| ЖСЃКїШзхUIPЃЈгУЛЇЖДВьЦНЬЈЃЉЭЈЙ§ЖдШ§ЗНЪмжкЪ§ОнЕФЛуОлЁЂЧхЯДЁЂжЧФмдЫЫуЃЌЙЙНЈСЫХгДѓЕФОЋзМШЫШКЪ§ОнжааФЃЌЬсЙЉЗсИЛЕФгУЛЇЛЯёЪ§ОнвдМАЪЕЪБГЁОАЪЖБ№ФмСІЁЃБОЮФНщЩмСЫїШзхгУЛЇЖДВьЦНЬЈЕФЙІФмКЭМмЙЙЃЌЛЙдНЈЩшЙ§ГЬжагіЕНЕФММЪѕФбЕуКЭНтОіЗНЪНЁЃ
вдгУЛЇЖДВьЦНЬЈЕФФПБъЖЈЮЛЮЊГіЗЂЕуЃЌзлКЯММЪѕгывЕЮёашЧѓЕФПМСПНјааМмЙЙЩшМЦЃЌгУЛЇЖДВьЦНЬЈЕФЙІФмАќРЈШЫШКЙмРэЁЂШЫШКЖДВьЗжЮіЁЂздЖЈвхБъЧЉЁЂШЫШКРЉеЙЁЂЛЯёВщбЏЗўЮёЕШЁЃЮФеТЛЙНщЩмСЫЛЯёБъЧЉЕФЩњГЩЁЂЕзВуДцДЂвдМАЦНЬЈЙІФмЁЃ
вЛЁЂзмЬхНщЩм
1.1. гУЛЇЖДВьЦНЬЈЕФЖЈЮЛ
їШзх UIPЃЈгУЛЇЖДВьЦНЬЈЃЉЃЌЭЈЙ§ЖдШ§ЗНЪмжкЪ§ОнЕФЛуОлЁЂЧхЯДЁЂжЧФмдЫЫуЃЌЙЙНЈСЫХгДѓЕФОЋзМШЫШКЪ§ОнжааФЃЌЬсЙЉЗсИЛЕФгУЛЇЛЯёЪ§ОнвдМАЪЕЪБЕФГЁОАЪЖБ№СІЁЃ
ЖдФкЃКЮоЗьЖдНгИїРрвЕЮёЦНЬЈЕФЪ§ОнгІгУЃЌШчЙуИцЦНЬЈЁЂPUSHЭЦЫЭЁЂИіадЛЏЭЦМіжЎМфНЈСЂСЫЪ§ОнЭЈЕРЃЌжЇГжЙЋЫОМЖЕФОЋзМгЊЯњЃЌЯћЯЂМАЪБЫЭДяЗўЮёЕШГЁОАЁЃгЊЯњаЇЙћЦРЙРЃЌЗДРЁЪ§ОнПЩНјвЛВНМгЙЄЃЌгУгкЬсЩ§ЛЯёБъЧЉжЪСПЁЃ
ЖдЭтЃКЭъЩЦЖдЪ§ОнЕФЙмРэМАЪфГіСїГЬЃЌвдПЊЗХНгПкаЮЪНЮЊШЋаавЕДгвЕепЬсЙЉБъзМЕФОЋзМШЫШКБъЧЉЃЌАяжњгХЛЏЭЖЗХКЭЬсЩ§гЊЯњаЇЙћЁЃДяЕНЖдЪмжкЕФОЋзМЭЖЗХЃЌЪЭЗХЪ§Онеце§МлжЕ!
1.2. гУЛЇЖДВьЦНЬЈЕФКЫаФашЧѓ
гУЛЇЖДВьЦНЬЈЕФКЫаФашЧѓАќРЈМИИіВПЗжЃК
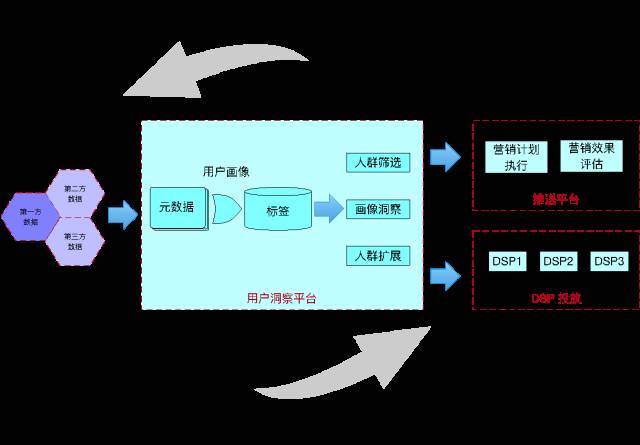
БъЧЉЩњГЩ
гУЛЇЖДВьЕФКЫаФЪЧгУЛЇЛЯёЃЌБиаыгаЭъЩЦЕФЛњжЦКЭСїГЬРДЩњГЩгУЛЇБъЧЉЁЃ
ШЫШКЖДВь
жИЖЈБъЧЉЬѕМўбЁЯюбЁГігУЛЇШКЬхЃЌжИЖЈвЊЗжЮіЕФБъЧЉЃЌЭЈЙ§ОлКЯдЫЫуЃЌЗжЮігУЛЇИУгУЛЇШКЕФЬиеїЁЃ
ЪмжкЗжЗЂ
ВЩШЁвЛЖЈЕФММЪѕЪжЖЮЃЌАбжИЖЈШЫШКЭЦжСЯТгЮЕФгЊЯњЧўЕРЃЈЙуИцЦНЬЈЁЂЭЦЫЭЦНЬЈЁЂOTAЕШЃЉ
БъЧЉВщбЏ
ЖдЯТгЮЯЕЭГЬсЙЉВщбЏНгПкЃЌЕїгУЗНжИЖЈгУЛЇБъЪЖЃЈimeiЃЉВщбЏИУгУЛЇЕФЛЯёБъЧЉЁЃР§ШчЕБгУЛЇдкЗУЮЪФГИівГУцЕФЪБКђЃЌЙуИцЦНЬЈЛсВщбЏгУЛЇЕФЛЯёаХЯЂвдШЗЖЈЙуИцЮЛгІИУеЙЪОЪВУДФкШнЁЃ
1.3. Ъ§ОнСїЪгЭМ
ДгЪ§ОнСїЕФНЧЖШПДЃЌгУЛЇЖДВьЯЕЭГПЩЛЎЗжЮЊМИИіНзЖЮЃКБъЧЉЩњГЩЁЂБъЧЉДцДЂЁЂЦНЬЈЙІФмЁЂЖдЭтЗўЮёЃЌШчЯТЭМЃК
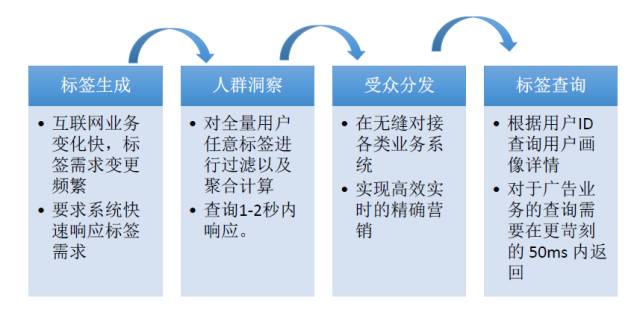
БъЧЉЩњГЩ
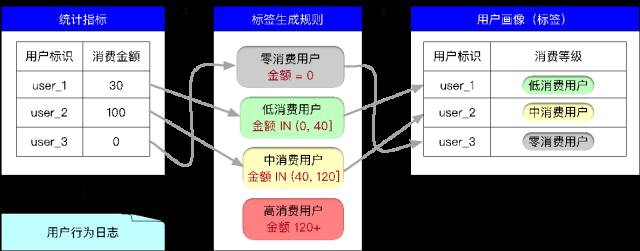
ДгЪБаЇадНЧЖШЃЌБъЧЉЗжЮЊСНРрЃКРыЯпМЦЫугыЪЕЪБМЦЫуЁЃ
РыЯпБъЧЉ
етаЉБъЧЉЮЊгУЛЇЕФОВЬЌЪєадЃЌБШШчгУЛЇадБ№ЁЂФъСфЁЂжАвЕЁЂЕиРэЮЛжУЕШЃЌ етаЉБъЧЉЭЈЙ§РыЯпМЦЫуЩњГЩЃЌУПЬьМЦЫувЛДЮМДПЩЁЃБъЧЉЩњГЩЕФЯрЙиМЦЫуШЮЮёЪЧгЩДѓЪ§ОнЦНЬЈЬсЙЉМЦЫуФмСІЃЌШЮЮёЕїЖШЯЕЭГ(МЏГЩПЊЗЂЦНЬЈ)ЖдЯрЙизївЕНјааЕїЖШКЭЙмРэЁЃ
ЪЕЪББъЧЉ
етаЉБъЧЉЮЊгУЛЇЕФЖЏЬЌЪєадЃЌШчЕиРэЮЛжУЃЌЫбЫїааЮЊЕШЃЌашвЊЭЈЙ§СїЦНЬЈНјааЪЕЪБМЦЫуЩњГЩЃЈИќаТЃЉЃЌР§ШчЛЇЯждкЫбЫїСЫвЛИіШШУХЙиМќДЪЛђвЛПюВњЦЗЃЌЮвУЧОЭЛсИљОнетаЉааЮЊНјааОЋзМЭЦМіЃЌдкжЎКѓЕФвЛЖЮЪБМфФкЫћЛсПДЕНЯргІВњЦЗЕФЙуИцЁЃ
ДгМЦЫуЩњГЩЗНЪНЃЌБъЧЉвВПЩЗжЮЊСНРрЃКЭГМЦРрБъЧЉКЭЫуЗЈРрБъЧЉЁЃ
ЭГМЦРрБъЧЉ
ИљОнгУЛЇааЮЊжБНгНјааОлКЯдЫЫуЩњГЩЕФБъЧЉЃЌжагУЛЇЕФЯћЗбЕШМЖЃЌЩшБИЪєадЕШЁЃ
ЫуЗЈРрБъЧЉ
ЪЙгУЛњЦїбЇЯАЫуЗЈНјааЪєаддЄВтЩњГЩЕФБъЧЉЃЌШчгУЛЇЕФадБ№ЃЌжАвЕЃЌаЫШЄАЎКУЕШЁЃ
БъЧЉДцДЂ
МЦЫуЩњГЩЕФБъЧЉЛсЭЌЪБДцДЂдкElasticSearchЁЂHBaseКЭRedisРяЁЃЦфжа ElasticSearch
жївЊгУгкЪЕЯжЦНЬЈЙІФмЃЌШчШЫШКЩИбЁЁЂЛЯёЖДВьЕШЁЃЖј Hbase гы Redis гУгкЪЕЯжЛЯёВщбЏЁЃ
ЦНЬЈЙІФм
дкгУЛЇЛЯёЕФЛљДЁЩЯЙЙНЈЗсИЛЕФШЫШКЩИбЁЁЂЖДВьЗжЮігыЪмжкЗжЗЂЙІФмЁЃ
ЖдЭтЗўЮё
ЭЈЙ§ПЊЗХЦНЬЈЃЈOpenAPIЃЉЖдЯТгЮЯЕЭГЃЈШч push ЦНЬЈЃЌ OTA ЦНЬЈЃЌ ЙуИцЦНЬЈЕШЃЉЬсЙЉЗўЮёЁЃ
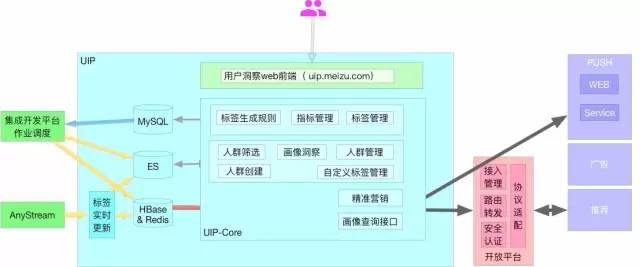
1.4. змЬхМмЙЙ
гУЛЇЖДВьЦНЬЈЕФзмЬхМмЙЙЭМШчЯТ ЃК
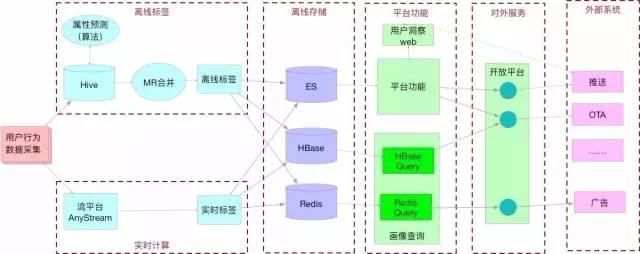
МЏГЩПЊЗЂЦНЬЈзївЕЕїЖШЃЌХфжУКЭдЫааРыЯпМЦЫуШЮЮёЃЈHive&MR)
СїЦНЬЈ(AnyStream)ИКд№ЪЕЪББъЧЉМЦЫу
ЙмРэФЃПщЩњГЩЕФЯрЙиЙцдђЃЌДцДЂдкMySQLЃЌЙЉБъЧЉЩњГЩШЮЮё(Hive/MR/СїЦНЬЈЃЉЪЙгУ
гУЛЇЛЯёЃЈБъЧЉЃЉПэБэБЃДцдкESЩЯ
HbaseКЭRedisЬсЙЉkvВщбЏ
ЪЙгУПЊЗЂЦНЬЈЃЈOpenAPIЃЉЬсЙЉЖдЭтНгПк
ЖўЁЂБъЧЉЩњГЩЙ§ГЬ
2.1 ЭГМЦРрБъЧЉ
ЙЫУћЫМвхЃЌЭГМЦРрБъЧЉПЩгЩгУЛЇааЮЊЭЈЙ§жБНгЕФЭГМЦМЦЫуЖјЩњГЩЁЃР§ШчЮвУЧашвЊМЦЫуУћЮЊЁАЯћЗбЕШМЖЁБЕФБъЧЉЃЈЗжЮЊЕЭЁЂжаЁЂИпШ§ИіЕШМЖЃЉ
етИіБъЧЉЕФЩњГЩЙ§ГЬЗжЮЊ 3 ВНЃК
жИБъЭГМЦЃЌЭЈЙ§ Hive МЦЫуЩњГЩЃЛ
БъЧЉЩњГЩЙцдђЃЌЭЈЙ§жИБъЙмРэ/БъЧЉЙмРэФЃПщЮЌЛЄЃЛ
ЛљгкЭГМЦжИБъ + БъЧЉЩњГЩЙцдђЃЌгУ MR ЩњГЩЃЛ
змНсЃКЭГМЦжИБъгыЛЯёЩњГЩЗжРыЁЃ
АбжИБъКЭЙцдђЗжПЊЕФФПЕФЪЧЛёШЁИќИпЕФСщЛюадЃЌБШШчвЕЮёЗЂеЙжЎКѓЃЌашвЊАбБъЧЉЕФШ§ИіЕШМЖБфГЩ Lv1, Lv2,
Ё, Lv10ЕШ 10 ИіЕШМЖЃЌЮвУЧжЛашвЊИќИФЙцдђЖјВЛашвЊаоИФжИБъЭГМЦТпМЃЌЪЕЯжБъЧЉЩњГЩЙцдђЕФХфжУЛЏЁЃ
2.2 ЫуЗЈРрБъЧЉ
вЛаЉБъЧЉЃЌБШШчШЫПкЪєадЃЌЪЧУЛгаАьЗЈжБНгЭГМЦГіРДЕФЃЌЮвУЧашвЊНшжњЛњЦїбЇЯАЫуЗЈРДНјаадЄВтЁЃ
ФЃаЭбЕСЗ
бЁШЁИпжУаХЖШзЪСЯЃЈР§ШчгУЛЇзЂВсаХЯЂЃЉ+гУЛЇааЮЊЪ§ОнзїЪфШыНјааФЃаЭбЕСЗЁЃР§ШчадБ№БъЧЉЃЌЮвУЧЪЙгУгУЛЇааЮЊНјааФЃаЭбЕСЗЃЌПЩгУЛЇзЂВс
Flyme еЪКХЫљЬюаДЕФадБ№аХЯЂзїЮЊИпжУаХЖШЕФзЪСЯНјааМрЖНбЕСЗЁЃ
ЪєаддЄВт
ИљОнгУЛЇЕФааЮЊЪ§ОнЃЌЪЙгУбЕСЗКУЕФФЃаЭНјаадЄВтЃЌЪфГіЯргІЕФБъЧЉЁЃ
2.3. ЕЅжЕБъЧЉгыЖржЕБъЧЉ
ЕЅжЕБъЧЉ
ЕЅжЕБъЧЉЪЧжИгУЛЇдкИУБъЧЉЯТжЛФмШЁвЛИіжЕЃЌВЛФмЖрбЁЁЃР§ШчадБ№вЊУДЪЧФаЃЌвЊУДЪЧХЎЃЌвЊУДЪЧЮДжЊЁЃ
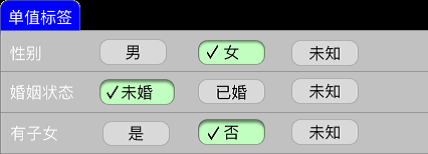
ЖржЕБъЧЉ
ЖржЕБъЧЉЪЧжИгУЛЇПЩвдШЁИУБъЧЉЯТЕФЖрИіШЁжЕзщКЯЁЃБШШчгУЛЇПЩвдгаЖрИіаЫШЄАЎКУ

ЖржЕБъЧЉЕФДцдкЃЌЛсгАЯьДцДЂВщбЏв§ЧцЕФбЁаЭКЭДцДЂНсЙЙЩшМЦЁЃ
2.4 БъЧЉЩњГЩЙ§ГЬзмЪі
РыЯпБъЧЉМЦЫуЙ§ГЬЃК
ЖрИіЭГМЦгыЫуЗЈЭъГЩКѓЃЌЪЙгУвЛИі MR зївЕЖдЩњГЩЕФжИБъМЏгыЫуЗЈБъЧЉМЏНјааКЯВЂЁЃ
ЫљгаЕФЭГМЦжИБъгыЫуЗЈБъЧЉКЯВЂЕНвЛеХзмБэжЎКѓЃЌгЩвЛИіЭЈгУЕФ MR ИљОнХфжУКУЕФЙцдђЩњГЩБъЧЉПэБэЁЃ
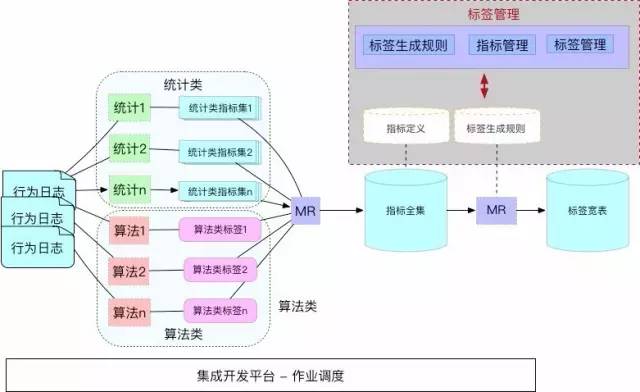
КУДІ
ХфжУЛЏЙмРэЃЌЬсЙЉ Web UI ЙмРэБъЧЉЕФЩњУќжмЦк
ЛљгкХфжУЩњГЩБъЧЉЃЌБъЧЉПэБэЪ§ОнгыдЊЪ§Он100%вЛжТ
ДцдкЕФВЛзуЃК
ФПЧАХфжУЛЏЙмРэжЛКИЧЕНзюжеЕФБъЧЉПэБэЩњГЩЁЃгыЩЯгЮЕФжИБъЭГМЦКЭЫуЗЈдЄгаЭбНкЁЃ
ЩЯгЮМЦЫуЙ§ГЬЪЧЕЅЖРПЊЗЂЃЌжИБъЖЈвхжЛЪЧСэЭтХфжУЕФЪ§ОнУшЪіЃЈПЩФмДцдкВЛвЛжТЃЉ
вЛаЉБъЧЉЯТЯпЃЈЗЯГ§ЃЉКѓЃЌЯргІЕФЩЯгЮШЮЮёЕФвРРЕашвЊСэЭтЗЯГ§ЃЌЗёдђЛсвХСєЮогУЕФзївЕРЫЗбМЦЫузЪдДЁЃ
ИФНјЗНЯђ
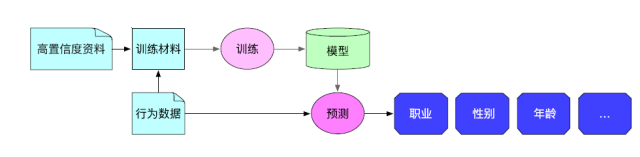
РЉДѓБъЧЉЙмРэЕФЙІФмЗЖЮЇЃЌгыЕїЖШЦНЬЈДђЭЈЃЌАбжИБъЩњГЩгыЫуЗЈдЄВтЕШШЮЮёЙмРэЦ№РДЁЃ
жИБъМЦЫувВХфжУЛЏЃЌдіМгБъЧЉЮоашЪжаД Hive Лђ MR ГЬађЃЌШЋВПдкХфжУЦНЬЈЩЯЭъГЩЁЃ
здЖЏЙмРэзївЕвРРЕЃЌвЛаЉБъЧЉЯТЯпКѓЃЌздЖЏЪЖБ№ВЂЩОГ§ЮогУвРРЕЃЌгХЛЏБъЧЉЩњГЩЙ§ГЬЁЃ
2.5. ЪЕЪББъЧЉ
ЪЕЪБМЦЫувРРЕгкСїЦНЬЈЃЌСїЦНЬЈИљОнгУЛЇааЮЊзіЪЕЪББъЧЉЕФМЦЫуВЂДцДЂЕН ElasticSearchЁЂHBase
гы RedisЁЃ
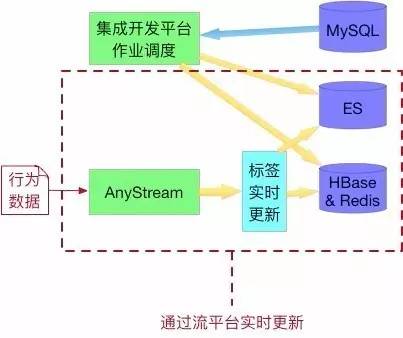
ЪЕЪББъЧЉОйР§ЃК
БШШчЪЕЪБЮЛжУБъЧЉПЩвдИљОнгУЛЇЕФЕиРэЮЛжУЪЖБ№гУЛЇЕФЫљДІГЁОАЃЌЛЙПЩвдВњЩњЦфЫћЕФвЛаЉБШШчЫбЫїЁЂжЇИЖЕФЪЕЪББъЧЉЁЃ
Ш§ЁЂБъЧЉДцДЂ
3.1. БъЧЉДцДЂзмРР
БъЧЉЕФДцДЂжївЊгаСНПщЃКESКЭHBase&RedisЁЃ
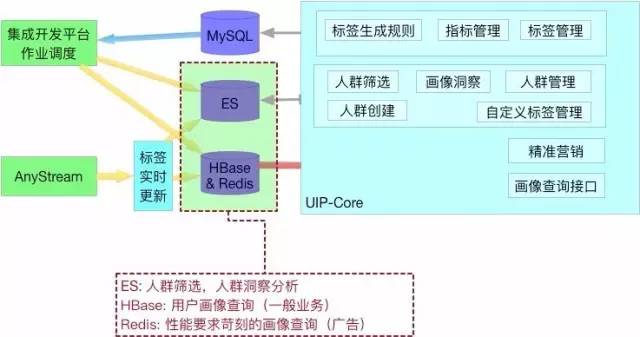
ElasticSearchЃЈESЃЉЪЧвЛИіЛљгкLuceneЙЙНЈЕФПЊдДЁЂЗжВМЪНЁЂRESTfulЫбЫїв§ЧцЁЃФмЙЛДяЕНЪЕЪБЫбЫїЃЌЮШЖЈЁЂПЩППЁЂПьЫйЁЃ
Лљгк ES ЪЕЯжЖдШЋСПгУЛЇШЮвтБъЧЉНјаадкЯпЩИбЁКЭОлКЯЗжЮіЃЌУыМАЯьгІЁЃ
Hbase ЬсЙЉДѓЭЬЭТСПЕФkey/value ВщбЏЁЃ
адФмвЊЧѓИќЮЊПСПЬЕФkey/value ВщбЏЃЈЙуИцЦНЬЈЃЉЭЈЙ§ЪЙгУ Redid РДЪЕЯжЁЃ
3.2. ElasticSearch (ES)
РњЪЗЃКVertica
зюГѕЯЕЭГНЈЩшЪБЪЧЪЙгУ vertica зїЮЊБъЧЉПэБэДцДЂЁЃЫцзХЪ§ОнСПдіГЄКЭЕїгУДЮЪ§ЕФБЉдіЃЌ vertica
ж№НЅГЩЮЊЦПОБЁЃ
ЩчЧјАцга 3 ИіНкЕуКЭ 1T ДцДЂШнСПЯожЦ
ЫцзХЪ§ОнЙцФЃКЭЕїгУЪ§БЉдіЃЌадФмГіЯжЦПОБ
ЖдгкЖржЕБъЧЉЃЌжЛФмВЩгУcsvЗНЪНБЃДцдкvarcharзжЖЮЃЌадФмЕЭЯТ
ЖржЕБъЧЉМьЫїЪЙгУзжЗћДЎ LIKE ВйзїЃЛОлКЯЫфФмЭЈЙ§вЛаЉ trick РДжЇГжЃЌЕЋадФмЬЋВюЁЃ
ЯжзДЃКElasticSearch
ФмЙЛДяЕНЪЕЪБЫбЫїЃЌЮШЖЈЃЌПЩППЃЌПьЫйЁЃ
дкЯпИќаТЃЈЪЕЪБ/зМЪЕЪБИќаТЃЉ
жЇГжИпВЂЗЂВщбЏЃЌЫЎЦНРЉеЙФмСІЧП
КмКУЕижЇГжЖржЕБъЧЉДцДЂКЭЗжЮіГЁОАЃЈarrayЃЉ
3.3. HBase гы Redis
ПМТЧГЩБОвђЫиЃЌжївЊЪЙгУ Hbase РДЬсЙЉ KV ВщбЏ
HBase ЬсЙЉЕЭГЩБОЃЌИпЭЬЭТСПЕФ kv ВщбЏ
ТњзуДѓВПЗжвЕЮёЕФВщбЏашЧѓ
ВПЗжвЊЧѓПСПЬЕФвЕЮёЃЌЪЙгУ Redis зїЮЊВЙГф
ЙуИцвЕЮёЬсГі 50ms ФкЕФВщбЏбгГйЃЌетжжПСПЬвЊЧѓашгУ Redis ЪЕЯжЁЃ
RedisДцДЂФПЧАжЛЗўЮёгкЙуИцЦНЬЈЕФВщбЏЕїгУЁЃ
ЫФЁЂЦНЬЈЙІФмНщЩм
4.1. жївЊЙІФмСаБэ

ШЫШКЙмРэ
ПЩгЩСНжжЗНЪНДДНЈШЫШК
ЭЈЙ§БъЧЉЬѕМўШІЖЈШЫШКЃЈБШШчЕигђЁЂадБ№ЁЂЯћЗбВуДЮЕШБъЧЉЃЉДДНЈЃЛ
СэвЛжжЪЧЭЈЙ§ЕМШыгУЛЇСаБэРДДДНЈЃЌЮвУЧПЩвдЭЈЙ§ЕМШы umid, imeiЃЌ flyme uidЃЌmsisdnЕШЖржжIDДДНЈШЫШКЁЃ
ЛЯёЖДВь
ЪЧЖдШЫШКЬиеїЕФЗжЮіЃЌЪзЯШЭЈЙ§жИЖЈБъЧЉЬѕМўбЁЯюШІЖЈгУЛЇШКЬхЃЌШЛКѓЪЧжИЖЈЯывЊЗжЮіЕФжИБъЃЌЭЈЙ§ОлКЯдЫЫуЗжЮігУЛЇШКЕФЬиеїЁЃ
ЪмжкЗжЗЂ
ЖдНгЯТгЮЕФгЊЯњЯЕЭГЃЌВЩШЁвЛЖЈЕФММЪѕЪжЖЮЃЌАбжИЖЈШЫШКЭЦжСЯТгЮЕФгЊЯњЧўЕРЃЈЙуИцЦНЬЈЁЂЭЦЫЭЦНЬЈЁЂOTAЕШЃЉЃЌНЋБъЧЉЯЕЭГКЭЯТгЮЮоЗьСЌНгаЮГЩгЊЯњБеЛЗЁЃ
ЛЯёВщбЏ
ЪЧЖдЯТгЮЯЕЭГЬсЙЉВщбЏНгПкЃЌЕїгУЗНжИЖЈгУЛЇБъЪЖЃЈimeiЃЉВщбЏИУгУЛЇЕФЛЯёБъЧЉЁЃ
4.2. ЛЯёЖДВьЙІФм
ЙІФмЫЕУїЃК
Step 1. жИЖЈБъЧЉЬѕМўбЁЯюбЁГігУЛЇШКЬх
Step 2. жИЖЈвЊЗжЮіЕФБъЧЉЃЌЭЈЙ§ОлКЯдЫЫуЃЌЗжЮігУЛЇЬиеїЁЃ
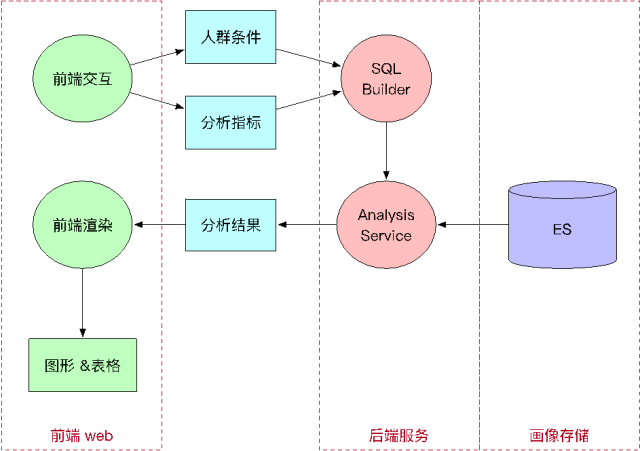
ДгКѓЖЫЗўЮёЕУЕНЗжЮіНсЙћКѓЃЌЧАЖЫвдЭМБэЕФЗНЪНеЙЯжНсЙћЃЌжБЙлЕиеЙЪОЫљбЁЕФШЫШКЬиеїЁЃ
Р§згЃКШЫШКЬѕМўгыжИБъ 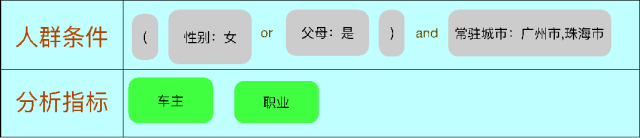
ЗжЮіНсЙћЪОвтШчЯТ
4.3. ЪмжкЗжЗЂЙІФм
ЁАЪмжкЗжЗЂЁБЪЧгУЛЇЖДВьЦНЬЈЪЕЯжгыЯТгЮЕФгЊЯњЁЂЭЦЫЭЁЂЙуИцЦНЬЈЮоЗьСЌНгЃЌЪЧДђЭЈгЊЯњБеЛЗЕФЙиМќЙІФмЁЃЯТУцЪЙгУвЛИіМђЕЅЕФР§згРДЫЕУїЪмжкЗжЗЂЕФСїГЬЃК
бЁдёгУЛЇШК

вдЩЯСаБэЪЧЭЈЙ§ШЫШКЙмРэЯрЙиЙІФмДДНЈЕФШЫШКСаБэбЁдёЦфжавЛИіШЫШКНјааЁАЪмжкЗжЗЂЁБЁЃ
бЁдёЯТгЮЕФгЊЯњЦНЬЈ
бЁдёЭъШЫШКжЎКѓЃЌбЁдёгЊЯњЧўЕРЃЌетРяЮвУЧбЁдё push ЦНЬЈЁЃ
БрМИпМЖбЁЯю
бЁдёСЫЧўЕРжЎКѓЃЌЛсЯдЪОЖдгІЕФЁАИпМЖбЁЯюЁБЃЌИпМЖбЁЯюЕФФкШнЪЧЖЏЬЌЕФЃЌРяУцЕФбЁЯюСаБэШЁОігкЕБЧАгУЛЇдкФПБъЧўЕРЩЯЕФШЈЯоЁЃ

ИпМЖбЁЯювђЫљбЁЧўЕРЖјвьЃЌгЩЗўЮёЦїЖЫЖЏЬЌЩњГЩЃЌЧАЖЫЖЏЬЌфжШОЁЃ
Р§ШчЖдгкЫљбЁЕФ push ЦНЬЈЃЌашвЊбЁдёЭЦЫЭЕФФПБъгІгУЃЈШчїШзхзЪбЖЁЂїШзхЩчЧјЃЉЃЌЭЦЫЭРраЭЃЈЭЈжЊРИЭЦЫЭЁЂЭИДЋЭЦЫЭЃЉЕШЁЃ
ИљОнЕБЧАгУЛЇдкФПБъЦНЬЈгЕгаЕФШЈЯоРДШЗЖЈбЁЯюСаБэЁЃ
вГУцЬјзЊ
дкЩЯвЛВНбЁдёЭъИпМЖбЁЯюКѓЃЌЕуЛїЁАШЗЖЈЁБАДХЅЃЌМДПЩЬјзЊЕНФПБъЦНЬЈЯргІЕФвГУцЁЃЬјзЊ URL ЭЈЙ§КѓЖЫAPIНЛЛЅЃЌгЩФПБъЦНЬЈЖЏЬЌЩњГЩЃЌНЕЕЭЦНЬЈМфЕФёюКЯЃЌЭЌЪБРћгкЪЕЯжЁАЮоЗьЁБЖдНгЁЃ
дкБОР§жаЃЌЬјзЊЕН push ЦНЬЈЖдгІЕФДДНЈЭЦЫЭШЮЮёЕФвГУцКѓЃЌФПБъЪмжкЃЈШЫШКЃЉЁЂЭЦЫЭЕФФПБъгІгУЃЌЭЦЫЭРраЭЖМвбдкЧАУцЕФВНжшбЁКУЃЌжЛашвЊЬюЩйСПЕФЦфЫќаХЯЂЃЈШчЮяСЯ/ЮФАИЃЉМДПЩЁЃ
ЮхЁЂзмНс
гУЛЇЛЯёзїЮЊДѓЪ§ОнЕФИљЛљЃЌЮЊНјвЛВНОЋзМЁЂПьЫйЕФЗжЮігУЛЇааЮЊЁЂЯћЗбЕШживЊаХЯЂЃЌЬсЙЉзуЙЛЕФЪ§ОнЛљДЁЃЌШУЮвУЧїШзхИќКУЕФЮЊгУЛЇЬсЙЉИпМлжЕЕФЗўЮёЁЃ
МАЪБЗЂЯжгыЭкОђгУЛЇЧБдкЕФашЧѓЃЌИљОнгУЛЇЕФЯВКУЭЦМіКЯЪЪЕФЗўЮёКЭФкШнЃЌЬсЩ§гУЛЇЬхбщЃЛ
жЇГХОЋзМЕФЙуИцЭЖЗХЃЌЬсИпСїСПБфЯжЕФФмСІЁЃ |









