙ§БъЧЉЕФЗНЪНРДевЕНЁЃЕБЯыевОпЬхвЛЗнЪ§ОнЕФЪБКђПЩвдЭЈЙ§етИіНчУцЃЌЕувЛаЉБъЧЉЃЌЩИбЁГівЛаЉЪ§ОнБэЃЌЩѕжСдкЫбЫїПђРяУцЫбЪ§ОнЕФЙиМќзжЁЃЕБВщЕНЪ§ОнБэЕФЪБКђПЩвддкгвВрАДХЅЃЌНЋЯдЪОГіБэНсЙЙЃЌЛЙгаБэаХЯЂЃЌБэаХЯЂБэУїСЫетИіБэгаЖрЩйСаЃЌетИіБэЕФИКд№ШЫЪЧЪВУДЃЌЛЙгаЙигкЪ§ОнжЪСПЃЌБэЕФЪ§ОнСПЕФБфЛЏЧщПіЕШЕШЃЌШчЙћФуЯыЩъЧыПЩвдЕуЛїзюгвБпЕФШЈЯоПЊЭЈЁЃећЬхПЊЭЈСїГЬвВЪЧздЖЏЛЏЕФЁЃетЪЧеыЖдЪ§ОневВЛЕНЕФЮЪЬтзіЕФвЛаЉИФНјЁЃ
еыЖдзЪдДЮЪЬтвЊБмУтДѓЙјЗЙЃЌБиаывЊв§ШыеЫКХИХФюЃЌзЪдДАДеееЫКХдЄСєгыИєРыЁЃЮвУЧЛЎЗжСЫВЛЭЌЕФХфЖюЃЌИљОндЄЫуЁЂвЕЮёашЧѓШЅЩъЧыХфЖюЃЌШЛКѓЮвУЧЕїећХфЖюЁЃеыЖдЖгСаетПщЮвУЧЛЎЗжЖрИіЖгСаЃЌУПИівЕЮёЯпгаздМКЕФЖгСаЃЌВЛЭЌвЕЮёЯпВЛФмПчЖгСаЬсНЛШЮЮёЃЌУПИіЖгСаЛЎЗжГіВЛЭЌзЪдДЃЌзЪдДжївЊЪЧеыЖдвЕЮёЯпашЧѓЖјЖЈЕФЁЃЭЈЙ§етаЉИФНјПЩвдДяЕНзЪдДЕФИєРывдМАЪЪЖШЕФЙВЯэЁЃ
гаСЫеЫКХЕФИХФюжЎКѓЮвУЧОЭПЩвдЭГМЦУПИівЕЮёЯпзЪдДЪЙгУЧщПіЁЃЮвУЧУПЬьЖМЛсгаБЈБэЁЃЯдЪОСЫвЕЮёЯпЕФМЦЫуКЭДцДЂзЪдДЕФЪЙгУЧщПіЃЌЩѕжСЪЧJobЕФЯИНкЧщПіЁЃ
НгЯТРДЮвЛсНщЩмвЛЯТвЕЮёЯпПЊЗЂаЇТЪЕЭЯТЮЪЬтЕФИФНјЃЌЪЕМЪЩЯЮвУЧдквзгУадЩЯвВзіСЫКмЖрИФНјЁЃЪзЯШЮвУЧПЊЗЂСЫдЦДАЦНЬЈЃЌЫќжївЊНтОіСЫдЊаХЯЂВщевЁЂЪ§ОнВщбЏЁЂПЩЪЧЛЏеЙЪОКЭЖрЮЌЗжЮіетаЉашЧѓЁЃШЛКѓеыЖдШЮЮёПЊЗЂетПщЮвУЧПЊЗЂСЫ58DPНтОіСЫдЊаХЯЂПЊЗЂЁЂзївЕЙмРэгыЭГМЦЕШЁЃЮвУЧеыЖдЪЕЪБЖрЮЌЗжЮіПЊЗЂСЫЗЩСїЃЌЪЕЪБзївЕПЊЗЂШЋВПХфжУЛЏЁЂЭЌЪБжЇГжЖржжЭГМЦЫузгЁЂздЖЏЭМБэЩњГЩЕШЕШЁЃЛЙгаNightFuryЃЌСїГЬздЖЏЛЏЙмРэЦНЬЈЁЃ

етЪЧдЦДАЕФНчУцЃЌЩЯУцЪЧвЛИіSQLВщбЏНчУцЃЌЯТУцЪЧПЩЪгЛЏВњЦЗНчУцЃЌетЪЧЮвУЧЪ§ОнПЩЪгЛЏЕФвЛИіНсЙћЁЃ

ШЛКѓЙигкШЮЮёПЊЗЂЕФЛАЃЌЮвУЧгУ58DPРДзіШЮЮёПЊЗЂЃЌПЩвджЇГжЕФВЛЭЌШЮЮёЃЌКИЧФПЧАЕФЫљгажїСїзївЕвдМАзївЕвРРЕЕШЙмРэЁЃетЪЧ58DPЕФвГУцЃЌПЩвдЩшжУЛљБОаХЯЂЁЂЕїЖШМАвРРЕЕШЁЃ
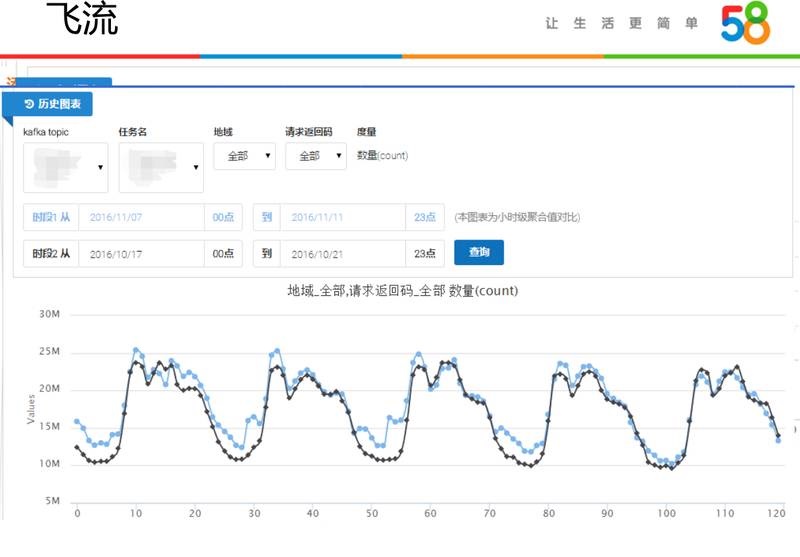
ЗЩСїЪЧжЇГжжмЦкадЕФЭГМЦЁЂШЋЬьРлМЦадЕФЭГМЦЃЌДѓМвПЩвдЖЈвхЭГМЦЗНЗЈЁЂЖЈвхШЮЮёЕФвЛаЉЛљБОаХЯЂЃЌЩшжУЮЌЖШЁЂЩшжУЖШСПЃЌЩшжУЭъжЎКѓОЭеЙЯжСЫЭМаЮЃЌвВЬсЙЉСЫИњзђЬьЕФЖдБШЧщПіЁЃЕБдкЭМРяЕуШЮКЮвЛИіЕуЕФЪБКђЃЌПЩвдПДЕНВЛЭЌЮЌЖШзщКЯЯТдкетИіЕуЩЯЕФЪ§ОнЗжВМЃЌЕуЛїСНИіЕуПЩвдПДЕНВЛЭЌЮЌЖШЯТСНИіЕуЕФЗжВМЖдБШЁЃеыЖдРњЪЗЪ§ОнПЩвдНјааЖдБШЃЌЮвУЧПЩвдАбЪБМфРЕФИќГЄЃЌПЩвдВщПДВЛЭЌжмЕФЪЕЪБЭГМЦНсЙћЃЌЖјВЛЪЧвЛЬьЁЃ
етЪЧNightFuryЕФНчУцЃЌетОЭЪЧЮвУЧдЫЮЌЕФздЖЏЛЏЙмРэЦНЬЈЃЌДѓМвПЩвдПДЕНгаКмЖрИіСїГЬКЭШЈЯоЕФПЊЭЈЩъЧыЃЌБэЕЅЕФЬюаДЁЂЙЄЕЅЩѓХњЃЌЩѓХњжЎКѓЕФвЛаЉСїГЬШЋВПЪЧздЖЏЛЏЕФЁЃ
адФм
адФмЗНУцЃЌжївЊЗжЮЊЫФИіЗНУцЃК
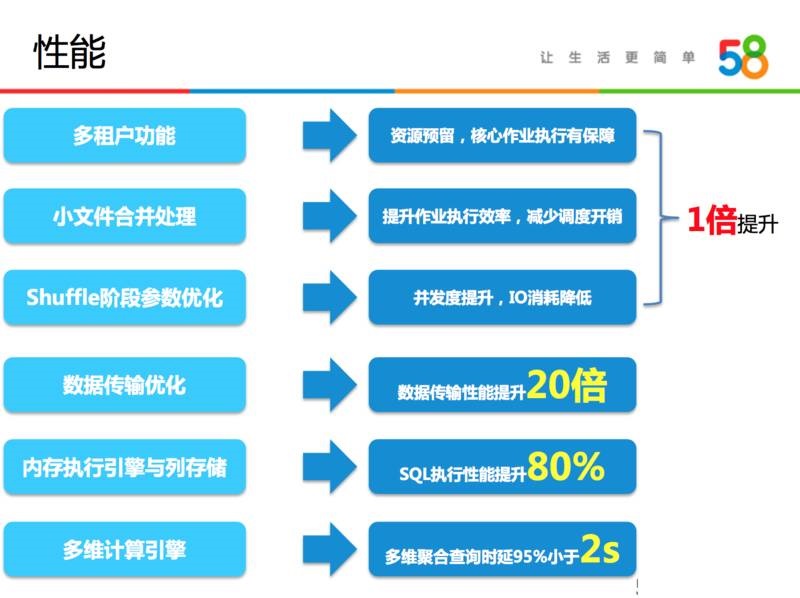
MRзївЕадФмЁЂЪ§ОнЪеМЏадФмЁЂSQLВщбЏадФмКЭЖрЮЌЗжЮіЕФадФмЁЃеыЖдMRзївЕадФмЃЌЮвУЧв§гУЖрзтЛЇЙІФмЃЌзЪдДдЄСєЃЌКЫаФзївЕжДаагаБЃеЯЁЃ
ЕкЖўЕуаЁЮФМўКЯВЂДІРэЃЌПЩвдЬсЩ§ШЮЮёжДаааЇТЪЃЌМѕЩйЕїЖШБОЩэЕФПЊЯњЁЃ
ЕкШ§ЕуЮвУЧеыЖдShuffleНзЖЮВЮЪ§гХЛЏЃЌПЩвдЪЕЯжВЂЗЂЖШЬсЩ§ЃЌIOЯћКФНЕЕЭЁЃ
ОЙ§Ш§ИіЗНУцЕФИФНјжЎКѓЃЌЮвУЧећЬхШЮЮёЕФдЫааЪБМфЪЕМЪЩЯгавЛБЖзѓгвЕФЬсЩ§ЁЃЪ§ОнДЋЪфгХЛЏЗНУцЃЌЮвУЧОЙ§ЯћЯЂКЯВЂИФНјЪ§ОнДЋЪфадФмЃЌЬсЩ§СЫ20БЖЁЃдкSQLгХЛЏЗНУцЮвУЧв§гУФкДцжДаав§ЧцгыСаДцДЂЗНАИЕФНсКЯЃЌдкЭЌЕШзЪдДЧщПіЯТеыЖдЯпЩЯвЛАйЖрЬѕSQLНјааВтЪдЃЌзмЬхадФмДѓИХЬсЩ§80%ЁЃдкЖрЮЌМЦЫуетПщЃЌЮвУЧв§ШыKylinЃЌеыЖдЖрЮЌЕФВщбЏ95%вдЩЯВщбЏФмПижЦдк2sвдФкЁЃ
вьЙЙМЦЫу
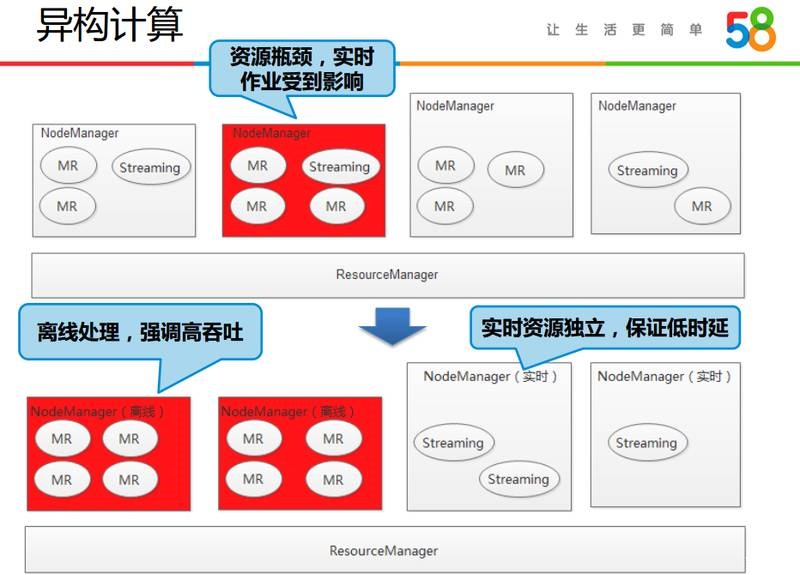
вьЙЙМЦЫуЗНУцЮвУЧУцСйСЫСНИіжївЊЮЪЬтЃЌвЛИіЪЧзївЕЕФвьЙЙЃЌЮвУЧгаЖржжРраЭЕФзївЕЃЌБШШчЫЕЪЕЪБзївЕЧПЕїЕЭЪБбгЃЌЖјРыЯпзївЕЧПЕїИпЭЬЭТЃЌетБОЩэОЭЪЧУЌЖмЕФЃЌдѕУДНтОіетИіУЌЖмЁЃЕкЖўЗНУцЪЧЛњЦївьЙЙЃЌCPUЁЂФкДцЁЂЭјТчЁЂДХХЬХфжУВЛЭЌЃЌетжжвьЙЙЛЗОГгжвЊдѕУДАьЁЃ
ДгЩЯУцЭМжаПЩвдПДГіЃКШчЙћЪЕЪБзївЕЕФtaskКЭХњДІРэзївЕЕФtaskБЛЕїЖШЕНвЛЬЈЛњЦїЩЯСЫЃЌШчЙћХњДІРэзївЕАбзЪдДеМТњСЫЃЈР§ШчЭјТчДјПэЃЉЃЌдђЪЕЪБзївЕЕФtaskБиНЋЪеЕНгАЯьЁЃЫљвдЃЌашвЊЖдЪЕЪБзївЕКЭХњДІРэзївЕзіИєРыВХааЁЃ
зізЪдДИєРыЃЌЮвУЧЕФЫМТЗЪЧВЩгУБъЧЉЛЏЃЌИјУПИіNodeManagerИГгшВЛЭЌБъЧЉЃЌБэЪОВЛЭЌЛњЦїБЛЗжХфСЫВЛЭЌБъЧЉЃЛзЪдДЖгСавВИГгшВЛЭЌБъЧЉЃЌШЛКѓдкRMЕїЖШЪБЃЌБЃжЄЯрЭЌБъЧЉЕФЖгСаРяШнЦїзЪдДБиДгЯрЭЌБъЧЉЕФNodeManagerЩЯЗжХфЕФЁЃетбљОЭПЩвдЭЈЙ§БъЧЉЕФВЛЭЌДяЕНЮяРэЩЯЕФзЪдДИєРыФПБъЁЃ
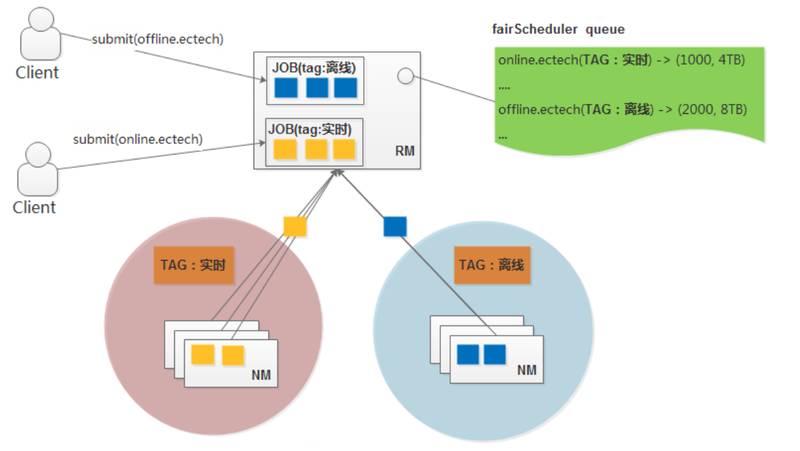
етеХЭМЪЧЪЕЯжЭМЁЃЪзЯШПЩвдПДЕНNodeManagerЗжГЩСЫСНИіМЏКЯЃЌвЛИіЪЧЪЕЪБЕФЃЌвЛИіЪЧРыЯпЕФЃЌВЛЭЌЕФЖгСавВБЛИГгшСЫЪЕЪБЛђРыЯпЕФБъЧЉЃЌЕБгУЛЇЬсНЛвЛИіjobЕФЪБКђЫќПЩвджИЖЈвЛИіЖгСаЃЌЬсНЛЕНРыЯпЖгСаРяОЭЪЧРыЯпШЮЮёЃЌResourceManagerОЭЛсАбетИізївЕЫљашвЊЕФзЪдДЗжХфЕНРыЯпБъЧЉЕФNodeManagerЩЯЃЌетбљОЭПЩвдзіЕНЮяРэзЪдДИєРыЁЃ
ЮДРДЙцЛЎ
вдЩЯжївЊЪЧНщЩмСЫЮвУЧзюНќвЛФъАызіЕФвЛаЉЙЄзїЁЃНгЯТРДЮвЛсНщЩмвЛЯТЮДРДЕФЙцЛЎЁЃЪзЯШОЭЪЧЩюЖШбЇЯАЁЃетИіИХФюНёФъЗЧГЃЛ№БЌЃЌЩѕжСЪЧвЊБЌеЈСЫЃЌЩюЖШбЇЯАдк58етПщашЧѓвВЪЧТљЧПСвЕФЁЃФПЧАЩюЖШбЇЯАЙЄОпгаетУДЖрЃЌcaffeЁЂtheanoЁЂtorchЕШЕШЗЧГЃЖрЃЌдѕУДзіећКЯЃЌдѕУДНЕЕЭЪЙгУГЩБОЃЌетЪЧЕквЛИіЮЪЬтЁЃЕкЖўИіЮЪЬтЃЌЛњЦїЪЧгаЯоЕФЃЌдѕУДИпаЇРћгУзЪдДЃЌашвЊАбЛњЦїЗжХфФЃЪНБфГЩзЪдДЗжХфФЃЪНЁЃЛЙгаЙтгаЕЅЛњЕФЛњЦїбЇЯАЛђепЩюЖШбЇЯАЙЄОпЛЙВЛЙЛЃЌвђЮЊадФмЬЋВюЃЌЫљвдЮвУЧашвЊНЋЩюЖШбЇЯАбЕСЗЗжВМЪНЛЏЁЃЮвУЧзіСЫвЛИіГѕВНЕФВтЪдЃЌеыЖдcaffeгыTensorflowЙЄОпЕФЗжВМЪНЛЏбЕСЗзіСЫБШНЯЃЌ4ПЈЯрЖдгкЕЅПЈФЃаЭбЕСЗадФмЬсЩ§100%~170%ЃЌЫљвдЗжВМЪНЛЏЕФЙЄзїБОЩэвтвхвВЪЧЗЧГЃДѓЕФЁЃ
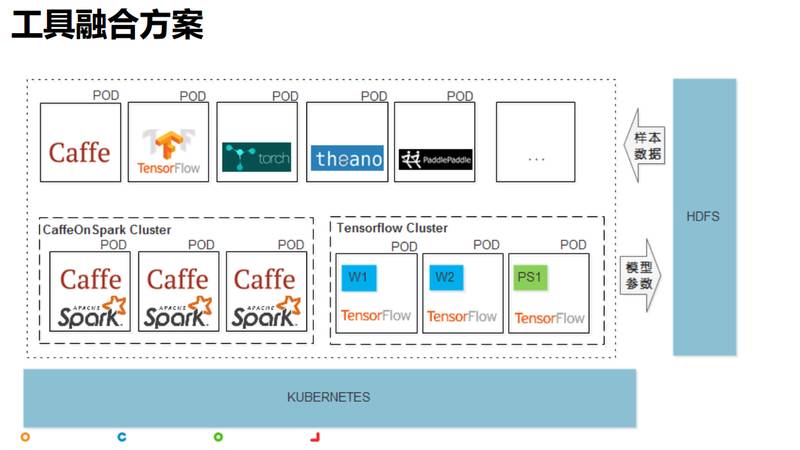
етИіЭМеЙЪОЕФЪЧЙЄОпШкКЯЗНАИЁЃЮвУЧетРяРћгУЕФЪЧKubernetesЃЌжЇГжжїСїЕФЩюЖШбЇЯАЙЄОпЃЌУПИіЙЄОпзіГЩОЕЯёаЮГЩPODЃЌгУЛЇашвЊЕФЛАПЩвджБНгАбPODЗжЗЂИјЫћЃЌгУЛЇдкбЕСЗЕФЪБКђДгHDFSЩЯжБНгРШЁбљБОЃЌВЂЧвАббЕСЗЕФВЮЪ§ЛиаДЕНHDFSЩЯЃЌвВОЭЪЧЫЕЭЈЙ§HDFSзіЪ§ОнЕФЙВЯэЃЌЭЈЙ§етжжФЃЪНПЩвдКмЧсЫЩЕижЇГжЖржжЩюЖШбЇЯАЙЄОпЃЌвВПЩвдДяЕНАДЫљашзЪдДСПНјаазЪдДЕФЗжХфФПБъЁЃ
СэЭтЮвУЧЛсзівЛИіЩюЖШбЇЯАЙЄОпЗжВМЪНЕФИФдьЃЌЪЧеыЖдcaffeЃЌЮвУЧгУЕФЪЧCaffeOnSparkЃЌМДАбећИіЗжВМЪНЕФЗНАИзіГЩФЃАхЙЉгУЛЇЪЙгУЁЃЪзЯШЦєЖЏЖрИіPODЃЌЭЈЙ§PODЦєЖЏвЛИіSparkМЏШКЃЌШЛКѓдйЬсвЛИіSpark
jobРДзібЕСЗЃЌзюКѓдкећИібЕСЗНсЪјжЎКѓдйАбМЏШКЭЃЕєЁЃTensorflowвВЪЧвЛбљЕФЃЌЪзЯШЦєЖЏtensorflowМЏШКЃЌШЛКѓЬсНЛШЮЮёЃЌШЮЮёбЕСЗЭъвдКѓдйАбМЏШКЭЃЕєЁЃЦфЫћЙЄОпЗжВМЪНЛЏЮвУЧвВЛсВЩШЁРрЫЦЕФЫМТЗНтОіЁЃвдЩЯЪЧЙигкЩюЖШбЇЯАетПщЮвУЧФПЧАЕФвЛаЉЙЄзїЁЃ

ЦфДЮЃЌЪЧЙигкПеМфзЪдДРћгУТЪЕФЁЃФПЧАЮвУЧгавЛЧЇЖрЬЈЛњЦїЃЌДцДЂЪЧКмДѓЕФГЩБОЁЃжЎЧАвВЬсЕНСЫЃЌЮвУЧЪЧЪєгкЛЈЧЎЕФВПУХЃЌЫљвдбЙСІЗЧГЃДѓЁЃФЧдѕУДНкЪЁГЩБОЪЧвЛИіКмживЊЕФЮЪЬтЁЃГ§СЫДЋЭГбЙЫѕжЎЭтЃЌЛЙФмзіЪВУДЃПHDFS
RAIDЪЧвЛИіБШНЯКУЕФНтОіЗНАИЁЃHDFS RAIDВЩгУЪЧRCБрТыЃЌРрЫЦRAID6ЃЌБШШчвЛИіЮФМўгаmИіПщЃЌИљОнmИіПщЩњГЩkИіаЃбщПщЃЌШЛКѓФмБЃжЄkИіПщЖЊЪЇЕФЧщПіЯТЪ§ОнЛЙФмевЛиРДЃЌОйИіР§згРДЫЕЃЌБШШчЮФМў2.5GДѓаЁЃЌ256MвЛИіПщЃЌПЩвдЗжГЩ10ИіПщЃЌИљОнRCЫуЗЈдйЩњГЩ4ИіаЃбщПщЃЌПЩвдБЃжЄЖЊСЫ4ИіПщЧщПіЯТЃЌЪ§ОнЖМФмевЛиРДЁЃдкетИіР§згжаЃЌ3ИББОЧщПіЯТЃЌвЛЙВашвЊ30ИіПщЃЌЖјВЩгУHDFS
RAIDЃЌНіашвЊ14ИіПщЁЃЕЋЫћУЧЕФПЩППадвЛбљЃЌПеМфеМгУЧщПіШДВюСЫ57%ЁЃ
ОпЬхЪЕЪЉЪБЃЌЕквЛВНЖдМЏШКЪ§ОнНјааРфШШЗжЮіЃЌRAIDБЯОЙгааЉадФмЮЪЬтЃЌвЛЕЉЪ§ОнгаЮЪЬтЃЌФувЊЭЈЙ§МЦЫуВХФмЛжИДЃЌЪЦБиЛсдьГЩадФмЕЭЯТЃЌЫљвдеыЖдРфЪ§ОнзіПЯЖЈЪЧЗчЯезюЕЭЕФЁЃЕкЖўВНОЭЪЧбЙЫѕ+archive+RAIDЃЌЭЈЙ§Ш§ЗНУцММЪѕНсКЯАбЮФМўЪ§КЭПеМфШЋВПНкЪЁГіРДЁЃЙщЕЕЪЕМЪЩЯЪЧЛсБфЛЛФПТМЕФЃЌЮЊСЫзіЪЪХфЃЌЮвУЧЭЈЙ§ШэСЌНгЙІФмЃЌзіЕНЖдгУЛЇЭИУїЁЃзюКѓдкЪ§ОнЖСШЁЪБЃЌШчЙћЪЧRAIDЪ§ОнЃЌОЭвЊОпБИЪЕЪБRAIDаоИДЙІФмВХФмБЃжЄдкЪ§ОнШБЪЇЕФЧщПіЯТВЛгАЯьЪ§ОнЕФЗУЮЪЁЃ
КѓајЮвУЧЛсЖдМЦЫузЪдДРћгУТЪдйзіНјвЛВНЬсЩ§ЁЃСэЭтвВЛсПМТЧStormКЭYARNРЉеЙадЁЃЛЙгаKubernetesЕїЖШгХЛЏЃЌБШШчеыЖдGPUзЪдДЙмРэЙІФмЁЃ
вдЩЯОЭЪЧЮвНёЬьЯыНщЩмЕФШЋВПФкШнЁЃдкНсЪјжЎЧАЧыдЪаэЮвдйзівЛЯТзмНсЁЃ
ЪзЯШЮвНщЩмСЫ58ФПЧАЕФДѓЪ§ОнЦНЬЈМмЙЙЪЧдѕУДбљЕФЃЌМђЕЅРДЫЕОЭЪЧЁА342ЁБЃЌШ§ИіВуДЮЁЂЯИЗжЮЊЫФИізгВуЁЂХдБпСНСаЁЃЫљвдДѓМввЊзіДѓЪ§ОнЦНЬЈНЈЩшЙЄзїЃЌетМИИіЗНУцЪЧБиБИЕФЁЃ
ЕкЖўИіЗНУцЮвжиЕуЕФНщЩмСЫ58дквЛФъАыЕФЪБМфФкЕФММЪѕИФНјЁЃЕквЛЕуЪЧЙигкЮШЖЈадЃЌжївЊДгFlumeКЭHDFSРЉеЙадЗНУцжиЕуНщЩмСЫЮвУЧЕФНтОіЗНАИЃЌОйСЫШ§ИіАИР§РДЫЕУїЭЛЗЂЮЪЬтЃЌВЛЪЧЫЕгаСЫПЩгУадКЭРЉеЙадОЭЭђЪТOKСЫЃЌЛЙвЊНтОіЭЛЗЂЮЪЬтЁЃеыЖдЦНЬЈжЮРэЪзЯШНщЩмСЫвЛЯТЪ§ОнКЭзЪдДЕФжЮРэЗНЗЈЃЌНгзХгжНщЩмСЫЙигквзгУадЗНУцЕФИФНјЃЌЮвУЧЬсЙЉСЫвЛЯЕСаЦНЬЈРДЬсИпПЊЗЂШЫдБЕФПЊЗЂаЇТЪЁЃ
ЕкШ§ЗНУцДгадФмЩЯНщЩмСЫЮвУЧетБпзіЕФгХЛЏЙЄзївдМАгХЛЏЕФНсЙћЪЧдѕУДбљЕФЃЛ
ЕкЫФЗНУцНщЩмСЫдквьЙЙЛЗОГЯТШчКЮжЇГжВЛЭЌЬиеїЕФзївЕНјааКЯРэЕїЖШЁЃ
зюКѓЮвНщЩмСЫ58ЩюЖШбЇЯАЦНЬЈНЈЩшЗНУцвдМАДцДЂзЪдДПеМфРћгУТЪгХЛЏЗНУцЕФФкШнЁЃвдЩЯОЭЪЧЮвНёЬьЕФШЋВПФкШнЃЌЯЃЭћЖдДѓМвгаАяжњЁЃ
|









