| 深度学习因其高准确率及通用性,成为机器学习中最受关注的领域。这种算法在2011—2012年期间出现,并超过了很多竞争对手。最开始,深度学习在音频及图像识别方面取得了成功。此外,像机器翻译之类的自然语言处理或者画图也能使用深度学习算法来完成。深度学习是自1980年以来就开始被使用的一种神经网络。神经网络被看作能进行普适近似(universal
approximation)的一种机器。换句话说,这种网络能模仿任何其他函数。例如,深度学习算法能创建一个识别动物图片的函数:给一张动物的图片,它能分辨出图片上的动物是一只猫还是一只狗。深度学习可以看作是组合了许多神经网络的一种深度结构。
与其他已有的机器学习算法相比,深度学习需要大量参数及训练数据。这也是我们介绍能在Spark上运行的深度学习框架的原因。要想在企业环境中稳定地进行深度学习的训练,必须要有一个可靠而快速的分布式引擎。
Spark被视为目前最适合运行深度学习算法的平台,是因为:
1.基于内存的处理架构对于使用机器学习的迭代计算,特别是深度学习,十分适合。
2.Spark的几个生态系统如MLlib及Tachyon对于开发深度学习模型很有用。
本文我们将介绍一些Spark能用的深度学习框架。这些框架和深度学习一样,都是比较新的库。很可能你在使用它们的过程中遇到一些bug或者缺少一些操作工具,但是报告问题(issue)及发送补丁将会使它更加成熟。
H2O
H2O是用h2o.ai开发的具有可扩展性的机器学习框架,它不限于深度学习。H2O支持许多API(例如,R、Python、Scala和Java)。当然它是开源软件,所以要研究它的代码及算法也很容易。H2O框架支持所有常见的数据库及文件类型,可以轻松将模型导出为各种类型的存储。深度学习算法是在另一个叫作sparkling-water的库中实现的(http://h2o.ai/product/sparkling-water/)。它主要由h2o.ai开发。要运行sparkling-water,需要使用Spark
1.3或以上的版本。
安装
1.首先需要从h2o网站下载最新的sparking-water。
| http://h2o-release.s3.amazonaws.com/sparkling-water/rel-1.3/1/index.html)
|
2.把它指向Spark的安装目录。
| $
export Spark_HOME=/path/to/your/spark |
3.启动sparkling-shell,这个接口与spark-shell类似。
| $
cd ~/Downloads
$ unzip Sparkling-water-1.3.1.zip
$ cd Sparkling-water-1.3.1
$ bin/Sparkling-shell |
sparkling-water源码中包含几个例子。不幸的是,有些例子在Spark
1.5.2版本上无法正常运行。深度学习的demo也有相同的问题。你得等待这些问题被解决,或者自己写几个能在Spark运行的补丁。
deeplearning4j
deeplearning4j是由Skymind开发的,Skymind是一家致力于为企业进行商业化深度学习的公司。deeplearning4j框架是创建来在Hadoop及Spark上运行的。这个设计用于商业环境而不是许多深度学习框架及库目前所大量应用的研究领域。Skymind是主要的支持者,但deeplearning4j是开源软件,因此也欢迎大家提交补丁。deeplearning4j框架中实现了如下算法:
1.受限玻尔兹曼机(Restricted Boltzmann Machine)
2.卷积神经网络(Convolutional Neural Network)
3.循环神经网络(Recurrent Neural Network)
4.递归自编码器(Recursive Autoencoder)
5.深度信念网络(Deep-Belief Network)
6.深度自编码器(Deep Autoencoder)
7.栈式降噪自编码(Stacked Denoising Autoencoder)
这里要注意的是,这些模型能在细粒度级别进行配置。你可以设置隐藏的层数、每个神经元的激活函数以及迭代的次数。deeplearning4j提供了不同种类的网络实现及灵活的模型参数。Skymind也开发了许多工具,对于更稳定地运行机器学习算法很有帮助。下面列出了其中的一些工具。
Canova (https://github.com/deeplearning4j/Canoba)是一个向量库。机器学习算法能以向量格式处理所有数据。所有的图片、音频及文本数据必须用某种方法转换为向量。虽然训练机器学习模型是十分常见的工作,但它会重新造轮子还会引起bug。Canova能为你做这种转换。Canova当前支持的输入数据格式为:
– CSV
–原始文本格式(推文、文档)
–图像(图片、图画)
–定制文件格式(例如MNIST)
1.由于Canova主要是用Java编写的,所以它能运行在所有的JVM平台上。因此,可以在Spark集群上使用它。即使你不做机器学习,Canova对你的机器学习任务可能也会有所裨益。
2.nd4j(https://github.com/deeplearning4j/nd4j)有点像是一个numpy,Python中的SciPy工具。此工具提供了线性代数、向量计算及操纵之类的科学计算。它也是用Java编写的。你可以根据自己的使用场景来搭配使用这些工具。需要注意的一点是,nd4j支持GPU功能。由于现代计算硬件还在不断发展,有望达到更快速的计算。
3.dl4j-spark-ml (https://github.com/deeplearning4j/dl4j-spark-ml)是一个Spark包,使你能在Spark上轻松运行deeplearning4j。使用这个包,就能轻松在Spark上集成deeplearning4j,因为它已经被上传到了Spark包的公共代码库(http://spark-packages.org/package/deeplearning4j/dl4j-Spark-ml)。
因此,如果你要在Spark上使用deeplearning4j,我们推荐通过dl4j-spark-ml包来实现。与往常一样,必须下载或自己编译Spark源码。这里对Spark版本没有特别要求,就算使用最早的版本也可以。deeplearning4j项目准备了样例存储库。要在Spark上使用deeplearning4j,dl4j-Spark-ml-examples是可参考的最佳示例(https://
github.com/deeplearning4j/dl4j-Spark-ml-examples)。下面列出如何下载及编译这个代码库。
| $
git clone git@github.com:deeplearning4j/dl4j-spark-mlexamples.git
$ cd dl4j-Spark-ml-examples
$ mvn clean package -DSpark.version=1.5.2 \
-DHadoop.version=2.6.0 |
编译类位于target目录下,但是可以通过bin/run-example脚本运行这些例子。当前有三种类型的例子:
1.ml.JavaIrisClassfication——鸢尾花(iris
flower)数据集分类。
2.ml.JavaLfwClassfication——LFW人脸数据库分类。
3.ml.JavaMnistClassfication——MNIST手写数据分类。
我们选择第3个例子,对MNIST手写数据集运行分类模型的训练。在运行这个示例之前,需要从MNIST站点下载训练数据(http://yann.lecun.com/exdb/
mnist/)。或者,你可以使用下面的命令下载:
| ##
下载手写数据的图像
$ wget http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
$ gunzip train-images-idx3-ubyte
## 下载与上述图像对应的标签
$ wget http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
$ gunzip train-labels-idx1-ubyte
And the put the two files on data direcotry
under dj4j-spark-ml-examples.
$ mv train-images-idx3-ubyte \
/path/to/dl4j-spark-ml-examples/data
$ mv train-labels-idx1-ubyte \
/path/to/dj4j-spark-ml-examples/data |
差不多可以开始运行训练进程了。你需要注意的最后一点是Spark
executor及driver的内存大小,因为 MNIST数据集和它的训练模型将会很大。它们要用到大量内存,因此我们建议你提前修改bin/run-example脚本中设置的内存大小。可以通过如下命令修改bin/run-example脚本的最后一行:
| exec
spark-submit \
--packages "deeplearning4j:dl4j-spark-ml:0.4-rc0"
\
--master $EXAMPLE_MASTER \
--class $EXAMPLE_CLASS \
--driver-memory 8G \ # <- Changed from 1G
--executor-memory 8G \ # <- Changed from
4G
"$SPARK_EXAMPLES_JAR" \
"$@" |
现在开始训练:
| $
MASTER=local[4] bin/run-example ml.JavaMnistClassfication |
为了指定本地Spark的master配置,我们已经在bin/run-example脚本的前面设置了MASTER环境变量。这种训练需要花一些时间,由你的环境及机器规格决定。这个例子运行了一种叫作“卷积神经网络”的神经网络。其参数细节是通过MultiLayerConfiguration类设置的。由于deeplearning4j有一个Java接口,就算你不习惯Spark的Scala语言也没关系,它是很容易引入的。下面简单解释一下这个例子中的卷积神经网络参数。
1.seed——此神经网络会使用像初始网络参数这样的随机参数,这个种子就用于产生这些参数。有了这个种子参数,在开发机器学习模型的过程中更容易进行测试与调试。
2.batchSize——像递度下降之类的迭代算法,在更新模型之前会汇总一些更新值,batchSize指定进行更新值计算的样本数。
3.iterations——由一个迭代进程保持模型参数的更新。这个参数决定了此迭代处理的次数。通常来说,迭代越长,收敛的概率越高。
4.optimizationAlgo——运行前述的迭代进程,必须用到几种方法。随机梯度下降(Stochastic
Gradient
Descent,SGD)是目前为止最先进的方法,这种方法相对来讲不会落入局部最小值,还能持续搜索全局最小值。
5.layer——它是深度学习算法的核心配置。这个深度学习神经网络有几个名为layer的网络组。这个参数决定了在每一层中使用哪种类型的层。例如,在卷积神经网络的案例中,ConvolutionLayer被用于从输入的图像中提取出特征。这个层能学习一个给定的图片有哪种类型的特征。在一开始就放置这个层,将改善整个神经网络预测的精确性。每个层也能用给定的参数进行配置。
| new
ConvolutionLayer.Builder(10, 10)
.nIn(nChannels) // 输入元素的数目
.nOut(6) // 输出元素的数目
.weightInit(WeightInit.DISTRIBUTION)
// 参数矩阵的初始化方法
.activation("sigmoid") // 激活函数的类型
*build()) |
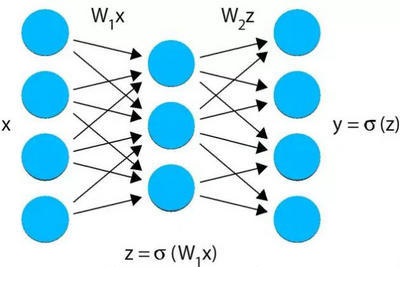
上图展现了神经网络的通用结构。由于ConvolutionalLayer也是一种神经网络,两种网络的部件基本上是相同的。神经网络有一个输入(x)及输出(y)。它们都是向量格式的数据。在上图中,输入为一个四维向量,而输出也是一个四维向量。输出向量y是怎样计算出来的呢?每层都有一个参数矩阵。在本例中,它们用W表示。x与W相乘得到下一个向量。为了增强这个模型的表达,这个向量被传给某个非线性激活函数(σ),例如逻辑sigmoid函数(logistic
sigmoid function)、Softmax函数。使用这个非线性函数,神经网络就能逼近任意类型的函数。然后用z与另一个参数矩阵W相乘,并再次应用激活函数σ
。
你可以看到ConvolutionLayer的每个配置。nIn及nOut是输入向量vector(x)及输出向量vector(z)的维度。activation是这个层的激活函数,由逻辑sigmoid函数与修正线性单元所选择。根据你的问题,输入及输出的维度能被立即确定。其他参数应当通过网格搜索来优化,这一点将在后面讲述。
每一层(layer)的选择我们自己常常是很难决定的。这需要了解一些知识,而且对要解决的特定问题要有一定的研究。deeplearning4j项目也提供了一份介绍性文档(http://deeplearning4j.org/convolutionalnets.html)。虽然理解这份文档需要一点数学及线性代数知识,但它仍然是描述卷积神经网络工作原理的最简单的文档。
1.backprop——反向传播(backpropagation)是目前用于更新模型参数(W)最先进的方法。因此,这个参数应当总是true。
2.pretrain——由于有预训练(pretraining),多层网络能从输入数据提取出特征,获得经过优化的初始参数。也推荐把它设为true。
在这里我们无法描述机器学习的全部细节。但是通常来说,这些算法主要用于图像识别、文本处理及垃圾邮件过滤等场景。deeplearning4j的官方站点上(http://deeplearning4j.org)不仅有对如何deeplearning4j的介绍,也有对深度学习的一般讨论,你还能学到前沿的技术与概念。
SparkNet
SparkNet由加州大学伯克利分校AMP实验室于2015年11月发布。而Spark最早就是由AMP实验室开发的。因此,说SparkNet
是“运行在Spark上的官方机器学习库”一点儿也不为过。此库提供了读取RDD的接口,以及兼容深度学习框架Caffe(http://caffe.berkeleyvision.org/)的接口。SparkNet通过采用随机梯度下降(Stochastic
Gradient Descent)获得了简单的并行模式。SparkNet job能通过Spark-submit提交。你可以很轻松地使用这个新库。
SparkNet的架构很简单。SparkNet负责分布式处理,而核心的学习过程则委托给Caffe框架。SparkNet通过Java
native访问Caffee框架提供的C API。Caffee是用C++实现的,Caffe的C包装器写在SparkNet的libcaffe目录下。所以SparkNet的整体代码库相对较小。Java代码(CaffeLibrary.java)进一步包装了这个库。为了在Scala世界里使用CaffeLibrary,Caffe还提供了CaffeNet。下图展现了CaffeNet的层级。
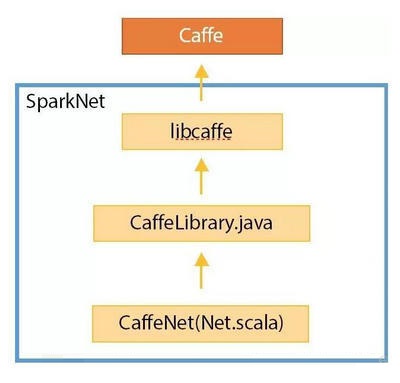
如果你熟悉Scala,那么开发SparkNet的应用程序时只需要考虑CaffeNet。而且你也可以使用Spark
RDD。它是通过一个JavaDataLayer C++代码的包装器来实现的。除此之外,SparkNet能加载Caffe格式的模型文件。这个扩展通常是通过.prototxt来设置的:
| val
netParameter
= ProtoLoader.loadNetPrototxt(sparkNetHome
+ "your-caffemodel.prototxt") |
替换模型的输入,你可以在Spark上训练自己的数据。SparkNet还提供了实用程序:
| val
newNetParameter =
ProtoLoader.replaceDataLayers(netParameter,
trainBatchSize, testBatchSize,
numChannels, height, width) |
顾名思义,每个参数的含义定义了每个阶段的批量大小和输入大小(训练、测试等)。这些参数的细节都可以在Caffe官方文档中进行确认(http://caffe.
berkeleyvision.org/tutorial/net_layer_blob.html)。换句话说,使用SparkNet,你就可以在Spark上通过Scala语言轻松使用Caffe。如果你已经能熟练使用Caffe,那么SparkNet对你而言可能会很容易上手。
|









