1. Ī≥ĺį
«į∂ő Īľšĺ©∂ęĻęŅ™Ńň√śŌÚĶŕ∂ĢłŲ ģ∂ĢńÍĶń’Ŭ‘ĻśĽģ£¨ĪŪ ĺĺ©∂ęĹę»ę√ś◊ŖŌÚľľ űĽĮ£¨īůѶ∑Ę’Ļ»ňĻ§÷«ń‹ļÕĽķ∆ų»ň◊‘∂ĮĽĮľľ ű£¨ĹęĻż»•īęÕ≥∑Ĺ ĹĻĻ÷ĢĶń”Ň ∆»ę√ś…żľ∂°£ĺ©∂ęY ¬“Ķ≤Ņň≥ ∆≥…ŃĘ£¨ł√ ¬“Ķ≤ŅĹę“‘∑ĢőŮ∑ļŃ„ Řő™ļň–ń£¨◊Ň÷ō÷«ń‹Ļ©”¶ń‹Ń¶ĶńīÚ‘ž£¨ļň–ń Ļ√Ł «ņŻ”√»ňĻ§÷«ń‹ľľ űņī«ż∂ĮŃ„ ŘłÔ–¬°£
1.1 ĺ©∂ęĶńĻ©”¶Ńī
ĺ©∂ę“Ľ÷Ī÷¬Ń¶”ŕÕ®ĻżĽ•Ń™ÕÝĶÁ…ŐĹ®ŃĘ–Ť«ů≤ŗ”ŽĻ©łÝ≤ŗĶńĺę◊ľ°ĘłŖ–ß∆•Ňš£¨Ļ©”¶ŃīĻ‹ņŪ «Ń„ ŘŃ™Ķų÷–Ķńļň–ńń‹Ń¶£¨ «Ń„ Ř∆ĹŐ®ń‹Ń¶ĶńĻōľŁŐŚŌ÷£¨“≤ «Ļ©”¶…Ő”Žĺ©∂ęĹŰ√‹ļŌ◊ųĶńҶīÝ£¨łŁ «őīņīĺ©∂ę÷«ń‹ĽĮ…Ő“ĶŐŚ≤ľĺ÷÷–Ķńļň–ńĽ∑Ĺŕ°£
ńŅ«įĺ©∂ę‘ŕ»ęĻķ∑∂őßńŕĶń‘ň”™256łŲīů–Õ≤÷Ņ‚£¨įīĻ¶ń‹Ņ…Ľģ∑÷ő™RDC°ĘFDC°ĘīůľĢ÷––ń≤÷°ĘīůľĢőņ–«≤÷°ĘÕľ ť≤÷ļÕ≥« –≤÷Ķ»Ķ»°£RDC£®Regional Distribution Center£©ľī«Ý”Ú∑÷∑Ę÷––ń£¨Ņ…ņŪĹ‚ő™“Ľľ∂≤÷Ņ‚£¨ŌÚĻ©Ľű…Ő≤…ĻļĶń…Ő∆∑ĽŠ”ŇŌ»ňÕÕý’‚ņÔ£¨“Ľį„…Ť÷√‘ŕ÷––ń≥« –£¨ł≤ł«∑∂őßīů°£FDC£®Forward Distribution Center£©ľī«Ý”Ú‘ň◊™÷––ń£¨Ņ…ņŪĹ‚ő™∂Ģľ∂≤÷Ņ‚£¨ł≤ł«“Ľ–©÷–°Ę–°–Õ≥« –ľįĪŖ‘∂Ķō«Ý£¨Õ®≥£ĽŠłýĺ›–Ť«ůĹę…Ő∆∑ī”RDCĶųŇšĻżņī°£

ĹŠļŌ»ňĻ§÷«ń‹°Ęīů żĺ›Ķ»ľľ ű£¨ĺ©∂ę ◊Ō»ī”Ļ©Ľű…Őń«ņÔļŌņŪ≤…Ļļ∂®ŃŅĶń…Ő∆∑ĶĹRDC£¨‘Ŕłýĺ› Ķľ –Ť«ůĶųŇšĶĹFDC£¨»Ľļů‘ňÕýņŽŅÕĽß◊ÓĹŁĶńŇšňÕ’ĺ£¨◊ÓļůŅžĶ›‘ĪĹę…Ő∆∑īÝĶĹŅÕĽß ÷÷–°£’‚÷Ľ «ĺ©∂ęĻ©”¶ŃīŐŚŌĶ÷–“ĽłŲ∆’Õ®Ķń≥°ĺį£¨Ķę’ż“Úő™”–’‚—ýĶńŐŚŌĶ£¨ ĻĶ√ĺ©∂ę∂‘”√ĽßĶńŌž”¶ňŔ∂»īůīůŐŠłŖ£¨”√ĽßŐŚ—ťīůīůŐŠ…ż°£
1.2 ĺ©∂ęĻ©”¶Ńī”ŇĽĮ
”√ĽßŐŚ—ťŐŠ…żĶńÕ¨ Ī“≤įťňś◊ŇīůŃŅ◊ ĹūĶńÕ∂»ŽļÕ≥…ĪĺĶńŐŠłŖ£¨≥…ĪĺĪō–ŽĶ√ĶĹŅō÷∆£¨’ŻłŲŐŚŌĶ≤Ňń‹∑ĘĽ”≥Ų◊ÓīůĶńľŘ÷Ķ£¨”ŕ «∂‘Ļ©”¶ŃīĶń”ŇĽĮĺÕŌ‘Ķ√÷ŃĻō÷ō“™Ńň°£
ĺ©∂ę◊‘īÚĹ®ŃĘĻ©”¶Ń¨ŐŚŌĶĶńń«“ĽŐž∆ū£¨ĺÕ≤Ľ∂ŌĶōĹÝ––łńĹÝļÕ”ŇĽĮ£¨≤Ę«“ҨѶ…Ó»ŽĶĹĻ©”¶ŃīĶń√Ņ“ĽłŲĽ∑Ĺŕ°£”ŇĽĮ∆š Ķ «“Ľ√Ň‘ň≥Ô—ßő Ő‚£¨–ŤŅľ¬«‘ŕłų÷÷ĺŲ≤ŖńŅĪÍ÷ģľš»Áļő∆Ĺļ‚“‘īÔĶĹ◊Óīů ’“ś£¨‘ŕ’‚łŲĻż≥Ő÷––Ť“™Ņľ¬«ļ‹∂ŗő Ő‚£¨į—’‚–©Ņľ¬««Ś≥Ģ£¨ő Ő‚ĺÕ»›“◊Ĺ‚ĺŲŃň°£ĺŔľłłŲľÚĶ•Ķńņż◊”£ļ
- …Ő∆∑≤ĻĽű£ļŅľ¬«‘ŕ ≤√ī Īľš£¨łÝńńłŲRDC≤…Ļļ ≤√ī…Ő∆∑£¨≤…ĻļŃŅ «∂ŗ…Ŕ£Ņ
- …Ő∆∑Ķų≤¶£ļŅľ¬«‘ŕ ≤√ī Īľš£¨łÝńńłŲFDCĶųŇš ≤√ī…Ő∆∑£¨ĶųŇšŃŅ «∂ŗ…Ŕ£Ņ
- ≤÷īĘ‘ň”™£ļ‘ŕīůīŔņīŃŔ÷ģľ £¨≤÷Ņ‚ļÕŇšňÕ’ĺ“™‘ŲŇš∂ŗ…Ŕ»ň ÷°Ę∂ŗ…ŔŃĺĽű≥Ķ£Ņ
ňš»ĽŅī…Ō»•’‚–©ő Ő‚∂ľļ‹»›“◊Ľōīū£¨Ķę◊–ŌłŌŽŌŽ»ī”÷ļ‹ń—łÝ≥Ųīūįł£¨‘≠“ÚĺÕ‘ŕ”ŕŌŽ“™◊ŲĶĹĺę»∑≤Ľ «ń«√ī»›“◊Ķń ¬«ť£¨ĺÕń√≤ĻĽűņīňĶ£¨≤ĻĶńŐę∂ŗĽŠ‘Ųľ”Ņ‚īś≥…Īĺ£¨≤ĻĶńŐę…ŔĽŠ‘Ųľ”»ĪĽű≥…Īĺ£¨÷Ľ”–ļŌņŪĶń≤ĻĽűŃŅ≤Ňń‹◊ŲĶĹ≥…Īĺ◊ÓĶÕ°£
1.3 ‘§≤‚ľľ ű‘ŕĺ©∂ęĻ©”¶ŃīĶń◊ų”√
ĹŤ÷ķĽķ∆ų—ßŌį°Ęīů żĺ›Ķ»ŌŗĻōľľ ű£¨ĺ©∂ę‘ŕļ‹∂ŗĻ©”¶Ńī”ŇĽĮő Ő‚…Ō∂ľ“—ĺ≠ ĶŌ÷ŌĶÕ≥ĽĮ£¨”…ŌĶÕ≥◊‘∂ĮłÝ≥Ų”ŇĽĮĹ®“ť£¨≤Ę”Ž…ķ≤ķŌĶÕ≥ŌŗѨŔ£¨ ĶŌ÷»ęŃų≥Ő◊‘∂ĮĽĮ°£‘ŕ’‚ņÔ”–“ĽŌÓľľ ű∆ū◊Ň÷ŃĻō÷ō“™ĶńĶÕ≤„÷ß≥Ň◊ų”√--‘§≤‚ľľ ű°£ĺ›ī÷¬‘Ļņň„£¨1%Ķń‘§≤‚◊ľ»∑∂»ĶńŐŠ…żŅ…“‘Ĺŕ‘ľ żĪ∂Ķń‘ň”™≥…Īĺ°£
‘ű—ýņŪĹ‚‘§≤‚‘ŕĻ©”¶Ńī”ŇĽĮ÷–Ķń◊ų”√ńōń√…Ő∆∑≤ĻĽűĺŔņż£¨“Ľľ“Ļęňĺő™ŃňĪ£÷§Ņ‚∑Ņ≤Ľ»ĪĽű£¨Ņ…ń‹ĽŠ∆Ķ∑ĪĶńī”Ļ©Ľű…Őń«ņÔ≤Ļ≥šīůŃŅ…Ő∆∑£¨’‚—ý◊Ųňš»Ľ≤ĽĽŠ»ĪĽű£¨ĶęŅ…ń‹ĽŠ‘ž≥…łŁ∂ŗ¬Ű≤Ľ≥Ų»•Ķń…Ő∆∑Ľż—Ļ‘ŕ≤÷Ņ‚÷–£¨ī”∂Ý Ļ…Ő∆∑Ķń÷‹◊™¬ ĹĶĶÕ£¨Ņ‚īś≥…Īĺ‘Ųľ”°£∑ī÷ģ£¨’‚ľ“Ļęňĺ”–Ņ…ń‹ő™Ńň◊∑«ůŃ„Ņ‚īś∂Ý≤Ļļ‹…ŔĶń…Ő∆∑£¨Ķę’‚ĺÕŅ…ń‹≥ŲŌ÷—Ō÷ōĶń»ĪĽűő Ő‚£¨ī”∂Ý ĻŌ÷Ľű¬ ĹĶĶÕ£¨—Ō÷ō”įŌž”√ĽßŐŚ—ť£¨»ĪĽű≥…Īĺ‘Ųľ”°£”ŕ «ő Ő‚ĺÕņīŃň£¨“™≤Ļ∂ŗ…Ŕ…Ő∆∑≤ŇļŌ £¨ ≤√ī Īľš≤ĻĽű£¨’‚ĺÕ–Ť“™»®ļ‚Ņľ¬«Ńň£¨◊Ó÷’ńŅĶń «“™ ĻŅ‚īś≥…ĪĺļÕ»ĪĽű≥…ĪĺīÔĶĹ“ĽłŲ∆Ĺļ‚°£
Ņľ¬«“ĽŌ¬ľę∂ň«ťŅŲ£¨Ķ»Ņ‚īśĹĶĶĹŃ„ Ī‘Ŕ»•≤ĻĽű£¨’‚ ĪĻ©Ľű…ŐĹ”ĶĹ≤ĻĽűÕ®÷™ļůĹęĽűőÔ‘ňÕý≤÷Ņ‚°£Ķę «’‚√ī◊Ų”–łŲő Ő‚£¨“Úő™‘ňňÕĻż≥Ő–Ť“™ Īľš£¨’‚∂ő ĪľšŅ‚∑ŅĺÕ»ĪĽűŃň°£ń«‘ű√īįžńōĺÕ «ņŻ”√‘§≤‚ľľ ű°£ņŻ”√‘§≤‚ő“√«Ņ…“‘ľ∆ň„≥Ųőīņī…Ő∆∑‘ŕÕĺĶń’‚∂ő ĪľšņÔŌķŃŅīůłŇ «∂ŗ…Ŕ£¨»Ľļůő“√«»√≤÷Ņ‚Ī£÷§’‚łŲŃŅ£¨ĶÕ”ŕ’‚łŲŃŅĺÕłÝĻ©Ľű…ŐŌ¬īÔ≤ĻĽűÕ®÷™£¨”ŕ «ő Ő‚Ķ√“‘Ĺ‚ĺŲ°£◊‹∂Ý—‘÷ģ£¨‘§≤‚ľľ ű‘ŕ’‚ņÔ∑ĘĽ”Ńň÷ō“™Ķń◊ų”√£¨≥…ő™ĻōľŁĶń“ĽłŲĽ∑°£
2. ĺ©∂ꑧ≤‚ŌĶÕ≥
2.1 ‘§≤‚ŌĶÕ≥Ĺť…‹

‘§≤‚ŌĶÕ≥‘ŕ’ŻłŲĻ©”¶ŃīŐŚŌĶ÷–ī¶‘ŕ◊ÓĶ◊≤„≤Ę«“∆ūĶĹ“ĽłŲ÷ß≥ŇĶń◊ų”√£¨÷ß≥÷…Ō≤„Ķń∂ŗłŲĺŲ≤Ŗ”ŇĽĮŌĶÕ≥£¨∂Ý’‚–©ĺŲ≤Ŗ”ŇĽĮŌĶÕ≥ņŻ”√ĺę◊ľĶń‘§≤‚ żĺ›ĹŠļŌ‘ň≥Ô—ßľľ űĶ√≥Ų◊Ó”ŇĶńĺŲ≤Ŗ£¨≤ĘĹęĹŠĻŻŐŠĻ©łÝłŁ…Ō≤„Ķń“ĶőŮ÷ī––ŌĶÕ≥ĽÚ «“ĶőŮ∑Ĺ÷ĪĹ” Ļ”√°£
ńŅ«į£¨‘§≤‚ŌĶÕ≥÷ų“™÷ß≥÷»żīů“ĶőŮ£ļŌķŃŅ‘§≤‚°ĘĶ•ŃŅ‘§≤‚ļÕGMV‘§≤‚°£∆š÷–ŌķŃŅ‘§≤‚÷ų“™÷ß≥÷…Ő∆∑≤ĻĽű°Ę…Ő∆∑Ķų≤¶£ĽĶ•ŃŅ‘§≤‚÷ų“™÷ß≥÷≤÷Ņ‚°Ę’ĺĶ„Ķń‘ň”™Ļ‹ņŪ£ĽGMV‘§≤‚÷ų“™÷ß≥÷Ōķ Ř≤Ņ√Ňľ∆ĽģĶń∂®÷∆°£
ŌķŃŅ‘§≤‚įī’’≤ĽÕ¨ő¨∂»”÷Ņ…“‘∑÷ő™RDC≤…Ļļ‘§≤‚°ĘFDCĶų≤¶‘§≤‚°Ę≥« –≤÷Ķų≤¶‘§≤‚°ĘīůĹ®≤÷≤ĻĽű‘§≤‚°Ę»ę«ÚĻļŌķŃŅ‘§≤‚ļÕÕľ ťīŔŌķ‘§≤‚Ķ»£ĽĶ•ŃŅ‘§≤‚”÷Ņ…∑÷ő™Ņ‚∑ŅĶ•ŃŅ‘§≤‚°ĘŇšňÕ÷––ńĶ•ŃŅ‘§≤‚ļÕŇšňÕ’ĺĶ•ŃŅ‘§≤‚Ķ»£®‘ŕ’‚ņÔ°įĶ•ŃŅ°Ī≤Ę∑«÷ł”√ĽßňýŌ¬∂©Ķ•ĶńŃŅ£¨∂Ý «Ĺę∂©Ķ•≤ūĶ•ļůŃų◊™ĶĹ≤÷Ņ‚÷–ĶńĶ•ŃŅ°£ņż»Á“ĽłŲ”√ĽßĶń∂©Ķ•÷–įŁņ®3ľĢőÔ∆∑£¨∆š÷–ŃĹłŲīůľĢ∆∑ļÕ“ĽłŲ–°ľĢ∆∑£¨‘ŕĺ©∂ęĶńĻ©”¶ŃīĽ∑Ĺŕ÷–Ņ…ń‹ĽŠĹę∆š÷–ŃĹłŲīůľĢ∆∑◊ť≥…“ĽłŲĶ•Õ∂∑ŇĶĹīůľĢ≤÷÷–£¨∂ÝĹęń«łŲ–°ľĢĶ•∂ņ“ĽłŲĶ•Õ∂∑ŇĶĹ–°ľĢ≤÷÷–£¨Ķ•ŃŅ÷łĶń «≤ūĶ•ļůĶńŃŅ£©£ĽGMV‘§≤‚÷ß≥÷ĶĹ…Ő∆∑Ń£∂»°£
2.2 ‘§≤‚ŌĶÕ≥ľ‹ĻĻ
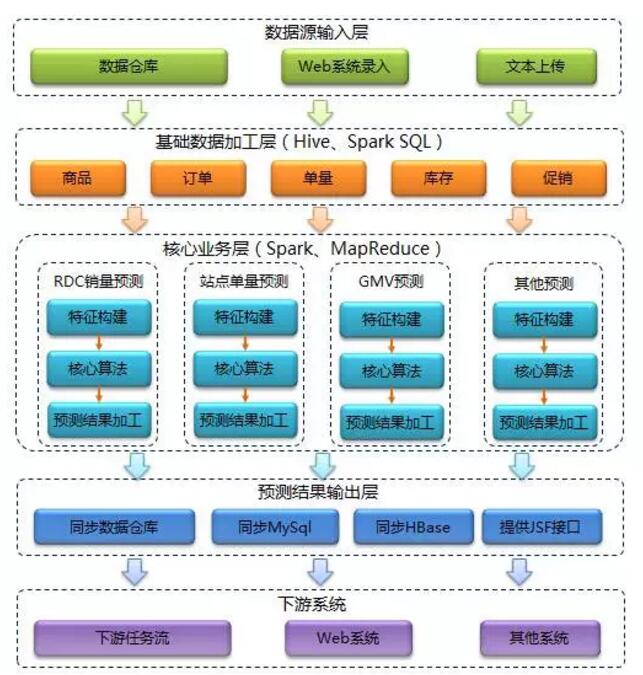
’ŻŐŚľ‹ĻĻī”…Ō÷ŃŌ¬“ņīő «£ļ żĺ›‘ī š»Ž≤„°ĘĽýī° żĺ›ľ”Ļ§≤„°Ęļň–ń“ĶőŮ≤„°Ę żĺ› š≥Ų≤„ļÕŌ¬”őŌĶÕ≥°£ ◊Ō»ī”Õ‚≤Ņ żĺ›‘īĽŮ»°ő“√«ňý–ŤĶń“ĶőŮ żĺ›£¨»Ľļů∂‘Ľýī° żĺ›ĹÝ––ľ”Ļ§«ŚŌī£¨‘ŔÕ®Ļż Īľš–ÚŃ–°ĘĽķ∆ų—ßŌįĶ»»ňĻ§÷«ń‹ľľ ű∂‘ żĺ›ĹÝ––ī¶ņŪ∑÷őŲ£¨◊Óļůľ∆ň„≥Ų‘§≤‚ĹŠĻŻ≤ĘÕ®Ļż∂ŗ÷÷Õĺĺ∂Õ∆ňÕłÝŌ¬”őŌĶÕ≥ Ļ”√°£
- żĺ›‘ī š»Ž≤„£ļĺ©∂ę żĺ›≤÷Ņ‚÷–īśīĘ◊Ňő“√«–Ť“™Ķńīů≤Ņ∑÷“ĶőŮ żĺ›£¨ņż»Á∂©Ķ•–ŇŌĘ°Ę…Ő∆∑–ŇŌĘ°ĘŅ‚īś–ŇŌĘĶ»Ķ»°£∂Ý∂‘”ŕīŔŌķľ∆Ľģ żĺ›‘Úīů≤Ņ∑÷ņī◊‘”ŕ≤…Ōķ»ň‘ĪÕ®ĻżWebŌĶÕ≥¬ľ»ŽĶń–ŇŌĘ°£≥żīň÷ģÕ‚ĽĻ”–“Ľ–°≤Ņ∑÷ żĺ›Õ®ĻżőńĪĺ–ő Ĺ÷ĪĹ”…ŌīęĶĹHDFS÷–°£
- Ľýī° żĺ›ľ”Ļ§≤„£ļ‘ŕ’‚“Ľ≤„÷ų“™Õ®ĻżHive∂‘Ľýī° żĺ›ĹÝ––“Ľ–©ľ”Ļ§«ŚŌī£¨»•ĶŰ≤Ľ–Ť“™Ķń◊÷∂ő£¨Ļż¬ň≤Ľ–Ť“™Ķńő¨∂»≤Ę«ŚŌī”–ő Ő‚Ķń żĺ›°£
- ļň–ń“ĶőŮ≤„£ļ’‚≤„ «ŌĶÕ≥ĶńĶńļň–ń≤Ņ∑÷£¨ļŠŌÚŅī”÷Ņ…∑÷ő™»ż≤„£ļŐō’ųĻĻĹ®°Ę‘§≤‚ň„∑®ļÕ‘§≤‚ĹŠĻŻľ”Ļ§°£◊›ŌÚŅī «”…∂ŗŐű“ĶőŮŌŖ◊ť≥…£¨Īňīň÷ģľš≤Ľ∑Ę…ķ»őļőĹĽľĮ°£
- Őō’ųĻĻĹ®£ļĹę÷ģ«į«ŚŌīĻżĶńĽýī° żĺ›Õ®ĻżĹŁ“Ľ≤ĹĶńī¶ņŪ◊™ĽĮ≥…ĪÍ◊ľłŮ ĹĶńŐō’ų żĺ›£¨ŐŠĻ©łÝļů–Ýň„∑®ń£–Õ Ļ”√°£
- ļň–ńň„∑®£ļņŻ”√ Īľš–ÚŃ–∑÷őŲ°ĘĽķ∆ų—ßŌįĶ»»ňĻ§÷«ń‹ľľ űĹÝ––ŌķŃŅ°ĘĶ•ŃŅĶń‘§≤‚£¨ «‘§≤‚ŌĶÕ≥÷–◊Óő™ļň–ńĶń≤Ņ∑÷°£
- ‘§≤‚ĹŠĻŻľ”Ļ§£ļ‘§≤‚ĹŠĻŻŅ…ń‹‘ŕłŮ ĹļÕ“Ľ–©Őō ‚–‘“™«ů…Ō≤Ľń‹¬ķ◊„Ō¬”őŌĶÕ≥£¨ňý“‘ĽĻ–Ť“™łýĺ› Ķľ «ťŅŲ∂‘∆šĹÝ––ľ”Ļ§ī¶ņŪ£¨Ī»»Á‘Ųľ”ĪÍ◊ľ≤Ó°ĘīŔŌķĪÍ ∂Ķ»∂ÓÕ‚–ŇŌĘ°£
- ‘§≤‚ĹŠĻŻ š≥Ų≤„£ļĹę◊Ó÷’‘§≤‚ĹŠĻŻÕ¨≤ĹĽōĺ©∂ę żĺ›≤÷Ņ‚°ĘMySql°ĘHBaseĽÚ÷∆◊ų≥…JSFĹ”ŅŕĻ©∆šňŻŌĶÕ≥‘∂≥ŐĶų”√°£
- Ō¬”őŌĶÕ≥£ļįŁņ®Ō¬”ő»őőŮŃų≥Ő°ĘŌ¬”őWebŌĶÕ≥ļÕ∆šňŻŌĶÕ≥°£
3. ‘§≤‚ŌĶÕ≥ļň–ńĹť…‹
3.1 ‘§≤‚ŌĶÕ≥ļň–ń≤„ľľ ű—°–Õ
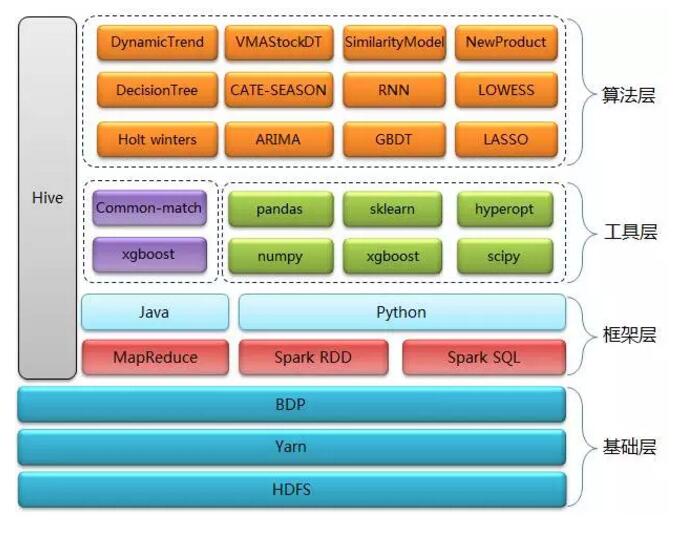
‘§≤‚ŌĶÕ≥ļň–ń≤„ľľ ű÷ų“™∑÷ő™ňń≤„£ļĽýī°≤„°ĘŅÚľ‹≤„°ĘĻ§ĺŖ≤„ļÕň„∑®≤„
Ľýī°≤„£ļ
HDFS”√ņī◊Ų żĺ›īśīĘ£¨Yarn”√ņī◊Ų◊ ‘īĶų∂»£¨BDP£®Big Data Platform£© «ĺ©∂ę◊‘ľļ—–∑ĘĶńīů żĺ›∆ĹŐ®£¨ő“√«÷ų“™”√ňŁņī◊Ų»őőŮĶų∂»°£
ŅÚľ‹≤„£ļ
“‘Spark RDD°ĘSpark SQL°ĘHiveő™÷ų£¨ MapReduce≥Ő–Ú’ľ“Ľ–°≤Ņ∑÷£¨ «‘≠Ō»“ŇŃŰŌ¬ņīĶń£¨ńŅ«į’ż÷ū≤ĹŐśĽĽ≥…Spark RDD°£ —°‘ŮSpark≥żŃň∂‘–‘ń‹ĶńŅľ¬«Õ‚£¨ĽĻŅľ¬«ŃňSpark≥Ő–ÚŅ™∑ĘĶńłŖ–߬ °Ę∂ŗ”Ô—‘Őō–‘“‘ľį∂‘Ľķ∆ų—ßŌįň„∑®Ķń÷ß≥÷°£‘ŕSparkŅ™∑ʔԗ‘…Ōő“√«—°‘ŮŃňPython£¨‘≠“Ú”–“‘Ō¬»żĶ„£ļ
- Python”–ļ‹∂ŗ≤ĽīŪĶńĽķ∆ų—ßŌįň„∑®įŁŅ…“‘ Ļ”√£¨Ī»∆ūSparkĶńMLlib£¨ň„∑®Ķń◊ľ»∑∂»łŁłŖ°£ő“√«”√GBDT◊ŲĻż∂‘Ī»£¨∑ĘŌ÷xgboostĪ»MLlibņÔ√śŐŠĻ©ĶńŐŠ…ż ųń£–Õ‘§≤‚◊ľ»∑∂»łŖ≥ŲīůłŇ5%~10%°£ňš»Ľ÷ĪĹ” Ļ”√Spark◊‘īÝĶńĽķ∆ų—ßŌįŅÚľ‹ĽŠĹŕ °ő“√«ĶńŅ™∑Ę≥…Īĺ£¨Ķꑧ≤‚◊ľ»∑∂»∂‘”ŕő“√«ņīňĶ÷ŃĻō÷ō“™£¨√ŅŐŠ…ż1%Ķń◊ľ»∑∂»£¨ĺÕŅ…ń‹ĽŠīÝņī≥…ĪĺĶń≥…Ī∂ĹĶĶÕ°£
- ő“√«ĶńÕŇ∂”÷–įŁņ®Ņ™∑ĘĻ§≥Ő ¶ļÕň„∑®Ļ§≥Ő ¶£¨∂‘”ŕň„∑®Ļ§≥Ő ¶∂Ý—‘ňŻ√«łŁ…√≥§ Ļ”√PythonĹÝ–– żĺ›∑÷őŲ£¨ Ļ”√JavaĽÚScalaĽŠ”–≤Ľ–°Ķń—ßŌį≥…Īĺ°£
- ∂‘Ī»∆šňŻ”Ô—‘£¨ő“√«∑ĘŌ÷ Ļ”√PythonĶńŅ™∑ʖ߬ «◊ÓłŖĶń£¨≤Ę«“∂‘”ŕ“ĽłŲ–¬»ň£¨—ßŌįPythonĪ»—ßŌį∆šňŻ”Ô—‘łŁľ”»›“◊°£
Ļ§ĺŖ≤„£ļ
“Ľ∑Ĺ√śő“√«ĽŠĹŠļŌ◊‘…Ū“ĶőŮ”–’Ž∂‘–‘ĶńŅ™∑Ę“Ľ–©ň„∑®£¨ŃŪ“Ľ∑Ĺ√śő“√«ĽŠ÷ĪĹ” Ļ”√“ĶĹÁĪ»ĹŌ≥… žĶńň„∑®ļÕń£–Õ£¨’‚–©ň„∑®∂ľ∑‚◊į‘ŕĶ໿∑ĹPythonįŁ÷–°£ő“√«Ī»ĹŌ≥£”√ĶńįŁ”–xgboost°Ęnumpy°Ępandas°Ęsklearn°ĘscipyļÕhyperoptĶ»°£
Xgboost£ļňŁ «Gradient Boosting MachineĶń“ĽłŲC++ ĶŌ÷£¨xgboost◊ÓīůĶńŐōĶ„‘ŕ”ŕ£¨ňŁń‹ĻĽ◊‘∂ĮņŻ”√CPUĶń∂ŗŌŖ≥ŐĹÝ––≤Ę––£¨Õ¨ Ī‘ŕň„∑®…Ōľ”“‘łńĹÝŐŠłŖŃňĺę∂»°£
numpy£ļ «PythonĶń“Ľ÷÷Ņ™‘īĶń ż÷Ķľ∆ň„ņ©’Ļ°£’‚÷÷Ļ§ĺŖŅ…”√ņīīśīĘļÕī¶ņŪīů–Õĺō’ů£¨Ī»Python◊‘…ŪĶń«∂Ő◊Ń–ĪŪĹŠĻĻ“™łŖ–ßĶń∂ŗ£®ł√ĹŠĻĻ“≤Ņ…“‘”√ņīĪŪ ĺĺō’ů£©°£
pandas£ļ «Ľý”ŕNumPy Ķń“Ľ÷÷Ļ§ĺŖ£¨ł√Ļ§ĺŖ «ő™ŃňĹ‚ĺŲ żĺ›∑÷őŲ»őőŮ∂ÝīīĹ®Ķń°£Pandas ń…»ŽŃňīůŃŅŅ‚ļÕ“Ľ–©ĪÍ◊ľĶń żĺ›ń£–Õ£¨ŐŠĻ©ŃňłŖ–ßĶō≤Ŕ◊ųīů–Õ żĺ›ľĮňý–ŤĶńĻ§ĺŖ°£
sklearn£ļ «Python÷ō“™ĶńĽķ∆ų—ßŌįŅ‚£¨÷ß≥÷įŁņ®∑÷ņŗ°ĘĽōĻť°ĘĹĶő¨ļÕĺŘņŗňńīůĽķ∆ų—ßŌįň„∑®°£ĽĻįŁļ¨ŃňŐō’ųŐŠ»°°Ę żĺ›ī¶ņŪļÕń£–Õ∆ņĻņ»żīůń£Ņť°£
scipy£ļ «‘ŕNumPyŅ‚ĶńĽýī°…Ō‘Ųľ”Ńň÷ŕ∂ŗĶń ż—ß°ĘŅ∆—ß“‘ľįĻ§≥Őľ∆ň„÷–≥£”√ĶńŅ‚ļĮ ż°£ņż»ÁŌŖ–‘īķ ż°Ę≥£őĘ∑÷∑Ĺ≥Ő ż÷Ķ«ůĹ‚°Ę–ŇļŇī¶ņŪ°ĘÕľŌŮī¶ņŪļÕŌ° Ťĺō’ůĶ»Ķ»°£
ň„∑®≤„£ļ
ő“√«”√ĶĹĶńň„∑®ń£–Õ∑«≥£∂ŗ£¨‘≠“Ú «ĺ©∂ęĶń…Ő∆∑∆∑ņŗ∆Ž»ę°Ę“ĶőŮłī‘”£¨–Ť“™łýĺ›≤ĽÕ¨Ķń«ťŅŲ≤…”√≤ĽÕ¨Ķńň„∑®ń£–Õ°£ő“√«”–“ĽłŲ∂ņŃĘĶńŌĶÕ≥ņīő™ň„∑®ń£–Õ”Ž…Ő∆∑÷ģľšĹ®ŃĘ∆•ŇšĻōŌĶ£¨”––©Ī»ĹŌłī‘”Ķń‘§≤‚“ĶőŮĽĻ–Ť“™ Ļ”√∂ŗłŲń£–Õ°£ő“√« Ļ”√Ķńň„∑®◊‹ŐŚ…ŌŅ…“‘∑÷ő™»żņŗ£ļ Īľš–ÚŃ–°ĘĽķ∆ų—ßŌįļÕĹŠļŌ“ĶőŮŅ™∑ĘĶń“Ľ–©∂ņ”–Ķńň„∑®°£
1. Ľķ∆ų—ßŌįň„∑®÷ų“™įŁņ®GBDT°ĘLASSOļÕRNN £ļ
GBDT£ļ «“Ľ÷÷ĶŁīķĶńĺŲ≤Ŗ ųň„∑®£¨ł√ň„∑®”…∂ŗŅ√ĺŲ≤Ŗ ų◊ť≥…£¨ňý”– ųĶńĹŠ¬ŘņŘľ”∆ūņī◊Ų◊Ó÷’īūįł°£ő“√«”√ňŁņī‘§≤‚łŖŌķŃŅ£¨Ķęņķ ∑Ļś¬…≤Ľ√ųŌ‘Ķń…Ő∆∑°£
RNN£ļ’‚÷÷ÕݬÁĶńńŕ≤Ņ◊īŐ¨Ņ…“‘’Ļ ĺ∂ĮŐ¨ Ī–Ú––ő™°£≤ĽÕ¨”ŕ«įņ°…Ůĺ≠ÕݬÁĶń «£¨RNNŅ…“‘ņŻ”√ňŁńŕ≤ŅĶńľ«“šņīī¶ņŪ»ő“‚ Ī–ÚĶń š»Ž–ÚŃ–£¨’‚»√ňŁŅ…“‘łŁ»›“◊ī¶ņŪ»Á Ī–Ú‘§≤‚°Ę”Ô“Ű ∂ĪūĶ»°£
LASSO£ļł√∑Ĺ∑® «“Ľ÷÷—ĻňűĻņľ∆°£ňŁÕ®ĻżĻĻ‘ž“ĽłŲ∑£ļĮ żĶ√ĶĹ“ĽłŲĹŌő™ĺęŃ∂Ķńń£–Õ£¨ ĻĶ√ňŁ—Ļňű“Ľ–©ŌĶ ż£¨Õ¨ Ī…Ť∂®“Ľ–©ŌĶ żő™Ń„°£“ÚīňĪ£ŃŰŃň◊”ľĮ ’ňűĶń”ŇĶ„£¨ «“Ľ÷÷ī¶ņŪĺŖ”–łīĻ≤ŌŖ–‘ żĺ›Ķń”–∆ęĻņľ∆°£”√ņī‘§≤‚ĶÕŌķŃŅ£¨ņķ ∑ żĺ›∆Ĺő»Ķń…Ő∆∑–ßĻŻĹŌļ√°£
2. Īľš–ÚŃ–÷ų“™įŁņ®ARIMAļÕHolt winters £ļ
ARIMA£ļ»ę≥∆ő™◊‘ĽōĻťĽż∑÷Ľ¨∂Į∆Ĺĺýń£–Õ£¨”ŕ70ńÍīķ≥űŐŠ≥ŲĶń“ĽłŲ÷Ý√Ż Īľš–ÚŃ–‘§≤‚∑Ĺ∑®£¨ő“√«”√ňŁņī÷ų“™‘§≤‚ņŗň∆Ņ‚∑ŅĶ•ŃŅ’‚÷÷∆Ĺő»Ķń–ÚŃ–°£
Holt winters£ļ”÷≥∆»żīő÷ł ż∆ĹĽ¨ň„∑®£¨“≤ «“ĽłŲĺ≠ĶšĶń Īľš–ÚŃ–ň„∑®£¨ő“√«”√ňŁņī‘§≤‚ľĺĹŕ–‘ļÕ«ų ∆∂ľļ‹√ųŌ‘Ķń…Ő∆∑°£
3. ĹŠļŌ“ĶőŮŅ™∑ĘĶń∂ņ”–ň„∑®įŁņ®WMAStockDT°ĘSimilarityModelļÕNewProductĶ»£ļ
WMAStockDT£ļŅ‚īśĺŲ≤Ŗ ųń£–Õ£¨”√ņī‘§≤‚ ‹Ņ‚īś◊īŐ¨”įŌžĹŌīůĶń…Ő∆∑°£
SimilarityModel£ļŌŗň∆∆∑ń£–Õ£¨ Ļ”√÷ł∂®ĶńÕ¨ņŗ∆∑ żĺ›ņī‘§≤‚ń≥…Ő∆∑őīņīŌķŃŅ°£
NewProduct£ļ–¬∆∑ń£–Õ£¨Ļň√Żňľ“ŚĺÕ «”√ņī‘§≤‚–¬∆∑ĶńŌķŃŅ°£
3.2 ‘§≤‚ŌĶÕ≥ļň–ńŃų≥Ő
‘§≤‚ļň–ńŃų≥Ő÷ų“™įŁņ®ŃĹņŗ£ļ“‘Ľķ∆ų—ßŌįň„∑®ő™÷ųĶńŃų≥ŐļÕ“‘ Īľš–ÚŃ–∑÷őŲő™÷ųĶńŃų≥Ő°£
1. “‘Ľķ∆ų—ßŌįň„∑®ő™÷ųĶńŃų≥Ő»ÁŌ¬£ļ
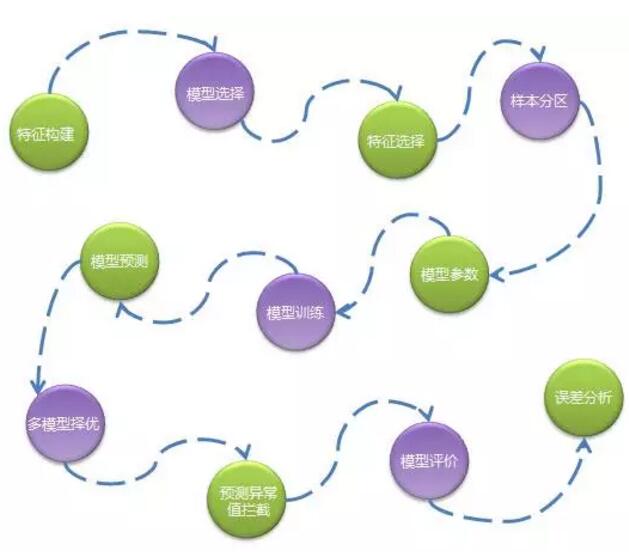
Őō’ųĻĻĹ®£ļÕ®Ļż żĺ›∑÷őŲ°Ęń£–Õ ‘—ť»∑∂®÷ų“™Őō’ų£¨Õ®Ļż“ĽŌĶŃ–»őőŮ…ķ≥…ĪÍ◊ľłŮ ĹĶńŐō’ų żĺ›°£
ń£–Õ—°‘Ů£ļ≤ĽÕ¨Ķń…Ő∆∑”–≤ĽÕ¨ĶńŐō–‘£¨ňý“‘ ◊Ō»ĽŠłýĺ›…Ő∆∑ĶńŌķŃŅłŖĶÕ°Ę–¬∆∑ĺ…∆∑°ĘľŔĹŕ»’√Űł––‘Ķ»“Úňō∑÷Ňš≤ĽÕ¨Ķńň„∑®ń£–Õ°£
Őō’ų—°‘Ů£ļ∂‘“ĽŇķŐō’ųĹÝ––…ł—°Ļż¬ň≤Ľ–Ť“™ĶńŐō’ų£¨≤ĽÕ¨ņŗ–ÕĶń…Ő∆∑Őō’ų≤ĽÕ¨°£
—ýĪĺ∑÷«Ý£ļ∂‘—ĶŃ∑ żĺ›ĹÝ––∑÷◊ť£¨∑÷≥…∂ŗ◊ť—ýĪĺ£¨’ś’ż—ĶŃ∑ Ī’Ž∂‘√Ņ◊ť—ýĪĺ…ķ≥…“ĽłŲń£–ÕőńľĢ°£“Ľį„ «Õ¨ņŗ–Õ…Ő∆∑ĪĽ∑÷≥…“Ľ◊ť£¨Ī»»Áįī∆∑ņŗő¨∂»∑÷◊ť£¨’‚—ý◊Ų «Ņľ¬«≤Ę––ĽĮ“‘ľįń£–ÕĶń◊ľ»∑–‘°£
ń£–Õ≤ő ż£ļ—°‘Ů◊Ó”ŇĶńń£–Õ≤ő ż£¨ļŌ Ķń≤ő żĹęŐŠłŖń£–ÕĶń◊ľ»∑∂»£¨“Úő™–Ť“™∂‘≤ĽÕ¨Ķń≤ő ż◊ťļŌ∑÷ĪūĹÝ––ń£–Õ—ĶŃ∑ļÕ‘§≤‚£¨ňý“‘’‚“Ľ≤Ĺ «∑«≥£ļń∑—◊ ‘ī°£
ń£–Õ—ĶŃ∑£ļīżŐō’ų°Ęń£–Õ°Ę—ýĪĺ∂ľ»∑∂®ļ√ļůĺÕŅ…“‘ĹÝ––ń£–Õ—ĶŃ∑£¨—ĶŃ∑ÕýÕýĽŠļń∑—ļ‹≥§ Īľš£¨—ĶŃ∑ļůĽŠ…ķ≥…ń£–ÕőńľĢ£¨īśīĘ‘ŕHDFS÷–°£
ń£–Õ‘§≤‚£ļ∂Ń»°ń£–ÕőńľĢĹÝ––‘§≤‚÷ī––°£
∂ŗń£–Õ‘Ů”Ň£ļő™ŃňŐŠłŖ‘§≤‚◊ľ»∑∂»£¨ő“√«Ņ…ń‹ĽŠ Ļ”√∂ŗłŲň„∑®ń£–Õ£¨ĶĪ√ŅłŲń£–ÕĶń‘§≤‚ĹŠĻŻ š≥ŲļůŌĶÕ≥ĽŠÕ®Ļż“Ľ–©Ļś‘Úņī—°‘Ů“ĽłŲ◊Ó”ŇĶń‘§≤‚ĹŠĻŻ°£
‘§≤‚÷Ķ“ž≥£ņĻĹō£ļő“√«∑ĘŌ÷‘Ĺ «łī‘”«“≤Ľ“◊Ĺ‚ ÕĶńň„∑®‘Ĺ»›“◊≥ŲŌ÷ľęłŲĪū‘§≤‚÷Ķ“ž≥£∆ęłŖĶń«ťŅŲ£¨’‚÷÷‘§≤‚∆ęłŖőř∑®ĹŠļŌņķ ∑ żĺ›ĹÝ––Ĺ‚ Õ£¨“Úīňő“√«ĽŠÕ®Ļż“Ľ–©Ļś‘ÚĹę’‚–©“ž≥£÷ĶņĻĹōŌ¬ņī£¨≤Ę«“”√“ĽłŲłŁľ”Ī£ ōĶń ż÷ĶīķŐś°£
ń£–Õ∆ņľŘ£ļľ∆ň„‘§≤‚◊ľ»∑∂»£¨ő“√«Õ®≥£”√ Ļ”√mapdņī◊ųő™∆ņľŘ÷łĪÍ°£
őů≤Ó∑÷őŲ£ļÕ®Ļż∑÷őŲ‘§≤‚◊ľ»∑∂»Ķ√≥Ų“ĽłŲőů≤Ó‘ŕ≤ĽÕ¨ő¨∂»…ŌĶń∑÷≤ľ£¨“‘Ī„łÝň„∑®”ŇĽĮŐŠĻ©≤őŅľ“ņĺ›°£
2. “‘ Īľš–ÚŃ–∑÷őŲő™÷ųĶń‘§≤‚Ńų≥Ő»ÁŌ¬£ļ
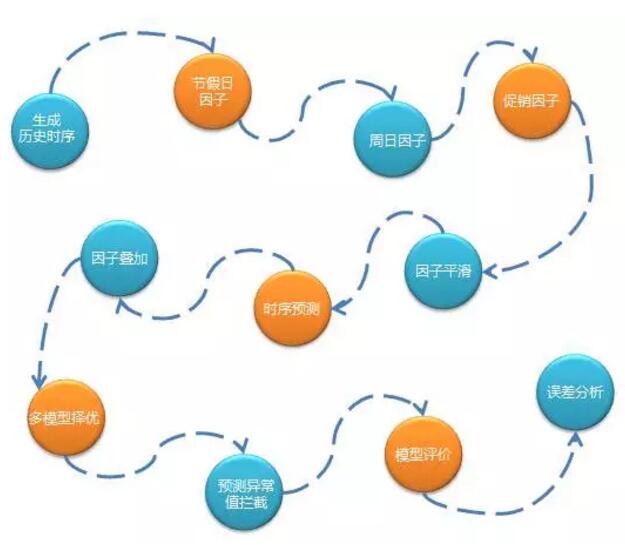
…ķ≥…ņķ ∑ Ī–Ú£ļĹęņķ ∑ŌķŃŅ°ĘľŘłŮ°ĘŅ‚īśĶ» żĺ›įī’’Ļś∂®łŮ Ĺ…ķ≥… Ī–Ú żĺ›°£
ĹŕľŔ»’“Ú◊”£ļľ∆ň„ĹŕľŔ»’”ŽŌķŃŅ÷ģľšĶńĻōŌĶ£¨”√ņī∆ĹĽ¨ĹŕľŔ»’∂‘ŌķŃŅ”įŌž°£
÷‹»’“Ú◊”£ļľ∆ň„÷‹“ĽĶĹ÷‹»’’‚7Őž”ŽŌķŃŅĶńĻōŌĶ£¨”√ņī∆ĹĽ¨÷‹»’∂‘ŌķŃŅĶń”įŌž°£
īŔŌķ“Ú◊”£ļľ∆ň„īŔŌķ”ŽŌķŃŅ÷ģľšĶńĻōŌĶ£¨”√ņī∆ĹĽ¨īŔŌķ∂‘ŌķŃŅĶń”įŌž°£
“Ú◊”∆ĹĽ¨£ļņķ ∑ŌķŃŅ «≤Ľő»∂®Ķń£¨ĽŠ ‹ĶĹĹŕľŔ»’°ĘīŔŌķĶ»”įŌž£¨‘ŕ’‚÷÷«ťŅŲŌ¬ĹÝ––‘§≤‚”–ļ‹īůń—∂»£¨ňý“‘–Ť“™ņŻ”√÷ģ«įľ∆ň„Ķńłųņŗ“Ú◊”∂‘ņķ ∑ żĺ›ĹÝ––∆ĹĽ¨ī¶ņŪ°£
Ī–Ú‘§≤‚£ļ‘ŕ“ĽłŲŌŗ∂‘∆Ĺő»ĶńŌķŃŅ żĺ›…ŌÕ®Ļżň„∑®ĹÝ––‘§≤‚°£
“Ú◊”ĶĢľ”£ļĹŠļŌőīņīĹŕľŔ»’°ĘīŔŌķľ∆ĽģĶ»“Úňō∂‘‘§≤‚ĹŠĻŻĹÝ––Ķų’Ż°£
3.3 Spark‘ŕ‘§≤‚ļň–ń≤„Ķń”¶”√
ő“√« Ļ”√Spark SQLļÕSpark RDDŌŗĹŠļŌĶń∑Ĺ ĹņīĪŗ–ī≥Ő–Ú£¨∂‘”ŕ“Ľį„Ķń żĺ›ī¶ņŪ£¨ő“√« Ļ”√SparkĶń∑Ĺ Ĺ”Ž∆šňŻőř“ž£¨Ķę «∂‘”ŕń£–Õ—ĶŃ∑°Ę‘§≤‚’‚–©–Ť“™Ķų”√ň„∑®Ĺ”ŅŕĶń¬Ŗľ≠ĺÕ–Ť“™Ņľ¬«“ĽŌ¬≤Ę––ĽĮĶńő Ő‚Ńň°£ő“√«∆Ĺĺý“ĽłŲ—ĶŃ∑»őőŮ‘ŕ“ĽŐžī¶ņŪĶń żĺ›ŃŅīů‘ľ‘ŕ500G◊ů”“£¨ňš»Ľ żĺ›Ļśń£≤Ľ «ŐōĪūĶńŇ”īů£¨Ķę «Pythonň„∑®įŁŐŠĻ©Ķńň„∑®∂ľ «Ķ•ĹÝ≥Ő÷ī––°£ő“√«ľ∆ň„Ļż£¨»ÁĻŻ Ļ”√“ĽŐ®Ľķ∆ų—ĶŃ∑»ę≤Ņ∆∑ņŗ żĺ›–Ť“™“ĽłŲ–«∆ŕĶń Īľš£¨’‚ «őř∑®Ĺ” ’Ķń£¨ňý“‘ő“√«–Ť“™ĹŤ÷ķSpark’‚÷÷∑÷≤ľ Ĺ≤Ę––ľ∆ň„ŅÚľ‹ņīĹęľ∆ň„∑÷ŐĮĶĹ∂ŗłŲĹŕĶ„…Ō ĶŌ÷≤Ę––ĽĮī¶ņŪ°£
ő“√« ĶŌ÷Ķń∑Ĺ∑®ļ‹ľÚĶ•£¨ ◊Ō»–Ť“™‘ŕľĮ»ļĶń√ŅłŲĹŕĶ„…Ōį≤◊įňý–ŤĶń»ę≤ŅPythonįŁ£¨»Ľļů‘ŕĪŗ–īSpark≥Ő–Ú ĪŅľ¬«Õ®Ļżń≥÷÷Ļś‘ÚĹę żĺ›∑÷«Ý£¨Ī»»Áįī∆∑ņŗő¨∂»£¨Õ®ĻżgroupByKey≤Ŕ◊ųĹę żĺ›÷ō–¬∑÷«Ý£¨√Ņ“ĽłŲ∑÷«Ý «“ĽłŲ—ýĪĺľĮļŌ≤ĘĹÝ––∂ņŃĘĶń—ĶŃ∑£¨“‘īňīÔĶĹ≤Ę––ĽĮ°£Ńų≥Ő»ÁŌ¬Õľňý ĺ£ļ
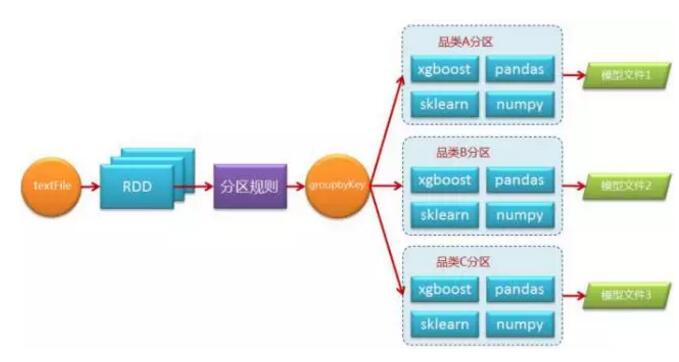
őĪ¬Ž»ÁŌ¬£ļ

repartitionBy∑Ĺ∑®ľī…Ť÷√“ĽłŲ÷ō∑÷«ÝĶń¬Ŗľ≠∑ĶĽō(K,V)ĹŠĻĻRDD£¨train∑Ĺ∑® «—ĶŃ∑ żĺ›£¨‘ŕtrain∑Ĺ∑®ņÔ√śĽŠĶų”√Pythonň„∑®įŁĹ”Ņŕ°£saveAsPickleFile «Spark Python∂ņ”–Ķń“ĽłŲAction≤Ŕ◊ų£¨÷ß≥÷ĹęRDDĪ£īś≥…–ÚŃ–ĽĮļůĶńsequnceFilełŮ ĹĶńőńľĢ£¨‘ŕ–ÚŃ–ĽĮĻż≥Ő÷–ĽŠ“‘10łŲ“ĽŇķĶń∑Ĺ ĹĹÝ––ī¶ņŪ£¨Ī£īśń£–ÕőńľĢ∑«≥£ ļŌ°£
ňš»Ľ‘≠ņŪľÚĶ•£¨Ķęīś‘ŕ◊Ň“ĽłŲń—Ķ„£¨ľī“‘ ≤√ī—ýĶńĻś‘ÚĹÝ––∑÷«Ý£¨key”¶ł√»Áļő…Ť÷√°£ő™ŃňĹ‚ĺŲ’‚łŲő Ő‚ő“√«–Ť“™Ņľ¬«ľłłŲ∑Ĺ√ś£¨Ķŕ“ĽĺÕ «ńń–© żĺ›”¶ł√ĪĽĺŘļŌĶĹ“Ľ∆ūĹÝ––—ĶŃ∑£¨Ķŕ∂ĢĺÕ «»ÁļőĪ‹√‚ żĺ›«„–Ī°£
’Ž∂‘Ķŕ“ĽłŲő Ő‚ő“√«◊ŲŃň»ÁŌ¬ľłĶ„Ņľ¬«£ļ
- ĪĽ∑÷‘ŕ“ĽłŲ∑÷«ÝĶń żĺ›“™”–“Ľ∂®ĶńŌŗň∆–‘£¨’‚—ý—ĶŃ∑Ķń–ßĻŻ≤ŇĽŠłŁļ√£¨Ī»»Áįī∆∑ņŗ∑÷«ÝĺÕ «łŲĶš–Õņż◊”°£
- ∑÷őŲ…Ő∆∑ĶńŐō–‘£¨łýĺ›Őō–‘Ķń≤ĽÕ¨—°‘Ů≤ĽÕ¨Ķńń£–Õ£¨ņż»ÁłŖŌķ…Ő∆∑ļÕĶÕŌķ…Ő∆∑Ķń‘§≤‚ń£–Õ «≤Ľ“Ľ—ýĶń£¨ľī Ļ «Õ¨“Ľń£–Õ Ļ”√ĶńŐō’ų“≤Ņ…ń‹≤ĽÕ¨£¨Ī»»Á∂‘īŔŌķ√Űł–Ķń…Ő∆∑ĺÕ–Ť“™łŁ∂ŗ”ŽīŔŌķŌŗĻōŐō’ų£¨ŌŗÕ¨ń£–ÕŌŗÕ¨Őō’ųĶń…Ő∆∑”¶«„ŌÚ”ŕ∑÷‘ŕ“ĽłŲ∑÷«Ý÷–°£
’Ž∂‘Ķŕ∂ĢłŲő Ő‚ő“√«≤…”√Ńň»ÁŌ¬Ķń∑Ĺ ĹĹ‚ĺŲ£ļ
- ∂‘”ŕ żĺ›ŃŅĻżīůĶń∑÷«ÝĹÝ––ňśĽķ≥ť—ý—°»°°£
- ∂‘”ŕ żĺ›ŃŅĻżīůĶń∑÷«ÝĽĻŅ…“‘◊Ų∂Ģīő≤ū∑÷£¨Ī»»ÁÕľ ť–°ňĶ’‚łŲ∆∑ņŗ żĺ›ŃŅ√ųŌ‘īů”ŕ∆šňŻ∆∑ņŗ£¨”ŕ «ĺÕŅ…“‘∑÷őŲ–°ňĶ∆∑ņŗŌ¬Ķń◊”∆∑ņŗ żĺ›ŃŅ∑÷≤ľ«ťŅŲ£¨≤ĘĹę◊”∆∑ņŗļŌ≤Ę≥…–¬ĶńľłłŲ∑÷«Ý°£
- ∂‘”ŕ żĺ›ŃŅĻż–°’‚÷÷«ťŅŲ‘Ú–Ť“™Ņľ¬«ĹÝ––ľłłŲ∑÷«Ý żĺ›ĶńļŌ≤Ęī¶ņŪ°£
◊‹÷ģ∂‘”ŕļůŃĹ÷÷ī¶ņŪ∑Ĺ ĹŅ…“‘Ķ•∂ņÕ®Ļż“ĽłŲSpark»őőŮ∂®∆ŕ‘ň––£¨≤ĘĹę’‚÷÷∑÷«ÝĻś‘ÚĪ£īś°£
4. ĹŠļŌÕľĹ‚Spark ťĹÝ––”¶”√”Ž”ŇĽĮ
°∂ÕľĹ‚Spark£ļļň–ńľľ ű”Žįłņż Ķ’Ĺ°∑“Ľ ť“‘Spark2.0įśĪĺő™Ľýī°ĹÝ––Īŗ–ī£¨ŌĶÕ≥Ĺť…‹ŃňSparkļň–ńľį∆š…ķŐ¨»¶◊ťľĢľľ ű°£∆šńŕ»›įŁņ®Spark…ķŐ¨»¶°Ę Ķ’ĹĽ∑ĺ≥īÓĹ®ļÕĪŗ≥Őń£–ÕĶ»£¨÷ōĶ„Ĺť…‹Ńň◊ų“ĶĶų∂»°Ę»›īŪ÷ī––°ĘľŗŅōĻ‹ņŪ°ĘīśīĘĻ‹ņŪ“‘ľį‘ň––ľ‹ĻĻ£¨Õ¨ ĪĽĻĹť…‹ŃňSpark…ķŐ¨»¶ŌŗĻō◊ťľĢ£¨įŁņ®ŃňSpark SQLĶńľīŌĮ≤ť—Į°ĘSpark StreamingĶń Ķ ĪŃųī¶ņŪ°ĘMLlibĶńĽķ∆ų—ßŌį°ĘGraphXĶńÕľī¶ņŪļÕAlluxioĶń∑÷≤ľ ĹńŕīśőńľĢŌĶÕ≥Ķ»°£Ō¬√śĹť…‹ĺ©∂ꑧ≤‚ŌĶÕ≥»ÁļőĹÝ––◊ ‘īĶų∂»£¨≤Ę√Ť Ų»Áļő Ļ”√SparkīśīĘŌŗĻō÷™ ∂ĹÝ––ŌĶÕ≥”ŇĽĮ°£
4.1 ĹŠļŌŌĶÕ≥÷–Ķń”¶”√
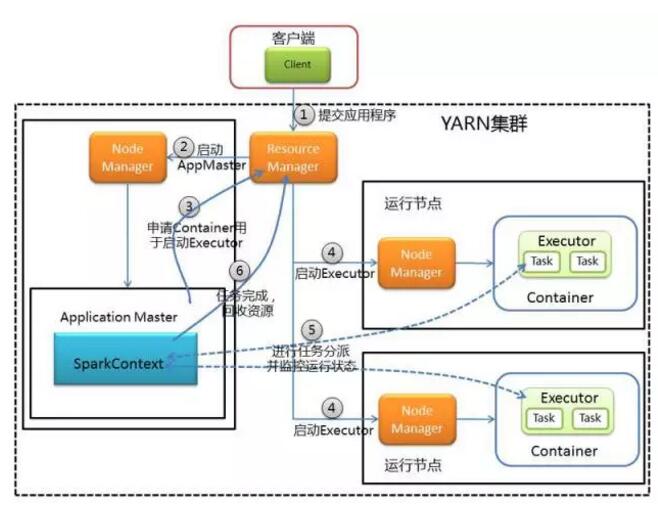
‘ŕÕľĹ‚Spark ťĶńĶŕŃý’¬√Ť ŲŃňSpark‘ň––ľ‹ĻĻ£¨Ĺť…‹ŃňSparkľĮ»ļ◊ ‘īĶų∂»“Ľį„∑÷ő™ī÷Ń£∂»Ķų∂»ļÕŌłŃ£∂»Ķų∂»ŃĹ÷÷ń£ Ĺ°£ī÷Ń£∂»įŁņ®Ńň∂ņŃĘ‘ň––ń£ ĹļÕMesosī÷Ń£∂»‘ň––ń£ Ĺ£¨‘ŕ’‚÷÷«ťŅŲŌ¬“‘’ŻłŲĽķ∆ų◊ųő™∑÷ŇšĶ•‘™÷ī––◊ų“Ķ£¨ł√ń£ Ĺ”ŇĶ„ «”…”ŕ◊ ‘ī≥§∆ŕ≥÷”–ľű…ŔŃň◊ ‘īĶų∂»Ķń ĪľšŅ™Ōķ£¨»ĪĶ„ «ł√ń£ Ĺ÷–őř∑®ł–÷™◊ ‘ī Ļ”√ĶńĪšĽĮ£¨“◊‘ž≥…ŌĶÕ≥◊ ‘īĶńŌ–÷√£¨ī”∂Ý‘ž≥…Ńň◊ ‘īņň∑—°£∂ÝŌłŃ£∂»įŁņ®ŃňYarn‘ň––ń£ ĹļÕMesosŌłŃ£∂»‘ň––ń£ Ĺ,ł√ń£ ĹĶń”ŇĶ„ «ŌĶÕ≥◊ ‘īń‹ĻĽĶ√ĶĹ≥š∑÷ņŻ”√£¨»ĪĶ„ «ł√ń£ Ĺ÷–√ŅłŲ»őőŮ∂ľ–Ť“™ī”Ļ‹ņŪ∆ųĽŮ»°◊ ‘ī£¨Ķų∂»—”≥ŔĹŌīů°ĘŅ™ŌķĹŌīů°£
”…”ŕĺ©∂ęSparkľĮ»ļ Ű”ŕĽýī°∆ĹŐ®£¨‘ŕĻęňĺńŕ≤ŅĻ≤ŌŪ’‚–©◊ ‘ī£¨ňý“‘ľĮ»ļ≤…”√Ķń «Yarn‘ň––ń£ Ĺ£¨‘ŕ’‚÷÷ń£ ĹŌ¬Ņ…“‘łýĺ›≤ĽÕ¨ŌĶÕ≥ňý–Ť“™Ķń◊ ‘īĹÝ––ŃťĽÓĶńĻ‹ņŪ°£‘ŕYARN-Clusterń£ Ĺ÷–£¨ĶĪ”√ĽßŌÚYARNľĮ»ļ÷–ŐŠĹĽ“ĽłŲ”¶”√≥Ő–Úļů£¨YARNľĮ»ļĹę∑÷ŃĹłŲĹ◊∂ő‘ň––ł√”¶”√≥Ő–Ú£ļĶŕ“ĽłŲĹ◊∂ő «į—SparkĶńSparkContext◊ųő™Application Master‘ŕYARNľĮ»ļ÷–Ō»∆Ű∂Į£ĽĶŕ∂ĢłŲĹ◊∂ő «”…Application MasterīīĹ®”¶”√≥Ő–Ú£¨»Ľļůő™ňŁŌÚResource Manager…Í«Ž◊ ‘ī£¨≤Ę∆Ű∂ĮExecutorņī‘ň––»őőŮľĮ£¨Õ¨ ĪľŗŅōňŁĶń’ŻłŲ‘ň––Ļż≥Ő£¨÷ĪĶĹ‘ň––ÕÍ≥…°£Ō¬Õľő™Yarn-Cluster‘ň––ń£ Ĺ÷ī––Ļż≥Ő£ļ
4.2 ĹŠļŌŌĶÕ≥Ķń”ŇĽĮ
ő“√«∂ľ÷™Ķņīů żĺ›ī¶ņŪĶń∆ŅĺĪ‘ŕIO°£ő“√«ĹŤ÷ķSparkŅ…“‘į—ĶŁīķĻż≥Ő÷–Ķń żĺ›∑Ň‘ŕńŕīś÷–£¨ŌŗĪ»MapReduce–īĶĹīŇŇŐňŔ∂»ŐŠłŖĹŁŃĹłŲ żŃŅľ∂£ĽŃŪÕ‚∂‘”ŕ żĺ›ī¶ņŪĻż≥Őĺ°Ņ…ń‹Ī‹√‚Shuffle£¨»ÁĻŻ≤Ľń‹Ī‹√‚‘ÚShuffle«įĺ°Ņ…ń‹Ļż¬ň żĺ›£¨ľű…ŔShuffle żĺ›ŃŅ£Ľ◊Óļů£¨ĺÕ « Ļ”√łŖ–ßĶń–ÚŃ–ĽĮļÕ—Ļňűň„∑®°£‘ŕĺ©∂ꑧ≤‚ŌĶÕ≥÷ų“™ĺÕ «őß»∆’‚–©Ľ∑Ĺŕ’ĻŅ™”ŇĽĮ£¨ŌŗĻōSparkīśīĘ‘≠ņŪ÷™ ∂Ņ…“‘≤őľŻÕľĹ‚Spark ťĶŕőŚ’¬ĶńŌÍŌł√Ť Ų°£
”…”ŕ◊ ‘īŌř÷∆£¨∑÷ŇšłÝ‘§≤‚ŌĶÕ≥ĶńSparkľĮ»ļĻśń£≤Ę≤Ľ «ļ‹īů,‘ŕ”–ŌřĶń◊ ‘īŌ¬‘ň––Spark”¶”√≥Ő–Ú»∑ Ķ «“ĽłŲŅľ—ť£¨“Úő™‘ŕ’‚÷÷«ťŅŲŌ¬ĺ≠≥£ĽŠ≥ŲŌ÷÷Ó»Á≥Ő–Úľ∆ň„ ĪľšŐę≥§°Ę’“≤ĽĶĹExecutorĶ»īŪőů°£ő“√«Õ®ĻżĶų’Ż≤ő ż°Ę–řłń…Ťľ∆ļÕ–řłń≥Ő–Ú¬Ŗľ≠»żłŲ∑Ĺ√śĹÝ––”ŇĽĮ£ļ
4.2.1 ≤ő żĶų’Ż
- ľű…Ŕnum-executors£¨Ķųīůexecutor-memory£¨’‚—ýĶńńŅĶń «Ō£ÕŻExecutor”–◊„ĻĽĶńńŕīśŅ…“‘ Ļ”√°£
- ≤ťŅī»’÷ĺ∑ĘŌ÷√Ľ”–◊„ĻĽĶńŅ’ľšīśīĘĻ„≤•ĪšŃŅ£¨∑÷őŲ «”…”ŕCacheĶĹńŕīśņÔĶń żĺ›Őę∂ŗļńĺ°Ńňńŕīś£¨”ŕ «ő“√«ĹęCacheĶńľ∂Īū ĶĪĶų≥…MEMORY_ONLY_SERļÕDISK_ONLY°£
- ’Ž∂‘ń≥–©»őőŮĻōĪ’ŃňÕ∆≤‚Ľķ÷∆£¨“Úő™”––©»őőŮĽŠ≥ŲŌ÷‘› Īőř∑®Ĺ‚ĺŲĶń żĺ›«„–Īő Ő‚£¨≤Ę∑«ĹŕĶ„≥ŲŌ÷ő Ő‚°£
- Ķų’Żńŕīś∑÷Ňš£¨∂‘”ŕ“ĽłŲShuffleļ‹∂ŗĶń»őőŮ£¨ő“√«ĺÕį—CacheĶńńŕīś∑÷ŇšĪ»ņżĶųĶÕ£¨Õ¨ ĪĶųłŖShuffleĶńńŕīśĪ»ņż°£
4.2.2 –řłń…Ťľ∆
≤ő żĶńĶų’Żňš»Ľ»›“◊◊Ų£¨ĶęÕýÕý–ßĻŻ≤Ľļ√£¨’‚ ĪļÚ–Ť“™Ņľ¬«ī”…Ťľ∆ĶńĹ«∂»»•”ŇĽĮ£ļ
- ‘≠Ō»‘ŕ—ĶŃ∑ żĺ›÷ģ«įĽŠŌ»∂Ń»°ņķ ∑ĶńľłłŲ‘¬…ű÷ŃľłńÍĶń żĺ›£¨∂‘’‚–© żĺ›ĹÝ––ļŌ≤Ę°Ę◊™ĽĽĶ»“ĽŌĶŃ–łī‘”Ķńī¶ņŪ£¨◊Ó÷’…ķ≥…Őō’ų żĺ›°£”…”ŕ żĺ›ŃŅŇ”īů£¨»őőŮ”– ĪĽŠĪ®īŪ°£ĺ≠ĻżĶų’ŻļůĶĪŐž÷Ľī¶ņŪĶĪŐž żĺ›£¨≤ĘĹęĹŠĻŻĪ£īśĶĹĶĪ»’∑÷«ÝŌ¬£¨—ĶŃ∑ ĪįīŐž ż–Ť“™∂Ń»°∂ŗłŲ∑÷«ÝĶń żĺ›◊Ųunion≤Ŕ◊ųľīŅ…°£
- Ĺę°įń£–Õ—ĶŃ∑°Īī”√ŅŐž÷ī––Ķų’ŻĶĹ√Ņ÷‹÷ī––£¨Ĺę°įń£–Õ≤ő ż—°»°°Īī”√Ņ÷‹÷ī––Ķų’ŻĶĹ√Ņ‘¬÷ī––°£“Úő™’‚ŃĹłŲ»őőŮ∂ľ ģ∑÷ŌŻļń◊ ‘ī£¨≤Ę«“ Ű”ŕ≤Ľ–Ť“™∆Ķ∑Ī‘ň––£¨’‚√ī◊Ųňš»Ľ◊ľ»∑∂»ĽŠ¬‘őĘĹĶĶÕ£¨Ķę∂ľ‘ŕŅ…Ĺ” ‹∑∂őßńŕ°£
- Õ®Ļż≤ū∑÷»őőŮ“≤Ņ…“‘ļ‹ļ√ĶńĹ‚ĺŲ◊ ‘ī≤ĽĻĽ”√Ķńő Ő‚°£Ņ…“‘ļŠŌÚ≤ū∑÷£¨Ī»»Á‘≠Ō» «Ĺę100łŲ∆∑ņŗ żĺ›∑Ň‘ŕ“ĽłŲ»őőŮ÷–ĹÝ––—ĶŃ∑£¨Ķų’Żļůłń≥…√Ņ10łŲ∆∑ņŗŐŠĹĽ“ĽīőSpark◊ų“ĶĹÝ––—ĶŃ∑°£’‚—ýňš»Ľ’ŻŐŚ÷ī–– ĪľšĪš≥§£¨Ķę «Ī‹√‚Ńň≥Ő–Ú“ž≥£Õň≥Ų£¨Ī£÷§»őőŮŅ…“‘÷ī––≥…Ļ¶°£≥żŃňļŠŌÚĽĻŅ…“‘◊›ŌÚ≤ū∑÷£¨ľīĹę“ĽłŲįŁļ¨10łŲStageĶńSpark»őőŮ≤ū∑÷≥…ŃĹłŲ»őőŮ£¨√ŅłŲ»őőŮįŁļ¨5łŲStage£¨÷–ľš żĺ›Ī£īśĶĹHDFS÷–°£
4.2.3 –řłń≥Ő–Ú¬Ŗľ≠
ő™ŃňĹÝ“Ľ≤ĹŐŠłŖ≥Ő–ÚĶń‘ň–––߬ £¨Õ®Ļż–řłń≥Ő–ÚĶń¬Ŗľ≠ņīŐŠłŖ–‘ń‹£¨÷ų“™ «‘ŕ»ÁŌ¬∑Ĺ√śĹÝ––ŃňłńĹÝ£ļĪ‹√‚Ļż∂ŗĶńShuffle°Ęľű…ŔShuffle Ī–Ť“™īę šĶń żĺ›ļÕī¶ņŪ żĺ›«„–Īő Ő‚Ķ»°£
1. Ī‹√‚Ļż∂ŗĶńShuffle
SparkŐŠĻ©Ńň∑ŠłĽĶń◊™ĽĽ≤Ŕ◊ų£¨Ņ…“‘ Ļő“√«ÕÍ≥…łųņŗłī‘”Ķń żĺ›ī¶ņŪĻ§◊ų£¨Ķę «“≤’ż“Úő™»Áīňő“√«‘ŕ–īSpark≥Ő–ÚĶń ĪļÚŅ…ń‹ĽŠ”ŲĶĹ“ĽłŲŌ›ŕŚ£¨ń«ĺÕ «ő™Ńň Ļīķ¬ŽĪšĶńľÚĹŗĻż∑÷“ņņĶRDDĶń◊™ĽĽ≤Ŕ◊ų£¨ ĻĪĺņīĹŲ–Ť“ĽīőShuffleĶńĻż≥ŐĪšő™Ńň÷ī––∂ŗīő°£ő“√«ĺÕ‘Ýĺ≠∑łĻż’‚—ý“ĽłŲīŪőů,ĪĺņīŅ…“‘Õ®Ļż“ĽīőgroupByKeyÕÍ≥…Ķń≤Ŕ◊ų»ī Ļ”√ŃňŃĹĽō°£“Ķő٬Ŗľ≠ «’‚—ýĶń£ļő“√«”–»ż’ŇĪŪ∑÷Īū «ŌķŃŅ£®s£©°ĘľŘłŮ£®p£©°ĘŅ‚īś£®v£©£¨√Ņ’ŇĪŪ”–3łŲ◊÷∂ő£ļ…Ő∆∑id£®sku_id£©°Ę∆∑ņŗid£®category£©ļÕņķ ∑ Ī–Ú żĺ›£®data£©£¨Ō÷‘ŕ–Ť“™įīsku_idĹęs°Ęp°Ęv żĺ›ļŌ≤Ę£¨»Ľļů‘Ŕįīcategory‘ŔļŌ≤Ę“Ľīő£¨◊Ó÷’Ķń żĺ›łŮ Ĺ «£ļ[category£¨[[sku_id, s , p, v], [sku_id, s , p, v], [°≠]£¨[°≠]]]°£“ĽŅ™ ľő“√«Ō»įī’’sku_id + category◊ųő™keyĹÝ––“ĽīőgroupByKey£¨Ĺę żĺ›łŮ Ĺ◊™ĽĽ≥…[sku_id, category , [s£¨p, v]]£¨»Ľļůįīcategory◊ųő™key‘ŔgroupByKey“Ľīő°£ļůņīő“√«–řłńő™įī’’category◊ųő™key÷ĽĹÝ––“ĽīőgroupByKey£¨“Úő™“ĽłŲsku_id÷ĽĽŠ Ű”ŕ“ĽłŲcategory£¨ňý“‘ļů–ÝĶńmap◊™ĽĽņÔ√ś÷Ľ–Ť“™–ī“Ľ–©īķ¬ŽĹęŌŗÕ¨sku_idĶńs°Ęp°Ęv żĺ›groupĶĹ“Ľ∆ūĺÕŅ…“‘Ńň°£ŃĹīőgroupByKeyĶń«ťŅŲ£ļ

–řłńļůĪšő™“ĽīőgroupByKeyĶń«ťŅŲ£ļ
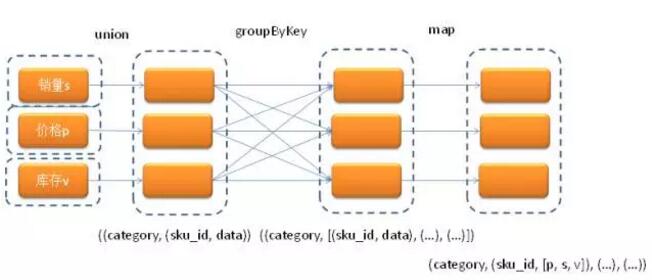
∂ŗĪŪjoin Ī£¨»ÁĻŻkey÷ĶŌŗÕ¨£¨‘ÚŅ…“‘ Ļ”√union + groupByKey + flatMapValues–ő ĹĹÝ––°£Ī»»Á£ļ–Ť“™ĹęŌķŃŅ°ĘŅ‚īś°ĘľŘłŮ°ĘīŔŌķľ∆ĽģļÕ…Ő∆∑–ŇŌĘÕ®Ļż…Ő∆∑Īŗ¬ŽŃ¨Ĺ”ĶĹ“Ľ∆ū£¨“ĽŅ™ ľ Ļ”√Ķń «join◊™ĽĽ≤Ŕ◊ų£¨ĹęľłłŲRDDĪňīňjoin‘ŕ“Ľ∆ū°£ļůņī∑ĘŌ÷’‚—ý◊Ų‘ň––ňŔ∂»∑«≥£¬ż£¨”ŕ «ĽĽ≥…union+groypByKey+flatMapValue–ő Ĺ£¨’‚—ý◊Ų÷Ľ–ŤĹÝ––“ĽīőShuffle£¨’‚—ý–řłńļů‘ň––ňŔ∂»Ī»“‘«įŅž∂ŗŃň°£ Ķņżīķ¬Ž»ÁŌ¬£ļ
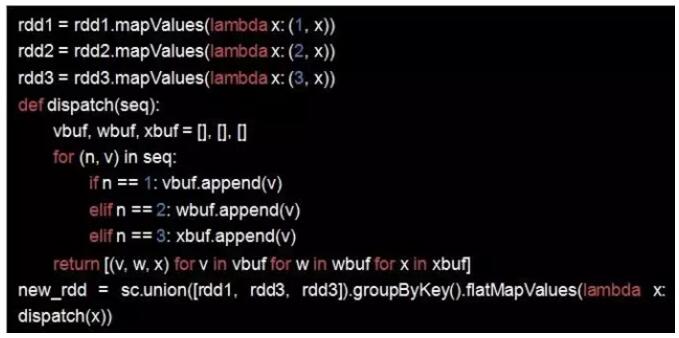
»ÁĻŻŃĹłŲRDD–Ť“™‘ŕgroupByKeyļůĹÝ––join≤Ŕ◊ų£¨Ņ…“‘ Ļ”√cogroup◊™ĽĽ≤Ŕ◊ųīķŐś°£Ī»»Á£¨ Ĺęņķ ∑ŌķŃŅ żĺ›įī∆∑ņŗĹÝ––ļŌ≤Ę£¨»Ľļů‘Ŕ”Žń£–ÕőńľĢĹÝ––join≤Ŕ◊ų£¨Ńų≥Ő»ÁŌ¬£ļ

Ļ”√cogroupļů£¨ĺ≠Ļż“ĽīőShuffleĺÕŅ…ÕÍ≥…ŃňŃĹ≤Ĺ≤Ŕ◊ų£¨–‘ń‹īů∑ýŐŠ…ż°£
2. ľű…ŔShuffle Īīę šĶń żĺ›ŃŅ
- ‘ŕShuffle≤Ŕ◊ų«įĺ°ŃŅĹę≤Ľ–Ť“™Ķń żĺ›Ļż¬ňĶŰ°£
- Ļ”√comebineyeByKeyŅ…“‘łŖ–߬ Ķń ĶŌ÷»őļőłī‘”ĶńĺŘļŌ¬Ŗľ≠°£
comebineyeByKey Ű”ŕĺŘļŌņŗ≤Ŕ◊ų£¨”…”ŕňŁ÷ß≥÷map∂ňĶńĺŘļŌňý“‘Ī»groupByKey–‘ń‹ļ√£¨”÷”…”ŕňŁĶńmap∂ň”Žreduce∂ňŅ…“‘…Ť÷√≥…≤Ľ“Ľ—ýĶń¬Ŗľ≠£¨ňý“‘ňŁ÷ß≥÷Ķń≥°ĺįĪ»reduceByKey∂ŗ£¨ňŁĶń∂®“Ś»ÁŌ¬£ļ

reduceByKeyļÕgroupByKeyńŕ≤Ņ Ķľ «Ķų”√ŃňcomebineyeByKey£¨
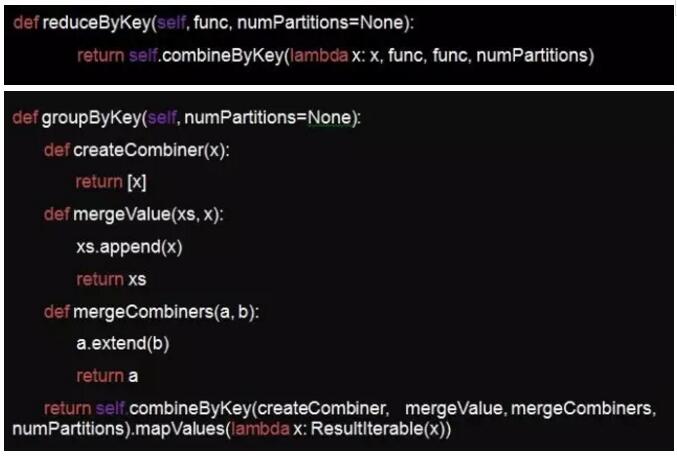
ő“√«÷ģ«į”–ļ‹∂ŗłī‘”Ķńőř∑®”√reduceByKeyņī ĶŌ÷ĶńĺŘļŌ¬Ŗľ≠∂ľÕ®ĻżgroupByKeyņīÕÍ≥…Ķń£¨ļůņī»ę≤ŅŐśĽĽő™comebineyeByKeyļů–‘ń‹ŐŠ…żŃň≤Ľ…Ŕ°£
3. ī¶ņŪ żĺ›«„–Ī
”––© ĪļÚĺ≠Ļż“ĽŌĶŃ–◊™ĽĽ≤Ŕ◊ų÷ģļů żĺ›ĪšĶ√ ģ∑÷«„–Ī£¨‘ŕ’‚—ý«ťŅŲŌ¬ļů–ÝĶńRDDľ∆ň„–߬ ĽŠ∑«≥£Ķń‘„ł‚£¨—Ō÷ō Ī≥Ő–ÚĪ®īŪ°£”ŲĶĹ’‚÷÷«ťŅŲÕ®≥£ĽŠ Ļ”√repartition’‚łŲ◊™ĽĽ≤Ŕ◊ų∂‘RDDĹÝ––÷ō–¬∑÷«Ý£¨÷ō–¬∑÷«Ýļů żĺ›ĽŠĺý‘»∑÷≤ľ‘ŕ≤ĽÕ¨Ķń∑÷«Ý÷–£¨Ī‹√‚Ńň żĺ›«„–Ī°£»ÁĻŻ «ľű…Ŕ∑÷«Ý Ļ”√coalesce“≤Ņ…“‘īÔĶĹ–ßĻŻ£¨ĶęĪ»∆ūrepartition≤Ľ◊„Ķń «∑÷Ňš≤Ľ «ń«√īĺý‘»°£
5.–°ĹŠ
ňš»Ľĺ©∂ęĶń‘§≤‚ŌĶÕ≥“—ĺ≠ő»∂®‘ň––Ńňļ‹≥§“Ľ∂ő Īľš£¨Ķę «ő“√«“≤ŅīĶĹŌĶÕ≥Īĺ…ŪĽĻīś‘ŕ◊Ňļ‹∂ŗīżłńĹÝĶńĶō∑Ĺ£¨Ĺ”Ō¬ņīő“√«ĽŠ‘ŕ‘§≤‚◊ľ»∑∂»ĶńŐŠłŖ°ĘŌĶÕ≥–‘ń‹Ķń”ŇĽĮ°Ę∂ŗ“ĶőŮ÷ß≥÷ĶńĪ„Ĺ›–‘…ŌĹÝ––łńĹÝ°£őīņī£¨ňś◊Ňīů żĺ›°Ę»ňĻ§÷«ń‹ľľ ű‘ŕĺ©∂ęĻ©”¶ŃīĻ‹ņŪ÷–Ķń Ļ”√‘Ĺņī‘Ĺ∂ŗ£¨‘§≤‚ŌĶÕ≥“≤Ĺę∑ĘĽ”≥ŲłŁīů◊ų”√£¨∂‘”ŕĺ©∂ꑧ≤‚ŌĶÕ≥Ķń—–∑ĘĻ§◊ų“≤Ĺę «≥š¬ķ◊ŇŐŰ’Ĺ”Žņ÷»§°£
īū“…Ľ∑Ĺŕ
Q1£ļ”√hive«ŚŌīÕÍ“‘ļůĶń żĺ›ĽĻīś‘ŕhive÷–¬ū£Ņń«‘≠ ľ żĺ›ĽĻĪ£Ń۬ū£ŅĽÚ’ŖňĶĪ£ŃŰ∂ŗĺ√£Ņ–Ľ–ĽņŌ ¶£°
—Ó∂¨‘Ĺ£ļ«ŚŌīļů żĺ›ĽĻĽŠīśĽōhive£¨‘≠ ľ żĺ›≤ĽĽŠ…ĺ£¨Ķę‘ŕ«ŚŌī◊™ĽĽĻż≥Ő÷–Ņ…ń‹ĽŠ÷ī––∂ŗłŲhiveĹŇĪĺ£¨ĽŠ≤ķ…ķļ‹∂ŗ÷–ľš żĺ›£¨’‚–©÷–ľš żĺ›÷ĽĽŠĪ£ŃŰ“Ľ∂ő Īľš£¨»Ľļů◊‘∂Į…ĺ≥ż£® «įī ĪľšĹÝ––∑÷«ÝĶń£©°£
Q2£ļľł÷÷ŌłĽĮĶń≥°ĺį£¨»Ápromotion£¨fast sale£¨…Ő∆∑skuĶńĽ≠ŌŮ «∑Ů”–£Ņ
—Ó∂¨‘Ĺ£ļ∂‘”ŕīŔŌķ’‚÷÷«ťŅŲĽŠ“ż»Žņķ ∑īŔŌķŌķŃŅ◊ųő™Őō’ų£¨‘§≤‚ Ī“≤ĽŠĹŠļŌīŔŌķľ∆Ľģ£¨īŔŌķľ∆Ľģ∂ľ «ŐŠ«į¬ľ»ŽĶĹŌĶÕ≥÷–Ķń£¨≥żīňĽĻ–Ť“™∑÷őŲľŘłŮ°ĘPV‘ŕ…Ő∆∑…ŌĶń√Űł–≥…Ķń°£∂‘”ŕŅžŌŻ∆∑–Ť“™ĹŠļŌ…Ő∆∑Ķń…ķ√Ł÷‹∆໕◊Ų°£
Q3£ļįīľ‹ĻĻŅī£¨ń«÷÷ĹĽĽ•ŐĹňų–‘Ķń«Ž«ů£¨ņŗň∆”ŕ“‘«įsql«Ž«ů»•≤÷Ņ‚ņŐ“ĽŌ¬ żĺ›ŅīŅīĶń«ťŅŲ£¨ «”√sparksqlņī÷ß≥Ҭū£Ņ“Ľį„Ōž”¶ ĪľšīůłŇ»Áļő£Ņ
Ļýĺį’į£ļ∂‘£¨ņŽŌŖ żĺ› «Õ®ĻżSparkSQLĹÝ––≤ť—Į£¨Ōž”¶ Īľš“ņņĶ”ŕľĮ»ļĶńĻśń£°Ę≤ť—ĮĶń żĺ›ŃŅľįSQLĶńłī‘”≥Ő∂»£¨ ‘ŕ‘§≤‚ŌĶÕ≥ Ļ”√Ķń żĺ›īůłŇ500GB£¨…ŔĶń2∑÷÷”◊ů”“£¨◊Ó∂ŗ≤Ľ≥¨Ļż20∑÷÷”°£
Q4£ļ«Žő »Áļő—°‘Ůń£–Õ «≤ĽÕ¨∆∑ņŗ”–≤ĽÕ¨ń£–Õ¬ū
—Ó∂¨‘Ĺ£ļ≤ĽÕÍ»ę «łýĺ›∆∑ņŗ∑÷ń£–Õ£¨ĽĻ“™Ņľ¬« «∑ŮłŖŌķŃŅ∆∑°Ę «∑Ů≥§ő≤∆∑°Ę «∑Ů–¬∆∑°Ę «∑Ů «ľĺĹŕ–‘Ī»ĹŌ√ųŌ‘Ķń…Ő∆∑Ķ»°£
Q5£ļĹŕľŔ»’“Ú◊”‘ű√īŃŅĽĮ£Ņ
—Ó∂¨‘Ĺ£ļ ◊Ō»“™ĹÝ––∆ĹĽ¨£¨ĺ°ŃŅį—∆šňŻł…»Ň“Úňō»•ĶŰ£¨‘Ŕľ∆ň„ĹŕľŔ»’∆ŕľš”Ž«įļů“Ľ∂ő Īľšĺý÷Ķ∂‘Ī»£¨“™◊Ę“‚Ņľ¬«—ŰņķļÕŇ©ņķ£¨ĽĻ”–»ÁĻŻ–¬∆∑ĽĻĽŠłýĺ›Õ¨∆∑ņŗĽÚÕ¨∆∑Ň∆ĹÝ––Őśīķ°£
|









