| вЛЁЂKafkaМђНщ
KafkaЪЧвЛжжИпЭЬЭТСПЁЂЗжВМЪНЁЂЛљгкЗЂВМ/ЖЉдФЕФЯћЯЂЯЕЭГЃЌзюГѕгЩLinkedInЙЋЫОПЊЗЂЃЌЪЙгУScalaгябдБраДЃЌФПЧАЪЧApacheЕФПЊдДЯюФПЁЃ
ИњRabbitMQЁЂRocketMQЕШФПЧАСїааЕФПЊдДЯћЯЂжаМфМўЯрБШЃЌKakfaОпгаИпЭЬЭТЁЂЕЭбгГйЕШЬиЕуЃЌдкДѓЪ§ОнЁЂШежОЪеМЏЕШгІгУГЁОАЯТБЛЙуЗКЪЙгУЁЃ
БОЮФжївЊМђЕЅНщЩмKafkaЕФЩшМЦдРэЁЃ
ЖўЁЂKafkaМмЙЙ
ЛљБОИХФюЃК
brokerЃКKafkaЗўЮёЦїЃЌИКд№ЯћЯЂДцДЂКЭзЊЗЂ
topicЃКЯћЯЂРрБ№ЃЌKafkaАДееtopicРДЗжРрЯћЯЂ
partitionЃКtopicЕФЗжЧјЃЌвЛИіtopicПЩвдАќКЌЖрИіpartitionЃЌtopicЯћЯЂБЃДцдкИїИіpartitionЩЯ
offsetЃКЯћЯЂдкШежОжаЕФЮЛжУЃЌПЩвдРэНтЪЧЯћЯЂдкpartitionЩЯЕФЦЋвЦСПЃЌвВЪЧДњБэИУЯћЯЂЕФЮЈвЛађКХ
ProducerЃКЯћЯЂЩњВњеп
ConsumerЃКЯћЯЂЯћЗбеп
Consumer GroupЃКЯћЗбепЗжзщЃЌУПИіConsumerБиаыЪєгквЛИіgroup
ZookeeperЃКБЃДцзХМЏШКbrokerЁЂtopicЁЂpartitionЕШmetaЪ§ОнЃЛСэЭтЃЌЛЙИКд№brokerЙЪеЯЗЂЯжЃЌpartition
leaderбЁОйЃЌИКдиОљКтЕШЙІФм
Ш§ЁЂKafkaЩшМЦдРэ
3.1 Ъ§ОнДцДЂЩшМЦ
partitionвдЮФМўаЮЪНДцДЂдкЮФМўЯЕЭГЃЌФПТМУќУћЙцдђЃК<topic_name>-<partition_id>ЃЌР§ШчЃЌУћЮЊtestЕФtopicЃЌЦфга3ИіpartitionЃЌдђKafkaЪ§ОнФПТМжага3ИіФПТМЃКtest-0,
test-1, test-2ЃЌЗжБ№ДцДЂЯргІpartitionЕФЪ§ОнЁЃ
partitionЕФЪ§ОнЮФМў
partitionжаЕФУПЬѕMessageАќКЌСЫвдЯТШ§ИіЪєадЃК
1.offset
2.MessageSize
3.data
ЦфжаoffsetБэЪОMessageдкетИіpartitionжаЕФЦЋвЦСПЃЌoffsetВЛЪЧИУMessageдкpartitionЪ§ОнЮФМўжаЕФЪЕМЪДцДЂЮЛжУЃЌЖјЪЧТпМЩЯвЛИіжЕЃЌЫќЮЈвЛШЗЖЈСЫpartitionжаЕФвЛЬѕMessageЃЌПЩвдШЯЮЊoffsetЪЧpartitionжаMessageЕФidЃЛMessageSizeБэЪОЯћЯЂФкШнdataЕФДѓаЁЃЛdataЮЊMessageЕФОпЬхФкШнЁЃ
partitionЕФЪ§ОнЮФМўгЩвдЩЯИёЪНЕФMessageзщГЩЃЌАДoffsetгЩаЁЕНДѓХХСадквЛЦ№ЁЃ
ШчЙћвЛИіpartitionжЛгавЛИіЪ§ОнЮФМўЃК
1.аТЪ§ОнЪЧЬэМгдкЮФМўФЉЮВЃЌВЛТлЮФМўЪ§ОнЮФМўгаЖрДѓЃЌетИіВйзїгРдЖЖМЪЧO(1)ЕФЁЃ
2.ВщевФГИіoffsetЕФMessageЪЧЫГађВщевЕФЁЃвђДЫЃЌШчЙћЪ§ОнЮФМўКмДѓЕФЛАЃЌВщевЕФаЇТЪОЭЕЭЁЃ
KafkaЭЈЙ§ЗжЖЮКЭЫїв§РДЬсИпВщеваЇТЪЁЃ
Ъ§ОнЮФМўЗжЖЮsegment
partitionЮяРэЩЯгЩЖрИіsegmentЮФМўзщГЩЃЌУПИіsegmentДѓаЁЯрЕШЃЌЫГађЖСаДЁЃУПИіsegmentЪ§ОнЮФМўвдИУЖЮжазюаЁЕФoffsetУќУћЃЌЮФМўРЉеЙУћЮЊ.logЁЃетбљдкВщевжИЖЈoffsetЕФMessageЕФЪБКђЃЌгУЖўЗжВщевОЭПЩвдЖЈЮЛЕНИУMessageдкФФИіsegmentЪ§ОнЮФМўжаЁЃ
Ъ§ОнЮФМўЫїв§
Ъ§ОнЮФМўЗжЖЮЪЙЕУПЩвддквЛИіНЯаЁЕФЪ§ОнЮФМўжаВщевЖдгІoffsetЕФMessageСЫЃЌЕЋЪЧетвРШЛашвЊЫГађЩЈУшВХФмевЕНЖдгІoffsetЕФMessageЁЃЮЊСЫНјвЛВНЬсИпВщевЕФаЇТЪЃЌKafkaЮЊУПИіЗжЖЮКѓЕФЪ§ОнЮФМўНЈСЂСЫЫїв§ЮФМўЃЌЮФМўУћгыЪ§ОнЮФМўЕФУћзжЪЧвЛбљЕФЃЌжЛЪЧЮФМўРЉеЙУћЮЊ.indexЁЃ

Ыїв§ЮФМўжаАќКЌШєИЩИіЫїв§ЬѕФПЃЌУПИіЬѕФПБэЪОЪ§ОнЮФМўжавЛЬѕMessageЕФЫїв§ЁЃЫїв§АќКЌСНИіВПЗжЃЌЗжБ№ЮЊЯрЖдoffsetКЭpositionЁЃ
ЯрЖдoffsetЃКвђЮЊЪ§ОнЮФМўЗжЖЮвдКѓЃЌУПИіЪ§ОнЮФМўЕФЦ№ЪМoffsetВЛЮЊ0ЃЌЯрЖдoffsetБэЪОетЬѕMessageЯрЖдгкЦфЫљЪєЪ§ОнЮФМўжазюаЁЕФoffsetЕФДѓаЁЁЃОйР§ЃЌЗжЖЮКѓЕФвЛИіЪ§ОнЮФМўЕФoffsetЪЧДг20ПЊЪМЃЌФЧУДoffsetЮЊ25ЕФMessageдкindexЮФМўжаЕФЯрЖдoffsetОЭЪЧ25-20
= 5ЁЃДцДЂЯрЖдoffsetПЩвдМѕаЁЫїв§ЮФМўеМгУЕФПеМфЁЃ
positionЃЌБэЪОИУЬѕMessageдкЪ§ОнЮФМўжаЕФОјЖдЮЛжУЁЃжЛвЊДђПЊЮФМўВЂвЦЖЏЮФМўжИеыЕНетИіpositionОЭПЩвдЖСШЁЖдгІЕФMessageСЫЁЃ
indexЮФМўжаВЂУЛгаЮЊЪ§ОнЮФМўжаЕФУПЬѕMessageНЈСЂЫїв§ЃЌЖјЪЧВЩгУСЫЯЁЪшДцДЂЕФЗНЪНЃЌУПИєвЛЖЈзжНкЕФЪ§ОнНЈСЂвЛЬѕЫїв§ЁЃетбљБмУтСЫЫїв§ЮФМўеМгУЙ§ЖрЕФПеМфЃЌДгЖјПЩвдНЋЫїв§ЮФМўБЃСєдкФкДцжаЁЃЕЋШБЕуЪЧУЛгаНЈСЂЫїв§ЕФMessageвВВЛФмвЛДЮЖЈЮЛЕНЦфдкЪ§ОнЮФМўЕФЮЛжУЃЌДгЖјашвЊзівЛДЮЫГађЩЈУшЃЌЕЋЪЧетДЮЫГађЩЈУшЕФЗЖЮЇОЭКмаЁСЫЁЃ

змНс
ВщевФГИіoffsetЕФЯћЯЂЃЌЯШЖўЗжЗЈевГіЯћЯЂЫљдкЕФsegmentЮФМўЃЈвђЮЊУПИіsegmentЕФУќУћЖМЪЧвдИУЮФМўжаЯћЯЂoffsetзюаЁЕФжЕУќУћЃЉЃЛШЛКѓЃЌМгдиЖдгІЕФ.indexЫїв§ЮФМўЕНФкДцЃЌЭЌбљЖўЗжЗЈевГіаЁгкЕШгкИјЖЈoffsetЕФзюДѓЕФФЧИіoffsetМЧТМЃЈЯрЖдoffsetЃЌpositionЃЉЃЛзюКѓЃЌИљОнpositionЕН.logЮФМўжаЃЌЫГађВщевГіoffsetЕШгкИјЖЈoffsetжЕЕФЯћЯЂЁЃ
гЩгкЯћЯЂдкpartitionЕФsegmentЪ§ОнЮФМўжаЪЧЫГађЖСаДЕФЃЌЧвЯћЯЂЯћЗбКѓВЛЛсЩОГ§ЃЈЩОГ§ВпТдЪЧеыЖдЙ§ЦкЕФsegmentЮФМўЃЉЃЌетжжЫГађДХХЬIOДцДЂЩшМЦЪЧKafkaИпадФмКмживЊЕФдвђЁЃ
3.2 ЩњВњепЩшМЦ
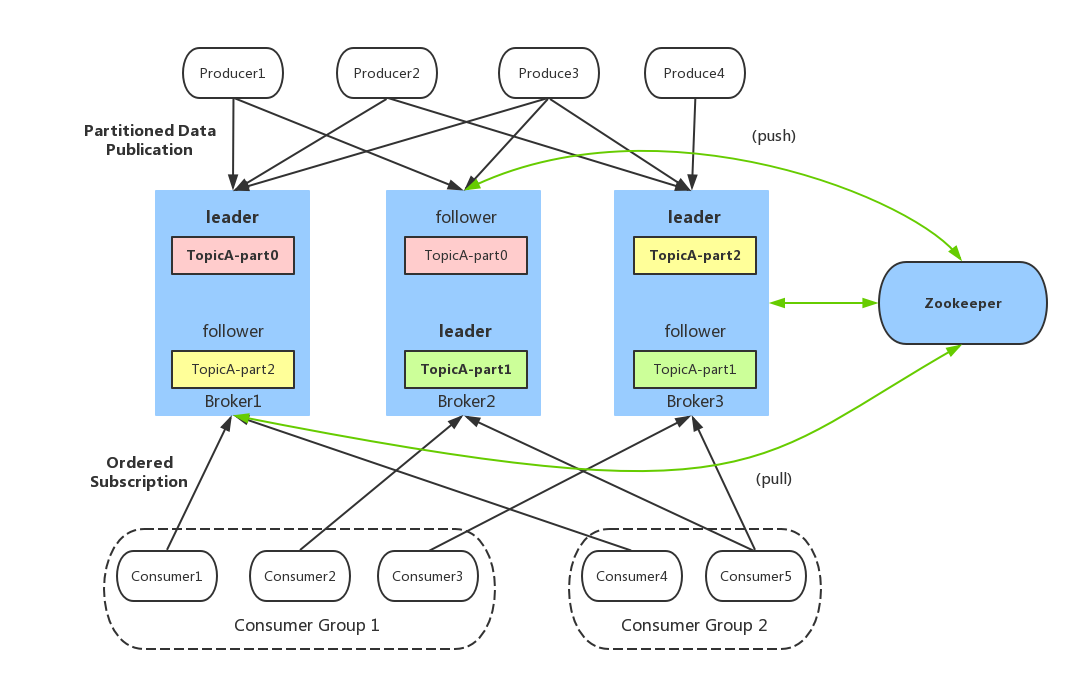
ИКдиОљКтЃКгЩгкЯћЯЂtopicгЩЖрИіpartitionзщГЩЃЌЧвpartitionЛсОљКтЗжВМЕНВЛЭЌbrokerЩЯЃЌвђДЫЃЌЮЊСЫгааЇРћгУbrokerМЏШКЕФадФмЃЌЬсИпЯћЯЂЕФЭЬЭТСПЃЌproducerПЩвдЭЈЙ§ЫцЛњЛђепhashЕШЗНЪНЃЌНЋЯћЯЂЦНОљЗЂЫЭЕНЖрИіpartitionЩЯЃЌвдЪЕЯжИКдиОљКтЁЃ
ХњСПЗЂЫЭЃКЪЧЬсИпЯћЯЂЭЬЭТСПживЊЕФЗНЪНЃЌProducerЖЫПЩвддкФкДцжаКЯВЂЖрЬѕЯћЯЂКѓЃЌвдвЛДЮЧыЧѓЕФЗНЪНЗЂЫЭСЫХњСПЕФЯћЯЂИјbrokerЃЌДгЖјДѓДѓМѕЩйbrokerДцДЂЯћЯЂЕФIOВйзїДЮЪ§ЁЃЕЋвВвЛЖЈГЬЖШЩЯгАЯьСЫЯћЯЂЕФЪЕЪБадЃЌЯрЕБгквдЪБбгДњМлЃЌЛЛШЁИќКУЕФЭЬЭТСПЁЃ
3.3 ЯћЗбепЩшМЦ
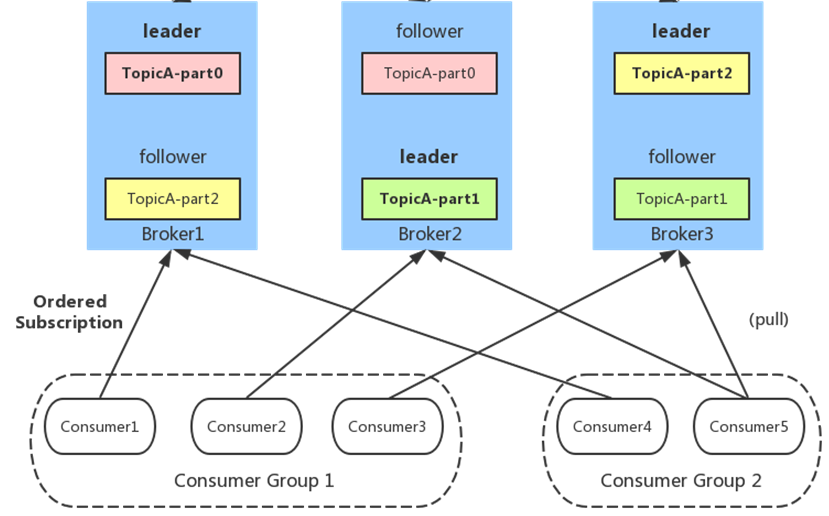
1.ШЮКЮConsumerБиаыЪєгквЛИіConsumer Group
2.ЭЌвЛConsumer GroupжаЕФЖрИіConsumerЪЕР§ЃЌВЛЭЌЪБЯћЗбЭЌвЛИіpartitionЃЌЕШаЇгкЖгСаФЃЪНЁЃШчЭМЃЌConsumer
Group 1ЕФШ§ИіConsumerЪЕР§ЗжБ№ЯћЗбВЛЭЌЕФpartitionЕФЯћЯЂЃЌМДЃЌTopicA-part0ЁЂTopicA-part1ЁЂTopicA-part2ЁЃ
3.ВЛЭЌConsumer GroupЕФConsumerЪЕР§ПЩвдЭЌЪБЯћЗбЭЌвЛИіpartitionЃЌЕШаЇгкЗЂВМЖЉдФФЃЪНЁЃШчЭМЃЌConsumer
Group 1ЕФConsumer1КЭConsumer Group 2ЕФConsumer4ЃЌЭЌЪБЯћЗбTopicA-part0ЕФЯћЯЂЁЃ
4.partitionФкЯћЯЂЪЧгаађЕФЃЌConsumerЭЈЙ§pullЗНЪНЯћЗбЯћЯЂЁЃ
5.KafkaВЛЩОГ§вбЯћЗбЕФЯћЯЂ
ЖгСаФЃЪН
ЖгСаФЃЪНЃЌжИУПЬѕЯћЯЂжЛЛсгавЛИіConsumerЯћЗбЕНЁЃKafkaБЃжЄЭЌвЛConsumer GroupжажЛгавЛИіConsumerЛсЯћЗбФГЬѕЯћЯЂЁЃ
дкConsumer GroupЮШЖЈзДЬЌЯТЃЌУПвЛИіConsumerЪЕР§жЛЛсЯћЗбФГвЛИіЛђЖрИіЬиЖЈpartitionЕФЪ§ОнЃЌЖјФГИіpartitionЕФЪ§ОнжЛЛсБЛФГвЛИіЬиЖЈЕФConsumerЪЕР§ЫљЯћЗбЃЌвВОЭЪЧЫЕKafkaЖдЯћЯЂЕФЗжХфЪЧвдpartitionЮЊЕЅЮЛЗжХфЕФЃЌЖјЗЧвдУПвЛЬѕЯћЯЂзїЮЊЗжХфЕЅдЊЃЛ
ЭЌвЛConsumer GroupжаЃЌШчЙћConsumerЪЕР§Ъ§СПЩйгкpartitionЪ§СПЃЌдђжСЩйгавЛИіConsumerЛсЯћЗбЖрИіpartitionЕФЪ§ОнЃЛШчЙћConsumerЕФЪ§СПгыpartitionЪ§СПЯрЭЌЃЌдђе§КУвЛИіConsumerЯћЗбвЛИіpartitionЕФЪ§ОнЃЛЖјШчЙћConsumerЕФЪ§СПЖргкpartitionЕФЪ§СПЪБЃЌЛсгаВПЗжConsumerЮоЗЈЯћЗбИУTopicЯТШЮКЮвЛЬѕЯћЯЂЃЛ
ЩшМЦЕФгХЪЦЪЧЃКУПИіConsumerВЛгУЖМИњДѓСПЕФbrokerЭЈаХЃЌМѕЩйЭЈаХПЊЯњЃЌЭЌЪБвВНЕЕЭСЫЗжХфФбЖШЃЌЪЕЯжвВИќМђЕЅЃЛПЩвдБЃжЄУПИіpartitionРяЕФЪ§ОнПЩвдБЛConsumerгаађЯћЗбЁЃ
ЩшМЦЕФСгЪЦЪЧЃКЮоЗЈБЃжЄЭЌвЛИіConsumer GroupРяЕФConsumerОљдШЯћЗбЪ§ОнЃЌЧвдкConsumerЪЕР§ЖргкpartitionИіЪ§ЪБЕМжТгааЉConsumerЛсЖіЫРЁЃ
ШчЙћгаpartitionЛђепConsumerЕФдіМѕЃЌЮЊСЫБЃжЄОљКтЯћЗбЃЌашвЊЪЕЯжConsumer
RebalanceЃЌЗжХфЫуЗЈШчЯТЃК

brokerЖдConsumerЩшМЦдРэЃК
1.ЖдгкУПИіConsumer GroupЃЌбЁОйГівЛИіBrokerзїЮЊCoordinatorЃЈ0.9АцБОвдЩЯЃЉЃЌгЩЫќWatch
ZookeeperЃЌДгЖјМрПиХаЖЯЪЧЗёгаpartitionЛђепConsumerЕФдіМѕЃЌШЛКѓЩњГЩRebalanceУќСюЃЌАДеевдЩЯЫуЗЈжиаТЗжХфЁЃ
2.ЕБConsumer GroupЕквЛДЮБЛГѕЪМЛЏЪБЃЌConsumerЭЈГЃЛсЖСШЁУПИіpartitionЕФзюдчЛђзюНќЕФoffsetЃЈZookeeperМЧТМЃЉЃЌШЛКѓЫГађЕиЖСШЁУПИіpartition
logЕФЯћЯЂЃЌдкConsumerЖСШЁЙ§ГЬжаЃЌЫќЛсЬсНЛвбОГЩЙІДІРэЕФЯћЯЂЕФoffsetsЃЈгЩZookeeperМЧТМЃЉЁЃ
3.ЕБвЛИіpartitionБЛжиаТЗжХфИјConsumer GroupжаЕФЦфЫћConsumerЃЌаТЕФConsumerЯћЗбЕФГѕЪМЮЛжУЛсЩшжУЮЊ(дРДConsumer)зюНќЬсНЛЕФoffsetЁЃ
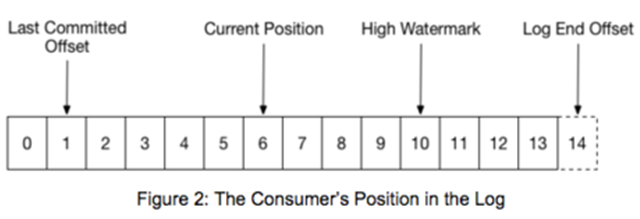
ШчЭМЃЌLast Commited OffsetжИConsumerзюНќвЛДЮЬсНЛЕФЯћЗбМЧТМoffsetЃЌCurrent
PositionЪЧЕБЧАЯћЗбЕФЮЛжУЃЌHigh WatermarkЪЧГЩЙІПНБДЕНlogЕФЫљгаИББОНкЕуЃЈpartitionЕФЫљгаISRНкЕуЃЌЯТЮФНщЩмЃЉЕФзюНќЯћЯЂЕФoffsetЃЌLog
End OffsetЪЧаДШыlogжазюКѓвЛЬѕЯћЯЂЕФoffset+1ЁЃ
ДгConsumerЕФНЧЖШРДПДЃЌзюЖржЛФмЖСШЁЕНHigh watermarkЕФЮЛжУЃЌКѓУцЕФЯћЯЂЖдЯћЗбепВЛПЩМћЃЌвђЮЊЮДЭъШЋИДжЦЕФЪ§ОнЛЙУЛПЩППДцДЂЃЌгаЖЊЪЇПЩФмЁЃ
ЗЂВМЖЉдФФЃЪН
ЗЂВМЖЉдФФЃЪНЃЌгжжИЙуВЅФЃЪНЃЌKafkaБЃжЄtopicЕФУПЬѕЯћЯЂЛсБЛЫљгаConsumer GroupЯћЗбЕНЃЌЖјЖдгкЭЌвЛИіConsumer
GroupЃЌЛЙЪЧБЃжЄжЛгавЛИіConsumerЪЕР§ЯћЗбЕНетЬѕЯћЯЂЁЃ
3.4 ReplicationЩшМЦ
зїЮЊЯћЯЂжаМфМўЃЌЪ§ОнЕФПЩППадвдМАЯЕЭГЕФПЩгУадЃЌБиШЛвРРЕЪ§ОнИББОЕФЩшМЦЁЃ
KafkaЕФreplicaИББОЕЅдЊЪЧtopicЕФpartitionЃЌвЛИіpartitionЕФreplicaЪ§СПВЛФмГЌЙ§brokerЕФЪ§СПЃЌвђЮЊвЛИіbrokerзюЖржЛЛсДцДЂетИіpartitionЕФвЛИіИББОЁЃЫљгаЯћЯЂЩњВњЁЂЯћЗбЧыЧѓЖМЪЧгЩpartitionЕФleader
replicaРДДІРэЃЌЦфЫћfollower replicaИКд№ДгleaderИДжЦЪ§ОнНјааБИЗнЁЃ
ReplicaОљдШЗжВМЕНећИіМЏШКЃЌReplicaЕФЫуЗЈШчЯТЃК
1.НЋЫљгаBrokerЃЈМйЩшЙВnИіBrokerЃЉКЭД§ЗжХфЕФPartitionХХађ
2.НЋЕкiИіPartitionЗжХфЕНЕкЃЈi mod nЃЉИіBrokerЩЯ
3.НЋЕкiИіPartitionЕФЕкjИіReplicaЗжХфЕНЕкЃЈ(i
+ j) mode nЃЉИіBrokerЩЯ
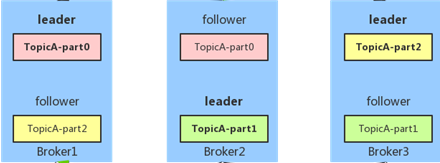
ШчЭМЃЌTopicAгаШ§ИіpartitionЃКpart0ЁЂpart1ЁЂpart2ЃЌУПИіpartitionЕФreplicaЪ§ЕШгк2ЃЈвЛИіЪЧleaderЃЌСэвЛИіЪЧfollowerЃЉЃЌАДеевдЩЯЫуЗЈЛсОљдШТфЕНШ§ИіbrokerЩЯЁЃ
brokerЖдreplicaЙмРэЃК
бЁОйГівЛИіbrokerзїЮЊcontrollerЃЌгЩЫќWatch ZookeeperЃЌИКд№partitionЕФreplicaЕФМЏШКЗжХфЃЌвдМАleaderЧаЛЛбЁОйЕШСїГЬЁЃ
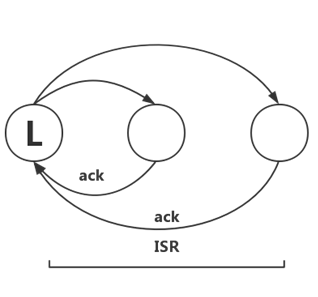
In-Sync-Replica(ISR)
ЗжВМЪНЯЕЭГдкДІРэНкЕуЙЪеЯЪБЃЌашвЊдЄЯШУїШЗНкЕуЕФЁБfailureЁБКЭЁБaliveЁБЕФЖЈвхЁЃЖдгкKafkaНкЕуЃЌХаЖЯЪЧЁБaliveЁБгавдЯТСНИіЬѕМўЃК
1.НкЕуБиаыКЭZookeeperБЃГжаФЬјСЌНг
2.ШчЙћНкЕуЪЧfollowerЃЌБиаыДгleaderНкЕуЩЯИДжЦЪ§ОнРДБИЗнЃЌЖјЧвБИЗнЕФЪ§ОнЯрБШleaderЖјбдЃЌВЛФмТфКѓЬЋЖрЁЃ
KafkaНЋТњзувдЩЯЬѕМўЕФreplicaНкЕуШЯЮЊЪЧЁБin syncЁБЃЈЭЌВНжаЃЉЃЌГЦЮЊIn-Sync-Replica(ISR)ЁЃ
KafkaЕФZookeeperЮЌЛЄСЫУПИіpartitionЕФISRаХЯЂЃЌРэЯыЧщПіЯТЃЌISRАќКЌСЫpartitionЕФЫљгаreplicaЫљдкЕФbrokerНкЕуаХЯЂЃЌЖјЕБФГаЉНкЕуВЛТњзувдЩЯЬѕМўЪБЃЌISRПЩФмжЛАќКЌВПЗжreplicaЁЃР§ШчЃЌЩЯЭМжаЕФTopicA-part0ЕФISRСаБэПЩФмЪЧ[broker1,broker2,broker3]ЃЌвВПЩФмЪЧ[broker1,broker3]КЭ[broker1]ЁЃ
Ъ§ОнПЩППад
KafkaШчКЮБЃжЄЪ§ОнПЩППадЃПЪзЯШПДЯТЃЌProducerЩњВњвЛЬѕЯћЯЂЃЌИУЯћЯЂБЛШЯЮЊЪЧЁБcommittedЁБЃЈМДbrokerШЯЮЊЯћЯЂвбОПЩППДцДЂЃЉЕФЙ§ГЬЃК
1.ЯћЯЂЫљдкpartitionЕФISR replicasЛсЖЈЪБвьВНДгleaderЩЯХњСПИДжЦЪ§Онlog
2.ЕБЫљгаISR replicaЖМЗЕЛиackЃЌИцЫпleaderИУЯћЯЂвбОаДlogГЩЙІКѓЃЌleaderШЯЮЊИУЯћЯЂcommittedЃЌВЂИцЫпProducerЩњВњГЩЙІЁЃетРяКЭвдЩЯЁБaliveЁБЬѕМўЕФЕкЖўЕуЪЧВЛУЌЖмЕФЃЌвђЮЊleaderгаГЌЪБЛњжЦЃЌleaderЕШISRЕФfollowerИДжЦЪ§ОнЃЌШчЙћвЛЖЈЪБМфВЛЗЕЛиackЃЈПЩФмЪ§ОнИДжЦНјЖШТфКѓЬЋЖрЃЉЃЌдђleaderНЋИУfollower
replicaДгISRжаЬоГ§ЁЃ
3.ЯћЯЂcommittedжЎКѓЃЌConsumerВХФмЯћЗбЕНЁЃ
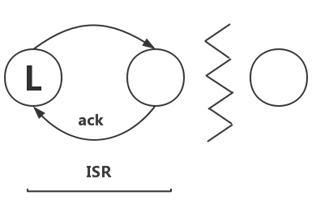
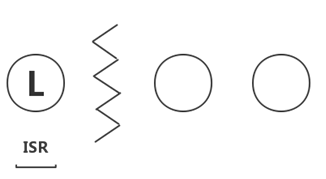
ISRЛњжЦЯТЕФЪ§ОнИДжЦЃЌМШВЛЪЧЭъШЋЕФЭЌВНИДжЦЃЌвВВЛЪЧЕЅДПЕФвьВНИДжЦЃЌетЪЧKafkaИпЭЬЭТКмживЊЕФЛњжЦЁЃЭЌВНИДжЦвЊЧѓЫљгаФмЙЄзїЕФfollowerЖМИДжЦЭъЃЌетЬѕЯћЯЂВХЛсБЛШЯЮЊcommittedЃЌетжжИДжЦЗНЪНМЋДѓЕФгАЯьСЫЭЬЭТСПЁЃЖјвьВНИДжЦЗНЪНЯТЃЌfollowerвьВНЕФДгleaderИДжЦЪ§ОнЃЌЪ§ОнжЛвЊБЛleaderаДШыlogОЭБЛШЯЮЊвбОcommittedЃЌетжжЧщПіЯТШчЙћfollowerЖМИДжЦЭъЖМТфКѓгкleaderЃЌЖјШчЙћleaderЭЛШЛхДЛњЃЌдђЛсЖЊЪЇЪ§ОнЁЃЖјKafkaЕФетжжЪЙгУISRЕФЗНЪНдђКмКУЕФОљКтСЫШЗБЃЪ§ОнВЛЖЊЪЇвдМАЭЬЭТСПЃЌfollowerПЩвдХњСПЕФДгleaderИДжЦЪ§ОнЃЌЪ§ОнИДжЦЕНФкДцМДЗЕЛиackЃЌетбљМЋДѓЕФЬсИпИДжЦадФмЃЌЕБШЛЪ§ОнШдШЛЪЧгаЖЊЪЇЗчЯеЕФЁЃ
KafkaБОЩэЖЈЮЛгкИпадФмЕФMQЃЌИќЖрзЂжиЯћЯЂЭЬЭТСПЃЌдкДЫЛљДЁЩЯНсКЯISRЕФЛњжЦШЅОЁСПБЃжЄЯћЯЂЕФПЩППадЃЌЕЋВЛЪЧОјЖдПЩППЕФЁЃ
ЗўЮёПЩгУад
KafkaЫљгаЪеЗЂЯћЯЂЧыЧѓЖМгЩleaderНкЕуДІРэЃЌгЩвдЩЯЪ§ОнПЩППадЩшМЦПЩжЊЃЌЕБISRЕФfollower
replicaЙЪеЯКѓЃЌleaderЛсМАЪБЕиДгISRСаБэжаАбЫќЬоГ§ЕєЃЌВЂВЛгАЯьЗўЮёПЩгУадЃЌФЧУДЕБleaderЙЪеЯКѓЛсдѕбљФиЃПШчКЮбЁОйаТЕФleaderЃП
leaderбЁОй
1.KafkaдкZookeeperДцДЂpartitionЕФISRаХЯЂЃЌВЂЧвФмЖЏЬЌЕїећISRСаБэЕФГЩдБЃЌжЛгаISRРяЕФГЩдБreplicaВХЛсБЛбЁЮЊleaderЃЌВЂЧвISRЫљгаЕФreplicaЖМгаПЩФмГЩЮЊleaderЃЛ
2.leaderНкЕухДЛњКѓЃЌZookeeperФмМрПиЗЂЯжЃЌВЂгЩbrokerЕФcontrollerНкЕуДгISRжабЁОйГіаТЕФleaderЃЌВЂЭЈжЊISRФкЕФЫљгаbrokerНкЕуЁЃ
вђДЫЃЌПЩвдПДГіЃЌжЛвЊISRжажСЩйгавЛИіreplicaЃЌKafkaОЭФмБЃжЄЗўЮёЕФПЩгУадЃЈЕЋВЛБЃжЄЭјТчЗжЧјЯТЕФПЩгУадЃЉЁЃ
ШнджКЭЪ§ОнвЛжТад
ЗжВМЪНЯЕЭГЕФШнджФмСІЃЌИњЦфБОЩэеыЖдЪ§ОнвЛжТадПМТЧЫљбЁдёЕФЫуЗЈгаЙиЃЌР§ШчЃЌZookeeperЕФZabЫуЗЈЃЌraftЫуЗЈЕШЁЃKafkaЕФISRЛњжЦКЭетаЉMajority
VoteЫуЗЈЖдБШШчЯТЃК
1.ISRЛњжЦФмШнШЬИќЖрЕФНкЕуЪЇАмЁЃМйШчreplicaНкЕуга2f+1ИіЃЌУПИіpartitionзюЖрФмШнШЬ2fИіЪЇАмЃЌЧвВЛЖЊЪЇЯћЯЂЪ§ОнЃЛЕЋЯрЖдMajority
VoteбЁОйЫуЗЈЃЌжЛФмзюЖрШнШЬfИіЪЇАмЁЃ
2.дкЯћЯЂcommittedГжОУЛЏЩЯЃЌISRашвЊЕШ2fИіНкЕуЗЕЛиackЃЌЕЋMajority
VoteжЛашЕШf+1ИіНкЕуЗЕЛиackЃЌЧвВЛвРРЕДІРэзюТ§ЕФfollowerНкЕуЃЌвђДЫMajority
VoteгагХЪЦ
3.ISRЛњжЦФмНкЪЁИќЖрreplicaНкЕуЪ§ЁЃР§ШчЃЌвЊБЃжЄfИіНкЕуПЩгУЃЌISRЗНЪНжСЩйвЊfИіНкЕуЃЌЖјMajority
VoteжСЩйашвЊ2f+1ИіНкЕуЁЃ
ШчЙћЫљгаreplicaЖМхДЛњСЫЃЌгаСНжжЗНЪНЛжИДЗўЮёЃК
1.ЕШISRШЮвЛНкЕуЛжИДЃЌВЂбЁОйЮЊleaderЃЛ
2.бЁдёЕквЛИіЛжИДЕФНкЕуЃЈВЛвЛЖЈЪЧISRжаЕФНкЕуЃЉЮЊleader
ЕквЛжжЗНЪНЯћЯЂВЛЛсЖЊЪЇЃЈжЛФмЫЕетжжЗНЪНзюгаПЩФмВЛЖЊЖјвбЃЉЃЌЕкЖўжжЗНЪНПЩФмЛсЖЊЯћЯЂЃЌЕЋФмОЁПьЛжИДЗўЮёПЩгУЁЃетЪЧПЩгУадКЭвЛжТадГЁОАЕФСНжжПМТЧЃЌKafkaФЌШЯбЁдёЕкЖўжжЃЌгУЛЇвВПЩвдзджїХфжУЁЃ
ДѓВПЗжПМТЧCPЕФЗжВМЪНЯЕЭГЃЈМйЩш2f+1ИіНкЕуЃЉЃЌЮЊСЫБЃжЄЪ§ОнвЛжТадЃЌзюЖржЛФмШнШЬfИіНкЕуЕФЪЇАмЃЌЖјKafkaЮЊСЫМцЙЫПЩгУадЃЌдЪаэзюЖр2fИіНкЕуЪЇАмЃЌвђДЫЪЧЮоЗЈБЃжЄЪ§ОнЧПвЛжТЕФЁЃ
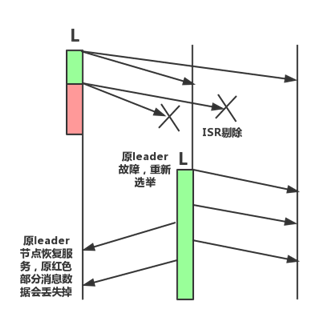
ШчЭМЫљЪОЃЌвЛПЊЪМISRЪ§СПЕШгк3ЃЌе§ГЃЭЌВНЪ§ОнЃЌКьЩЋВПЗжПЊЪМЃЌleaderЗЂЯжЦфЫћСНИіfollowerИДжЦНјЖШЬЋТ§ЛђепЦфЫћдвђЃЈЭјТчЗжЧјЁЂНкЕуЙЪеЯЕШЃЉЃЌНЋЦфДгISRЬоГ§КѓЃЌleaderЕЅНкЕуДцДЂЪ§ОнЃЛШЛКѓЃЌleaderхДЛњЃЌДЅЗЂжиаТбЁОйЕкЖўНкЕуЮЊleaderЃЌжиаТПЊЪМЭЌВНЪ§ОнЃЌЕЋКьЩЋВПЗжЕФЪ§ОндкаТleaderЩЯЪЧУЛгаЕФЃЛзюКѓдleaderНкЕуЛжИДЗўЮёКѓЃЌжиаТДгаТleaderЩЯИДжЦЪ§ОнЃЌЖјКьЩЋВПЗжЕФЪ§ОнвбОЯћЗбВЛЕНСЫЁЃ
вђДЫЃЌЮЊСЫМѕЩйЪ§ОнЖЊЪЇЕФИХТЪЃЌПЩвдЩшжУKafkaЕФISRзюаЁreplicaЪ§ЃЌЕЭгкИУжЕКѓжБНгЗЕЛиВЛПЩгУЃЌЕБШЛЪЧвдЮўЩќвЛЖЈПЩгУадКЭЭЬЭТСПЮЊЧАЬсСЫЁЃ
жиИДЯћЯЂ
ЯћЯЂДЋЪфгаШ§жжЗНЪНЃК
1.At most onceЃКЯћЯЂПЩФмЛсЖЊЪЇЃЌЕЋВЛЛсжиИДДЋЪф
2.At least onceЃКЯћЯЂВЛЛсЖЊЪЇЃЌЕЋПЩФмжиИДДЋЪф
3.Exactly onceЃКЯћЯЂБЃжЄЛсБЛДЋЪфвЛДЮЧвНіДЋЪфвЛДЮ
KafkaЪЕЯжСЫЕкЖўжжЗНЪНЃЌМДЃЌПЩФмДцдкжиИДЯћЯЂЃЌашвЊвЕЮёздМКБЃжЄЯћЯЂУнЕШадДІРэЁЃ
3.5 ИпЭЬЭТЩшМЦ
1.ЖдгкpartitionЃЌЫГађЖСаДДХХЬЪ§ОнЃЌвдЪБМфИДдгЖШO(1)ЗНЪНЬсЙЉЯћЯЂГжОУЛЏФмСІЁЃ
2.ProducerХњСПЯђbrokerаДЪ§Он
3.ConsumerХњСПДгbrokerРЪ§Он
4.ШежОбЙЫѕ
5.TopicЗжЖрИіpartitionЃЌЬсИпВЂЗЂ
6.brokerСуПНБДЃЈZero CopyЃЉЃЌЪЙгУsendfileЯЕЭГЕїгУЃЌНЋЪ§ОнжБНгДгpage
cacheЗЂЫЭЕНsocketЩЯ
7.ProducerПЩХфжУЪЧЗёЕШД§ЯћЯЂcommittedЁЃШчЙћProducerЩњВњЯћЯЂЃЌУПДЮЖМБиаыЕШISRДцДЂКѓВХЗЕЛиЃЌЪБбгЛсКмИпЃЌНјЖјгАЯьећЬхЯћЯЂЕФЭЬЭТСПЁЃЮЊСЫНтОіетИіЮЪЬтЃЌвЛЗНУцProducerПЩвдХфжУМѕЩйpartitionЕФИББОЪ§ЃЌР§ШчЃЌISRДѓаЁЮЊ1ЃЛСэвЛЗНУцЃЌдкВЛЬЋЙизЂЯћЯЂПЩППДцДЂЕФГЁОАЯТЃЌProducerПЩвдЭЈЙ§ХфжУбЁдёЪЧЗёЕШД§ЯћЯЂcommittedЃЌШчЯТЃК
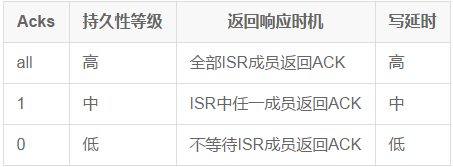
Acks ГжОУадЕШМЖ ЗЕЛиЯьгІЪБЛњ аДбгЪБ
all Ип ШЋВПISRГЩдБЗЕЛиACK Ип
1 жа ISRжаШЮвЛГЩдБЗЕЛиACK жа
0 ЕЭ ВЛЕШД§ISRГЩдБЗЕЛиACK ЕЭ
етЪЧгУЛЇдкЯћЯЂЭЬЭТСПКЭГжОУЛЏжЎМфзіЕФШЈКтбЁдёЃЌГжОУЛЏЕШМЖдНИпЃЌЩњВњЯћЯЂЭЬЭТСПдНаЁЃЌЗДжЎЃЌГжОУЛЏЕШМЖдНЕЭЃЌЭЬЭТСПдНИпЁЃ
3.6 HAЛљБОдРэ
broker HA
brokerМЏШКаХЯЂгЩZookeeperЮЌЛЄЃЌВЂбЁОйГівЛИіcontrollerЁЃЫљгаpartitionЕФleaderбЁОйЖМгЩcontrollerОіЖЈЃЌНЋleaderЕФБфИќжБНгЭЈЙ§rpcЗНЪНЭЈжЊашвЊЮЊДЫзіГіЯьгІЕФbrokersЃЛcontrollerвВИКд№діЩОtopicвдМАpartition
replicaЕФжиаТЗжХфЁЃ
controllerдкZookeeperЩЯзЂВсwatchЃЌвЛЕЉгаbrokerхДЛњЃЌЦфЖдгІдкZookeeperЕФСйЪБНкЕуздЖЏБЛЩОГ§ЃЌcontrollerЖдхДЛњbrokerЩЯЕФЫљгаpartitionжиаТЗжХфаТleaderЃЛШчЙћcontrollerхДЛњЃЌЦфЫћbrokerЭЈЙ§ZookeeperбЁОйГіаТЕФcontrollerЃЌШЛКѓЭЌбљЖдхДЛњbrokerЩЯЕФЫљгаpartitionжиаТЗжХфаТleaderЁЃ
partition HA
partition leaderЫљдкЕФbrokerхДЛњЃЌШчЩЯЫљЪіЃЌbroker controllerИљОнЖЏЬЌЮЌЛЄЕФISRЃЌЛсжиаТдкЪЃЯТЕФbrokerЛњЦїжабЁГіISRРяУцЕФвЛИіГЩдБГЩЮЊаТЕФleaderЁЃШчЙћISRжажСЩйгавЛИіfollowerЃЌдђПЩвдШЗБЃвбОcommittedЕФЪ§ОнВЛЖЊЪЇЃЛЗёдђбЁдёШЮвтвЛИіreplicaзїЮЊleaderЃЌИУГЁОАПЩФмЛсгаЧБдкЕФЪ§ОнЖЊЪЇЃЛШчЙћpartitionЫљгаЕФreplicaЖМхДЛњСЫЃЌОЭЮоЗЈБЃжЄЪ§ОнВЛЖЊЪЇСЫЃЌгаСНжжЛжИДЗНАИЃЌЩЯЮФвбНщЩмЙ§ЁЃ
|









