|
гУЛЇЛЯёзїЮЊЁАДѓЪ§ОнЁБЕФКЫаФзщГЩВПЗжЃЌдкжкЖрЛЅСЊЭјЙЋЫОжавЛжБгаЦфЖРЬиЕФЕиЮЛЁЃ
зїЮЊЙњФкТУгЮOTAЕФСьЭЗбђЃЌаЏГЬвВгазХЭъЩЦЕФгУЛЇЛЯёЦНЬЈЬхЯЕЁЃФПЧАгУЛЇЛЯёЙуЗКгУгкИіадЛЏЭЦМіЃЌВТФуЯВЛЖЕШ;еыЖдТУгЮЪаГЁЃЌаЏГЬИќНЋЦфгІгУгкЁАЗПаЭХХађЁБЁАЛњЦБХХађЁБЁАПЭЗўЭЖЫпЁБЕШжюЖрЬиЩЋСьгђЁЃБОЮФНЋДгФПЕФЃЌМмЙЙЁЂзщГЩЕШМИЗНУцЃЌДјФуСЫНтаЏГЬдкИУСьгђЕФЪЕМљЁЃ
1.аЏГЬЮЊЪВУДзігУЛЇЛЯё
ЪзЯШЃЌЯШЗжЯэвЛЯТаЏГЬгУЛЇЛЯёЕФГѕждЁЃвЛАуРДЫЕЃЌЭЦМіЫуЗЈЛљгкСНИідРэЁАИљОнШЫЕФЯВКУЭЦМіЖдгІЕФВњЦЗЁБЁАЭЦМіКЭФПБъПЭШЫЬиеїЯрЫЦПЭШЫЯВКУЕФВњЦЗЁБЁЃЖјетСНЬѕЖМРыВЛПЊгУЛЇЛЯёЁЃ
ИљОнгУЛЇаХЯЂЁЂЖЉЕЅЁЂааЮЊЕШЕШЭЦВтГіЦфЯВКУЃЌдйеыЖдадЕФИјГіВњЦЗПЩвдМЋДѓЬсЩ§гУЛЇИаЪмЃЌФмБмУтгУЛЇБЛЮоЙЪДђШХЕФВЛЪЪИаЁЃЭЌЪБеыЖдВЛЭЌЛЯёЕФгУЛЇЬсЙЉИіадЛЏЕФЗўЮёвВЪЧаЏГЬгУЛЇЛЯёЕФГіЗЂЕужЎвЛЁЃ
2.аЏГЬгУЛЇЛЯёЕФМмЙЙ
2.1.аЏГЬгУЛЇЛЯёЕФВњЦЗМмЙЙ
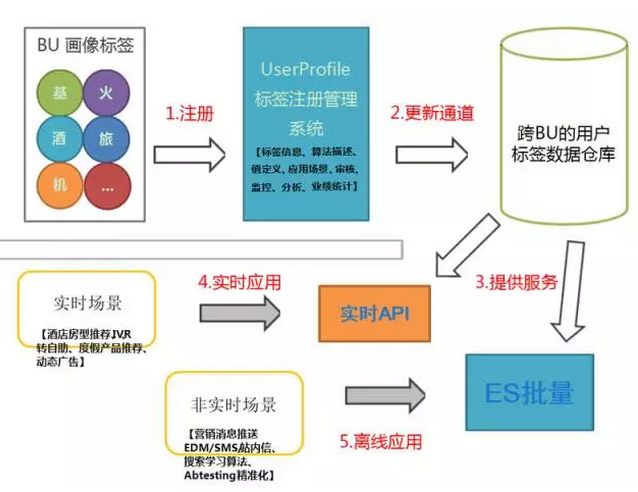
ШчЩЯЭМЫљЪОЃЌаЏГЬгУЛЇЛЯёЕФВњЦЗМмЙЙДѓЬхПЩвдзмНсЮЊ:
зЂВс
ВЩМЏ
МЦЫу
ДцДЂ/ВщбЏ
МрПи
ЫљгаЕФгУЛЇЛЯёЖМЛсдкЁБUserProfileЦНЬЈЁБжаНјаазЂВсЃЌгЩзЈШЫЩѓКЫЃЌЩѓКЫЭЈЙ§ЕФЛЯёВХПЩвддкЁАЪ§ОнВжПтЁБжаСїзЊ;жЎКѓЛсЭЈЙ§гУЛЇаХЯЂЁЂЖЉЕЅЁЂааЮЊЕШЕШНјаааХЯЂВЩМЏЃЌВЩМЏЕФФПБъЪЧУїШЗЕФЁЂКЃСПЕФЁЂЮоађЕФЁЃ
аХЯЂЪеМЏЕФЯТвЛВНЪЧЛЯёЕФМЦЫуЃЌаЏГЬгазЈШЫжЦЖЈМЦЫуЙЋЪНЁЂЫуЗЈЁЂФЃаЭЃЌЖјМЦЫуЗжЮЊХњСП(ЗЧЪЕЪБ)КЭСїЪН(ЪЕЪБ)СНжжЃЌОЙ§бЯУмЕФМЦЫуЃЌЛЯёНјШыЁАЛЯёВжПтЁБжа;ЖјИљОнВЛЭЌЕФЪЙгУГЁОАЃЌЮвУЧгжЛсЬсЙЉЪЕЪБКЭХњСПСНжжВщбЏAPIЙЉИїЕїгУЗНЪЙгУЃЌЪЕЪБЕФЗўЮёВржиИпПЩгУЃЌХњСПЗўЮёВржиИпЭЬЭТ;зюКѓЫљгаЕФЛЯёЖМдкМрПиЦНЬЈжаЕУЕНгааЇЕФМрПиКЭЦРЙРЃЌБЃжЄЛЯёЕФзМШЗадЁЃ
2.2.аЏГЬгУЛЇЛЯёЕФММЪѕМмЙЙ
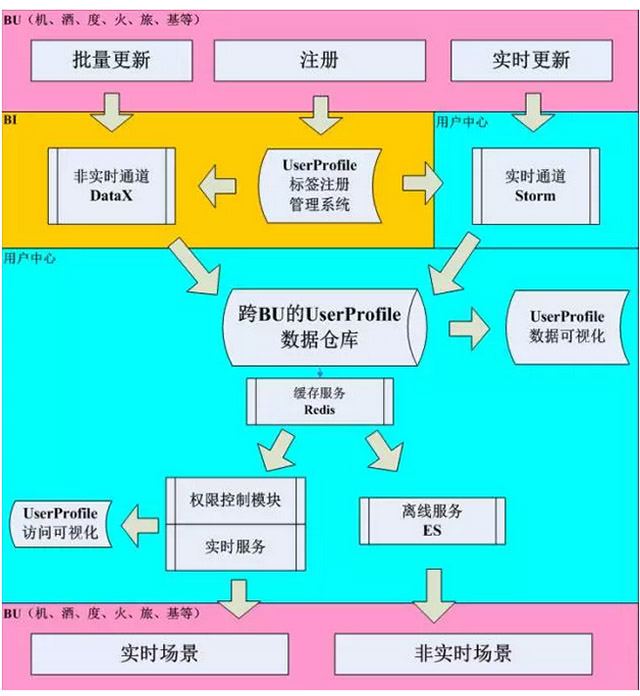
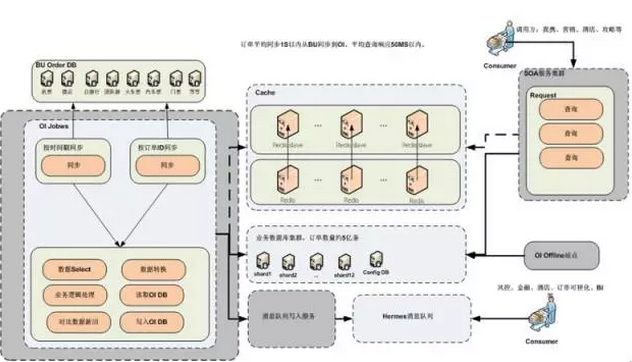
аЏГЬЗЂеЙЕННёЬьЙцФЃЃЌИќЧПЕїЫЩёюКЯЁЂИпФкОлЃЌЪЕааBUЛЏЕФЙмРэФЃЪНЁЃЖјгУЛЇЛЯёЪЧвЛжжПчBUЕФФЃаЭЃЌЙЪДгММЪѕМмЙЙВуУцЃЌаЏГЬгУЛЇЛЯёЬхЯЕШчЩЯЭМЫљЪОЁЃ
ИїBUЖМПЩвдЙБЯзгаМлжЕЕФЛЯёЃЌЖјЛљДЁВПУХвВЛсИљОнBUЕФашвЊВЛЖЯжЦзїаТЕФЛЯёЁЃЛЯёОЙ§ПЊдДЧвОЮвУЧЖўДЮПЊЗЂЕФDataXКЭStormНјШыаЏГЬПчBUЕФUserProfileЪ§ОнВжПтЁЃдкВжПтжЎЩЯЃЌЮвУЧЛсгаRedisЛКДцВувдБЃжЄЪ§ОнЕФИпПЩгУЃЌЭЌЪБгаЪЕЪБКЭНшжњelasticsearchСНжжЗНЪНЕФAPIЃЌЙЉЕїгУЗНЪЙгУЁЃ
ИУМмЙЙгаШчЯТЙиМќЕуЃК
1.гавьВНКЭЪЕЪБСНжжЭЈЕРТњзуВЛЭЌГЁОАЁЂВЛЭЌЛЯёЕФашвЊЃЌЪТЪЕРрЛЯёвЛАуВЩгУЪЕЪБМЦЫуЗНЪНЃЌЖјИДКЯРрЛЯёвЛАуВЩгУвьВНЗНЪНЁЃ
2.аЏГЬЧПЕїзЈШЫзЈгУЃЌУПИіШЫзіздМКзюЪЪКЯЕФЪТЁЃЙЪећИіUserProfileЪЧЖрИіЭХЖгКЯзїЭъГЩЕФЃЌЦфжаАќРЈЕЋВЛЯогкИїBUЕФПЊЗЂЁЂBIЃЌЛљДЁЕФПЊЗЂЁЂBIЕШЁЃ
3.ЫљгаAPIЖМЪЧПЩНЕМЖЁЂПЩШлЖЯЕФЃЌПЩвдИљОнашвЊЧаЪ§ОнСїСПЁЃ
4.гЩгкгУЛЇЛЯёМЋЮЊУєИаЃЌГігкЪ§ОнАВШЋЕФПМТЧЃЌЮвУЧВщбЏЗўЮёгабЯИёЕФШЈЯоПижЦЗНАИЃЌЫљгааХЯЂБиаыОЙ§ЪкШЈВХПЩвдЗУЮЪЁЃ
5.ГігкЖдгУЛЇЛЯёзМШЗадИКд№ЕФФПЕФЃЌЮвУЧгазЈУХЕФUserProfileЪ§ОнПЩЪгЛЏЦНЬЈМрПиЪ§ОнЕФвЛжТадЁЂПЩгУадЁЂе§ШЗадЁЃ
ЩЯЪіЪЧгУЛЇЛЯёЕФзмЬхУшЪіЃЌЯТУцЮвНЋЯъЯИЗжЯэИїИіЯИНкЁЃ
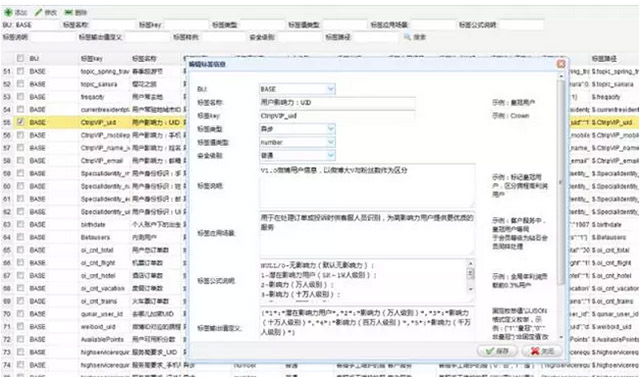
ШчЩЯЭМЫљЪОЃЌгУЛЇЛЯёЕФзЂВсдквЛИіЕфаЭЕФMisЯЕЭГжаЭъГЩЃЌUserProfileЪ§ОнЕФЬсЙЉЗНдкетРяЩъЧыЃЌгЩзЈШЫЩѓКЫЁЃЩъЧыЪБЃЌБиаыЬюаДЛЯёЕФКЌвхЁЂМЦЫуЗНЪНЁЂПЩФмЕФжЕЕШЁЃ
3.аЏГЬгУЛЇЛЯёЕФзщГЩ
3.1.аХЯЂВЩМЏ
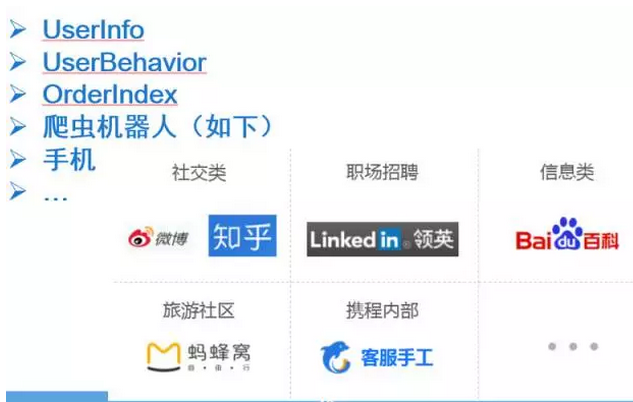
ЛљДЁаХЯЂЕФВЩМЏЪЧЪ§ОнСїзЊЕФПЊЪМЃЌЮвУЧЛсЪеМЏUserInfo(БШШчгУЛЇИіШЫаХЯЂЁЂгУЛЇГіааШЫаХЯЂЁЂгУЛЇЛ§ЗжаХЯЂ)ЁЂUBT(гУЛЇдкAPPЁЂЭјеОЁЂКЯзїеОЕуЕФааЮЊаХЯЂ)ЁЂгУЛЇЖЉЕЅаХЯЂЁЂХРГцаХЯЂЁЂЪжЛњAPPаХЯЂЕШЁЃЖјЩЯЪіУПИіЛљДЁаХЯЂЕФВЩМЏгжЪЧвЛИізЈУХСьгђЁЃБШШчЯТЭМеЙЪОСЫгУЛЇЖЉЕЅаХЯЂВЩМЏСїГЬЁЃ
3.2.ЛЯёМЦЫу
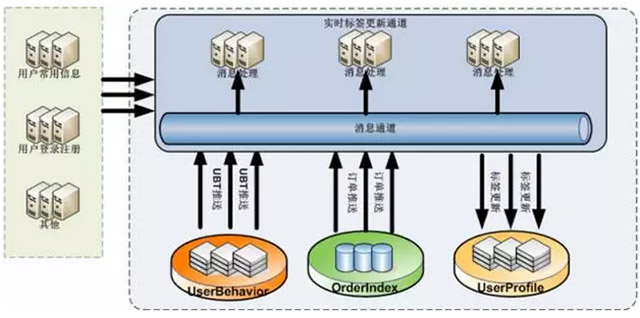
ЛљДЁаХЯЂЪЧКЃСПЕФЁЂЮоађЕФЃЌВЛОМгЙЄУЛгаЬЋДѓЕФМлжЕЁЃЙЪгУЛЇЛЯёЕФМЦЫуЪЧЪ§ОнСїзЊЕФЙиМќЫљдкЁЃЮвУЧЕФBIЭХЖгЛсжЦЖЈбЯУмЕФЙЋЪНКЭФЃаЭЃЌИљОнГЁОАЕФашвЊЃЌжЦЖЈЙцдђКЭВЮЪ§ЃЌЖдВЩМЏаХЯЂзівьВНМЦЫуЁЃетбљЕФМЦЫугЩгкКФЪБНЯГЄЃЌвЛАуЮвУЧЛсВЩгУT+NЕФЗНЪНвьВНИќаТЃЌИљОнЛЯёЕФВЛЭЌЃЌЪ§ОнаТЯЪЖШЕФвЊЧѓврВЛЭЌЁЃЖЏЬЌКЭзщКЯБъЧЉДѓЖрВЩгУвьВНЗНЪНМЦЫуИќаТЁЃHiveЁЂDataXЕШПЊдДЙЄОпБЛЪЙгУдкетИіВНжшжаЁЃ
ЖјгааЉЛЯёЪЧЪТЪЕЛђЖдаТЯЪЖШвЊЧѓБШНЯИпЕФЃЌЙЪЮвУЧЛсВЩгУKafka+StormЕФСїЪНЗНАИШЅЪЕЪБИќаТМЦЫуЁЃБШШчЯТЭМЃЌUBT(гУЛЇааЮЊЪ§Он)ЪЙгУЯћЯЂЭЈЕРHermesЖдНгKafka+StormЮЊUserProfileЕФЪЕЪБМЦЫуЬсЙЉСЫгаСІЕФжЇГжЁЃ
3.3.аХЯЂДцДЂ
гУЛЇЛЯёЕФЪ§ОнЪЧКЃСПЕФЃЌБЛГЦзїзюЕфаЭЕФЁБДѓЪ§ОнЁБЃЌЙЪShardingЗжВМЪНДцДЂЁЂЗжЦЌММЪѕЁЂЛКДцММЪѕБЛБиШЛЕФв§ШыНјРДЁЃ
аЏГЬЕФгУЛЇЛЯёВжПтвЛЙВга160ИіЪ§ОнЗжЦЌЃЌЗжВМдк4ИіЮяРэЪ§ОнМЏШКжаЃЌЭЌЪБВЩгУПчIDCШШБИЁЂвЛжїЖрБИЁЂSSDЕШжїСїШэгВМўММЪѕЃЌБЃжЄЪ§ОнЕФИпПЩгУЁЂИпАВШЋЁЃ
гЩгкгУЛЇЛЯёЕФЕФЪЙгУГЁОАЗЧГЃЖрЁЂЕїгУСПвВвьГЃХгДѓЃЌетОЭвЊЧѓгУЛЇЛЯёЕФВщбЏЗўЮёвЛЖЈвЊзіЕНИпПЩгУЁЃЙЪЮвУЧВЩгУздНЕМЖЁЂПЩШлЖЯЁЂПЩЧаСїСПЕШЗНАИЃЌдкВжПтЧАЖЫдіМгЛКДцЁЃШчЯТЭМЫљЪОЃЌЪ§ОнВжПтКЭЛКДцЕФДцДЂФПЕФВЛЭЌЃЌЙЪЪЧвьЙЙЕФЁЃ
3.4.ИпПЩгУВщбЏ
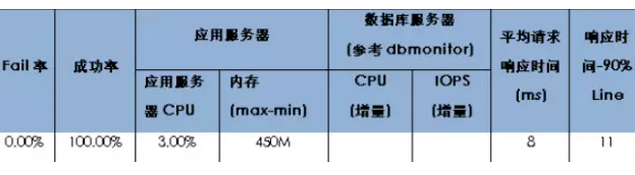
ЯьгІЪБМфКЭTPSЪЧКтСПЗўЮёПЩгУадЕФЙиМќжИБъЃЌаЏГЬвЊЧѓЫљгаAPIЯьгІЪБМфЕЭгк250ms(АќРЈЭјТчКЭПђМмТёЕуЯћКФ)ЃЌЖјЮвУЧгУЛЇЛЯёЪЕЪБЗўЮёВЩгУздНЕМЖЁЂПЩШлЖЯЁЂздЖЬТЗЕШММЪѕЃЌЗўЮёЦНОљЯьгІЪБМфПижЦдк8ms(АќРЈЭјТчКЭПђМмТёЕуЯћКФ)ЃЌ99%ЯьгІЪБМфПижЦдк11msЁЃ
ДѓВПЗжГЁОАЖМЪЧЭЈЙ§ЕЅИігУЛЇЛёШЁгУЛЇЛЯёЃЌЕЋВПЗжгЊЯњГЁОАдђашвЊТњзуЬиЖЈЛЯёЕФгУЛЇШКЬхЃЌБШШчЛёШЁФъСфДѓгк30ЫъЁЂЯћЗбФмСІЧПЁЂгаЧззгЦЋКУЕФХЎадЁЃетжжЧщПіЯТЛсЗЕЛиДѓСПгУЛЇЃЌДЫЪБОЭашвЊНшжњХњСПВщбЏЙЄОпЁЃОЙ§ЖрДЮММЪѕбЁаЭЃЌЮвУЧОіЖЈВЩгУelasticsearchзїЮЊХњВщбЏЕФЦНЬЈЃЌЗтзАГЩAPIКѓКмКУЕФжЇГжЩЯЪіГЁОАЁЃ
3.5.МрПиКЭИњзй
дкЪ§ОнСїзЊЕФзюКѓЃЌЪ§ОнЕФзМШЗадЪЧКтСПгУЛЇЛЯёМлжЕЕФЙиМќжИБъЁЃЛљгкИпжЪСПаХЯЂгХгкДѓЪ§СПаХЯЂЕФЛљЕїЃЌЮвУЧЩшжУСЫЖрВуМрПиЦНЬЈЁЃДгЖрИіЮЌЖШКтСПЪ§ОнЕФзМШЗадЁЃБШШчОЭгУЛЇЯћЗбФмСІетИіЛЯёЃЌЮвУЧДггУЛЇЕШМЖЁЂгУЛЇОЦЕъаЧМЖЁЂгУЛЇЛњЦБСНВеЕШЖрИіЮЌЖШНјаабщжЄКЭИЋе§ЁЃЭЌЪБЮвУЧЛЙвЊМрПиЪ§ОнЕФЛЗБШКЭЭЌБШБэЯжЃЌГіЯжНЯДѓБъзМВюЁЂЗНВюВЈЖЏЕФЪ§ОнЃЌЮвУЧЛсжиаТЦРЙРЫуЗЈЁЃ
ЩЯЪіЫљгаЛЗНкзщГЩСЫаЏГЬПчBUгУЛЇЛЯёЦНЬЈЁЃЕБШЛММЪѕШеаТдТвьЃЌЮвУЧвВдкВЛЖЯИќаТКЭОжВПДДаТЃЌЛђаэУїФъгжЛсгаКмЖраТЕФММЪѕБЛв§ШыЕНЮвУЧгУЛЇЛЯёжаЃЌЯЃЭћЮвЕФЗжЯэЖдФугаЫљАяжњЁЃ
зїепНщЩмжмдДЃЌаЏГЬММЪѕжааФЛљДЁвЕЮёбаЗЂВПИпМЖбаЗЂОРэЃЌДгЪТШэМўПЊЗЂ10грФъЁЃ2012ФъМгШыаЏГЬЃЌЯШКѓВЮгыжЇИЖЁЂгЊЯњЁЂПЭЗўЁЂгУЛЇжааФЕФЩшМЦКЭбаЗЂЁЃ
|









