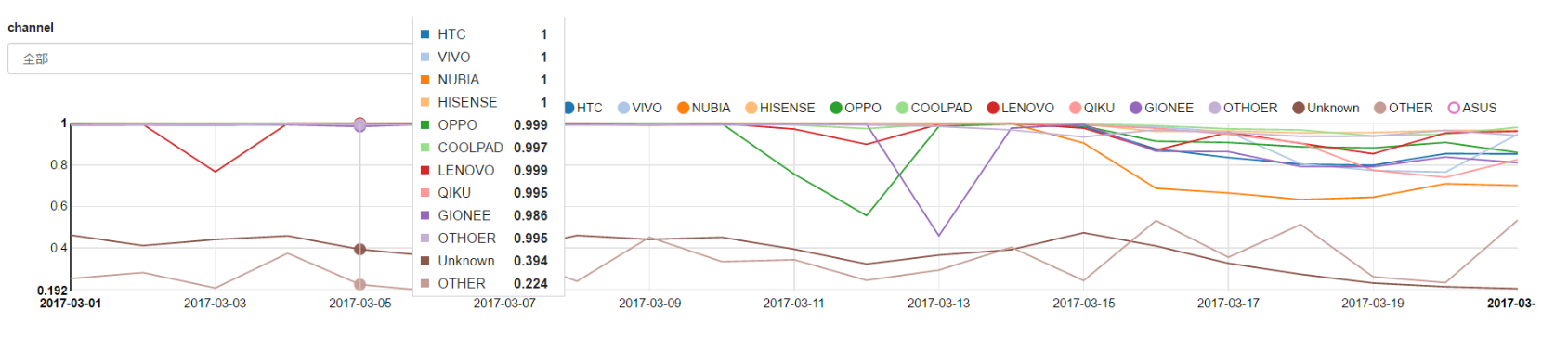
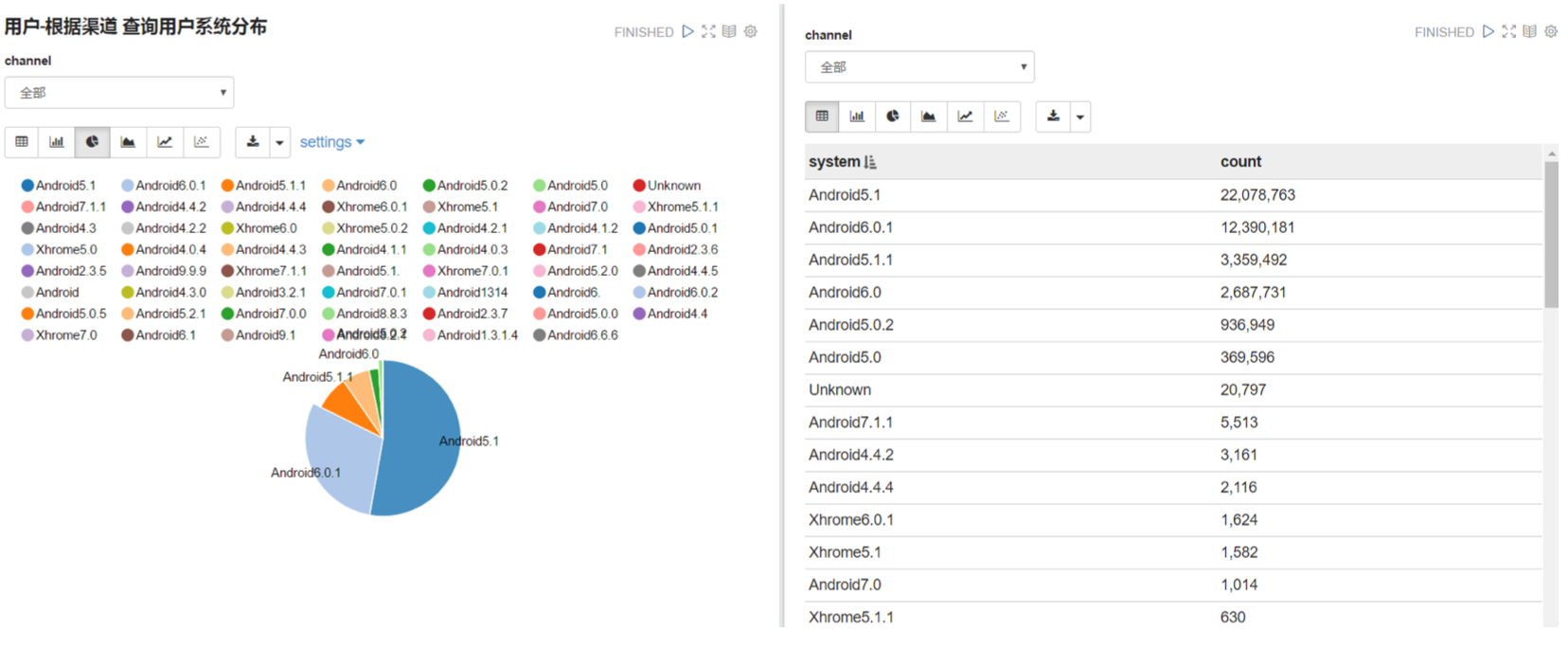
| 
ЭМ 1 ДѓЪ§ОнЩњЬЌЬхЯЕ
ПДзХЭМ 1 ДѓМвПЩФмЛсИаЕНЪьЯЄЃЌгжЛђепЛсОѕЕУВПЗжгааЉФАЩњЃЌетЪЧвЛеХЛуМЏСЫФПЧАДѓЪ§ОнЩњЬЌЯТДѓЖрЪ§ГЩЪьзщМўЕФМмЙЙЭМЁЃжкЫљжмжЊЃЌДѓЪ§ОнЩњЬЌКмИДдгЃЌЖдгкИіШЫРДЫЕЃЌвЊШЋВПбЇЛсПЩФмвЊЛЈЗбКУМИФъЪБМфЁЃЖјЖдгкЦѓвЕРДЫЕЃЌвЊзюДѓГЬЖШЗЂЛгЦфМлжЕЃЌЙЙНЈвЛИіГЩЪьЮШЖЈЁЂЙІФмЖрбљЕФДѓЪ§ОнЦНЬЈЃЌЦкМфЛЈЗбЕФЪБМфвдМАШЫСІГЩБОзХЪЕФбвдЙРСПЃЌИќКЮПіЛЙашвЊПМТЧГжајЮЌЛЄЕФЮЪЬтЁЃетОЭЪЧЦпХЃЕФPandoraДѓЪ§ОнЦНЬЈСщИаЕФРДдДЃЌЮвУЧЙЙНЈвЛИіДѓЪ§ОнЦНЬЈЃЌзїЮЊВњЦЗЬсЙЉИјгУЛЇЃЌПьЫйАяжњгУЛЇЭкОђЪ§ОнМлжЕЁЃ
1. PandoraЕФБГОАКЭНтОіЕФЮЪЬт
ЦпХЃЪЧвддЦДцДЂЦ№МвЕФЙЋЫОЃЌЦНЬЈЩЯгазХДѓСПЕФЪ§ОнЁЂвЕЮёШежОвдМАдЫЮЌМрПиЪ§ОнЃЌЛљгкЖдетаЉЪ§ОнЕФЙмРэвдМАЗжЮіЕФашЧѓЃЌPandoraЕЎЩњСЫЁЃЮвУЧДюНЈСЫвЛИіПЩППЕФДѓЪ§ОнЦНЬЈЃЌНЋДѓЪ§ОнЩњЬЌжаЕФИїИізщМўХфЬзГЩвЛИіЬхЯЕЗЂЛгзїгУЃЌгУРДНтОіЪЕМЪвЕЮёжаХіЕНЕФЗБЫіЁЂИДдгЁЂЖрбљЛЏЕФЮЪЬтЁЃетИіДѓЪ§ОнЦНЬЈЕФЙЄзїДгЪ§ОнЕФВЩМЏБувбПЊЪМЃЌЭЈЙ§вЛЬѕЪ§ОнзмЯпЃЌдйИљОнвЕЮёашЧѓЗжСїЕНВЛЭЌЕФЯТгЮВњЦЗЃЌДгДцДЂЕНЪ§ОнПЩЪгЛЏЃЌДгЪЕЪБЕФЪ§ОнБфЛЛЕНРыЯпЕФЫуЗЈЗжЮіЃЌЮвУЧЙЙНЈвЛИіШЋеЛЕФДѓЪ§ОнЗжЮіВњЦЗЁЃ
гыДЫЭЌЪБЃЌЮвУЧдкДѓЪ§ОнЦНЬЈжЎЩЯЙЙНЈСЫвЕЮёЙЄзїСїЕФИХФюЃЌШУгУЛЇжЛашЙиаФЙЙНЈЗћКЯЫћУЧвЕЮёФЃаЭЕФЙЄзїСїЃЌЖјЮоашОпБИДѓЪ§ОнММЪѕБГОАЁЃВЛНіДѓДѓНЕЕЭСЫгУЛЇЭкОђДѓЪ§ОнМлжЕЕФГЩБОЃЌИќЮЊживЊЕФЪЧШЅГ§СЫДѓЪ§ОнММЪѕУХМїЃЌЪЙЕУИїааИївЕЕФзЈМвПЩвдИќКУЕФЪЉеЙздМКЖдвЕЮёЕФЩюЖШРэНтЁЃ
дкЙЄзїСїЩЯЃЌгУЛЇВЛНіПЩвдЧхЮњЕФМрПиздМКЕФЪ§ОнСїЖЏЃЌЧсЫЩЙЙНЈИїРрЪЕЪБЁЂРыЯпЕФЪ§ОнБфЛЏгыздЖЈвхМЦЫуЃЌЛЙПЩвдАДашЕЏадРЉШнЁЂПьЫйЕїЖШдЦЖЫзЪдДЃЌНЕЕЭСЫдЫЮЌЕФГЩБОЁЃгыДЫЭЌЪБЃЌЮвУЧМЏГЩСЫЩчЧјжаДѓСПЕФгХауПЊдДШэМўЃЌЖдЦфНјаагХЛЏМАЖЈжЦЃЌвЛЗНУцвдБуЗЂЛгЦфИќЧПДѓЕФЙІФмЃЌСэвЛЗНУцЃЌвВШУЪьЯЄЪЙгУетРрПЊдДШэМўЕФгУЛЇПЩвдзіЕНПьЫйЧЈвЦЃЌЮоЗьЧаЛЛЪЙгУЁЃ
2. PandoraЕФЙІФмЬиЕугыгІгУГЁОА
ФЧУДЃЌPandoraЕНЕзЪЧвЛИідѕбљЕФЦНЬЈФиЃПЙЄзїСїгжЪЧдѕбљЕФФиЃПШУЮвУЧЪзЯШРДжБЙлЕФПДвЛЯТЙЄзїСїЕФЪЙгУаЮЬЌЃЌШчЭМ
2 ЫљЪОЁЃ
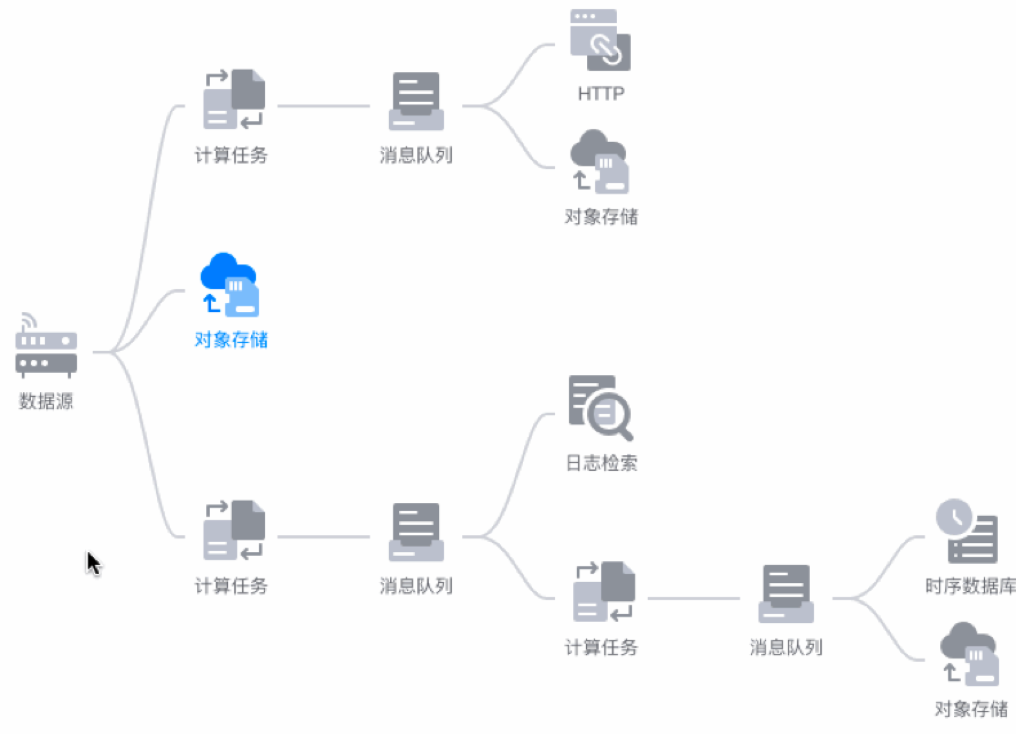
ЭМ 2 ЙЄзїСїаЮЬЌ
зюзѓБпЕФЪ§ОндДЪЧЙЄзїСїЕФЦ№ЕуЃЌЪ§ОндДПЩвдЪЧвЛИіЃЌвВПЩвдЪЧЖрИіЁЃдкЪЕЪБМЦЫуЕФЙЄзїСїжаЃЌЮвУЧжЛФмгавЛИіЪ§ОндДЃЌетИіЪ§ОндДОЭЪЧЪ§ОнЪеМЏЛуОлЕФжааФЃЌвВПЩвдРэНтЮЊЪ§ОнзмЯпЃЌЫљгаВЛЭЌжеЖЫЕФЪ§ОнДђЯђЪ§ОндДЃЌдйЭЈЙ§Ъ§ОндДИљОнвЕЮёашЧѓЗжЗЂЕНВЛЭЌЯТгЮЃЛдкРыЯпЙЄзїСїжаЃЌЮвУЧПЩвдгаЖрИіЪ§ОндДЃЌВЛЭЌЕФЪ§ОндДДњБэЕФЪЧДцДЂдкВЛЭЌЕиЗНЕФРыЯпЪ§ОнЃЌПЩвдЪЧЦпХЃдЦДцДЂжаЕФВЛЭЌЮФМўЃЌгжЛђЪЧHDFSЕШВЛЭЌРраЭЕФЪ§ОнВжПтЁЃ
ВЛЙмЪЧЪЕЪБЛЙЪЧРыЯпЃЌДгЪ§ОндДПЊЪМЃЌФуОЭПЩвдИљОнашвЊзіВЛЭЌРраЭЕФДІРэЁЃ
зюЛљБОЕФДІРэЪЧЖдЪ§ОнНјаавЛаЉЖЈжЦЛЏЕФМЦЫуЃЌБШШчФуПЩФмашвЊЖдУПЬьКЃСПЕФЪ§ОнНјаавЛИіЖЈЪБЗжЮіЛуОлЕФЙІФмЃЌМЦЫуУПЗжжггаЖрЩйЬѕЪ§ОнЁЂУПаЁЪБгаЖрЩйЬѕЪ§ОнЃЌДгЖјЫѕМѕЪ§ОнЙцФЃНкдМДцДЂГЩБОЃЌЛђепДгжаЩњГЩвЛЗнЪ§ОнШеБЈЁЂжмБЈЕШЕШЃЛгжБШШчдкетИіаХЯЂБЌеЈЕФЪБДњЃЌФуДгЭјЩЯзЅШЁСЫКЃСПЕФЪ§ОнЃЌашвЊЖдЪ§ОнНјаавЛаЉЧхЯДЁЂЙ§ТЫЁЂЩОбЁЃЌвдДЫЗжЮіЩчЛсШШЕуЛђЦфЫћгаМлжЕЕФаХЯЂЃЛгжБШШчФуЯыЖдЪ§ОнзівЛИібгЩьЛђРЉеЙЃЌзюГЃМћЕФОЭЪЧЖдвЛИіIPЛёШЁЫќЕФдЫгЊЩЬЁЂЫљдкЧјгђЕШаХЯЂЁЃФЧУДФуОЭПЩвдДДНЈвЛИіМЦЫуШЮЮёЃЌзюМђЕЅЕФБраДвЛаЉSQLгяОфОЭПЩвдзіЪ§ОнБфЛЛЃЛНјНзвЛаЉЕФЪЙгУЗНЪНОЭЪЧБраДвЛаЉUDF(гУЛЇздЖЈвхЕФКЏЪ§)ЃЌзівЛаЉНЯЮЊИДдгЕФБфЛЏЃЛИќИпНзЕФОЭЪЧжБНгБраДвЛРрВхМўЃЌжБНгЪЙгУДѓСПJavaЕФРрПтЖдЪ§ОнНјааВйзїЁЃЕБШЛЃЌдкРыЯпМЦЫужаЃЌГ§СЫЕЅИіЪ§ОндДЕФМЦЫуШЮЮёвдЭтЃЌФуЛЙПЩвдЖдСНИіЪ§ОндДЃЌврЛђЪЧСНИіМЦЫуШЮЮёЕФНсЙћНјааОлКЯЃЌШЛКѓдйНјааМЦЫуЕШЕШЁЃМЦЫуШЮЮёПЩвдТњзуФуЖдгкећИіЙЄзїСїЕФЭъећЪ§ОнДІРэашЧѓЁЃ
дкНјааЙ§вЛИіЛљБОЕФМЦЫувдКѓЃЌПЩФмзюГЃМћЕФвЛИіашЧѓОЭЪЧЖдетаЉМЦЫуКѓЕФЪ§ОнНјааМьЫїЃЌжБАзЕФЫЕОЭПЩвдВщбЏФуЕФЪ§ОнЁЃФЧУДФуПЩвдДДНЈвЛИіЕМГіЕНШежОМьЫїЃЌдкетРяФуОЭПЩвдЫбЫїФуЕФМЦЫуНсЙћЁЃЕБШЛЃЌФуЕФЪ§ОндкЪ§ОндДжавВЭъШЋПЩвдВЛОЙ§ШЮКЮМЦЫуШЮЮёЃЌжБНгЕМЯђШежОМьЫїЁЃгжЛђепФуЯЃЭћЖдЪ§ОнНјааИќЭъЩЦЕФЪЕЪБМрПиКЭЪ§ОнПЩЪгЛЏДІРэЃЌФЧУДОЭПЩвдЕМГіЕНЪБађЪ§ОнПтЃЌеыЖдДјгаЪБМфДСЕФЪ§ОнзіИпадФмЪ§ОнаДШыКЭВщбЏгХЛЏЃЌТњзуФуеыЖдЪЕЪБКЃСПЪ§ОнЕФМДЯЏВщбЏашЧѓЁЃ
СэвЛЗНУцЃЌФуЙЄзїСїМЦЫуКѓЕФНсЙћЃЌПЩвджБНгдйДЮЕМГіЕНЦпХЃдЦДцДЂНјаагРОУБЃДцЃЌЛђепгыКѓајЕФЪ§ОнНсКЯНјааЗжЮіЁЃФувВПЩвдРэНтЮЊЭЈЙ§ДѓЪ§ОнЗўЮёЃЌЦпХЃЕФдЦДцДЂБфГЩСЫвЛИіЪ§ОнВжПтЮЊПЭЛЇЬсЙЉЗўЮёЁЃжЎЧАвбОДцДЂдкЦпХЃдЦЩЯЕФЪ§Он(ШчCDNШежОЕШ)ЃЌЭъШЋПЩвджБНгЪЙгУЮвУЧЕФДѓЪ§ОнЦНЬЈНјааМЦЫуЃЌЮоашШЮКЮНгШыЙ§ГЬЁЃ
ЮЊСЫЗНБугУЛЇГфЗжРћгУздМКЕФЪ§ОнЃЌЮвУЧЩѕжСЬсЙЉСЫЕМГіЕН HTTP ЗўЮёЃЌгУЛЇПЩвдЙЙНЈздМКЕФ HTTP
ЗўЮёЦїРДНгЪмОЙ§PandoraДѓЪ§ОнЦНЬЈМЦЫуКѓЕФЪ§ОнЁЃ
3. PandoraЕФЯЕЭГМмЙЙгыБфЧЈ
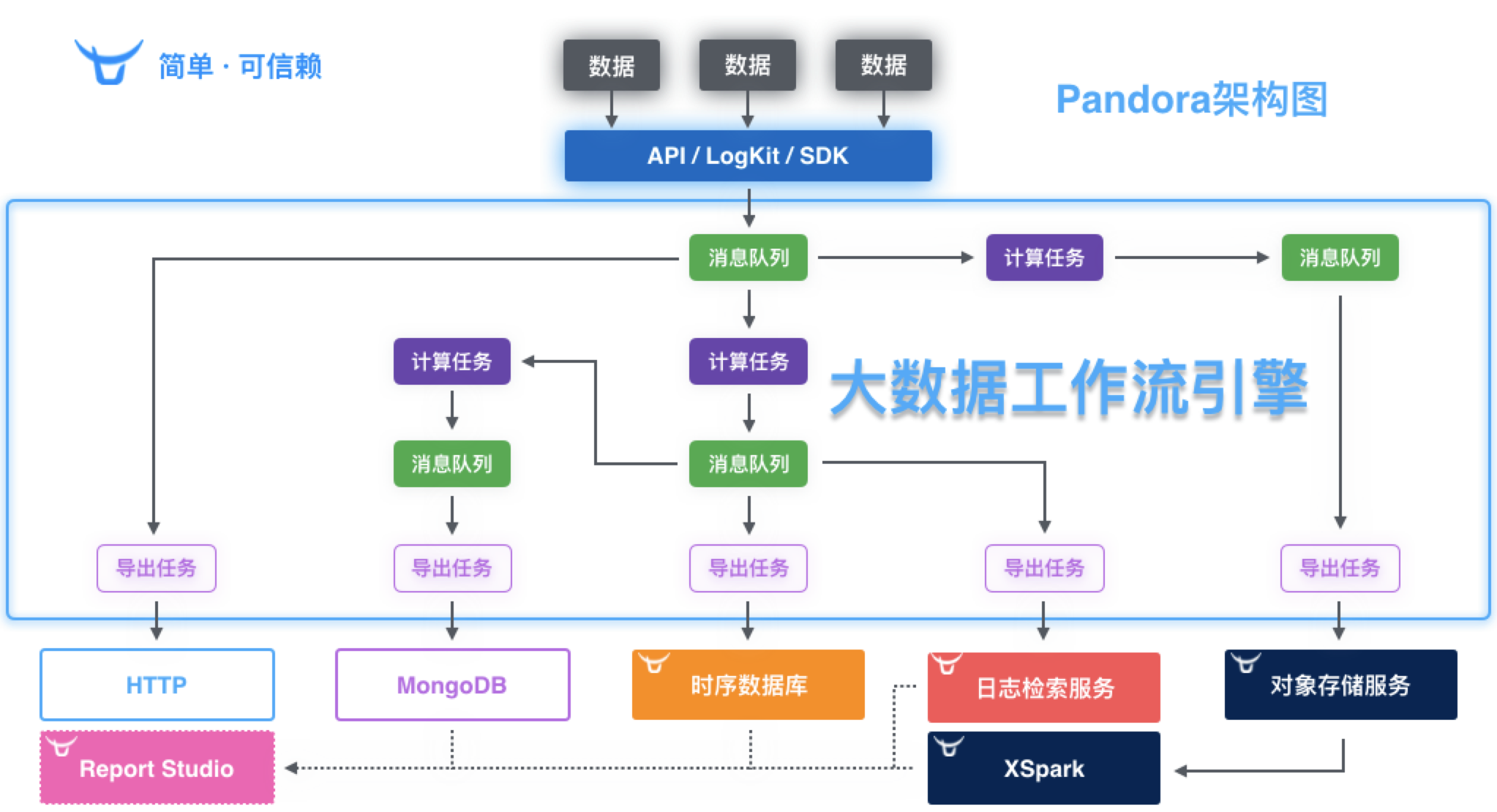
ЭМ 3 ВњЦЗМмЙЙЭМ
ЭМ 3 ЪЧ PandoraЕФВњЦЗМмЙЙЭМЃЌЛљБОЕФЙІФмдкЕк 2 НкжаОљвбНщЩмЃЌдкДЫВЛдйзИЪіЃЌдкНВНтЯЕЭГМмЙЙжЎЧАЃЌШУЮвУЧЖдееВњЦЗМмЙЙНјаавЛаЉЛљБОЕФЯЕЭГзщМўММЪѕУћГЦЕФЖдееЫЕУїЃЌвдБуЯТЮФУшЪіМђНрБугкРэНтЁЃЪ§ОнЭЈЙ§ЮвУЧЬсЙЉЕФЪ§ОнЩЯБЈЙЄОпlogkitЁЂИїРрSDKЛђепгУЛЇжБНгЕїгУПЊЗХAPIНгШыЃЌЪ§ОнНјШыКѓЮоТлЪЧЪ§ОндДБОЩэЛЙЪЧОЙ§МЦЫуШЮЮёКѓЕФСйЪБЪ§ОнДцДЂНкЕуЃЌЮвУЧЖМвЛГЦзїЯћЯЂЖгСаЃЌММЪѕЩЯГЦжЎЮЊPipelineЃЌЯёВЛЭЌЯТгЮЬсЙЉЕМГіЗўЮёЕФзщМўЮвУЧГЦжЎЮЊExportЃЌдкPipelineжаГаЕЃИїРрМЦЫуШЮЮёДІРэЕФзщМўЮвУЧГЦжЎЮЊTransformЃЌЯТгЮЕФЪБађЪ§ОнПтЗўЮёЮвУЧГЦжЎЮЊTSDBЃЌЯТгЮЕФШежОМьЫїЗўЮёЮвУЧГЦжЎЮЊLogDBЁЃ
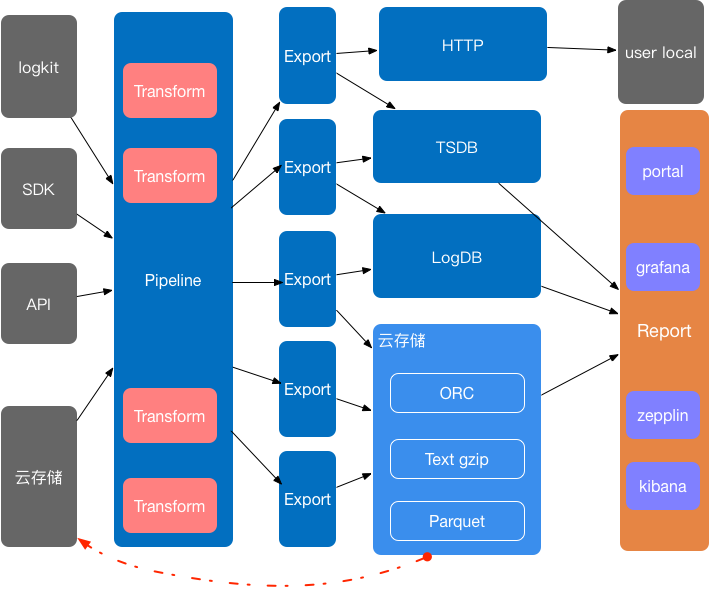
ЭМ 4 PandoraЯЕЭГМмЙЙЭМ
гаСЫетаЉЛљБОИХФюКѓЃЌШУЮвУЧЖдееЭМ 4 PanoraЯЕЭГМмЙЙЭМЃЌПЊЦєЮвУЧЕФPandoraМмЙЙбнНјжЎТУЁЃ
3.1 Ъ§ОнЩЯБЈ
зюзѓВрЕФзщМўЪЧЪ§ОнЪеМЏЕФВПЗжЃЌЪ§ОнРДдДгкПЭЛЇИїжжИїбљЕФЯЕЭГЁЃЯраХДѓВПЗжгУЛЇдкНгШыДѓЪ§ОнЦНЬЈЪБЃЌЖМЛсУцСйЪ§ОнЪеМЏетвЛФбЬтЃЌвЛЗНУцЯЃЭћЪ§ОнВЛжиВЛТЉШЋВПЪеМЏЩЯРДЃЌвЛЗНУцгжвЊЪ§ОнЪеМЏОЁПЩФмИпаЇЧвВЛЬЋЯћКФЛњЦїЕФИїРрзЪдДЃЌЭЌЪБЛЙвЊТњзуГЁОАИївьЕФВЛЭЌЧщПіЯТЕФЪ§ОнЪеМЏашЧѓЁЃЪьЯЄетПщЕФХѓгбПЩФмвВдчвбСЫНтЃЌЩчЧјвбОгаКмЖрВЛЭЌРраЭЕФПЊдДЪ§ОнЪеМЏЙЄОпЃЌжЊУћЕФАќРЈflumeЁЂlogstashЁЂfluentdЁЂtelegrafЕШЕШЃЌЫћУЧИїгаРћБзЃЌЙІФмЩЯДѓЖМТњзуашЧѓЃЌЕЋЪЧдкадФмЩЯКЭвЛаЉЗЧЭЈгУашЧѓЕФГЁОАЩЯВЛОЁШчШЫвтЁЃЮЊСЫИќКУЕФТњзугУЛЇВЛЭЌРраЭЕФашЧѓЃЌЮвУЧзджїбаЗЂСЫвЛИіПЩвдЪеМЏИїжжИїбљЪ§ОндДЪ§ОнЕФЙЄОпlogkitЃЌЭМ
5 ЪЧlogkitЕФЙІФмМмЙЙЪОвтЭМЁЃlogkitЪЙгУgoгябдБраДЃЌвдВхМўЕФаЮЪНЖЈжЦВЛЭЌЕФЪ§ОнЪеМЏНтЮіашЧѓЃЌДІРэИпаЇЁЂадФмЫ№КФЕЭЃЌЭЌЪБвВвбОПЊдДЃЌЮвУЧЗЧГЃЛЖгДѓМввЛЦ№ВЮгыЕНlogkitЕФЪЙгУКЭДњТыПЊЗЂЖЈжЦжаРДЃЌЮЊlogkit
ЬсЬсPRЃЌЕБШЛЃЌвВЗЧГЃРжвтНгЪмФњЙигкlogkitЕФШЮКЮвтМћЛђНЈвщЃЌжЛашдкgithubЬсissuesМДПЩЁЃ
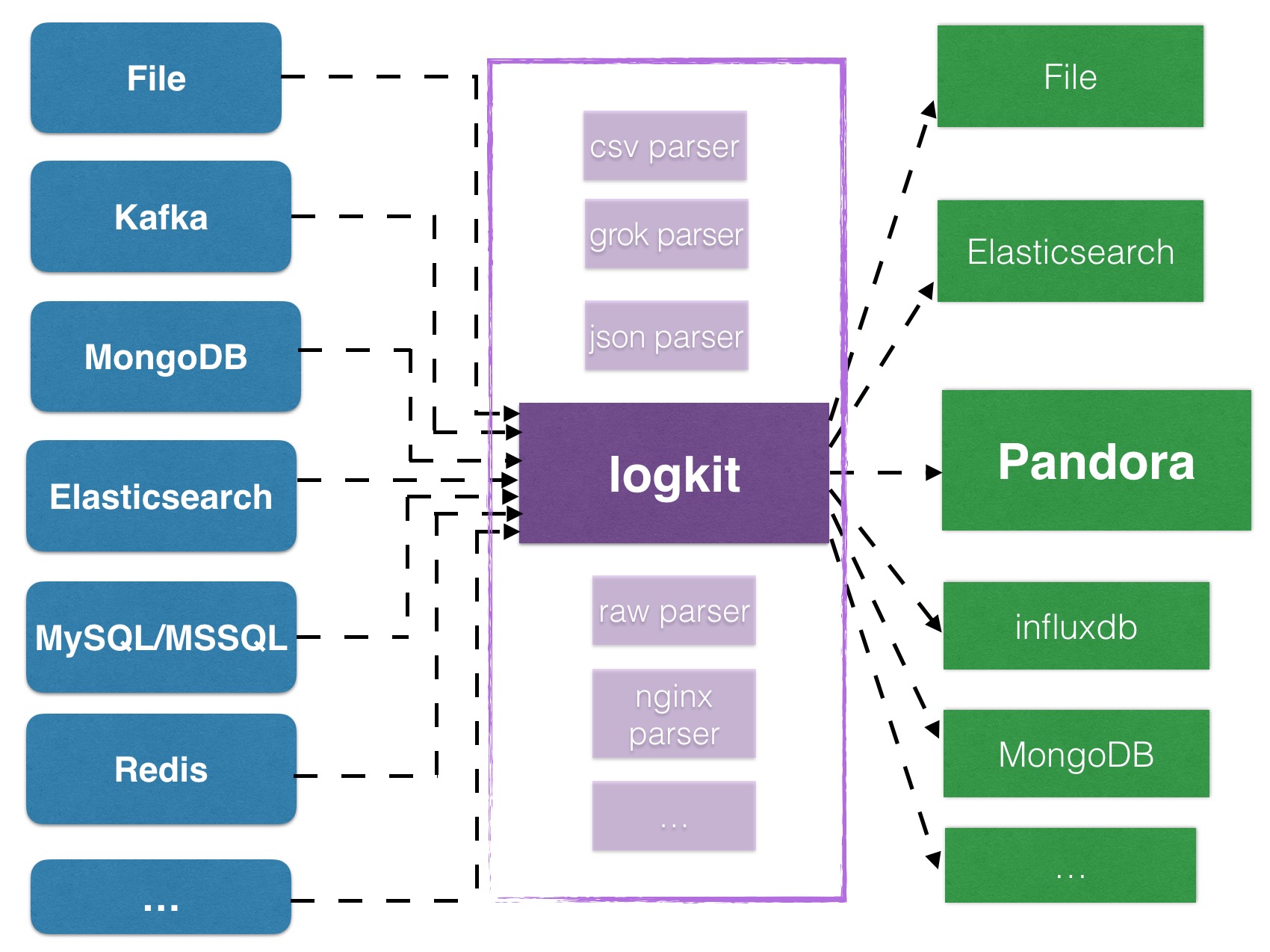
ЭМ 5 logkitЙІФмМмЙЙЪОвтЭМ
гаСЫетбљвЛПюЪ§ОнЪеМЏЙЄОпЃЌМИКѕ 90% ЕФЪ§ОнЪеМЏГЁОАЮвУЧвбОНтОіСЫЃЌЕЋЪЧЛЙЛсгажюШчiosЁЂandroidПЭЛЇЖЫЪ§ОнжБНгЩЯБЈЁЂвГУцЧыЧѓЕуЛїЪ§ОнжБНгЩЯБЈЕШашЧѓЃЌЮЊДЫЮвУЧЬсЙЉСЫИїРргябдЕФSDKЗНБугУЛЇЪЙгУЃЌвдУжВЙlogkitЙІФмЩЯЮоЗЈТњзуЕФашЧѓЁЃ
3.2 ДѓЪ§ОнзмЯпPipline
Ъ§ОнЪеМЏЩЯРДКѓЃЌОЭе§ЪННјШыЮвУЧЕФPandoraДѓЪ§ОнЦНЬЈСЫЁЃЫљгаЩЯБЈЕФЪ§ОнЮоТлзюжеЪЧЗёМЦЫуЛђДцДЂЃЌЖМЛсЭГвЛднДцНјШыЮвУЧЕФДѓЪ§ОнзмЯпPipelineЁЃЯраХОЙ§ЩЯУцЕФНщЩмЃЌКмЖрЖСепдчвбЗЂЯжЃЌPandoraАяжњгУЛЇИљОнВЛЭЌГЁОАбЁдёзюЪЪКЯЕФДѓЪ§ОнЗжЮіЗНЪНЁЃЖјетЬзФЃЪНЕФКЫаФЃЌЮугЙжУвЩЃЌОЭЪЧДІРэЪ§ОндкВЛЭЌДѓЪ§ОнВњЦЗМфЕФСїзЊЁЃ
PipelineОЭЪЧетбљвЛЬѕЪ§ОнзмЯпЃЌдкЪ§ОнзмЯпЕФЛљДЁЩЯЮвУЧДђЭЈвЛЬѕЬѕЙмЃЌИљОнЫљашЕФГЁОАЕМГіЕНКѓЖЫЯргІЕФДцДЂЗўЮёЩЯЁЃЭЌЪБОнДЫРДНјаазЪдДЗжХфКЭШЮЮёЙмРэЁЃетбљвЛРДЃЌОЭПЩвдБмУтгУЛЇММЪѕбЁаЭМАММЪѕМмЙЙгыЪЙгУзЫЪЦКЭвЕЮёГЁОАВЛЦЅХфЕФЧщПіЃЌЭЌЪБвВПЩвдРћгУдЦМЦЫуЕФгХЪЦЃЌАДашЗжХфЁЂПьЫйРЉШнЁЃ
3.2.1 ЛљгкconfluentЕФГѕАц
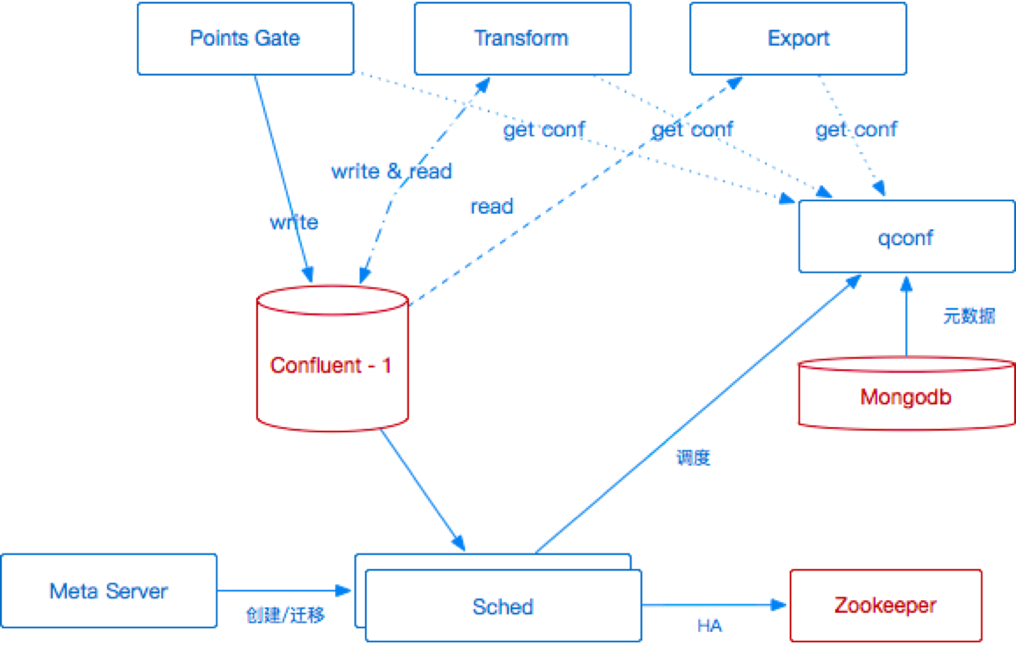
ЭМ 6 PipelineЕквЛАц
ШчЭМ 6 ЫљЪОЪЧЮвУЧЕФЕквЛАцМмЙЙЃЌЪЕЯжЩЯЮвУЧЭЈЙ§ЖЈжЦПЊдДАцБОЕФconfluentЃЌВЂАбЫќзїЮЊЮвУЧетИіМмЙЙЯЕЭГЕФКЫаФЁЃЪ§ОнвЊСїШыЯЕЭГЃЌЮвУЧЪзЯШЙЙНЈСЫвЛИі
Points GateЃЈAPI ЗўЮёЦїЃЉЃЌPoints Gate НтЮіаЃбщгУЛЇЕФЪ§ОнИёЪНВЂЕїгУconfluentжаkafka-RestЬсЙЉЕФrest
API НЋЪ§ОнаДШыЕНkafkaЃЌРћгУschema-registryЭъГЩЪ§ОнИёЪНЕФаЃбщвдМАЪ§ОнНтЮіЃЌЭЈЙ§kafkaЛёЕУЪ§ОнЙмЕРЕФФмСІЁЃ
дкНјаадЊЪ§ОнДДНЈЪБЃЌЮвУЧЕФЕїЖШЦїдкдЊЪ§ОнЗўЮёЦїЩЯДДНЈвЛИігУЛЇдЊЪ§ОнДцДЂдкMongoDBЕБжаЁЃЖдгкMongoDBЕФдЊЪ§ОнЗУЮЪЃЌЮвУЧЙЙНЈСЫвЛИіЖўМЖЛКДцЯЕЭГЃЈМДЭМжаqconfЃЉЃЌЪ§ОндкНјШыЛђепЕМГіЪБЖМЛсЭЈЙ§ЖўМЖЛКДцЗУЮЪдЊЪ§ОнЃЌетбљЪ§ОнОЭПЩвдПьЫйЕУЕНаЃбщЃЌПИзЁКЃСПЕФЪ§ОнЭЬЭТЁЃKafkaБОЩэАќКЌСЫZookeeperзщМўЃЌЮвУЧвВНшДЫРДБЃжЄећЬхЯЕЭГзщМўЕФЗўЮёЗЂЯжвдМАЪ§ОнвЛжТадетСНИіЮЪЬтЁЃ
ШЛЖјЃЌЫцзХгІгУЕФдіМгЃЌЪ§ОнСПдНРДдНДѓЃЌетбљЃЌЕЅИіЖЈжЦАцЕФ Confluent ВЂВЛФмТњзуетаЉЪ§ОнСПдіГЄЕФвЕЮёбЙСІЃЌвдМАгУЛЇВЛЖЯдіМгЕФГЁОАашЧѓЁЃkafka
topic(partition)ВЛЖЯдіГЄЕМжТећЬхЯьгІБфТ§ЃЌЮоЗЈПьЫйЧаЛЛджБИЕШД§ЮЪЬтШевцЭЙЯдЁЃдкетИіЛљДЁЩЯЃЌЮвУЧЖддБОЕФЯЕЭГМмЙЙНјааСЫЕїећЁЃ
3.2.2 PipelineЕФЩ§МЖ
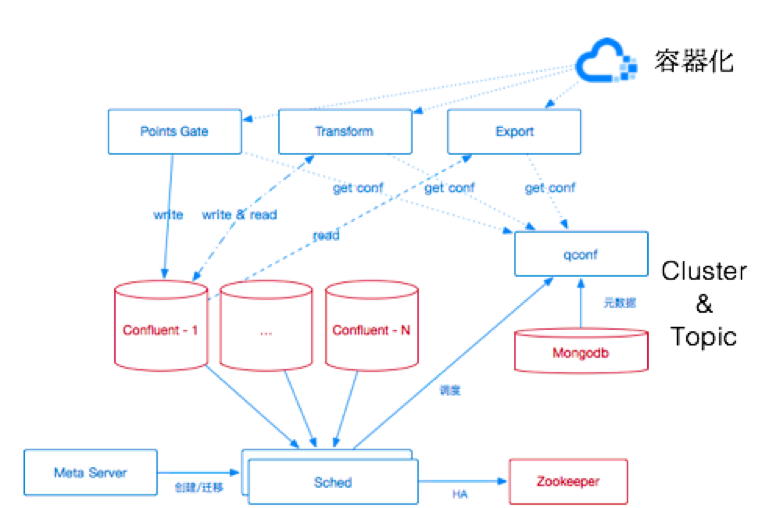
ЭМ 7 pipelineЕФЩ§МЖ
ШчЭМ 7 ЫљЪОЃЌЮвУЧЖдPipelineЕФЕквЛДЮећЬхЩ§МЖАќКЌСЫДѓСПЕФзщМўЛљДЁМмЙЙЕФЕїећЁЃЪзЯШЮвУЧЙЙНЈСЫConfluentЕФЖрМЏШКЯЕЭГЃЌНЋЕЅИіConfluentМЏШКЙцФЃПижЦдк100ЬЈЛњЦївдФкЃЌЗжЧјЪ§СППижЦдк1ЭђвдФкЃЌИљОнашЧѓЖдМЏШКНјааТЗгЩЁЃ
ПЩМћЭЈЙ§ЖрМЏШКЯЕЭГЃЌЮвУЧПЩвдКЯРэПижЦУПИіconfluentМЏШКЕФЙцФЃЃЌЭЌЪБИљОнЮвУЧЕФЕїЖШЦїАДееашвЊЧаЛЛгУЛЇЕНВЛЭЌЕФМЏШКЩЯЃЌЪЕЯжПьЫйЧаЛЛЁЂРЉШнЁЂШнджЁЂИєРыЕШЕїЖШашЧѓЁЃ
ЦфДЮЮвУЧЖдPoints GateЁЂTransformЁЂExportжаЮозДЬЌзщМўНјааСЫШнЦїЛЏДІРэЃЌРћгУЮвУЧЦпХЃФкВПЕФШнЦїдЦЦНЬЈЃЌЪЕЯжСЫЮозДЬЌЗўЮёЕФПьЫйВПЪ№ЁЂРЉШнвдМАЛвЖШЗЂВМЕШашЧѓЁЃ
етДЮМмЙЙЕФЕїећаЇЙћЯджјЃЌЮвУЧГЩЙІПЙзЁСЫУПЬьЩЯАйTBЃЌЧЇвкМЖЪ§ОнЕуЕФЪ§ОндіСПЁЃ
ВЛжЙгкДЫЃЌЮЊСЫИќИпЕФадФмЬсЩ§вдМАНкдМГЩБОЃЌЮвУЧдкЩЯЪіЩ§МЖжЎКѓНјааСЫЕкЖўДЮЕФМмЙЙЩ§МЖЁЃетДЮЩ§МЖжївЊЬхЯждкЖдConfluentЕФНјвЛВНЖЈжЦЃЈЛђепЫЕЬцЛЛЃЉЃЌЮвУЧВЛдйЪЙгУkafka-restЃЌЭЌЪБЖдДђЕуЕФЪ§ОнИёЪННјвЛВНгХЛЏЃЌгжвЛДЮНкдМСЫНќвЛАыЕФЛњЦїГЩБОЁЃ
3.3 Ъ§ОнЕМГіЗўЮёExport
дкНтОіСЫЪ§ОнзмЯпЮЪЬтвдКѓЃЌЮЪЬтЕФжижажЎжиздШЛЪЧШчКЮДІРэЪ§ОнЕМГіЕФЮЪЬтЁЃжкЫљжмжЊЃЌЪ§ОнЕМГіЦфЪЕОЭЪЧДгвЛИіЩЯгЮЯЕЭГРШЁЪ§ОнЃЌШЛКѓНЋЪ§ОндйЗЂЫЭЕНЯТгЮЯЕЭГЕФЙ§ГЬЁЃЕЋетРяУцЩцМАЕФФбЕуКЭЕїећПЩФмДѓЖрЪ§ЖМЪЧВЛЮЊШЫжЊЕФСЫЁЃдкНщЩмЮвУЧЕФЕМГіЗўЮёМмЙЙжЎЧАЃЌЗЧГЃгаБивЊУшЪівЛЯТеыЖдКЃСПЪ§ОнЕМГіЃЌЕНЕзгаФФаЉЬєеНЃП
3.3.1 Ъ§ОнЕМГіЕФЬєеН
ЪзЯШУцЖдЕФЕквЛДѓЬєеНздШЛЪЧИпЭЬЭТСПЕФЮЪЬтЃЌКЃСПЪ§ОнВЛЖЯгПШыДјРДЕФБиШЛЮЪЬтОЭЪЧЭјПЈКЭCPUЗжХфЕФЮЪЬтЃЌвЛЕЉСїСПЗжХфВЛОљЃЌОЭЛсГіЯжДѓСПвђЭјПЈЁЂCPUИКдиЙ§ИпДјРДЕФбгГйЃЌбЯжигАЯьЗўЮёПЩгУадЁЃ
ЯдШЛЃЌБЃжЄЕЭбгГйОЭЪЧЕкЖўИіЬєеНЃЌвЛЕЉИїИіСДТЗгавЛИіЛЗНкХфКЯВЛОљКтЃЌОЭЛсДјРДДѓСПбгГйЃЌШчКЮБЃжЄЕМГіЕФЩЯЯТгЮЪМжеБЃГжНЯИпЕФЭЬЭТСПЃЌДгЖјБЃжЄНЯЕЭЕФбгГйЃЌЪЧвЛИіЗЧГЃДѓЕФЕїећЁЃ
ЮЊСЫБЃжЄЕЭбгГйЃЌОЭвЊИќКУЕиЪЪХфЖржжЯТгЮЃЌЪЙЦфЪМжеБЃжЄИпЭЬЭТЃЌСЫНтЯТгЮВЛЭЌЗўЮёЕФЬиадЃЌВЂеыЖдетаЉЬиадЖЏЬЌЕФЕїећзЪдДЃЌврЪЧвЛИіКмДѓЕФЬєеНЁЃ
Г§ДЫжЎЭтЛЙгаЗжВМЪНЯЕЭГЕФГЃМћЮЪЬтЃЌашвЊБЃжЄЗўЮёИпПЩгУЃЌвдМАЫЎЦНРЉеЙЕФФмСІЁЃБЃжЄШЮЮёЕЅдЊБъзМЛЏЃЌШЮЮёСЃЖШПЩвдЧаЗжРЉеЙЃЛБЃжЄЕїЖШШЮЮёНкЕуЙЪеЯВЛгАЯьЦфЫћНкЕуЕФе§ГЃЕМГіЕШЕШЁЃ
зюЮЊживЊЕФЪЧздЖЏЛЏдЫЮЌЃЌЕБЕМГіЕФШЮЮёКИЧЪ§ЪЎЩЯАйЬЈЛњЦїКѓЃЌШЫСІвбОЮоЗЈОЋЯИЛЏДІРэУПЬЈЛњЦїЕФШЮЮёЗжХфЃЌзЪдДБиаыПЩвдздЖЏЕїЖШЁЂЕїећвдМАЙЙНЈЭГвЛЕФШЮЮёМрПиЁЃ
3.3.2 ЕМГіЗўЮёЙІФмНщЩмМАМмЙЙбнНј
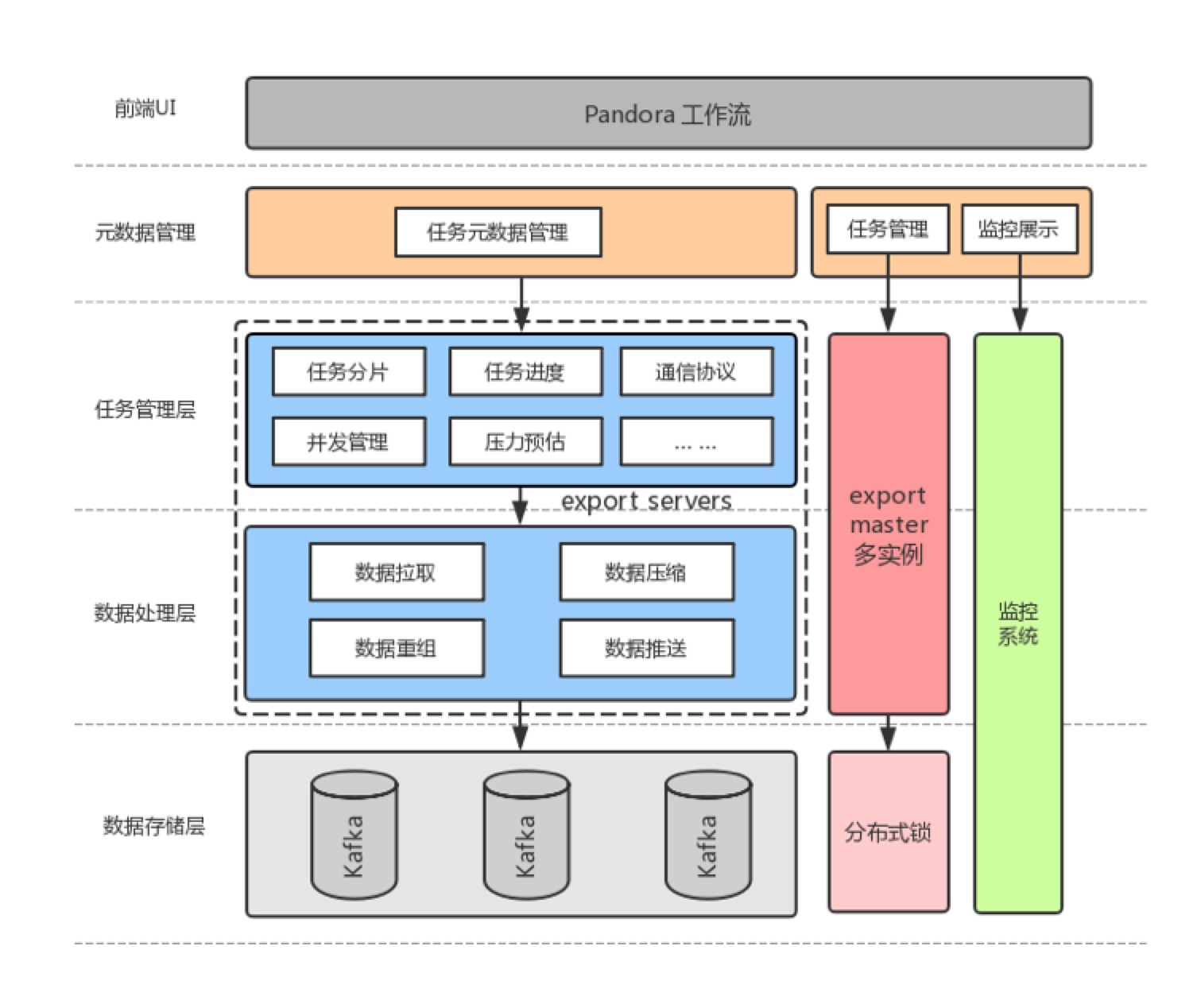
ЭМ 8 ЕМГіЗўЮёЙІФмМмЙЙЭМ
ШУЮвУЧРДПДвЛЯТЕМГіЗўЮёЕФЙІФмМмЙЙЭМЃЌШчЭМ 8 ЫљЪОЁЃЮвУЧЕФЕМГіЗўЮёжївЊЩцМАШ§ИіВуМЖЃЌвЛИіЪЧдЊЪ§ОнЙмРэЃЌдкетвЛВуБЃжЄШЮЮёЕФЗжХфвдМАМрПиеЙЪОЃЛЕкЖўВудђЪЧШЮЮёЙмРэВуЃЌГ§СЫЛљБОЕФШЮЮёЧаЗжЁЂВЂЗЂЙмРэвдМАЭЈаХавщжЎЭтЃЌЛЙАќКЌСЫбЙСІдЄЙРФЃПщЃЌИљОнжЎЧАЕФЪ§ОнСПдЄЙРЯТвЛНзЖЮЕФЪ§ОнСїСПЃЌДгЖјЕїећзЪдДЗжХфЃЛдйЯТвЛВудђЪЧЪ§ОнДІРэВуЃЌдкетвЛВуЭъГЩжюШчЪ§ОндЄШЁЁЂЪ§ОнаЃбщЁЂбЙЫѕвдМАЭЦЫЭЕНЯТгЮЕШШЮЮёЁЃ
дкзюГѕЕФАцБОжаЃЌЮвУЧЛсдк zookeeper ЩЯУцДДНЈвЛИіШЮЮё(task) ЃЌExport ЭЈЙ§ЗжВМЪНЫјЖдtaskНјааељЧРЃЌБЛЧРЕНЕФШЮЮёдђПЊЪМжБНгЕМГіЃЌШчЭМ
9 ЫљЪОЁЃ
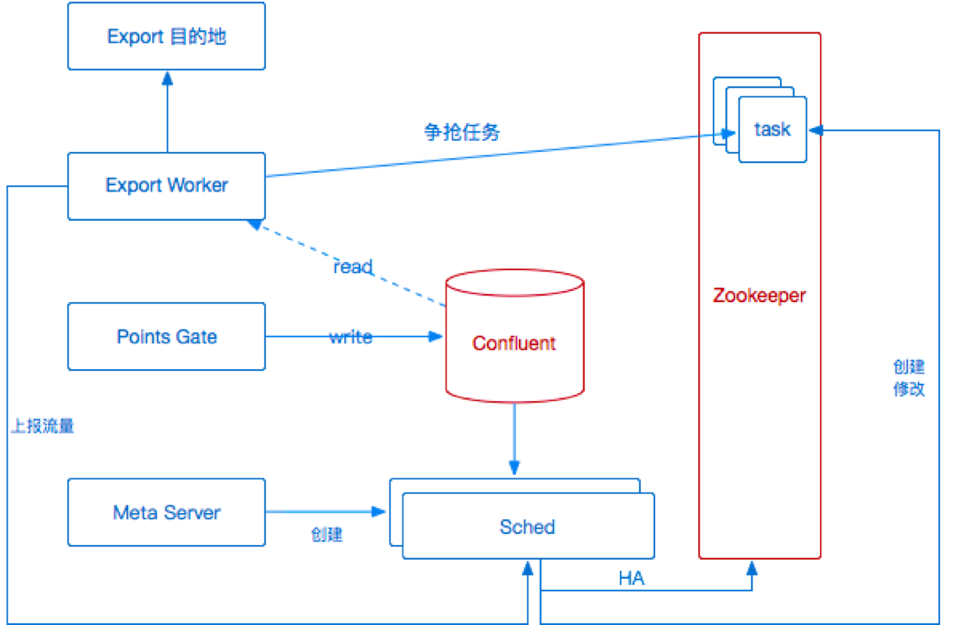
ЭМ 9 ГѕАцЕМГіЗўЮёМмЙЙ
дкетбљвЛИіГѕВНМмЙЙжаЃЌЮвУЧЛљБОЭъГЩСЫЫЎЦНРЉеЙвдМАИпПЩгУЕФашЧѓЃЌЭЌЪБзіСЫжюШчЪ§ОндЄШЁЃЌбгГйБЈОЏЁЂЪ§ОнМрПиЕШЖржжЙІФмКЭгХЛЏЁЃЕЋЪЧСїСПЩЯРДвдКѓЃЌКмШнвзГіЯжФГИіЛњЦїељШЁЕФШЮЮёСїСПБфДѓЃЌЕМжТДѓСПЪ§ОнДђЕНЭЌвЛЬЈЛњЦїЩЯЃЌЕМжТЭјПЈКЭCPUИКдиЙ§ИпЃЌбгГйМБОчЩ§ИпЁЃБОжЪЩЯОЭЪЧСїСПЗжВМВЛОљдШЃЌЕМжТЕМГіадФмЕЭЯТЃЌЛњЦїзЪдДЕФЦНОљРћгУТЪвВЕЭЁЃ
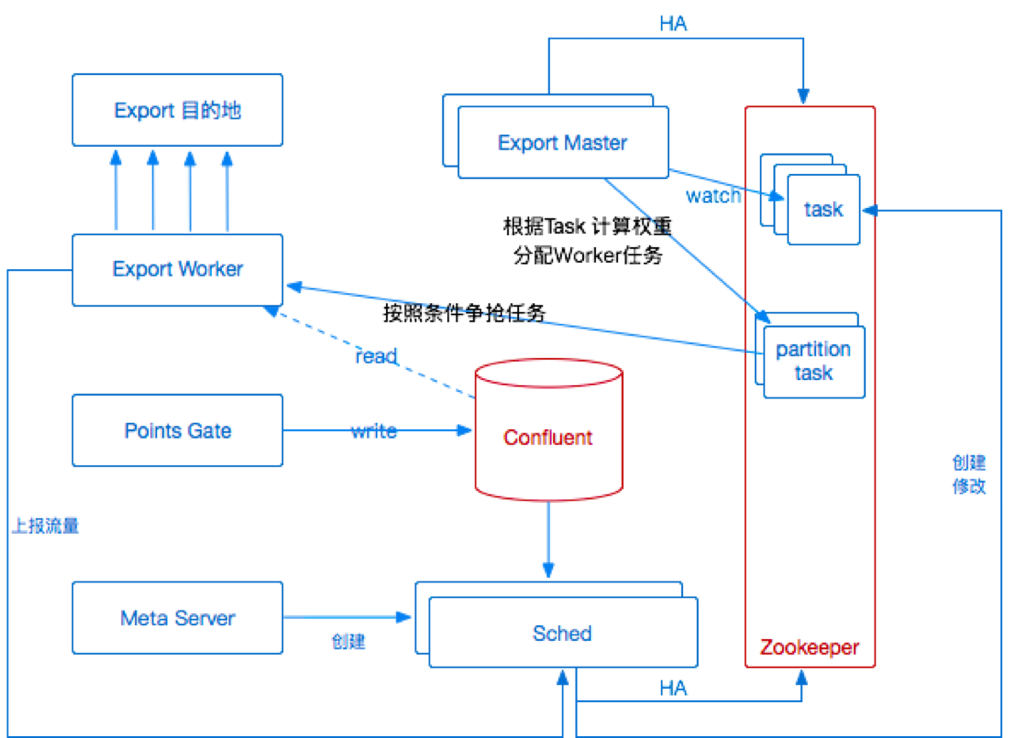
ЭМ 10 ЕквЛДЮЕМГіЗўЮёМмЙЙЩ§МЖ
ДЫЪБЃЌЮвУЧЖдИУЗНАИНјааЕквЛДЮМмЙЙЩ§МЖЃЌШчЭМ 10 ЫљЪОЁЃЮвУЧНЋдРДtopicМЖБ№ЕФШЮЮёАДееparitionНјааЗжВМЪНЯћЗбЁЃЮЊСЫЪЙЕУУПИіpartitionСЃЖШЕФШЮЮёДѓЬхЪЧОљЕШЕФЃЌЮвУЧНЋpartitionГадиЕФЪ§ОнСПАДееБъзМЛЏДІРэЃЌВЂИљОнРњЪЗСїСПНјаадЄВтЃЌдЄВтНсЙћГЌЙ§ЕБЧАЮвУЧЖЈжЦЕФБъзМЗћКЯЕФЖдгІШнСПМДДЅЗЂРЉШнЃЌетбљЕФБъзМЛЏгааЇМђЛЏСЫЕїЖШЕФФбЖШЁЃ
ЭЌЪБЮвУЧНЋдРДДПДтЕФexportИФЮЊmaster/workerНсЙЙЃЌMasterЖдЪеМЏЕНЕФШЮЮёНјаажїЖЏШЈКтЗжХфЃЌИљОнШЮЮёЕФРњЪЗСїСПНјааСїСПдЄВтЁЂЖдШЮЮёЕФpartitionЪ§СПЁЂУПИіexport
workerЕФЛњЦїзЪдДЪЃгрЧщПіЃЌНјаазлКЯЕїЖШЁЃЖдгквЛаЉЬиЪтШЮЮёзіЛњЦїКкАзУћЕЅАѓЖЈЕШЙІФмЁЃ
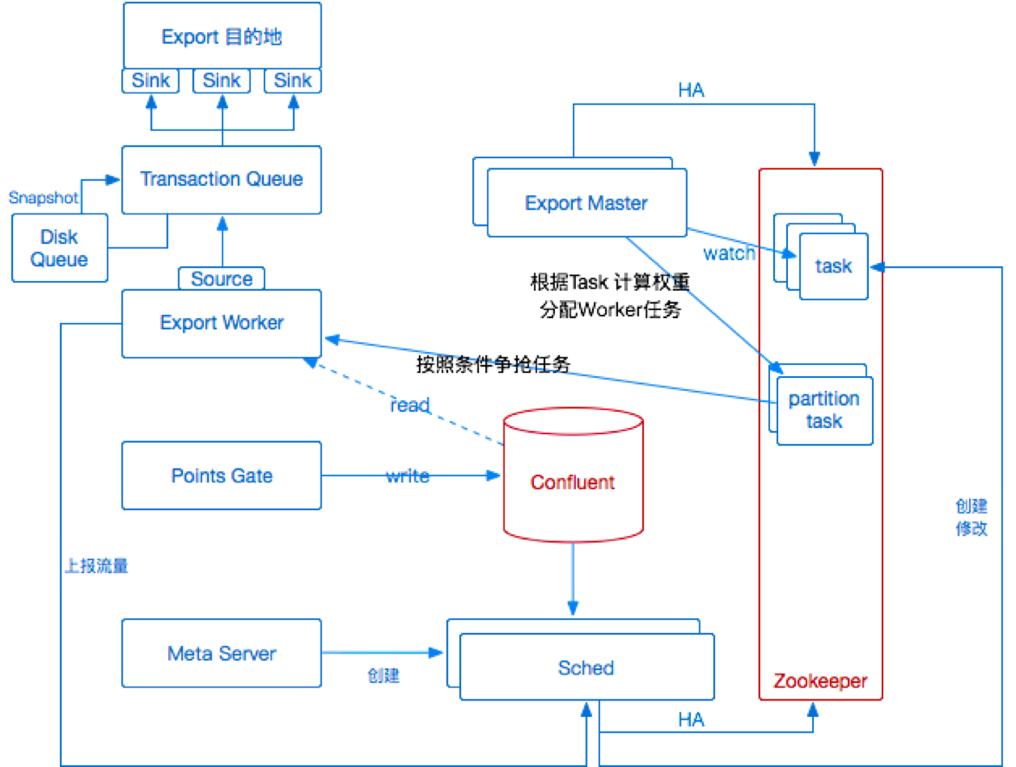
ЭМ 11 ЕкЖўДЮМмЙЙЩ§МЖЕФЕМГіЗўЮё
дкзіСЫЩЯЪіЙЄзївдКѓЃЌЮвУЧЛњЦїЕФећЬхРћгУТЪгаСЫКмДѓЕФЬсЩ§ЃЌЕЋЪЧгЩгкЯТгЮЯЕЭГЕФВЛЭЌЃЌаДШыЭЬЭТСПЪМжеВЮВюВЛЦыЃЌЮоЗЈЪМжеБЃГждквЛИіНЯИпЕФЫЎЦНЁЃЮЊСЫНтОіИУЮЪЬтЃЌЮвУЧдйДЮЖдМмЙЙНјаааЁЗЖЮЇЩ§МЖЃЌШчЭМ
11 ЫљЪОЃЌЮвУЧдкЕМГіЕФexport workerЖЫдіМгСЫвЛЬзЖдЯТгЮЯЕЭГЕФЪЪХфМгЫйФЃПщЁЃЦфКЫаФЫМТЗОЭЪЧАДееЯТгЮЕФЭЬЭТФмСІНјааздЖЏЕїНкЧыЧѓЬхДѓаЁвдМАВЂЗЂЖШЁЃетИіжївЊЪЧЮЊСЫНтОіЩЯЯТгЮДЋЪфЪ§ОнЫйЖШВЛЦЅХфЃЌвдМАЯТгЮЭЬЭТСПВЛЮШЖЈЕФЮЪЬтЁЃ
РрЫЦгкFlumeЕФЫМЯыЃЌЮвУЧЙЙНЈСЫвЛИіФкДцЖгСаЃЌвдЪТЮёЕФаЮЪНДгЖгСажаЛёШЁЪ§ОнЃЈЛђепЪЇАмЛиЙіЃЉЃЌИљОнЯТгЮЕФЧщПіЕїећЕЅДЮЪ§ОнЧыЧѓЕФДѓаЁКЭВЂЗЂЖШЃЌвдМАЕїећГіДэЕШД§ЪБМфЕШЁЃетбљвЛРДЃЌећИіЕМГіЕФЭЬЭТСПОЭПЩвдКмгааЇЕФНјааПижЦЃЌШЅГ§СЫУЋДЬЃЌМЋДѓЕФЬсИпСЫЛњЦїзЪдДЕФЪЙгУТЪвдМАЕМГіаЇТЪЁЃ
НтОіСЫЪ§ОнЕФЕМГіЮЪЬтЃЌЛљБОЩЯОјДѓВПЗжЪ§ОнСїзЊЕФЮЪЬтвВЖМНтОіСЫЁЃЯТУцЮвУЧПЊЪМЙизЂPandoraЯТгЮЕФвЛЯЕСаЗўЮёЁЃ
3.4 ЪБађЪ§ОнПтЗўЮёTSDB
TSDBЪЧЦпХЃЭъШЋзджїбаЗЂЕФЗжВМЪНЪБађЪ§ОнПтЗўЮёЁЃTSDBеыЖдЪБађЪ§ОнЖЈжЦДцДЂв§ЧцЃЌИљОнЪБађЪ§ОнДјгаЪБМфДСЕФЬиадЃЌЮвУЧеыЖдЪБМфДСзіЬиЪтЕФЫїв§ЃЌЪЕЯжЪ§ОнИпЫйЛуШыКЭЪЕЪБВщбЏЛёШЁЕФФмСІЃЛЭЌЪБЙЙНЈСЫМђЕЅЧвИпадФмЕФHTTPаДЕуКЭВщбЏНгПкЃЌЮЊВщбЏОлКЯЪ§ОнСПЩэЖЈжЦСЫРрSQLгябдЃЌЭъШЋМцШнПЊдДЩчЧјInfluxDBЕФAPIЃЌжЇГжЮоЗьЖдНгЕНGrafanaЃЌЖдЪ§ОнНјааИпБШР§бЙЫѕЃЌЪЕЯжЕЭГЩБОДцДЂЁЃГ§ДЫжЎЭтЃЌTSDBгЕгаПЊдДЩчЧјАцБОЕФInfluxDBЫљУЛгаЕФЗжВМЪНЁЂЖрМЏШКЁЂИпПЩгУЃЌЫЎЦНРЉШнЁЂвдМАЗжПтЗжБэФмСІЁЃ
ЭМ 12 TSDB ЛљБОНсЙЙЪОвтЭМ
ШчЭМ 12 ЫљЪОЃЌTSDBЪЧЮвУЧЛљгкtsmЙЙНЈЕФЗжВМЪНЪБађЪ§ОнПтЃЌгЕгаУПУы60ЭђЬѕМЧТМЕФаДШыадФмвдМАЪЕЪБВщбЏОлКЯЗжЮіЕФФмСІЁЃдкЗжВМЪНЗНУцЃЌГ§СЫЛљБОЕФЖрМЏШКЁЂЖрзтЛЇИєРыЕФИХФювдЭтЃЌЮвУЧЛЙеыЖдадЕФзіСЫСНИіЧПДѓЕФРЉШнЙІФмЃЌвЛИіЪЧИљОнЪБађНјаазнЯђМЏШКЧаИюЃЌНтОіКЃСПЪ§ОнаДШыЪБДХХЬЕФПьЫйРЉШнЮЪЬтЃЛСэвЛИідђЪЧИљОнгУЛЇЕФБъЧЉНјааЪ§ОнПтБэКсЯђЧаИюЃЌРрЫЦДЋЭГЪ§ОнЕФЗжПтЗжБэФмСІЁЃдкНјааСЫетСНДѓРЉеЙФмСІБфЛЛКѓЃЌЪ§ОнЕФаДШыКЭВщбЏвРОЩИпаЇЃЌЩѕжСВщбЏЫйЖШдкЗжПтЗжБэКѓадФмгаЫљЬсЩ§ЁЃ
ЮЊСЫЪЕЯжетбљЕФРЉШнЙІФмЃЌЮвУЧЛљгкДЫЙЙНЈСЫвЛИіЗжВМЪНМЦЫув§ЧцЃЌНтЮігУЛЇЕФSQLВЂБфГЩвЛИіИіжДааМЦЛЎЃЌНЋжДааМЦЛЎЯТЭЦжСВЛЭЌЕФTSMМЦЫув§ЧцЪЕР§жаНјааМЦЫуЃЌзюКѓдйНјааЪ§ОнreduceМЦЫуЗДРЁИјгУЛЇЁЃ
Г§СЫЪ§ОнаДШыадФмИпвдЭтЃЌЛЙжЇГжЪ§ОнМДЪБВщбЏЃЌЪ§ОнаДШыГЩЙІМДПЩВщбЏЃЌЪ§ОнСубгГйЃЛЭЌЪБжЇГжInfluxDBЕФГжајОлКЯЙІФмЃЌРрЫЦгкЖЈЪБШЮЮёвЛбљНЋГжајаДШыЕФЪ§ОнВЛЖЯНјааОлКЯМЦЫуЃЛЕБЕЅИігУЛЇЪ§ОнСПЙ§ДѓЪБЃЌгЕгаКсЯђЭиеЙФмСІЃЌМЏШКРЉеЙКѓаДШыадФмВЛДђелЃЌВщбЏаЇТЪИќИпЁЃеыЖдЪБађЪ§ОнЕФЬиадЃЌЮвУЧНЋЪ§ОнНјааРфШШЗжРыЃЌ
ЖдЪ§ОнАДееЪБМфЗжЦЌЃЌЪЙзюНќЕФЪ§ОнВщбЏадФмИќИпЁЃ
3.5 ШежОМьЫїЗўЮёLogDB
дкСЫНтЭъЮвУЧЕФЪБађЪ§ОнПтвдКѓЃЌШУЮвУЧРДПДвЛЯТЯТгЮЕФСэвЛДѓЗўЮёЃЌШежОМьЫїЗўЮёЃЌгжГЦLogDBЁЃШежОЫбЫїЦфЪЕЪЧМИКѕЫљгаММЪѕПЊЗЂШЫдБЖМЛсашвЊЕФЗўЮёЃЌДЋЭГНтОіЗНАИ(ELKЃЌElasticsearchЁЂLogstashЁЂKibana)
еыЖдаЁЪ§ОнСПВЛЛсГіЯжШЮКЮЮЪЬтЁЃЕЋЪЧЕБЪ§ОнСПЙ§гкХгДѓЪБЃЌетаЉЗНАИвВОЭВЛФЧУДЪЪгУСЫЁЃ
ЮвУЧLogDBЕФЕзВуПЩвдЭЈЙ§ВхМўЕФаЮЪННгШыВЛЭЌРраЭЕФЫбЫїв§ЧцЃЌАќРЈSolrЁЂElasticsearchЃЈМђГЦESЃЉЕШЃЌФПЧАГадиКЃСПЪ§ОнЫбЫїШЮЮёЕФЕзВув§ЧцжївЊЪЙгУЕФЪЧESЁЃгыЕЅДПЕФЪЙгУESВЛЭЌЃЌLogDBБОЩэЪЧвЛЬзЗжВМЪНЯЕЭГЃЌЙмРэЕФЕЅдЊПЩвдЪЧвЛИіESНкЕуЃЌвВПЩвдЪЧвЛИіESМЏШКЃЌЫљвдЮвУЧЙЙНЈСЫДѓСПЕФESМЏШКЃЌВЛЭЌЕФМЏШКгУвдЪЪХфВЛЭЌЕФгУЛЇвдМАВЛЭЌЕФЫбЫїашЧѓЁЃ
ДѓЬхЩЯЮвУЧНЋЫбЫїЕФашЧѓЗжЮЊСНРрЃЌвЛРрЪЧELKРрашЧѓЃЌеыЖдШчГЬађдЫааШежОЁЂвЕЮёЗУЮЪШежОЕШЪеМЏЫїв§ЃЌетРрашЧѓЕФЦеБщЬиЕуЪЧЪ§ОнСПДѓЃЌЪБаЇадИпЃЌДјгаЪБМфДСЃЌЮоашДцДЂЬЋГЄЪБМфЃЌЮоашИќаТЃЛСэвЛРрашЧѓРрЫЦгкЫбЫїв§ЧцЃЌЪ§ОнДцдкИќаТашвЊЃЌЧвЧПвРРЕгкВЛЭЌРраЭЕФЗжДЪЦїЃЌЪ§ОнРфШШВЛУїЯдЃЌВЛДјгаУїЯдЕФЪБМфЪєадЃЌЮвУЧГЦжЎЮЊЭЈгУМьЫїашЧѓЁЃетСНРрашЧѓЃЌLogDBЖМЪЧЭъШЋжЇГжЕФЃЌЕЋЪЧеыЖдетСНРрашЧѓЃЌЮвУЧзіЕФгХЛЏВЛЭЌЁЃ
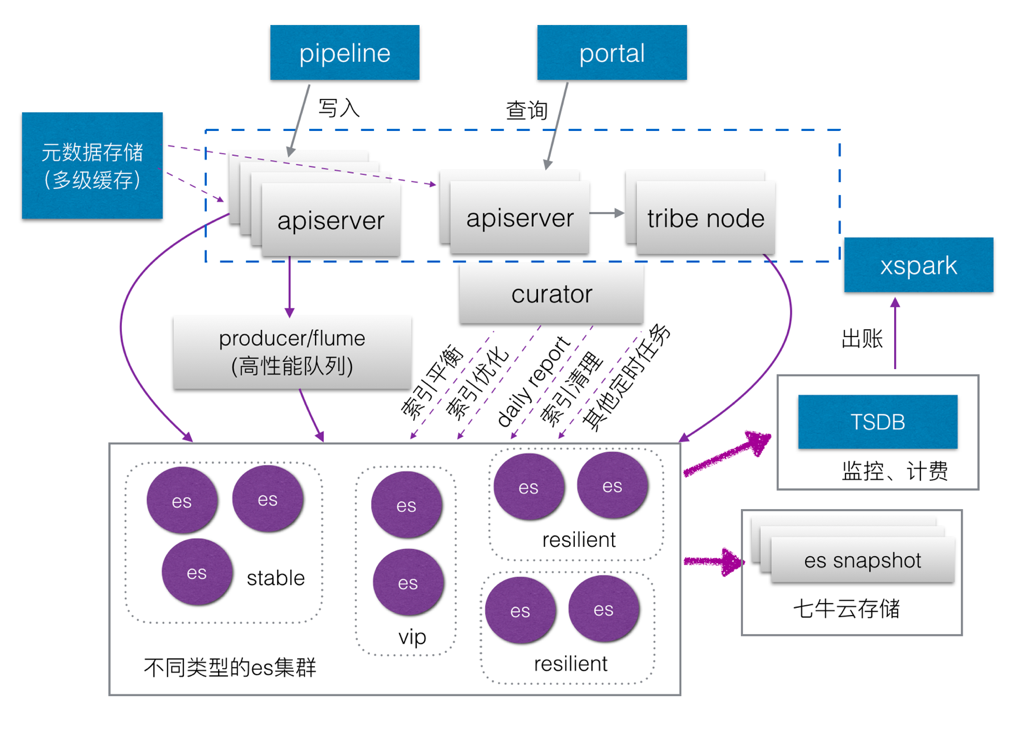
ЭМ 13 LogDBМмЙЙЭМ
дкЮвУЧЬжТлОпЬхЕФгХЛЏжЎЧАЃЌШУЮвУЧЯШРДПДвЛЯТLogDBЕФМмЙЙЭМЃЌ ШчЭМ 13 ЫљЪОЁЃЪзЯШЪЧЪ§ОнЕФаДШыЃЌLogDBЪЧPandoraЦНЬЈЯТгЮЗўЮёЃЌЩЯгЮжївЊЪЧжЎЧАЬсЕНЕФPipelineвдМАExportЁЃExportЕМГіЕФЪ§ОнЭЈЙ§apiseverНЋЪ§ОнЕМШыЕНВЛЭЌЕФESМЏШКЕБжаЃЌИљОнВЛЭЌгУЛЇЕФашЧѓИјЫћУЧЬсЙЉВЛЭЌЕФМЏШКЗўЮёЃЌМЏШКжЎМфвВПЩвдЯрЛЅНјааЧаЛЛЁЃ
ФЧУДШчКЮШЗШЯЪ§ОнЕНЕзЪ§ОнФФИіМЏШКФиЃПЮЊСЫЪЙЕУКЃСПЕФЪ§ОнПьЫйШЗШЯЃЌЮвУЧЖддЊЪ§ОнНјааСЫЖрМЖЛКДцЃЌАќРЈMongoDBЕФЪЕМЪДцДЂЁЂmemcachedЕФЖўМЖЛКДцЃЌвдМАБОЕиЕФЛКДцЃЌМЋДѓЬсИпСЫЪ§ОнаЃбщЕФЫйЖШЁЃГ§ДЫжЎЭтЃЌLogDBБОЩэвВЪЧPandoraЕФгУЛЇЃЌЪЙгУСЫTSDBЖдздЩэЪ§ОнНјааМрПиЃЌЪЙгУЦпХЃдЦДцДЂНјааЪ§ОнПьеегыБИЗнЁЃЭЌЪБНЋМЦЗбЪ§ОнЕМГіЕНдЦДцДЂЃЌРћгУЮвУЧЕФXSparkЛњЦїНјааРыЯпМЦЫуЁЃ
МмЙЙжаЪЃЯТЕФВПЗжЖМЪЧЮвУЧеыЖдВЛЭЌЫїв§зіЕФгХЛЏЁЃМђЖјбджЎЃЌЮвУЧЪзЯШЙЙНЈСЫвЛИіИпадФмЖгСаЃЌПЩвдШУЭтВПЕФЪ§ОнГжајИпЭЬЭТаДШыЃЛЭЌЪБЮвУЧЛЙЛсИљОнРњЪЗСїСПНјааЖЏЬЌЫїв§ЦНКтЁЂВЛЭЌМЏШКЕФЫїв§ПчМЏШКЦНКтЁЂЫїв§ЖЈЪБЧхРэЁЂVIPМЏШКИєРыЕШЙІФмЃЛВЂЧвЛсЖд
ES ЕФЫбЫїНјааЗжВНЫбЫїПижЦЃЌЛКДцРњЪЗЫбЫїЃЌгХЛЏгУЛЇЫбЫїЕФаЇТЪКЭЬхбщЕШЕШЁЃЙигкетвЛПщЕФЯъЯИФкШнЃЌЮвУЧЭХЖгдкжЎЧАвбОЗжЯэЙ§ЃЌПЩвддФЖСетЦЊЁЖЛљгкElasticsearchЙЙНЈЧЇвкСїСПШежОЫбЫїЦНЬЈЪЕеНЁЗЙЋжкКХЮФеТСЫНтИќЯъЯИЕФФкШнЁЃ
3.6 XSpark
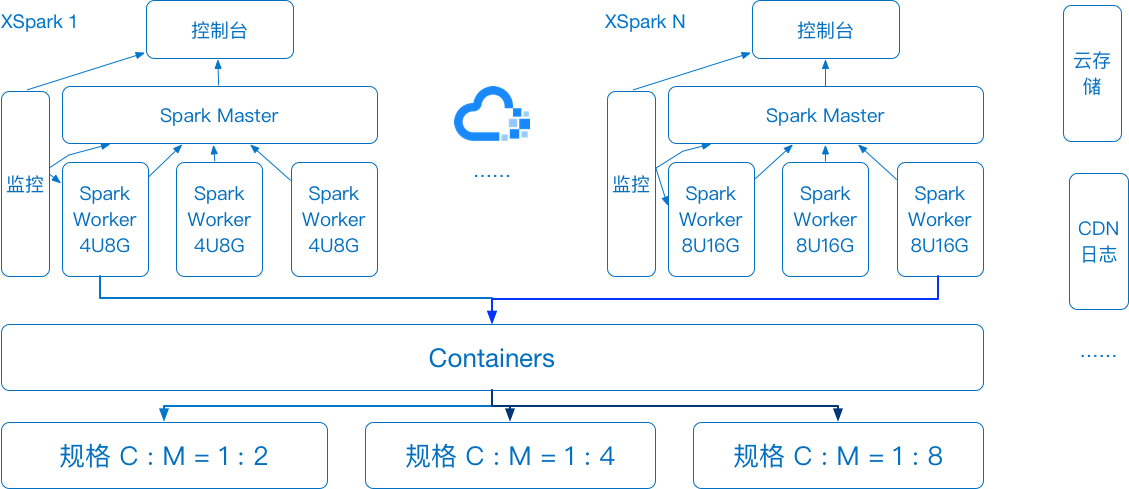
зюКѓгаЖСепПДЕНетРяЃЌвВаэЛсШЬВЛзЁЯыЮЪЃЌШчЙћжЛЪЧДПДтЕФЯыЪЙгУвЛИіИпЖШСщЛюЕФSparkМЏШКЃЌВЛЯЃЭћОЙ§PandoraИїРрИДдгЕФМЦЫуЁЂЕМГіЃЌЩѕжСЪ§ОнЖМУЛДцДЂдкЦпХЃЃЌПЩВЛПЩвдЯэЪмЦпХЃЕФSparkДѓЪ§ОнЗўЮёФиЃПЪЧЕФЃЌЭъШЋПЩвдЃЌетОЭЪЧЮвУЧЕФXSparkЃЁ
XSparkВЛНігыPandoraећЬхЭъШЋДђЭЈЃЌПЩвдАбЦпХЃдЦДцДЂЕБГЩвЛИіЪ§ОнВжПтЪЙгУЃЌгжЭъШЋПЩвдЖРСЂЪЙгУЁЃМДгУЛЇГ§СЫдкPipelineРяУцзіРыЯпМЦЫужЎЭтЃЌФуЛЙПЩвдбЁдёжБНгвЛМќЩњГЩвЛИіЛљгкШнЦїдЦЕФИіШЫзЈЪєSparkМЏШКЃЌжБНгЖСШЁФуздМКЕФЪ§ОндДЃЌжЛвЊSparkжЇГжЕФЪ§ОнИёЪНЃЌXSparkЖМжЇГжЁЃШчЙћФуЕФЪ§ОнвбОДцДЂдкЦпХЃдЦДцДЂЩЯЃЌXSparkПЩвджБНгИпаЇЖСШЁВЂМЦЫуЃЌXSparkЪЧPandoraЬсЙЉИјДѓЪ§ОнИпЖЫгУЛЇЕФвЛИіИпЖШСщЛюЕФРыЯпМЦЫуВњЦЗЁЃ
ЯдШЛЃЌШнЦїдЦЫљОпгаЕФгХЪЦXSparkШЋЖМОпБИЃЌФуЭъШЋПЩвдИљОнашвЊЖЏЬЌЩьЫѕЕФXSparkзЪдДЪ§СПгыЙцИёЃЌАДашЦєЭЃЕШЕШЁЃ
ЭМ 14 XSpark МмЙЙЭМ
ЭМ 14 ЪЧ XSpark ЕФМмЙЙЭМЁЃЮвУЧНЋSparkЕФmasterКЭworkerЗжЮЊВЛЭЌЕФШнЦїЃЌЪзЯШЦєЖЏSparkЕФmasterШнЦїЃЌЛёШЁmasterЕижЗЃЌШЛКѓдйИљОнгУЛЇЕФХфжУЃЌЦєЖЏЯргІЪ§СПЕФworkerШнЦїЃЌworkerШнЦїздЖЏЯђmasterзЂВсЁЃЭЌЪБШнЦїдЦЕФжЇГХЪЙЕУЮвУЧЕФXSparkПЩвддкдЫааЙ§ГЬжаНјааЫѕШнРЉШнЁЃ
ЭЌЪБXSparkвВПЊЗХСЫЭъећЕФSparkМрПивдМАЙмРэПижЦвГУцЃЌЭъШЋМцШнПЊдДЩчЧјЕФZepplinЪЙгУЗНЪНЁЃ
4 ЛљгкPandoraЕФДѓЪ§ОнЪЕеН
ФЧУДЮвУЧетбљЕФвЛЬзЯЕЭГЃЌгУЛЇЬхбщЕНЕзЪЧдѕУДбљЕФФиЃПЯТУцЮвУЧвдЪеМЏзюГЃМћЕФnginxШежОЮЊР§РДПДЯТЪЕМЪЬхбщЁЃ
ЪзЯШЃЌЮЊСЫШУгУЛЇзюЪцЪЪЕФНЋЪ§ОнЩЯДЋЕНЮвУЧЦНЬЈЃЌгУЛЇПЩвджБНгВПЪ№ЮвУЧЕФ logkit ЙЄОпЃЌШЛКѓДђПЊlogkitХфжУвГУцЃЌШчЭМ15ЫљЪОЁЃ
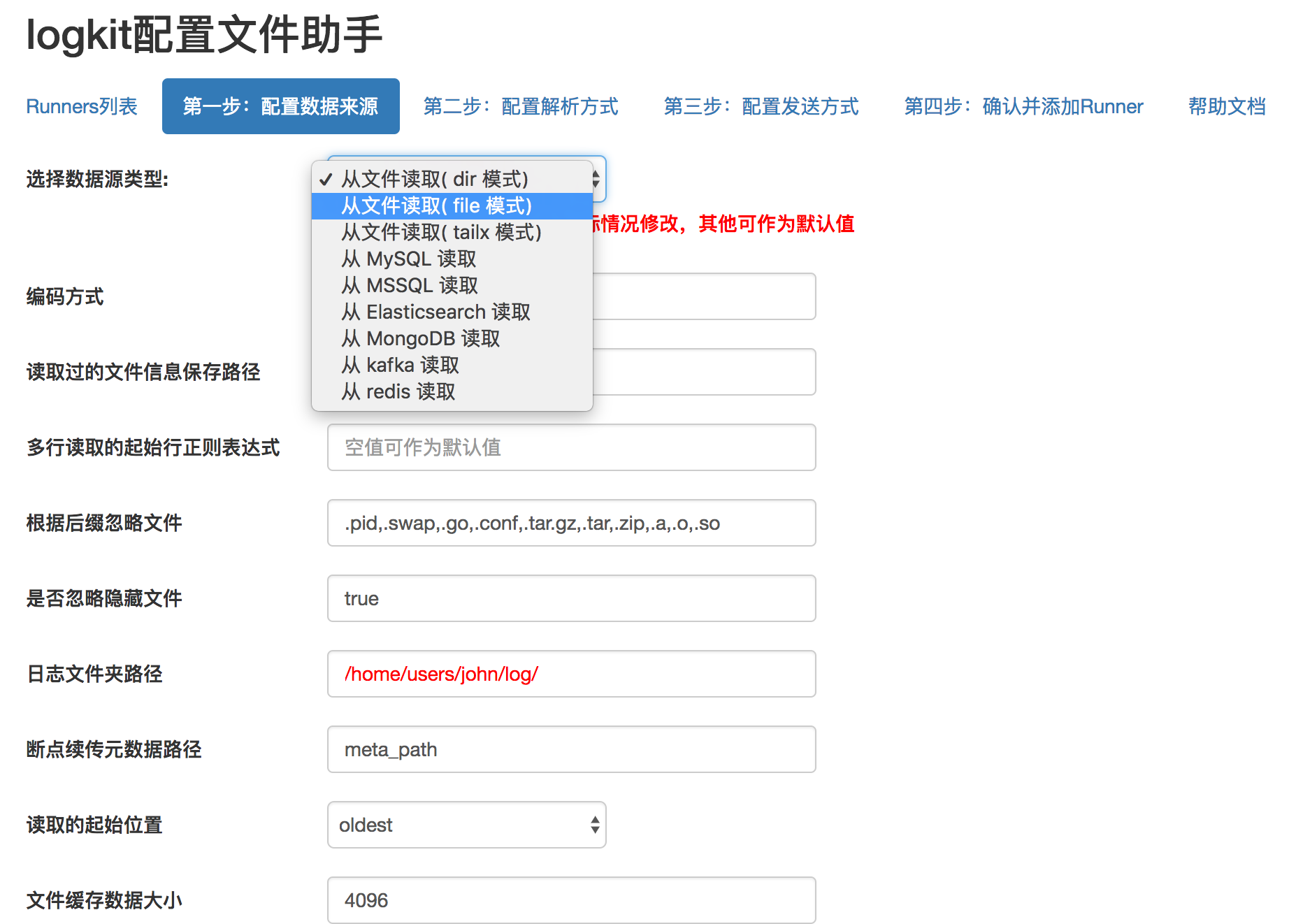
ЭМ 15 logkit ХфжУвГУц
ИљОнашвЊвЛВНВНбЁдёЪ§ОндДЁЂХфжУНтЮіЗНЪНЁЂЗЂЫЭЗНЪНзюКѓШЗШЯВЂЬэМгЁЃЕБШЛЃЌдкХфжУНтЮіЗНЪНЕФвГУцЃЌФуЛЙПЩвдЭЈЙ§вГУцдЄЯШГЂЪдНтЮіЦїХфжУЪЧЗёе§ШЗЃЌШчЭМ16ЫљЪОЁЃ
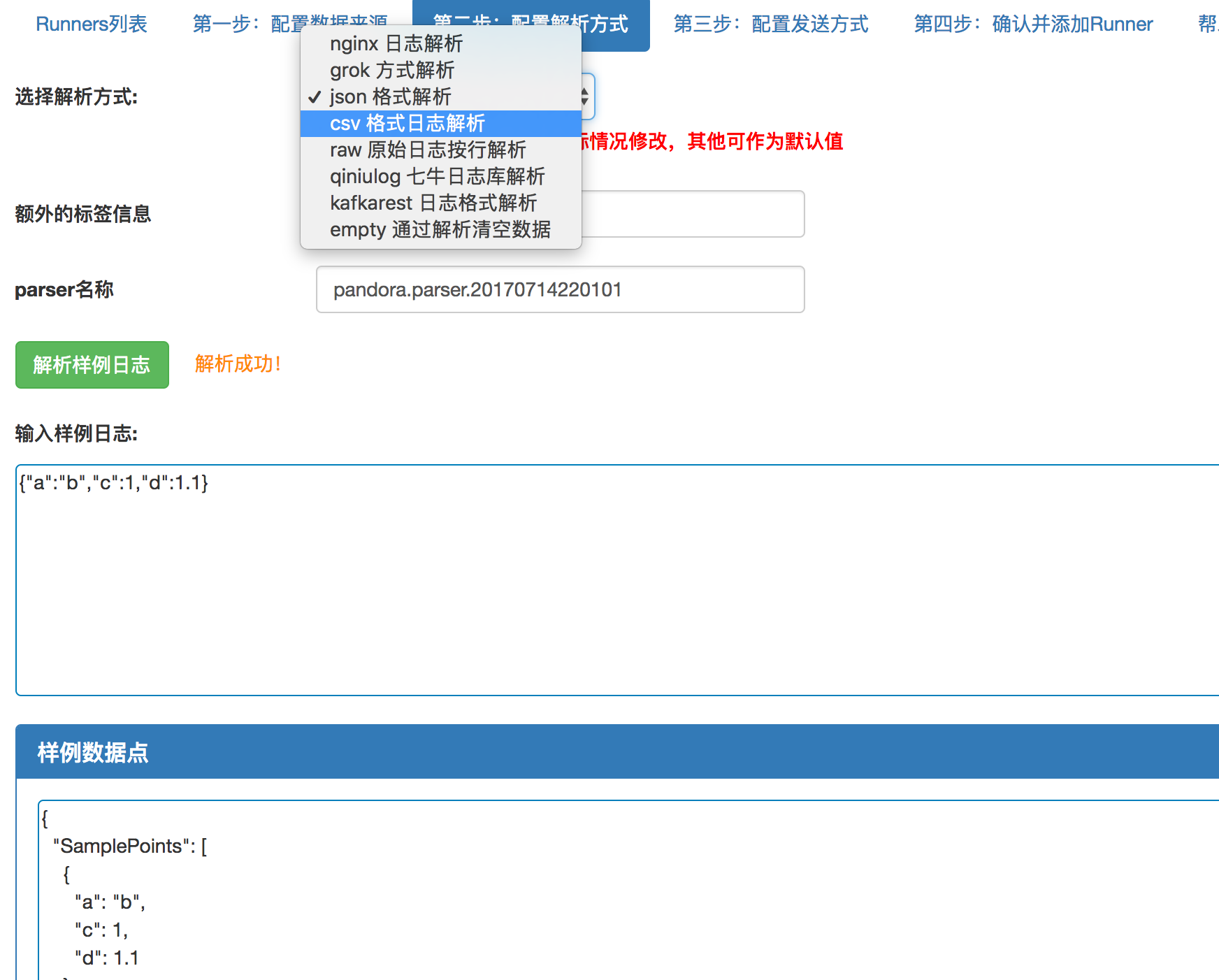
ЭМ 16 logkit ХфжУНтЮіЦї
ЭЈЙ§МђЕЅЕФМИВНХфжУКѓЃЌФуЕФЪ§ОнБувбОЩЯДЋЕНPandoraЦНЬЈЃЌВЂздЖЏЩњГЩСЫЙЄзїСїЃЌВЂЧвДДНЈКУСЫЕМГіЕНШежОМьЫїЗўЮёЃЌШчЭМ
17 ЫљЪОЁЃ
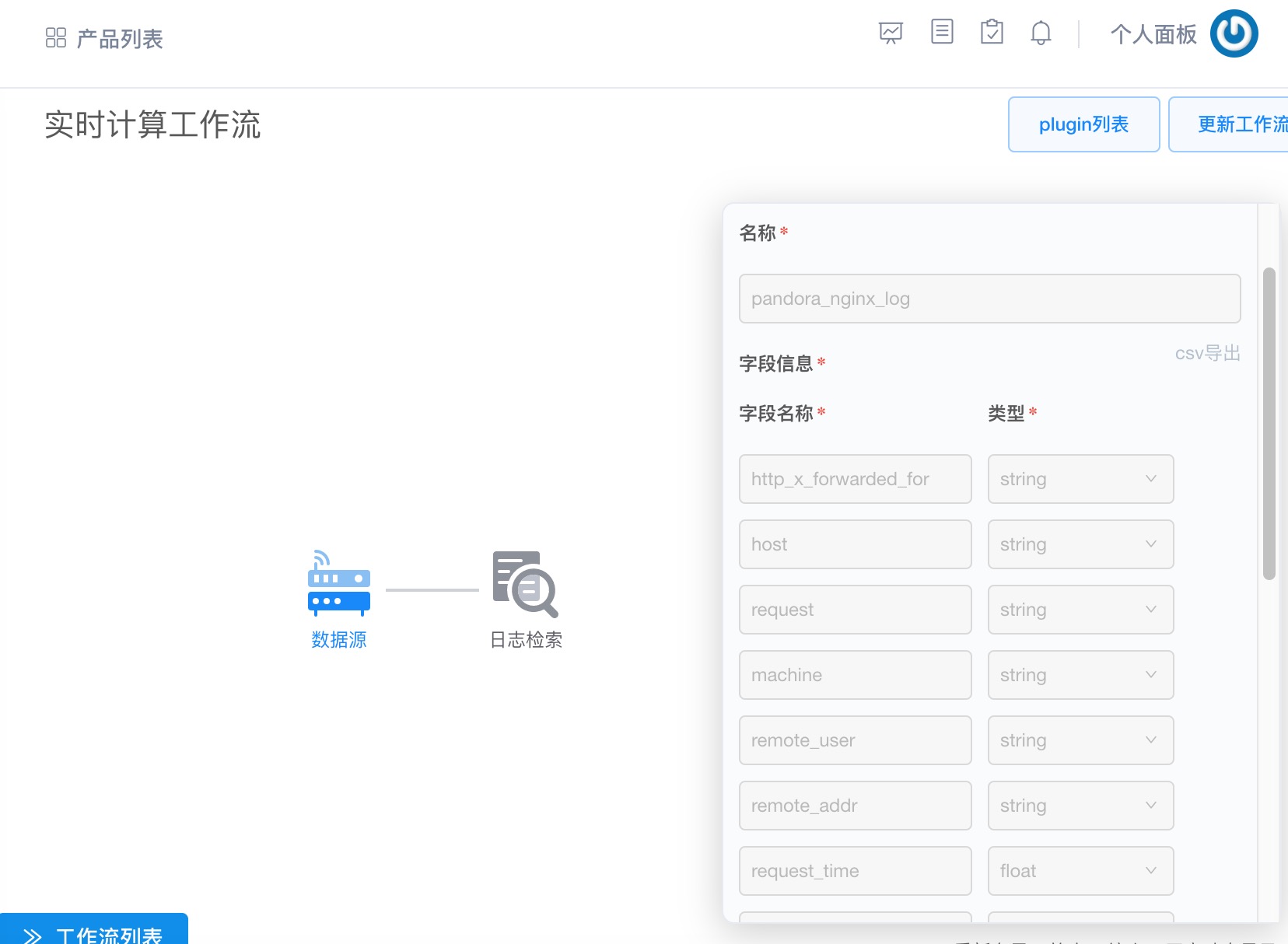
ЭМ 17 здЖЏДДНЈЕФЪЕЪБЙЄзїСї
дкЙЄзїСїжаЃЌФуЛЙПЩвдДДНЈвЛаЉМЦЫуШЮЮёзівЛаЉЗжЮіМЦЫуЃЌЕМГіЕНдЦДцДЂзїЮЊЪ§ОнМЦЫуЃЌЕМГіЕНЪБађЪ§ОнПтНјааИДдгЕФSQLВщбЏЁЃжЎКѓЕФДѓЪ§ОнЗжЮіЙЄзївВОЭЛсЯрЖдШнвзвЛаЉЁЃгаСЫетаЉзМБИЙЄзїЃЌЮвУЧОЭПЩвдПЊЪМНјааШежОМьЫїВщбЏЃЈЭМ
18 ЫљЪОЃЉЁЂЪ§ОнПЩЪгЛЏЃЈШчЭМ 19 ЫљЪОЃЉЁЂРыЯпЗжЮіЃЈШчЭМ 20 ЫљЪОЃЉЕШЙЄзїЁЃ
ЭМ 19 GrafanaЪ§ОнПЩЪгЛЏ
ЭМ 20 ЪЙгУXSparkРыЯпЗжЮі
4.1 ЪЕЪБЪ§ОнЗжЮіЪЕеН
дкЮвУЧетНіНіСНШ§ВНМђЕЅЕФВйзївдКѓЃЌОЭПЩвдПДЕНФФаЉЪЎЗжгаМлжЕЕФЪ§ОнФиЃП
ЪЕЪБзмгУЛЇЗУЮЪСП(ЧыЧѓЪ§ЭГМЦ)ЃЌШчЭМ 21 ЫљЪО

ЭМ 21 ЪЕЪБзмгУЛЇЗУЮЪСП
ЛњЦїЧыЧѓЪ§ЫцЪБМфБфЛЏЧїЪЦЃЌШчЭМ 22 ЫљЪО
ЭМ 22 ЛњЦїЧыЧѓЪ§ЫцЪБМфБфЛЏЧїЪЦ
ЪЕЪБЧыЧѓзДЬЌТыеМБШЃЌШчЭМ 23 ЫљЪО
ЭМ 23 ЪЕЪБЧыЧѓзДЬЌТыеМБШ
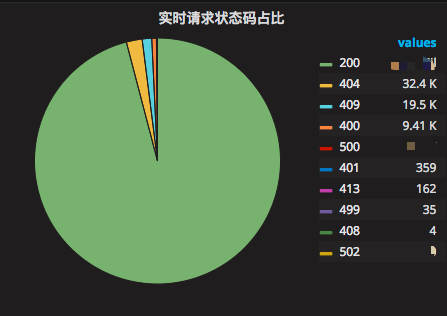
ЪЕЪБЧыЧѓTOPХХУћЃЌШчЭМ 24 ЫљЪО
ЭМ 24 ЪЕЪБЧыЧѓTOPХХУћ
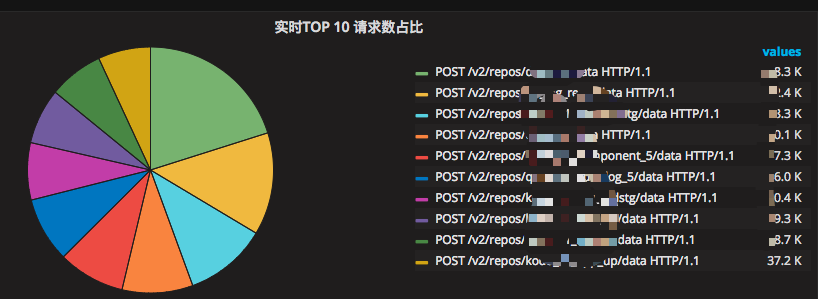
ЪЕЪБЧыЧѓРДдДIP TOPХХУћЃЌШчЭМ 25 ЫљЪО
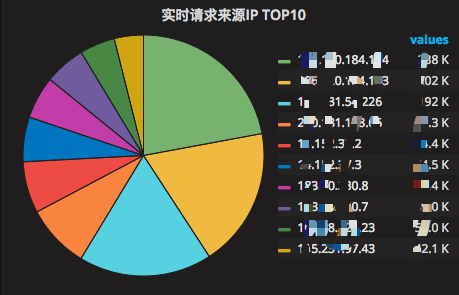 ) )
ЭМ 25 ЪЕЪБЧыЧѓРДдДIP TOPХХУћ
ЯьгІЪБМфЫцЪБМфБфЛЏЧїЪЦЭМЃЌШчЭМ 26 ЫљЪО
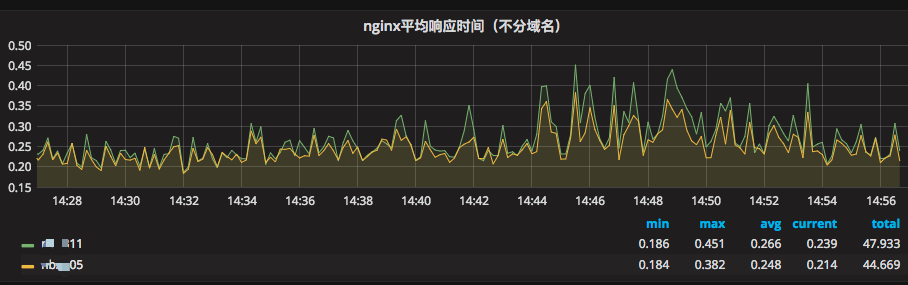
ЭМ 26 ЯьгІЪБМфЫцЪБМфБфЛЏЧїЪЦЭМ
ЪЕЪБгУЛЇЧыЧѓЕФПЭЛЇЖЫTOPХХУћЃЌШчЭМ 27 ЫљЪО
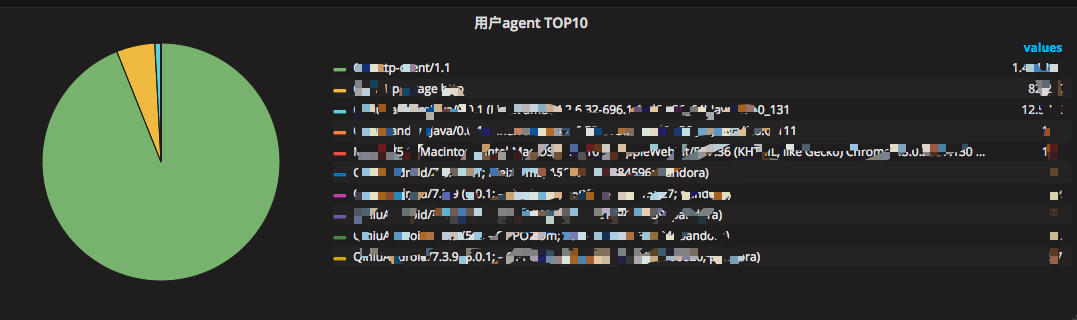
ЭМ 27 ЪЕЪБгУЛЇЧыЧѓЕФПЭЛЇЖЫTOPХХУћ
ЪЕЪБИљОнВЛЭЌЧщПіНјааОпЬхЪ§ОнЕФВщбЏЃЌАќРЈзДЬЌТыЁЂЯьгІЪБМфЗЖЮЇНјааЩИбЁЕШЃЌШчЭМ 28 ЫљЪО
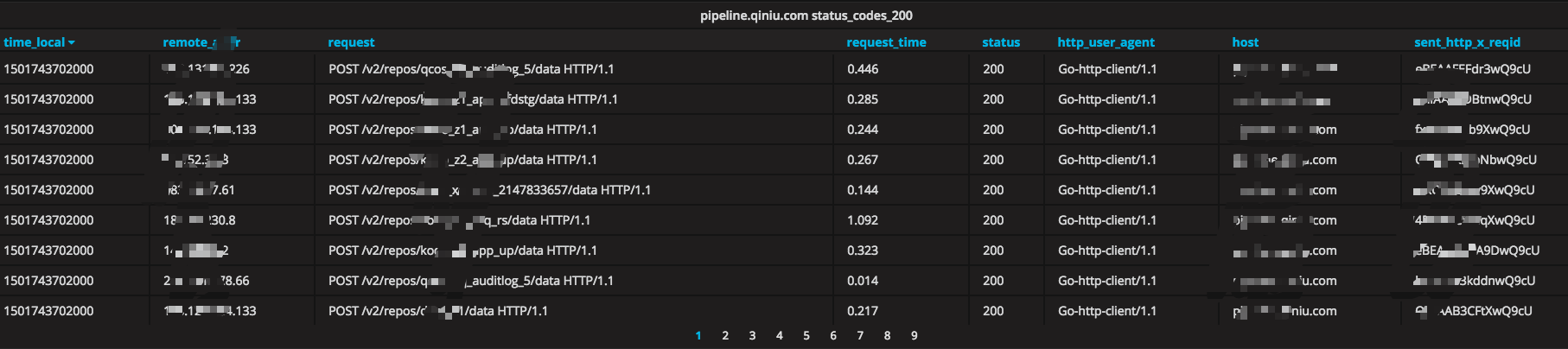
ЭМ 28 ЪЕЪБИљОнВЛЭЌЧщПіНјааОпЬхЪ§ОнЕФВщбЏ
ЦфЫћИќЖрздЖЈвхХфжУ...
здЖЈвхЕФ Grafana DashBoard ХфжУЪОР§ЃЌШчЭМ 29 ЫљЪО
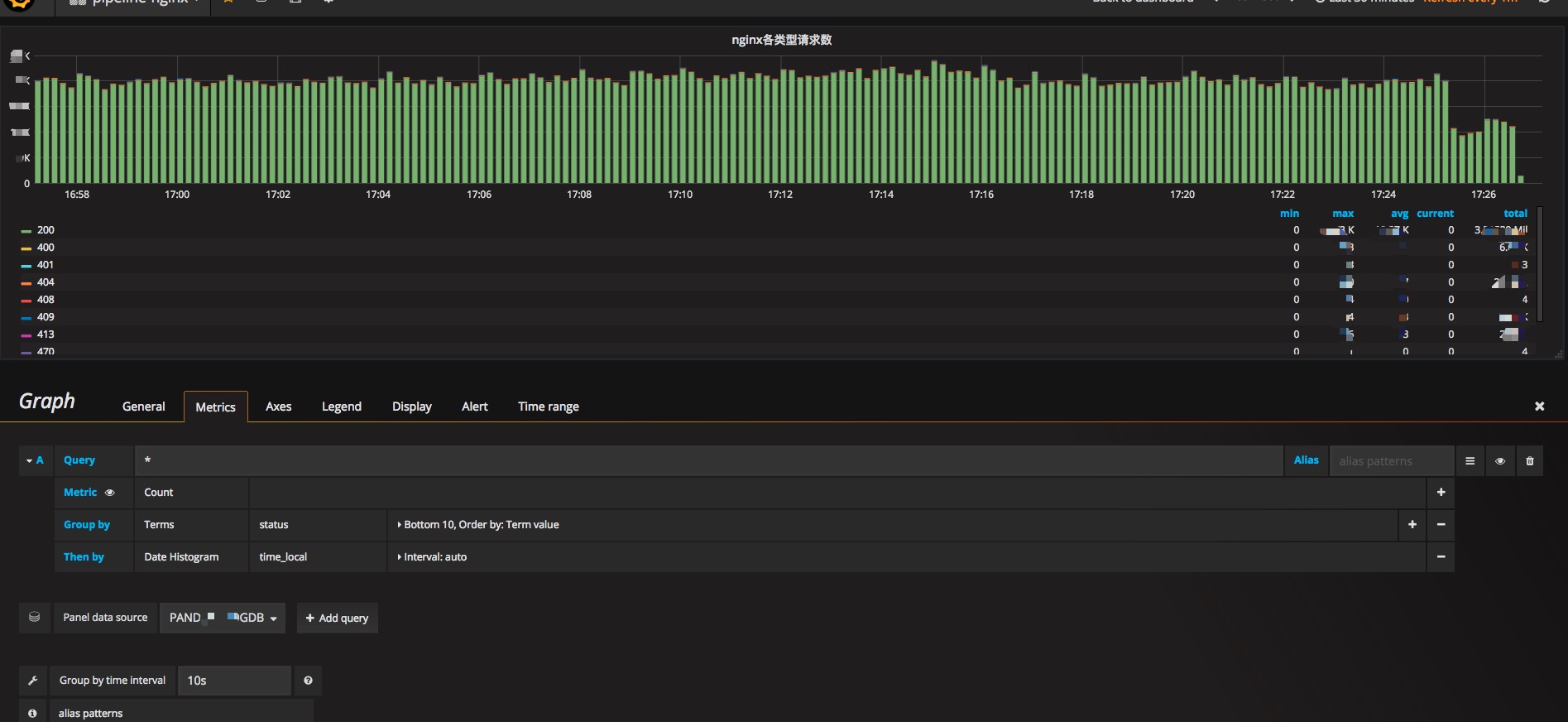
ЭМ 29 Grafana DashBoardХфжУЪОР§
ПЩМћЃЌНіНіМИВНМђЕЅЕФВйзїЃЌФуОЭНшжњPandoraЪЕЯжСЫКЃСПШежОЕФЪЕЪБМрПиЃЌЭЈЙ§ nginxШежО ЭъећЖјЯъОЁЕФ
СЫНтвЕЮёЕФСїСПШыПкЕФИїРрЧщПіЁЃ
4.2 ЪЕЪБЪ§ОнБЈОЏ
гаСЫЪЕЪБЕФЪ§ОнМрПиЃЌдѕУДФмЩйЕУСЫБЈОЏФиЃЌЮвУЧЛЙЬсЙЉСЫАќРЈ SlackЃЌ EmailгЪЯфЃЌWebhookЕШЪЎРДжжБЈОЏЗНЪНЁЃ
БШШчЫЕШчЭМ 30 ЃЌЮвУЧЩшжУСЫвЛИіЯьгІЪБМфДѓгк1000msЕФБЈОЏ
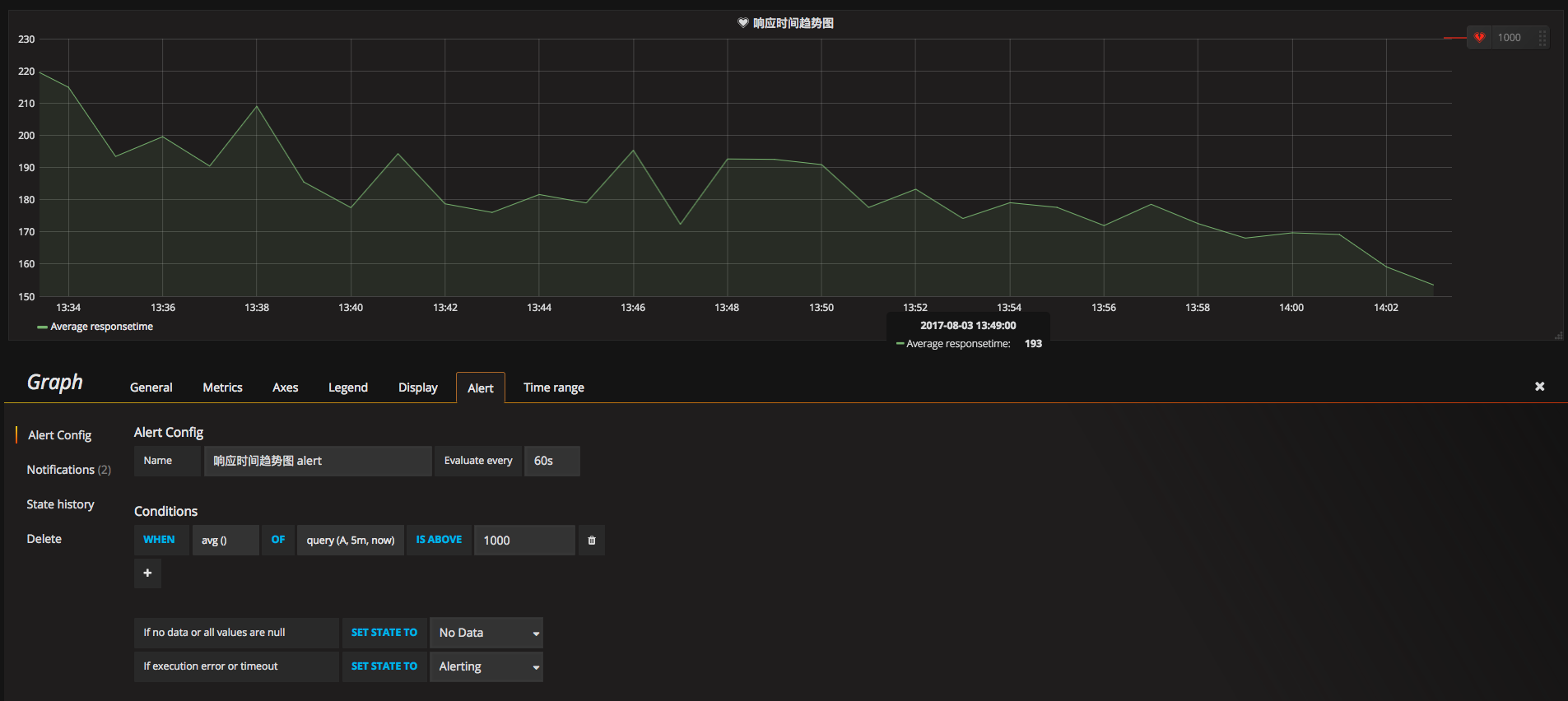
ЭМ 30 ЯьгІЪБМфДѓгк1000msБЈОЏ
LogDBВЩгУЕФЪЧЛљгкElasticsearchавщЕФБЈОЏЃЌетИіЛљгкElasticsearchавщЕФGrafanaБЈОЏЙІФмЪЧЦпХЃЖРМвХЖЃЁTSDBЪЧЛљгкInfluDBавщЃЌЪЙгУTSDBИќЪЧЭЌбљОпБИЩЯЪіЙІФмЁЃ
ФЧУДФњПЩвдПДЕНБЈОЏаЮЪНЪЧдѕУДбљЕФФиЃП
ЭМ 31 SlackБЈОЏЪОвтЭМ
ПДЕНЭМ 31 SlackЩЯЕФБЈОЏСЫТ№ЃПГ§СЫЛљБОЕФЮФзжЃЌЛЙЛсДјЩЯПсьХЕФБЈОЏЭМЦЌЃЁЭМЦЌЖМЛсБЛДцДЂЕНФњЦпХЃдЦДцДЂЕФbucketРяУцЃЁ
ЭМ 32 гЪМўБЈОЏЪОвтЭМ
ШчЭМ 32 ЫљЪОЃЌГЃЙцЕФгЪМўБЈОЏФкШнвВвЛбљПсьХЃЁ
4.3 РыЯпЗжЮі
ШчЙћФуЪЙгУРыЯпЗжЮіЃЌФЧУДПЩвдЛёЕУЕФФкШнОЭИќЖрСЫЃЌжЛвЊФуЪ§ОнгЕгаЕФЮЌЖШЃЌОЭПЩвдЭГМЦГіРДЃЌБШШчЮвУЧвдCDNШежОЮЊР§ЁЃ
гУЛЇЕиЧјЗжВМЃЌШчЭМ 33 ЫљЪО
ЭМ 33 гУЛЇЕиЧјЗжВМ
гУЛЇЛњаЭЗжВМЃЌШчЭМ 34 ЫљЪО
ЭМ 34 гУЛЇЛњаЭЗжВМЪі
ЛюдОгУЛЇЪ§ЫцЪБМфБфЛЏЧїЪЦЃЌШчЭМ 35 ЫљЪО

ЭМ 35 ЛюдОгУЛЇЪ§ЫцЪБМфБфЛЏЧїЪЦ
ИїРрЪжЛњЭМЦЌЯТдиЪ§ЃЌШчЭМ 36 ЫљЪО

ЭМ 36 ИїРрЪжЛњЭМЦЌЯТдиЪ§
ВЛЭЌЪБМфЦНОљЯТдиЫйЖШЃЌШчЭМ 37 ЫљЪО

ЭМ 37 ВЛЭЌЪБМфЦНОљЯТдиЫйЖШ
ВЛЭЌЪБМфе§ГЃЯьгІБШжиЃЌШчЭМ 38 ЫљЪО
ЭМ 38 ВЛЭЌЪБМфе§ГЃЯьгІБШжи
ВщбЏгУЛЇЯЕЭГЗжВМЃЌШчЭМ 39 ЫљЪО
ЭМ 39 ВщбЏгУЛЇЯЕЭГЗжВМ
Г§СЫЩЯЪіетаЉЃЌЛЙжЇГжИќЯИСЃЖШЕФЯТзъЙІФмЃЌПЩвдШЋЗНЮЛЮоЫРНЧЗжЮіФуЕФКЃСПЪ§ОнЁЃ
5 змНс
жСДЫЃЌБОДЮЕФPandoraДѓЪ§ОнЦНЬЈЕФМмЙЙбнНјгыЪЙгУЪЕеНЫуЪЧНщЩмЭъСЫЃЌЕЋЪЧЮвУЧPandoraДѓЪ§ОнВњЦЗЕФЕќДњЛЙдкВЛЖЯЯђЧАЃЌЛЙгаДѓСПДѓЪ§ОнЦНЬЈНЈЩшЕФЯИНкЕШД§ЮвУЧШЅЭъЩЦЁЃЛЖгЙуДѓХѓгбРДЪЙгУЮвУЧPandoraЕФДѓЪ§ОнВњЦЗЃЌЭЌЪБвВЛЖгИјЮвУЧЬсЬсНЈвщЃЌЮвУЧЗЧГЃдИвтЧуЬ§ФњЕФЙлЕуЃЁ
|









